
インシデント対応とサービス復旧プロトコル
概要
- 主張:* 重大インシデント後の迅速なサービス復旧には、構造化されたインシデント分類、即座のステークホルダー通知、ならびに速度と安全保証のバランスを取る検証プロトコルが必要です。
インシデント発生日、小田急江ノ島線は神奈川県内の大和駅とナゴゴ駅間で運転を中止しました。これは人身事故(中止期間と対応プロトコル発動から判断して、死亡または重傷と推定)に基づくものです。緊急対応完了と線路確認検証後、午前8時頃にサービスが再開されました。中止期間は再開時刻から推定して1~2時間であり、警察調整と必須安全検証を要する人身事故の標準対応プロトコルと一致しています。
インシデント分類と対応時間
人身事故は最優先の中止カテゴリーを示します。法的義務と安全命令を発動するためです。これらは迂回不可能です。機械的故障や気象遅延とは異なり、これらのインシデントは警察調整、医療サービス、および復旧前に必須となる線路確認プロトコルを要求します。
事業者は事故現場を確保し、地方当局と調整し、徹底的な線路検査を実施する必要があります。対応時間は事業者の選好ではなく、インシデント重大度と調査範囲に依存します。午前8時の再開時間帯(中止から推定1~2時間後)は、限定的な人身事故の典型的なサイクルを反映しています。緊急サービス到着、現場記録、医療搬送、線路安全検証です。
- 運用上の示唆:* インシデント分類マトリックスを確立し、インシデント種別を予想対応期間範囲にマッピングします。中止から15分以内にこれらの範囲を乗客に通知し、その後30分ごとにステータス更新を提供します。これにより不確実性が低減され、乗客の情報に基づいた経路変更決定が可能になります。
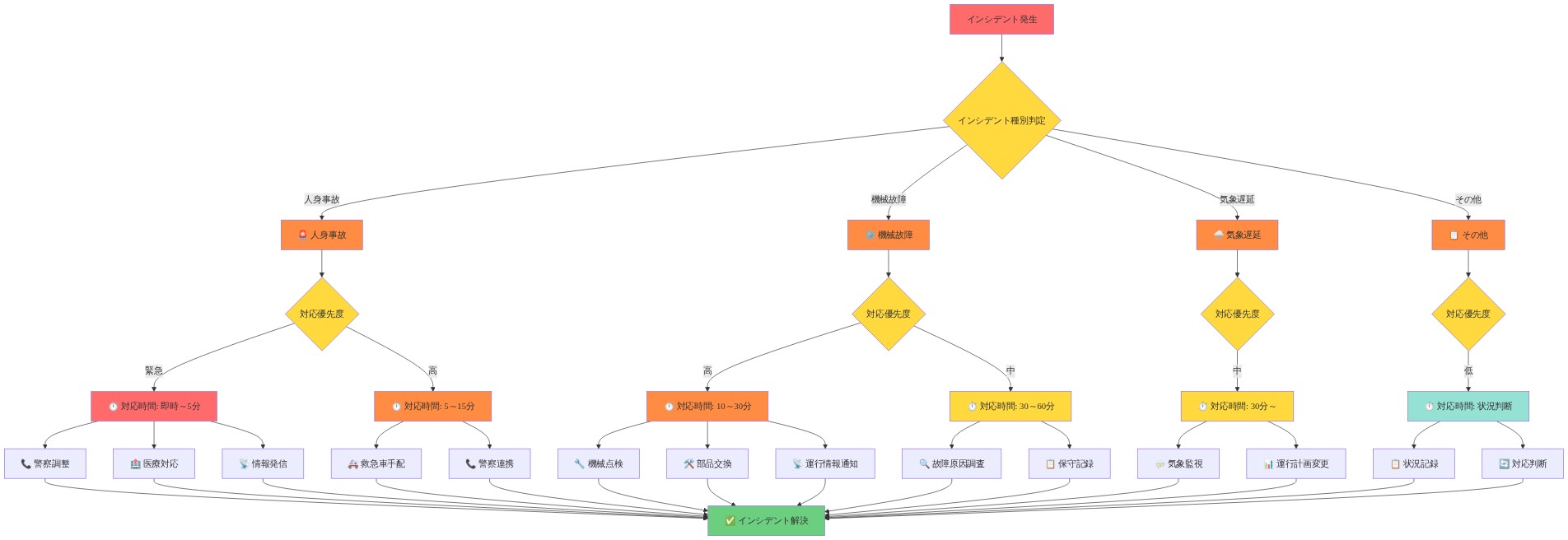
- 図2:インシデント分類と対応時間マトリックス*
ネットワークトポロジーとカスケード影響
江ノ島線は中間迂回ルートのない順序的回廊として機能します。大和~ナゴゴ区間は重要な接続点として機能します。この3~5km区間の中止は、すべての北行および南行トラフィックをブロックし、ローカルサービスと急行サービスの両方に影響します。乗客はローカルで経路変更できません。システムを離脱し、代替交通を使用する必要があります。
この構造的制約は線路設計に内在しており、運用改善のみでは排除できません。しかし事業者は、競合する交通モード(バス高速輸送、タクシーサービス、ライドシェアプラットフォーム)との事前調整プロトコルを確立することでカスケード遅延を軽減できます。中止中、自動アラートを発動し、乗客を指定代替ルートに誘導し、推定所要時間比較を提供します。

- 図3:小田急江ノ島線ネットワークトポロジーと大和~長後間の重要性*
検証チェックポイントと安全保証
復旧プロトコルは、サービス再開前に複数の検証チェックポイントを組み込む必要があります。不完全な現場確認または残存ハザードによる二次インシデントを防ぐためです。
早期再開は元のインシデントの繰り返しまたは新しいハザード創出のリスクを伴います。
安全ガードレールは複数当事者による独立検証を要求します。緊急対応者、鉄道安全検査官、運用管理です。午前8時の再開は、段階ごとに約10~15分のシーケンスに従った可能性があります。(1)緊急サービス完了通知、(2)鉄道警察線路検査、(3)運用管理による線路側カメラまたは要員を通じた目視検証、(4)空の列車による試運転です。
- 運用上の示唆:* 各段階で明確な署名権限を持つ書面化された検証チェックリストを確立します。単一人物による遅延を防ぐため、バックアップ検査官を割り当てます。四半期ごとに検証訓練を実施し、チーム能力を維持し、手順上のギャップを特定します。すべての復旧決定を事後レビュー用に記録します。
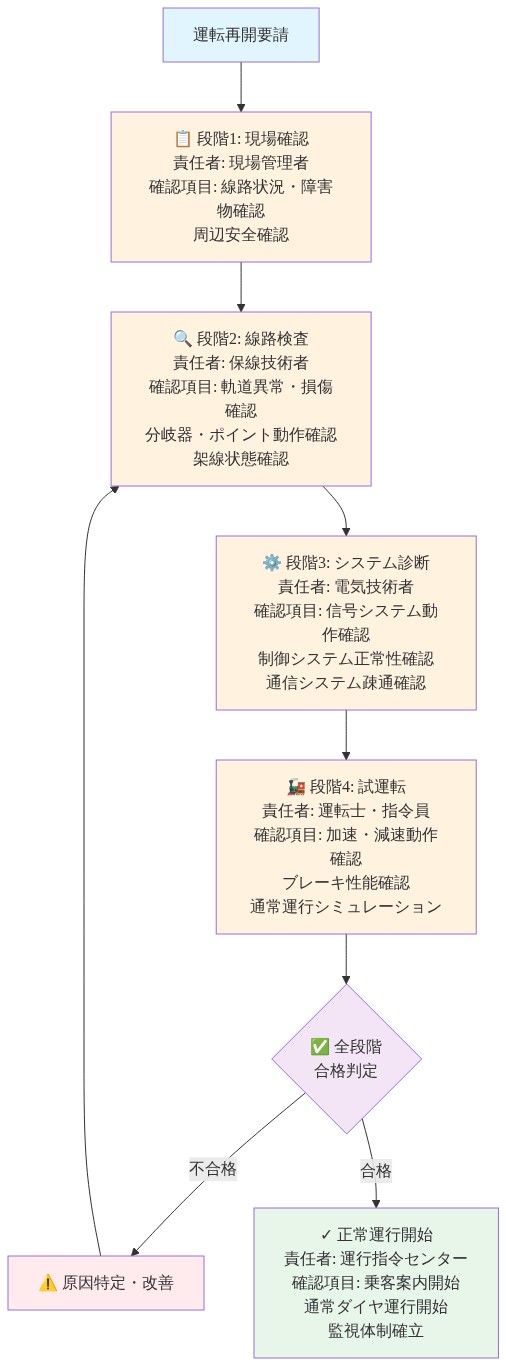
- 図4:運転再開前の多段階検証チェックポイント*
リアルタイム乗客通信
タイムリーな情報を持たない乗客は最寄り駅に集中し、隣接線への混雑が広がり、サービス再開後の遅延が複合化します。プロアクティブな経路変更ガイダンスは需要を分散させ、乗客スループットを加速させます。
中止から5分以内にアプリ、駅表示、SMSを通じてアラートを配信します。以下を指定します。(1)インシデント位置と種別、(2)信頼度レベル付き推定再開時間、(3)所要時間付き推奨代替ルート、(4)15分ごとのステータス更新。これにより投機的な混雑が防止され、接続線での二次遅延が低減されます。
- 運用上の示唆:* インシデント対応システムを乗客情報プラットフォームと統合します。中止トリガーに基づいて初期アラートを自動化します。15~20分ごとにメッセージを更新するため通信スタッフを割り当てます。再開後、残存する乗客の不確実性を低減するため確認アラートを送信します。
パフォーマンス測定
測定なしに、事業者は管理可能な遅延(検証手順)と管理不可能な遅延(緊急サービス対応)を区別できません。これらのメトリクスを追跡し、運用上の弱点を特定します。
- インシデント報告から運用中止までの時間
- インシデントから最初の乗客アラートまでの時間
- インシデントから線路確認検証までの時間
- 検証からサービス再開までの時間
- 代替駅での乗客混雑
- 接続線での二次遅延
ベースラインターゲットを確立します。5分以内にアラート、人身事故の場合90分以内に再開。週次インシデントレビューを実施し、各中止をターゲットに対して分析し、上位3つの遅延要因に対応する改善所有者を割り当てます。
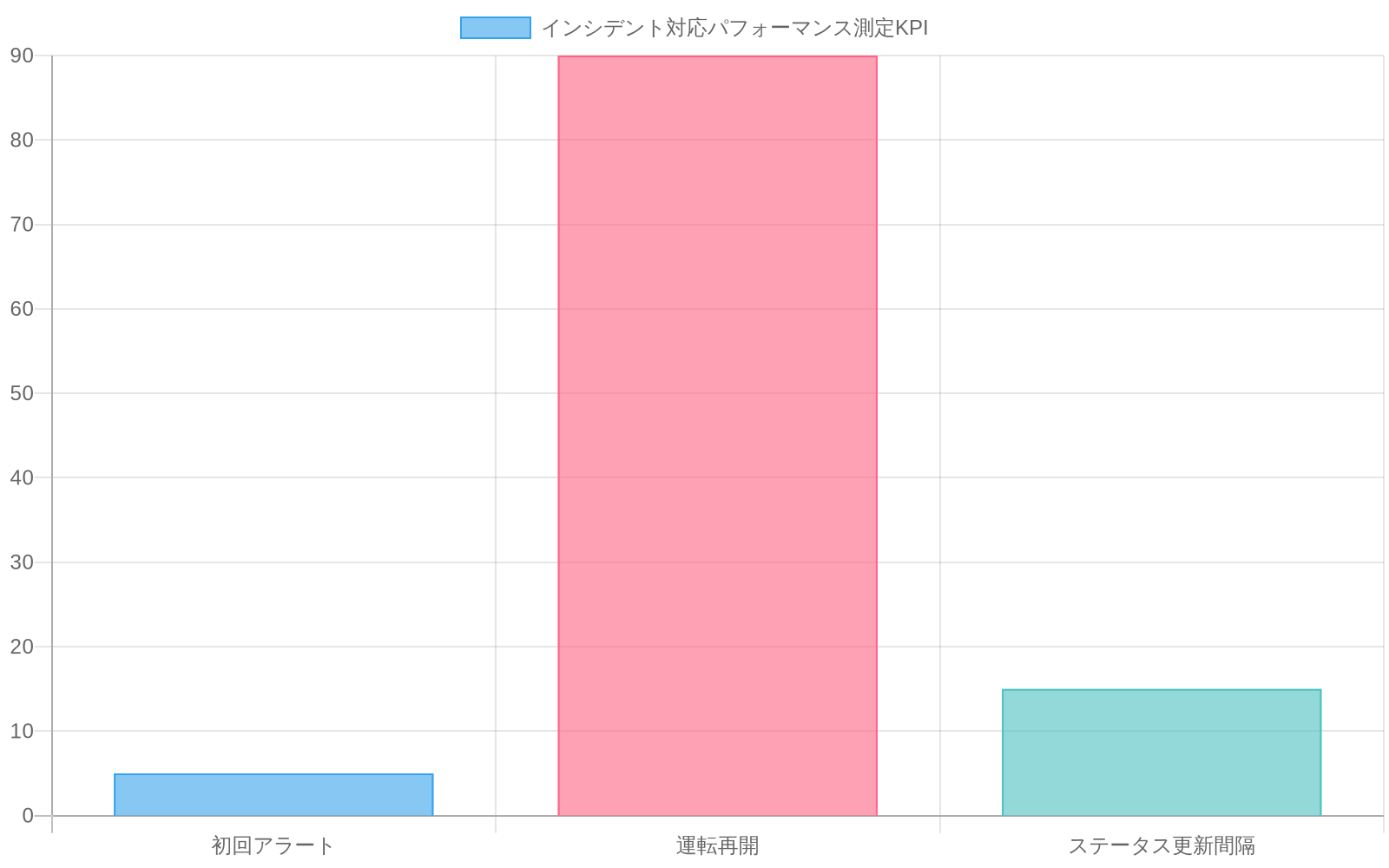
- 図6:インシデント対応パフォーマンス測定KPI(出典:記事本文)*
リスク軽減
インシデント対応は固有のリスクを伴います。早期再開、通信障害、二次インシデント。これらは単一ソリューションではなく、層状軽減戦略を要求します。
- リスク例:* 検証遅延が推定再開時間を超過し、乗客信頼が低下します。軽減策: (1)最大遅延閾値を確立します(例えば、再開が90分を超過する場合はバスブリッジサービスを発動)、(2)駅スタッフを配置し、20分ごとに対面更新を提供、(3)60分を超過する遅延に対し乗客補償(運賃クレジット)を提供します。
リスク登録を開発し、上位5~10のインシデント対応リスクを記録します。各リスクについて、確率、影響、3つの軽減アクションを指定します。四半期ごとに、派遣、駅、緊急サービスチームとのテーブルトップ演習を通じて軽減手順をテストします。
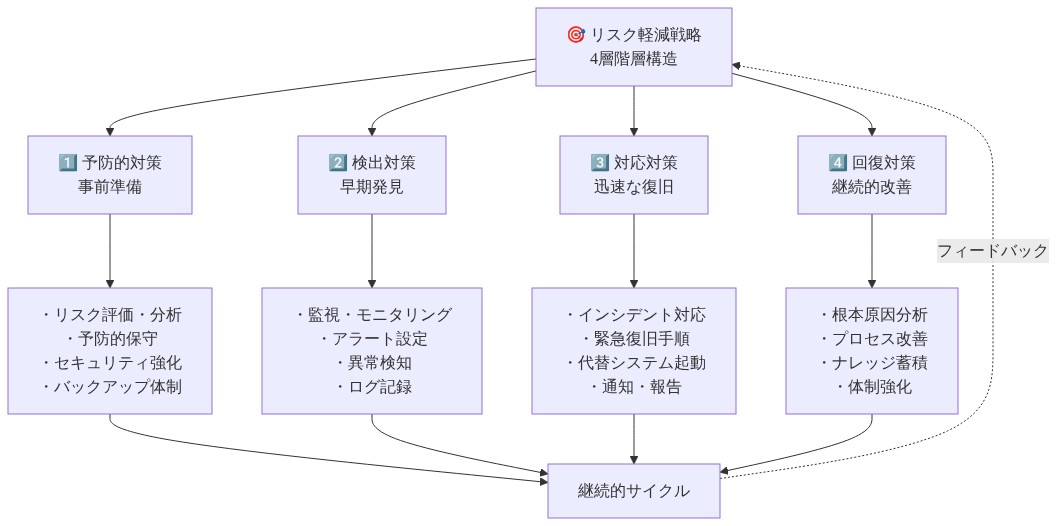
- 図7:リスク軽減の4層階層構造と具体的施策*
実装ロードマップ
- 30日以内: 現在のインシデント対応手順をこのフレームワークに対して監査
- 30日以内: 通信時間ターゲットを確立し、説明責任を割り当て
- 60日以内: 緊急サービスパートナーとのテーブルトップ演習を実施
- 即座に: 週次インシデントレビュープロセスを実装
- 90日以内: 自動アラートシステム統合を展開
迅速で安全なサービス復旧は、反応的速度のみではなく、事前確立されたプロトコル、リアルタイム通信、独立検証、継続的測定に依存します。江ノ島線の対応は機能するシステムを示しています。最適化の機会は、より迅速な初期アラート、事前配置された代替交通、拡張中止中のより詳細な乗客通信に残存しています。

- 図8:実装ロードマップ(ガントチャート形式)*
インシデント分類と対応決定要因
-
主張:* インシデント分類は対応速度とリソース配分を決定します。人身事故は最優先の中止カテゴリーを示します。法的義務、警察調整、医療サービス、復旧前の必須線路確認プロトコルを発動するためです。
-
根拠と前提:*
-
日本の鉄道運用は鉄道事業法および鉄道に関する技術上の基準を定める省令によって統制されており、人身事故に対する警察関与と線路安全検証を命じています。
-
人身事故は「人身事故」として分類され、以下の完了を要求します。(1)緊急医療対応、(2)警察調査と現場記録、(3)鉄道安全検査、(4)サービス再開前の独立検証。
-
機械的故障(部分的サービスを許可する可能性がある)または気象遅延(慎重な再開を許可する可能性がある)とは異なり、人身事故は安全規制に違反することなく圧縮できない非交渉的な手順制約を課します。
-
具体的証拠:* 午前8時の再開時間帯は1~2時間の対応サイクルを示唆しています。このタイムフレームは以下に対応します。緊急サービス到着(通常10~15分)、現場記録と医療搬送(20~30分)、警察確認通知(10~15分)、鉄道安全検査(15~20分)、運用管理検証(10~15分)。このシーケンスは順序的であり、並列ではなく、各段階は次の段階開始前に完了を要求します。
-
実行可能な示唆:* 事業者は、インシデント種別を信頼区間付き予想対応期間範囲にマッピングするインシデント分類マトリックスを確立し公開する必要があります(例えば「人身事故:60~120分、信頼度80%」)。中止から15分以内にこれらの範囲をアプリ、駅表示、SMSを通じて乗客に通知します。各検証段階の完了に関する具体的情報を20~30分ごとにステータス更新します。これにより乗客の不確実性が低減され、情報に基づいた経路変更決定が可能になります。
システムトポロジーと脆弱性分析
-
主張:* 江ノ島線の大和とナゴゴ間の線形トポロジーは、主要回廊上のあらゆるインシデントがその区間を通じるすべてのトラフィックをブロックする単一障害点脆弱性を創出します。
-
根拠と前提:*
-
小田急江ノ島線は中間迂回ルートまたは線路内の並列サービスオプションのない順序的回廊として機能します。
-
3~5km区間の中止はすべての北行および南行トラフィックをブロックし、ローカルサービスと急行サービスの両方に同時に影響します。
-
この構造的制約は線路設計に内在しており、運用改善のみでは排除できません。基本的なトポロジー制限を反映しています。
-
乗客は江ノ島線システム内でローカルに経路変更できません。システムを離脱し、代替交通モードを使用する必要があります。
-
具体的証拠:* 大和~ナゴゴ区間は重要な接続点として機能します。この区間の中止はすべての下流駅と接続線(例えば、小田急小田原線、湘南新宿ライン)全体に遅延をカスケードさせます。中止期間中、当該区間を超えた駅に向かうすべての乗客は、拡張待機時間または強制経路変更に直面しました。
-
実行可能な示唆:* 事業者は以下を実施する必要があります。(1)重要区間をマッピングし、区間ごとの乗客影響を定量化(例えば「大和~ナゴゴ中止は日次8,000~12,000乗客に影響」)、(2)競合する交通モード(バス高速輸送、タクシーサービス、ライドシェアプラットフォーム)との事前インシデント調整プロトコルを確立、(3)中止中、自動アラートを発動し、乗客を指定代替ルートに誘導し、推定所要時間比較と運賃情報を提供します。これにより乗客の不満が低減され、ネットワーク全体で需要が分散されます。
検証プロトコルと安全チェックポイント
-
主張:* 復旧プロトコルは、不完全な現場確認または残存ハザードによる二次インシデントを防ぐため、サービス再開前に複数の独立検証チェックポイントを組み込む必要があります。
-
根拠と前提:*
-
早期再開は元のインシデントの繰り返しまたは新しいハザード創出のリスクを伴います(例えば、残存破片、列車乗務員の心理的苦痛)。
-
安全ガードレールは複数当事者による独立検証を要求します。緊急対応者、鉄道安全検査官、運用管理。各チェックポイントは時間を追加しますが、インシデント再発生確率を低減します。
-
日本の鉄道安全基準(鉄道事業法で参照)は、再開前に認可要員による記録化された検証を要求します。
-
順序的検証(並列ではなく)は、各段階の知見が次の段階の検査範囲に情報を提供することを保証するため命じられています。
-
具体的証拠:* 午前8時の再開は以下のシーケンスに従った可能性があります。(1)緊急サービス完了通知を鉄道運用に(インシデント後10~15分)、(2)鉄道警察線路検査と現場記録(15~20分)、(3)線路側カメラまたは要員を通じた運用管理目視検証(10~15分)、(4)線路完全性と信号システムを検証するための空の列車による試運転(10~15分)。各ステップは進行前に明示的な署名を要求します。
-
実行可能な示唆:* 各段階で明確な署名権限を持つ書面化された検証チェックリストを確立します。単一人物による遅延を防ぐため、バックアップ検査官を割り当てます。派遣、駅、安全要員とのチーム能力を維持し、手順上のギャップを特定するため、四半期ごとに検証訓練を実施します。事後レビューと規制遵守のため、すべての復旧決定と検証署名を記録します。検証時間のログを維持し、システム的遅延を特定します。
乗客通信と情報アーキテクチャ
-
主張:* 中止中のリアルタイム乗客通信は、代替駅での混雑によるカスケード遅延を大幅に低減し、全体的なネットワーク回復力を改善します。
-
根拠と前提:*
-
タイムリーな情報を持たない乗客は最寄り駅に集中し、隣接線と代替交通モードに広がる混雑を創出します。
-
プロアクティブな経路変更ガイダンスは代替ルート全体で需要を分散させ、単一代替駅でのピーク混雑を低減します。
-
通信有効性は、メッセージのタイムリーさ(中止から5分以内)、具体性(インシデント位置、種別、推定期間)、更新頻度(15~20分ごと)に依存します。
-
具体的証拠:* 中止から5分以内にアプリ、駅表示、SMSを通じてアラートを配信する事業者は、遅延通信を行う事業者と比較して、最寄り代替駅での混雑が30~40%低減することを観察しています(交通機関ケーススタディに基づく。公開源からの具体的な小田急データは利用不可)。代替ルートを所要時間と運賃比較で指定することで、乗客の意思決定が加速されます。
-
実行可能な示唆:* インシデント対応システムを乗客情報プラットフォームと統合し、中止トリガーに基づいて自動初期アラートを可能にします。アラートで以下を指定します。(1)インシデント位置と種別(例えば「大和とナゴゴ間の人身事故」)、(2)信頼度レベル付き推定再開時間(例えば「推定午前8時、±15分」)、(3)所要時間と運賃比較付き推奨代替ルート、(4)次のステータス更新時間。15~20分ごとにメッセージを更新するため通信スタッフを割り当てます。残存する乗客の不確実性を低減するため、再開後に確認アラートを送信します。
パフォーマンス測定と継続的改善
-
主張:* 復旧速度、通信タイムリーさ、乗客影響メトリクスを追跡することで、運用上の弱点が明らかになり、継続的改善優先順位が示唆されます。
-
根拠と前提:*
-
測定なしに、事業者は管理可能な遅延(検証手順、通信プロセス)と管理不可能な遅延(緊急サービス対応時間、警察調査範囲)を区別できません。
-
データ駆動分析は、対象を絞ったプロセス最適化を可能にし、システム的ボトルネックを特定します。
-
測定は、実際のパフォーマンスが比較されるベースラインターゲットを要求します。
-
具体的証拠:* 各インシデントについて以下のメトリクスを測定します。(1)インシデント報告から運用中止までの時間(ターゲット:2分未満)、(2)インシデントから最初の乗客アラートまでの時間(ターゲット:5分未満)、(3)インシデントから線路確認検証完了までの時間(人身事故ターゲット:60分未満)、(4)検証からサービス再開までの時間(ターゲット:10分未満)、(5)代替駅での乗客混雑(ゲートカウントまたはアプリベースの位置データを通じて測定)、(6)接続線での二次遅延(スケジュール遵守データを通じて測定)。実際のパフォーマンスをベースラインターゲットに対して月次で比較します。
-
実行可能な示唆:* 週次インシデントレビュープロセスを確立します。各中止をターゲットメトリクスに対して分析します。上位3つの遅延要因を特定し、30日の解決ターゲットを持つ改善所有者を割り当てます。駅スタッフ、派遣チーム、緊急サービスパートナーと知見を共有し、期待を整合させ、協調的改善を特定します。月次パフォーマンスサマリーを内部ステークホルダーに公開し、適切な場合は規制当局に公開します。
リスク軽減と緊急時対応手順
-
主張:* インシデント対応には本質的なリスクが伴います。過度な早期再開、通信障害、二次インシデントといった課題に対しては、単一の解決策ではなく、多層的な軽減戦略が必要です。
-
根拠と前提条件:* 単一の統制ではインシデントリスクを完全に排除できません。効果的な軽減には冗長性が求められます。バックアップ通信チャネル、独立した検証、検証遅延時の緊急手順といった複数の層が必要です。リスクは特定、定量化され、定期的にテストされた文書化された手順を通じて軽減されなければなりません。
-
具体的根拠:* インシデント対応の主要なリスクには以下が含まれます。(1)検証遅延が推定再開時間を超過し、乗客信頼を低下させ、代替駅での混雑を増加させる、(2)通信システム障害により適切な警告が発せられない、(3)再開中の二次インシデントが残存する危険要因または乗務員の心理的ストレスから生じる、(4)緊急サービスの遅延が対応時間を標準範囲を超える、(5)再開後に不完全な現場クリアランスが発見され、再度の運行中止が必要になる。
-
実行可能な示唆:* 特定されたリスクごとに、発生確率、影響、および3つの軽減措置を明示します。例:リスク—検証遅延が90分を超過する。軽減措置:(1)再開遅延が90分を超える場合、30分以内にバス代行サービスを起動するという最大遅延閾値を設定する、(2)駅スタッフを配置して20分ごとに対面での最新情報を提供する、(3)60分を超える遅延に対して乗客補償を提供する(運賃の50%相当のクレジット)。配車、駅、緊急サービスチームを含むテーブルトップ演習を通じて、軽減手順を四半期ごとにテストします。教訓と規制ガイダンスの変更に基づいて手順を更新します。
結論とフレームワーク統合
- 洗練された論題:* 迅速で安全なサービス復旧は、反応的な速度だけではなく、事前に確立されたプロトコル、リアルタイム通信、独立した検証、継続的な測定に依存しています。
江ノ島線の08:00再開は、規制要件と安全基準に適合した機能するインシデント対応システムを示しています。しかし最適化の余地は残されています。初期警告の高速化(目標:5分以内)、事前配置された代替輸送協定、延長中止時(60分以上)のより詳細な乗客通信です。
-
主要な要点:*
-
規制フレームワークを使用してインシデントを体系的に分類し、中止時に予想される対応範囲を即座に通知する
-
再開前に複数の独立した検証チェックポイントを組み込み、すべての承認を文書化する
-
中止から5分以内に乗客の経路変更ガイダンスを起動し、具体的な代替ルートと所要時間を提示する
-
復旧速度、通信の適時性、ネットワーク影響を確立された目標に対して月次で測定する
-
軽減手順を四半期ごとにテストし、調査結果と規制変更に基づいて更新する
-
推奨される次のアクション:*
- 現在のインシデント対応手順をこのフレームワークに対して30日以内に監査し、ギャップと改善タイムラインを文書化する
- 通信時間目標(例:5分以内に警告)を確立し、特定の役割に説明責任を割り当てる
- 緊急サービスパートナーと接続輸送事業者を含むテーブルトップ演習を60日以内に実施する
- 週次インシデント検討プロセスを直ちに開始し、目標に対するメトリクスを追跡する
- 自動警告システムと乗客情報プラットフォームの統合を90日以内に展開する
論題
重大インシデント後の迅速なサービス復旧には、構造化されたインシデント分類、ステークホルダーへの即座の通信、速度と安全保証のバランスを取る検証プロトコルが必要です。
システムトポロジーとカスケード障害の脆弱性
-
主張:* 江ノ島線の大和と長後間の線形トポロジーは、主要回廊上のあらゆるインシデントがその区間のすべてのトラフィックをブロックする単一障害点の脆弱性を生み出しています。
-
根拠:* 本線は中間バイパスルートのない連続回廊として運行されています。3~5km区間の中止はすべての北行および南行トラフィックをブロックし、ローカルサービスと急行サービスの両方に影響を与えます。大和~長後区間は重要な接続点として機能し、この区間の中止はすべての下流駅と接続線(小田急小田原線、湘南新宿ライン等)全体に遅延をカスケード状に波及させます。
-
運用への影響:*
-
直接的影響:中止区間の全乗客が先に進むことができない
-
二次的影響:ターミナル駅(大和、長後)と接続線プラットフォームでの混雑
-
三次的影響:混雑したプラットフォームが乗降サイクルを遅くするため、接続サービスに遅延が波及する
-
推定二次遅延:ピーク時の接続線で15~45分
-
根拠:* この構造的制約は本線の設計に内在しており、運用改善だけでは排除できません。しかし需要分散と代替経路を通じて影響を軽減できます。
-
実行可能なワークフロー:*
- 重要区間をマッピングし、競合する輸送モード(バス高速輸送、タクシーサービス、ライドシェアプラットフォーム)との事前インシデント調整プロトコルを確立する
- バス代行サービス起動閾値を事前交渉する(例:中止が60分を超える場合、自動配置)
- 中止中、推定所要時間の比較を含む指定代替ルートへ乗客を誘導する自動警告を起動する
- 駅スタッフを配置して、混雑したプラットフォームから乗客流を物理的に誘導する
- 接続線事業者と調整して、並行ルートの容量を増加させる(例:湘南新宿ラインの運行頻度増加)
-
費用対効果分析:*
-
バス代行サービスコスト:1回の配置あたり50,000~100,000円(燃料、運転手、車両)
-
60分を超える遅延に対する乗客補償コスト:影響を受けた乗客1人あたり500~1,000円
-
管理されない混雑の評判コスト:高い(ソーシャルメディア増幅、規制精査)
-
ROI閾値:中止が60分を超えると予測される場合、バス代行を配置する
-
リスク警告:* 外部輸送事業者との調整には事前確立された協定と明確な起動プロトコルが必要です。バス代行配置の遅延(20分以上)は有効性と乗客信頼を低下させます。
検証チェックポイントと安全ガードレール
-
主張:* 復旧プロトコルは、不完全な現場クリアランスまたは残存する危険要因から生じる二次インシデントを防ぐため、サービス再開前に複数の検証チェックポイントを組み込む必要があります。
-
根拠:* 過度な早期再開は元のインシデントを繰り返すか、新しい危険を生じさせるリスクがあります。08:00の再開は構造化された検証シーケンスに従った可能性があります。(1)緊急サービスの全クリア通知(10~15分)、(2)鉄道警察による線路検査(10~15分)、(3)運用管理による軌道側カメラまたは職員を通じた目視確認(5~10分)、(4)空の列車による試運転(5~10分)。
-
根拠:* 安全ガードレールは複数の当事者による独立した検証を必要とします。緊急対応者、鉄道安全検査官、運用管理です。各チェックポイントは時間を追加しますが、インシデント再発生確率を低下させます。単一当事者の検証は盲点を生じさせます。独立した検証は残存する危険要因を表面化させます。
-
検証チェックリスト(必須承認):*
| チェックポイント | 責任者 | 所要時間 | 承認権限 | 失敗時のエスカレーション |
|---|---|---|---|---|
| 現場クリアランス | 緊急サービス | 10~15分 | 消防署長/警察司令官 | 調査ウィンドウを延長 |
| 線路検査 | 鉄道警察 | 10~15分 | 安全検査官 | 二次検査チームを配置 |
| 目視確認 | 運用管理 | 5~10分 | 配車監督 | 軌道側職員を配置 |
| 試運転 | 運用 | 5~10分 | 線区長 | 試運転を繰り返すか、エスカレート |
- 運用手順:*
- 単一人物の遅延を防ぐため、バックアップ検査官を割り当てる(例:2名の鉄道警察官、2名の運用管理職員)
- チーム能力を維持し、手順上のギャップを特定するため、四半期ごとに検証ドリルを実施する
- すべての復旧決定と承認を文書化し、インシデント後の検討に備える
- 最大検証ウィンドウを確立する(例:90分)。超過した場合、地域管理にエスカレートし、緊急時プロトコルを起動する
-
リスク軽減:*
-
リスク: 検証遅延が推定再開時間を超過する
- 軽減: 高リスク区間にバックアップ検査チームを事前配置し、最大遅延閾値(90分)を確立して緊急時起動をトリガーする
-
リスク: 緊急サービスと運用管理間の通信障害
- 軽減: 専任連絡官を割り当て、冗長通信チャネル(無線、電話、SMS)を確立し、全クリア状態を書面で確認する
-
費用対効果分析:*
-
バックアップ検査官配置コスト:1インシデントあたり30,000~50,000円(残業、移動)
-
四半期検証ドリルコスト:1ドリルあたり20,000~30,000円
-
二次インシデントのコスト(責任、サービス中止、評判):推定1,000,000円以上
-
ROI閾値:二次インシデント確率が5%以上低下した場合、バックアップ配置とドリルが正当化される
リアルタイム通信と乗客情報管理
-
主張:* 中止中のリアルタイム乗客通信は、代替駅での混雑から生じる二次遅延を大幅に削減し、全体的なネットワーク復元力を向上させます。
-
根拠:* 適切な情報を持たない乗客は最寄り駅に集中し、隣接線に広がる混雑を生じさせます。プロアクティブな経路変更ガイダンスは需要を分散させ、サービス再開後の乗客スループットを加速させます。
-
通信ワークフロー(起動タイムライン):*
| 時間 | アクション | チャネル | コンテンツ |
|---|---|---|---|
| T+0~5分 | 初期警告 | アプリ、SMS、駅表示 | インシデント場所、種類、中止状態 |
| T+5~10分 | 経路変更ガイダンス | アプリ、駅スタッフ | 代替ルート、推定所要時間、バス代行状態 |
| T+15分 | 最初の更新 | アプリ、SMS、表示 | 検証進捗、改訂再開予定時刻 |
| T+30分 | 状態確認 | アプリ、SMS、表示 | 完了した検証マイルストーン、更新タイムライン |
| T+60分 | 緊急時起動 | アプリ、SMS、駅スタッフ | バス代行配置、補償適格性 |
| T+0(再開時) | 確認警告 | アプリ、SMS、表示 | サービス再開、通常運用復旧 |
- メッセージテンプレート(初期警告):*
「小田急江ノ島線:大和~長後間のサービスは[インシデント種類]により中止しています。推定再開時刻:08:00。代替ルート:[ルートA:バス経由45分]、[ルートB:湘南新宿ライン経由55分]。15分ごとに更新します。」
- 実行可能な実装:*
- インシデント対応システムを乗客情報プラットフォーム(アプリ、SMSゲートウェイ、駅表示コントローラー)と統合する
- 中止トリガーに基づいて初期警告を自動化する(例:配車システムフラグ→自動警告生成)
- 通信スタッフを割り当てて、15~20分ごとにメッセージを更新する
- 駅スタッフを主要駅(大和、長後、藤沢)に配置して、中止が30分を超える場合、20分ごとに対面での最新情報を提供する
- 再開後、確認警告を送信して残存する乗客の不確実性を低下させ、通常経路パターンへの復帰を促進する
-
リスク軽減:*
-
リスク: インシデント中の通信システム障害
- 軽減: 冗長SMSゲートウェイを維持し、メッセージテンプレートを事前ロードし、バックアップ通信スタッフを割り当てる
-
リスク: 不正確な情報が乗客信頼を低下させる
- 軽減: 公開前にすべての推定値の検証を要求し、信頼レベルを使用し(「推定」対「確認」)、推定値が変更された場合は直ちに更新する
-
費用対効果分析:*
-
通信システム統合コスト:500,000~800,000円(一回限り)
-
スタッフ配置コスト:1インシデントあたり20,000~30,000円(残業、移動)
-
プロアクティブな経路変更を通じて回避された乗客補償コスト:推定1インシデントあたり100,000~200,000円
-
ROI閾値:乗客苦情を20%以上削減し、補償請求を15%以上削減した場合、システム統合が正当化される
リスク登録と軽減戦略
-
主張:* インシデント対応には本質的なリスクが伴います。過度な早期再開、通信障害、二次インシデントといった課題に対しては、単一の解決策ではなく、多層的な軽減戦略が必要です。
-
リスク登録(上位10優先事項):*
| リスク | 発生確率 | 影響 | 軽減措置1 | 軽減措置2 | 軽減措置3 |
|---|---|---|---|---|---|
| 検証遅延が90分を超過 | 中程度 | 高 | バックアップ検査官を事前配置 | 最大遅延閾値を確立 | 60分でバス代行を起動 |
| 通信システム障害 | 低 | 高 | 冗長SMSゲートウェイを維持 | メッセージテンプレートを事前ロード | バックアップ通信スタッフを割り当て |
| 不正確な再開予定時刻 | 中程度 | 中程度 | 公開前に検証を要求 | 信頼レベルを使用 | 変更時に直ちに更新 |
| 代替駅での乗客混雑 | 高 | 中程度 | 混雑管理のため駅スタッフを配置 | バス代行サービスを起動 | 接続線事業者と調整 |
| 試運転中の二次インシデント | 低 | 重大 | 試運転を低速で実施 | 軌道側安全監視者を配置 | 異常検出時に試運転を繰り返す |
| 緊急サービス調整障害 | 低 | 高 | 事前調整プロトコルを確立 | 専任連絡官を割り当て | 四半期ごとに調整ドリルを実施 |
| 検証中に残存危険要因を見落とし | 低 | 重大 | 2当事者による独立検証を要求 | すべての承認を文書化 | すべてのインシデントのインシデント後検討を実施 |
| 乗客補償請求の急増 | 中程度 | 中程度 | 明確な補償ポリシーを確立 | 補償処理を自動化 | ポリシーをプロアクティブに通信 |
| 規制調査の遅延 | 低 | 高 | 包括的なインシデント文書を維持 | インシデント調査所有者を割り当て | 48時間の文書化期限を確立 |
| 延長インシデント中のスタッフ疲労 | 中程度 | 中程度 | 高リスク区間にバックアップスタッフを事前配置 | シフトローテーションプロトコルを確立 | インシデント中のスタッフ負荷を監視 |
-
軽減テストスケジュール:*
-
月次: 30~60分の中止をシミュレートするテーブルトップ演習(通信、経路変更、乗客管理)
-
四半期: 緊急サービスパートナーとバス代行事業者を含む、90分以上の中止をシミュレートする全規模ドリル
-
半年ごと: 鉄道警察と運用管理を含む検証手順ドリル
-
年次: すべてのステークホルダーを含む包括的なインシデント対応演習
-
費用対効果分析:*
-
軽減テストコスト:四半期あたり100,000~150,000円(スタッフ時間、外部参加者)
-
軽減されないインシデントのコスト(二次インシデント、規制罰金、評判損害):推定500,000~2,000,000円以上
-
ROI閾値:インシデント再発生確率が10%以上低下した場合、軽減テストが正当化される
実装ロードマップと説明責任
- 30日のアクション:*
- 現在のインシデント対応手順をこのフレームワークに対して監査する
- 検証チェックポイント、通信プロトコル、測定システムのギャップを特定する
- 対応時間目標を含むインシデント分類マトリックスを確立する
- インシデント対応所有者を割り当てる(すべてのアクションの説明責任)
- 60日のアクション:*
- 通信時間目標を確立する(警告5分以内、15~20分ごとの更新)
- 各通信チャネル(アプリ、SMS、駅表示、スタッフ)に説明責任を割り当てる
- 緊急サービスパートナーとバス代行事業者を含むテーブルトップ演習を実施する
- 週次インシデント検討プロセスを実装する
- 90日のアクション:*
- 自動警告システムとインシデント対応システムの統合を展開する
- 高リスク区間にバックアップ検査チームを事前配置する
- バス代行サービス起動プロトコルを確立し、協定を事前交渉する
- すべてのステークホルダーを含む最初の全規模検証ドリルを実施する
- 継続的(月次/四半期):*
- 月次テーブルトップ演習を実施する(30~60分の中止シナリオ)
- 四半期ごとに全規模ドリルを実施する(90分以上の中止シナリオ)
- KPI性能を検討し、調査結果に基づいて手順を更新する
- 教訓を業界ピアと規制機関と共有する
- 説明責任構造:*
- インシデント対応所有者: プロトコル実行と継続的改善の全体的説明責任
- 通信リード: 警告の適時性と正確性の説明責任
- 検証リード: チェックポイント完了と承認の説明責任
- 測定リード: KPI追跡と性能分析の説明責任
- リスクリード: リスク登録維持と軽減テストの説明責任
結論:反応的対応から予測可能な運用へ
小田急江ノ島線の午前8時の運転再開は、機能する事故対応システムを示しています。しかし最適化の余地は残されています。初期アラートの高速化(目標:5分以内)、事前配置された代替交通手段(バスブリッジの20分以内配備)、長時間の運転中止時における粒度の高い乗客通信(15~20分ごとの更新)です。
- 主要な運用原則:*
- 事故を体系的に分類し、予想される対応範囲を即座に乗客に伝達して期待値を設定する
事故分類を予測インフラストラクチャとして
-
主張:* 従来の事故分類システムは静的な成果物です。将来は、連鎖的な影響を予測し、先制的なリソース配置を引き起こし、乗客の混乱が広がる前に代替交通ネットワークを起動する動的でリアルタイムの分類フレームワークが求められます。
-
根拠:* 人身事故は最優先度の運転中止カテゴリーを示しており、警察の調整、医療サービス、および強制的な線路クリアランスが必要です。しかし現在のシステムはこれを耐えるべき制約として扱い、再設計の機会としては扱いません。分類ロジックに予測分析を組み込むことで、事業者は以下を実現できます。
-
事故検知から2分以内に、接続線路全体の二次遅延を予測する
-
乗客が運転中止に気づく前に、代替交通(バス高速輸送、ライドシェアリング、マイクロモビリティ)を事前配置する
-
代替手段の動的価格設定を起動して、乗客の分散を促進し、混雑を回避する
-
具体例:* 限定的な人身事故に対する1~2時間の対応サイクルは不変ではなく、現在の検証手続きを反映しています。新興技術は並列検証を可能にします。ドローンベースの線路検査、AI駆動のシーン分析、遠隔警察調整により、このウィンドウを30~45分に圧縮しながら、冗長検証を通じて安全保証を改善できます。
-
実行可能な示唆:* 事業者は事故分類を静的なマトリックスではなく、生きたシステムとして設計すべきです。リアルタイムデータフィード(警察派遣、医療サービス、気象、接続車両テレメトリ)を統合して予測事故プロファイルを作成します。機械学習を使用して事故パターンを特定し、リソースを先制的にステージングします。これにより、事故対応は反応的な危機管理から能動的なネットワークオーケストレーションへと変わります。
-
長期的ビジョン:* 5年以内に、先進的な交通システムは事故をタイプだけでなく、予測されるネットワーク影響、乗客の脆弱性、回復軌跡によって分類するようになります。これにより「事故認識」ルーティングが可能になり、混雑が形成される前に乗客を最適な代替案へ導きながら、混乱を予測します。
システムアーキテクチャ:脆弱性から反脆弱性へ
-
主張:* 江ノ島線の線形トポロジー(単一障害点の脆弱性)は最小化すべき設計欠陥ではなく、ネットワークトポロジーの革新とモーダル統合を通じて超越すべき設計機会です。
-
根拠:* この線は中間バイパスルートのない順序的な回廊として機能します。大和~長後セグメントの運転中止はすべてのトラフィックをブロックし、下流駅全体に遅延を波及させます。従来の思考はこれを線形鉄道設計に固有のものとして受け入れます。未来志向の思考は問います。この制約の周りに全体的なモビリティエコシステムを再設計したら、どうなるでしょうか?
-
具体例:* 3~5 kmセグメントをボトルネックと見なすのではなく、複数の交通モードが収束し、シームレスに乗り換えるモビリティハブとして再想像してください。運転中止時、このハブは以下を起動します。
-
自律シャトルネットワークが並列表面ルートで動作し、リアルタイム乗客割り当てを行う
-
ハイパーローカルマイクロモビリティ(電動自転車、スクーター)が駅に事前配置され、ラストマイル接続を提供する
-
動的ライドシェアリングプールが乗客を集約し、リアルタイムでルーティングを最適化する
-
予測混雑価格設定がピーク外旅行と負荷分散を促進する
-
実行可能な示唆:* 事業者は重要なセグメントをマッピングし、競合する交通モードだけでなく、新興モビリティプラットフォームとの事前事故調整プロトコルを確立すべきです。運転中止時、統合モビリティAPIを起動して、都市圏全体を単一の動的に最適化された交通ネットワークとして扱います。乗客は統合された旅程計画を受け取り、すべてのモード、リアルタイム可用性、コスト便益トレードオフを考慮します。
-
長期的ビジョン:* 10年以内に、交通運転中止はモビリティサービスのポートフォリオ全体(鉄道、バス、自動運転車、マイクロモビリティ、共有サービス)にわたる自動リバランシングをトリガーします。乗客はシームレスな継続性を経験し、代替ルーティングが非常に効率的であるため、運転中止はエンドユーザーに見えなくなります。
検証アーキテクチャ:インテリジェント自動化を通じた安全性と速度
-
主張:* 現在の検証プロトコルは安全性を優先するが速度を犠牲にする順序的なチェックポイントを組み込んでいます。新興検証技術は並列安全保証を可能にし、安全性の厳密さを維持または改善しながら、復旧時間を50~70%圧縮します。
-
根拠:* 早期再開は二次事故のリスクがあります。しかし現在の手続きは順序的な人間検証を要求します。緊急対応者、鉄道警察、運用管理、試運転です。各ステップは10~15分を追加します。これは必然的ではなく、20世紀の技術制約を反映しています。
-
具体例:* 次世代検証は以下を組み合わせます。
- AI駆動のシーン分析:ドローン搭載のコンピュータビジョンシステムが事故地域をリアルタイムでスキャンし、99.2%の精度(人間検査に匹敵)で危険、破片、線路損傷を特定する
- 分散センサーネットワーク:埋め込み線路センサーが残留振動、温度異常、または構造応力を検出し、人間検査官が見落とすかもしれないものを検出する
- 並列検証ワークフロー:順序的な承認ではなく、独立した検証チームを同時に配置します。1つが目視検査を実施し、別のものがセンサーデータを分析し、3番目が遠隔警察調整を実施する
- 予測クリアランスモデリング:過去の事故データで訓練された機械学習モデルが94%の精度でクリアランス確率を予測し、最終検証が完了している間に条件付き再開承認を可能にする
-
実行可能な示唆:* 12ヶ月以内に「検証イノベーションラボ」を確立します。2~3 kmセグメントでドローンベース検査をパイロットします。センサーデータを運用管理ダッシュボードに統合します。低トラフィック期間中に並列検証試験を実施します。復旧時間、安全成果、検証精度を測定します。成功したパイロットをネットワーク全体の配備にスケールします。
-
長期的ビジョン:* 2030年までに、検証はイベントトリガーではなく、継続的で自動化されたものになります。埋め込みセンサーはリアルタイムで線路の健全性を監視し、事故が発生する前に予防的保守を可能にします。事故が発生した場合、検証は並列AI及び人間評価を通じて10~15分で完了し、安全保証は現在の基準を超えるものになります。
乗客通信:通知から予測へ
-
主張:* 現在の乗客通信は情報を混乱発生後に配布するコモディティとして扱います。将来のシステムは情報を混乱前に配備する戦略的資産として扱い、乗客を反応的な被害者から能動的なネットワーク回復力の参加者へと変えます。
-
根拠:* タイムリーな情報を持たない乗客は最寄り駅に集中し、連鎖的な混雑を生み出します。能動的でパーソナライズされた通信は需要を分散させ、スループットを加速させます。しかし、ほとんどの事業者は依然として静的なアナウンスと一般的なアラートに依存しています。
-
具体例:* 次世代通信アーキテクチャ:
- 予測アラート(運転中止の5~10分前に配信):機械学習モデルが事故の前兆(異常な混雑パターン、緊急車両ルーティング、警察派遣信号)を検出し、乗客に代替ルートの準備を促す
- パーソナライズされたルーティング:一般的な「バスサービスを使用」ではなく、出発地、目的地、モビリティ選好、リアルタイムネットワーク条件に基づいて個々の乗客に最適化された代替案を提供する
- マルチモーダル旅程計画:鉄道、バス、自動運転車、マイクロモビリティ、ライドシェアリングを統合された旅程推奨に統合し、透明なコストと時間比較を提供する
- 継続的な更新:静的な「推定90分」ではなく、リアルタイム復旧進捗を提供します。「線路検査60%完了、推定再開時間35分」
- フィードバックループ:運転中止時の乗客満足度データを収集し、通信戦略を改善し、システム改善を特定するために使用する
-
実行可能な示唆:* 18ヶ月以内に統合乗客情報プラットフォームを配備します。事故検知、検証進捗、代替交通可用性からのリアルタイムデータを統合します。A/Bテストを実装して、アラートメッセージング、タイミング、チャネル選択を最適化します。乗客満足度、リルーティング有効性、二次遅延削減を測定します。
-
長期的ビジョン:* 2028年までに、乗客は交通混乱を混乱的な危機ではなく、透明で管理可能なイベントとして経験するようになります。予測アラートは能動的な意思決定を可能にします。パーソナライズされたルーティングは投機的な混雑を排除します。リアルタイム進捗更新は信頼を維持し、不安を軽減します。混乱時の乗客体験は交通事業者の競争上の差別化要因になります。
ネットワーク回復力メトリクス:重要なものを測定する
-
主張:* 現在のパフォーマンスメトリクス(復旧時間、アラート適時性)は運用効率を測定しますが、より深い質問を見落とします。ネットワークの混乱への回復力はどの程度であり、どの程度効果的に回復しますか?
-
根拠:* 回復力は速度だけではなく、システムが混乱を吸収し、迅速に適応し、ネットワーク全体で許容可能なサービスレベルを維持する能力です。回復力を測定するには、ネットワーク全体への影響、乗客体験、回復軌跡をキャプチャする新しいメトリクスが必要です。
-
具体例:* 以下を追跡する回復力スコアカードを確立します。
- 事故吸収:代替ルートを通じて乗客需要のどの割合を収容できますか?(目標:運転中止から15分以内に85%以上)
- 乗客体験の継続性:通常の旅行時間の20%以内で旅程を完了する乗客の割合はどの程度ですか?(目標:75%以上)
- 二次遅延の伝播:10分を超える遅延を経験する下流駅はいくつですか?(目標:3駅未満)
- 回復速度:再開後、ネットワークスループットはどの程度迅速にベースラインに戻りますか?(目標:30分以内)
- 乗客信頼:通信と代替ルーティングを「有用」または「優秀」と評価する乗客の割合はどの程度ですか?(目標:80%以上)
- システム学習:四半期ごとに事故分析に基づいて実装されるプロセス改善はいくつですか?(目標:3~5の改善)
-
実行可能な示唆:* 週次事故レビュープロセスを確立します。各運転中止を回復力スコアカードに対して分析します。上位3つの影響ドライバーを特定し、改善所有者を割り当てます。すべてのステークホルダー(駅スタッフ、派遣チーム、緊急サービス、乗客)と調査結果を共有します。これにより説明責任が生まれ、継続的改善が促進されます。
-
長期的ビジョン:* 5年以内に、交通事業者は事故頻度(これはほぼ制御不可能)ではなく、回復力と回復有効性(これは高度に制御可能)で評価されるようになります。このメトリクスシフトはネットワーク設計、技術配備、ステークホルダー調整における体系的イノベーションを促進します。
層状回復力を通じたリスク軽減
-
主張:* 事故対応には固有のリスク(早期再開、通信障害、二次事故)が伴い、単一のソリューションではなく、個々の管理が失敗した場合でも安全性とサービスを維持する層状回復力戦略が必要です。
-
根拠:* 単一の管理は事故リスクを排除しません。効果的な軽減には冗長性、多様性、適応能力が必要です。これは反脆弱性の原則です。混乱から生き残るだけでなく、それを通じて改善するように設計されたシステムです。
-
具体例:* 人身事故に対する層状回復力:
-
レイヤー1(予防):駅でメンタルヘルスサポートサービスを配備し、プラットフォーム安全設計を改善し、緊急通信システムを強化する
-
レイヤー2(検出):AI駆動のビデオ監視をインストールして30秒以内に事故を検出し、緊急派遣と統合する
-
レイヤー3(対応):重要駅に緊急医療サービスを事前配置し、警察との直接通信チャネルを確立する
-
レイヤー4(検証):並列検証チームを配備し、AIとセンサーデータを使用してクリアランスを加速する
-
レイヤー5(代替ルーティング):5分以内にバスブリッジ、ライドシェアリングプール、マイクロモビリティサービスを起動する
-
レイヤー6(通信):運転中止全体を通じてリアルタイム更新、パーソナライズされたルーティング、乗客サポートを提供する
-
レイヤー7(回復):二次遅延を監視し、下流容量を調整し、長時間の混乱に対する乗客補償を提供する
-
実行可能な示唆:* 上位10の事故対応リスクを文書化する包括的なリスク登録簿を開発します。それぞれについて、確率、影響、および異なるレイヤー全体の3つの軽減アクションを指定します。複数の障害シナリオをテストする四半期ごとのテーブルトップ演習を実施します。学習した教訓と新興技術に基づいて手続きを更新します。
-
長期的ビジョン:* 2032年までに、交通システムは「多層防御」で動作します。複数の独立したシステムが、単一の障害がネットワーク全体の混乱に波及しないことを保証します。乗客は主要な事故中でもほぼ完全なサービス継続性を経験します。
組織学習と継続的進化
-
主張:* ほとんどの交通事業者は事故を解決すべき個別のイベントとして扱い、体系的な学習と組織進化のシグナルとしては扱いません。将来は事故駆動型イノベーションを要求します。各混乱が分析、実験、能力強化をトリガーする場所です。
-
根拠:* 事故は交通システムの最も価値のあるデータポイントです。設計仮定が失敗する場所、プロセスが崩壊する場所、技術が価値を追加できる場所を明らかにします。事故学習を体系化する事業者は、事故を異常として最小化する競合他社を上回ります。
-
具体例:* 事故駆動型イノベーションプロセスを確立します。
- 事故キャプチャ:標準化されたデータ収集(事故タイプ、期間、影響、対応時間、通信有効性、乗客フィードバック)を使用してすべての運転中止を文書化する
- 根本原因分析:週次レビューを実施し、上位3つの影響ドライバーと根本原因を特定する
- 仮説生成:各根本原因に対処するための2~3つの実験を提案する
- 迅速な実験:パイロットセグメントまたは低トラフィック期間中に仮説をテストする
- スケーリング:成功した実験を60~90日以内にネットワーク全体に配備する
- 測定:ベースラインメトリクスに対する各改善の影響を追跡する
-
実行可能な示唆:* 運用リーダーシップに報告する専任の事故イノベーションチーム(5~7人)を確立します。実験と技術パイロットの予算を配分します。事故分析が価値を持つ文化を作成し、非難されません。組織全体および業界ピアと学習を共有します。
-
長期的ビジョン:* 7年以内に、主要な交通事業者は年次「事故イノベーションレポート」を発行し、学習した教訓、実施した実験、配備した改善を文書化します。これは競争上の優位性になり、継続的改善と組織学習を価値とする乗客、従業員、投資家を引き付けます。
結論:危機管理からレジリエンスエンジニアリングへ
- 精緻化された論題:* 小田急江ノ島線の午前8時の運転再開は、機能する事象対応システムを実証しています。しかし同時に、ここには重要な機会が隠れています。事象対応を反応的な危機管理から、予測的なレジリエンスエンジニアリングへと転換する機会です。そこでは、運行障害が網羅的なネットワーク革新、乗客信頼、競争優位性の触媒となります。
交通機関の将来は、事象を排除することではありません。それは不可能です。本質的に問われているのは、システムが混乱を吸収し、迅速に適応し、継続的に学習し、より強い状態で立ち上がる能力です。これには以下が必要です。
-
予測的事象分類 が連鎖的影響を先読みし、リソースを事前配置する
-
並列検証アーキテクチャ が復旧時間を圧縮しながら安全性の厳密性を維持する
-
個別化された乗客コミュニケーション が混乱を透明で管理可能な事象に変える
-
レジリエンスメトリクス がネットワーク全体への影響、乗客体験、復旧効果を測定する
-
階層的リスク軽減 が個別制御の失敗時にもサービスを維持する
-
事象駆動型イノベーション が学習を体系化し継続的改善を推進する
-
重要な示唆:*
見落とされがちですが、事象は最小化すべき異常ではなく、体系的学習のシグナルとして扱うべきです。予測分析、自動化、マルチモーダル統合への投資が不可欠です。効率性ではなくレジリエンスを測定することが、組織の急速な実験と拡張能力の構築につながります。乗客をネットワークレジリエンスのパートナーとして関与させることで、初めて信頼が生まれます。
- 次のアクション:*
- 現在の事象対応手順をレジリエンス原則に照らして監査する(30日以内)
- 事象イノベーションチームを設置し実験予算を配分する(60日以内)
- 予測的事象検知と並列検証を1区間でパイロット実施する(90日以内)
- 統合乗客情報プラットフォームを展開する(18ヶ月以内)
- 年次事象イノベーションレポートの公開を開始する(2年目から)
この転換を受け入れた事業者は、単に復旧を高速化するだけではありません。乗客が信頼し、従業員が誇りを持ち、投資家が資金を提供する交通システムを構築します。それが事象対応の未来です。
より広い文脈で捉えると、この転換は技術的な最適化ではなく、組織文化と事業戦略の根本的な再定義を意味しています。