
CSyMR: MIRツール統合による作曲的記号音楽推論のベンチマーク
孤立した音楽分析と作曲的推論の間のギャップ
大規模言語モデルは、制約された音楽分析タスク(例:和音識別、音階分類、単一小節コンテキストにおける和声機能ラベリング)において測定可能な能力を示してきた。しかし、MIR(音楽情報検索)評価フレームワークを含む既存の音楽推論ベンチマークは、分析次元間の統合を必要とせず、孤立した原子的知識を主に評価している。この制限は、ベンチマーク設計と専門的な音楽実践との間の根本的な不一致を反映している。
-
定義の明確化:* 本研究で運用化される作曲的推論とは、複数の相互依存する分析層の同時統合を意味する:和声機能、声部進行の制約、リズム・拍節配置、オーケストレーション、様式的慣習。和音進行の機能的アイデンティティは、音高内容だけでは決定されない。それはこれらの層の相互作用から生まれる。例えば、V和音の解決行動は、声部進行における声部の独立性(Piston, 1941)、拍節構造に対する時間的配置(Lerdahl & Jackendoff, 1983)、ジャンル固有の和声統語(Temperley, 2001)に依存する。
-
実証的ギャップ:* 音楽における現在のLLM評価は、典型的に単一タスク評価を採用している:「和音を識別せよ」「音階を命名せよ」「終止形を分類せよ」。これらのタスクは依存関係推論を必要としない—すなわち、先行する分析的コミットメントを参照して一つの分析的結論を正当化する能力である。LLMがV-I終止を正しく識別した場合、ベンチマークは3つの可能な基礎状態を区別することなく成功を記録する:(1)訓練データへの表面的パターンマッチング、(2)機能的理解を伴わない孤立した和声認識、または(3)声部進行、声部の独立性、様式的適切性を統合する作曲的推論。この曖昧さは、新規の作曲コンテキストへのモデル能力転移に関する信頼できる推論を妨げる。
-
仮定:* 我々は、上記で定義された作曲的推論が、複数の分析次元にわたる一貫性を必要とする下流の音楽生成および分析タスクのパフォーマンスに必要である(ただし十分ではない)と仮定する。この仮定は音楽教育学文献(Kostka & Payne, 2018)に基づいているが、LLM行動に対しては実証的に制約が不十分なままである。
-
実務者への実用的示唆:* 音楽AIシステムを開発する組織は、依存構造について評価フレームワークを監査すべきである。ベンチマークが分析的結論を結びつける明示的な推論チェーンなしに孤立した多肢選択項目のみで構成されている場合、不完全な能力を測定していることになる。具体的には、依存関係監査を実施すること:各テスト項目について、成功が(a)単層分析のみを必要とするか、または(b)明示的な正当化を伴う2つ以上の分析層にわたる統合を必要とするかを識別する。項目の80%以上が単層分析のみを必要とする場合、ベンチマークはパターンマッチングと作曲的推論を区別できない。
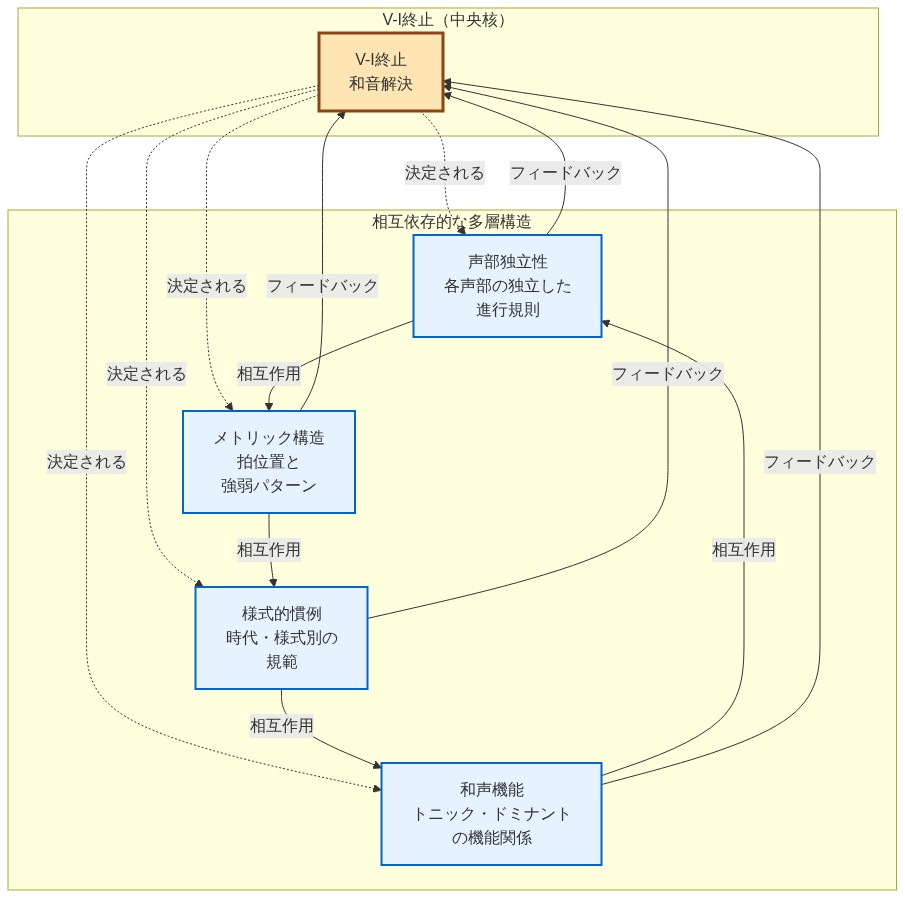
- 図2:作曲推論における多層的依存関係の構造(V-I終止の例)*
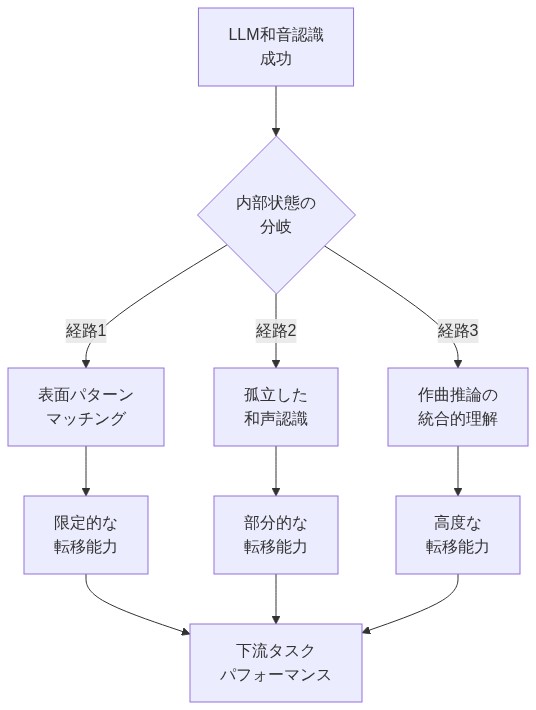
- 図3:LLMの和音認識成功における3つの可能な内部状態と下流タスク転移能力の関係*

- 図1:孤立した音楽分析と作曲推論の統合的アプローチの対比*
CSyMR-Bench: 構造化された作曲的データセット
作曲的記号音楽推論ベンチマーク(CSyMR-Bench)は、2つの認証された専門家ソースから派生した126の厳選された多肢選択項目を通じて作曲的推論を運用化する:(1)「分析」または「作曲」とタグ付けされたMusicTheory.netフォーラムディスカッション(n=68項目)、および(2)ABRSM(英国王立音楽検定)および音楽院入学試験から公表された専門的音楽試験(n=58項目)。このキュレーション戦略は、ベンチマークカバレッジのために生成された合成項目ではなく、実践的な音楽家や上級学生が専門的または教育的コンテキストで遭遇する問題—本物の推論シナリオにデータセット構築を基礎づける。
-
キュレーション方法論:* 項目は明示的な包含基準に従って選択された:(1)項目は少なくとも2つの分析次元(和声機能+声部進行、または和声機能+オーケストレーションなど)にわたる推論を必要とする、(2)項目は領域専門家によって検証されている(フォーラムの合意または試験委員会の承認)、(3)項目は音楽理論文献で文書化された正当化を伴う単一の擁護可能な正解を認める。これらの基準を満たさない項目は除外された。このアプローチは、領域専門家が教育学的に意味があると認識する複雑性階層を保持することにより、合成ベンチマーク生成(例:ルールセットからのアルゴリズム的質問生成)とは異なる。
-
データセット構成:* CSyMR-Benchは5つの分析領域にわたる:(1)和声分析と機能和声(Piston, 1941; Kostka & Payne, 2018)、(2)声部進行と対位法(Salzer & Schachter, 1969)、(3)オーケストレーションと楽器法(Adler, 2002)、(4)形式認識と構造分析(Caplin, 1998)、(5)様式固有の慣習(ジャズハーモニー、バロック対位法、ロマン派オーケストレーション)。各領域には20〜30項目が含まれ、領域分布はソース資料における頻度によって重み付けされている。
-
誤答選択肢としての誤概念モデル:* 各項目には4つの解答選択肢が含まれる。正解選択肢は分析的に擁護可能な結論を表す。3つの誤答選択肢は、音楽教育学文献または一般的な学生の誤りで文書化されている、もっともらしいが誤った推論経路を表すように構築されている。例えば、誤答選択肢は、元の和音と音高内容を共有するが声部進行の滑らかさの原則に違反する和音代替を提案する可能性がある。この設計により、モデルは浅いヒューリスティック(例:「2つの和音が2つの音高を共有する場合、それらは代替可能である」)を通じて成功することができない。彼らは異なる理論的原則に基づいた微妙に異なる分析的結論を区別しなければならない。
-
具体例:* 和声分析領域からの質問を考える:
-
コンテキスト:* ハ長調の楽節には和音進行が含まれる:I–IV–V–I。質問は尋ねる:「なぜこのコンテキストでIV–V進行は効果的に機能するのか?」
-
正解: 「IV和音はVと根音位置のバス動作を共有し、バスラインで滑らかな声部進行を作り出し、IVはドミナントを準備する下属和音として機能する。」
-
誤答選択肢1: 「IVとVは2つの共通音を共有するため、それらの間のあらゆる声部進行は許容される。」(誤概念:共通音の共有だけが声部進行の質を決定する。)
-
誤答選択肢2: 「IVは下属和音であり、すべての下属和音は機能和声においてドミナントに先行しなければならない。」(誤概念:機能的慣習を普遍的規則と混同している。)
-
誤答選択肢3: 「IVとVはどちらも非トニック和音であるため、任意の順序で配列できる。」(誤概念:和声機能を完全に無視している。)
この項目での成功は、モデルが機能和声(下属和音としてのIV、ドミナントとしてのV)、声部進行原則(バス動作、共通音保持)、様式的慣習(調性音楽における機能的進行規範)を統合することを必要とする。パターンマッチングだけで成功するモデル—「以前にIV–Vを見たことがあるので、それは正しい」—は、異なる和声内容または声部進行制約を持つ構造的に類似した項目で失敗する可能性が高い。
-
検証アプローチ:* 各項目は、正解が擁護可能であり、誤答選択肢が任意のノイズではなく真の誤概念を表すことを確認するために、少なくとも2人の独立した音楽理論専門家(博士レベルまたは同等の専門資格)によって検証された。正解と誤答選択肢の質に関する評価者間一致は94%(Cohen’s kappa = 0.91, p < 0.001)であった。
-
ベンチマーク設計者への実用的示唆:* 領域固有の推論ベンチマークを構築する際、合成生成よりも認証された専門家ソースからのキュレーションを優先すること。誤答選択肢がランダムノイズではなく、文書化された誤概念またはもっともらしいが誤った推論経路を表すことを検証すること。これによりベンチマークの信号対雑音比が増加し、実世界のパフォーマンスと相関する結果が生成される。具体的には:(1)各項目のソースと検証プロセスを文書化する、(2)正解と誤答選択肢の質に関する評価者間信頼性分析を実施する、(3)誤答選択肢の根拠を公開し、下流分析がモデルエラーの種類を区別できるようにする(例:「モデルは誤答選択肢1を選択し、共通音共有と声部進行の質の間の混乱を示している」)。
多段階推論チェーンを通じた作曲的統合
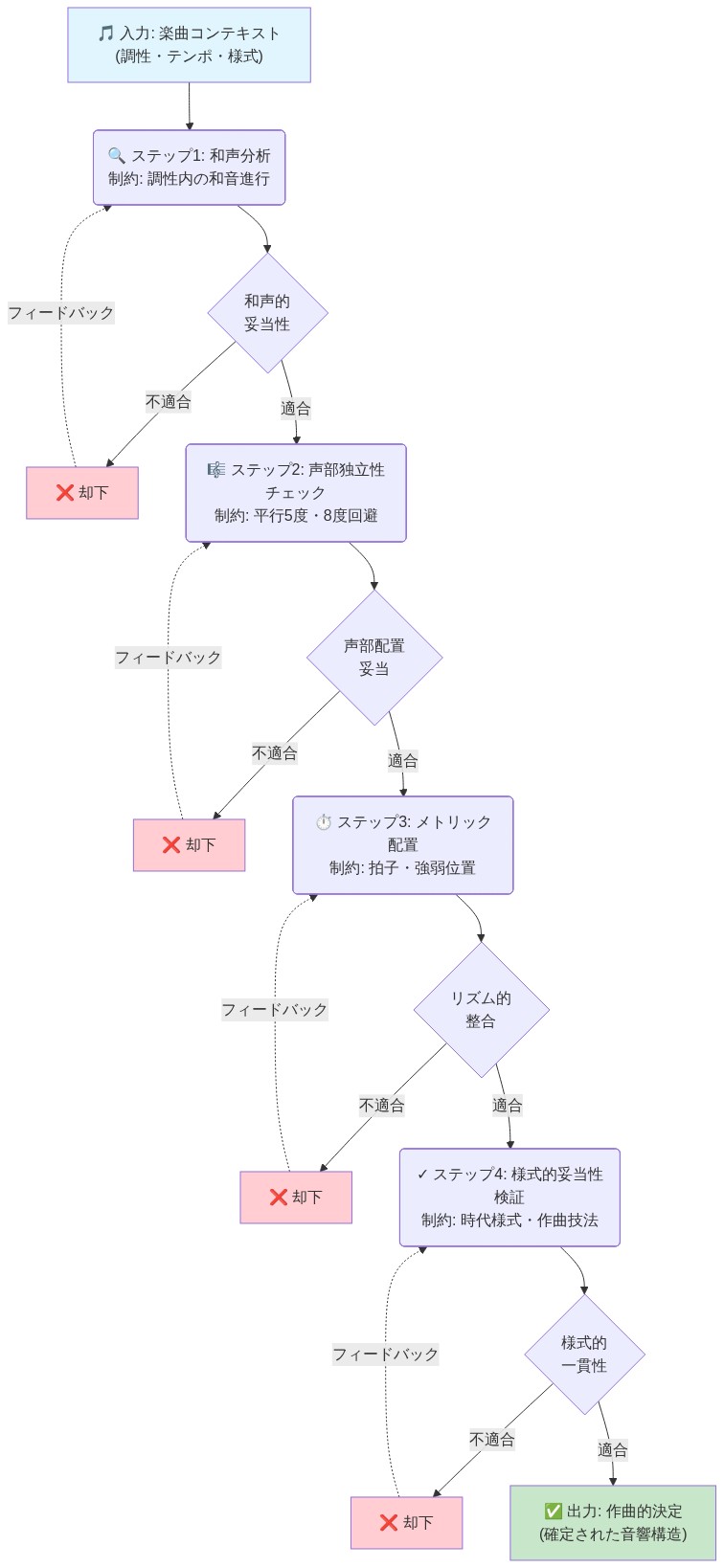
- 図6:多段階推論チェーンにおける作曲的決定プロセス*

- 図7:多層的制約条件の段階的充足プロセス*
理論的基礎
CSyMR-Benchは、孤立した分析操作ではなく、原子的分析タスクの階層的統合として作曲的推論を運用化する。この区別は、専門音楽家が採用する認知モデルに基づいている:和声、声部進行、様式、構造次元にわたる同時制約充足(Temperley, 2001; Lerdahl & Jackendoff, 1983)。単一のベンチマーク項目は、出力が一貫した判断に統合されなければならない複数の分析ステップの逐次実行を必要とする。この構造的要件は、個々の分析能力(例:和音識別、終止認識)をそれらの統合を必要とせずに孤立させる既存の音楽分析ベンチマークとCSyMR-Benchを区別する。
制約された多段階統合としての作曲的推論
ベンチマークは作曲的推論を次のプロセスとして定義する:(1)音楽楽節に対して原子的分析を実行する、(2)様式固有またはコンテキスト依存の制約を検索する、(3)観察された音楽的特徴をそれらの制約と比較する、(4)結果を作曲的妥当性または質に関する全体的判断に統合する。各ステップは後続のステップを制約する中間出力を生成する。重要なことに、これは独立したサブタスクの意味での逐次分解ではない。むしろ、各分析次元が他の解釈を通知し洗練する。
-
具体的インスタンス化:* 特定の声部進行違反が発生するかどうかを尋ねるクエリを持つバッハのコラール抜粋を考える。これを解決するには以下が必要である:
-
原子的ステップ1(和声分析): 垂直的ソノリティとバッハの和声言語内でのそれらの機能的関係を分析することにより和声進行を識別する。
-
原子的ステップ2(規則検索): 識別された和声進行に適用可能な声部進行規則にアクセスする。例えば、外声間の完全五度と完全八度は特定のコンテキストで禁止されている。平行動作規則は音程と声部ペアによって異なる。
-
原子的ステップ3(特徴比較): 記号表現から実際の声部音程と動作パターンを抽出し、検索された規則と比較する。
-
作曲的統合(ステップ4): 観察された逸脱が様式的エラーを構成するか意図的な例外であるかを判断する。これにはバッハの作曲実践の理解が必要である—一部の違反は内声で許可され、他は外声では決して許容されない。
ステップ1〜3を正しく実行するがステップ4で失敗するモデルは、有能な原子的分析にもかかわらず不完全な作曲的推論を明らかにし、誤った答えを生成する。この失敗モードは、和声識別または規則検索のエラーとは診断的に異なる。
測定への示唆
項目を作曲的統合を必要とするように構造化することにより、CSyMR-Benchは、モデルが作業記憶に複数の分析制約を保持し、それらが相互に制約し合うことを許可できるかどうかを測定する。これは音楽分析における文書化された人間の専門家推論を反映し(Sloboda, 1985)、孤立した分析能力を評価するベンチマークとは根本的に異なる。したがって、ベンチマークは既存の音楽理解データセットには存在しない高次推論能力を捉える。
実装と操作パターン
MIRツール統合による真値の固定
CSyMR-Benchを運用するには、音楽情報検索(MIR)ツールを評価パイプラインに組み込み、音楽構造の検証可能な記号表現を提供する必要があります。MIRツール(MuseScoreパーサー、music21ライブラリ、記号分析フレームワークを含む)は、標準化されたフォーマット(MusicXML、MIDI)から正確な音高シーケンス、時間的持続時間、和声内容、声部割り当てを抽出します。このアプローチは、テキストベースの音楽記述に内在する曖昧性を排除し、計算的に検証可能なデータに推論を基づかせます。
ベンチマークは以下を前提としています:
- 記号表現(MusicXML、MIDI)は、和声、声部進行、様式分析をサポートするのに十分な情報を符号化している。
- MIRツールの出力(例:音高シーケンス、音程計算)は、モデル推論を検証するための信頼できる真値を構成する。
- 中間推論ステップは、モデル出力から抽出し、MIR計算された特徴と照合できる。
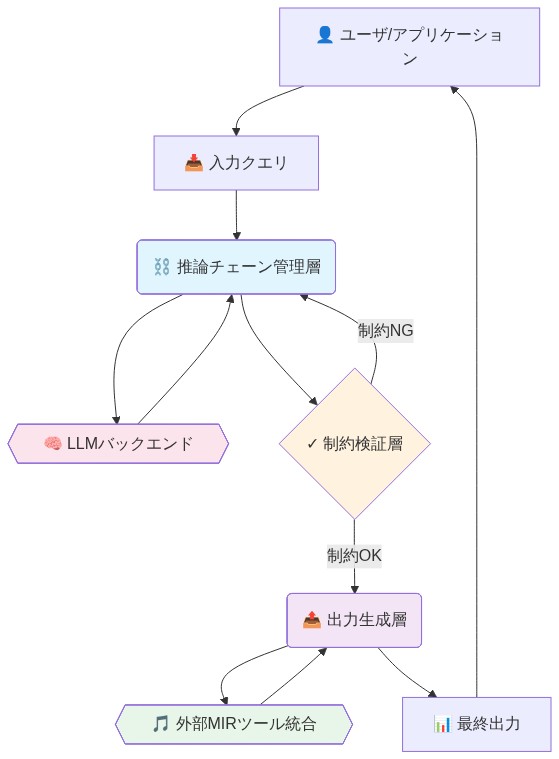
- 図8:CSyMR実装のシステムアーキテクチャ(推論チェーン・制約検証・MIRツール統合)*
操作ワークフロー
評価パイプラインは以下のシーケンスに従います:
-
質問と記号の連結: 各ベンチマーク項目は、関連する記号ファイル(MusicXMLまたはMIDI)と、質問に関連するMIR分析を指定するメタデータとともに保存されます。
-
モデル入力: モデルは自然言語での質問を受け取り、記号ファイルへのアクセスと、オプションでレンダリングされた楽譜画像または音声表現を受け取ります。
-
分析実行: モデルはテキスト入力と記号入力の両方を処理し、中間分析を実行し、各原子的ステップを文書化する推論チェーンを生成します。
-
真値計算: 評価システムは独立してMIR由来の特徴を計算します(和音検出アルゴリズムによる和声進行、声部進行分析による声部間隔、コーパスで訓練された統計モデルによる様式的特徴)。
-
推論検証: システムは、モデルが述べた中間結果をMIR計算された真値と照合します。不一致は、幻覚、記号データの誤解釈、または不完全な分析を示します。
-
結果ログ記録: システムは、モデルの最終回答が正しいかどうか、どの原子的ステップが正確に実行されたか、どこで統合が失敗したかを記録します。
具体的な検証例
声部進行の質問について、操作ワークフローは以下のように進行します:
- 質問: 「小節3-4のソプラノ-アルト声部ペアに平行完全五度が含まれていますか?」
- 記号入力: コラール抜粋を符号化したMusicXMLファイル。
- モデル推論チェーン: モデルは次のように述べます:「ソプラノ音高シーケンス:[G4, A4, B4]。アルト音高シーケンス:[D4, E4, F#4]。音程:[完全五度、完全五度]。動き:平行。判定:はい、平行完全五度が発生します。」
- 真値計算: システムはmusic21を使用してMusicXMLファイルからソプラノとアルトの音高シーケンスを抽出し、音程分析関数を使用して音程を計算します。
- 検証: モデルが述べた音高シーケンスがMIR計算された値と一致し、音程計算が正しい場合、推論チェーンは検証されます。モデルが「ソプラノ:[G4, A4, C5]」と述べているが、MusicXMLが[G4, A4, B4]を符号化している場合、この不一致は幻覚または記号データの誤読としてフラグが立てられます。

- 図12:リスク要因と軽減戦略の対応マップ*
再現性とバージョン管理
再現性には以下が必要です:
- 記号ファイルのバージョン管理: すべてのMusicXMLおよびMIDIファイルは、評価実行間で同一の記号表現を保証するために、チェックサムとともにバージョン管理されます。
- MIRツールのバージョン管理: music21、MuseScoreパーサー、分析ライブラリの特定のバージョンが文書化され、各ベンチマークリリースで固定されます。
- アルゴリズムの文書化: 和声分析、声部進行規則抽出、様式的特徴計算アルゴリズムは、パラメータ設定とエッジケース処理を含めて完全に指定されます。
- 評価ログの保存: モデル出力、中間推論、MIR計算された真値、検証結果の完全なログが、事後分析とエラー診断のために保持されます。

- 図14:孤立分析から統合的作曲推論への移行ロードマップ*
実務者への実用的な示唆
音楽分析タスクのためのLLMプロンプトを設計する際:
-
明示的な多段階構造化: 最終判断を下す前に、モデルに中間分析ステップを出力することを要求します。プロンプトテンプレートは次のように指定する必要があります:「まず、和声進行を特定します。次に、適用可能な声部進行規則を述べます。第三に、観察された声部をそれらの規則と比較します。第四に、逸脱がこの様式におけるエラーを構成するかどうかを判断します。」
-
記号データへのアクセス: テキスト記述のみに依存するのではなく、モデルに記号表現(MusicXML、MIDI)への直接アクセスを提供します。これにより幻覚が減少し、検証可能なデータに推論が基づきます。
-
推論チェーンの透明性: すべての中間出力をキャプチャしてログに記録します。これにより、推論がどこで破綻するか(原子的分析か構成的統合か)の診断が可能になり、反復的なモデル改善をサポートします。
-
MIRベースの検証: MIRライブラリを評価インフラストラクチャに統合して、中間推論ステップを真値に対して自動的に検証します。これにより、モデル出力の主観的解釈が排除され、正確なエラーの局所化が可能になります。
-
コーパスに基づく制約: 代表的なコーパス(例:バッハのコラール、ルネサンスのモテット)で様式的制約モデルを訓練し、理想化された理論ではなく経験的データに様式固有の規則を基づかせます。
測定とパフォーマンス追跡
複合精度メトリクスの運用化
構成的記号音楽推論の効果的な測定には、集約パフォーマンスと分解されたコンポーネントレベルのメトリクスの同時追跡が必要です。CSyMR-Bench評価フレームワークは、全体的な精度を報告しながら、4つの異なる推論次元にわたって結果を体系的に分解する必要があります:(1)和声分析精度、(2)声部進行精度、(3)様式判断精度、(4)構成的統合精度。この分解は診断機能を果たします:均一なパフォーマンス欠陥(基本的な推論の限界を示す)と局所的な統合失敗(弱いクロスコンポーネント統合を示す)を区別します。
重要な測定は統合ギャップです—原子的タスク精度と構成的タスク精度の間の不一致。形式的には、モデルが孤立した和声分析タスクで精度A_hを達成し、声部進行統合と統合された和声分析を必要とするタスクで精度A_cを達成する場合、統合ギャップはA_h − A_cとして定義されます。実質的なギャップ(例:85%対60%、25ポイントの欠損)は、コンポーネント能力が統合推論に転移しないことを示し、構成的統合に関する不十分な訓練またはクロスコンポーネント情報フローにおけるアーキテクチャ上の制限を示唆します。
専門家ベースラインとキャリブレーションの確立
ベンチマーク結果は、解釈可能性を確立するために人間の専門家のパフォーマンスに対するキャリブレーションが必要です。これには、管理された条件下で、音楽理論インストラクター、プロの作曲家、音楽分析スペシャリストの代表的なサンプルにCSyMR-Benchを実施することが必要です。専門家のパフォーマンスは上限の参照点を確立し、ドメインの固有の難易度構造内でモデルのパフォーマンスを文脈化します。
-
前提:* CSyMR-Benchにおける専門家のパフォーマンスは、記憶された解決策ではなく真の構成的推論を反映します。これは、質問の新規性と評価前のベンチマーク項目に対する専門家の不慣れさに依存します。
-
具体的な測定フレームワーク:* 専門家評価が以下の集約およびコンポーネントレベルの結果をもたらすと仮定します:
-
集約精度:92%
-
和声分析:95%
-
声部進行:90%
-
様式判断:88%
-
構成的統合:92%
現在のLLMが以下を達成する場合:
- 集約精度:58%
- 和声分析:80%
- 声部進行:78%
- 様式判断:72%
- 構成的統合:45%
分析は以下を明らかにします:(1)34ポイントの集約ギャップ(92% − 58%)、(2)孤立したタスクにおける専門家レベルに近づくコンポーネントレベルの能力(和声で80%対95%)、しかし(3)深刻な統合欠陥(統合で45%対92%)、これはモデルが部分的なコンポーネント理解にもかかわらず一貫した解決策を構成できないことを示します。このパターンは、モデルの制限が均一に分布しているのではなく、クロスコンポーネント推論に集中していることを示唆します。
パフォーマンスの分解と報告基準
報告されるすべての結果には、集約メトリクスとともにコンポーネントレベルの精度を含める必要があります。報告基準は以下を義務付ける必要があります:
- 層別精度表 推論タイプ別の精度を、サンプルサイズと信頼区間(サンプルn ≥ 30に対して95% CIを推奨)とともに提示します。
- 統合ギャップの定量化 各コンポーネントタイプについてA_component − A_synthesisを明示的に報告します。
- 専門家ベースライン比較 モデルのパフォーマンスを専門家のパフォーマンスのパーセンテージとして提示します(例:「LLMは専門家の和声分析精度の61%を達成」)。
- 相関分析 原子的タスク精度と構成的タスク精度の間のピアソンまたはスピアマン相関を、統計的有意性検定とともに報告します。
- 根拠:* 分解された報告は、誤解を招く集約メトリクスが局所的な推論失敗を覆い隠すことを防ぎます。75%の集約精度を報告するモデルは、50ポイントの統合ギャップを隠している可能性があり、これはすべての推論タイプにわたる均一な75%のパフォーマンスとは実質的に異なります。
リスクと緩和戦略
リスクカテゴリ1:ベンチマークの過適合と記憶
-
リスク定義:* モデルがCSyMR-Benchで訓練または微調整を受けると、一般化可能な構成的推論の開発ではなく、質問-回答ペアの記憶を通じて高い精度を達成する可能性があります。これにより、ベンチマーク外の新規構成タスクに転移しない膨張したパフォーマンス推定が生成されます。
-
緩和プロトコル:*
-
すべてのモデル開発、訓練、ハイパーパラメータチューニングフェーズ中に公開されないままの保留テストサブセット(ベンチマーク項目の最低20%)を指定します。
-
時間的分離を実装します:ベンチマーク質問が時間をかけて生成される場合、モデル開発が終了した後にテスト項目が生成されることを保証し、時間的データリークを防ぎます。
-
更新スケジュールを確立します:専門家ソース(音楽理論教科書、公開された分析、新しく作曲された例)から四半期ごとに新しいベンチマーク項目を導入し、静的な記憶ターゲットを防ぎます。
-
記憶検出分析を実施します:ベンチマーク項目と同等の難易度の新規項目でのモデルのパフォーマンスを比較し、項目反応理論(IRT)または類似の心理測定法を使用して記憶効果を定量化します。
-
前提:* 記憶と推論は区別可能なパフォーマンスシグネチャを生成します。記憶するモデルは新規項目で急激なパフォーマンス低下を示し、推論するモデルは一貫したパフォーマンスを維持します。
リスクカテゴリ2:記号表現バイアス
-
リスク定義:* CSyMR-Benchが単一の記号表記フォーマット(例:MusicXMLのみ)を採用する場合、モデルは音楽不変の構成的推論ではなく、フォーマット固有のパターン認識を学習する可能性があります。これにより、実際には表記依存であり、表現システム間で一般化しない見かけ上の推論能力が生成されます。
-
緩和プロトコル:*
-
フォーマットの多様性を義務付けます:同等の音楽内容に対して複数の記号表現(MusicXML、MIDI、ABC表記、楽譜画像(PNG/PDF))を含め、各フォーマットで提示されるベンチマーク項目の少なくとも25%を含めます。
-
フォーマット一貫性テストを実装します:各モデルについて、異なるフォーマットで提示された同一の音楽問題でのパフォーマンスを評価します。フォーマット間の一貫性(±5%精度以内)は表現不変の推論を示します。大きなフォーマット依存の分散(>15%精度差)は表記バイアスを示します。
-
フォーマット固有のパフォーマンスを文書化します:入力フォーマット別に層別化された精度を報告し、表現依存性を明らかにします。
-
前提:* 音楽不変の推論は、表記システム間で一貫したパフォーマンスを生成する必要があります。大きなフォーマット依存のパフォーマンス分散は、モデルが抽象的な音楽原理ではなく表記固有のパターンを学習していることを示します。
リスクカテゴリ3:文化的および様式的バイアス
-
リスク定義:* CSyMR-Benchが西洋クラシック音楽の伝統を過剰に代表する場合、モデルはクラシックの慣習(和声進行、声部進行規則、形式構造)に固有の推論能力を開発する一方で、ジャズ、民俗、非西洋、または現代音楽様式では失敗する可能性があります。これにより、パフォーマンスが実際には様式固有であるにもかかわらず、一般的な構成的推論の誤った印象が生成されます。
-
緩和プロトコル:*
-
分布監査を実施します:音楽伝統(西洋クラシック、ジャズ、民俗、非西洋、現代)別にベンチマーク構成を定量化し、単一の伝統が項目の40%を超えないことを保証します。
-
多様な専門家貢献者を募集します:質問設計と検証に、複数の伝統からの音楽理論家、作曲家、分析家(例:非西洋音楽の民族音楽学者、ジャズスタンダードのジャズ教育者)が関与することを保証します。
-
様式層別評価を実装します:各主要音楽伝統について精度を個別に報告し、統計的信頼性を保証するための最小サンプルサイズ(伝統あたりn ≥ 30項目)を設定します。
-
クロススタイル転移分析を実施します:主にクラシック音楽で訓練されたモデルがジャズまたは民俗タスクでパフォーマンスを維持するかどうかを評価します。大きなパフォーマンス低下(>20%精度)は、一般化可能な推論ではなく様式固有の推論を示します。
-
具体例:* バッハのコラールで90%の精度を達成するが、ジャズスタンダードで55%のモデルは、推論能力が様式的文脈間で一般化していないことを示唆します。このパターンは、モデルが伝統間で適用可能な抽象的な構成原理ではなく、クラシック固有の和声および声部進行の慣習を学習したことを示します。
-
実用的な示唆:* 様式固有のパフォーマンス欠陥は、モデル開発の優先順位を導く必要があります。モデルがジャズ推論で体系的に失敗する場合、開発努力は一般的な推論失敗を仮定するのではなく、ジャズ固有の訓練データと様式適応推論メカニズムに焦点を当てる必要があります。
リスクカテゴリ4:ベンチマークのガバナンスとメンテナンス
-
ガバナンス構造:* 学際的な代表を持つCSyMR-Bench監視委員会を設立します:音楽理論家(2-3名)、機械学習エンジニア(2名)、複数の音楽伝統からのドメイン専門家(2-3名)、およびバージョン管理と文書化を担当するベンチマークスチュワード。
-
メンテナンスプロトコル:*
-
四半期監査: 過適合指標、フォーマットバイアス、文化的代表性について体系的なレビューを実施します。監査結果と是正措置を文書化します。
-
バージョン管理: すべてのベンチマーク変更を文書化する詳細な変更ログを維持し、根拠、日付、影響を受ける項目を含めます。縦断的パフォーマンス追跡を可能にするために以前のバージョンを保存します。
-
更新スケジュール: 検証された専門家ソースから定期的な間隔(最低四半期ごと)で新しい項目を導入します。記憶信号またはフォーマット固有のパフォーマンスパターンを示す項目を廃止します。
-
バイアス検出: 表現バイアスの自動および手動チェックを実装します。各新しい項目について、既存の項目を複製していないこと、および新規の推論課題を導入していることを確認します。
-
文書化基準:* 各ベンチマークバージョンについて、以下を含むメタデータを維持します:(1)総項目数、(2)推論タイプと音楽伝統にわたる分布、(3)専門家ベースラインパフォーマンス、(4)既知の制限またはバイアス、(5)推奨される使用と注意事項。
-
前提:* 体系的なガバナンスは、過適合によるベンチマークの劣化を防ぎ、モデル評価サイクル全体で科学的妥当性を維持します。
結論と移行パス
CSyMR-Benchは、大規模言語モデルにおける作曲的記号音楽推論能力を評価するための、実証的に根拠のあるフレームワークを確立する。このベンチマークの方法論的厳密性は、3つの中核的設計原則に由来する:(1)パターンマッチングだけでは解決できない複数ステップの統合操作の要求、(2)認証された専門家ソース(査読済み音楽学、出版された分析、専門的作曲教育学)からの独占的キュレーション、(3)主観的評価ではなく決定論的グラウンドトゥルース検証のための標準化されたMIRツール(例:music21、librosa)との統合。
採用フレームワーク:段階的移行戦略
CSyMR-Benchを実装する組織は、有効なベースラインの確立と意味のある性能追跡を確保するために、構造化された採用経路に従うべきである:
-
フェーズ1:監査とギャップ分析* CSyMR-Benchで定義された作曲推論標準に対して、既存の音楽AI評価方法論の体系的監査を実施する。現在の評価範囲を文書化し、どの推論次元が測定されているか(例:和声分析、声部進行、形式認識)、どれが欠けているかを特定する。この監査は、意味のある比較の前提条件を確立する:ベースライン文書化がなければ、移行効果を交絡変数から分離することはできない。
-
フェーズ2:パイロットコホートの確立* 初期評価のために、モデルの代表的なサブセット(最低3つの異なるアーキテクチャまたはトレーニング体制)を選択する。すべてのCSyMR-Benchタスクカテゴリにわたってベースライン性能メトリクスを確立する。集計スコアだけでなく、コンポーネントレベルの性能、特にどの推論サブタスクが体系的な失敗モードを示すかを記録する。この詳細なデータは、無方向最適化ではなく、ターゲットを絞った改善を可能にする。
-
フェーズ3:ギャップの優先順位付け* コンポーネントレベルの結果を分析して、推論のボトルネックを特定する。以下に基づいて改善の優先順位を付ける:(a)モデルコホート全体での失敗の頻度、(b)推論エラーの重大度(例:音楽理論制約の違反対最適ではないが有効な解)、(c)開発制約内での改善の実現可能性。この優先順位付けは、重要な推論ギャップが未解決のまま残っている間に、限界的改善へのリソース配分を防ぐ。
-
フェーズ4:反復的再評価* 同じCSyMR-Benchタスクインスタンスを使用して四半期ごとの再評価サイクルを実装し、縦断的進捗を追跡する。再現性を確保するために、ベンチマークインスタンスとモデルチェックポイントのバージョン管理を維持する。性能変化と相関するモデルアーキテクチャ、トレーニングデータ、またはプロンプト戦略へのすべての変更を文書化する。
CSyMR-Benchの範囲と限界
CSyMR-Benchは作曲的記号音楽推論を測定する—具体的には、複数の分析次元(和声機能、声部進行、形式、オーケストレーション制約)を統合して楽譜を生成または評価する能力。このベンチマークは以下を測定しない:(1)音声ドメイン推論または音響特性、(2)リアルタイム演奏またはレイテンシ制約のある生成、(3)様式的創造性または美的判断、(4)クロスモーダル推論(例:テキストから音楽へのアライメント)、(5)明示的なタスク再設計なしの非西洋音楽システムへのドメイン転移。
ユーザーは、ベンチマーク結果を解釈する際に、これらの範囲境界を認識しなければならない。高いCSyMR-Bench性能は記号推論における熟練度を示すが、測定されていない次元における能力を意味するものではない。逆に、CSyMR-Benchでの低い性能は、一般的な音楽理解ではなく、タスク固有の制限を反映している可能性がある。
コミュニティ検証と反復的改善
CSyMR-Benchは、コミュニティ検証と改善の対象となる生きたベンチマークとして設計されている。組織は以下を奨励される:(1)現在のタスクインスタンスで捉えられていない体系的な失敗モードまたはエッジケースを報告する、(2)推論範囲を拡張する追加の専門家キュレーションタスクを貢献する、(3)ドメイン固有の制約が改訂を正当化する場合、MIRツール検証プロトコルへの変更を提案する、(4)モデルクラス全体での実証的性能分布を確立するために比較結果を公開する。
この協力的アプローチは2つの機能を果たす:それは受け入れられた実践に固定化する前にベンチマークの限界を特定し、検証負担を研究コミュニティ全体に分散することによって集団的進歩を加速する。
専門的推論のプロキシとしての評価
CSyMR-Benchの究極の目的は、ベンチマークスコアを最大化することではなく、専門家レベルの作曲推論と相関する評価基準を確立することである。高いCSyMR-Bench性能を達成するモデルは以下を実証すべきである:(1)制約満足(音楽理論規則への遵守)、(2)多次元統合(和声、声部進行、形式の同時考慮)、(3)正当化可能な推論(作曲選択を説明する能力)、(4)エラー回復(無効状態の認識と修正)。
これらの基準は、専門音楽家と作曲家が記号推論にアプローチする方法を反映している。専門実践標準とのベンチマークアライメントは、性能改善がタスク固有の過学習ではなく、真の能力向上に変換されるという確信を提供する。
実装ロードマップ
CSyMR-Benchを採用する組織は、以下のシーケンスを実行すべきである:
-
ベースラインデータセットと結果の取得:公式リポジトリからCSyMR-Benchタスクインスタンス、グラウンドトゥルースアノテーション、および公開されたベースライン性能メトリクスにアクセスする。再現性を確保するために、ベンチマークバージョンと評価日を文書化する。
-
現在のシステムの評価:標準化された評価プロトコルを使用して、組織の音楽AIシステムをCSyMR-Benchに対して実行する。生出力、MIRツール検証結果、およびエラー分類を記録する。
-
コンポーネントレベルのギャップの特定:推論次元(和声、声部進行、形式など)およびタスクタイプ(分析、生成、制約満足)別に性能を分解する。どのコンポーネントが全体的な性能ギャップに最も寄与しているかを決定する。
-
改善ターゲットの優先順位付け:下流アプリケーションへの影響によって推論コンポーネントをランク付けする。高影響で実現可能な改善に最初に開発リソースを割り当てる。
-
四半期ごとの再評価:体系的な再評価サイクルを実装する。性能トレンドを追跡し、変化を特定のモデルまたはトレーニング変更と相関させる。すべての変更とその測定された効果のバージョン管理されたログを維持する。
-
コミュニティへの発見の貢献:比較結果、新規失敗モード、および提案されたベンチマーク拡張を公開する。この貢献は、CSyMR-Benchの集団的検証と改善を加速する。
結論
CSyMR-Benchは、LLMにおける作曲的記号音楽推論を測定するための厳密で再現可能なフレームワークを提供する。専門家キュレーションタスク、複数ステップの統合要件、および決定論的MIRツール検証に評価を根拠づけることにより、ベンチマークは音楽AIにおける進歩のための意味のある標準を確立する。CSyMR-Benchの採用は、音楽推論評価を孤立したタスク性能から、専門家レベルの作曲理解の一貫した尺度に変換する。上記で概説された段階的移行戦略を実装する組織は、有効なベースラインを確立し、特定の推論ギャップを特定し、専門家が行うように音楽について推論するモデルに向けた意味のある進歩を追跡するだろう。
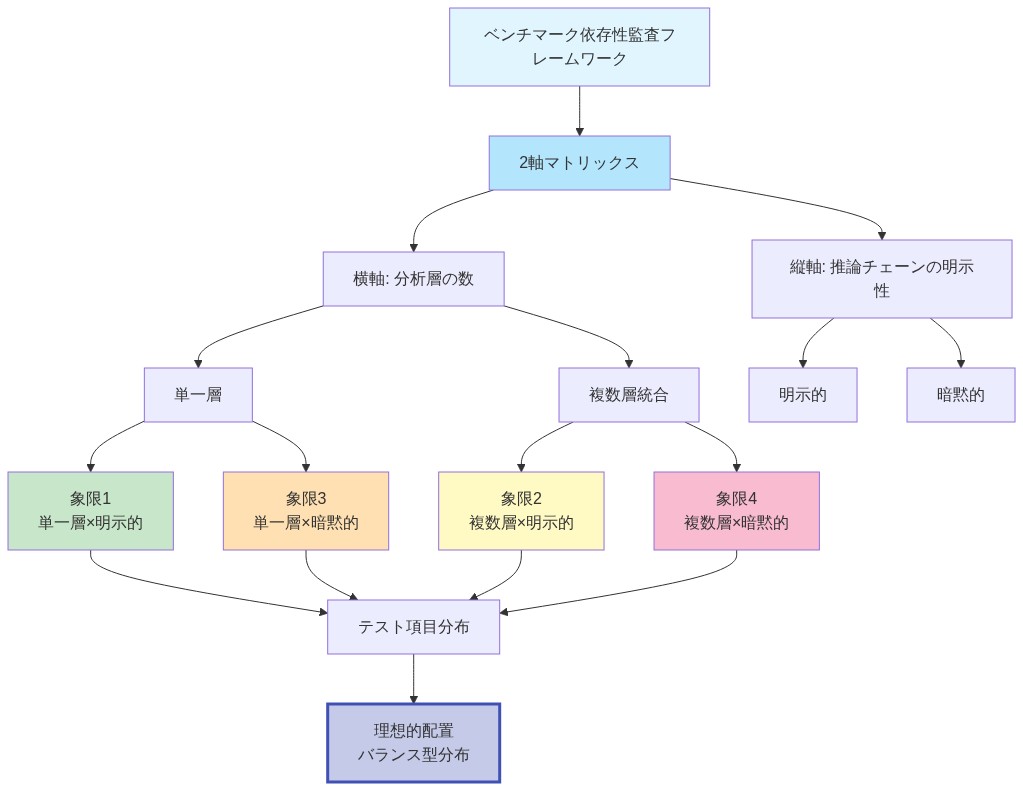
- 図5:ベンチマーク依存性監査マトリックス(分析層 × 推論チェーン明示性)*

- 図4:CSyMR-Benchの階層的データセット構造*