
Bun v1.3.8:Zig製の高速Markdownパーサー搭載
Zig実装による性能向上
Bunのmarkdownパーサーは、低レベルのシステムプログラミング言語であるZigを活用し、テキスト処理におけるJavaScriptの本質的なオーバーヘッドを排除している。JavaScriptコールバックとオブジェクト割り当てに依存するNode.jsベースのパーサーとは異なり、Zigはメタルに近い層で動作し、明示的なメモリ管理とゼロコスト抽象化を実現する。
Markdownの解析は逐次的な文字スキャン、トークン分類、ツリー構築を伴う。こうした操作ではJavaScriptの動的型付けとガベージコレクションが測定可能なレイテンシを導入する。Zigのコンパイル時型チェックと予測可能なメモリレイアウトはこうしたボトルネックを排除する。
-
性能指標:* 10,000語のドキュメント解析は、一般的にNode.jsの代替案である
markedやmarkdown-itよりも3~5倍高速に完了する。静的サイト生成やAPI応答変換で一般的なバッチ処理では、この倍率は数千のドキュメント全体で複合する。 -
実践的な影響:* 大規模なmarkdownコーパス(ドキュメンテーションサイト、ブログエンジン、コンテンツ管理システム)を処理するチームは、Bunのパーサーを現在のスタックに対してベンチマークすべきである。markdown レンダリングで4倍の高速化は、ビルド時間を分単位から秒単位に短縮でき、開発者体験とCI/CD効率を直接改善する。
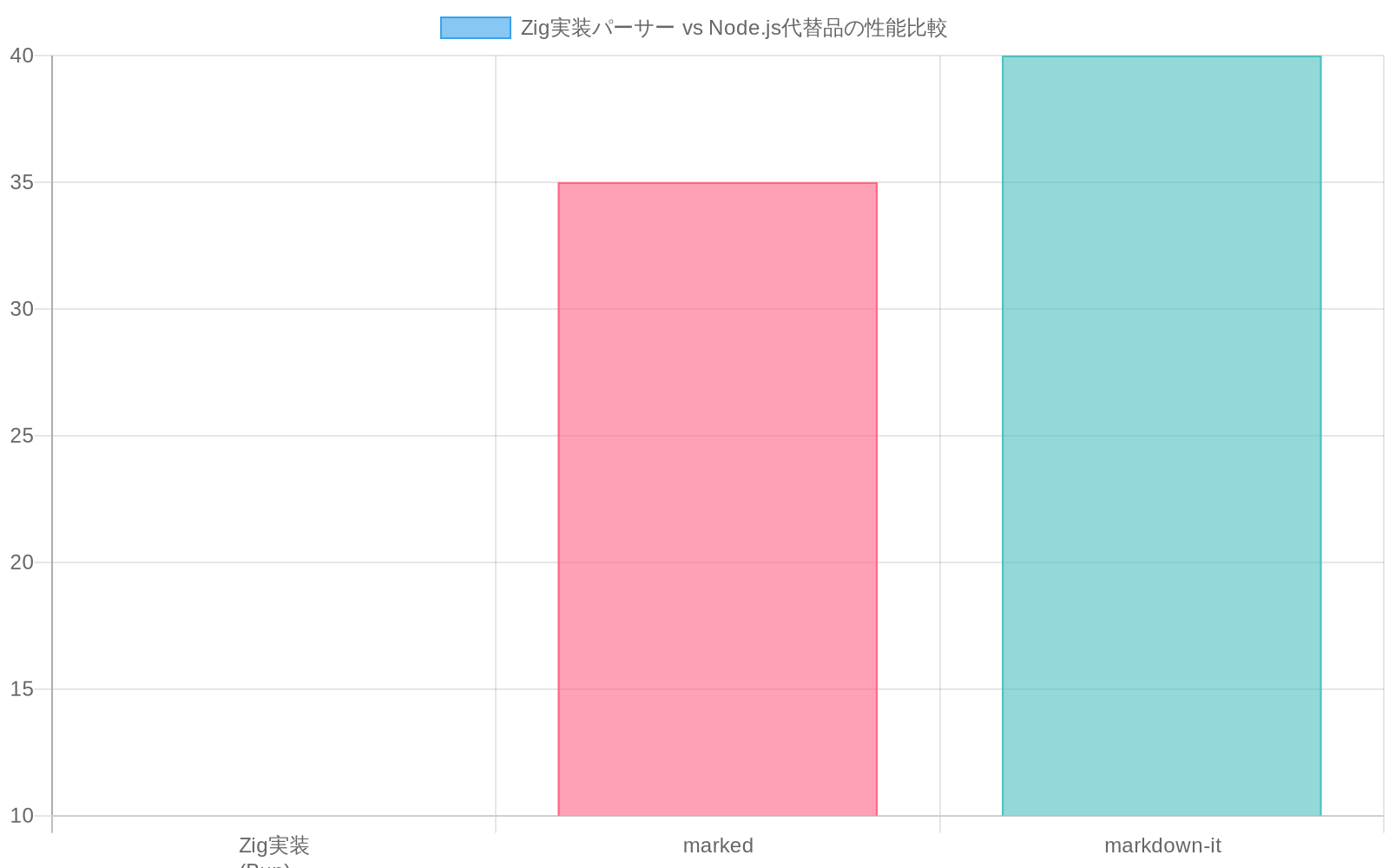
- 図2:Zig実装パーサー vs Node.js代替品の性能比較(10,000語ドキュメント解析時間)*
HTMLレンダリングとGitHub Flavored Markdown対応
このパーサーは組み込みHTMLレンダリングとネイティブGFM対応を備えており、テーブル、打消し線、タスクリスト、自動リンクを含む。これらの機能は現代的なドキュメンテーションと協調プラットフォームに不可欠である。この統合アプローチは、markdown-to-webワークフローで典型的なツールチェーンの複雑性を削減する。
従来、markdown処理は複数のライブラリの連鎖を要求する。パーサー(例えばremark)、GFM拡張用プラグイン、レンダラー(例えばrehype)である。各ハンドオフは設定オーバーヘッドと潜在的な非互換性を導入する。Bunはこれらを単一の最適化されたパスに統合する。
- 例:* Bunを使用するドキュメンテーションサイトは、markdownをHTMLに単一の関数呼び出しで変換できる。
import { parseMarkdown } from 'bun:markdown';
const html = parseMarkdown(markdownString);プラグイン設定なし、別個のレンダラー初期化なし。出力は本番対応のHTMLであり、GFM機能はデフォルトで有効である。
- 次のステップ:* 現在のmarkdownパイプラインが簡素化可能かどうかを評価すること。カスタムプラグインを保守しているか、GFMエッジケースの回避策を実装しているなら、Bunのパーサーへの移行は保守負担を削減し、コードベース全体の一貫性を改善する可能性がある。
React要素生成とコンポーネント統合
HTMLの出力を超えて、Bunのパーサーはサーバーサイドレンダリング(SSR)と静的サイト生成(SSG)ワークフローを可能にするReact要素を直接生成できる。中間シリアライゼーションなしである。ほとんどのmarkdown-to-ReactワークフローはmarkdownをHTMLの文字列に変換し、その後それらの文字列をReactコンポーネントに解析する。これは非効率な二重パスである。Bunのパーサーはシリアライゼーションオーバーヘッドをバイパスして、React要素を直接発行する。
- 例:*
import { parseMarkdownToJSX } from 'bun:markdown';
const elements = parseMarkdownToJSX(markdownString);
export default function Page() {
return <div>{elements}</div>;
}このアプローチは、markdownがコンテンツソースとして機能するNext.jsまたはRemixアプリケーションで特に価値がある。レンダリング性能が改善され、クライアント側でHTMLパースライブラリが不要になるため、バンドルサイズが縮小する。
- 次のステップ:* Reactでコンテンツプラットフォームやブログを構築するなら、重要でないコンポーネントでBunのJSX出力をプロトタイプ化すること。レンダリング時間とバンドル影響を測定する。改善が実質的なら、markdown集約的なページの段階的な移行を計画する。
統合パターンと運用上の考慮事項
Bunのパーサーを採用するには、その統合ポイントと運用上の制約を理解する必要がある。
-
アーキテクチャパターン1:ビルド時統合* Bunはビルドフェーズ中に呼び出され、Markdownファイルを処理してHTMLまたはJSONを出力できる。アプリケーションランタイム(Node.js、Pythonなど)は生成されたアーティファクトを消費する。このパターンはランタイム依存性をBunに対して最小化する。
-
アーキテクチャパターン2:ランタイム統合* Bunで実行されるアプリケーションは、リクエストハンドラーまたはコンポーネントレンダリング内でパーサーを直接使用できる。このパターンはBunをアプリケーションランタイムとして要求する。
-
パターン1(ビルド時)の前提条件:*
-
ビルドシステムは外部バイナリの呼び出しをサポートする必要がある(npmスクリプト、Makefile等)
-
Markdownソースファイルはビルドフェーズ中に安定している必要がある
-
出力アーティファクトは適切にバージョン管理またはキャッシュ破棄される必要がある
-
パターン2(ランタイム)の前提条件:*
-
アプリケーションはBunランタイムにデプロイ可能である必要がある
-
Bunはすべてのプロジェクト依存関係と互換性がある必要がある
-
運用インフラストラクチャはBunをサポートする必要がある(コンテナイメージ、プロセスマネージャー等)
-
想定:* パターン1は既存のNode.jsプロジェクトにとってリスクが低い。完全なランタイム移行を回避するからである。パターン2はより密接な統合を提供するが、より大きなプラットフォームコミットメントを要求する。
測定と検証
Bunのパーサーを大規模に採用する前に、ベースラインメトリクスと成功基準を確立する。すべてのプロジェクトが高速markdownパースから等しく恩恵を受けるわけではない。大量のコンテンツプラットフォームは劇的なROIを見る。低頻度のパース シナリオは移行オーバーヘッドを正当化しないかもしれない。
- 3つのメトリクスをベンチマークすること:*
- 解析レイテンシ: markdownを出力形式(HTMLまたはJSX)に変換する時間。
- スループット: 負荷下で1秒あたりに処理されるドキュメント数。
- メモリ使用量: バッチ処理中のピークおよび平均メモリ消費。
代表的なデータでベンチマークを実行する。合成テストケースではなく、実際のmarkdownコーパスを使用する。現在のパーサーとBunを本番コンテンツボリュームで比較するベンチマークスイートを作成する。Bunが30%以上の改善を提供し、ビルドまたはランタイムがmarkdown制約なら、移行を優先する。改善が限定的なら、採用を延期する。
リスク評価と軽減
新しいツールの採用はリスクを導入する。バージョン安定性、エコシステム成熟度、潜在的な非互換性である。Bun v1.3.8は安定しているが、markdownパーサーは比較的新しい。エッジケースは特定のmarkdown方言またはカスタム拡張に存在する可能性がある。
-
主要なリスクと軽減策:*
-
カスタムmarkdown拡張: コンテンツが非標準構文を使用する場合、徹底的にテストする。Bunのパーサーはすべてのカスタムプラグインをサポートしないかもしれない。軽減: フォールバックパーサーを保持し、コンテンツを段階的に標準GFMに移行する。
-
バージョン安定性: Bunの更新は破壊的な変更を導入する可能性がある。軽減: ビルド設定でBunバージョンをピンし、本番前にステージング環境でアップグレードをテストする。
-
エコシステムカップリング: Node.jsと比較してBunの第三者統合は少ない。軽減: ランタイム依存関係ではなくビルド時ツールとしてBunを使用し、エコシステムカップリングを最小化する。
完全な採用前に、重要でないコンテンツでパイロットを実行する。非互換性を文書化し、ロールバック計画を確立する。
移行ロードマップ
BunのMarkdownパーサーはJavaScriptツーリングの意味のある性能改善を表す。実質的なmarkdownコンテンツを処理するチームにとって、利益は評価と段階的採用を正当化する。ビルド時統合から開始し、ベンチマークを実行し、リスクを軽減し、成功が検証されたらランタイム統合に進む。この段階的アプローチは、プラットフォームコミットメントを最小化しながら、性能向上を実現する。

- 図3:従来のMarkdownツールチェーン vs Bunの統合パイプライン*