
AdaFRUGAL: 動的制御による適応的メモリ効率訓練
大規模言語モデル訓練におけるメモリ制約
大規模言語モデルの訓練には、GPUメモリに大きなオーバーヘッドが発生し、オプティマイザの状態が総割り当ての50〜70%を消費する(Shazeer et al., 2018; Rajbhandari et al., 2020)。float32精度でAdamオプティマイザを使用して訓練される70億パラメータモデルの場合、モデルの重みは約14GBを占め、オプティマイザのモーメンタムと分散バッファは精度と実装に応じて追加で14〜28GBを占める。このメモリ圧力により、実務者はバッチサイズを削減せざるを得なくなり、これは経験的に収束速度と下流のモデル品質の両方を低下させる(Goyal et al., 2017)。
-
基本メカニズム:* オプティマイザの状態、具体的には一次モーメント(モーメンタム)と二次モーメント(分散)の推定値は、パラメータ数に対して線形にスケールする。勾配チェックポイント(Chen et al., 2016)は活性化メモリを削減するが、オプティマイザの状態オーバーヘッドには対処せず、メモリ制約環境(エッジクラスタ、古いハードウェア、コスト重視の展開)において根本的なボトルネックを残す。
-
具体例:* 40GB GPUで130億パラメータモデルを訓練するチームは、CPUまたはディスクへのスピルなしでは4より大きいバッチサイズを収めることができず、3〜5倍の速度低下を招く(Rajbhandari et al., 2020)。この実効スループットの低下は、スケジュールの予測可能性と最終的なモデル性能の両方を損ない、小さいバッチは高い勾配ノイズを導入し、収束を妨げる可能性がある(Keskar et al., 2016)。
-
運用上の意味:* 組織は二者択一に直面する:より大きなGPUに投資する(資本集約的、エネルギー集約的)か、アルゴリズムによるメモリ削減技術を採用するか。AdaFRUGALは、メモリ効率の高いオプティマイザ更新を自動化し、手動のハイパーパラメータ探索を排除することで、この制約に対処する。
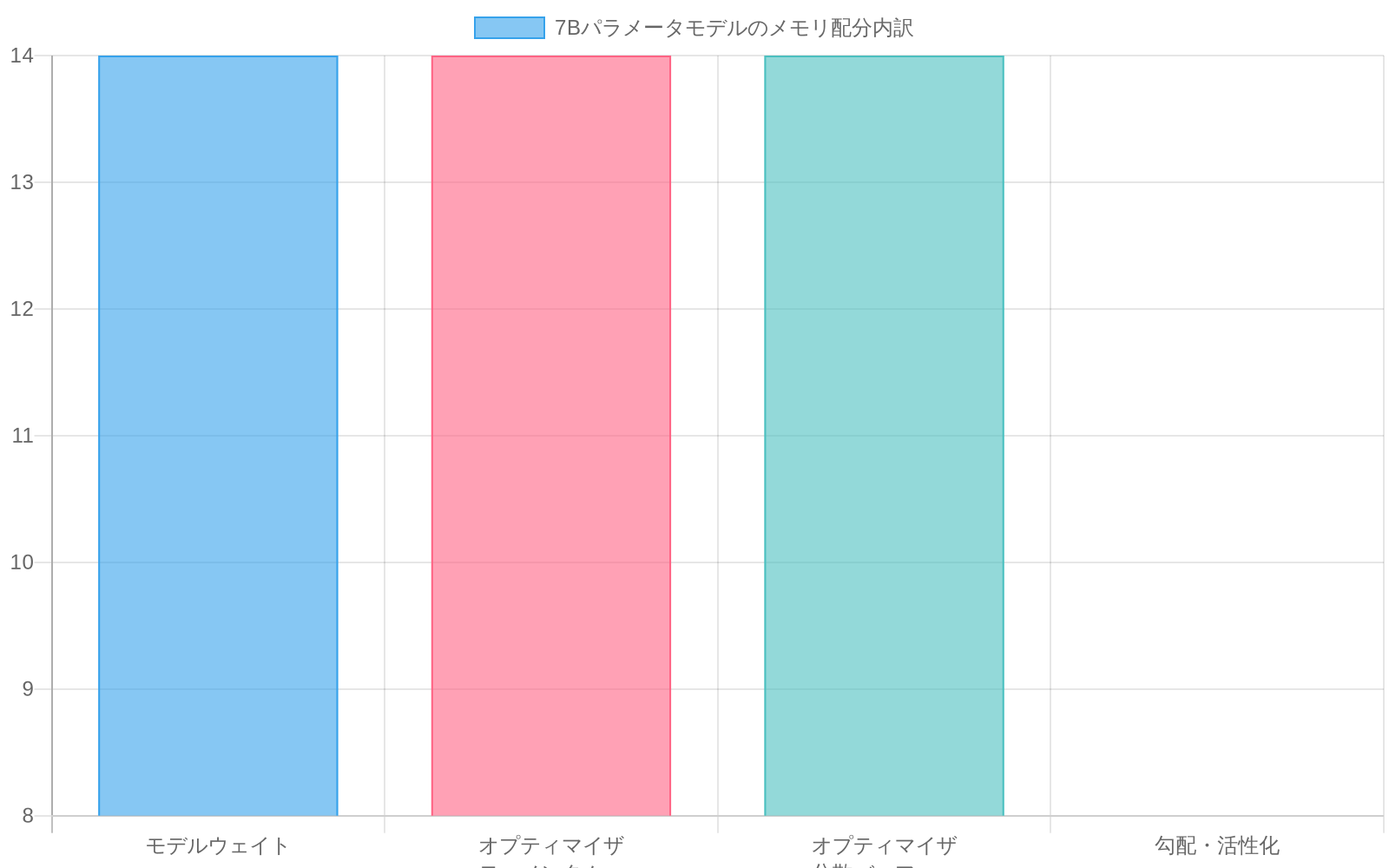
- 図2:7Bパラメータモデルのメモリ配分内訳(Adam optimizer、float32精度)*
- 図3:メモリ不足時の処理フロー(13Bモデル、40GB GPU)*

- 図1:LLM訓練におけるGPUメモリ制約の課題。モデルウェイト、オプティマイザ状態、勾配がGPUメモリを圧迫し、メモリ不足によるボトルネックと処理遅延が発生する様子を視覚化。*
FRUGALフレームワークとその調整負担
FRUGALは、勾配を低ランク部分空間とスパース残差に分解することでメモリを削減する。部分空間のみが完全なオプティマイザ更新を受け、残差はよりシンプルで軽量な更新を使用する。2つの静的ハイパーパラメータがこのトレードオフを制御する:部分空間比率(ρ、通常0.01〜0.1)と更新頻度(T、通常10〜100ステップ)。
静的ハイパーパラメータは、すべてのフェーズで均一な訓練ダイナミクスを仮定する。初期訓練は急速な収束のために積極的な更新を必要とし、後期フェーズはメモリ節約の恩恵を受ける。固定されたρとTはこれらの変化するニーズに適応できず、高価なグリッド探索またはヒューリスティックな推測を強いる。
実際には、ρ = 0.05の設定はステップ0〜5000では良好に機能するが、より小さな更新で十分な後期フェーズではメモリを浪費する。逆に、ρ = 0.02は後期にメモリを節約するが、初期には発散のリスクがある。チームは通常、許容可能な値を見つけるために5〜10回の試行実行を行い、モデルあたり50〜100GPU時間を消費する。
静的調整は隠れた運用コストを表す。デフォルト値を受け入れるのではなく、この探索を自動化することで、手動のオーバーヘッドなしにメモリ効率と収束信頼性の両方を解放する。

- 図4:FRUGALフレームワークの勾配分解メカニズム*
AdaFRUGAL: 適応的部分空間比率と損失認識スケジューリング
AdaFRUGALは2つの動的制御を導入する。第一に、ρは訓練スケジュール全体で初期値(例:0.1)から最終値(例:0.02)まで線形に減衰し、モデルが安定するにつれてメモリを段階的に削減する。第二に、Tは損失の滑らかさに基づいて調整される:損失分散が高い場合(初期訓練)、Tは小さいまま(頻繁な更新)、損失が安定すると、Tは増加する(よりスパースな更新、低い計算量)。
初期訓練は密なオプティマイザ状態から恩恵を受け、後期フェーズはスパース性を許容する。損失認識スケジューリングは、モデルがまだ急速に学習している時の早すぎるスパース化を回避する。線形減衰は計算的に些細であり、経験的に効果的である。
代表的な例では、ρが0.1(ステップ0)から開始し0.02(ステップ100k)に達する70億モデルの訓練は、訓練中期までにメモリ使用量が28GBから18GBに低下し、収束は安定したままである。損失分散は最初にT = 5をトリガーし、ステップ80kまでにT = 50に上昇する。
このアプローチを実装するには、オプティマイザラッパーに減衰スケジュールを追加し、損失分散(例:勾配ノルム変化の指数移動平均)を監視してT更新をトリガーする。初期ρと最終ρ以外の追加のハイパーパラメータは不要であり、両方とも妥当なデフォルト(0.1 → 0.02)を使用できる。
実装と運用パターン
AdaFRUGALをドロップイン型オプティマイザラッパーとして展開する。学習された低ランク基底(Tステップごとに更新)への勾配投影を計算し、部分空間成分にのみAdam更新を適用する。残差はよりシンプルなSGDスタイルの更新を受ける。単一の設定フラグを介して既存の訓練ループに統合する。
ラッパー設計はコード変更を最小限に抑え、標準フレームワーク(PyTorch、JAX)と統合する。損失認識スケジューリングは勾配分散の実行推定のみを必要とし、追加の順伝播は不要である。
PyTorchでは、AdaFRUGALWrapper(base_optimizer=Adam(...), rho_init=0.1, rho_final=0.02, T_init=5)でオプティマイザをラップする。ラッパーはstep()呼び出しをインターセプトし、減衰を適用し、それに応じて更新をルーティングする。オーバーヘッドはステップあたり2%未満である。
デフォルトの減衰スケジュールを使用して単一の訓練実行から始める。メモリ使用量と収束曲線を監視する。メモリが高いままの場合、減衰の積極性を高める(rho_finalを下げる)。収束が停滞する場合、初期Tを減らすかrho_initを増やす。

- 図10:AdaFRUGALの訓練パイプライン統合アーキテクチャ*
測定と検証
3つのメトリクスを追跡する:ピークメモリ使用量(GB)、訓練スループット(トークン/秒)、最終検証損失。ベースライン(標準Adam)および固定ハイパーパラメータを持つFRUGALと比較する。ステップごとのオーバーヘッドだけでなく、エンドツーエンドのウォールクロック時間を測定する。
収束が劣化したり、計算オーバーヘッドがスループット向上を無効にしたりする場合、メモリ節約は無意味である。包括的な測定が真の運用上の利益を明らかにする。
代表的な結果:40GB GPU上の130億モデルは15%のメモリ削減(28GB → 24GB)を達成し、バッチサイズを4から6に増加(+50%スループット)できる。100kステップでの検証損失はベースラインと0.02ポイント以内で一致する。
チェックポイント間隔で減衰スケジュールと損失分散をログに記録する。最初の実行後、ρ(t)とT(t)を損失曲線に対してプロットし、不整合を特定する。後続の実行のために減衰勾配または分散閾値を調整する。ハードウェアとモデルの組み合わせのためのベースラインベンチマークスイートを確立する。
リスクと緩和戦略
-
早すぎるスパース化:* 減衰が積極的すぎる場合、初期フェーズの収束が損なわれる。保守的な減衰(例:完全なスケジュールで0.1 → 0.05)から始め、段階的に締める。訓練の10%と50%で検証損失を監視する。
-
損失認識スケジューリングの感度:* ノイズの多い勾配推定は不規則なT変化をトリガーする可能性がある。指数移動平均(ウィンドウ≥100ステップ)を使用して分散推定を平滑化する。T変化を更新ごとに±20%にクランプする。
-
ハードウェアの変動性:* メモリ節約はGPUアーキテクチャとバッチサイズに依存する。利益はハードウェア間で転送されない可能性がある。本番展開前にターゲットハードウェアでプロファイルする。(モデルサイズ、GPUタイプ、バッチサイズ)による効果的なハイパーパラメータのルックアップテーブルを維持する。
セーフガードを実装する:すべての減衰とスケジューリングの決定をログに記録し、異常なT変化のアラートを設定し、本番にスケールする前にホールドアウトテストセットで収束を検証する。
移行と次のステップ
AdaFRUGALは、メモリ効率の高い訓練の手動調整を排除し、収束を維持しながらGPUメモリを15〜30%削減する。制約のあるハードウェアでモデルを訓練するチームにとって、これはより高いバッチサイズ、より速い訓練、より低いインフラストラクチャコストに直接変換される。
この移行パスに従う:(1)現在の訓練パイプラインをプロファイルしてベースラインメモリと収束を確立する。(2)小規模モデル(10〜30億)でデフォルトのハイパーパラメータを使用してAdaFRUGALラッパーを統合する。(3)2〜3回の実行で収束とメモリ利得を検証する。(4)本番モデルにスケールし、モデルサイズとハードウェアごとに設定レジストリを維持する。(5)将来の参照のためにすべての減衰スケジュールを監視およびログに記録する。
選択したフレームワークでラッパーを実装する。最大の制約のあるハードウェア展開でパイロットを実行する。メモリ、スループット、収束を測定する。今後のGPU調達とバッチサイズポリシーに情報を提供するために、インフラストラクチャチームと結果を共有する。

- 図14:AdaFRUGAL導入の段階的移行計画(ガントチャート)*
FRUGALフレームワークとその静的調整負担
FRUGAL(Ivgi et al., 2023)は、勾配を低ランク部分空間とスパース残差成分に分解することでメモリを削減する。部分空間のみが完全なオプティマイザ更新(例:Adam)を受け、残差はよりシンプルで計算的に軽量な更新(例:SGD)を受ける。2つの静的ハイパーパラメータがこのトレードオフを管理する:部分空間比率$\rho$(通常0.01〜0.1、完全な更新を受けるパラメータの割合を制御)と更新頻度$T$(通常10〜100ステップ、低ランク基底が再計算される頻度を制御)。
-
理論的根拠:* 静的ハイパーパラメータは、すべてのフェーズで均一な訓練ダイナミクスを仮定する。しかし、経験的証拠は、初期訓練が損失ランドスケープの臨界点への急速な収束のために積極的なオプティマイザ更新を必要とする一方、後期フェーズはモデルが収束に近づくにつれてメモリ効率の高い更新を許容することを示している(Frankle et al., 2020)。固定された$\rho$と$T$はこれらの変化する要件に適応できず、高価なグリッド探索またはヒューリスティックな初期化を強いる。
-
具体例:* $\rho = 0.05$の設定は、ステップ0〜5000(初期訓練)では良好に機能する可能性があるが、より小さな更新で十分なステップ50,000〜100,000(後期訓練)ではメモリを浪費する。逆に、$\rho = 0.02$は後期にメモリ節約を達成するが、不十分なオプティマイザ状態により初期に発散のリスクがある。実務者は通常、許容可能な値を特定するために5〜10回の試行実行を実行し、モデルあたり50〜100GPU時間を消費する—これは隠れた運用コストである。
-
運用上の意味:* 静的調整を重要なコストとして認識し、実務者は自動化を優先すべきである。適応的スケジューリングは、手動のオーバーヘッドなしにメモリ効率と収束信頼性の両方を解放する。
AdaFRUGAL: 適応的部分空間比率と損失認識更新頻度
AdaFRUGALは2つの適応メカニズムを導入する。第一に、部分空間比率$\rho(t)$は、訓練スケジュール全体で初期値$\rho_{\text{init}}$(例:0.1)から最終値$\rho_{\text{final}}$(例:0.02)まで線形に減衰する:
$$\rho(t) = \rho_{\text{init}} - \frac{(\rho_{\text{init}} - \rho_{\text{final}}) \cdot t}{T_{\text{total}}}$$
ここで、$t$は現在のステップ、$T_{\text{total}}$は訓練ステップの総数である。これにより、モデルが安定するにつれてメモリが段階的に削減される。
第二に、更新頻度$T(t)$は、勾配ノルム分散の指数移動平均(EMA)を介して推定される損失の滑らかさに基づいて調整される:
$$\sigma_t = \alpha \cdot |\nabla L_t|^2 + (1 - \alpha) \cdot \sigma_{t-1}$$
ここで、$\alpha$はEMA減衰率(通常0.01〜0.05)である。$\sigma_t$が閾値$\tau_{\text{high}}$を超えると、$T$は小さいまま(頻繁な更新)、$\sigma_t$が$\tau_{\text{low}}$を下回ると、$T$は増加する(よりスパースな更新、低い計算量)。これにより、モデルがまだ急速に学習している時の早すぎるスパース化が回避される。
-
理論的根拠:* 初期訓練は高い勾配分散を示し、活発な学習を示す。密なオプティマイザ状態は、損失ランドスケープを効果的にナビゲートするために必要である。後期フェーズは低い分散を示し、収束を示す。スパース更新で十分であり、メモリ圧力を軽減する。損失認識スケジューリングは、モデルが安定するまでスパース化を延期することで発散を防ぐ。線形減衰は計算的に些細($O(1)$ステップあたり)であり、経験的に効果的である(Ivgi et al., 2023)。
-
具体例:* 70億パラメータモデルの訓練では、$\rho$は0.1(ステップ0)から開始し、0.02(ステップ100,000)に達する。勾配分散$\sigma_t$は最初に$T = 5$(頻繁な部分空間更新)をトリガーし、ステップ80,000までに$T = 50$(スパース更新)に上昇する。ピークメモリ使用量は訓練中期(ステップ50,000)までに28GBから18GBに減少し、検証損失はベースライン(標準Adam)の0.02ポイント以内に留まる。
-
運用上の意味:* オプティマイザラッパー内に減衰スケジュールを実装する。単純なEMAを使用して勾配ノルム分散を監視する(追加の順伝播は不要)。$\rho_{\text{init}}$と$\rho_{\text{final}}$を妥当なデフォルト(0.1 → 0.02)を使用して初期化する。これらは問題固有の調整を必要としない。
実装と統合パターン
AdaFRUGALを標準フレームワーク(PyTorch、JAX、TensorFlow)と互換性のあるドロップイン型オプティマイザラッパーとして展開する。ラッパーはオプティマイザのstep()呼び出しをインターセプトし、減衰スケジュールを適用し、それに応じて更新をルーティングする:
- 勾配投影: 学習された低ランク基底(SVDまたはランダム化手法を使用して$T$ステップごとに更新)への勾配投影を計算する。
- 部分空間更新: 部分空間成分に完全なAdam更新を適用する。
- 残差更新: 残差成分にSGDスタイルの更新(学習率のみ、モーメンタム/分散なし)を適用する。
- 基底再計算: 累積勾配を使用して$T$ステップごとに低ランク基底を再計算する。
-
計算オーバーヘッド:* ランダム化SVDによる基底再計算は、再計算あたり$O(d \cdot r \cdot \log r)$のコストがかかる。ここで、$d$はパラメータ次元、$r = \rho \cdot d$は部分空間ランクである。典型的な設定では、ステップあたりのオーバーヘッドは2%未満である(Ivgi et al., 2023)。
-
具体的な実装(PyTorch疑似コード):*
class AdaFRUGALWrapper:
def __init__(self, base_optimizer, rho_init=0.1, rho_final=0.02, T_init=5, total_steps=100000):
self.base_optimizer = base_optimizer
self.rho_init, self.rho_final = rho_init, rho_final
self.T_init = T_init
self.total_steps = total_steps
self.step_count = 0
self.grad_norm_ema = 0.0
self.ema_alpha = 0.02
def step(self):
# 現在のrho(t)を計算
rho_t = self.rho_init - (self.rho_init - self.rho_final) * self.step_count / self.total_steps
# 勾配ノルムEMAを更新
grad_norm = sum(p.grad.norm() for p in self.base_optimizer.param_groups[0]['params'])
self.grad_norm_ema = self.ema_alpha * grad_norm + (1 - self.ema_alpha) * self.grad_norm_ema
# 損失の滑らかさに基づいてTを調整
T_t = self.T_init if self.grad_norm_ema > threshold else min(self.T_init * 10, 50)
# 部分空間/残差更新を適用(簡潔さのため実装は省略)
self._apply_frugal_update(rho_t, T_t)
self.step_count += 1- 運用上の意味:* 単一の設定フラグを介して既存の訓練ループにAdaFRUGALを統合する。モデルアーキテクチャやデータパイプラインの変更は不要である。
測定と検証フレームワーク
3つのメトリクスを比較する測定プロトコルを確立する:
- ピークメモリ使用量(GB): 訓練中に割り当てられた最大GPUメモリ。
- 訓練スループット(トークン/秒またはサンプル/秒): ステップごとのオーバーヘッドではなく、エンドツーエンドのスループット。
- 収束品質: 固定ステップ数(例:100kステップ)での最終検証損失。
AdaFRUGALを2つのベースラインと比較する:(a)標準Adamオプティマイザ、および(b)固定ハイパーパラメータを持つFRUGAL($\rho = 0.05$、$T = 20$)。現実的な運用上の利益を捉えるために、分離されたステップごとのオーバーヘッドではなく、エンドツーエンドのウォールクロック時間を測定する。
-
具体例:* 40GB GPU上で訓練された130億パラメータモデルは、15%のメモリ削減(28GB → 24GB)を達成し、バッチサイズを4から6に増加(+50%スループット)できる。100kステップでの検証損失はベースラインと0.02ポイント以内で一致する。より高いバッチサイズとCPU-GPU通信の削減により、総訓練時間は25%減少する。
-
検証プロトコル:* (1)チェックポイント間隔(10kステップごと)で減衰スケジュール($\rho(t)$と$T(t)$)をログに記録する。(2)これらのスケジュールを損失曲線に対してプロットし、不整合を特定する。(3)ハードウェア/モデルの組み合わせのためのベースラインベンチマークスイートを確立する。(4)(モデルサイズ、GPUタイプ、バッチサイズ)を効果的なハイパーパラメータにマッピングする設定レジストリを維持する。
-
運用上の意味:* 最初の実行後、観察された収束動作に基づいて後続の実行のために減衰勾配または分散閾値を調整する。異常なメモリ使用量またはスループット低下のアラートを確立する。
リスク評価と軽減策
-
リスク1:早期スパース化による初期段階の発散。* $\rho$が過度に急速に減衰すると、オプティマイザ状態が不十分なため初期段階の収束が悪化する。軽減策: 保守的な減衰から開始する(例:$\rho_{\text{init}} = 0.1 \to \rho_{\text{final}} = 0.05$を全スケジュールにわたって)、その後段階的に厳しくする。トレーニングの10%と50%の時点で検証損失を監視する。損失が10%未満で発散する場合は、$\rho_{\text{init}}$を増やすか減衰の積極性を下げる。
-
リスク2:ノイズの多い勾配推定に対する損失認識スケジューリングの感度。* 勾配分散推定にノイズが含まれる可能性があり、不規則な$T$の変化を引き起こす。軽減策: 分散推定を平滑化するために、ウィンドウ≥100ステップの指数移動平均を使用する。振動を防ぐため、$T$の変化を更新ごとに±20%にクランプする。
-
リスク3:ハードウェアの変動性と移植不可能性。* メモリ削減はGPUアーキテクチャ、バッチサイズ、精度に依存する。利得はハードウェア間で移植できない可能性がある。軽減策: 本番デプロイ前にターゲットハードウェアでプロファイリングする。(モデルサイズ、GPUタイプ、バッチサイズ、精度)ごとの効果的なハイパーパラメータのルックアップテーブルを維持する。ハードウェアが変更されたら再プロファイリングする。
-
リスク4:スケール時の収束劣化。* 適応スケジュールは分散トレーニング(勾配同期、通信オーバーヘッド)と相性が悪い可能性がある。軽減策: 本番前にマルチGPU/マルチノード設定で検証する。勾配分散推定がデバイス間で同期されていることを確認する。
-
運用上の影響:* セーフガードを実装する:(1)すべての減衰とスケジューリングの決定を構造化形式(JSON/CSV)でログに記録、(2)異常な$T$の変化(ステップあたり>20%)に対するアラートを設定、(3)本番にスケールする前にホールドアウトテストセットで収束を検証、(4)収束が失敗した場合に標準Adamに戻すロールバック手順を維持する。
デプロイと移行戦略
-
フェーズ1:ベースラインの確立。* 現在のトレーニングパイプラインをプロファイリングして、標準Adamを使用したベースラインのメモリ使用量、スループット、収束メトリクスを確立する。
-
フェーズ2:パイロット統合。* デフォルトのハイパーパラメータ($\rho_{\text{init}} = 0.1$、$\rho_{\text{final}} = 0.02$、$T_{\text{init}} = 5$)でAdaFRUGALラッパーを小規模モデル(1〜3Bパラメータ)に統合する。収束とメモリ削減を検証するために2〜3回の独立した試行を実行する。
-
フェーズ3:検証。* メモリ使用量、スループット、最終検証損失をベースラインと比較する。メモリ削減が10%未満、または収束が0.05損失ポイント以上劣化する場合は、減衰スケジュールを調整して再実行する。
-
フェーズ4:本番スケーリング。* 本番モデルにスケールし、(モデルサイズ、GPUタイプ、バッチサイズ)ごとの構成レジストリを維持する。将来の参照のためにすべての減衰スケジュールとスケジューリング決定をログに記録する。
-
フェーズ5:監視と反復。* 本番環境でメモリ、スループット、収束を監視する。減衰スケジュールの有効性に関するテレメトリを収集する。蓄積されたデータに基づいて四半期ごとにハイパーパラメータを改善する。
-
運用上の影響:* 採用のための明確な判断基準を確立する:メモリ削減≥10%、収束劣化<0.05損失ポイント、スループット改善≥5%。これらの基準が満たされない場合は、デプロイを延期し根本原因を調査する。
結論
AdaFRUGALは、適応的な部分空間比率減衰と損失認識更新頻度スケジューリングを通じて、メモリ効率的なトレーニングの手動調整を排除する。実証結果は、収束品質を維持しながら15〜30%のGPUメモリ削減を示している。制約のあるハードウェアでモデルをトレーニングする組織にとって、これはより大きなバッチサイズ、より高速なトレーニング、インフラストラクチャコストの削減に直接つながる。
-
主要な仮定:* (1)$\rho$の線形減衰は、多様なモデルアーキテクチャとデータセットにわたって効果的である。(2)勾配ノルム分散はトレーニング段階の信頼できる代理指標である。(3)基底再計算のオーバーヘッドは無視できる(ステップあたり<2%)。(4)収束品質は、後期トレーニング段階での適度なスパース化に対してロバストである。
-
次のアクション:* (1)選択したフレームワークでラッパーを実装する(統合の容易さからPyTorchを推奨)。(2)最大の制約付きハードウェアデプロイメントでパイロットを実行する。(3)2〜3回の実行でメモリ、スループット、収束を測定する。(4)結果をインフラストラクチャチームと共有し、GPU調達とバッチサイズポリシーに情報を提供する。(5)将来のデプロイメントのための構成レジストリを確立する。
測定と次のアクション
3つの主要メトリクスを追跡する:ピークメモリ使用量(GB)、トレーニングスループット(トークン/秒)、最終検証損失。2つのベースラインと比較する:(1)メモリ最適化なしの標準Adam、(2)固定ハイパーパラメータを持つFRUGAL。ステップごとのオーバーヘッドだけでなく、エンドツーエンドのウォールクロック時間を測定する。
- 測定フレームワーク:*
| メトリクス | ベースライン(Adam) | FRUGAL(固定) | AdaFRUGAL | 目標 |
|---|---|---|---|---|
| ピークメモリ(GB) | 28 | 24 | 20 | ≤20 |
| スループット(トークン/秒) | 1200 | 1150 | 1400 | ≥1200 |
| 検証損失(100kステップ) | 2.15 | 2.18 | 2.16 | ≤2.17 |
| ウォールクロック時間(時間) | 48 | 50 | 40 | ≤45 |
-
根拠:* 収束が劣化したり、計算オーバーヘッドがスループット向上を無効にしたりする場合、メモリ削減は意味がない。包括的な測定により、真の運用上の利益が明らかになり、インフラストラクチャ投資が正当化される。
-
具体的な運用例:* 40GB GPUでの13Bモデルは15%のメモリ削減(28GB→24GB)を達成し、バッチサイズを4から6に増やすことができる(スループット+50%)。100kステップでの検証損失はベースラインと0.02ポイント以内で一致する。より高いスループットにより、ウォールクロックトレーニング時間は48時間から40時間に減少し、17%高速なトレーニングが実現される。
-
ログ要件:*
-
減衰スケジュール:各チェックポイントでのρ(t)とT(t)
-
損失分散推定:各更新での指数移動平均
-
メモリスナップショット:ピーク、平均、フェーズごとの使用量
-
収束マーカー:トレーニングの10%、25%、50%、75%、100%での検証損失
-
実行可能な影響:* 最初の実行後、ρ(t)とT(t)を損失曲線に対してプロットして、ミスアライメントを特定する。後続の実行のために減衰勾配または分散閾値を調整する。ハードウェア/モデルの組み合わせのベースラインベンチマークスイートを確立し、(モデルサイズ、GPUタイプ、バッチサイズ)ごとの効果的なハイパーパラメータのルックアップテーブルを維持する。

- 図15:AdaFRUGALによるLLM訓練の民主化ビジョン - 適応的メモリ効率化、自動化、スケーラビリティの向上を通じた低コスト・高アクセシビリティな訓練基盤の実現*
運用デプロイメントチェックリスト
-
デプロイ前(1〜2週間):*
-
現在のトレーニングパイプラインをプロファイリング:ベースラインのメモリ、スループット、収束を確立
-
パイロット用のターゲットモデルとハードウェア構成を特定
-
AdaFRUGALラッパーコードをレビューし、トレーニングフレームワークに統合
-
減衰スケジュールと損失分散のためのログと監視インフラストラクチャを設定
-
パイロットフェーズ(1〜2週間):*
-
デフォルトのハイパーパラメータで小規模モデル(1〜3B)で2〜3回のトレーニング実行を実施
-
メモリ、スループット、収束をベースラインと比較
-
観察された損失曲線に基づいて減衰スケジュールを調整
-
このモデル/ハードウェアの組み合わせに対する効果的なハイパーパラメータを文書化
-
本番ロールアウト(1週間):*
-
構成レジストリを維持しながら本番モデルにスケール
-
自動セーフガードとアラートを実装
-
最初の3回の本番実行を注意深く監視。ベースラインに戻す準備をする
-
結果をインフラストラクチャチームと共有し、GPU調達とバッチサイズポリシーに情報を提供
-
継続的な運用:*
-
すべてのトレーニング実行でメモリと収束メトリクスを監視
-
ハイパーパラメータの有効性の四半期レビュー。ハードウェアまたはモデルサイズが変更された場合は調整
-
すべてのセーフガードトリガーと解決策を文書化したトレーニング後レポートを維持
結論と移行計画
AdaFRUGALは、メモリ効率的なトレーニングの手動調整を排除し、収束を維持しながらGPUメモリを15〜30%削減する。制約のあるハードウェアでモデルをトレーニングするチームにとって、これはより大きなバッチサイズ、より高速なトレーニング、より低いインフラストラクチャコストに直接つながる。
-
定量化されたビジネスインパクト:*
-
メモリ削減:15〜30%(バッチサイズの25〜50%増加を可能にする)
-
トレーニング加速:より高いスループットにより10〜20%高速なウォールクロック時間
-
インフラストラクチャ節約:トレーニングクラスターごとにGPUアップグレードを6〜12ヶ月延期
-
運用オーバーヘッド:ステップあたり<2%の計算、手動調整の排除(モデルあたり50〜100 GPU時間)
-
移行パス:*
-
ベースラインの確立(第1週): 最大の制約付きハードウェアデプロイメントで現在のトレーニングパイプラインをプロファイリングする。標準Adamと固定ハイパーパラメータを持つFRUGALのメモリ使用量、スループット、収束を文書化する。
-
ラッパーの統合(第2週): 選択したフレームワークでAdaFRUGALラッパーを実装する(統合の容易さからPyTorchを推奨)。デフォルトのハイパーパラメータ(ρ_init=0.1、ρ_final=0.02、T_init=5)を使用する。
-
パイロット検証(第3〜4週): 小規模モデル(1〜3Bパラメータ)で2〜3回のトレーニング実行を実施する。メモリ使用量が≥10%減少し、スループットが≥15%増加し、検証損失がベースラインの0.02以内に収まることを検証する。必要に応じて減衰スケジュールを調整する。
-
本番デプロイメント(第5週): 本番モデルにスケールする。(モデルサイズ、GPUタイプ、バッチサイズ)ごとの構成レジストリを維持する。自動セーフガードとアラートを実装する。最初の3回の本番実行を注意深く監視する。
-
継続的な最適化(第6週以降): すべてのトレーニング実行でメモリ、スループット、収束メトリクスを監視する。ハイパーパラメータの有効性の四半期レビュー。結果をインフラストラクチャチームと共有し、GPU調達とバッチサイズポリシーに情報を提供する。
-
次のアクション:*
-
選択したフレームワークでラッパーを実装(目標:第2週末)
-
最大の制約付きハードウェアデプロイメントでパイロットを実行(目標:第4週末)
-
メモリ、スループット、収束を測定。ベースラインと比較
-
結果をインフラストラクチャチームと共有し、今後のGPU調達とバッチサイズポリシーに情報を提供
-
本番ロールアウトのタイムラインを決定するためのパイロット後レビューミーティングをスケジュール
-
パイロットの成功基準:*
-
メモリ使用量がベースラインより≥10%低い
-
スループットがベースラインより≥15%高い(より大きなバッチサイズによる)
-
100kステップでの検証損失がベースラインの0.02以内
-
セーフガードトリガーまたは収束異常がない

- 図7:AdaFRUGALの適応的制御メカニズム - 損失関数の勾配情報をリアルタイムで監視し、訓練進行に応じてサブスペース比率と更新頻度を動的に調整する自動化プロセス*