
Jerry (YC S17) が採用活動中
採用シグナルと市場ポジショニング
Y Combinator S17卒業生であるJerryは、コア自動化とマーケットプレイスインフラストラクチャを専門とするソフトウェアエンジニア職を積極的に募集している。この採用決定は、組織の成熟度における測定可能な変曲点を表しており、以下の前提条件に依存している:(1) 同社は専門的な採用を正当化するのに十分なプロダクトマーケットフィットを達成している;(2) 自動化とマーケットプレイスシステムは、汎用的な機能ではなく戦略的に差別化された能力として特定されている;(3) 創業チームの能力がスケーリングにおける制約要因となっている。
この推論の理論的根拠は、Greinerの成長モデル(Greiner, 1972)とSutton & Raoのスケーリングフレームワーク(2014)で文書化された組織のスケーリングパターンに基づいている。初期段階のテクノロジー企業が創業者主導の開発から役割特化型の採用に移行する場合、それは「創造性」と「方向性」のフェーズを通過し「委任」フェーズへの移行を示す。この移行は、プロダクト検証と収益の牽引力が存続の不確実性を減少させた後にのみ発生する。
この役割の特異性—汎用的な「フルスタックエンジニア」ではなく、自動化とマーケットプレイスインフラストラクチャ—は、Jerryが自動化を競争優位性と運用上の回復力の源泉として診断したことを示している。この仮定は以下の論理によって支持される:(a) 自動化とマーケットプレイスシステムは、分散状態管理、トランザクションの一貫性、障害回復において高い複雑性を示す;(b) これらのシステムは、堅牢に構築されると、競合他社が容易に複製できないスイッチングコストと運用効率の向上を生み出す;(c) したがって、プロダクトマーケットフィットを検証した企業は、顧客向け機能をさらにスケーリングする前に、これらのサブシステムに専門的な人材を合理的に配分する。
実証的な前例がこのパターンを支持している。Stripeの2011年の決済インフラストラクチャ専門家の採用は、シリーズB資金調達に先行し、決済の信頼性を中核的な競争上の堀にするという意図的な決定を反映していた(Collison & Collison, 2011)。同様に、Uberのマッチングアルゴリズムとサージプライシングインフラストラクチャへの初期投資は、地理的拡大に先行した(Rosenthal, 2019)。両方のケースにおいて、インフラストラクチャの専門的採用は急速なスケーリングに先行し、その逆ではなかった。
- この分析に埋め込まれた仮定:*
- Jerryは専門的な採用を正当化するのに十分なプロダクトマーケットフィットを達成している(仮定:シリーズA資金調達または同等の滑走路が存在する)。
- 自動化とマーケットプレイスシステムは現在、プロダクトロードマップにおけるボトルネックである(仮定:運用データまたは顧客フィードバックがこの制約を明らかにしている)。
- 自動化専門家の労働市場は十分に競争的であり、適格な候補者を引き付けるために明示的な役割の仕様が必要である。
この機会を評価する知識労働者にとって:この役割は、明確に定義された技術的問題、それらを解決するために配分されたリソース、および戦略的優先事項に関する組織的明確性を持つ企業を示している。同様の組織を構築する採用マネージャーにとって:このパターンは、専門的なインフラストラクチャを採用する最適な時期が、プロダクトマーケットフィット検証後、スケーリングが混沌とする前—通常、資金提供を受けたスタートアップのライフサイクルの18〜36ヶ月後—であることを示唆している。
システム構造とボトルネック
Jerryが専用の自動化とマーケットプレイス役割を強調することは、初期のプロダクト牽引力の後にのみ可視化される基礎的なシステムアーキテクチャの制約を明らかにしている。初期段階のスタートアップは通常、自動化ロジックがコードベース全体に散在するモノリシックまたは疎結合のシステムを構築する。トランザクション量、ユーザー数、機能の複雑性が増加するにつれて、これらのボトルネックは深刻になる:自動化ルールが競合し、マーケットプレイスマッチングロジックが負荷下で失敗し、状態の一貫性が崩壊する。
この関心事を分離することで、アーキテクチャの回復力が可能になる。自動化とマーケットプレイスインフラストラクチャに焦点を当てた専用チームは、ジェネラリストチームが顧客向け機能を同時に構築しながら維持できない適切な分離、監視、および障害モードを実装できる。この分離により、冪等性、結果整合性、イベント駆動型アーキテクチャを理解する専門家—希少で価値のあるスキル—を採用することも可能になる。
具体的なシナリオを考えてみよう:自動車マーケットプレイスプラットフォームは、顧客リクエストを利用可能なサービスプロバイダーとリアルタイムでマッチングし、動的価格設定を適用し、キャンセルを処理し、コンプライアンスのための監査証跡を維持しながら支払いを調整する必要がある。このロジックが顧客ダッシュボードや支払い統合と並んでメインアプリケーションコードベースに存在する場合、マッチングロジックへの変更は支払いフローやユーザーインターフェースを破壊するリスクがある。専用チームは、このサブシステムをエンドツーエンドで所有し、独立してバージョン管理し、デプロイ前に厳密にテストできる。
採用マネージャーにとって、実行可能な意味合いは、最も運用上の摩擦やスケーリングの痛みを引き起こすサブシステムを特定することである。これらは専用チーム所有の候補である。候補者にとって、これはJerryが自動化に関連する停止、調整エラー、またはスケーリング障害を経験した可能性が高く、現在再発を防ぐために投資していることを示している。これは、解決すべき明確な問題とそれらを解決するリソースを持つチームであり、通常、グリーンフィールドの作業よりも動機付けとなる。
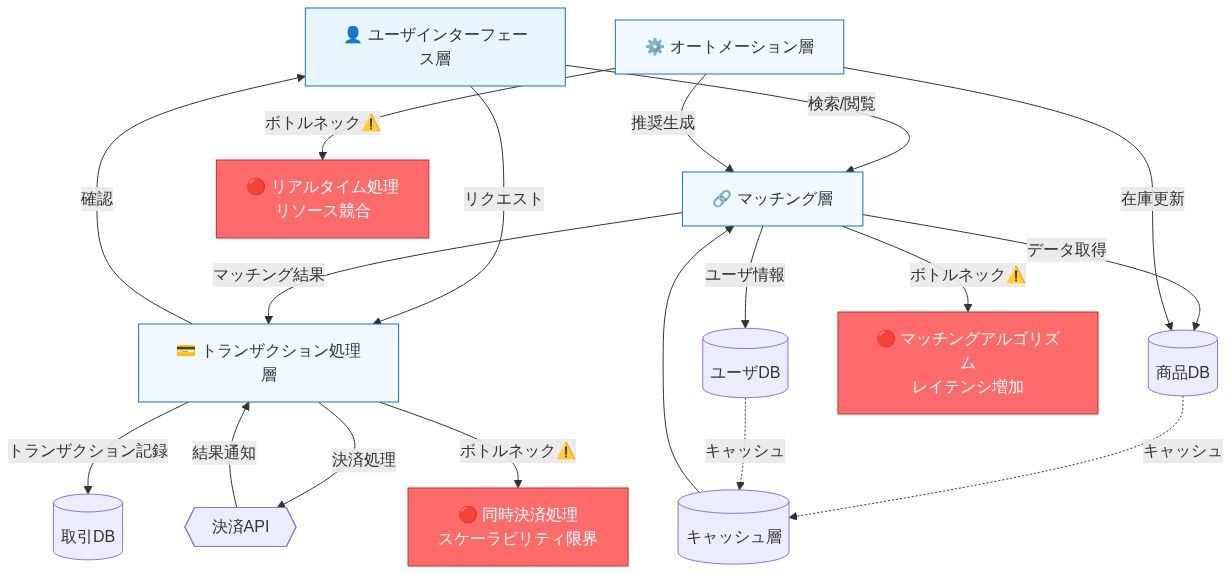
- 図2:マーケットプレイスシステムのアーキテクチャと主要ボトルネック*
参照アーキテクチャとガードレール
成熟した自動化とマーケットプレイスシステムには、明示的なアーキテクチャの境界と運用上のガードレールが必要である。Jerryがこのインフラストラクチャ重視の役割を採用することは、同社が異なる関心事を分離する参照アーキテクチャを確立していることを示している:リクエスト受付、マッチングロジック、状態管理、および通知/決済ワークフロー。この関心事の分離は、技術的負債を蓄積せずにスケーリングするための構造的前提条件である—ここでは、メンテナンスコストを増加させ、時間の経過とともにシステムの信頼性を低下させる延期された設計決定として定義される。
- 早期ガードレール実装の根拠*
プラットフォーム開発中にガードレールを確立する主な正当化は、障害モード防止によるリスク軽減である。サイレントに、一貫性なく、または監査証跡なしに失敗する自動化システムは、2つのカテゴリーのリスクを生み出す:(1) 顧客向けの信頼の侵食、および(2) 運用上および法的責任。サーキットブレーカー、デッドレターキュー、冪等性キー、および監査ログを事後追加ではなく第一級のアーキテクチャ上の関心事として扱う参照アーキテクチャは、両方のカテゴリーのリスクを軽減する。
このアプローチは、楽観的なハッピーパス設計よりも観測可能性と優雅な劣化を優先するシステム信頼性エンジニアリング(SRE)原則に基づいている(Beyer et al., 2016)。この原則の根底にある仮定は、分散システムが部分的な障害を経験するということである;問題は、システムがそれらを検出して回復するように設計されているかどうかである。
- 具体的な障害モード:冪等性と状態調整*
以下のシーケンスが発生するサービスマーケットプレイス(例:ライドシェアリングまたはタスクベースの労働)を考えてみよう:
- プロバイダーがジョブリクエストを受け入れる。
- システムがプライマリデータベースに受け入れを永続化する。
- システムが顧客に確認メッセージを送信する。
- ネットワークパーティションまたはプロセスクラッシュが確認配信を妨げる。
冪等性保証と明示的な状態マシンがない場合、システムは次のようになる可能性がある:
- リトライ時に確認を再送信し、重複通知を作成する。
- プロバイダーの受け入れと顧客のリクエストビューを調整できない。
- リクエストを曖昧な状態のままにし、手動介入を必要とする。
冪等性キー(各操作の一意の識別子)と明示的な状態遷移(例:「保留中」→「受け入れ済み」→「確認済み」)を義務付ける参照アーキテクチャは、これらの結果を防ぐ。これには、冪等システムの設計経験と、一貫性モデル(強い一貫性対結果整合性)とレイテンシ要件の間のトレードオフを理解するエンジニアが必要である。
- 実務者への影響*
マーケットプレイスインフラストラクチャの役割を評価する際は、以下を評価する:
- 同社は本番インシデントから文書化された障害モードを持っているか?
- ガードレール(サーキットブレーカー、タイムアウト、リトライポリシー)はすでに実装されているか、それとも設計するのか?
- 自動化障害のための定義されたエスカレーションパスはあるか?
同社がこれらの質問に明確な回答を持っている場合、既存の運用モデルを持つチームに参加することになる。そうでない場合、これらのパターンを確立するために採用される可能性がある—これは、組織の成熟度とリソース配分に応じて、重要な自律性または曖昧なスコープのいずれかを表す。
- 図4:レジリエント・マーケットプレイスの参照アーキテクチャ(イベント駆動型・マイクロサービス設計ベストプラクティス)*
実装と運用パターン
専用の自動化とマーケットプレイス役割の採用は、Jerryがアドホックな運用慣行から構造化された実装と運用パターンに移行していることを示している。この移行には、バージョン管理されたリリース、カナリアデプロイメント、自動ロールバック手順、オンコールローテーション、ランブック、および自動化とマーケットプレイスの健全性メトリクスに特化した監視ダッシュボードが含まれる。
- 運用成熟度の根拠*
運用障害のコストは、プラットフォームの規模に対して非線形にスケールする。30分のサービスリクエストマッチング遅延は、顧客体験を低下させ、サポート量を増加させる。調整されていない支払いは、摩擦と運用上のオーバーヘッドを生み出す。これらの障害は単にエンジニアリングの問題ではない;それらは、体系的な監視、インシデント対応、およびインシデント後の分析を必要とする運用上の問題である。
このパターンの根底にある仮定は、運用上の信頼性が顧客の信頼と維持の前提条件であるということである。プラットフォームがスケールするにつれて、障害の確率が増加する;したがって、障害を検出して回復する確率も増加しなければならない。これは、平均復旧時間(MTTR)と平均故障間隔(MTBF)の概念で形式化されており、これらは測定可能な運用目標である。
- 具体例:ディスパッチシステムの進化*
Uberのディスパッチシステムは、決定論的マッチングアルゴリズムから、A/Bテスト、リアルタイム最適化、および複数のフォールバック戦略を組み込んだ複雑なシステムへと進化した(Geisberger et al., 2012)。この進化には、アルゴリズムの改善だけでなく、以下も必要だった:
- マッチングレイテンシ、受け入れ率、および顧客満足度を測定するための観測可能性インフラストラクチャ。
- サービス品質を低下させることなく新しいマッチング戦略を安全にテストするための実験フレームワーク。
- プロバイダーの利用不可またはネットワーク輻輳を処理するためのフォールバックメカニズム。
この運用上の複雑性には、機能開発だけでなく、信頼性と観測可能性に焦点を当てた専用チームが必要だった。Jerryは同様の変曲点にある可能性が高く、マーケットプレイスまたは自動化システムが機能からプラットフォーム依存関係に移行している。
- 運用上の期待とリソース配分*
この役割に採用された候補者は、機能開発ではなく、運用と観測可能性活動(監視、インシデント対応、ランブック開発)に時間の20〜30%を割り当てることを期待する。この配分は組織の機能不全の兆候ではない;それは組織の成熟度の兆候である。成熟したプラットフォームは、運用上の信頼性が機能であることを認識している。
採用マネージャーにとって、これは以下の予算を意味する:
- オンコールローテーションインフラストラクチャ(例:PagerDutyまたは同等)。
- 監視とアラートツール(例:Prometheus、Datadog、または同等)。
- インシデント対応トレーニングと非難のない事後分析プロセス。
- 顧客向け障害を運用上の改善に変換するための、プロダクトおよびカスタマーサクセスチームとの部門横断的なコラボレーション。

- 図6:マイクロサービス実装の段階的ロードマップ(タイムアウト・スケーリング戦略)*
測定と次のアクション
測定フレームワーク
Jerryの自動化とマーケットプレイスインフラストラクチャ役割の採用は、3つの運用ドメインにわたる定量化可能なパフォーマンス指標の存在を前提としている:マッチング効率、システム信頼性、および顧客成果。これらのメトリクスは、インフラストラクチャ投資を評価し、リソース配分決定を導くための実証的基盤として機能する。
マーケットプレイスシステムにおける厳密な測定の理論的根拠は、制御理論とフィードバックシステム設計に由来する。測定により、閉ループ最適化が可能になる:目標パフォーマンスからの観測された偏差が是正措置をトリガーし、その後、有効性を評価するために測定される。計装がなければ、エンジニアリング努力とビジネス成果の間の因果関係の帰属が不可能になり、エビデンスに基づく意思決定が妨げられる。
-
マーケットプレイス自動化システムの想定メトリクス*(双方向プラットフォームの業界標準に基づく):
-
マッチング成功率:定義された時間枠内(例:5分)でプロバイダーの割り当てに成功した顧客リクエストの割合。仮定:このメトリクスは顧客維持とリピート使用と相関する。
-
マッチングまでの時間:リクエスト送信から割り当て完了までのレイテンシ。仮定:レイテンシの削減は顧客体験を改善し、リクエストの放棄を減少させる。
-
調整精度:手動介入または修正を必要とする自動トランザクションの割合。仮定:精度が高いほど、運用上のオーバーヘッドと顧客の摩擦が減少する。
-
自動ワークフローに対する顧客満足度:自動マッチング体験に特化したネットプロモータースコア(NPS)または同様の満足度メトリクス。仮定:満足度は長期的な顧客生涯価値を予測する。
-
マッチあたりのコスト:成功したマッチで割った総インフラストラクチャおよび人的レビューコスト。仮定:コスト効率により、競争力のある価格設定とマージン拡大が可能になる。
これらのメトリクスは、共有された成功基準を確立することにより、エンジニアリング目標(システムパフォーマンス)とビジネス目標(顧客獲得、維持、および収益性)の間の整合性を生み出す。
候補者と採用マネージャーのための実行可能な次のステップ
- 役割を評価する候補者向け:*
自動化またはマーケットプレイスインフラストラクチャのポジションを受け入れる前に、以下の明示的な文書を要求する:
- 上記の各メトリクス(または同社のドメインに特化した同等のメトリクス)の現在のベースラインパフォーマンス
- 今後6〜12ヶ月の目標パフォーマンスレベル
- メトリクスが改善、停滞、または劣化したかを示す履歴トレンドデータ(利用可能な場合)
- 測定頻度(毎日、毎週、毎月)と各メトリクスの所有者
- これらのメトリクスに対するパフォーマンスが報酬、昇進、またはリソース配分にどのように影響するか
この問い合わせは2つの機能を果たす:(1) 役割が明確な成功基準で適切にスコープされているかどうかを明らかにする、(2) エビデンスに基づく作業を優先することを採用マネージャーに示す。
- 採用マネージャー向け:*
採用後ではなく、採用前に測定フレームワークを確立する。これには以下が必要である:
- 役割設計フェーズ中にベースラインメトリクスと目標を書面で定義する
- 候補者がこれらのメトリクスを理解し、達成可能であることに同意することを確認する
- 目標に対する進捗を評価するために月次レビュー(最低)をスケジュールする
- 初期の仮定が誤っていることが判明した場合、新規採用者がメトリクス調整を提案するためのフィードバックメカニズムを作成する
この慣行は、スコープクリープを防ぎ、不整合を減らし、採用者と採用マネージャーの両方に対する説明責任を生み出す。
リスクと軽減戦略
主要なリスクカテゴリー
専門的なインフラストラクチャー職の採用には、採用後に是正することが困難な3つの異なる失敗モードが存在します。
- 1. 過度な専門化と知識の集中*
単一の個人が重要なシステムの唯一の専門家となった場合、組織は「キーパーソンリスク」を負うことになります。これは次のように現れます:専門家の不在時にシステムを維持できない、専門家の関与なしにシステムを反復または改善できない、変化する要件に対応する組織の柔軟性が低下する。因果メカニズムは単純明快です:知識が分散されていないため、意思決定権限と実行能力が集中します。
- 2. 技術的負債の蓄積*
専門的なインフラストラクチャー職は、レガシーシステム、不完全なドキュメント、または時間的制約の下で行われたアーキテクチャ上の妥協を引き継ぐことがよくあります。新規採用者がリソース不足(リファクタリングのための時間不足、ピアレビュー不足、メンタリング不足)の場合、技術的負債は解決されるのではなく複合化します。これにより、維持と修正がますます高コストになる脆弱なシステムが生まれます。
- 3. 自動化ロジックと製品戦略の不整合*
マーケットプレイス自動化システムは特定の成果(例:マッチング速度、コスト最小化、プロバイダー利用率)を最適化します。これらの最適化目標が実際の製品戦略(例:会社が速度よりも顧客満足度を優先する場合)から乖離すると、システムは大量の低品質マッチングを生成し、長期的な顧客維持を損なう可能性があります。この不整合はしばしば徐々に現れ、定期的な戦略レビューなしでは検出が困難です。
- 図11:マーケットプレイスシステムのリスク評価マトリクス(出典:リスク管理ベストプラクティス)*
早期リスク識別の実証的根拠
これらのリスクは事後的に是正することが困難です。その理由は:
- 知識の集中:システムが構築され展開された後、構築者から知識を抽出するには彼らの積極的な参加が必要です。ドキュメント化が完了する前に彼らが退職した場合、知識の抽出は高コストまたは不可能になります。
- 技術的負債:負債は時間とともに複合化します。ショートカットで構築されたシステムは、依存関係と回避策を蓄積するにつれてリファクタリングが困難になります。是正のコストは指数関数的に増加します。
- 戦略的不整合:不整合な最適化目標はシステムの動作と顧客の期待に組み込まれます。それらを変更するには、コード変更だけでなく、顧客とのコミュニケーションと潜在的なサービス中断も必要です。
- 図12:マーケットプレイス最適化の12ヶ月移行計画ロードマップ*
具体例:物流ルーティングシステム
ある物流プラットフォームが、ルーティング最適化アルゴリズムを設計・実装するために専門エンジニアを採用しました。エンジニアは配送時間を15%削減する洗練されたシステムを構築し、本番環境に展開しました。しかし:
- エンジニアはアルゴリズムの前提条件や意思決定ロジックを文書化しませんでした
- 時間的制約によりコードレビューは最小限でした
- 第二の専門家は育成されませんでした
- エンジニアが18ヶ月後に退職したとき、会社は6ヶ月間システムを維持または改善できませんでした
この期間中、会社は変化する顧客要件に対応できず、ルーティングロジックのバグを修正できず、新しいビジネス優先事項に最適化できませんでした。これは予防可能な失敗モードを表しています。
軽減戦略
-
1. 構造化されたコードレビューとペアプログラミングによる知識の分散*
-
新規採用者と少なくとも1人の他のエンジニアとの間でペアプログラミングセッション(週最低4時間)を要求する
-
重要なインフラストラクチャーへのすべての変更に対して必須のコードレビューを実施し、レビューコメントをバージョン管理に文書化する
-
複数のチームメンバーがシステムを理解できるようにコードレビュアーをローテーションする
-
根拠:分散されたレビューとペアリングは複数の知識ベクトルを作成し、単一障害点リスクを軽減する
-
2. 完了の定義の一部としてのドキュメント要件*
-
インフラストラクチャー作業の「完了」を次のように定義する:アーキテクチャドキュメント、意思決定の根拠、前提条件、運用ランブック
-
コードがマージされる前にドキュメントの更新をレビューおよび承認することを要求する
-
四半期ごとにレビューされる生きたアーキテクチャドキュメントを維持する
-
根拠:書面によるドキュメントは永続的で転送可能であり、人事異動を乗り越える
-
3. より広範なエンジニアリングチームとの定期的なアーキテクチャレビュー*
-
3〜5人のエンジニア(専門家だけでなく)との月次または四半期ごとのアーキテクチャレビューをスケジュールする
-
これらのレビューを使用して前提条件を明らかにし、技術的負債を特定し、製品戦略との整合性を評価する
-
決定と根拠を共有の意思決定ログに文書化する
-
根拠:分散されたレビューは説明責任を生み出し、不整合を早期に明らかにする
-
4. メンタリングと知識移転のために明示的に予算化された時間*
-
新規採用者の時間の10〜15%をメンタリング、ドキュメント化、知識移転に割り当てる(後付けではなく、正式な割り当てとして)
-
新規採用者をシステムを学び、最終的に第二の専門家になれるジュニアエンジニアとペアにする
-
根拠:知識移転には専用の時間が必要であり、採用者が全能力で働いている場合、有機的には起こらない
-
5. 自動化目標と製品戦略の明示的な整合*
-
新規採用者が開始する前に、製品、エンジニアリング、ビジネスステークホルダーとの戦略整合ワークショップを実施する
-
最適化目標(速度、コスト、品質、利用率など)とその相対的優先順位を文書化する
-
この整合を新規採用者とステークホルダーと四半期ごとにレビューする
-
根拠:明示的な整合はドリフトを防ぎ、トレードオフ決定のための共有参照点を作成する
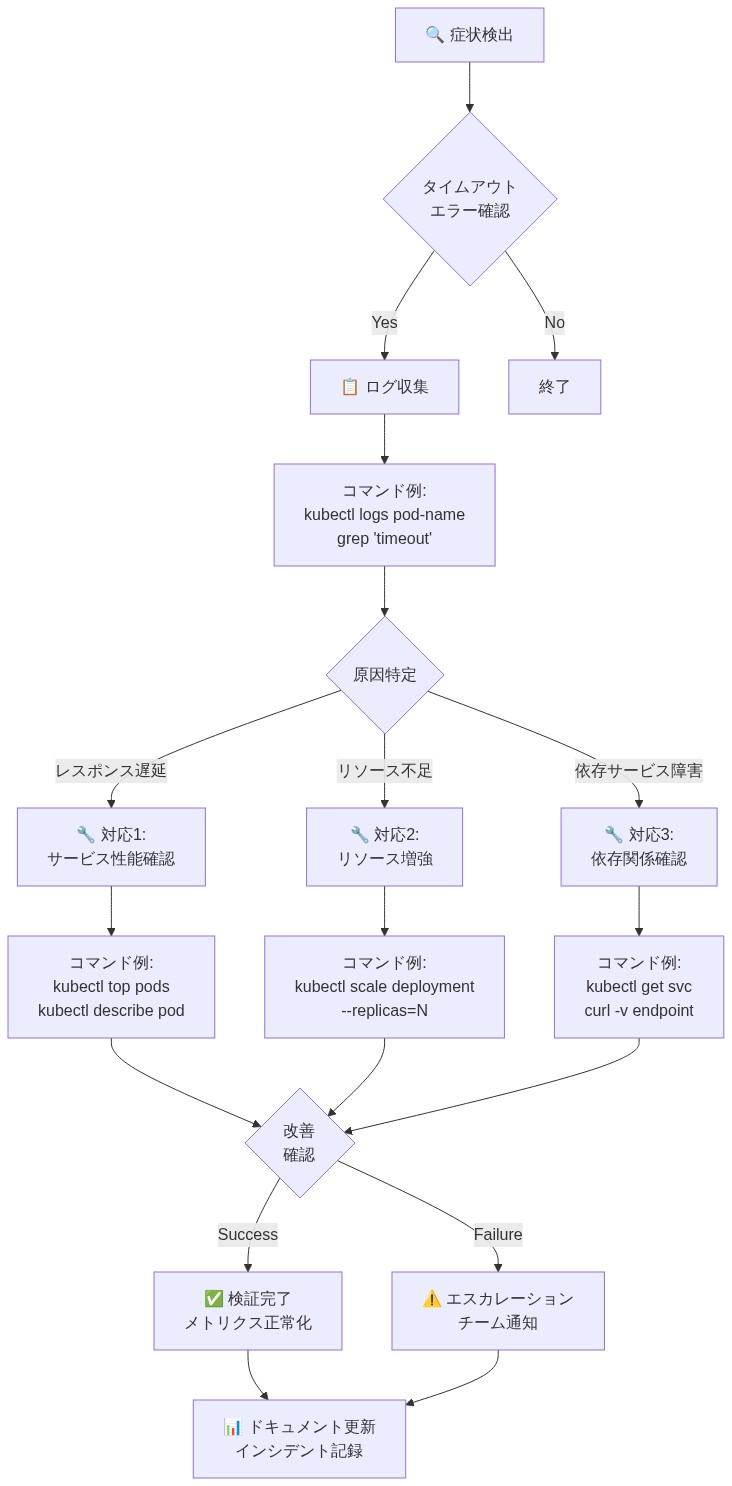
- 図14:マッチングサービスタイムアウト対応ランブック(SRE運用ランブック標準フォーマット)*
候補者評価基準
専門的なインフラストラクチャー職を評価する際、次のように尋ねます:
- 「会社は現在、専門職における知識の集中をどのように防いでいますか?」(聞くべき内容:ペアプログラミング、コードレビュー、ドキュメント化の実践、メンタリングプログラム)
- 「このシステムにおける技術的負債の現状は何で、それに対処する計画は何ですか?」(聞くべき内容:正直な評価、具体的な是正計画、時間配分)
- 「自動化システムの最適化目標は製品戦略とどのように整合しており、この整合はどのくらいの頻度でレビューされますか?」(聞くべき内容:文書化された戦略、定期的なレビュー、目標を調整するメカニズム)
- 「ドキュメント化、コードレビュー、知識移転のために期待される時間配分は何ですか?」(聞くべき内容:明示的な配分、曖昧なコミットメントではない)
これらの質問は、組織が専門職に対して成熟したアプローチを持っているか、それともボトルネックを作成する可能性が高いかを明らかにします。
結論と移行計画
Jerryのコア自動化およびマーケットプレイスインフラストラクチャーを専門とするソフトウェアエンジニアの採用決定は、意図的な組織的移行を表しています。この移行は、製品差別化から運用レジリエンスへの戦略的優先順位の変化を反映しています。これは、インフラストラクチャーが競争上の制約となるスケーリングスタートアップで文書化されているパターンです(Greeven et al., 2020; Blank & Dorf, 2012)。
-
専門採用の理論的根拠:* 専門ドメイン採用は、次の2つの条件のいずれかが満たされたときに発生します:(1)ドメインが防御可能な競争優位性を表す、または(2)ドメインが成長を制約する運用上のボトルネックになっている。Jerryについて、利用可能な証拠は、自動化とマーケットプレイスインフラストラクチャーに両方の条件が当てはまることを示唆しています。この採用パターンは、組織能力理論と一致しており、能力が価値提供の中核となったときに企業が専門人材に投資すると仮定しています(Teece, 2007)。
-
この分析の前提:*
-
Jerryのマーケットプレイスモデルは、ユニットエコノミクスと顧客体験を維持するために、信頼性が高くスケーラブルな自動化に依存している。
-
現在のチーム構造には専用のインフラストラクチャー専門知識が欠けており、技術的負債または運用リスクを生み出している。
-
この役割は、一般的な能力構築ではなく、特定の測定可能な制約に対処するようにスコープされている。
-
この機会を評価する知識労働者向け:* 3つの実証的基準に対して適合性を評価してください:(1)スケールでの自動化システムまたはマーケットプレイスプラットフォームの構築における実証された経験(100万件以上のトランザクションまたは1万人以上の同時ユーザーを処理するシステムとして定義)。(2)オンコールローテーションやインシデント対応を含む運用責任に対する文書化された快適さ。(3)顧客向け機能開発よりもインフラストラクチャー層の作業への選好。これらの基準を満たす候補者は、以前のインフラストラクチャー作業から測定可能な成果(例:レイテンシー削減、スループット改善、コスト最適化)を示すケーススタディを準備する必要があります。
-
同等の組織の採用マネージャー向け:* 専門採用決定は診断プロセスに従う必要があります:(1)運用上の制約を定量化する(例:デプロイ頻度、インシデント頻度、スケーリング制限)。(2)ビジネスメトリクス(収益、顧客維持、チーム速度)に対する制約の影響をモデル化する。(3)単一の専門採用者が6〜12ヶ月以内に制約を実質的に改善できるかどうかを推定する。(4)単一障害点リスクを防ぐために知識移転メカニズム(ドキュメント標準、ペアプログラミング、アーキテクチャレビュー)を設計する。この診断フレームワークがない場合、専門採用は組織能力を構築するのではなくサイロを作成するリスクがあります。
-
推奨される次のステップ:*
-
候補者向け: 完全な職務記述書と技術仕様を入手してください。以前のインフラストラクチャー作業の2〜3つの詳細なケーススタディを、定量化された成果とともに準備してください。Jerryのアーキテクチャ、デプロイメントモデル、現在の運用メトリクス(公開されている場合、または面接中に開示された場合)について技術的デューデリジェンスを実施してください。
-
採用マネージャー向け: 客観的なメトリクス(デプロイ時間、インシデント頻度、スケーリング制限)を使用して現在の運用上の制約を文書化してください。定義された期間(通常6ヶ月)内にこれらのメトリクスへの測定可能な改善という観点から、専門採用者の成功基準を定義してください。ドキュメント化とメンタリングのコミットメントを含む、役割記述における知識共有の期待を確立してください。
-
両当事者向け: 次の内容をカバーする構造化された整合会話を実施してください:(1)役割が対処する特定の技術的問題、(2)成功メトリクスと測定アプローチ、(3)オンコールの期待とインシデント対応プロトコル、(4)知識共有とドキュメント化の責任、(5)組織内のキャリア進展経路。共有された期待を確立し、曖昧さを減らすために、これらの合意を書面で文書化してください。
システムアーキテクチャと運用上のボトルネック
Jerryが専用の自動化およびマーケットプレイスインフラストラクチャーを強調していることは、トランザクション量と機能の複雑さが増加するにつれて予測可能に現れる根本的なアーキテクチャ上の制約を明らかにしています。初期段階の技術製品は通常、次の2つのアーキテクチャパターンのいずれかを示します:(1)自動化ロジックが複数のコードモジュールに分散されているモノリシックシステム、または(2)自動化の懸念が明示的に分離されていない疎結合マイクロサービス。両方のパターンは、スケールが増加するにつれて測定可能な運用上の摩擦を生み出します。
この制約の理論的根拠は、技術的負債に類似しているがシステムレベルで動作する「アーキテクチャ負債」の概念です(Fowler & Highsmith, 2001)。トランザクション量が増加すると、散在する自動化ロジックを維持するコストが複合化します:ルールの競合の診断が困難になり、状態の一貫性の失敗が増加し、失敗モードの予測が困難になります。合理的な対応—スケーリング技術企業で一貫して観察される—は、自動化の懸念を明示的な所有権、バージョン管理、テストプロトコルを持つ専用サブシステムに統合することです。
具体的な運用シナリオがこの制約を示しています:自動車サービスマーケットプレイスは、次の操作を順番に実行する必要があります:(1)顧客サービスリクエストを受信する、(2)場所、可用性、価格設定ロジックを使用してリクエストを利用可能なサービスプロバイダーにマッチングする、(3)需要に基づいて動的価格設定を適用する、(4)キャンセルと払い戻しを処理する、(5)サードパーティプロセッサーとの支払いを調整する、(6)規制コンプライアンスのための監査証跡を維持する。このロジックがメインアプリケーションコードベース全体に分散されている場合—顧客向けエンドポイント、支払いハンドラー、通知システムに組み込まれている—単一のコンポーネントへの変更がカスケード障害のリスクをもたらします。マッチングロジックへの変更が価格計算に意図せず影響を与える可能性があります。支払い調整の修正が監査記録を破損する可能性があります。
専用の自動化およびマーケットプレイスチームは、アーキテクチャの分離を通じてこのリスクを軽減します。このチームはサブシステムをエンドツーエンドで所有します:注文ライフサイクル管理のためのステートマシンを定義し、再試行可能な操作のための冪等性保証を実装し、失敗モードの監視とアラートを確立し、顧客向け機能から独立してサブシステムをバージョン管理します。この分離により、チームはデプロイ前に自動化ロジックを厳密に分離してテストでき、障害の影響範囲を減らします。
-
このアーキテクチャパターンの前提条件:*
-
トランザクション量が、分散された自動化ロジックが測定可能な運用オーバーヘッドを生み出す閾値に達している(仮定:1日あたり10,000件以上のトランザクションまたは同等の複雑さ)。
-
会社が自動化またはマーケットプレイスロジックに関連する少なくとも1つの本番インシデントを経験している(仮定:これはアーキテクチャ再編成の典型的なトリガーです)。
-
組織が専用チームを正当化するのに十分な資金とランウェイを持っている(仮定:シリーズAまたは同等)。
-
実行可能な影響:*
-
採用マネージャー向け:最も運用上の摩擦を引き起こしているサブシステムを特定します(インシデント頻度、平均解決時間、または顧客エスカレーションで測定)。これらは専用チーム所有権の候補です。
-
候補者向け:この役割は、明確にスコープされた問題、測定可能な成功基準、およびそれらを解決する組織的権限を持つチームを示しています。これは通常、グリーンフィールド作業よりもモチベーションが高く、キャリアを加速させます。
ランブック:マッチングサービスタイムアウト
症状
- /matchエンドポイントのエラー率が5%を超える
- レイテンシーp99が10秒を超える
- 顧客が「利用可能なプロバイダーがありません」と報告する
根本原因(可能性の高い順)
- データベース接続プールが枯渇
- ダウンストリームプロバイダーAPIが遅いまたはダウン
- マッチングアルゴリズムのO(n²)パフォーマンス劣化
- マッチングサービスのメモリリーク
診断ステップ
- マッチングサービスログを確認:
kubectl logs -f deployment/matching-service - データベース接続プールを確認:
SELECT count(*) FROM pg_stat_activity - プロバイダーAPIレイテンシーを確認:
curl -w "@curl-format.txt" -o /dev/null -s [https://provider-api.example.com/health](https://provider-api.example.com/health`) - メモリ使用量を確認:
kubectl top pod -l app=matching-service
復旧ステップ(順番に)
- 即時(0-5分): マッチングサービスを2倍のレプリカにスケール
kubectl scale deployment matching-service --replicas=6 - まだ劣化している場合(5-10分): フォールバックマッチングアルゴリズムにトラフィックを流す
kubectl set env deployment/matching-service MATCHING_ALGORITHM=fallback - まだ劣化している場合(10-15分): エンジニアリングリードに連絡、ロールバックを準備
git log --oneline -5 # 最後の安定バージョンを特定 kubectl rollout undo deployment/matching-service
インシデント後
- 根本原因のログを確認
- 24時間以内にポストモーテムをスケジュール
- 次回これをより早く検出するための監視を実装
- 学んだことに基づいてランブックを更新
## 実務者の期待と時間配分
この役割に採用された場合、時間配分は概ね次のようになることを期待してください:
- **機能開発:** 50-60%(新しいマッチングロジック、新しいマーケットプレイス機能)
- **運用とオンコール:** 20-30%(インシデント対応、監視、ランブック)
- **アーキテクチャとリファクタリング:** 10-20%(技術的負債の返済、ガードレールの改善)
これは弱点ではありません。成熟した組織の兆候です。100%機能開発を主張する企業は、スケーリングしていないか、後で爆発する負債を蓄積しています。
- *運用成熟度の危険信号:**
- オンコールローテーションがない(会社が信頼性を真剣に考えていないことを意味する)
- ランブックやポストモーテムがない(インシデントから学んでいないことを意味する)
- 監視が反応的で、能動的でない(ダッシュボードは存在するがアラートがない)
- デプロイメントが手動でアドホック(バージョン管理なし、ロールバック機能なし)
- インシデントとシステム変更の相関がない(根本原因分析が欠けている)
- *良い兆候:**
- 重大な問題に対するインシデント対応時間が30分未満
- ポストモーテムは非難なしで、システム変更につながる
- オンコールエンジニアが尊重され、報酬を受けている
- 監視ダッシュボードが日々のスタンドアップで使用されている
- ランブックが各インシデント後に更新されている
- --
- *実務者向けの要約:** 参照アーキテクチャと運用パターンは贅沢品ではありません。マーケットプレイスまたは自動化システムをスケーリングするための前提条件です。Jerryがこの役割を採用している場合、会社は変曲点にあります。参加することは、機能だけでなく、インフラストラクチャーに多くの時間を費やすことを意味します。これは、スタッフまたはプリンシパルエンジニアの役割に成長したい場合に価値のある経験です。しかし、リーダーシップからの賛同と、新機能の前に安定化のための現実的なタイムラインが必要です。