
若年ユーザーを保護するため、ChatGPTは年齢を予測するようになる
ChatGPTにおける年齢予測技術の仕組み
ChatGPTは、会話内の言語的および行動的パターンを分析してユーザーを年齢層に分類する機械学習ベースの年齢推定システムを採用しており、特に18歳未満のユーザーの識別に重点を置いている。このシステムは決定論的分類ではなく確率的推論に基づいて動作し、成人/未成年の二値的指定ではなく、年齢層全体にわたる信頼度分布を生成する。
基礎となるメカニズムは、複数の言語的および行動的変数を検証する:語彙の複雑さ(語彙の洗練度と単語頻度分布)、統語パターン(文の長さ、節の埋め込み、文法構造の種類)、パラ言語的マーカー(絵文字の頻度、大文字使用パターン、略語の慣習)、話題への関心(主題の選択と関与の深さ)、コミュニケーション成熟度の指標(視点取得、抽象的推論、時間的推論)。これらの特徴は、年齢ラベルが文書化されたユーザー情報を通じて確立された匿名化データセットで訓練されたモデルを通じて処理され、観察可能なコミュニケーションパターンと年齢層との相関関係を作り出す。
-
理論的基盤:* このアプローチは、年齢に関連する認知発達がコミュニケーションスタイルに測定可能な差異を生み出すという前提に基づいている(Pinker, 1994; Kemper & Sumner, 2001)。発達心理言語学は、児童期から青年期にかけての言語的複雑さの体系的な変化を記録しているが、個人差は依然として大きい。
-
実装の根拠:* 未成年者は、成人向けコンテンツ、暴力的素材、自傷行為や搾取を助長する可能性のあるアドバイスへのアクセスを含む、文書化された暴露リスクに直面している(boyd, 2014; Livingstone et al., 2011)。自動年齢分類により、明示的な年齢確認を必要とせずに保護的なコンテンツフィルタリングが可能になり、基本的な安全対策を確立しながらユーザーの摩擦を減らすことができる。
-
具体例:* 形式的な数学用語、複雑な従属節、学術的内容への持続的な集中を用いて微積分の宿題について質問するユーザーは、簡略化された語彙、頻繁な絵文字、ビデオゲームのメカニクスについての議論を用いるユーザーと比較して、16-18歳の年齢層に対してより高い信頼度スコアを受け取る—ただし、どちらの分類も確実性には達しない。システムは確率分布を割り当てる:最初のユーザーは[0.05確率 <13歳、0.15確率 13-15歳、0.60確率 16-18歳、0.20確率 18歳以上]を受け取る可能性があり、2番目のユーザーは[0.35、0.45、0.15、0.05]を受け取る。
-
実用的な意味:* システムは設定可能な信頼度閾値で動作する。不確実性が所定の限界を超えると、ChatGPTはより若い年齢層と一致する保護措置をデフォルトとする。言語パターンが分類境界付近(特に17-19歳)に該当するユーザーは、より保守的なフィルタリングを経験する。リアルタイム分析により、予測は単一の会話内で洗練される—最初のメッセージが暫定的な分類を確立するが、システムは相互作用パターンが蓄積されるにつれて推定を更新し、証拠が修正を正当化する場合は会話の途中での再分類を可能にする。
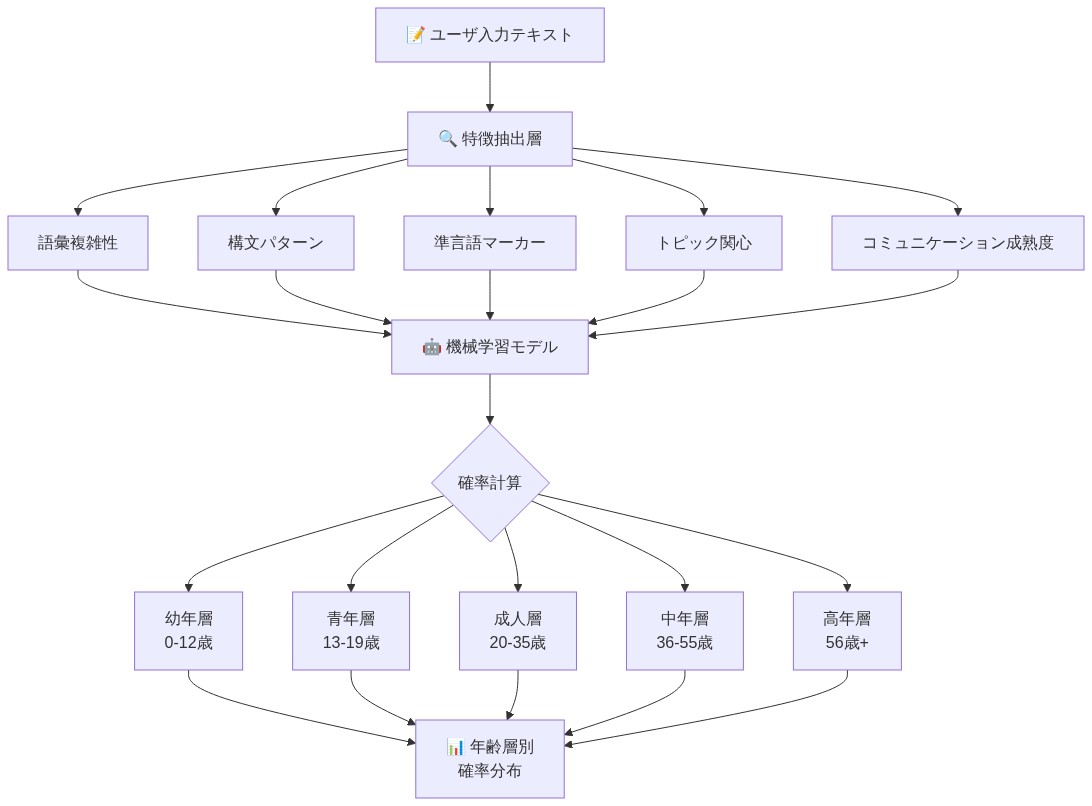
- 図2:年齢予測モデルの入力変数と処理フロー*
識別された未成年者に対するコンテンツフィルタリングプロトコル
ユーザーが18歳未満である可能性が高いと分類されると、システムは絶対的なブロックではなく段階的なコンテンツ制限を有効にする。フィルタリングアーキテクチャは複数の次元で動作する:特定のカテゴリーに対する完全な話題回避(例:自傷行為の詳細な指示、児童搾取素材)、機密性の高い話題に対する応答の修正(トーンの変更、技術的深度の削減、教育的枠組みの包含)、正当な教育的質問に対する条件付きアクセス(健康情報、人間関係のガイダンス、安全に関する話題)。
-
理論的基盤:* 青少年の情報ニーズに関する研究は、完全なコンテンツブロックが正当な健康教育と安全学習を妨げることを示している(Livingstone & Helsper, 2008)。段階的フィルタリングは、搾取的なコンテンツへの暴露を防ぎながら、教育的アクセスを維持しようとする。
-
段階的アプローチの根拠:* 二値的ブロックは逆インセンティブを生み出す—正当な健康情報を求める未成年者は、信頼性の低い情報源に頼る可能性がある。ニュアンスのあるフィルタリングは、年齢ベースの保護が発達段階に適した情報アクセスを排除すべきではないことを認識している。
-
具体例:* 18歳未満と分類されたユーザーが「避妊方法はどのように機能しますか?」と尋ねると、健康教育に適した事実的で臨床的な情報—作用機序、有効性率、副作用プロファイル—を明示的な画像や性的な枠組みなしで受け取る。同じユーザーが露骨な性的コンテンツを求めると、説明付きの拒否を受け取る。自傷行為に関する質問は専門的な応答プロトコルをトリガーする:システムは危機対応リソース情報(全国自殺予防ライフライン、危機テキストライン)を提供し、方法の詳細な議論を避け、メンタルヘルス専門家によって設計された支援的な言語を含み、異なる文脈でハームリダクションを議論する可能性のある成人ユーザープロトコルとは異なる。
-
実用的な意味:* 保護者と教育者は、制限がスペクトラム上で動作し、絶対的なブロックとしてではないことを認識すべきである。正当な教育目的で機密性の高い話題を研究する学生は、事実情報へのアクセスを保持する。ただし、詳細な有害な指示、極端な暴力描写、または搾取的素材の要求は一貫した拒否に直面する。応答が不適切に制限的であると考えるユーザーはレビューを要求できるが、異議申し立ては文書化された安全パラメータ内で動作し、明らかに有害なコンテンツカテゴリーの保護を無効にしない。

- 図5:年齢層別コンテンツフィルタリング適用フロー*

- 図4:未成年向けコンテンツフィルタリング保護メカニズム*
実装タイムラインとユーザーエクスペリエンスの変更
機能の展開は、地理的地域とプラットフォームタイプ(ウェブ、モバイルアプリケーション、API統合)全体で段階的に行われる。初期展開は、新規ユーザーアカウントと確立された相互作用履歴のないアカウントを優先する。既存のユーザーは、年齢ベースのフィルタリングがアクティブであることを示す明示的なインターフェース指標を伴う段階的な統合を経験する。システム通知は、年齢保護プロトコルにより応答が修正された場合にユーザーに通知する。
-
段階的展開の根拠:* 段階的な展開により、全面的な有効化の前にシステムパフォーマンスの監視、エラー検出、および改良が可能になる。透明なユーザーコミュニケーションは混乱を減らし、情報に基づいた使用をサポートする。
-
具体例:* 新しいモバイルアプリケーションユーザーは、「若年ユーザー向けの安全機能がこのアカウントでアクティブです」と記載されたオンボーディングバナーを見る。既存のユーザーは、特定の話題カテゴリーに対する応答の可用性の変化に気付き、「この応答は年齢保護設定に基づいて制限されています」と示す説明テキストが表示される。共有家族デバイスは、アカウントレベルの分類ではなくセッションベースの年齢予測を実装し、同じデバイス上の異なるユーザーが個々の会話パターンに基づいて異なるフィルタリングを受け取ることを可能にする。
-
実用的な意味:* ユーザーは、完全な機能互換性にアクセスし、正確なフィルタリングを受け取るために、現在のアプリケーションバージョンに更新する必要がある。システムは既存の会話履歴にフィルタリングを遡及的に適用しない—過去のやり取りは変更されないまま残る。年齢予測は定期的に(通常はセッション境界または長期間の非アクティブ後に)リセットされ、現在の会話パターンに基づいて再推定が必要になる。共有デバイスユーザーは、各個別セッションの言語パターンに応じて、セッション間で一貫性のないフィルタリングを経験する可能性がある。デバイスレベルの設定は、会話レベルで動作するリアルタイム言語分析を無効にしない。
精度の課題と誤検出管理
年齢予測は確率的に動作するため、分類エラーが発生する。不正確さの体系的な原因には以下が含まれる:簡略化されたコミュニケーションスタイルを採用する成人(非ネイティブ英語話者、言語障害のあるユーザー、意図的な文体の選択)、洗練された語彙を使用する未成年者、および分類を回避するために意図的に言語パターンを変更するユーザー。システムは、誤検出率を最小限に抑えるための検証経路と継続的学習メカニズムを組み込んでいる。
-
理論的基盤:* 分類精度は、特徴の質とトレーニングデータの代表性に依存する。多くの特徴について、年齢グループ内の言語的変動は年齢グループ間の変動を超えており、本質的な分類困難を生み出している(Argamon et al., 2007)。
-
エラー管理の根拠:* 過度のフィルタリングは成人ユーザーを苛立たせ、システムの信頼を損なう;過少フィルタリングは未成年者を危害にさらす。システムは保守的なバイアスを実装する—偽陰性よりも偽陽性を優先する—が、不必要な制限を最小限に抑えるための修正メカニズムを提供する。
-
具体例:* 単純な文構造と限られた語彙を使用する成人の非ネイティブ英語話者は、未成年者としての誤検出分類を受ける可能性がある。このユーザーは、文書化された認証(政府発行のID、クレジットカード確認、または機関のメール)を通じて年齢確認を要求できる。システムは、修正からのフィードバックをモデルの再トレーニングに組み込み、将来の相互作用で類似の言語パターンの精度を向上させる。年齢推定が決定境界付近(通常17-19歳)に該当するユーザーは、未成年分類の信頼度が中程度であっても、保護不足のリスクを最小限に抑えるためにシステムがより厳格なフィルタリングを適用するグレーゾーンを経験する。
-
実用的な意味:* 一貫した誤分類を経験するユーザーは、実際の年齢の文書を添えてサポートに連絡する必要がある。検証プロセスは通常、最小限の身元確認を必要とし、24-48時間以内に完了する。修正は、そのユーザーの将来の相互作用のシステム精度を向上させ、類似のユーザー集団のモデル改善に貢献する。ユーザーは、年齢境界付近での持続的な注意が意図的なシステム設計哲学を反映していることを理解すべきである:不確実性の場合、保護は利便性よりも優先される。

- 図8:年齢予測における分類エラーのメカニズム*
プライバシーへの影響とデータ取り扱い慣行
年齢予測データは、未成年者データ収集を規制する規制と一致した強化されたプライバシー保護を受ける。年齢推定に使用される会話コンテンツは分類目的で処理される可能性があるが、年齢決定のために永続的に保持されることはない。年齢予測はデフォルトで永続的なユーザープロファイルではなくセッションにリンクされる;アカウントベースのシステムは、明示的なユーザーの同意と明確なデータ保持ポリシーを持つリピーターユーザーの年齢カテゴリーを保持する。
-
規制の枠組み:* 実装は、13歳未満のユーザーに対する児童オンラインプライバシー保護法(COPPA)要件、欧州管轄区域の16歳未満のユーザーに対する一般データ保護規則(GDPR)規定、および同等の地域規制(例:カリフォルニア州居住者に対するカリフォルニア消費者プライバシー法)に準拠している。
-
プライバシー保護の根拠:* データ保持を最小限に抑えることで、侵害リスクとプライバシー暴露が減少する。規制遵守には、特に高度な法的保護の対象となる未成年者集団に対して、慎重なデータガバナンスが必要である。
-
具体例:* セッションベースの年齢予測は、ユーザーのログアウト時に期限切れになる;ユーザープロファイルに永続的な年齢分類は残らない。アカウントベースのユーザーは、プライバシー設定を通じて予測された年齢カテゴリーにアクセスし、修正または再分類を要求できる。すべての年齢関連データは、転送中(TLS 1.2以上)および保存時(AES-256または同等)に暗号化を受ける。COPPA規制地域(13歳未満)のユーザーは、強化された保護を受ける:保護者通知オプション、制限されたデータ収集、およびアカウント作成のための明示的な保護者の同意要件。
-
実用的な意味:* ユーザーは、データ保持の好みを理解し、プライバシーの優先順位に合わせたオプションを構成するために、プライバシー設定を確認する必要がある。ユーザーは、分類に影響を与えた特定の言語的特徴を含む、年齢がどのように決定されたかを示すデータアクセスレポートを要求できる。機関ユーザー(学校、図書館)は、学生集団にChatGPTを展開する前に、コンプライアンス文書を確認する必要がある。プライバシーポリシーには管轄区域固有の詳細が含まれている;ユーザーは、自分の地域での権利に関する情報(例:GDPRデータ主体の権利、CCPA削除権)についてこれらの文書を参照する必要がある。
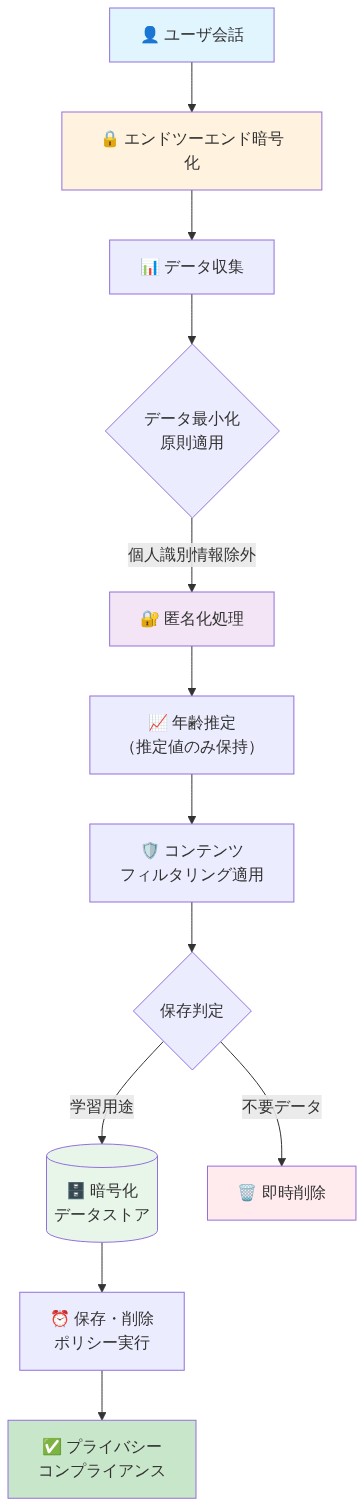
- 図9:プライバシー保護を考慮したデータハンドリングフロー*
保護者管理と家族アカウント管理
保護者は、特定のユーザーを未成年者として指定する家族アカウントを構成でき、保護者の判断がシステム分類と異なる場合に自動予測を無効にできる。監視機能は、会話の要約とフィルターアクティビティログを提供する。制限レベルは、家族固有のポリシーに対応するためにデフォルト設定を超えてカスタマイズできる。
-
保護者管理の根拠:* 家族は、コンテンツへの暴露と情報アクセスに関して多様な快適レベルを維持している。明示的な保護者管理は、基本的な安全保護を維持しながら、この変動に対応する。
-
具体例:* 保護者は家族アカウントを確立し、16歳の子供を未成年ユーザーとして指定する。保護者は、議論された話題とシステムによってトリガーされたコンテンツ制限の週次要約を受け取る。保護者は、追加の教育コンテンツ(例:健康クラスのプロジェクトのための詳細な健康情報)を許可するようにフィルターを調整するか、より厳格なデフォルトを維持できる。認証メカニズムは、子供がアカウント操作を通じて保護者管理をバイパスすることを防ぐ。
-
実用的な意味:* 最も明確な制御実装のために、初期設定中に家族アカウントを構成する。制限が存在する理由、どのコンテンツカテゴリーが禁止されているか、および保護措置の根拠について子供と明示的にコミュニケーションを取る。未成年者が18歳に達したときの移行を計画する—制限の段階的な調整は、健全な自律性の発達をサポートし、突然のアクセス変更を防ぐ。子供の相互作用パターンを理解し、積極的な議論または追加のガイダンスが必要な領域を特定するために、監視レポートを定期的に確認する。
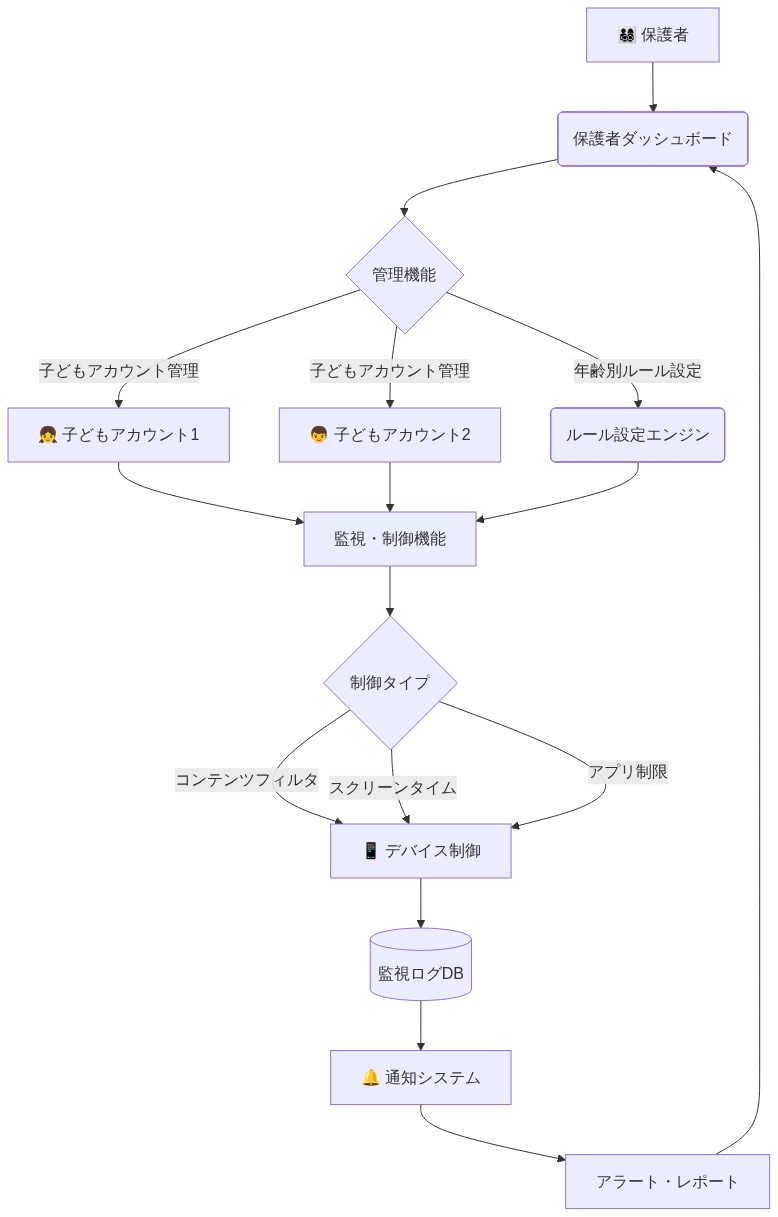
- 図11:ファミリーアカウント管理システムのアーキテクチャ*
教育機関および機関展開の考慮事項
ChatGPTを展開する学校、図書館、およびその他の機関は、未成年ユーザー集団の明示的な認識を伴う機関アカウントを構成する必要がある。管理制御は大規模なアクセスを管理する。コンプライアンス文書は、学生プライバシー法(米国のFERPA、他の管轄区域の同等の規制)および機関ポリシーへの遵守を保証する。
-
規制の枠組み:* 教育機関は、学生データ保護、情報アクセス、および注意義務に関する特定の法的義務に直面している。機関展開には、これらの義務への文書化されたコンプライアンスが必要である。
-
機関構成の根拠:* 機関展開には、未成年ユーザー集団の明示的な承認と文書化された保護措置が必要である。カスタマイズ可能なフィルタリングは、保護を維持しながら教育使命と整合する。
-
具体例:* 学校は教室での使用のためにChatGPTを構成し、すべてのアカウントを学生アクセスとして指定する。教師は、使用パターンとフィルターアクティビティを示す管理ダッシュボードを受け取る。フィルタリングパラメータは、搾取的なコンテンツと詳細な有害な指示をブロックしながら、正当な教育目的のための機密性の高い歴史的話題(例:ホロコースト史、奴隷制、大量虐殺)に関する研究を許可する。コンプライアンス文書は、機関監査要件をサポートし、学生保護における適切な注意を示す。
-
実用的な意味:* 機関は、展開前にコンプライアンスレビューを完了し、学生プライバシー義務に関して法律顧問と相談する必要がある。年齢保護機能と学生が制限に遭遇したときの応答プロトコルについてスタッフをトレーニングする。教育の自由と保護のバランスを取るためにフィルタリングをカスタマイズする—歴史的暴力に関する研究は、危害を引き起こす指示の要求とは根本的に異なる。適切な使用に関する明確なポリシーを確立し、実装前に学生と保護者にこれらを伝える。フィルタリングのカスタマイズを文書化し、機関ポリシーと法的要件へのコンプライアンスを示す記録を維持する。
主要なポイントと次のアクション
年齢予測技術は、AI安全性実装における重要な運用上の転換を表しており、手動の年齢確認を必要とせずに未成年者を自動的に保護します。このシステムは、段階的なフィルタリングを通じて保護と使いやすさのバランスを取っていますが、精度の限界とプライバシーへの配慮により、すべての関係者グループによる慎重な管理が必要です。
-
個人ユーザー向け:* 最新のアプリケーションバージョンに更新してください。フィルタリングが文書化された安全性の優先事項を反映していることを理解してください。継続的に誤分類される場合は検証経路を使用してください。データ取り扱い慣行を理解するためにプライバシー設定を確認してください。
-
保護者向け:* 初期設定時にファミリーアカウントを構成してください。監視機能とフィルタリングのカスタマイズオプションを確認してください。子供たちと境界線についてコミュニケーションを取ってください。未成年者が成人に達する際の移行を計画してください。
-
機関向け:* 法律顧問に相談しながら、展開前にコンプライアンスレビューを完了してください。教育的文脈に合わせてフィルタリングをカスタマイズしてください。機能の操作と対応プロトコルについてスタッフをトレーニングしてください。コンプライアンス措置の文書を維持してください。
-
すべての関係者向け:* AIと未成年者保護に関する進化する規制を監視してください。この機能は、より広範なAI安全性の実践と規制の枠組みに影響を与える可能性が高い、新興の業界標準を表しています。

- 図14:教育機関でのChatGPT導入ロードマップ(段階的導入フレームワーク)*
精度の課題と誤検知管理:堅牢な分類に向けて
年齢予測は確率的であり、決定論的ではありません。これは、システムがどのように理解され、展開されるべきかを形作る基本的な特性です。簡略化されたコミュニケーションスタイルを持つ成人、非ネイティブスピーカー、意図的に言語パターンを変更するユーザー、神経多様性のあるコミュニケーションスタイルを持つ個人は、誤検知を生み出します。システムは検証経路と継続的な学習を通じてこれらに対処しますが、この課題自体が重要な将来の発展を示しています。
-
戦略的根拠:* 過度なフィルタリングは成人ユーザーを苛立たせ、AIシステムへの信頼を損ないます。フィルタリング不足は未成年者を危害にさらします。システムは慎重さに傾きますが、不必要な制限を最小限に抑えるための修正メカニズムを提供します。この設計哲学—まず保護し、後で最適化する—は、AIシステムが多様な集団と相互作用するにつれて、業界全体で標準となる可能性があります。重要な革新は完璧な精度ではなく、優雅な劣化です:不確実な場合、システムは安全性をデフォルトとしながら、修正のための経路を提供します。
-
具体例:* 簡単な文章を使用する成人の非ネイティブ英語話者は、未成年者としてフラグが立てられる可能性があります。彼らは文書化された認証を通じて年齢確認を要求できます。これは通常、最小限の身元確認を必要とするプロセスです。システムは修正から学習し、類似の言語パターンの精度を向上させます。18歳近くのユーザーは、システムがリスクを最小限に抑えるためにより厳格なフィルタリングを適用するグレーゾーンを経験します。これは、発達的移行期間を認識する意図的な選択です。
-
知識労働者への実用的な示唆:* 継続的に誤分類される場合は、文書を添えてサポートに連絡してください。修正が将来のやり取りのシステム精度を向上させることを期待してください—あなたのフィードバックはシステム改善に貢献します。ユーザーは、年齢境界付近での持続的な慎重さがシステムの設計哲学を反映していることを理解すべきです:保護は利便性よりも優先されます。この原則は、AIシステムが成熟するにつれて他のAIシステムにも拡張される可能性が高く、AIが敏感な分類に関する不確実性をどのように扱うかについての新しい標準を作り出します。
プライバシーへの影響とデータ取り扱い慣行:透明性を通じた信頼の構築
年齢予測データは厳格なプライバシー保護を受けますが、アプローチ自体がAIシステムが敏感な推論をどのように扱うべきかについて示唆に富んでいます。推定に使用される会話内容は処理される可能性がありますが、年齢分類の目的で永続的に保持されることはありません。予測はデフォルトで永続的なユーザープロファイルではなくセッションにリンクされますが、アカウントベースのシステムは再訪ユーザーのために年齢カテゴリを保持します。これは、パーソナライゼーションとプライバシーのバランスを取る設計です。
-
戦略的根拠:* データ保持を最小限に抑えることで、侵害リスクとプライバシー露出が減少し、GDPR、COPPA、地域法への規制コンプライアンスには慎重なデータガバナンスが必要です。このアプローチは、プライバシーと機能性がどのように共存できるかを示しています:システムは広範な個人データ保持を必要とせずに保護目的を達成します。このモデルは、他の業界がユーザーに関する敏感な推論にどのようにアプローチするかに影響を与える可能性があります。
-
具体例:* セッションベースの年齢予測はログアウト後に期限切れとなり、永続的な追跡を防ぎます。アカウントベースのユーザーは、予測された年齢カテゴリを表示し、修正を要求できます。暗号化は、転送中および保存中のすべての年齢関連データを保護します。COPPA規制地域のユーザーは、強化された保護と保護者通知オプションを受け取ります。機関展開には、年齢決定がどのように行われたかを示す監査証跡が含まれ、コンプライアンス文書をサポートします。
-
機関リーダーへの実用的な示唆:* データ保持の設定を理解するためにプライバシー設定を確認してください。ユーザーはデータ削除を要求し、年齢がどのように決定されたかを示すレポートにアクセスできます。機関は、学生集団にChatGPTを展開する前にコンプライアンス文書を確認する必要があります。プライバシーポリシーはデータ取り扱いを詳述しています。管轄区域固有の権利についてはこれらを参照してください。より広い教訓:AIシステムがユーザーについてどのように推論を行うかについての透明性は、競争上および倫理上の必要性になりつつあります。
保護者管理とファミリーアカウント管理:情報に基づいた保護の実現
保護者は、特定のユーザーを未成年者として指定するファミリーアカウントを構成でき、必要に応じて自動予測を上書きできます。監視機能は会話の要約とフィルターログを提供します。制限レベルはデフォルト設定を超えてカスタマイズでき、家族が独自の安全ポリシーに対する主体性を維持する枠組みを作成します。
-
戦略的根拠:* 家族は、文化的価値観、発達的準備状況、個別の状況に基づいて、コンテンツ露出に対してさまざまな快適レベルを持っています。明示的な保護者管理は、ベースラインの安全性を維持しながら、多様な家庭のポリシーに対応します。このアプローチは、万能の保護は可能でも望ましくもないことを認識しています—家族はAI支援の安全性の恩恵を受けながら、独自の価値観を実装するためのツールを必要としています。
-
具体例:* 保護者がファミリーアカウントを設定し、16歳の子供を未成年者として指定します。彼らは、議論されたトピックとトリガーされたコンテンツ制限の週次要約を受け取ります。彼らは追加の教育コンテンツを許可するようにフィルターを調整できます—おそらく第二次世界大戦を研究している学生のために歴史的紛争に関する詳細な回答を有効にする—またはより厳格なデフォルトを維持できます。認証により、子供たちが管理をバイパスすることを防ぎます。システムは、子供たちが成熟するにつれて制限の段階的な緩和をサポートし、成人レベルのアクセスへの移行を可能にします。
-
保護者への実用的な示唆:* 最も明確な管理のために、初期構成中にファミリーアカウントを設定してください。制限が存在する理由と禁止されているコンテンツについて子供たちとコミュニケーションを取り、安全性を罰ではなく共有された価値として位置づけてください。未成年者が18歳になるときの移行を計画してください—制限の段階的な調整は健全な自律性の発達をサポートします。子供のやり取りパターンを理解し、懸念事項に積極的に対処するために、監視レポートを定期的に確認してください。より深い原則:保護者管理は、監視ではなく、情報に基づいた保護を可能にすべきです—この区別は、AIシステムが家族の文脈で普及するにつれて、ますます重要になります。
教育および機関展開の考慮事項:学習環境における安全性の拡大
ChatGPTを展開する学校や図書館は、すべてのユーザーを学生として認識する機関アカウントを構成する必要があります。管理制御により、大規模なアクセス管理が可能になります。コンプライアンス文書は、学生プライバシー法と機関ポリシーへの遵守を保証します。この枠組みは、機関がケアの義務を維持しながらAIツールを展開する方法を変革します。
-
戦略的根拠:* 機関展開には、未成年ユーザー集団の明示的な認識と文書化された保護措置が必要です。カスタマイズ可能なフィルタリングは、保護を維持しながら教育的使命と整合します。このアプローチにより、機関は安全性を損なうことなく、AIの教育的利点—パーソナライズされた個別指導、研究支援、執筆フィードバック—を活用できます。このモデルは、AIが保護的監視を維持しながら教育アクセスをどのように拡大できるかを示しています。
-
具体例:* 学校が教室での使用のためにChatGPTを構成し、すべてのアカウントを学生アクセスとして指定します。教師は、使用パターンとどのトピックが最も多くの質問を生成するかについての集計データを示す管理ダッシュボードを受け取ります。フィルタリングパラメータは、正当な教育目的のために敏感なトピックに関する研究—歴史的暴力、医学的状態、社会問題—を許可しながら、搾取的なコンテンツをブロックします。文書はコンプライアンス監査をサポートします。システムは機関展開から学習し、教育的要求と有害な要求を区別する能力を向上させます。
-
機関リーダーへの実用的な示唆:* 法務およびプライバシーチームに相談しながら、展開前にコンプライアンスレビューを完了してください。学生が制限に遭遇したときの年齢保護機能と対応プロトコルについてスタッフをトレーニングしてください。教育の自由と保護のバランスを取るためにフィルタリングをカスタマイズしてください—歴史的暴力に関する研究は、有害な指示の要求とは根本的に異なります。適切な使用に関する明確なポリシーを確立し、実装前に学生と保護者にこれらを伝えてください。この技術が機関の教育的使命をどのように強化できるかを検討してください:AI支援の個別指導、研究サポート、執筆フィードバックは、安全性が後付けではなく組み込まれている場合により実現可能になります。
主要なポイントと次のアクション:適応型AIの未来に向けて
年齢予測技術は、AI安全性アーキテクチャにおける重要な転換を表しており、手動検証を必要とせずに未成年者を自動的に保護します。システムは段階的なフィルタリングを通じて保護と使いやすさのバランスを取りますが、精度の限界とプライバシーへの配慮には、慎重で継続的な管理が必要です。さらに重要なことに、この技術は、AIシステムがユーザーの特性、文脈、ニーズにインテリジェントに適応する未来を指し示しています—これは、技術が多様な集団にどのようにサービスを提供するかを再形成するフロンティアです。
-
個人ユーザー向け:* 改善された精度と機能の恩恵を受けるために最新バージョンに更新してください。フィルタリングが恣意的な制限ではなく、意図的な安全性の優先事項を反映していることを理解してください。誤分類された場合は検証経路を使用し、フィードバックを通じてシステム改善に貢献してください。
-
保護者向け:* ファミリーアカウントを早期に構成し、監視機能を確認し、制限ではなく共有された価値として子供たちと境界線についてコミュニケーションを取ってください。子供たちが成熟するにつれて段階的な移行を計画し、自律性への健全な発達をサポートしてください。
-
機関向け:* 展開前にコンプライアンスレビューを完了し、教育的文脈に合わせてフィルタリングをカスタマイズし、新機能についてスタッフをトレーニングしてください。年齢認識AIが機関の使命をどのように強化できるかを検討してください—パーソナライズされた学習、研究サポート、執筆支援は、安全性が組み込まれている場合により実現可能になります。
-
すべての関係者向け:* AIと未成年者保護に関する進化する規制を監視してください。この機能は、より広範な業界慣行に影響を与える可能性が高い新興標準を表しています。これらの技術に思慮深く関与し、「これは安全か?」だけでなく、「これは教育、家族支援、人間開発にとって何が可能かをどのように再形成するか?」と問いかけてください。その答えが次世代のAIシステムを定義します。