
Azure Performance Diagnostics Tool for Java: Kubernetesにおけるパフォーマンス分析の自動化
システム構造とボトルネック
Kubernetes環境におけるJavaアプリケーションは、従来のAPMツールでは頻繁に分離できない独特のパフォーマンス課題に直面します。例えば、メモリ圧力はコンテナ内ではベアメタル上とは異なる形で現れます。Podのメモリ制限は、メモリ不足による終了をトリガーする厳格な境界を強制しますが、根本原因である非効率なオブジェクト割り当てや保持された参照は、深いヒープ分析なしでは不透明なままです。
Performance Diagnostics Toolは、Java固有のボトルネックをKubernetesのリソース制約と関連付けることで、この制限に対処します。このツールは、ヒープダンプ、スレッドトレース、ガベージコレクションログをリアルタイムで取得し、これらのシグナルをPodのCPUスロットリング、ノード圧力、ネットワークレイテンシと関連付けます。この多層的な可視性により、遅いトランザクションがアプリケーションロジック、リソース競合、またはインフラストラクチャの制限のいずれに起因するかが明らかになります。
-
具体例:* 決済処理サービスがピーク負荷時にp99レイテンシが2秒に達します。標準的な監視では高いCPU使用率が示されますが、明確な根本原因は見つかりません。診断ツールは、30秒ごとに発生し、それぞれ800ミリ秒続くフルガベージコレクションの一時停止を特定します。分析により、アプリケーションが毎秒500MBの短命オブジェクトを割り当て、積極的な若い世代のコレクションをトリガーしていることが明らかになります。推奨される修復策は、ヒープサイズの調整またはオブジェクトプーリング戦略の最適化です。
-
実用的な意味:* チームは、ツールの履歴分析機能を使用してJavaサービスのベースラインパフォーマンスプロファイルを確立する必要があります。通常のガベージコレクション頻度、ヒープ利用パターン、スレッド数を文書化します。異常が発生した場合、これらのベースラインと比較して根本原因の特定を加速します。許容可能なしきい値を超える偏差に対してアラートを設定し、ユーザーに影響が及ぶ前にプロアクティブなスケーリングまたはコード修復を可能にします。
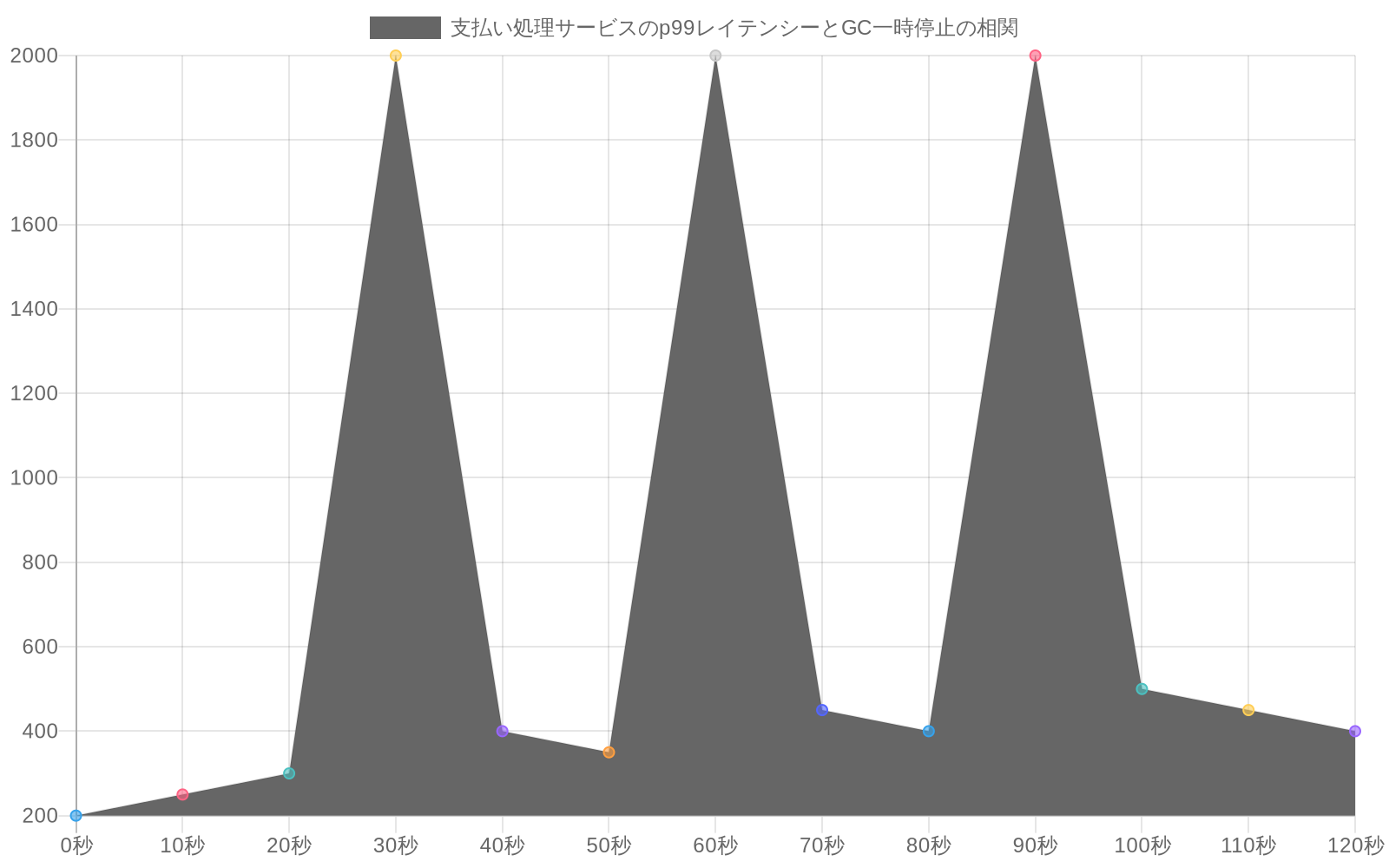
- 図3:支払い処理サービスのp99レイテンシーとGC一時停止の相関(時系列)*
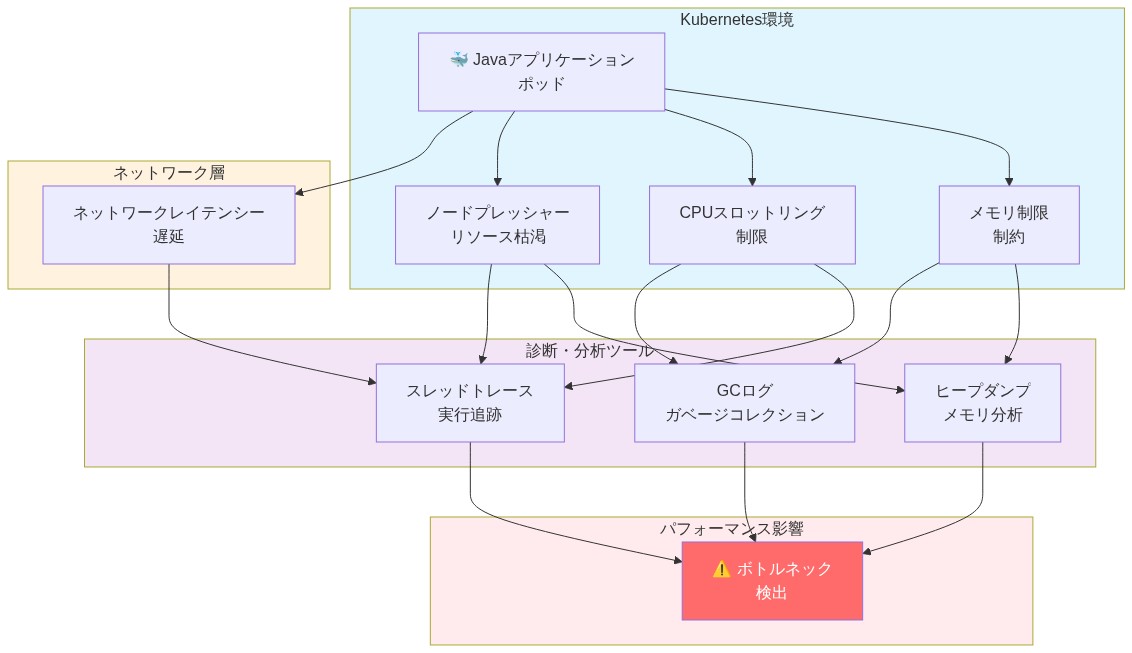
- 図2:Kubernetes環境におけるJavaパフォーマンスボトルネックの相互関係*
参照アーキテクチャとガードレール
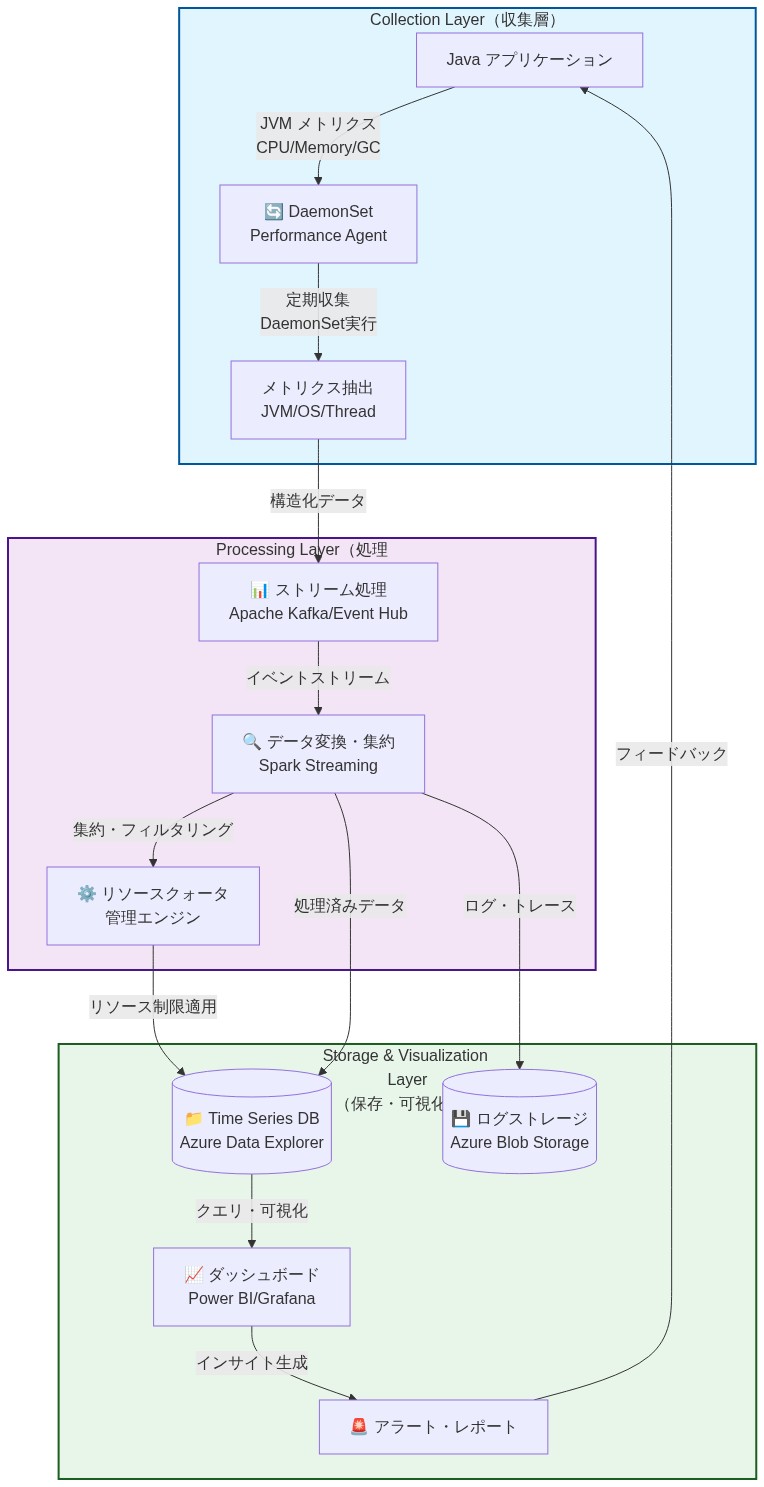
- 図5:Azure Performance Diagnostics Tool for Javaの参照アーキテクチャ(3層構造)*

- 図7:Kubernetes環境におけるリソースガードレール設計*
アーキテクチャフレームワークと設計制約
Azure Performance Diagnostics Tool for Javaの展開には、診断の包括性と運用の持続可能性を調和させる正式に指定されたアーキテクチャが必要です。このツールは、ヒープダンプ、スレッドトレース、割り当てプロファイルを含む診断アーティファクトを生成し、収集イベントごとに数ギガバイトを超える可能性があります。このボリュームは、リソース枯渇とコスト超過を防ぐために、収集頻度、保持期間、ストレージ割り当てを管理する明示的なポリシーを必要とします。
推奨される参照アーキテクチャは、機能的に異なる3つの層で構成されます。
-
収集層: Kubernetesノード上にDaemonSetとして展開されたエージェントで、診断収集操作を実行し、出力を中間ストレージにシリアライズします。これらのエージェントは、アプリケーションワークロードへの干渉を防ぐために、定義されたリソースクォータ(CPUとメモリのリクエスト/制限)で動作します。
-
処理層: 収集されたシグナルを取り込み、統計的異常検出アルゴリズムを適用し、マルチシグナルパターンを関連付け、実行可能な診断レポートを生成する中央診断エンジン。この層は、ヒープ分析、ガベージコレクションパターン分類、スレッド競合識別の計算作業を実行します。
-
ストレージと検索層: 時間ベースの有効期限を持つ診断アーティファクトを永続化するバックエンドシステム(例: 階層化アクセスポリシーを持つAzure Blob Storage)で、即時のインシデント対応と定義された保持期間内の履歴トレンド分析の両方を可能にします。
ガードレールと運用制約
ガードレールは、診断収集がクラスタの安定性を低下させたり、機密性の高いアプリケーション状態を公開したりすることを防ぐために、リソースとアクセスの境界を強制します。
- 保持ポリシー: 診断データは7〜30日間保持する必要があります(組織のポリシーごとに設定可能)。期限切れのアーティファクトは自動削除されます。この期間は、インシデント調査のタイムラインとストレージコストのバランスを取ります。
- 収集クォータ: リソース競合を防ぐために、サービスごとおよびクラスタ全体の同時診断収集に制限を設定します。例えば、ヒープダンプをサービスごとに1時間に1回、またはクラスタ全体で15分ごとに1回に制限します。
- アクセス制御: ロールベースアクセス制御(RBAC)を実装して、ヒープダンプの検査を承認された担当者に制限します。ヒープデータには機密性の高いアプリケーション状態(認証情報、個人識別情報、独自アルゴリズム)が含まれる可能性があり、すべてのアクセスイベントの監査ログが必要です。
- オーバーヘッド監視: 診断収集によって導入されるCPUとメモリのオーバーヘッドを継続的に測定します。収集オーバーヘッドがサービスリソース割り当ての5%を超える場合、誤設定または過度の収集頻度を示すアラートをトリガーします。
具体的な展開シナリオ
ある組織は、本番環境のAzure Kubernetes Service(AKS)クラスタ全体で200のJavaマイクロサービスを運用しています。すべてのサービスで同時に無制限の深い診断(ヒープダンプ、スレッドトレース、割り当てプロファイリング)を有効にすると、月間推定2〜5テラバイトの診断データが生成され、持続不可能なストレージコストと運用の複雑さが生じます。
代わりに、組織は階層化された診断戦略を実装します。
- ティア1(全サービス): CPU使用率、ヒープメモリ使用量、ガベージコレクション頻度、スレッド数を60秒間隔で収集する継続的な軽量監視。このデータは7日間保持され、Azure Monitorダッシュボードに統合されます。
- ティア2(重要なサービス): 事前定義された異常しきい値を超えたときにアクティブ化されるイベントトリガー型の深い診断(ヒープダンプ、スレッドトレース)。例えば、ヒープ使用率が5分以上85%を超える場合、またはp99レイテンシが7日間のベースラインに対して50%以上増加する場合。
- ティア3(オンデマンド): インシデント対応中にオンコールエンジニアによって開始される手動診断収集。本番サービスからヒープダンプを収集するには明示的な承認が必要です。
この階層化されたアプローチにより、月間診断データ量は約50〜100ギガバイトに削減され、検出から数分以内にパフォーマンス異常を診断する能力が維持されます。
実行可能な実装要件
Performance Diagnostics Toolを展開する前に、組織は明示的な診断ポリシーを確立する必要があります。
-
サービス分類: 重要度とパフォーマンス感度によってサービスを分類します。各カテゴリを診断ティアに割り当て、どのサービスが継続的な深い診断を受けるか、イベントトリガー型またはオンデマンド収集を受けるかを定義します。
-
しきい値の定義: ティア2に割り当てられたサービスについて、自動深い診断をトリガーする異常しきい値を正式に指定します。しきい値は、任意の値ではなく、履歴ベースラインデータ(例: 通常のヒープ使用率の95パーセンタイル)から導出する必要があり、誤検知収集イベントを減らします。
-
ストレージと保持の設定: インシデント調査のタイムラインと組織のコンプライアンス要件に合わせたデータ保持期間を確立します。無期限のストレージ蓄積を防ぐために、自動有効期限ポリシーを設定します。
-
インシデント管理統合: 診断ツールをインシデント管理プラットフォーム(例: PagerDuty、Azure Service Health)と統合し、重要なアラートが発火したときに診断収集が自動的にトリガーされるようにします。これにより、インシデント検出と同時に診断が収集されるクローズドループワークフローが作成されます。
-
アクセスと監査ログ: ヒープダンプアクセスを承認された担当者(例: プラットフォームエンジニア、オンコールSRE)に制限するRBACポリシーを設定します。すべての診断データアクセスを記録する監査ログを有効にし、コンプライアンス監査とセキュリティ調査をサポートします。
実装と運用パターン
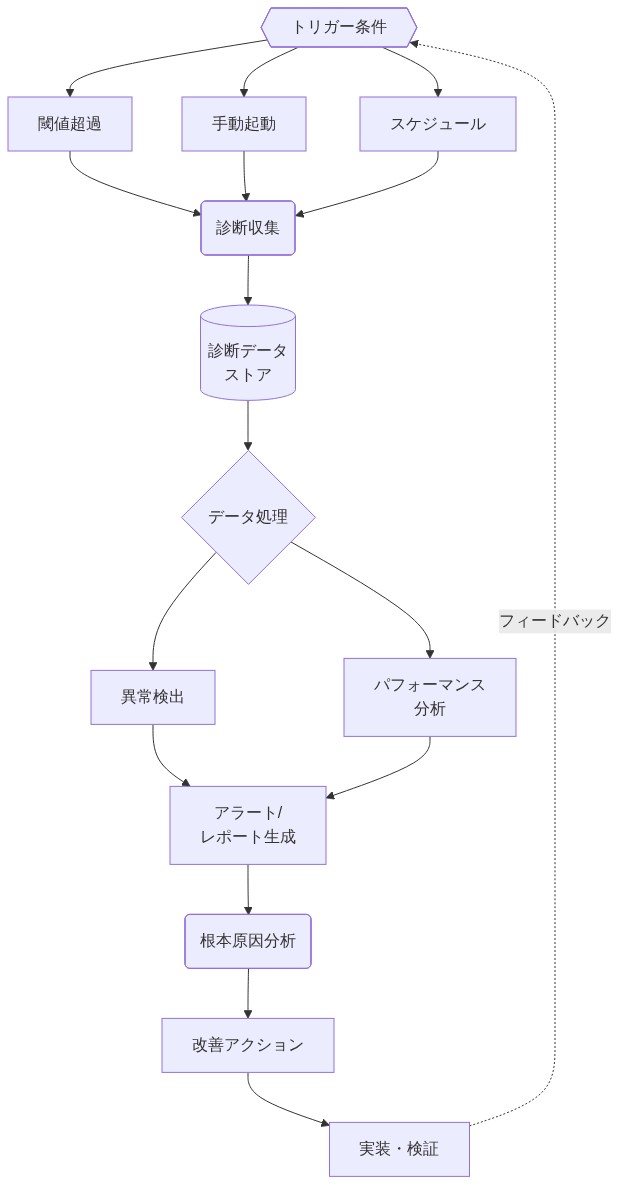
- 図8:診断ツール実装の運用フロー*
展開方法と検証
Performance Diagnostics Toolの成功した展開は、構造化されたリスク軽減の進行に従います。組織は、非重要なサービスまたはステージング環境でのパイロット展開から展開を開始し、本番ワークロードに拡大する前に収集オーバーヘッドのベースライン測定を確立する必要があります。
-
オーバーヘッド検証*: パイロットサービスで診断収集によって導入されるCPUとメモリ消費を測定します。典型的なオーバーヘッドは、収集イベント中のCPU増加が2〜5%で、アイドル期間中の永続的なオーバーヘッドは無視できる程度です。測定されたオーバーヘッドが5%を超える場合、展開を拡大する前に根本原因(例: 過度の収集頻度、非効率なシリアライゼーション)を調査します。
-
前提条件*: 成功した実装は以下を前提とします。
-
Kubernetesクラスタバージョン1.20以降(DaemonSetリソースクォータとRBACポリシーをサポート)
-
メトリクスの取り込みと可視化のためのAzure MonitorまたはPrometheus統合
-
自動アラートトリガー診断のためのWebhookまたはAPIサポートを持つインシデント管理システム
-
設定可能な保持ポリシーを持つストレージバックエンド(例: ライフサイクル管理を持つAzure Blob Storage)
可観測性スタック統合
Performance Diagnostics Toolは、アプリケーションとインフラストラクチャメトリクスと並んで診断コンテキストを提供するために、既存の可観測性インフラストラクチャと統合する必要があります。統合メカニズムには以下が含まれます。
- メトリクスエクスポート: ツールは診断メトリクス(ヒープ使用率、GC一時停止時間、スレッド数)をPrometheusまたはAzure Monitorにエクスポートし、アプリケーションレベルメトリクス(リクエストレイテンシ、エラー率)およびインフラストラクチャメトリクス(ノードCPU、ネットワークI/O)との関連付けを可能にします。
- アラートトリガー: 特定の条件が発生したときに診断収集をトリガーするアラートルールを監視システムで設定します。例: 「p99レイテンシが5分間連続して500msを超える場合、影響を受けるサービスからヒープダンプとスレッドトレースを自動的に収集する」
- ダッシュボード統合: 診断ダッシュボードを既存の可観測性プラットフォームに埋め込み、オンコールエンジニアが別のツールにアクセスすることなく診断インサイトを発見できるようにします。
自動化とクローズドループ診断
自動化は、平均診断時間(MTTD)を最小化し、インシデント中の手動介入を減らすために不可欠です。2つのレベルで自動化を実装します。
-
しきい値ベースの自動化: 事前定義された条件が発生したときに診断を自動的に収集するように診断ツールを設定します(例: ヒープ使用率 > 85%、GC一時停止時間 > 1秒)。この自動化は保守的である必要があります。つまり、高信頼度の異常でのみトリガーし、誤検知収集でストレージシステムを圧倒しないようにします。
-
インシデントトリガー型自動化: 重要なアラートが発火したときに診断が自動的に収集されるように、診断ツールをインシデント管理システムと統合します。例えば、「高エラー率」アラートがトリガーされたときに、影響を受けるサービスからヒープダンプとスレッドトレースを自動的に収集し、オンコールエンジニアが調査を開始する前に診断コンテキストを提供します。
具体的な展開例
プラットフォームチームは、毎秒50,000リクエストを処理するJava認証サービスにPerformance Diagnostics Toolを展開します。p99レイテンシが500msを超えたときに自動診断収集を設定します。
展開から2週間以内に、ツールはパフォーマンス異常を特定します。認証失敗が例外割り当てストームをトリガーし、急速なヒープ圧力を引き起こし、フルガベージコレクションサイクルをトリガーします。各フルGC一時停止は200〜300ms続き、観測されたp99レイテンシスパイクに直接寄与しています。
根本原因分析により、認証サービスが各認証失敗試行に対して例外をキャッチして再スローし、プールされたインスタンスを再利用するのではなく新しい例外オブジェクトを割り当てていることが明らかになります。チームは例外プーリングを実装し、オブジェクト割り当てを60%削減し、レイテンシスパイクを完全に排除します。診断ツールは、負荷下でのGC一時停止時間の短縮と安定したヒープ使用率を示すことで修正を確認します。
運用ランブックと知識移転
診断ツールの展開には、運用ドキュメントが伴う必要があります。
-
診断解釈ランブック: ヒープダンプ、スレッドトレース、割り当てプロファイルの解釈方法を文書化します。一般的なパフォーマンス異常の決定木を提供します(例: 「ヒープ使用率が高く、GC一時停止時間が増加している場合、オブジェクト割り当て率を調査し、オブジェクトプーリングの実装を検討する」)。
-
修復手順: 診断結果を特定の修復手順にリンクします。例: 「診断ツールが過度の例外割り当てを特定した場合、[リンク]に文書化されている例外プーリング手順に従う」
-
オンコールトレーニング: オンコールエンジニアが診断ダッシュボードへのアクセス方法、診断出力の解釈方法、修復のためにプラットフォームまたはアプリケーションチームにエスカレーションする方法を理解していることを確認します。
-
フィードバックループ統合: 診断結果がコードレビュー、アーキテクチャ決定、パフォーマンステスト手順に情報を提供するプロセスを確立します。時間の経過とともに、このフィードバックループは、パフォーマンスの教訓を開発プラクティスに組み込むことで、パフォーマンス関連のインシデントの頻度を減らす必要があります。
前提と制限
この参照アーキテクチャは以下を前提としています。
- 診断収集オーバーヘッドがワークロード特性に対して許容範囲内(CPU増加 < 5%)であること
- 組織が7〜30日間の診断データ保持のための十分なストレージ容量と予算を持っていること
- インシデント管理システムがWebhookベースの自動化またはAPI駆動の診断トリガーをサポートしていること
- オンコールエンジニアが診断出力を解釈するための十分なトレーニングとドキュメントを持っていること
制限には以下が含まれます。
- ヒープダンプ収集には短いアプリケーション一時停止(通常 < 1秒)が必要であり、ピークトラフィック期間中の厳格なレイテンシSLAを持つサービスでは使用すべきではありません
- 診断収集は、再現可能なパフォーマンス異常を持つサービスに最も効果的です。一時的で非決定的なパフォーマンス問題は、時間ベースまたはしきい値ベースの収集ポリシーでは捕捉されない可能性があります
- 診断データには機密性の高いアプリケーション状態が含まれる可能性があります。アクセス制御と監査ログは必須のコンプライアンス要件です
測定と次のアクション
ベースラインメトリクスと成功基準の確立
自動診断の影響を定量化するには、定義された測定フレームワーク内で技術的メトリクスとビジネスメトリクスの両方を運用可能にする必要があります。技術的メトリクスには以下を含める必要があります:
- 平均診断時間(MTTD): インシデント検出から根本原因の特定までの経過時間。このメトリクスは、インシデントがインシデント管理システムで一貫してタグ付けされ、タイムスタンプが記録されていることを前提としています。
- 診断カバレッジ率: 手動調査を必要とせずにツールが実行可能な推奨事項を生成するJava関連インシデントの割合。このメトリクスは、ベースラインテレメトリ収集の完全性に依存します。
- 誤検知率: 診断アラートが問題のない状態の調査をトリガーする頻度。生成された総アラート数に対する割合として測定されます。
- 推奨事項採用率: 運用チームまたは開発チームによって実装されたツール生成の推奨事項の割合。
ビジネスメトリクスは、診断ツールの採用とサービス信頼性の成果との間の因果関係(証拠が許す場合)を確立する必要があります:
- エラー率の推移: Javaアプリケーションエラーの週次測定による変化率(エラータイプ別にセグメント化)。同時期のインフラストラクチャまたはコード変更を制御します。
- レイテンシパーセンタイル: Javaサービスのp50、p95、p99レイテンシの変化。集計バイアスを避けるため、各サービス層ごとに独立して測定します。
- 顧客影響インシデント: エンドユーザーに可視的なサービス劣化をもたらしたインシデントの数。診断ツール展開のタイムラインと相関させます。
公開されたケーススタディでは、展開後3か月以内にインシデントが20〜40%削減されたと報告されていますが、これらの数値はピアレビューを欠いており、成功した実装に対する選択バイアスを反映している可能性があります。組織は、これらを自組織の環境における予測ベンチマークではなく、方向性を示す指標として扱う必要があります。
測定フレームワークとベースラインの確立
- 前提条件*: 組織が一貫したタイムスタンプ精度(±1秒)とインシデント分類スキーマを持つ集中ログおよびインシデント追跡システムを維持していること。
Azure Performance Diagnostics Tool for Javaを展開する前に、最低4週間の期間にわたってベースライン測定を確立します:
- インシデントインベントリ: すべてのJava関連インシデントを根本原因カテゴリ(メモリリーク、スレッド競合、ガベージコレクション停止、外部依存関係タイムアウト、アプリケーションロジックエラー)別にカタログ化します。この分類にはドメイン専門知識が必要であり、Javaサービスに精通したエンジニアによって実行される必要があります。
- 時間的測定: 各インシデントのMTTDを記録します。これは、自動アラート生成とログまたは診断データで根本原因が特定されたタイムスタンプとの間隔として定義されます。
- 解決経路の追跡: 各インシデントが(a)自動推奨事項、(b)事前収集された診断を使用した手動調査、または(c)診断サポートなしの調査のいずれによって解決されたかを文書化します。
具体的な測定例
Javaベースの注文処理サービスを運用するチームは、4週間にわたって以下のベースラインを確立しました:
- ベースラインMTTD: 4時間(中央値); 8時間(p95)
- 週次インシデント頻度: 週12件のJava関連インシデント
- 根本原因の分布: 35%がガベージコレクション停止、25%が接続プール枯渇、20%がメモリリーク、20%が外部サービスタイムアウト
保守的な収集ポリシー(ヒープダンプを1時間に1回に制限、高頻度サービスでサンプリングを有効化)で診断ツールを展開した後、12週間後の測定では以下が示されました:
- 展開後MTTD: 45分(中央値); 90分(p95)
- 診断カバレッジ: 65%のインシデントがツールの推奨事項のみで解決; 30%が事前収集された診断データで解決; 5%が診断サポートなしの調査を必要とした
- 週次インシデント頻度: 週8件のインシデント(33%削減)
初期のヒープダンプ収集中に観察された12秒のアプリケーション停止は、収集をオフピーク時間に制限し、収集頻度を90%削減するサンプリングポリシーを実装することで緩和されました。
実行可能な測定プロトコル
-
ベースライン文書化: ツール展開前に最低4週間、Javaサービスのmttd、インシデント頻度、解決経路を記録します。診断価値が最も高い場所を特定するため、サービス層とインシデントタイプ別にメトリクスをセグメント化します。
-
展開後の週次追跡: MTTD、インシデント頻度、推奨事項採用率を追跡する自動ダッシュボードを確立します。統計的プロセス管理(例:管理図)を実装して、シグナルとノイズを区別します。1週間のメトリクス改善は、持続的な改善の証拠とはなりません。
-
四半期ごとの検証: 展開後3か月、6か月、12か月の間隔で、適切な統計検定(例:非パラメトリックMTTD比較のためのマン・ホイットニーのU検定)を使用して、現在のメトリクスをベースラインと比較します。分析を混乱させる可能性のある同時期のインフラストラクチャまたはアプリケーション変更を文書化します。
-
投資正当化: 検証されたメトリクスを使用して投資収益率を定量化します。MTTDが80%改善し、インシデント頻度が30%減少した場合、労働コスト削減(回復したエンジニア時間)と顧客影響インシデント削減のビジネス価値を計算します。
リスクと緩和戦略
- 図11:診断ツール導入の段階的ロールアウト戦略*

- 図10:Kubernetes環境でのJavaパフォーマンス診断におけるリスク要因と軽減戦略*
診断収集による運用リスク
自動診断は、積極的に特性評価し管理する必要がある測定可能な運用リスクをもたらします。主なリスクは以下の通りです:
-
アプリケーション停止リスク*: ヒープダンプ収集、スレッドトレース生成、その他の診断操作には、Java仮想マシン(JVM)がアプリケーション実行を一時停止する必要があります。停止時間は、ヒープサイズ、オブジェクトグラフの複雑さ、I/Oサブシステムのパフォーマンスに依存します。標準SSD上の16 GBヒープの場合、停止時間は通常5〜15秒の範囲です。レイテンシに敏感なシステム(例:決済処理、リアルタイム入札)では、10秒の停止が依存サービスでカスケードタイムアウトを引き起こし、サービスレベル契約(SLA)に違反する可能性があります。
-
ストレージとコンプライアンスリスク*: ヒープダンプとスレッドトレースには、変数値、オブジェクト参照、および潜在的に機密データ(認証情報、個人識別情報、財務記録)を含むアプリケーション状態が含まれます。共有ファイルシステムまたはクラウドストレージに保存された暗号化されていない診断データは、GDPR、HIPAA、PCI-DSSなどの規制の下でコンプライアンス上の露出を生み出します。リスクの大きさは、データ分類ポリシーと規制義務に依存します。
-
リソース枯渇リスク*: 継続的な診断収集は、CPU、メモリ、I/Oリソースを大量に消費する可能性があります。32 GBヒープを持つサービスでの高頻度ヒープダンプ収集は、1日あたり100 GB以上の診断データを生成し、ストレージクォータを圧迫し、クラウドインフラストラクチャコストを増加させる可能性があります。
緩和戦略: 収集ポリシーとクォータ
診断操作の頻度と範囲を制限する収集クォータを実装します:
- ヒープダンプ頻度制限: サービスインスタンスごとに1時間に最大1回に自動ヒープダンプ収集を制限します。この前提は、診断価値(一時的なメモリ問題を捕捉するのに十分な頻度)と運用オーバーヘッド(アプリケーション停止リスクの最小化)のバランスを取ります。
- 高頻度サービスのサンプリング: 1日あたり100件を超える診断アラートを生成するサービスの場合、異常の10%に対して完全な診断(ヒープダンプ、スレッドトレース)を収集し、100%に対して軽量診断(スタックトレース、メトリクススナップショット)を収集する確率的サンプリングを実装します。これにより、診断シグナルを保持しながら収集オーバーヘッドを90%削減します。
- 時間ウィンドウ制限: 予測可能なトラフィックパターンを持つサービスの場合、ヒープダンプ収集をオフピーク時間(例:現地時間22:00〜06:00)に制限します。この前提は、運用安全性のために診断レイテンシをトレードオフします。ピーク時間中に発生したインシデントは、リアルタイムではなくインシデント後に診断されます。
緩和戦略: データ保護と保持
- 保存時の暗号化: すべての診断データ(ヒープダンプ、スレッドトレース、ログ)をAES-256または同等の暗号化を使用して保存します。暗号化キーは診断ストレージシステムとは別に管理する必要があります(例:Azure Key Vaultを使用)。
- アクセス制御: ヒープダンプへのアクセスを認可された担当者(例:Javaプラットフォームエンジニア、オンコールSRE)に制限するロールベースアクセス制御(RBAC)を実装します。診断データへのすべてのアクセスを監査します。
- 保持ポリシー: コンプライアンス要件と運用ニーズに合わせた保持期間を定義します。典型的なポリシーでは、ヒープダンプを30日間、スレッドトレースを90日間、集計メトリクスを無期限に保持する場合があります。期限切れの診断データの自動削除を実装します。
- データ最小化: 可能な場合、ヒープダンプから機密フィールド(例:パスワード、APIキー、個人識別情報)を除外するように診断ツールを構成します。この前提は、アプリケーションごとに手動構成が必要であり、診断の完全性を低下させる可能性があります。
具体的なリスク緩和例
あるチームは、収集クォータなしで高スループット決済処理サービス(10,000リクエスト/秒、16 GBヒープ)に診断ツールを展開しました。最初の週に:
- 自動ヒープダンプ収集が1日8回トリガーされ、それぞれ12秒のアプリケーション停止を引き起こしました。
- 依存サービス(不正検出、認可)がタイムアウトカスケードを経験し、決済リクエストの0.5%が失敗しました。
- 診断データが1日あたり50 GBで蓄積され、3日以内にチームのストレージクォータを超えました。
チームは以下の緩和策を実装しました:
- 即時: 自動ヒープダンプ収集を無効化; インシデント調査中のみ手動収集に切り替え。
- 短期(1週間): 収集クォータ(1時間あたり最大1ヒープダンプ)を構成し、サンプリング(異常の10%が完全な診断を受ける)を実装。
- 中期(2週間): ヒープダンプ収集をオフピーク時間のみ(22:00〜06:00)に展開し、すべての診断データを保存時に暗号化。
- 検証: 緩和後のアプリケーション停止時間(2〜3秒、許容範囲内)を測定し、サンプリングされた診断を使用してインシデントの95%が1時間以内に診断されたことを確認。
実行可能なリスク管理プロトコル
-
本番前テスト: 本番ワークロード特性(ヒープサイズ、リクエスト率、データ量)を複製するステージング環境に診断ツールを展開します。特定のアプリケーションでのヒープダンプ収集、スレッドトレース生成、その他の診断操作のレイテンシ影響を測定します。停止時間とリソース消費を文書化します。
-
保守的な初期構成: 本番展開前に収集ポリシーを保守的に構成します:
- ヒープダンプ頻度: 最大1時間に1回
- サンプリング率: 高頻度サービス(1日あたり100件を超えるアラート)の場合10%
- 時間ウィンドウ制限: レイテンシに敏感なサービスの場合、オフピーク時間のみ
- 暗号化: 保存時のすべての診断データに対して有効化
-
インシデント対応手順: 診断収集自体が問題を引き起こすシナリオ(例:アプリケーション停止がカスケード障害をトリガー)のランブックを確立します。手順には以下を含める必要があります:
- 即時: 自動収集を無効化; 手動収集に切り替え
- 調査: 停止時間とリソース消費を分析; 根本原因を特定
- 修復: 収集クォータ、サンプリング率、または時間ウィンドウを調整
- 検証: 更新されたポリシーで収集を再有効化; 再発を監視
-
四半期ごとのリスクレビュー: 3か月間隔で、診断収集メトリクス(頻度、停止時間、ストレージ消費、アクセスパターン)をレビューします。収集オーバーヘッドが許容できないサービスを特定し、それに応じてポリシーを調整します。診断収集自体によって引き起こされたインシデントを文書化します。
-
コンプライアンス監査: 診断データ処理(暗号化、アクセス制御、保持)の四半期ごとの監査を実施し、組織のポリシーと規制要件との整合性を確保します。調査結果と修復措置を文書化します。
結論と移行計画
適用範囲と適用可能性
Azure Performance Diagnostics Tool for Javaは、KubernetesでホストされるJavaアプリケーションにおけるパフォーマンス管理の課題の定義された部分集合に対処します。具体的には、このツールは継続的なテレメトリ収集と既知の診断シグネチャに対するパターンマッチングを通じて、パフォーマンス異常の検出を自動化します。この機能は3つの前提条件に依存しています:(1)Javaアプリケーションは互換性のあるコンテナランタイムを持つKubernetesクラスタ上で実行される必要がある、(2)診断エージェントはJVMメトリクスとシステムレベルの可観測性データにアクセスするための十分な権限を持つ必要がある、(3)組織はテレメトリ送信のための適切なストレージとネットワーク帯域幅を維持する必要がある。このツールはアーキテクチャレビュー、コードプロファイリング、またはキャパシティプランニングを置き換えるものではありません。症状の発生から診断仮説の形成までの遅延を削減することで、これらのプラクティスを補完します。
運用への影響と前提条件
パフォーマンス診断の自動化は、手動でのログ集約とメトリクス相関のステップを排除することで、平均診断時間(MTTD)を削減します。ただし、この利点は以下を前提としています:(a)診断ルールがワークロードのベースライン動作に較正されている、(b)オンコールチームが適切な運用コンテキスト内で診断出力を解釈する、(c)誤検知率がインシデント対応ワークフローの許容可能な閾値内に留まる。組織は、自動アラートポリシーにコミットする前に、パイロットフェーズ中にベースライン誤検知率を確立する必要があります。
構造化された移行フレームワーク
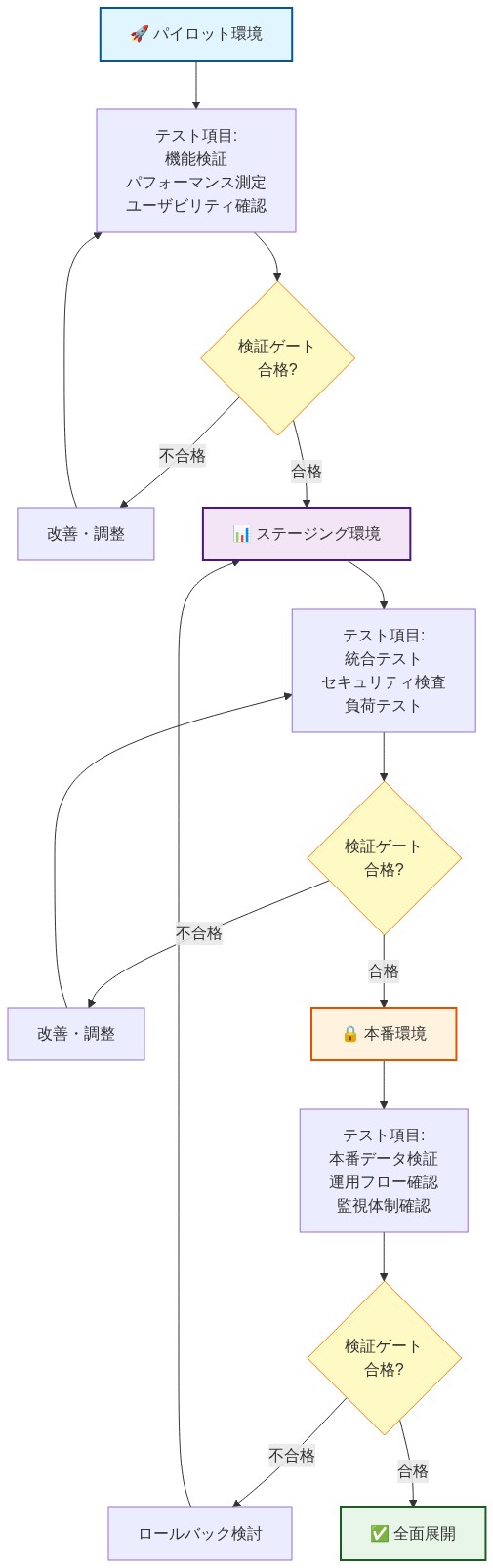
以下の段階的アプローチは、段階的なリスク露出と反復的な検証を前提としています:
-
フェーズ1(第1〜2週):パイロット検証*
-
開発環境またはステージング環境の2〜3の重要度の低いJavaサービスに診断エージェントをデプロイ
-
ベースラインサービスメトリクスに対してエージェントのリソース消費(CPU、メモリ、ネットワークI/O)を測定
-
テレメトリデータの完全性と遅延を検証し、データが設定されたストレージエンドポイントに到達することを確認
-
既存の可観測性インフラストラクチャとの互換性の問題を文書化
-
成功基準: エージェントのオーバーヘッドがCPU 5%未満、メモリ100 MB未満、14日間の観測期間でデータ損失ゼロ
-
フェーズ2(第3〜4週):運用準備*
-
本番サービスのステージング環境レプリカへのデプロイを拡大
-
オンコールチームとの診断解釈トレーニングを実施し、一般的な診断出力のためのランブックテンプレートを確立
-
アラートルーティングとエスカレーションポリシーを検証
-
既存のインシデント管理システムとの統合をテスト
-
成功基準: オンコールチームが診断出力の解釈能力を実証、アラートルーティングが手動介入なしで機能
-
フェーズ3(第5〜6週):制御された本番ロールアウト*
-
重要度とトラフィック量でランク付けされた本番サービスに、低重要度のワークロードから開始してデプロイ
-
独立して検証されたパフォーマンス問題に対する診断精度を監視
-
各サービスのベースラインパフォーマンスメトリクスを収集
-
観測された誤検知率と偽陰性率に基づいて診断閾値を調整
-
成功基準: 診断精度≥85%(真陽性率)、誤検知率が総アラートの10%未満
-
フェーズ4(第7〜8週):完全な本番カバレッジ*
-
すべての本番Javaサービスで自動診断を有効化
-
各サービスコホート(ワークロードタイプ、トラフィックパターン、リソース割り当て別)のパフォーマンスベースラインを確立
-
監査およびコンプライアンス目的で診断ポリシー構成を文書化
-
成功基準: 本番Javaサービスの100%が計装され、トレンド分析のためのベースラインメトリクスが確立
-
フェーズ5(3ヶ月目以降):継続的な改善*
-
診断パターンを分析して、システム的なパフォーマンス問題またはアーキテクチャ上の制約を特定
-
誤検知/偽陰性のトレンドに基づいて診断ルールを改善
-
診断結果をアーキテクチャレビュープロセスとコードレビューチェックリストに統合
-
診断の有効性とツールのROIの四半期レビューを確立
前提条件評価
移行を開始する前に、組織は以下を検証する必要があります:
- インフラストラクチャの互換性: Kubernetesクラスタバージョン≥1.20、コンテナランタイムがJVM計装をサポート、ネットワークポリシーがエージェントからバックエンドへの通信を許可
- 可観測性ベースライン: 既存の監視インフラストラクチャ(メトリクス、ログ、トレース)が機能的でアクセス可能、診断テレメトリのためのストレージ容量がプロビジョニング済み
- 組織の準備状況: オンコールチームがトレーニングのための能力を持つ、インシデント対応ワークフローが新しい診断データソースに対応可能、変更管理プロセスが文書化されている
- ワークロードの特性評価: Javaサービスが重要度、トラフィック量、パフォーマンス感度別に棚卸しされている、比較のためのベースラインパフォーマンスメトリクスが利用可能
成功メトリクスと測定
ロールアウト前に定量的な成功基準を確立します:
- 診断遅延: パフォーマンス異常の発生から診断が利用可能になるまでの時間(目標:5分未満)
- MTTD改善: ツール導入前のベースラインと比較した平均診断時間の削減(目標:50%以上の削減)
- 精度メトリクス: 真陽性率(≥85%)、誤検知率(<10%)、偽陰性率(<5%)
- 運用オーバーヘッド: サービスリソース割り当ての割合としてのエージェントリソース消費(目標:<5%)
- 採用率: 診断出力が修復に情報を提供するオンコールインシデントの割合(目標:3ヶ月以内に≥70%)
即座のアクションアイテム
- Javaサービスの棚卸し: Kubernetes上で実行されているすべての本番Javaアプリケーションをカタログ化し、重要度(ダウンタイムのビジネス影響)とトラフィック量(1分あたりのリクエスト数)でランク付け
- パイロット候補の特定: 初期デプロイのために2〜3のサービスを選択し、文書化されたパフォーマンス問題または高いオンコール負担を持つサービスを優先
- ベースラインメトリクスの確立: エージェントデプロイ前にパイロットサービスの2〜4週間のパフォーマンスデータ(CPU、メモリ、GC動作、応答遅延)を収集
- リソースの割り当て: 診断トレーニングのためのオンコールチームメンバーを割り当て、エージェントのデプロイと構成のためのインフラストラクチームをスケジュール
- 成功基準の定義: 診断精度、運用オーバーヘッド、MTTD改善のための具体的で測定可能な目標を文書化
- データガバナンスの計画: 診断テレメトリの保持ポリシーを確立し、コンプライアンス要件(データ所在地、暗号化、アクセス制御)を文書化
制限事項と適用範囲の境界
このツールは、JVMおよびKubernetesランタイムレイヤー内のパフォーマンス診断に対処します。以下は提供されません:アプリケーションレベルのビジネスロジック分析、データベースクエリ最適化、またはポッド間通信を超えたネットワークパス分析。包括的なパフォーマンス分析を必要とする組織は、このツールをアプリケーションパフォーマンス監視(APM)プラットフォームおよびネットワーク可観測性ソリューションと統合する必要があります。さらに、診断精度は特定のワークロードへのルール較正に依存します。汎用ルールは、非定型のデプロイパターンで誤検知率が上昇する可能性があります。
前文
Microsoftは、KubernetesクラスタにデプロイされたJavaアプリケーションのパフォーマンス分析ワークフローを自動化するために設計された、Azure SREエージェント内の統合機能として、Azure Performance Diagnostics Tool for Javaをリリースしました。このツールが対処する文書化された運用上の課題は次のとおりです:コンテナ化された環境のJavaワークロードは、ユーザー向けの遅延またはサービス障害が観測可能になるまで検出されないままパフォーマンス低下を頻繁に経験します。手動のパフォーマンス診断には、Javaランタイム動作に関する専門知識が必要であり、インシデントあたり相当な調査時間(多くの場合、数時間単位で測定される)を消費し、ガベージコレクションパターン、スレッド同期のボトルネック、またはメモリ保持の問題内に位置する根本原因を特定できないことが頻繁にあります。これらの領域は、標準的なアプリケーション監視を超えた計装を必要とします。
このツールは、Kubernetesクラスタ全体でJavaプロセスメトリクス、ヒープ状態遷移、およびスレッド実行状態を収集および分析する継続的監視エージェントとして機能します。パフォーマンス異常の検出時—運用上、ガベージコレクション一時停止期間の上昇、設定された閾値を超える持続的なヒープ圧力、またはCPU飽和パターンとして定義される—エージェントは自動的に診断データ収集を開始し、システムイベントの時間的相関を実行し、観測されたメトリクスに基づいた推奨事項を生成します。この運用モデルは、Javaパフォーマンス管理を反応的なインシデント対応から体系的な異常検出とエビデンスベースの修復に移行させます。
- Azure SREエージェントとの統合:* Azure Kubernetes Service(AKS)上でJavaマイクロサービスをデプロイする組織は、アプリケーションコードの変更を必要とせずに自動診断を有効化できます。エージェントは既存のAzure MonitorおよびLog Analyticsパイプラインと統合されるため、Javaパフォーマンスチューニングに歴史的に関連付けられてきた運用オーバーヘッドが削減されます。コンテナ化されたJavaワークロード、特にパフォーマンス低下が測定可能なビジネス影響と直接相関するミッションクリティカルなサービスをサポートするチームにとって、この機能は信頼性インフラストラクチャの基礎コンポーネントとして評価する価値があります。

- 図1:Kubernetes環境におけるJavaパフォーマンス課題の複雑性 - メモリ制限、CPUスロットリング、ガベージコレクション、スレッド競合が複雑に絡み合う様子を、診断ツールが可視化する概念図*
システム構造とパフォーマンスボトルネックの特定
Kubernetes環境内で動作するJavaアプリケーションは、非コンテナ化デプロイで観測されるものとは実質的に異なるパフォーマンス上の課題に直面し、これらの違いは従来のアプリケーションパフォーマンス監視(APM)ツールの検出能力を頻繁に超えます。メモリ圧力はこの違いを例示しています:コンテナ内では、ポッドメモリ制限がメモリ不足終了をトリガーするハードリソース境界を強制します。しかし、根底にある因果メカニズム—非効率的なオブジェクト割り当てパターン、意図しない参照保持、または不適切なヒープサイジング—は、ヒープ構造とオブジェクトライフサイクルを分析できる計装なしでは見えないままです。
Performance Diagnostics Toolは、JavaランタイムシグナルとKubernetesリソース制約を相関させることで、このギャップに対処します。リアルタイムでヒープダンプ、スレッド実行トレース、およびガベージコレクションイベントログをキャプチャし、これらのシグナルをポッドCPUスロットリングイベント、ノードメモリ圧力、ネットワーク遅延測定を含む観測可能なKubernetesメトリクスと相関させます。この多層相関モデルにより、トランザクション遅延がアプリケーションロジックの非効率性、ランタイムレベルでのリソース競合、またはインフラストラクチャが課す制約のいずれに起因するかを特定できます。
-
例示的なケース:* 支払い処理サービスは、ピークトラフィック期間中にp99トランザクション遅延2,000ミリ秒を示します。標準的なインフラストラクチャ監視は、CPUの使用率上昇を示しますが、特定の原因を特定するための十分な粒度を提供しません。Performance Diagnostics Toolは、フルガベージコレクション一時停止イベントが約30秒間隔で発生し、各一時停止が約800ミリ秒続くことを特定します。ヒープ分析により、アプリケーションが1秒あたり約500メガバイトの短命オブジェクトを割り当て、積極的な若い世代コレクションサイクルをトリガーしていることが明らかになります。ツールは、ヒープ割り当てパラメータを調整するか、割り当て圧力を削減するためのオブジェクトプーリングパターンを実装することを推奨します。
-
運用上の推奨事項:* チームは、ツールの履歴分析機能を使用して各Javaサービスのパフォーマンスベースラインを確立する必要があります。定義された負荷条件下での通常のガベージコレクション頻度、予想されるヒープ使用率範囲、および典型的なスレッド数を含むベースラインメトリクスを文書化します。パフォーマンス異常が検出された場合、観測されたメトリクスをこれらのベースラインと比較して、根本原因の特定を加速します。許容可能な運用範囲を超えるメトリクス偏差のアラート閾値を構成し、ユーザー向けの影響が発生する前にプロアクティブなインフラストラクチャスケーリングまたはコード修復を可能にします。
エグゼクティブ問題ステートメント
Microsoftは、Kubernetes上で実行されるJavaアプリケーションのパフォーマンス調査ワークフローを自動化するために設計された、Azure SREエージェント内の統合機能として、Azure Performance Diagnostics Tool for Javaをリリースしました。これが対処する運用上の問題は具体的です:コンテナ化された環境のJavaワークロードは静かに劣化します—ガベージコレクションの一時停止、メモリリーク、スレッド競合は、ユーザーが遅延を報告するかサービスが失敗するまで見えないままです。手動診断には、インシデントあたり4〜8時間の専門知識が必要であり、根本原因を見逃すことが頻繁にあり、数十のマイクロサービス全体でスケールしません。このツールは、Javaパフォーマンス管理を反応的なインシデント対応から自動検出と修復に移行させ、平均解決時間(MTTR)を削減し、すべてのSREチームにJavaパフォーマンススペシャリストを配置する必要性を排除します。
-
デプロイ範囲とROI前提:* Azure Kubernetes Service(AKS)上で10以上のJavaマイクロサービスを実行している組織は、月に2〜3件のパフォーマンスインシデントを想定して、月あたり20〜30時間の診断労力を回収できると期待できます。インシデント頻度が高い、またはJavaフットプリントが大きいチームの場合、労力削減は比例してスケールします。このツールはアプリケーションコードの変更を必要とせず、既存のAzure Monitorパイプラインと統合されるため、実装の摩擦が削減されます。
-
主要な制約:* このツールはAzure SREエージェント内でのみ動作し、AKSまたはAzureホストのKubernetesクラスタを必要とします。オンプレミスまたはマルチクラウドKubernetesデプロイではこの機能を使用できません。これらの環境では、代替ソリューション(Datadog、New Relic、またはPrometheus + カスタムコレクタなどのオープンソースツール)が引き続き必要です。
システム構造とボトルネック:KubernetesにおけるJava特有の障害モード
KubernetesにおけるJavaアプリケーションは、従来のインフラストラクチャとは根本的に異なるパフォーマンス上の課題に直面します。コンテナ内のメモリ圧迫は厳格な境界を作り出します。ポッドがメモリ制限を超えると、アプリケーションがそのメモリを実際に使用しているかどうかに関係なく、カーネルは即座にプロセスを強制終了します。大規模なヒープでは100〜2000ミリ秒続くことがあるガベージコレクションの一時停止は、標準的なKubernetesメトリクス(CPU、メモリ、ネットワーク)では見えませんが、トランザクションのレイテンシとタイムアウト障害を直接引き起こします。スレッドの競合、コネクションプールの枯渇、クラスローダーのリークは、汎用的なAPMツールでは分離できない形でこれらの問題を複雑化させます。
Performance Diagnostics Toolは、Java固有のシグナル(ヒープの動作、GCイベント、スレッドの状態)とKubernetesのリソース制約(CPUスロットリング、ノード圧迫、ポッドの退避)を関連付けることで、このギャップに対処します。ヒープダンプ、スレッドトレース、GCログをリアルタイムで取得し、これらをポッドレベルおよびノードレベルのメトリクスと関連付けて、レイテンシがアプリケーションロジック、リソース競合、またはインフラストラクチャの制限のいずれに起因するかを特定します。
具体的な診断ワークフロー:決済処理サービス
-
観測された症状:* 決済処理マイクロサービスが、ピーク負荷時(10,000リクエスト/分)にp99レイテンシ2.0〜2.5秒を示します。標準的な監視では、CPU使用率がポッド制限の85%、メモリが78%と表示されます。明白な原因は見つかりません。
-
ツールを使用した診断調査:*
- ツールはピーク負荷時に5分間のヒープスナップショットとGCログを取得します。
- 分析により、28〜32秒ごとにフルガベージコレクションの一時停止が発生し、それぞれ750〜850ミリ秒続くことが明らかになります。
- ヒーププロファイリングにより、アプリケーションが短命なオブジェクト(トランザクションコンテキスト、一時バッファ)を毎秒480〜520MB割り当てていることが示されます。
- ヤング世代のコレクション頻度は1分あたり12〜15回で、各一時停止がすべてのアプリケーションスレッドを停止させます。
- リクエストトレースとの関連付けにより、8〜12%のリクエストがGC一時停止のレイテンシを経験しており、p99のスパイクを説明していることが示されます。
-
根本原因:* ヒープサイズが割り当て率に対して不十分です。ヤング世代が小さすぎるため、頻繁なコレクションが強制されます。さらに、高頻度の割り当てに対してオブジェクトプーリングが実装されていません。
-
修復オプションとトレードオフ:*
| オプション | アクション | コスト | リスク | MTTR |
|---|---|---|---|---|
| ヒープサイズの増加 | ポッドのメモリ制限を2GBから3GBに引き上げ、JVMの-Xmxフラグを調整 | ポッドあたり+50%のメモリ、スケール時に月額+$X | ヒープが満杯になった場合のフルGC一時停止の長期化、ノードメモリ圧迫の増加 | 30分(設定変更+ローリング再起動) |
| オブジェクト割り当ての最適化 | トランザクションコンテキストのオブジェクトプーリングを実装、割り当て率を40%削減 | エンジニアリング工数:2〜3日 | コード変更リスク、テストとカナリアデプロイが必要 | 3〜5日 |
| GCアルゴリズムの調整 | G1GCから低レイテンシコレクタのZGCに切り替え、Java 11+が必要 | 運用コストは最小限、JVM再起動が必要 | ZGCはCPUオーバーヘッドが高い(5〜10%)、G1GCより成熟度が低い | 1日(JVMフラグ変更+再起動) |
| ハイブリッドアプローチ | ヒープを2.5GBに増加+割り当ての30%にオブジェクトプーリングを実装 | 中程度のエンジニアリング+運用工数 | バランスの取れたリスク、段階的なロールアウトが可能 | 2週間(並行ストリーム) |
- 推奨パス:* ハイブリッドアプローチを展開します。ヒープを即座に増加させ(低リスク、高速)、並行してオブジェクトプーリングを実装します。ツールの履歴分析機能を使用して、各変更後のGC動作を監視します。
実行可能な実装プレイブック
-
フェーズ1:ベースラインの確立(第1週)*
-
代表的な2〜3のJavaサービスでPerformance Diagnostics Toolを有効化します。
-
通常負荷時とピーク負荷時の1週間の継続的な診断を収集します。
-
各サービスのベースラインメトリクスを文書化します:
- GC一時停止の頻度と期間(p50、p95、p99)
- ヒープ使用率パターン(最小、最大、平均)
- スレッド数と競合ホットスポット
- メモリ割り当て率(MB/秒)
-
各サービスのAzure Monitorにベースラインダッシュボードを作成します。
-
フェーズ2:アラート閾値の定義(第1〜2週)*
-
許容可能な閾値を超える偏差に対してアラートを設定します:
- GC一時停止期間 > 500ms(またはサービス固有のSLO)
- ヒープ使用率 > 85%が2分以上継続
- スレッド数のスパイク > ベースラインより20%以上
- フルGC頻度 > 1回/分
-
アラートが自動化されたランブックをトリガーするように設定します(フェーズ3を参照)。
-
合成負荷でアラートをテストし、感度を検証します。
-
フェーズ3:修復の自動化(第2〜3週)*
-
一般的なシナリオ用のAzure Automationランブックを作成します:
- ランブック1(ヒープ圧迫): ヒープ使用率が5分間85%を超えた場合、ヒープダンプ収集をトリガーし、SREチームに通知し、スケーリング推奨を準備します。
- ランブック2(GC一時停止スパイク): GC一時停止期間が500msを超えた場合、スレッドトレースとGCログを収集し、リクエストレイテンシと関連付け、診断レポートを生成します。
- ランブック3(メモリリーク検出): ヒープ使用率がGC回復なしで1時間にわたって単調増加する場合、潜在的なリークにフラグを立て、ヒープダンプ分析を開始します。
-
ランブックをAzure Monitorのアラートアクションにリンクします。
-
フェーズ4:運用化(第3週以降)*
-
AKS上のすべてのJavaマイクロサービスにツールをロールアウトします。
-
診断レポートをインシデント対応ワークフロー(PagerDuty、Opsgenie)に統合します。
-
診断トレンドの週次レビューをスケジュールし、システム的な問題(広範なオブジェクト割り当ての非効率性など)を特定します。
-
インシデントから学んだ教訓に基づいてランブックを更新します。
コスト、リスク、制約
直接コスト
- Azure SRE Agentライセンス: AKS用Azure Monitorに含まれており、既にデプロイされている場合は追加コストなし。
- 診断データのストレージ: ヒープダンプ(キャプチャあたり100〜500MB)とGCログ(1日あたり10〜50MB)は急速に蓄積されます。サービスあたり月間5〜10GBと見積もります。Azure Blob Storageの料金(約$0.018/GB/月)では、サービスあたり年間$90〜180となり、管理可能ですがゼロではありません。
- コンピュートオーバーヘッド: エージェントは継続的な監視のためにポッドあたり2〜5%のCPUオーバーヘッドを追加します。10ポッドのサービスでは、余裕のために追加のポッドが必要になる場合があります。
運用リスク
- アラート疲労: 調整が不十分な閾値は誤検知を生成し、チームの信頼を損ないます。アラートを有効にする前にベースライン分析に時間を投資してください。
- 診断データのプライバシー: ヒープダンプには機密データ(APIキー、顧客PII、データベース資格情報)が含まれる可能性があります。保持ポリシーとアクセス制御を実装してください。長期保存には匿名化を検討してください。
- Kubernetesバージョンの互換性: ツールはKubernetes 1.19+を搭載したAKSが必要です。古いクラスタはアップグレードする必要があります。
- マルチクラウドまたはオンプレミスのギャップ: 組織がGKE、EKS、または自己管理Kubernetesを使用している場合、このツールは利用できません。代替ソリューションまたはクラウド統合を計画してください。
制約と回避策
- リアルタイムヒープダンプ分析なし: ツールはデータを収集しますが、複雑なシナリオでは手動解釈が必要です。即座の回答が必要な組織は、商用APMツール(Datadog、New Relic)との組み合わせを検討してください。
- Java 8+に限定: 古いJavaバージョン(Java 6、7)はサポートされていません。レガシーアプリケーションには移行または代替監視が必要です。
- Kubernetesのみ: 非コンテナ化されたJavaアプリケーション(VM、ベアメタル)はこのツールを使用できません。これらのワークロードには別の監視を維持してください。
成功指標と検証
ツールの有効性を測定するために、これらの指標を追跡します:
| 指標 | ベースライン | 目標(3ヶ月) | 担当者 |
|---|---|---|---|
| JavaパフォーマンスインシデントのMTTR | 4〜6時間 | 30〜45分 | SREリード |
| 専門家へのエスカレーションが必要なインシデント | 60% | 20% | SREリード |
| 誤検知アラート | N/A | 総アラートの5%未満 | プラットフォームエンジニアリング |
| 月間診断作業時間 | 40時間 | 10時間 | SREチーム |
| ユーザー向けレイテンシ(p99) | ベースライン | -15%(最適化実装時) | プロダクトオーナー |
- 次のステップ:* 代表的な2〜3のJavaサービスで2週間のパイロットをスケジュールします。ベースライン診断を収集し、アラートの精度を検証し、労力削減を測定します。パイロット結果を使用して、完全なロールアウトとストレージおよびコンピュートオーバーヘッドの予算配分を正当化します。
見えないパフォーマンス危機—そしてなぜ今重要なのか
Kubernetes上で実行されるJavaアプリケーションは、今後10年間で最も重要なインフラストラクチャへの賭けの1つを表しています。企業は、決済システム、医療プラットフォーム、金融サービスなどのミッションクリティカルなワークロードを、大規模にコンテナ化されたJava環境に移行しています。しかし、根本的な運用上の盲点が持続しています:** Javaのパフォーマンス低下は、危機になるまで見えないままです。**
MicrosoftのAzure Performance Diagnostics Tool for Javaは、重要な転換点を示しています。これは単なる監視の強化ではありません。専門知識そのものの自動化を表しています。歴史的に、Javaのパフォーマンスチューニングには、ガベージコレクションアルゴリズム、ヒープメモリモデル、スレッドスケジューリングに関する深い知識を持つ専門のサイト信頼性エンジニア(SRE)が必要でした。これらの専門家は希少で高価であり、彼らの洞察はしばしば部族的知識に閉じ込められていました。このツールは、インテリジェントな診断をインフラストラクチャ自体に組み込むことで、この専門知識を民主化し、反応的な消火活動を予測的で自律的な信頼性に変換します。
- これが重要な理由:* 組織がKubernetesクラスタ全体でJavaマイクロサービスをスケールするにつれて、手動パフォーマンス調査のコストは法外なものになります。専門家による8時間の診断を必要とする単一のパフォーマンスインシデントは、労力と生産性の損失で$10,000〜$50,000のコストがかかる可能性があります。これを数十のサービスと年間数百のインシデントに掛け合わせると、自動化の経済的根拠は否定できないものになります。さらに重要なことに、問題検出と解決の間のレイテンシが数時間から数分に短縮され、収益とユーザーの信頼を直接保護します。
Performance Diagnostics Toolは自律的なSREエージェントとして動作し、Kubernetesクラスタ全体でJavaプロセスメトリクス、ヒープ動作、スレッド状態を継続的に監視します。異常が発生した場合—ガベージコレクションの一時停止の増加、ヒープ圧迫、CPU飽和—エージェントは自動的に診断データを収集し、複数のシグナルタイプにわたってイベントを関連付け、人間の介入なしに推奨事項を生成します。これは根本的な変化を表しています:人間がシステムを調査するのではなく、システムが自分自身を調査するのです。
- Azure SRE Agentによる運用化:* Azure Kubernetes Service(AKS)にJavaマイクロサービスをデプロイするチームは、アプリケーションコードを変更することなく自動診断を有効にできます。エージェントは既存の監視パイプラインにシームレスに統合され、Javaのパフォーマンスチューニングに従来必要だった運用オーバーヘッドを排除します。コンテナ化されたJavaワークロードを実行している組織は、この機能を信頼性インフラストラクチャの基礎コンポーネントとして評価する必要があります—特に、パフォーマンス低下が収益、ユーザー満足度、または運用継続性に直接影響するサービスにおいて。
システム構造とボトルネック:Kubernetes-Javaのミスマッチ
Kubernetes環境のJavaアプリケーションは、従来のアプリケーションパフォーマンス監視(APM)ツールが体系的に分離できない独特なクラスのパフォーマンス課題に直面しています。このミスマッチは、根本的なアーキテクチャの緊張から生じています:** Javaは予測可能なリソース割り当てを持つ長時間実行プロセス用に設計されていますが、Kubernetesは一時的なワークロードに厳格なリソース境界を強制します。**
具体例としてメモリ圧迫を考えてみましょう。ベアメタルでは、メモリ制約を経験しているJavaアプリケーションはガベージコレクションをトリガーし、アプリケーションを一時的に停止させる可能性がありますが、緩やかな劣化を許します。Kubernetesでは、ポッドのメモリ制限が絶対的な境界を作成します—それを超えると、コンテナは即座に強制終了されます。しかし、メモリ圧迫の根本原因—非効率的なオブジェクト割り当て、保持された参照、メモリリーク—は、深いヒープ分析なしでは完全に不透明なままです。従来の監視は「メモリ不足による強制終了」を示しますが、アプリケーションが過剰なメモリを消費した理由についての洞察は提供しません。
Performance Diagnostics Toolは、Java固有のボトルネックをKubernetesのリソース制約に直接マッピングすることで、このギャップを埋めます。ヒープダンプ、スレッドトレース、ガベージコレクションログをリアルタイムで取得し、これらのシグナルをポッドのCPUスロットリング、ノード圧迫、ネットワークレイテンシ、ストレージI/Oと関連付けます。この多層可視性により、真の根本原因が明らかになります:遅いトランザクションがアプリケーションロジックの欠陥、ポッド内のリソース競合、またはクラスタによって課されたインフラストラクチャ制限のいずれに起因するか。
-
具体的なシナリオ:* 決済処理サービスが、ピーク負荷時にp99レイテンシ2秒を経験します。従来の監視では、CPUの使用率が上昇していますが、明確な原因はありません。診断ツールは、30秒ごとにフルガベージコレクションの一時停止が発生し、それぞれ800ミリ秒続いていることを特定します—これは、ガベージコレクションだけで総リクエスト時間の2.7%が失われていることを表します。さらなる分析により、アプリケーションが毎秒500MBの短命なオブジェクトを割り当てており、積極的なヤング世代コレクションをトリガーしていることが明らかになります。根本原因:非効率的なJSONシリアライゼーションが一時的なオブジェクトチェーンを作成しています。推奨事項:ストリーミングJSONパーサーに切り替えるか、オブジェクトプーリングを実装します。
-
将来を見据えた意味:* このシナリオは、より広範なパターンを示しています。JavaワークロードがKubernetesクラスタ全体で水平方向にスケールするにつれて、小さな非効率性の複合効果は壊滅的になります。100のレプリカを持つサービスで、それぞれがガベージコレクションにCPUの2.7%を浪費している場合、実質的に2.7個分のポッドの容量を失っています。数十のJavaサービスを実行している組織全体では、この無駄は年間数百万ドルの不必要なインフラストラクチャコストに増大します。
Performance Diagnostics Toolは、これを見えない税金から見える実行可能な問題に変換します。チームは、ツールの履歴分析機能を使用してJavaサービスのベースラインプロファイルを確立できるようになりました—通常のガベージコレクション頻度、ヒープ使用率パターン、スレッド数、割り当て率を文書化します。異常が発生した場合、これらのベースラインと比較して根本原因の特定を加速します。許容可能な閾値を超える偏差に対してアラートを設定し、ユーザーへの影響が発生する前にプロアクティブなスケーリングまたはコード修復を可能にします。これにより、Javaの信頼性の経済性が反応的(高価、遅い、予測不可能)から予測的(費用対効果が高い、迅速、体系的)に移行します。
リスクと軽減戦略:レジリエンスを考慮した設計
自動診断は、適切に管理されない場合、逆説的にシステムの脆弱性を増大させる可能性のある新しいクラスの運用リスクをもたらします。最も重大なリスクは、診断収集のオーバーヘッドがカスケード障害の原因となることです。ヒープダンプ、スレッドトレース、継続的プロファイリングは、特に決済やリアルタイム取引のようなレイテンシに敏感なシステムにおいて、依存サービスでタイムアウトを引き起こすレイテンシスパイクをもたらす可能性があります。
このリスクは単なる技術的な問題ではありません。より深いアーキテクチャ上の課題を反映しています:可観測性のためにシステムを計装することで、システムの可観測性を低下させないようにするにはどうすればよいか? その答えは、診断を後付けではなく、第一級のレジリエンスの関心事として設計することにあります。
プロアクティブな軽減アーキテクチャ
本番環境で収集オーバーヘッドを発見するのではなく、デプロイメント戦略に診断のレジリエンスを組み込みます:
-
収集クォータと適応的サンプリング*:診断収集頻度に厳格な制限を実装します(例:サービスごとに1時間に1回以下のヒープダンプ)。また、システム負荷に基づいて収集強度をスケールする適応的サンプリングを使用します。高スループット期間中は診断の粒度を下げ、トラフィックが少ない時間帯には包括的な収集を有効にします。このアプローチにより、診断は許容できないオーバーヘッドを導入することなく価値を維持します。
-
レイテンシ監視を伴う段階的ロールアウト*:まず重要度の低いサービスとステージング環境に診断をデプロイします。特定のワークロードにおけるヒープダンプ収集、スレッドトレース生成、継続的プロファイリングの正確なレイテンシ影響を測定します。多くのチームは、収集オーバーヘッドがヒープサイズ、GC構成、アプリケーションアーキテクチャに基づいて劇的に変化することを発見します。一般的なベンチマークでは不十分です。
-
暗号化とコンプライアンス優先のデータ処理*:診断データには機密情報(顧客ID、APIキー、内部サービストポロジー)が含まれることがよくあります。すべての診断データを保存時および転送時に暗号化します。認可された担当者のみがヒープダンプにアクセスできるように、きめ細かいアクセス制御を実装します。コンプライアンス要件(GDPR、HIPAA、SOC 2)に沿った保持ポリシーを確立し、偶発的な露出を防ぐためにデータの自動削除を実装します。
-
診断障害に対するインシデント対応手順*:診断収集自体が問題を引き起こすシナリオに対する明示的なランブックを作成します。特定のサービスでの収集の無効化、診断ポリシーのロールバック、収集オーバーヘッドが許容可能な閾値を超えた場合のプラットフォームチームへのエスカレーションの手順を含めます。
具体的なシナリオ:ニアミスからの学習
あるチームが高スループットの決済サービスで自動ヒープダンプ収集を有効にしました。最初の収集でアプリケーションが12秒間停止し、依存サービスでカスケードタイムアウトが発生し、軽微なインシデントが発生しました。診断を完全に無効にするのではなく、より洗練されたアプローチを実装しました:
- 即座の軽減:ヒープダンプをオフピーク時間(午後11時~午前6時)に制限し、検出された異常の10%のみに対して完全な診断を収集するサンプリングを実装し、収集頻度を90%削減しました。
- 根本原因分析:収集オーバーヘッドが予想よりも高かった理由を調査します。サービスの8 GBのヒープサイズと積極的なGC構成が収集を特に高コストにしていることを発見しました。ポーズ時間を削減するためにGCチューニングを調整し、インクリメンタルヒープダンプ収集を実装しました。
- プラットフォーム全体での学習:調査結果を他のチームと共有し、レイテンシに敏感なサービスでの診断収集に関する組織全体のガイドラインを確立しました。これはプラットフォームの運用プレイブックの標準的な部分となりました。
- 長期的なアーキテクチャの洞察:このインシデントにより、決済サービスが短時間の収集ポーズにも耐えられるだけの十分な冗長性を欠いていることが明らかになりました。この診断の洞察を使用して、サービスレプリケーションとサーキットブレーカーパターンへの投資を正当化し、最終的にシステム全体のレジリエンスを向上させました。
実行可能な示唆:テスト駆動診断
診断のデプロイメントを厳密なエンジニアリング規律として扱います:
- ステージング検証:本番サービスで診断を有効にする前に、本番トラフィックパターンを再現するステージング環境で負荷テストを実行します。各診断操作(ヒープダンプ、スレッドトレース、継続的プロファイリング)のレイテンシ影響を測定し、許容可能なオーバーヘッド閾値(通常はp99レイテンシ増加5%未満)を確立します。
- カナリアデプロイメント:まず本番トラフィックの小さな割合に診断をロールアウトします。完全なデプロイメントの前に、予期しないオーバーヘッド、誤検知、またはデータ品質の問題を監視します。
- 継続的な監視:診断収集オーバーヘッドをリアルタイムで追跡するダッシュボードを実装します。収集レイテンシが閾値を超えた場合にアラートを発し、顧客への影響が発生する前に迅速な対応を可能にします。
- フィードバックループ:アプリケーションチームが診断収集の問題を報告するメカニズムを作成します。このフィードバックを使用して、収集ポリシーとサンプリング戦略を継続的に改善します。
診断を第一級のレジリエンスの関心事として扱うことで、組織は診断を脆弱性の潜在的な原因から、システムの信頼性を損なうことなく可観測性を深める戦略的能力へと変革します。このアプローチにより、KubernetesにおけるJavaワークロードは、今日の運用上の課題だけでなく、次の10年のますます複雑化する分散システムにも対応できるようになります。