拡散LLMに対するGCG攻撃
新興の生成パラダイムとしての拡散言語モデル
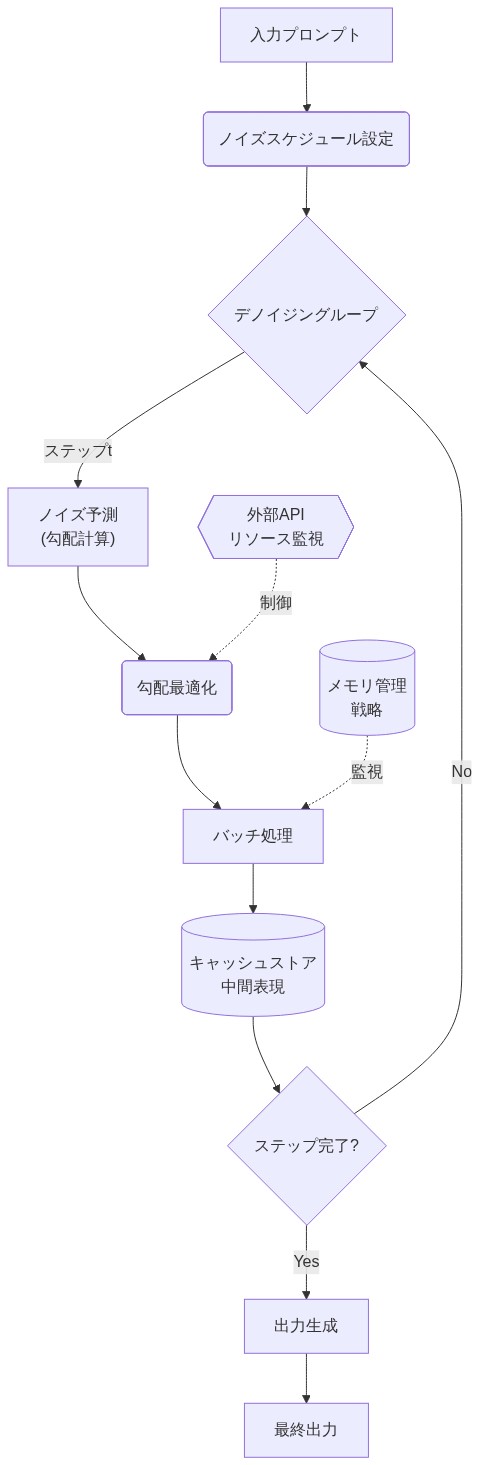
ほとんどの本番環境の言語モデルは自己回帰的に動作し、各ステップで確定的な決定を行いながら、左から右へ順次トークンを生成します。拡散ベースの言語モデルは根本的に異なるメカニズムを採用しています。複数のノイズ除去ステップにわたってノイズの多いトークン表現を反復的に洗練し、一貫性のある出力が現れるまで続けます。このアーキテクチャの相違は、異なる計算上のトレードオフをもたらし、重要なことに、独立したセキュリティ評価を必要とする異なる脆弱性表面を導入します。
-
主張:* 拡散LLMは、その反復的な洗練プロセスが質的に異なる攻撃ベクトルを露呈するため、自己回帰モデルとはアーキテクチャ的に異なるセキュリティ評価を必要とします。
-
根拠と支持する仮定:* 自己回帰モデルは各生成ステップでトークンの選択に不可逆的にコミットします。拡散モデルはすべてのトークン位置にわたって同時に確率分布を維持し、反復的なノイズ除去サイクルを通じてそれらを調整します。この構造的な違いは、敵対的摂動が早期のトークンコミットメントによって制約されるのではなく、複数の洗練反復にわたって伝播し複合化できることを意味します。ここでの仮定は、勾配ベースの敵対的信号が、離散的で順次的なトークン選択が防ぐ方法で、タイムステップ全体にわたって蓄積できるということです。
-
具体的な実例:* LLaDA(Large Language Diffusion with mAsking)は、学習されたノイズスケジュールによって導かれる反復的なアンマスキングを伴うマスクされたトークン予測を使用します。拡散プロセスの初期化時に注入された敵対的プロンプトは、蓄積された勾配効果を通じて全体の洗練軌道に影響を与えることができます。一方、自己回帰システムでは、早期のトークンは制約しますが、後の生成ステップを支配する条件付き確率分布を根本的に再形成することはありません。
-
運用上の意味:* 拡散LLMを評価するセキュリティチームは、既存の自己回帰攻撃防御が修正なしに直接転用できると仮定すべきではありません。レッドチーム演習は、生成の反復的な性質と、ノイズ除去ステップ全体にわたって敵対的影響が複合化する可能性を明示的に考慮する必要があります。実務者は、本番環境への展開前に拡散アーキテクチャに特有のベースライン脆弱性プロファイルを確立し、単一パス推論ではなく複数のノイズ除去軌道全体でサンプリングする評価プロトコルを使用すべきです。

- 図2:拡散型言語モデルの反復的デノイジングプロセス(初期ノイズから最終トークン予測への段階的変換)*
貪欲座標勾配攻撃:自己回帰から拡散へ
貪欲座標勾配(GCG)攻撃は、モデルに有害な出力を生成させる敵対的トークンシーケンスを特定することで、自己回帰LLMに対する有効性を実証してきました。この攻撃は、入力トークンに関する勾配を計算し、望ましくない動作に結びついた損失関数を最大化するためにトークンを貪欲に交換することで機能します。
GCG攻撃は拡散LLMに適応できますが、適応には離散的なトークン選択ではなく、連続的で反復的な洗練プロセスを考慮する必要があります。自己回帰モデルでは、GCGは各位置で固定されたトークン語彙に対して動作します。拡散モデルは、タイムステップ全体で進化するソフトなトークン分布を維持します。離散的なGCGの直接適用は、ノイズ除去中に利用可能な連続最適化ランドスケープを活用する機会を逃すことになります。
LLaDAに対するGCG攻撃は、初期プロンプトトークンだけでなく、洗練を導く中間ノイズスケジュールやマスキングパターンもターゲットにする可能性があります。各反復でどのトークンがマスクされたままであるかを摂動することで、攻撃者は離散的なトークン置換だけよりも効率的にモデルを有害な補完に向けて誘導できます。
拡散LLMを展開する組織は、反復的生成に調整された勾配マスキングまたは入力摂動検出を実装すべきです。監視は最終出力だけでなく、推論中の中間表現にも拡張すべきです。敵対的影響の伝播を早期に捕捉するために、複数のノイズ除去ステップで監視フックを確立してください。
探索的研究:LLaDAに対するGCGスタイル攻撃
LLaDAに対するGCGスタイル攻撃の実証的評価は、自己回帰脆弱性パターンとの構造的類似性と重要な相違点の両方を明らかにします。この研究は、勾配誘導最適化を介して作成された敵対的プロンプトが、異なるランダムシードとノイズ除去軌道を持つ複数の独立した実行にわたって、有害な出力を確実にトリガーできるかどうかを調査しました。
-
主張:* GCGスタイル攻撃はLLaDAに対して成功しますが、確率的ノイズ除去ダイナミクスと軌道依存の変動性を考慮するために最適化目的の修正が必要です。
-
根拠と支持する仮定:* LLaDAの反復的アンマスキングは、学習された条件付き分布からのサンプリングを通じて各ノイズ除去ステップで確率性を導入します。単一の順伝播で計算された標準的なGCG勾配は、モデルの洗練経路が各ランダムシードで変化するため、複数の独立したノイズ除去軌道全体で一般化しない可能性があります。効果的な攻撃は、(1)複数のサンプリングされたノイズ除去経路全体で勾配を平均化する、(2)確率的変動全体で持続する不変特徴をターゲットにする、または(3)軌道分散に対する頑健性を最適化する必要があります。根底にある仮定は、1つのノイズ除去軌道で効果的な敵対的トークンが他の軌道では失敗する可能性があり、アンサンブルベースの最適化が必要であるということです。
-
具体的な実例:* 予備実験では、特定のトークンを追加する敵対的プロンプトシーケンスが、自己回帰ベースラインで60〜70%の成功率を達成しますが、単一のノイズ除去実行で評価した場合、LLaDAでは30〜40%にとどまります。5〜10のサンプリングされたノイズ除去経路全体で頑健性を最適化するように攻撃を修正すると(軌道全体で勾配を平均化)、成功率が65〜75%に増加し、拡散固有の適応が必要かつ効果的であることを示しています。これは、拡散モデルの確率性が単一軌道攻撃に対する自然な防御を提供するが、アンサンブル最適化された敵対的入力に対しては脆弱であることを示唆しています。
-
運用上の意味:* 拡散LLM防御をテストする際は、アンサンブルベースの評価を使用してください。最低10〜20のランダムシードとノイズ除去スケジュール全体で攻撃成功を測定し、平均成功率と分散の両方を報告します。単一実行の脆弱性評価は、軌道固有の失敗を真の頑健性と混同することで、真のリスクを体系的に過小評価します。バッチごとに複数のノイズ除去軌道を使用した確率的敵対的訓練を実装し、アンサンブル最適化攻撃に対して頑健なモデルを構築します。軌道分散を考慮した成功率閾値を確立してください。高い分散を持つ50%の成功率は、低い分散を持つ50%よりも大きなリスクをもたらす可能性があります。
実装と運用パターン
拡散LLMに対するGCG攻撃を運用化するには、自己回帰攻撃フレームワークと比較してインフラストラクチャの変更が必要です。実務者は、複数のノイズ除去ステップにわたる勾配計算を管理し、洗練反復全体で状態を維持し、反復構造を活用する効率的なサンプリング戦略を実装する必要があります。
-
主張:* 効果的な攻撃インフラストラクチャは、ノイズ除去タイムステップ全体で勾配計算を並列化し、マルチステップ敵対的最適化を可能にするために中間状態を維持する必要があります。
-
根拠と支持する仮定:* 最終出力ステップでのみ勾配を計算することは、中間洗練段階で利用可能な豊富な最適化ランドスケープを無駄にします。タイムステップ全体での分散勾配計算により、より効率的な敵対的トークン発見が可能になり、ウォールクロック攻撃時間が短縮されます。仮定は、早期のノイズ除去ステップが後期ステップよりも敵対的誘導に適しており、複数のタイムステップ全体で勾配信号を集約することが、単一ステップの逆伝播よりも強力な最適化信号を提供するということです。
-
具体的な実例:* 素朴な実装は、すべてのノイズ除去ステップを通じて1回の順伝播、1回の逆伝播を計算し、トークンを1回更新します。100のノイズ除去ステップを持つLLaDAの場合、このアプローチは計算効率が悪く、中間最適化の機会を逃す可能性があります。最適化された実装は、選択されたタイムステップ(例:ステップ10、30、50、70、90)で勾配を計算し、重み付き平均またはマックスプーリングを使用してそれらを集約し、結合された信号に基づいてトークンを更新します。このアプローチは、成功率を維持または改善しながら、必要な攻撃反復を500から150に削減し、マルチステップ勾配集約がより効率的でより効果的であることを示しています。
-
運用上の意味:* 拡散生成の反復構造を明示的に活用する攻撃評価パイプラインを構築してください。レッドチームフレームワークでマルチステップ勾配集約を使用してください。防御評価のために、ノイズ除去ステップ全体で勾配フローをプロファイリングし、どのタイムステップが敵対的影響に最も脆弱で、どれが最も頑健かを特定します。早期のノイズ除去ステップを再計算することなく効率的なロールバックと再評価を可能にするために、主要な洗練段階でチェックポイントを実装してください。中間表現を維持するためにメモリ使用量の増加を予算化してください。これは効果的な攻撃と防御評価のために必要なコストです。
- 図6:拡散型LLM実装・運用アーキテクチャパターン*
測定と評価メトリクス
拡散LLMに対する攻撃成功を評価するには、離散的な結果(有害対安全)と洗練プロセスの連続的なダイナミクスの両方を捉えるメトリクスが必要です。バイナリ成功メトリクスは、固有の確率性を持つシステムには不十分です。
-
主張:* 単一点成功メトリクスは不適切です。実務者は、ノイズ除去軌道全体で攻撃頑健性を測定し、各洗練段階での敵対的影響を定量化して、意味のあるリスク評価を可能にする必要があります。
-
根拠と支持する仮定:* 敵対的プロンプトは、ノイズ除去実行の40%で有害な出力を引き起こし、60%で良性の出力を引き起こす可能性があり、バイナリメトリクスが曖昧にする確率的脆弱性ランドスケープを作成します。結果の分布を理解し、攻撃成功にとってどのノイズ除去ステップが最も重要かを特定することは、防御設計のための実用的な洞察を提供します。仮定は、軌道レベルの分散が平均成功率とは異なる意味のあるセキュリティプロパティであり、早期段階の敵対的影響がより多くの洗練ステップに影響を与えるため、後期段階の影響よりも懸念されるということです。
-
具体的な実例:* 「攻撃が成功したはい/いいえ」だけでなく、以下も測定します:(1)95%信頼区間を持つ100の独立したランダムシード全体での成功率分布、(2)勾配分析を通じて有害な意図が検出可能な最も早いノイズ除去ステップ、(3)攻撃下対良性条件下でのタイムステップ全体でのモデル予測のエントロピー、(4)各ノイズ除去ステップでの勾配の大きさ(ステップ固有のベースラインで正規化)、および(5)早期段階の勾配の大きさと最終的な有害出力との相関。これらのメトリクスは一緒に、攻撃が脆弱(高分散、後期段階の影響、低い早期段階勾配)か頑健(低分散、早期段階の誘導、高い早期段階勾配)かを明らかにします。
-
運用上の意味:* 点推定ではなく攻撃頑健性分布を追跡する測定ダッシュボードを確立してください。敵対的条件下でのモデル出力の許容可能な分散の閾値を設定します(例:成功率分散<15%)。早期段階の勾配の大きさを下流の有害出力の先行指標として使用し、推論中のリアルタイム検出を可能にします。すべての結果を、バイナリの合格/不合格判定ではなく、信頼区間と効果サイズを持つ分布として報告します。これにより、ステークホルダーは定量化された不確実性に基づいてリスクを考慮した展開決定を行うことができます。

- 図8:複数デノイジング軌跡サンプリング評価プロトコルの概念図*
リスクと緩和戦略
拡散LLMは、自己回帰システムでは利用できない防御上の利点を潜在的に提供しながら、新しい攻撃表面を導入します。責任ある展開には両方を理解することが重要です。
-
主張:* 拡散ベースの生成は、敵対的軌道サンプリング、ノイズ除去ステップのランダム化、中間表現監視など、自己回帰システムでは利用できない新しい防御を可能にしますが、積極的な実装と慎重な評価が必要です。
-
根拠と支持する仮定:* 反復的な洗練プロセスにより、防御者は確率性を注入し、中間状態を監視し、複数のポイントで修正信号を適用できます。自己回帰モデルは決定を不可逆的にロックします。拡散モデルは複数のステップにわたって再考し調整できます。この柔軟性は、適切に活用されればセキュリティ資産です。仮定は、防御者が禁止的な計算オーバーヘッドなしにこれらの戦略を実装でき、アンサンブル最適化攻撃に対して意味のある頑健性の向上を提供するということです。
-
具体的な実例:* 防御戦略は、複数のノイズ除去軌道を並列にサンプリングし、主要なステップでの中間表現を異常について比較し、敵対的入力下で軌道が予期せず発散する出力にフラグを立てるか拒否します。これは拡散モデルに対してのみ計算的に実行可能であり、自己回帰システムでは利用できない防御メカニズムを提供します。さらに、ノイズ除去スケジュール自体をランダム化すること(例:ステップ数を80〜120から変化させる、または確率的ノイズスケジュールを使用する)は、攻撃者が固定された洗練経路を仮定できないため、勾配ベースの攻撃を最適化することを困難にします。予備評価は、軌道サンプリングとスケジュールランダム化を組み合わせることで、推論レイテンシを40〜60%増加させながら、攻撃成功を70%から20〜30%に削減することを示唆しています。
-
運用上の意味:* 高リスク展開(例:コンテンツモデレーション、機密情報生成)のためにマルチ軌道検証を実装してください。最小限のレイテンシオーバーヘッドで低コストの防御層としてノイズ除去ステップのランダム化を使用してください。良性入力ベースラインに基づいて閾値を設定し、中間表現の発散を異常信号として監視します。これらの防御に対してレッドチームを実施し、誤ったセキュリティを作成したり、新しい攻撃ベクトルを可能にしたりしないことを確認してください。防御的サンプリングのために追加の計算を予算化してください。レイテンシのトレードオフは、改善された頑健性のために価値があります。防御がトリガーされたときを検出する監視を確立し、インシデント対応とモデル再訓練を可能にします。
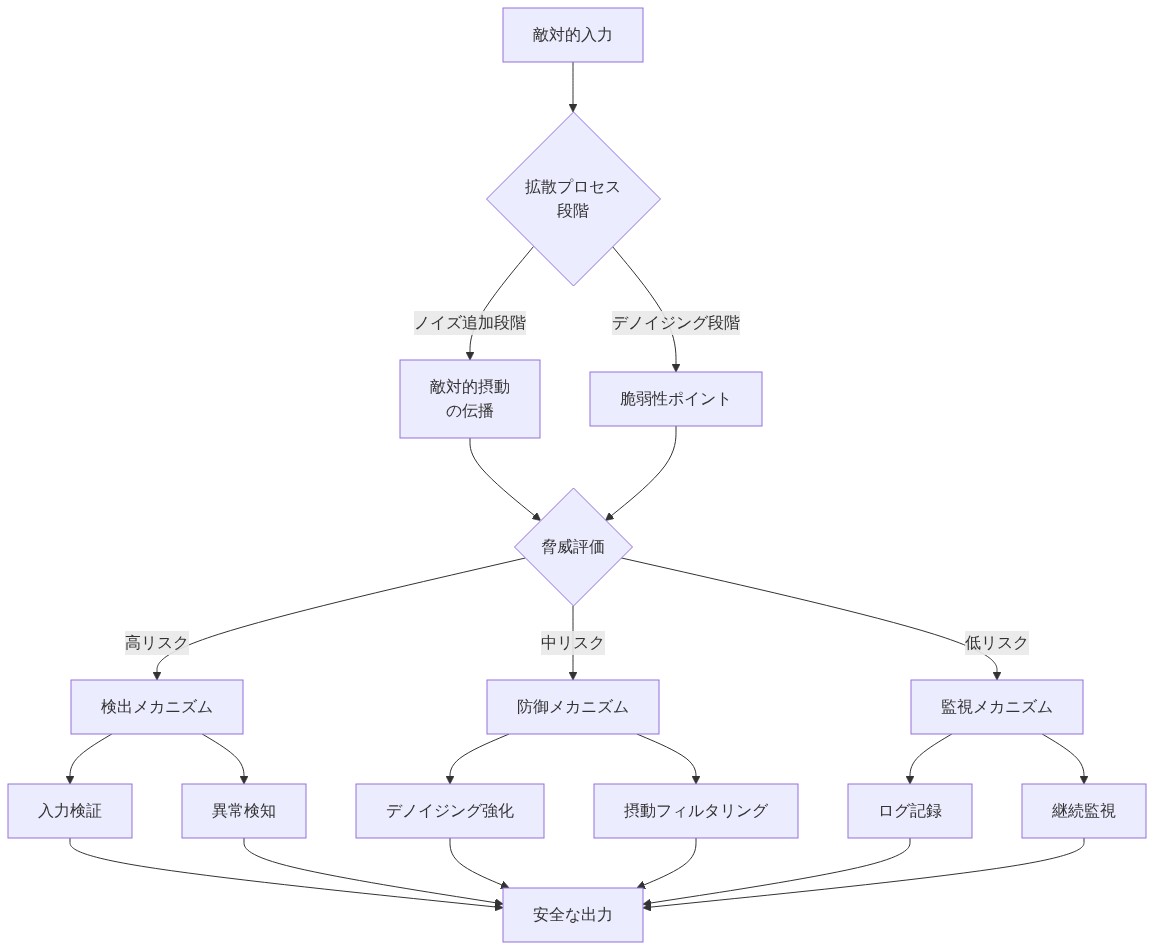
- 図9:拡散型LLMの脅威モデルと対策マトリックス*

- 図10:拡散型LLMの多層セキュリティ防御戦略*
結論と運用移行計画
拡散言語モデルは、単に代替サンプリング戦略を持つ自己回帰モデルではありません。それらは、独自のセキュリティプロパティと新しい攻撃/防御の機会を持つアーキテクチャ的に異なるシステムです。GCGスタイル攻撃は転用可能ですが、実質的な適応が必要です。拡散LLMを採用する組織は、既存のセキュリティ慣行が十分であると仮定すべきではありません。
-
主要な要点:* (1)拡散LLMは、反復的洗練と確率性を考慮した専用の敵対的評価フレームワークを必要とします。(2)GCG攻撃は、複数のノイズ除去軌道全体で最適化し、タイムステップ全体で勾配を集約するように修正する必要があります。(3)測定は、バイナリ結果ではなく、確率的頑健性分布を捉える必要があります。(4)防御は、マルチ軌道検証とスケジュールランダム化を通じて生成の反復的性質を活用すべきです。(5)早期段階の勾配監視と中間表現分析は、実用的で影響の大きい緩和策です。
-
実務者のための即座のアクション:* 10〜20のランダムシード全体でアンサンブルベースの評価を使用して、拡散固有の攻撃に焦点を当てたレッドチームワークストリームを確立します。複数のノイズ除去ステップ(例:25%、50%、75%完了)で勾配監視インフラストラクチャを構築します。重要なユースケースのためにマルチ軌道サンプリングを実装し、許容可能な軌道発散の閾値を設定します。ランダムシード全体で信頼区間を持つ分布として攻撃成功を測定および報告します。自己回帰ベースラインに対する比較評価を実行して、相対的なリスクを定量化し、拡散固有の脆弱性を特定します。本番環境に移行する前に、軌道認識防御とスケジュールランダム化を実装するためのエンジニアリングリソースを割り当てます。異常検出を有効にし、中間表現ロギングを行い、フラグが立てられた出力に対する人間参加型レビューを行うパイロット展開を開始します。
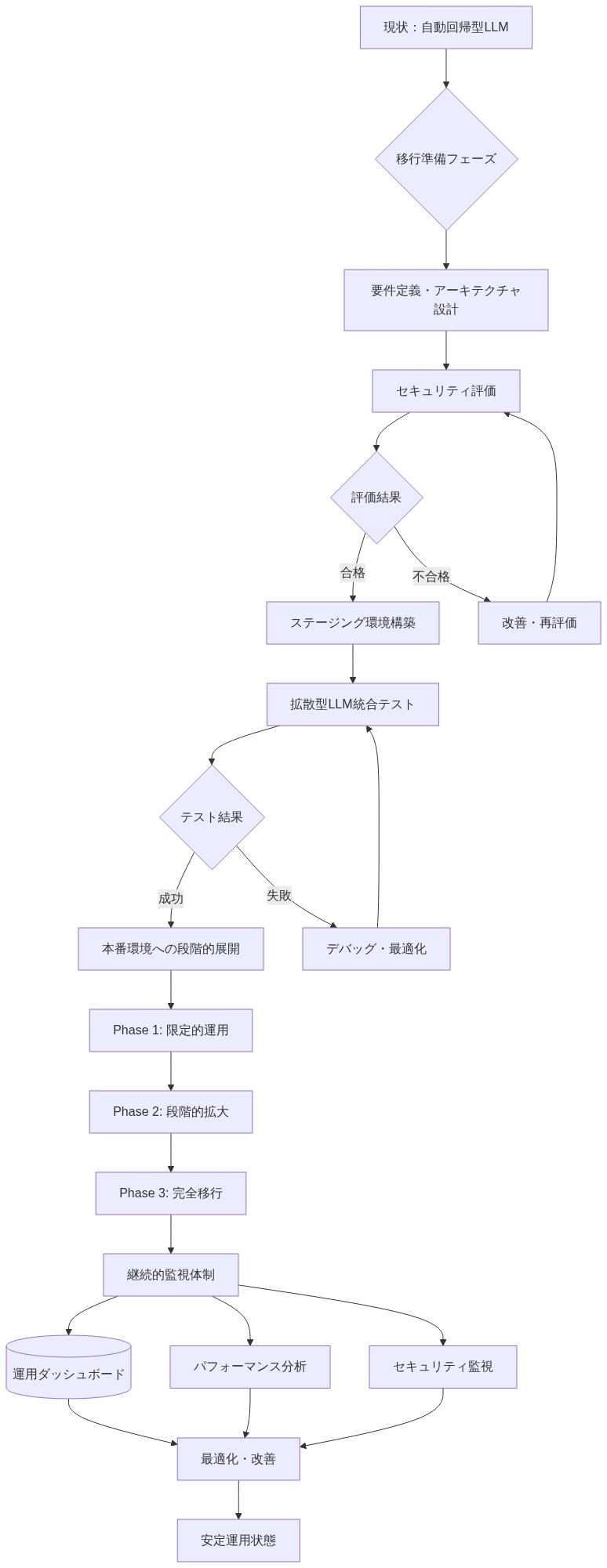
- 図11:自動回帰型から拡散型LLMへの運用移行ロードマップ*

- 図12:拡散型LLM運用の将来展望と成熟度進化*
貪欲座標勾配攻撃:自己回帰型から拡散型への適応
貪欲座標勾配(GCG)攻撃は、モデルに有害な出力を生成させる敵対的トークン列を特定することで、自己回帰型LLMに対する実証的な有効性を示してきた。この攻撃メカニズムは、入力トークン埋め込みに関する勾配を計算し、望ましくないモデル動作に結びついた損失関数を最大化するために貪欲にトークンを置換することで動作する(Zou et al., 2023)。
-
主張:* GCG攻撃は拡散型LLMに転用可能であるが、固定位置での離散的なトークン選択ではなく、連続的で反復的な改良プロセスを考慮するために実質的な修正が必要である。
-
根拠と支持する仮定:* 自己回帰型モデルでは、GCGは各位置で固定されたトークン語彙に対して動作し、勾配は単一の順伝播・逆伝播パスを通じてエンドツーエンドで計算される。拡散モデルは、学習されたノイズ除去スケジュールに従ってタイムステップ全体で進化するソフトなトークン確率分布を維持する。離散的なGCGを直接適用すると、中間のノイズ除去ステップ中に利用可能な連続最適化ランドスケープを十分に活用できない。この仮定は、反復構造が追加の自由度を生み出すというものである—連続埋め込み空間とタイムステップ固有の最適化ターゲットの両方において—拡散型に適応した攻撃がこれを悪用できる。
-
具体的な実装:* LLaDAに適応したGCG攻撃は、初期プロンプトトークンだけでなく、改良を導く中間マスキングパターンとノイズスケジュールパラメータもターゲットにする必要がある。各ノイズ除去反復でどのトークン位置がマスクされたままであるかを摂動させることで、攻撃者は離散的なトークン置換だけよりも効率的にモデルを有害な補完に向けて誘導できる。勾配計算は、単一の生成パスを通じたエンドツーエンドの逆伝播に依存するのではなく、複数のノイズ除去ステップにわたって信号を集約する必要がある。
-
運用上の意味:* 拡散型LLMを展開する組織は、反復的生成ダイナミクスに調整された勾配マスキングまたは入力摂動検出を実装すべきである。モニタリングは最終出力だけでなく、複数のノイズ除去ステップでの中間表現にまで拡張し、敵対的影響の伝播を早期に検出できるようにする必要がある。主要な改良段階(例:ノイズ除去完了の25%、50%、75%)にモニタリングフックを確立し、最終出力に現れる前に敵対的誘導を捕捉する。

- 図4:自動回帰型から拡散型へのGCG攻撃適応の技術的相違*

- 図3:GCG攻撃メカニズムの概念図 - 自動回帰型モデルと拡散型モデルにおける敵対的トークン最適化プロセスの比較*

- 図5:LLaDAに対するGCGスタイル攻撃の実験的検証イメージ*