
実行トレースを通じた悪意ある動作の証明可能な暴露
法的証拠としての実行トレース
-
主張:* 実行トレース—実行時のプログラム動作の詳細でタイムスタンプ付きの記録—は、技術的および法的精査に耐える命令レベルの操作を捕捉することで、悪意ある活動の法的に防御可能な証拠を提供する。
-
定義上の前提条件:* ここでの実行トレースは、プログラム動作の因果連鎖を再構築するのに十分な粒度と時間的順序で記録されたイベント(関数呼び出し、システムコール、メモリアクセス、ネットワークI/O)のシーケンスとして定義される。これは人間が読める要約であるアプリケーションログや、プロセス間通信のみを捕捉するネットワークパケットとは異なる。
-
根拠:* 従来の検出方法—シグネチャマッチング、統計的異常検出、動作ヒューリスティック—は抽象化された、または不完全なシグナルに基づいて動作する。攻撃者は難読化、多態性、回避技術を通じてこの抽象化ギャップを悪用する(Ször & Ferrie, 2004)。実行トレースは、プログラムが実行を主張したものや外部観察者が推測したものではなく、プログラムが実際に実行した基本的真実を捕捉する。形式検証(モデル検査、定理証明)と組み合わせると、トレースは証明可能な証拠となる。アナリストは、確率的に推測するのではなく、特定の悪意ある操作が発生したことを機械的に検証できる。
-
具体例:* 侵害されたWebサービスが外部IPアドレスへの予期しないアウトバウンドHTTPS接続を行い、データベースレコードを流出させる。従来の検出では、ネットワークIDSシグネチャや異常な送信量を通じてこれをフラグ付けする可能性がある。実行トレースは正確なシーケンスを記録する:(1)どのライブラリのどの関数がソケット呼び出しを開始したか、(2)呼び出された正確なシステムコール(socket、connect、send)、(3)各呼び出しに渡されたデータ、(4)戻り値とエラーコード、(5)各時点でのコールスタック。アナリストはこのトレースを再生し、サービスのソースコードに対してシーケンスを検証し、正当なコードパスがこの動作を生成できなかったことを証明できる。
-
仮定:* この主張は、トレースが十分な忠実度で収集され(重要なイベントを失うサンプリングや集約がない)、暗号的整合性保証(追加専用、署名付き)で保存されることを前提としている。トレースがサンプリングされているか損失がある場合、証拠価値は低下する。
-
実行可能な示唆:* 認証、決済処理、データアクセス制御、または暗号操作を扱う重要なサービスに、デプロイ時に実行トレースを記録するよう計装する。軽量なトレース機構(LinuxのeBPF、WindowsのEvent Tracing for Windows、インタープリタ実行時の言語固有プロファイラ)を使用して、実行時のオーバーヘッドを最小限に抑える(目標:CPU<5%、レイテンシ増加<10%)。トレースを暗号ハッシュ付きの追加専用ストレージに保存する(例:ハッシュチェーンされたログエントリ)。インシデントが発生した場合、証明グレードの証拠を所有することになる:「コードが実行した正確な操作シーケンスがこれです」であり、状況証拠ではない:「完全に信頼できないログに基づいて何か悪いことが起こったと思われます」。
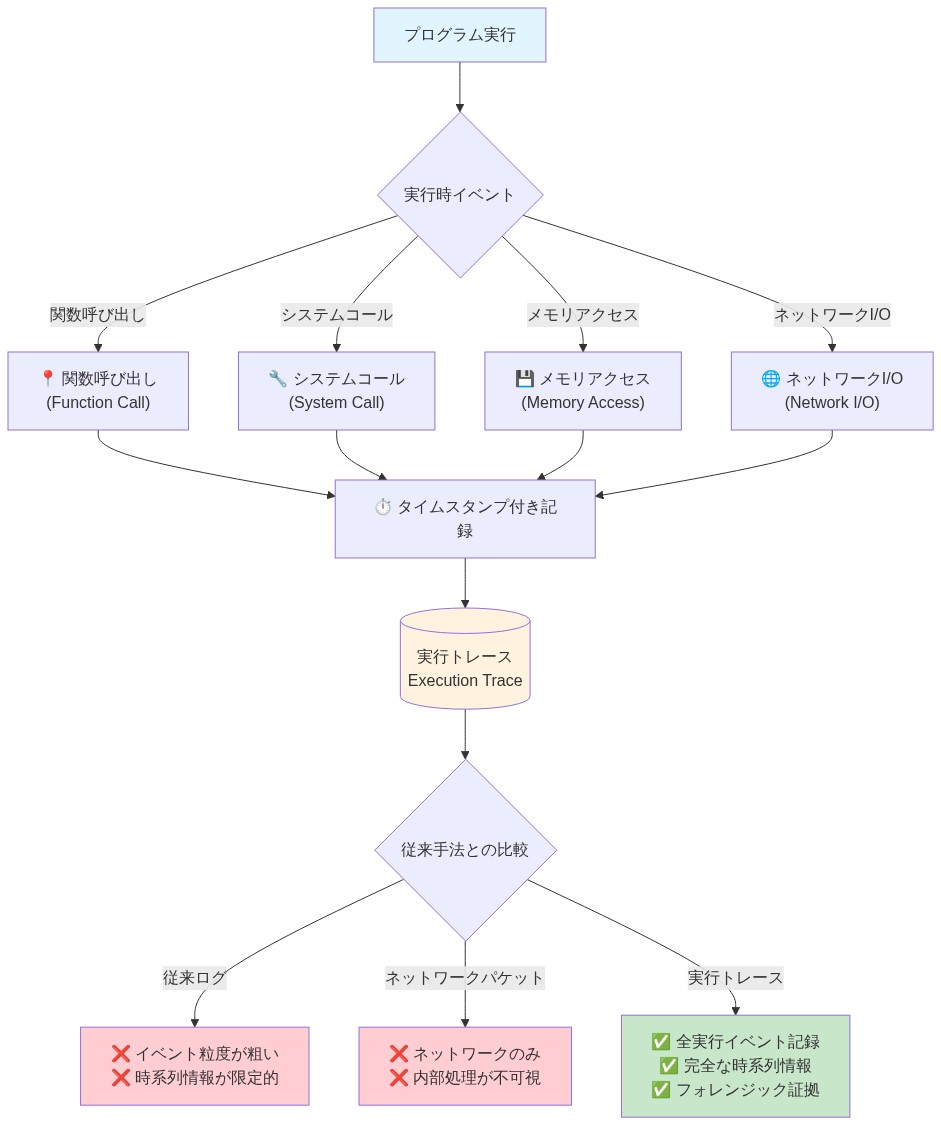
- 図2:実行トレースの構成要素と記録フロー*

- 図3:データ流出事件における実行トレースのシーケンス例(Webサービスの機密データ送信プロセス)*
システムアーキテクチャとインフラストラクチャの制約
-
主張:* ほとんどの組織は、パフォーマンスやコストのボトルネックを生じさせることなく、大規模に実行トレースを捕捉、保存、分析するためのアーキテクチャ基盤を欠いている。
-
根拠:* トレースは冗長である。単一のトランザクションで数キロバイトのトレースデータが生成される可能性がある。数千のサービス全体でトレースを集約すると、ストレージとクエリの課題が生じる。既存のログパイプラインは、この量や粒度のために設計されていない。ボトルネックは検出ロジックではなく、インフラストラクチャである。
-
具体例:* 金融サービス企業が50のマイクロサービスに実行トレースを計装する。48時間以内に、トレース量は1日あたり10TBを超える。法的分析のためのクエリレイテンシはミリ秒から分に跳ね上がる。インフラストラクチャは自身のデータの下で崩壊する。
-
実行可能な示唆:* 階層化されたトレースアーキテクチャを設計する。各ホストで24〜48時間、完全なトレースをローカルに捕捉する。要約(コールグラフ、システムコール数、異常フラグ)を無期限に中央ストレージに集約する。高速な法的クエリを可能にするために、カラム形式(Parquet)と時系列データベース(ClickHouse、Prometheus)を使用する。重要でないパスにはサンプリングを実装する。トレースオーバーヘッドのために計算容量の15〜20%を予算化する。デプロイ前に本番規模のトラフィックでパイプラインをテストする。

- 図4:実行トレース収集とシステムインフラストラクチャの制約の相互作用*
参照アーキテクチャ:収集、正規化、検証
-
主張:* トレースベースの検出のための参照アーキテクチャには、収集、正規化、検証の3つの層が必要である。
-
根拠:* 生のトレースは異種である—異なる実行時(JVM、Go、Python)は異なる形式を生成する。正規化は共通のスキーマを作成し、サービス間の法的分析を可能にする。検証は期待される動作からの逸脱を検出するために形式的ルールを適用する。
-
具体例:* レイヤー1は言語固有のエージェントを介してトレースを収集する。レイヤー2はそれらを正規形式(例:OpenTelemetry)に変換する。レイヤー3はポリシーエンジンを実行する:「プロセスXが事前の承認ZなしにシステムコールYを呼び出した場合、異常としてフラグを立てる」。この3層アプローチは、収集を分析から切り離し、エージェントの再デプロイなしにポリシーの更新を可能にする。
-
実行可能な示唆:* 正規化標準としてOpenTelemetryを採用する。トレースをローカルコレクタに送信するエージェントをデプロイし、コレクタはバッチ処理して中央ストレージに転送する。各サービスのベースライン動作モデルを定義する:期待されるコールチェーン、許可されたシステムコール、通常のレイテンシ。このモデルを使用して、トレースが逸脱したときにアラートを生成する。高信頼度のルール(例:「データベースサービスはアウトバウンドHTTP呼び出しを行うべきではない」)から始め、誤検出に基づいて洗練する。
運用パターン:サンプリング、保持、アラート
-
主張:* トレースベースの検出を運用化するには、大規模で実用的であり続けるために、サンプリング、保持、アラートにおける自動化が必要である。
-
根拠:* 手動のトレース分析はスケールしない。自動化は、どのトレースを保持し、どれを破棄し、いつ調査をトリガーするかを決定する必要がある。これには明確なポリシーとフィードバックループが必要である。
-
具体例:* サービスは1分あたり100,000のリクエストを処理する。すべてのトレースをサンプリングすることは実行不可能である。代わりに、通常のトラフィックの0.1%をサンプリングするが、リスク基準に一致するトレース(例:異常なユーザーエージェント、認証失敗の試み、大規模なデータ転送)は100%サンプリングする。完全なトレースを7日間保持し、要約を90日間保持する。アラートが発火したとき、完全なトレースは法的再生のために利用可能である。
-
実行可能な示唆:* 適応的サンプリングを実装する:通常のトラフィックには低レート、異常には高レート。ヘッドベース(トレース開始時に決定)ではなく、テールベースサンプリング(完全なトレースを見た後に保持を決定)を使用する。アラートルーティングを自動化する:高信頼度の発見をセキュリティチームに即座にルーティングし、低信頼度の発見をバッチレビューのためのキューにルーティングする。アナリストが誤検出をマークし、アラートしきい値が自動的に調整されるフィードバックループを構築する。
測定:証明品質、調査時間、誤検出コスト
-
主張:* トレースベースの検出の有効性を測定するには、従来の検出率を超えたメトリクスが必要である:証明品質、調査時間、誤検出コスト。
-
根拠:* 検出は行動につながる場合にのみ価値がある。証明品質(アナリストが発見を検証する容易さ)、調査時間(アナリストが何が起こったかを理解する速さ)、誤検出コスト(脅威でないものの調査に費やされる時間)が実世界の影響を決定する。
-
具体例:* メトリック1:「証明品質スコア」—アナリストはトレースを再生することで悪意ある動作を再現できるか?トレースの完全性に基づいて0〜10でスコア付けする。メトリック2:「理解までの平均時間」—アナリストが何が起こったかの要約を書けるまでにどれくらいかかるか?インシデントごとにこれを追跡する。メトリック3:「誤検出コスト」—アナリストは週に何時間を脅威でないものの調査に費やしているか?6か月以内にこれを50%削減することを目指す。
-
実行可能な示唆:* インシデント対応ワークフローにこれらのメトリクスを捕捉するよう計装する。各インシデント後に尋ねる:「トレースは何が起こったかを証明したか?」および「どれくらい時間がかかったか?」週次で集約する。証明品質が低い場合、トレース計装を改善する。調査時間が長い場合、クエリツールまたはダッシュボードを改善する。誤検出が多い場合、アラートルールを厳格化する。月次で測定し反復する。
リスク軽減:プライバシー、敵対的トレース、システムの複雑性
-
主張:* トレースベースの検出は3つのカテゴリのリスクを導入する:プライバシー露出、敵対的トレース操作、運用の複雑性。
-
根拠:* トレースには機密データ(パスワード、APIキー、顧客PII)が含まれる可能性がある。攻撃者は正常に見えるが悪意ある意図を隠すトレースを作成する可能性がある。複雑なシステムは予期しない方法で失敗する。
-
具体例:* トレースがログイン失敗時にユーザーのパスワードを平文で捕捉する。トレースアクセス権を持つ悪意ある内部者がそれを読む。別に、攻撃者はサンプリング時に通常のトラフィックのように見える遅い分散攻撃を作成する。トレースシステムはそれを見逃す。
-
実行可能な示唆:* 収集時にトレースから機密フィールドを編集する(パスワードをハッシュ化、PIIをマスク)。法的価値を破壊することなく集約統計にノイズを追加するために差分プライバシー技術を使用する。トレースを暗号的に検証する:攻撃者が偽造または変更できないようにハードウェアキーで署名する。四半期ごとに既知の攻撃パターンに対してシステムをテストする。人間の監視を維持する—自動化だけに頼らない。「トレース懐疑論者」の役割を割り当てる:システムが騙される可能性のある方法を見つけることが仕事である人。
移行戦略:段階的ロールアウトと組織の準備
-
主張:* トレースベースの検出への移行は、フラグの切り替えではなく、段階的ロールアウトを必要とする複数四半期の取り組みである。
-
根拠:* 組織は一度にすべてを計装することはできない。優先順位付け、テスト、フィードバックループは持続可能な採用に不可欠である。
-
具体例:* Q1:認証および決済サービスを計装する。Q2:データアクセスとAPIゲートウェイを追加する。Q3:すべてのマイクロサービスに拡大する。Q4:インシデント対応ワークフローと統合する。各フェーズには2〜4週間のテストと調整が含まれる。
-
実行可能な示唆:* 1つの高価値サービスから始める。トレースをデプロイし、2週間実行し、データを分析し、ポリシーを洗練する。学んだことを文書化する。次に拡大する。ビジネスケースを構築する:「トレースベースの検出は調査時間を60%削減し、パターンマッチングが見逃した3つのインシデントを捕捉した」。これを使用して次のフェーズの予算を正当化する。トレースインフラストラクチャを所有する専任チーム(2〜3人のエンジニア)を割り当てる。エステート全体で本番成熟度に達するまで6〜12か月を計画する。投資は、より速いインシデント対応とより強力な法的証拠を通じて報われる。
システム構造とアーキテクチャのボトルネック
-
主張:* ほとんどの組織は、禁止的なパフォーマンス、ストレージ、またはコストのボトルネックを生じさせることなく、大規模に実行トレースを捕捉、保存、クエリするためのアーキテクチャ基盤を欠いている。
-
根拠:* 実行トレースは本質的に冗長である。マイクロサービスによって処理される単一のHTTPリクエストは、10〜100 KBのトレースデータを生成する可能性がある(計装の深さに依存)。1秒あたり10,000のリクエストを処理するサービスは、1日あたり100〜1,000 GBのトレースデータを生成する。典型的な企業の50〜500のマイクロサービス全体でトレースを集約すると、従来のログ集約パイプライン(Splunk、ELK、Datadog)の容量を超えるストレージ需要(年間ペタバイト)とクエリレイテンシ(法的分析のために秒から分)が生じる。ボトルネックは検出ロジックではなく、インフラストラクチャである:ストレージ容量、クエリパフォーマンス、コスト。
-
具体例:* 金融サービス企業が、中程度の計装深度(関数の入出力、システムコール、ネットワークI/O)で50のマイクロサービスに実行トレースを計装する。48時間以内に、トレース量は1日あたり10〜15 TBに達する。すべてのトレースを集中型Elasticsearchクラスタに保存しようとすると、クエリレイテンシが100ミリ秒から30秒以上に劣化する。ストレージコストは年間50万ドルを超える。インフラストラクチャは自身のデータ量の下で崩壊する。
-
仮定:* これは、フィルタリング、サンプリング、または階層化戦略が実施されていないことを前提としている。これらの戦略を実装する組織は、ストレージ需要を90%以上削減できる(次のセクションを参照)。
-
実行可能な示唆:* 階層化されたトレースアーキテクチャを設計する:(1)ローカル層:各ホストで24〜48時間、ローカルストレージ(例:メモリマップファイル、ローカルSSD)に完全な非サンプリングトレースを捕捉する。(2)集約層:トレースをコンパクトな表現(コールグラフ、システムコールヒストグラム、異常フラグ)に定期的に要約し、中央ストレージに転送する。(3)中央層:要約をカラム形式(Apache Parquet)と時系列データベース(ClickHouse、Prometheus、または類似)に無期限に保存する。重要でないパスにはテールベースサンプリングを実装する:リスク基準に一致するトレース(異常なユーザーエージェント、認証失敗、大規模なデータ転送)の100%を捕捉するが、通常のトラフィックは0.1〜1%のみ。トレースオーバーヘッドのために計算容量の15〜20%を予算化する。本番環境にデプロイする前に、本番規模のトラフィック(10K〜100Kリクエスト/秒)で負荷テストを実施する。ストレージの増加を週次で測定し、ストレージが予算を超える場合はサンプリングレートを調整する。
参照アーキテクチャ:3層モデル
-
主張:* トレースベースの検出のための参照アーキテクチャには、データ取得を分析から切り離し、エージェントの再デプロイなしにポリシーの更新を可能にするために、収集、正規化、検証の3つの異なる層が必要である。
-
定義上の前提条件:*
-
収集層:実行イベントを傍受して記録する言語固有または実行時固有のエージェント。
-
正規化層:異種トレース形式を正規スキーマに変換する変換パイプライン。
-
検証層:期待される動作からの逸脱を検出するために形式的ルールを適用するポリシーエンジン。
-
根拠:* 生のトレースは異種である。Javaアプリケーション(JVMTIまたはバイトコード計装を介して計装)は、Goアプリケーション(eBPFまたは実行時フックを介して計装)やPythonアプリケーション(sys.settraceまたはネイティブ拡張を介して計装)とは異なる構造、タイミングセマンティクス、メタデータを持つトレースを生成する。正規化がなければ、法的分析はこれらの違いを考慮する必要があり、エラーと複雑性が導入される。正規スキーマはサービス間の法的分析を可能にする:アナリストは、形式間の変換なしに、サービスAの関数呼び出しをサービスBの対応するシステムコールと相関させることができる。検証ルールは一度書かれ、エステート全体に均一に適用できる。
-
具体例:*
-
レイヤー1(収集):JavaエージェントはJVMTIを使用してメソッドの入出力イベントとシステムコール傍受をフックする。GoサービスはeBPFを使用してシステムコールとネットワークイベントを捕捉する。Pythonサービスはsys.settraceを使用して関数呼び出しを記録する。
-
レイヤー2(正規化):各エージェントはローカルのOpenTelemetryコレクタにトレースを送信する。コレクタはそれらを正規形式に変換する:
{timestamp, service_id, trace_id, span_id, operation_type, operation_name, arguments, return_value, error_code, call_stack}。 -
レイヤー3(検証):ポリシーエンジンは次のようなルールを評価する:「service_type == ‘database’ AND operation_type == ‘syscall’ AND operation_name == ‘connect’ AND destination_port NOT IN [3306, 5432, 27017]の場合、異常としてフラグを立てる」。このルールは基礎となる実行時に関係なく均一に適用される。
-
仮定:* このアーキテクチャは、正規化が重要な法的情報を失うことなく実行できることを前提としている。正規化が損失を伴う場合(例:コールスタックや引数値を破棄)、証拠価値は低下する。
-
実行可能な示唆:* 正規化標準としてOpenTelemetryを採用する(CNCF支援、言語非依存、拡張可能)。ローカルのOpenTelemetryコレクタ(例:OpenTelemetry Collector、Jaegerエージェント)にトレースを送信する言語固有のエージェントをデプロイする。トレースをバッチ処理して中央ストレージ(例:Jaegerバックエンド、ClickHouse、またはカスタムストア)に転送するようにコレクタを構成する。各サービスのベースライン動作モデルを定義する:期待されるコールチェーン(例:「HTTPリクエスト→データベースクエリ→キャッシュルックアップ」)、許可されたシステムコール(例:「データベースサービスはsocket、connect、またはsendを呼び出すべきではない」)、通常のレイテンシ分布。このモデルを検証層のポリシールールとしてエンコードする。このモデルを使用して、トレースが逸脱したときにアラートを生成する。高信頼度のルール(例:「データベースサービスはアウトバウンドHTTP呼び出しを行うべきではない」)から始め、誤検出に基づいて洗練する。各ルールをその根拠と保護するビジネスコンテキストとともに文書化する。
実装と運用パターン
-
主張:* トレースベースの検知を大規模に運用するには、実用的でコスト効率の高い状態を維持するために、サンプリング、保持、アラートの自動化が必要である。
-
根拠:* 手動のトレース分析は、週に数件のインシデントを超えると拡張性がない。自動化は、どのトレースを保持し、どれを破棄し、いつ調査をトリガーするかを決定する必要がある。これには、明確でデータ駆動型のポリシーと、閾値を調整するためのフィードバックループが必要である。
-
具体例:* あるサービスが毎分100,000件のリクエストを処理している。すべてのトレースをサンプリングすることは実現不可能である(ストレージとクエリのコストが法外になる)。代わりに、適応型サンプリングを実装する:(1) 通常の特性を持つリクエスト(典型的なレイテンシ、成功応答、通常のユーザーエージェント)の0.1%をサンプリングする。(2) 軽度の異常を持つリクエスト(わずかに高いレイテンシ、異常だが疑わしくないユーザーエージェント)の10%をサンプリングする。(3) リスク基準に一致するリクエスト(認証失敗、大規模データ転送、本来行うべきでないサービスからの外部ネットワーク呼び出し、応答時間>10秒)の100%をサンプリングする。完全なトレースを7日間保持し、要約を90日間保持する。アラートが発火したとき、完全なトレースがフォレンジック再生と分析のために利用可能である。
-
前提:* これは、リスク基準を合理的な精度で定義できることを前提としている。リスク基準が広すぎると、ストレージとアラートのコストが法外になる。狭すぎると、悪意のある活動を見逃す。
-
実行可能な示唆:* ヘッドベースサンプリング(トレース開始時に決定)ではなく、テールベースサンプリング(完全なトレースを観察した後に保持を決定)を実装する。脅威モデルに基づいてリスク基準を定義する:侵害を示す可能性が最も高い操作は何か?(例:認証サービスが外部呼び出しを行う、データベースサービスがデータディレクトリ外のファイルにアクセスする、APIゲートウェイが予期しない宛先にリクエストを転送する)。これらの基準を評価し、保持決定を割り当てるサンプリングポリシーエンジンを使用する。アラートルーティングを自動化する:高信頼度の発見(例:既知の例外がないポリシー違反)をセキュリティチームに即座にルーティングし、低信頼度の発見をバッチレビュー用のキューにルーティングする。アナリストが誤検知をマークし、アラート閾値が自動的に調整されるフィードバックループを構築する(例:特定のルールのアラートの10%が誤検知の場合、閾値を上げるか例外を追加する)。サンプリングレートとアラート量を毎週監視する。アラート量がチームの能力を超える場合は、閾値を厳しくするか、誤検知を減らすためにより多くのコンテキストを追加する。
測定と効果指標
-
主張:* トレースベース検知の効果を測定するには、従来の検知率(真陽性、偽陽性)を超える指標が必要である:証明品質、調査時間、偽陽性コスト。
-
根拠:* 検知は、それが行動につながる場合にのみ価値がある。調査に4時間かかる高信頼度アラートは、15分で済む低信頼度アラートよりも価値が低い。週に100件の偽陽性を生成する検知システムは、アナリストの時間を浪費し、信頼を損なう。証明品質—アナリストが発見を検証し、ステークホルダーに説明できる容易さ—が、検知が修復につながるか、誤報として却下されるかを決定する。
-
定義上の前提条件:*
-
証明品質: トレースを再生することで悪意のある動作を再現し、ソースコードまたはポリシーに対して検証できるかどうかを測定するスコア(0〜10)。
-
平均理解時間(MTTU): アラート生成からアナリストが何が起こったかの要約を書くまでの経過時間。
-
偽陽性コスト: 非脅威の調査に費やされる週あたりの総アナリスト時間。
-
具体例:*
-
指標1(証明品質): アラートが発火:「サービスXが203.0.113.45への外部HTTPS呼び出しを行った。」アナリストはトレースをクエリし、完全なコールスタックを取得し、サービスXの正当なコードパスが外部呼び出しを行うべきでないことを検証し、宛先IPが承認されたホワイトリストにないことを確認する。証明品質:9/10。対比:「サービスXが異常なネットワーク動作を示した。」アナリストは要約統計を見るが、基礎となるトレースにアクセスできない。証明品質:3/10。
-
指標2(MTTU): アラートが14:00に発火。アナリストは14:05にトレースを取得し、14:12に悪意のある操作を特定し、14:18に要約を書く。MTTU:18分。これをインシデントごとに追跡し、週ごとに集計する。
-
指標3(偽陽性コスト): 1週間で50件のアラートが発火。40件は真陽性(悪意があるまたはポリシー違反が確認された)、10件は偽陽性(正当な動作が誤分類された)。偽陽性に費やされたアナリスト時間:10アラート × 30分/アラート = 300分 = 5時間。これを毎週追跡する。
-
前提:* これらの指標は、アナリストがアラートを調査できること、およびインシデントが一貫して追跡されることを前提としている。アナリストの能力が限られているか、インシデント追跡が不完全な場合、これらの指標は信頼性が低くなる。
-
実行可能な示唆:* インシデント対応ワークフローを計装して、これらの指標を自動的にキャプチャする。各アラートの後に記録する:(1) アラートタイムスタンプ、(2) アナリスト割り当てタイムスタンプ、(3) アナリスト要約完了タイムスタンプ、(4) アナリスト評価(真陽性、偽陽性、または結論が出ない)、(5) 証明品質スコア(アナリストの自己評価またはピアレビュー)。週ごとに集計する。証明品質が低い(<5/10)場合は、トレース計装を改善する:トレースに詳細を追加し、コールスタックがキャプチャされることを確認し、機密フィールドが編集されているがフォレンジック価値が保持されていることを検証する。MTTUが高い(>30分)場合は、クエリツールまたはダッシュボードを改善する:一般的な調査用の事前構築クエリを構築し、コールグラフの視覚化を追加し、ワンクリックトレース再生を有効にする。偽陽性が高い(>20%)場合は、アラートルールを厳しくする:コンテキストを追加する(例:「データベースサービスからホワイトリストにないIPへの外部呼び出し」)か、アラートを出す前に複数のシグナルを要求する。毎月測定して反復する。目標を設定する:証明品質>8/10、MTTU<20分、偽陽性率<10%。
リスク、前提、および緩和戦略
-
主張:* トレースベース検知は、明示的に緩和する必要がある新しいリスク—プライバシー露出、敵対的トレース操作、運用の複雑さ—をもたらす。
-
根拠:* トレースには機密データ(パスワード、APIキー、顧客PII、セッショントークン)が含まれる可能性がある。トレースストレージへのアクセス権を持つ敵対者は、このデータを流出させることができる。敵対者は、正常に見えるが悪意のある意図を隠すトレースを作成する可能性がある(例:サンプリングされると通常のトラフィックのように見える遅い分散攻撃)。複雑なトレーシングインフラストラクチャは、新しい障害モードを導入する:設定ミス、データ損失、またはパフォーマンス低下。
-
具体例:*
-
プライバシーリスク: トレースがログイン失敗時にユーザーのパスワードを平文でキャプチャする。トレースストレージへの読み取りアクセス権を持つ悪意のある内部者がパスワードを読み取り、それを使用してユーザーのアカウントを侵害する。
-
敵対的トレース操作: 攻撃者が24時間にわたって遅い分散データ流出を実行し、10分ごとに1 MBを送信する。0.1%のサンプリングでは、単一の流出イベントをキャプチャする確率は低い。攻撃は検出されない。
-
運用の複雑さ: 設定ミスのトレースエージェントが重要なサービスのCPUの80%を消費し、レイテンシが急上昇し、顧客向けリクエストが失敗する。
-
前提:* これらのリスクは、敵対者が特定の能力(トレースストレージへのアクセス、特定のトラフィックパターンを作成する能力、サンプリングレートの知識)を持つことを前提としている。各リスクの深刻度は、脅威モデルとシステム内のデータの機密性に依存する。
-
実行可能な示唆:*
-
プライバシー緩和: トレースがホストを離れる前に、収集時に機密フィールドをトレースから編集する。編集ポリシーを使用する:パスワードをハッシュ化(一方向)、PIIをマスク(例:顧客IDをハッシュに置き換える)、APIキーを最後の4文字に切り詰める。すべてのエージェントで編集が一貫して適用されることを検証する。四半期ごとに監査を実施する:トレースをサンプリングし、機密データが存在しないことを検証する。個々のトレースのフォレンジック価値を破壊することなく、集計統計にノイズを追加する差分プライバシー技術を使用する(例:「データベースサービスが1,000 ± 50のクエリを実行した」)。
-
敵対的トレース操作緩和: トレースを暗号的に検証する。敵対者がトレースを偽造または変更できないように、ハードウェアセキュリティモジュール(HSM)キーで各トレースに署名する。レートベースのアラートを実装する:サービスが時間枠内でN回以上の外部接続を行う場合、サンプリングに関係なくアラートを出す(すべてのイベントを保存せずにこれを検出するために、HyperLogLogのような確率的カウンターを使用する)。既知の攻撃パターンに対してシステムを四半期ごとにテストする:遅い流出、多態性マルウェア、特権昇格。人間の監視を維持する:自動化だけに頼らない。「トレース懐疑論者」の役割を割り当てる:システムが騙される方法を見つけ、緩和策を提案することが仕事である人。
-
運用の複雑さ緩和: 本番環境にデプロイする前に、本番規模のトラフィック(10K〜100Kリクエスト/秒)でステージング環境でトレースエージェントをテストする。エージェントのCPUとメモリ使用量を継続的に監視する。エージェントのオーバーヘッドが閾値を超える場合にアラートを設定する(
システム構造とボトルネック
-
主張:* ほとんどの組織は、パフォーマンスやコストのボトルネックを作成せずに、大規模に実行トレースをキャプチャ、保存、分析するためのアーキテクチャ基盤を欠いている。
-
これが重要な理由:* トレースは冗長である。単一のHTTPリクエストは、呼び出し深度とシステムコール量に応じて、500バイトから5 KBのトレースデータを生成できる。毎秒10,000リクエストを処理するサービスは、1日あたり5〜50 GBのトレースデータを生成する。これを50〜100のマイクロサービスにスケーリングすると、既存のログパイプラインでは処理できないデータ問題が発生する。ボトルネックは検知ロジックではなく、インフラストラクチャである。
-
具体例:* ある金融サービス会社が50のマイクロサービスに実行トレーシングを計装する。48時間以内に、トレース量は1日あたり10〜15 TBに達する。1日あたりギガバイトのログ用に設計された既存のELKスタック(Elasticsearch、Logstash、Kibana)が崩壊する。フォレンジック分析のクエリレイテンシがミリ秒から5〜10分に跳ね上がる。ストレージコストが月額50,000ドルを超える。プロジェクトが停滞する。
-
実現可能性評価:* これを解決するには、単にツールを追加するだけでなく、アーキテクチャの変更が必要である。インフラストラクチャの再設計に3〜6か月、トレーシングオーバーヘッド用に計算能力の15〜20%を予算する。
-
実行可能なワークフロー:*
-
階層化されたトレースアーキテクチャを設計する:
- ティア1(ホット): 各ホストにローカルに24〜48時間保存される完全なトレース。即座のフォレンジックに使用される。
- ティア2(ウォーム): 集計された要約(コールグラフ、システムコールカウント、異常フラグ、レイテンシパーセンタイル)が30日間中央ストレージに送信される。
- ティア3(コールド): コンプライアンスと履歴分析のために90〜365日間保持される圧縮アーカイブ。
-
クエリパターンに合わせたストレージ技術を選択する:
- 高速集計クエリを持つ時系列トレースデータにはClickHouseまたはTimescaleDB。
- バッチフォレンジック分析にはS3上のParquetファイル(データベースストレージより安価)。
- 即座のトレースアクセスには各ホスト上のローカルSQLiteまたはRocksDB。
-
サンプリング戦略を実装する:
- 通常のトラフィック(通常のリクエスト、成功した操作)の0.1〜1%をサンプリングする。
- 異常なトラフィック(認証失敗、異常なレイテンシ、大規模データ転送、エラー応答)の100%をサンプリングする。
- テールベースサンプリングを使用する:完全なトレースを収集し、完全な全体像を見た後に保持を決定する。
-
コストと容量を見積もる:
- サービスあたり1日あたり1〜5 GBのトレースデータを想定する(リクエスト量と計装深度によって異なる)。
- 50サービスの場合:1日あたり50〜250 GB、または月間1.5〜7.5 TB。
- ストレージコスト:月額30〜150ドル(S3標準)または月額500〜2,000ドル(データベース)。
- 計算コスト:既存インフラストラクチャの15〜20%(収集と集計のためのCPU)。
-
コミットする前に本番規模のトラフィックでパイプラインをテストする。 2〜3のサービスで2週間パイロットを実行する。実際のオーバーヘッド、ストレージ、クエリレイテンシを測定する。
- リスクフラグ:*
- フォレンジック検索のクエリレイテンシが30秒を超える場合、アナリストはシステムを放棄する。
- ストレージコストがセキュリティ予算の10%を超える場合、異なる保持戦略が必要である。
- 収集オーバーヘッドが25%を超える場合、本番パフォーマンスに影響を与えるリスクがある。

- 図13:リスク・仮定・軽減戦略のマッピング*
参照アーキテクチャとガードレール
-
主張:* トレースベース検知の参照アーキテクチャには、収集、正規化、検証の3つの層が必要である。各層には明確な責任と障害モードがある。
-
これが重要な理由:* 生のトレースは異質である。Javaアプリケーションは1つの形式でトレースを生成し、Goサービスは別の形式、Pythonスクリプトは3番目の形式で生成する。正規化がなければ、サービス間でトレースを相関させたり、一貫した検知ルールを適用したりすることはできない。3層アーキテクチャは関心事を分離し、各層が独立して進化できるようにする。
-
具体例:*
-
レイヤー1(収集): 言語固有のエージェント(Javaエージェント、Go eBPFフック、Pythonラッパー)がローカルコレクターにトレースを送信する。各エージェントはそのランタイムを知っている。
-
レイヤー2(正規化): ローカルコレクターがトレースをOpenTelemetry形式(ベンダー中立の標準)に変換する。バッチ化して中央ストレージに転送する。
-
レイヤー3(検証): ポリシーエンジンが正規化されたトレースに対してルールを実行する。ルールの例:「データベースサービスが事前の承認なしに外部HTTP接続を開始した場合、異常としてフラグを立てる。」
この分離により、エージェント(レイヤー1)を再デプロイせずに検知ルール(レイヤー3)を更新できる。
-
実現可能性評価:* 標準化の努力(スキーマとルールを定義するために2〜4週間)と継続的なメンテナンスが必要である。見返りは運用の柔軟性とサービス間フォレンジックである。
-
実行可能なワークフロー:*
-
正規化標準としてOpenTelemetryを採用する。 ベンダー中立で、広くサポートされており、このユースケース用に設計されている。
-
収集エージェントをデプロイする:
- JVMサービスの場合: OpenTelemetry Javaエージェントを使用する(ゼロコード計装)。
- Goサービスの場合: eBPFベースの収集を使用する(Cilium、Falco、またはカスタム)。
- Pythonサービスの場合: 自動計装を備えたOpenTelemetry Python SDKを使用する。
- コンパイル済みバイナリの場合: システムレベルのトレーシングを使用する(eBPF、ETW)。
-
各ホストにローカルコレクター(例:OpenTelemetry Collector)を構成して:
- エージェントからトレースを受信する。
- サンプリングポリシーを適用する(異常の100%を保持、通常のトラフィックの0.1%を保持)。
- 機密フィールドを編集する(パスワード、APIキー、PII)。
- バッチ化して中央ストレージに転送する。
-
各サービスのベースライン動作モデルを定義する:
- 予想される呼び出しチェーン(例:「APIハンドラー → データベースクエリ → キャッシュ検索」)。
- 許可されたシステムコール(例:「データベースサービスはsocket、read、writeを呼び出すべきだが、forkやexecは決して呼び出さない」)。
- 通常のレイテンシ範囲(例:「データベースクエリは10〜500ミリ秒で完了すべき」)。
- 許可された外部宛先(例:「決済サービスはStripe APIを呼び出せるが、ランダムなIPは呼び出せない」)。
-
次のようなルールを持つポリシーエンジンを実装する:
- 「サービスXが事前の承認ZなしにシステムコールYを呼び出した場合、異常としてフラグを立てる。」
- 「呼び出しレイテンシが通常の10倍を超える場合、潜在的なDoSまたはリソース枯渇としてフラグを立てる。」
- 「サービスが未知のIPへの外部接続を行う場合、レビュー用にフラグを立てる。」
-
高信頼度ルールから始める(例:「データベースサービスは外部HTTP呼び出しを決して行うべきでない」)。2〜4週間にわたって偽陽性に基づいて改良する。
- リスクフラグ:*
- ベースラインモデルが不正確な場合、偽陽性率が高くなる。通常の動作をプロファイリングする時間を投資する。
- ルールが厳しすぎると、アナリストはアラートを無視する(アラート疲労)。緩すぎると、実際のインシデントを見逃す。
- 正規化が不完全な場合、サービス間でトレースを相関させることができない。
測定と次のアクション
-
主張:* トレースベース検知の有効性を測定するには、従来の検知率を超えた指標が必要である。証拠の質、調査時間、誤検知コストに焦点を当てる—これらは実世界への影響と相関する指標である。
-
重要性:* 検知は行動につながる場合にのみ価値がある。1日に1,000件のアラートを生成するが99%が誤検知であるシステムは、役に立たないどころか有害である—アナリストの時間を浪費する。運用上の影響を測定する指標(何が起こったかをどれだけ早く理解できるか、証拠はどれだけ確実か)は、単純な検知数よりも重要である。
-
具体例:*
-
指標1: 証拠品質スコア(0–10)。 各インシデント後に問う:「アナリストはトレースを再生することで悪意のある動作を再現できるか?」トレースが完全で決定的であれば10点、不完全または曖昧であれば0点とする。目標: 6ヶ月以内にインシデントの90%で8点以上。
-
指標2: 平均理解時間(MTTU)。 アナリストが何が起こったかの要約を書けるようになるまでの時間は?アラートから「根本原因特定」までを測定する。目標: インシデントの80%で30分未満。
-
指標3: 誤検知コスト。 アナリストが脅威でないものの調査に週何時間費やしているか?アナリストの時給を掛ける。目標: 6ヶ月以内に50%削減。
-
指標4: 検知遅延。 インシデント発生からシステムが検知するまでの時間は?目標: インシデントの95%で5分未満。
-
実現可能性評価:* インシデント対応ワークフローの計装が必要(1–2週間)。見返りはデータ駆動型の最適化とビジネスケースの正当化である。
-
実行可能なワークフロー:*
-
インシデント対応プロセスを計装する:
- アラートが発火したら、タイムスタンプとアラートIDを記録する。
- アナリストが調査を開始したら、タイムスタンプを記録する。
- アナリストが要約を書いたら(根本原因特定)、タイムスタンプを記録する。
- インシデントが解決したら、タイムスタンプと結果(真陽性、偽陽性、要調査)を記録する。
-
証拠品質データを収集する:
- 各インシデント後、アナリストに問う:「0–10のスケールで、トレースはどれだけ完全でしたか?」これをフォームまたはアンケートで取得する。
- インシデント結果と相関させる: 高品質のトレースはより速い解決につながるか?
-
指標を週次で計算する:
- 証拠品質スコア: アナリスト評価の平均。
- MTTU: アラートから「根本原因特定」までの平均時間。
- 誤検知コスト: (誤検知数) × (平均調査時間) × (アナリスト時給)。
- 検知遅延: インシデント開始からアラートまでの平均時間。
-
ダッシュボードを作成し、これらの指標を時系列で表示する。セキュリティリーダーシップと月次で共有する。
-
指標を使って改善を推進する:
- 証拠品質スコアが低い場合(< 6)、トレース計装を改善する。システムコール、関数呼び出し、またはネットワークI/Oを追加する。
- MTTUが高い場合(> 60分)、クエリツールまたはダッシュボードを改善する。アナリストがSQLを書かずに使用できるトレース再生ツールを構築する。
- 誤検知コストが高い場合(> 20時間/週)、アラートルールを厳格化するか閾値を上げる。
- 検知遅延が高い場合(> 30分)、サンプリングレートを下げるかアラートルーティングを改善する。
-
月次で反復する: 指標をレビューし、最大のボトルネックを特定し、対処する。4週間後に再度測定する。
- リスクフラグ:*
- 測定しなければ最適化できない。測定は任意ではない。
- 指標がビジネス成果(コスト、時間、リスク)と結びついていなければ、リーダーシップは改善に資金を提供しない。
- 測定しても行動しなければ、アナリストはシステムへの信頼を失う。
システムアーキテクチャとインフラストラクチャの転換点
-
ビジョン:* 次世代のセキュリティインフラストラクチャは、検知アルゴリズムではなく、自重で崩壊するボトルネックを作らずに惑星規模で実行データを捕捉、正規化、クエリする能力によって定義される。
-
課題:* 実行トレースは設計上冗長である。単一のトランザクションで数キロバイトのトレースデータが生成される。毎秒10,000リクエストを処理する単一のマイクロサービスは、日次でテラバイトを生成する。これを数百のサービスを持つ組織全体にスケールすると、インフラストラクチャの問題は存亡に関わるものになる。ほとんどの組織のログパイプラインは、疎で高レベルのイベント用に設計されている。実行トレースは全く異なるアーキテクチャを要求する—クエリレイテンシを分単位ではなくミリ秒単位に保ちながら、桁違いに多いデータを処理するものを。
ボトルネックは検知ロジックではない。インフラストラクチャである。そしてここに機会がある: このインフラストラクチャ問題を最初に解決する組織は、何年もの間フォレンジック上の優位性を持つことになる。
-
具体的シナリオ:* ある金融サービス企業が50のマイクロサービスに実行トレースを計装する。48時間以内に、トレース量は日次10TBに達する。ミリ秒で完了すべきフォレンジッククエリが今や分単位でかかる。中央ストレージシステムがボトルネックになる。組織は選択を迫られる: トレースを放棄するか、データパイプライン全体を再構築するか。ほとんどは放棄を選ぶ。勝者は再構築を選ぶ—そして非対称的な優位性を得る。
-
アーキテクチャ上の必須事項:* 収集、集約、分析を分離する階層型トレースアーキテクチャを設計する:
-
階層1(ローカル): 各ホストで24–48時間、完全でサンプリングされていない実行トレースを捕捉する。ローカルのリングバッファストレージを使用する(最小限のI/Oオーバーヘッド)。これは「ホット」なフォレンジックデータ—即座の再生と分析が可能。
-
階層2(リージョナル): 要約—コールグラフ、syscallカウント、レイテンシ分布、異常フラグ—を無期限にリージョナルストレージに集約する。フォレンジッククエリ用に最適化されたカラムナーフォーマット(Parquet、ORC)と時系列データベース(ClickHouse、VictoriaMetrics、Prometheus)を使用する。これは「ウォーム」データ—クエリ可能だが完全な忠実度ではない。
-
階層3(アーカイブ): コンプライアンスと長期パターン分析のために、匿名化され圧縮されたトレース要約を保持する。これは「コールド」データ—めったにアクセスされないが法的に防御可能。
適応的サンプリングを実装する: リスク基準に一致するトレース(異常なユーザーエージェント、認証失敗、大規模データ転送、権限昇格)の100%を捕捉するが、通常のトラフィックは0.1–1%のみ。ヘッドベース(トレース開始時に決定)ではなくテールベースサンプリング(完全なトレースを観察した後に保持を決定)を使用する。これにより、インフラストラクチャコストを管理可能に保ちながら、脅威を見逃すことがない。
-
予算の現実:* トレースオーバーヘッドのために計算能力の15–20%を割り当てる。これは任意ではない—フォレンジック確実性のコストである。これをセキュリティ予算の事後的な追加ではなく項目として扱う組織は、より速いインシデント対応と削減された調査コストを通じて12ヶ月以内にROIを見るだろう。
-
実行可能な次のステップ:* 大規模展開の前に、ステージング環境で本番規模のトラフィックでパイプラインをテストする。現在のピーク負荷の10倍をシミュレートする。ストレージ増加、クエリレイテンシ、CPUオーバーヘッドを測定する。ボトルネックを特定する。修正する。その後のみ本番に移行する。このステップをスキップする組織は、フォレンジックデータが最も重要な実際のインシデント中に、厳しい方法で学ぶことになる。
参照アーキテクチャ: 三層検証スタック
-
ビジョン:* セキュリティ証拠の未来は、集中型検知ではなく、あらゆる利害関係者—アナリスト、監査人、規制当局、裁判所—が独立して検証できる分散型の検証可能な証拠である。
-
フレームワーク:* 実行トレースベースの検知には、それぞれ異なる目的を果たす三つの層が必要である:
-
層1 – 収集(分散計装):* ランタイム自体からトレースを発行する言語固有のエージェントを展開する。JVMアプリケーションはJava Flight RecorderまたはDatadog APMを使用する。GoサービスはeBPFまたはGoの組み込みトレースを使用する。PythonはOpenTelemetryまたはPyroscopeを使用する。各エージェントはネイティブフォーマットでトレースを捕捉し、ローカルコレクターに転送する。コレクターはトレースをバッチ処理し、メタデータ(サービス名、バージョン、環境)を追加し、中央ストレージに転送する。この層は設計上分散されている—単一障害点なし、最小限のレイテンシ、言語非依存。
-
層2 – 正規化(標準スキーマ):* 異種トレースフォーマットを統一スキーマに変換する。OpenTelemetryを標準として採用する—これは業界標準になりつつあり、すべての主要な可観測性ベンダーとクラウドプロバイダーによってサポートされている。正規化層は、JVMスタックトレース、Goゴルーチントレース、Pythonコールスタックを共通フォーマットにマッピングする: スパン(作業単位)、イベント(離散的発生)、属性(メタデータ)。これにより収集と分析が分離され、サービス間フォレンジックが可能になる。三つの言語で三つのサービスにまたがる悪意のあるコールチェーンは、単一のクエリ可能なナラティブになる。
-
層3 – 検証(ポリシーエンジン):* 各サービスのベースライン動作モデルを定義する。期待されるコールチェーンは何か?どのsyscallが呼び出されるべきか?通常のレイテンシは何か?どの外部サービスに接続すべきか?実際のトレースをこれらのベースラインと比較するポリシーエンジンを構築する。ルールには以下が含まれる可能性がある:
-
「データベースサービスはアウトバウンドHTTP呼び出しを行うべきではない」
-
「認証サービスはファイルシステムに書き込むべきではない」
-
「決済サービスはユーザープロファイルデータにアクセスすべきではない」
-
「APIゲートウェイは内部IPのレート制限をバイパスすべきではない」
トレースがポリシーから逸脱すると、エンジンはそれを異常としてフラグ付けする。重要なことに、エンジンは証拠オブジェクトも生成する: 違反を示す最小限のトレース抜粋。この証拠オブジェクトが利害関係者に提示するもの—信頼度スコアではなく、証拠である。
-
具体的実装:* マイクロサービスがユーザー認証リクエストを処理する。層1はOpenTelemetryエージェントを介してトレースを捕捉する。層2はそれらを標準スキーマに正規化する。層3はポリシーを実行する:「認証サービスが事前のホワイトリストエントリなしに外部APIを呼び出す場合、異常としてフラグ付けする。」攻撃者がサービスを侵害し、流出エンドポイントへの呼び出しを追加すると、ポリシーエンジンは即座にそれを検知し、正確なコールチェーンを示す証拠オブジェクトを生成する。この証拠オブジェクトは暗号的に署名され不変である。
-
実行可能な展開:* 層1と層2から始める。重要なサービス全体にOpenTelemetryエージェントを展開する。2–4週間トレースを流す。データを分析する。正常とは何かを理解する。その後、高信頼度ルールのみで層3を実装する。誤検知を生成する過度に広範なポリシーを避ける。フィードバックに基づいて洗練する。ベースラインの品質を測定する: 正当なトレースがポリシーに違反する頻度は?低信頼度ルールに拡大する前に、誤検知率を1%未満にすることを目指す。
大規模運用: 自動化、フィードバック、レジリエンス
-
ビジョン:* トレースベース検知の運用化とは、人間の介入なしに学習、適応、改善するシステムを構築することを意味する—一方で高リスクの決定には人間の監視を維持する。
-
自動化の必須事項:* 手動トレース分析はスケールしない。セキュリティアナリストに毎日数千のトレースをレビューするよう求めることはできない。自動化はサンプリング決定、保持ポリシー、アラート、初期トリアージを処理しなければならない。しかしフィードバックループのない自動化はアラート疲労と脅威の見逃しにつながる。解決策は閉ループシステムである: 自動検知、人間による検証、継続的な洗練。
-
サンプリング戦略:* リスクに適応する多レベルサンプリングを実装する:
-
通常トラフィック: 0.1–1%でサンプリング。要約のみ保持(コールグラフ、レイテンシ分布)。
-
異常トラフィック: 50–100%でサンプリング。フォレンジック再生のために完全なトレースを保持。
-
高リスクトラフィック: 100%でサンプリング。完全なトレースを無期限に保持。
「高リスク」を運用的に定義する: 認証失敗の試み、権限昇格、異常な地理的起源、大規模データ転送、既知の悪意のあるIPへの呼び出し、またはベースライン動作からの逸脱。テールベースサンプリングを使用する: 完全なトレースを観察し、その後保持を決定する。これにより、ストレージコストを管理可能に保ちながら、脅威を決して破棄しないことが保証される。
-
保持ポリシー:* 階層型保持を実装する:
-
完全トレース: 7日間(ホットストレージ、高速クエリ)
-
トレース要約: 90日間(ウォームストレージ、低速クエリ)
-
匿名化集約: 2年以上(コールドストレージ、コンプライアンス)
リスクスコアに基づいて保持を自動化する。高リスクトレースはより長く保持される。低リスクトレースはより速く要約されアーカイブされる。これはフォレンジック能力とコストのバランスを取る。
-
アラートとトリアージ:* 信頼度と影響に基づいてアラートをルーティングする:
-
高信頼度 + 高影響: セキュリティチームへの即時エスカレーション。例:「データベースサービスが既知のC2サーバーへの予期しないアウトバウンド呼び出しを行った。」
-
高信頼度 + 低影響: バッチレビューのためにキューイング。例:「APIサービスが異常なパラメータで内部ロギングサービスを呼び出した。」
-
低信頼度 + 高影響: 検証のために人間のアナリストにエスカレート。例:「決済サービスのコールチェーンで異常検知(信頼度65%)。」
-
低信頼度 + 低影響: パターン分析のためにアーカイブ。例:「非重要サービスのベースラインレイテンシからのわずかな逸脱。」
ルーティングロジックを自動化する。機械学習を使用して、どのアラートがアナリストによって検証されるかを予測し、それらを優先する。フィードバックループを構築する: アナリストが誤検知をマークし、アラート閾値が自動的に調整される。
-
具体的ワークフロー:* マイクロサービスで異常な動作を示すトレースが到着する。ポリシーエンジンは信頼度スコア(0–100)を割り当てる。信頼度 > 80で影響が「重大」の場合、アラートは事前生成された証拠オブジェクトとともに即座にオンコールセキュリティエンジニアにルーティングされる。信頼度が60–80の場合、アラートはセキュリティアナリストによるバッチレビューのためにキューイングされる。信頼度 < 60の場合、トレースはパターン分析のためにアーカイブされる。アナリストはキューイングされたアラートをレビューし、真陽性/偽陽性としてマークする。システムは学習する: パターンXを持つアラートの90%が偽陽性の場合、パターンXの閾値を下げる。時間とともに、誤検知率が低下し、アナリストの効率が向上する。
-
実行可能な実装:* このワークフローを段階的に構築する。最初は高信頼度ルールのみから始める。誤検知率を週次で測定する。誤検知が5%未満に低下したら、低信頼度ルールを追加する。最初は単純なヒューリスティック(信頼度スコア、影響レベル)に基づいてアラートルーティングを自動化する。機械学習は後で追加する。アラートパイプラインを所有する専任チーム(2–3人のエンジニア)を割り当てる。彼らの仕事は誤検知を低く保ち、調査時間を短くすることである。
測定:検知率を超えて
-
ビジョン:* セキュリティ効果の真の尺度は、どれだけの脅威を検知したかではなく、何が起こったかをどれだけ迅速に証明し、その証明に基づいて行動できるかである。
-
重要な指標:* 従来のセキュリティ指標(検知率、誤検知率)は必要だが不十分である。これらはシステムがラボ環境で機能するかどうかを示す。実世界で機能するかどうかは示さない。より重要な3つの指標がある:
-
指標1 – 証明品質スコア(0–10):* インシデント後、アナリストはトレースを再生することで悪意のある動作を再現できるか?技術者でない関係者に説明できるか?法廷で提示できるか?各インシデントをスコア化する:
-
10:完全なトレースが利用可能、動作は再現可能、証明は完璧。
-
7–9:トレースはほぼ完全、わずかな欠落、証明は強力。
-
4–6:トレースは部分的、欠落には推論が必要、証明は状況証拠的。
-
1–3:トレースは断片的、証明は弱い。
週次で集計する。目標:インシデントの90%が8以上のスコア。スコアが低い場合は、トレース計装を改善する。収集ポイントを追加する。高リスクトラフィックのサンプリングレートを増やす。
-
指標2 – 平均理解時間(MTTU):* アナリストが何が起こったかの要約を書くのにどれくらい時間がかかるか?アラートが発火した時点で計測を開始する。アナリストがインシデントの1段落の要約を書けるようになった時点で停止する。インシデントごとにこれを追跡する。週次および月次で集計する。
-
第1週:平均MTTUは4時間。
-
第3ヶ月:平均MTTUは1.5時間(62%改善)。
-
第6ヶ月:平均MTTUは45分(81%改善)。
この指標はビジネスへの影響と直接相関する。理解が速いということは、対応が速く、封じ込めが速く、損害が少ないことを意味する。MTTUを使用して、より優れたクエリツール、ダッシュボード、自動化への投資を正当化する。
-
指標3 – 誤検知コスト(時間/週):* 脅威でないものの調査にどれだけのアナリスト時間が浪費されているか?これを徹底的に追跡する。アナリストが週に20時間を誤検知に費やしている場合、年間1,000時間となり、これはアナリストの給与の半分に相当する。これを使用してアラートルールの厳格化やベースラインの改善を正当化する。
-
第1週:週20時間を誤検知に費やす。
-
第3ヶ月:週10時間(50%削減)。
-
第6ヶ月:週5時間(75%削減)。
目標:週5時間未満。これを超える場合、アラートルールが緩すぎる。厳格化する。
-
副次的指標:* これらも追跡する:
-
トレース完全性: 完全なトレースが利用可能なインシデントの割合は?目標:95%以上。
-
クエリレイテンシ: アナリストがトレースをクエリする速度は?目標:フォレンジッククエリで5秒未満。
-
ストレージ効率: トレースあたり何バイトのストレージか?目標:トレースあたり100 KB未満(圧縮あり)。
-
インシデント解決時間: 検知から封じ込めまでどれくらいか?目標:重大インシデントで30分未満。
-
実行可能な実装:* インシデント対応ワークフローを計装して、これらの指標を自動的に取得する。各インシデント後に問う:「トレースは何が起こったかを証明したか?」(証明品質)、「どれくらい時間がかかったか?」(MTTU)、「これは誤検知だったか?」(誤検知コスト)。週次で集計する。チームと指標を共有する。可視化する。改善を祝う。次のフェーズの予算を正当化するために使用する。
リスク、敵対的シナリオ、および緩和策
-
ビジョン:* 最も危険な仮定は、トレースベースの検知が完璧であるというものである。そうではない。敵対者は適応する。問題は、彼らがトレースを回避しようとするかどうかではなく、彼らの回避技術をどれだけ迅速に検知し対抗できるかである。
-
リスク1 – プライバシー漏洩:* トレースには機密データが含まれる可能性がある:平文のパスワード、APIキー、顧客のPII、健康情報。トレースアクセス権を持つ悪意のある内部者はこのデータを流出させることができる。トレースストレージの侵害はすべてを露出させる。
-
緩和策:* ストレージ時ではなく収集時に機密フィールドを編集する。機密パターンを識別する編集ポリシーエンジンを使用する(クレジットカード番号の正規表現、パスワードのハッシュ化、PIIのマスキング)、そしてトレースがホストを離れる前にそれらを削除する。差分プライバシーを使用する:個々のデータポイントは不明瞭になるがパターンは可視のままになるように、集計統計に慎重に調整されたノイズを追加する。トレースストレージに厳格なアクセス制御を実装する:保存時の暗号化、アクセスに多要素認証を要求、すべての読み取りを監査する。トレースストレージを本番システムから分離する。本番データベースが侵害されても、トレースは安全なままである。
-
リスク2 – 敵対的トレース操作:* コード実行権限を持つ攻撃者は、悪意のある活動を隠すためにトレースを偽造または変更できる。彼らはサンプリング時には正常に見えるが、サンプリングされていないデータに悪意のある意図を隠すトレースを作成する。
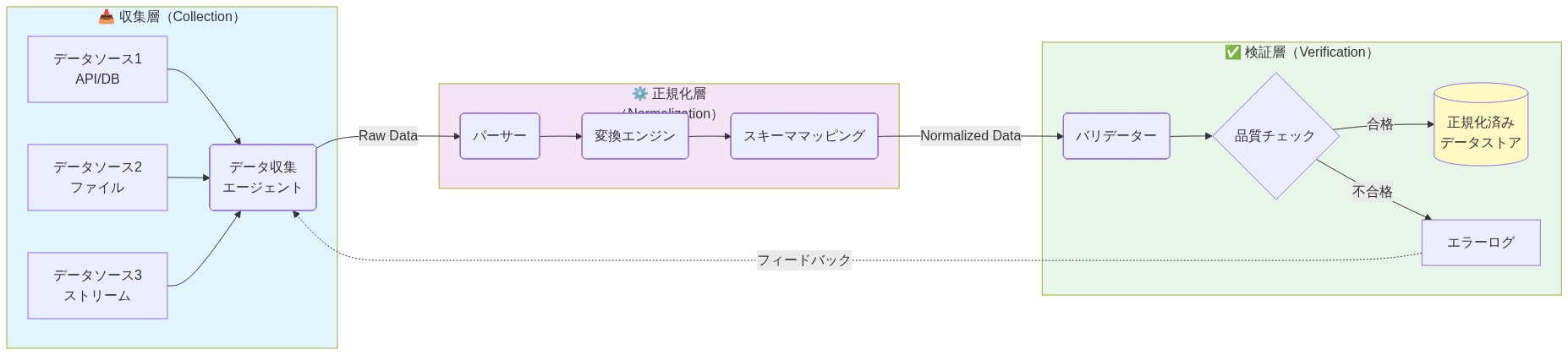
- 図5:参照アーキテクチャ:収集・正規化・検証の3層モデル*
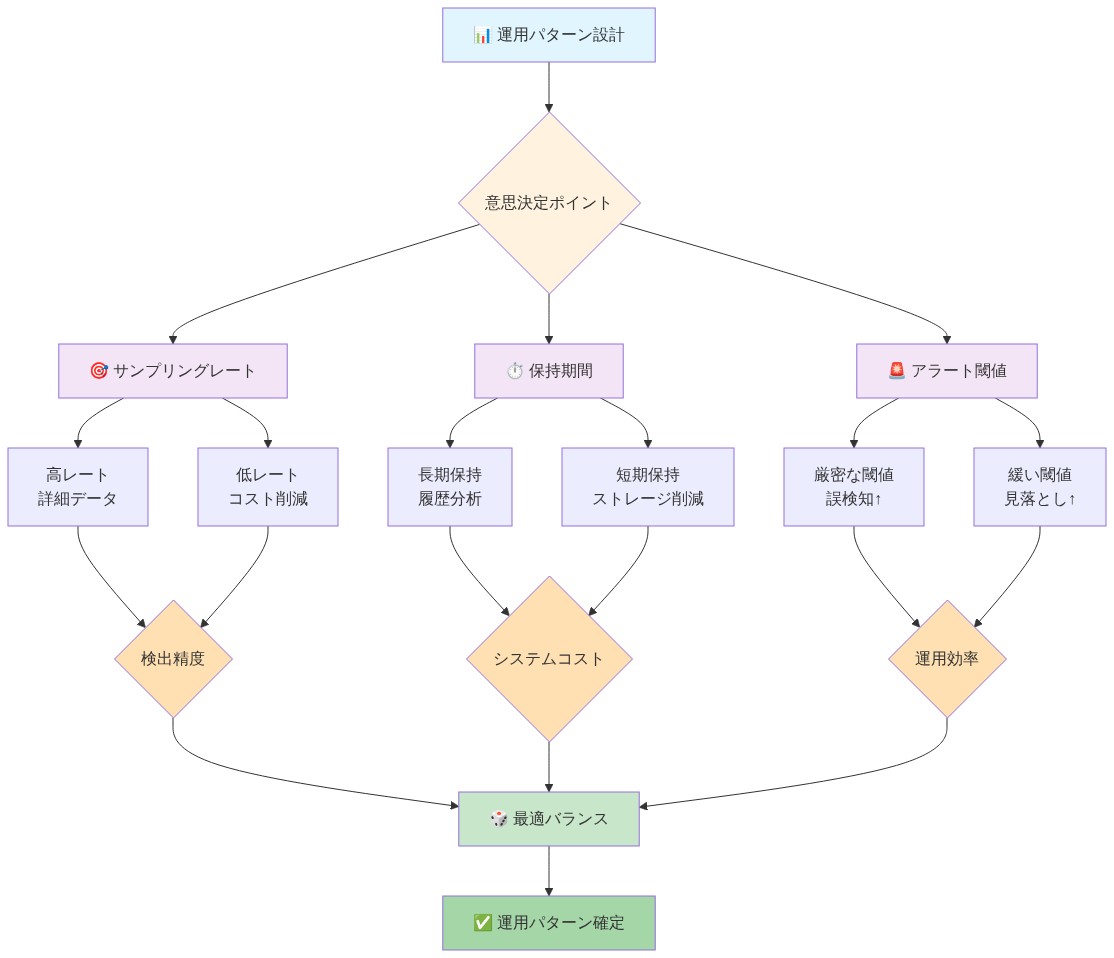
- 図6:運用パターン:サンプリング・保持・アラートの相互関係と意思決定フロー*
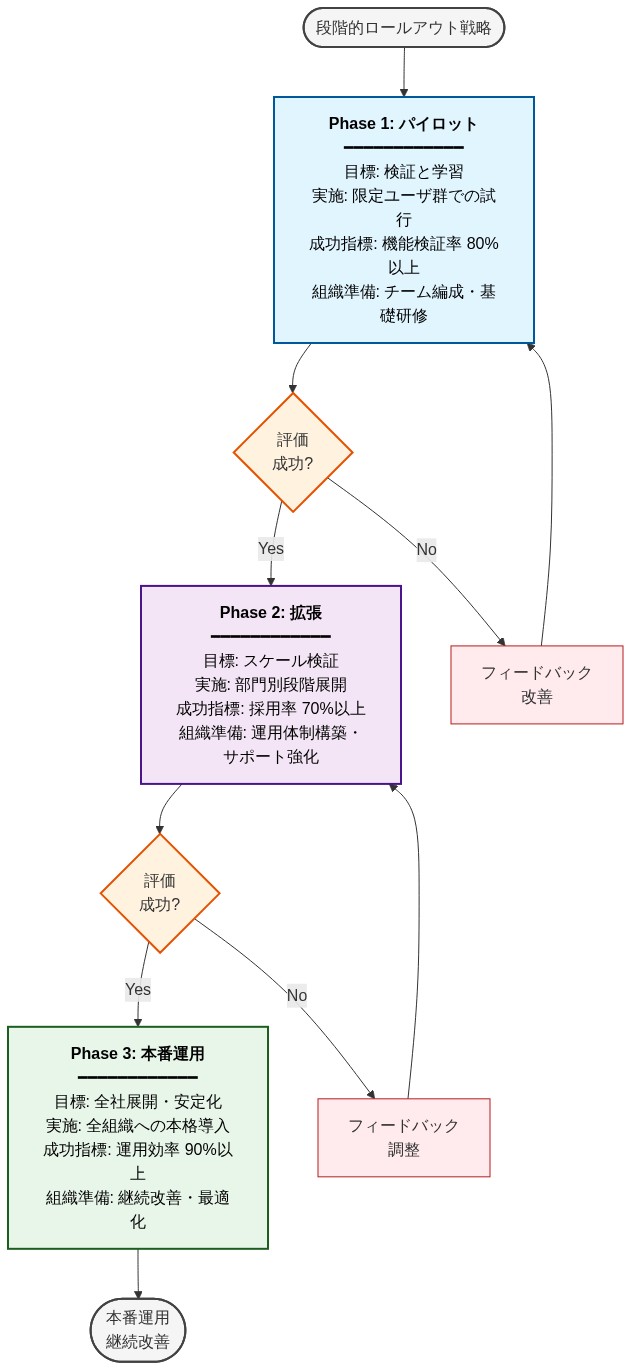
- 図9:段階的ロールアウト戦略:3フェーズの実装計画と組織的準備*

- 図8:リスク軽減:プライバシー・敵対的トレース・システム複雑性 データソース:コンセプトイメージ*