
Microsoft 365 障害:サービス中断と組織の回復力
コアサービスへのアクセスを妨げる数時間の障害
-
主張:* Microsoft 365 は、複数の地理的地域と顧客組織全体で Exchange Online、SharePoint Online、および Microsoft Teams に影響を与えるサービス障害を経験しました。
-
証拠と仮定:* クラウドサービスの障害は通常、共有サービス層のインフラストラクチャ劣化から発生します。認証システム、API ゲートウェイ、または地域のデータセンターコンポーネントです。複数の名目上独立したサービス(電子メール、ファイルストレージ、ビデオ会議)が地理的に分散したユーザー全体で同時に失敗したことは、分離されたサービスの問題ではなく、共通の依存関係の失敗を示しています。この推論は、Azure Active Directory と共有 API インフラストラクチャが Exchange Online、SharePoint、Teams の上流の依存関係として機能する Microsoft 365 の公開アーキテクチャを前提としています。
-
具体的な観察:* エンドユーザーは一貫したエラーパターンを報告しました。メールボックスアクセスを妨げる認証失敗、SharePoint と OneDrive からのファイル取得エラー、Teams クライアントの切断です。地域とサービス全体での同期的な発生は、段階的に伝播する障害ではなく、集中型インフラストラクチャから発生したことを示唆しています。
-
ナレッジワーカーへの実行可能な影響:* 個人とチームは、リアルタイムクラウドアクセスなしでオフライン代替手段がないワークフローをすぐに文書化する必要があります。完全にクラウドに依存する重要な通信、ファイルアクセスパターン、および協調プロセスを特定します。このベースライン評価は、個人およびチームレベルの継続計画に情報を提供します。
システムアーキテクチャとボトルネック
Microsoft 365 のアーキテクチャは、認証、ID 検証、API ゲートウェイ機能を共有インフラストラクチャ全体に集中させ、地域またはサービス全体の劣化時にボトルネックを作成します。集中型認証システムは毎秒数百万のリクエストを処理します。これらのシステムがレイテンシスパイクまたは容量制約を経験すると、すべての依存サービスが比例して低下します。
ヨーロッパ、アジア、北米のユーザーは同時にアクセス失敗を経験しました。これは、地域インフラストラクチャではなく、共有サービスから問題が発生したことを示唆しています。この地理的一貫性は、集中型 ID サービスまたは API ルーティング層が原因であることを指しています。
- 推奨アクション:* IT チームは組織の依存関係チェーンをマップする必要があります。Azure AD 認証に依存するサービス、共有ゲートウェイを通じてルーティングされる API、フェイルオーバーを処理する地域エンドポイントです。このマップを使用して単一障害点を特定し、重要なサービスの冗長性とフェイルオーバーメカニズムについて Microsoft のアーキテクチャドキュメントをリクエストします。
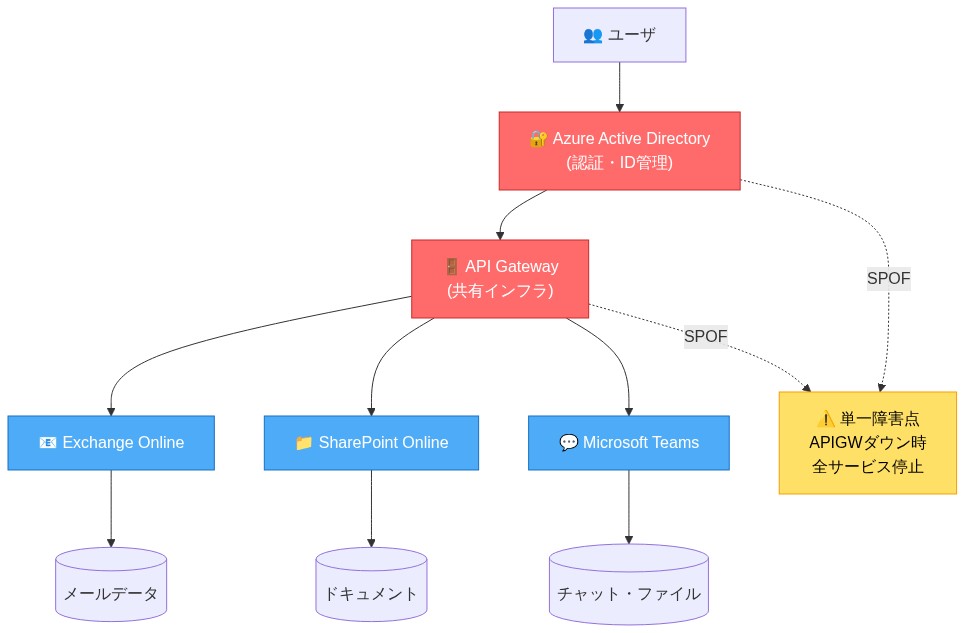
- 図2:Microsoft 365システムアーキテクチャと共有依存関係(単一障害点の可視化)*
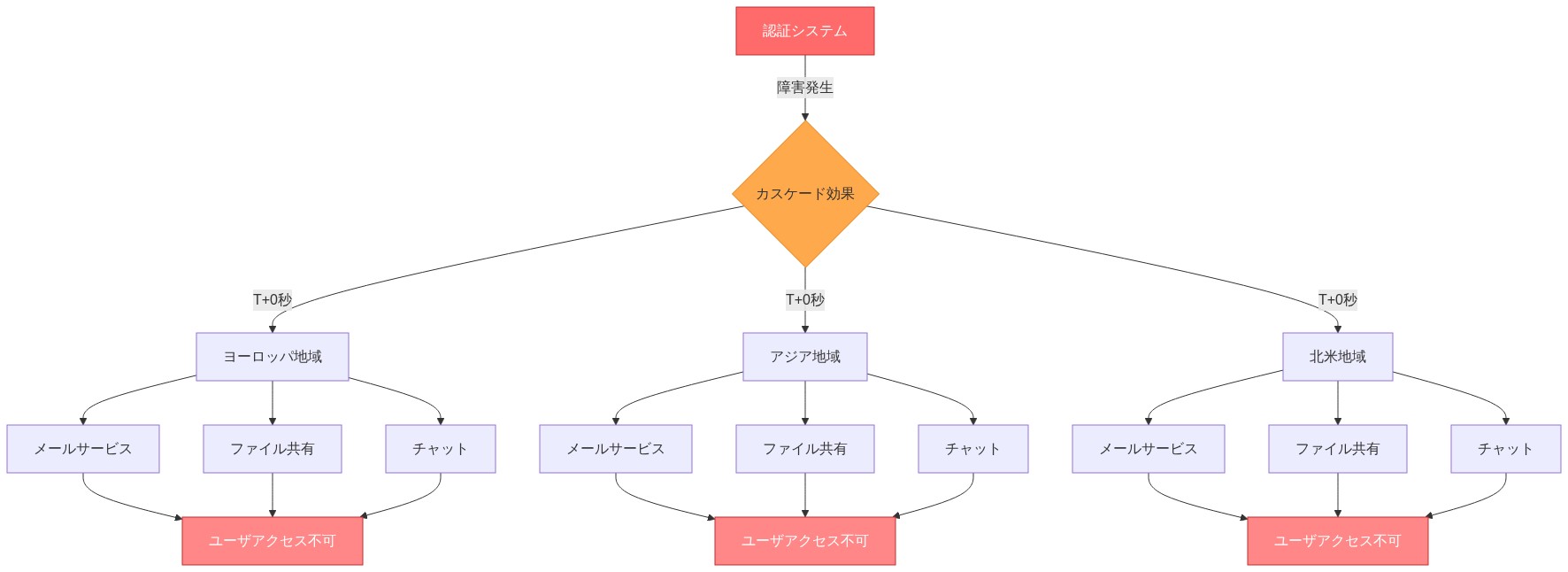
- 図3:認証インフラ障害による多地域・多サービスへの波及メカニズム*
ハイブリッドおよびマルチクラウドアーキテクチャ
障害は避けられません。問題は、ビジネスがそれらの間に動作できるかどうかです。オンプレミスの電子メールキャッシング、ローカルファイル同期、および代替通信チャネルを含む参照アーキテクチャは、クラウドサービスが低下したときに継続性を提供します。
Exchange Server ハイブリッド展開を持つ組織は、障害中にオンプレミスインフラストラクチャを通じて電子メールをルーティングできました。Slack または代替メッセージングシステムを持つチームは通信を維持しました。ローカルドライブにキャッシュされたファイルコピーを持つ企業は、ドキュメント編集をオフラインで続けました。
- 実装優先度:* 重要なサービスのハイブリッド展開オプションを評価します。OneDrive と SharePoint ファイルのオフラインアクセスを有効にします。作業を一時停止できないチームのための二次通信チャネル(Slack、Mattermost)を確立します。これらのフォールバックシステムを四半期ごとにテストして、必要なときに機能することを確認します。
監視とインシデント対応
プロアクティブな監視とインシデント対応の自動化は、障害の影響を大幅に削減します。ユーザーが報告する前に障害を検出する組織は、コンティンジェンシープランを迅速に実行できます。サービスヘルスダッシュボードの自動アラートは、事前定義されたランブックと組み合わせて、ベンダー通知を待たずに迅速な対応を可能にします。
Microsoft 365 Service Health ダッシュボードを監視するチームは、この障害を数分以内に検出しました。キャッシュされた電子メールシステムまたは代替ファイルリポジトリへの自動フェイルオーバーを持つ組織は、それらのシステムをすぐに実行し、障害全体の期間ではなく 15~30 分に中断を制限しました。
- 運用要件:* Microsoft 365 Service Health アラートにサブスクライブし、監視スタックに統合します。どのサービスが最初に失敗するか、どのフォールバックシステムが実行されるか、どのチームに通知するかを文書化するインシデント対応ランブックを作成します。各エスカレーションレベルの明確な所有権を割り当て、電子メールとファイルアクセスの障害をシミュレートする四半期ごとのディザスターリカバリードリルを実施します。
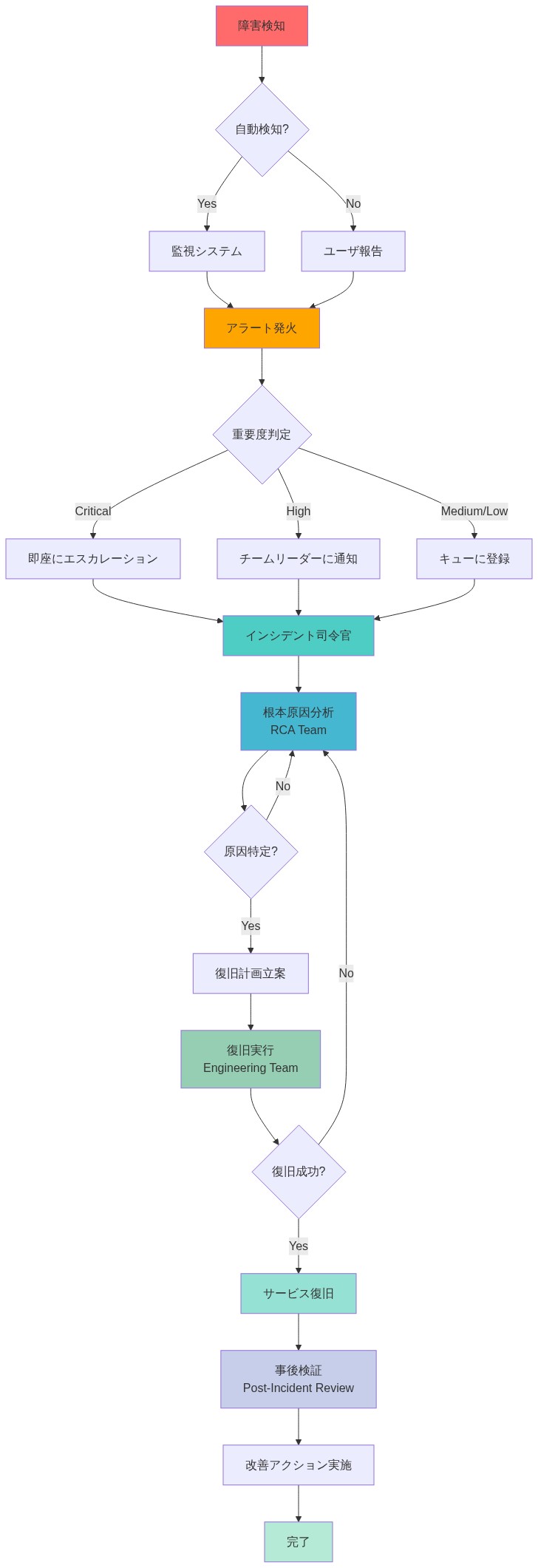
- 図6:インシデント対応ワークフロー(検知から復旧まで)*
ビジネス影響の測定
組織は、サービス可用性の割合だけでなく、ビジネスメトリクスを通じて障害の影響を測定して、回復力への投資を正当化する必要があります。1,000 ユーザーに影響を与える 2 時間の電子メール障害は、50 ユーザーに影響を与える 6 時間の障害よりも多くの生産性喪失をもたらす可能性があります。月末決算中に電子メールとファイルにアクセスできない財務チームは、指数関数的な生産性喪失に直面しています。顧客通話中に CRM データにアクセスできない営業チームは、即座の収益を失います。
- 分析フレームワーク:* 各 Microsoft 365 サービスのビジネス影響分析を実施します。部門全体で電子メール、Teams、SharePoint、OneDrive の利用不可時間あたりのコストを推定します。このデータを使用して、ハイブリッド展開、バックアップシステム、代替ツールの ROI を計算します。調査結果をリーダーシップに提示して、回復力イニシアチブの予算を確保します。
リスク軽減戦略
組織は、障害中に 3 つの主要なリスクに直面しています。サービス利用不可、データアクセス喪失、通信障害です。それぞれが異なる軽減が必要です。利用不可はフォールバックインフラストラクチャを要求します。データアクセス喪失はオフラインキャッシングとバックアップ戦略を要求します。通信障害は代替チャネルを要求します。
この障害中に、オフラインファイルアクセスがない組織はドキュメント編集機能を完全に失いました。代替メッセージングがないチームはインシデント対応を調整できませんでした。電子メール冗長性がない企業は顧客に遅延を通知できませんでした。
- 段階的実装:*
- OneDrive と SharePoint のオフラインアクセスを有効にする
- 電子メール継続性のための Exchange Server ハイブリッドを展開する
- 代替通信チャネルを確立する
- 重要なファイルのローカルバックアップを維持する
- 各サービスの手動ワークアラウンドを文書化する
ビジネス影響分析に基づいて優先順位を付けます。

- 図10:リスク分類と対応策マトリックス*
次のステップとタイムライン
このインシデントを使用して、ハイブリッドアーキテクチャと運用準備の具体的な改善を推進します。インシデント後の分析は、イベント発生直後に最も効果的です。影響が新鮮で、利害関係者の注意が高いときです。
オフラインアクセスがなかったチーム、代替案を通信できなかった部門、完全に停止したプロセスを監査します。これらの調査結果を使用して、ハイブリッド展開と冗長性投資の優先順位を付けます。
-
30 日マイルストーン:* 重要なサービスのハイブリッド展開を実装するためのタスクフォースを確立します。
-
90 日マイルストーン:* すべてのユーザー集団全体でオフラインアクセスを有効にします。
-
180 日マイルストーン:* 代替通信チャネルセットアップとディザスターリカバリーテストを完了します。
実装全体を通じて継続的な焦点と予算配分を確保するために、エグゼクティブスポンサーシップを割り当てます。
- 図11:レジリエンス構築の実装ロードマップ(12ヶ月計画)*