
未来の相関を解く:時空間予測のための結合周波数領域学習
ポイント単位の損失関数が時空間構造を見落とす理由
標準的な予測モデルは平均二乗誤差(MSE)または平均絶対誤差(MAE)を最適化します。これらの目的関数は、各空間位置と時間ステップで予測誤差を独立に罰します。このアプローチは暗黙の仮定に基づいています。すなわち、ポイント単位の誤差を最小化することが、交通ネットワーク、気象グリッド、センサアレイといったグラフ構造データに内在する依存関係を自動的に捉えるという仮定です。経験的証拠と理論的分析は、この仮定が成立しないことを示しています。
- メカニズムと理論的ギャップ*:損失関数が個々のノードと時間ステップにおける予測誤差の大きさのみを罰する場合、モデルが隣接ノード間の空間相関を学習したか、時間を通じて繰り返される時間パターンを学習したかについて、明示的な監督を提供しません。形式的には、位置iと時刻tにおける予測ŷと真値yを考えます。MSEベースの訓練は以下を最小化します。
$$\mathcal{L}{\text{MSE}} = \frac{1}{NT} \sum{t=1}^{T} \sum_{i=1}^{N} (\hat{y}{i,t} - y{i,t})^2$$
この目的関数はyのスペクトル構造、すなわち空間次元と時間次元の両方における周波数全体のエネルギー分布に対して無関心です。モデルは低いMSEを達成しながら、周波数内容が真値から大きく乖離する予測を生成できます。鋭い遷移が生じるべき場所で滑らかな変動を予測したり、周期的なリズムを完全に見落としたりします。
-
具体的な反例*:200個の交差点を持つ交通流ネットワークを考えます。2つのモデルが検証セットで15%の正規化MSEを達成したとします。モデルAは空間的に相関のない予測を生成します。各交差点の予測は経験的平均を中心とした独立ノイズです。モデルBは、ネットワークトポロジーを尊重する予測を生成し、上流の渋滞が物理的に現実的な速度で下流に伝播します。両モデルはMSE目的関数を等しく最小化します。しかし、モデルBは流れ伝播の因果構造を保持するため、運用上優れています。これらの予測を消費する下流システム(信号制御器、リソース配分アルゴリズム、異常検知器)はこの一貫性に依存しています。
-
運用上の帰結*:予測を消費するシステムは通常、時空間の一貫性を前提とします。相関構造を破壊する15%の大きさの誤差は、それを保持する20%の大きさの誤差より運用上悪化しています。訓練目的と運用要件の間のこのズレは、現在の実践における体系的な盲点を表しています。
-
仮定と前提条件*:この分析は、(1)基礎となるデータが利用可能な時空間構造(自己相関、空間的一貫性、伝播パターン)を示し、(2)下流アプリケーションがこの構造に依存していることを前提としています。これらの仮定は、ほとんどの地理空間およびネットワークベースの予測タスクに当てはまりますが、完全にランダムまたは完全に相関のないデータには適用されません。
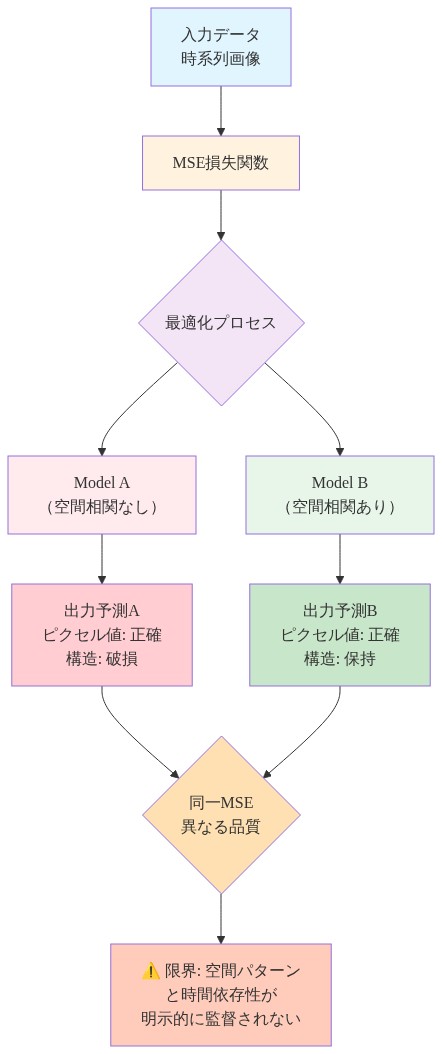
- 図2:MSE損失関数が見落とす空間相関構造と時間パターン依存性*
周波数領域手法が隠れた依存関係を明らかにする方法
フーリエ変換とウェーブレット変換は信号を周波数成分に分解し、周期的構造と自己相関を明示的にします。最近の研究は周波数領域分解を時系列予測に適用しており、トレンド、季節性、残差ノイズを分離し、予測精度の向上が文書化されています(Oreshkin et al., 2021; Zhou et al., 2022)。この時間周波数分析は確立されています。
しかし、時間周波数分析だけではグラフ構造データには不十分です。交通ネットワークは、時系列自己相関(渋滞パターンは時間単位および日単位の周波数で繰り返される)だけでなく、空間相関(隣接する交差点は流れ保存を通じて相互に影響する)および交差項(空間的近接性と時間的ラグの相互作用)を示します。FreDF(Zhou et al., 2022)のような既存の周波数領域手法は時間自己相関を処理します
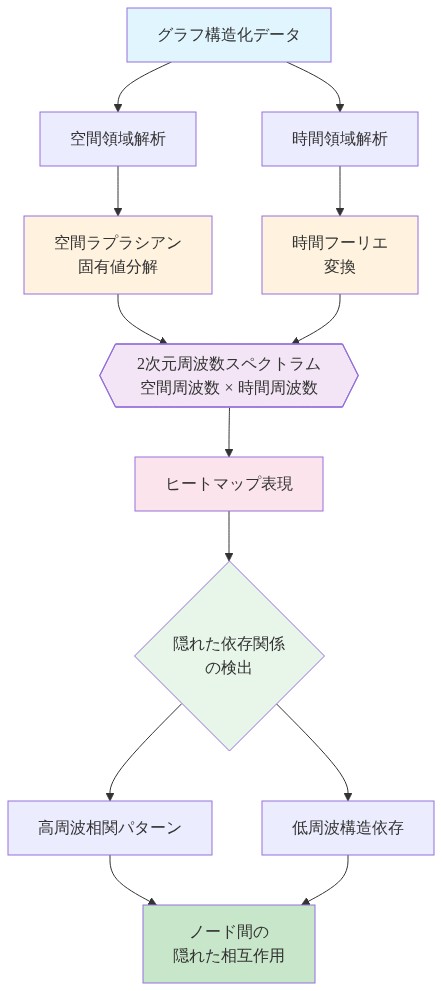
- 図5:空間周波数と時間周波数の2次元スペクトラム構造 - グラフ信号処理における隠れた依存関係の周波数領域解析*