
元Google社員がAI搭載学習アプリで子どもたちを魅了しようとしている
教育システムは現代のスキル需要に遅れをとっている
-
主張:* 従来のカリキュラムは長期的な開発サイクルで運用されており、現代の労働市場の要件から体系的に乖離し、教育成果と雇用主のスキル期待との間に文書化されたギャップを生み出している。
-
根拠と証拠:* 教育機関は通常3〜5年のサイクルでカリキュラムを改訂するが、産業界のスキル需要は測定可能な頻度で変化する。世界経済フォーラムの「仕事の未来レポート」(2023年)は、AIリテラシー、デジタルツールの習熟度、適応的問題解決を、ほとんどのK-12カリキュラムに欠けている重要な能力として特定している。同時に、米国労働統計局は、データ解釈、自動化リテラシー、部門横断的な協働における持続的なスキル不足を報告しており、これらは標準化された教育にほとんど統合されていない領域である。この構造的な不整合は、教育学的原則ではなく制度的慣性を反映している。
-
運用化された例:* 4年間の標準化された数学と理科の教育を修了した高校卒業生は、通常、手続き的問題解決における能力を示すが、応用領域への露出が欠けている:ビジネスモデル分析、契約交渉の仕組み、個人的な財務リスク評価など。初級レベルの雇用は、自動化ツール、定量的データ解釈、協働的問題解決への実証された快適さをますます要求しており、これらは偶発的な露出ではなく、明示的な指導と実践を必要とする能力である。
-
行動の前提条件:* 教育技術プロバイダーは、3つのデータソースを統合することでベースラインのスキルギャップ分析を確立する必要がある:(1)労働市場データベース(O*NET、LinkedInスキルトレンド);(2)対象地域全体にわたる構造化された雇用主調査;(3)セクター固有の協会からの業界トレンドレポート。現代の学習プラットフォームを採用する機関は、雇用主が地理的およびセクター的文脈内で重大な不足として報告する上位10のスキルに対処するカリキュラムモジュールを優先すべきである。これには、進化する需要シグナルとの整合性を維持するために、年次更新ではなく四半期ごとのカリキュラムレビューサイクルが必要である。

- 図4:従来教育と産業需要のスキルギャップ分析*

- 図1:AI駆動型学習プラットフォームによる次世代教育の実現(コンセプトイメージ)*
AI搭載学習エクスペディション:カリキュラムイノベーション
-
主張:* 物語に埋め込まれたAIガイド付き学習シーケンスは、状況的認知と内発的動機づけ理論から確立された原則を活用し、シナリオベースの意思決定を通じて抽象的な概念を運用化できる。
-
根拠と証拠:* 認知科学研究(Lave & Wenger, 1991; Csikszentmihalyi, 1990)は、学習者が能動的な意思決定を必要とする本物の文脈に埋め込まれたとき、手続き的および概念的知識をより持続的に保持することを実証している。「エクスペディション」フレームワーク—学習者が意味のある結果を伴う相互接続された課題を通じて進行する—は、複雑なトピックに対する認知的足場を提供しながら内発的動機づけを活性化する。AIパーソナライゼーションは、認知的過負荷と刺激不足の両方を防ぐことで、「最近接発達領域」(Vygotsky, 1978)内でエンゲージメントを維持しながら、ペースと難易度を動的に調整する。
-
運用化された例:* 講義やワークシートベースの演習を通じて金融リテラシー教育を提供するのではなく、エクスペディションは学習者をシミュレートされたベンチャーのための資本獲得をナビゲートする創業者として位置づける。学習者は本物の決定ポイントに遭遇する:価格戦略の調整、異なる成長シナリオ下でのバーンレート計算、投資家ピッチの準備。AI評価チェックポイントは、物語の流れを中断することなく理解を評価する。困難を示す学習者は、ターゲットを絞った足場(実例、ガイド付き質問)を受け取る;上級学習者は、より高次の課題(ベンチャー資金集中に関する倫理的ジレンマ、市場飽和のダイナミクス、ステークホルダー紛争解決)に遭遇する。
-
実装の前提条件:* EdTechチームは、学習目標を物語アークに体系的にマッピングすることでエクスペディションをプロトタイプ化すべきである。学習者が意味のある結果(後続のオプションを進めるまたは制約する成功/失敗状態)を伴ってターゲットスキルを適用する3〜5の決定ポイントを特定する。物語の進行を停止させることなく概念的理解を評価するAIチェックポイントを統合する。異質な能力レベルにわたる50〜100人の学習者でパイロットを実施;定量的エンゲージメント指標(セッション期間、完了率、習得までの時間)と定性的データ(自己報告された自信、知覚された関連性に関する学習者インタビュー)を収集する。500人以上の学習者に拡大する前に、パイロットデータに基づいてコンテンツとAIパラメータを反復する。
参照アーキテクチャとガードレール
堅牢な技術的および教育学的セーフガードは、AI搭載学習が年齢に適切で、正確で、学習科学と整合していることを保証する。フィルタリングされていないAIは、誤解を招く情報、不適切なコンテンツを生成したり、バイアスを強化したりする可能性がある。教育アプリケーションは、消費者向けAIよりも厳格なガードレールを要求する。
AIチューターが学習パスを推奨する場合、ガードレールは以下を保証する必要がある:(1)推奨がアルゴリズムの効率性ではなく教育学的研究と整合している;(2)説明が権威ある情報源に対してファクトチェックされている;(3)システムが教育者のレビューのために決定を記録している;(4)個人データが販売されたり、行動広告に使用されたりしない。
教育者、児童安全専門家、データ倫理学者を組み合わせたコンテンツレビュー委員会を設立する。信頼できる知識ベースを使用した自動ファクトチェックパイプラインを実装し、展開前にAI生成フィードバックに対する人間の承認を要求する。推奨アルゴリズムに対して四半期ごとにバイアス監査を実施し、親や規制当局との透明性のためにすべてのAI決定ロジックを文書化する。
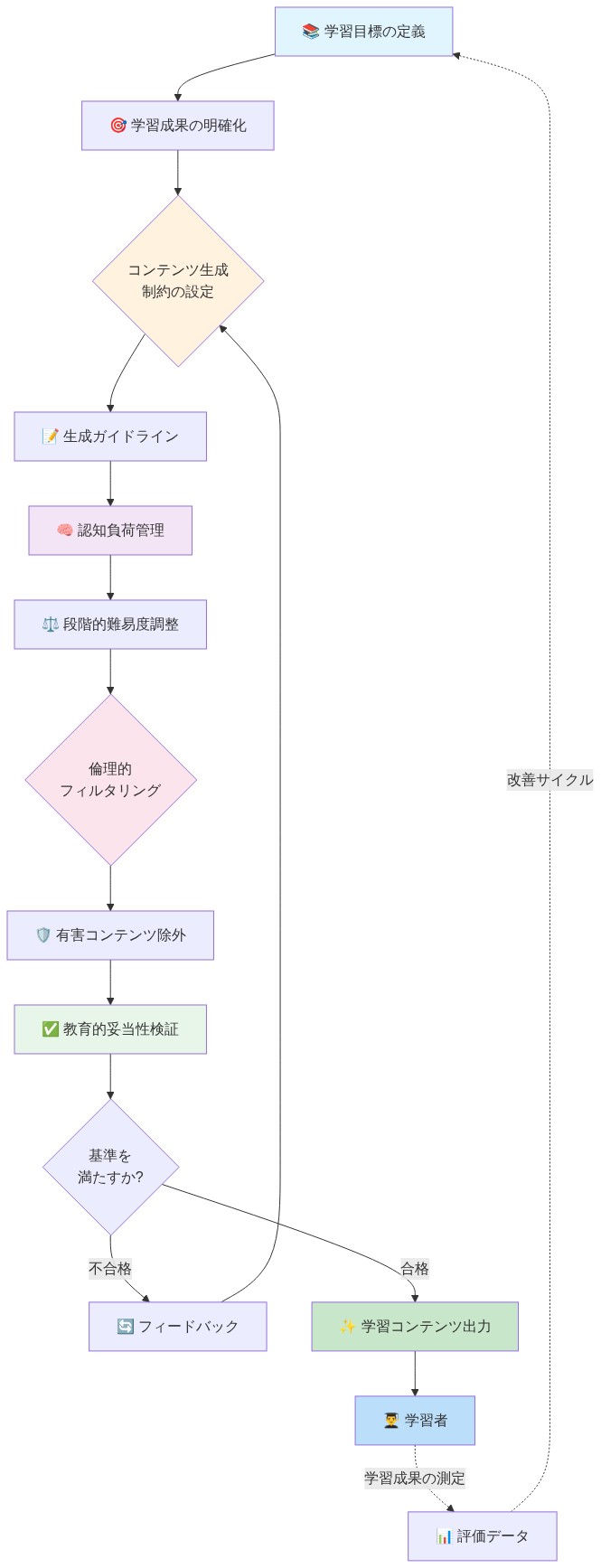
- 図8:ペダゴジカルガードレール実装フロー(教育的制約の多段階検証プロセス)*
- 図7:AI駆動型学習プラットフォームの参照アーキテクチャ*
実装と運用パターン
-
主張:* AI搭載学習プラットフォームの持続可能な展開には、定義された成功基準を伴う段階的ロールアウト、継続的な運用監視、スケーリング中の品質低下を防ぐための明示的な機能的所有権が必要である。
-
根拠と証拠:* 教育技術の急速で制御されていないスケーリングは、しばしばユーザーエクスペリエンスの低下、データセキュリティインシデント、評判の損傷をもたらす(例:Turnitinの2023年の盗作検出失敗;Cheggの2021年のデータ侵害)。段階的実装により、チームはインフラストラクチャのボトルネックを特定し、教育学的ワークフローを洗練し、範囲を拡大する前に制度的知識を構築できる。明確な機能的所有権は、調整の失敗と説明責任のギャップを防ぐ。
-
運用化された例:*
-
フェーズ1(1〜3ヶ月): 5校にわたる500人の学習者に展開;インフラストラクチャの安定性(99.5%の稼働時間目標)、ベースラインエンゲージメント追跡、教育者のオンボーディングを優先する。専任サポートスタッフを割り当てる(250人の学習者あたり1 FTE)。問題を表面化するために週次の運用レビューを実施する。
-
フェーズ2(4〜6ヶ月): 2,000人の学習者に拡大;教育者ダッシュボード(リアルタイムの学習者進捗、AI推奨の透明性)、親コミュニケーションツール(週次進捗サマリー)、インシデント対応手順を導入する。サポートスタッフを比例的に増やす。
-
フェーズ3(7〜12ヶ月): 10,000人以上の学習者に拡大;高度な分析(コホートレベルの成果追跡、スキル転移測定)、フェーズ1〜2のデータに基づくパーソナライゼーションの洗練、AIリテラシーに関する教育者向け専門能力開発を実装する。
-
成功の前提条件:* 開始前に各フェーズの定量的成功指標を定義する(例:フェーズ1:80%のセッション完了率、<2%の重大インシデント率;フェーズ2:70%の教育者ダッシュボード採用率、90%の親コミュニケーション開封率)。プラットフォームの信頼性、コンテンツ品質、教育者の能力向上、親コミュニケーションに対して単一の機能的所有者を割り当てる。文書化されたアクションアイテムと解決タイムラインを伴う週次運用レビューを確立する。一般的な障害モード(認証失敗、コンテンツ配信エラー、エンゲージメント低下)に対するエスカレーション手順と修復手順を含むランブックを維持する。

- 図9:AI学習プラットフォームの段階的実装パターン(コンセプトイメージ)*
測定と次のアクション
学習成果には、定量的エンゲージメント指標とスキル開発および学習者の自信の定性的評価のバランスをとる厳密な測定が必要である。エンゲージメントだけでは学習を保証しない;プラットフォームは娯楽的でありながら教育学的に空虚である可能性がある。
週次追跡:セッション期間、クイズパフォーマンス、エクスペディション完了率。月次:エクスペディション目標に整合したスキル評価を実施し、自信と動機づけについて学習者を調査する。四半期ごと:観察された生徒の行動変化について教師フォーカスグループを実施し、スキルが教室プロジェクトや実世界の決定に転移するかどうかを分析する。
開始前にベースライン指標を確立する。エクスペディションデザイン、AI足場戦略、報酬構造を比較するためにA/Bテストを使用する。結果を四半期ごとに教育者と親に透明に共有し、データに基づいてコンテンツとAIパラメータを調整する。コホートがクイズスコアが高いにもかかわらず金融リテラシーへの自信が低い場合、エクスペディションが深い理解なしに表面レベルの知識を構築しているかどうかを調査する。
リスクと緩和戦略
AI搭載教育は、アルゴリズムバイアス、データプライバシー侵害、自動化への過度の依存、公平性のギャップなど、積極的な緩和を必要とする新しいリスクを導入する。
AIシステムはトレーニングデータからバイアスを継承する;パーソナライゼーションアルゴリズムは、特定の人口統計を狭いキャリアパスに向けて不注意に誘導する可能性がある。裕福な学校からのデータで主に訓練されたAIシステムは、実際の能力に関係なく、類似の学生に高度なエクスペディションを推奨し、他の学生には補習パスを提案する可能性がある。
開始前および毎年その後にバイアス監査を実施する。プライバシーバイデザイン原則を実装する:必要なデータのみを収集し、可能な限り匿名化し、明示的な同意を得る。学習者の進行に影響を与えるすべてのAI推奨に対する人間の監視を義務付ける。リソースが不足している学校に無料または補助金付きアクセスを提供し、教育者がアルゴリズムバイアスを認識し挑戦するように訓練する。
結論と移行計画
AI搭載学習エクスペディションは教育を近代化するための実行可能な経路を表すが、成功は技術を教育者の代替としてではなく、人間中心のエコシステム内のツールとして扱うことに依存する。最も効果的な学習環境は、AIのパーソナライゼーションとスケールを教育者の判断、共感、メンターシップと組み合わせる。
明確なマイルストーンを持つ12ヶ月の移行計画を策定する:ステークホルダーの整合(1ヶ月目)、パイロット開始(2ヶ月目)、教育者トレーニング(2〜3ヶ月目)、段階的スケーリング(4〜9ヶ月目)、完全展開(12ヶ月目)。進捗と課題について教師、親、生徒と定期的にコミュニケーションをとる。教育者がプラットフォームの進化を形作るフィードバックループを確立する。学習成果だけでなく、教師の満足度と教室のダイナミクスも測定する。コース修正に備える;すべてのエクスペディションがすべての学習者集団にわたって等しく共鳴するわけではない。
参照アーキテクチャと教育学的ガードレール
-
主張:* AI媒介教育システムは、消費者向けAIアプリケーションよりも厳格なコンテンツ検証、バイアス緩和、透明性プロトコルを必要とし、発達段階の集団に対する高まったリスクと教育機関に対する受託者義務を反映している。
-
根拠と証拠:* フィルタリングされていない大規模言語モデルは、測定可能な率で事実的に不正確な情報を生成する(Huang et al., 2023);バイアスのあるデータセットで訓練された推奨アルゴリズムは人口統計的格差を永続化する(Buolamwini & Buolamwini, 2018);不透明なAI意思決定は教育者の主体性と親の信頼を損なう。未成年者にサービスを提供する教育アプリケーションは、FERPA(家族教育権およびプライバシー法)、COPPA(児童オンラインプライバシー保護法)、および新興の州レベルのAIガバナンスフレームワークへのコンプライアンスを要求する。教育学的完全性は、AI推奨がアルゴリズムの効率性だけでなく、学習科学の原則と整合することを要求する。
-
運用化された例:* AIシステムは、学習者のクイズパフォーマンスに基づいてパーソナライズされた学習パスを推奨する。ガードレールは以下を保証する:(1)推奨が、エンゲージメント指標だけを最適化するのではなく、検証された教育学的研究(例:習熟度ベースの進行、間隔を置いた検索実践)と整合している;(2)生成された説明における事実的主張が権威ある知識ベース(査読済みソース、カリキュラム基準)に対して検証されている;(3)すべてのAI駆動の推奨が、教育者のレビューとオーバーライドのために決定根拠とともに記録されている;(4)学習分析に必要な最小限を超えて個人を特定できる情報が保持されていない;(5)学習者データが販売、ライセンス供与、または行動広告に使用されていない。
-
展開の前提条件:* 教育者(主題専門家)、児童発達専門家、データ倫理学者、法律顧問で構成されるコンテンツレビュー委員会を設立する。キュレートされた知識ベース(例:学術データベース、カリキュラム基準)を使用した自動ファクトチェックパイプラインを実装する。本番展開前にすべてのAI生成フィードバックに対する人間の専門家の承認を要求する。推奨アルゴリズムに対して四半期ごとにバイアス監査を実施し、異なる影響を検出するために学習者の人口統計(人種、社会経済的地位、性別、障害状況)によって成果を分解する。親、教育者、規制当局との透明性のために、すべてのAI決定ロジックを平易な言語で文書化する。学習分析に必要な最小限(通常、完了後12〜24ヶ月)にストレージを制限するデータ保持ポリシーを確立する。
測定と成果評価
-
主張:* 学習効果は、エンゲージメント指標、スキル習得指標、転移測定を組み合わせた三角測量評価を通じて測定されなければならず、エンゲージメントだけでは学習の不十分な証拠であることを認識する。
-
根拠と証拠:* エンゲージメント指標(セッション期間、完了率)は学習成果と弱い相関を示す(Karpicke & Roediger, 2008)。プラットフォームは、最小限の概念的理解を提供しながら高いエンゲージメントを維持できる。厳密な測定には、プロセス指標(行動的エンゲージメント)、成果指標(スキル習得)、転移指標(新しい文脈への適用)の追跡が必要である。
-
運用化された例:*
-
週次追跡: セッション期間、エクスペディション完了率、クイズパフォーマンス、学習者進行速度。
-
月次評価: エクスペディション学習目標に整合したスキル習得評価(例:計算精度だけでなく価格戦略推論を測定する金融リテラシー評価);自信と知覚された関連性に関する学習者自己報告調査。
-
四半期評価: 観察された行動変化に関する教育者フォーカスグループ(例:金融計画の議論の増加、無関係な領域での問題解決の改善);スキル転移の分析(例:学習者は教室プロジェクトや個人的決定で金融概念を適用するか?);公平性成果の分析(異なる影響を検出するために学習者の人口統計によってすべての指標を分解)。
-
厳密性の前提条件:* 事前事後比較を可能にするために、開始前にベースライン指標を確立する。プラットフォーム効果を交絡変数から分離するために、ランダム化比較試験または準実験デザイン(マッチした比較グループ)を使用する。エクスペディションデザイン、AI足場戦略、報酬構造に対してA/Bテストを実装;結果を四半期ごとに教育者と親に透明に報告する。コホートが高いクイズパフォーマンスを示すが金融リテラシーへの自信が低い場合、エクスペディションが深い概念的理解や転移能力なしに表面レベルの手続き的知識を構築しているかどうかを調査する。エンゲージメント指標だけでなく、成果データに基づいてコンテンツとAIパラメータを反復的に調整する。
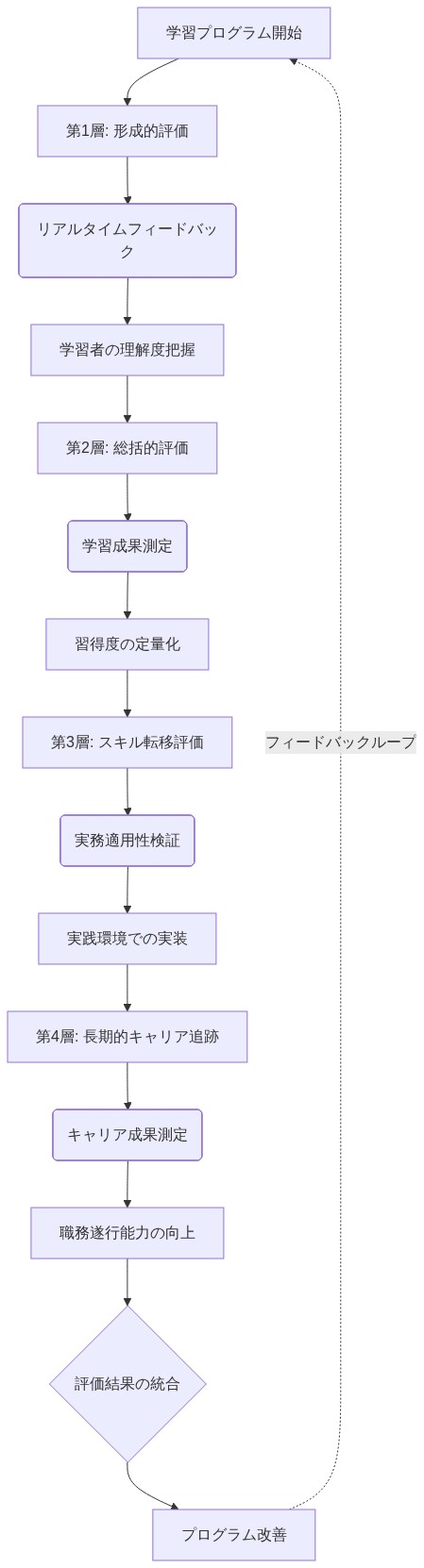
- 図11:多層的学習成果評価フレームワーク*
リスク、軽減戦略、および公平性に関する考慮事項
-
主張:* AI搭載教育システムは、アルゴリズムバイアス、データプライバシーの露出、自動化への過度の依存、教育格差の悪化など、新規で測定可能なリスクをもたらし、積極的でエビデンスに基づいた軽減策を必要とする。
-
根拠とエビデンス:* バイアスのあるデータセットで訓練された機械学習システムは、人口統計学的格差を永続化し増幅する(Bolukbasi et al., 2016)。パーソナライゼーションアルゴリズムは、能力に関係なく、特定の人口統計学的グループをより狭い学術的またはキャリアパスに不注意に誘導する可能性がある(Lambrecht & Tucker, 2019)。パーソナライゼーションのためのデータ収集は、特に未成年者に対してプライバシーの露出を生み出す(Livingstone & Helsper, 2008)。過度の自動化は人間の相互作用を減少させ、メンターシップと社会的感情的サポートを必要とする学習者に潜在的に害を及ぼす。プラットフォームアクセスの不平等は、既存の教育格差を永続化させる。
-
運用化された例:* 裕福な学校からのデータで主に訓練されたAIシステムは、実証された能力に関係なく、同様の社会経済的背景を持つ学習者には高度な探求を推奨し、他の学習者には補習的パスを提案する可能性がある。軽減策:(1)展開前に訓練データの人口統計学的代表性を監査する;(2)人間の教育者が四半期ごとにAI推奨事項を審査し上書きすることを要求する;(3)低所得学校が平等なプラットフォームアクセス、教育者トレーニング、技術サポートを受けることを保証する;(4)異なる影響を検出するために、すべての成果指標を学習者の人口統計学的属性別に分解する;(5)推奨システムにアルゴリズム公平性制約(例:人口統計学的パリティ、均等化オッズ)を実装する。
-
リスク管理の前提条件:* 開始前および毎年その後、人種、社会経済的地位、性別、障害の有無、英語学習者の地位別に成果を分解してバイアス監査を実施する。プライバシー・バイ・デザイン原則を実装する:学習分析に必要なデータのみを収集する;可能な場合はデータを匿名化する;保護者から明示的で十分な情報に基づいた同意を得る;データ保持期限を確立する(通常、完了後12〜24ヶ月)。学習者の進行またはパス推奨に影響を与えるすべてのAI推奨事項に対する人間の教育者の監督を義務付ける。リソースが不足している学校に無料または補助金付きのプラットフォームアクセスを提供する;高ニーズ集団にサービスを提供する学校に追加の教育者トレーニングリソースを割り当てる。教育者がアルゴリズムバイアスを認識し挑戦するよう訓練する;教育者が疑わしいバイアスを報告するためのフィードバックメカニズムを確立する。継続的なリスク管理を監督するために、教育者、保護者、児童擁護者、データ倫理学者の代表を含むデータガバナンス委員会を設立する。
結論と採用フレームワーク
-
主張:* AI搭載学習探求は、テクノロジーを教育者の判断、メンターシップ、社会的感情的サポートを置き換えるものではなく、人間の教育者の能力を増幅するツールとして扱うことを条件として、K-12教育を近代化するための実行可能でエビデンスに裏付けられたアプローチを表す。
-
根拠とエビデンス:* 教育技術介入のメタ分析(Hattie, 2008; Tamim et al., 2015)は、学習成果に対するテクノロジーの効果量が控えめ(d ≈ 0.30–0.40)であり、実装の質と教育者の関与に大きく依存することを示している。最も効果的な学習環境は、AIのパーソナライゼーションとスケーラビリティを教育者の専門的判断、共感、メンターシップと組み合わせる。持続可能な採用には、テクノロジーの能力と限界についての明示的なステークホルダーコミュニケーションが必要である。
-
運用化された例:* 学校は透明性のあるメッセージでプラットフォームを採用する:「このツールは各学習者の旅をパーソナライズし、メンターシップと社会的感情的サポートのための教育者の時間を解放します。」教育者は、AIダッシュボードの解釈、推奨事項を上書きするタイミングの特定、自動化への過度の依存の兆候の認識、解放された時間をより深い生徒との会話に使用することについて、20時間の専門能力開発を受ける。保護者は、AI駆動の洞察と教育者の観察の両方を説明する四半期ごとの進捗レポートを受け取る。学習者は、AIがパーソナライズされたガイダンスを提供するが、教育者が学習パスについて最終決定を下すことを理解する。
-
持続可能な採用の前提条件:* 明示的なマイルストーンを含む12ヶ月の採用計画を策定する:(1)ステークホルダーの調整と賛同(1ヶ月目);(2)500人の学習者でのパイロット開始(2ヶ月目);(3)教育者の専門能力開発(2〜3ヶ月目);(4)2,000人の学習者への段階的拡大(4〜6ヶ月目);(5)10,000人以上の学習者への完全展開(7〜12ヶ月目)。進捗、課題、コース修正について教師、保護者、学習者と定期的にコミュニケーションを取る。教育者がプラットフォームの進化を形成する正式なフィードバックメカニズムを確立する;四半期ごとの教育者諮問委員会会議を実施する。学習成果だけでなく、教育者の満足度、教室のダイナミクス、学習者の主体性も測定する。コース修正に備える;すべての探求デザインが学習者集団や学校の文脈全体で等しく共鳴するわけではない。成果データとステークホルダーのフィードバックに基づいて、コンテンツ、AIパラメータ、実装タイムラインを調整する柔軟性を維持する。
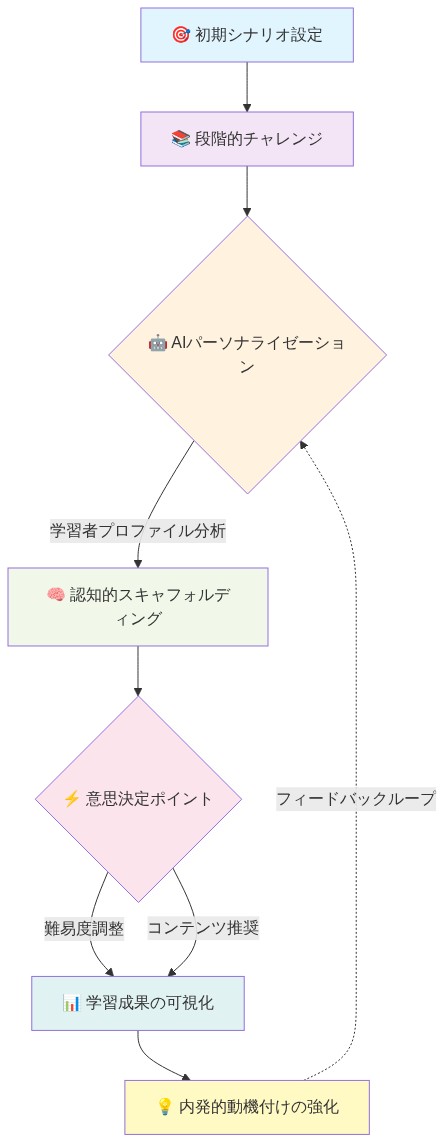
- 図6:AI駆動型学習遠征のプロセスフロー*

- 図5:AI駆動型学習遠征フレームワークの概念図*
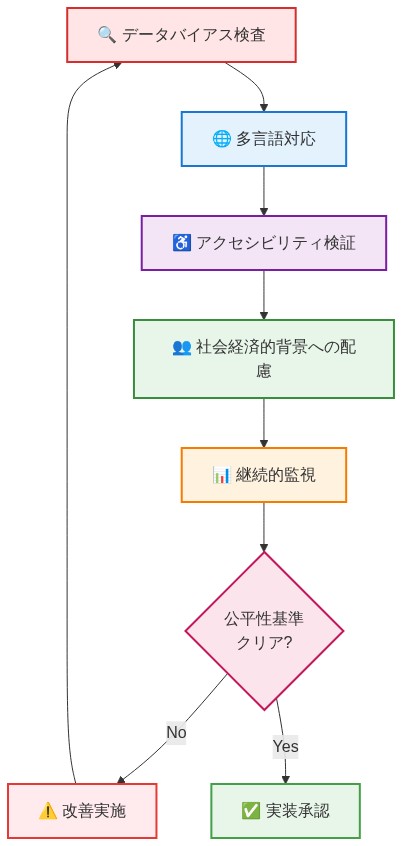
- 図13:公平性確保のための実装チェックリスト*