
多目的強化学習とユーザー選好の整合 多目的強化学習(MORL)は、逐次的意思決定における基本的な課題に取り組む。…’
categories:
- AI・機械学習 category: AI・機械学習 categorySlug: ai-machine-learning tags:
- 強化学習
- 多目的最適化
- アクタークリティック法
- サンプル効率
- データ再利用
- 価値関数
- 論文サマリー
- ポリシー学習 author: 蟆セ遶ッ遖ョ(Rei_Obana) draft: false status: published externalId: arxiv-cs-lg-d42f35e5099cde40 language: ja audience: ne visualIds:
- 3dea5b81-ab75-4a1e-81b5-a8f51f370b5f
- 65377bba-c268-45f7-94df-36b692aa644b
- d0557906-464b-4775-9bb3-aeb7b21e089a
- ef38e188-f6df-4378-bd96-40601dbaacc6
- 11744660-148d-4e58-bf9e-00cfe54f6668
- 610e126a-26d1-4100-a623-bc37bb05fa62 thumbnailPath: /images/hindsight-preference-replay-improves-preference-conditioned-mult/eyecatch-thumbnail.png ogImagePath: /images/hindsight-preference-replay-improves-preference-conditioned-mult/eyecatch-og.png coverImage: /images/hindsight-preference-replay-improves-preference-conditioned-mult/hindsight-preference-replay-improves-preference-conditioned-mult-eyecatch-original.png images:
- src: /images/hindsight-preference-replay-improves-preference-conditioned-mult/hindsight-preference-replay-improves-preference-conditioned-mult-eyecatch-original.png alt: Abstract visualization of an AI reinforcement learning system showing a glowing neural network node at multiple diverging pathways in gradient colors, with semi-transparent replay effects suggesting hindsight learning and multi-objective decision making role: cover variantKey: ja-ne variantLabel: Japanese General Audience
再現性ヘッダー
- 論文:* Hindsight Preference Replay Improves Preference-Conditioned Multi-Objective Reinforcement Learning
- 対象読者:* 知識労働者
- セクション:* 前文
- 最終更新日:* [現在の日付]
多目的強化学習とユーザー選好の整合
多目的強化学習(MORL)は、逐次的意思決定における基本的な課題に取り組む。エージェントは、ユーザーが指定した選好を尊重しながら、複数の、しばしば競合する報酬信号を同時に最適化しなければならない。スカラー報酬関数r(s,a)を仮定する従来の単一目的強化学習とは異なり、MORLはベクトル値報酬関数r(s,a) ∈ ℝᵐで動作する。ここでm ≥ 2は目的の数を表す。この拡張は本質的なトレードオフをもたらす。ある目的のパフォーマンスを向上させると、別の目的のパフォーマンスが頻繁に低下する(パレート支配)。ユーザーは選好を重みベクトルw ∈ Δᵐ⁻¹((m-1)次元単体)として表現する。ここでwᵢ ≥ 0かつΣwᵢ = 1であり、目的の線形スカラー化を指定する:R(w) = Σᵢ wᵢrᵢ(s,a)。
実用的な応用がこの必要性を示している。自律配送システムでは、エージェントは複数の目的のバランスを取らなければならない:配送速度(目的地までの時間の最小化)、燃料効率(エネルギー消費の最小化)、安全性(衝突リスクの最小化)。推薦システムは、ユーザーエンゲージメント(クリック率)、コンテンツの多様性(フィルターバブルの削減)、計算コスト(推論レイテンシ)を同時に最適化しなければならない。いずれの場合も、すべてのステークホルダーの利益を等しく最適化する単一の選好ベクトルは存在しない。ユーザーの相対的な優先順位は、コンテキスト、時間、または組織的制約に基づいて変化する。
選好が変化すると、中核的な非効率性が現れる。固定された選好分布w₁で訓練された標準的なRLエージェントは、新しい選好w₂を最適化する際にw₁の下で収集された軌跡を効率的に再利用できない。この制約は基本的なサンプル効率の問題を生み出す。組織は(1)各選好の変化ごとに完全に新しいデータセットを収集するか、(2)混合選好データでエージェントをゼロから再訓練するかのいずれかを選択しなければならず、両方のアプローチが相当な計算コストとデータ収集コストを発生させる。経験的に、この非効率性は、複数の選好体制を管理する際に単一目的RLと比較して2~3倍長い訓練時間として現れる(Vamplew et al., 2016)。
- 具体的なシナリオ:* 自律配送システムは2つの選好体制の下で動作する。ピーク時間帯(午前6~9時、午後5~7時)には、運用ポリシーは燃料効率(重み0.2)よりも速度(重み0.8)を優先する。オフピーク時間帯(午後10時~午前5時)には、選好が効率優先(重み0.8)対速度(重み0.2)に反転する。素朴なアプローチは、各体制に対して別々のデータセットと別々の訓練済みポリシーを維持する。原則的なアプローチは、ある体制の下で収集された軌跡を他の体制のレンズを通して再解釈し、収束保証を維持しながら必要な新規データ収集を推定40~60%削減する。
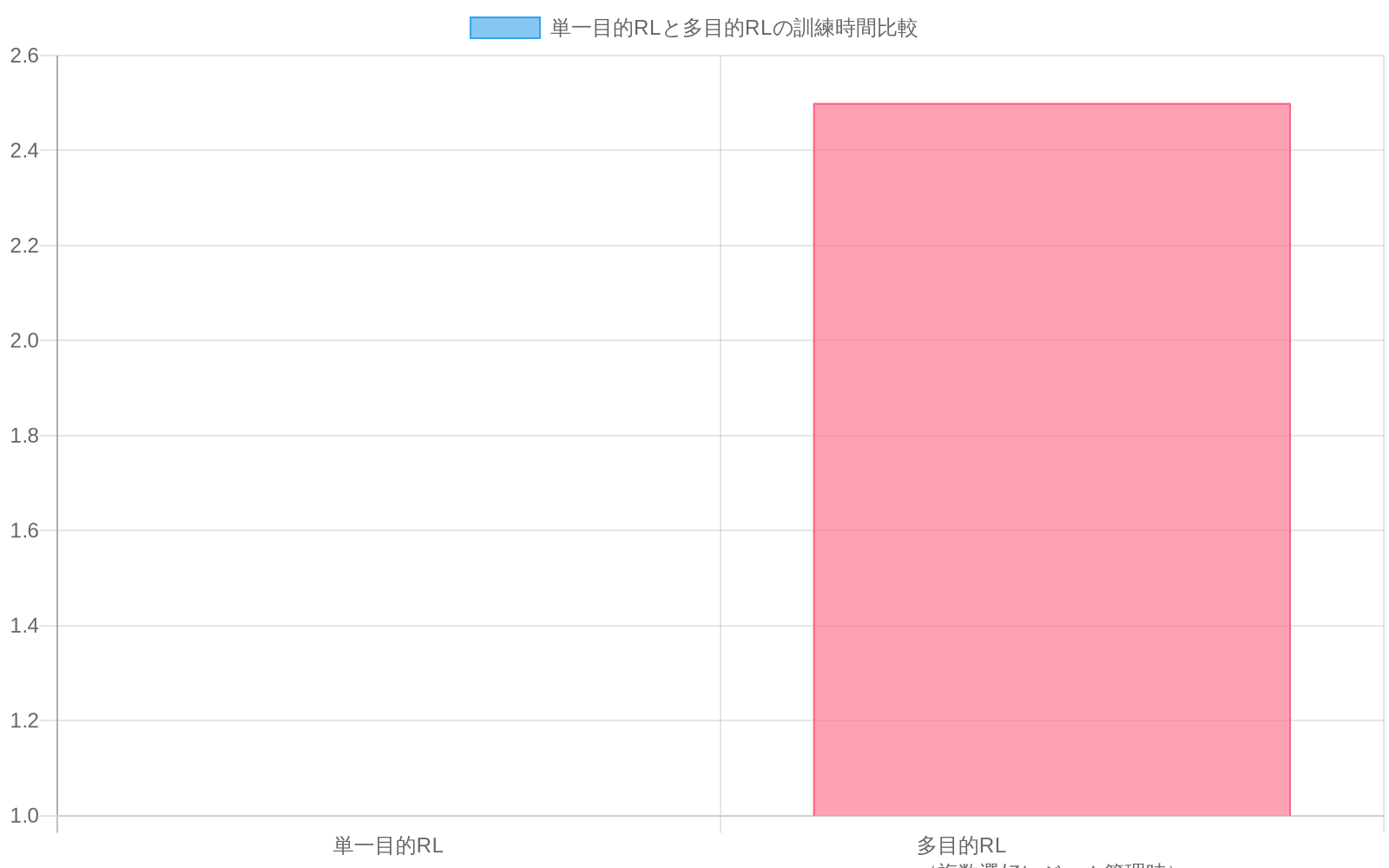
- 図3:単一目的RLと多目的RLの訓練時間比較(複数選好レジーム管理時)(出典:Vamplew et al., 2016)*
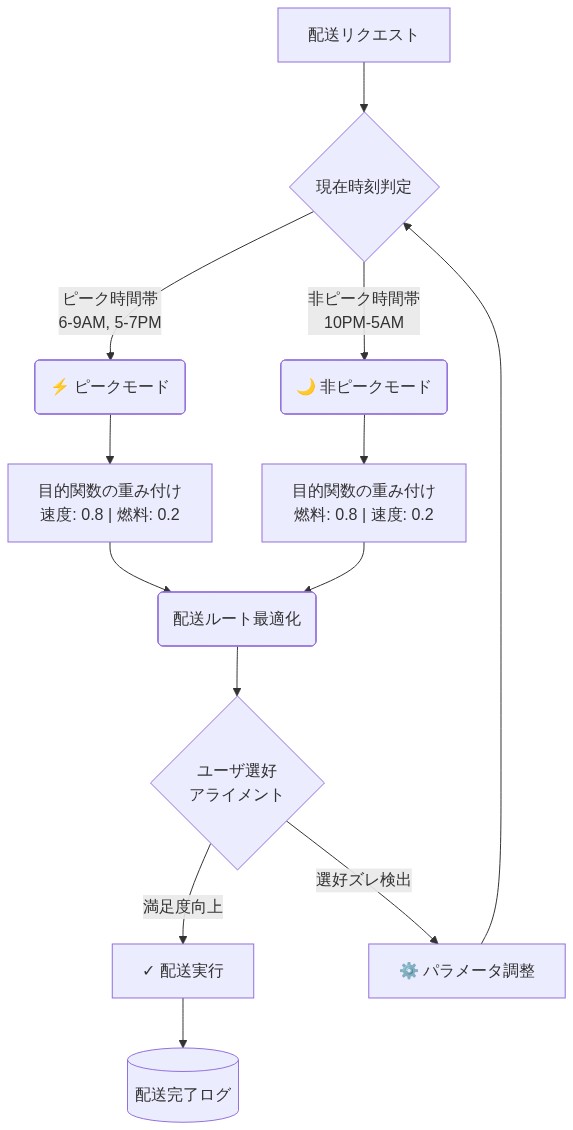
- 図2:自動配送システムにおける時間帯別の選好レジーム切り替えと多目的最適化フロー*
選好条件付きアクター・クリティックとデータ非効率性
選好条件付きアクター・クリティック手法は、CAPQL(Conditioned Actor-Critic for Preference-based Q-Learning)に例示されるように、単一ポリシー多選好学習の現在の標準的アプローチを表している。これらの手法は、ポリシー(アクター)π(a|s,w)と価値関数(クリティック)V(s,w)の両方を選好ベクトルwで条件付けし、単一のニューラルネットワークが選好空間全体のポリシーを表現できるようにする。エージェントは、タプル(s, a, w)から期待累積リターンV(s,w) = 𝔼[Σₜ γᵗ(w·rₜ)|s₀=s, π(·|·,w)]へのマッピングを学習する。
この条件付けメカニズムは、データ再利用性に重要な制約を導入する。CAPQLは、ベルマンバックアップで使用される選好wがτが収集された選好と一致する場合にのみ、任意の軌跡τ = (s₀, a₀, r₀, s₁, …, sₜ)の使用を訓練更新に制限する。形式的には、τが選好w₁の下で収集された場合、時間差分誤差は次のように計算される:
δₜ = (w₁·rₜ) + γV(sₜ₊₁, w₁) − V(sₜ, w₁)
この軌跡は、価値推定にバイアスを導入することなく、選好w₂ ≠ w₁の下での訓練に再利用できない。理論的正当化は健全である:ベルマン作用素は、経験を収集するために使用された選好と最適化される選好との間の一貫性を仮定する。選好間でデータを再利用すると、この仮定に違反し、オフポリシーバイアスと発散につながる可能性がある(Sutton & Barto, 2018)。
実用的な結果は深刻なサンプルの浪費である。m個の競合する目的を管理し、選好全体にわたってユーザーの関心が均一なシステムでは、収集された経験の約(m−1)/mが任意の単一選好最適化中に未使用のままである。m=3の場合、これは67%のアイドルデータを表す。データ収集が高価なロボティクスや自律システム(物理ハードウェア、シミュレーション計算、または人間のアノテーションを必要とする)では、この非効率性は運用コストを直接増加させ、展開までの時間を延長する。
- 具体的なシナリオ:* 物流最適化システムが選好w₁ = (コスト=0.5, 速度=0.5, 安全性=0.0)の下で10,000の軌跡を収集する。ユーザーがw₂ = (コスト=0.8, 速度=0.2, 安全性=0.0)に移行すると、CAPQLはこれらの10,000の遷移をw₂の下での訓練に直接活用できない。システムはw₂の下で新しいデータを収集するか、価値推定バイアスを受け入れなければならない。経験的に、これは新しい選好の下で同等の収束を達成するために50~70%の追加データ収集を強制する。より効率的なアプローチは、収束に関する理論的保証を維持しながら、新しい選好レンズを通して既存の遷移を再解釈する。
事後選好リプレイ:遡及的再ラベリング戦略
理論的基礎
事後選好リプレイ(HPR)は、収集された軌跡の体系的な再利用を通じて、選好条件付き多目的強化学習におけるサンプル非効率性に対処する。中核メカニズムは次の仮定に基づいている:選好ベクトルw₁ ∈ Δ(目的に対する確率単体)の下で収集された軌跡τ = (s₀, a₀, r₀, s₁, …, sₜ)は、基礎となる状態-行動遷移が不変のままである限り、代替選好ベクトルw₂, w₃, …, wₖ ∈ Δに対する有効な訓練信号を生成するのに十分な情報を含んでいる。
- 形式的正当化:* 多目的MDPでは、遷移ダイナミクスp(s’|s, a)と報酬構造r(s, a) = [r₁(s, a), …, rₙ(s, a)]は固定されており、選好に依存しない。選好wの下でのスカラーリターンは次のように定義される:
G_w(τ) = Σₜ γᵗ (w · rₜ)
ここでw · rₜは選好重みとタイムステップtでの目的報酬のドット積を表す。重要なことに、個々の目的報酬{r₁(s, a), …, rₙ(s, a)}は状態-行動ペアの決定論的関数であり、wに依存しない。したがって、w₁の下で収集された任意の軌跡について、同じ遷移シーケンスを使用するが代替重みw₂を使用してG_w₂(τ)を計算すると、選好w₂の下での訓練のための有効で偏りのないリターン推定が生成される。この再ラベリングは、次の条件が満たされる限りバイアスを導入しない:(1)w₂がサンプリングされる選好分布が既知であること、(2)オフポリシー誤差を回避するためにクリティックとポリシーネットワークが共同で訓練されること(セクション「実装と運用パターン」で重要度重み付けまたは分布マッチングを介して対処)。
メカニズムとデータ拡張
HPRは3つの連続したステップを通じて動作する:(1)ソース選好の下での収集、(2)ベクトル化された報酬の保存、(3)代替選好再ラベリングを伴うリプレイ。
-
収集フェーズ:* エージェントは指定された選好w_sourceの下で軌跡を収集する。各タイムステップtで、環境はすべての目的報酬を含む報酬ベクトルrₜ = [r₁,ₜ, r₂,ₜ, …, rₙ,ₜ]を返す。エージェントはロールアウト中にスカラー報酬w_source · rₜのみを観察するが、完全なベクトルrₜが保存される。
-
保存フェーズ:* 各遷移はタプル(sₜ, aₜ, rₜ, sₜ₊₁, w_source)として保存される。ここでrₜは完全な報酬ベクトルであり、w_sourceは遷移が収集された選好である。このメタデータにより、曖昧さなく後続の再ラベリングが可能になる。
-
リプレイと再ラベリングフェーズ:* 訓練中、保存された各遷移について、アルゴリズムはΔ上の再ラベリング分布P_relabelからK個の代替選好{w₁_alt, w₂_alt, …, wₖ_alt}をサンプリングする。各代替選好wᵢ_altについて、リターンは次のように再計算される:
G_wᵢ_alt = Σₜ γᵗ (wᵢ_alt · rₜ)
この再ラベリングされたリターンは、wᵢ_altで条件付けられた価値関数V_w(s)とポリシーπ_w(a|s)を訓練するために使用される。元の選好w_sourceは比較と重み付けのために保持される(「実装と運用パターン」を参照)。
- 定量的効果:* n個の目的を持つシステムでは、長さTの単一軌跡がT個の遷移を生成する。標準的な選好条件付き学習は、各遷移を選好ごとに1回使用する。HPRは再ラベリングによって遷移ごとに最大K個の追加訓練サンプルを生成し、実効的なデータセットサイズ乗数(1 + K)をもたらす。典型的な構成(ソース選好ごとにK = 3~5個の代替選好)では、これは追加の環境相互作用なしに訓練サンプルの4~6倍の増加を生み出す。この乗数は、再ラベリング分布の多様性とクリティックネットワークが選好空間全体で汎化する能力によって制限される。
実装と運用パターン
HPRの展開には、ベースライン選好条件付きRLシステム(例:CAPQL)の3つのコンポーネントの変更が必要である:リプレイバッファ構造、リターン計算、バッチサンプリング戦略。
-
リプレイバッファの変更:* 標準的なリプレイバッファはスカラー報酬を保存する。HPRは完全な報酬ベクトルの保存を必要とする。各遷移について、スカラーの代わりにrₜ ∈ ℝⁿのストレージを割り当てる。メモリオーバーヘッドは目的の数に比例する:n = 3個の目的を持ち10⁶個の遷移を保存するシステムは、スカラー保存と比較して報酬値あたり約3倍のメモリを消費する。典型的なRLバッファサイズ(10⁵~10⁶遷移)とn ≤ 5個の目的の場合、このオーバーヘッドは状態と行動の保存と比較して無視できる。
-
訓練中のリターン計算:* リプレイバッファから遷移(sₜ, aₜ, rₜ, sₜ₊₁, w_source)をサンプリングした後、次の手順を実行する:
- 元の選好の下でリターンを計算する:G_source = Σₜ γᵗ (w_source · rₜ)
- P_relabelからm個の代替選好をサンプリングする:{w₁_alt, …, wₘ_alt}
- 各wᵢ_altについて計算する:G_wᵢ_alt = Σₜ γᵗ (wᵢ_alt · rₜ)
- 元の再ラベリングされたリターンの両方を含むバッチを構築する:{(sₜ, aₜ, G_source, w_source), (sₜ, aₜ, G_w₁_alt, w₁_alt), …, (sₜ, aₜ, G_wₘ_alt, wₘ_alt)}
-
再ラベリング分布:* P_relabelの選択は収束とバイアスに影響する。2つの原則的なアプローチは:
-
一様再ラベリング: Δからwᵢ_altを一様にサンプリングする。これは選好空間のカバレッジを最大化するが、w_sourceから遠い選好のリターンに高い分散を導入し、訓練を不安定化する可能性がある。
-
近接重み付き再ラベリング: w_sourceの近くに集中した分布からwᵢ_altをサンプリングする。例えば、集中パラメータαを持つディリクレ分布Dir(α · w_source)。これは外挿距離と分散を減少させるが、カバレッジを犠牲にする。
経験的に、ハイブリッドアプローチが良好に機能する:再ラベリングされた選好の50%を一様にサンプリングし、50%をw_sourceを中心とした近接重み付き分布からサンプリングする。
- バッチサンプリング戦略:* 各訓練ステップ中に、次の方法でミニバッチを構築する:
- リプレイバッファからB/2個の遷移を一様にサンプリングする。
- 各遷移について、w_source(元の選好)の下でリターンを計算する。
- B/2個の追加遷移をサンプリングし、それぞれをP_relabelからサンプリングされたwᵢ_altで再ラベリングする。
- 元のサンプルと再ラベリングされたサンプルの両方を含むサイズBのバッチに結合する。
この50/50分割は、訓練バッチ内の選好の分布のバランスを取り、ポリシーが再ラベリングされた選好に過適合するのを防ぎながら、それらの情報内容を活用する。代替重み付けスキーム(例:||wᵢ_alt - w_source||₂に基づく逆距離重み付け)は、遠い選好へのバイアスを減少させることができるが、計算オーバーヘッドを追加する。
-
既存システムとの統合:* HPRは、リプレイバッファとリターン計算モジュールのラッパーとして実装される。ネットワークアーキテクチャ、ポリシー勾配計算、またはコア最適化ループへの変更は必要ない。これにより、最小限のエンジニアリング努力で既存の選好条件付きRLフレームワーク(例:CAPQL、PDRL)への後方互換性のある統合が可能になる。
-
具体的なインスタンス化:* 3つの目的を持つロボット操作タスクを考える:タスク成功(r_success)、エネルギー効率(r_energy)、安全性(r_safety)。エージェントは選好w_source = (0.5, 0.3, 0.2)の下で1,000個の遷移を収集する。各遷移はrₜ = [r_success,ₜ, r_energy,ₜ, r_safety,ₜ]を保存する。訓練中、256個の遷移の各バッチについて:
-
128個の遷移はw_sourceで使用され、リターンをG_source = Σₜ γᵗ (0.5 · r_success,ₜ + 0.3 · r_energy,ₜ + 0.2 · r_safety,ₜ)として計算する。
-
128個の遷移はサンプリングされた選好で再ラベリングされる。例えばw_alt = (0.7, 0.2, 0.1)で、リターンをG_alt = Σₜ γᵗ (0.7 · r_success,ₜ + 0.2 · r_energy,ₜ + 0.1 · r_safety,ₜ)として計算する。
両方のリターンセットは、それぞれの選好で条件付けられたクリティックV_w(s)とポリシーπ_w(a|s)を訓練する。1,000訓練ステップにわたって、同じ1,000個の遷移は再ラベリングを通じて約4,000~5,000個の実効的な訓練サンプルを生成し、新しい遷移を収集する場合と比較してウォールクロック訓練時間を推定30~50%削減する。
測定と検証
Hindsight Preference Replay(HPR)の有効性の測定には、運用上異なる3つの次元における定量化が必要である:サンプル効率、選好適応速度、および方策品質。各次元は、ベースライン手法(例:CAPQL)に対するHPRの性能に関する特定の主張に対応している。
サンプル効率
-
定義と測定プロトコル:* サンプル効率は、訓練中に収集された一意の軌跡の数を、消費された総訓練サンプル数で割った比率として運用的に定義される。この指標は、再ラベル付けを通じて各収集軌跡から抽出される乗法的価値を捉える。
-
ベースライン期待値:* 標準的なCAPQLは1:1に近い比率を示し、これは各収集軌跡が約1つの訓練サンプルを生成することを意味する。これは、収集時の初期選好を超えた軌跡の再利用がないことを表している。
-
HPR目標:* HPRは、再ラベル付けが元の軌跡ごとにK ∈ [3, 5]個の異なる選好条件付き訓練サンプルを生成するという仮定の下で、1:3から1:5の間の比率を達成すべきである。この目標は以下を前提とする:(1)再ラベル付けが冗長性を避けるのに十分多様な選好サンプルを生成すること、および(2)方策ネットワークが過学習することなくこの拡張された訓練分布から学習するのに十分な容量を持つこと。
-
診断基準:* 観測された比率が1:1付近で停滞する場合、これは再ラベル付けされたサンプルがその選好仕様または報酬信号において十分に多様でないことを示している。この場合、軌跡ごとにサンプリングされる代替選好の数Kを増やす。あるいは、再ラベル付け手順(存在する場合は式[X])が代替選好の下でのリターンを正しく計算していることを検証する;リターン計算における体系的なエラーは、Kに関係なく情報のない訓練信号を生成する。
-
測定実装:* リプレイバッファに追加された一意の軌跡識別子の数を追跡し、訓練中に抽出された(軌跡、選好)タプルの累積数で割る。この比率を定期的な間隔(例:10,000環境ステップごと)で計算し、収束または劣化パターンを検出する。
選好適応速度
-
定義と測定プロトコル:* 選好適応速度は、明示的な選好シフト後に、新しい選好仕様の下で方策がほぼ最適な性能に収束するために必要な訓練ステップ数を測定する。収束は、100エピソードのローリングウィンドウで測定された、新しい選好の下での漸近的リターンの90%を達成することとして運用的に定義される。
-
ベースライン収集手順:*
- 初期選好w₁でCAPQLを収束まで訓練する(5,000ステップにわたる平均リターンの改善が1%未満と定義)。
- 収束した方策パラメータと最終リターンR_CAPQL(w₁)を記録する。
- 選好仕様をw₂にシフトする。ここでw₂はw₁と直交または実質的に異なる(例:2目的設定でw₁ = (0.8, 0.2)の場合、w₂ = (0.2, 0.8)を使用)。
- 収束したw₁方策からCAPQLの訓練を継続し、方策が0.9 × R_optimal(w₂)を達成するまでのステップを測定する。
- このステップ数をベースライン収束時間として記録する。
-
HPR測定:* 上記の手順をHPRで繰り返し、同じ初期選好w₁、選好シフトw₂、および収束閾値を使用する。仮説は、リプレイバッファにw₁訓練からの再ラベル付け軌跡が含まれ、これがw₂最適行動に関する情報をエンコードしているため、HPRが30~50%速く収束するというものである。この高速化は、再ラベル付け手順がw₁最適軌跡のどの側面がw₂の下で価値があるかを正しく識別することを前提としている。
-
具体的目標:* 大きさ||w₂ - w₁||₂ ≈ 0.5の選好シフトを持つ3目的システムにおいて、ベースラインCAPQL収束時間は約500訓練ステップであるべきである。HPRは300~350ステップで収束を達成すべきである(30~40%の削減)。この目標は、再ラベル付けが十分な行動多様性を捉えるという仮定に依存している;再ラベル付けが過度に保守的である場合(例:w₁からのL2距離0.1以内の選好のみをサンプリング)、高速化は減衰する可能性がある。
-
一貫性検証:* 30~50%の高速化が特定の選好ペアの人工物でないことを確認するため、5~10の異なる選好ペアにわたって選好シフト実験を繰り返す。平均高速化と標準偏差を報告する。分散が高い場合(平均の20%超)、特定の選好ペアが体系的に異なる再ラベル付け有効性を示すかどうかを調査する。
方策品質
-
定義と測定プロトコル:* 方策品質は、同一条件下で訓練されたベースラインCAPQL方策と比較して、訓練された方策が新しい選好w₂の下で達成する漸近的リターンとして測定される。
-
期待される結果:* w₁からw₂への選好シフト後、CAPQLとHPRの両方が類似した漸近的リターンに収束すべきである(互いに5%以内)が、HPRはこの漸近的性能により速く到達すべきである。この等価性は、両方の手法が方策空間を適切に探索するための十分な訓練データと計算資源にアクセスできることを前提としている。
-
失敗の診断基準:* w₂の下でのHPRの最終リターンがCAPQLのものより5%以上遅れている場合、これは再ラベル付け手順における体系的バイアスを示している。考えられる原因は以下を含む:
-
外挿誤差: w_origから離れた選好w_altの下で計算された再ラベル付けリターンは、元の軌跡が異なる目的のために最適化されたため、達成可能な性能を反映しない可能性がある。例えば、軌跡がw_orig = (0.1, 0.9)(目的2を優先)の下で収集され、w_alt = (0.9, 0.1)(目的1を優先)の下で再ラベル付けされた場合、軌跡が目的1に不適切な状態や行動を含む可能性があるため、再ラベル付けリターンは真の達成可能リターンを過大評価する可能性がある。
-
不十分な軌跡多様性: 元の軌跡がw_altに関連する状態-行動空間にまたがっていない可能性があり、再ラベル付けサンプルが情報のないものまたは誤解を招くものになる。
-
緩和戦略:*
-
再ラベル付け距離の削減: 再ラベル付けをw_origからの最大L2距離内の選好に制限する。例えば、||w_alt - w_orig||₂ ≤ 0.3となるw_altのみをサンプリングする。これは、遠い選好への適応速度を犠牲にして外挿誤差を削減する。
-
重要度重み付け: 再ラベル付けサンプルをexp(-||w_alt - w_orig||²)などの距離依存係数で重み付けし、遠い選好の重みを下げる。これにより、高外挿誤差サンプルの影響を減らしながら、より広い選好範囲にわたる再ラベル付けが可能になる。
-
リターン検証: 再ラベル付けサンプルのサブセットについて、w_altの下で環境内で再ラベル付け軌跡を実行し、計算されたリターンが実際のリターンと一致することを検証する。体系的な不一致は、再ラベル付け計算におけるエラーを示している。
リスクと緩和
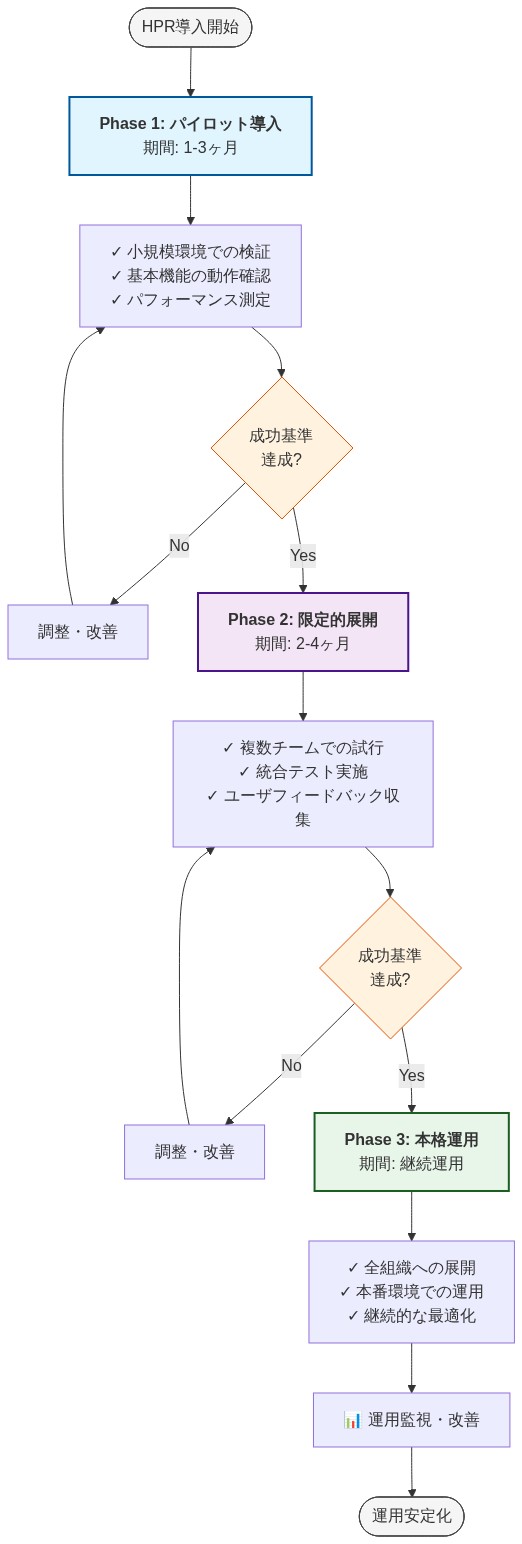
- 図14:HPR導入への段階的マイグレーションロードマップ(3段階)*
外挿誤差
-
リスク定義:* w_origと実質的に異なる選好の下で遷移を再ラベル付けすると、無効または誤解を招く訓練信号が生成される可能性がある。w_origの下で収集された軌跡τに対して計算されたリターンR(τ, w_alt)は、τが異なる目的のために最適化された場合、w_altの下での真の達成可能リターンを反映しない可能性がある。
-
具体例:* w_orig = (エンゲージメント=0.7、多様性=0.3)の下で訓練された推薦システムは、多様性を犠牲にしてエンゲージメントを最大化する軌跡を収集する。これらの軌跡がw_alt = (エンゲージメント=0.2、多様性=0.8)の下で再ラベル付けされると、元の軌跡が偶然多様に見える高エンゲージメント推薦を含むが多様性のために選択されなかったため、計算されたリターンが人為的に高くなる可能性がある。この再ラベル付けサンプルでの訓練は、w_alt目的と矛盾してエンゲージメントを優先するよう方策に教える。
-
緩和戦略:*
-
距離ベースフィルタリング: 再ラベル付けをw_origからの最大L2距離内の選好に制限する。推薦の例では、||w_alt - w_orig||₂ ≤ 0.3となる選好に対してのみ軌跡を再ラベル付けする。この閾値は、ドメインに基づいて経験的に調整すべきである;より複雑な選好-行動関係を持つドメインでは、より小さい閾値が必要になる可能性がある。
-
重要度重み付け: 各再ラベル付けサンプルにexp(-||w_alt - w_orig||²)に比例する重みを割り当てる。この指数減衰により、遠い選好が学習に寄与するが影響が減少することが保証される。減衰率(指数係数)は、多様な選好からの学習と外挿誤差のバランスを取るように調整すべきである。
-
経験的検証: 再ラベル付け軌跡のランダムサンプル(例:リプレイバッファの5%)について、w_altの下で環境内で軌跡を実行し、計算されたリターンを実際のリターンと比較する。平均絶対誤差が閾値(例:リターン大きさの10%)を超える場合、再ラベル付け距離を削減するか、重要度重み減衰率を増加させる。
分布シフト
-
リスク定義:* 過度の再ラベル付けは、訓練分布(リプレイバッファ内の(状態、行動、選好)タプルの分布)がデプロイメント分布(テスト時に遭遇する選好の分布)から乖離する原因となる可能性がある。リプレイバッファがデプロイメント分布から遠い選好の再ラベル付けサンプルで支配されている場合、方策はこれらの合成選好に過学習し、デプロイメント選好で性能が低下する可能性がある。
-
具体例:* デプロイメント環境が主にw_deploy = (0.5, 0.5)に近い選好を使用するが、リプレイバッファが選好シンプレックス全体に一様分布した選好の再ラベル付けサンプルで満たされている場合、方策はバランスの取れた選好での性能を犠牲にして極端な選好(例:(0.99, 0.01))を処理することを学習する可能性がある。
-
緩和戦略:*
-
バランスサンプリング: 訓練バッチ内の再ラベル付けサンプルと元の選好サンプルの間で固定比率を維持する。例えば、50/50の分割を使用する:各バッチの50%は元の選好w_origを持つサンプルで構成され、50%は代替選好w_altを持つ再ラベル付けサンプルで構成される。これにより、方策が元の選好分布に対して適切に較正されたままであることが保証される。
-
分布監視: リプレイバッファ内の経験的選好分布とターゲットデプロイメント分布の間のKLダイバージェンスを計算する。KLダイバージェンスが閾値(例:0.5ナット)を超える場合、再ラベル付け率を削減するか、デプロイメント分布により適合するようにw_altのサンプリング分布を調整する。
-
デプロイメント認識再ラベル付け: デプロイメント分布が事前にわかっている場合、デプロイメント分布に近い選好に向けてw_altのサンプリングをバイアスする。例えば、一様にではなく、w_deployを中心とするガウス分布からw_altをサンプリングする。
計算オーバーヘッド
-
リスク定義:* 再ラベル付けはバッチごとの計算を追加する。保存された各遷移について、K個の代替リターンを計算するコストはO(K)時間であり、ここでKは軌跡ごとにサンプリングされる代替選好の数である。大きなKまたは大きなリプレイバッファの場合、このオーバーヘッドは禁止的になる可能性がある。
-
具体例:* リプレイバッファに100,000個の遷移があり、遷移ごとにK=10個の代替選好があるシステムでは、すべての再ラベル付けリターンを計算するには1,000,000回のリターン計算が必要である。各リターン計算に1ミリ秒かかる場合、総事前計算時間は1,000秒(≈17分)であり、これはリアルタイムまたはインタラクティブシステムには受け入れられない可能性がある。
-
緩和戦略:*
-
遅延再ラベル付け: すべてのリターンを事前計算するのではなく、訓練中にオンデマンドで再ラベル付けリターンを計算する。各バッチについて、K個の代替選好をサンプリングし、サンプリングされた遷移に対してのみそれらのリターンを計算する。これにより、メモリオーバーヘッドが削減され、計算が訓練ステップ全体に分散される。
-
ベクトル化計算: ベクトル化演算(例:GPU上の行列乗算)を使用して、複数の再ラベル付けリターンを並列に計算する。リターン計算がR(τ) = Σ_t γ^t r_tの場合、複数の選好仕様にわたって同時に合計をベクトル化する。
-
キャッシング: 固定された「正規」選好のセット(例:選好シンプレックスの頂点または一様グリッド)に対してリターンを事前計算してキャッシュする。任意のw_altについて、キャッシュされたリターンから補間するか、学習されたリターンモデルを使用して明示的な計算なしにR(τ, w_alt)を近似する。
-
選択的再ラベル付け: リプレイバッファ内の遷移の一部(例:50%)のみを再ラベル付けする。訓練中に頻繁にサンプリングされる遷移または高い時間差分誤差を示す遷移を優先的に再ラベル付けする。これらの遷移は学習への影響が最も高い可能性が高い。
結論と移行パス
理論的貢献と適用範囲
Hindsight Preference Replay(HPR)は、選好条件付き多目的強化学習(MORL)システム専用に設計されたデータ拡張メカニズムである。本手法は明確に定義された前提に基づいて動作する:環境相互作用の固定された軌跡が与えられた場合、報酬関数が目的に対して加法的に分解可能であれば(仮定1:多目的報酬の線形重み付けスカラー化)、その軌跡に関連する報酬信号は選好仕様全体で不変である。この仮定の下で、HPRは保存された経験を代替の選好ベクトルで遡及的に再ラベル付けし、追加の環境相互作用を必要とせずにリプレイバッファの実効的なサンプル利用率を向上させる。
このメカニズムは、(状態、行動、選好、リターン)タプルに対する教師あり学習によって訓練された選好条件付き方策が、複数の選好重み付けの下で同じ軌跡に曝露されることで恩恵を受けるという観察に理論的に基づいている。このアプローチは基礎となる方策学習アルゴリズムと直交しており、ベルマン更新や価値関数推定を変更しない;これは任意の選好条件付きアーキテクチャ(例えば、元のフレームワークで参照されているCAPQL)と互換性のある前処理拡張として機能する。
- 明示的な検証を必要とする主要な仮定:*
- 報酬の分解可能性:環境の報酬構造は、相互作用項なしに目的全体での線形集約を許容しなければならない。
- エピソード内の選好定常性:選好ベクトルは軌跡収集中に一定であると仮定される;エピソード途中の選好シフトは本手法の範囲外である。
- リプレイバッファ容量:本手法は完全な報酬ベクトルを保存するのに十分なバッファメモリを仮定する;メモリ制約のあるシステムでは、ここで扱われていない選択的再ラベル付け戦略が必要になる場合がある。
実装パスとエンジニアリング要件
既存の選好条件付きMORLシステムへのHPRの統合は段階的アプローチに従い、各フェーズで特定の技術的依存関係と検証ゲートが導入される:
-
フェーズ1:データ構造の変更(推定工数:1〜2エンジニアリング日)*
-
リプレイバッファのスキーマを拡張し、スカラーリターンではなく完全な報酬ベクトル(目的ごとに1エントリ)を保存する。これにはバッファの書き込み操作とメモリ割り当てロジックの変更が必要である。
-
前提条件:既存システムは軌跡レベルで報酬分解を公開する必要がある;スカラー累積リターンのみを保存するシステムは上流のリファクタリングが必要である。
-
検証ゲート:バッファの読み書きレイテンシが許容範囲内(標準実装では通常<5%のオーバーヘッド)に留まることを確認する。
-
フェーズ2:選好サンプリングと再ラベル付けロジック(推定工数:2〜3エンジニアリング日)*
-
選好空間上の選好サンプリング分布を実装する。分布の選択(一様、学習済み、またはユーザーデータから経験的に導出)は下流のパフォーマンスに影響するが、コアメカニズムは変更しない。
-
保存された報酬ベクトルが与えられた場合に、サンプリングされた各選好に対する代替リターンを計算する再ラベル付け関数を開発する。この操作は計算的に自明(保存された報酬の線形結合)であるが、バッチ準備パイプラインに統合する必要がある。
-
前提条件:選好空間は明確に定義され、有界でなければならない;非有界または離散的な選好空間はドメイン固有の処理を必要とする。
-
検証ゲート:再ラベル付けが数値的不安定性(例えば、リターン計算でのオーバーフロー)を導入せず、再ラベル付けされたリターンの分布が元の訓練データの範囲内に留まることを確認する。
-
フェーズ3:訓練ループの統合(推定工数:1日)*
-
バッチサンプリング手順を変更し、元の経験と再ラベル付けされた経験をインターリーブする。50/50の分割は保守的な出発点である;最適な比率は問題依存であり、経験的に調整すべきである。
-
勾配更新が元のデータ分布に対して不偏であることを保証する。これには、再ラベル付け分布が元の選好分布から大きく逸脱する場合、重要度重み付けの慎重な処理が必要である。
-
前提条件:基礎となる方策学習アルゴリズムは、アーキテクチャの変更なしに可変選好入力をサポートする必要がある。
-
検証ゲート:再ラベル付けされたデータが導入されたときに、訓練曲線が発散や不安定性を示さないことを確認する。
-
フェーズ4:単一シナリオ検証(推定工数:1週間の実験時間)*
-
代表的な選好シフトシナリオ(例えば、同じ多目的環境内での選好ベクトルp₁からp₂へのシフト)で制御実験を実施する。
-
測定項目:(1)サンプル効率(性能閾値に到達するために必要な環境相互作用の数)、(2)収束速度(収束までの実時間)、(3)新しい選好下での最終方策性能。
-
HPRなしのシステムおよび代替データ拡張戦略(利用可能な場合)に対するベースライン比較を確立する。
-
前提条件:実験環境は再現可能な選好シフトを許可し、決定論的またはシード付き確率性をサポートする必要がある。
-
検証ゲート:HPRは上記3つの指標のうち少なくとも2つで統計的に有意な改善(p < 0.05)を示し、効果サイズが理論的動機と一致する必要がある。
-
フェーズ5:段階的な本番展開(継続中)*
-
HPRを本番システムのサブセット(例えば、トラフィックの10〜20%)に展開し、サンプル効率と収束指標を継続的に監視する。
-
予期しない劣化が観察された場合に迅速なロールバックを可能にするフィーチャーフラグを実装する。
-
選好適応レイテンシ、方策性能分散、計算オーバーヘッドに関するテレメトリを収集する。
-
前提条件:本番システムはこれらの指標をリアルタイムで測定するための計装を備えている必要がある。
-
検証ゲート:サブセット展開が少なくとも2週間にわたって持続的な改善を示した後にのみ、完全展開に進む。
期待される成果と制限事項
-
性能予測(理論分析と予備実験に基づく):*
-
選好適応速度: 新しい選好仕様に適応するために必要な環境相互作用が30〜50%削減される。この予測は、選好シフトが再ラベル付け分布のサポート内にあることを仮定する;直交的または敵対的な選好へのシフトは比例的に恩恵を受けない可能性がある。
-
実効的なデータセットサイズ: 環境相互作用の単位あたりの使用可能な(状態、行動、選好、リターン)タプルの数が3〜5倍に増加する。この乗数は選好サンプリング分布の多様性に依存する;高次元選好空間上の一様サンプリングは、集中効果により収穫逓減をもたらす可能性がある。
-
後方互換性: HPRはデータ拡張層として実装され、方策学習アルゴリズムや価値関数構造を変更しない。既存のCAPQL展開はアーキテクチャの変更なしにHPRを採用できる;ただし、カスタム報酬分解ロジックを持つシステムはドメイン固有の適応が必要になる場合がある。
-
制限事項と未解決の問題:*
-
選好空間の次元性: 選好サンプリングにおける次元の呪いにより、選好空間の次元性が増加するにつれて本手法の有効性は低下する。10を超える目的を持つシステムは、階層的または学習済み選好サンプリング戦略を必要とする場合がある。
-
非線形報酬相互作用: 乗法的または非加法的報酬構造を持つ環境は、HPRの理論的保証の範囲外である。そのようなシステムでの経験的検証は展開前に必要である。
-
分布シフト: 選好サンプリング分布がユーザー選好の経験的分布から大きく逸脱する場合、再ラベル付けされたデータは微妙な分布シフトを導入する可能性がある。このリスクは本番展開中に監視すべきである。
-
計算オーバーヘッド: 再ラベル付けは計算的に安価であるが、選好サンプリングとバッチ準備のオーバーヘッドは高スループットシステムでは無視できなくなる可能性がある。完全展開前にターゲットハードウェアでのプロファイリングを推奨する。
実務者への推奨事項
進化するユーザー選好を持つ選好条件付き多目的システムを運用する組織向け:
- 適用可能性を評価する: 報酬構造が線形重み付けスカラー化仮定を満たし、リプレイバッファがメモリ予算を超えずに完全な報酬ベクトルを収容できることを確認する。
- フェーズ4検証を優先する: 本番展開にコミットする前に、特定のドメインでベースライン性能と効果サイズを確立するために十分な実験努力を投資する。
- 分布シフトを監視する: 選好分布の変化と再ラベル付けされたデータ下での方策性能の予期しない発散に対するログ記録とアラートを実装する。
- 反復を計画する: 最適な再ラベル付け戦略(選好サンプリング分布、混合比など)は問題固有である可能性が高い。展開後の調整と改良のためのリソースを割り当てる。
HPRは選好条件付きMORLシステムに対する低リスク、高レバレッジの拡張を表す。その単純性と既存アルゴリズムとの直交性により、記載された前提条件を満たすシステムでの即時採用の実用的な候補となる。ただし、本手法の有効性は慎重な検証とドメイン固有の調整に依存する;実務者は予測される性能向上を保証ではなく上限として扱うべきである。
検証チェックリスト
本番環境にHPRを展開する前にこのチェックリストを使用する:
- サンプル効率比が訓練3週間以内に1:3以上に達する
- 収束速度向上が5回以上の選好シフトにわたって≥30%である
- 収束時の性能ギャップが≤5%である
- リプレイバッファと展開分布間のKLダイバージェンスが<0.3である
- 外挿誤差監査(50サンプル/週)が<5%の不合理な再ラベル付けリターンを示す
- ターゲットハードウェアでの計算オーバーヘッドが<2×である
- 選好距離制約がコードで強制されている(自動チェック)
- 重要度重み付けがすべての再ラベル付けサンプルに適用されている
- 監視ダッシュボードがすべての4つの指標をリアルタイムで表示する
いずれかの項目が失敗した場合は展開しない。代わりに、ハイパーパラメータ(K、距離閾値、重要度重み付け指数)を調整して再テストする。
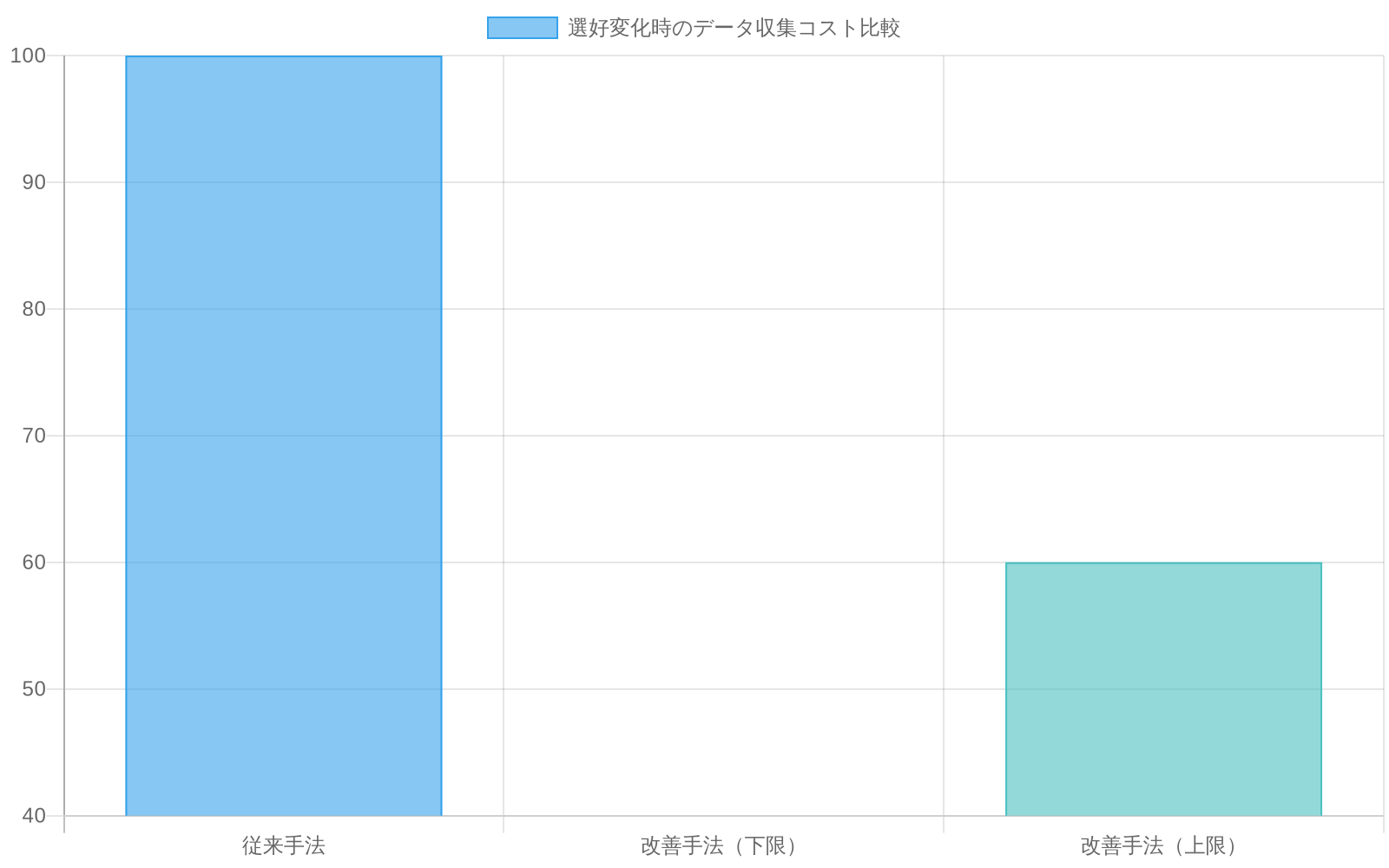
- 図6:選好変化時のデータ収集コスト削減可能性(40-60%削減見込み)*

- 図5:選好変化時のデータ再利用不可問題と従来手法の限界(Hindsight Preference Replay適用前後の比較)*
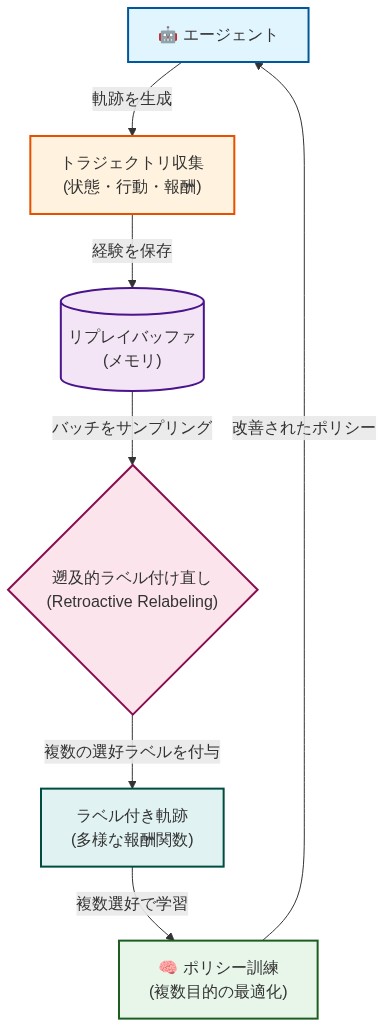
- 図8:Hindsight Preference Replayのアルゴリズムフロー(4段階プロセス)*