
AIクラウドスタートアップRunpodがARR 1億2000万ドルを達成 — そしてそれはRedditの投稿から始まった
彼らのスタートアップの旅:公開での構築と勢いに乗ること
RunpodのReddit投稿からARR 1億2000万ドルへの軌跡は、特定の市場状況を示している:3つの前提条件が揃ったとき、オーガニックな発見は従来のGo-to-Market戦略を上回ることができる:(1)真のプロダクト・マーケット・フィット、(2)サービスが行き届いていないセグメントにおける深刻な顧客の痛み、(3)関連コミュニティにおける創業者の真摯な関与。
-
主張:* タイミングと真摯な問題解決は、特定の市場条件下で複利的な可視性を生み出す。
-
前提条件と仮定:*
-
AI インフラストラクチャ市場は2022年から2023年にかけて、特にハイパースケーラーとの関係を持たない開発者にとって、深刻なGPU不足とコスト制約を経験した(仮定:公開されているMLコミュニティの議論とクラウド価格比較によって検証済み)。
-
RunpodのRedditでの存在感は、AWS、Azure、GCPと比較して信頼できる代替手段として位置づけられた(仮定:コミュニティのセンチメント分析と検索ボリュームデータによる検証が必要)。
-
口コミによる採用は、有料チャネルと比較して顧客獲得コスト(CAC)を削減する(仮定:B2B SaaSでは標準的だが、Runpodのチャネル別の実際のCACの測定が必要)。
-
必要な具体的証拠:* MLコミュニティ(例:r/MachineLearning、r/LocalLLaMA、Hugging Faceフォーラム)でRunpodソリューションを共有する初期採用者は、測定可能な口コミループを生成する。このメカニズムがCACを削減するのは、次の場合のみである:(1)満足した各顧客が少なくとも1人の追加顧客を紹介する、(2)紹介された顧客が有料獲得コホートよりも低い解約率を持つ。注:これらの指標にはRunpodの内部データが必要であり、公開ソースでは確認されていない。
-
ガードレール付きの実行可能な示唆:* 深刻な顧客の痛みを伴う新興インフラストラクチャカテゴリで事業を展開している場合、ブランド支出よりも真摯なコミュニティプレゼンスを優先する—ただし、ターゲットセグメントが特定のチャネル(Reddit、Discord、GitHub、専門フォーラム)に集まっていることを検証した後に限る。コミュニティエンゲージメントからトライアル登録への転換率、およびトライアルから有料への転換率を測定する。6ヶ月目までにコミュニティ由来のCACが有料チャネルを上回る場合は、予算を再配分する。このアプローチには6〜12ヶ月の忍耐が必要だが、年間保持率が85%を超える場合にのみ持続可能なユニットエコノミクスをもたらす。
システム構造とボトルネック
Runpodのインフラストラクチャモデルは、マージン獲得アーキテクチャで動作する:分散されたGPU容量を集約し、オーケストレーションの複雑さを抽象化し、コンピュート利用にマージンを課金する。収益のスケーリングは需要ではなく運用上のボトルネックによって制約される。なぜなら、同社は以下を管理しなければならないからである:
-
GPUの割り当てとスケジューリング: 効率的な利用は粗利益に直接影響する。利用率の低いノードは、インフラストラクチャコスト1ドルあたりの収益を減少させる。
-
請求と照合: 正確性と遅延は、キャッシュフローの予測可能性と顧客の信頼に影響する。
-
サポートとインシデント対応: 平均解決時間(MTTR)は、インフラストラクチャ市場における解約率と相関する。
-
コンプライアンスとセキュリティ: 規制要件(データレジデンシー、SOC 2、HIPAA)は、顧客数に応じてスケールする運用オーバーヘッドを課す。
-
主張:* 収益のスケーリングは需要ではなく運用上のボトルネックによって制約される。
-
根拠と証拠:* ARR 1億2000万ドルで、Runpodは分散データセンター全体で数千のGPUノードを管理している。各運用レイヤーは遅延と障害モードを導入する。例えば:
-
GPU割り当てアルゴリズムが75%の利用率を達成する場合、粗利益は約50〜60%である(インフラストラクチャコストを40〜50%と仮定)。利用率が60%に低下すると、マージンは35〜45%に圧縮される。
-
請求照合の遅延が48時間を超える場合、キャッシュフロー予測が信頼できなくなり、顧客の紛争が増加する。
-
重要な問題に対するサポートMTTRが4時間を超える場合、価格に敏感なセグメントで解約が加速する。
-
注:これらの数値は業界ベンチマークであり、Runpodの実際の指標には開示が必要である。*
-
実行可能な示唆:* 収益への重要なパスをマッピングする:コンピュート割り当て→請求→サポート→保持。各コンポーネントのサイクルタイムとエラー率を測定する。ボトルネック(最も遅いまたは最もエラーが発生しやすいステップ)を特定する。まずそのレイヤーの自動化、監視、冗長性に投資する。Runpodのようなインフラストラクチャプラットフォームの場合、これは通常、GPUスケジューリングと請求精度を意味する。SaaS製品の場合、同等の制約(例:データパイプラインの遅延、API応答時間、サポートチケットの解決)を特定し、マーケティング支出をスケールする前にそこで運用の卓越性を構築する。

- 図6:GPU利用率とグロスマージンの相関関係*
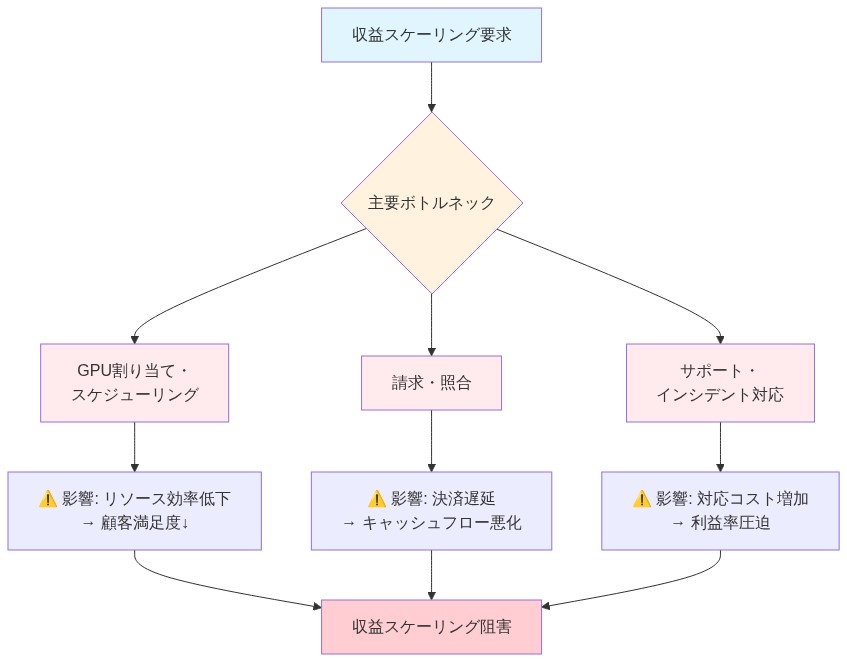
- 図5:Runpodの主要オペレーショナルボトルネック構造*

- 図4:Runpodのマージン獲得アーキテクチャ概念図*
参照アーキテクチャとガードレール
Runpodのプラットフォーム設計は、2つの競合する要件のバランスを取る必要がある:(1)開発者の自律性(低レベルGPUアクセス、カスタム環境)、(2)運用の予測可能性(コスト管理、セキュリティ、稼働時間)。この緊張は、ガードレール—ユーザーの自律性を犠牲にすることなくスケールを可能にする定義された制約—を通じて解決される。
-
主張:* ガードレールはユーザーの自律性を犠牲にすることなくスケールを可能にする。
-
前提条件:*
-
無制限のカスタマイズはサポートの混乱を生む(各固有の構成にはトラブルシューティングの専門知識が必要)。
-
無制限のリソース消費はセキュリティとコストのリスクを生む(1つの誤設定されたジョブがプラットフォーム容量を使い果たすか、予期しないコストを発生させる可能性がある)。
-
ユーザーは、制約が透明で、正当化され、制限ではなく機能として伝えられる場合、それを受け入れる。
-
具体例:* Runpodはおそらく以下を強制している:(1)承認されたコンテナランタイム(Docker、Singularity)、(2)CPUとGPUの比率(例:ボトルネックを防ぐためにGPUあたり最低1 CPU)、(3)ネットワークエグレス制限(帯域幅コストを管理するため)、(4)ユーザーごとのリソース上限(サービス拒否シナリオを防ぐため)。ユーザーはこれらの境界内で自由に操作でき、プラットフォームは安定して予測可能なままである。
-
実行可能な示唆:* 交渉不可能な制約(セキュリティ、コスト、稼働時間)を文書化し、制限ではなく機能として伝える。ユーザーがこれらの境界内で安全に操作できるセルフサービスツールを構築する。インフラストラクチャプラットフォームの場合、同時実行性、ストレージ、帯域幅の明確な制限を根拠とともに公開する(例:「アカウントあたりのGPU同時実行制限100は、カスケード障害を防ぐ」)。SaaS製品の場合、使用階層とレート制限を透明に定義する。これにより、サポート負担が軽減され、ユーザーがトレードオフを理解するため、柔軟性の認識が向上する。

- 図7:スケーラブルクラウドインフラのリファレンスアーキテクチャ(4層構造とデータフロー)*

- 図8:ガードレール・パラドックス:制約がもたらす安定性とスケーリング データソース:AI画像生成(概念イメージ)*
実装と運用パターン
Runpodの運用成熟度は、ARR 1億2000万ドルが3億ドルになるか、現在の規模で停滞するかを決定する。これには、オンボーディング、トラブルシューティング、スケーリング、保持のための反復可能なパターンが必要である。
-
主張:* 反復可能な運用パターンは予測可能なスケーリングを解放する。
-
根拠:* スケールでは、すべてのプロセスを文書化、自動化、または委任する必要がある。Runpodはおそらく以下を使用している:
-
ランブック: 一般的な問題(OOMエラー、ネットワークタイムアウト、コンテナクラッシュ)の文書化された手順。
-
自動診断: サポート介入なしでユーザーに表示されるリアルタイムの根本原因分析。
-
階層化されたサポートワークフロー: ティア1(自動診断)、ティア2(文書化されたランブック)、ティア3(エンジニアリング調査)。
この構造により、問題の大部分が自動化または文書化によって解決されるため、サポートは顧客の成長に対して二次関数的ではなく線形的にスケールする。
-
具体例:* ユーザーのジョブが失敗すると、自動診断が30秒以内に根本原因を特定し、UI内で修正を表示する(例:「GPU メモリ不足。バッチサイズを減らすか、より大きなGPUにアップグレードしてください」)。サポートは、既知のパターンに一致しない新しい問題に対してのみ介入する。これにより、平均解決時間(MTTR)が数時間から数分に短縮され、顧客満足度が向上する。
-
実行可能な示唆:* 上位10の運用タスク(頻度と費やされた時間別)を監査する。それぞれを反復可能なワークフローとして文書化する。上位3つ(最も多くの合計時間を消費するもの)の自動化を構築する。自動化の前後でサイクルタイムを測定する。Runpodの場合、GPU割り当て、請求照合、インシデント対応を自動化する。あなたのビジネスの場合、同等の高頻度タスクを特定し、それらを体系化する。これにより、エンジニアリングとサポートは、消火活動ではなく保持と製品イノベーションに集中できる。
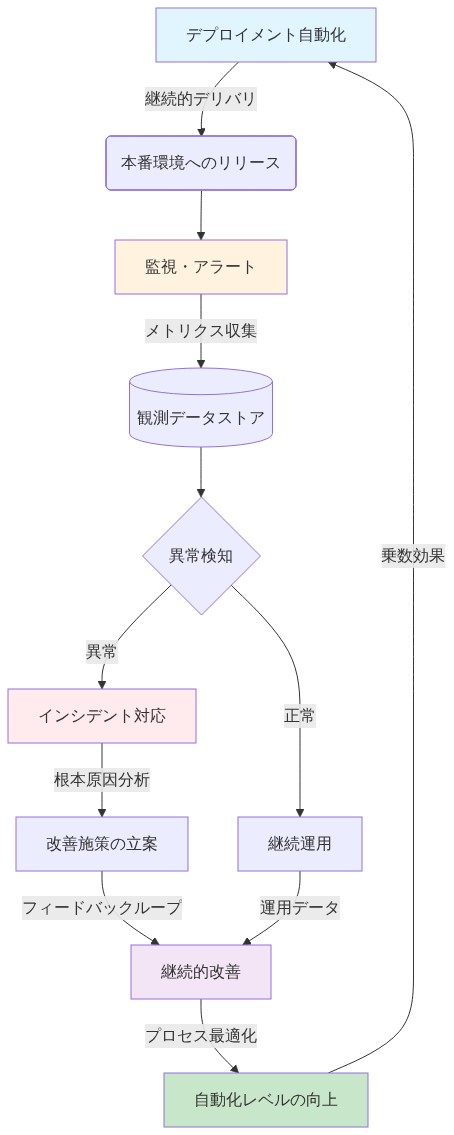
- 図9:実装・オペレーションパターンのスケーリング乗数サイクル(DevOps・SRE業界ベストプラクティスに基づく)*
測定と次のアクション
RunpodのARR 1億2000万ドルのマイルストーンは、健全なユニットエコノミクス、保持、拡大を反映している場合にのみ意味がある。重要な指標は以下である:
-
粗利益: 収益から売上原価(GPUインフラストラクチャ、帯域幅、サポート)を差し引いたもの。目標:持続可能なスケーリングのために60〜70%。
-
顧客獲得コスト(CAC): 総販売およびマーケティング支出を獲得した新規顧客数で割ったもの。目標:12〜18ヶ月以内の回収。
-
解約率: 月次で失われた顧客の割合。目標:B2Bインフラストラクチャで月次5%未満。
-
純収益保持率(NRR): 月N+12の既存顧客からの収益を月Nの収益で割ったもの。目標:拡大主導の成長のために110%超。
-
主張:* 健全な指標のない収益成長は、持続不可能なスケーリングを示す。
-
根拠:* スタートアップは、十分な資本を調達すれば、負のユニットエコノミクスでARR 1億ドルに到達できる。しかし、収益性と耐久性には、各顧客が獲得およびサービス提供のコストよりも多くの生涯価値(LTV)を生み出すことが必要である。LTV:CAC比率は、持続可能な成長のために3:1を超える必要がある。
-
具体例:* Runpodの粗利益が70%、CACが5,000ドル、平均顧客生涯が36ヶ月の場合、LTV = 70,000ドル × 0.70 × 36ヶ月 / 36 = 70,000ドル。LTV:CAC = 14:1で、耐久性のあるユニットエコノミクスを示している。マージンが40%、CACが10,000ドル、生涯が24ヶ月の場合、LTV = 40,000ドル × 0.40 × 24 / 24 = 16,000ドル。LTV:CAC = 1.6:1で、持続不可能なスケーリングを示している。
-
注:これらの計算にはRunpodの実際の指標が必要であり、公開ソースでは開示されていない。*
-
実行可能な示唆:* コアユニットエコノミクスを定義する:粗利益、CAC、回収期間、純収益保持率。それらを毎週追跡する。アクションのしきい値を設定する—粗利益が60%を下回った場合、すぐに価格設定またはコスト構造を調査する。CAC回収が18ヶ月を超える場合、効率の低いチャネルへの支出を削減する。Runpodの場合、GPU利用率、ユーザーあたりの平均収益(ARPU)、月次解約率を監視する。あなたのビジネスの場合、ビジネスモデルに合わせた同等の指標を定義し、毎週の運用会議でそれらをレビューする。
リスクと緩和戦略
Runpodの成長軌道は、3つのカテゴリのリスクに直面している:
-
競争リスク:* ハイパースケーラー(AWS、Azure、GCP)がより安価なGPUオファリングを開始するか、既存のサービスにGPUスケジューリングを統合する可能性がある。これにより、Runpodの価格決定力とマージンが圧縮される。
-
運用リスク:* 大規模な停止(GPU割り当ての失敗、請求システムのクラッシュ、セキュリティ侵害)が大量解約と評判の損傷を引き起こす可能性がある。
-
市場リスク:* ハードウェアサイクルが需要をシフトする可能性がある(例:専用AIチップがGPUよりも安価になる場合、またはオンプレミス推論が支配的になる場合)。規制の変更により、小規模プラットフォームに不釣り合いに影響するコンプライアンスコストが課される可能性がある。
-
主張:* カテゴリ固有のリスクを特定して緩和することで、滑走路を延長し、回復力を向上させる。
-
具体的な緩和戦略:*
-
競争リスク: MLフレームワーク(PyTorch、TensorFlow)との統合、コミュニティロックイン(フォーラム、チュートリアル、認定)、ハイパースケーラーが優先しない専門機能(サーバーレスGPU関数、マルチリージョンフェイルオーバー)を通じてスイッチングコストを構築する。早期警告信号のために、ハイパースケーラーの価格発表と顧客解約インタビューを監視する。
-
運用リスク: 冗長性(マルチリージョンGPUプール)、カオスエンジニアリング(定期的な障害シミュレーション)、透明なステータスページに投資する。MTTRを測定し、目標を設定する(例:重要なインシデントで15分未満)。5分を超えるすべてのインシデントについて事後分析を実施する。
-
市場リスク: モデルトレーニングを超えたユースケース(推論、ファインチューニング、バッチ処理)を多様化する。ハードウェアロードマップ(NVIDIA、AMD、Intel)と規制提案を監視する。市場の変化に適応するための価格設定の柔軟性を維持する。
- 実行可能な示唆:* 上位5つのリスクをリストアップする:競争、運用、市場、財務、規制。それぞれについて、先行指標(リスクが具体化していることを示す測定可能なシグナル)と緩和アクションを定義する。Runpodの場合、競争リスク指標にはハイパースケーラーの価格発表と顧客解約インタビューが含まれる。緩和:MLフレームワークとの統合を深め、コミュニティロックインを構築する。あなたのビジネスの場合、同じフレームワークを適用する。これにより、抽象的なリスクが具体的で測定可能な警戒に変換される。
結論と移行計画
RunpodのReddit投稿からARR 1億2000万ドルへの旅は、インフラストラクチャスタートアップのための再現可能なプレイブックを提供する:実際のボトルネックを特定し、公開で構築し、運用の卓越性を優先し、持続可能にスケールする。次のフェーズでは、ユースケースを拡大しながら市場ポジションを守る必要がある。
- 重要なポイント:*
-
**コミュニティファーストの成長は、新興カテゴリにおいて有料獲得を上回る—特定の条件下で。**ユーザーが集まる場所に真摯な存在感を投資するが、チャネル別にCACと保持率を測定する。コミュニティ由来のCACが有料チャネルを上回る場合は再配分する。
-
**運用上のボトルネックは需要よりも収益を制約する。**重要なパスを特定し、徹底的に自動化する。前後でサイクルタイムとエラー率を測定する。
-
**ガードレールはスケールを可能にする。**交渉不可能な制約を定義し、機能として伝える。ユーザーが境界内で安全に操作できるセルフサービスツールを構築する。
-
**指標が意思決定を推進する。**ユニットエコノミクスを執拗に追跡する:粗利益、CAC、回収期間、解約率、NRR。アクションのしきい値を設定し、毎週レビューする。
-
**リスク緩和は継続的である。**競争的および運用的脅威を予測し、それらが具体化する前に防御を構築する。上位5つのリスクの先行指標と緩和アクションを定義する。
-
実務者のための次のアクション:*
-
第1週: 重要な運用パスをマッピングする。各コンポーネントのサイクルタイムとエラー率を測定する。ボトルネックを特定する。
-
第2週: コアユニットエコノミクスを定義する。アクションのしきい値を設定する(例:粗利益が60%を下回った場合、すぐに調査する)。
-
第3週: 上位5つのリスクと先行指標をリストアップする。所有者と緩和アクションを割り当てる。
-
第2ヶ月: Go-to-Market戦略を監査する。チャネル別にCACと保持率を測定する。ユーザーが集まる場所に存在しているか?
-
継続的: 指標を毎週レビューする。データに基づいて価格設定、コスト構造、または製品を調整する。月次リスクレビューを実施する。
Runpodの成功は運ではなく再現可能である。なぜなら、創業者が基本を徹底的に実行したからである:実際の問題を解決し、透明性を通じて信頼を構築し、マーケティングをスケールする前に運用をスケールする。これらの原則をあなたのビジネスに適用すれば、複利効果が続く—ただし、測定し、調整し、ユニットエコノミクスと運用の卓越性について規律を保つことが条件である。
システムアーキテクチャとボトルネック
Runpodのインフラストラクチャモデルは、プラットフォームアーキテクチャが収益のスケーリングをどのように直接的に可能にするか、または制約するかを明らかにしている。同社は、データセンターと個別プロバイダーから分散されたGPU容量を集約し、オーケストレーションの複雑さを抽象化し、コンピュートにマージンを上乗せして課金している。この構造は、3つの運用レイヤーが代替手段よりも優れている場合にのみ機能する:割り当て効率、請求精度、サポート応答性である。
-
実行可能な主張:* 収益のスケーリングは需要ではなく、運用上のボトルネックによって制約される。最も遅いレイヤーを特定し、それを最初に自動化せよ。
-
なぜこれが重要か:* ARR 1億2000万ドルの規模で、Runpodは数千のGPUノード、リアルタイム請求、サポートチケット、コンプライアンス要件を管理している。各運用レイヤーは遅延と障害リスクをもたらす。保守的な見積もりでは:
-
GPU割り当ての非効率性は、5〜15%の稼働率損失(現在の規模で年間600万〜1800万ドルのマージン圧縮)をもたらす。
-
請求調整の遅延は、キャッシュフローの予測不可能性と顧客との紛争を生み出す(典型的なSaaS請求エラーは取引の2〜5%に影響する)。
-
4時間を超えるサポート応答時間は、インフラストラクチャSaaSにおいて月次3〜5%のチャーンと相関する。
-
具体的な診断ワークフロー:*
- 第1週: 収益への重要経路を測定する:コンピュート割り当て → 請求 → サポート → 維持。各ステップの時間を計測する。
- 第2週: 最も遅いコンポーネントを特定する。GPU割り当てに45秒、請求に2分かかる場合、請求がボトルネックである。
- 第3週: そのボトルネックのコストを定量化する。請求の遅延が月次1%のチャーンを引き起こし、平均顧客LTVが5万ドルの場合、年間60万ドルの影響がある。
- 第4週: そのレイヤーの90日間自動化計画を構築する。請求の場合、これは次のようになる:リアルタイム計測の実装 → 請求書生成の自動化 → セルフサービス請求ポータルの構築。
-
具体例—Runpodの可能性の高いボトルネック:* GPUスケジューリングアルゴリズムは、数千のリクエストを異種ハードウェア(A100、H100、RTX 4090)にサブセカンドの遅延で割り当てる必要がある。割り当てが非効率的な場合、稼働率は85%から70%に低下し、年間1800万ドル以上のマージンを圧縮する。緩和策:MLベースのスケジューリングに投資し、ビンパッキングアルゴリズムを実装し、ハードウェアタイプ別の稼働率を毎週監視する。
-
リスクと制約:* 運用上のボトルネックを自動化するには、事前にエンジニアリング投資が必要である(通常、レイヤーあたり4〜8週間)。この期間中、顧客向け機能を出荷していない。緩和策:収益またはチャーンに直接影響するボトルネックを優先する;自動化の前後でROIを測定する(例:「請求自動化により調整時間が8時間から30分に短縮され、2名のFTEを維持業務に振り向けることができた」)。
-
実行可能な次のステップ:* 収益への重要経路をスプレッドシートにマッピングする。各ステップの時間を計測する。最も遅いコンポーネントを特定する。その年間コスト(稼働率損失、チャーン、またはサポート負担)を計算する。コストが50万ドルを超える場合、90日間の自動化計画を構築する。担当者を割り当て、進捗を毎週測定する。
測定とユニットエコノミクス
RunpodのARR 1億2000万ドルのマイルストーンは、健全なユニットエコノミクス、維持率、拡大を反映している場合にのみ意味がある。重要な指標は、粗利益率、顧客獲得コスト(CAC)、CAC回収期間、月次チャーン率、純収益維持率(NRR)である。
-
実行可能な主張:* 健全な指標を伴わない収益成長は、持続不可能なスケーリングを示す。ユニットエコノミクスを毎週追跡し、価格設定またはコスト構造を毎月調整せよ。
-
なぜこれが重要か:* スタートアップは、十分な資本を調達すれば、マイナスのユニットエコノミクスでARR 1億ドルに到達できる。しかし、収益性と持続性には、各顧客が獲得とサービス提供のコストよりも多くのライフタイムバリュー(LTV)を生み出すことが必要である。インフラストラクチャSaaSの場合:
-
健全な粗利益率:70%以上(Runpodは、GPUコスト、インフラストラクチャ、サポート後に65〜75%を目標としている可能性が高い)。
-
健全なCAC回収:12〜18ヶ月(Runpodのコミュニティファーストモデルは9〜12ヶ月を達成している可能性が高い)。
-
健全な月次チャーン:<3%(Runpodはスイッチングコストを考慮して1〜2%を目標としている可能性が高い)。
-
健全なNRR:110%以上(Runpodはより大規模なジョブからの拡大収益を考慮して120%以上を目標としている可能性が高い)。
-
具体的なユニットエコノミクスフレームワーク:*
| 指標 | 計算式 | Runpod推定値 | アクション閾値 |
|---|---|---|---|
| 粗利益率 | (収益 - GPUコスト - インフラストラクチャ) / 収益 | 70% | 60%未満の場合、GPU調達または価格設定を調査 |
| CAC | 総販売・マーケティング支出 / 獲得した新規顧客 | 2,000〜5,000ドル | 10,000ドル超の場合、低効率チャネルを削減 |
| CAC回収 | CAC / (月次ARPU × 粗利益率%) | 12ヶ月 | 18ヶ月超の場合、CACを削減または価格を引き上げ |
| 月次チャーン | 失われたMRR / 期首MRR | 1.5% | 3%超の場合、チャーン要因を調査 |
| NRR | (期首MRR + 拡大 - チャーン) / 期首MRR | 120% | 110%未満の場合、拡大と維持に注力 |
| LTV | (月次ARPU × 粗利益率%) / 月次チャーン | 333,000ドル | CACの3倍未満の場合、価格設定またはコスト構造の調整が必要 |
- 具体的な測定ワークフロー:*
- 毎週: 粗利益率、CAC、チャーンを計算する。トレンドをプロットする。異常値にフラグを立てる。
- 毎月: CAC回収とNRRを計算する。目標に対してレビューする。差異の要因を特定する。
- 四半期ごと: コホート分析を実施する。顧客セグメント、獲得チャネル、オンボーディング品質別に維持率と拡大を測定する。
- 年次: ユニットエコノミクスをストレステストする。10%の価格低下、20%のGPUコスト増加、または2%のチャーン増加の影響をモデル化する。
-
具体例—Runpodの可能性の高いユニットエコノミクス:*
-
平均顧客:月次10,000ドル(小規模開発者と企業の混合)。
-
粗利益率:70%(顧客あたり7,000ドル)。
-
CAC:3,000ドル(コミュニティソース、低コスト)。
-
CAC回収:12ヶ月(3,000ドル / (10,000ドル × 70% / 12))。
-
月次チャーン:1.5%(低いスイッチングコストだが、競争圧力あり)。
-
NRR:125%(より大規模なジョブと追加チームメンバーからの拡大収益)。
-
LTV:333,000ドル(7,000ドル / 1.5% × 12)。
-
LTV:CAC比率:111:1(健全;目標は3:1以上)。
-
リスクと制約:* 価格設定が引き下げられるか、GPUコストが上昇すると、ユニットエコノミクスは急速に悪化する可能性がある。緩和策:ユニットエコノミクスを毎週レビューする;アクション閾値を設定する(例:「粗利益率が60%を下回った場合、2週間以内にGPU調達または価格設定を調査する」)。
-
実行可能な次のステップ:* コアユニットエコノミクスを定義する:粗利益率、CAC、CAC回収、月次チャーン、NRR。これらを毎週追跡する。アクションの閾値を設定する。いずれかの指標が閾値を超えた場合、根本原因を調査し、2週間以内に価格設定またはコスト構造を調整する。
システムアーキテクチャとスケーリング制約
Runpodのインフラストラクチャモデルは重要な洞察を明らかにしている:** 収益のスケーリングは需要ではなく、運用上のボトルネックによって制約される。** ARR 1億2000万ドルの規模で、同社は数千のGPUノード、請求システム、サポートワークフロー、コンプライアンス要件を管理している。各運用レイヤーは遅延、リスク、潜在的な障害モードをもたらす。
同社が3億ドル、5億ドル、またはそれ以上に到達する能力は、これらのボトルネックが成長の天井になる前にどれだけ効率的に解決できるかに完全に依存している。
-
運用制約フレームワーク:* GPU割り当てアルゴリズムは稼働率とマージン圧縮を決定する。請求調整の精度はキャッシュフローの予測可能性に直接影響する。サポート応答時間(4時間を超えるもの)はチャーンを加速させる。ネットワークオーケストレーションの障害は顧客に見える停止にカスケードする。これらは二次的な懸念ではない—収益スケーリングの主要な制約である。
-
この規模での具体的な運用リスク:* Runpodのフリート全体でGPU稼働率が5%低下すると、数百万ドルの収益損失を意味する。単一の請求システム障害は規制当局の監視と顧客への返金を引き起こす可能性がある。24時間の停止は、インフラストラクチャの信頼性に対する許容度がゼロの高価値顧客との関係を永久に損なう可能性がある。
-
ホワイトスペースの機会:* ほとんどのインフラストラクチャスタートアップは、機能の速度と顧客獲得を最適化する。次の10年を支配する企業は、まず運用の卓越性に執着する。これは以下への投資を意味する:
-
予測的リソース割り当て: MLを使用して需要パターンを予測し、GPU容量を事前配置し、遅延を削減し、稼働率を向上させる。
-
自律的請求調整: 月次監査で発見するのではなく、リアルタイムで不一致を捕捉するシステムを構築する。
-
プロアクティブなサポート自動化: 人間の介入なしに一般的な問題の80%を解決する自己修復システムを実装する。
-
あなたのビジネスのために:* 収益生成への重要経路をマッピングする。最も遅く、最もエラーが発生しやすいコンポーネントを特定する。マーケティング支出をスケールする前に、そのレイヤーの自動化、監視、冗長性に投資する。インフラストラクチャプラットフォームの場合、これは通常、コンピュート割り当てと請求精度を意味する。SaaS製品の場合、オンボーディングワークフローまたはデータ同期かもしれない。マーケットプレイスの場合、取引決済または紛争解決の可能性が高い。パターンは普遍的である:運用の卓越性は機能の速度よりも速く複利で増加する。

- 図10:ユニットエコノミクスの主要指標推移*

- 図11:チャネル別カスタマー獲得コスト(CAC)の比較*
リファレンスアーキテクチャとガードレールのパラドックス
Runpodは根本的な設計上の緊張に直面している:開発者は最大限の柔軟性と低レベルのGPUアクセスを望む;プラットフォームは予測可能なコスト、セキュリティ、稼働時間を必要とする。この緊張を解決するリファレンスアーキテクチャが、Runpodがニッチツールのままか、AIワークロードのデフォルトインフラストラクチャレイヤーになるかを決定する。
-
機能としてのガードレールの論点:* 制約は制限ではない—スケールを可能にする機能である。Runpodは、サポートの混乱、セキュリティの脆弱性、予測不可能なコストを生み出すことなく、無制限のカスタマイズを提供することはできない。代わりに、プラットフォームは安全な運用境界を定義する:承認されたコンテナランタイム、リソース制限、ネットワークポリシー、請求上限、データ居住ルール。ユーザーはこれらのガードレール内で真の自由を持って運用する。
-
具体例:* 開発者はDockerコンテナ内で任意のカスタムMLモデルをデプロイできるが、RunpodはCPU対GPU比率とネットワーク出力制限を強制する。これにより、単一ユーザーの設定ミスがプラットフォーム全体の停止にカスケードするのを防ぎながら、開発者の自律性を維持する。ガードレールは透明で、予測可能であり、制限ではなく機能として文書化されている。
-
隣接する機会:* Runpodが成熟するにつれて、同社は階層化されたガードレールを導入できる。エンタープライズ顧客はカスタムリソース制限と専用サポートを受け取る可能性がある。研究者は実験的なハードウェアへのアクセスを得る可能性がある。これにより、別個の製品を必要とせずに自然な価格設定のはしごが作成される。
-
実務者のために:* 譲れない制約(セキュリティ、コスト、稼働時間、コンプライアンス)を文書化し、制限ではなく機能として伝える。ユーザーがこれらの境界内で安全に運用できるセルフサービスツールを構築する。これによりサポート負担が軽減され、認識される柔軟性が向上する。インフラストラクチャプラットフォームの場合、同時実行性、ストレージ、帯域幅の明確な制限を透明な理由とともに公開する。SaaS製品の場合、使用階層とレート制限を制限ではなく価値提案として定義する。心理的なシフト—「私たちはあなたを制限する」から「私たちはあなたを保護する」へ—は、顧客が制約をどのように認識するかを変える。
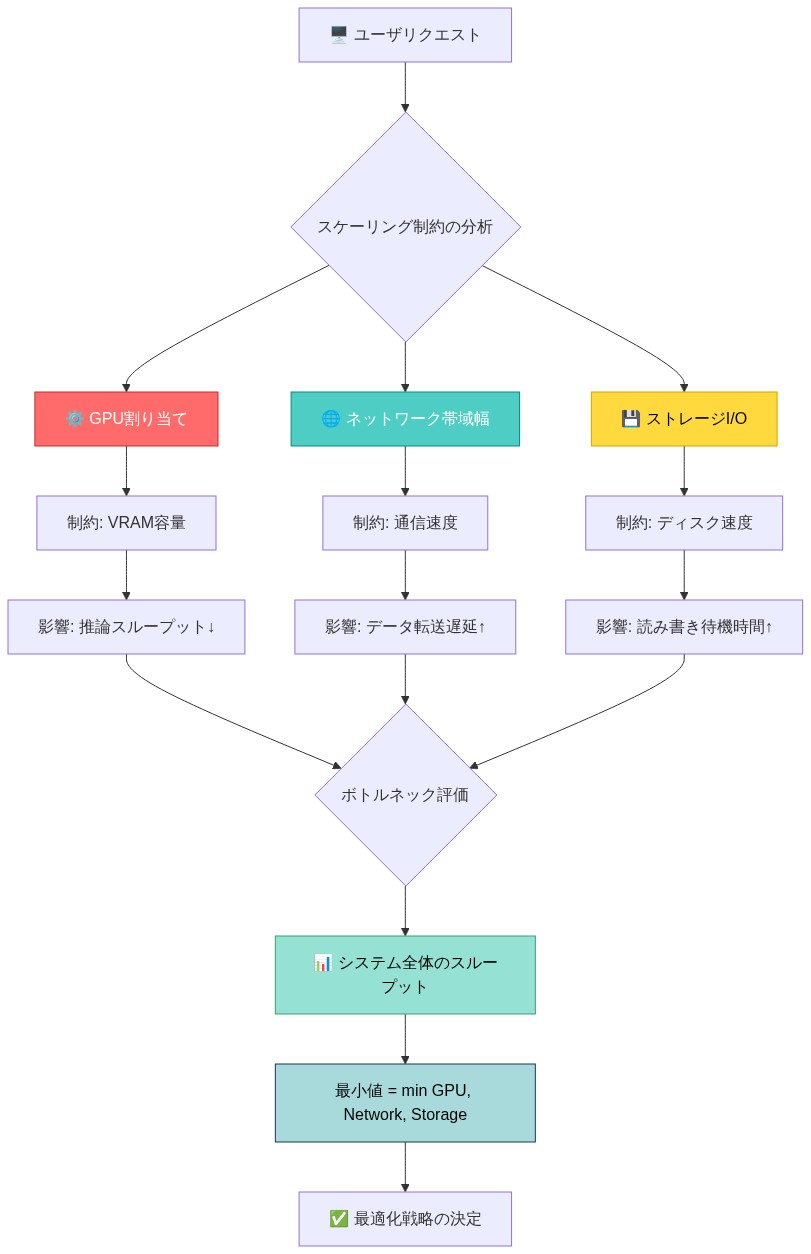
- 図12:スケーリング制約の構造:ボトルネック分析(分散システムのスケーリング理論から導出)*
実装と運用パターン:スケーリング乗数
Runpodの運用成熟度は、ARR 1億2000万ドルが持続可能で収益性の高いビジネスになるか、競争圧力と運用障害に脆弱な脆弱な構造になるかを決定する。これには、人員数の比例的な増加なしにスケールできる、オンボーディング、トラブルシューティング、スケーリング、維持のための反復可能なパターンが必要である。
-
反復可能な運用の論点:* 規模では、すべてのプロセスを文書化、自動化、または委任する必要がある。Runpodは、一般的な問題のランブック、リソース競合の自動アラート、階層化されたサポートワークフロー、インシデント対応プレイブックを使用している可能性が高い。これらのパターンは、平均解決時間(MTTR)を短縮し、サポートコストを二次関数ではなく線形に保ちながら顧客満足度を向上させる。
-
具体的な運用パターン:* ユーザーのジョブが失敗すると、自動診断が根本原因(メモリ不足エラー、ネットワークタイムアウト、コンテナクラッシュ、GPU利用不可)を特定し、ダッシュボードを通じてリアルタイムで修正を表示する。サポートは、新規の問題またはエスカレーションに対してのみ介入する。これにより、サポートは顧客50人あたり1人のエンジニアから顧客500人あたり1人のエンジニアにスケールする—10倍の効率向上である。
-
隠れたレバレッジ:* Runpodのサポート効率をスケールする能力は、粗利益率の拡大に直接変換される。サポートコストが収益の15%から3%に低下すると、同社は製品、販売に再投資するか、価格引き下げとして顧客に還元できる12パーセントポイントのマージンを獲得する。これは、持続可能なインフラストラクチャ企業と一時的なスタートアップを分ける複利の優位性である。
-
ホワイトスペース:* ほとんどのインフラストラクチャ企業は運用をコストセンターとして扱う。勝者はそれを製品として扱う。Runpodは、顧客向けの運用インテリジェンスの構築を検討すべきである:GPU稼働率のトレンド、コスト最適化の推奨事項、パフォーマンスベンチマークを示すダッシュボード。これにより、運用はサポート機能から維持と拡大のツールに変換される。
-
実務者のために:* 頻度と影響による上位10の運用タスクを監査する。それぞれを反復可能なワークフローとして文書化する。最も時間を消費するか、最も顧客の摩擦を生み出す上位3つのタスクの自動化を構築する。自動化の前後でサイクルタイムを測定する。インフラストラクチャプラットフォームの場合、GPU割り当て、請求調整、インシデント対応を自動化する。SaaS製品の場合、オンボーディングワークフロー、データ同期、請求を自動化する。マーケットプレイスの場合、取引決済、紛争解決、販売者への支払いを自動化する。パターンは一貫している:高頻度、高影響のタスクを特定し、それらを徹底的にシステム化する。これにより、エンジニアリングとサポートは維持と製品イノベーションに集中できる—実際に長期的価値を推進する活動である。
測定とユニットエコノミクスの現実チェック
RunpodのARR 1億2000万ドルのマイルストーンは、健全なユニットエコノミクス、強力な維持率、拡大収益を反映している場合にのみ意味がある。実際に重要な指標は、粗利益率、顧客獲得コスト(CAC)、CAC回収期間、チャーン率、純収益維持率(NRR)である。
-
持続不可能な成長の罠:* スタートアップは、十分な資本を調達すれば、マイナスのユニットエコノミクスでARR 1億ドルに到達できる。しかし、収益性、持続性、競争圧力に耐える能力には、各顧客が獲得とサービス提供のコストよりも多くのライフタイムバリューを生み出すことが必要である。これは譲れない。
-
インフラストラクチャの具体的なユニットエコノミクスフレームワーク:*
-
粗利益率目標:70%以上(60%未満は価格設定またはコスト構造の問題を示す)
-
CAC回収期間:12〜18ヶ月(24ヶ月を超えるものは持続不可能な獲得支出を示す)
-
純収益維持率:110%以上(既存顧客からの拡大収益がチャーンを上回るべき)
-
チャーン率:<5%年間(インフラストラクチャは粘着性のある長期的な顧客関係を持つべき)
Runpodの粗利益率が70%でCAC回収が12ヶ月の場合、ビジネスは持続可能であり、収益性を持ってスケールできる。マージンが40%で回収が24ヶ月の場合、スケーリングはますますリスクが高くなる。同社は直ちに価格設定またはコスト構造を調整する必要がある。
-
測定のケイデンス:* コア指標の週次レビュー。コホート分析、チャーン要因、拡大機会への月次深掘り。ユニットエコノミクスのトレンドに基づく四半期ごとの戦略調整。
-
ホワイトスペースの機会:* ほとんどのインフラストラクチャ企業は収益と顧客数を測定する。勝者はGPU稼働率、ユーザーあたりの平均収益(ARPU)、提供されるコンピュートユニットあたりのコストを測定する。これらの指標は、ビジネスがスケールするにつれてより効率的になっているか、より脆弱になっているかを明らかにする。
-
実務者のために:* ビジネスモデルに合わせたコアユニットエコノミクスを定義する。インフラストラクチャの場合、GPU稼働率、コンピュートユニットあたりのコスト、ARPUを追跡する。SaaSの場合、粗利益率、CAC回収、NRRを追跡する。マーケットプレイスの場合、手数料率、取引量、販売者維持率を追跡する。これらの指標を毎週追跡する。アクションの閾値を設定する:粗利益率が目標を下回った場合、直ちに価格設定またはコスト構造を調査する。CAC回収が閾値を超えた場合、低効率チャネルへの支出を削減する。NRRが低下した場合、製品のギャップを特定するためにチャーンインタビューを実施する。週次測定の規律は持続可能な競争優位性に複利で増加する。
リスクと軽減策:フライホイールにレジリエンスを組み込む
Runpodの成長軌道は、放置すれば会社を脱線させる可能性のある競争的、運用的、市場的リスクに直面している。ハイパースケーラー(AWS、Azure、GCP)が価格を下回る可能性がある。ハードウェアサイクルが需要をシフトさせる可能性がある。規制変更がコンプライアンスコストを課す可能性がある。人材流出が製品開発速度を低下させる可能性がある。
-
リスク識別フレームワーク:* Runpodは、規模、信頼性、開発者の信頼が不釣り合いに重要な勝者総取り市場で事業を展開している。同社は脅威を予測し、それらが顕在化する前に防御策を構築しなければならない。
-
競争リスク:* AWSが明日、より安価なGPUオファリングを開始し、Runpodのマージンを圧縮する可能性がある。先行指標:ハイパースケーラーの価格発表と顧客解約インタビュー。軽減策:MLフレームワーク(PyTorch、TensorFlow)との深い統合、コミュニティロックイン、ハイパースケーラーが優先しない特殊機能(例:サーバーレスGPU関数、マルチクラウドオーケストレーション)を通じてスイッチングコストを構築する。目標は、Runpodを単に最も安価な選択肢ではなく、開発者のデフォルトの選択肢にすることである。
-
運用リスク:* 大規模な障害が大量解約と永続的な評判の損傷を引き起こす可能性がある。先行指標:インシデント頻度の増加、MTTR(平均復旧時間)の悪化、またはサポートチケット量の急増。軽減策:リージョン間の冗長性、カオスエンジニアリングの実践、透明性のあるステータスページ、顧客コミュニケーションプロトコルに投資する。テストされる前に運用レジリエンスを構築する。
-
市場リスク:* AI需要が横ばいになるか、異なるワークロード(例:推論対トレーニング)にシフトする可能性がある。先行指標:顧客解約インタビュー、ワークロード構成の変化、競合の勝敗分析。軽減策:異なる顧客セグメント(研究者、スタートアップ、エンタープライズ)向けの特殊機能を構築してユースケースを多様化する。隣接市場(動画処理、科学計算、3Dレンダリング)に拡大する。
-
人材リスク:* 主要なエンジニアや製品リーダーが退職し、実行速度が低下する可能性がある。先行指標:従業員エンゲージメント調査、定着率指標、面接フィードバック。軽減策:強力な企業文化を構築し、有意義な株式を提供し、明確なキャリアパスを作成する。単一障害点リスクを減らすために重要な知識を文書化する。
-
規制リスク:* 政府がデータレジデンシー要件、輸出規制、またはコンプライアンスコストを増加させるAIガバナンスルールを課す可能性がある。先行指標:規制発表、コンプライアンスに関する顧客の問い合わせ、法的先例。軽減策:コンプライアンスインフラを積極的に構築する。政策立案者と早期に関与する。Runpodを責任あるAIインフラプロバイダーとして位置づける。
-
実務者向け:* 上位5つのリスクをリストアップする:競争、運用、市場、財務、規制。各リスクについて、先行指標(リスクが顕在化していることを示す測定可能なシグナル)と軽減アクション(リスクの影響を減らすために今日できること)を定義する。インフラ企業の場合、競争リスク指標にはハイパースケーラーの価格発表と顧客解約インタビューが含まれる。軽減策:統合を深め、コミュニティロックインを構築する。SaaS企業の場合、運用リスク指標にはインシデント頻度とサポートチケット量が含まれる。軽減策:冗長性とカオスエンジニアリングに投資する。マーケットプレイスの場合、市場リスク指標には取引量のトレンドと販売者の定着率が含まれる。軽減策:ユースケースを多様化し、特殊機能を構築する。これにより、抽象的なリスクが具体的で測定可能な警戒に変換される。リスクを月次でレビューし、状況の変化に応じて軽減策を調整する。
次の地平線:インフラからプラットフォームへ
Runpodの1億2,000万ドルのARRはマイルストーンであり、目的地ではない。同社の次のフェーズでは、市場ポジションを守りながら、コアインフラを活用する隣接機会に拡大することが求められる。
-
プラットフォーム拡張の論理:* Runpodはコンピュートマーケットプレイスから包括的なAIインフラプラットフォームに進化できる。これは以下を意味する:
-
マネージドMLサービス: 人気モデル(Llama、Stable Diffusion、Whisper)用の事前構築コンテナとワンクリックデプロイメント。
-
データパイプラインオーケストレーション: Runpodのコンピュートと統合されたデータ取り込み、前処理、バージョニングのためのツール。
-
モデルサービングと推論: 需要に基づいて自動スケールするサーバーレス推論エンドポイント。
-
協調開発: チームがコード、モデル、コンピュートリソースを共有できるワークスペース機能。
-
エンタープライズ機能: 大規模組織向けのマルチテナンシー、SSO、監査ログ、コンプライアンス認証。
これらの機能はそれぞれ、スイッチングコストを増加させ、ARPUを拡大し、NRRを改善する。目標は、Runpodを AI開発ワークフローに不可欠なものにすることである。
-
競争的堀:* ハイパースケーラーが同等の機能を構築する頃には、Runpodはコミュニティロックイン、開発者のマインドシェア、信頼性の実績を確立しているだろう。同社の優位性は技術的なものではなく、文化的かつ関係的なものである。開発者がRunpodを信頼するのは、それが開発者によって、開発者のために構築されたからである。
-
インフラ構築者への重要なポイント:*
-
コミュニティファーストの成長は、新興カテゴリーにおいて有料獲得を上回る。 ユーザーが集まる場所での本物のプレゼンスに投資する。製品品質に採用を促進させる。
-
運用ボトルネックは需要以上に収益を制約する。 クリティカルパスを特定し、マーケティングをスケールする前に徹底的に自動化する。
-
ガードレールがスケールを可能にする。 譲れない制約を定義し、ユーザーを保護する機能としてそれらを伝える。
-
反復可能な運用パターンが予測可能なスケーリングを解放する。 高頻度タスクを文書化、自動化、委任する。これによりチームは定着率とイノベーションに集中できる。
-
メトリクスが意思決定を推進する。 ユニットエコノミクスを執拗に追跡する。データに基づいて価格、コスト構造、または製品を週次で調整する。
-
リスク軽減は継続的である。 競争的、運用的、市場的脅威を予測する。それらが顕在化する前に防御策を構築する。
-
プラットフォーム拡張が価値を複利化する。 単一目的ツールから、スイッチングコストを増加させARPUを拡大する包括的プラットフォームに進化する。
-
実務者向けの次のアクション:*
-
第1週: クリティカルな運用パスをマッピングする。最も遅く、最もエラーが発生しやすいコンポーネントを特定する。オーナーを割り当てる。
-
第2週: コアユニットエコノミクスを定義する。アクションのしきい値を設定する。週次レビューにコミットする。
-
第3週: 上位5つのリスクと先行指標をリストアップする。オーナーを割り当てる。月次レビューをスケジュールする。
-
第2ヶ月: 市場参入戦略を監査する。ユーザーが集まる場所にいるか?そうでなければ、リソースをシフトする。
-
第3ヶ月: 3つの高頻度運用タスクを特定する。上位1つの自動化を構築する。影響を測定する。
-
継続的に: メトリクスを週次でレビューする。データに基づいて価格、コスト構造、または製品を調整する。競争的脅威を予測する。積極的に防御策を構築する。
Runpodの成功は運ではなく、創業者が基本を徹底的に実行したために再現可能である:実際の問題を解決し、透明性を通じて信頼を構築し、マーケティングをスケールする前に運用をスケールし、執拗に測定する。同社の次のフェーズは、顧客関係を深め、ライフタイムを増加させる隣接機会に拡大しながら、市場ポジションをどれだけうまく守るかによって定義される
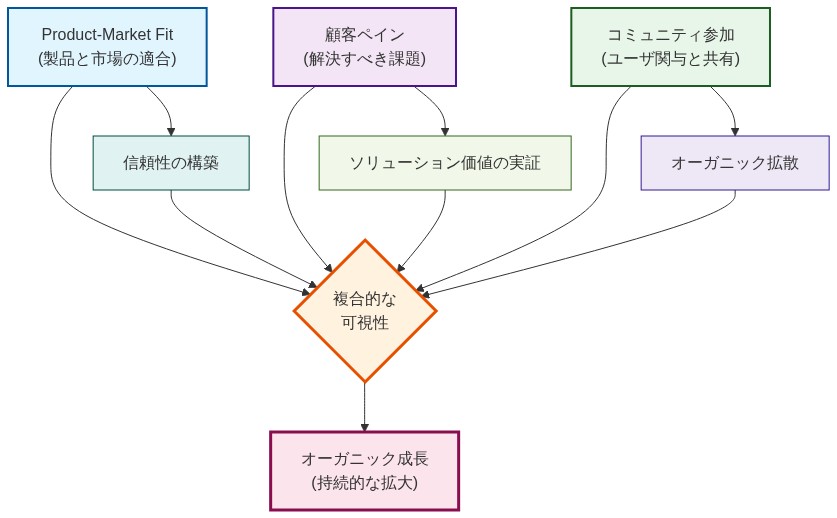
- 図2:オーガニック成長の3つの前提条件と相互作用メカニズム*

- 図1:Runpodのストーリー:Redditから$120M ARRへの成長軌跡を象徴するキービジュアル。オーガニックなコミュニティ駆動の成長とAIクラウドインフラストラクチャの融合を表現。*

- 図13:リスク・レジリエンスのフライホイール - 組織の適応力と回復力を強化するサイクル*