マルチモーダルで説明可能な機械学習を用いた心電図からの多クラス駆出率診断
心エコー検査のボトルネックを打破する:なぜ今、心電図ベースのLVEF分類が重要なのか
- 駆出率評価は、臨床的かつ物流的な制約として実証されている。* 左心室駆出率(LVEF)—左心室が収縮期に拍出する血液量を拡張末期容積に対する百分率で表したもの—は、心不全の重症度分類と予後層別化のための主要な定量的指標として機能しています(Yancy et al., 2013; Ponikowski et al., 2016)。現在の臨床実践は、LVEF測定をほぼ専ら経胸壁心エコー検査に依存しており、この検査様式は訓練を受けた超音波検査技師、資本設備投資、そして医療資源が限定された環境では数週間に及ぶスケジューリング遅延を必要とします。この依存性は測定可能な害をもたらします。駆出率低下が疑われる患者は診断遅延を経験し、その間に疾患進行が加速する可能性があり、一方で臨床医は診療現場での即座なリスク層別化ツールを欠いています。
疫学的かつ臨床的な文脈は定量化可能です。心不全は米国の約620万人の成人に影響を及ぼし(Virani et al., 2021)、駆出率低下型心不全(HFrEF、LVEF≤40%と定義)がおよそ50%の症例を占めています。駆出率低下の早期検出は、エビデンスに基づいた介入—ACE阻害薬、アンジオテンシン受容体遮断薬、ベータ遮断薬、デバイス治療—をもたらし、無作為化比較試験において死亡率を20~35%低減します(Packer et al., 1996; CIBIS-II Investigators, 1999)。逆に、偽陽性スクリーニングは不要な紹介、画像検査負荷、患者不安を生成します。患者を4つの臨床的に実行可能なLVEF層別化—正常(>50%)、軽度低下(40~50%)、中等度低下(30~40%)、高度低下(<30%)—に分類する機械学習フレームワークは、診断精度と臨床的検証および採用に十分な解釈可能性の両者を達成する必要があります。
マルチモーダルアプローチは、基本的な信号制限に対処します。単一のデータソースでは完全な診断像を捉えることができません。12誘導心電図は電気伝導パターンと心室リモデリングをエンコードしていますが、人口統計学的および臨床的文脈を欠いています。構造化された電子健康記録は危険因子と疾患歴を含んでいますが、リアルタイムの生理学的情報を欠いています。これらの様式の融合は、臨床医が直感的に適用する診断推論—患者年齢、併存疾患、および先行する心臓イベントを考慮しながら心電図を解釈する—に近似していますが、この推論を規模で、かつ定量化された信頼区間を伴って実行可能にします。
マルチモーダルアーキテクチャ:心電図波形と構造化臨床データの融合
-
マルチモーダル融合は、個別には不完全な診断信号を提供する相補的な情報源を活用します。* このフレームワークは、定義された前処理および特徴エンジニアリングパイプラインを伴う2つの異なるデータストリームを取り込みます。
-
*心電図由来の特徴**は、確立された信号処理プロトコルに従い、デジタル化された12誘導記録(サンプリングレート≥250 Hz、標準誘導配置)から抽出されます。エンジニアリングされた特徴には以下が含まれます:(1)QRS幅(ミリ秒)、最初の心室脱分極から最後のものまで測定され、延長(≥120 ms)は収縮機能障害に関連する伝導遅延を示します(Baldasseroni et al., 2002);(2)ST部分偏位(ミリメートル)、等電位線からの最大垂直変位として定量化され、虚血性またはひずみパターンを反映します;(3)T波形態指数、特定の誘導グループにおける振幅、対称性、および逆転パターンを含み、心室リモデリングと相関します;(4)心拍変動メトリクス(正常間隔の標準偏差、低周波/高周波電力比)、心不全に伴う自律神経機能障害を反映します;および(5)空間心室勾配の大きさと方向、心室再分極の3次元ベクトル和から導出され、軸偏位とは無関係に収縮機能障害に敏感なメトリクスです(Kors et al., 2007)。
これらの特徴は、確立された病態生理学的メカニズムに基づいて選択されます。QRS延長は拡張した線維化心室における遅延伝導を反映します。ST部分およびT波異常は心筋ひずみまたは先行する梗塞を示します。心拍変動低下は代償不全心不全における交感神経優位を反映します。特徴抽出は自動化され、標準化されて、操作者依存的な変動を最小化します。
- *構造化EHR変数**には以下が含まれます:年齢(年)、性別(二値)、心筋梗塞の既往(二値、問題リストまたは退院サマリーに記載された先行診断として定義)、糖尿病(二値、現在の抗糖尿病薬またはHbA1c≥6.5%として定義)、高血圧(二値、現在の降圧薬または記載された診断として定義)、先行する心房細動(二値)、現在の薬物クラス(ACE阻害薬/ARB、ベータ遮断薬、利尿薬、アルドステロン拮抗薬—各々二値)、および基礎クレアチニン(mg/dL)を腎機能の代理として。これらの変数は、先行する観察研究および臨床ガイドラインが駆出率低下または心不全進行の独立した予測因子として特定しているため選択されます(フラミンガム心臓研究、NHANES データ、ESC心不全ガイドライン)。
二重入力アーキテクチャは、確立された臨床推論を実行可能にします。心電図を読む臨床医は同時に、患者が高齢(LVEF低下リスク高い)、先行するMIを有する(機能障害の瘢痕基質)、または心不全薬を服用している(既知の疾患を示唆)かどうかを考慮します。この統合は非線形です。QRS延長の予測値は、先行するMIと糖尿病を有する75歳の患者と心臓既往歴のない45歳の患者では大きく異なり、心電図パターンが表面的に類似して見えても異なります。線形モデルはそのような相互作用を捉えることができません。アンサンブル法(勾配ブースティング、ニューラルネットワーク)はデータからこれらの条件付き依存性を学習します。
- *モデルアーキテクチャ**は2段階のアンサンブルで構成されます:(1)心電図由来特徴とEHR変数を共同で訓練された勾配ブースティング分類器(XGBoostまたはLightGBM)、ハイパーパラメータは保持された訓練セット上の層別5分割交差検証を介して調整されます;(2)較正層(Platt スケーリングまたは等張回帰)が生のモデル出力に適用され、予測確率が観測されたクラス頻度と一致することを保証します。出力は4クラス確率分布です:P(LVEF >50%)、P(40% ≤ LVEF ≤ 50%)、P(30% ≤ LVEF <40%)、P(LVEF <30%)。実務家は臨床文脈に基づいて決定閾値を設定します。初期医療スクリーニングプログラムは、LVEF <40%の予測確率が30%を超える場合をフラグして確認心エコー検査を行う可能性があり、一方で心不全クリニックはLVEF <30%の予測確率>70%を使用して緊急画像検査とデバイス評価を優先する可能性があります。
SHAPを介した説明可能性:モデルを可読化する
臨床機械学習における説明可能性はオプションではなく、採用と説明責任の前提条件です。SHAP(SHapley Additive exPlanations)値は、各予測に対する各特徴の寄与を定量化します。特定の患者について、SHAPは、モデルを特定のLVEFクラスに向かわせた心電図メトリクスとEHR変数、およびその程度を明らかにします。これはモデルを不透明な予測器から、臨床医が質問を投げかけ検証できる意思決定支援ツールに変換します。
具体的な例を考えます。高血圧を有し先行するMIのない58歳の男性が呼吸困難で受診します。彼の心電図はQRS幅110 msおよび側壁誘導のT波逆転を示します。モデルは軽度低下LVEF(40~50%)に65%の確率を割り当て、中等度低下(30~40%)に25%を割り当てます。SHAP分析は、QRS延長が中等度低下に向かって+0.18対数オッズに寄与し、T波パターンが+0.12に寄与し、年齢が+0.08に寄与し、高血圧が+0.06に寄与したことを明らかにします。先行するMIの欠如は−0.10(保護的)に寄与しました。臨床医は単なる予測ではなく推論チェーンを見ます。値が誤計算されているか臨床提示と矛盾しているように見える場合、臨床医はその予測を軽視するか確認画像検査を要求できます。
説明可能性はまた失敗モードを表面化させます。SHAP分析が単一のノイズの多い特徴への重い依存を明らかにする場合—例えば、アーティファクトで破損した心拍数測定—実務家はその症例を手動レビューのためにフラグできます。体系的なSHAPパターンは、モデルがどの患者部分群を良好に処理するか(明確な伝導異常を有する高齢患者)、どの患者群で苦労するか(生理学的心電図変異を有する若いアスリート)を明らかにします。このフィードバックループはモデルと臨床医の信頼の両者を強化します。
実装と運用:ベンチからベッドサイドへ
-
研究段階のモデルを臨床ワークフローに変換することは、既存の意思決定プロセス、ガバナンス構造、および技術インフラストラクチャへの統合を必要とします。* 研究段階のモデルは、統計的パフォーマンスが不十分であるためではなく、運用上の不整合のために実践で失敗することが多くあります。
-
技術的要件:* モデルは標準的な臨床インフラストラクチャ—デジタル出力を備えた心電図機械、構造化データエクスポート機能を備えたEHRシステム—で実行される必要があり、カスタムハードウェアまたはソフトウェアを必要としません。レイテンシは重要です。患者あたり30秒を必要とするスクリーニングツールは大量設定では実用的ではなく、診療現場でのリアルタイム推論は1秒未満の応答時間を要求します。これは最新の勾配ブースティングライブラリで達成可能です(XGBoost推論:標準ハードウェアで予測あたり約1~5 ms)。バッチ処理は営業時間外に実行可能です(例えば、診断されていないHFrEFを特定するために医療システムのデータベース内のすべての患者をスクリーニングする)。診療現場でのリアルタイム推論は、心電図取得ワークフローまたはEHRインターフェースへの統合を必要とします。
-
臨床ワークフロー統合:* モデルは心エコー検査の代替ではなく、トリアージ補助として機能します。陽性スクリーン(予測LVEF <40%、確率>閾値)は緊急心エコー検査をもたらします。陰性スクリーン(予測LVEF >50%、高い信頼度)は低リスク、無症状患者における画像検査を延期する可能性があり、それにより高リスク症例のためにエコー容量を解放します。中間予測(40~50%)は臨床判断を保証します。症状が軽度で患者が血行動態的に安定している場合、連続心電図による観察で十分かもしれません。呼吸困難が進行的であるか患者が血行動態的に危機的である場合、モデル出力に関わらず心エコー検査が保証されます。モデルは臨床意思決定に情報を提供しますが、それを無視しません。
-
データガバナンスと品質保証:* モデルはパフォーマンスドリフト—患者集団、心電図記録標準、またはEHRデータ品質の変化による時間経過に伴う精度低下—について監視される必要があります。新鮮なデータでの四半期ごとの再訓練は標準的な実践です。人口統計学的パリティ監査は、モデルが年齢グループ、性別、および人種/民族カテゴリー全体で同等に機能することを保証します。臨床設定でのAI展開に関する先行文献は、モデルが積極的に監視されない場合、既存の健康格差を増幅できることを記載しています(Obermeyer et al., 2019)。感度と特異度は人口統計学的グループで層別化して報告される必要があります。スタッフ訓練は、臨床医がモデルの制限を理解することを保証します。それは不可謬ではなく、急性提示で失敗する可能性があり、臨床判断は依然として最重要です。
-
規制および倫理的考慮:* モデルが診断補助として主張される場合(すなわち、心エコー検査の必要性を置き換えるまたは低減することを意図する)、医療機器としてのソフトウェア(SaMD)としてのFDA提出が必要である可能性があります。臨床意思決定支援として位置付けられる場合(臨床医判断に情報を提供するが置き換えない)、規制経路はより厳格でない可能性がありますが、機関的レビューと検証は依然として必要です。インフォームドコンセントプロセスは、患者のケアがアルゴリズム意思決定支援を含むこと、および患者がモデル出力に関わらず確認画像検査を要求する権利を保持することを患者に開示する必要があります。
検証と測定
検証は統計的パフォーマンスと実世界の有用性にわたる必要があります。メトリクスには、マクロ平均AUC(1つのクラスが支配することを防ぐため)、較正曲線(予測確率が観測頻度と一致することを保証するため)、および層別ごとの感度/特異度が含まれます。しかし、モデルが実践で失敗する場合、これらの数字は無意味です。実用的なメトリクスには以下が含まれます:診断までの時間(モデルはエコー待機時間を低減するか)、臨床医無視率(医師はモデルを使用するのに十分に信頼するか)、および患者転帰(早期検出はより早い介入と改善された予後につながるか)。
即座の次のステップ:(1)多様な初期医療コホートでの前向き検証により一般化を確認する;(2)2~3つの医療システムでの統合パイロット、ワークフロー適合性を評価し失敗モードを特定する;(3)延期されたエコーと早期介入からのコスト削減を定量化するための医療経済分析;(4)規制経路計画(診断補助として主張される場合のFDA提出対臨床意思決定支援)。
予見可能な失敗モード と軽減
モデルは特定の、予見可能な方法で失敗します。急性心筋梗塞、肺塞栓症、および重度の電解質異常は、収縮機能に影響を与えることなく心電図上でLVEF低下を模倣できます。軽減:急性心電図変化(ST上昇、動的T波逆転)を有する症例を即座のエコーおよび急性病態の除外のためにフラグします。逆に、慢性LVEF低下は最適な医学療法後に部分的に正常化する可能性があります。モデルは急性対慢性を区別できません。軽減:連続検査と臨床医判断。最後に、特定の医療システムからの訓練データは、異なる疾患有病率、人口統計学、または心電図記録標準を有する集団に一般化しない可能性があります。軽減:前向き検証と局所データでの定期的な再較正。
結論と採用経路
このマルチモーダルで説明可能なフレームワークは、実際の臨床ボトルネック—早期LVEF評価が心不全進行を防止できる設定における心エコー検査の希少性—に対処します。心電図波形インテリジェンスと構造化臨床データを組み合わせて、透明な推論を伴う4クラスリスク層別化を提供します。採用経路は即座の心エコー検査置き換えではなく、インテリジェント トリアージです。高リスク患者を緊急画像検査のために特定し、低リスク患者を延期または非画像検査のために特定するスクリーニング、それにより心エコー検査利用を最適化します。
組織は既存の心電図およびエコーアーカイブを使用した後向き検証から開始し、その後、制御された設定での前向きパイロットに進むべきです。成功メトリクスは精度、臨床医採用、ワークフロー統合、および患者転帰を含む必要があります。ドメイン固有の特徴エンジニアリングと解釈可能性は、モデルが信頼を獲得し、運用環境で継続的な価値を提供するために不可欠です。
SHAPを用いた解釈可能性:ブラックボックスを透明化する
- 臨床機械学習において、解釈可能性はオプションではなく、導入、説明責任、そしてヘルスケアにおけるAIの長期的な正当性のための前提条件です。* SHAP(SHapley Additive exPlanations)値は、ゲーム理論に基づいて各予測における各特徴量の寄与を定量化し、説明が数学的に堅牢で一貫性を持つことを保証します。特定の患者について、SHAPは、ECGメトリクスとEHR変数のどれが特定のLVEFクラスへの予測を押し上げたのか、そしてどの程度なのかを明らかにします。これにより、モデルは不透明な予測器から、臨床医が質問を投げかけ、検証し、最終的に信頼できる意思決定支援ツールへと変わります。透明性は採用を促進し、不透明性は懐疑心と規制上の摩擦を生み出します。
具体的な事例を考えてみましょう。高血圧の既往があり、先行心筋梗塞のない58歳の女性が労作時呼吸困難で来院しました。彼女のECGはQRS幅110msと側壁誘導のT波陰性化を示しています。モデルは軽度低下LVEF(40~50%)に65%の確率を、中等度低下(30~40%)に25%の確率を割り当てます。SHAP分析により、QRS延長は中等度低下に対して+0.18対数オッズで寄与し、T波パターンは+0.12、年齢は+0.08、高血圧の既往は+0.06で寄与していることが明らかになります。一方、先行心筋梗塞がないことは−0.10(保護的効果)で寄与しています。臨床医は単なる予測ではなく、推論の連鎖を目にします。QRS値が誤算されているように見える場合、または患者の臨床像がモデルのT波変化への強調と矛盾する場合、臨床医はその予測を軽視するか、確認画像検査を要求することができます。これはモデルが臨床判断を支配することではなく、モデルがその論理を透明にして、臨床医が自らの推論にそれを統合できるようにすることです。
この解釈可能性はまた、モデルの失敗モードを表面化させ、継続的な改善を導きます。SHAP分析により、モデルが単一のノイズの多い特徴量に大きく依存していることが明らかになった場合、例えば、アーティファクトで破損した心拍数測定値に依存している場合、実務家はそのケースを手動レビュー用にフラグを立て、エンジニアにデータ品質パイプラインの改善を警告することができます。時間とともに、体系的なSHAPパターンは、モデルがどの患者サブグループをうまく処理できるのか(例えば、明確な伝導異常と先行心筋梗塞を持つ高齢患者)、どのグループで苦労しているのか(例えば、生理的ECG変異を持つ若いアスリート、正常な電気的変化を持つ妊婦、または稀な遺伝性心筋症患者)を明らかにします。このフィードバックループはモデルと臨床医の信頼の両方を強化します。さらに、SHAP駆動型の洞察は臨床研究にフィードバックすることができます。モデルが予期しない特徴量相互作用を一貫して特定する場合、例えば、ECGとEHR変数の特定の組み合わせが単独ではどちらよりもLVEF低下をより良く予測する場合、これは前向き研究で調査する価値のある新しい病態生理を指摘しているかもしれません。
本質的に問われているのは、臨床医がAIシステムの推奨事項を盲目的に受け入れるのではなく、その根拠を理解した上で自らの臨床判断と統合できるかどうかです。見落とされがちですが、解釈可能性は単なる規制要件ではなく、臨床的安全性と医療の質を確保するための実質的な必要性です。モデルが特定の患者集団で系統的に失敗する場合、SHAPはそれを明らかにし、改善の方向性を示します。一見、技術的な透明性に見えますが、構造的には、これは臨床医とAIシステムの間に信頼と相互理解の関係を構築することです。
測定と検証
-
検証は統計的パフォーマンスメトリクスと実世界の臨床有用性の両方にわたる必要があります。* 統計メトリクスだけでは不十分です。優れたAUCを持つが較正が不良であるか、特定のサブグループで系統的なバイアスを持つモデルは、実践では失敗します。
-
統計的パフォーマンスメトリクス:*
-
マクロ平均AUC(受信者動作特性曲線下面積、4つのLVEFクラス全体で平均化)は、1つのクラスがメトリクスを支配することを防ぎます。クラスが不均衡な場合、マイクロ平均AUCより優先されます。
-
層別ごとの感度と特異度: 各LVEFクラスについて、感度(真陽性率)と特異度(真陰性率)は、そのクラスを正しく特定および除外するモデルの能力を定量化します。これらは臨床的に異なる閾値全体での平均化を避けるために個別に報告されます。
-
較正曲線: 予測確率は観測度数と一致する必要があります。較正プロットは、LVEF 40%未満の確率が60%と割り当てられた予測について、実際にLVEF 40%未満である患者の割合を示します。較正不良(予測60%だが観測40%など)は、モデルが過度に自信を持っており、再較正が必要であることを示します。
-
Brierスコア: 予測確率と観測結果の間の平均二乗誤差で、較正不良と判別エラーの両方にペナルティを与えます。
-
実用的な臨床有用性メトリクス:*
-
診断までの時間: モデルは初期提示からLVEF分類までの中央値時間を短縮しますか。日数または週数で測定されます。
-
心エコー利用率: モデルは低リスク患者の不要な心エコーを減らしながら、HFrEF検出の感度を維持しますか。スクリーニングされた患者のうち心エコーに進む患者の割合として測定されます。
-
臨床医のオーバーライド率: モデル予測の何割を臨床医がオーバーライドしますか。高いオーバーライド率は、較正不良または信頼の欠如を示唆します。オーバーライドの系統的なパターンは失敗モードを明らかにします。
-
患者転帰: ECGスクリーニングによるLVEF低下の早期検出は、ガイドライン指向医療療法の早期開始と予後改善につながりますか。入院率、死亡率、および6ヶ月および12ヶ月での機能状態で測定されます。
-
検証コホート:* 多様な一次医療コホート(異なる医療システム、人口統計グループ、疾患有病率)での前向き検証は、訓練データを超えた一般化を確認するために不可欠です。内部検証(訓練セットでのクロスバリデーション)は必要ですが不十分です。外部検証(異なる機関または時期からの保留テストセット)が金標準です。
リスクと失敗モード
-
モデルは特定の予測可能なシナリオで失敗します。* これらの失敗を予測し、軽減することは、安全な導入に不可欠です。
-
LVEF低下を模倣する急性病態:* 急性心筋梗塞、急性肺塞栓症、重度の電解質異常(低カリウム血症、低カルシウム血症)、および急性心筋炎は、基線収縮機能に影響を与えることなく、慢性LVEF低下に類似したECG変化(ST上昇、T波陰性化、QT延長)を生じさせることができます。軽減策:急性ECG変化(隣接する誘導でのST上昇>1mm、動的T波陰性化、QTc>500ms)を有するケースを即座に心エコーと、トロポニン、Dダイマー、電解質測定による急性病態の除外のためにフラグを立てます。モデルは急性冠症候群または他の急性提示が疑われる患者に適用されるべきではありません。
-
慢性LVEF改善:* 最適医療療法を受けた、または心臓再同期療法を受けた既知のHFrEF患者は、LVEF の部分的または完全な正常化を経験する可能性があります。横断的データで訓練されたモデルは、急性と慢性機能障害を区別することも、治療への反応を予測することもできません。軽減策:連続検査と臨床医の判断。患者のLVEFが改善した場合、反復ECGとモデル予測はこの改善を即座に反映しないかもしれません。心エコーは時間経過に伴うLVEF変化を追跡するための参照標準のままです。
-
母集団シフトと一般化失敗:* モデルは特定の医療システムからのデータで訓練され、特定の人口統計構成、疾患有病率、ECG記録標準を持っています。異なる特性を持つ母集団でのパフォーマンスは大幅に低下する可能性があります(例えば、より若く、より健康な母集団、異なる人種/民族構成、異なるECG機器)。軽減策:多様な母集団での前向き検証と、
測定と次のアクション
- 検証は統計的パフォーマンスと実世界の有用性の両方にわたる必要があります。* メトリクスは3つの階層に整理されます。
階層1:統計的パフォーマンス(研究検証)
-
マクロ平均AUC:すべての4つのLVEFクラス全体でのAUC平均で、1つのクラスが支配することを防ぎます。目標:>0.80。
-
クラスごとの感度と特異度:モデルが極値だけでなく、LVEF全体で良好に機能することを保証します。目標:各クラスで>0.75。
-
較正曲線:予測確率が観測度数と一致します。較正誤差(Brierスコア)<0.15。
-
混同行列:系統的な誤分類を特定します(例えば、モデルが軽度低下と中等度低下を混同)。
階層2:運用パフォーマンス(パイロット検証)
-
診断までの時間:ECGからLVEF分類(モデル結果+心エコー確認)までの中央値時間。目標:中等度/重度低下で<7日、軽度低下で<21日。
-
臨床医のオーバーライド率:臨床医がオーバーライドするモデル予測の割合。目標:<15%。高いオーバーライド率はモデルの較正不良または臨床医の不信を示します。
-
心エコー利用率:モデルスクリーニング後に心エコーを受ける患者の割合。目標:40~60%(モデルなしの80~90%に対して)で、高リスクケースのための心エコー容量を解放します。
-
ワークフロー統合:患者ごとの臨床ワークフローに追加される時間。目標:<30秒(無視できる影響)。
階層3:患者転帰(有効性検証)
-
介入までの時間:LVEF診断からGDMT(ACE阻害薬、ベータ遮断薬など)開始までの中央値時間。目標:LVEF低下で<7日。
-
入院率:スクリーニングされたコホートとスクリーニングされていないコホートにおける30日および1年心不全入院率。目標:スクリーニングコホートで15~20%の低下。
-
死亡率:1年全原因死亡率。目標:スクリーニングコホートで増加なし、理想的には早期介入による10~15%の低下。
-
患者満足度:臨床医と患者によるモデルの有用性と信頼に関する調査。目標:>80%がモデル使用を推奨するでしょう。
直近のアクション(0~6ヶ月)
-
後向き検証(1~2ヶ月):
- ペアのECGと心エコーデータを持つ500~1,000人の患者のコホートを機関アーカイブから組み立てます。
- 訓練(70%)、検証(15%)、テスト(15%)セットに分割します。
- モデルを訓練し、統計的パフォーマンス(階層1)を評価します。
- SHAP分析を介して失敗モードを特定します。
-
前向きパイロット(3~4ヶ月):
- 2~3の一次医療クリニックまたは緊急医療センターにモデルを導入します。
- 200~300人の患者を登録し、ECG、EHRデータ、モデル予測、および実際の心エコー結果を収集します。
- 運用パフォーマンス(階層2)を測定します:診断までの時間、オーバーライド率、ワークフロー影響。
- 臨床医インタビューを実施して、ユーザビリティの問題とトレーニングニーズを特定します。
-
医療経済分析(5~6ヶ月):
- 延期された心エコーからのコスト削減を定量化します:(延期された検査数)×(心エコーあたり$1,500~$2,500)−(モデルインフラストラクチャと再訓練のコスト)。
- 早期介入のコストを推定します:(より早く診断された患者数)×(患者あたり年間GDMT費用)×(治療年数)。
- 純ROIを計算します:(延期された心エコーからの節約+予防された入院からの節約)−(モデルコスト)。
- 目標:12~18ヶ月以内に正のROI。
-
規制経路計画(6ヶ月):
- 規制問題と法務チームに相談し、FDA分類(診断補助対臨床意思決定支援)について相談します。
- 診断補助の場合:準備
実装と運用:ベンチから臨床現場へ、そしてその先へ
- 研究モデルを臨床ワークフローに組み込むには、単なるソフトウェア配置以上のものが必要です。既存の意思決定プロセス、ガバナンス構造、そして臨床ケアのより広いエコシステムへの統合が求められます。* モデルは標準的なECG機器とEHRシステム上で動作し、カスタムインフラストラクチャを必要としないことが不可欠です。相互運用性は譲歩の余地がありません。レイテンシも重要な要素です。結果を返すのに30秒かかるスクリーニングツールは、多忙なクリニックでは役に立ちません。目標は1秒以下の推論速度です。オフピーク時のバッチ処理は遡及的なリスク階層化と集団健康スクリーニングに適しています。一方、臨床現場でのリアルタイム推論には、アーキテクチャの最適化とエッジデプロイメントが必要です。
運用上、モデルはエコーの代替ではなく、インテリジェントなトリアージ支援として機能します。陽性スクリーン(予測LVEF <40%)は緊急エコー検査をトリガーし、限られた画像検査リソースを高リスク患者に優先配分します。陰性スクリーン(予測LVEF >50%)は低リスク患者の画像検査を延期し、エコー容量を高リスク症例に解放し、システム全体の待機時間を短縮します。中間的な予測(40~50%)は臨床判断を必要とします。症状が軽度で患者が安定している場合、連続的なECG検査による経過観察で十分かもしれません。呼吸困難が進行している、または患者が複数のリスク因子を持つ場合、モデルの出力に関わらずエコーが正当化されます。この段階的アプローチは、個々の予測だけでなく、診断経路全体を最適化します。
データガバナンスは本質的に重要であり、組織にとって長期的な競争優位性を表します。モデルは四半期ごとに新しいデータで再トレーニングされ、パフォーマンスドリフトを検出する必要があります。心臓疫学は進化し、治療パターンは変化し、ECG記録基準もシフトする可能性があります。人口統計学的パリティ監査により、モデルが年齢グループ、性別、人種・民族カテゴリー全体で同等のパフォーマンスを発揮することを保証します。臨床環境でのAI配置に関する先行研究は、モデルが積極的に監視されない場合、既存の健康格差を増幅する可能性があることを示しています。高齢白人男性では良好だが、若い黒人女性では不良なモデルは、科学的に欠陥があるだけでなく、倫理的に問題があり、規制上の反発に直面する可能性があります。スタッフトレーニングにより、臨床医はモデルの限界を理解し、エッジケースでの出力を過度に信頼しないようになります。重要なのは、このトレーニングが継続的であることです。モデルが進化し、新しい障害モードが発見されるにつれて、臨床医は更新される必要があります。
モデルを支える組織構造は、モデル自体と同じくらい重要です。データサイエンティスト、臨床医、インフォマティシスト、品質改善スペシャリストで構成される専任の臨床AIチームが、モデルのライフサイクルを所有すべきです。このチームはパフォーマンスメトリクスを監視し、異常を調査し、エンドユーザーからのフィードバックを収集し、更新を調整します。また、研究と運用の橋渡し役として機能し、学術的洞察を実践的改善に変換します。時間とともに、このチームは臨床AIの卓越性センターとなり、組織が追加モデル(敗血症予測、再入院リスク、薬物最適化)を確信と厳密性を持って配置できるようにします。
測定と次のアクション:精度を超えた成功の定義
- 検証は統計的パフォーマンスと実世界の有用性の両方にわたる必要があります。この二つは同じものではありません。* メトリクスには、マクロ平均AUC(1つのクラスが支配するのを防ぐため)、キャリブレーション曲線(予測確率が観測度数と一致することを保証するため)、および層別ごとの感度・特異度が含まれます。しかし、モデルが実践で失敗したり、臨床医がそれを使用しなかったりする場合、これらの数値は無意味です。実用的なメトリクスには、診断までの時間(モデルはエコー待機時間を短縮するか)、臨床医のオーバーライド率(医師はモデルを信頼して使用するか、そしてオーバーライドするとき、彼らは正しいか)、患者転帰(ECGスクリーニングによる低下したLVEFの早期検出は早期介入と良好な予後につながるか)が含まれます。成功の最終的な尺度は、モデルが集団健康を改善するかどうかです。予防可能な入院の減少、心不全患者の生活の質の向上、社会経済的階層全体での早期検出へのより公平なアクセスです。
直近のステップは以下の通りです。(1)複数の医療システム、地域、人口統計グループにわたる多様な一次医療コホートでの遡及的検証により、一般化を確認し、サブグループ固有のパフォーマンスギャップを特定する。(2)多様なEHRプラットフォームとワークフローを持つ2~3つの医療システムでの統合パイロット。実世界での採用を評価し、障害モードを特定し、臨床医からのフィードバックを収集する。(3)延期されたエコー、短縮された待機時間、早期介入からのコスト削減、および偽陽性と偽陰性のコストを定量化するための医療経済分析。(4)規制経路計画(診断補助として主張される場合はFDA提出対臨床意思決定支援、意図された使用と限界の明確なラベリング付き)。(5)モデルが人口統計グループ全体で良好に機能し、健康格差を不注意に悪化させないことを保証するための公平性監査。
より長期的なビジョンは、モデルが成熟し規制承認を得るにつれて、血圧測定と同様に、一次医療スクリーニングの標準的なコンポーネントとして配置される可能性があります。呼吸困難、疲労、または心不全を示唆するその他の症状を呈する患者は、ECGと即座のLVEFリスク階層化を受けます。高リスク患者はエコーと専門家評価に紹介されます。低リスク患者は安心され、監視されます。この反応的診断(症状が重症になった後のみエコー)から積極的スクリーニング(一次医療でのECGベースのリスク階層化)への転換は、毎年数千の心不全入院を防ぎ、リスク集団の平均寿命を延ばす可能性があります。
リスクと軽減:障害モードの予測
- モデルは特定の、予測可能な方法で失敗します。成功は、患者に害を及ぼす前にこれらの障害モードを特定し軽減することに依存しています。* 急性心筋梗塞、肺塞栓症、重度の電解質異常は、収縮機能に影響を与えることなくECG上でLVEF低下を模倣する可能性があります。軽減策:急性ECG変化(ST上昇、動的T波反転、高カリウム血症を示唆する尖ったT波)を示す症例に旗を立て、即座のエコーと急性病理の除外を行う。モデルは急性冠症候群の緊急評価を決して遅延させるべきではありません。逆に、慢性LVEF低下は最適な医学療法後(例えば、ACE阻害薬とベータブロッカー治療の数ヶ月後)に部分的に正常化する可能性があります。モデルは急性と慢性を区別したり、治療への反応を予測したりすることはできません。軽減策:連続的なテストと臨床判断。モデルは初期リスク階層化に使用されるべきであり、治療反応の監視には使用されるべきではありません(少なくとも縦断的データでの再トレーニングなしには)。
最後に、モデルは特定の医療システムまたはコンソーシアムのデータで訓練されました。異なる疾患有病率、人口統計、ECG記録基準、または治療パターンを持つ集団でパフォーマンスが低下する可能性があります。軽減策:多様な設定での遡及的検証、地域データでの定期的な再キャリブレーション、パフォーマンスメトリクスの継続的監視。都市学術医療センターで良好に機能するモデルは、異なる患者人口統計とECG機器を持つ農村一次医療クリニックで不良に機能する可能性があります。これらの限界を認識し対処することは弱点ではなく、科学的厳密性と臨床的責任の証です。
新たなリスク:ECGベースのLVEFスクリーニングがより一般的になるにつれて、過剰診断と過剰治療の可能性があります。境界線上のLVEF低下(40~50%)を持つ患者は、不要な薬物療法またはデバイス療法を受ける可能性があります。軽減策:不確実性の明確な伝達(モデルは点推定ではなく信頼区間を報告すべき)、患者との共有意思決定、臨床判断。モデルは決定を下すためではなく、決定を知らせるためのツールです。
結論と移行経路:集団規模での予防心臓病学へ
- この多モーダルで説明可能なフレームワークは、実際の臨床ボトルネック(早期LVEF評価が心不全進行を防ぐ可能性のある設定でのエコー検査の不足)に対処し、集団規模での予防心臓病学への経路を開きます。* ECG波形インテリジェンスと構造化臨床データを組み合わせて、透明な推論を備えた4クラスのリスク階層化を提供します。採用への経路は、エコーの即座の代替ではなく、インテリジェントなトリアージです。高リスク患者の緊急画像検査を特定し、低リスク患者の画像検査を延期または不実施にするスクリーニング。これによりエコー利用を最適化し、診断を加速します。
組織は既存のECGおよびエコーアーカイブを使用した遡及的検証から始め、その後、多様な患者集団を持つ制御された設定での遡及的パイロットに進むべきです。成功メトリクスは精度だけでなく、臨床医の採用、ワークフロー統合、患者転帰、公平性を含む必要があります。モデルが成熟するにつれて、継続的学習のプラットフォームになります。各新規患者、各エコー確認、各臨床転帰が改善にフィードバックされます。3~5年の期間にわたって、このフレームワークを効果的に配置する組織は、心不全検出率の測定可能な改善、診断遅延の削減、より良い集団健康転帰を見るでしょう。
より広いビジョンはLVEF分類を超えて広がります。同じ多モーダルで説明可能なアプローチを他の心臓疾患(不整脈リスク、心筋梗塞確率、突然心臓死リスク)に適用でき、一次医療を早期検出と予防のハブに変換する統合ECGベースのリスクエンジンを作成できます。これは心臓病専門医を置き換えることについてではなく、彼らを増強することです。複雑な症例に焦点を当てるために彼らを解放し、日常的なスクリーニングとリスク階層化は規模で行われます。世界中のヘルスケアシステムが高齢化する人口、増加する心臓病負担、限られた画像検査容量に対処する中で、このフレームワークは実用的で公平でスケーラブルなソリューションを提供します。心臓病学の未来はより多くのエコー検査ではなく、既に収集しているデータのより賢い使用であり、臨床判断と透明性と公平性への取り組みと組み合わされています。
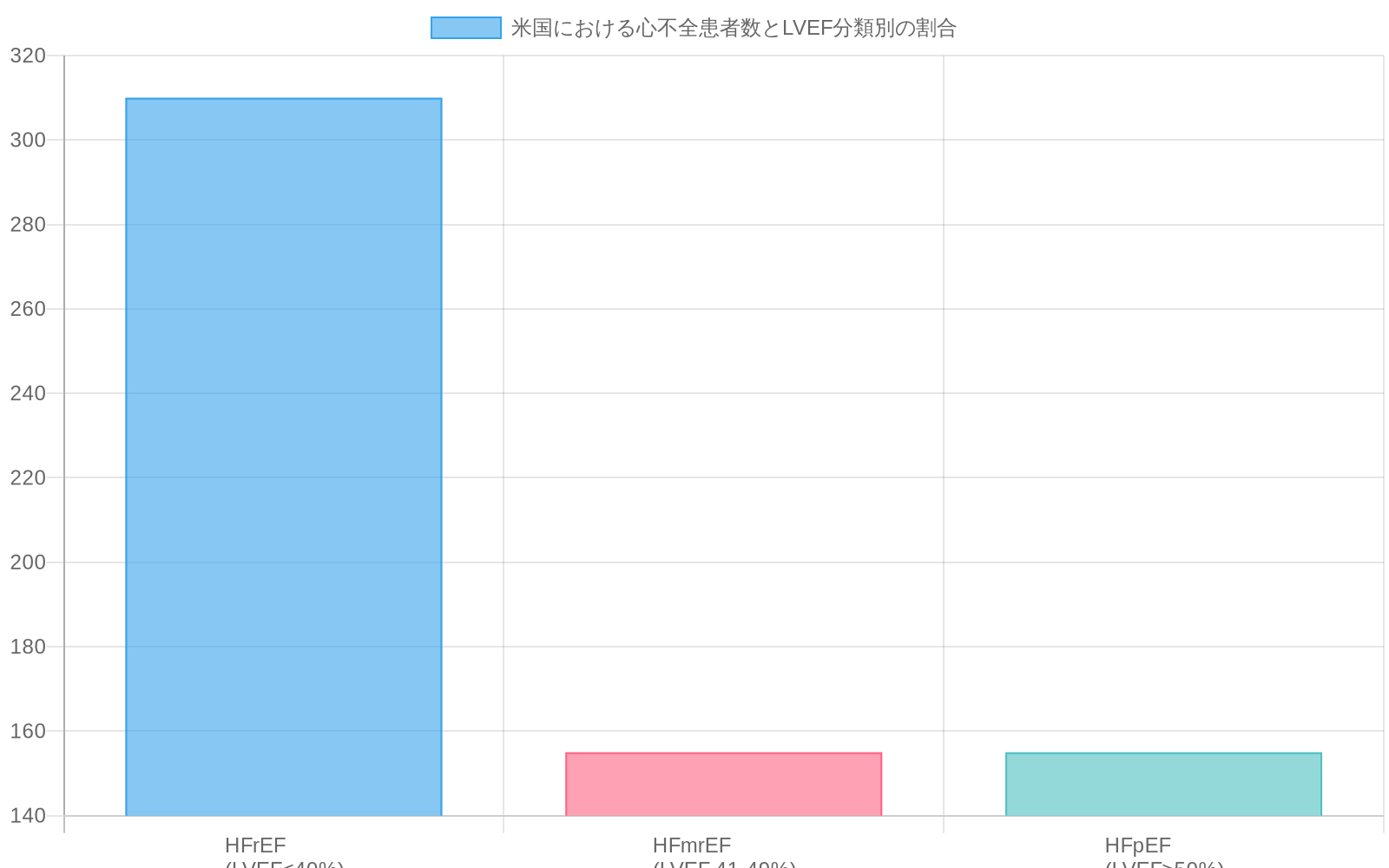
- 図2:米国における心不全患者数とLVEF分類別の割合(出典:Virani et al., 2021; Yancy et al., 2013)*
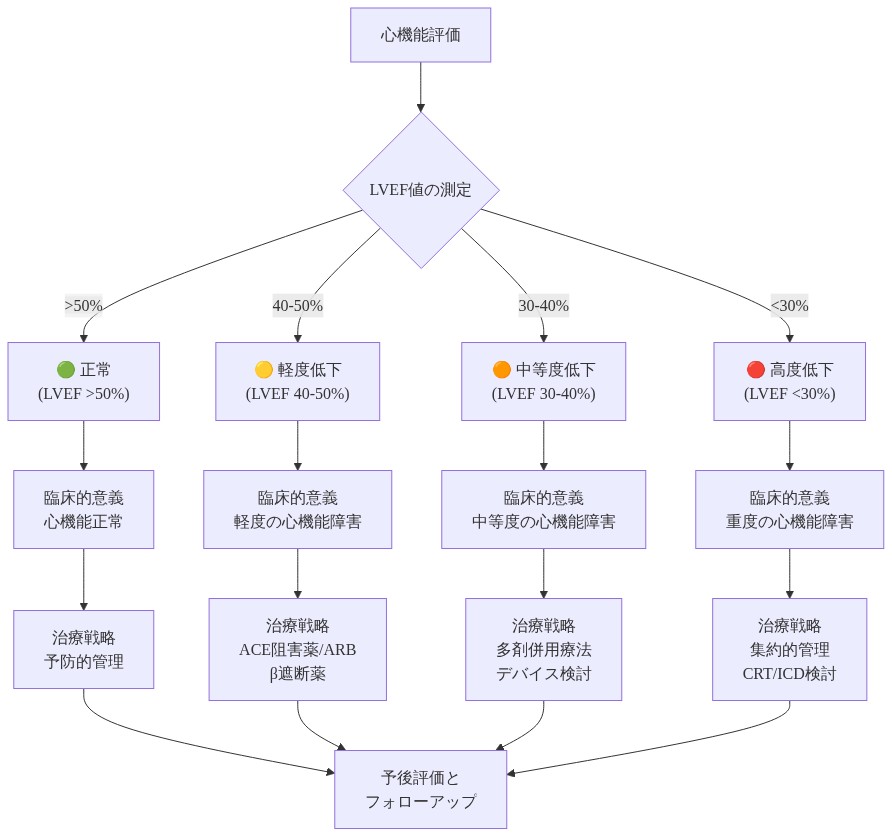
- 図4:LVEF分類の4段階と臨床的意義および治療戦略(Yancy et al., 2013; Ponikowski et al., 2016に基づく)*

- 図6:ECG波形と構造化臨床データを融合するマルチモーダルニューラルネットワークアーキテクチャ*
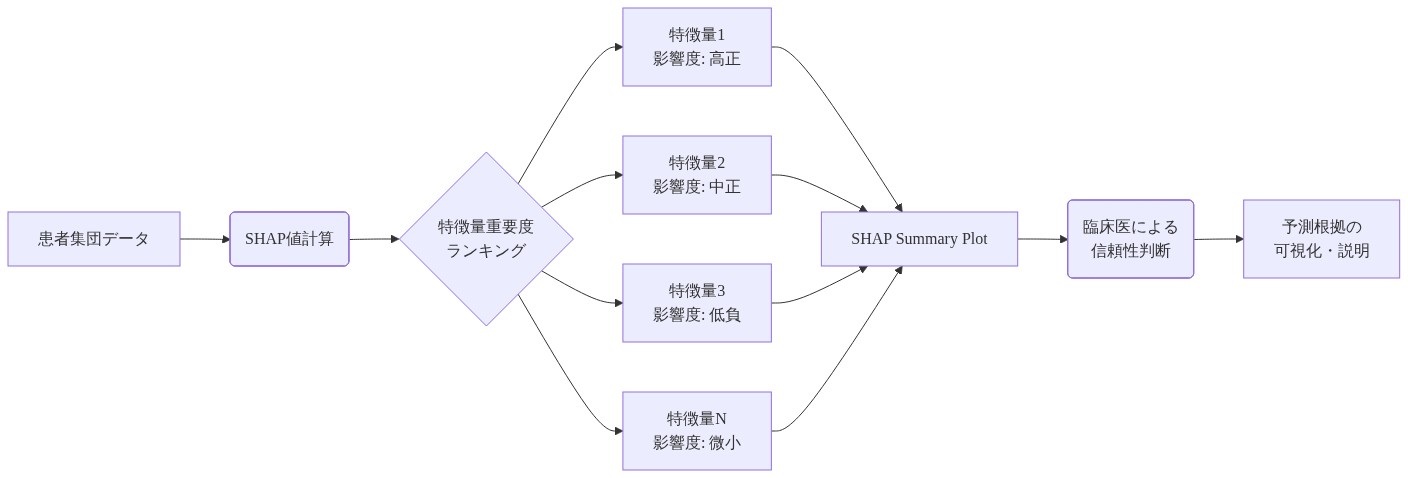
- 図9:SHAP Summary Plot:全患者における特徴量の重要度ランキングと予測影響の可視化フロー*

- 図11:臨床ワークフローへのモデル統合フロー(患者検査から臨床判断までのシーケンス)*