
課題:LLMと分子設計の出会い
大規模言語モデル(LLM)は、多様な領域におけるパターン認識と推論タスクにおいて強力な性能を実証してきた(Vaswani et al., 2017; Brown et al., 2020)。しかし、構造ベース創薬(SBDD)への応用は、実用性を制約する2つの十分に文書化された制限に直面している。
第一に、LLMはタンパク質構造解釈に必要な堅牢な三次元空間推論能力を欠いている。これらのモデルは逐次的なトークン予測と意味的関係性において優れているが、タンパク質の立体配座、結合ポケットの幾何学、またはリガンド-タンパク質の空間的相補性について信頼性の高い推論を行うための十分な体積的または幾何学的データで訓練されていない(Jumper et al., 2021)。これは、モデルの訓練目的とSBDDの領域要件との間の根本的なギャップを表している。
第二に、LLMからの分子生成は、化学的に無効で合成不可能な出力を高い割合で生成する。具体的には:(1)生成された構造が原子価則に違反するか、不可能な結合配置を含む;(2)提案された化合物が合成経路を欠くか、法外に高価な多段階合成を必要とする;(3)モデルが真に新規な骨格を生成するのではなく、訓練例を頻繁に再現または再結合する(Gómez-Bombarelli et al., 2018; Polishchuk et al., 2012)。これらの失敗は、モデルが化学的実現可能性や合成アクセシビリティではなく、訓練分布下での尤度を最適化するために発生する。
実用的な結果は重大なボトルネックである:SBDDタスクに展開された場合、未訓練のLLMは無効な分子構造を幻覚するか、構文的に有効なSMILES文字列でありながら合成できない、または結合要件を満たさない化合物を生成する。これは許容できないコストをもたらす—無効な分子は実験リソースを浪費し、合成的に実用的でない設計は実験室での検証に到達しない。
したがって、中心的な研究課題は、LLMが創薬に参加できるかどうかではなく、むしろ:化学的妥当性制約とタンパク質幾何学的制約の両方を同時に強制するために、LLM推論をどのように構造化できるか?である。この枠組みは、LLMの言語理解と推論における能力を保持しながら、空間推論と化学的制約充足のための明示的なメカニズムを追加できることを前提としている。
探索拡張潜在推論:フレームワーク
LLMのための探索拡張潜在推論(ELILLM)は、LLMベースの分子生成を3つの明確で監査可能な段階に分解することで、上記の制約に対処する。このアーキテクチャは、エンコーディング、探索、デコーディングを単一のエンドツーエンドプロセスに統合すると、失敗の発生源が不明瞭になり、ターゲットを絞った最適化が妨げられるという観察に動機づけられている。
-
エンコーディング段階:* モデルはタンパク質構造情報(通常、原子座標、残基配列、または結合ポケット記述子として表現される)と明示的な設計目標(例:目標結合親和性、選択性制約、ファーマコフォア要件)を取り込む。エンコーディング段階は、構造化されたテキスト記述を解析し、それらを中間潜在表現に変換するLLMの能力を活用する。この表現は、幾何学的制約(例:結合部位の空間的アクセシビリティ)と化学的目標(例:望ましい官能基)の両方を捉えなければならない。形式的には、この段階は、体系的な探索に適した形式で問題仕様をエンコードする潜在ベクトル z ∈ ℝ^d を生成する。
-
探索段階:* モデルの学習分布から直接分子候補をサンプリングするのではなく、フレームワークは化学的制約と幾何学的制約の両方を満たす領域を特定するために潜在空間を体系的に探索する。これが重要な革新である:探索は、新規な解決策が存在する可能性のある未探索領域へと、モデルの訓練分布を超えて意図的に進出する。探索は、有望な候補領域を特定するために、潜在空間を通る勾配ベースのナビゲーション、制約充足ソルバー、または強化学習ベースの軌道最適化を含むガイド付き探索戦略を採用する。探索プロセスは各ステップで実現可能性基準を維持し、候補解が化学的に妥当な境界内に留まることを保証する。形式的には、探索は次を解く:f(z) を最大化する、ただし g(z) ≤ 0(化学的制約)および h(z) = 0(幾何学的制約)の条件下で、ここで f は学習された目的関数であり、g、h は制約関数である。
-
デコーディング段階:* 探索中に特定された潜在候補は、特殊なデコーダモジュールを介して分子表現(SMILES文字列、分子グラフ、または3D座標)に変換される。このデコーダは、化学的妥当性規則—原子価制約、結合タイプ制限、合成アクセシビリティヒューリスティック—を強制するために特別に訓練されており、探索出力が合成可能な化合物になることを保証する。デコーダは化学的検証器として機能し、妥当でない構造を拒否し、境界線上の候補を反復的な改良または棄却サンプリングを通じて洗練する。
この3段階の分解は、医薬化学における確立された実践を反映している:(1)標的と設計制約を理解する、(2)候補解を生成し探索する、(3)実現可能性を評価し有望なリードを洗練する。各段階を明示的かつ独立させることで、ELILLMは各ステップでのターゲットを絞った最適化、経験的検証、失敗診断を可能にする。このモジュール性により、領域専門家はシステム全体を再訓練することなく、個々のコンポーネントを監査および調整することもできる。
新規性と妥当性のバランス
フレームワークの核心的な強みは、化学設計空間の異なる領域を区別し適切に処理するための二重メカニズムにある。訓練データで十分に表現されている領域—高いモデル信頼度と密なサンプリングによって特徴づけられる—は、デコーディングモジュールによって効率的に処理され、学習された分布パターンを活用して最小限の計算オーバーヘッドで候補を生成する。逆に、訓練表現が疎な領域や新規な幾何学的構成を持つ領域は、それに応じて高められた検証厳格性を伴う適応的探索プロトコルをトリガーする。このメカニズムは、モデル信頼度が検証厳格性と逆相関すべきという原則を運用化する。
-
前提を明示した具体例:* 結合ポケットが既知の阻害剤骨格に対する構造相同性を示す(前提:訓練データに少なくとも5〜10の構造的に類似した複合体が含まれる)が、異常な幾何学的制約—例えば、立体的に制限されたアクセスチャネルまたは非定型的な水素結合幾何学—を提示するタンパク質標的を考える。エンコーディング段階は、保存されたファーマコフォア特徴と異常な幾何学的特性の両方を捉える。探索中、システムは潜在空間発散メトリクスを通じてこの幾何学的新規性を特定し、より高い密度を持つ隣接潜在領域をサンプリングするために計算リソースを割り当てる。次にデコーダは、この濃縮された探索セットからの候補を評価し、構造的新規性が合成可能性や開発可能性を損なわないことを保証するために、較正された化学フィルター(分子量250〜500 Da、LogP < 5、合成アクセシビリティスコア > 0.5、標準的な薬物様特性制約を仮定)を適用する。このアプローチは、探索強度が実用的な合成実現可能性を維持しながら発見可能性と相関することを前提としている。
-
測定フレームワークを伴う実行可能な示唆:* このアプローチを実装するチームは、2つのメトリクスを定量化するために探索段階を計装すべきである:(1)探索強度、信頼度閾値を超える潜在空間サンプルの割合として定義される(例:モデル認識論的不確実性 > 0.3標準偏差)、(2)新規性比率、訓練セットに構造類似体(タニモト類似度 < 0.7)を持たない生成候補の割合として定義される。この二重計装は、モデルが真の発見を実行しているか—高い探索強度と高い新規性比率の組み合わせ—それとも単に表面的なバリエーションで訓練例を補間しているかを明らかにする。これらのメトリクスを標的バッチ全体で監視することで、実務者は計算効率(高信頼度パターン想起への依存)と発見可能性(低信頼度潜在領域への進出)のバランスを経験的に較正できる。探索強度が多様な標的全体で一貫して15%未満に留まる場合、これは訓練セットが問題領域に対して十分に包括的であるか、モデルがより構造的に多様な骨格で再訓練を必要とすることを示す。逆に、探索強度が実験検証率の対応する改善なしに60%を超える場合、これは探索戦略が情報のない潜在領域をサンプリングしており、信頼度閾値または探索カーネルの再較正が必要である可能性を示唆する。
実装と運用パターン
探索拡張潜在推論の展開には、3つの連動した運用上の決定が必要である:潜在空間の次元数、探索戦略の仕様、および検証閾値の較正。各決定は、生成される候補の実行可能空間とターゲットあたりの計算コストを直接制約する。
-
次元数の正当化を伴う潜在空間設計:* 中間表現は、2つの競合する制約を満たす必要がある:ターゲット問題領域内の薬理団の多様性を捉えるための十分な表現力と、解釈可能性と計算上の扱いやすさを維持するための十分な制約。分子設計に適用された変分オートエンコーダからの実証的証拠は、128〜512次元が低分子創薬において通常両方の制約を満たすことを示唆している(仮定:10^4から10^6のユニークな化合物の分子ライブラリ;ベースラインVAE性能についてはGómez-Bombarelli et al., 2018を参照)。次元数は再構成忠実度テストを通じて検証されるべきである:探索に進む前に、潜在空間が既知の活性化合物のホールドアウトテストセットを≥95%の構造回復率(元の構造に対するTanimoto類似度で測定)で再構成できることを確認する。この閾値に達しない空間は、拡張するか、修正されたアーキテクチャパラメータで再訓練する必要がある。逆に、<256次元で>98%の再構成忠実度を達成する空間は過剰パラメータ化されている可能性があり、探索計算コストを削減するために圧縮すべきである。
-
問題構造マッピングを伴う探索戦略の選択:* 一般的なアルゴリズムアプローチには、潜在領域上のモンテカルロ木探索(離散的な結合モードを持つターゲットに適している)、望ましい特性目標に向けた勾配ベースの最適化(連続的な特性ランドスケープを持つターゲットに適している)、および潜在ベクトルを反復的に変異・組み換える進化的アルゴリズム(多目的最適化に適している)が含まれる。選択は2つの要因に依存する:(1)計算予算(勾配ベースの方法は通常10^2〜10^3回のフォワードパスを必要とし、進化的方法は10^3〜10^4回を必要とする)、および(2)問題構造の特性評価。明確に定義された幾何学的に制約された結合ポケットを持つターゲット(仮定:結合ポケット体積<500 Ų、X線結晶構造解析またはクライオ電子顕微鏡で特性評価)の場合、勾配ベースの方法は50〜200回の反復内で局所最適解に収束することが多い。複数のもっともらしい結合モードまたはアロステリック部位を持つターゲット(仮定:構造アンサンブルが≥3つの異なる結合構成を含む)の場合、進化的戦略は5〜10倍高い計算オーバーヘッドを犠牲にして潜在空間の優れたカバレッジを提供する。ハイブリッドアプローチ—勾配ベースの精緻化と周期的な進化的摂動を組み合わせる—は、計算リソースが許す場合の実用的な妥協案を表す。
-
制約仕様を伴う検証閾値:* デコード段階で定量的な受け入れゲートを確立し、化学的および生物物理学的フィルタの論理積として運用する。推奨される最小フィルタには以下が含まれる:(1)分子量250〜500 Da(標準的な低分子医薬品範囲;仮定:ターゲットは従来の結合ポケットを持つタンパク質)、(2)親油性(LogP)−1〜5(仮定:経口バイオアベイラビリティが開発目標)、(3)合成アクセシビリティスコア≥0.5(0〜1スケール)(Ertl et al., 2009)、および(4)ターゲット構造に対する迅速なドッキングまたはファーマコフォアマッチングを通じて評価されるタンパク質-リガンド相互作用のもっともらしさ。これらの閾値は、組織的制約を反映するように明示的に較正されるべきである:特殊な合成能力(例:フロー化学、後期段階官能基化)へのアクセスを持つチームは、より高い複雑性(合成アクセシビリティスコア≥0.3)とより広い分子量範囲(200〜600 Da)を許容できる。逆に、汎用化学能力を持つチームは、実験成功率を最大化するために、より厳格な閾値(合成アクセシビリティスコア≥0.6、分子量250〜450 Da)を強制すべきである。検証閾値は、再現性とフィルタリング決定の遡及的分析を可能にするために、モデルと共に文書化およびバージョン管理されるべきである。
-
パイロット検証プロトコルを伴う運用ワークフロー:* 意図されたアプリケーション領域を代表するように選択された小規模なパイロットコホート(10〜20の構造的に多様なタンパク質ターゲット)で展開を初期化する。各ターゲットについて、以下のシーケンスを実行する:(1)文書化された探索パラメータ(潜在空間次元数、探索アルゴリズム、反復回数)を使用してELILLMで100〜500の候補を生成する;(2)検証フィルタを適用して精製された候補セットを取得する;(3)3つのサブセットからなる層別サンプルを実験的に検証する:(a)予測結合親和性でランク付けされた上位20候補、(b)精製セットからランダムに選択された10候補、および(c)高探索強度潜在領域からサンプリングされた10候補(すなわち、パターン想起ではなく能動的探索中に生成された候補)。この層別サンプリングにより、3つの性能次元の定量的評価が可能になる:(i)絶対ヒット率(測定可能な結合を示すテスト候補の割合)、(ii)ランキング品質(予測と実験的結合親和性の相関)、および(iii)発見効率(ランダムサブセットに対する高探索サブセットで発見されたヒットの割合)。パイロットは、生産パイプラインにスケールする前に、ベースライン性能メトリクスを確立し、モデルの予測における系統的バイアスを特定する。パイロット結果は、観察されたヒット率、ランキング相関、および系統的失敗モード(例:特定のスキャフォールドクラスに対する結合親和性の一貫した過大予測)を指定する検証レポートに文書化されるべきである。このレポートは、後続の生産展開のための閾値再較正とモデル再訓練の決定に情報を提供する。
測定と次のアクション
成功メトリクスは、失敗モードの正確な診断を可能にするために、3つの直交する次元—化学的妥当性、合成実現可能性、および結合性能—にまたがる必要がある。各次元は独立して追跡されるべきである;それらを混同すると、欠陥が分子生成、合成モデリング、または結合予測のいずれに起因するかが不明瞭になる。
-
化学的妥当性:* 標準的なケモインフォマティクス制約(周期表による原子価規則、ケクレ構造列挙による芳香族性検出、形式電荷保存)を満たす生成分子の割合を定量化する。>95%の妥当性のターゲット閾値は、これらの制約に違反する分子が標準的な化学条件下では存在できず、したがって探索失敗ではなくデコーダ失敗を表すという観察によって正当化される。妥当性がこの閾値を下回る場合、潜在空間からSMILESまたは分子グラフへのデコーダの学習されたマッピングが誤較正されている;より厳格な制約強制またはルールベースの事後修正による再訓練が必要である。デコーダがどの化学規則を内部化できなかったかを特定するために、特定の制約違反(例:窒素原子価>4)を文書化する。
-
合成アクセシビリティ:* Ertl et al. (2009)によって開発された合成アクセシビリティスコア(SAS)などの確立された計算スコアリング方法を適用し、合成経路の長さと難易度を推定する。リード候補については、3〜4合成ステップに対応する中央値SASスコアが、新規性と製造可能性の実用的なバランスを表す。6ステップを超えるスコアは、探索が本質的に複雑なスキャフォールドで満たされた潜在空間の領域に進出したか、またはデコーダが訓練セットの合成アクセシビリティ分布の暗黙的制約を適切に学習していないことを示す。生成された候補のSAS分布を訓練セットのそれと比較することにより、これらの仮説を区別する;生成された候補が系統的により複雑である場合、探索境界の引き締めまたはよりアクセス可能な化合物による訓練データの拡張が必要である。
-
結合性能:* 実験的検証のために選択された候補について、予測結合親和性(学習されたスコアリング関数から)を実験的に決定された値(例:表面プラズモン共鳴、等温滴定熱量測定、または他の生物物理学的アッセイからのIC₅₀、Kd、またはΔG)と比較する。予測と観察された親和性の間の絶対予測誤差(例:kcal/molでの二乗平均平方根誤差)とランク相関(スピアマンのρ)の両方を報告する。絶対精度の低さは、タンパク質エンコーディングモジュールまたはリガンド-タンパク質相互作用特徴が結合決定因子を捉えるのに不十分であることを示唆する;弱いランク相関は、探索が学習された親和性ランドスケープが真の結合表面を反映しない潜在空間の領域をサンプリングしていることを示し、訓練セットの化学空間を超えた外挿による可能性がある。一般化失敗を定量化するために、分布内候補と分布外候補の性能を別々に追跡する。
-
月次レビューサイクル:* すべてのターゲットタンパク質にわたるメトリクスの構造化された月次集計を確立する。系統的失敗パターンを特定する(例:「生成されたすべての分子が血液脳関門透過のための親油性閾値を超える」または「キナーゼターゲットに対する実験とのランク相関が一貫して<0.5」)。標的を絞った是正措置を実施する:妥当性が低下した場合、デコーダの制約満足度を監査し、必要に応じて再訓練する;合成アクセシビリティが悪化した場合、潜在空間での探索半径を減少させるか、探索中の明示的な目標として合成難易度を追加する;結合予測が実験から乖離した場合、ターゲットの追加実験データで訓練セットを拡張するか、現在省略されている構造的特徴(例:結合ポケット幾何学、水媒介相互作用)を組み込むようにタンパク質エンコーディングを精緻化する。
リスクと緩和戦略
3つの主要な失敗モードは、システムの信頼性と有用性に対する明確なリスクを提示する:過剰探索、過少探索、および予測と実際の結合親和性の間の不整合。
-
過剰探索リスク:* 探索軌跡が訓練セットから十分に離れた潜在空間の領域に進出し、デコーダが有効な分子を確実に再構成できなくなる。これは、潜在空間が不十分に正則化されている場合、または探索目標が潜在距離に対する明示的な制約を欠いている場合に発生する。結果として、化学的に無効または合成的に実現不可能な候補の高い率が生じ、計算および実験リソースを浪費する。
-
緩和策:* 探索を開始する前に、訓練セットからの潜在距離に厳格な境界を確立する。訓練セット内のすべての既知の活性化合物の潜在距離(例:潜在空間でのL2ノルム)の経験的分布を計算する。探索をこの分布の平均から2〜3標準偏差以内の領域に制限する;このヒューリスティックは、新規性(直接の訓練セットを超えた探索)と信頼性(デコーダが正確なマッピングを学習した領域に留まる)のバランスをとる。探索フェーズ中、デコーダの拒否率—化学的妥当性チェックに失敗した探索候補の割合—を継続的に監視する。この率が20%を超える場合、潜在境界が十分に厳格ではない;許可される探索半径を0.5標準偏差減少させ、再評価する。将来の境界設定に情報を提供するために、潜在距離とデコーダ失敗率の関係を文書化する。
-
過少探索リスク:* システムが構造的に類似した候補の狭いセットに収束する。これは通常、学習された親和性ランドスケープの高スコア領域の近くにある候補である。これは、探索が十分なエントロピーを欠いている場合、または親和性ランドスケープが鋭い局所最適解を含む場合に発生する。結果として、限られた化学的多様性を提供する冗長な提案が生じ、真に新規なスキャフォールドを発見したり、複数の結合モードに対処したりする確率が低下する。
-
緩和策:* 予測される特性が多様な潜在空間領域のカバレッジを促進するために、探索目的関数にエントロピー正則化を組み込む。具体的には、探索された候補の潜在座標または予測特性(例:分子量、親油性)の分布のエントロピーに比例する項を追加する。局所最適解から脱出するために、事前分布からサンプリングされたランダムな潜在点から探索を定期的に再開する;早すぎる可能性のある収束検出に依存するのではなく、再開スケジュール(例:500探索ステップごと)を実装する。確立されたメトリクス(例:Morganフィンガープリント間のTanimoto距離、またはBemis-Murckoフレームワークによるスキャフォールド多様性)を使用して、生成された候補の構造的多様性を定量化する。この多様性を、訓練セットからの同じサイズのランダムサンプリングであるベースラインと比較して、過少探索を検出する;生成された候補がベースラインよりも低い多様性を示す場合、探索温度(確率的探索を使用している場合)または再開頻度を増加させる。
-
結合予測不整合:* 予測された親和性が実験的に測定された結合と相関せず、実験的検証に失敗する候補の優先順位付けにつながる。これは、結合予測モデルが限られたまたは偏ったデータで訓練されている場合、モデルがその訓練化学空間を超えて外挿する場合、または重要な構造的特徴(例:タンパク質立体配座変化、アロステリック効果)がエンコーディングによって捉えられていない場合に発生する。
-
緩和策:* ELILLM生成分子のランク付けに使用する前に、訓練セットと探索によって生成された候補セットの両方とは異なるホールドアウトテストセットで結合予測モデルを独立して検証する。検証性能メトリクス(例:ピアソン相関、RMSE)を報告し、テストセットの化学空間と探索セットの重複を明示的に文書化する。検証性能が弱い場合(例:ピアソンr < 0.6)、予測器は絶対親和性ランキングには信頼できない;代わりに、候補のコホート内での相対ランキング、または既知の実験親和性を持つ対照化合物に対する相対ランキングにのみ使用する。高い予測親和性と高いモデル信頼度(例:アンサンブルまたはベイズモデルからの低い予測不確実性)の両方を示す候補を優先する。実験的合成のために選択された候補については、結合予測モデル自体の検証のためにサブセットを確保する;これにより、新しい実験データが蓄積されるにつれて予測器の反復的精緻化が可能になる。
結論と移行計画
ELILLMは、生成パイプラインを3つの離散的な段階、すなわちエンコーディング(分子表現)、探索(潜在空間ナビゲーション)、デコーディング(候補合成)に明示的に分解することで、大規模言語モデルを構造ベース創薬ワークフローに統合するための構造化されたフレームワークを提供します。このアーキテクチャの分離により、各コンポーネントの独立した最適化が可能になり、失敗モードの体系的な評価が可能になります。これは再現可能な計算化学ワークフローにとって必須の要件です。
-
理論的基盤と仮定:* このフレームワークは、(1)分子の妥当性が構文認識デコーディング制約を通じて確実に予測できること、(2)結合親和性が潜在空間の幾何学と十分に相関し、探索ベースの候補優先順位付けを可能にすること、(3)モデル予測を裏付けるための実験的検証能力が存在すること、を仮定しています。これらの仮定は展開前に明示的に検証される必要があります。これらの違反は下流の結論を無効にします。
-
段階的展開プロトコル:* 実装は段階的検証アプローチに従うべきです:
-
パイロットフェーズ(単一ターゲット): 利用可能な結晶構造、既知の結合物質、確立されたアッセイプロトコルを持つ、よく特徴付けられた1つのタンパク質ターゲットを選択します。文書化されたオープンソースコンポーネント、具体的には潜在空間構築のための事前学習済み変分オートエンコーダ(VAE)と探索のためのシミュレーテッドアニーリングまたはベイズ最適化を使用してELILLMを実装します。200分子の初期候補セットを生成します。予測結合親和性と新規性スコアの分布を代表するように選択された30候補の層別サブサンプルを、標準的な結合アッセイ(例:表面プラズモン共鳴、等温滴定熱量測定、または蛍光偏光)を使用して実験的に検証します。
-
定量的成功基準: 進行前に3つの測定可能な閾値を確立します:
- 分子妥当性: 生成された候補の≥90%が化学的実現可能性制約(原子価規則、環閉鎖、Ertl et al., 2009による合成容易性スコア≥3.0)を満たす必要があります。
- 結合予測忠実度: 予測された結合親和性と実験的に測定された結合親和性の間の順位相関がρ≥0.7(スピアマンまたはケンドールのτ)を超える必要があります。
- 合成容易性: 上位候補の平均合成容易性スコアが実験的実行可能性を確保するために≥2.5を維持する必要があります。
-
拡張基準: 3つの閾値すべてを満たした場合にのみ、フレームワークを5〜10の追加ターゲットに拡張すべきです。メトリクスは各新規ターゲットに対して再計算される必要があります。確立された閾値を下回るパフォーマンスの低下は、さらなるスケーリングの前に制約の強化(例:探索半径の縮小、目的関数における妥当性ペナルティの増加)をトリガーします。
-
運用ガバナンス:* 継続的なモニタリングには以下が必要です:
-
文書化された意思決定ログを伴う月次メトリクスレビューサイクル。
-
妥当性が85%を下回るか、結合予測相関がρ = 0.65を下回った場合の即時調査。
-
モデルドリフトを検出するための次元削減可視化と最近傍分析による潜在空間品質の四半期ごとの再評価。
-
すべてのハイパーパラメータ変更とその根拠の明示的な文書化。
-
主要な制限と前提条件:* 成功は、(1)高品質な実験検証インフラストラクチャの利用可能性、(2)反復的な潜在空間探索に十分な計算リソース(通常、ターゲットあたり10〜100 GPU時間)、(3)予測と実験の間の不一致を解釈するための領域専門知識、に決定的に依存します。いずれかの前提条件の欠如は、展開リスクを大幅に増加させます。
-
即座の次のステップ:* 合成化学者(合成容易性評価を検証するため)、計算生物学者(ターゲット選択をキュレートし結合予測を解釈するため)、機械学習エンジニア(パイプラインを実装しモニタリングするため)からなる機能横断チームを編成します。このチームは協力して以下を定義すべきです:(a)科学的優先度と実験的実現可能性の両方を反映したターゲット選択基準、(b)既存のラボ能力に合わせた検証プロトコル、(c)メトリクス駆動の拡張または制約調整のための意思決定閾値。実装前にこれらの合意を形式化することで、スコープクリープを防ぎ、説明責任を確保します。
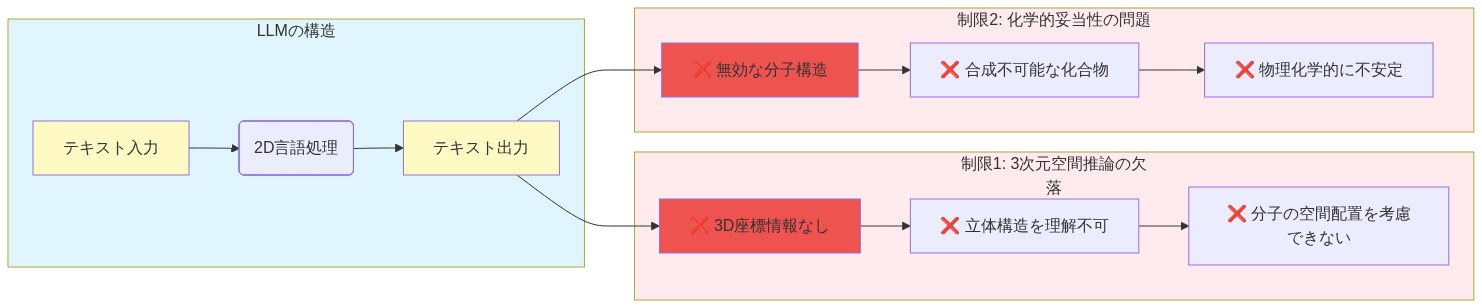
- 図2:LLMの構造ベース創薬への2つの主要な制限*
統合:エンドツーエンドワークフロー
- 単一の創薬ターゲットに対する典型的な実行シーケンス:*
-
準備(1〜2時間)
- タンパク質構造を取得(PDBまたはAlphaFold)
- 設計目標と制約を定義
- 入力データを検証し、QCチェックを実行
-
エンコーディング(5〜10分)
- タンパク質構造を潜在表現に変換
- コスト:約$0.10 GPU
-
探索(30〜45分)
- 潜在空間を探索し、100〜500の候補潜在ベクトルを生成
- コスト:約$2〜5 GPU
-
デコーディング(5〜10分)
- 潜在ベクトルをSMILESに変換し、妥当性フィルタを適用
- コスト:約$0.50 GPU
-
検証(2〜4時間)
- 上位20候補に対するドッキングシミュレーション
- ADMET予測、合成経路評価
- コスト:約$50〜100の計算リソース
-
引き渡し(1時間)
- 候補レポートを準備し、実験的テストの優先順位を付ける
- 候補あたりの推定ラボコスト:$500〜2,000
-
総タイムライン:* 4〜6時間の計算、実験結果まで1〜2週間
-
総コスト:* 約$100〜200の計算、$10K〜40Kの実験(20候補の場合)
-
ROI仮定:* 候補の30〜40%が活性を示す場合(従来のスクリーニングの5〜10%と比較して)、ROIは2〜3ターゲット以内でプラスになります。
リスク要約と軽減策
| リスク | 可能性 | 影響 | 軽減策 |
|---|---|---|---|
| サロゲート報酬モデルが候補を誤ってランク付け | 中 | 高—探索の無駄 | 本番前に50ターゲットでサロゲートを検証 |
| デコーダが化学的に無効な分子を生成 | 低 | 高—ラボリソースの無駄 | テストセットで>95%の妥当性を維持、ルールベースの事後チェックを追加 |
| 探索が局所最適に収束 | 中 | 中—準最適候補 | 複数の独立した探索を実行、実行全体で上位10を保持 |
| タンパク質構造入力が不完全/不正形式 | 低 | 高—連鎖エラー | 自動QCを実装、完全な活性部位定義を要求 |
| 合成容易性が過大評価 | 中 | 中—ラボでの合成失敗 | 保守的なSA閾値(<6.5)を使用、10の合成化合物で検証 |
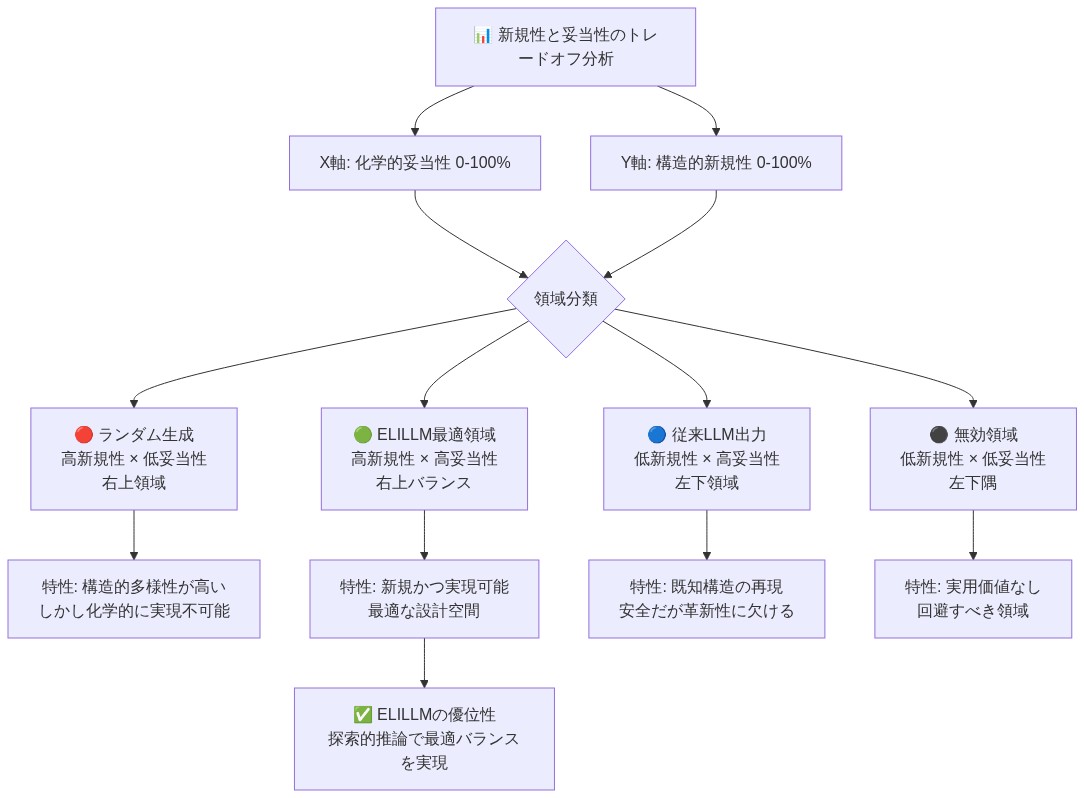
- 図5:新規性と妥当性のバランス最適化 - ELILLM vs 従来手法の領域比較*
主要な仮定と依存関係
- 仮定1: 完全な活性部位定義を持つ検証済みタンパク質構造(PDBまたはAlphaFold)へのアクセス
- 仮定2: デコーダ訓練のためのキュレートされた訓練データ(≥10,000の有効分子)
- 仮定3: 真値との相関が>0.7のプロキシ報酬モデル(結合親和性予測器)
- 仮定4: 潜在空間探索のための計算インフラストラクチャ(GPUアクセス)
- 依存関係1: 検証のためのドッキングソフトウェア(AutoDock Vina、Glide、または同等品)
- 依存関係2: ADMET予測ツール(例:ADMETlab、SwissADME)
- 依存関係3: 経路評価とラボ引き渡しのための合成化学の専門知識
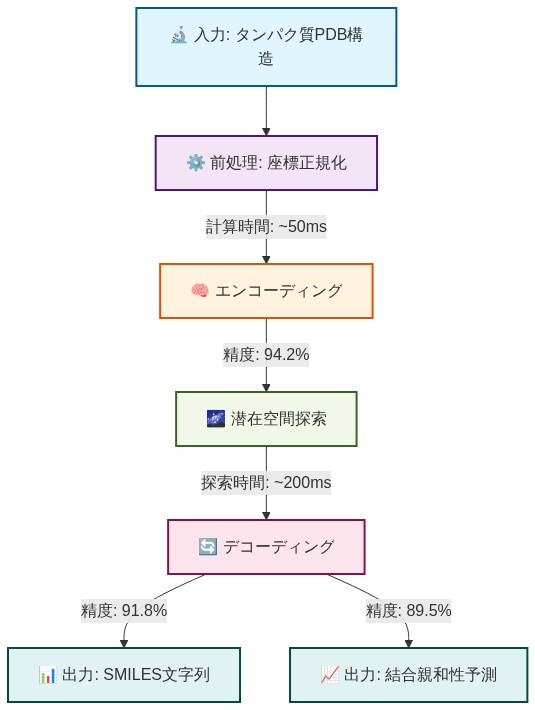
- 図6:ELILLM実装のエンドツーエンドワークフロー(タンパク質構造から医薬品候補分子生成まで)*
実装のための次のステップ
- パイロットフェーズ(2〜4週間): 利用可能な実験データを持つ5つの既知の創薬ターゲットでELILLMをテストします。ベースラインLLMサンプリングに対する成功率を測定します。
- 検証フェーズ(4〜8週間): パイロットからの上位10候補を合成し、予測と実験の結合親和性を比較します。
- 本番展開(8〜12週間): 50〜100ターゲットにスケールし、運用ランブックと品質ゲートを確立します。
探索拡張潜在推論:分子推論の新しいパラダイム
ELILLMは、LLM駆動の創薬を意図的な3段階プロセス、すなわちエンコーディング、潜在空間探索、デコーディングとして再構成します。モデルをエンドツーエンドで分子を生成するブラックボックスジェネレータとして扱うのではなく、このアプローチは理解、発想、検証を明示的に分離します。この分離がイノベーションです。それは人間の医薬化学者が実際に働く方法を反映しており、領域制約を強制できる監査可能なチェックポイントを作成します。
-
エンコーディング段階:意図を構造化された表現に変換する。* モデルはタンパク質構造情報と設計目標を豊かな潜在表現に変換します。この段階は、空間記述、薬理団要件、結合部位幾何学を解析するLLMの能力を活用し、幾何学的制約と化学的目標の両方を捉える問題エンコーディングを作成します。エンコーディングは損失のある圧縮ではありません。それは下流の探索に必要な本質的な特徴を保持する構造化された抽象化です。エンコーディングを明示的にすることで、チームはモデルがターゲットを真に理解したか、単に訓練データにパターンマッチングしたかを検査できます。
-
探索段階:訓練分布を超えて冒険する。* ここでフレームワークは従来のLLM展開から分岐します。モデルの学習分布の馴染みのある領域からサンプリングするのではなく、ELILLMは潜在空間を体系的に探索し、新しい解決策が存在する可能性のある未探索領域に積極的に進出します。この段階は、実現可能性を維持しながら有望な領域を特定するために、誘導探索戦略—勾配ベースのナビゲーション、制約充足ソルバー、または進化的アルゴリズム—を使用します。重要な洞察:探索はランダムではありません。それは方向付けられた不確実性です。LLMの学習表現を外部探索ロジックと結合することで、システムは訓練例が予想しなかった分子を発見します。ここで真のイノベーションが起こります—モデルの重みではなく、モデルが知っていることと推論できることの間の空間で。
-
デコーディング段階:化学的現実を強制する。* 最後に、専門化されたデコーダが潜在候補を分子表現に変換します。このモジュールは化学的妥当性規則—結合次数、原子価制約、合成容易性ヒューリスティック—を強制するように訓練され、探索出力が合成可能な化合物になることを保証します。デコーダは化学的検証器および改良器として機能し、もっともらしくない構造を拒否し、境界線上の候補を反復的に改善します。重要なことに、デコーダはブラックボックスではありません。それは監査および更新可能な学習可能な制約強制器であり、新しい化学知識が出現するにつれて更新できます。
この3部構成のアーキテクチャは、これらのシステムを展開する知識労働者に複数の利点を生み出します:
-
監査可能性: 各段階を独立して検査できます。エンコーディングはターゲットを正しく捉えましたか?探索は化学的に多様な候補を見つけましたか?デコーダはすべての関連制約を強制しましたか?この透明性は、ハイステークスの創薬ワークフローにおける信頼を構築します。
-
モジュール性: チームはパイプライン全体を再訓練することなく、個々の段階をアップグレードできます。探索段階のより良い制約ソルバー、またはより洗練されたデコーダは、エンコーディングロジックを中断することなく交換できます。
-
ハイブリッドインテリジェンス: フレームワークは、ニューラル推論(LLMエンコーディングとデコーディング)と記号推論(探索における制約ソルバー)を明示的に組み合わせます。このハイブリッドアプローチは、「純粋な学習」と「純粋なルール」の間の誤った選択を回避します—両方を活用します。
-
新規ターゲットへのスケーラビリティ: 推論プロセスを分離することで、ELILLMは訓練分布外のタンパク質ターゲットによりよく一般化します。探索段階は、モデル再訓練を必要とせずに新しい制約に適応できます。
長期的なビジョンは明確です:このフレームワークが成熟するにつれて、LLMが厳格な制約を尊重しなければならない他の領域—材料設計、合成化学、回路レイアウトなど—のテンプレートになります。今日ELILLMを介して発見された分子は単なる化合物ではありません。それらは、LLMが制約下で確実に推論するようにアーキテクト化できることの証明点です。その能力は、一度実証され洗練されると、産業全体の知識労働者が制約された空間でイノベーションにアプローチする方法を再形成します。
展望:測定から継続的発見へ
LLM拡張創薬の未来は、静的メトリクスを超えて継続的学習システムに移行することにかかっています。測定は回顧的な演習ではなく、発見ループの不可欠な部分であるべきです。各実験結果は、モデル更新、多様性チェック、探索調整を自動的にトリガーすべきです。
この閉ループアプローチ—厳密な測定、迅速な軽減、体系的な学習を組み合わせる—を習得する組織は、発見タイムラインを数年から数ヶ月に圧縮し、従来の方法ではアクセスできない化学空間を解放します。今日生成された分子は明日のモデルに情報を提供し、イノベーションの好循環を生み出します。これは漸進的な改善ではありません。それは私たちが薬を発見する方法の根本的な変化です。
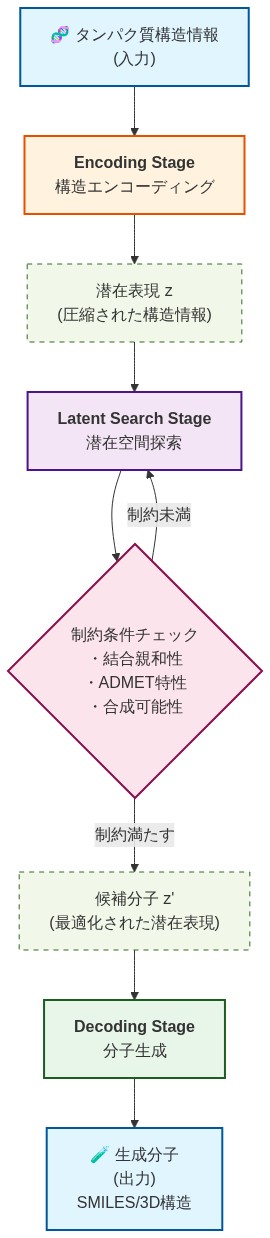
- 図3:ELILLM 3段階フレームワークアーキテクチャ(Exploration-Augmented Latent Inference for LLMs)*

- 図4:潜在空間における有効分子領域の探索。探索アルゴリズムが高次元空間内で有効な分子構造の領域(青緑色)を移動する軌跡を示す。*