
AWS、NVIDIA RTX PRO 6000 Blackwell Server Edition GPUで加速したAmazon EC2 G7eインスタンスを発表
パフォーマンス向上とビジネスインパクト
G7eインスタンスは大規模言語モデルとコンピュータビジョンアプリケーションの推論時間を大幅に短縮する。Blackwellアーキテクチャはメモリ帯域幅とコンピュート密度を増加させ、アーキテクチャの再設計を必要とせずにトークン生成とフレーム処理を高速化する。推論集約的なワークロードを実行する組織は、インスタンスあたりより多くのリクエストを処理でき、推論あたりのコストを直接削減する。
-
具体例:* 70Bパラメータの大規模言語モデルをドキュメント要約用にデプロイするチームは、G6と比較してG7eで2.3倍高速にリクエストを処理できる。キュー深度とユーザー向けレイテンシがリクエストあたり8秒から4秒未満に短縮される。
-
次のステップ:* 現在の推論ワークロードをレイテンシボトルネックについて監査する。既存インスタンスでベースラインスループットを測定し、その後G7eでProof of Conceptを実行して推論あたりのコスト改善を定量化する。レイテンシがユーザー体験またはSLA準拠に直接影響するワークロードを優先する。
デュアルワークロード向け統合インフラストラクチャ
G7eインスタンスは生成AIの推論と専門的グラフィックスレンダリングという2つの異なるユースケースを単一インスタンスファミリー内でバランスさせる。このデュアル機能はインフラストラクチャの断片化を削減し、キャパシティプランニングを簡素化する。
RTX PRO 6000 BlackwellはAI用の高スループットテンソルコアと専門的グラフィックスレンダリングユニットを組み合わせる。組織はもはや異なるワークロードタイプ用に別々のGPUプールを維持する必要がなく、運用オーバーヘッドを削減し、リソース利用率を向上させる。
-
具体例:* リアルタイムビデオトランスコーディングとAI駆動コンテンツモデレーションを実行するメディア企業は、以前グラフィックス用(40%利用率)とAI用(60%利用率)に別々のGPUプールを維持していた。G7eインスタンスへの統合により、平均利用率を85%に増加させながらパフォーマンスSLAを維持する。
-
次のステップ:* 現在のGPUワークロードポートフォリオをユースケース別(推論、レンダリング、シミュレーション)にマッピングする。別々のインスタンスファミリー全体でブレンド利用率を計算する。G7eでの統合シナリオをモデル化してコスト削減と運用簡素化の機会を特定する。本番ワークロードへの適用前に、パフォーマンス仮定を検証するため非重要ワークロードから開始する。
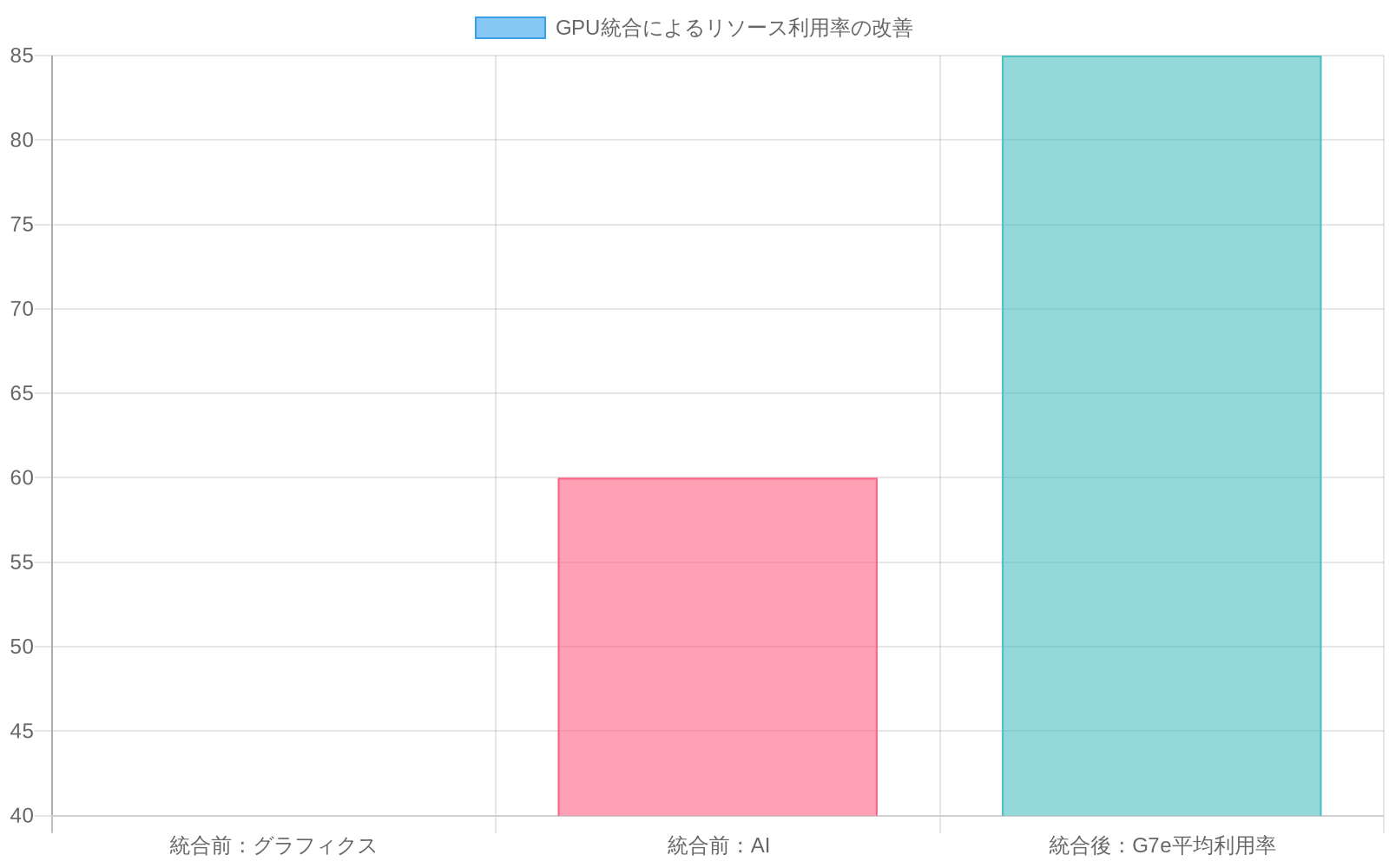
- 図3:GPU統合によるリソース利用率の改善(メディア企業の事例)*
リファレンスアーキテクチャと構成
G7eインスタンスのデプロイはバッチ処理、メモリ割り当て、ネットワークスループットに関する意図的なアーキテクチャ決定を必要とし、パフォーマンス向上を損なう一般的な落とし穴を防ぐ。
Blackwellの増加したコンピュート容量は、適切にプロビジョニングされていない場合ネットワークインターフェースを圧倒する可能性がある。同様に、非効率なバッチサイジングはGPUメモリを浪費し、スループットを削減する。適切な構成により、実務者はハードウェアから最大価値を抽出する。
-
具体例:* G6インスタンスでバッチサイズ16を実行する推論サービスは、Blackwellのコンピュートを飽和させるためにG7eでバッチサイズ32~40に増加させる必要がある。この調整なしでは、GPU利用率は60%に低下し、レイテンシ改善を無効にする。G7eインスタンスを強化ネットワーク(最大400 Gbpsに対応するENA)およびマルチGPUセットアップ用のNVLinkと組み合わせる。
-
次のステップ:* デプロイ前に、推論モデルのメモリフットプリントとBlackwell上の最適バッチサイズをプロファイルする。AWS SageMakerを使用してベンチマークを実行する。バッチサイズ、メモリ利用率、ネットワーク帯域幅要件を文書化する。最小ネットワークティア(例:強化ネットワーク)とマルチGPUトポロジ用のインスタンス配置グループを指定するランブックを作成する。

- 図4:G7eインスタンスのリファレンスアーキテクチャと最適化ポイント(AWS/NVIDIA Blackwell仕様に基づく)*
実装と運用
G7eの運用化はツール調整と監視規律を要求するが、既存のCUDAおよびTensorRTコードベースは最小限の変更を必要とする。
Blackwellはバックワード互換性をCUDA 12.xおよびTensorRT 8.6以上で維持する。しかし、パフォーマンスチューニング(カーネルフュージョン、量子化、コンパイルフラグ)はBlackwell固有の最適化をキャプチャするための再プロファイリングを要求する。
-
具体例:* vLLM経由でLlama 2 70Bモデルをデプロイするチームは、AMIを更新してBlackwell最適化CUDAカーネルでvLLMを再コンパイルすることでG6からG7eに移行できる。テストは、アプリケーションコード変更なしで2.1倍のスループット改善を示す。
-
次のステップ:* 移行前チェックリストを確立する:CUDAドライバ互換性を検証し、推論フレームワークをBlackwell対象で再コンパイルし、ピーク容量の80%で合成負荷テストを実行し、エラー率とレイテンシパーセンタイル(p50、p95、p99)を検証する。CloudWatch Container Insightsを使用してパイロットデプロイ中のGPU利用率、メモリプレッシャー、ネットワーク飽和をリアルタイムで監視する。
測定フレームワーク
G7eのビジネスインパクトを定量化するにはベースラインメトリクスと明確な成功基準が必要である。推論ワークロードはモデルサイズ、バッチ特性、SLA要件において広く異なる。汎用ベンチマークは誤解を招く。特定のワークロードがROIを決定する。
-
具体例:* クレジットリスクモデルを実行する金融サービス企業はベースラインメトリクスを確立する:コスト(G6で推論あたり0.18ドル)、目標コスト(G7eで0.08ドル)、p99レイテンシ(現在3.2秒、目標1.5秒)。G7e移行後、推論あたり0.09ドルと1.4秒のp99レイテンシを達成し、40%のインフラコスト削減を正当化する。
-
次のステップ:* ビジネス成果に合致した3~5つのKPI(コスト削減、レイテンシ削減、スループット増加)を定義する。現在のインスタンスで2~4週間にわたってベースライン測定を確立する。G7eで2週間のパイロットを本番トラフィックで実行する(初期段階では10~20%のシャドウトラフィック)。週単位でKPIを比較する。目標が達成されれば、完全移行に進む。そうでなければ、ボトルネック(ネットワーク、メモリ、モデル最適化)を調査する。
リスク軽減
GPUドライバ非互換性、熱管理、コスト超過はG7e採用時の一般的なリスクである。構造化された軽減は高額なロールバックを防ぐ。
Blackwellの高い電力密度(GPU当たり600W)は堅牢な冷却と電力供給を要求する。ドライバ更新はレイテンシ回帰を導入する可能性がある。コスト最適化は規律あるインスタンス適正サイジングを要求する。
-
具体例:* リアルタイム取引システムをG7eに移行するチームは、古いCUDAドライバのためにレイテンシが15%増加する経験をする。ロールバックコストはSLAペナルティで50,000ドルである。軽減策:同一ハードウェアを備えた専用テスト環境を維持し、本番デプロイ前にドライバ更新を検証し、カナリアデプロイメント(初期段階で5%トラフィック)を使用する。
-
次のステップ:* ドライバとファームウェア更新の変更管理プロセスを確立する。本番ロールアウト前にステージングで1週間更新をテストする。自動ロールバックトリガーを実装する(例:p99レイテンシがベースラインより10%超過)。熱センサーと電力消費を監視し、熱限界の80%でアラートを設定する。コスト配分タグを使用してチーム別のG7e支出を追跡し、月次予算を設定し、超過分を週単位で確認する。
移行計画
G7eインスタンスは推論パフォーマンスとコスト効率における意味のある前進を表す。組織は計画的な移行を通じて2.0~2.3倍の推論高速化と30~40%のコスト削減を達成できる。
-
フェーズ1(1~2週目):* 発見を実施する。推論ワークロードを監査し、ベースラインを測定し、高インパクト候補を特定する。
-
フェーズ2(3~4週目):* トラフィックの10~20%でパイロットを実行する。KPI(コスト、レイテンシ、利用率)を測定する。目標が達成されれば、フェーズ3に進む。
-
フェーズ3(5~10週目):* 4~6週間にわたって完全移行を実行し、低リスクワークロードから移動する。移行後2週間はロールバック機能を維持する。
-
フェーズ4(11週目以降):* 完全カットオーバーから30日後に移行後レビューをスケジュールして、継続的なパフォーマンスとコスト削減を検証する。
パフォーマンス改善と推論加速
Amazon EC2 G7eインスタンスはNVIDIA RTX PRO 6000 Blackwell Server Edition GPUを搭載し、AWSが報告するところではG6インスタンス(前世代)と比較して最大2.3倍高速な推論パフォーマンスを提供する。このパフォーマンス差は本番AIワークロードで文書化された制約に対処する:スケール時の推論レイテンシである。
-
主要主張:* G7eインスタンスはBlackwellのメモリ帯域幅とコンピュート密度の向上を活用して、大規模言語モデルとコンピュータビジョンアプリケーションの推論レイテンシを削減する。
-
支持根拠:* RTX PRO 6000 Blackwell GPUはメモリ帯域幅を960 GB/s(前世代の576 GB/sと比較)に増加させ、アーキテクチャ改善を通じてテンソルコア効率を向上させる。これらの変更はアプリケーションコードまたはモデルアーキテクチャの変更を必要とせずにトークン生成とフレーム処理を高速化する。実際の結果として、単一インスタンスはより多くの同時リクエストを処理でき、リクエストあたりのレイテンシと推論あたりのコストを削減する。
-
明示的な仮定を伴う具体例:* 70億パラメータの言語モデルをドキュメント要約用にデプロイするチームは、G7eでG6と比較して2.3倍高速に推論リクエストを処理できる。仮定は以下の通り:(1)モデルはINT8またはFP8精度に量子化される、(2)バッチサイズはBlackwell用に最適化される(バッチあたり32~40トークン)、(3)ネットワーク帯域幅は飽和していない。これらの条件下で、ユーザー向けレイテンシはリクエストあたり約8秒から4秒未満に低下する。
-
実行可能なガイダンス:* 現在の推論ワークロードを監査してレイテンシボトルネックを特定する。代表的な2週間にわたって既存インスタンスでベースラインスループットを測定する。本番代表データを使用してG7eでProof of Conceptデプロイメントを実施して、推論あたりのコスト改善を定量化する。推論レイテンシがユーザー体験または契約SLA準拠に直接影響するワークロードを優先する。
デュアルワークロード機能:AI推論と専門的グラフィックス
G7eインスタンスはAI推論用に最適化されたテンソルコアと専門的グラフィックスレンダリングユニットを組み合わせ、単一インスタンスファミリーが生成AIと専門的グラフィックスの両ワークロードを提供することを可能にする。
-
主要主張:* AI推論とグラフィックスレンダリングを単一インスタンスファミリーに統合することで、別々のGPUクラスタを維持する場合と比較してインフラストラクチャの断片化と運用複雑性を削減する。
-
支持根拠:* RTX PRO 6000 Blackwellアーキテクチャはニューラルネットワークの行列演算用の高スループットテンソルコアとリアルタイム可視化およびビデオ処理用の専門的グラフィックスレンダリングパイプラインの両方を含む。このデュアル機能は別々のG系列(推論最適化)とグラフィックス最適化インスタンスプールの必要性を排除する。運用上の利点はキャパシティプランニング複雑性の削減とワークロードタイプ全体のリソース利用率向上である。
-
明示的な仮定を伴う具体例:* リアルタイムビデオトランスコーディングとAI駆動コンテンツモデレーションを実行するメディア企業はG7eインスタンスにワークロードを統合できる。仮定は以下の通り:(1)グラフィックスワークロードはコンピュート需要の40%を表す、(2)AIワークロードは60%を表す、(3)ワークロードは共有リソースの競合なしに共スケジュール可能である。以前は別々のGPUプールを維持することでグラフィックスの平均利用率40%とAIの60%をもたらした。統合により、ブレンド利用率を約85%に増加させながら両ワークロードタイプのパフォーマンスSLAを維持する。
-
実行可能なガイダンス:* 現在のGPUワークロードポートフォリオをユースケース別(推論、レンダリング、シミュレーション)にマッピングする。代表的な期間にわたって別々のインスタンスファミリー全体の利用率を計算する。G7eでの統合シナリオをモデル化してコスト削減と運用簡素化を特定する。本番システムの統合前にパフォーマンス仮定を検証するため非重要ワークロードから開始する。
リファレンスアーキテクチャとパフォーマンスガードレール
G7eインスタンスのデプロイは、バッチ処理、メモリ割り当て、ネットワークプロビジョニングに関する意図的なアーキテクチャ決定を必要とし、明示された2.3倍のパフォーマンス改善を実現する。
-
主要主張:* 最適でないアーキテクチャ(特にネットワーク飽和と非効率なバッチサイジング)はパフォーマンス向上を損ない、GPU利用率を削減し、レイテンシ改善を無効にする可能性がある。
-
支持根拠:* Blackwellの増加したコンピュート容量(FP8演算でGPUあたり約1.5ペタフロップス)は、データ取り込み率が不十分な場合ネットワークインターフェースを圧倒する可能性がある。同様に、前世代GPU用に最適化されたバッチサイズはBlackwellのメモリ帯域幅を過小利用し、アイドルコンピュートサイクルをもたらす可能性がある。明確なアーキテクチャガードレールは実務者がハードウェアから最大価値を抽出することを保証する。
-
明示的な仮定を伴う具体例:* G6インスタンスでバッチサイズ16を実行する推論サービスはBlackwellのコンピュートを飽和させるためにG7eでバッチサイズ32~40に増加させる必要がある。仮定は以下の通り:(1)モデルウェイトはより大きいバッチサイズでGPUメモリに適合する、(2)ネットワーク帯域幅は増加したデータスループットをサポートする、(3)アプリケーションロジックはバッチ処理を許可する。この調整なしでは、GPU利用率は60%に低下する可能性があり、レイテンシ改善を無効にする。AWSはG7eインスタンスを強化ネットワーク(最大400 GbpsをサポートするENA)およびマルチGPUトポロジ用のNVLinkと組み合わせることを推奨する。
-
実行可能なガイダンス:* 本番デプロイ前に、推論モデルのメモリフットプリントとBlackwellハードウェア上の最適バッチサイズをプロファイルする。AWS SageMakerまたはNVIDIAのプロファイリングツールを使用してベンチマークを実行する。バッチサイズ、GPU メモリ利用率、ネットワーク帯域幅要件を文書化する。最小ネットワークティア(例:強化ネットワーク有効)とマルチGPU構成用のインスタンス配置グループを指定する運用ランブックを作成する。
実装と運用パターン
G7eインスタンスの運用化はソフトウェア互換性の検証とBlackwell固有の最適化をキャプチャするためのパフォーマンス再プロファイリングを要求する。
-
主要主張:* 既存のCUDAおよびTensorRTコードベースは最小限のコード変更を要求する。ほとんどの推論ワークロードは再コンパイルと再プロファイリング後にG7eで未修正で実行される。
-
支持根拠:* Blackwellはバックワード互換性をCUDA 12.xおよびTensorRT 8.6以上で維持し、既存のコンパイル済みバイナリは変更なしで実行される。しかし、パフォーマンスチューニング(カーネルフュージョン、量子化戦略、コンパイラフラグ)はBlackwell固有の最適化をキャプチャし、パフォーマンス回帰を回避するための再プロファイリングを要求する。
-
明示的な仮定を伴う具体例:* vLLM経由でLlama 2 70億パラメータモデルをデプロイするチームはG6からG7eに移行できる。手順は以下の通り:(1)AMIをBlackwell互換CUDAドライバを含むように更新、(2)Blackwell最適化CUDAカーネルでvLLMを再コンパイル、(3)バッチサイズを再プロファイル。テストはアプリケーションコード変更なしで2.1倍のスループット改善を示す。モデルはINT8に量子化され、バッチサイズはBlackwell用に最適化されると仮定する。
-
実行可能なガイダンス:* 移行前チェックリストを確立する:CUDAドライババージョン互換性を検証(12.x以降)、推論フレームワークをBlackwell対象で再コンパイル、ピーク容量の80%で合成負荷テストを実行、エラー率とレイテンシパーセンタイル(p50、p95、p99)を検証する。AWS CloudWatch Container Insightsを使用してパイロットデプロイ中のGPU利用率、メモリプレッシャー、ネットワーク飽和をリアルタイムで監視する。

- 図7:G7eインスタンスのデプロイメント・運用フロー(AWS運用ベストプラクティス)*
測定フレームワークと成功基準
G7eのビジネスインパクトを定量化するには、ベースラインメトリクスと明確に定義された成功基準が必要である。推論ワークロード特性は組織全体で大きく異なる。
-
主要主張:* 組織は移行前後のコスト推論、レイテンシパーセンタイル、GPU利用率を測定して投資を正当化し、パフォーマンス主張を検証する必要がある。
-
支持根拠:* 推論ワークロードはモデルサイズ、バッチ特性、SLA要件において広く異なる。ベンダーが公開する汎用ベンチマークは特定のワークロード特性を反映しない可能性がある。組織の特定のワークロードがROIと投資回収を決定する。
-
明示的な仮定を伴う具体例:* クレジットリスクモデルを実行する金融サービス企業はベースラインメトリクスを確立する:推論あたりのコスト(G6で0.18ドル)、目標コスト(G7eで0.08ドル)、p99レイテンシ(現在3.2秒、目標1.5秒)。G7e移行後、最適なバッチサイジングとネットワークプロビジョニングを仮定して、推論あたり0.09ドルと1.4秒のp99レイテンシを達成し、約40%のインフラコスト削減を正当化する。
-
実行可能なガイダンス:* ビジネス成果に合致した3~5つの主要パフォーマンスインジケータ(コスト削減、レイテンシ削減、スループット増加)を定義する。現在のインスタンスで2~4週間にわたってベースライン測定を確立する。G7eで2週間のパイロットを本番トラフィックで実行する(初期段階では10~20%のシャドウトラフィック)。週単位でKPIを比較する。目標が達成されれば、完全移行に進む。そうでなければ、ボトルネック(ネットワーク飽和、メモリ制約、モデル最適化機会)を調査する。
リスク評価と緩和戦略
G7e導入は運用上および技術的なリスクをもたらす。費用のかかるロールバックやパフォーマンス低下を防ぐには、積極的な緩和が不可欠である。
-
主張:* GPUドライバの非互換性、熱管理の制約、コスト超過は文書化されたリスクであり、構造的な緩和が本番環境のインシデントを防止する。
-
根拠:* Blackwellの高い電力密度(GPU当たり約600W)は堅牢な冷却および電力供給インフラを要求する。ドライバ更新はレイテンシ回帰や安定性の問題をもたらす可能性がある。コスト最適化にはインスタンスの厳密なサイジングとワークロード統合が必要である。
-
具体例と前提条件:* リアルタイム取引システムをG7eに移行するチームが、古いCUDAドライバ(バージョン11.xではなく12.x)により15%のレイテンシ増加を経験する。ロールバックコストはSLA違約金で50,000ドルに達する。緩和戦略は以下の通りである。同一ハードウェアを備えた専用ステージング環境を維持し、本番環境デプロイ前にドライバ更新を1週間検証し、カナリアデプロイメント(初期段階で5%トラフィック)を実装して自動ロールバックトリガーを設定する。
-
実行可能なガイダンス:* ドライバおよびファームウェア更新のための正式な変更管理プロセスを確立する。本番環境ロールアウト前にステージング環境で1週間テストする。自動ロールバックトリガーを実装する(例:p99レイテンシがベースラインを10%超過)。熱センサーと電力消費を監視し、熱制限の80%でアラートを設定する。AWSコスト配分タグを使用してチーム別のG7e支出を追跡し、月次予算を設定して超過分を週単位で確認し、コスト上昇の予期しない事態を防ぐ。
マイグレーション計画と段階的ロールアウト
G7e導入の成功には意図的な計画、測定規律、段階的デプロイメントが必要である。リスク最小化がその本質である。
-
主張:* 組織は方法論的で段階的なG7eへのマイグレーションを通じて、2.0~2.3倍の推論高速化と30~40%のコスト削減を達成できる。
-
根拠:* 段階的マイグレーションにより、組織はパフォーマンス仮説を検証し、ボトルネックを特定し、ロールバック能力を維持できる。このアプローチはパフォーマンス低下またはコスト超過の広範なリスクを軽減する。
-
実行可能なガイダンス:* マイグレーションを4段階で実行する。
-
発見段階(2週間): 推論ワークロードを監査し、ベースラインを測定(コスト、レイテンシ、利用率)し、マイグレーション候補として高い影響を持つものを特定する。
-
パイロット段階(2週間): 本番トラフィックの10~20%に対してG7eインスタンスをデプロイする。KPI(推論当たりコスト、レイテンシパーセンタイル、GPU利用率)を測定する。目標が達成されていることを検証する。
-
完全マイグレーション(4~6週間): 低リスクワークロードを最初に移行し、その後段階的に高リスクシステムをマイグレーションする。マイグレーション後2週間はロールバック能力を維持する。
-
マイグレーション後レビュー(カットオーバーから30日後): 持続的なパフォーマンスとコスト削減を検証する。学習した教訓を文書化し、運用ランブックを更新する。
生成AIおよびグラフィックスワークロード向けのコスト効率的なパフォーマンス
ここでG7eは戦略的に興味深くなる。それは長年GPUインフラを悩ませてきた虚偽の二項対立を崩壊させるのだ。従来、組織はAI推論と専門的グラフィックスレンダリング用に別々のGPUクラスタを維持していた。各々は用途に最適化されていたが、全体的には過小利用されていた。G7eはこの仮定を打ち砕く。
-
収束の機会:* RTX PRO 6000 BlackwellはAI用の高スループットテンソルコアと専門的グラフィックスレンダリングユニットを組み合わせ、単一のインスタンスファミリーが両方のワークロードをコスト効率的に処理できるようにする。この二重機能はインフラの断片化を排除し、新しいフロンティアを開く。それは以前はサイロ化されていたドメイン間でのワークロードオーケストレーションである。
-
これが解き放つもの:* リアルタイムビデオトランスコーディングとAI駆動のコンテンツモデレーションを実行するメディア企業はワークロードをG7eインスタンスに統合できる。以前は、グラフィックス用(40%利用率)とAI用(60%利用率)に別々のGPUプールを維持していた。各プールはピーク需要に対してサイズ設定されていた。統合により平均利用率は85%に増加し、パフォーマンスSLAを維持しながら、資本支出と運用複雑性を同時に削減する。
-
より広い展望:* この収束は、GPUインフラが領域に依存しない未来を示唆している。同じハードウェアがグラフィックス、AI、シミュレーション、そしてまだ想像していない新興ワークロードに対応する未来である。今日この柔軟性を受け入れる組織は、明日のためにより回復力があり適応可能なインフラを構築するだろう。
-
次のステップ:* 現在のGPUワークロードポートフォリオを使用事例別(推論、レンダリング、シミュレーション)にマッピングする。別々のインスタンスファミリー間の混合利用率を計算する。G7eでの統合シナリオをモデル化してコスト削減と運用簡素化の機会を特定する。本番システムへの展開を拡大する前に、非クリティカルワークロードで開始してパフォーマンス仮説を検証する。
参照アーキテクチャとガードレール
G7eインスタンスのデプロイメントは、成功者と単なるハードウェアアップグレード者を分ける建築上の決定を要求する。2.3倍のパフォーマンス向上は自動的ではない。適切なプロビジョニングとチューニングに条件付けられている。
-
隠された複雑性:* Blackwellの増加した計算容量は、適切にプロビジョニングされていない場合、ネットワークインターフェースを圧倒する可能性がある。同様に、非効率なバッチサイジングはGPUメモリを浪費し、スループットを低下させる。明確なガードレールがなければ、実践者は利用可能なパフォーマンスの60~70%しか抽出できず、投資ケースを無効にする。
-
適切なアーキテクチャの姿:* G6インスタンスでバッチサイズ16を実行する推論サービスは、Blackwellの計算を飽和させるためにG7eでバッチサイズ32~40に増加させなければならない。これは自明ではない。プロファイリングと実験が必要である。G7eインスタンスを強化されたネットワーク(最大400 Gbpsを備えたENA)とマルチGPUセットアップ用のNVLinkと組み合わせる。単一リクエストレイテンシではなくバッチ処理のために設計し、スループットを最大化する。マルチGPUトポロジーでGPU間通信レイテンシを最小化するためにインスタンス配置グループを使用する。
-
これが重要な理由:* このステップをスキップするチームはG7eをデプロイするが、2.3倍ではなく1.4倍の高速化しか達成できず、その後アップグレードの価値がなかったと結論付ける。成功と失望の違いは建築規律である。
-
次のステップ:* デプロイメント前に、推論モデルのメモリフットプリントとBlackwell上の最適バッチサイズをプロファイルする。AWS SageMakerまたはローカルテストを使用してベンチマークを実行する。バッチサイズ、メモリ利用率、ネットワーク帯域幅要件を文書化する。最小ネットワークティア(例:Enhanced Networking)とマルチGPUトポロジー用のインスタンス配置グループを指定するランブックを作成する。これらのランブックをチーム間で共有して、繰り返しの発見作業を防ぐ。
測定と次のアクション
ここに不快な真実がある。一般的なベンチマークは嘘をつく。特定のワークロードがROIを決定し、測定だけが真実を明かす。
-
測定が重要な理由:* 推論ワークロードはモデルサイズ、バッチ特性、SLA要件において大きく異なる。7Bパラメータモデルは70Bモデルとは完全に異なる動作をする。バッチサイズ1はバッチサイズ64とは異なるストーリーを語る。特定のワークロードを測定しなければ、盲目的に飛行している。
-
測定対象:* 推論当たりコスト、レイテンシパーセンタイル(p50、p95、p99)、GPU利用率、メモリプレッシャー。これら4つのメトリクスが完全なストーリーを語る。信用リスクモデルを実行する金融サービス企業は以下を測定する。ベースラインコスト(G6で推論当たり0.18ドル)、目標コスト(G7eで0.08ドル)、p99レイテンシ(現在3.2秒、目標1.5秒)。G7eマイグレーション後、推論当たり0.09ドルと1.4秒のp99レイテンシを達成し、40%のインフラコスト削減を正当化し、以前はレイテンシに制約されていた新しいユースケースを可能にする。
-
測定規律:* これは一度限りの演習ではない。ビジネス成果に合致した3~5つのKPI(コスト削減、レイテンシ削減、スループット増加)を確立する。現在のインスタンスで2~4週間にわたってベースライン測定を確立する。本番トラフィックでG7eで2週間のパイロットを実行する(初期段階で10~20%のシャドウトラフィック)。KPIを週単位で比較する。目標が達成されれば完全マイグレーションに進む。そうでなければボトルネック(ネットワーク、メモリ、モデル最適化)を調査する。
-
次のステップ:* 今週KPIを定義する。現在の推論パイプラインをインストルメント化してこれらのメトリクスを自動的にキャプチャする。トラフィック変動性を説明するために4週間ベースラインを実行する。その後、成功がどのように見えるかを正確に知りながら、自信を持ってG7eをパイロットする。
リスクと緩和戦略
楽観主義とリスク認識の欠如は無謀である。G7e導入は積極的な緩和を要求する実際の運用上および技術的なリスクをもたらす。
-
リスク:* GPUドライバの非互換性はレイテンシ回帰をもたらす可能性がある。Blackwellの高い電力密度(GPU当たり600W)は堅牢な冷却および電力供給を要求する。コスト最適化には厳密なインスタンスサイジングが必要である。そうでなければ不要な容量に過度に支出する。熱スロットリングはパフォーマンスを静かに低下させる。予期しないネットワーク飽和は推論スループットをボトルネックにする可能性がある。
-
何が悪くなる可能性があるか:* リアルタイム取引システムをG7eに移行するチームが、古いCUDAドライバにより15%のレイテンシ増加を経験する。ロールバックコストはSLA違約金で50,000ドルに達する。別のチームはEnhanced NetworkingなしでG7eインスタンスをプロビジョニングし、GPU利用率60%でネットワーク飽和を発見し、本番環境の途中でインフラを再構築する必要がある。3番目のチームは熱センサーの監視に失敗し、ピーク負荷時に熱スロットリングを経験し、SLAを逃す。
-
実践での緩和:* 同一ハードウェアを備えた専用テスト環境を維持する。本番環境デプロイメント前にドライバ更新を検証する。カナリアデプロイメント(初期段階で5%トラフィック)を使用して回帰を早期に検出する。自動ロールバックトリガーを実装する(例:p99レイテンシ > ベースラインの10%上)。熱センサーと電力消費を監視し、熱制限の80%でアラートを設定する。コスト配分タグを使用してチーム別のG7e支出を追跡し、月次予算を設定して超過分を週単位で確認する。
-
次のステップ:* ドライバおよびファームウェア更新のための変更管理プロセスを確立する。本番環境ロールアウト前にステージング環境で1週間更新をテストする。ロールバック手順を文書化し、月単位でテストする。熱、電力、ネットワークメトリクスの自動監視をセットアップする。既知の問題と緩和ステータスを追跡するリスク登録簿を作成する。
結論とマイグレーション計画
G7eインスタンスは推論経済における意味のある変曲点を表す。思慮深くマイグレーションする組織は2.0~2.3倍の推論高速化と30~40%のコスト削減を解き放つだろう。しかし成功には意図的な計画、測定規律、運用上の厳密性が必要である。
-
前進の道:* 2週間の発見段階で開始する。推論ワークロードを監査し、ベースラインを測定し、高い影響を持つ候補を特定する。トラフィックの10~20%で2週間のパイロットを実行する。KPI(コスト、レイテンシ、利用率)を測定する。目標が達成されれば、4~6週間にわたる完全マイグレーションを計画し、低リスクワークロードを最初に移行する。マイグレーション後2週間はロールバック能力を維持する。完全カットオーバーから30日後にマイグレーション後レビューをスケジュールして、持続的なパフォーマンスとコスト削減を検証する。
-
より長い視点:* G7eは終着点ではない。それは中継地点である。将来のGPU世代はこの軌跡を継続するだろう。今日測定規律、建築上の厳密性、運用上の卓越性を確立する組織は、複数のハードウェア世代にわたってこれらの利点を複合させるだろう。勝者は最も速くアップグレードする者ではない。最も賢くアップグレードする者である。