
分割と洗練:会話における感情認識のためのマルチモーダル表現と説明可能性の強化
感情認識におけるマルチモーダル信号
-
主張:* 会話文脈における感情認識には、3つの異なる情報源を統合するシステムが必要である:モダリティ固有の手がかり(個々のチャネルに固有の信号)、モダリティ間で共有される信号(冗長な情報)、および創発的相互作用(マルチモーダルの組み合わせからのみ生じる相乗的パターン)。
-
根拠と理論的基盤:* 感情状態は複数のコミュニケーションチャネルにわたって同時に現れる:音響特徴(基本周波数、スペクトル特性、時間的ダイナミクス)、視覚特徴(Ekman & Friesen, 1978による顔面動作単位;身体姿勢;視線方向)、および言語特徴(語彙選択、統語構造、意味内容)。単一モダリティアプローチまたは一般的な後期融合アーキテクチャは、チャネル間の重要な相互作用を捉えることができない。感情の不一致現象—言語内容が副言語的または視覚的信号と矛盾する場合—は、個々のモダリティでは完全に特徴付けることができない相乗的信号を表す。例えば、話者が「大丈夫です」と述べながら、声の緊張(高いピッチ、発話速度の低下)と欲求不満の顔面微表情(皺眉筋の収縮)を示す場合、この矛盾はマルチモーダルの組み合わせから生じるため、診断的な感情的重みを持つ。
-
具体例:* カスタマーサービスのやり取りにおいて、担当者の言語出力(「喜んでお手伝いします」)は忍耐を表現するかもしれないが、同時に音響分析は声の緊張(ジッター、シマー、または調和対雑音比の低下)を明らかにし、視覚分析は述べられた感情状態と一致しない微表情を検出する。転写されたテキストのみで動作するシステムは感情価を誤分類する。音響ストレスマーカーと顔面緊張パターン間の相乗的信号に注目するシステムは、根底にある感情状態をより正確に捉える。
-
前提条件と仮定:* この主張は、(1) 感情が複数の独立したチャネルを通じて部分的に観察可能であること、(2) これらのチャネルが冗長な情報と固有の情報の両方を含むこと、(3) チャネル間の相互作用効果が感情分類にとって意味があること、を仮定している。これらの仮定は以下の条件下で成立する:記録が十分な音響的および視覚的忠実度を捉えていること、話者がすべてのモダリティにわたって意図的に感情を隠していないこと、および注釈者が固有の主観性にもかかわらず信頼性の高い真の感情ラベルを付けることができること。
-
実行可能な示唆:* モダリティ固有の特徴抽出経路と融合層の間で明示的なアーキテクチャ分離を持つ感情認識パイプラインを設計する。音響、視覚、言語特徴のための独立したエンコーダを表現を組み合わせる前に実装する。この設計選択により以下が可能になる:(a) 最終予測へのモダリティごとの寄与の測定、(b) 各モダリティ経路の独立した検証とデバッグ、(c) 1つのモダリティが利用できないか破損している場合の優雅な劣化。
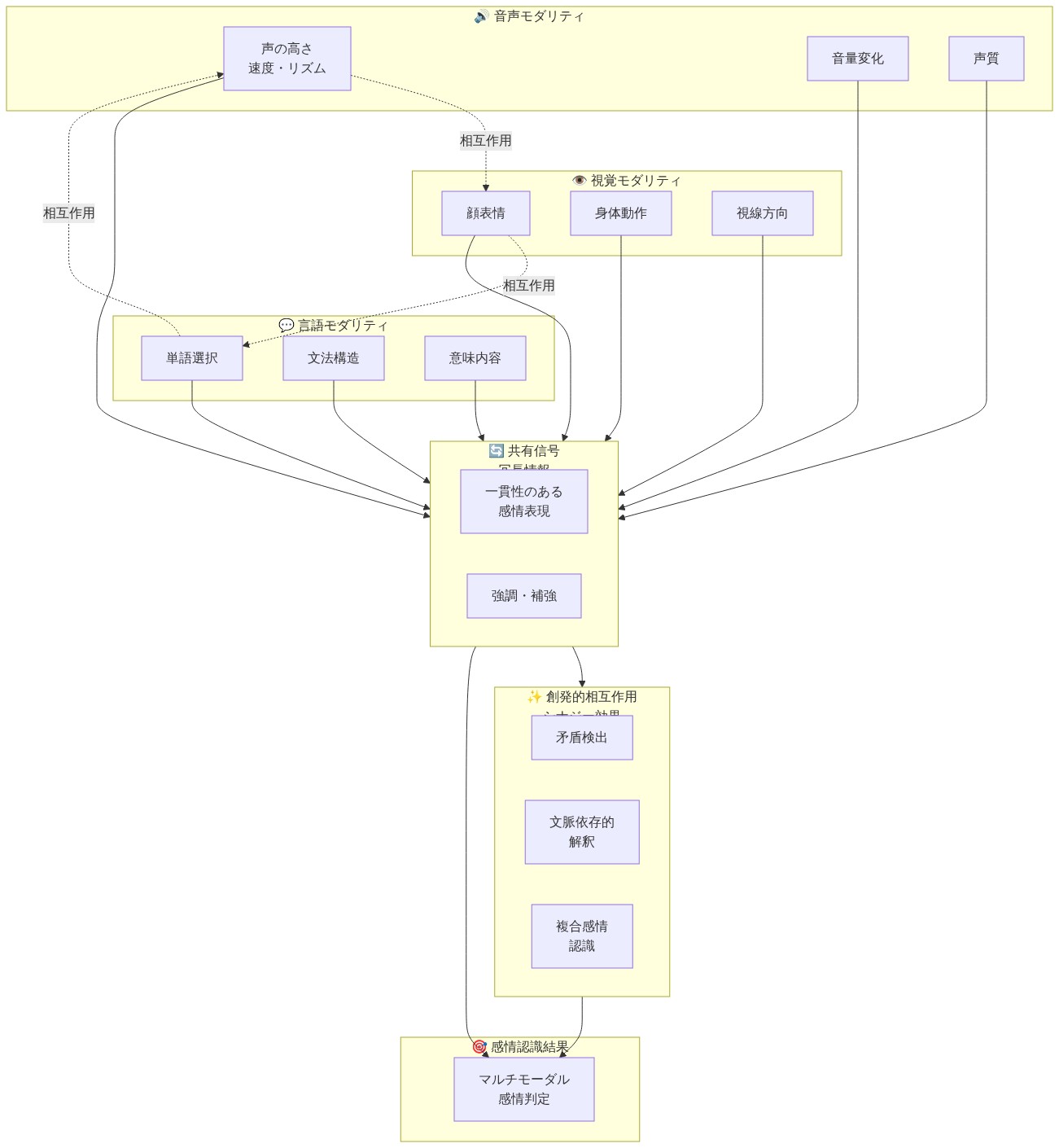
- 図2:感情認識における3つの信号タイプの分類と相互作用*

- 図3:感情の不一致の例:言語と非言語信号の矛盾。顧客サービス代表者の肯定的な言語表現と、ピッチ上昇や顔の微表情に表れた不安・不満の非言語信号が対立している状態を示す。マルチモーダル感情認識において、このような不一致の検出が重要である。*
情報理論的分解
-
主張:* 固有、冗長、相乗的情報成分—部分情報分解(PID)を通じて形式化される—は、感情予測へのマルチモーダル寄与を理解するための原理的で定量的な枠組みを提供する。
-
理論的基盤:* 情報理論、特に部分情報分解(Williams & Beer, 2010; Griffith & Koch, 2014)は、予測変数とターゲット間の相互情報量を4つの非負の成分に分解する:
-
固有情報: 他のモダリティから回復できない、1つのモダリティによって提供される情報。
-
冗長情報: 複数のモダリティに同時に存在する情報。
-
相乗的情報: 複数のモダリティの共同観察からのみ生じる情報;個々のモダリティには存在しない。
形式的には、モダリティM₁、M₂、M₃と感情ラベルEについて:
I(M₁, M₂, M₃; E) = U(M₁) + U(M₂) + U(M₃) + R(M₁, M₂, M₃) + S(M₁, M₂, M₃)
ここで、Uは固有情報、Rは冗長性、Sは相乗効果を示す。この分解は、どのモダリティペアまたはトリプレットが予測に最も寄与するかを明らかにし、融合メカニズムが個々のモダリティにすでに存在する情報を単に複製するのではなく、真の予測価値を追加する場所を特定する。
-
具体例:* 500の会話クリップを含む検証セットの分析により、以下の分解が得られる:音響特徴は40%の固有情報を寄与し(例:テキストやビデオでは検出できない声の震え)、視覚-音響冗長性は25%を占め(例:明るい韻律と笑顔の両方に現れる明白な幸福)、テキスト-音響相乗効果は35%を占める(例:言葉と音調の不一致を通じて検出される皮肉)。この定量的内訳は、リソース配分を直接的に示す:音響エンコーダは実質的なモデル容量を必要とし、視覚処理は部分的に冗長である可能性があり最適化できる可能性があり、テキスト-音響融合層は全体的なパフォーマンスにとって重要である。
-
前提条件と仮定:* PID分析は、(1) 相互情報量が有限サンプルから信頼性高く推定できること(高次元設定ではバイアスの対象となる)、(2) 感情ラベルが注釈者間で十分に一貫していること(評価者間信頼性 ≥ 0.70、コーエンのカッパ)、(3) モダリティが根底にある感情状態を条件として条件付き独立であること(協調的な感情表示では成立しない可能性がある簡略化仮定)、を仮定している。推定方法には、ビニングベースのアプローチ(Timme et al., 2014)とモデルベースのアプローチ(Ince, 2017)があり、それぞれ小サンプル体制で既知のバイアスがある。
-
実行可能な示唆:* 確立された推定方法(例:連続特徴のためのガウスコピュラ近似、またはバイアス補正を伴う離散化)を使用して、検証セットで部分情報分解メトリクスを計算する。これらの測定値を使用してアーキテクチャの決定を導く:情報タイプに比例してモデル容量を割り当て、冗長な経路を削減または統合し、相乗的融合メカニズムを強化する。PID推定値とその信頼区間を文書化する;これらをベースラインとして使用し、アーキテクチャの変更が情報フローを保持するか劣化させるかを監視する。
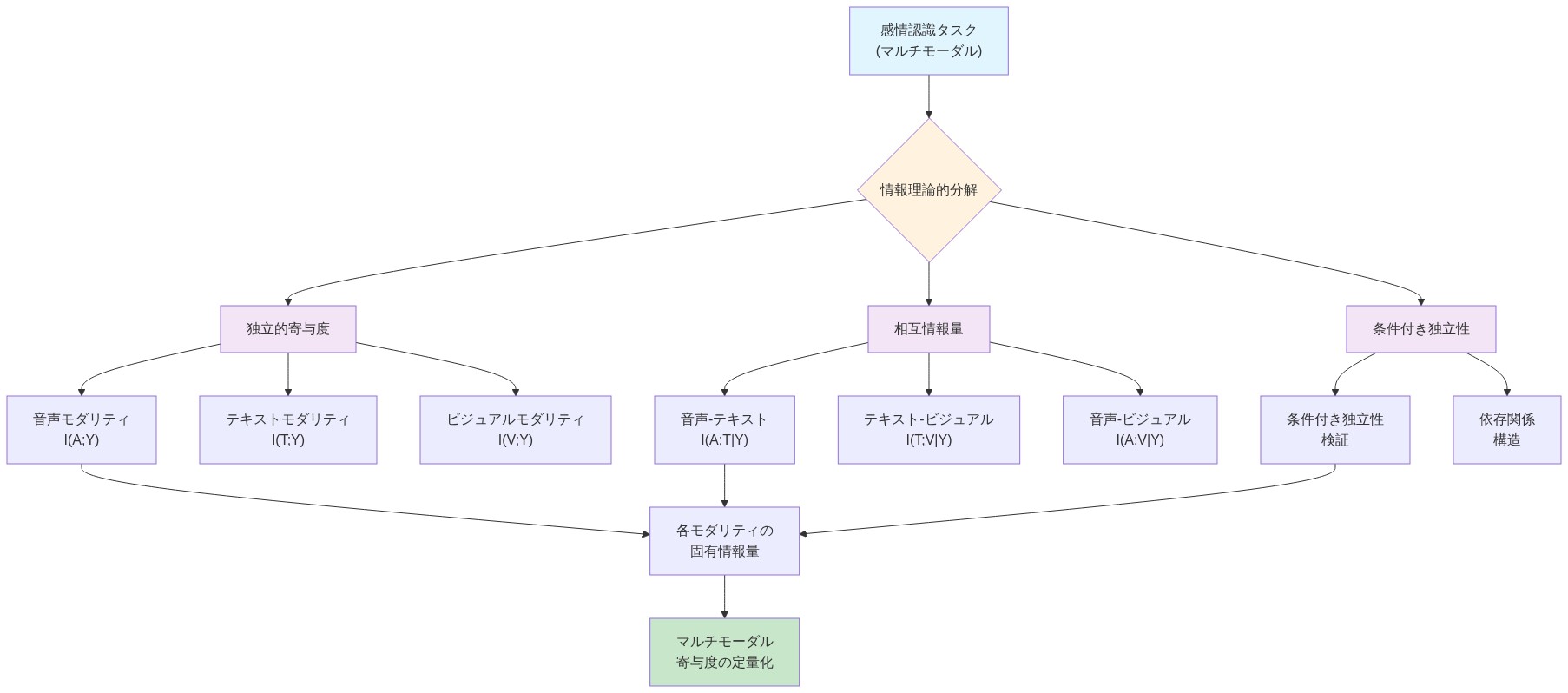
- 図4:情報理論的分解:マルチモーダル寄与度の定量化*
実装アーキテクチャと操作
-
主張:* モダリティ固有の特徴抽出とクロスモーダル融合の明示的な分離を持つモジュラー分割・洗練アーキテクチャは、モノリシックなエンドツーエンドアプローチと比較して、予測精度と説明可能性の両方を向上させる。
-
根拠と設計原則:* モノリシックなエンドツーエンドモデル(例:連結されたマルチモーダル入力を取り込む単一の深層ネットワーク)は、どのモダリティが各予測に寄与するかを不明瞭にし、パフォーマンスが低下したときのデバッグを複雑にする。各モダリティのための明確な分岐を持ち、その後に制御された融合段階が続くモジュラーアーキテクチャは、以下を可能にする:(1) 各コンポーネントの独立した検査と検証、(2) 1つのモダリティのパフォーマンスが低下したときの対象を絞った再トレーニング、(3) 1つのモダリティが欠落または破損している場合の優雅な劣化、(4) 特定のモダリティの組み合わせへの予測の帰属。
-
具体的なアーキテクチャ:* 3つの並列エンコーダを実装する:
-
音響エンコーダ: メル周波数ケプストラム係数(MFCC、13〜40係数)と25〜50ミリ秒ウィンドウでのデルタ特徴を抽出する。韻律ダイナミクスを捉えるために時間的畳み込みネットワーク(TCN)または双方向LSTMを通過させる。出力:音響埋め込み(例:256次元ベクトル)。
-
視覚エンコーダ: 確立された方法(例:OpenFace 2.0; Baltrusaitis et al., 2018)を使用して顔面ランドマークと動作単位(AU)を検出する。AU強度と頭部姿勢を抽出する。完全接続ネットワークまたはトランスフォーマーを通過させる。出力:視覚埋め込み(256次元)。
-
言語エンコーダ: 転写されたテキストをトークン化し、事前トレーニングされた言語モデル(例:BERT; Devlin et al., 2019)またはドメイン固有の微調整されたバリアントを通過させる。[CLS]トークンから文脈埋め込みを抽出するか、トークン表現を平均プールする。出力:言語埋め込み(256次元)。
-
融合層:* 埋め込みを連結し、融合段階を通過させる:
-
ペアワイズ相互作用: 埋め込みペア(音響-視覚、音響-言語、視覚-言語)の要素ごとの積と注意重み付けされた組み合わせを計算する。
-
三方向相乗効果: すべての3つのモダリティ間の相互作用を捉える相乗効果項を計算する(例:学習されたテンソル積またはゲートメカニズムを介して)。
-
最終分類: 融合された表現を多層パーセプトロンを通過させて、感情クラスまたは次元スコア(価、覚醒)を予測する。
-
前提条件と仮定:* このアーキテクチャは、(1) モダリティ固有の特徴が確立された方法を使用して意味のある形で抽出できること、(2) 異なるモダリティからの埋め込みが次元とスケールにおいて比較可能であること(正規化が必要)、(3) 融合層が過学習せずに意味のある相互作用を学習できること(正則化と十分なトレーニングデータが必要)、を仮定している。前提条件には以下が含まれる:同期されたマルチモーダル記録の利用可能性、十分なトレーニングデータ(感情クラスごとに≥1,000サンプル)、および複数のエンコーダをトレーニングするための計算リソース。
-
実行可能な示唆:* 明確なインターフェースとバージョン管理を持つモジュラーエンコーダを実装する。すべてのトレーニングおよび検証サンプルの中間埋め込みをログに記録する。モダリティごとの寄与スコアを示すダッシュボードを構築する(例:注意重みまたは勾配ベースの帰属を介して)。単一モダリティ、ペア、およびすべての3つでパフォーマンスをテストして、パフォーマンスベースラインを確立し、どの組み合わせが最も有益かを特定する。再現可能な形式(例:構成ファイル、コンテナ化された環境)でアーキテクチャとハイパーパラメータを文書化する。
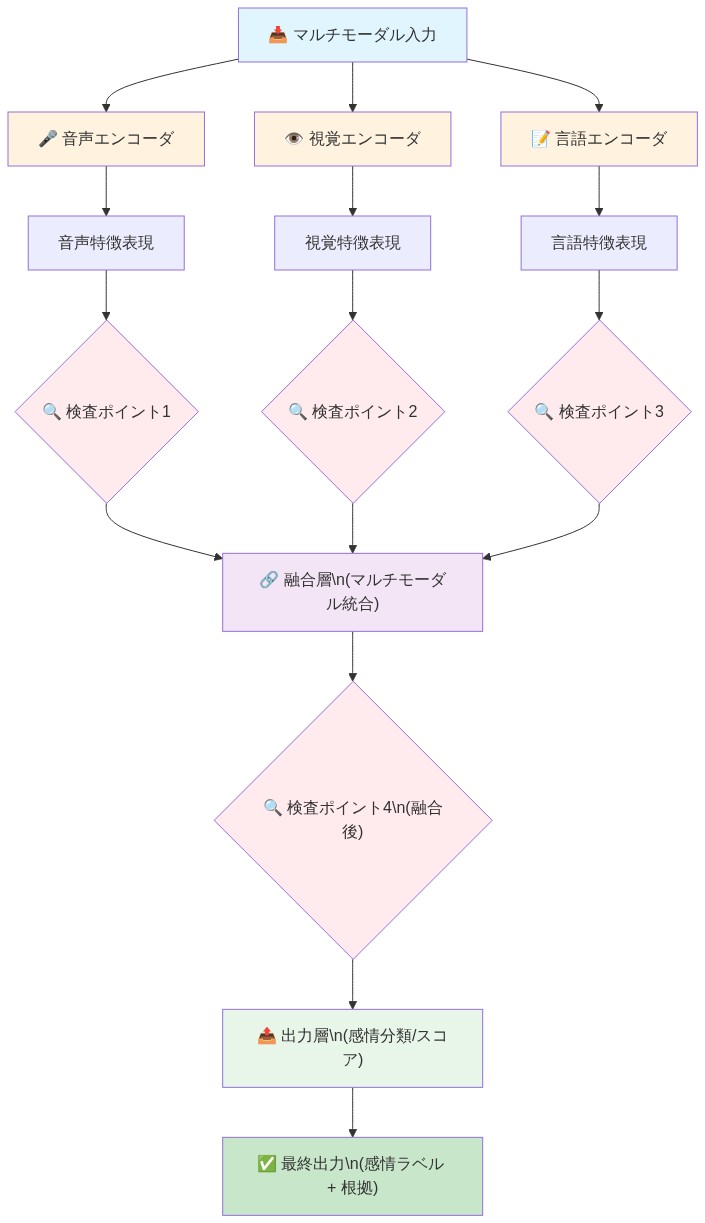
- 図5:モジュール型マルチモーダル感情認識システムのアーキテクチャ(Divide and Refineアプローチに基づく検査可能設計)*
測定と検証プロトコル
-
主張:* 人口統計グループと感情状態にわたるモダリティ寄与と予測信頼度の厳密で層別化された測定は、バイアスを特定し、感情認識システムの責任ある展開を確保するために不可欠である。
-
根拠と測定フレームワーク:* 感情は本質的に主観的である;真のラベルは注釈者の解釈、文化的規範、文脈を反映する。集約精度のみを測定すること(例:全体的なF1スコア)は、特定の感情状態、話者の人口統計、または音響条件における体系的な失敗を隠す。サブグループ間でモダリティ寄与を追跡することで、システムが潜在的にバイアスのかかった信号(例:民族性や性別と相関する視覚的手がかり、年齢やアクセントと相関する音響特徴)に依存しているかどうかが明らかになる。
-
具体例:* バランスの取れたテストセットにわたって、男性と女性の話者について怒りの認識を別々に評価する。システムが全体で92%の精度を達成するが、女性話者では78%しか達成しないと仮定する。モダリティごとの精度を計算することで、どのモダリティがギャップを引き起こすかを調査する:音響特徴は女性で85%を達成する可能性がある(男性では95%)、これは音響エンコーダが主に男性の声でトレーニングされたか、怒りとは無関係な性別相関音響パターンを学習したことを示唆する。視覚特徴は女性で80%を達成する可能性がある(男性では88%)、これは視覚エンコーダが性別バイアスまたは文化的に特異的な顔面表情パターンを学習したことを示唆する。
-
測定プロトコル:*
-
層別化された評価セット: テストデータを以下で分割する:(a) 感情クラス(怒り、喜び、悲しみ、中立など)、(b) 話者の人口統計(性別、年齢、アクセント/母国語)、(c) 会話文脈(カスタマーサービス、ピアツーピア、構造化インタビュー)、(d) モダリティの利用可能性(すべての3つのモダリティ、ペア、単一モダリティ)。
-
グループごとのメトリクス: 各層について、以下を計算する:精度、適合率、再現率、F1スコア、およびモダリティごとの寄与(注意重み、勾配ベースの帰属、またはアブレーションを介して)。ブートストラップリサンプリングを使用して95%信頼区間を計算する。
-
信頼度較正: 予測された信頼度スコアが実際の精度と一致するかどうかを測定する。層にわたって期待較正誤差(ECE)と最大較正誤差(MCE)を計算する。較正が不十分な信頼度スコアは、モデルが特定のサブグループで過信または過小評価していることを示す。
-
公平性メトリクス: 人口統計的パリティ(グループ間の等しい精度)、等化オッズ(グループ間の等しい真陽性率と偽陽性率)、および較正パリティ(グループ間の等しい信頼度較正)を計算する。許容可能な閾値を設定する(例:人口統計グループ間の精度分散 ≤ 5%)。
-
前提条件と仮定:* このプロトコルは、(1) 真のラベルが十分に信頼できること(評価者間一致 ≥ 0.70)、(2) テストセットが層別化分析を可能にするために十分に大きくバランスが取れていること(層ごとに≥100サンプル)、(3) 人口統計カテゴリが分析にとって意味があり倫理的に正当化されること、を仮定している。前提条件には以下が含まれる:人口統計メタデータへのアクセス、グループごとの分析のための十分な計算リソース、および調査結果に基づいて行動する組織的コミットメント。
-
実行可能な示唆:* 感情、話者の人口統計、会話文脈、およびモダリティの利用可能性によって層別化された評価セットを確立する。検証パイプラインでグループごとの精度、モダリティごとの寄与、および信頼度較正の計算を自動化する。グループ間の許容可能なパフォーマンス分散の明示的な閾値を設定する(例:最大5%の精度差)。新しいモデルバージョンがトレーニングされたときに回帰を即座にフラグ付けする。すべての調査結果を文書化し、ステークホルダーに透明に伝達する。
リスク軽減とロバスト性
-
主張:* マルチモーダル感情認識システムは、欠落または劣化したモダリティ、敵対的入力、モダリティ固有のバイアスといった新たな故障モードを導入するため、積極的な特定と軽減が必要である。
-
根拠と故障モード分析:* 高品質なスタジオ録音と制御された照明で訓練されたシステムは、ノイズの多い電話通話、低解像度のウェブカメラ、または屋外環境に展開されると壊滅的に失敗する可能性がある。個々のモダリティを標的とする敵対的攻撃(例:音声に慎重に作成されたノイズを追加する、またはビデオに知覚できない摂動を加える)は、システムを欺くことができる。訓練データのバイアス(例:顔表情データセットの多様性の制限、音響訓練データで過小評価されているアクセント)は、エンコーダーを通じて静かに伝播し、展開時に体系的なエラーとして現れる。
-
具体例:* 各モダリティを独立して劣化させることで、システムのロバスト性をテストする:
-
音声劣化: 背景ノイズを追加(SNR = 10、5、0 dB)、より低いサンプルレートに圧縮(16 kHz、8 kHz)、パケット損失を導入(5%、10%)。
-
視覚劣化: ビデオをより低い解像度に圧縮(480p、240p)、フレームレートを削減(15 fps、10 fps)、ガウスぼかしを追加。
-
言語劣化: 転写エラーを導入(5%、10%の単語誤り率)、発話を切り詰める、句読点を削除。
各劣化レベルでの精度低下を測定する。音声劣化が40%の精度損失(92% → 55%)を引き起こし、視覚劣化がわずか5%の損失(92% → 87%)しか引き起こさないとする。これは、システムが脆弱であること、つまり音声品質に過度に依存していることを示している。軽減策:拡張音声(ノイズ注入、時間伸縮、ピッチシフト)で再訓練し、ロバスト性を向上させる。
- ロバスト性テストスイート:*
-
欠落モダリティ: 1つ以上のモダリティが利用できない場合のパフォーマンスを評価する。フォールバック戦略を確立する(例:音声が欠落している場合、視覚信号と言語信号の重みを増やす)。
-
ノイズと圧縮: 各モダリティを現実的な範囲で体系的に劣化させる。劣化レベルの関数として精度を測定する。急峻な精度劣化曲線を持つモダリティ(脆弱)と緩やかな曲線を持つモダリティ(ロバスト)を特定する。
-
敵対的摂動: 勾配ベースの方法(FGSM、PGD)を使用して、個々のモダリティを標的とする敵対的例を生成する。敵対的攻撃に対するロバスト性を測定する。必要に応じて敵対的例で再訓練する。
-
ドメインシフト: 分布外データ(例:異なる言語、アクセント、年齢層、感情強度範囲)でのパフォーマンスを評価する。パフォーマンス低下を測定し、どのモダリティが最も影響を受けるかを特定する。
-
仮定と前提条件:* この分析は、(1)標準的な拡張技術を使用して劣化を現実的にシミュレートできること、(2)システムの故障モードが再現可能で測定可能であること、(3)軽減策(例:データ拡張、アーキテクチャの変更)を実装および検証できることを仮定している。前提条件には、多様なテストデータへのアクセス、広範なテストのための計算リソース、モデルを再訓練する能力が含まれる。
-
実行可能な示唆:* 欠落モダリティ、ノイズ注入、圧縮、敵対的摂動をカバーするロバスト性テストスイートを構築する。これらのテストを毎月または各モデル更新後に実行する。弱いモダリティを標的とするデータ拡張で訓練する(例:音声が脆弱な場合、ノイズで大幅に拡張する)。フォールバック戦略を実装する:音声品質が低い場合(信号対雑音比またはその他のメトリクスを介して検出)、視覚信号と言語信号の重みを増やす。すべての故障モードを文書化し、エンドユーザーと利害関係者に明確に伝える。
説明可能性とユーザーの信頼
-
主張:* 予測を特定のモダリティの組み合わせとその相互作用に透明に帰属させることは、ユーザーの信頼を構築し、人間による監視を可能にし、高リスクアプリケーション(メンタルヘルススクリーニング、顧客満足度モニタリング)において不可欠である。
-
根拠と説明可能性フレームワーク:* システムが感情状態を予測する場合、利害関係者はその理由を理解する必要がある。帰属方法—注意重み、SHAP(SHapley Additive exPlanations)値、層別関連性伝播(LRP)、またはモダリティ寄与スコアなど—は予測を解釈可能にする。この透明性は、誤った感情検出が不適切な介入を引き起こす可能性がある高リスク設定(例:メンタルヘルス危機対応、カスタマーサービスエスカレーション)で特に重要である。
-
帰属方法:*
-
注意重み: 融合層が注意メカニズムを使用する場合、注意重みは予測に最も関連するモダリティ特徴を直接示す。注意を時間とモダリティにわたるヒートマップとして可視化する。
-
SHAP値: 予測への各モダリティの寄与に対するシャープレイ値を計算する。SHAP値は堅固なゲーム理論的基盤を持ち、一貫した局所的に正確な説明を提供する。個別のSHAP値と相互作用項の両方を計算する。
-
層別関連性伝播(LRP): 予測の関連性をネットワークを通じて逆方向に伝播し、入力特徴とモダリティに重要度スコアを割り当てる。LRPは関連性が保存されることを保証する。
運用化と次のステップ
分割と洗練のマルチモーダル感情認識を展開するには、体系的なアーキテクチャ設計、厳密な測定、実世界の展開条件に対する継続的な検証が必要である。
- 主要な実装優先事項:*
- モダリティ信号を固有、冗長、相乗的コンポーネントに分解し、アーキテクチャとリソース配分を導く。
- 明確なインターフェースを持つモジュラーエンコーダーを実装し、検査、デバッグ、段階的劣化を可能にする。
- サブグループとモダリティ全体で厳密に測定し、バイアスと故障モードを早期に捕捉する。
- 弱いモダリティを標的とする敵対的テストと拡張を通じてロバスト性を優先する。
- 予測をモダリティの寄与にリンクする透明な説明を提供し、人間による監視を可能にする。
-
実装タイムライン:*
-
第1〜2週: 現在の感情認識システムを監査する。モダリティが融合される場所と寄与が追跡されているかどうかを特定する。モジュラー代替アーキテクチャを設計する。
-
第3〜4週: 個別のエンコーダーと融合層を実装する。検証セットで情報理論的分解を計算する。
-
第5〜6週: モダリティごとの精度、グループごとのパフォーマンス、予測信頼度を追跡する測定ダッシュボードを構築する。ベースラインメトリクスを確立する。
-
第7〜8週: ロバスト性テスト(欠落モダリティ、ノイズ、敵対的入力)を実行する。故障モードを文書化し、軽減策に優先順位を付ける。
-
第9〜10週: 説明可能性層を実装し、サンプル説明を生成する。利害関係者からフィードバックを収集する。
-
継続的: CI/CDパイプラインで測定と検証を自動化する。層別化されたパフォーマンスを毎月レビューする。新しい故障モードが現れたら拡張データで再訓練する。
成功は完璧さではなく、体系的な改善にある。各測定はシステムが弱い場所を明らかにし、各テストは新しいリスクを発見し、各説明は信頼を構築する。マルチモーダル感情認識を静的なモデルではなく進化するシステムとして扱うことで、実際の会話における責任ある透明な展開の基盤を作る。
情報理論的分解:マルチモーダル寄与の定量化
-
ビジョン:* 情報理論は、マルチモーダル信号を分解するための原理的な言語を提供し、組織が直感駆動のアーキテクチャ設計から証拠駆動のリソース配分と戦略的能力構築へ移行することを可能にする。
-
基本的主張:* 固有、冗長、相乗的情報コンポーネントは、感情予測へのマルチモーダル寄与を理解するための厳密なフレームワークを提供する。この分解は、ブラックボックスの融合問題を透明な最適化課題に変換する。
-
根拠:* 情報理論は、マルチモーダル信号の3つのカテゴリーに対する形式的定義を提供する:
-
固有情報は、1つのモダリティから得られ、他のモダリティからは回復できない(例:微妙な声の震え、マイクロ表情、稀な単語選択)。この信号は高価値だが脆弱で、モダリティの品質に依存する。
-
冗長情報は、複数のモダリティにわたって現れる(例:顔表情と明るいトーンの両方における明白な幸福)。この信号はロバストだが、独立して処理される場合は計算コストが高い。
-
相乗的情報は、組み合わせからのみ現れる(例:単語とトーンの不一致を通じて検出される皮肉、視線と発話の非同期を通じた欺瞞)。この信号は、しばしば最も予測的であり、抽出が最も困難である。
これらのコンポーネントを定量化することで、どのモダリティペアが予測に最も寄与し、融合が真の価値を追加する場所が明らかになる。この洞察は即座に戦略的意味を持つ:エンジニアリング努力をどこに投資すべきか、冗長性をどこで削減できるか、新しい融合メカニズムがどこで新しい予測力を解放するかを教えてくれる。
- 具体例:* カスタマーサービスセンターからの500の会話クリップのデータセットを分析し、部分情報分解(PID)メトリクスを計算すると、次のことがわかる:
- 予測信号の40%は固有の音声特徴(声のストレス、発話速度の変化、呼吸パターン)から来る
- 25%は冗長な視覚-音声の重複から来る(両方のモダリティが明白な感情状態を示す)
- 35%は相乗的なテキスト-音声相互作用から来る(声の配信と組み合わされた単語選択が意図を明らかにする)
この内訳は、音声エンコーダーが相当なモデル容量と計算投資に値すること、一部の視覚処理が音声と冗長である可能性があること(効率向上の機会を示唆)、テキスト-音声融合層が予測パフォーマンスに重要であることを即座に教えてくれる。また、展開戦略も示唆する:音声品質が劣化するノイズの多い環境では、壊滅的なパフォーマンス損失なしにテキスト-音声相乗効果に重みをシフトできる。
-
将来の展望:* 組織が感情認識を多様なコンテキスト—コールセンター、リモートワークプラットフォーム、教育環境、医療—に展開するにつれて、情報理論的分解はコンテキスト固有の感情信号を理解するための診断ツールになる。医療提供者は固有の視覚情報が支配的であることを発見するかもしれない(姿勢に見られる患者の不安)、一方、リモートワークプラットフォームは相乗的なテキスト-ビデオ信号が支配的であることを発見するかもしれない(チャット感情と組み合わされた顔表情)。この適応性は、責任あるコンテキスト認識展開の鍵である。
-
実行可能な示唆:* 検証セットで部分情報分解(PID)メトリクスを計算し、固有、冗長、相乗的寄与を測定する。これらの測定を使用してアーキテクチャの決定を導く:情報タイプに比例してモデル容量を割り当て、冗長なパスを削減し、相乗的融合メカニズムを強化する。このデータ駆動アプローチは、推測を証拠に置き換える。PID計算を、精度とF1スコアと並んで、モデル評価パイプラインの標準部分として確立する。新しい訓練データを追加したり、新しいコンテキストに展開したりするときにPIDメトリクスがどのようにシフトするかを追跡する—これらのシフトは、アーキテクチャが適応を必要とする時期を示す。
実装アーキテクチャと運用:モジュラーで検査可能なシステムの構築
-
ビジョン:* モジュラーな分割と洗練のアーキテクチャは、検査、デバッグ、継続的改善を可能にするため、高リスクAIシステムの業界標準になりつつある—感情認識をブラックボックスの予測ツールから運用インテリジェンスシステムに変換する。
-
基本的主張:* 分割と洗練のアーキテクチャは、モダリティ固有の特徴抽出をクロスモーダル融合から明示的に分離し、パフォーマンスと説明可能性の両方を向上させる。この分離は贅沢ではない—決定が人々の生活と生計に影響を与える実世界の設定における責任ある展開の前提条件である。
-
根拠:* モノリシックなエンドツーエンドモデルは、どのモダリティが各予測に寄与するかを不明瞭にし、故障のデバッグ、バイアスの監査、新しいコンテキストへの適応を不可能にする。各モダリティに対する個別のブランチを持ち、その後に制御された融合段階が続くモジュラー設計により、各コンポーネントを独立して検査、検証、調整できる。この分離は、1つのモダリティが欠落または破損している場合の段階的劣化も可能にする—これは実世界の展開における一般的なシナリオである(例:照明が悪いビデオ通話、背景ノイズのある電話通話、ビデオのないチャット会話)。
-
具体例:* 3つの並列エンコーダーを構築する:
- 音声エンコーダー: 生音声 → MFCC(メル周波数ケプストラム係数)+ 時間的CNN → 128次元音声埋め込み。韻律的特徴を捕捉:ピッチ、強度、リズム、声質。
- 視覚エンコーダー: ビデオフレーム → 顔検出 + アクションユニット抽出(OpenFaceまたは類似のものを使用)→ 空間-時間的CNN → 128次元視覚埋め込み。顔表情、頭の動き、視線方向を捕捉。
- 言語エンコーダー: 転写 → BERTトークン化 → トランスフォーマー層 → 128次元言語埋め込み。意味内容、感情、感情の言語マーカーを捕捉。
これら3つの埋め込みを、以下を計算する融合層に供給する:
- ペアワイズ相互作用: 音声-視覚注意、音声-言語注意、視覚-言語注意
- 3方向相乗効果: 3つのモダリティすべてを組み合わせた場合にのみ現れる信号を捕捉する学習メカニズム
- 最終感情分類: 感情カテゴリ(喜び、悲しみ、怒り、恐怖、中立など)に対するソフトマックス
推論時に、どの埋め込みが予測に最も寄与したかを可視化し、どの融合メカニズムが発火したかを特定し、決定を特定の音声フレーム、顔表情、または単語まで追跡できる。このトレーサビリティは、デバッグと利害関係者の信頼構築に非常に貴重である。
-
将来の展望:* 会話AIシステムがより洗練されるにつれて、モジュラーアーキテクチャは新しいコンテキストと新しいモダリティへの迅速な適応を可能にする。システム全体を再訓練することなく、生理学的モダリティ(ウェアラブルからの心拍数、皮膚コンダクタンス)または行動モダリティ(タイピング速度、マウス移動パターン)を追加することを想像してみてください。モジュラー設計は、この進化をシームレスにする。
-
実行可能な示唆:* 明確なインターフェース(例:各エンコーダーが固定サイズの埋め込みを出力)を持つモジュラーエンコーダーを実装する。訓練セットと検証セットのすべてのサンプルに対して中間埋め込みをログに記録する。モダリティごとの寄与スコア、注意重み、融合メカニズムの活性化を示すダッシュボードを構築する。単一のモダリティ、ペア、および3つすべてでパフォーマンスをテストし、ベースラインを確立し、モダリティの依存関係を理解する。この運用上の透明性は、迅速なデバッグを可能にし、システムの決定に対する利害関係者の信頼を構築する。すべての新しい感情認識コンポーネントにモジュラー設計を要求するコードレビュープロセスを確立する。
測定と検証プロトコル:厳格で階層化された評価
-
ビジョン:* 厳格な測定プロトコルは、集約された精度指標から階層化されたコンテキスト認識型評価へとシフトしており、組織が多様な集団やシナリオにわたって公平に機能するという確信を持って感情認識システムを展開できるようにしています。
-
基本的主張:* モダリティの貢献度と予測信頼度の厳格な測定は、感情認識システムを責任を持って展開するために不可欠です。感情は主観的であり、正解ラベルはしばしばアノテーターのバイアスやコンテキストの喪失を反映します。集約された精度のみを測定すると、特定の感情状態や人口統計グループにおける失敗が隠されてしまいます。
-
根拠:* 全体で92%の精度を達成しているが、特定の人口統計グループでは78%の精度しかないシステムは、「92%正確」ではなく、バイアスがかかっています。サブグループ全体でモダリティの貢献度を追跡することで、システムが潜在的にバイアスのかかった信号(例:民族性、年齢、性別と相関する視覚的手がかりへの過度の重み付け)に依存しているかどうかが明らかになります。この洞察は責任ある展開にとって重要です:システムが害を引き起こす前にバイアスを特定し、軽減することができます。
-
具体例:* 2,000件のカスタマーサービス通話のデータセットで、男性話者と女性話者について怒り認識モデルを個別に評価します。次のことがわかります:
-
全体精度:89%
-
男性話者:91%の精度
-
女性話者:84%の精度
ギャップを調査し、モダリティごとの貢献度を計算すると、次のことがわかります:
- 男性話者の場合、音声が予測信号の50%を貢献(声のストレスは強い怒りの指標)
- 女性話者の場合、音声は35%しか貢献していない(声のストレスがあまり顕著でないか、異なる形で表現されている)
- 女性話者の場合、モデルは視覚的手がかり(表情)に過度に依存しており、これはトレーニングデータにおける性別ステレオタイプの影響を受けている可能性がある
この発見は、音声エンコーダーが主に男性の声でトレーニングされたか、視覚エンコーダーが感情とは無関係な性別相関特徴を学習したことを示唆しています。これで的を絞った対策を取ることができます:多様な女性の声でトレーニングデータを拡張し、音声エンコーダーを再トレーニングし、ギャップが縮小することを検証します。
-
将来の展望:* 感情認識システムが医療、教育、職場環境に展開されるにつれて、階層化された評価はコンプライアンス要件となります。組織は、自社のシステムが人口統計グループ、感情状態、展開コンテキストにわたって公平に機能することを実証する必要があります。このシフトは、多様で高品質なトレーニングデータセットと、集約された精度を超える評価方法論への投資を促進します。
-
実行可能な示唆:* 感情カテゴリ、話者の人口統計(性別、年齢、アクセント、言語能力)、会話コンテキスト(カスタマーサービス、医療、教育)、モダリティの可用性(完全なマルチモーダル、音声のみ、ビデオのみ、テキストのみ)によって階層化された評価セットを確立します。グループごとの精度、モダリティごとの貢献度、信頼度キャリブレーション、偽陽性/偽陰性率を計算します。グループ間の許容可能なパフォーマンス分散の閾値を設定します(例:どのグループも5%を超える精度ギャップがあってはならない)。これらの測定を検証パイプラインで自動化し、回帰を即座にフラグ付けします。階層化されたパフォーマンス指標を月次でレビューし、必要に応じてトレーニングデータやモデルアーキテクチャを調整します。
リスク軽減とロバスト性:プロアクティブな故障モード管理
-
ビジョン:* マルチモーダルシステムは、プロアクティブな特定と軽減を必要とする新しい故障モードを導入します—ロバスト性テストをマスターする組織は、優雅に劣化し、多様な実世界の条件にわたってパフォーマンスを維持するシステムを構築します。
-
基本的主張:* マルチモーダルシステムは、モダリティの欠落、敵対的入力、モダリティ固有のバイアス、分布シフトなど、プロアクティブな軽減を必要とする新しい故障モードを導入します。高品質の音声、ビデオ、テキストでトレーニングされたシステムは、ノイズの多い電話通話や低解像度のウェブカメラに展開されると壊滅的に失敗する可能性があります。
-
根拠:* 実世界の展開条件がトレーニング条件と一致することはほとんどありません。音声品質は変動します(背景ノイズ、圧縮、帯域幅の制限)。ビデオ品質は変動します(照明、解像度、フレームレート)。テキスト品質は変動します(タイプミス、略語、コードスイッチング)。個々のモダリティを標的とする敵対的攻撃はシステムを欺くことができます。トレーニングデータのバイアス(例:表情データセットの多様性の限界、音声データセットで過小評価されている地域アクセント)は、エンコーダーを通じて静かに伝播します。ロバストなシステムは、これらの課題を予測し、優雅に劣化する必要があります。
-
具体例:* 各モダリティを個別に劣化させることで、システムのロバスト性をテストします:
-
音声劣化: さまざまなSNRレベル(20dB、10dB、5dB)で背景ノイズ(オフィスのおしゃべり、交通、機械)を追加します。精度の低下を測定します。
- 結果:精度が89%から5dB SNRで72%に低下。システムは脆弱で、音声品質に過度に依存しています。
-
視覚劣化: ビデオを低解像度に圧縮します(720p → 360p → 180p)。精度の低下を測定します。
- 結果:精度が89%から180pで86%に低下。システムは視覚劣化に対してロバストです。
-
テキスト劣化: タイプミスを導入します(5%、10%、15%の割合でランダムな文字置換)。精度の低下を測定します。
- 結果:精度が89%から15%のタイプミス率で85%に低下。システムはテキストノイズに対して合理的にロバストです。
この分析により、音声が弱点であることが明らかになります。これで的を絞った対策を取ることができます:拡張データ(ノイズ注入、圧縮)で音声エンコーダーを再トレーニングし、フォールバック戦略を実装し(音声品質が悪い場合、視覚とテキスト信号の重みを増やす)、展開制約を設定します(SNR < 10dBの通話では人間のレビューなしでシステムを使用しない)。
-
将来の展望:* 感情認識システムがリモートワークプラットフォームから医療、教育まで、ますます多様なコンテキストに展開されるにつれて、ロバスト性は重要な差別化要因となります。ノイズの多い、低帯域幅、低照度の条件にわたってパフォーマンスを維持するシステムは、より価値があり、より信頼できるものになります。
-
実行可能な示唆:* 以下をカバーする包括的なロバスト性テストスイートを構築します:
-
モダリティの欠落: 音声のみ、ビデオのみ、テキストのみ、およびすべての組み合わせでパフォーマンスを評価します。
-
ノイズ注入: さまざまなSNRレベルで音声に現実的なノイズ(背景のおしゃべり、交通、機械)を追加します。
-
圧縮: ビデオをより低い解像度に、音声をより低いビットレートに圧縮します。
-
敵対的摂動: 各モダリティに小さく的を絞った摂動を適用し、精度の低下を測定します。
-
分布シフト: 異なるドメインのデータでテストします(例:カスタマーサービスでトレーニングし、医療でテスト)。
これらのテストを月次で実行し、時間の経過とともに結果を追跡します。どの故障モードが最も重要かを特定し、軽減策に優先順位を付けます。弱いモダリティを標的とするデータ拡張でトレーニングします。フォールバック戦略を実装します:音声品質が悪い場合、視覚とテキスト信号の重みを増やします。すべての故障モードを文書化し、エンドユーザーと利害関係者に明確に伝えます。
説明可能性とユーザーの信頼:説明責任のための透明な帰属
-
ビジョン:* 透明で人間が読める説明は、感情認識システムの基本要件になりつつあります—説明可能性を優先する組織は、ユーザーが信頼し、規制当局が承認するシステムを構築します。
-
基本的主張:* 特定のモダリティの組み合わせへの予測の透明な帰属は、ユーザーの信頼を構築し、人間の監視を可能にします。システムが感情状態を予測するとき、利害関係者はその理由を理解する必要があります。この透明性は、メンタルヘルススクリーニング、顧客満足度モニタリング、従業員の幸福評価など、誤った感情検出が不適切な介入を引き起こす可能性がある高リスク設定で特に重要です。
-
根拠:* ブラックボックスの予測(「フラストレーションが検出されました、信頼度0.87」)は実行可能ではなく、信頼を損ないます。透明な説明(「モデルは、音声で検出された声のストレス(0.45の貢献)、トランスクリプトのネガティブな単語(0.35の貢献)、単語選択と声の配信の不一致(0.20の相乗的貢献)に基づいてフラストレーションを予測します」)により、人間のレビュアーは予測が信頼できるか、手動レビューが必要かを迅速に評価できます。この透明性は、責任ある展開の前提条件でもあります:組織がバイアスを監査し、失敗をデバッグし、影響を受ける個人に決定を説明できるようにします。
-
具体例:* 各予測について、構造化された説明レポートを生成します:
予測:フラストレーション(信頼度:0.87)
モダリティの貢献:
- 音声:0.45(声のストレスが検出されました:ピッチの上昇、より速い話速、不規則な呼吸)
- テキスト:0.35(ネガティブな単語:「問題」「課題」「できない」;低いセンチメントスコア:-0.62)
- 視覚:
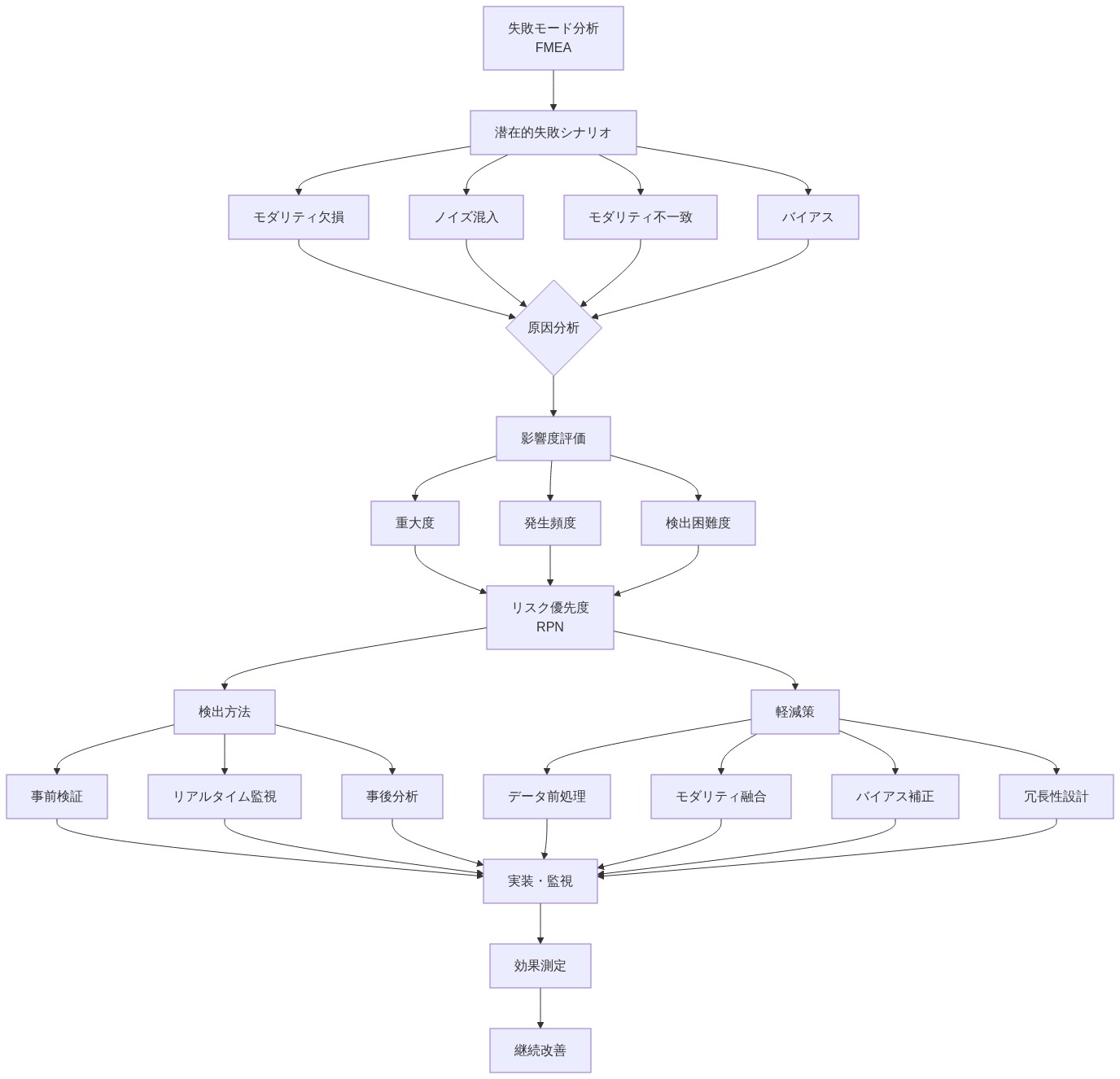
- 図9:失敗モード分析(FMEA):マルチモーダル感情認識における潜在的リスク要因と軽減策*

- 図10:ロバストネステストの実世界シナリオ - 背景ノイズ、照明不足、マスク着用、複数話者、感情表現の文化的差異を含む堅牢性評価環境*
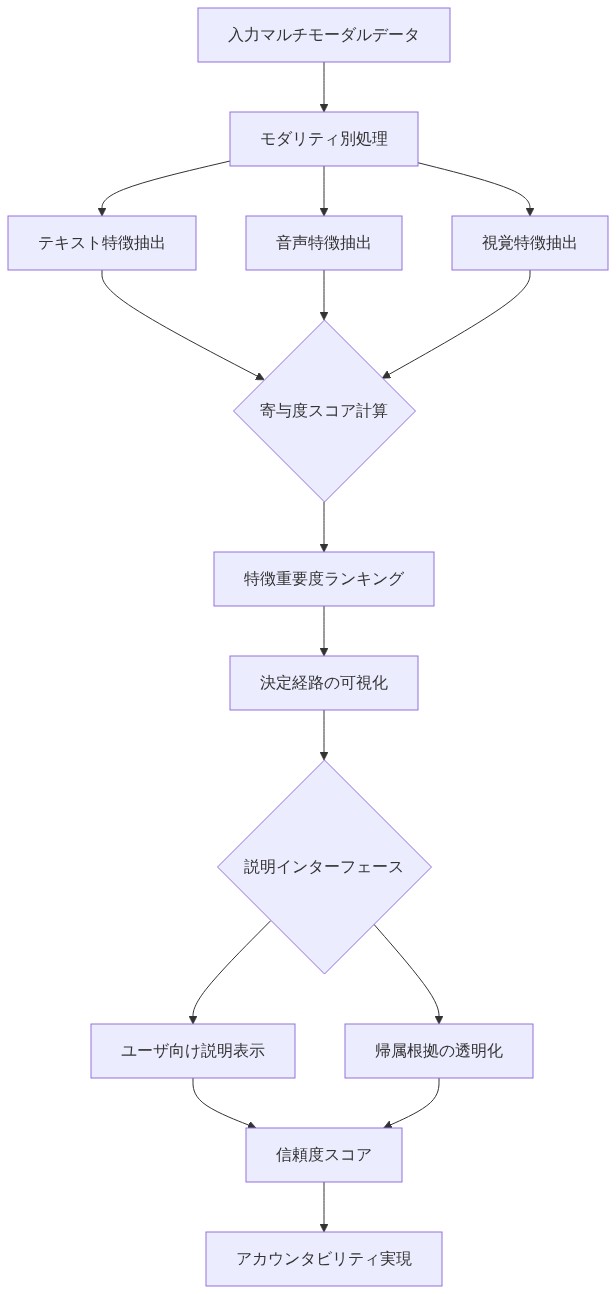
- 図11:説明可能性フレームワーク:透明な帰属と説明インターフェース(マルチモーダル感情認識における説明可能性設計)*

- 図14:マルチモーダル感情認識の実世界応用シーン(カスタマーサービス、メンタルヘルスケア、教育、人間-ロボット相互作用)*