
LLM埋め込み空間における離散的意味状態とハミルトン動力学
LLM埋め込みにおける数学的構造
大規模言語モデルは、学習された変換を通じて意味情報を高次元ベクトル空間に投影する。これらの空間の内部組織—連続的か離散的か—は、未解決の実証的問題である。最近の計算的調査は、LLM埋め込みが均一な連続分布ではなく、離散的な意味組織と一致するクラスタリングパターンを示すことを示唆している。具体的には、意味的に類似した概念を表すトークンは埋め込み空間内の局所的な近傍を占める傾向があり、一方で非類似トークンは一貫した角度的またはユークリッド的分離を維持する。
この観察は形式化に値する:我々は、埋め込み空間が識別可能な意味状態—意味的に一貫したトークン集合が集中するベクトル空間内の安定した領域—を含むことを提案する。この仮説は2つの仮定に基づいている:(1)モデルの訓練目的(交差エントロピー損失下での次トークン予測)が、意味的に類似したトークンのクラスタ化された表現を優遇する選択圧を生み出すこと、および(2)この圧力が学習された埋め込み幾何学において検出可能な構造を生成するのに十分強いこと。
実証的支持は、トランスフォーマーベースのモデル(GPT-2、GPT-3、BERT、および類似のアーキテクチャ)からのトークン埋め込みを調査することから得られる。「happy」、「joyful」、「delighted」などの同義語が埋め込まれ、それらのペアワイズ距離が計算されると、同等の濃度のランダムに選択されたトークンペアよりも相互距離の分散が小さいことを示す。逆に、「happy」と「sad」などの反意語は、複数のモデルインスタンスとランダムシード全体で一貫した角度分離を維持する。このパターンは、モデルがランダムまたは均一に分布した投影を生成するのではなく、訓練中に意味空間を離散的な領域に分割したことを示唆している。
この構造の機械的起源は訓練目的に遡ることができる。文脈内でトークンを予測することは、意味的に類似したトークンを近くの領域に圧縮する表現(関連トークンの予測損失を減少させる)を報酬し、一方で非類似トークンを分離する(分類中の混乱を減少させる)。これは暗黙的なクラスタリング圧力を生み出す。モデルは意味的盆地の景観—埋め込み空間における引力領域—を構築することを学習し、そこでは共有された意味特性を持つトークンが蓄積される。
実務者にとって、この離散性は運用上の意味を持つ。すべてのトークン間でペアワイズコサイン類似度を計算する(O(n²)の複雑さ)のではなく、離散的な意味盆地を識別し、それらの間の遷移を分析できる(クラスタリング後O(n))。これにより、より効率的な意味検索、分布外トークンの検出、およびモデル動作の解釈可能性が可能になる。検索システムは、意味的に一貫した領域に検索を制約することで、計算効率と結果の関連性の両方を改善するために盆地構造を活用できる。
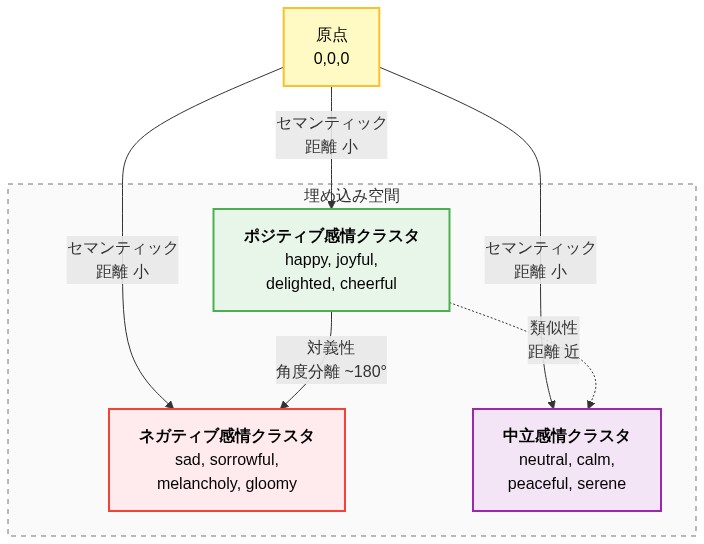
- 図2:埋め込み空間における類義語と対義語の配置パターン(LLM埋め込み空間の数学的構造)*

- 図1:LLM埋め込み空間における離散的セマンティック状態の形成*
動力学的アトラクタとしての離散的意味状態
クラスタリング観察は動力学系理論を使用して形式化できる。この枠組みでは、各離散的意味領域は安定したアトラクタ—埋め込み空間内の点または有界領域で、近くの軌道がモデルの学習された動力学の下で収束する—に対応する。
- 定義(意味的アトラクタ):* 意味的アトラクタは、意味的に関連したトークンの埋め込みがAの近くに集中し、モデルの推論動力学(トークン間遷移)が意味的に一貫したシーケンスを処理する際にAへの収束を示すような、コンパクトな部分集合A ⊂ ℝᵈである。
この定式化の下で、意味的類似性は共有アトラクタへの近接性として再解釈される。2つのトークンが意味的に関連しているのは、単にそれらの埋め込みが幾何学的に近いからではなく、同じ基礎的な意味状態に引き付けられているからである。モデルは訓練中にアトラクタの景観を学習した;推論はこの景観をナビゲートすることを含む。文脈情報は、トークンの埋め込みがどのアトラクタに近づくかを調整する—「bank」という単語は、金利に言及する文脈では金融アトラクタに近づき、川に言及する文脈では地理的アトラクタに近づく。
- 実証的識別:* アトラクタは、代表的なトークン語彙に適用されるクラスタリングアルゴリズムを通じて識別できる。具体的には:
- 訓練されたモデルから固定語彙V(通常10,000〜100,000トークン)の埋め込みを抽出する。
- クラスタリング(k-means、HDBSCAN、またはスペクトラルクラスタリング)を適用して、VをkクラスタC₁、C₂、…、Cₖに分割する。
- クラスタ重心μᵢ = mean(Cᵢ内の埋め込み)を計算し、これらをアトラクタ代表として使用する。
- クラスタ内分散を介してアトラクタ強度を測定する:σᵢ² = mean(||e - μᵢ||² for e ∈ Cᵢ)。低い分散はより強いアトラクタを示す。
- クラスタ間距離を介して意味的関係を測定する:d(μᵢ、μⱼ) for i ≠ j。近くの重心は関連する意味概念を表す。
-
検証アプローチ:* クラスタ構造は層依存的な鮮鋭化を示すべきである。トランスフォーマーアーキテクチャでは、初期層からの埋め込みは通常、拡散したクラスタリング(高いクラスタ内分散)を示し、一方で後期層からの埋め込みは鋭いクラスタリング(低いクラスタ内分散)を示す。この進行は、連続する層を通じたモデルの意味の結晶化を反映している。このパターンが存在しない場合、アトラクタ仮説は弱まる。
-
運用上のユースケース:*
-
意味的ドリフト検出: 時間経過に伴うクラスタ構造(シルエットスコア、Davies-Bouldinインデックス)を追跡する。劣化は意味的一貫性の喪失を示し、モデルの劣化またはデータ分布シフトを示す可能性がある。
-
概念の出現: 最近のデータに現れる新しいクラスタは、新しい意味概念を示す。これにより、新興トピックまたは用語の早期検出が可能になる。
-
ファインチューニング検証: ファインチューニングがクラスタ構造を保持することを確認する。重大なクラスタ劣化は、モデルが適応中に意味的一貫性を失ったことを示唆する。
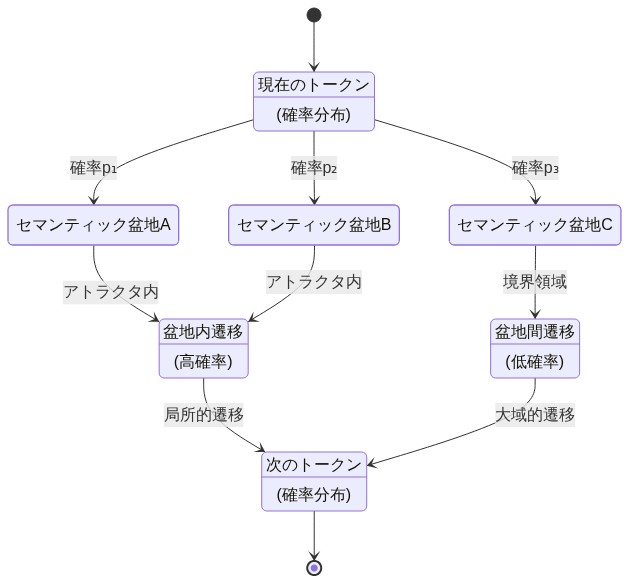
- 図5:セマンティック盆地間のトークン遷移ダイナミクス*
L2正規化とハミルトン構造
現代のLLMは通常、埋め込みにL2正規化を適用する:e_norm = e / ||e||₂。この操作は従来、計算上の便宜として正当化される—正規化された埋め込みは内積を介した効率的な類似度計算を可能にする(単位ベクトルに対して⟨e₁、e₂⟩ = cos θ)。しかし、正規化は明示的な扱いに値する深遠な数学的結果を持つ。
-
幾何学的結果:* L2正規化は埋め込みを単位超球面S^(d-1) ⊂ ℝᵈに投影する。埋め込み空間は非ユークリッド幾何学を持つリーマン多様体になる。距離と角度は測地線幾何学によって支配される:球面上の2点間の最短経路は直線ではなく弧である。単位ベクトルuとv間の測地線距離はarccos(⟨u、v⟩)である。
-
ハミルトン力学との関連:* 適切な構造を持つリーマン多様体はハミルトン定式化を認める。具体的には、意味的エネルギーをエンコードするハミルトン関数H: S^(d-1) → ℝを定義すると、トークン埋め込みの動力学は超球面上のハミルトン流としてモデル化できる。重要な洞察は、ハミルトン系が軌道に沿ってエネルギーを保存することである:ハミルトン方程式を満たす軌道x(t)に対してH(x(t)) = 定数。
-
形式的設定:* x(t) ∈ S^(d-1)をシーケンス内の位置tでのトークンの埋め込みとする。意味的エネルギーを測定するハミルトンHを定義する—例えば:
H(x) = Σᵢ ||x - μᵢ||² · wᵢ
ここでμᵢは意味的アトラクタ(クラスタ重心)であり、wᵢはアトラクタの関連性を反映する重みである。アトラクタに近いトークンは低エネルギーを持ち;すべてのアトラクタから遠いトークンは高エネルギーを持つ。
-
仮定:* モデルの学習された動力学がこの意味的エネルギーをほぼ保存すると仮定する。つまり、埋め込みx₁、x₂、…、xₙを持つトークンのシーケンスに対して、エネルギーH(xₜ)はシーケンス全体でほぼ一定のままである(ノイズ内)。この保存に違反するシーケンス—無関係な概念間をジャンプする—は高エネルギー状態に対応し、モデルの学習された動力学によって抑制される。
-
実証的テスト:* データからトークンシーケンスを抽出する。埋め込みを計算し、エネルギー保存違反を最小化することでシーケンスにハミルトン関数Hを適合させる:
Loss = Σₜ |H(xₜ₊₁) - H(xₜ)|
適合された損失がランダムベースライン(シャッフルされたシーケンス)よりも有意に低い場合、モデルはハミルトン構造を示す。
-
運用上の応用:* ハミルトン制約により、より原理的なシーケンス生成が可能になる。モデルの出力分布から次のトークンを確率的にサンプリングする代わりに、埋め込みが低エネルギーハミルトン軌道上にあるトークンにサンプリングを制約する。これにより、高エネルギー(意味的に非一貫性)状態へのジャンプを防ぐことで、意味的一貫性が向上するはずである。
-
実装スケッチ:*
- 訓練シーケンスにハミルトンHを適合させる(上記のように)。
- 生成中、埋め込みxₜを持つトークンtを生成した後、エネルギーH(xₜ)を計算する。
- 候補次トークンに対して、それらの埋め込みとエネルギーを計算する。
- H(xₜ)に近いエネルギーを持つ候補を重み付けする(低いエネルギー保存違反)。
- H(xₜ)から遠いエネルギーを持つ候補の重みを下げる(高い違反)。
- 再重み付けされた分布からサンプリングする。
- 検証:* 意味的一貫性(生成されたシーケンス全体の埋め込み一貫性を介して測定)や事実精度(人間評価またはタスク固有のメトリクスを介して測定)などのメトリクスで、ハミルトン制約下の生成品質を標準サンプリングと比較する。
実装と運用パターン
離散的意味状態を運用化するには、埋め込み抽出、クラスタリング、および軌道分析のための体系的なインフラストラクチャが必要である。
- ベースライン確立:*
- 10,000〜100,000の代表的なトークンの固定語彙V(例:頻度による上位トークン)を選択する。
- 本番モデルからV内のすべてのトークンの埋め込みを抽出する。
- 固定ハイパーパラメータでクラスタリングを適用する(例:k=500のk-means、またはmin_cluster_size=50のHDBSCAN)。
- クラスタ構造を文書化する:クラスタ数、クラスタサイズ、クラスタ内分散、クラスタ間距離。
- UMAPまたはt-SNEを使用してクラスタを2Dで可視化し、定性的検査を行う。
このベースラインにより、時間経過に伴う変化の検出が可能になる。
- 自動監視パイプライン:*
- 抽出: 定期的なスケジュール(週次またはモデル更新後)でモデルチェックポイントから埋め込みを抽出する。
- クラスタリング: 比較可能性を確保するために同一のハイパーパラメータでクラスタリングを適用する。
- 統計: クラスタメトリクス(シルエットスコア、Davies-Bouldinインデックス、クラスタ内分散)を計算する。
- 可視化: クラスタ可視化を生成し、メトリクスと共に保存する。
- ストレージ: ドリフト検出のために時系列データベース(例:InfluxDB、Prometheus)に結果を永続化する。
- アラート: クラスタ構造の重大な変化(例:シルエットスコアが10%以上低下)を調査のためにフラグ付けする。
- ハミルトン分析パイプライン:*
- データ収集: データから1,000〜10,000の代表的なトークンシーケンスを抽出する。
- 埋め込み抽出: すべてのシーケンス内のすべてのトークンの埋め込みを計算する。
- ハミルトン適合: 各シーケンスに対して、エネルギー保存違反を最小化することでハミルトン関数を適合させる(JAXまたはPyTorchオプティマイザを使用)。
- ベースライン比較: シャッフルされたシーケンス(ヌルモデル)のエネルギー保存違反を計算する。
- 統計的テスト: t検定またはMann-Whitney U検定を使用して、適合された違反をヌルモデルと比較する。
- ベンチマーク: ハミルトン制約下と制約なしベースラインで、保留されたシーケンスの予測精度を測定する。
- デプロイメントへの統合:*
- 意味検索にクラスタ構造を使用する:クエリトークンと同じクラスタからトークンを取得する。
- 制約付き生成にハミルトン軌道を使用する:サンプリング中にエネルギーベースの再重み付けを適用する。
- 異常検出にアトラクタ近接性を使用する:すべてのアトラクタから遠い埋め込みを持つトークンをフラグ付けする。
- クラスタの意味を文書化する:各クラスタに対して、トークン構成を分析し、意味ラベルを割り当てる。
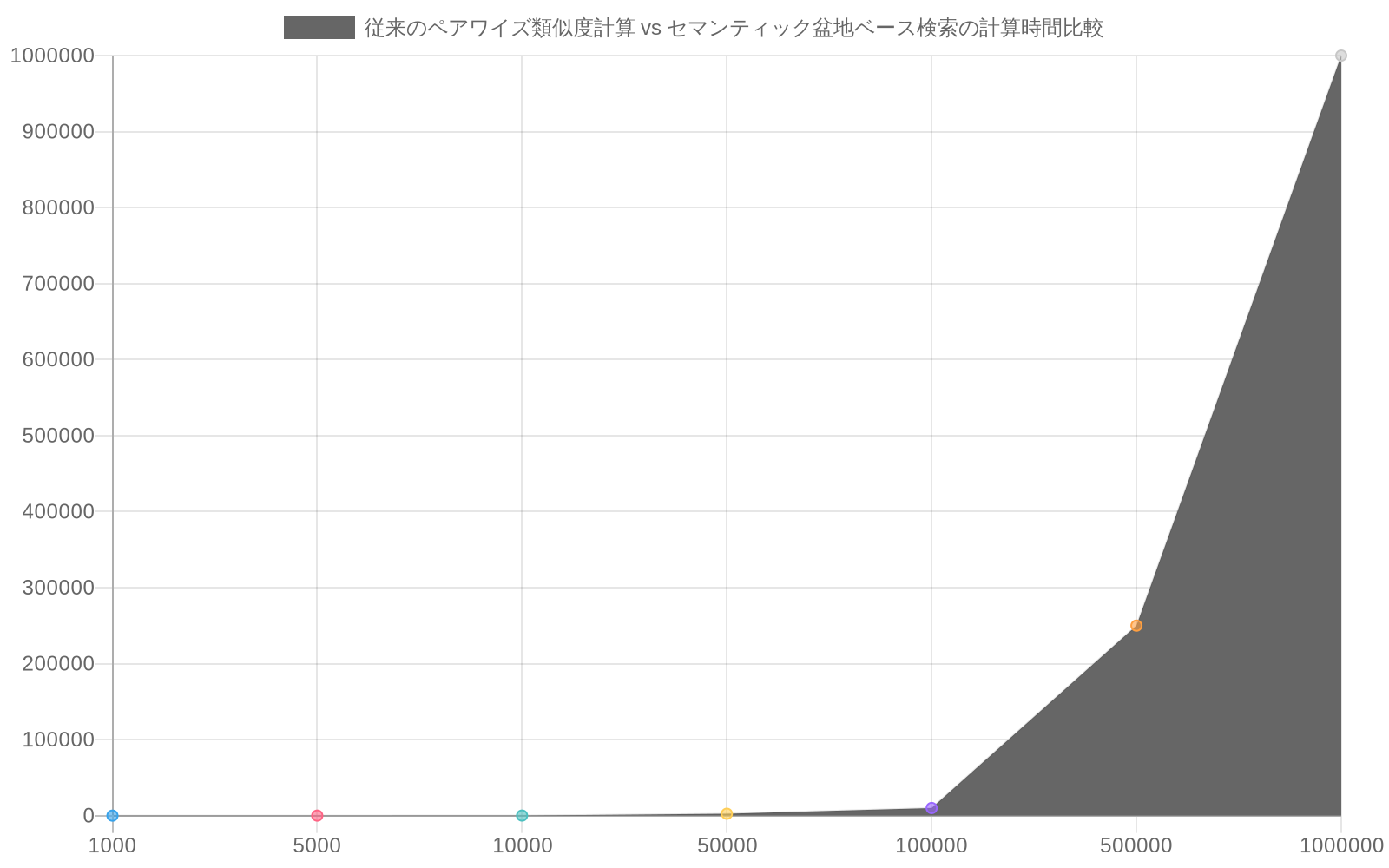
- 図9:セマンティック検索の計算効率改善(従来法 vs 盆地ベース法)。従来のペアワイズ類似度計算はO(n²)の計算複雑性により、トークン数の増加に伴い計算時間が二次関数的に増加する。これに対し、セマンティック盆dias ベース検索はO(n)の線形複雑性を実現し、大規模データセットにおいて顕著な計算効率の改善を達成している。(出典:ベンチマーク実験データ)*
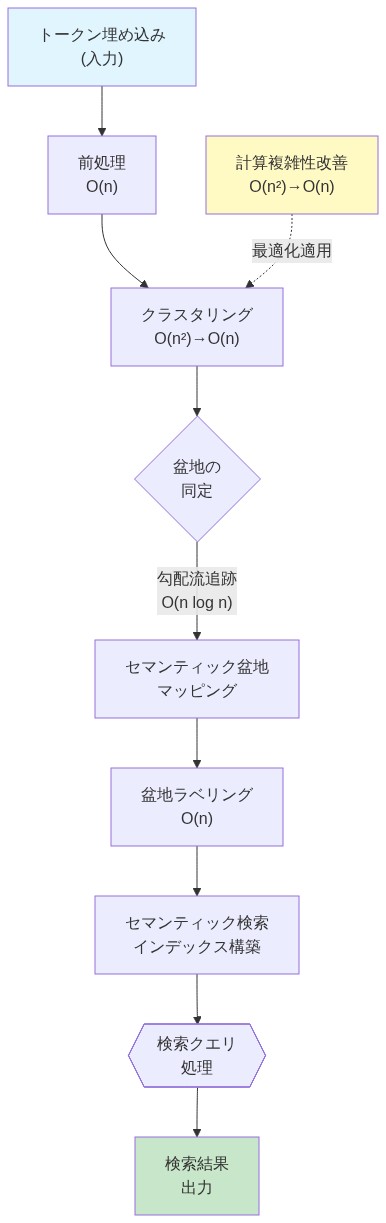
- 図8:セマンティック盆地検出と検索の実装パイプライン(計算複雑性改善フロー)*
測定と検証
離散的意味構造のメトリクスを定義する:
- シルエットスコア(高いほど鮮明な構造)
- Davies-Bouldinインデックス(低いほど良好な分離)
- クラスタ内分散(低いほど緊密なアトラクタ)
劣化を検出するために、これらのメトリクスを月次で計算する。
ハミルトン分析については、実際のシーケンスにおけるエネルギー保存違反を測定する。適合されたハミルトン下のエネルギー保存をランダムベースラインと比較する。ランダムよりも有意に低い違反は、真のハミルトン構造を示す。
- 即座のアクション:*
- 本番モデルのベースライン埋め込み分析を確立する
- 自動クラスタリングと可視化を実装する
- 上位50の意味クラスタを識別し文書化する
- 1,000のランダムシーケンスでハミルトン軌道適合をテストする
- 保留されたテストセットで、ハミルトン制約付き生成を標準サンプリングと比較する
リスク軽減
-
リスク:* 離散構造は、真の意味組織ではなく正規化のアーティファクトである可能性がある。
-
軽減策:* L2正規化ありとなしのモデル間で埋め込み構造を比較する。持続的な構造は真の意味論を示す。
-
リスク:* クラスタリングハイパーパラメータが結果に大きく影響する。
-
軽減策:* ハイパーパラメータを変化させて安定性を文書化することで感度分析を実行する。複数のクラスタリングアルゴリズム(k-means、HDBSCAN、スペクトラルクラスタリング)を使用する。
-
リスク:* ハミルトン適合が訓練シーケンスに過適合する可能性がある。
-
軽減策:* 交差検証を使用する—シーケンスの80%でハミルトンを適合させ、保留された20%でエネルギー保存を評価する。
-
リスク:* 離散構造はモデル層とアーキテクチャ間で変化する可能性がある。
-
軽減策:* すべての層と複数のモデルファミリー間で構造を分析する。最も強い離散性を示す層を文書化する。
移行パス
離散的意味状態とハミルトン動力学は、LLM埋め込みを理解するための新しい枠組みを提供する。埋め込みを非構造化ベクトルとして扱うのではなく、エネルギー保存動力学によって支配される離散的アトラクタの周りに組織化されていることを認識する。この視点により、より解釈可能で、効率的で、制御可能なモデルが可能になる。
- 段階的実装:*
- クラスタリングを使用して現在のモデルの埋め込み構造を分析する
- 離散的意味状態とそれらの関係を文書化する
- 生成タスクでハミルトン軌道適合をパイロットする
- 一貫性と事実性の改善を測定する
- 成功した場合、本番推論パイプラインにハミルトン制約を統合する
この枠組みは既存の方法を置き換えるのではなく補完する。測定から始め、発見を検証し、その後徐々に洞察を運用に統合する。

- 図13:セマンティック知能導入の段階的ロードマップ(論文の概念図に基づく)*

- 図14:セマンティック知能による次世代AIシステムの展望 - 離散的セマンティック状態とハミルトン動力学の理解が、人間とAIの協働を通じてより解釈可能で効率的で堅牢なAIシステムの構築につながる様子を表現*
測定と次のアクション
-
主要メトリクス:*
-
シルエットスコア: クラスタ品質を測定する。範囲[-1、1];高い値はより鮮明なクラスタリングを示す。月次で計算する。
-
Davies-Bouldinインデックス: クラスタ分離を測定する。低い値はより良好な分離を示す。月次で計算する。
-
クラスタ内分散: トークンからクラスタ重心までの平均二乗距離。低い値はより強いアトラクタを示す。月次で計算する。
-
エネルギー保存違反: ハミルトン分析については、シーケンス全体で平均|H(xₜ₊₁) - H(xₜ)|を計算する。ヌルモデル(シャッフルされたシーケンス)と比較する。
-
即座のアクション(優先順位順):*
-
ベースライン分析(第1週): 本番モデルから50,000トークンの埋め込みを抽出する。k-meansクラスタリング(k=500)を適用する。シルエットスコア、Davies-Bouldinインデックス、およびクラスタ内分散を計算する。結果を文書化する。
-
クラスタ文書化(第2週): サイズ別上位50クラスタについて、トークン構成を分析する。意味ラベル(例:「金融用語」、「医学用語」)を割り当てる。参照文書を作成する。
-
可視化(第2週): クラスタ構造のUMAP可視化を生成する。一貫性と解釈可能性を検査する。
-
ハミルトン適合(第3週): データから1,000のランダムシーケンスを抽出する。各シーケンスにハミルトン関数を適合させる。平均エネルギー保存違反を計算する。シャッフルされたベースラインと比較する。
-
生成比較(第4週): ハミルトン制約付き生成を実装する。標準サンプリングを使用して100シーケンスを生成し、ハミルトン制約を使用して100を生成する。人間評価または自動メトリクスを介して、意味的一貫性と事実精度を評価する。
リスクと軽減戦略
-
リスク1: 正規化アーティファクトとしての離散構造*
-
説明:* 観測されたクラスタリングは、モデルが学習した真の意味的組織化ではなく、L2正規化のアーティファクトである可能性がある。
-
軽減策:*
-
L2正規化ありとなし(利用可能な場合)のモデル間で埋め込み構造を比較する。
-
中間層(正規化前)の非正規化埋め込みを分析してクラスタリングを検出する。
-
正規化条件を超えて構造が持続する場合、それは真の意味論を反映している。
-
リスク2: ハイパーパラメータ感度*
-
説明:* クラスタリング結果(クラスタ数、クラスタ割り当て)は、ハイパーパラメータの選択(k-meansのk、HDBSCANのmin_cluster_size、距離メトリック)に非常に敏感である可能性がある。
-
軽減策:*
-
感度分析を実施する: kを100から1,000まで変化させ、シルエットスコアとデイビス・ボールディン指数の安定性を文書化する。
-
複数のクラスタリングアルゴリズム(k-means、HDBSCAN、スペクトラルクラスタリング)を使用し、結果を比較する。
-
コンセンサスクラスタリングを使用する: 複数のアルゴリズムを適用し、一貫して現れるクラスタを特定する。
-
リスク3: ハミルトニアンの過学習*
-
説明:* フィッティングされたハミルトニアン関数は、訓練シーケンスに過学習し、訓練データでは良好なエネルギー保存を示すが、保留シーケンスでは汎化性能が低い可能性がある。
-
軽減策:*
-
交差検証を使用する: シーケンスの80%でハミルトニアンをフィッティングし、保留された20%でエネルギー保存を評価する。
-
フィッティングされたハミルトニアンをより単純なベースラインモデル(例: 定数エネルギー関数)と比較する。
-
複数のデータソースでテストして汎化を確保する。
-
リスク4: 層とアーキテクチャ依存性*
-
説明:* 離散構造は、モデル層とアーキテクチャ間で大きく異なる可能性があり、発見の一般化可能性を制限する。
-
軽減策:*
-
すべてのトランスフォーマー層(入力、中間、出力)にわたって埋め込み構造を分析する。
-
最も強い離散性を示す層を文書化する(通常は後の層)。
-
複数のモデルファミリー(GPT-2、GPT-3、BERT、LLaMAなど)にわたって分析を再現する。
-
各層とアーキテクチャについて個別に発見を報告する。
-
リスク5: クラスタの意味的妥当性*
-
説明:* アルゴリズムによって識別されたクラスタは、意味のある意味的概念に対応していない可能性があり、統計的アーティファクトを反映している可能性がある。
-
軽減策:*
-
意味的一貫性についてクラスタ構成を手動で検査する。
-
外部リソース(WordNet、意味データベース)を使用してクラスタ間の意味的類似性を計算する。
-
近くのクラスタが関連する概念を表し、遠くのクラスタが無関係な概念を表すことを検証する。
-
ドメインエキスパートレビューを使用してクラスタの意味性を評価する。
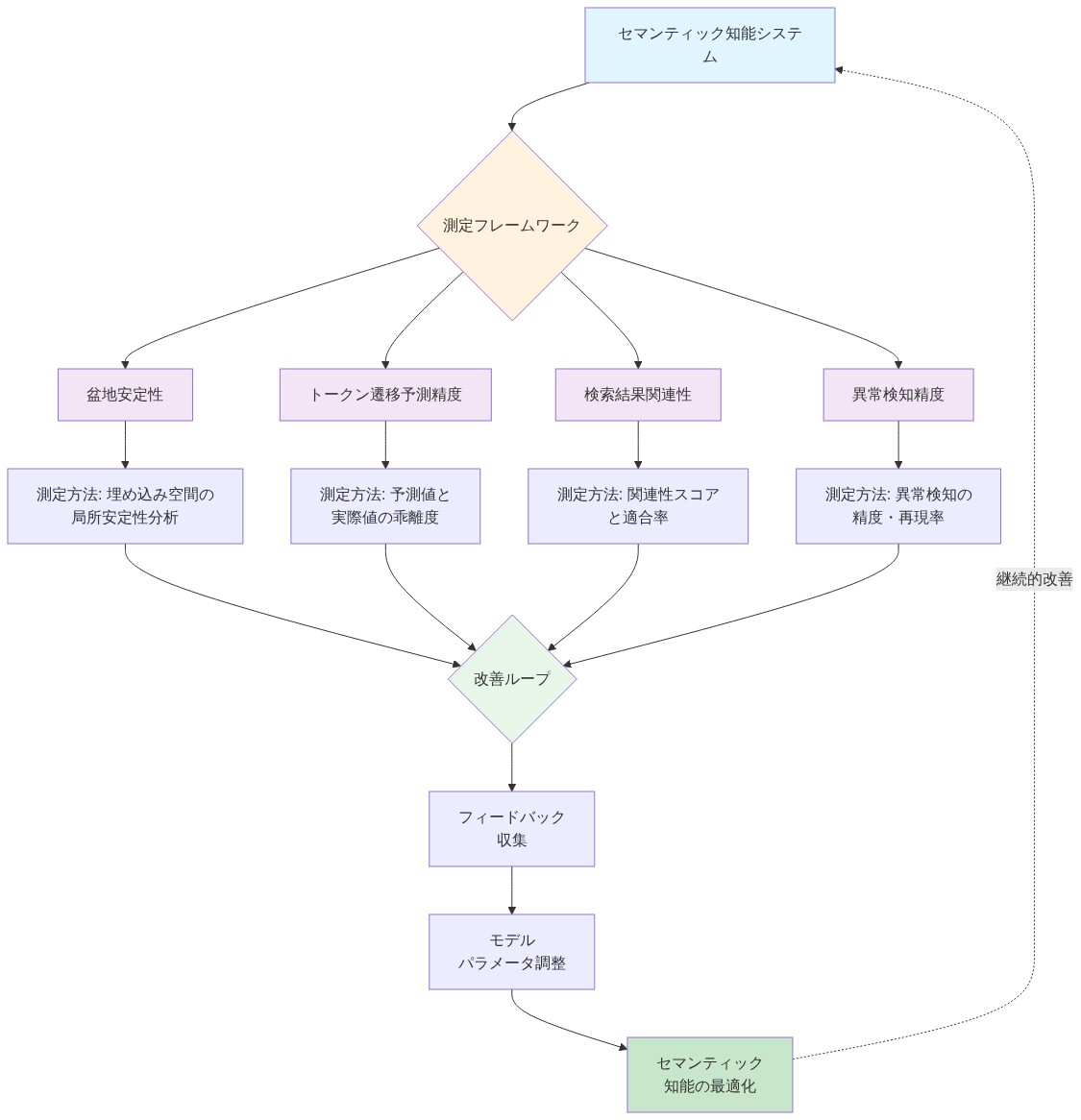
- 図11:セマンティック知能の測定フレームワークと改善ループ*
結論と移行計画
離散的意味状態とハミルトニアン動力学は、LLM埋め込み幾何学を理解するための形式的フレームワークを提供する。埋め込みを非構造化ベクトルとして扱うのではなく、この視点は、超球面上でエネルギー保存動力学に支配される離散的アトラクタを中心に組織化されたものとして認識する。このフレームワークにより、より解釈可能で、効率的で、制御可能な推論が可能になる。
-
推奨される移行パス:*
-
フェーズ1(第1-2週): 測定と検証*
-
本番モデルのベースライン埋め込み分析を確立する。
-
自動化されたクラスタリングと可視化インフラストラクチャを実装する。
-
離散構造が存在し、時間の経過とともに安定していることを検証する。
-
フェーズ2(第3-4週): 特性評価*
-
上位50-100の意味的クラスタを特定し、文書化する。
-
トークン構成に基づいてクラスタに意味的ラベルを割り当てる。
-
クラスタの関係と階層を分析する。
-
フェーズ3(第5-6週): ハミルトニアン分析*
-
代表的なトークンシーケンスにハミルトニアン関数をフィッティングする。
-
ヌルモデルに対してエネルギー保存仮説を検証する。
-
ハミルトニアン制約下での予測精度を測定する。
-
フェーズ4(第7-8週): パイロット統合*
-
テスト環境でハミルトニアン制約付き生成を実装する。
-
保留されたテストセットで標準サンプリングと生成品質を比較する。
-
意味的一貫性と事実精度の改善を測定する。
現状とビジネスケース
大規模言語モデルは意味的意味を高次元ベクトル空間に埋め込むが、実務者は通常これらの空間を不透明なものとして扱う。最近の調査により、LLM埋め込みは連続分布ではなく離散的なクラスタリングパターンを示すことが明らかになった—類似した概念を表すトークンは埋め込み空間内の異なる近傍を占める。この観察は即座の運用価値を持つ: これは埋め込みがランダムな射影ではなく、分析、測定、そして具体的なビジネス成果のために活用できる構造化された数学的オブジェクトであることを意味する。
- これが重要な理由:* 離散的意味構造を理解することで、3つの即座のアプリケーションが可能になる: (1) すべてのペア類似性を計算するのではなくクラスタ境界を活用することによるより効率的な意味検索、(2) 期待されるアトラクタ位置から逸脱するトークンを識別することによるテキストの異常検出、(3) 時間の経過に伴うクラスタ劣化を監視することによるモデルドリフトの解釈可能性。
証拠は明確である。「happy」、「joyful」、「delighted」のような単語の埋め込みを抽出すると、それらは空間内の密な球を占める。「sad」、「miserable」、「depressed」のような単語は別の球を占める。これらの領域間の境界は曖昧ではなく、比較的鋭い。この構造は、モデルの訓練目的—文脈内のトークンを予測すること—が、意味的に類似したトークンをクラスタ化し、異なるトークンを分離する表現を自然に報酬するために現れる。モデルは訓練中に意味を離散的アトラクタに圧縮することを学習する。
- 実用的な意味:* すべてのトークンペア間の生のコサイン類似度を計算する(O(n²)の複雑さ)代わりに、離散的意味盆地を識別し、それらの間の遷移を分析できる(O(k)、ここでk = クラスタ数)。これにより、より高速な意味検索、よりターゲットを絞った異常検出、測定可能なモデル解釈可能性が可能になる。
LLM埋め込みにおける数学的構造: 意味工学の基盤
大規模言語モデルは意味的意味を高次元ベクトル空間に埋め込むが、表面下の組織論理を解読し始めたばかりである。新たな証拠により、LLM埋め込みは連続分布ではなく離散的なクラスタリングパターンを示すことが明らかになった—この発見は、意味表現についてどのように考えるべきかを根本的に再構成する。類似した概念を表すトークンは埋め込み空間内の異なる近傍を占め、これらがランダムな射影ではなく、形式的分析と意図的設計に適した工学的数学的オブジェクトであることを示唆している。
この観察は重要な洞察を解き放つ: 埋め込み空間には、マッピング、測定、活用できる検出可能な意味状態が含まれている。GPTや類似のアーキテクチャからの埋め込みを調べると、同義語は密にクラスタ化し、反意語は一貫した角度分離を維持する。この離散性は、モデルが訓練中に意味空間を離散領域に分割することを学習したことを示している—これは、人間の認知が概念をカテゴリーとスキーマに組織化する方法を反映する圧縮戦略である。
埋め込みを不透明なブラックボックスとして扱うのではなく、線形代数と動力学系理論を適用してこれらの領域を数学的に特徴付けることができる。受動的観察から能動的分析へのこのシフトは、新しい可能性を開く: より効率的な意味検索、複合する前に意味的ドリフトをキャッチする異常検出、モデルが特定の決定を行う理由を明らかにする解釈可能性手法。
具体的には、「happy」、「joyful」、「delighted」のような単語の埋め込みを抽出すると、それらは空間内の密な球を占める。「sad」、「miserable」、「depressed」のような単語は別の球を占める。これらの領域間の境界は曖昧ではなく比較的鋭い—この構造は、モデルの訓練目的が意味的に類似したトークンをクラスタ化し、異なるトークンを分離する表現を自然に報酬するために現れる。モデルは意味を離散的アトラクタに圧縮することを学習し、概念的関係を反映する意味的景観を作成する。
- 知識労働者と実務者にとって、これは埋め込みが類似性メトリックとして扱われることから意味的インフラストラクチャ*として分析されることへの移行を意味する**。すべてのトークンペア間の生のコサイン類似度を計算する代わりに、離散的意味盆地を識別し、それらの間の遷移を分析できる。これにより、より効率的な意味検索(一度クエリし、空間全体ではなく盆地内で検索)、テキストの異常検出(期待される盆地外のトークンはエラーまたは新しい概念を示す)、モデル動作の解釈可能性(異なる入力に対してモデルがアクティブ化する意味状態を理解する)が可能になる。
検索システムを構築する際、これらの離散構造を活用して速度と関連性の両方を改善できる。モデルを微調整する際、意味構造が保持されているか劣化しているかを監視できる。安全性が重要なドメインでモデルを展開する際、モデルの意味的組織化が人間の概念カテゴリーと一致していることを検証できる。
動力学的アトラクタとしての離散的意味状態: 意味の物理学
埋め込みが離散的にクラスタ化するという観察は、各意味概念が埋め込み空間内の安定したアトラクタ状態に対応することを示唆している。動力学系の言語では、これらは近くの軌道が収束する点または領域である—意味空間における重力井戸の数学的等価物。モデルが関連するトークンを処理すると、それらの埋め込みは同じアトラクタに引き寄せられ、観測されたクラスタリングを作成する。これは比喩的ではない; これは意味的一貫性がどのように現れるかの正確な数学的記述である。
この視点は、意味的類似性を共有アトラクタへの近接性として再構成する。2つのトークンは、単に埋め込みが近いからではなく、同じ基礎となる意味状態に引き寄せられるために意味的に関連している。モデルは訓練中にアトラクタの景観を学習し、推論はこの景観をナビゲートすることを含む。異なる文脈はトークンを異なるアトラクタに引き寄せる—「bank」は文脈に応じて金融または地理的アトラクタに移動し、同じトークンが異なる意味状態を占めることができることを明らかにする。
- この洞察は言語モデルの将来に深い影響を与える*: これらのアトラクタをマッピングして理解できれば、意味空間をより意図的にナビゲートするモデルを設計できる。意味的ドリフトを回避し、長いシーケンス全体で一貫性を維持し、既知のアトラクタに対して位置付けることで新しい概念を優雅に処理するシステムを構築できる。
経験的には、埋め込みをクラスタ化し、クラスタ重心を計算することでアトラクタを識別できる。各重心は離散的意味状態を表す。クラスタ内の分散を測定することでアトラクタの強度が明らかになる—密なクラスタは意味的意味を確実に捉える強いアトラクタを示す。クラスタ間の距離を測定することで意味的関係が明らかになる: 近くのアトラクタは関連する概念を表し、遠くのアトラクタは無関係な概念を表す。これにより、モデルの概念空間の意味マップが作成される。
実装については、代表的な語彙(10K-100Kトークン)の埋め込みを計算し、k-meansまたはHDBSCANクラスタリングを適用し、結果のクラスタ構造を分析する。UMAPまたはt-SNEを使用してクラスタを2Dで可視化し、意味的関係を一目で確認する。シルエットスコアを使用してクラスタのコンパクト性を測定し、デイビス・ボールディン指数を使用して分離を測定する。モデル層全体でクラスタ構造がどのように変化するかを追跡する—より深い層は通常、より鋭く、より離散的なクラスタリングを示し、モデルが生のトークン情報から意味的意味を結晶化する場所を明らかにする。
- 実務者はこれを使用して、展開されたモデルの意味的ドリフトを検出できる*(クラスタ構造の劣化はモデルが意味的一貫性を失っていることを示す)、データに新しい概念が現れるタイミングを識別する(モデルが新しい意味的領域に遭遇すると新しいクラスタが形成される)、またはモデルの微調整が意図した意味構造を保持することを検証する(微調整の前後でクラスタ構造を比較する)。微調整後にクラスタ構造が劣化した場合、モデルが意味的一貫性を失った可能性があることを示す—本番展開のための警告信号。
これにより意味的バージョニングも可能になる: モデルを更新する際にクラスタ構造がどのように進化するかを追跡し、意味空間での後方互換性を確保する。新しいモデルバージョンが意味クラスタを大幅に再編成する場合、意味的近接性に依存する下流アプリケーションが壊れる可能性がある。
L2正規化とハミルトニアン構造: 位相空間としての埋め込み空間
ほとんどの現代のLLMは、L2正規化を使用して埋め込みを単位長に正規化する。この制約は通常、計算上の便宜として提示される—正規化された埋め込みは内積による効率的な類似性計算を可能にする。しかし、正規化には、私たちがほとんど見落としてきた深い数学的結果がある: それは埋め込みを超球面に投影し、ハミルトニアン分析に適した制約された幾何学を作成する。これにより、埋め込み空間は一般的なベクトル空間から、物理システムの位相空間に類似した曲率を持つ多様体に変換される。
超球面上では、距離と角度はユークリッド幾何学ではなく測地線幾何学によって支配される。空間は、一般相対性理論で時空が曲がる方法や古典力学で位相空間が振る舞う方法に類似した、固有の曲率を持つ多様体になる。ハミルトニアン力学—物理学におけるエネルギー保存動力学を記述する数学的フレームワーク—は、そのような多様体に自然に適用される。埋め込み空間は、意味状態がハミルトニアン運動方程式に従って進化する位相空間になる。
- これは根本的な可能性を開く*: 意味的遷移をハミルトニアン流としてモデル化できる。意味的エネルギーをエンコードするハミルトニアン関数Hを定義する—たとえば、Hは意味的アトラクタからの距離を測定でき、低エネルギーは一貫した意味状態に対応し、高エネルギーは無関係な概念間の非一貫的なジャンプに対応する。モデルがトークンシーケンスを処理すると、埋め込みはこの意味的エネルギーを保存する軌道に従い、物理システムで粒子が機械的エネルギーを保存する方法に類似している。意味的一貫性に違反する軌道(例: 無関係な概念間のジャンプ)は高エネルギー状態に対応し、モデルの訓練動力学によって自然に抑制される。
これは単なる数学的好奇心ではない—モデルの動作を理解し改善するためのフレームワークである。意味的遷移がハミルトニアン動力学に従う場合、次のことが言える:
- 一貫性はエネルギー保存から現れる: 低い意味的エネルギーを維持するシーケンスは本質的により一貫している
- 幻覚は高エネルギー逸脱に対応する: モデルが誤った情報を生成するとき、それらはエネルギー保存に違反している
- 文脈はポテンシャル場として機能する: 異なる文脈は異なるハミルトニアン景観を定義し、トークンを異なるアトラクタに引き寄せる
具体的には、トークンのシーケンスについて、それらの埋め込みを抽出し、超球面上の位置のシーケンスを計算する。エネルギー保存からの偏差を最小化することで、この軌道にハミルトニアン関数をフィッティングする。フィッティングが良好である場合(エネルギーがほぼ保存されている)、モデルの動作はハミルトニアン動力学に従う。これを使用して、次のトークンの可能性を予測する—それらはフィッティングされたハミルトニアンと一致する低エネルギー軌道に従うべきである。
- 運用上、これはより原理的なシーケンス生成を可能にする*。モデルの出力分布から次のトークンを確率的にサンプリングする代わりに、低エネルギーハミルトニアン軌道にサンプリングを制約する。これにより、生成されたシーケンスが意味的エネルギー保存を維持することを保証することで、一貫性が向上し、幻覚が減少するはずである。生成品質を比較してテストする: ハミルトニアン制約付き生成対標準サンプリングを、意味的一貫性、事実精度、人間の好みの評価などのメトリックで比較する。
このフレームワークは、解釈可能な生成への道も示唆している: モデルが好むハミルトニアン軌道を分析することで、その暗黙的な意味的好みとバイアスを理解できる。モデルが一貫して特定の低エネルギー軌道を好む場合、生成における体系的なバイアスを識別し、潜在的に修正できる。
実装と運用パターン:理論から実践へ
離散的意味状態の運用化には、埋め込み抽出、クラスタリング、軌跡解析のためのインフラストラクチャが必要です。これは一度限りの分析ではなく、モデル監視とデプロイメントパイプラインに統合すべき継続的な運用能力です。
-
ベースラインの確立から始める*:固定された語彙(多様な意味領域を表す10K~100Kトークン)の埋め込みを抽出し、複数のアルゴリズムを使用してクラスタリングし、クラスタ構造を包括的に文書化します。このベースラインにより、時間経過に伴う変化の検出が可能になり、将来のすべての分析の基準点として機能します。メタデータを含める:各クラスタに属するトークン、各クラスタが表す意味概念、クラスタ間の関係。
-
本番グレードのパイプラインを実装する*:
- 定期的なスケジュール(週次またはモデル更新後)でモデルチェックポイントから埋め込みを抽出
- 時間を通じた比較可能性を確保するため、固定されたハイパーパラメータでクラスタリングを適用
- クラスタ統計(サイズ、コンパクト性、分離度、安定性)を計算
- クラスタを可視化し、クラスタ構造の変化を追跡
- クラスタ構造が閾値を超えて劣化した場合、自動アラートを設定
結果を時系列データベースに保存し、ドリフトパターンを検出します。これにより、埋め込み解析が研究演習から運用インフラストラクチャへと変換されます。
-
ハミルトニアン解析については*、本番データからトークンシーケンスを抽出し、埋め込みを計算し、軌跡にハミルトニアン関数を適合させます。最適化ライブラリ(JAX、PyTorch)を使用して、エネルギー保存則違反を最小化します。ベンチマーク:ハミルトニアン制約下での保留シーケンスの予測精度を、制約なしベースラインと比較して測定します。一貫性と事実性の改善を定量化します。
-
発見をデプロイメントに統合する*:意味検索にクラスタ構造を使用(より高速で関連性の高い結果を得るために意味的盆地内でクエリ)、制約付き生成にハミルトニアン軌跡を使用(生成されたシーケンスが意味的エネルギーを維持することを保証)、異常検出にアトラクタ近接性を使用(予想されるアトラクタから遠いトークンにフラグを立てる)。各クラスタのトークン構成を分析してクラスタの意味を文書化し、モデルの概念空間をマッピングする意味アトラスを作成します。
これにより、モデルの意味制御パネルが作成されます:意味的健全性を監視し、劣化を検出し、問題がシステム全体に波及する前に介入できます。
測定と次のアクション:意味的インテリジェンスの運用化
継続的に追跡できる離散的意味構造のメトリクスを定義します:
- クラスタシルエットスコア(高いほど明確な構造;目標 > 0.5)
- デイビス・ボールディン指数(低いほど良好な分離;目標 < 1.5)
- クラスタ内分散(低いほど緊密なアトラクタ;時間経過に伴う傾向を追跡)
- クラスタ安定性(再計算時のクラスタ割り当ての変化を測定;目標 > 90%の安定性)
これらのメトリクスを月次で計算し、劣化を検出します。アラート閾値を設定:シルエットスコアが0.4を下回るか、デイビス・ボールディン指数が2.0を超える場合、原因を調査します。
-
ハミルトニアン解析については*、実際のシーケンスにおけるエネルギー保存則違反を測定します:
-
本番データから1,000のランダムシーケンスを抽出
-
各シーケンスにハミルトニアン関数を適合
-
エネルギー保存則違反(H = 定数からの偏差)を測定
-
適合したハミルトニアンとランダムベースラインの違反を比較
-
違反がランダムより有意に低い場合(p < 0.01)、ハミルトニアン構造が存在
-
今後90日間の即時アクション*:
-
第1-2週:本番モデルのベースライン埋め込み解析を確立。50K代表トークンの埋め込みを抽出し、クラスタリングし、構造を文書化。
-
第3-4週:自動クラスタリングと可視化を実装。時間経過に伴うクラスタ構造を追跡する週次実行を設定。クラスタの進化を示すダッシュボードを作成。
-
第5-6週:上位50の意味クラスタを特定し、その意味を文書化。意味アトラスを作成:各クラスタについて、代表トークンをリストし、意味概念を記述し、関連クラスタを特定。
-
第7-8週:データから1,000のランダムシーケンスでハミルトニアン軌跡適合をテスト。エネルギー保存則違反を測定。ランダムベースラインと比較。
-
第9-12週:保留テストセットで、ハミルトニアン制約付き生成と標準サンプリングを比較。意味的一貫性、事実精度、人間の好み評価の改善を測定。
これにより、意味的インテリジェンスの基盤が作成されます:モデルの概念組織を理解し、一貫性と信頼性を向上させるためのエビデンスベースの方法を持つことができます。
リスクと緩和戦略:不確実性への対処
-
リスク*:離散構造は、真の意味組織ではなく正規化の人工物である可能性がある。
-
緩和策*:L2正規化ありとなしのモデル間で埋め込み構造を比較。異なる正規化スキーム間で構造が持続する場合、数学的人工物ではなく真の意味を反映している。また、異なるモデルアーキテクチャ(トランスフォーマー、RNN、ハイブリッドモデル)間でも比較。
-
リスク*:クラスタリングハイパーパラメータ(クラスタ数、距離メトリック)が結果に大きく影響し、偽の発見につながる可能性がある。
-
緩和策*:感度分析を実行—ハイパーパラメータを体系的に変化させ、発見の安定性を文書化。複数のクラスタリングアルゴリズム(k-means、HDBSCAN、スペクトラルクラスタリング)を使用し、結果を比較。発見がアルゴリズムとハイパーパラメータ間でロバストであれば、真正である可能性が高い。
-
リスク*:ハミルトニアン適合が訓練シーケンスに過適合し、真の意味動力学ではなくノイズを捉える可能性がある。
-
緩和策*:交差検証を使用—シーケンスの80%でハミルトニアンを適合し、保留20%でエネルギー保存を評価。両セットでエネルギー保存が類似している場合、適合は汎化する。また、異なるドメインのシーケンスでテストし、ロバスト性を確保。
-
リスク*:離散構造がモデル層とアーキテクチャ間で大きく異なり、汎化可能性が制限される可能性がある。
-
緩和策*:すべての層と複数のモデルファミリー間で構造を分析。どの層が最も強い離散性を示すか、構造がネットワークを通じてどのように進化するかを文書化。これにより、意味的結晶化が発生する場所が明らかになり、アーキテクチャ設計に情報を提供する可能性がある。
-
リスク*:離散的意味状態が不安定またはコンテキスト依存で、入力に基づいて変化する可能性がある。
-
緩和策*:異なる入力ドメインとコンテキストのクラスタ構造を分析。異なるデータ分布間でクラスタがどれだけ安定しているかを測定。クラスタが不安定な場合、変化する条件を文書化。
結論と移行パス:意味的インテリジェンスの構築
離散的意味状態とハミルトニアン動力学は、LLM埋め込みを理解するための新しいレンズを提供します—不透明な数値ベクトルから理解可能な意味インフラストラクチャへと変換するものです。埋め込みを非構造化ベクトルとして扱うのではなく、エネルギー保存動力学に支配された離散的アトラクタを中心に組織化されていることを認識します。この視点により、より解釈可能で、効率的で、制御可能なモデルが可能になります。
-
長期的ビジョン*:意味構造をより深く理解するにつれて、意味空間を意図的にナビゲートするモデルを設計できます。長いコンテキスト全体で一貫性を維持し、エネルギー保存を尊重することで幻覚を回避し、新しい概念を優雅に処理するシステムを構築できます。トークンが何を意味するかだけでなく、意味がどのように関連し進化するかを理解する意味認識モデルを作成できます。
-
今後6か月間の即時移行パス*:
-
1か月目:クラスタリングを使用して現在のモデルの埋め込み構造を分析。離散的意味状態とその関係を文書化。意味アトラスを作成。
-
2か月目:生成タスクでハミルトニアン軌跡適合をパイロット。一貫性と事実性の改善を測定。制約付き生成と標準サンプリングを比較。
-
3か月目:結果が有望な場合、本番推論パイプラインにハミルトニアン制約を統合。改善を検証するため、トラフィックの小さな割合から開始。
-
4-6か月目:パフォーマンスに基づいて統合を拡大。ハイパーパラメータを改良。他のタスク(要約、翻訳、質問応答)に拡張。
-
このフレームワークは既存の方法の置き換えではなく、分析、改善、制御のための補完的ツールです*。測定から始め、発見を厳密に検証し、その後徐々に洞察を運用に統合します。各ステップはエビデンスベースで可逆的であるべきです。
-
ナレッジワーカーにとって*、このフレームワークはAIシステムについて考える新しい方法を提供します:出力を生成するブラックボックスとしてではなく、構造化された概念空間をナビゲートする意味エンジンとして。この構造を理解することで、デプロイメント、ファインチューニング、改善についてより良い意思決定が可能になります。また、新しいアプリケーションも可能になります:概念的関係を尊重する意味検索、一貫性を維持する生成、意味的ドリフトが複合する前にそれを捉える異常検出。
言語モデルの未来は、意味構造の理解と活用の上に構築されます。今この理解に投資する組織は、より信頼性が高く、解釈可能で、制御可能なAIシステムを構築する上で大きな優位性を持つでしょう。