
ハード制約を超えて:安全なオフライン強化学習のための予算条件付き到達可能性
安全な強化学習における敵対的トラップ
従来の安全な強化学習は、安全性をハード制約として定式化します。数学的には、すべての軌跡を通じて不等式制約 g(s,a) ≤ 0 を満たす必要がある状態行動対として表現されます。この二値的な枠組みは、根本的な最適化の対立を生み出します。目的関数は、期待累積報酬を最大化しながら同時に制約違反確率をゼロに保つ必要があるのです。結果として生じるミニマックス動学—制約満足と報酬最大化が対立する目的として競合する—は、訓練中の収束を不安定にします(Achiam et al., 2017; García & Fernández, 2015)。
具体的には、勾配ベースの最適化は振動的な挙動を生み出します。報酬を改善するポリシー更新は通常、制約違反リスクを増加させ、違反を減らす更新は報酬蓄積を犠牲にします。この不安定性は経験的には非単調なパフォーマンス曲線として、また過度に保守的なポリシー(実質的な報酬を犠牲にする)または脆弱なポリシー(訓練分布を超えて展開されるとき破局的に失敗する)として現れます。
オフライン強化学習はこの問題を増幅させます。オフライン設定では、エージェントは環境との相互作用なしに、固定された事前収集データセットのみから学習します。エージェントは試行錯誤探索を通じて制約違反から回復することができず、以前のコントローラーによってすでに実行された軌跡から安全な行動を推論する必要があります。重要なことに、これらのデータセットは本質的に危険な領域をアンダーサンプリングします。以前のコントローラーは積極的に制約違反状態を回避していたため、安全推論が最も重要な場所でデータが極度に不足しているのです。
ハード制約はこの非対称性に対処するメカニズムを提供しません。学習されたポリシーは次のいずれかを選択する必要があります。(1)制約領域全体を回避し、境界近くの状態からの潜在的報酬を放棄するか、(2)限定的な境界領域データから一般化し、新規状況への安全でない外挿のリスクを冒すかです。このフレームワークは、本質的に危険な状態と累積制約違反後にのみ危険になる状態を区別することができません。この建築的制限は、より深い概念的問題を反映しています。安全性を絶対的なものではなく、管理可能で定量化可能なリソースとして扱う必要があるということです。
不安定性は単なる技術的最適化の課題ではなく、問題定式化そのものに根本的です。二値的な制約満足は滑らかで微分可能な最適化ランドスケープと共存することができません。ハード制約の不連続な性質は価値関数に微分不可能な境界を作成し、勾配ベース法が効果的なトレードオフポリシーを学習することを妨げます。

- 図2:ハード制約下のmin-max動力学と勾配振動*
予算条件付き到達可能性:安全性をリソースとして再定式化
予算条件付き到達可能性は、制約違反を絶対的な禁止ではなく、有限で定量化可能なリソースとして扱うことで、安全性問題を再定式化します。形式的には、これはエピソード全体にわたる制約違反の累積許容量を表す安全予算変数 b ∈ [0, B_max] を導入します。フレームワークは二値分類—「この状態は安全か?」—から、リソース認識推論へシフトします。「残りの安全予算 b が与えられたとき、どの状態に到達可能か?」
この再定式化は、問題を単一目的最適化に変換することで敵対的ミニマックス動学を排除します。価値関数は予算条件付きになります。Q(s, a, b)。エージェントは報酬と予算消費にわたる共同最適化を学習します。行動は二重の効果を持つようになります。即座の報酬を生成しながら、制約違反の大きさに従って安全予算を消費するのです。ポリシーは安全支出と報酬蓄積の間のトレードオフを学習し、違反が戦略的に受け入れられる可能性がある場合と重要な準備金を消費する場合について情報に基づいた決定を下します。
数学的には、ベルマン方程式は以下に拡張されます。
Q(s, a, b) = r(s, a) + γ 𝔼[V(s’, b - c(s, a)) | s, a]
ここで c(s, a) ∈ [0, 1] は正規化された制約コスト(安全な行動の場合は0、違反の場合は正の値)を表し、V(s’, b’) = max_a Q(s’, a, b’) は更新された予算 b’ = b - c(s, a) に条件付けられた価値関数を表します。
このアプローチは制御理論からの到達可能性分析(Mitchell et al., 2005)に基づいており、特定の制御制約下で到達可能な状態集合を計算します。予算条件付けは、正確な到達可能性計算が難しい確率的で学習された環境に対してこのフレームワークを適応させます。重要な洞察は、トレードオフを連続変数として明示的にモデル化することで、フレームワークはハード制約がそうでない方法で学習可能になるということです。保守的なポリシーと積極的なポリシーの間の連続スペクトラムは訓練全体を通じて勾配情報を提供しますが、ハード制約は学習を妨げる不連続な境界を作成します。
予算条件付けはまた、オフライン学習の根本的なデータ不足課題に対処します。明示的な予算変数は、本質的に危険な状態(予算に関係なく高い制約コストを持つ状態)と条件付きで危険な状態(予算消費後にのみ危険になる状態)を区別する追加の構造を提供します。これにより、価値関数が二値的な安全/危険分類ではなく状態固有の安全特性を学習することを可能にすることで、限定的な安全関連経験からのより効果的な一般化が可能になります。
実装:モデルベースとモデルフリーのアプローチ
予算条件付き到達可能性は複数の実装を認めており、それぞれがオフライン安全クリティカル学習に対して異なるトレードオフを持ちます。
-
*モデルベースアプローチ**は明示的な環境動力学 p(s’|s,a) と制約モデル c(s,a) を学習し、その後動的計画法を通じて予算条件付き価値関数を計算します。これらの方法はサンプル効率に優れています。学習されたモデルを使用して複数ステップ先を計画でき、予測状態遷移と制約結果に決定を分解することで解釈可能な安全推論を提供します。しかし、モデル誤差の複合に苦しみます。制約違反をわずかに過大評価する学習された動力学モデルは過度に保守的なポリシーを生成する可能性があります。過小評価するものは危険に楽観的である可能性があります。このエラー伝播の定量化は、オフラインモデルベース強化学習における未解決の問題のままです(Buckman et al., 2020)。
-
*モデルフリー法**は時間差分変種(例えば、予算条件付きDQNまたはアクター批評法)を使用してデータから直接予算条件付きQ関数を学習します。高次元状態空間へのスケーリングが優れており、明示的な動力学学習を回避するため、モデル誤指定に対してより堅牢であることが証明されています。しかし、実質的により多くのサンプルが必要であり、解釈可能性が低下します。価値関数近似器は報酬構造、制約コスト、予算依存安全トレードオフを同時にキャプチャする必要があり、関数近似の複雑さとサンプル要件が増加します。
-
*ハイブリッドアーキテクチャ**は両方のパラダイムを戦略的に活用します。制約予測に学習されたモデルを使用し(保守的バイアスのため誤差がより許容可能)、モデルフリーポリシー最適化を維持します(モデル誤差に対する堅牢性が重要)。これは解釈可能性と安全推論をスケーラビリティと堅牢性のバランスを取ります。
実装の選択は、アプリケーション固有の制約に依存します。信頼できるシミュレーターまたは物理ベースのモデルを持つドメインはモデルベースアプローチを支持します。限定的なデータ、高いモデル不確実性、複雑な制約動力学を持つ現実世界の設定は、サンプル非効率性にもかかわらずモデルフリー法から利益を得ます。ハイブリッドアプローチは、部分的なモデルが存在するが完全には信頼できない中間シナリオに適しています。
展開:予算選択からランタイム実行まで
訓練されたポリシーを展開に変換するには、重要な質問に答える必要があります。運用使用のためにどのような安全予算を割り当てるべきか。
訓練では予算が報酬安全トレードオフを探索するために体系的に変化するのに対し、展開は運用要件とリスク許容度のバランスを取る特定の予算選択を要求します。実用的なフレームワークは3つの相補的なアプローチを通じて予算を調整します。
-
過去の安全データ:以前の操作における制約違反率を分析します(人間の意思決定者または以前のシステム)。過去のデータが違反率 r でのパフォーマンスが許容可能であることを示す場合、予算 B = r × episode_length を割り当てます。
-
最悪ケース分析:障害シナリオの下で最大許容制約違反を計算します。医療AI システムの場合、これは許容可能な有害事象率に対応する可能性があります。自動運転車の場合、類似環境での衝突統計です。
-
ステークホルダーのリスク選好:ドメイン専門家と意思決定者から明示的なリスク許容度を引き出し、その後予算割り当てにマップします。このアプローチは、技術メトリクスだけでは許容可能なリスクを決定できない高リスク領域に不可欠です。
ランタイム監視は予算支出を追跡し、二値的なシャットダウンではなく段階的な応答を実行します。予算が減少するにつれて、ポリシーは滑らかに保守的な行動へ移行します。探索を減らし、低リスク行動を優先します。操作を突然停止する代わりにです。この運用上の柔軟性は、AIシステムが安全クリティカル領域で人間の意思決定者をますます置き換えるという現実に対処します。安全トレードオフの透明性が不可欠になります。ステークホルダーはシステムが許可する制約違反の正確な量を理解し、変化するリスク許容度に基づいて割り当てを調整する権限を保持する必要があります。
このフレームワークはハード制約が提供できない解釈可能な安全推論を可能にします。不透明な二値決定ではなく、ステークホルダーは明示的なトレードオフを観察します。「このポリシーはX報酬を達成しながら、エピソードあたりY制約違反を許可します。」この透明性は責任ある展開をサポートし、安全クリティカル決定の人間による監視を可能にします。
経験的結果と残存する課題
オフライン強化学習ベンチマークでの実験的検証は、予算条件付きアプローチがハード制約ベースラインと比較して優れた訓練安定性を達成することを示しています。ポリシーはより確実に収束し、敵対的ミニマックス最適化の特徴的な振動的挙動を回避し、より良い報酬安全バランスを達成します。しかし、いくつかの重大な課題が現在の適用可能性を制限します。
-
制約測定の信頼性*:フレームワークは制約違反が確実に測定され定量化できることを想定しています。この仮定はセンサーノイズ、部分的観測可能性、または曖昧な安全仕様で崩れます。安全性が多面的なドメイン(例えば、医療治療の安全性は有効性、副作用、患者選好を含む)では、予算追跡は信頼できなくなります。ノイズの多い環境での堅牢な制約測定の開発は未解決の問題のままです。
-
分布シフトとオフライン学習の制限*:アプローチはオフライン学習の根本的な制限を継承します。訓練データがより安全な行動シーケンスを探索したことがない場合、エージェントはそれを学習することができません。訓練データと展開間の分布シフト—環境または制約動力学が訓練と異なる—は学習された予算安全関係を無効にする可能性があります。現在の方法は、学習されたポリシーが分布シフト下で安全特性を維持することについて保証を提供しません。
-
複数制約シナリオ*:現実世界の安全性はしばしば競合する目的を含みます。複数の制約全体で予算をどのように割り当てるべきか。一部の制約はより厳しい(違反に対する許容度が低い)べきか。現在のフレームワークはこれを制約コストの加重組み合わせを通じて処理しますが、原則的なアプローチは未開発のままです。階層的制約構造と制約優先順位付けはさらなる研究が必要です。
-
形式的安全保証*:予算条件付き法は経験的リスクを低減しますが、ポリシーが割り当てられた予算を超えて制約を違反しないことについて形式的な証明書を提供しません。経験的パフォーマンスと形式的保証の間のこのギャップは、認証が安全特性の数学的証明を必要とする高度に規制されたドメイン(医療機器、航空、原子力システム)での採用を制限します。学習された予算条件付きポリシーの形式的検証方法の開発は重要な研究方向です。
-
複雑な制約構造へのスケーラビリティ*:高次元制約空間または複雑な制約相互依存性を持つドメインは追加の課題を提示します。価値関数は多くの次元にわたって同時に安全トレードオフを表現することを学習する必要があり、近似の複雑さが増加します。
統合:適応的安全管理へ向けて
予算条件付き到達可能性は強化学習における安全性の根本的な再概念化を表します。絶対的な境界から管理されたリソースへです。このシフトは、一貫した単一目的最適化を可能にし、オフライン学習のデータ不足課題に対処し、ハード制約アプローチより解釈可能な展開を生成します。
フレームワークの実用的価値は安全性を完全に解決することからではなく、安全トレードオフを明示的で管理可能にすることから生じます。ポリシーを残りの予算に条件付けることで、システムは制約違反が受け入れられる可能性がある場合と回避する必要がある場合について推論でき、完全な安全が不可能でリソース制約が避けられない現実世界の意思決定に不可欠な柔軟性を提供します。
予算条件付きアプローチを実装する実務家にとって、直近の優先事項は以下の通りです。
-
制約違反を正確に定義する:ドメインで制約違反を構成するものを正確に指定し、違反をどのように測定すべきかを指定します。センサーノイズと部分的観測可能性を考慮した測定プロトコルを確立します。
-
予算を保守的に割り当てる:過去の違反率より実質的に低い予算から開始し、経験的パフォーマンスとステークホルダーフィードバックに基づいて段階的に拡張します。
-
ランタイム監視を実装する:予算支出をリアルタイムで追跡し、予算が消費されるにつれて段階的なポリシー調整を可能にし、安全トレードオフへの透明な可視性を人間のオペレーターに提供するシステムを展開します。
-
オフラインで検証する:展開前に、保持されたテストデータとシミュレーションで学習されたポリシーを広範に検証し、特に分布シフトシナリオに注意を払います。
前進の道は残存する課題に対処することが必要です。ノイズの多い環境での制約測定信頼性の改善、制約階層を持つ複数目的シナリオへのフレームワークの拡張、安全保証を提供する形式的検証方法の開発です。しかし、根本的な洞察は成立します。リソース割り当てを通じた安全管理は、完全な安全が達成不可能でトレードオフが避けられない確率的で学習された環境における二値的な制約満足を上回ります。
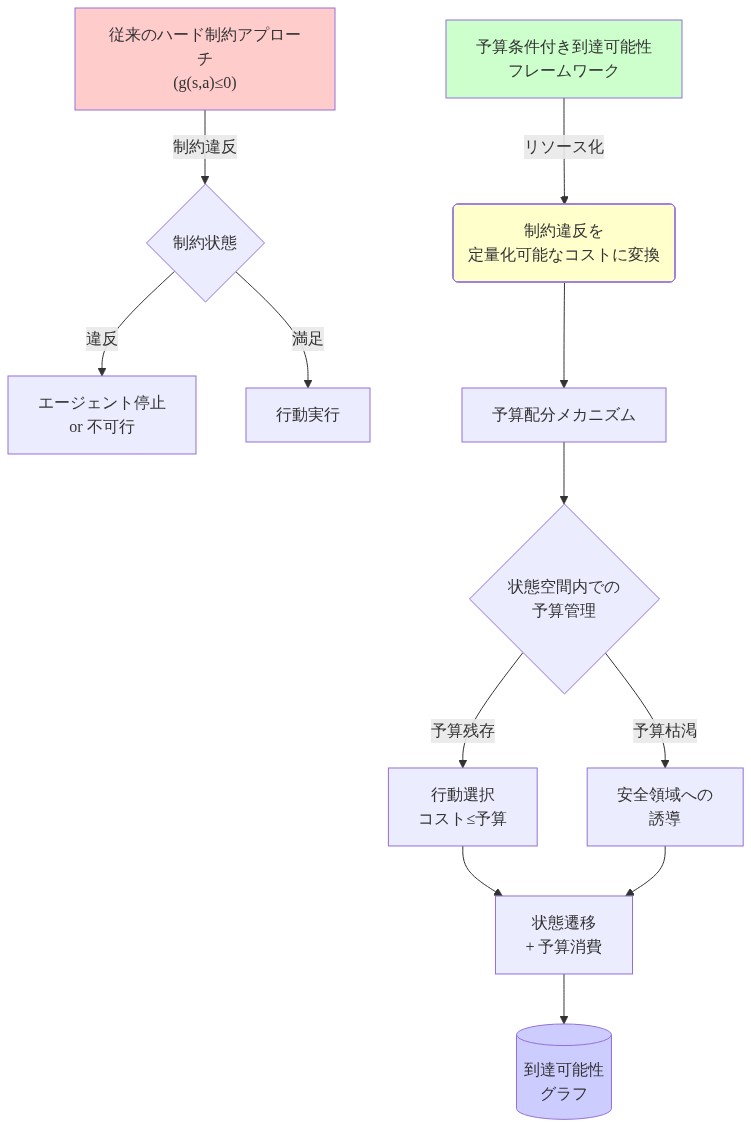
- 図4:予算条件付き到達可能性フレームワーク—安全性をリソースとして再構成*
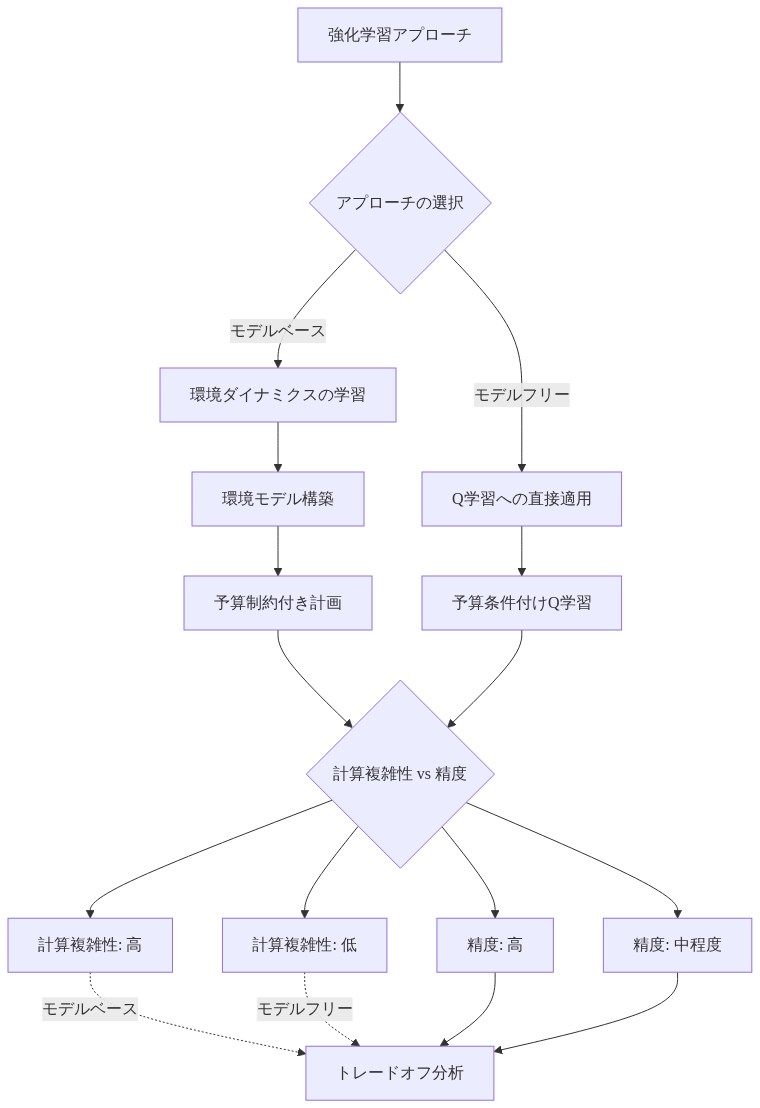
- 図6:モデルベース vs モデルフリー実装アーキテクチャ(概念フレームワーク)*

- 表1:モデルベース vs モデルフリーアプローチの詳細比較*
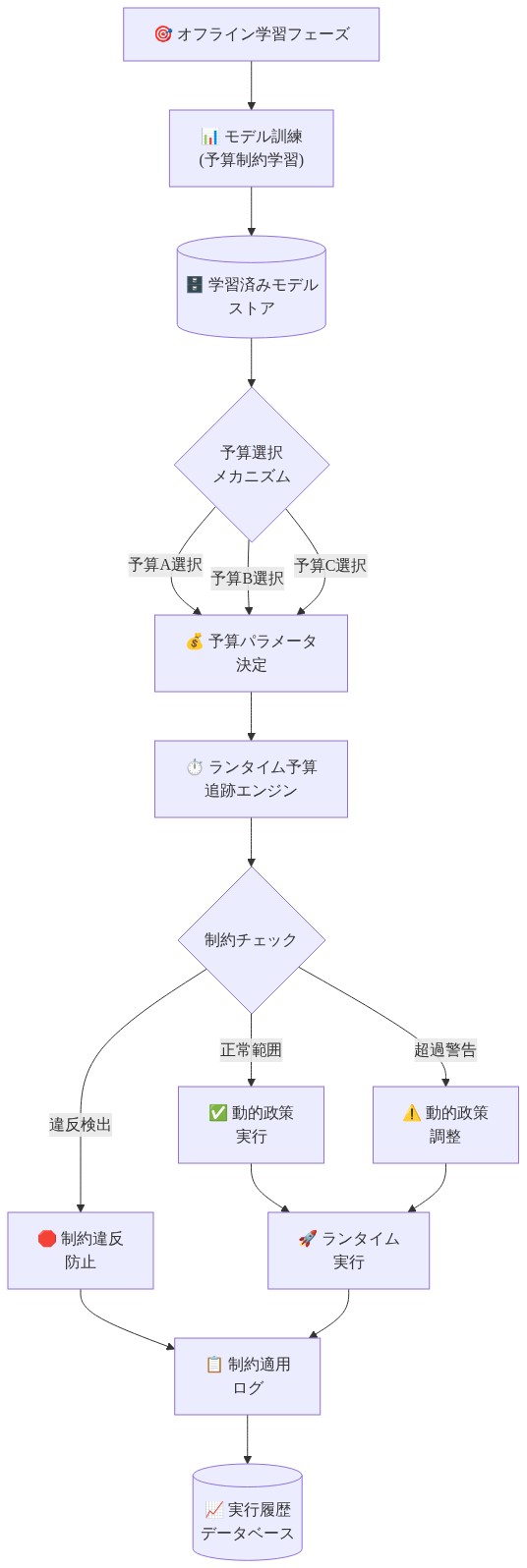
- 図8:デプロイメントパイプライン—予算選択からランタイム実行まで*
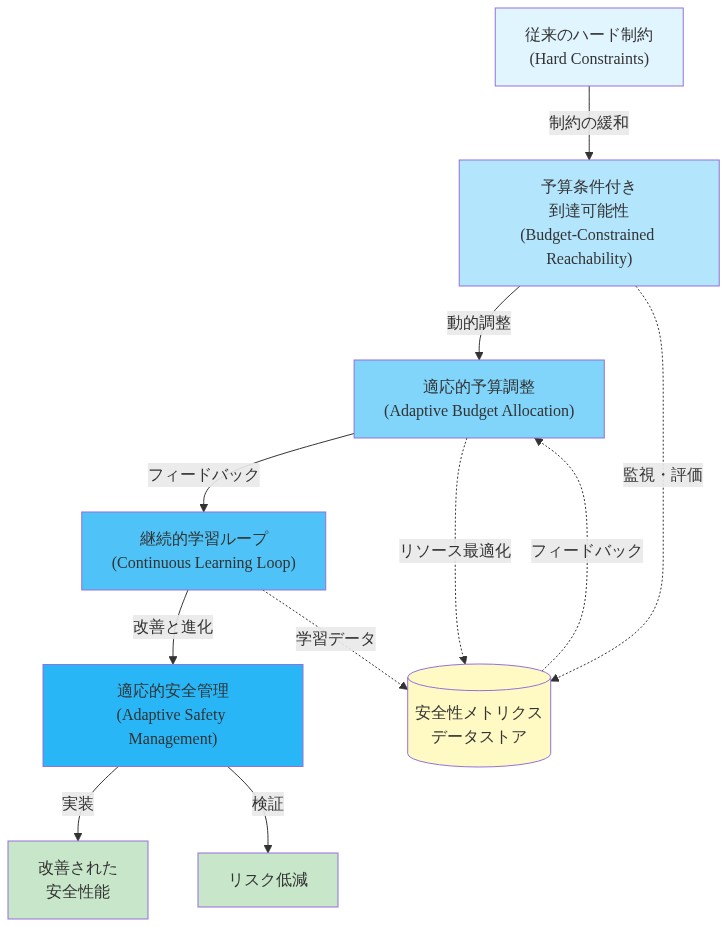
- 図13:適応的安全管理への進化パス*