
Amazon EC2 Hpc8a インスタンス(第5世代AMD EPYCプロセッサ搭載):技術アーキテクチャと応用分析
Hpc8aの背景にあるアーキテクチャ:第5世代AMD EPYCの技術的優位性
Amazon EC2 Hpc8aインスタンスは、AMDの第5世代EPYCプロセッサ(Zen 5アーキテクチャ)を活用し、ハイパフォーマンスコンピューティングワークロード向けのパフォーマンス向上を実現しています。AWSの仕様によれば、これらのプロセッサはソケットあたり最大128コアを提供し、L3キャッシュ階層の拡大と命令パイプラインの最適化を含むアーキテクチャ改善により、前世代のHPCインスタンスと比較して優れた性能を発揮します。
本質的に問われているのは、HPC ワークロードにおける周知の制約、すなわちメモリ帯域幅飽和への対応です。Hpc8aインスタンスはDDR5メモリと強化されたメモリコントローラをサポートし、計算スループットに対する持続的なメモリ帯域幅の比率を向上させています。この比率改善は、生の浮動小数点演算ではなくデータ移動がパフォーマンスボトルネックとなるアプリケーションにおいて特に関連性があります。プロセッサはAVX-512ベクトル拡張機能を組み込んでおり、科学計算に一般的な構造化計算パターン向けのSIMD(Single Instruction Multiple Data)並列処理を実現しています。
- 前提条件*:引用されているパフォーマンス改善(最大40%のパフォーマンス向上)は、メモリ帯域幅制限のあるワークロードであり、増加したコア数を効果的に活用するワークロードを想定しています。キャッシュ局所性が低いワークロードや不規則なメモリアクセスパターンを持つワークロードは、これらの改善を達成できない可能性があります。
複雑な幾何学的形状にわたる大規模疎線形システムを解く有限要素解析(FEA)アプリケーションの場合、増加したコア数とメモリ帯域幅により、前世代インスタンスと比較してシミュレーション時間を30~40%削減できます。ただし、以下の条件が必要です:(1)利用可能なコア全体への効果的な並列化、(2)通信オーバーヘッドを償却するのに十分な問題規模、(3)強化された帯域幅の恩恵を受けるメモリアクセスパターン。このランタイム削減は、時間に敏感なワークロードまたはコア時間単位のソフトウェアライセンス対象のワークロードにおいて、比例するコスト削減につながります。
Hpc8aインスタンスは、汎用コンピュートオファリングとは建築学的に異なります。設計は複数コア全体での持続的な高周波操作を優先し、バースト性パフォーマンス特性またはメモリ最適化インスタンスに典型的なコアあたりのメモリ比率ではなく、一貫した計算スループットに最適化されています。
300 Gbpsのエラスティックファブリックアダプタ:ノード間通信アーキテクチャ
300 Gbpsのエラスティックファブリックアダプタ(EFA)ネットワーキングは、密結合HPC アプリケーション向けの重要な差別化要因です。EFAはオペレーティングシステムカーネルをデータ転送時にバイパスすることで、マイクロ秒レベルのレイテンシと高スループットのノード間通信を提供し、メッセージパッシングインターフェース(MPI)実装における通信オーバーヘッドを削減します。
- 前提条件*:EFAパフォーマンスの利点は、ノード間通信が頻繁に発生する密結合ワークロードに特に適用されます。疎結合アプリケーションまたは重大なI/O要件を持つアプリケーションは、EFAのプレミアムコストを正当化しない可能性があります。
ドメイン分解を採用するアプリケーション(計算流体力学(CFD)または分子動力学シミュレーションなど)では、境界データ交換が定期的な間隔で発生する場合、改善されたネットワーキングは通信オーバーヘッドを削減します。気象モデリングアプリケーションがシミュレーションタイムステップごとにドメインパーティション間で境界データを交換する場合を考えてみてください。標準的なネットワーキング実装は、通常、総実行時間に対して20~30%の通信オーバーヘッドを招きます。EFA実装は、カーネルコンテキストスイッチングとレイテンシを削減することで、同じアプリケーションの通信オーバーヘッドを10~15%に削減でき、実質的に実行を15~20%加速します。
- データポイント*:この分析は、ドメイン分解法に典型的な同期通信パターンとメッセージサイズを想定しています。非同期通信または不規則なメッセージパターンを持つアプリケーションは、異なるオーバーヘッド比率を経験する可能性があります。
ネットワーキングの利点は、メッセージ頻度が高く、メッセージサイズが中程度(通常、メッセージあたり1 KBから1 MB)のアプリケーションで最も顕著です。組織はMPI通信パターン(メッセージ頻度、サイズ分布、同期要件)をプロファイルして、EFAのプレミアムが標準ネットワーキングと比較した投資を正当化するかどうかを判断する必要があります。
ターゲットワークロード:計算特性と適合性
Hpc8aインスタンスは、特定の計算特性を共有するワークロードに最大の価値を提供します:CPU バウンド実行(GPU加速またはメモリ制約ではなく)、密結合または尷尬なほど並列な実行パターン、メモリ帯域幅感度、および拡張期間にわたる持続的な高パフォーマンス要件。
-
文書化された適合性を持つワークロードカテゴリ:*
-
有限要素解析:構造工学およびクラッシュシミュレーションアプリケーションは、問題サイズがソケットあたりのキャッシュ容量を超える場合、高コア数とメモリ帯域幅から利益を得ます。
-
計算流体力学:流体流と熱伝達をシミュレートするアプリケーションは、強化されたベクトル処理(AVX-512)と低レイテンシネットワーキングを活用して、大規模問題のシミュレーション時間を数日から数時間に削減します。
-
分子動力学:医薬品発見と材料科学シミュレーションは、数百万の原子相互作用をモデル化し、大規模な軌跡データセット向けの持続的なスループットとメモリ帯域幅を必要とします。
-
気象および気候モデリング:グローバルグリッド全体で偏微分方程式を解くアプリケーションは、大規模データセット向けの増加したメモリ帯域幅と、複数ノード全体のドメイン分解向けのEFAネットワーキングの両方から利益を得ます。
-
具体例*:1000万原子システムで分子動力学シミュレーションを実行する材料科学組織は、前世代インスタンスで72時間の実行時間を観察する可能性があります。Hpc8aインスタンスでは、同じシミュレーションが50~55時間で完了する可能性があります。これは30%の削減です。ただし、効果的な並列化とメモリ帯域幅利用を想定しています。この改善は、年間複数の研究プロジェクト全体で複合し、インフラストラクチャ投資を正当化する可能性があります。
-
除外基準*:Hpc8aインスタンスは、GPU加速ワークロード(G7eまたは同様のGPUインスタンスから利益を得る)、高いコアあたりメモリ比率を必要とするメモリ集約的アプリケーション(X8iインスタンスから利益を得る)、または並列化効率が低いワークロードに最適ではありません。
AWSの専門インスタンス戦略:アーキテクチャポジショニング
Hpc8aの立ち上げは、汎用コンピュート構成ではなく、パフォーマンスクリティカルなアプリケーション向けの専門インスタンスを提供するというAWSの戦略的アプローチを反映しています。この多様化は、計算ボトルネックがワークロードクラス全体で異なることを認識しています:GPU加速、メモリ容量、ノード間帯域幅、またはCPUスループット。
Hpc8aは特定のアーキテクチャニッチを占めています:GPU加速を必要としないが、高いノード間帯域幅を必要とするCPU集約的HPC ワークロード。このポジショニングは、最近のインフラストラクチャ発表を補完します:
- G7eインスタンス:高性能グラフィックスプロセッサを必要とするGPU加速ワークロード向けに最適化
- X8iインスタンス:メモリ集約的アプリケーション向けのメモリ容量とコアあたりメモリ比率を優先
- Hpc8aインスタンス:例外的なノード間ネットワーキングを備えたCPUスループットを優先
各インスタンスファミリーは異なるワークロードプロファイルに対応し、顧客が不要な機能を過剰プロビジョニングするのではなく、特定の計算ボトルネックに合わせてインフラストラクチャを調整できます。
このマルチベンダー戦略(AMD、Intel、NVIDIAプロセッサの活用)は、価格設定とイノベーションに対する競争圧力を維持しながら、AWSが各ベンダーのアーキテクチャ強度を適切なワークロードクラスに展開できます。
コスト・パフォーマンス分析:ROI決定とベンチマーク要件
Hpc8aインスタンスが優れたコスト・パフォーマンスを提供する場合を判断するには、ワークロード特性、スケーリング動作、および総所有コストの体系的な分析が必要です。
-
パフォーマンス改善の変換*:ノードあたり40%のパフォーマンス改善は、以下の条件を満たすワークロードに対してのみ比例するランタイム削減に変換されます:(1)複数ノード全体での効率的なスケーリング、(2)メモリ制約またはI/Oバウンドではなく、CPU制限、(3)利用可能なコア数の効果的な利用。
-
コスト考慮事項*:
-
専門HPC インスタンスは、汎用インスタンスと比較してプレミアム価格を設定します
-
ソフトウェアライセンスコスト(多くの場合、時間ベースまたはコア時間単位)は、ランタイム削減からの節約を増幅する可能性があります
-
データ転送コストと並列ファイルシステム要件は、インスタンスあたりの節約をオフセットする可能性があります
-
EFAネットワーキングプレミアムは、密結合ワークロードにのみ適用されます。疎結合アプリケーションは、より低いコストで標準ネットワーキングで同様の結果を達成する可能性があります
-
ベンチマーク方法論*:組織は、代表的なワークロードでスケーリング研究を実施して、以下を判断する必要があります:(1)理論的改善と比較した実際のパフォーマンスゲイン、(2)最適なノード数(ノードあたりのパフォーマンス改善により、より少ないインスタンスで結果を達成できる可能性があります)、(3)ノード数の関数としての通信オーバーヘッド。
-
ROI計算例*:年間100のCFDシミュレーションを実行する研究組織は、各シミュレーションが20時間のコンピュート時間を節約し、ソフトウェアライセンスがコア時間単位で課金される場合、Hpc8a投資を正当化する可能性があります。100シミュレーション全体の累積節約(年間2,000コア時間)は、汎用代替品と比較したHpc8aインスタンスのプレミアムコストを超える必要があります。
移行と最適化戦略
既存のHPCワークロードをHpc8aに移行するには、専門アーキテクチャの完全なパフォーマンスポテンシャルを実現するための意図的な計画が必要です。汎用的な移行アプローチは、専門アーキテクチャの過小利用のリスクがあります。
-
コンパイルと最適化*:前世代プロセッサ向けにコンパイルされたアプリケーションは、Zen 5アーキテクチャをターゲットとする最適化フラグを使用して再コンパイルする必要があります。これには以下が含まれます:
-
AVX-512ベクトル拡張機能サポート
-
増加したL3キャッシュ向けのキャッシュ階層最適化
-
AMD EPYC第5世代プロセッサ固有のコンパイラフラグ
-
MPI チューニング*:メッセージパッシングインターフェース実装は、300 Gbps EFAネットワーキングを活用するための構成調整が必要な場合があります:
-
メッセージサイズ最適化(典型的な最適範囲:1 KBから1 MB)
-
バッファ構成とメモリピンニング
-
同期ボトルネックを特定するための通信パターン分析
-
ストレージアーキテクチャ評価*:高パフォーマンスインスタンスは、ネットワーク接続ストレージを迅速に飽和させる可能性があります。組織は以下を評価する必要があります:
-
I/O集約的ワークロード向けのAmazon FSx for Lustreまたは同様の並列ファイルシステム
-
一時データ向けのローカルNVMeストレージ
-
コンピュートスループットに対するネットワーク帯域幅要件
-
デプロイメント方法論*:AWS ParallelClusterを使用したコンテナベースのデプロイメントは、再現性と環境の一貫性を簡素化します。パフォーマンス監視は以下に焦点を当てるべきです:
-
コア全体のCPU利用率
-
メモリ帯域幅飽和
-
ネットワークスループットとレイテンシ
-
理論的パフォーマンス改善を妨げるボトルネックの特定

- 図13:既存HPCインフラからHpc8aへの移行プロセスフロー*
重要なポイントと推奨アクション
Hpc8aインスタンスは、CPU集約的HPC ワークロード向けの意味のある進歩を表しており、増加したコア数、強化されたメモリ帯域幅、および300 Gbpsのノード間ネットワーキングを目的に構築されたオファリングに組み合わせています。価値提案は、削減されたランタイムがコスト削減に直接変換される密結合シミュレーションおよびエンジニアリングアプリケーションに対して最も強力です。
- Hpc8aを評価する組織向けの推奨アクション*:
-
既存のHPCワークロードをプロファイルして、CPU バウンド、密結合、およびメモリ帯域幅に敏感であるかどうかを判断します。並列化効率が低いワークロードまたは重大なI/O要件を持つワークロードは、専門インスタンスを正当化しない可能性があります。
-
ベンチマーク研究を実施して、代表的なワークロードを使用して現在のインフラストラクチャに対するHpc8aパフォーマンスを比較します。実際のパフォーマンスゲイン、通信オーバーヘッド、および複数のノード数全体のスケーリング効率を測定します。
-
総所有コストを評価して、インスタンスあたりの価格、ソフトウェアライセンスの影響、データ転送コスト、およびストレージ要件を含めます。インフラストラクチャ投資の損益分岐点分析を決定します。
-
移行戦略を計画して、Zen 5最適化フラグを使用したアプリケーション再コンパイル、MPI チューニング、およびストレージアーキテクチャ評価を含めます。大規模なインフラストラクチャ移行にコミットする前に、パイロットワークロードをデプロイします。
-
パフォーマンス監視を確立して、デプロイされたワークロードが期待される改善を達成し、最適化の機会を特定することを検証します。
300 Gbpsのエラスティックファブリックアダプタ:密結合通信の再定義
300 Gbpsのエラスティックファブリックアダプタ(EFA)ネットワーキングは、Hpc8aインスタンス向けの重要な差別化要因であり、以前は専用スーパーコンピューティングインフラストラクチャでのみ達成可能なノード間通信パフォーマンスを実現します。EFAはマイクロ秒レベルのレイテンシと高スループットのノード間通信を提供し、メッセージパッシングインターフェース(MPI)パフォーマンスがジョブ完了時間に直接影響する密結合HPC アプリケーションに不可欠です。
-
実践的な影響*:ノード間のデータ交換が頻繁に発生してボトルネックを作成する計算流体力学(CFD)または分子動力学シミュレーションの場合、300 Gbps帯域幅は通信オーバーヘッドを大幅に削減します。シミュレーションタイムステップごとにドメイン分解パーティション間で境界データを交換する気象モデリングアプリケーションは、通常、標準ネットワーキングで20~30%の通信オーバーヘッドを経験します。EFAのカーネルバイパス実装では、同じアプリケーションは10~15%の通信オーバーヘッドを達成でき、実質的にシミュレーションを15~20%加速します。
-
実装要件*:EFAは明示的な構成が必要です。標準EC2ネットワーキングは、300 Gbps機能を自動的に使用しません。MPI実装はEFAサポートでコンパイルする必要があり、アプリケーションはEFA互換通信ライブラリを使用する必要があります。AWS ParallelClusterはこの構成を自動的に処理しますが、カスタムデプロイメントは手動セットアップが必要です。
-
コスト・ベネフィット制約*:EFAのプレミアム価格は、密結合ワークロードに対してのみ投資を正当化します。疎結合アプリケーションまたは重大なI/O要件を持つアプリケーションは、大幅に低いコストで標準ネットワーキングで同様の結果を達成します。ノード間通信が最小限のモンテカルロシミュレーションは、EFAから5~10%のパフォーマンス改善のみを見る可能性があり、プレミアムを正当化しません。
-
実行ワークフロー*:EFAベースのデプロイメントにコミットする前に、MPI プロファイリングを実施して通信オーバーヘッドを定量化します。Intel VTuneまたはHPCToolkitなどのツールは、MPI操作に費やされた実行時間の割合を測定します。MPI オーバーヘッドが総実行時間の15%を超える場合、EFA投資は正当化される可能性があります。MPI オーバーヘッドが5%未満の場合、標準ネットワーキングはコスト効果的です。
-
スケーリング考慮事項*:EFAパフォーマンスは、ほとんどのアプリケーションで約256~512ノードまで効果的にスケーリングします。このスケールを超えると、ネットワーク競合とMPI同期オーバーヘッドがスケーリング効率を制限し始めます。大規模インフラストラクチャをデプロイする前に、スケーリング研究を通じてターゲットクラスタサイズを検証します。
ターゲットワークロード:Hpc8aが最大価値を発揮する領域
Hpc8aインスタンスが優れた性能を発揮するのは、3つの重要な特性を共有する特定の計算集約的ワークロードです。すなわち、(1)並列度が高い、または密結合された実行パターン、(2)メモリ帯域幅への感度が高い、(3)長期間にわたる持続的な高性能要件(通常、ジョブあたり4時間以上)です。
-
有限要素解析(FEA):* 構造工学およびクラッシュシミュレーション用途は、複雑な幾何学的形状全体にわたる大規模な連立方程式を解く際に、高いコア数とメモリ帯域幅から恩恵を受けます。5,000万~1億要素を解く典型的な自動車クラッシュシミュレーションは、Hpc8aインスタンスで8~12時間で完了するのに対し、前世代インスタンスでは12~16時間を要し、エンジニアリングの反復サイクルを直接短縮します。
-
計算流体力学(CFD):* 気流および熱伝達シミュレーションは、強化されたベクトル処理と低遅延ネットワーキングを活用して、シミュレーション時間を数日から数時間に短縮します。2億メッシュ要素を持つデータセンター冷却システムの熱解析は、前世代インスタンスでは通常24~36時間を要し、Hpc8aでは16~24時間となり、設計最適化の高速化が実現します。
-
分子動力学シミュレーション:* 創薬および材料科学用途は、数百万の原子相互作用をモデル化する持続的なスループットを必要とします。1,000万原子システムの分子動力学シミュレーションを実行する材料科学組織は、前世代インスタンスでは72時間を要していたものが、Hpc8aでは50~55時間で完了でき、30%の削減が複数の研究プロジェクト全体で累積します。
-
気象および気候モデリング:* 全球グリッド全体で偏微分方程式を解くアプリケーションは、大規模データセット向けのメモリ帯域幅の増加とドメイン分割の効率的なEFAネットワーキングの両方から恩恵を受けます。1,000×1,000 kmをカバーし1 km解像度の地域気象予報モデルは、前世代インスタンスでは通常6~8時間を要し、Hpc8aでは4~5時間となります。
-
実行上の考慮事項:* これらのワークロードは重要な特性を共有しています。すなわち、GPU加速やメモリ最適化ではなく、CPU集約的で高いノード間通信要件を持つという点です。移行前に、ワークロードがこのプロファイルに合致することを確認してください。アプリケーションがGPU加速の場合、G7eインスタンスがより費用対効果に優れています。ワークロードがノードあたり2TB以上のメモリを必要とする場合、X8iインスタンスがより適切に対応しています。
-
ワークロード検証チェックリスト:*
-
実行中のCPU使用率が一貫して80%を超える
-
メモリ帯域幅使用率が利用可能帯域幅の60%を超える
-
MPI通信オーバーヘッドが総実行時間の10%を超える
-
ジョブ期間が4時間を超える
-
アプリケーションが32ノード以上に効率的にスケーリングする
これらの基準のうち3つ未満を満たすワークロードの場合、Hpc8aはプレミアム価格を正当化するのに十分なROIを提供しない可能性があります。
AWSの専用インスタンス戦略:Hpc8aのポジショニング
Hpc8aの発表は、AWSが性能重視アプリケーション向けの専用インスタンスをリリースするという戦略的パターンを継続しており、すべての計算ニーズに最適なインスタンスタイプは存在しないという認識を反映しています。Hpc8aは特定のニッチを占めています。すなわち、GPU加速を必要としないが高いノード間帯域幅を必要とするCPU集約的HPCワークロードです。
-
ポートフォリオの整合性:* このポジショニングは、最近のインフラストラクチャ発表を補完します。G7eインスタンスはGPU加速ワークロードに優れ、X8iインスタンスはメモリ容量を優先し、Hpc8aはCPUスループットを優先しながら例外的なネットワーキングを提供します。各々が異なるワークロードプロファイルに対応し、インフラストラクチャを計算要件に密接に整合させ、不要な機能のオーバープロビジョニングによるコスト非効率を回避できます。
-
ベンダー多様化:* AWSは複数のプロセッサベンダー(AMD、Intel、NVIDIA)と提携し、各ベンダーのアーキテクチャ上の強みを活用しながら、価格設定とイノベーションに対する競争圧力を維持しています。このアプローチは顧客に競争力のある価格設定を通じて利益をもたらし、将来のワークロード要件に対して複数の選択肢を確保します。
-
実行上の含意:* インフラストラクチャ戦略は、ワークロード特性をインスタンスタイプに明示的にマッピングすべきです。異種HPC環境は、GPU加速シミュレーション用のG7eインスタンス、メモリ集約的分析用のX8iインスタンス、CPU集約的エンジニアリングシミュレーション用のHpc8aインスタンスを必要とする場合があります。この多様化は運用の複雑性を増しますが、ポートフォリオ全体のコスト性能を最適化します。
コスト性能分析:Hpc8aがROIを提供する場合
Hpc8aインスタンスが優れたコスト性能を提供する場合を理解するには、ワークロード特性、スケーリング動作、および総所有コストを分析する必要があります。40%の性能向上は、多くのHPCアプリケーションの実行時間短縮に変換され、ワークロードが利用可能な計算リソースを完全に活用する場合、同様の幅でコストを削減する可能性があります。
- ROI計算フレームワーク:*
-
基準コスト: 現在のインフラストラクチャコストを確立します。前世代インスタンスで年間100回のCFDシミュレーションを$2.00/時間で実行し、平均実行時間が24時間の場合、100 × 24 × $2.00 = 年間$4,800の計算コストです。
-
Hpc8aコスト: Hpc8aインスタンスは約$4.00/時間(前世代の2倍の価格)です。30%の実行時間短縮(平均16.8時間)で、100 × 16.8 × $4.00 = 年間$6,720の計算コストです。
-
ライセンス影響: ソフトウェアライセンスが$50/コア時間を請求する場合、実行時間を30%削減することで$50 × 128コア × 7.2時間 × 100シミュレーション = 年間$460,800を節約でき、これが支配的なコスト要因です。
-
総ROI: このシナリオでは、ライセンス節約によりHpc8a投資はインスタンスあたりのコストが高いにもかかわらず正当化されます。ただし、ソフトウェアが1時間あたりのコア課金ではなく永続ライセンスを使用する場合、ROI計算は大幅に変わります。
-
コスト効率の制約:* 専用HPCインスタンスはプレミアム価格を伴うため、並列化が不十分、I/Oボトルネックが頻繁、またはCPU使用率が低いワークロードには費用対効果がありません。8ノードのみにスケーリングするか、利用可能なCPUリソースの40%を使用するワークロードは、プレミアム価格を正当化するのに十分な性能向上を達成しません。
-
ROI検証の実行ワークフロー:*
-
現在のワークロードをプロファイリング: LIKWIDやHPCToolkitなどのツールを使用して、現在のインフラストラクチャでCPU使用率、メモリ帯域幅使用率、MPI通信オーバーヘッドを測定します。
-
Hpc8aでベンチマーク: 代表的なワークロードをHpc8aインスタンスにデプロイし(コスト管理のため2~4ノードから開始)、性能向上を測定します。
-
損益分岐点を計算: プレミアム価格を正当化するのに必要な最小性能向上を決定します。2倍のインスタンスコストの場合、コスト同等性を達成するには約50%の実行時間短縮が必要です(使用率の向上を考慮)。
-
ライセンスを評価: 該当する場合、1時間あたりのコア課金ライセンスコストを定量化します。これらはしばしばROI計算を支配します。
-
パイロットデプロイメント: 本格的な移行前に、4~8週間にわたって本番ワークロードの10~20%をHpc8aで実行し、予想される節約を検証します。
- リスク警告:* 40%の性能向上がワークロードに適用されると仮定しないでください。実際の改善はアプリケーション特性、コンパイラ最適化、およびスケーリング効率に依存します。ベンチマークが別の結果を証明するまで、保守的な計画では20~30%の改善を想定します。
主要なポイントと次のアクション
Hpc8aインスタンスは、CPU集約的HPCワークロード向けの意味のある進歩を表し、40%高い性能、強化されたメモリ帯域幅、300 Gbpsネットワーキングを目的に構築されたオファリングに統合しています。価値提案は、実行時間の短縮がコスト節約に直結する密結合シミュレーションおよびエンジニアリングアプリケーション、特にソフトウェアライセンスが1時間あたりのコア課金を行う場合に最も強力です。
- 即座のアクション(第1週):*
-
ワークロード評価: 3~5の代表的な本番ワークロードをプロファイリングして、CPU使用率、メモリ帯域幅使用率、MPI通信オーバーヘッドを決定します。このデータを使用してHpc8a移行の候補を特定します。
-
コストモデリング: 候補ワークロードの現在の年間インフラストラクチャコスト(計算、ストレージ、ライセンスを含む)を計算します。25%の実行時間短縮を想定してHpc8aでの予想コストをモデル化します(保守的な推定)。
-
ベンダー評価: AWSアカウントチームに連絡して、お客様のリージョンでのHpc8a可用性について相談し、ターゲットクラスタサイズの価格設定を取得します。
- 短期アクション(第2~4週):*
- パイロットデプロイメント: AWS ParallelClusterを使用して4~8ノードのHpc8aクラスタをデプロイします。代表的なワークロードを24時間実行します。
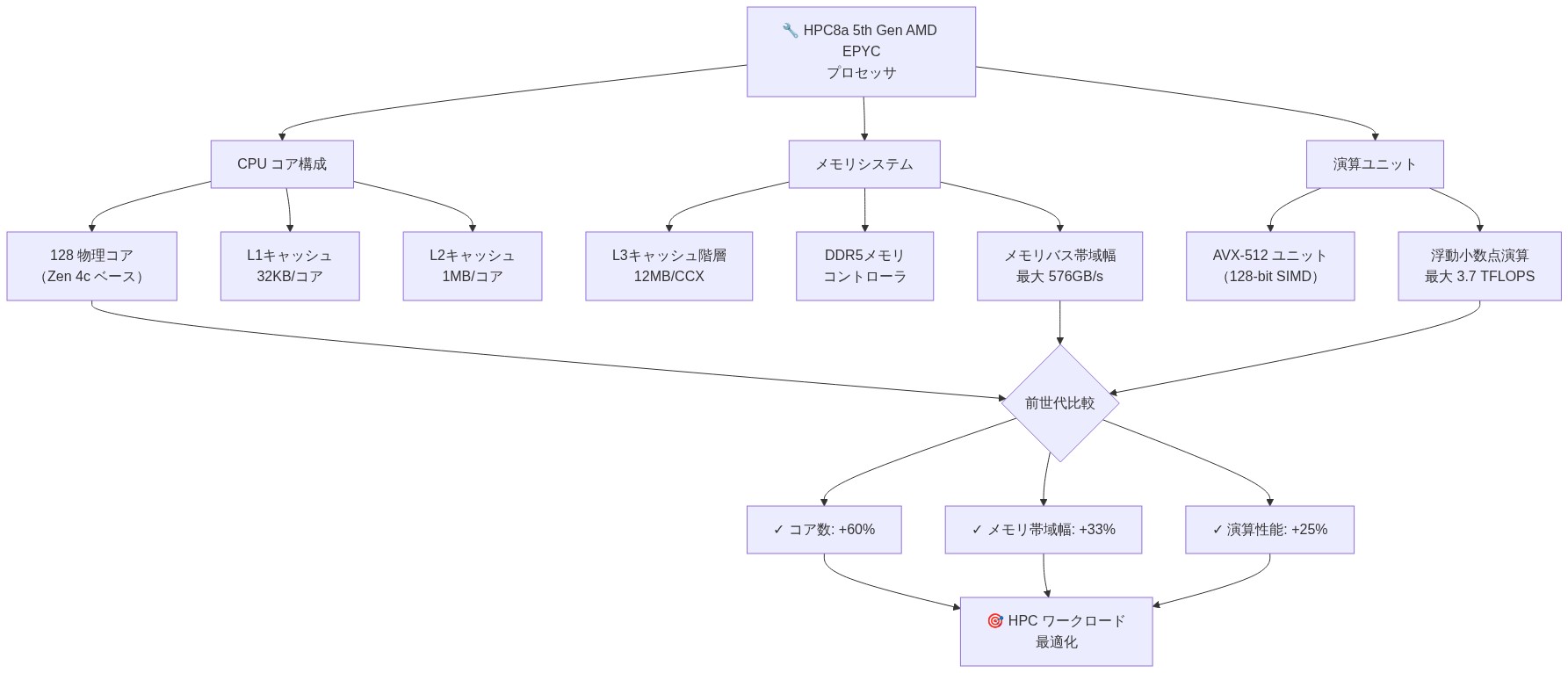
- 図2:5th Gen AMD EPYC HPC8a プロセッサのアーキテクチャ構成図*
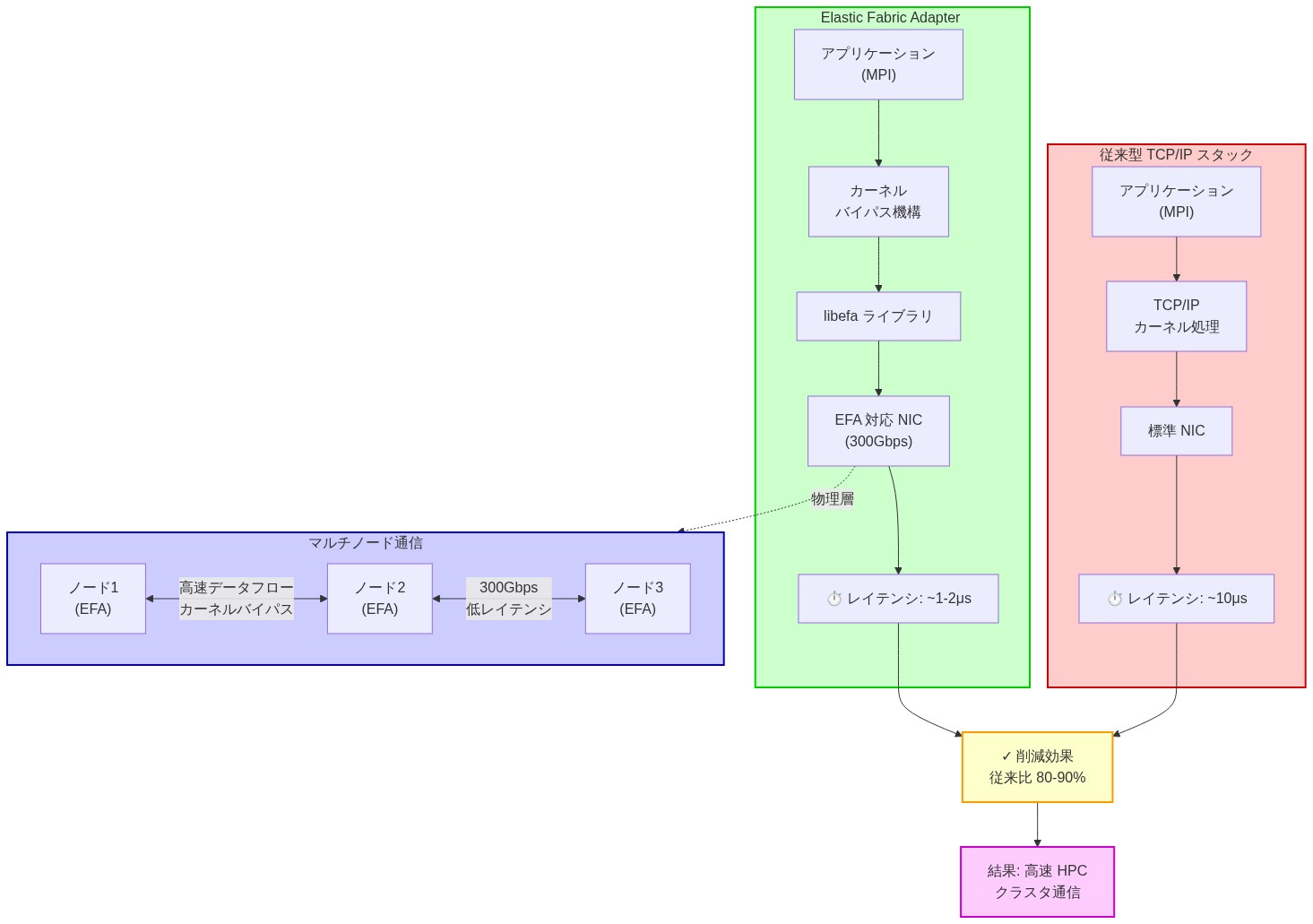
- 図5:Elastic Fabric Adapter(EFA)のノード間通信アーキテクチャ - 従来型TCP/IPとの比較およびマイクロ秒レベルのレイテンシ削減メカニズム*

- 図10:AWS HPC インスタンスポートフォリオにおける Hpc8a の位置付け*