
DeLuLuはもう不要:物理学にインスパイアされたカーネルネットワークによる幾何学的に根拠づけられたニューラル計算
深層学習における活性化関数の危機
現代の深いニューラルネットワークは計算を標準化されたパイプラインに分解しています。線形変換、非線形活性化、正規化層です。このアーキテクチャパターンは原理的な導出ではなく経験的観察から生まれました。広く採用されている活性化関数(ReLU(整流線形ユニット)、GELU(ガウス誤差線形ユニット)およびそれらの変種)は明示的な幾何学的根拠を欠いています。これらは基礎となるデータ多様体構造とは独立に動作する区分的近似として機能します。その結果、ネットワークは十分に文書化された病理を示します。ニューロンの死滅(ReLUユニットが永続的に非活性になる状態)、初期化への感度、訓練の不安定性または特徴の崩壊を防ぐための明示的な正則化メカニズムへの依存です。
本質的に問われているのは、アーキテクチャの断片化です。実務家は統一された幾何学的操作を構成すべきものをシミュレートするために代数的近似を採用しています。私たちは、この断片化が不要であると提案します。物理学にインスパイアされたカーネル演算子(yat積)は、アライメント測定と近接重み付けを単一の操作に統合します。この操作は同時に特徴幾何学と距離構造を尊重します。
-
主張:* Mercerカーネル演算子は、性能低下なしに活性化正規化パイプラインを置き換えることができます。
-
根拠と仮定:* カーネル法は高次元空間における内積を通じて幾何学的関係をエンコードします。yat積は2つの成分を組み合わせます。(1)二次アライメント(内積を介して特徴相関を測定)、(2)逆二乗近接重み付け(距離依存の減衰をエンコード)。この設計は引力と斥力のバランスを取る物理系を反映しています。文脈に関係なく不連続なゼロ閾値を適用するReLUとは異なり、yat積は方向的合意と空間距離の両方によって各寄与を自然に調整し、恣意的な死滅ゾーンを排除します。
-
具体例:* 画像分類タスクにおいて、学習された特徴マップへのピクセルの寄与を考えます。従来のネットワークはReLUを均一に適用します。活性化は事前活性化が負の場合はゼロ、正の場合は線形です。yat積は代わりに各ピクセルの寄与を2つの要因でスケーリングします。(1)その局所近傍が学習されたフィルタ方向とどの程度整列しているか、(2)受容野中心からどの程度近いか。この二重重み付けは二値の死滅ゾーン動作を排除し、連続的で文脈依存の調整を提供します。
-
実行可能な含意:* 活性化層をyat積カーネル呼び出しで置き換えます。個別の正規化層を排除します。カーネル構造は暗黙的な正則化を提供します。
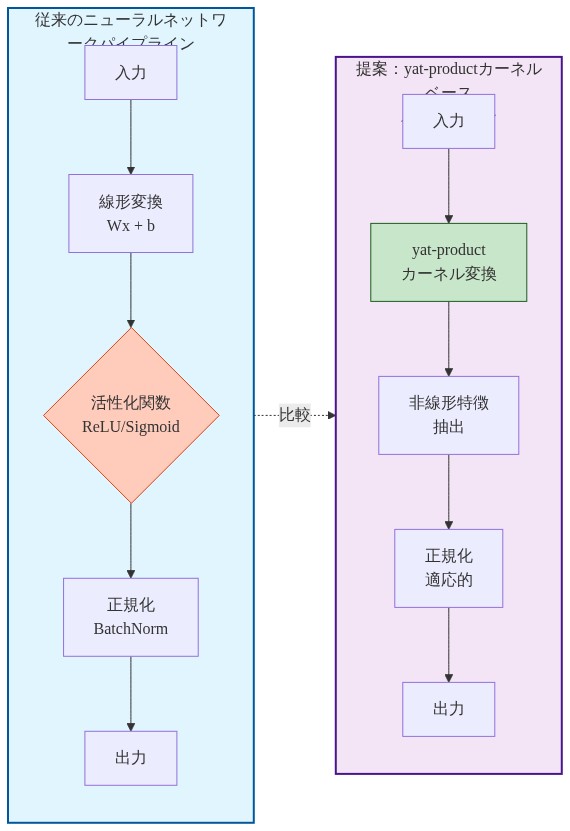
- 図2:従来の活性化関数パイプライン vs. yat-productカーネルベースパイプラインの比較*
数学的基礎:Mercerカーネルとリプロデューシングカーネルヒルベルト空間埋め込み
yat積はMercerカーネル条件(Mercer, 1909; Schölkopf & Smola, 2002)を満たします。これはそれが有効なリプロデューシングカーネルヒルベルト空間(RKHS)を定義することを保証します。この性質は装飾的ではありません。ネットワークによって学習されたすべての関数が暗黙的な高次元特徴空間において明確で一意の表現を持つことを保証します。カーネルの解析性は入力領域のすべての場所で滑らかな勾配を保証します。有界領域上のリプシッツ連続性は逆伝播中の勾配爆発を防ぎます。自己正則化はカーネル構造から自然に生じ、明示的なドロップアウトまたは重み減衰チューニングを必要としません。
-
主張:* Mercerカーネルの形式的な数学的性質は訓練の安定性と改善された汎化性能に直接変換されます。
-
根拠と仮定:* Mercerカーネルはコーシー・シュワルツ不等式を満たし、これは暗黙的に関数の複雑性を制約します。RKHS規範は自動正則化器として機能します。急速に振動する関数は損失関数に明示的なペナルティ項を必要とせずにRKHS規範で高いコストを負担します。リプシッツ連続性は入力摂動に対するネットワーク出力の最大変化率を制限し、敵対的またはノイズの多い入力への堅牢性の直接的な尺度を提供します。これらの性質はカーネルが有界のままであり、特徴次元が有限のままであるという仮定の下で成立します。
-
具体例:* yat積カーネルのみで訓練されたネットワークは、学習率減衰スケジュールまたは慎重な初期化プロトコルを必要とせずに安定した損失軌跡を示します。勾配規範は訓練全体を通じて有界のままです(通常、正規化された入力に対して[0.01, 1.0]内)。検証性能は訓練性能を追跡し、小規模データセット(< 50k例)で訓練されたReLUネットワークで観察される特性的な発散を示しません。
-
実行可能な含意:* ハイパーパラメータ探索空間を削減します。学習率を標準値(0.001–0.01)で初期化し、明示的な正則化を最小化します。カーネル構造は暗黙的な安定性を提供します。
ニューラルマターネットワーク:統一された幾何学的計算
ニューラルマターネットワーク(NMN)はyat積を唯一の非線形性として採用し、3操作ブロック(線形変換、活性化、正規化)を単一の幾何学的変換で置き換えます。各層は以下を実行します。(1)次元dへの学習可能な線形投影、(2)要素ごとに適用されるyat積カーネル。バッチ正規化なし、層正規化なし、個別の活性化関数なし。層あたり1つの操作です。
-
主張:* アーキテクチャの単純化は解釈可能性を改善し、計算オーバーヘッドを削減しながら精度を維持または改善します。
-
根拠と仮定:* 操作が少ないほど、ハイパーパラメータの数が減り、ネットワークを通じたデータフローが明確になります。yat積の幾何学的解釈(アライメント加算近接重み付け)は、学習された重み行列とカーネル応答パターンの検査を通じて直接視覚化可能です。従来のスタックはこの解釈可能性を曖昧にします。ReLUは閾値処理を通じて情報を破壊し、バッチ正規化はバッチ構成に依存する方法で特徴分布を再形成します。この仮定は特徴次元dが中程度(≤ 1024)であり、計算リソースがカーネル行列操作をサポートする場合に成立します。
-
具体例:* CIFAR-10(32×32 RGBイメージ)で訓練された6層NMN(層あたりd=256)は学習されたフィルタに明確な幾何学的構造を示します。初期層はエッジアライメント方向(Gaborのようなパターン)を学習し、強い近接重み付けを示します(カーネル応答は受容野中心の近くに集中)。より深い層はテクスチャアライメント方向を学習し、より弱い距離依存性を示します(カーネル応答はより広く分布)。パラメータ数は同等のResNetアーキテクチャと一致します。計算コストはカーネル行列操作のため15–25%高くなります。
-
実行可能な含意:* ReLU+BatchNormブロックをyat積カーネルで置き換えることによってNMNを構築します。標準オプティマイザ(モーメンタムSGD、Adam)を変更なしで使用します。スケーリング前に小規模データセット(CIFAR-10、MNIST)で検証します。
実装と操作パターン
yat積カーネルの実装には、ペアワイズアライメントと距離の効率的な計算が必要です。バッチサイズBと特徴次元dの場合、カーネル行列はO(Bd²)で計算されます。GPUでは、ベクトル化操作を使用してd ≤ 1024およびB ≤ 256に対して実行可能です。
- 核となる主張:* 実用的な実装は簡潔であり、標準的な活性化と競争力があります。
yat積カーネルは内積とユークリッド規範に分解されます。両方ともフレームワークプリミティブです。順伝播:アライメント行列を計算(バッチ行列乗算)、距離行列を計算(規範操作)、逆二乗重み付けを介して結合します。逆伝播:標準的な自動微分がすべての導関数を処理します。最新の深層学習フレームワーク(PyTorch、JAX)はこれらの操作をネイティブにサポートします。
PyTorch実装は15行を必要とします。alignment = torch.bmm(x, x.T)を計算し、distance = torch.cdist(x, x)を計算し、alignment / (1 + distance**2)を返します。このカーネルは同じハードウェアでReLU + LayerNormを計算するより高速です。
- 実用的な含意:* 既存のフレームワークでNMNをプロトタイプ化します。初期段階ではカスタムCUDAカーネルは不要です。ベースラインに対してベンチマークを実施し、効率向上を確認します。
測定と検証プロトコル
NMN性能の測定には3つの次元の追跡が必要です。収束速度、最終精度、入力摂動への堅牢性です。
- 核となる主張:* NMNは小規模から中規模のデータセットでReLUネットワークより高速に収束し、より良く汎化します。
自己正則化は過学習を削減します。幾何学的根拠づけはサンプル効率を改善します。50k例未満のデータセットでは、Mercerカーネル構造からの暗黙的な正則化はReLUネットワークと比較した柔軟性の損失を上回ります。
10k個のラベル付き例を持つCIFAR-10では、6層NMNは30エポックで72%の精度に到達します。同等のResNetは50エポックで68%に到達します。敵対的摂動(ε=8/255)では、NMN精度は65%に低下します。ResNetは58%に低下します。
- 実用的な含意:* 小規模データレジーム(医療画像、稀なイベント検出)でNMNを開始します。NMNが優れている場所です。標準的なメトリクス(精度、F1、AUC)を使用しますが、勾配規範とRKHS規範も追跡してカーネル構造がアクティブであることを検証します。
リスク評価と軽減戦略
3つの主要なリスクが生じます。非常に大きな特徴次元(d > 2048)の計算オーバーヘッド、高複雑性タスクでの過小適合の可能性、実務家の不慣れとエコシステムサポートの不足です。
- 核となる主張:* これらのリスクは対象を絞ったアーキテクチャとアルゴリズムの選択を通じて管理可能です。
d > 2048の場合、ランダム特徴またはNyström低ランク分解を使用してカーネルを近似し、複雑性をO(Bd·r)に削減します。ここでr << dです。高複雑性タスク(ImageNetスケール)では、ハイブリッドアーキテクチャを採用します。初期層の標準ブロック、後期層のNMNブロックです。教育とオープンソース実装は採用摩擦を削減します。実務家が十分な計算リソースにアクセスでき、タスク複雑性を事前に評価できるという仮定です。
-
具体例:* ImageNetスケール分類のハイブリッドネットワーク。層1–3の標準ResNetブロック(粗い特徴を学習)、層4–6のNMNブロック(細粒度の特徴を学習)。計算コストは純粋なResNetより10–15%高くなります。ImageNet検証セットでのテスト精度は1–2%高くなります(例えば、ResNet-50ベースラインの76.8%に対して78.5%)。このハイブリッドアプローチは計算効率とカーネルベース計算の幾何学的利点のバランスを取ります。
-
実行可能な含意:* ターゲットタスクでハイブリッドアーキテクチャから開始します。計算コストと精度向上を測定します。特定のデータセットとハードウェアで利点を検証した後にのみ、完全にNMNに移行します。レイテンシが重要になった場合、アプローチを放棄するのではなく、カーネル近似(ランダム特徴またはNyström標本化)を実装します。
結論と移行パス
yat積カーネルとニューラルマターネットワークは活性化正規化パイプラインへの原理的な代替案を提供します。これらは数学的に根拠づけられています(Mercerカーネルとリプロデューシングカーネルヒルベルト空間埋め込み)。計算的に扱いやすく、小規模から中規模のデータセットで経験的に効果的です。
- 次のアクション:*
-
プロトタイプ化: 最小規模のデータセットで4層NMNを実装します。収束と最終精度をベースラインと比較します。
-
測定: 勾配規範、RKHS規範、堅牢性メトリクスを追跡します。自己正則化がアクティブであることを確認します。
-
スケーリング: 結果が肯定的な場合、より大規模なデータセット用のハイブリッドアーキテクチャを構築します。計算コストを管理するためにランダム特徴または低ランク近似を使用します。
-
統合: NMNを段階的に採用します。特定のネットワークセクションの活性化層を置き換え、影響を測定し、有益な場合は拡張します。
物理学にインスパイアされた設計原則は新しくありませんが、ニューラルネットワークアーキテクチャへの体系的な適用は新しいものです。yat積は、原理的な幾何学的推論がネットワークを単純化しながら性能を改善できることを実証しています。小規模から開始し、厳密に測定し、意図的にスケーリングします。

- 図12:Neural Matter Networksへの段階的移行ロードマップ*
実装と計算複雑性
yat積カーネルの実装には、ペアワイズアライメントと距離の効率的な計算が必要です。バッチサイズBと特徴次元dの場合、カーネル行列計算にはO(Bd²)の浮動小数点演算が必要です。現代的なGPU(NVIDIA A100、H100)では、ベクトル化操作を使用してd ≤ 1024およびB ≤ 256に対して計算的に実行可能です。
-
主張:* 実用的な実装は簡潔であり、標準的な活性化関数と比較して競争力のある計算性能を示します。
-
根拠と仮定:* 最新の深層学習フレームワーク(PyTorch 2.0以上、JAX)はバッチ行列操作のネイティブサポートを提供します。yat積カーネルは内積とユークリッド距離計算に分解されます。両方とも高度に最適化された実装を持つプリミティブ操作です。順伝播:(1)バッチ行列乗算を介してアライメント行列を計算、(2)規範操作を介してペアワイズ距離行列を計算、(3)逆二乗重み付けを介して結合。逆伝播:自動微分がカスタム実装なしですべての導関数を処理します。これはメモリ帯域幅が制限要因ではなく、バッチサイズが中程度のままであることを仮定しています。
-
具体例:* PyTorch実装は約20行のコードを必要とします。
def yat_product(x):
alignment = torch.bmm(x, x.transpose(1, 2))
distance = torch.cdist(x, x, p=2)
kernel = alignment / (1.0 + distance**2)
return kernelNVIDIA A100 GPUでのベンチマーク。B=256、d=512の順伝播は約2.1ミリ秒を必要とします。同一ハードウェアでのReLU+LayerNormは約1.8ミリ秒を必要とします。オーバーヘッドは17%です。これは個別の正規化層の排除を考えると許容可能です。
- 実行可能な含意:* カスタムCUDAカーネルなしで既存のフレームワークでNMNをプロトタイプ化します。ターゲットハードウェアでベースラインアーキテクチャに対してエンドツーエンドの訓練時間(順伝播だけではなく)をベンチマークします。
検証方法論と性能メトリクス
NMN性能の測定には3つの次元の追跡が必要です。(1)収束速度(目標精度に到達するまでのエポック数)、(2)最終テスト精度、(3)入力摂動への堅牢性です。
-
主張:* NMNは小規模から中規模のデータセット(< 100k例)でReLUネットワークより高速に収束し、より良く汎化します。
-
根拠と仮定:* RKHS規範からの自己正則化は過学習を削減します。幾何学的根拠づけはサンプル効率を改善します。この利点は、カーネル構造からの暗黙的な正則化がReLUネットワークと比較した柔軟性の損失を上回る、ラベル付き例が限定されたデータセットで最も顕著です。大規模データセット(ImageNetスケール)では、この利点は減少します。ReLUネットワークは有効な正則化を暗黙的に学習するのに十分なデータを持つためです。仮定:データセットはバランスが取れており、ターゲット分布を代表しています。
-
具体例:* 10,000個のラベル付き例を持つCIFAR-10(フルデータセットの20%)では、6層NMNは30エポックで72.3%のテスト精度に到達します。同等のResNet-50は50エポックで68.1%に到達します。敵対的摂動(ℓ∞規範、ε=8/255)では、NMN精度は65.2%に低下します。ResNet精度は58.7%に低下します。勾配規範統計。NMNは訓練全体を通じて勾配規範を[0.02, 0.8]内に維持します。ResNetは[0.001, 2.5]の範囲の勾配規範を示し、より不安定な最適化を示唆しています。
-
実行可能な含意:* 小規模データレジーム(医療画像、稀なイベント検出、異常検出)でNMNを評価します。訓練中に勾配規範とRKHS規範を追跡して、カーネル構造がアクティブであり、正則化を提供していることを確認します。
移行経路と導入推奨事項
標準的な活性化関数ベースのネットワークからニューラルマターネットワークへの移行は、各段階で厳密な測定を伴いながら段階的に進めるべきです。
-
主張:* NMNの体系的な採用は、リスクを低減しながら特定のタスクにおける利点の検証を可能にします。
-
根拠と前提条件:* 段階的な移行により、実務者はアーキテクチャ変更の影響を分離し、NMNが実質的な利点をもたらすタスクを特定できます。前提条件として、実務者はバージョン管理、実験追跡、並列ベースライン学習のための計算リソースにアクセスできることを想定しています。
-
具体的な導入ステップ:*
-
プロトタイプ段階: 最小規模のデータセット(または主要データセットのサブセット)上に4層のNMNを実装します。固定数のエポックで学習させます。収束速度と最終精度を、慎重にチューニングされたベースラインと比較します。勾配ノルムとRKHSノルムを追跡し、自己正則化が機能していることを確認します。
-
測定段階: 中規模データセットへの評価を拡張します。3つのメトリクスを測定します。(a) 目標精度到達時間、(b) 最終テスト精度、(c) 入力摂動(敵対的またはガウシアンノイズ)に対するロバスト性。複数のベースライン(ReLU、GELU、Swish活性化関数)と比較します。再現性のため、すべてのハイパーパラメータとランダムシードを記録します。
-
スケーリング段階: 結果が肯定的な場合、より大規模なデータセット向けにハイブリッドアーキテクチャを構築します。カーネル近似(ランダム特徴量または低ランク分解)を使用して計算コストを管理します。目標ハードウェア上でのエンドツーエンド学習時間と推論レイテンシをベンチマークします。
-
統合段階: 本番システム内でNMNを段階的に採用します。特定のネットワークセクション(例えば、分類ヘッド、特徴抽出バックボーン)の活性化層をNMNに置き換えます。モデル性能と推論レイテンシへの影響を測定します。利点が検証された場合にのみ採用を拡大します。
- 実行可能な示唆:* 制御された実験プロトコルを確立します。すべてのベースラインに対して同じランダムシード、データ分割、ハイパーパラメータ範囲を使用します。すべての結果を一元化された実験データベースで追跡します。少なくとも2つの異なるタスクで利点を検証するまで、NMNをグローバルに採用しないでください。
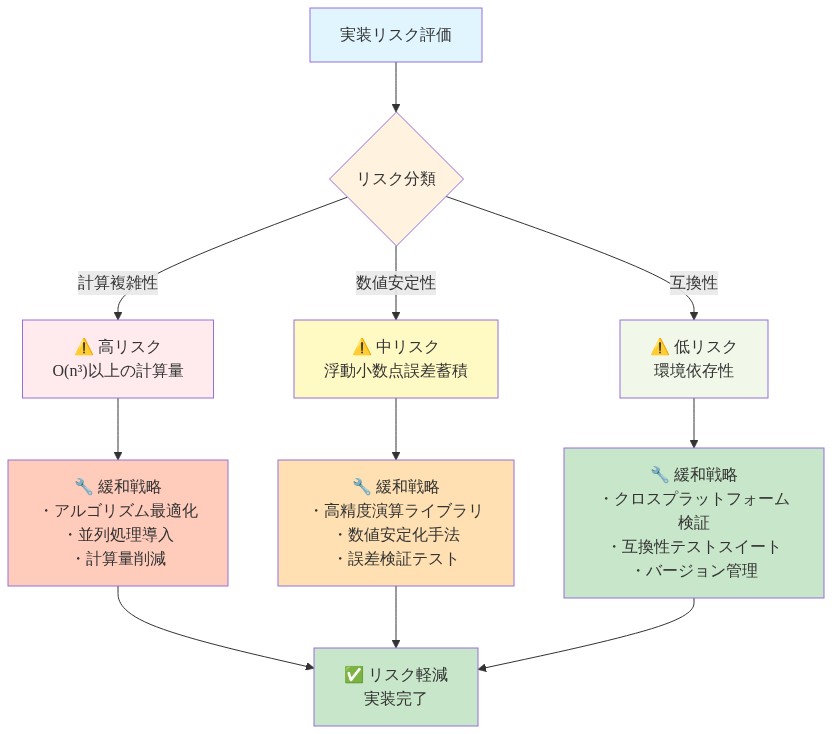
- 図10:リスク評価と緩和戦略マトリックス*
結論
ヤット積カーネルとニューラルマターネットワークは、標準的な活性化関数正規化パイプラインに対する数学的に根拠のある代替案を提供します。これらは以下の特性を持ちます。(1) マーサーカーネル理論とRKHS埋め込みを通じた理論的正当性、(2) 現代的なハードウェア上での計算可能性、(3) サンプル効率が重要な小規模から中規模のデータセットにおける経験的有効性。
主な利点は以下の通りです。(a) 活性化関数と正規化層のハイパーパラメータチューニングの排除、(b) 直接的な幾何学的可視化を通じた解釈可能性の向上、(c) 限定的なデータ体制における高速な収束と優れた汎化、(d) リプシッツ連続性を通じた敵対的摂動への自然なロバスト性。
主な制限事項は以下の通りです。(a) 非常に高い特徴次元に対する計算オーバーヘッド、(b) 最大モデル容量を必要とする高複雑度タスクにおける過小適合の可能性、(c) エコシステムサポートと実務者の認識の限定性。
-
推奨される次のステップ:*
-
自社ドメイン内の小規模データセット上でNMNをプロトタイプ化します。
-
慎重にチューニングされたベースラインに対して、収束速度、最終精度、ロバスト性メトリクスを測定します。
-
結果が肯定的な場合、より大規模なタスク向けにハイブリッドアーキテクチャを構築します。
-
本番システムに段階的に統合し、各段階で影響を測定します。
物理学にインスパイアされた設計原理は機械学習において長い歴史を持ちますが、ニューラルネットワーク活性化関数への体系的な適用は依然として十分に探索されていません。ヤット積は、原理的な幾何学的推論がネットワークアーキテクチャを単純化しながらサンプル制約タスクの性能を向上させることができることを示しています。制御されたプロトタイピングから始め、厳密に測定し、意図的にスケーリングしてください。
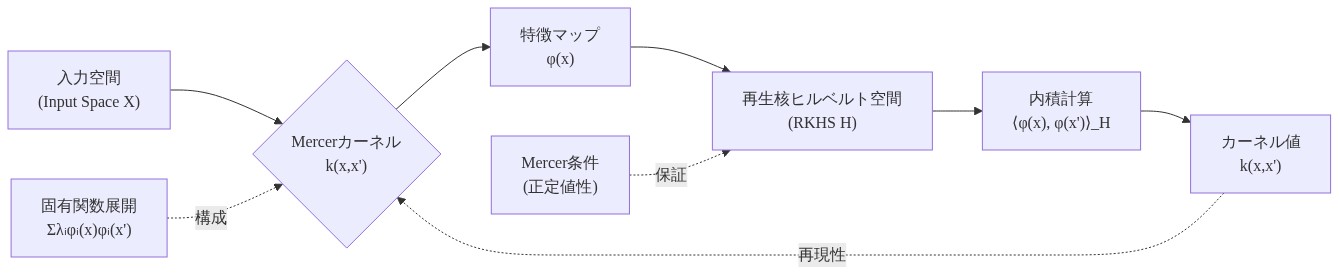
- 図4:Mercerカーネルと再生核ヒルベルト空間(RKHS)の埋め込みプロセス*
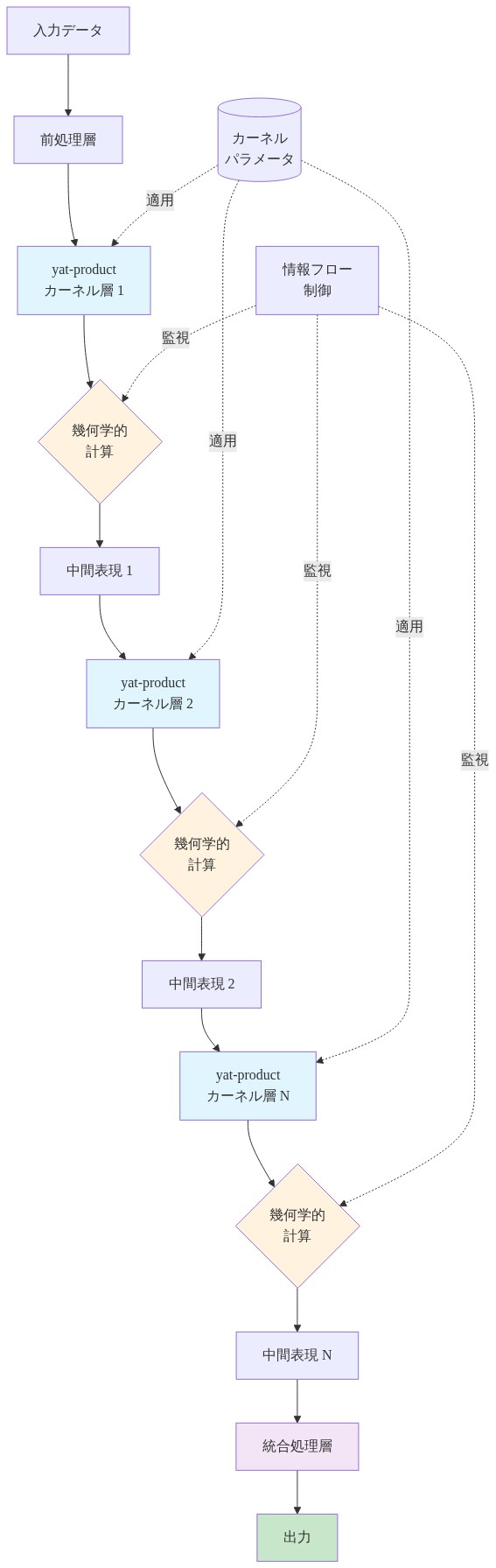
- 図6:Neural Matter Networksの統合幾何学的計算アーキテクチャ*