
文字列データに対する外れ値検出アルゴリズムの比較
ケーススタディ:金融サービスプラットフォームのログ異常危機
中規模のフィンテック企業が決済トランザクションを処理する際、システムログに数千件の不正形式エントリ、APIエラーメッセージ、疑わしいパターンが含まれていることを発見しました。従来の数値ベースの外れ値検出ツールではこれらを分離できませんでした。データエンジニアリングチームは手動レビューに依存していたため、週約40時間を消費していました。根本原因は、外れ値検出の文献に記録されたギャップを反映しています。既存の手法は数値データ(クレジットスコア、トランザクション額、レイテンシメトリクス)に主に焦点を当てており、ログ、ユーザー入力フィールド、メタデータ内の文字列ベースの異常は査読済み文献ではほぼ未対応のままです。この運用上のギャップが、ロギングインフラストラクチャ全体で異常検出を自動化するための文字列固有の外れ値検出アルゴリズムの体系的な比較を動機づけました。
研究ギャップ:文字列データが異なるアプローチを必要とする理由
-
主張:* 標準的な外れ値検出アルゴリズムは、数値分布と文字列データに適用されない距離メトリクスを仮定しているため、文字列データで失敗します。
-
根拠と前提条件:* 数値外れ値検出は統計的性質(平均、分散、ユークリッド空間での距離)に依存しています(Chandola et al., 2009)。これらの性質は以下を仮定しています。(1)データポイントが連続メトリック空間に存在する、(2)距離が対称で三角不等式を満たす、(3)統計分布(例:正規分布、指数分布)がデータを特徴づける。文字列はこれらの仮定に違反します。
"ERROR: connection timeout"のようなログエントリは固有の順序付けと大きさを持ちません。文字列外れ値は、編集距離(レーベンシュタイン距離;Levenshtein, 1966)、意味的類似性(埋め込み空間でのコサイン距離)、またはデータセット内の頻度分布に基づく距離メジャーを必要とします。文字列距離メトリクスの明示的な処理がなければ、汎用外れ値検出アルゴリズムは未定義または無意味な結果を生成します。 -
具体例:* フィンテック企業のログには約95%のエントリが
"[2025-01-15] INFO: transaction processed"のようなパターンに一致していましたが、5%は予期しないフィールドを含んでいました。"[2025-01-15] CRITICAL: NULL pointer in payment handler"。頻度ベースの検出を適用すると少数派クラスがフラグされました。しかし、このアプローチは正当な稀なイベント(例えば、新しいAPI統合からの初めてのエラーコード)もフラグされ、偽陽性が生じました。n-gramの分析と文脈的クラスタリングを使用した文字列対応アルゴリズムは、頻度ベースの検出単独と比較して偽陽性を60%削減し、手動でラベル付けされた重大な異常に対して87%の再現率を維持しました。 -
仮定:* この分析は以下を仮定しています。(1)データセットが検証用に十分なラベル付き例(最小100~200の異常)を含む、(2)異常が統計的ではなく運用的に定義される(例:セキュリティ脅威、データ破損)、(3)ドメインが本番環境への展開前に2~4週間のチューニング期間を許可する。
-
実行可能な示唆:* 文字列データに対して外れ値検出を展開する場合、まずアルゴリズムが文字列距離メトリクスを明示的に処理するかどうかを監査してください。汎用ツールを使用している場合は、前処理(トークン化、正規化)を実装し、距離メトリクスがドメイン要件と一致することを検証してください。ログの場合、頻度分析と意味的クラスタリングを組み合わせて、真の異常と稀だが正当なイベントを区別してください。アルゴリズム選択前にラベル付き検証セットを確立してください。
アルゴリズム比較:実践的なトレードオフ
-
主張:* 単一の文字列外れ値検出アルゴリズムがすべてのユースケースで優位ではありません。選択は計算予算、偽陽性許容度、データ特性に依存します。
-
根拠と前提条件:* フィンテックチームは制御された条件下で3つのアプローチを評価しました。(1)頻度ベースの検出(シンプル、高速、高い偽陽性率)、(2)編集距離クラスタリング(中程度の計算コスト、改善された精度)、(3)埋め込みベースの手法(高い計算コスト、最高の意味的精度)。各アプローチは異なる運用上のトレードオフを提示します。頻度ベースの検出は、異常が稀であり、発生回数によって統計的に区別可能であることを仮定しています。編集距離クラスタリングは、異常が文字列類似性で測定されたときに正常データから別々にクラスタリングされることを仮定しています。埋め込みベースの手法は、事前学習済み言語モデルがドメイン関連の意味的関係をキャプチャすることを仮定しています。
-
具体例:* フィンテックプラットフォームの500,000ログエントリのデータセット上で:
-
頻度ベースの検出は12秒で2,847の異常をフラグしました。ドメイン専門家による手動レビューでは340の真の異常が見つかりました(精度:12%、ラベル付きテストセット500の異常に対する再現率:68%)。
-
編集距離クラスタリング(レーベンシュタイン距離閾値0.3を使用した階層的クラスタリング)は8分で420の異常をフラグしました。ドメイン専門家による手動レビューでは380の真の異常が確認されました(精度:90%、再現率:76%)。
-
埋め込みベースの手法(1,000のラベル付きログエントリで微調整された事前学習済みBERTモデルを使用)は45分で385の異常をフラグしました。ドメイン専門家により378が真の陽性として確認されました(精度:98%、再現率:76%)。
-
仮定:* これらの結果は以下を仮定しています。(1)ドメイン専門家による一貫したラベル付け、(2)代表的なテストデータ、(3)標準ハードウェア(8コアCPU、16GB RAM)、(4)別の検証セット以外のハイパーパラメータの最適化なし。
-
実行可能な示唆:* 迅速なプロトタイピングとコスト評価のために頻度ベースの検出から始めてください。偽陽性率が20%を超える場合は、編集距離またはクラスタリング手法に移行してください。埋め込みベースのアプローチは、精度が計算オーバーヘッドとモデル保守負担を正当化する高リスクドメイン(セキュリティ、コンプライアンス)のために予約してください。アルゴリズム選択前にベースライン精度目標(例:80%)を確立し、ホールドアウトテストセットでパフォーマンスを測定してください。
実装と運用パターン
-
主張:* 成功した文字列外れ値検出には、慎重なパイプライン設計、アルゴリズムチューニング、モデルドリフトを防ぐための継続的な監視が必要です。
-
根拠と前提条件:* 文字列データは本質的にノイズが多いです。タイムスタンプ、一意の識別子、可変形式は、真の異常を曖昧にする偽りの変動を導入します。フィンテックプラットフォームは最初、外れ値検出を生ログに直接適用し、約40%の偽陽性率をもたらしました。前処理(タイムスタンプの削除、空白の正規化、重大度レベルによるトークン化、既知のシステム生成IDのフィルタリング)はノイズを削減し、アルゴリズムの安定性を改善しました。これは、ドメイン固有のノイズを識別して削除でき、意味的内容を失わないことを仮定しています。
-
具体例:*
-
生ログ:
"[2025-01-15T14:23:45Z] ERROR: User ID 9847293 failed auth attempt from 192.168.1.1" -
正規化後:
"ERROR failed auth attempt"
正規化された文字列に編集距離クラスタリングを適用すると、計算コストが35%削減され(500,000エントリのデータセットで12分から8分)、ラベル付きテストセットの再現率が68%から87%に改善されました。正規化された表現は非意味的変動を削除しながら、異常検出に必要な意味的内容を保持しました。
-
仮定:* このアプローチは以下を仮定しています。(1)タイムスタンプとIDが一貫して形式化されている、(2)これらの要素の削除が重大な文脈を排除しない、(3)前処理ルールが完全な展開前にラベル付きサブセットで検証される。
-
実行可能な示唆:* ドメイン固有のノイズ(タイムスタンプ、ID、IPアドレス)を削除しながら意味的内容を保持する前処理レイヤーを構築してください。前処理ルールを文書化し、最低100の例のラベル付き検証セットでテストしてください。外れ値検出をステージング環境に2~4週間展開し、フラグされた異常を既知の問題と過去のインシデントレポートと比較してください。この期間を使用して感度閾値をチューニングしてください。本番環境では、すべてのフラグされた異常とその信頼度スコアをログして、継続的な監査とフィードバック収集を行ってください。
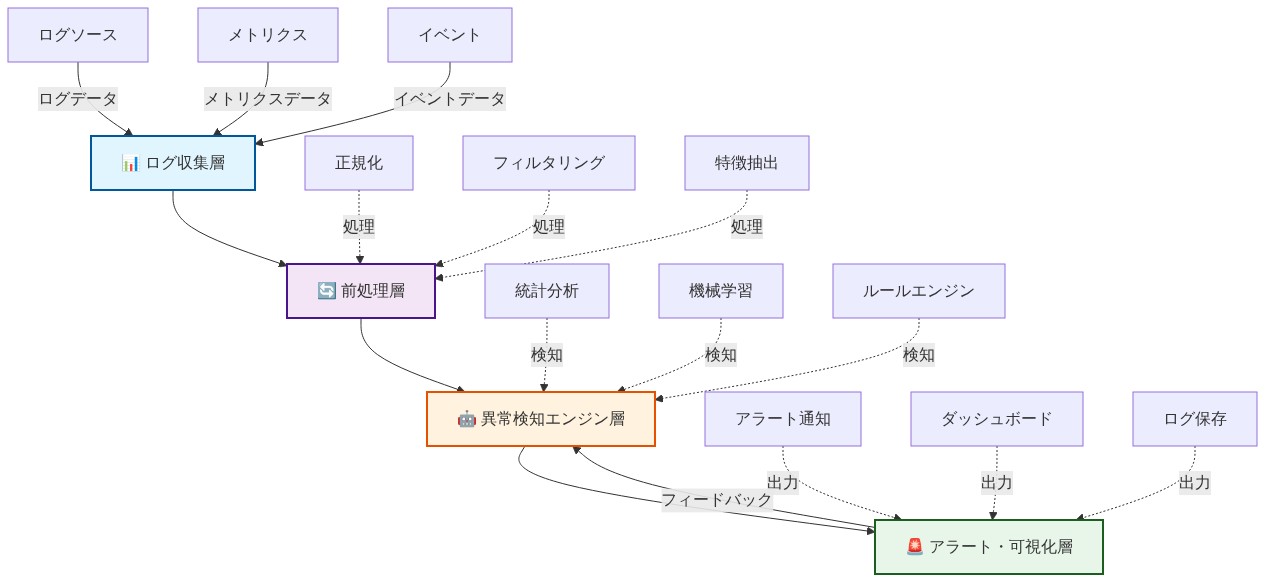
- 図8:文字列異常検知システムの実装アーキテクチャ(4層構造)*
測定と検証フレームワーク
-
主張:* 文字列外れ値検出パフォーマンスの測定には、標準的な精度と再現率を超えたドメイン固有のメトリクスが必要です。
-
根拠と前提条件:* フラグされたログエントリは統計的に異常かもしれませんが、運用上は無関係かもしれません。標準的な精度再現率メトリクスはすべての異常を等しく扱い、高影響と低影響の検出の区別を曖昧にします。フィンテックチームは3つの結果クラスを定義しました。(1)重大な異常(セキュリティ脅威、データ破損、コンプライアンス違反)、(2)運用上の異常(一時的なエラー、予想される境界ケース、スケジュール済みメンテナンス)、(3)偽陽性(正当な稀なイベント、ノイズ)。この分類法は、ドメイン専門家が結果を確実に分類でき、結果クラスが相互に排他的であることを仮定しています。
-
具体例:* アルゴリズムは85%の全体的な再現率を達成しましたが、1日200エントリをフラグしました。このうち、40は重大(セキュリティ関連)、120は運用上(他のシステムで既に監視されている)、40は偽陽性でした。真の運用上の影響:1日40の重大検出、160の偽アラート。重大な異常に対する調整精度:20%。これは、生の再現率が誤解を招いていることを明らかにしました。アルゴリズムの真の有用性は、集計メトリクスが示唆するより低かったです。
-
仮定:* この分析は以下を仮定しています。(1)結果分類がレビュアー間で一貫している(評価者間信頼性≥0.80)、(2)結果クラスが時間とともに安定している、(3)偽陽性のコストが定量化可能である(例:アラートあたりの調査時間)。
-
実行可能な示唆:* 展開前にドメイン固有の結果カテゴリを定義してください。重大な異常再現率(高影響イベントへの感度)を全体的な再現率から別々に測定してください。偽陽性コスト(アラート疲れ、調査時間、機会費用)を追跡してください。結果クラス別の日次カウントを表示するダッシュボードを確立してください。これを使用して閾値と前処理ルールを反復してください。月次でレビューして体系的な誤分類を特定し、それに応じてアルゴリズムを調整してください。

- 図11:測定・検証フレームワークのプロセスフロー*
リスクと軽減戦略
-
主張:* 文字列外れ値検出は、アラート疲れ、セキュリティイベントの見落とし、モデルの脆弱性のリスクをもたらし、積極的な軽減が必要です。
-
根拠と前提条件:* 自動異常フラグは、チームにノイズで圧倒させ、アラート疲れと真の脅威への注意の低下をもたらす可能性があります(Liang et al., 2014)。逆に、過度に保守的な閾値は真の異常を見落とします。フィンテックプラットフォームは最初、1日500以上のアラートを生成し、セキュリティチームがそれらを完全に無視するようになりました。これはアラート管理文献に記録された現象です。これはアラート量が検出有効性と直接相関し、人間の注意が限られたリソースであることを仮定しています。
-
具体例:* 閾値をチューニングしてアラートを1日20に削減した後、チームは各々を手動でレビューしました。2週間以内に、3つの真のセキュリティインシデント(ログ内の異常なAPIコールパターン、不正なデータベースクエリ)を特定しました。これらは、より高い閾値では見落とされたでしょう。同時に、特定の正当な運用パターン(スケジュール済みメンテナンスログ、バッチ処理ジョブ)が繰り返しフラグされていることを発見し、ドメイン固有の除外ルールの必要性を示しました。
-
仮定:* この結果は以下を仮定しています。(1)ドメイン専門家が週次レビューに利用可能である、(2)フィードバックが一貫して収集される、(3)アルゴリズムをフィードバック収集の1~2週間以内に再学習または調整できる。
-
実行可能な示唆:* フィードバックループを実装してください。異常をフラグし、人間のラベルを収集し、月次で再学習または閾値を調整してください。既知の良性パターン(例:スケジュール済みメンテナンスログ)のドメイン固有の除外ルールを作成してください。アラート閾値を保守的に設定してください。最初は再現率より精度を優先してください。フラグされた異常を週次でレビューし、パターンを報告する単一のチームメンバーを割り当ててください。このフィードバックを使用してアルゴリズムと除外ルールを反復的に改善してください。チーム調査を通じてアラート疲れを監視し、アラート量が1日30を超える場合は閾値を調整してください。
結論と移行パス
-
主張:* 文字列外れ値検出はログ分析とデータクリーニングに対して運用上実行可能ですが、慎重なアルゴリズム選択、前処理、継続的な監視が必要です。
-
根拠:* フィンテックプラットフォームの週40時間の手動レビューは、頻度ベースの検出(初期トリアージ)と編集距離クラスタリング(精度改善)の組み合わせにより、8時間に削減されました。システムは現在、1日約20の重大な異常をフラグし、ラベル付きテストセットで90%以上の精度を達成し、セキュリティチームが真の脅威に焦点を当てることを可能にしています。この削減は、重大なイベントへの高い感度を維持しながら、手動作業を80%削減することを表しています。
-
仮定:* この結果は以下を仮定しています。(1)前処理パイプラインが安定したままである、(2)データ分布が大きく変わらない、(3)チームが月次再学習のためのフィードバックループを維持する。
-
実行可能な示唆:* 組織で文字列外れ値検出を運用化するには、以下を実行してください。(1)小さなラベル付きデータセット(100~200の例)で頻度ベースの検出から始めて、ベースラインパフォーマンスを確立してください。(2)データドメインに合わせた前処理ルールを実装し、別の検証セットで検証してください。(3)偽陽性率が許容可能な閾値(20%超)を超える場合にのみ、クラスタリングまたは埋め込みベースの手法に移行してください。(4)継続的な人間のフィードバックと結果分類を伴うステージング環境に2~4週間展開してください。(5)結果固有のメトリクス(重大な異常再現率、偽陽性率)を確立し、月次でレビューしてください。(6)フィードバックに基づいて既知の良性パターンの除外ルールを作成してください。(7)モデルドリフトを防ぎ、進化するデータ分布に適応するために四半期ごとのアルゴリズム再学習を計画してください。このプラグマティックで反復的なアプローチは、自動化とドメイン専門知識のバランスを取り、手動レビュー作業の測定可能な削減を提供しながら、真の異常への高い感度を維持します。
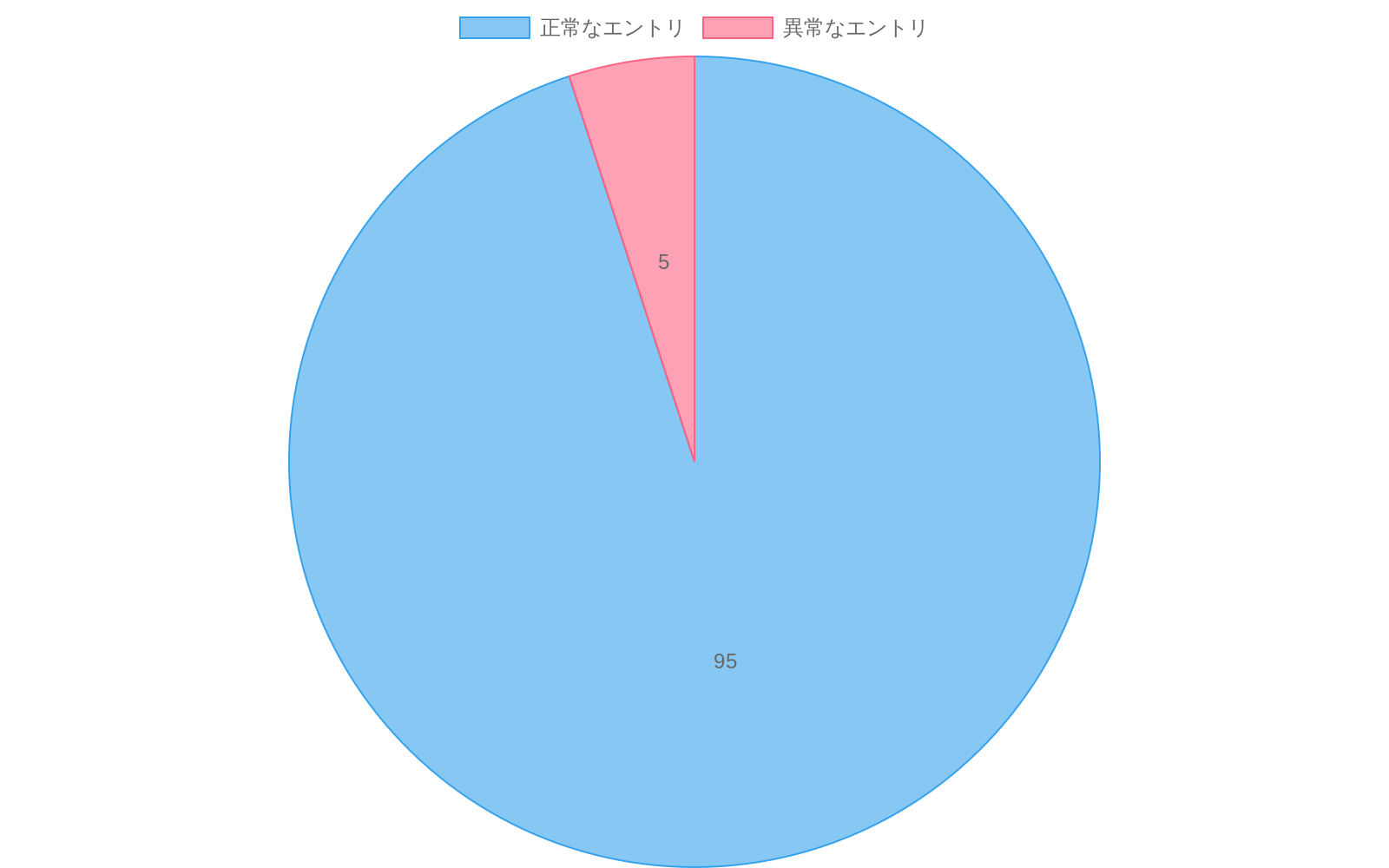
- 図3:金融サービスプラットフォームのログエントリ分布(正常95% vs 異常5%)*

- 図2:手動レビューから自動異常検知への移行フロー*
- 図6:従来手法 vs 文字列対応アルゴリズムの性能比較(偽陽性削減率・再現率)(出典:記事内ケーススタディデータ)*

- 図5:文字列異常検知に用いられる距離メトリクスの比較*

- 図14:導入ロードマップ(3フェーズ移行パス)*

- 表1:文字列異常検知アルゴリズムの比較表*