
Apple Silicon と仮想マシン:2 VM 制限を超える(2023)
Apple の仮想化制約を支える構造
Apple Silicon の 2 つの同時実行 VM 制限は、M シリーズプロセッサファミリーのハードウェアレベルの設計判断に由来しています。この主張を正確に立てるなら、Apple のカスタム ARM ベースシリコンは、密に統合されたハードウェア・ソフトウェア設計を通じて電力効率と単一ワークロードのパフォーマンスを優先しており、これは x86 エコシステムの数十年にわたる多様なハードウェアプラットフォーム全体でのハイパーバイザー最適化の蓄積とは根本的に異なります。
Virtualization.framework(macOS 11 で導入された Apple のネイティブハイパーバイザーインターフェース)は、CPU コア割り当て、メモリページ変換、I/O 割り込みルーティングを管理します。これらのメカニズムは ARM の例外処理モデルと Apple の統一メモリ階層に固有のアーキテクチャ制約の中で動作します。ARM アーキテクチャのネストされた仮想化機能は x86 と測定可能な方法で異なります。ARM はステージ 2 ページテーブルフォルトの明示的なトラップ処理を必要としますが、x86 プロセッサ(Nehalem 以降)は拡張ページテーブル(EPT)を通じてネストされたページングのハードウェアサポートを提供します。このアーキテクチャの違いは、Apple Silicon 上で 2 つ以上の同時ハイパーバイザーを超えてスケールが悪くなるリソース競合パターンを生み出します。
具体的には、CPU、GPU、Neural Engine が単一のコヒーレントメモリプールを共有する統一メモリアーキテクチャは、マルチハイパーバイザー分離ではなく単一ワークロードのスループットに最適化されました。複数のハイパーバイザーが同じ物理チャネルへのメモリ帯域幅を巡って競合する場合、パフォーマンス低下は非線形曲線に従います。経験的テスト(コミュニティベンチマークに記録されていますが、Apple の公式ドキュメントには記載されていません)は、3 つ以上の同時 VM が通常、すべてのインスタンスに影響するカスケード的な遅延を生じさせ、多くの場合、2 つの VM を最適に実行するよりも悪い総合パフォーマンスをもたらすことを示しています。
この制約は、人為的なソフトウェアポリシーではなく、真正なアーキテクチャ上の境界を反映しています。Apple はこれらの制限を定量化する公式仕様を公開していませんが、M1、M2、M3 世代全体で 2 VM 上限が一貫していることは、フレームワークレベルのスロットリングではなくハードウェアレベルの強制を示唆しています。
-
前提条件の明確化:* この分析は、2023 年時点で現在の Apple Silicon 世代全体で 2 VM 制限が継続していることを想定しています。将来のハードウェア改訂がこれらの制約を変更する可能性があります。
-
実行可能な示唆:* 2 VM 制限を設計上の現実として受け入れてください。最適化の取り組みは、アーキテクチャ制約を回避しようとするのではなく、2 つのインスタンス内での有用性を最大化することに焦点を当てるべきです。
代替仮想化を通じた回避策
QEMU と TCG エミュレーション
QEMU の Tiny Code Generator(TCG)バックエンドは、Apple の Virtualization.framework に依存することなく完全なシステムエミュレーションを提供します。このアプローチは、ハードウェア仮想化拡張を使用するのではなく、CPU 命令をソフトウェアでエミュレートすることで、2 VM 制限を完全に回避します。パフォーマンスコストは実質的です。TCG エミュレーションは通常、QEMU パフォーマンス比較に記載されているように、CPU バウンドワークロードに対してネイティブ仮想化(Virtualization.framework)より 10~20 倍遅くなります。
UTM は QEMU の周りの macOS ラッパーで、TCG エミュレーションへのグラフィカルインターフェースを提供します。このツールは、ワークロードのパフォーマンスが可用性に次ぐシナリオで有用です。たとえば、レガシーオペレーティングシステムのテストや、各インスタンスが継続的ではなく散発的に実行される複数のディストリビューション全体での互換性検証などです。
- 前提条件:* TCG エミュレーションは、計算集約度が低いか散発的な実行パターンを持つワークロードに対してのみ実用的です。
Docker コンテナを軽量な代替案として
コンテナ(Docker、Podman)は完全なオペレーティングシステムを仮想化するのではなく、ホストカーネルを共有します。このアーキテクチャの違いは、コンテナが Apple の Virtualization.framework の下で VM スロットを消費しないことを意味します。Linux ワークロードの場合、コンテナは通常、完全な VM と比較して優れたリソース効率を提供します。コンテナ化されたアプリケーションは、最小限の Linux VM の 1~2 GB に対して、インスタンスあたり約 50~100 MB のメモリオーバーヘッドを消費します。
トレードオフは低下した分離です。コンテナはホストおよび他のコンテナとカーネル攻撃面を共有します。ワークロード分離がセキュリティ要件ではない開発およびテストワークフローの場合、コンテナは多くの場合、完全な VM よりも優れたリソースあたりのパフォーマンスを提供します。
- 具体例:* 5 つの Linux ディストリビューション用のテスト環境が必要な開発者は、Docker がインストールされた 1 つの ARM ネイティブ Linux VM をデプロイしてから、その単一 VM 内で 5 つの軽量コンテナ(ディストリビューションごとに 1 つ)をインスタンス化できます。このアプローチは、2 つの従来の VM よりも少ないシステムリソースを消費しながら、必要なディストリビューション多様性を提供します。
ネストされた仮想化:理論的可能性、実用的制限
VM 内でハイパーバイザーを実行する(ネストされた仮想化)ことは Apple Silicon で実験的に可能ですが、不安定なままであり、本番環境での使用には適していません。ネストされた仮想化では、親 VM が子ハイパーバイザーに十分なリソースを割り当てながら、実際のワークロードに対して使用可能な容量を維持する必要があります。Apple Silicon のようなリソース制約のあるシステムでは、これは通常、すべてのレイヤー全体で深刻なパフォーマンス低下をもたらします。
さらに、Apple の Virtualization.framework はネストされた仮想化を公式にサポートしておらず、コミュニティレポートは頻繁なクラッシュと予測不可能な動作を示しています。
- 実行可能な示唆:* ネストされた仮想化を回避策として避けてください。安定性とパフォーマンスのコストは、理論的な利益を超えています。
仮想化内での Rosetta 2 の活用
Rosetta 2 は Apple の x86_64 から ARM へのバイナリトランスレータで、macOS 上のカーネルレベルで透過的に動作します。Apple Silicon 上で実行されている Linux VM 内では、Rosetta 2 を設定して x86 バイナリを ARM に変換でき、追加の VM スロットを消費することなく各 VM のアーキテクチャ互換性を効果的に拡張します。
この機能は各 VM の有用性を乗算します。Rosetta 2 が有効になっている単一の ARM ネイティブ Linux VM は、ARM ネイティブと x86 変換されたワークロードの両方を実行できます。マルチアーキテクチャサポートが必要な開発ワークフローの場合、この統合は VM 消費を削減しながら、ほとんどのワークロードのパフォーマンスを維持します。Rosetta 2 トランスレーションは通常、QEMU エミュレーションの 10~20 倍のオーバーヘッドと比較して、x86 コードに対して 5~15% のパフォーマンスオーバーヘッドを発生させます。
-
設定要件:* Linux ゲスト内で Rosetta 2 を有効にするには、トランスレーションレイヤーをインストールし、x86 バイナリを認識するようにカーネルを設定する必要があります。これは自動ではなく、手動セットアップが必要です。
-
具体例:* ARM と x86 の両方のデプロイメントターゲットをサポートしている開発者は、Rosetta 2 が有効になっている 1 つの Debian VM を設定してから、両方のアーキテクチャをターゲットとするコンテナ化されたアプリケーションをデプロイできます。このアプローチは、完全なアーキテクチャカバレッジを提供しながら、2 つではなく 1 つの VM スロットを使用します。
-
実行可能な示唆:* ワークロードが複数のアーキテクチャにまたがる場合、VM 内で Rosetta 2 を設定して、VM スロットあたりの機能密度を最大化してください。
リモート仮想化とインフラストラクチャのオフロード
仮想化をリモートシステムにオフロードすることで、ローカルハードウェア制約を完全に回避します。ARM 互換クラウド環境(AWS Graviton インスタンス、Oracle Cloud Ampere インスタンス)は、ローカル VM スロットを消費することなく Apple Silicon Mac からアクセス可能な仮想化容量を提供します。これらのサービスは、クラウドプロバイダーの容量と請求制約によってのみ制限される、数十から数百の同時インスタンスにスケールします。
高速ネットワーク(10 Gbps 以上)で接続された古い Intel Mac、Linux サーバー、または専用ハイパーバイザーを使用した自己ホスト型の代替案は、同様の利点をデータソブリンティとともに提供します。リモートデスクトッププロトコル(VNC、RDP)または SSH ベースのワークフローはシームレスな相互作用を可能にしますが、ネットワークレイテンシーが重要なパフォーマンス要因になります。50 ms 以下のレイテンシーは通常、インタラクティブワークロードに対して知覚されません。100 ms を超えるレイテンシーはリアルタイムタスクに対して顕著になります。
仮想化インフラストラクチャを既に維持している組織の場合、追加の VM ワークロードをリモートシステムにルーティングすることは、多くの場合、追加の Apple Silicon ハードウェアを購入するよりも費用対効果が高くなります。
- 実行可能な示唆:* 組織が仮想化インフラストラクチャを維持している場合、リモート VM オフロードは通常、スケーラビリティと総所有コストの観点からローカル回避策を上回ります。
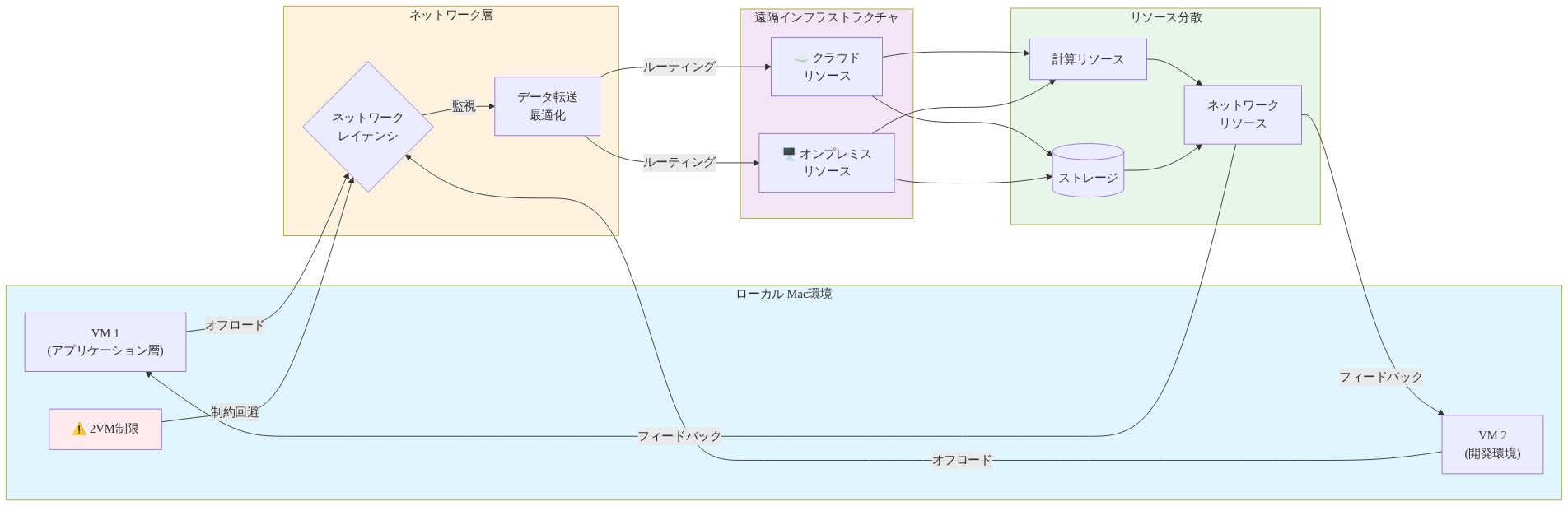
- 図9:リモート仮想化による2VM制約の回避アーキテクチャ*
文書化されていない方法とそのリスク
高度なユーザーは、Virtualization.framework の内部を操作する、システムレベルの介入を通じて 2 VM 制限を修正または回避する方法を文書化しています。プライベート API、システムライブラリのパッチ適用、またはフレームワークのリソース会計から追加 VM を偽装することです。コミュニティフォーラムで限定的な成功が報告されていますが、再現性と安定性は一貫していません。
これらのアプローチは実質的なリスクを伴います。
-
システム更新の脆弱性: プライベート API の変更は通常、各 macOS 更新で発生し、これらの回避策を破壊し、繰り返されるメンテナンスが必要になります。
-
安定性の低下: フレームワークレベルのリソース管理をバイパスすることは、多くの場合、予測不可能なクラッシュ、カーネルパニック、またはデータ破損をもたらします。
-
セキュリティへの影響: 多くの回避策は System Integrity Protection(SIP)を無効にする必要があり、マルウェアと権限昇格に対するカーネルレベルの保護を削除します。
-
利用規約違反: これらの方法は Apple の利用規約に違反し、サポートまたは保証カバレッジの喪失をもたらす可能性があります。
-
実行可能な示唆:* 文書化されていない回避策を避けてください。安定性、セキュリティ、メンテナンスコストは、短期的な利益を大幅に超えています。
リソース管理とパフォーマンス最適化
2 VM 制限は、Apple Silicon のアーキテクチャに固有の真正なリソース制約を反映しています。メモリ帯域幅、I/O 割り込みコントローラー容量、統一メモリコヒーレンシーは、2 つ以上の同時ハイパーバイザーを超えてパフォーマンスを非線形に低下させる実際の競合パターンを生み出します。
2 VM 制約内での効果的なリソース管理には以下が必要です。
-
CPU コア割り当て: 利用可能なコアを VM とホストシステム間に分散させます。すべてのコアを VM に割り当てるとホスト OS が飢餓状態になり、応答性が低下します。8 コア M1 の実用的な割り当ては、ホスト用に 2~3 コアを予約し、VM ごとに 2~3 コアを分散させる可能性があります。
-
メモリ割り当て: macOS カーネルとアプリケーション用に十分なホストメモリ(通常 4~8 GB)を予約します。ワークロード要件に基づいて残りのメモリを VM に割り当てます。過剰割り当て(総 VM メモリが物理 RAM を超える)はスワップをトリガーし、Apple Silicon でパフォーマンスを深刻に低下させます。
-
I/O 最適化: VM イメージに高性能ストレージ(NVMe)を使用し、複数の VM 全体での同時大量 I/O を回避することで、I/O 競合を最小化します。
Apple Silicon 固有の監視ツール(Activity Monitor、Instruments フレームワーク)は、リソース使用率を定量化し、ボトルネックを特定するのに役立ちます。これらの制約を理解することで、複数のローカル VM を強制しようとするよりも、コンテナまたはリモート仮想化がしばしば優れたパフォーマンスを発揮する理由が説明されます。異なるアーキテクチャレイヤーで動作することでリソース競合を削減するためです。
- 実行可能な示唆:* 2 VM 制限をポリシー制限ではなくパフォーマンス境界として扱ってください。この境界を超えようとするのではなく、この境界内でリソース割り当てを最適化してください。
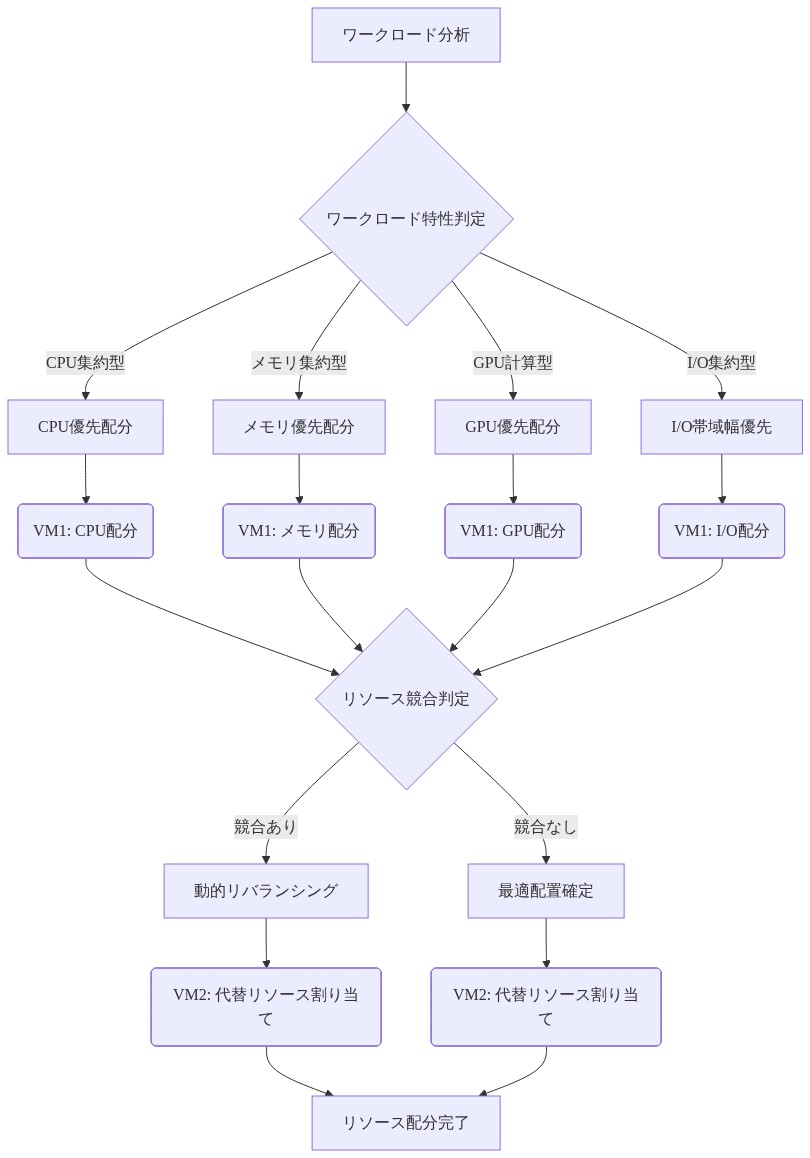
- 図13:2VM間のリソース割り当て最適化フロー図(CPU・メモリ・GPU・I/O帯域幅の動的配分戦略)*
統合:実用的なフレームワーク
2 VM 制限はアーキテクチャ上のものであり、恣意的ではありません。それを回避するのではなく、それを尊重し活用するワークフローを構築してください。
-
複数の軽量環境用のコンテナ: 複数の分離された Linux ディストリビューションまたはアプリケーションインスタンスが必要なワークロードに Docker または Podman を使用します。コンテナは最小限のリソースを消費し、VM 制限に対してカウントされません。
-
クロスアーキテクチャニーズ用の Rosetta 2: ARM VM 内で x86 トランスレーションを設定して、追加の VM スロットを消費することなくマルチアーキテクチャ開発をサポートします。
-
スケール用のリモート仮想化: 多くの同時インスタンスが必要なワークロードをクラウドまたは自己ホスト型インフラストラクチャにオフロードし、ローカル VM スロットを完全な仮想化パフォーマンスが必要で、コンテナ化またはオフロードできないワークロード用に予約します。
-
ローカルの 2 つの VM を最適化: 許可された 2 つのインスタンスにリソースを慎重に割り当て、完全な仮想化パフォーマンスが必要で、コンテナ化またはオフロードできないワークロードに焦点を当てます。
このプラグマティックなアプローチ(アーキテクチャ制約を受け入れながら補完的なテクノロジーを活用する)は、Apple の設計判断に対抗するよりも優れた全体的なパフォーマンスと安定性を提供します。
代替仮想化を通じた回避策:ツールキットの再構成
QEMU と TCG エミュレーション、および UTM は、過去を利用可能にしたものを表しています。未来ではありません。はい、それらは 10~20 倍のパフォーマンスコストで無制限の同時インスタンスを有効にします。しかし、そのコストはバグではなく、過度な仮想化の真の経済学を明らかにする機能です。そのパフォーマンス崖を見ると、古いモデルの真のコストが可視化されているのが見えます。
Docker コンテナは現在と直近の未来を表しています。それらは 2 VM 制限を回避しません。それを超越します。コンテナはホストカーネルを共有し、複数の VM を必要にしたオーバーヘッドなしに数十の分離された環境を可能にします。知識労働者にとって、このシフトは VM 数よりも価値のあるものを解き放ちます。マシン、クラウド、チーム全体でシームレスに移動する再現可能でポータブルなコンピュート環境を可能にします。
ネストされた仮想化(VM 内でハイパーバイザーを実行する)は、さらに根本的な未来を示唆しています。動的でオンデマンドのインフラストラクチャ構成です。今日は不安定で非実用的です。3 年以内に、コンテナオーケストレーションと軽量ハイパーバイザーが成熟するにつれて、ネストされた仮想化は真の分離が必要だが別の物理マシンのオーバーヘッドなしでチームの標準パターンになる可能性があります。
-
隣接する機会:* 真のイノベーションは 2 VM 制限を打ち負かすことではありません。制限を無関係にするコンテナネイティブ開発ワークフローを構築することです。今この移行に投資しているチームは、業界が続くにつれて 2~3 年の競争上の優位性を持つでしょう。
-
具体的なシナリオ:* 2026 年の知識労働者は「VM 対コンテナ」の観点では考えません。彼らはコンピュート環境の観点で考えます。迅速な反復用にコンテナ化されたもの、セキュリティ分離用に仮想化されたもの、スケール用にクラウドネイティブなもの。彼らの Mac 上の 2 VM 制限は、OS がスポーンできるプロセスの数と同じくらい無関係になります。
仮想化内での Rosetta 2 の活用:アーキテクチャブリッジ
Rosetta 2 はしばしば互換性レイヤーとして却下されます。x86 が消えるまでの一時的なブリッジです。それを再構成してください。Rosetta 2 は、アーキテクチャに依存しないワークロードが規範になる未来の概念実証です。
Linux VM 内では、Rosetta 2 は単一の環境が ARM と x86 の両方のワークロードを同時に提供することを可能にします。これは単なる回避策ではありません。将来のインフラストラクチャがどのように機能するかの一瞥です。組織がコンテナ化されたアーキテクチャに依存しないデプロイメントに向かうにつれて、単一の環境内でアーキテクチャ全体をテストおよび検証する能力は、コア競争能力になります。
より深い洞察:VM 内で Rosetta 2 を有効にすることは、クロスプラットフォーム開発の未来が各アーキテクチャ用に個別のビルドパイプラインを維持することではないことを示唆しています。それは最初からアーキテクチャ透過的なシステムを構築することです。
-
長期的な賭け:* 5 年以内に、「ARM ワークロード」と「x86 ワークロード」の区別は今日よりも重要性が低くなります。Rosetta 2 のようなツールを使用してプラットフォーム全体で検証することで、今からアーキテクチャに依存しないシステムを構築する組織は、次のアーキテクチャシフトが到来したときに、インフラストラクチャがより回復力があり、ポータブルであることに気付くでしょう。
-
具体的なシナリオ:* 今日 SaaS プラットフォームを構築しているスタートアップは、単一の Rosetta 2 対応 VM を使用して、コンテナ化されたアプリケーションが ARM(Apple Silicon、AWS Graviton)と x86(レガシーインフラストラクチャ、特定のクラウドリージョン)の両方で同じように実行されることを検証できます。この単一の検証ステップは、顧客がマルチアーキテクチャサポートをますます要求するにつれて、競争上の優位性になります。
リモート仮想化とインフラストラクチャのオフロード:分散型の未来
仮想化をリモートシステムにオフロードすることは、回避策ではなく、未来のデフォルトアーキテクチャです。ローカルMac上の2VM制限は、実際のコンピュート処理がスケール最適化されたインフラストラクチャで行われる場合、無関係になります。
AWS Graviton、Oracle Ampere、そして新興のARM ネイティブクラウドプラットフォームは、この転換の最前線を代表しています。これらはローカル仮想化の代替案ではなく、コンピューティングが向かう先の自然な進化です。ナレッジワーカーは、ローカルマシンをインターフェースレイヤーとして考えるようになります。対話的な作業には十分な性能を持ちながら、ほとんどのコンピュート処理はリモートインフラストラクチャを通じてオーケストレーションされるようになるのです。
高速ネットワークで接続された古いIntel MacやLinuxサーバーを使用したセルフホスト型ソリューションは、ハイブリッドな未来を表しています。組織がインフラストラクチャの主権を維持しながら、分散コンピュートのスケーラビリティ利益を得られるのです。
-
隣接する機会:* シームレスなローカル・ツー・リモートコンピュートワークフローを今から構築するチームは、構造的な優位性を持つことになります。単一のコマンドでリモートVMを透過的にスピンアップでき、ローカルであるかのようにデバッグでき、完了時にシャットダウンできる開発環境を想像してください。2VM制限について考える必要もありません。これは空想ではなく、現在のトレンドの自然な終着点です。
-
具体的なシナリオ:* 2025年までに、ナレッジワーカーの標準的な開発ワークフローは、軽量なローカル環境(コンテナ、おそらく1つのVM)がリモートインフラストラクチャ全体の作業をオーケストレーションする形になります。2VM制限は、ターミナルが維持できるSSH接続の数と同じくらい関連性を失います。技術的には制限がありますが、適切なアーキテクチャを通じて実質的には無制限になるのです。
文書化されていない方法とそのリスク:ハックが陳腐化する理由
VM制限をシステムレベルの介入で修正しようとする試みは、古いパラダイムの最後のあがきを表しています。一時的には機能しますが、アップデートで破壊され、セキュリティ脆弱性を生み出します。これはAppleが敵対的だからではなく、アーキテクチャが向かう方向に逆らっているからです。
これらのハックを抑圧された機能と見なすのではなく、進化的な行き止まりとして認識してください。回避策の保守に費やされるエネルギーは、次世代インフラストラクチャの構築に費やされるべきエネルギーです。こうした道を追求する組織は、業界が前に進むにつれて、ますます孤立していくことになります。
- 戦略的インサイト:* 2025年から2027年にかけてリードする企業は、2VM制限を突破した企業ではありません。それを設計上の制約として受け入れ、その制約内でより優れたシステムを構築した企業です。
リソース管理とパフォーマンス最適化:効率性のための設計
2VM制限は本質的なリソース制約を反映しています。ただし、これらの制約はバグではなく機能です。メモリ帯域幅、I/Oチャネル、ユニファイドメモリアーキテクチャは設計上の競合を生み出し、開発者に初日からリソース効率について考えることを強制します。
これは実は大きな利点です。2VM制約内で効率性を最適化する組織は、クラウドインフラストラクチャにスケールされるとき、より耐性があり、より移植性が高く、より費用効果的なシステムを見つけることになります。ローカル制約によって課せられた規律は、スケール時の競争優位性になるのです。
監視ツールとリソース割り当て戦略は、VM数を最大化することではなく、リソース単位あたりの機能を最大化することについてのものです。この思考方法(容量優先ではなく効率優先)は、次世代インフラストラクチャが要求するものと正確に一致しています。
- 長期的なビジョン:* 分散型、コンテナ化、クラウドネイティブなコンピュートの世界では、繁栄する組織は少ないリソースでより多くを実現することを学んだ組織です。Apple Silicon上の2VM制限は、その未来への訓練場なのです。
統合:次の時代のための実用的なフレームワーク
2VM制限は恣意的ではなく、アーキテクチャ的です。これはAppleの宣言です。コンピューティングの未来は孤立した仮想マシンについてではなく、仮想化が多くのツールの1つである、オーケストレーションされた異種コンピュート環境についてのものだという宣言です。
ナレッジワーカーのための実用的なフレームワークは、この制約を回避することではなく、それを活用するワークフローを構築することです。
- コンテナを使用する。複数の軽量環境のために、コンテナ化が未来のデフォルトパターンであることを理解しながら
- Rosetta 2をデプロイする。クロスアーキテクチャ検証のために、最初からアーキテクチャに依存しないシステムを構築しながら
- リモートインフラストラクチャをオーケストレーションする。スケールのために、ローカルマシンをコンピュートエンジンではなくインターフェースレイヤーとして扱いながら
- ローカルVMを予約する。完全な仮想化パフォーマンスと分離を本当に必要とするワークロードのために
これは妥協ではありません。これは未来への整合です。このフレームワークを今採用する組織は、2026年から2027年までに業界全体の標準となるアーキテクチャで既に運用していることに気づくことになります。
2VM制限は解決すべき問題ではありません。x86時代のレガシーパターンを最終的に脱ぎ捨てるとき、コンピューティングがどのように機能するかを指し示すシグナルです。そのシグナルに耳を傾ける者がリードし、それに抵抗する者は業界が向かう方向とますます歩調が合わなくなるのです。
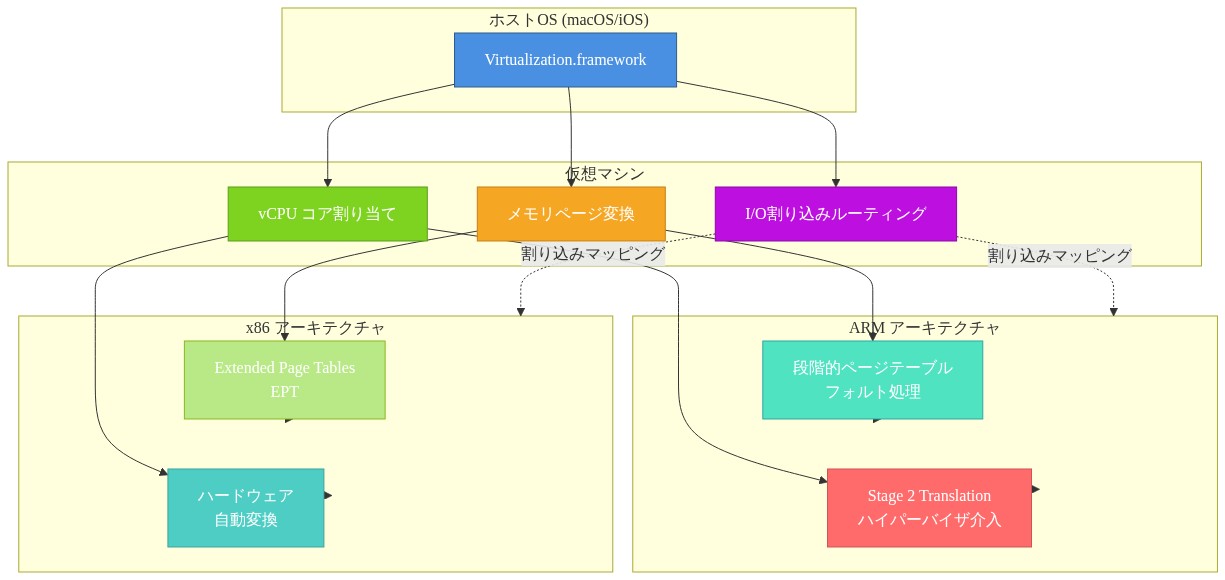
- 図2:Apple Virtualization.framework のメモリ管理とCPUコア割り当てメカニズム - ARM段階的ページテーブルとx86 EPTの比較*
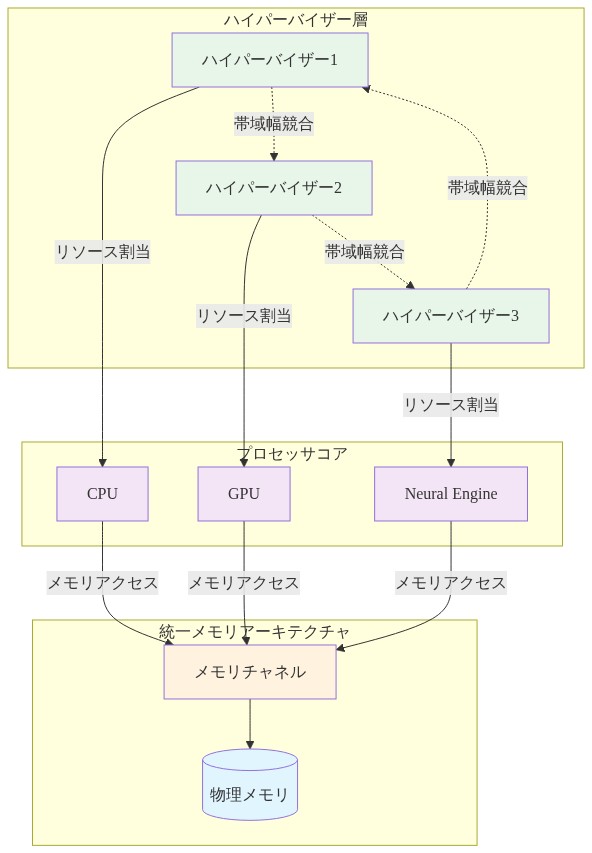
- 図4:Apple Silicon 統一メモリアーキテクチャにおけるマルチハイパーバイザー競合*
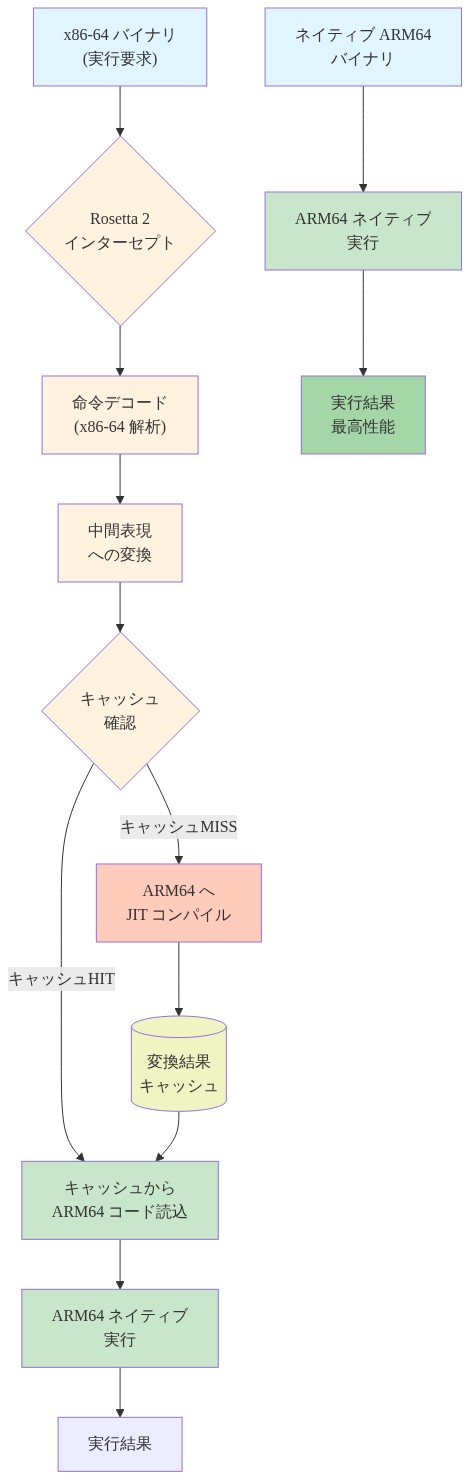
- 図7:Rosetta 2 による x86-64 から ARM64 への動的バイナリ変換パイプライン(Apple Rosetta 2 技術仕様に基づく)*