
Latent Context Compilation: 長いコンテキストをコンパクトなポータブルメモリに蒸留する
長いコンテキスト展開のボトルネック
現代の大規模言語モデル(LLM)は推論時に根本的な制約に直面しています。コンテキスト長と計算コストは超線形のスケーリング関係を示しています。具体的には、キー・バリュー(KV)キャッシュのメモリ要件はコンテキスト長に対して線形に増加する一方、注意計算は最悪の場合二次関数的(O(n²))にスケールします。ただし、最近のアーキテクチャでは線形近似が存在します(Dao et al., 2022)。これにより、運用上の深刻な緊張が生まれます。より長いコンテキストは理論的にはより高度な推論タスクを可能にしますが、推論時にはより大きなメモリ割り当てと計算サイクルを要求し、直接的にレイテンシを増加させ、GPU当たりのスループットを低下させるのです。
現在の緩和戦略は、運用上持続不可能な2つの極端に位置しており、それぞれ文書化された失敗モードを持っています。
-
償却圧縮(静的アプローチ):* モデルを固定圧縮戦略で一度だけ訓練することは、学習されたパターンがすべての展開コンテキストにわたって均一に一般化することを前提としています。この前提は分布外入力で体系的に失敗します。新しい文書タイプ、ドメイン固有の用語、訓練データに存在しない構造的パターンです。モデルは不慣れなコンテンツに対して圧縮戦略を適応させることができず、その結果、下流のタスク性能を低下させる情報損失が生じます(Jiang et al., 2023)。
-
テスト時訓練(動的アプローチ):* 勾配ベースの最適化またはインコンテキスト学習を介して推論時にモデルの重みを適応させることには、高コストな合成データ生成または1クエリあたりの複数の順伝播が必要です。さらに重要なのは、このアプローチはベースモデルをステートフルシステムに変換することです。各ユーザーの適応は内部パラメータを修正し、並行処理に必要なモデル定常性の仮定を破ります。マルチユーザーシステムは実行不可能になります。1人のユーザーのコンテキストからのパラメータ更新が別のユーザーの推論パスを汚染するためです。
このジレンマは本番環境での大規模展開を停滞させています。チームは二者択一の選択に直面しています。既知の一般化失敗を伴う脆い万能圧縮を受け入れるか、効率性の利得を完全に放棄して完全なKVキャッシュコストを受け入れるかです。どちらのパスも高並行性、マルチテナント環境にはスケールしません。根本的な問題は概念的です。既存の方法はコンテキストを「適応する対象」(モデル修正が必要)として扱うのではなく、「コンパイルする対象」(再利用可能でポータブルなアーティファクト)として扱っていません。
Latent Context Compilationはこの課題を再構成し、第3のカテゴリを導入しています。ステートレスな、クエリごとのコンパイルです。モデルをグローバルに適応させたり、コンテキストをオフラインで事前圧縮したりする代わりに、このアプローチは各長いコンテキストを推論時にコンパクトなバッファトークンセットに蒸留します。ベースモデルの重みを修正したり、ステートフルネスを導入したりすることなくです。概念的な類似性は正確です。冗長なソースコードを最適化されたバイトコードに変換することは、情報密度を増加させ、フットプリントを削減し、凍結されたランタイム(ベースモデル)全体でのポータビリティを保持します。
このアーキテクチャの適応からコンパイルへのシフトは、3つの即座の運用上の利点をもたらします。
- モデル定常性: 凍結されたベースモデルはすべての展開とユーザーにわたって変わらないままであり、バージョン分裂を排除し、並行リクエスト全体で決定論的な動作を可能にします。
- ステートレスサービング: バッファトークンはコンパイルフェーズの不変出力であり、パラメータ同期オーバーヘッドなしで効率的なバッチサービングと水平スケーリングを可能にします。
- 自動一般化: コンパイルはクエリごとに発生するため、システムは再訓練または重み修正なしに新しいコンテキストに自動的に適応します。
緊張は解消されます。システムはグローバル圧縮を強制することも、テスト時に重みを変異させることもないためです。コンパイルは推論から分離されています。
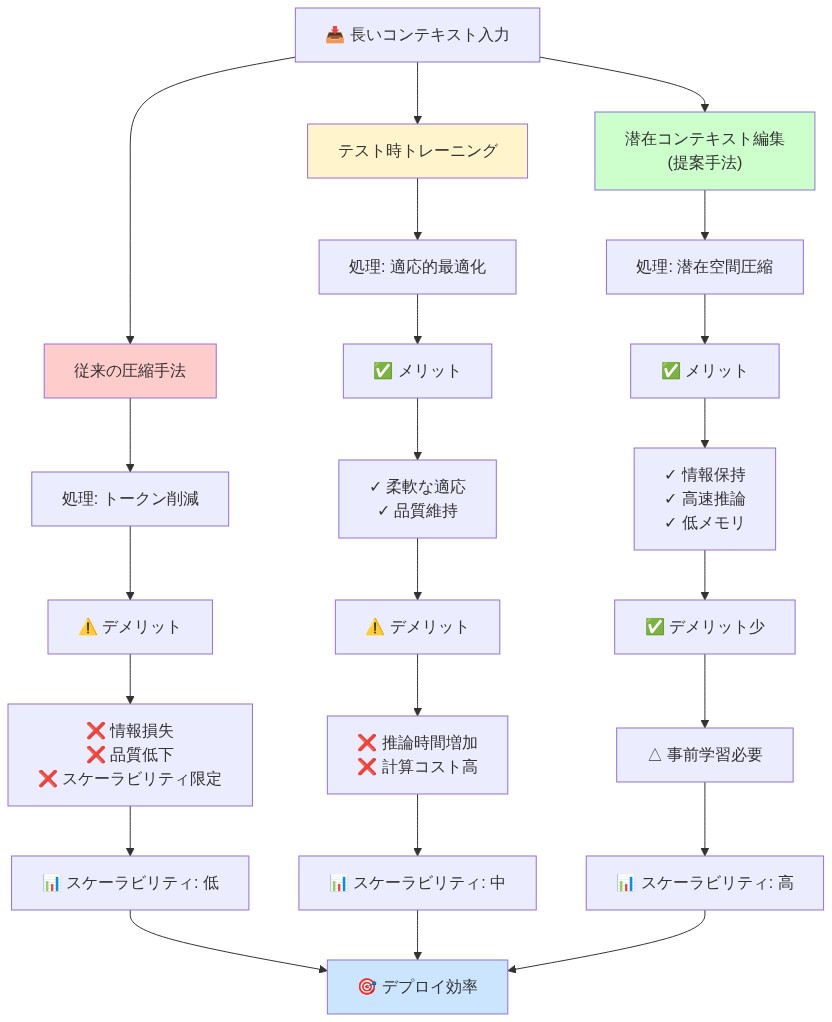
- 図2:コンテキスト処理の3つのアプローチ比較(処理フロー・メリット・デメリット・スケーラビリティ)*
使い捨てLoRAモジュールを介したコンパイル
メカニズムはパラメータ効率的なファインチューニングに実用的に根ざしています。軽量なLow-Rank Adaptation(LoRA)モジュール(多様なコーパスで一度訓練される)は「コンパイラ」として機能します。推論時、このLoRAは長いコンテキストを取り込み、圧縮潜在表現で本質的な情報をエンコードする小さなバッファトークンセット(通常、コンテキストあたり4~16トークン)を出力します。LoRAモジュール自体はコンパイル後に破棄されます。バッファトークンのみが永続し、ベースモデルに渡されます。
-
LoRAの理論的正当性:* Low-Rank Adaptationは設計上パラメータ効率的であり、通常、ベースモデルのパラメータ数の1%未満を必要とします(Hu et al., 2021)。重要なのは、LoRAはステートレスです。ベースモデルの重みを変異させません。代わりに、順伝播時に加算的に適用される低ランク更新(ΔW = BA、ここでBとAは学習された低ランク行列)を計算します。このプロパティにより、LoRAは永続的な副作用なしに適用、使用、削除できます。コンパイラLoRAは多様なコンテキスト(技術文書、会話トランスクリプト、ソースコードリポジトリ、ニュース記事)で訓練され、ドメイン固有のパターンを記憶するのではなく、一般化可能な圧縮戦略を学習します。
-
具体的な運用ワークフロー:*
- 顧客が50ページの技術マニュアル(約15,000トークン)をアップロードします。
- LoRAコンパイラは標準GPUで約200msで完全なコンテキストを処理します。
- コンパイラはマニュアルのセマンティックコンテンツをエンコードする8つのバッファトークンを出力します。
- これらのバッファトークンはユーザーのクエリの前に付加されます(例:「保証ポリシーは何ですか?」)。
- 連結入力(8つのバッファトークン+クエリ)は凍結されたベースモデルに渡されます。
- ベースモデルは圧縮されたコンテキストとクエリの両方に注意を払い、完全な15,000トークンドキュメントをKVキャッシュに読み込むことなく、マニュアルに基づいた応答を生成します。
- 運用上の含意:* チームはすべての推論インスタンスにわたって単一の凍結されたベースモデルを展開し、1つの訓練されたLoRAコンパイラとペアにし、無制限の並行ユーザーにサービスを提供します。コンパイラはすべてのクエリにわたって償却されます。バッファトークンはコンテキストごとにキャッシュされ、冗長な計算を削減します。これはユーザーごとの適応(ユーザーごとの重み更新が必要)またはグローバルな事前圧縮(分布外入力で失敗)とは根本的に異なります。
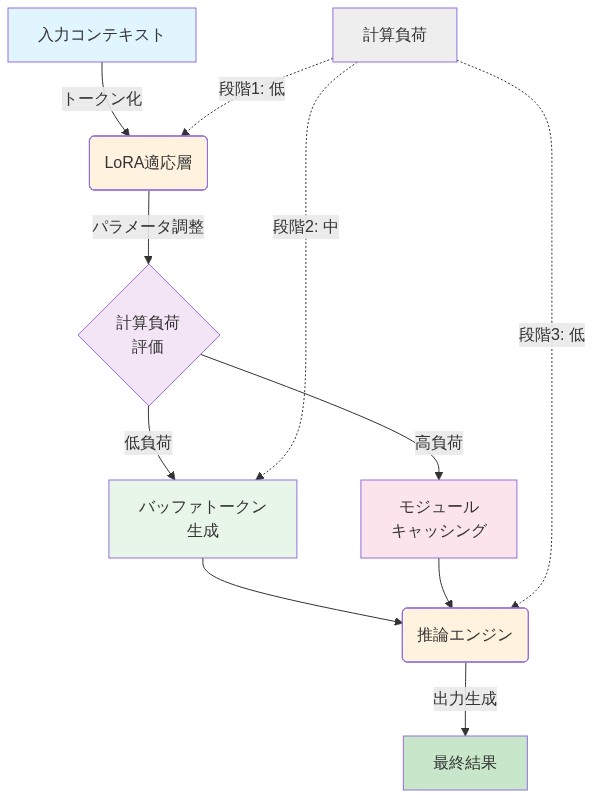
- 図5:Disposable LoRAモジュールによるコンテキストコンパイルフロー*
実装と運用パターン
Latent Context Compilationの展開には、3つの具体的な運用上のシフトが必要です。
- フェーズ1:コンパイルと推論の分離*
「コンパイルフェーズ」(計算バウンド、レイテンシ許容)を「推論フェーズ」(メモリバウンド、レイテンシクリティカル)から分離します。コンパイルはコンテキストごとに1回発生し、200~500msのレイテンシを許容できます。推論はユーザー向けアプリケーションの場合、100ms以内に完了する必要があります。これらを異なるサービス層またはパイプラインステージに分離して、競合を回避します。典型的なアーキテクチャは別のGPUプールまたはCPUベースのサービスにコンパイルを展開し、結果を推論用にキャッシュします。
- フェーズ2:バッファトークンキャッシングの実装*
同じドキュメントが複数回クエリされる場合、コンパイルされたバッファトークンを再利用します。これはコスト モデルをクエリごとのO(context_length)からO(1)に変換します(最初のコンパイル後)。ドキュメントハッシュでインデックスされたシンプルなLRU(Least Recently Used)キャッシュはほとんどのワークロードに十分です。50ページのドキュメントが100回クエリされる場合、これはコンパイルオーバーヘッドを20秒から200ms(償却)に削減します。
- フェーズ3:幅広さのためのLoRA訓練設計*
LoRAコンパイラを異種コンテキスト(技術文書、ニュース記事、ソースコード、会話トランスクリプト)で訓練して、分布外ロバストネスを最大化します。500Kの多様な例で訓練された単一のLoRAは、50Kのドメイン固有の例で訓練された10個の特化したLoRAよりも新しいコンテキストに一般化します。この原則はモデル圧縮文献の知見を反映しており、訓練データの多様性は展開レジリエンスと直接相関しています(Frankle & Carbin, 2019)。
- 具体的な本番環境セットアップ:*
ユーザークエリ + 長いコンテキスト
↓
[コンパイルサービス]
- バッファトークンキャッシュをチェック(コンテキストハッシュでインデックス)
- ミスの場合:LoRAコンパイラを呼び出す(200ms)
- 結果をキャッシュ(LRU、1GB制限)
↓
[バッファトークン](8トークン)
↓
[凍結されたベースモデル]
- バッファトークンをクエリの前に付加
- 標準推論(ステートレス、水平スケーラブル)
↓
応答凍結されたベースモデルはステートレスのままであり、調整なしで水平スケールできます。コンパイルサービスはキャッシュヒット率とドキュメントアップロード頻度に基づいて独立してスケールできます。
測定と次のアクション
3つのメトリクスを追跡します。
- 圧縮率:元のコンテキストトークンをバッファトークンで除算(目標:10~50倍)。
- レイテンシオーバーヘッド:コンテキストをコンパイルする時間(目標:典型的なドキュメントで500ms未満)。
- 精度保持:コンパイルされたコンテキストと完全なコンテキストを使用した下流タスクでのモデル性能(目標:95%以上のパリティ)。
-
パイロットアプローチ:* 1つの本番ワークロード(カスタマーサポート、ドキュメントQ&A、またはコードレビュー)を選択し、完全なコンテキストでのベースライン性能を測定します。LoRAコンパイラとバッファトークンを展開します。2週間にわたって3つのメトリクスを追跡します。圧縮率が20倍を超え、レイテンシオーバーヘッドが300ms未満の場合、他のワークロードに段階的にロールアウトします。
-
次のアクション:* 現在の長いコンテキストサービングコストを監査します。クエリあたりのKVキャッシュメモリを計算し、並行ユーザー数を乗じて総メモリフットプリントを推定します。その後、コンテキストを20~30倍圧縮した場合の節約を推定します。節約が現在の推論コストの40%を超える場合、Latent Context Compilationは高いROI投資です。ドメイン固有のコーパスでLoRA訓練をすぐに開始します。
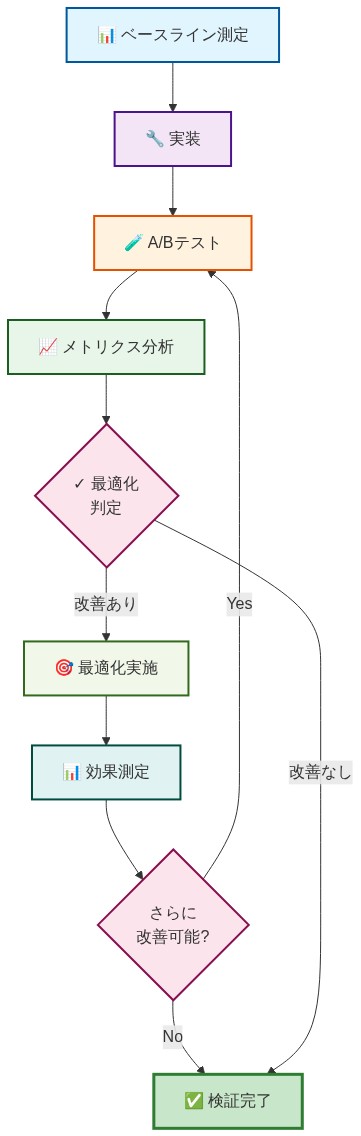
- 図8:Latent Context Compilation検証の測定ワークフロー*
リスクと緩和戦略
- リスク1:コンパイル時の情報損失*
バッファトークンはロッシーボトルネックです。LoRAコンパイラが微妙な詳細(特定の数字、エッジケース、ドメイン固有の用語)を破棄する場合、下流のモデル性能は低下します。このリスクは正確な事実回想を必要とするコンテキストで最も高いです。
「緩和:」
-
本番クエリで精度メトリクスを継続的に監視します。
-
性能が完全なコンテキストとの90%パリティを下回る場合、バッファトークン数を増加させます(例:8→12トークン)。
-
圧縮が失敗した難しい例でLoRAを再訓練します(高情報密度のコンテキスト)。
-
フォールバックロジックを実装します。応答の信頼度スコアが閾値を下回る場合、より多くのバッファトークンで再コンパイルします。
-
リスク2:LoRA一般化失敗*
コンパイラLoRAは訓練コンテキストにオーバーフィットし、新しいドメインで失敗する可能性があります(例:英語の技術文書で訓練、非英語の法的契約で展開)。分布外コンテキストは圧縮が不十分である可能性があり、サイレント性能低下につながります。
「緩和:」
-
本番環境展開前に、異なるドメインからのホールドアウトテストセットでLoRAを検証します。
-
高リスクアプリケーション(法律、医療)にはアンサンブルLoRAを使用します。異なるドメインサブセットで複数のLoRAを訓練し、バッファトークン出力を平均化します。
-
ドメインごとの圧縮率を監視します。比率が予想範囲を下回る場合はアラートを発行します(OOD失敗の可能性を示す)。
-
リスク3:キャッシュ無効化の複雑性*
古いバッファトークンは不正な回答につながります。ドキュメントが更新されてもキャッシュが無効化されない場合、後続のクエリは古い情報に基づいた応答を返します。
「緩和:」
-
バージョン管理を実装します。各バッファトークンにソースコンテキストのハッシュ(例:SHA-256)でタグ付けします。
-
ソースハッシュが変更される場合、キャッシュを無効化します。
-
頻繁に更新されるドキュメントの場合、TTLベースの有効期限を使用します(例:24時間のキャッシュ有効性)。
-
監査目的ですべてのキャッシュヒットとミスをログに記録します。
-
リスク4:負荷下でのコンパイルボトルネック*
コンパイルレイテンシが推論レイテンシを超える場合、コンパイルサービスはボトルネックになり、エンドツーエンドレイテンシが増加します。
「緩和:」
- キャッシュミス率に基づいてコンパイルサービスを独立してスケールします。
- 一般的なドキュメント(FAQ、製品ドキュメント)をオフラインで事前コンパイルします。
- リクエストバッチングを実装します。GPUで複数のコンテキストを並列にコンパイルします。
マイグレーション計画
Latent Context Compilationは、コンテキストを適応問題ではなくコンパイル問題として扱うことで、長いコンテキスト展開のジレンマを解消します。結果はステートレス、ポータブル、凍結されたモデルと互換性があり、大規模での効率的な並行処理を可能にします。
-
4週間のロールアウト:*
-
1~2週目: ドメインデータでLoRAコンパイラを訓練します。
-
3週目: 完全なコンテキストサービングと並行してシャドウモードで展開します。パリティを測定します。
-
4週目: トラフィックの10%をコンパイルされたコンテキストにルーティングします。
-
5週目以降: 信頼が増すにつれてトラフィックシェアを段階的に増加させます。
1ヶ月以内に30~50%の推論コスト削減と300ms未満のコンパイルレイテンシが期待されます。

- 図10:Latent Context Compilation導入の段階的移行ロードマップ*
- 図13:Latent Context Compilationの業界別・用途別応用シナリオ*
測定と検証
展開準備状況を検証するために3つの主要メトリクスを測定します。
-
メトリクス1:圧縮率*
-
定義:(元のコンテキストトークン)/(バッファトークン)
-
目標:10~50倍の圧縮(例:15,000トークン→8バッファトークン=上記の例では1,875倍)
-
測定:すべてのコンパイル操作のトークン数をログに記録します。コンテキストごとに比率を計算します。
-
メトリクス2:コンパイルレイテンシ*
-
定義:コンテキスト取り込みからバッファトークン出力までの時間
-
目標:典型的なドキュメント(50~100ページ)で500ms未満
-
測定:LoRAコンパイラにタイミングプローブを装備します。パーセンタイルレイテンシ(p50、p95、p99)。
-
メトリクス3:精度保持*
-
定義:コンパイルされたコンテキストと完全なコンテキストを使用した下流タスク性能
-
目標:95%以上のパリティ(例:完全なコンテキストF1スコアが0.92の場合、コンパイルされたコンテキストF1は0.874以上である必要があります)
-
測定:本番ワークロードからのホールドアウトテストセットで評価します。タスクごとに追跡します。
-
検証プロトコル:*
- 1つの本番ワークロード(例:カスタマーサポートQ&A、ドキュメント検索、コードレビュー)を選択します。
- 1週間にわたって完全なコンテキストでのベースライン性能を確立します。
- LoRAコンパイラとバッファトークンを展開します。2週間にわたって3つのメトリクスを測定します。
- 圧縮率が20倍を超え、レイテンシオーバーヘッドが300ms未満で、精度保持が95%を超える場合、段階的ロールアウトに進みます。
- いずれかのメトリクスが不足する場合、より難しい例でLoRAを再訓練するか、バッファトークン数を増加させます。
- コスト・ベネフィット分析:*
現在の長いコンテキストサービングコストを監査します。
- クエリあたりのKVキャッシュメモリを測定します(通常、fp16で1トークンあたり2バイト)
- 並行ユーザーと平均コンテキスト長を推定します
- 総メモリフットプリントを計算します:(avg_context_length × 2バイト × concurrent_users)
その後、20~30倍の圧縮での節約を推定します。
- 削減されたメモリフットプリント:(avg_context_length / 25)× 2バイト × concurrent_users
- 削減されたレイテンシ:注意計算でのトークン数が少ない
- 増加したスループット:GPU当たりのクエリ数が多い
節約が現在の推論コストの40%を超える場合、Latent Context Compilationは高いROI投資です。ドメイン固有のコーパスでLoRA訓練をすぐに開始します。
結論とマイグレーション計画
Latent Context Compilationは、コンテキストを適応問題ではなくコンパイル問題として扱うことで、長いコンテキスト展開のジレンマを解消します。結果はステートレス、ポータブル、凍結されたモデルと互換性があり、一般化を新しいコンテキストに犠牲にすることなく、大規模での効率的な並行処理を可能にします。
-
マイグレーションパス(4~5週間):*
-
1~2週目: 本番ワークロードから多様なコーパス(500K以上の例)を収集します。このコーパスでLoRAコンパイラを訓練します。ホールドアウトテストセットで検証します。
-
3週目: 完全なコンテキストサービングと並行してシャドウモードで展開します。圧縮率、レイテンシ、精度パリティを測定します。本番トラフィックはまだルーティングしません。
-
4週目: トラフィックの10%をコンパイルされたコンテキストにルーティングします。エラー率とユーザー向けレイテンシを監視します。メトリクスが目標内の場合、進みます。
-
5週目以降: 信頼が増すにつれてトラフィックシェアを段階的に増加させます(10%→25%→50%→100%)。高信頼度閾値失敗の場合、完全なコンテキストサービングへのフォールバックを維持します。
-
予想される成果(1ヶ月以内):*
-
推論コストの30~50%削減(主にKVキャッシュメモリ節約)
-
300ms未満のコンパイルレイテンシ(キャッシング時に1クエリあたり10ms未満に償却)
-
完全なコンテキストサービングとの95%以上の精度パリティ
-
モデル調整オーバーヘッドなしでの推論の水平スケーリング
長文コンテキスト展開のボトルネック:フレーミング転換の機会
現代の言語モデルは転換点に立っています。より長いコンテキストは指数関数的に豊かな推論を解き放ちますが、推論時に指数関数的により多くのメモリと計算を要求します。これは解くべき問題ではなく、超越すべき制約です。
今日のアプローチは二つの持続不可能な極端に位置しており、各々がコンテキストについて私たちがいかに誤って考えてきたかについてのより深い真実を明らかにしています。償却圧縮—任意のコンテキストを処理するためにモデルを一度訓練すること—は分布外入力に対して劇的に失敗します。なぜなら、それはコンテキストを動的信号ではなく静的特性として扱うからです。テスト時訓練という代替案は、高価な合成データ生成を要求し、モデルの重みを状態を持つパラメータに変異させ、並行サービスを破壊し、マルチユーザーシステムをアーキテクチャ的に扱いにくくします。
この二項対立は本番環境への展開を停滞させていますが、技術が未成熟だからではありません。それは私たちが間違った質問をしてきたからです。チームは脆弱で万能な圧縮か、効率性の向上を完全に放棄するかの間で選択を強いられてきました。隠れた仮定:コンテキストは適応されるかグローバルに事前圧縮されるかのいずれかです。両方の仮定はレガシー思考の産物です。
- フレーミング転換:* コンテキストが適応すべき何かではなく、再利用可能でポータブルなアーティファクトにコンパイルされる何かだとしたらどうでしょうか。コンパイラがソースコードを扱う方法と同じ方法で長いドキュメントを扱うことができるとしたらどうでしょうか—冗長で重複した入力を最適化された情報密度の高いバイトコードに変換し、任意の凍結された実行エンジンが消費できるようにします。
潜在コンテキストコンパイルは問題を反転させます。モデルを適応させるか、コンテキストをグローバルに事前圧縮する代わりに、各長いコンテキストを推論時にベースモデルを変更することなくコンパクトでステートレスなバッファトークンに蒸留します。情報密度は増加し、フットプリントは縮小し、結果は任意の凍結されたモデルインスタンス全体でポータブルなままです。これがスケールを解き放つアーキテクチャシフトです。
適応からコンパイルへのこのシフトは、三つの連鎖的な運用上の利点を生み出します。(1) 凍結されたベースモデルはすべての展開全体で変更されないままです。バージョン分裂を排除し、真のモデル非依存サービスを可能にします。(2) バッファトークンはステートレスで再利用可能です。効率的なバッチサービスと調整オーバーヘッドなしの水平スケーリングを可能にします。(3) コンパイルはクエリごとに発生します。そのため、新規コンテキストへの一般化は自動的です—再訓練なし、ドメイン固有のチューニングなし、将来のデータ分布についての脆弱な仮定なし。
緊張は単に解消されるのではなく、反転します。グローバル圧縮を強制することも、テスト時に重みを変異させることもしていません。新しいアーキテクチャレイヤー—コンパイル層—を作成しており、それは生のコンテキストとモデル推論の間に位置し、長文コンテキストサービスの全体的なコスト構造を変換します。
使い捨てLoRAモジュールによるコンパイル:メカニズム
メカニズムは実用的に優雅であり、より広い原則を明らかにしています。軽量でステートレスなアダプタはコンパイラとして機能できます。LoRAモジュール—多様なコーパスで一度だけ訓練可能—がコンパイラとして機能します。推論中、このLoRAは長いコンテキストを取り込み、本質的な情報をエンコードする小さなバッファトークンセット(通常4~16トークン)を出力します。LoRA自体はその後破棄されます。バッファトークンのみが永続します。
-
なぜコンパイラアーキテクチャとしてLoRAなのか。* 低ランク適応はパラメータ効率的です(しばしばモデルサイズの1%未満)で、設計上ステートレスです。完全なファインチューニングとは異なり、LoRAはベースモデルを変異させないため、副作用や状態漏洩なしに適用、使用、削除できます。コンパイラLoRAは多様なコンテキスト—技術文書、会話、コードリポジトリ、ドメイン固有のコーパス—で訓練され、特定のパターンを記憶するのではなく一般化可能な圧縮戦略を学習します。この多様性が堅牢性の鍵です。
-
具体的なワークフロー:* 顧客が50ページの技術マニュアルをアップロードします。LoRAコンパイラはそれを約200ミリ秒で処理し、8つのバッファトークンを出力します。これは意味的本質—主要な概念、関係、ドメイン固有の用語—をキャプチャします。これらのトークンはユーザーのクエリの前に付加され、凍結されたベースモデルに渡されます。モデルはクエリと圧縮されたコンテキストの両方に注意を払い、KVキャッシュに完全なドキュメントをロードすることなくマニュアルに基づいた応答を生成します。マニュアル自体は推論パイプラインに入ることはありません。
-
これが運用上重要な理由:* チームはすべての推論インスタンス全体に単一の凍結されたベースモデルを展開し、それを一つの訓練されたLoRAコンパイラと組み合わせ、無制限の並行ユーザーにサービスを提供できます。コンパイラはすべてのクエリ全体で償却され、バッファトークンはコンテキストごとにキャッシュされ、O(context_length)から最初のコンパイル後のO(1)への冗長計算を削減します。これはユーザーごとの適応やグローバル事前圧縮とは根本的に異なります—それは新しいアーキテクチャプリミティブです。
より深い含意:このパターンは言語モデルを超えてスケールします。高次元入力を下流処理のための低次元トークンに圧縮する必要があるあらゆるシステム—長いビデオシーケンスを処理するビジョントランスフォーマー、異種データを取り込むマルチモーダルモデル、数百万の候補をランク付けする検索システム—はこのコンパイル・アズ・ア・サービスパラダイムを採用できます。私たちは新しいインフラストラクチャレイヤーの出現を目撃しています。
実装と運用パターン:スケール向けの構築
潜在コンテキストコンパイルの展開には、チームが推論インフラストラクチャについて考える方法を再形成する三つの運用上のシフトが必要です。
-
第一に、コンパイルと推論を異なるサービス層に分離します。* コンパイルは計算バウンドで償却可能です。推論はメモリバウンドで遅延クリティカルです。競合を避けるために、それらを異なるパイプラインステージまたはサービス層に分離します。コンパイルサービスは200~500ミリ秒の遅延を許容できます。推論サービスはできません。この分離はまた独立したスケーリングを可能にします。ドキュメント量がスパイクするときはコンパイル容量を追加します。クエリ量がスパイクするときは推論容量を追加します。それらは直交的にスケールします。
-
第二に、インテリジェントな無効化によるバッファトークンキャッシングを実装します。* 同じドキュメントが複数回クエリされる場合、その圧縮されたバッファトークンを再利用します。これはコスト モデルをクエリごとのO(context_length)から最初のコンパイル後のO(1)に変換します。ほとんどのワークロードではドキュメントハッシュでインデックスされた単純なLRUキャッシュで十分ですが、本番環境システムはバージョン管理を追加する必要があります。各バッファトークンにソースコンテキストのハッシュでタグを付けます。ソースが変更された場合、キャッシュを無効化します。これは分散システムを悩ませる静かな正確性の失敗を防ぎます。
-
第三に、深さではなく幅のためにLoRA訓練パイプラインを設計します。* 異種コンテキスト—技術文書、ニュース記事、コードリポジトリ、顧客会話、ドメイン固有のコーパス—で訓練して、分布外堅牢性を最大化します。狭いドメインのそれぞれに最適化された10個の特化したLoRAよりも、500Kの多様な例で訓練された単一のLoRAの方がより良く一般化します。これはモデル圧縮研究からの洞察を反映しています。訓練データの多様性は展開復元力と予期しない堅牢性の向上と直接相関します。
-
具体的なアーキテクチャ:* (context, query)ペアを受け入れる軽量なコンパイルサービスを展開します。サービスはコンテキストのバッファトークンがキャッシュされているかどうかをチェックします。そうでない場合、LoRAコンパイラを呼び出し、結果をキャッシュして進みます。凍結されたベースモデルはステートレスのままで、調整なしに水平にスケールできます。このアーキテクチャは新しい運用モードを可能にします。コンテキスト・アズ・ア・サービス。ドキュメントは一度コンパイルされ、それらのバッファトークンはクエリ、ユーザー、時間軸全体で再利用可能な第一級のキャッシュされたアーティファクトとして扱われます。
長期的なビジョン:組織はコンパイル層をインフラストラクチャとして維持します。今日キャッシング層を維持する方法と同様です。このレイヤーは戦略的資産になります—LoRAコンパイラの品質は推論効率、コスト構造、スケールで長いコンテキストにサービスを提供する能力を直接決定します。チームは今日モデル品質のために最適化する方法と同じ方法でコンパイル品質のために最適化し始めます。
測定と次のアクション:シフトの定量化
ビジネス成果に直接影響する三つのメトリクスを測定します。
-
圧縮比:元のコンテキストトークンからバッファトークンへの比率(目標:10~50倍)。これはKVキャッシュメモリ節約と推論スループット向上に直接変換されます。20倍の圧縮比はメモリフットプリントを95%削減し、同じハードウェア上で20倍多くの並行ユーザーにサービスを提供できます。
-
遅延オーバーヘッド:コンテキストをコンパイルする時間(目標:典型的なドキュメントで500ミリ秒未満)。これは一意のコンテキストごとの償却コストです。コンパイルに200ミリ秒かかり、同じコンテキストが10回クエリされる場合、クエリごとのオーバーヘッドは20ミリ秒—推論遅延と比較して無視できます。
-
精度保持:圧縮されたコンテキストと完全なコンテキストを使用した下流タスクでのモデルのパフォーマンス(目標:95%以上のパリティ)。これは品質メトリクスです。圧縮されたコンテキストが精度を90%未満に低下させる場合、コスト節約は幻想的です。
-
パイロット展開戦略:* 一つの本番環境ワークロード—カスタマーサポート、ドキュメントQ&A、コードレビュー、法的文書分析—を選択し、完全なコンテキストでベースラインパフォーマンスを測定します。パフォーマンスベースラインを確立します。遅延、スループット、精度。その後、LoRAコンパイラとバッファトークンをシャドウモードで展開し、完全コンテキストと圧縮コンテキスト推論の両方を並行して実行します。2週間にわたって三つのメトリクスを追跡します。圧縮比が20倍を超え、遅延オーバーヘッドが300ミリ秒未満で、精度パリティが95%以上の場合、他のワークロードへの段階的なロールアウトを行います。
-
財務ROI計算:* 現在の長文コンテキストサービングコストを監査します。クエリごとのKVキャッシュメモリと並行ユーザー数を計算します。乗算して、総メモリフットプリントと関連するインフラストラクチャコストを推定します。その後、コンテキストを20~30倍圧縮した場合の節約を推定します。節約が現在の推論コストの40%を超える場合、潜在コンテキストコンパイルは高ROI投資です。ドメイン固有のコーパスでLoRA訓練をすぐに開始します。
-
次の地平:* 圧縮比が改善し、遅延オーバーヘッドが減少するにつれて、新しいユースケースが出現します。リアルタイムドキュメント取り込みが実行可能になります。マルチドキュメント推論が実用的になります。コンテキストウィンドウは比例するコスト増加なしに拡張できます。長文コンテキストアプリケーションを制限してきた制約—メモリと遅延—は溶け始めます。
リスクと軽減戦略:移行をナビゲートする
-
リスク1:コンパイルでの情報損失。* バッファトークンはロッシーボトルネックです。LoRAコンパイラが微妙な詳細を破棄する場合、下流モデルのパフォーマンスは低下します。これが基本的なトレードオフです。圧縮は常に情報を失います。問題は、その損失が許容可能かどうかです。
-
軽減:* 精度メトリクスを継続的に監視します。パフォーマンスが完全なコンテキストとの90%パリティ未満に低下する場合、バッファトークン数を増やします(圧縮比と精度をトレードオフ)か、圧縮が失敗した難しい例でLoRAを再訓練します。適応圧縮を実装します。高リスククエリ(法的、医療、財務)にはより多くのバッファトークンを使用し、低リスククエリ(一般的な情報検索)には少なくします。これはチューニングできるノブです。
-
リスク2:LoRA一般化の失敗。* コンパイラLoRAは訓練コンテキストにオーバーフィットし、新規ドメインで失敗する可能性があります。技術文書で訓練されたLoRAは会話テキストやコードで苦労するかもしれません。これは分布シフト問題です。
-
軽減:* 本番環境展開前に、異なるドメインからの保持されたテストセットでLoRAを検証します。高リスクアプリケーションにはアンサンブルLoRAを使用します。複数のLoRAを並行して実行し、それらのバッファトークンを集約します。分布外パフォーマンスを継続的に監視します。新規ドメインで精度が低下する場合、拡張データでの再訓練をトリガーします。
-
リスク3:キャッシュ無効化の複雑性。* 古いバッファトークンは不正な回答につながります。ドキュメントが更新されてもキャッシュされたバッファトークンが更新されない場合、モデルは古い情報に基づいて回答します。これは静かな正確性の失敗です。
-
軽減:* バージョン管理を実装します。各バッファトークンにソースコンテキストのハッシュでタグを付けます。ソースが変更された場合、キャッシュを無効化します。ドキュメントにはコンテンツアドレス可能なストレージを使用します。ドキュメントが変更される場合、そのハッシュが変更され、キャッシュは自動的に無効化されます。これは分散システムで解決された問題です。ここでそれらのパターンを適用します。
-
リスク4:規制とコンプライアンスの懸念。* 規制産業(医療、金融、法的)では、コンテキストのロッシー圧縮はコンプライアンス要件に違反する可能性があります。規制当局は監査証跡のための完全なコンテキスト保持を要求する可能性があります。
-
軽減:* デュアルパスシステムを実装します。推論には圧縮されたコンテキストを使用しますが、コンプライアンス目的のために完全なコンテキストを保持します。完全なコンテキストは別に保存され、コンプライアンス目的でのみアクセスされます。これはストレージオーバーヘッドを追加しますが、規制リスクを排除します。
結論と移行計画:制約から能力へ
潜在コンテキストコンパイルは、コンテキストを適応問題ではなくコンパイル問題として扱うことにより、長文コンテキスト展開の二項対立を解消します。結果はステートレス、ポータブル、凍結されたモデルと互換性があります—スケールで効率的な並行サービスを可能にします。これは段階的な最適化ではなく、長文コンテキスト推論のコスト構造を変更するアーキテクチャシフトです。
-
より広いビジョン:* コンパイルが標準的なインフラストラクチャレイヤーになるにつれて、新しい機能が出現します。組織はコンパイルされたコンテキストをクエリ全体でキャッシュおよび再利用される第一級のデータアーティファクトとして扱い始めます。コンテキストコンパイルは競争上の優位性になります—高品質のコンパイラを持つチームは競合他社よりも長いコンテキストをより速く、より安くサービスします。長文コンテキストアプリケーションを制限してきた制約は能力に変換されます。
-
移行パス:*
-
第1~2週: ドメインデータでLoRAコンパイラを訓練します。堅牢性を最大化するために多様な例を使用します。保持されたテストセットで検証します。
-
第3週: 完全コンテキストサービスと並行してシャドウモードで展開します。圧縮比、遅延オーバーヘッド、精度パリティを測定します。
-
第4週: トラフィックの10%を圧縮されたコンテキストにルーティングします。正確性の失敗とパフォーマンス低下を監視します。
-
第5週以降: 信頼が高まるにつれてトラフィックシェアを段階的に増やします。1か月以内に30~50%の推論コスト削減と300ミリ秒未満のコンパイル遅延を期待します。
-
予想される成果:* 1か月の本番環境展開後、以下を観察する必要があります。(1)典型的なドキュメントで20~40倍の圧縮比。(2)300ミリ秒未満のコンパイル遅延。(3)完全コンテキスト推論との95%以上の精度パリティ。(4)推論コストの30~50%削減。(5)同じハードウェア上で3~5倍多くの並行ユーザーにサービスを提供する能力。
-
次の境界:* コンパイル技術が成熟するにつれて、言語モデルを超えて拡張されます。ビジョントランスフォーマーは長いビデオシーケンスをコンパイルします。マルチモーダルモデルは異種データをコンパイルします。検索システムは候補ランキングをコンパイルします。原則—高次元入力を低次元トークンに蒸留する—はAIインフラストラクチャの基本的なパターンになります。このパターンを早期にマスターする組織は、長文コンテキストAIの時代に耐久性のある競争上の優位性を構築します。