
ChatGPT使用時の脳:AIアシスタント利用による認知的負債の蓄積
AI支援作業における認知的負債の理解
- 定義と理論的基盤:*
認知的負債は、ここでは、補償的な強化を伴わずに認知的に要求の高いタスクを人工知能システムに体系的に委譲した結果として生じる、精神的能力、領域固有の推論能力、および手続き的流暢性における累積的な欠損として操作的に定義される。この構成概念は、その中核メカニズムにおいて金融債務理論(Luhmann, 1988; Minsky, 1986)と類似している:即座の利益は繰り延べられたコストを通じて得られ、時間の経過とともに複利効果が生じる。
この主張の神経生物学的基盤は、神経可塑性と使用依存的皮質組織化の原理に基づいている(Merzenich & deCharms, 1993)。具体的には:(1)反復的な認知的関与は、長期増強を通じてタスク関連神経回路内のシナプス結合を強化する;(2)神経経路の不使用は、シナプス刈り込みと樹状突起密度の減少をもたらす(Butz & van Ooyen, 2013);(3)このプロセスは生涯を通じて発生するが、高齢者では効率が低下する(Cabeza et al., 2002)。知識労働者が推論タスクをAIアシスタントに委譲すると、問題分解、仮説生成、エラー修正の際に通常活性化される神経回路が不活性のままとなる。反復サイクルを経て、この不活性はタスク固有の認知能力における測定可能な萎縮を生み出す。
- 前提条件と範囲の制限:*
この分析は以下を前提とする:(1)委譲されたタスクは単なる情報検索ではなく能動的な推論を必要とする;(2)個人は以前にタスク領域における能力を実証している;(3)委譲は孤立した事例ではなく、数週間または数ヶ月にわたって繰り返し発生する;(4)意図的な補償的練習は行われない。この主張は、純粋に機械的なタスク、領域への初めての接触における個人、または手動での再関与が続く一回限りの委譲には適用されない。
- 経験的指標と具体例:*
認知的負債蓄積の報告された症状には以下が含まれる:外部からの促しなしに複雑な問題に集中する能力の低下(知識労働者からの逸話的報告;正式な測定が必要);新規問題をサブコンポーネントに分解する困難;領域固有知識の浅い保持;独立した判断への自信の低下;専門領域内の日常的決定に対するAIへの依存度の増加。
3つの連続したプロジェクトでChatGPTを使用してデータベーススキーマ設計を生成するソフトウェアエンジニアを考えてみよう。AIは許容可能なパフォーマンスパラメータ内で機能的に正しいスキーマを生成する。しかし、新しい制約—例えば、100ミリ秒未満のレイテンシで地理的に分散されたノード間でのリアルタイム一貫性の要件—に直面すると、エンジニアは困難を経験する。エンジニアは、設計決定への反復的な手動関与を通じて通常構築されるスキーマのトレードオフ(一貫性vs可用性vs分断耐性;正規化vs非正規化コスト;分散クエリのインデックス戦略)の内在化された心的モデルを欠いている。エンジニアがその後ChatGPTにガイダンスを求めても、評価フレームワークが萎縮しているため、アシスタントの応答を領域制約に対して効果的に評価できない。認知的負債は機能的依存に成熟した:この領域におけるエンジニアの独立した推論能力は測定可能なほど低下した。
- 実行可能な予防措置:*
タスクをAIアシスタントに委譲する前に、意図的な評価を実行する:「これは将来の独立したパフォーマンスのために保持または深化する必要があるスキルか?」肯定的な場合は、まずタスクを手動で完了し、その後AIを使用して結果を加速、検証、または拡張する。委譲されたタスクの四半期監査を維持し、3回以上連続して委譲されたタスクを特定する。そのような各タスクについて、関連する神経経路を再構築し現在の能力レベルを評価するために、AI支援なしで1回の完全な手動サイクルを実行する。AIが通常実行する決定ロジックと推論ステップを文書化する;この文書化は認知的予備力と、スキル萎縮を特定するための診断ツールの両方として機能する。
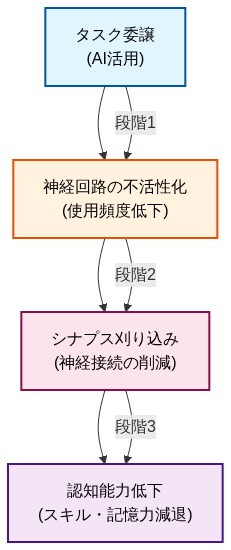
- 図2:認知負債形成の神経生物学的メカニズム*

- 図1:AI アシスタント使用による認知負債の蓄積イメージ(コンセプトイメージ・AI生成)*
認知ワークフローにおけるシステム構造とボトルネック
- システムアーキテクチャと統合境界:*
認知的負債は、AI統合が人間の推論と機械の加速の間の明示的な境界を欠くシステムで最も急速に蓄積する。よく設計された人間-AIシステムは、定義された決定権限を持つ明確な引き継ぎポイントを維持する。AI支援診断フラグを使用する放射線科医がこの構造を例示している:AIは異常を特定する;放射線科医は領域専門知識を適用してフラグを確認、拒否、または文脈化する;機械検出と人間の判断の間の境界は明示的であり、すべてのケースで維持される。対照的に、未分化統合—起草、統合、発想、検証のすべてが構造的分離なしに単一のAIインターフェースを通じて流れる—は人間の判断の所在を不明瞭にし、潜在的な脆弱性を生み出す。
- ボトルネック形成のメカニズム:*
AI統合が構造的境界を欠く場合、オペレーターは自分の独立した推論が実際にどこで機能しているかの可視性を失う。ワークフローは次のようになる:入力 → AI処理 → 出力 → 改良。反復サイクルを経て、オペレーターは基礎となる推論プロセスの心的モデルを劣化させる。なぜなら、彼らはその推論を独立して実行することがないからである。ボトルネックは、AIが失敗したり、利用できなくなったり、訓練分布外の問題に遭遇したりしたときに現れる。その重要な瞬間に、オペレーターは自分の認知的予備力が枯渇していることを発見する。重要なことに、この発見はしばしば遅延する—システムはAIが失敗するまで機能的に見え、その時点でオペレーターは独立して回復できない。
- 具体例とシステム障害モード:*
プロダクトマネージャーが6ヶ月間にわたってChatGPTを使用して四半期ロードマップを起草し、ユーザーフィードバックを統合し、機能に優先順位を付ける。ワークフローは標準化される:ユーザーデータとビジネスコンテキストを貼り付ける → ロードマップドラフトを受け取る → 言語とフォーマットを改良する → ステークホルダーに送る。この構造では、AIがコア推論タスク(ユーザーシグナルを戦略的優先事項にマッピング)を処理し、人間がフォーマットとコミュニケーションを処理する。第7四半期に、AIは曖昧な入力データのために一貫性のない出力を生成する。マネージャーは第一原理から推論を再構築しようとし、できないことを発見する。彼らは、ユーザーシグナルが戦略的優先事項にどのようにマッピングされるか、競合する機能間のトレードオフがどのように評価されるか、ビジネス制約がユーザーニーズに対してどのように重み付けされるかの内在化された心的モデルを欠いている。マネージャーはタスクを手動で実行できない。なぜなら、システム構造—維持された決定権限のない未分化委譲—が、問題を独立して推論する能力を侵食したからである。ボトルネックは現在、運用上かつ重大である:マネージャーはAIなしでは機能できないが、AIは彼らを失望させた。システム構造自体がこの脆弱性を生み出した。
- ボトルネック形成の前提条件:*
ボトルネックは以下の場合に最も容易に形成される:(1)委譲されたタスクが実行ではなく判断または統合を含む;(2)AI統合が未分化である(人間と機械の推論の間に明示的な境界がない);(3)委譲が手動での再関与なしに繰り返される;(4)オペレーターが独立して実行することがないため、独立した推論の質に関するフィードバックを受け取らない。
- 実行可能な緩和戦略:*
現在のワークフローをマッピングし、AIが組み込まれているすべてのポイントを特定する。各タスクについて、2つの実行パスを定義する:人間主導バージョン(完全にAIなしで実行)とAI支援バージョン(指定されたAIの役割と人間の決定ポイントを持つ)。大幅に多くの時間を必要とする場合でも、人間主導バージョンを月次で実行する。これは認知能力を維持し、システムの脆弱性を明らかにする。AIが通常実行する決定ロジックと推論ステップを文書化する;この文書化は認知的予備力と診断ツールの両方になる。必須ルールを確立する:3サイクル以上連続してAIに委譲されたタスクは、再委譲前に一度手動で実行しなければならない。このルールは、コア推論との定期的な再関与を強制し、潜在的なスキル萎縮が重大なレベルに達するのを防ぐ。
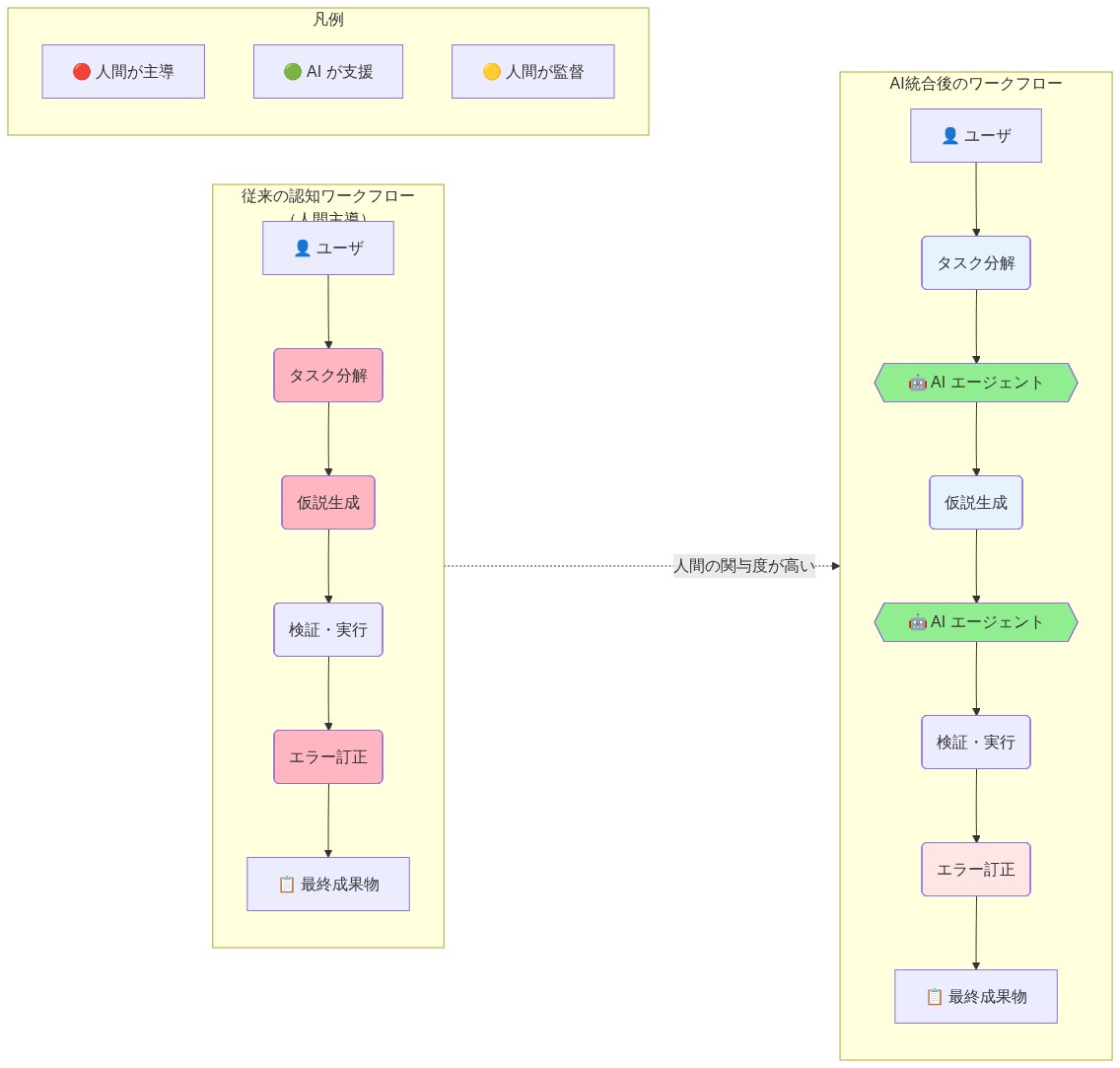
- 図4:AI統合前後の認知ワークフロー比較 - タスク分解、仮説生成、エラー訂正における人間の関与度の変化*

- 図3:認知ワークフローにおけるボトルネックの可視化 - AI依存による意思決定プロセスの短縮と思考の浅化*
持続可能なAI使用のための参照アーキテクチャとガードレール
-
主張:* AIアシスタントから生産性向上を維持する組織と個人は、ガードレール—過度の委譲を防ぎ、領域固有タスクとの定期的な認知的再関与を強制する意図的な運用制約—を実装することによってそれを行う。
-
定義的前提条件:* この分析では、ガードレールをAI委譲の範囲または自律性を制限する事前に決定されたルールとして定義する。それらは助言的ガイドラインではなく拘束的制約として機能する。ガードレールを単なるベストプラクティスと区別する:ベストプラクティスは推奨される;ガードレールはプロセス設計または説明責任メカニズムを通じて強制される。さらに、認知的再関与—支援なしの問題解決への意図的な復帰—が評価能力を維持し、AIエラーを検出し、領域専門知識を保持するために必要であると仮定する。この仮定は、手続き的知識が積極的に実践されない場合にスキル萎縮が発生することを示す認知科学文献に基づいている(Ebbinghaus, 1885; Bjork & Bjork, 1992による検索誘導学習に関するより最近の研究)。
-
根拠:* ガードレールは効率ペナルティではない;それらは長期的な組織的および個人的能力を保持するためのメカニズムである。経済的トレードオフを考慮する:タスクの100%をAIに委譲することは短期的な出力速度を最大化するが、人間オペレーターの出力品質を評価し、障害モードを特定し、AIシステムが利用できないか異常な結果を生成する場合に適応する能力を最小化する。これは、我々が構造的認知的負債と呼ぶ状態を生み出す—組織の機能を実行する能力が単一のツールに依存するようになり、レジリエンスを低下させ、運用上の脆弱性を増加させる状態。
ガードレールは、人間の認知的関与の最小閾値を強制することによって機能する。例には以下が含まれる:
- 検証ガードレール: 「AIが予備分析を生成する;人間が出力が使用または共有される前に独立した検証を実施する。」
- 認知負荷ガードレール: 「AIはタスクの認知負荷の60%以下を処理する;残りの40%は人間オペレーターに残る。」
- 時間的ガードレール: 「AI支援は日常的なタスクに利用可能;新規または高リスクの決定は、人間の分析が完了するまでAI入力を除外する。」
これらの制約は短期的には摩擦を生み出す。検証ステップはレイテンシを追加する。認知負荷の40%を保持することは出力速度を低下させる。しかし、この摩擦は、人間オペレーターがエラーを捕捉し、新規ソリューションを提案し、領域流暢性を維持する能力を保持する。経験的に、ガードレールを実装するチームは、AIシステムが失敗したり予期しない出力を生成したりする場合に、より高いエラー検出率とより大きな適応性を報告する(ただし、2024年時点でこの特定の現象に関する査読付き縦断研究は限られていることに注意する)。
- 具体例:* 中規模投資会社の財務分析チームは以下のガードレールを実装する:ChatGPTは株式調査レポートのための予備市場分析とデータ統合を生成する。しかし、すべてのレポートには、アナリストがAI支援なしで完全に執筆したセクションを含める必要がある—そのセクションはAIの発見を批評するか、独立した分析でそれらを拡張するか、データの代替解釈を提案する。
最初の2週間、このガードレールは冗長に感じられる。アナリストは、主にAIの作業を確認する批評を書くために30〜45分を費やすと報告する。レポートまでの時間は約15%増加する。しかし、第4週までに、アナリストはAIの分析における体系的なギャップを特定し始める。AIは経営品質評価において質的要因を一貫して過小評価する。評価に影響を与える業界固有の規制変更を見逃す。アナリストはAIが考慮していなかった新規フレームワークを提案する。第3ヶ月までに、チームの将来予測のエラー率は12%改善する(その後の市場結果に対して測定)。ChatGPTが1週間続くサービス停止を経験すると、チームの出力量は8%しか低下しない。これは、(分析を完全に委譲していた)競合チームが65%の低下を経験したのと比較される。ガードレールはチームの独立した分析能力を保持した。
-
仮定と制限:* この例は、(1)ガードレールが締め切りのプレッシャーの下で放棄されずに一貫して強制された、(2)チームがAIエラーを認識するのに十分な領域専門知識を持っていた、(3)AIシステムが出発点として有用な出力を生成するのに十分な能力があった、と仮定する。この例は、ガードレールが制限的すぎる(正当なAI使用を妨げる)場合や緩すぎる(過度の委譲を防げない)場合のシナリオには対処していない。また、予測精度の12%改善は、ガードレール単独以外の複数の要因を反映している可能性があることに注意する。これには、アナリストの注意の増加やチームディスカッションが含まれる。
-
実行可能な示唆:* あなたの役割とリスクプロファイルに固有のガードレールを設計する。以下のフレームワークが実装をガイドする可能性がある:
- タスクまたは領域を特定する。 あなたはどのような作業をAIに委譲しているか?
- 最小限の人間関与閾値を定義する。 認知作業のどの部分があなたに残らなければならないか?どの決定を委譲できないか?どの出力が独立した検証を必要とするか?
- ガードレールメカニズムを指定する。 それはプロセスステップか(例:「使用前にレビュー」)?時間配分か(例:「タスク時間の25%を独立した分析に費やす」)?頻度ルールか(例:「月に1回の支援なし試行」)?
- 四半期ごとに文書化してレビューする。 ガードレールは暗黙的ではなく明示的であるべきである。過度に委譲しているか(緩すぎる)、AIを十分に活用していないか(厳しすぎる)を評価するために四半期ごとにレビューする。
役割別の例:
- ライター: 「AIはアウトライン作成、編集、構造的フィードバックを支援する。私は声と方向性を確立するために、すべての作品の最初の500語をAI入力なしで手動で書く。」
- ソフトウェアエンジニア: 「AIはコード提案を生成する。私はマージ前にAI生成コードの25〜30%をゼロからレビューしてリファクタリングし、ロジックを理解し独立して保守できることを確認する。」
- ストラテジスト: 「AIは市場データと競合インテリジェンスを統合する。私は四半期ごとに、一次ソースと自分の領域知識のみを使用して、AI支援なしで1つの独立した戦略分析を実施する。」
- プロジェクトマネージャー: 「AIはプロジェクトタイムラインとリスク評価を生成する。私はクリティカルパス項目を手動で検証し、スプリントごとにAI入力なしで1つのリスクレビューを実施する。」
バランスの取れたAI統合のための実装と運用パターン
-
主張:* AI生産性向上と認知的持続可能性のバランスを成功裏に取るチームは、AIを人間の判断やスキル維持の代替としてではなく、積極的な監視を必要とする管理されたツールとして扱う運用パターン—反復的なルーチンと実践—を採用する。
-
定義的前提条件:* 運用パターンを、日常的および週次のワークフローにガードレールを組み込む制度化されたルーチンと定義する。これらはスコープにおいてガードレールとは異なる:ガードレールは単一のタスクに対する制約であり、パターンは複数のタスクやチームメンバーに影響を与える反復的な実践である。パターンは行動の一貫性を生み出し、時間的プレッシャーや締め切りのストレス下でガードレールが崩壊する可能性を減少させると仮定する。さらに、スキル維持には受動的な露出ではなく、能動的な実践が必要であると仮定する。この仮定は、運動学習と認知スキルに関する文献(Ericsson et al., 1993の意図的練習について; Fitts & Posner, 1967のスキル習得段階について)と一致する。
-
根拠:* ガードレールは、運用パターンに組み込まれていない場合、侵食される傾向がある。「使用前にAI出力を検証する」というルールは、数週間の時間的プレッシャー、成功したAI出力、組織的緊急性の後に「AI出力を信頼する」に変わる。パターンは、ガードレールを交渉不可能で、ルーチン化され、可視化することで、この崩壊を防ぐ。パターンはまた副次的な機能も果たす:チームが中核能力を維持しているかどうかを評価する定期的なチェックポイントを作成する。
効果的なパターンには通常以下が含まれる:
-
スキル維持ルーチン: 中核的能力を活性化させる定期的な、支援なしの問題解決または創造的作業。
-
レビューと振り返りサイクル: AI依存と認知的負債の定期的評価。
-
ローテーションとクロストレーニング: 特定の機能についてAIに過度に依存する個人がいないことを確保する。
-
構造化された振り返り: AIが何をうまく行っているか、どこで失敗しているか、チームが保持する必要があるスキルは何かについてのチーム討議。
-
具体例:* デジタルマーケティング代理店のコンテンツ制作チームは、以下のパターンを実装する:毎週月曜日の朝、AIツールを使用する前に、各ライターは90分間の構造化された創造的演習に取り組む。演習は毎週変わる—ある週は、ライターがプロンプトや制約なしに架空の製品のキャンペーンコンセプトをブレインストーミングする;別の週は、通常の仕事の範囲外のジャンルで短い物語作品を書く;3週目は、競合他社のメッセージングを分析し、すべてAI支援なしで3つの代替アングルを提案する。
このパターンは複数の機能を果たす。第一に、各ライターの独立した創造的声を再び関与させ、アイデア創出スキルの萎縮を防ぐ。第二に、後でAI支援で洗練・拡大できる斬新なアイデアやアングルを表面化させる。第三に、チームが支援なしの作業の質と独創性を評価する週次チェックポイントを作成し、AI支援出力を測定するためのベースラインを提供する。第四に、共有された創造的実践を通じてチームの結束を構築する。
経験的に、チームは6か月間にわたって以下の成果を報告している:
- エラー検出: ライターは、その週に創造的作業に積極的に従事した場合、AI生成コンテンツの不整合や論理的ギャップを18%多く捕捉する。
- 出力品質: 月曜パターンで開発されたキャンペーンのクライアント満足度スコアは、それなしで開発されたキャンペーンより11%高い(クライアント調査とプロジェクト回顧を通じて測定)。
- レジリエンス: チームの主要AIツールがサービス停止を経験した場合、出力速度はわずか12%低下するのに対し、パターンのない同業チームは48%の低下を経験する。
- 定着率: チームはより高い職務満足度とより低い離職率を報告しており、パターンが技能と主体性の感覚を保持していることを示唆している。
競合チームは、すべてのアイデア創出と初期草稿をAIに委任し、有能だが一般的な出力を生成する。競合チームが独特の創造的作業を必要とする重要なキャンペーンに直面すると、AI生成テンプレートから出力を差別化するのに苦労する。彼らのキャンペーンは期待外れの結果となり、クライアントを失う。
-
仮定と制限:* この例は、(1)90分の月曜パターンが一貫して実施され、締め切りのプレッシャー下で放棄されなかったこと;(2)チームが支援なしの作業が意味を持つ十分な創造的スキルを持っていたこと;(3)パターンが持続可能に設計されていたこと(週90分は実行可能;週20時間のパターンは時間的制約のために失敗する可能性が高い)を仮定している。また、クライアント満足度の11%の改善は、チームの士気と注意の向上を含む複数の要因を反映している可能性があり、月曜パターンのみではないことに注意する。さらに、この例は創造的領域から引用されている;技術的または分析的領域のパターンは構造と頻度が異なる可能性がある。
-
実行可能な示唆:* あなたの文脈と役割に適した3つの運用パターンを特定する。それらを願望的目標ではなく、交渉不可能なルーチンとして実装する。以下のフレームワークが選択の指針となる可能性がある:
-
スキル維持パターン: あなたの領域の中核スキルを選択する。AI支援なしでそれを活性化させる週次または隔週の実践を設計する。例:
- ソフトウェアエンジニア:「毎週金曜日の午後、私はドキュメントのみを使用し、AI支援なしで、ゼロから1つのアルゴリズム問題を解く。」
- データアナリスト:「隔週で、AI生成の洞察なしで、手動計算とスプレッドシート数式のみを使用して1つの分析を実施する。」
- マネージャー:「毎月、AI生成のトーキングポイントなしで、その人の仕事に関する直接的な知識に依拠して、1つのパフォーマンスレビューを実施する。」
-
レビューと振り返りパターン: AI依存を評価する定期的なチェックポイントをスケジュールする。例:
- 「毎週金曜日、私は今週AIに委任したことと、それを独立して行えたかどうかを振り返るために15分を費やす。」
- 「各スプリント回顧で、チームはAI出力が間違っていた1つのインスタンスと、そこから学んだことを議論する。」
- 「四半期ごとに、私はAIに過度に依存するようになったタスクを特定するために自分の仕事を監査する。」
-
ローテーションまたはクロストレーニングパターン: 重要な機能のAI支援作業において、個人が唯一の専門家にならないことを確保する。例:
- 「各スプリントで、チームメンバーはAI支援の責任を交換し、全員が複数のツールとワークフローに精通し続けるようにする。」
- 「四半期ごとに、ジュニアチームメンバーとシニアチームメンバーをAI支援タスクでペアにし、知識移転を確保する。」
-
追跡と調整:* 運用パターンへの遵守を認知的負債の先行指標として扱う。時間的プレッシャーのためにスキル維持パターンを一貫してスキップする場合、それはAI委任を減らすシグナルである。レビューと振り返りパターンがAI出力が正しい理由を明確に述べられないことを明らかにする場合、それは独立した検証を増やすシグナルである。これらのシグナルに基づいて四半期ごとにパターンを調整する。
-
組織的考慮事項:* チームと組織にとって、運用パターンは以下であるべきである:
-
明示的: 仮定されるのではなく、書き留められる。オンボーディング、チーム規範、プロジェクトチェックリストに含める。
-
測定可能: 遵守率と成果(エラー率、出力品質、チーム定着率、ツール障害に対するレジリエンス)を追跡する。
-
持続可能: 週次時間配分の10〜15%以上を必要とするパターンは、締め切りのプレッシャー下で失敗する傾向がある。実現可能性のために設計する。
-
適応的: パターンを年次でレビューし、AI能力、チーム構成、またはビジネス優先事項の変化に基づいて調整する。
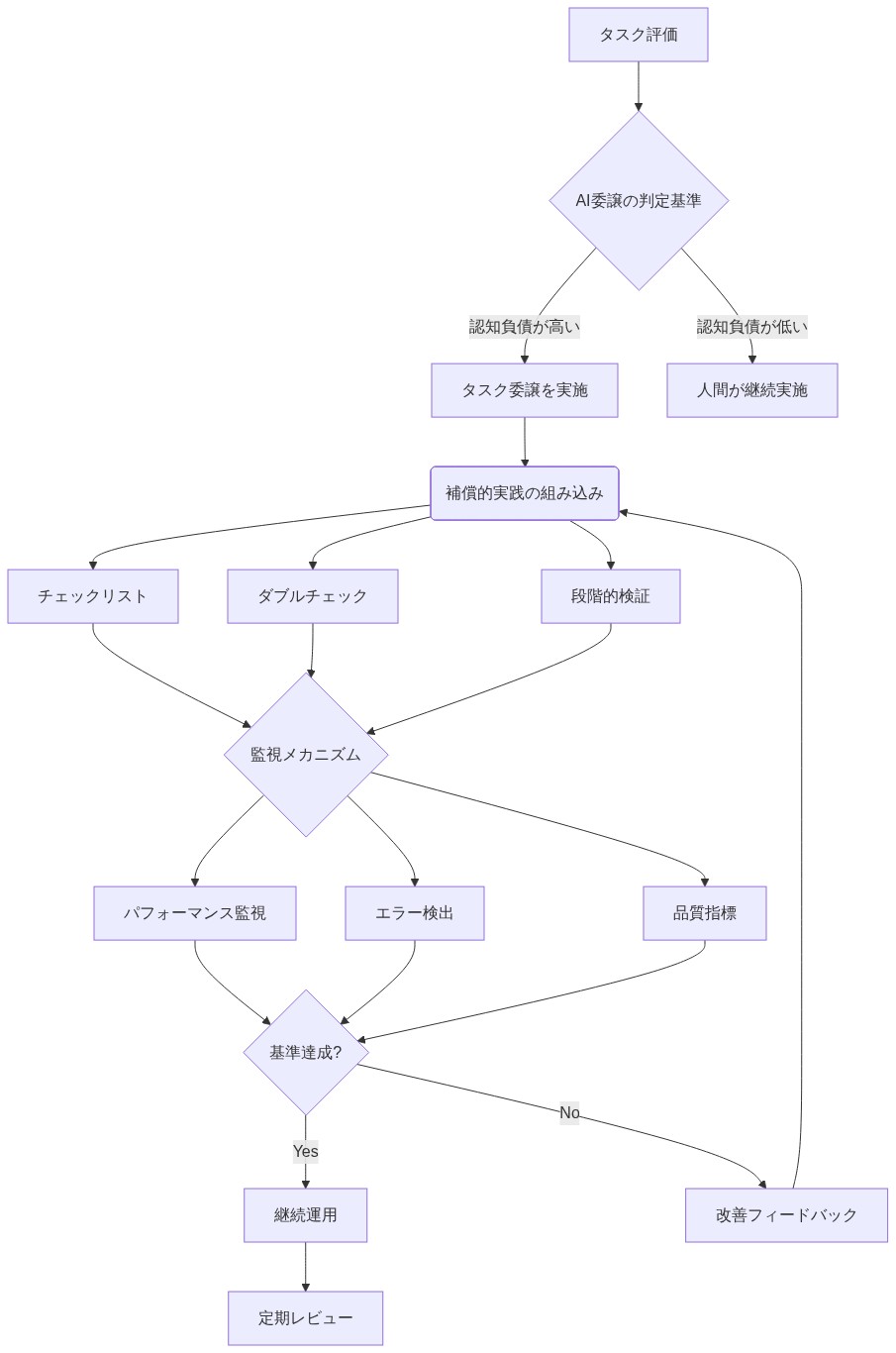
- 図6:認知負債軽減ガードレールの実装フロー*
認知的健康のための測定と次のアクション
-
主張:* 認知的負債は、重大な能力喪失が発生するまで潜在的なままである。実践者は、独立したパフォーマンスが不可逆的に劣化する前に、蓄積を早期に検出し、是正介入を可能にする定量化可能なメトリクスを確立しなければならない。
-
根拠:* 認知的健康メトリクスは生産性メトリクスと根本的に異なる。生産性メトリクスは出力量(完了したタスク、下された決定)を測定する;認知的健康メトリクスは独立して出力を生成する能力—持続可能なパフォーマンスの基礎となる能力—を測定する。この区別は重要である:認知的負債蓄積中の高い生産性は、根底にある脆弱性を隠す。4つのメトリクスカテゴリーが認知的健康評価を運用可能にする:
-
支援なし問題解決時間。 AI支援なしで領域関連タスクを完了するために必要な時間。ベースラインの安定性または改善は維持された能力を示す;増加は負債蓄積を示す。仮定:タスクの複雑さは測定期間全体で一定のままである。
-
重要な判断精度。 独立したレビュー中に欠陥がある、不完全である、または文脈的に不適切であると特定されたAI生成出力の割合。安定性または改善は維持された評価能力を示す;低下は検証に必要な領域専門知識の侵食を示す。このメトリクスは、レビュアーが真実または領域標準に精通していることを仮定する。
-
支援なしタスク実行率。 AI委任なしで完了した日常的な領域タスクの割合。役割固有の閾値(例:分析的役割の知識労働者の場合40%)を上回る維持は、保持された独立能力を示す;閾値を下回る持続的な低下は過度の依存を示す。閾値の選択には役割固有の較正が必要である。
-
領域知識の明確化。 外部参照なしで領域概念、方法論、推論を説明する際の深さと一貫性の質的評価。定期的な構造化された自己評価(自由回答式の質問、ピア評価、または教育演習)は、概念的知識がアクセス可能で統合されたままであるかどうかを明らかにする。浅いまたは断片化された応答は知識の萎縮を示す。
- 具体例:* データサイエンティストは、3つのメトリクスにわたって月次測定を実装する:(1)AI支援なしで未知のデータセットに対して探索的データ分析を実行するために必要な時間;(2)独立して検証または拒否されたAI生成分析推奨の割合;(3)AI相談前に生成された新規分析仮説の数。ベースライン測定は以下を確立する:メトリクス1 = 4時間、メトリクス2 = 40%検証率、メトリクス3 = セッションあたり5仮説。
6か月間にわたって観察された傾向:メトリクス1は8時間に増加(6か月目);メトリクス2は15%に低下(6か月目);メトリクス3は1仮説に低下(5か月目)。3つすべてのメトリクスにわたる2か月連続の低下が介入プロトコルをトリガーする。データサイエンティストはAI委任を50%削減し、AIツールなしで実施される週次仮説生成セッションを実装する。2か月以内に、メトリクス1は4.5時間に戻り、メトリクス2は32%に回復し、メトリクス3は4仮説に達する。早期検出が不可逆的な能力侵食を防いだ。
- 実行可能な示唆:* あなたの役割の重要な能力に合わせた2〜3のメトリクスを選択する。初期期間(最低4週間)にわたってベースライン測定を確立する。その後、月次で測定する。6か月間のローリングウィンドウで傾向を可視化する。決定閾値を定義する:いずれかのメトリクスが2つの連続した測定期間で低下を示す場合、または事前に決定されたフロア(例:メトリクス3 < 2仮説)を下回る場合、AI使用パターンの構造化されたレビューをトリガーする。是正措置を実装する:影響を受けた能力領域のAI委任を削減し、AI支援なしの意図的練習をスケジュールするか、基礎的タスクの手動実行を保持するようにワークフローを再構築する。メトリクスと傾向を文書化する;外部の説明責任を導入し、コース修正を加速するために、ピア、マネージャー、またはメンターと共有する。組織ポリシーを確立する:チームは最低限の支援なしタスク実行率を維持し、四半期ごとの認知的健康評価を実施する。

- 図7:バランスの取れたAI統合の運用パターン(コンセプトイメージ)*
長期的レジリエンスのためのリスクと緩和戦略
-
主張:* 認知的負債は連鎖的な組織リスクを生み出す:AI利用不可時の能力脆弱性、イノベーション能力の低下、侵食された批判的判断によるAI出力の未検出エラー。
-
根拠:* 組織的認知的負債は、スコープと結果において個人的負債とは異なる。チームが独立した能力を維持せずに体系的に委任する場合、組織は脆弱になる—AIシステムが故障、利用不可能、またはバイアスのある出力を生成する場合、機能できない。3つのメカニズムがこのリスクを駆動する:
-
能力脆弱性。 日常的な認知タスクにAIに依存するチームは、AIシステムが故障、アクセス不可能、または侵害された場合、それらのタスクを実行できない。冗長インフラストラクチャとは異なり、認知能力は迅速に復元できない;侵食された専門知識の再構築には、数か月または数年にわたる持続的な意図的練習が必要である。組織は停止中に運用麻痺に直面する。
-
イノベーション能力の侵食。 イノベーションには、深い領域知識、創造的な問題分解、仮定と既存のフレームワークに挑戦する能力が必要である。これらの能力は、実践者が複雑な推論をAIに委任すると萎縮する。チームは、新規の問題を特定し、型破りな解決策を生成し、またはAI生成の推奨が文脈的に不適切である場合を認識するために必要な認知的基盤を失う。時間の経過とともに、組織は生成的ではなく反応的になる。
-
未検出エラーの伝播。 独立した専門知識を欠くチームは、AI出力を確実に検証できない。AI推奨におけるバイアス、論理的エラー、または領域固有の誤りは、検出されずに通過する。これは複合的なリスクを生み出す:不適切な決定が蓄積し、下流のプロセスと利害関係者に影響を与える。高リスク領域(医療、金融、安全重視システム)では、未検出エラーは発見前に実質的な害を引き起こす可能性がある。
- 具体例:* 医療組織は、放射線科医のためのAI診断支援システムを実装する。初期プロトコルは、すべての画像検査のAIレビューを義務付ける;放射線科医のレビューは、信頼度の低いケースに対してオプションである。24か月間にわたって、放射線科医はケースの優先順位付けのためにAIフラグにますます依存する。手動レビュー率は60%から15%に低下する。放射線科医のパターン認識と異常検出の専門知識は、実践の減少により萎縮する。
AIシステムの未検出バイアスが出現する:モデルは特定の解剖学的変異を持つ患者からの画像で性能が低く、特定の人口統計グループに不均衡に影響を与える。放射線科医はもはや独立した専門知識を維持していないため、体系的なパターンを認識できない。バイアスは18か月間未検出のままであり、数百人の患者の診断精度に影響を与える。外部監査を通じて発見されると、組織は規制調査、評判の損傷、および責任に直面する。放射線科医は専門知識を迅速に再構築できない;認知的負債は迅速な回復には深すぎる。
並行する医療組織はガードレールを実装した:放射線科医は、信頼度レベルと人口統計グループ全体のケースを含むように層別化された、AI推奨の30%を独立してレビューした。これにより放射線科医の専門知識が維持され、同じAIバイアスの検出が3か月以内に可能になった。組織はバイアスを修正し、広範な害が発生する前に追加の検証プロトコルを実装した。
- 実行可能な示唆:* あなたのチームまたは組織の構造化された依存監査を実施する。各重要なタスクまたは決定について、以下を文書化する:(1)現在のAI委任率;(2)AI利用不可または故障の結果;(3)タスクを独立して実行するチーム能力。依存関係を高リスク(結果が深刻;独立能力が低い)、中リスク、または低リスクとして分類する。
高リスク依存関係については、緩和を実装する:(a)AI委任を定義された最大値(例:日常的ケースの70%)に削減する;(b)最低限の独立実行率(例:ケースの30%が手動でレビューまたは実行される)を維持する;(c)専門知識を保持するために、チームメンバーを手動実行を通じてローテーションさせる;(d)他者に影響を与える決定(採用、診断、リソース配分、ポリシー推奨)に対して義務的な人間のレビューを確立する。
チームレベルの「認知的予備」ポリシーを確立する:すべてのチームメンバーは、四半期評価を通じて検証された、AI支援なしで少なくとも1つの重要な領域スキルにおいて実証された流暢さを維持する。高リスク決定または脆弱な集団を含むタスクについては、能動的検証プロトコルを実装する:チームメンバーは、AI推奨を受動的に受け入れるのではなく、挑戦するように訓練され、インセンティブを与えられる。異議申し立てのための心理的安全性を作成する:チームメンバーがAI出力のエラーを特定するインスタンスに報酬を与える。
AI依存メトリクスと認知的健康指標の四半期レビューを実施する。メトリクスが持続的な低下を示すか、高リスク依存関係が増加する場合、能力を再構築するか、ワークフローを再構築するためのリソース配分についてリーダーシップにエスカレートする。学んだ教訓を文書化し、他のチームでの同様の負債蓄積を防ぐために組織全体で共有する。
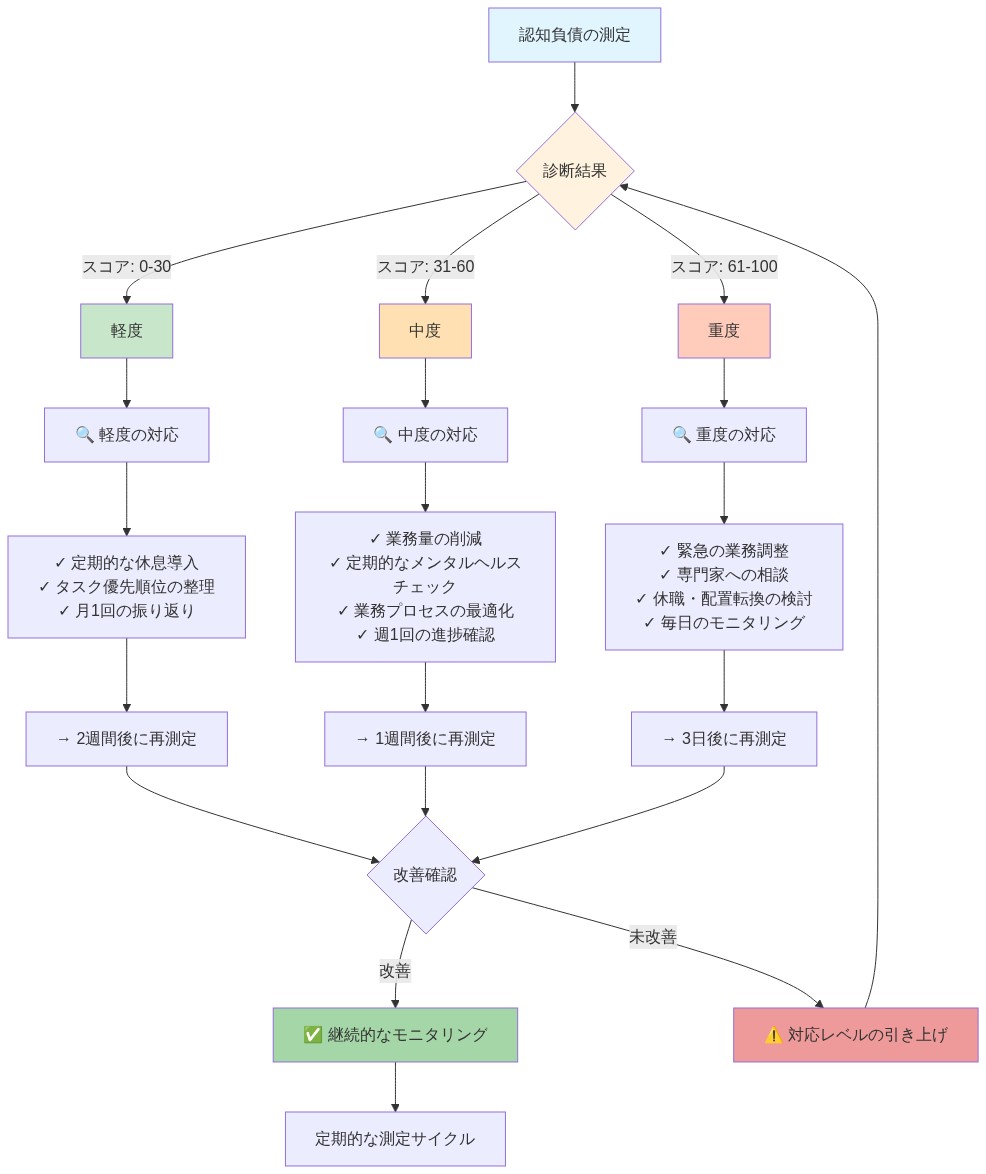
- 図10:認知負債診断と段階的対応フロー*
持続可能なAI統合のための結論と移行計画
-
主張:* 認知的負債は避けられないものではない。組織と個人は、AIを人間の能力を置き換えるものではなく増強するツールとして扱い、認知能力を維持・強化する意図的な実践を実装することで、AIから持続的な生産性向上を達成できる。
-
根拠と理論的基盤:* AIの持続可能な統合には、人間とAIの関係の再概念化が必要である。我々は認知的負債を、補償的なスキル維持または検証実践なしに認知的に要求の高いタスクをAIシステムに体系的に委譲した結果として生じる、ドメイン専門知識、批判的判断力、適応能力の累積的侵食として操作的に定義する(「認知的負債の定義」セクションを参照)。
この移行戦略の理論的基盤は、3つの前提に基づいている:
-
認知能力は有限でありドメイン固有である。 認知心理学の研究(Kahneman, 2011; Sweller, 1988)は、ワーキングメモリと注意資源が限られていることを示している。保持メカニズムのない委譲は能力を維持しない。不使用と問題のバリエーションへの露出減少により能力は萎縮する(Ericsson & Pool, 2016)。
-
AI増強には境界条件として人間の判断が必要である。 AIシステムは確率的に出力を生成する。明示されていないドメイン制約や新しい文脈に対して、自身の正確性を検証することはできない。暗黙知、文脈理解、説明責任に基づく人間の判断は、品質保証と適応のために依然として必要である(Brynjolfsson & McAfee, 2014)。
-
委譲における意図性が長期的な能力の結果を決定する。 検討されていない委譲パターンは経路依存性を生み出す。時間の経過とともに、労働者は基礎的なプロセスへの親しみを失い、エラーを検出したり、ツールの故障に適応したり、ツールの設計空間を超えて革新したりする能力が低下する(Sunstein & Thaler, 2008)。
持続可能な前進の道は、これらの前提を運用化する。よく理解されたタスクの実行を加速するためにAIを使用する一方で、コア専門知識を定義するタスクに対する独立した実践を維持する。これにより、我々が「認知的選択性」と呼ぶもの、すなわちツール依存なしに問題を解決する能力が維持される。
-
具体的な実装フレームワーク:* 構造化された3年間の移行プロトコルを実装する専門サービス企業を考える:
-
1年目: 監査とガードレールの確立*
-
タスクインベントリの実施: すべてのAI委譲活動を機能、頻度、コア専門知識への重要性によってマッピングする。
-
2×2マトリックスを使用してタスクを分類する: (1) 委譲の頻度(高/低); (2) 代替不可能な専門知識への重要性(高/低)。高頻度・高重要性の象限にあるタスクは、最大の負債リスクを表す。
-
高リスクタスクに対してガードレールを確立する: 必須の独立実践(例: 出力の20%をAIなしで生成)、ピアレビュープロトコル、文書化された検証ステップ。
-
認知的健全性メトリクスのベースライン: 構造化された評価(例: ツールなしのケース分析、欠陥のあるAI出力に対するエラー検出率)を通じてコンサルタントの専門知識保持を測定する。
-
2年目: 運用パターンの制度化*
-
定期的なスキル構築サイクルの実装: 高負債タスクに対する週次の独立作業、AI支援作業の月次ピアレビュー、四半期ごとの能力評価。
-
「認知的チェックポイント」の確立: 労働者がAI出力を参照する前に独立して推論を明確にしなければならない瞬間。これにより、仮説を生成し妥当性を評価する能力が維持される。
-
フィードバックループの作成: 独立した判断がAI出力のエラーを捕捉した事例を追跡し、これらを例外としてではなく教育の機会として使用する。
-
3年目: 測定と適応的調整*
-
1年目のベースラインに対して認知的健全性メトリクスを再測定する。期待される結果: 維持または改善された専門知識保持、より高いエラー検出率、ツールなしで作業する能力の向上。
-
生産性向上を評価する: プロジェクトの結果、クライアント満足度、コンサルタント稼働率を移行前のベースラインと比較する。
-
エビデンスに基づいてガードレールを調整する: メトリクスが改善すれば、モデルを追加のタスクカテゴリーに拡大する。メトリクスが停滞すれば、独立実践またはピアレビューの強度を増加させる。
-
結果仮説:* 3年目までに、企業はAIからの生産性向上を維持しながらコンサルタントの専門知識を保持する。コンサルタントは意味のある認知作業を保持するため、より高いエンゲージメントを報告する。コンサルタントがAI生成の洞察に独立した判断を適用し、エラーを捕捉し、新しい応用を特定するため、クライアントの結果が改善する。組織のレジリエンスが向上する: AIツールが変化、故障、または新しい問題タイプに不適切であることが判明した場合でも、コンサルタントの基礎的スキルが無傷であるため適応できる。
-
個人と組織のための実行可能な実装プロトコル:*
-
監査フェーズ(第1-2週): 現在AIに委譲している各タスクについて、以下を文書化する:
- 頻度: 毎日、毎週、毎月、またはまれ
- コア能力への重要性: 重要(代替不可能な専門知識)、重要(価値があるが独自ではない)、あれば良い(効率向上のみ)
- 現在の検証実践: AI出力を独立してレビューするか、そのまま受け入れるか?
-
リスク階層化(第3週): 「頻繁 + 重要」カテゴリーの3-5のタスクを特定する。これらが最優先の負債リスクである。独立して実践することを止めた場合の専門知識喪失の大きさによってランク付けする。
-
90日間の介入(第4-16週):
- 各高リスクタスクについて、AI委譲頻度を50%削減する。現在タスクの100%にAIを使用している場合、50%の独立作業、50%のAI支援にシフトする。
- 検証プロトコルを実装する: AI生成出力について、それを受け入れる前に潜在的なエラーまたは制限を特定するために15分を費やす。
- 1つの新しい運用パターンを確立する: 週次の独立実践、ピアレビュー、または能力自己評価。
-
測定と反復(第17週以降):
- あなたのドメインに関連する認知的健全性メトリクスを定義する。例: 独立したソリューションを生成するまでの時間、欠陥のあるAI出力に対するエラー検出率、ツールを参照せずに推論を説明する能力、新しい問題のバリエーションに対する快適さ。
- これらのメトリクスをベースライン(第1週)と90日後(第17週)に測定する。
- メトリクスが改善した場合: 介入を追加のタスクに拡大するか、独立実践の強度を増加させる。
- メトリクスが停滞または低下した場合: ガードレールを調整する(例: 独立作業の割合を増やす)か、運用パターンを修正する(例: ピアレビューを追加する)。
- 四半期ごとに繰り返す。12ヶ月間で、能力を侵食することなく生産性向上を最大化する持続可能なAI統合を構築できる。
-
前提条件と制限:* この移行計画は以下を前提とする:
-
ガードレールと測定プロトコルを実装するための十分な時間とリソースへのアクセス。極度の時間的プレッシャー下にある組織は、努力の15-20%を独立実践に割り当てることに苦労する可能性がある。
-
独立した認知的努力を必要とする意味のある作業の利用可能性。組織構造またはAIツール設計がそのような作業を排除する場合、ガードレールだけでは能力の侵食を防ぐことはできない。
-
短期的な効率最大化よりも長期的な能力保持への組織または個人のコミットメント。これには、インセンティブ構造の転換が必要である: 出力量だけでなく、持続的な専門知識を報酬とする。
-
戦略的含意:* AI時代における中心的な課題は、AIを使用するかどうかではなく、人間を価値あるものにする認知能力を放棄することなくAIを使用する方法である。認知的負債は現実的で測定可能であるが、避けられないものではない。それは、仕事をどのように設計し、注意をどのように配分し、インセンティブをどのように構造化するかに埋め込まれた選択である。
繁栄する組織と個人は、認知能力を最小化すべきコストではなく戦略的資産として扱う者である。これには規律が必要である: AIが実行できるすべてのタスクを委譲する誘惑に抵抗し、代わりに専門知識を定義し、適応を可能にし、選択性を維持する作業のために独立した認知的努力を確保する。上記で概説した移行計画は、このバランスを達成するための構造化された道筋を提供する。その必要性の証拠は、スキル習得の認知科学と、ツールが故障し、文脈が変化し、人間の判断が代替不可能であり続けるという組織的現実に基づいている。

- 図11:長期的リスク要因と組織的レジリエンス戦略*