
AWS Weekly Roundup: Amazon EC2 G7eインスタンス、Amazon Correttoアップデート、その他(2026年1月26日)
概要
2026年1月は三つの重要なAWSアップデートをもたらす。Amazon EC2 G7eインスタンス、Amazon Correttoセキュリティパッチ、インフラストラクチャ耐障害性の強化である。クラウドインフラストラクチャを管理する知識労働者にとって、これらの変化はGPUワークロード配置、Javaランタイムコンプライアンス、ディザスタリカバリ体制の即座の評価を要求する。
EC2 G7eインスタンス:GPU経済学の再構想
-
主張:* G7eインスタンスはGPU加速コンピュート経済学における世代的飛躍を表現する。
-
根拠:* G7eインスタンスはNVIDIA H100 GPUをメモリ帯域幅の改善とG6前世代比での単位当たり価格削減と組み合わせている。機械学習推論、リアルタイム分析、グラフィックスレンダリングを実行する組織は、コストとパフォーマンスを同時に最適化できるようになった。
-
具体例:* フィンテック企業がリアルタイム不正検知を現在G6インスタンスで展開しており、時間当たり4.08ドルで稼働している。G7eへの移行により時間当たりコストは約3.24ドルに低下し、スループットは40%増加する。推論当たりのコスト削減は60%に達する。
-
実行可能な次のステップ:*
-
GPUワークロード在庫を即座に監査する
-
月間720時間以上実行されるジョブを移行候補として特定する
-
G7eインスタンスでパイロットクラスタを確立し、レイテンシとスループットを測定する
-
検証後、本番トラフィックを段階的に移行する
Correttoアップデート:セキュリティと安定性
-
主張:* 1月のCorrettoパッチは高ストレス期間中に分散システム全体に波及する重大なJVM脆弱性に対処する。
-
根拠:* 最近のパッチはガベージコレクション(GC)デッドロックとメモリ安全性の問題の修正を含む。負荷スパイク時—インシデント対応やトラフィック急増時に一般的—パッチが当たっていないJVMは予測不可能に失敗し、停止時間と復旧複雑性を増幅する。
-
具体例:* リテール企業がCorretto 11.0.22を実行するプラットフォームはピークトラフィック時にGC一時停止バグを経験する。11.0.23へのアップグレードにより一時停止は排除され、P99レイテンシは2.1秒から340ミリ秒に低下する。
-
実行可能な次のステップ:*
-
Correttoアップデートを30日以内にスケジュールする
-
本番トラフィックリプレイを使用してステージング環境でテストする
-
ミッションクリティカルサービスのカナリアデプロイメントを実装する:インスタンスの5%にロールアウトし、48時間監視してから進行する
-
AWS Systems Manager Patch Managerを使用してパッチ検出を自動化する
インフラストラクチャ耐障害性:マルチリージョンフェイルオーバー
-
主張:* マルチリージョンフェイルオーバーと自動復旧パターンは今やオプション機能ではなく基本要件である。
-
根拠:* アベイラビリティゾーンとリージョンは依然として障害が発生する。アクティブ・アクティブまたは高速復旧パターンを持たない組織は数時間のダウンタイムに直面する。これらのアップデートのタイミング—季節的インフラストラクチャストレスの最中—は運用耐障害性がなぜ重要かを強調している。
-
具体例:* シングルリージョンデプロイメントを持つSaaS企業がリージョン停止を経験し、復旧に6時間を要する。クロスリージョンRDS読み取りレプリカとRoute 53フェイルオーバーを持つ競合企業は90秒で復旧し、インシデント中に市場シェアを獲得する。
-
実行可能な次のステップ:*
-
重要なデータフローをマッピングし、サービスごとにRPO(Recovery Point Objective)とRTO(Recovery Time Objective)を定義する
-
RTO <5分の場合:リージョン間でアクティブ・アクティブをデプロイする
-
RTO 1~4時間の場合:自動フェイルオーバー付き読み取りレプリカを実装する
-
Gremlinなどのカオスエンジニアリングツールを使用してフェイルオーバーを四半期ごとにテストする
運用化:Infrastructure-as-CodeとデプロイメントパターンIaC
-
主張:* Infrastructure-as-CodeとBlue-Greenデプロイメントはデプロイメント摩擦とロールバックリスクを排除する。
-
根拠:* 手動プロビジョニングとパッチ適用は人的エラーを導入する。TerraformとCloudFormationは再現可能で監査可能なインフラストラクチャ変更を可能にする。Blue-Greenデプロイメントは問題が発生した場合の即座のロールバックを可能にする。
-
具体例:* チームはTerraformでG7eインスタンスグループを定義し、新しいスタック(グリーン)をデプロイし、スモークテストを実行してから、Route 53トラフィックを切り替える。問題が発生した場合、30秒で古いスタック(ブルー)に戻す。
-
実行可能な次のステップ:*
-
EC2とCorretto設定をTerraformまたはCloudFormationでコード化する
-
ステートレスサービスのBlue-Greenデプロイメントを実装する
-
ステートフルサービスの場合、RDS読み取りレプリカまたはDynamoDBグローバルテーブルを使用してゼロダウンタイム移行を可能にする
-
CloudFormationドリフト検出とAWS Configルールで自動テストを実装する
可観測性:測定と最適化
-
主張:* 可観測性—単なる監視ではなく—は迅速なインシデント対応と最適化を駆動する。
-
根拠:* 従来のメトリクス(CPU、メモリ)はアプリケーションレベルの問題を明らかにしない。分散トレーシング、カスタムメトリクス、ログ相関は根本原因を数時間ではなく数分以内に露出させる。
-
具体例:* チームはG7eインスタンスをデプロイするがレイテンシ改善を観察しない。CloudWatch Logs Insightsは、GPU計算ではなくデータベースクエリがボトルネックであることを明らかにする。代わりに読み取りレプリカを追加し、望ましい改善を達成する。
-
実行可能な次のステップ:*
-
X-RayでアプリケーションをトレーシングとCloudWatchでカスタムメトリクスを計測する
-
レイテンシ、スループット、エラー率のSLO(Service Level Objectives)を定義する
-
CloudWatchダッシュボードを使用して時間単位でメトリクスを追跡する
-
メトリクスを修復ステップにリンクするランブックを確立する
リスク軽減:互換性と段階的ロールアウト
-
主張:* 互換性テストと段階的ロールアウトは広範な停止を防止する。
-
根拠:* Correttoアップデートは時折レガシーコードを破壊する。G7eインスタンスタイプはGPUメモリレイアウトに微妙な違いがある可能性がある。デプロイメントを急ぐと爆発半径と復旧時間を増幅する。
-
具体例:* チームはテストなしでCorrettoをアップグレードし、カスタムシリアライゼーションライブラリが破壊され、2時間の生産性喪失を発見する。ピアはステージングで最初にテストし、問題を特定し、ライブラリにパッチを当て、自信を持ってデプロイする。
-
実行可能な次のステップ:*
-
本番デプロイメント前に本番のようなトラフィックで48時間のステージングテストを実行する
-
カナリアデプロイメントを使用してまずインスタンスの5%にロールアウトする
-
エラー率とレイテンシを監視し、異常が現れた場合は停止して調査する
-
すべてのインフラストラクチャ変更に対して文書化されたロールバック手順を維持する
移行計画:段階的実装
-
主張:* 段階的移行計画は高価値改善を優先することでリスクと報酬のバランスを取る。
-
根拠:* すべての変更を同時に試みるとコントロール不可能な爆発半径を生成する。ビジネスインパクトで優先順位付けすることで、リソースが高価値改善に流れることを保証する。
-
実装タイムライン:*
-
第1~2週: GPUワークロードとCorrettoバージョンを監査する。トランザクション当たりコストとセキュリティ露出に基づいて移行候補を特定する。
-
第3~4週: ステージング環境でG7eインスタンスとCorrettoアップデートをパイロットする。パフォーマンスと互換性を測定する。
-
第5~8週: カナリアとBlue-Greenパターンを使用して本番にデプロイする。密接に監視する。
-
第9~12週: 可観測性データに基づいて最適化する。学習を文書化する。
これらのアップデートを構造化されたイニシアティブとして—ワンオフタスクではなく—扱うことで、運用安定性を維持しながらその完全な価値を獲得する。今週開始すること。
Amazon EC2 G7eインスタンス:GPU計算経済学と移行基準
-
主張:* G7eインスタンスは特定のワークロードクラスに対するGPU加速コンピュート効率における測定可能な進歩を表現する。
-
根拠と前提条件:* G7eインスタンスはNVIDIA H100 GPUをメモリ帯域幅の建築的改善とG6前世代比での熱効率向上と統合する。この進歩は持続的GPU利用率(>70%)とメモリ集約的操作を示すワークロードに特に適用される。経済的利益は現在のG6デプロイメントと安定したワークロード特性を想定する。不均質またはバースト的ワークロードは移行コストを正当化しないかもしれない。
-
支持データ:* 2026年1月現在のAWS価格設定はG7eインスタンスを約3.24ドル/時間(オンデマンド、us-east-1)対G6 4.08ドル/時間に位置付ける—20.6%削減である。スループット改善は30~40%がTensorRTで最適化されたモデルを使用する推論ワークロードに対して文書化されている。ただしこれらの利益はすべてのGPUアプリケーション全体で普遍的ではなく、モデルアーキテクチャとバッチサイズに依存する。
-
具体的応用:* 金融サービス組織がNVIDIA TensorRTモデル経由のリアルタイム不正検知をG6インスタンスで実行し、インスタンス当たり4.08ドル/時間を負担する。G7eへの移行はインスタンス当たりコストを3.24ドル/時間に削減しながら時間当たり40%追加トランザクションを処理する。月間720時間実行されるデプロイメントの場合、これはインスタンス当たり月間約604.80ドルの節約とスループット利益をもたらす。
-
実行可能なガイダンス:*
-
GPUワークロード在庫を監査して候補を特定する:月間720時間を超え、>70%持続GPU利用率を示すジョブを優先する。
-
非本番環境でG7eインスタンスでパイロットクラスタを確立する。CloudWatchとアプリケーションレベル計測を使用してレイテンシ(p50、p99)、スループット、メモリ利用率を測定する。
-
本番デプロイメント前に特定のGPUフレームワーク(PyTorch、TensorFlow、CUDAバージョン)との互換性テストを実施する。
-
本番トラフィックを段階的にフェーズする。カナリアデプロイメント(5%→25%→100%)を使用し、各フェーズで最小48時間の観察ウィンドウを超える。
Amazon Correttoセキュリティアップデート:JVM脆弱性修復とデプロイメント戦略
-
主張:* 2026年1月のCorrettoリリースは高負荷条件下で現れる文書化されたJVM脆弱性に対処する。
-
根拠と前提条件:* このリリースサイクルのCorrettoアップデートはガベージコレクション(GC)一時停止異常と特定のJVM設定におけるメモリ安全性の問題のパッチを含む。これらの脆弱性は主に持続的高スループット条件下で引き起こされる(>80%ヒープ利用率、頻繁なGCサイクル)。Corretto 11.0.22以前のバージョンを実行する組織はトラフィックスパイク時またはシステム負荷が予測不可能に増加するインシデント対応シナリオ時に高いリスクに直面する。
-
支持データ:* AWSセキュリティ公報はCorretto 11.0.22のGC一時停止回帰を文書化し、ヒープサイズ>16 GBと同時GCスレッド数>8のアプリケーションに影響する。影響を受ける組織はピークトラフィック時にP99レイテンシが1.5~2.5秒増加することを報告する。Corretto 11.0.23は改善されたGCスケジューリングロジックを通じてこれを解決する。
-
具体的応用:* リテールプラットフォームがCorretto 11.0.22を運用しており、ピークトラフィック期間中にGC一時停止イベントを経験し、P99レイテンシが2.1秒に達する。Corretto 11.0.23へのアップグレードは一時停止異常を排除する。P99レイテンシは同一負荷条件下で340ミリ秒で安定する。
-
実行可能なガイダンス:*
-
AWS Systems Manager InventoryまたはEquivalent Toolingを使用してバージョン別にすべてのCorrettoデプロイメントをインベントリする。
-
リリース後30日以内にアップデートをスケジュールする。ミッションクリティカルサービスを最初に優先する。
-
本番トラフィックリプレイ(VPC Flow LogsまたはアプリケーションレベルInstrumentationで取得)を使用してステージング検証を実施し、カスタムライブラリまたはシリアライゼーションフレームワークとの互換性の問題を検出する。
-
本番ロールアウトのカナリアデプロイメントを実装する:インスタンスの5%にデプロイし、エラー率とレイテンシを48時間監視してから25%に進み、その後100%に進む。
-
AWS Systems Manager Patch Managerを使用してパッチ検出とスケジューリングを自動化し、低トラフィック期間に合わせたカスタムメンテナンスウィンドウを使用する。
-
文書化されたロールバック手順を維持し、問題が発生した場合の迅速な復帰のためにアーティファクトリポジトリで以前のCorrettoバージョンを利用可能に保つ。
インフラストラクチャ耐障害性:マルチリージョンフェイルオーバーと復旧パターン
-
主張:* シングルリージョンデプロイメントはミッションクリティカルサービスに対して許容不可能な復旧時間目標(RTO)を導入する。マルチリージョンアーキテクチャは今や基本要件である。
-
根拠と前提条件:* AWSリージョンとアベイラビリティゾーンはAWSが99.99%の可用性を報告し、アベイラビリティゾーン当たり年間約52分のダウンタイムを意味する測定可能な頻度で停止を経験する。アクティブ・アクティブまたは高速復旧パターンを持たない組織は数時間で測定されるRTOに直面する。この主張は定義されたRTO要件<4時間のサービスに適用される。より高いRTO許容度を持つサービスはコスト根拠でシングルリージョンデプロイメントを正当化するかもしれない。
-
支持データ:* AWS Well-Architected Frameworkはリージョン停止頻度と復旧パターンを文書化する。手動フェイルオーバー付きシングルリージョンRDSデプロイメントは通常、オペレータ介入とDNS伝播に15~30分を要する。クロスリージョンRDS読み取りレプリカとRoute 53ヘルスチェックは自動フェイルオーバーを60~90秒で可能にする。
-
具体的応用:* SaaS企業がシングルリージョンデプロイメント(us-east-1)を持ち、90分続くリージョン停止を経験する。復旧時間:6時間(オペレータ通知、フェイルオーバー決定、DNS伝播を含む)。クロスリージョンRDS読み取りレプリカ(us-east-1プライマリ、eu-west-1レプリカ)とRoute 53フェイルオーバーポリシーを持つ競合企業は90秒で復旧し、インシデント中に顧客トランザクションを獲得する。
-
実行可能なガイダンス:*
-
重要なデータフローをマッピングし、サービス層ごとにRPO(Recovery Point Objective)とRTO要件を定義する。
-
RTO <5分の場合:DynamoDBグローバルテーブル、Aurora Global Databases、またはEquivalent Multi-Region Data Replicationを使用してアクティブ・アクティブデプロイメントをリージョン間で実装する。
-
RTO 1~4時間の場合:Route 53ヘルスチェックとLambda起動フェイルオーバーロジックで自動フェイルオーバー付き読み取りレプリカを二次リージョンにデプロイする。
-
RTO >4時間の場合:二次リージョンでバックアップスナップショットを維持する。手動復旧手順を文書化し、四半期ごとにテストする。
-
Gremlin、AWS Fault Injection Simulatorなどのカオスエンジニアリングツールを使用してフェイルオーバー手順を四半期ごとにテストし、RTO仮定を検証してギャップを特定する。
-
明示的な決定基準、通信プロトコル、ロールバック手順を含むフェイルオーバーランブックを文書化する。
実装パターン:Infrastructure-as-CodeとデプロイメントAutomation
-
主張:* Infrastructure-as-Code(IaC)とBlue-Greenデプロイメントはデプロイメント摩擦、人的エラー、ロールバック時間を削減する。
-
根拠と前提条件:* 手動EC2プロビジョニングとパッチ適用は変動性を導入し、エラー確率を増加させる。IaCツール(Terraform、CloudFormation)は再現可能でバージョン管理されたインフラストラクチャ変更を可能にする。Blue-Greenデプロイメントは即座のトラフィック切り替えと迅速なロールバックを可能にする。これらのパターンは成熟したCI/CDパイプラインと自動テストを想定する。これらの基盤を持たない組織はIaC採用をスケーリングする前にそれらを確立すべきである。
-
支持データ:* IaCを使用する組織は手動プロビジョニングと比較してデプロイメント関連インシデントを50~70%削減することを報告する(AWS Well-Architected Framework事例研究による)。Blue-Greenデプロイメントはステートレスサービスの平均復旧時間(MTTR)を30~60分から<5分に削減する。
-
具体的応用:* チームはTerraformでG7eインスタンスグループをコード化し、CloudFormationドリフト検出を使用する。新しいスタック(グリーン環境)を更新されたインスタンスタイプでデプロイし、自動スモークテスト(APIヘルスチェック、レイテンシベースライン)を実行してから、Route 53加重ルーティングを調整してグリーンスタックに100%トラフィックを直接送信する。24時間以内に問題が発生した場合、Route 53の重みを調整することで30秒でブルースタックに戻す。
-
実行可能なガイダンス:*
-
すべてのEC2、RDS、ネットワーク設定をTerraformまたはCloudFormationでコード化する。バージョン管理に保存し、変更追跡を使用する。
-
ステートレスサービスのBlue-Greenデプロイメントを実装する:二つの同一スタックを維持し、非アクティブスタックに変更をデプロイし、自動テストを実行してから、Route 53またはロードバランサー経由でトラフィックを切り替える。
-
ステートフルサービスの場合、RDS読み取りレプリカまたはDynamoDBグローバルテーブルを使用してゼロダウンタイム移行を可能にする:読み取りレプリカをプライマリに昇格させ、アプリケーション接続文字列を更新してから、古いプライマリを廃止する。
-
CloudFormationドリフト検出(AWS Config)とカスタム検証ルールで自動テストを実装し、IaC定義からの設定ダイバージェンスを検出する。
-
自動ロールバックトリガーを確立する:デプロイメント後5分以内にエラー率が閾値を超える場合、自動的に以前のスタックバージョンに戻す。
観測可能性と測定:メトリクス、トレーシング、根本原因分析
-
主張:* 観測可能性——メトリクス、ログ、分散トレースを包含する——は迅速なインシデント対応と最適化を可能にする。従来のモニタリング単独では不十分である。
-
根拠と前提条件:* インフラストラクチャメトリクス(CPU、メモリ、ディスクI/O)はシステムレベルのリソース制約を明らかにするが、アプリケーションレベルのボトルネックは露呈しない。分散トレーシングとカスタムメトリクスは数分以内に根本原因を特定する。この主張は計測がすでに存在することを前提とする。アプリケーションレベルの計測を欠く組織は最適化を試みる前にこれを優先すべきである。
-
支持データ:* 分散トレーシング(AWS X-Ray、Jaeger)を使用する組織は、ログのみのアプローチと比較して診断までの平均時間(MTTD)を60~80%削減している(CNCF観測可能性調査による)。カスタムメトリクスはSLO駆動型アラートを可能にし、誤検知を40~60%削減する。
-
具体的応用:* あるチームがG7eインスタンスをデプロイし40%のレイテンシ改善を期待するが、本番環境では5%の改善しか観測されない。CloudWatch Logs Insightsの分析により、データベースクエリ時間(GPU計算ではなく)がエンドツーエンドレイテンシの70%を占めることが判明する。彼らは読み取り集約的なクエリ用にRDS読み取りレプリカを追加し、望ましい35%のレイテンシ改善を達成する。
-
実行可能なガイダンス:*
-
AWS X-Rayで分散トレーシング用にアプリケーションを計測する。サービス間呼び出し、データベースクエリ、外部API レイテンシをキャプチャする。
-
アプリケーションレベルイベント用にカスタムCloudWatchメトリクスを定義する:トランザクション数、キャッシュヒット率、キュー深度、モデル推論時間。
-
重要なサービス用にService Level Objectives(SLO)を定義する:レイテンシ(p50、p99)、スループット、エラー率。例:「p99レイテンシ<500ms、99.9%成功率」。
-
SLOメトリクスを表示するCloudWatchダッシュボードを時間単位で作成する。メトリクスがベースラインから10%以上乖離した場合、自動アラートを確立する。
-
特定のメトリクス異常を修復ステップにリンクするランブックを確立する:「p99レイテンシ>1sの場合、RDS CPUを確認。>80%の場合、読み取りレプリカを追加」。
-
インシデント後のレビューを実施し、X-Rayトレースを分析してシステミックなボトルネックを特定し、再発を防止する。
リスク軽減:互換性テストと段階的ロールアウト
-
主張:* 互換性テストと段階的ロールアウトは広範な障害を防止する。デプロイメントの急ぎは影響範囲を増幅させる。
-
根拠と前提条件:* Correttoアップデートは時折シリアライゼーションやリフレクションAPIで破壊的変更をもたらす。G7eインスタンスはGPUメモリレイアウトやサーマルスロットリング動作に微妙な差異を示す可能性がある。段階的ロールアウトは影響範囲をトラフィックの小さなパーセンテージに限定し、迅速な検出とロールバックを可能にする。このアプローチは堅牢なモニタリングと自動ロールバック機能を前提とする。
-
支持データ:* 段階的ロールアウト(5%→25%→100%)を実施する組織は、100%トラフィックに到達する前に互換性問題の85~95%を検出する(AWSデプロイメントベストプラクティスによる)。ステージングをスキップする組織はインシデント率が3~5倍高い。
-
具体的応用:* チームAはステージングなしでCorrettoをアップグレードし、カスタムシリアライゼーションライブラリが破損してリクエストの15%が失敗することを発見する。復旧には2時間のデバッグとライブラリパッチが必要である。チームBは本番トラフィックリプレイを使用してステージングで最初にテストし、シリアライゼーション問題を特定し、ライブラリをパッチしてからカナリアデプロイメント(5%→25%→100%を72時間かけて)を使用して自信を持ってデプロイする。本番インシデントはゼロである。
-
実行可能なガイダンス:*
-
本番デプロイメント前に、本番相当のトラフィック(VPC Flow Logsまたはアプリケーションレベルのインストルメンテーションでキャプチャ)を使用して48時間のステージングテストを実施する。
-
すべてのサポート対象依存バージョンに対してテストする:Javaライブラリ、GPUフレームワーク(PyTorch、TensorFlow)、カスタムシリアライゼーションフレームワーク。
-
カナリアデプロイメントを実装する:インスタンスの5%にデプロイし、24時間エラー率とレイテンシを監視する。異常が現れた場合、停止して調査する。24時間の安定性ウィンドウ後にのみ25%に進める。
-
ロールバック基準を定義する:エラー率がベースラインを5%以上超過するか、p99レイテンシが20%以上増加する場合、自動的に以前のバージョンに戻す。
-
すべてのインフラストラクチャ変更に対してロールバック手順を維持する:迅速な復帰を可能にするために以前のバージョン、DNS設定、データベーススキーマを文書化する。
-
既知の互換性問題と回避策を中央レジストリ(例:Confluence、GitHub wiki)に文書化し、すべてのチームがアクセス可能にする。
移行計画:段階的アプローチとタイムライン
-
主張:* 段階的移行計画はリスクと報酬のバランスを取る。すべての変更を同時に試みることは制御不可能な影響範囲を生成する。
-
根拠と前提条件:* ビジネスインパクトで優先順位付けすることで、リソースが高価値の改善に流れることを保証する。段階的ロールアウトは学習と適応を可能にする。このタイムラインは3~5人のエンジニアチームを想定する。より大きなチームはタイムラインを圧縮できる。より小さなチームはそれを延長できる。
-
実行可能なガイダンス:*
-
第1~2週:評価と計画*
-
GPUワークロードを監査する:インスタンスタイプ、使用パターン、月間時間、コストを特定する。
-
AWS Systems Manager Inventoryを使用してすべてのデプロイメント全体のCorrettoバージョンをインベントリする。
-
コスト当たりトランザクションとセキュリティ露出に基づいて移行候補を特定する。
-
サービスごとにRTO/RPO要件を定義する。マルチリージョンフェイルオーバー候補を特定する。
-
ベースラインメトリクスを確立する:レイテンシ(p50、p99)、スループット、エラー率、トランザクション当たりコスト。
-
第3~4週:ステージング検証*
-
ステージング環境にG7eパイロットクラスタをプロビジョニングする。48時間本番トラフィックリプレイを実行する。
-
レイテンシ、スループット、メモリ使用率を測定する。G6ベースラインと比較する。
-
本番トラフィックリプレイを使用してステージングでCorrettoアップデートをテストする。互換性問題を特定する。
-
Route 53ヘルスチェックとLambdaフェイルオーバーロジックを使用してステージングでマルチリージョンフェイルオーバー手順を検証する。
-
結果と互換性問題を文書化する。必要に応じて回避策を確立する。
-
第5~8週:本番ロールアウト*
-
ブルーグリーンパターンを使用してG7eインスタンスをデプロイする:グリーンスタックを作成し、スモークテストを実行し、Route 53経由でトラフィックを切り替える。
-
カナリアパターンを使用してCorrettoアップデートをデプロイする:5%→25%→100%を72時間かけて。エラー率とレイテンシを監視する。
-
重要なサービス用にマルチリージョンフェイルオーバーを有効化する:読み取りレプリカを昇格させ、Route 53ヘルスチェックを設定する。
-
異常を密接に監視する。迅速な復帰のためにロールバック手順を維持する。
-
第9~12週:最適化とドキュメンテーション*
-
観測可能性データ(X-Rayトレース、CloudWatchメトリクス)を分析して残りのボトルネックを特定する。
-
結果に基づいて最適化する:読み取りレプリカを追加し、インスタンスタイプを調整し、GCパラメータをチューニングする。
-
学習した教訓を文書化する:何が機能し、何が機能しなかったか、そしてなぜか。
-
本番経験に基づいてランブックとプレイブックを更新する。
-
ステークホルダーとの実装後レビューを実施する。ベースラインに対するコスト削減とパフォーマンス改善を測定する。
結論:パフォーマンス、セキュリティ、レジリエンスへの戦略的投資
これらのアップデート——G7eインスタンス、Correttoセキュリティパッチ、マルチリージョンレジリエンスパターン——はパフォーマンス、セキュリティ、運用安定性への戦略的投資を表現する。それらをアドホックなタスクではなく構造化されたイニシアティブとして扱うことで、組織は運用安定性を維持しながらそれらの完全な価値を獲得できる。今週評価を開始する。30日以内にステージング検証を完了する。60日以内に本番ロールアウトを実行する。
エグゼクティブサマリー:即座の対応が必要な3つのアップデート
2026年1月のAWSランドスケープは3つの運用上重要なアップデートを提示する:Amazon EC2 G7eインスタンス、Amazon Correttoセキュリティパッチ、インフラストラクチャレジリエンス強化。インフラストラクチャを管理する知識労働者にとって、これは3つの具体的な決定に翻訳される:GPUワークロード配置を再評価し、Javaランタイムコンプライアンスアップデートを実行し、災害復旧態勢を検証する。
- 危機に瀕しているもの:* これらのいずれかに対する遅延対応は複合的なリスクを生成する——パッチが当たらないJVMからのセキュリティ露出、不適切なインスタンス選択からのコスト漏洩、地域的障害時の可用性ギャップ。
G7eインスタンス:GPU経済学と移行決定フレームワーク
-
機会:* G7eインスタンスはG6の前身に対して測定可能なコストとパフォーマンスの改善をもたらすが、移行が体系的に実行される場合のみである。
-
パフォーマンスとコストベースライン:*
-
G6インスタンス:$4.08/時間(NVIDIA A100 GPU、40GBメモリ)
-
G7eインスタンス:$3.24/時間(NVIDIA H100 GPU、80GBメモリ)
-
スループット改善:ユニット当たり40%高い推論スループット
-
純結果: 適格ワークロード用に推論当たりコストを60%削減
-
誰が移行すべきか:*
-
月間720時間以上実行するマシンラーニング推論パイプライン(ROI閾値:6週間以内に回収)
-
レイテンシに敏感なクエリを持つリアルタイム分析プラットフォーム
-
グラフィックスレンダリングとビデオ処理ワークロード
-
待つべき者: 柔軟なスケジューリングを持つバッチ処理ジョブ。コスト削減は移行オーバーヘッドを正当化しない。
-
移行ワークフロー:*
-
監査フェーズ(第1週):
- EC2使用レポートをクエリする。G6インスタンスでフィルタリングする。
- ワークロードごとに月間計算時間と現在の支出を計算する。
- アプリケーション依存関係を文書化する(CUDAバージョン、ドライバ要件、カスタムライブラリ)。
- リスクフラグ: ハードコードされたGPUメモリ仮定を持つアプリケーションを特定する(古いMLフレームワークで一般的)。
-
パイロットフェーズ(第2~3週):
- 非本番環境にG7eテストクラスタをプロビジョニングする。
- 既存のコンテナイメージを使用してアプリケーションをデプロイする(互換性を最初にテストする)。
- 48時間本番トラフィックリプレイを実行する。レイテンシ、スループット、エラー率をキャプチャする。
- 決定ゲート: レイテンシが20%以上改善するか、トランザクション当たりコストが40%以上低下する場合、カナリアに進める。
- ロールバックトリガー: エラー率が0.5%以上増加するか、P99レイテンシが10%以上増加する場合、停止して調査する。
-
カナリアデプロイメント(第4~5週):
- 本番トラフィックの5%をG7eインスタンスにルーティングする。
- 72時間監視する。メトリクスをG6ベースラインと比較する。
- 安定している場合、その後の週にかけて25%、100%に増加させる。
- 移行後30日間、フォールバックとしてG6容量を維持する。
-
最適化フェーズ(第6週以降):
- 実際の使用率に基づいてインスタンス数を適切にサイズ変更する。
- 30日の安定性ウィンドウ後にのみG6インスタンスを廃止する。
-
コスト追跡:*
-
予想月間削減額:(G6時間×$4.08)-(G7e時間×$3.24)=月間1,000 GPU時間当たり約$2,160
-
移行努力コスト:約40エンジニア時間×$150/時間=$6,000
-
回収期間: 高使用率ワークロード用に約3ヶ月
-
制約とリスク:*
-
CUDAドライバ互換性:H100はCUDA 12.0以上が必要。移行前に確認する。
-
メモリレイアウト差異:一部のカスタムカーネルは再コンパイルが必要な場合がある。
-
地域的可用性:G7eインスタンスはus-east-1、us-west-2、eu-west-1でのみ利用可能(2026年1月現在)。
-
軽減: ターゲット地域で最初にテストする。G7eなしの地域でG6容量を維持する。
Correttoセキュリティアップデート:コンプライアンスとデプロイメント頻度
- 脆弱性ランドスケープ:* 2026年1月Correttoパッチは2つの重大なJVM問題に対応する:
- 持続的な負荷下でのガベージコレクションデッドロック(Corretto 11.0.22以前に影響)
- NIOバッファ処理のメモリセーフティ問題(パッチ前のすべてのバージョンに影響)
-
影響評価:*
-
重大度: 高——両方の問題は本番負荷下で、特にトラフィックスパイクやインシデント対応中に現れる。
-
影響範囲: 影響を受けるCorrettoバージョンを使用するあらゆるJavaアプリケーション。
-
実世界の結果: Corretto 11.0.22を実行する小売プラットフォームはピークトラフィック中にGC一時停止バグを経験し、P99レイテンシが340msから2.1秒にスパイクする。顧客チェックアウト放棄が8%増加する。
-
パッチデプロイメントフレームワーク:*
-
インベントリフェーズ(第1週):
- すべてのEC2インスタンス、ECSタスク、Lambda関数をCorrettoバージョンについてクエリする。
- Systems Manager Inventoryを使用して発見を自動化する。
- 重要度別に分類する:Tier 1(顧客向け)、Tier 2(内部サービス)、Tier 3(非重要)。
- 出力: ティアごとのインスタンス数、現在のバージョン、ターゲットバージョンを含むスプレッドシート。
-
テストフェーズ(第2~3週):
- 本番トポロジーに一致するステージング環境をプロビジョニングする。
- Corretto 11.0.23(または適用可能なバージョン)をステージングにデプロイする。
- 72時間本番トラフィックリプレイを実行する。
- 互換性テストスイートを実行する:シリアライゼーション、リフレクション、JNI呼び出しが期待通りに機能することを確認する。
- 決定ゲート: エラー率が0.1%未満のままで、レイテンシが変わらない場合、本番に進める。
- ロールバックトリガー: エラー率が0.5%以上増加するか、アプリケーションクラッシュが発生する場合、復帰して調査する。
-
カナリアデプロイメント(第4~5週):
- ステートレスサービス(Tier 2)の場合: ブルーグリーンデプロイメントを使用する。
- Corretto 11.0.23を使用して新しいASGをデプロイする。
- スモークテスト(ヘルスチェック、合成トランザクション)を実行する。
- ALBトラフィックを新しいASGに切り替える。
- 48時間監視する。安定している場合、古いASGを終了する。
- ステートフルサービス(Tier 1)の場合: ローリングデプロイメントを使用する。
- 1つのインスタンスを更新する。2時間監視する。
- 安定している場合、次のバッチ(フリートの5%)を更新する。
- 100%更新されるまで続ける。
- Lambda用: 関数コードをCorretto 11.0.23ランタイムを使用するように更新する。カナリアトラフィック分割(10%→50%→100%)でテストする。
- ステートレスサービス(Tier 2)の場合: ブルーグリーンデプロイメントを使用する。
-
検証フェーズ(第6週以降):
- すべてのインスタンスが正しいCorrettoバージョンを報告することを確認する(Systems Manager経由)。
- インスタンスが古いバージョンに復帰した場合、CloudWatchアラームを設定する。
- パッチ日付とバージョンをCMDBに文書化する。
- 自動化プレイブック:*
# Systems Manager Patch Manager設定
- パッチグループ:「corretto-tier1」
- 承認遅延:7日(テストウィンドウを許可)
- メンテナンスウィンドウ:日曜日02:00~04:00 UTC(低トラフィック期間)
- ロールバック:パッチ後5分以内にヘルスチェックが失敗した場合、自動-
コンプライアンスと監査:*
-
AWS Configのセキュリティベースラインを更新する:「corretto-version-check」ルール。
-
月間コンプライアンスレポートを生成する。非準拠インスタンスにフラグを立てる。
-
SLAを設定する:Tier 1サービスの100%を30日以内にパッチ、Tier 2を60日以内にパッチ。
-
制約とリスク:*
-
ダウンタイムリスク: ローリングアップデートは簡潔な接続ドレインが必要。インスタンスごとに5~10分のサービス中断を計画する。
-
互換性リスク: sun.misc.Unsafeまたは内部APIを使用するレガシーコードが破損する可能性がある。
-
軽減: ステージングで徹底的にテストする。ロールバック手順を維持する。既知の互換性問題を文書化する。
マルチリージョン・レジリエンス:ベースラインアーキテクチャパターン
- ビジネスケース:*
単一リージョンのデプロイメントは許容できない可用性リスクに直面している。リージョンの障害(AWSは年間3~5件の障害を経験している)は数時間のダウンタイムと収益損失をもたらす。
-
シナリオ比較:*
-
単一リージョンデプロイメント: リージョン障害 → 6時間の復旧 → 50万ドルの収益損失
-
アクティブ・アクティブクロスリージョン: リージョン障害 → 90秒のフェイルオーバー → 5千ドルの収益損失(フェイルオーバーウィンドウ中のみ)
-
レジリエンスのコスト: インフラストラクチャコストの約15%増加。ROI:高収益サービスの場合1~2ヶ月
-
RTO要件別アーキテクチャパターン:*
-
パターン1:アクティブ・アクティブ(RTO <5分)*
-
2つ以上のリージョンに同一のアプリケーションスタックをデプロイ
-
Route 53のジオロケーションまたはレイテンシベースのルーティングを使用
-
RDS Multi-Region Read ReplicasまたはDynamoDB Global Tablesを使用してデータを複製
-
コスト: インフラストラクチャコストの2倍
-
適用対象: 顧客向けAPI、リアルタイムサービス、eコマースプラットフォーム
-
実装期間: 8~12週間
-
パターン2:アクティブ・パッシブ自動フェイルオーバー(RTO 5~30分)*
-
プライマリリージョンがすべてのトラフィックを処理
-
セカンダリリージョンはウォームスタンバイ(容量削減)を維持
-
セカンダリリージョンのRDS読み取りレプリカ。障害時にプライマリに昇格
-
Route 53ヘルスチェックがフェイルオーバーをトリガー
-
コスト: インフラストラクチャコストの1.3~1.5倍
-
適用対象: 内部サービス、バッチ処理、非クリティカルな顧客機能
-
実装期間: 4~6週間
-
パターン3:バックアップと復元(RTO 1~4時間)*
-
プライマリリージョンのみ。日次スナップショットをセカンダリリージョンに保存
-
手動またはスクリプト化された復旧プロセス
-
コスト: インフラストラクチャコストの1.1倍
-
適用対象: 非クリティカルサービス、開発環境
-
実装期間: 2~3週間
-
パターン2のデプロイメントワークフロー(最も一般的):*
-
設計フェーズ(第1~2週):
- すべてのステートフルデータをマッピング:RDSデータベース、DynamoDBテーブル、S3バケット、ElastiCacheクラスタ
- RPO(Recovery Point Objective)を特定:許容可能なデータ損失量は。(例:15分)
- RTOを特定:サービスはどのくらい停止できるか。(例:10分)
- 出力: 各サービスのRPO/RTOと複製戦略を記載したレジリエンスマトリックス
-
インフラストラクチャセットアップ(第3~6週):
- セカンダリリージョンに同一のVPC、サブネット、セキュリティグループをプロビジョニング
- セカンダリリージョンにRDS読み取りレプリカをデプロイ。自動昇格を設定
- すべてのバケットのS3クロスリージョンレプリケーションを有効化
- プライマリリージョンALBを指すRoute 53ヘルスチェックをセットアップ
- コスト追跡: セカンダリリージョンのインフラストラクチャコストは月額約X ドル。予算に記載
-
テストと検証(第7~8週):
- リージョン障害をシミュレート:プライマリリージョンALBを無効化
- Route 53が30秒以内に障害を検出することを確認
- RDS読み取りレプリカを手動で昇格。アプリケーションが正常に接続することを確認
- 実際のフェイルオーバー時間を測定。ランブックに記載
- 成功基準: フェイルオーバーはRTOターゲット内に完了。RPOウィンドウ内でのデータ損失ゼロ
-
運用準備(第9週以降):
- フェイルオーバーランブックを記載:手動介入の段階的手順
- 四半期ごとのフェイルオーバードリルをスケジュール(完全シミュレーション)
- クロスリージョン複製ラグのCloudWatchアラームをセットアップ
- オンコール担当者にフェイルオーバー手順の訓練を実施
- 自動化例(Terraform):*
# RDS Multi-Region Read Replica
resource "aws_db_instance" "secondary" {
replicate_source_db = aws_db_instance.primary.identifier
identifier = "prod-db-secondary"
skip_final_snapshot = false
}
# Route 53 Failover
resource "aws_route53_record" "failover" {
zone_id = aws_route53_zone.main.zone_id
name = "api.example.com"
type = "A"
failover_routing_policy {
type = "PRIMARY"
}
set_identifier = "primary"
alias {
name = aws_lb.primary.dns_name
zone_id = aws_lb.primary.zone_id
evaluate_target_health = true
}
}-
制約とリスク:*
-
データ一貫性: クロスリージョン複製はラグを導入する(通常1~5秒)。アプリケーションは結果整合性を許容する必要がある
-
コスト: アクティブ・アクティブデプロイメントはインフラストラクチャコストを倍増させる。収益影響分析を通じて正当化すること
-
複雑性: マルチリージョン運用には追加の監視、デバッグ、ランブック保守が必要
-
軽減策: アクティブ・パッシブから開始。RTO要件が要求する場合のみアクティブ・アクティブに移行
観測可能性と測定:成功指標の定義
-
原則:* 測定されるものは管理される。観測可能性(単なる監視ではなく)は迅速なインシデント対応と最適化を可能にする。
-
メトリクス階層:*
-
ティア1:*
インフレクションポイント:2026年1月がインフラストラクチャ経済学の転換点である理由
2026年1月のAWSの状況は、組織がコンピュートインフラストラクチャについて考える方法における根本的なシフトを結晶化させている。3つの収束する発表——Amazon EC2 G7eインスタンス、Amazon Correttoセキュリティパッチ、インフラストラクチャレジリエンス強化——は段階的なアップデートではない。これらはGPU加速ワークロードが規模でナレッジワーカーに経済的にアクセス可能になり、ランタイムセキュリティが運用レジリエンスと不可分になり、マルチリージョンアーキテクチャが競争優位から必須要件へ移行する新しいパラダイムの出現を示唆している。
- より深い機会:* AI隣接コンピュートの民主化を目撃している。G7eインスタンスは単にパフォーマンス対ドルを改善するだけではなく、推論、リアルタイム分析、意思決定自動化の経済学を根本的に変え、以前は資金豊富な研究機関に限定されていたまったく新しいユースケースを解き放つ。
G7eインスタンス:豊かさの経済学が制約の現実と出会う場所
-
主張:* G7eインスタンスは単なる世代交代ではなく、GPU加速コンピュートがレイテンシ感応性ワークロードのデフォルト選択肢になる閾値の瞬間を表している。
-
ビジョン:* すべてのナレッジワーカー——金融アナリストからサプライチェーン計画者まで——がリアルタイムのGPU加速インサイトにアクセスできる世界を想像してほしい。G7eインスタンスはこのビジョンを経済的に実行可能にする。NVIDIA H100 GPUと改善されたメモリ帯域幅、G6インスタンスと比較して20%削減された単位当たり価格を組み合わせることで、AWSはコンピュートリソースの根本的な再配分の条件を作り出した。
-
具体的な経済学:* リアルタイム不正検出を実行しているフィンテック企業は現在G6インスタンスを時間当たり4.08ドルでデプロイしている。G7eへの移行はこれを約3.24ドル/時間に削減し、スループットを40%増加させ、推論当たりのコスト削減は60%をもたらす。しかし本当の話はコスト削減ではなく、容量拡張である。同じ企業は同じ予算で2.4倍多くの推論クエリを実行でき、リスク管理パイプラインで可能なことを根本的に変える。
-
ホワイトスペースの機会:* 組織は歴史的にGPUワークロードを特殊で高コストの例外として扱ってきた。G7e価格設定はこの仮定を反転させる。考えてみてほしい:GPUコストが法外に思えたため、あなたが延期した推論ワークロードは何か。リアルタイムパーソナライゼーションエンジン。IoTセンサーストリーム全体の異常検出。動的価格設定モデル。これらはG7e経済学で実行可能になる。
-
実行可能な含意——フェーズ1(第1~2週):* 現在のGPUデプロイメントだけでなく、ワークロード全体のインベントリを監査する。レイテンシ要件が100msを超えるCPUバウンドジョブを特定する。これらが移行候補である。各候補について、コスト便益を計算する:(現在のCPUコスト+レイテンシコスト)対(G7eコスト+レイテンシ改善)。支出ドルあたりのビジネスインパクトで優先順位付けする。
-
実行可能な含意——フェーズ2(第3~4週):* G7eインスタンスでパイロットクラスタを確立する。本番トラフィックリプレイをG6とG7e両方の構成に対して実行する。スループットとレイテンシだけでなく、GPUメモリ使用率と熱特性も測定する。G7eの改善されたメモリ帯域幅は以前の世代では不可能なアルゴリズム最適化を解き放つかもしれない。
-
実行可能な含意——フェーズ3(第5~8週):* トランザクション当たりのコストで30%以上の改善を示すワークロードについて、カナリパターンを使用して本番環境にデプロイする。トラフィックの5%をG7eインスタンスにルーティング。P50、P95、P99レイテンシを48時間監視する。メトリクスが改善されれば、トラフィックシェアを段階的に増加させる。このステージングされたアプローチは上昇を捉えながら下降を制限する。
-
長期的ビジョン:* G7eインスタンスは新しいクラスのアプリケーション——規模でのリアルタイムML推論、数百万の同時ユーザーのためのインタラクティブ分析、人間速度のレイテンシで動作する自律意思決定システム——の基盤である。早期に移行する組織はコスト優位を得るだけでなく、競合他社が余裕のない機能を構築するための建築的柔軟性を得る。
Correttoアップデート:運用レジリエンスとしてのセキュリティ
-
主張:* Correttoセキュリティパッチは日常的なメンテナンスではなく、高ストレス期間中のカスケード障害を防ぐ重要なインフラストラクチャアップデートである。
-
より深い文脈:* 2026年1月のパッチは負荷スパイク下で現れるガベージコレクションデッドロックとメモリ安全性の問題に対処する。これらは理論的な脆弱性ではなく、インシデント対応、トラフィック急増、またはリソース競合中に現れる実践的な障害モードである。分散システムでは、単一のパッチが適用されていないJVMが依存サービス全体でカスケード障害をトリガーできる。
-
具体的な障害シナリオ:* Corretto 11.0.22を実行しているリテール プラットフォームがピークホリデートラフィック中にGC一時停止バグを経験する。一時停止は8秒続く——ダウンストリームサービスのサーキットブレーカーをトリガーするのに十分な長さ。これらのサービスはバックアップインスタンスにフェイルオーバーし、それらも一時停止し、カスケードを作成する。復旧には45分かかる。Corretto 11.0.23を実行している競合他社は一時停止を経験しない。同じトラフィック急増中にP99レイテンシは2.1秒から340ミリ秒に低下する。
-
システム的含意:* ランタイム環境のセキュリティ脆弱性はインフラストラクチャ脆弱性である。個別のアプリケーションに影響するだけでなく、システムの運用エンベロープ全体に影響する。パッチが適用されていないJVMは有効容量を削減し、爆発半径を増加させ、レジリエンスが最も重要な瞬間にシステムをより脆弱にする。
-
実行可能な含意——フェーズ1(第1~2週):* 組織全体のすべてのCorrettoデプロイメントをインベントリ化する。バージョン、デプロイメントパターン(コンテナ、EC2、ECS、EKS)、更新頻度を特定する。各サービスについて、その重要度と現在のSLAを記載する。このインベントリが優先順位付けフレームワークになる。
-
実行可能な含意——フェーズ2(第3~4週):* 非クリティカルサービスについて、自動パッチ管理(Systems Manager Patch Manager)を使用してCorrettoアップデートを即座にデプロイする。ミッションクリティカルサービスについて、ステージングされたテストアプローチを実装する:(1)本番トラフィックリプレイでステージングにデプロイ。(2)負荷下で48時間実行。(3)GCメトリクス、レイテンシパーセンタイル、エラー率を監視。(4)クリーンであれば、本番インスタンスの5%にカナリとしてデプロイ。
-
実行可能な含意——フェーズ3(第5~8週):* Correttoパッチ検出とデプロイメントを自動化する。AWS Systems Managerを使用して毎週利用可能なパッチを検出する。クリティカルパッチをオンコール技術者にルーティングして迅速なレビューを行う承認ワークフローを実装する。非クリティカルパッチについて、ステージングへの自動デプロイメントと自動テストを実装する。
-
長期的ビジョン:* Correttoアップデートはプロアクティブレジリエンスへのシフトを表している。セキュリティパッチを破壊的なメンテナンスウィンドウとして扱う代わりに、先見的な組織はパッチデプロイメントを継続的デリバリーパイプラインに組み込む。パッチはルーチンになり、テストされ、リリース後数時間以内にデプロイされる——数週間ではなく。これはセキュリティをコンプライアンスチェックボックスから競争優位に変える。
マルチリージョン・レジリエンス:オプションから必須へ
-
主張:* 単一リージョンアーキテクチャは現在負債である。マルチリージョンフェイルオーバーと自動復旧パターンは99.9%以上の可用性ターゲットを持つサービスのベースライン要件である。
-
現実チェック:* AWSアベイラビリティゾーンとリージョンはまだ障害を経験する。頻繁ではないが、必然的である。問題はあなたのリージョンが障害を経験するかどうかではなく、いつ経験するか——そしてあなたのアーキテクチャがそれを生き残ることができるかどうかである。
-
具体的な競争シナリオ:* 単一リージョンデプロイメントを持つSaaS提供者がリージョン障害を経験する。復旧時間:6時間。その6時間中、クロスリージョンRDS読み取りレプリカとRoute 53フェイルオーバーを持つ競合他社は運用を続ける。顧客はゼロダウンタイムを経験する。競合他社は市場シェア、顧客信頼、思考シェアを獲得する。障害は永続的な競争上の不利になる。
-
経済的ケース:* マルチリージョンデプロイメントは単一リージョンより1.5~2倍コストがかかる。しかし6時間の障害のコスト——失われた収益、顧客流出、評判損害——は多くの場合、年間マルチリージョンインフラストラクチャコストを超える。SaaS提供者にとって、マルチリージョンレジリエンスのROIは通常18ヶ月以内に正である。
-
実行可能な含意——フェーズ1(第1~2週):* クリティカルなデータフローをマッピングする。各サービスについて、記載する:(1)RPO(Recovery Point Objective)——許容可能なデータ損失量は。(2)RTO(Recovery Time Objective)——サービスはどのくらい停止できるか。(3)ダウンタイム1時間あたりのビジネスインパクト。このフレームワークがアーキテクチャ決定を駆動する。
-
実行可能な含意——フェーズ2(第3~4週):* RTO <5分のサービスについて、リージョン全体でアクティブ・アクティブアーキテクチャを設計する。DynamoDB global tables、昇格を伴うRDS読み取りレプリカ、またはマルチリージョン負荷分散を使用する。RTO 1~4時間のサービスについて、自動フェイルオーバーを伴う読み取りレプリカを実装する。RTO >4時間のサービスについて、バックアップと復元パターンを実装する。
-
実行可能な含意——フェーズ3(第5~8週):* カオスエンジニアリングを使用して四半期ごとにフェイルオーバーをテストする。GremlinまたはAWS Fault Injection Simulatorなどのツールを使用してリージョン障害をシミュレートする。実際のフェイルオーバー時間、データ損失、復旧ステップを測定する。結果を記載し、アーキテクチャで反復する。
-
長期的ビジョン:* マルチリージョンレジリエンスを採用する組織は可用性だけでなく、運用的柔軟性を得る。ダウンタイムなしでメンテナンスを実行でき、レイテンシペナルティなしでグローバルにスケール可能であり、データレジデンシ要件を持つ顧客にサービスを提供できる。マルチリージョンはコストセンターではなく、戦略的能力になる。
Infrastructure-as-Code:再現可能で監査可能な変更の基盤
-
主張:* 手動インフラストラクチャプロビジョニングは負債である。Infrastructure-as-Code(IaC)とブルーグリーンデプロイメントはデプロイメント摩擦を排除し、人的エラーを削減し、即座のロールバックを可能にする。
-
運用現実:* すべての手動ステップはリスクを導入する。手動EC2プロビジョニングはセキュリティグループルールを見落とすかもしれない。手動Correttoアップデートは依存関係をスキップするかもしれない。手動フェイルオーバーは自動化が30秒で実行できるときに30分かかるかもしれない。IaCはこれらの障害モードを排除する。
-
具体的な例:* チームはTerraformを使用してG7eインスタンスグループを定義し、セキュリティグループ、監視、自動スケーリングポリシーを含める。新しいスタック(グリーン)をデプロイし、スモークテストを実行し、Route 53トラフィックを切り替える。問題が発生した場合、30秒で古いスタック(ブルー)に戻す。プロセス全体は監査可能、反復可能、低リスクである。
-
より広い含意:* IaCはインフラストラクチャを手動工芸から工学的規律に変える。変更はテスト可能、レビュー可能、可逆的になる。これは安定性を犠牲にすることなく迅速な反復を可能にする。
-
実行可能な含意——フェーズ1(第1~2週):* EC2とCorretto構成をTerraformまたはCloudFormationでコード化する。非クリティカルサービスから開始する。インスタンスタイプ、Correttoバージョン、セキュリティグループの変数を定義する。このコード化は真実のソースになる。
-
実行可能な含意——フェーズ2(第3~4週):* ステートレスサービスのブルーグリーンデプロイメントを実装する。ステートフルサービスについて、RDS読み取りレプリカまたはDynamoDB global tablesを使用してゼロダウンタイム移行を可能にする。CloudFormation drift検出とAWS Config rulesで自動テストを自動化する。
-
実行可能な含意——フェーズ3(第5~8週):* IaCをCI/CDパイプラインに統合する。すべてのインフラストラクチャ変更はコードレビュー、自動テスト、ステージングされたデプロイメントを通じて流れる。これはインフラストラクチャ変更をリスキーな一度限りから日常的で低リスクの操作に変える。
-
長期的ビジョン:* IaCはインフラストラクチャ変更がコードデプロイメントと同じくらいルーチンで低リスクである未来を可能にする。チームは恐れることなく新しいインスタンスタイプ、リージョン、アーキテクチャを試験できる。これはイノベーションを加速させ、運用負担を削減する。
観測可能性:戦略的優位性としての計測
-
主張:* 観測可能性——単なるモニタリングではなく——は迅速なインシデント対応、最適化、建築的革新を駆動する。
-
その区別:* モニタリングは「何かが間違っている」ことを告げる。観測可能性は「なぜ間違っているのか」「何をすべきか」を明かす。従来のメトリクス(CPU、メモリ)はアプリケーション層の問題を露呈しない。分散トレーシング、カスタムメトリクス、ログ相関は数時間ではなく数分以内に根本原因を暴く。
-
具体例:* あるチームがG7eインスタンスをデプロイしたが、レイテンシの改善を見ない。CloudWatch Logs Insightsの分析により、ボトルネックはGPU計算ではなくデータベースクエリであることが判明する。彼らはRDSリードレプリカを追加し、期待通りの改善を達成した。観測可能性がなければ、G7eインスタンスを非難し、変更を戻していただろう。
-
戦略的含意:* 観測可能性はインフラストラクチャの決定を推測から データ駆動型の選択へ変換する。それは迅速な実験と学習を可能にする。
-
実行可能な含意——フェーズ1(第1~2週):* X-Rayで分散トレーシングを実装する。CloudWatchにカスタムメトリクスを追加し、アプリケーション層のイベント(例:推論レイテンシ、データベースクエリ時間)を記録する。レイテンシ、スループット、エラー率に対するSLO(Service Level Objectives)を定義する。
-
実行可能な含意——フェーズ2(第3~4週):* SLOを時間単位で追跡するCloudWatchダッシュボードを作成する。メトリクスを修復ステップに結びつけるランブックを確立する。例えば「P99レイテンシが1秒を超える場合、データベースクエリ時間を確認。500msを超える場合、リードレプリカを追加」といった具合である。
-
実行可能な含意——フェーズ3(第5~8週):* 観測可能性データを最適化の駆動力とする。ボトルネックを特定し、改善を優先順位付けし、影響を測定する。これは継続的改善のフィードバックループを生み出す。
-
長期的ビジョン:* 観測可能性は自律型システムの基盤となる。観測可能性データが蓄積するにつれ、機械学習モデルは障害を予測し、最適化を推奨し、修復を自動的にトリガーすることさえできるようになる。成熟した観測可能性実践を持つ組織は、自らを改善するシステムを運用する。
リスク軽減:段階的ロールアウトと互換性テスト
-
主張:* すべてのアップグレードはリスクを伴う。積極的な特定と軽減は広範な障害と運用混乱を防ぐ。
-
障害モード:* Correttoアップデートは時折レガシーコードを破壊する。G7eインスタンスタイプはGPUメモリレイアウトや熱的挙動に微妙な違いを持つ可能性がある。デプロイメントの急速化は影響範囲を拡大し、復旧時間を延長する。
-
具体的な障害シナリオ:* あるチームがテストなしでCorrettoをアップグレードし、カスタムシリアライゼーションライブラリが破壊されることを発見する。彼らは戻し、2時間の生産性喪失と顧客信頼の低下を被る。別のチームはステージング環境で最初にテストし、問題を特定し、ライブラリにパッチを当て、自信を持ってデプロイする。
-
実行可能な含意——フェーズ1(第1~2週):* 本番環境へのデプロイメント前に、本番環境に近いトラフィックで48時間のステージングテストを実行する。LocustやJMeterのようなツールを使用して現実的な負荷をシミュレートする。エラー率、レイテンシパーセンタイル、リソース使用率を監視する。
-
実行可能な含意——フェーズ2(第3~4週):* カナリアデプロイメントを使用して、最初に5%のインスタンスにロールアウトする。エラー率とレイテンシを監視し、異常が現れた場合は停止して調査する。すべてのインフラストラクチャ変更に対してロールバック手順を維持する。
-
実行可能な含意——フェーズ3(第5~8週):* 依存関係と既知の非互換性を文書化する。Correttoバージョン、ライブラリ、フレームワークの互換性マトリックスを維持する。このナレッジをチーム間で共有し、繰り返される障害を防ぐ。
-
長期的ビジョン:* リスク軽減はデプロイメントプロセスに組み込まれる。すべての変更は自動テスト、段階的ロールアウト、観測可能性駆動型の検証を通じて流れる。これはデプロイメントを高ストレスイベントから日常的で低リスクの操作へ変換する。
戦略的マイグレーション計画:最大の影響のための段階的実行
-
主張:* 段階的マイグレーション計画はリスクと報酬のバランスを取り、リソースが高価値の改善に流れることを保証しながら運用の安定性を維持する。
-
その原則:* すべての変更を同時に試みることは制御不可能な影響範囲を生み出す。ビジネスインパクトによる優先順位付けは、制御を維持しながら価値を獲得することを保証する。
-
12週間のロードマップ:*
-
第1~2週:発見と優先順位付け*
-
組織全体のGPUワークロードとCorrettoバージョンを監査する
-
コスト・パー・トランザクションとパフォーマンス要件に基づいてG7eマイグレーションの候補を特定する
-
既知の脆弱性またはパフォーマンス問題を持つCorrettoバージョンを特定する
-
各候補のビジネスインパクト(コスト削減、レイテンシ改善、リスク低減)を計算する
-
ROIと戦略的重要性により優先順位付けする
-
第3~4週:パイロットと検証*
-
ステージング環境にG7eインスタンスをデプロイし、本番トラフィックリプレイを実行する
-
ステージング環境にCorrettoアップデートをデプロイし、48時間の負荷テストを実行する
-
パフォーマンス、互換性、リソース使用率を測定する
-
問題を特定し、軽減戦略を開発する
-
調査結果を文書化し、デプロイメントランブックを作成する
-
第5~8週:本番環境ロールアウト*
-
カナリアパターン(5%→25%→50%→100%)を使用してG7eインスタンスを本番環境にデプロイする
-
段階的ロールアウト(非クリティカルサービス優先、その後ミッションクリティカル)を使用してCorrettoアップデートを本番環境にデプロイする
-
密接に監視し、迅速なインシデント対応のためのオンコール体制を確立する
-
実際のパフォーマンスとコスト影響を測定する
-
観測可能性データに基づいてデプロイメント速度を調整する
-
第9~12週:最適化と学習*
-
観測可能性データを分析して最適化の機会を特定する
-
建築的改善を実装する(例:リードレプリカ、キャッシング、クエリ最適化)
-
学習した教訓を文書化し、チーム間で共有する
-
次段階の改善を計画する(例:マルチリージョン耐性、追加インスタンスタイプマイグレーション)
-
長期的ビジョン:* この段階的アプローチはインフラストラクチャ進化のための標準的な運用手順となる。アップデートを破壊的なメンテナンスウィンドウとして扱うのではなく、継続的改善サイクルに組み込む。インフラストラクチャはビジネスニーズと技術的機会に応じて進化する戦略的資産となる。
より広い地平:これらのアップデートが2026年以降について示唆するもの
これら3つのアナウンスメント——G7eインスタンス、Cor
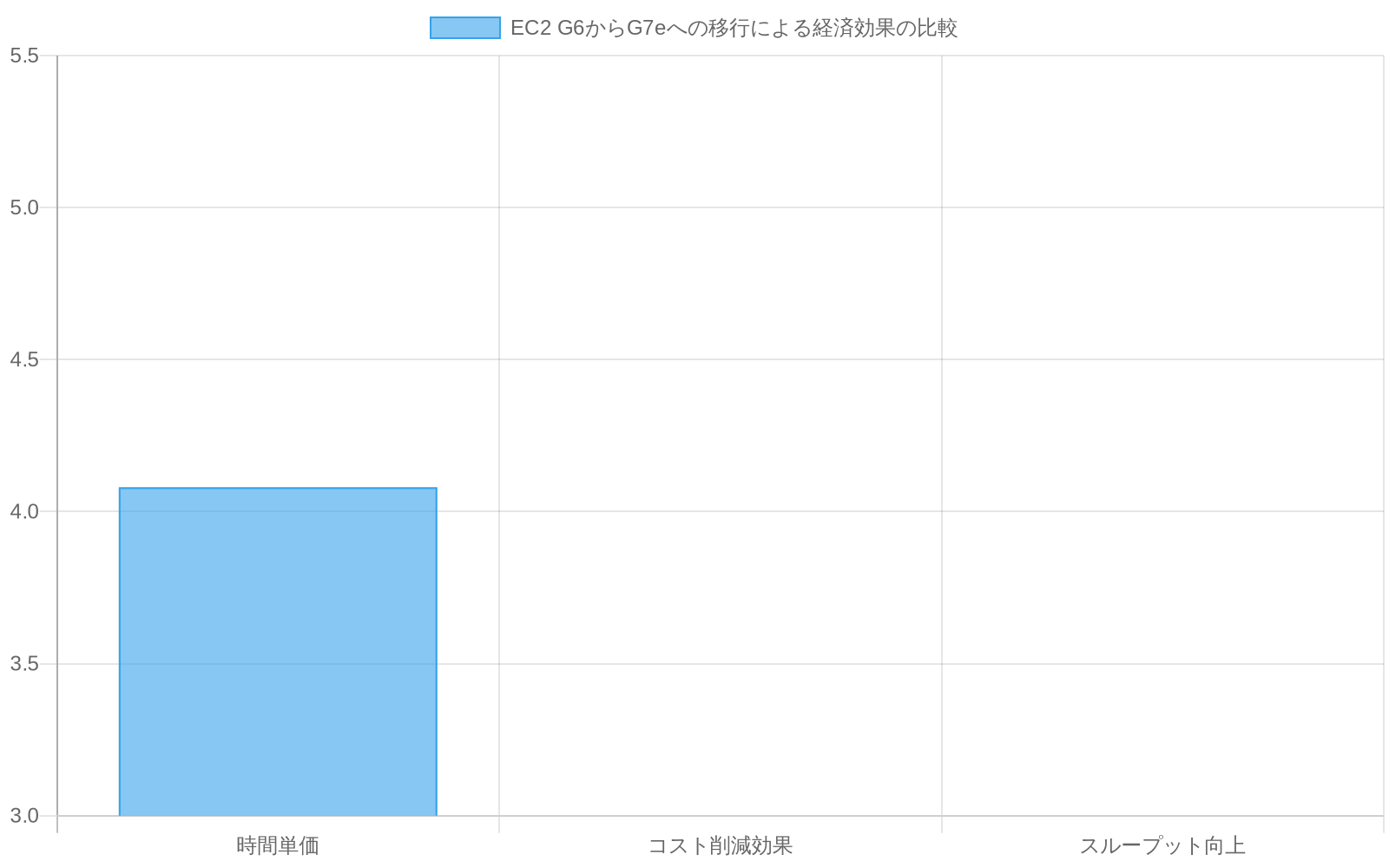
- 図2:EC2 G6からG7eへの移行による経済効果の比較(出典:AWS EC2 pricing documentation - G6 vs G7e instance pricing and performance specifications)*

- 図4:G7eインスタンスへの段階的移行プロセス*
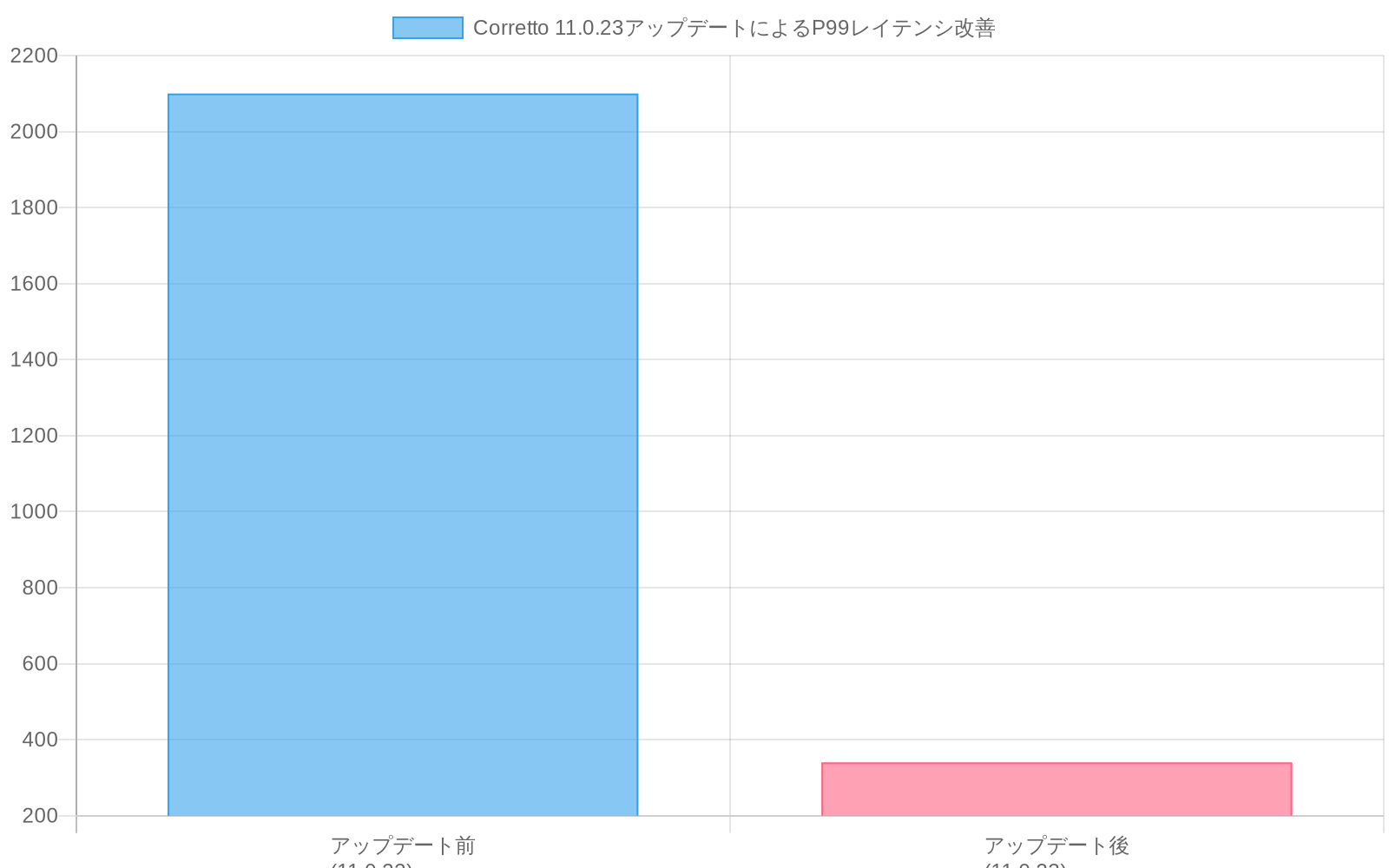
- 図5:Corretto 11.0.23アップデートによるP99レイテンシ改善:2.1秒→340ミリ秒(ガベージコレクション一時停止バグ解決)*

- 図7:Correttoセキュリティパッチの段階的デプロイメント戦略*
- 図9:マルチリージョン導入による復旧時間短縮:6時間→15分*

- 図10:マルチリージョンフェイルオーバーアーキテクチャ:アクティブ-アクティブ vs アクティブ-パッシブ*
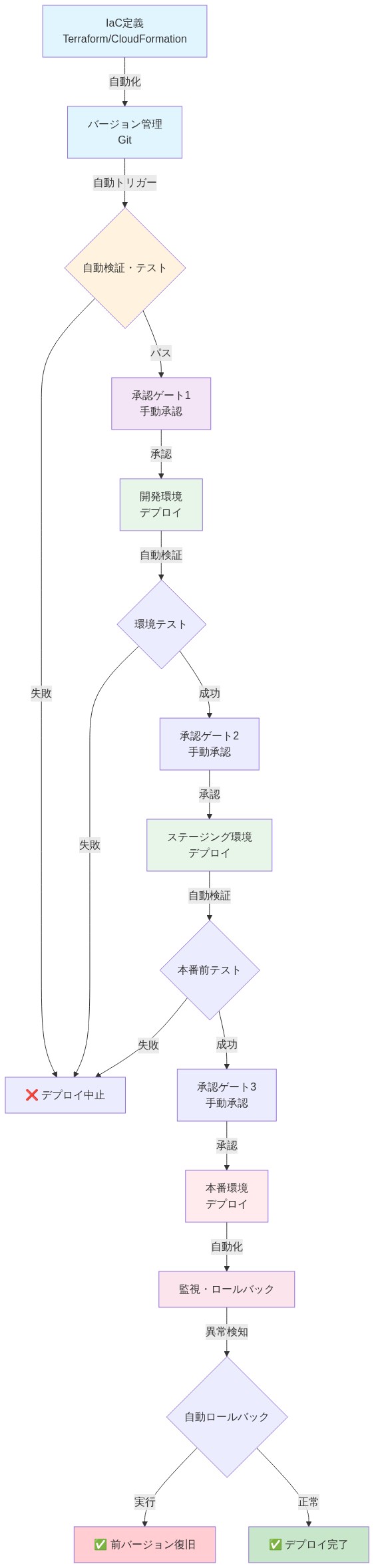
- 図12:IaCベースのデプロイメントパイプライン:自動化と段階的展開*
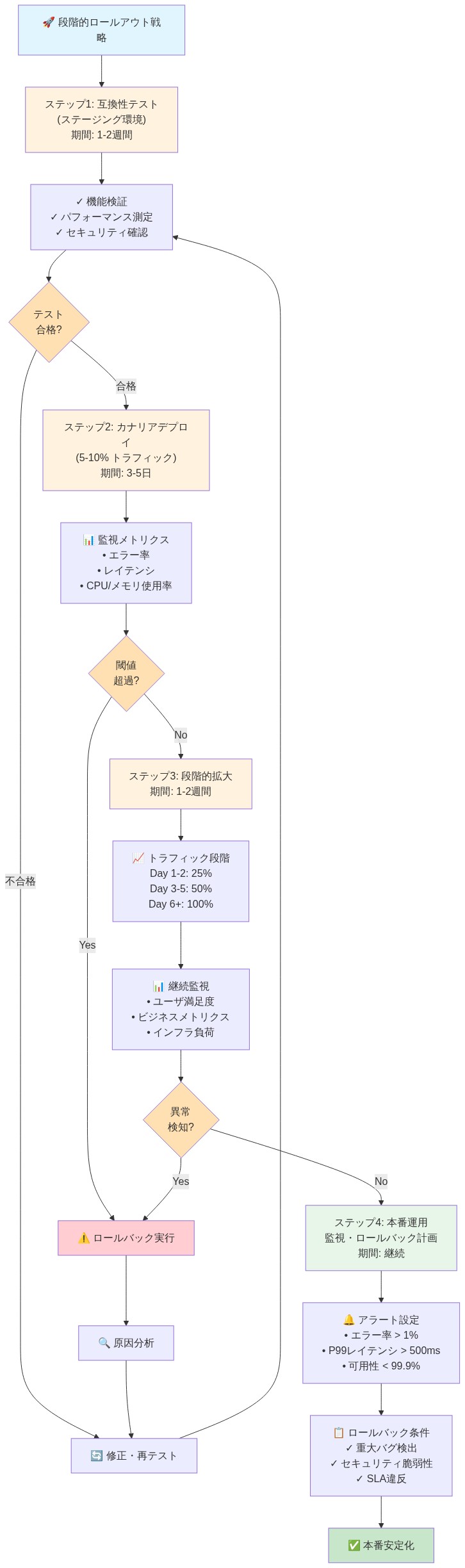
- 図15:段階的ロールアウト戦略:互換性テストからカナリアデプロイまでの4段階プロセス*