
書き直されたセクション:前文
ミスアライメントを超えたAIリスクの拡大する表面
AIセキュリティスタートアップへのベンチャーキャピタル資金調達は顕著に増加しており、これは脅威の状況がミスアライメントされたAIエージェントという狭い問題を超えて広がっているという認識によって推進されている。ミスアライメント—指定された目的から逸脱するAIシステムの動作として定義される—は、より広範なリスク分類法における一つの構成要素を表している。現代の組織は、無許可のツール展開、データ流出、規制違反、および既存のセキュリティ制御では適切に対処できない本番環境における創発的システム動作を含む、文書化された脅威に直面している。
この認識されたリスクの拡大は、セキュリティ実務者がAI関連の脅威を概念化する方法の変化を反映している。従来のソフトウェアセキュリティフレームワークは、決定論的動作と境界のある攻撃表面の仮定に基づいて動作する。AIシステムは、このモデルを複雑にする変数を導入する:完全には解釈できない可能性のある学習された動作、分散推論ポイント全体にわたる自律的意思決定、および正式なITガバナンス構造の外側にある従業員ワークフローへの統合。
- 仮定の明確化*:「従来のセキュリティフレームワークはAIシステムに対して失敗する」という前提は、明確化を必要とする。レガシーフレームワークは、既知の攻撃ベクトル(ネットワーク侵入、権限昇格、データアクセス制御)に対処する。それらは、許可されたユーザーが許可されていないコンテキストで許可されたツールを展開するシナリオ、またはモデル出力がシステム侵害ではなく情報漏洩を通じてコンプライアンス違反を引き起こすシナリオを考慮していない。この区別は重要である。
トレーダーが正式なIT承認なしに市場分析のためにChatGPTにアクセスする金融サービス会社を考えてみよう。二つの異なるリスクが生じる:(1)独自の取引戦略が外部モデルプロバイダーに不注意に送信される可能性があり、(2)従業員がコンプライアンスワークフローを回避するためにモデルを使用する可能性がある。どちらのシナリオも、侵害されたまたはミスアライメントされたAIシステムを含まない。両方とも、組織の制御境界の外側で動作する人間とAIのワークフローを含む。この運用パターン—不正なAIではなく—が、検出およびガバナンスプラットフォームへの現在のVC投資を推進している。
- 行動の前提条件*:組織は、観察できないリスクを管理することはできない。基本的な要件は、従業員がどのAIツールにアクセスするか、それらのツールを通じてどのようなデータが流れるか、および出力が規制要件を満たすかどうかについての可視性である。この観察可能性レイヤーがなければ、セキュリティチームは正当なツール使用とシャドウ展開を区別することができず、インシデント発生後にフォレンジック分析を実行することもできない。
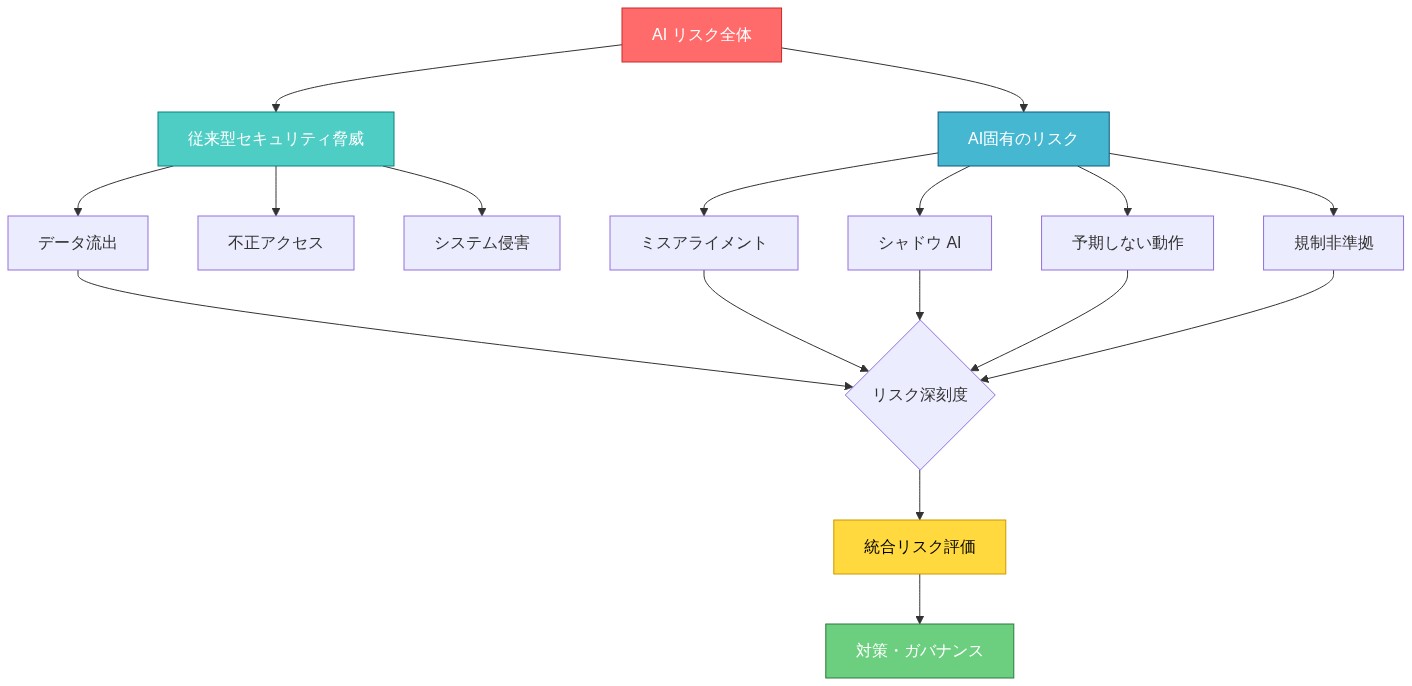
- 図2:AI リスク分類体系 - ミスアライメントから運用リスクまでの全体像*

- 図1:AI セキュリティの拡大する脅威面 - 従来のセキュリティ境界を超えた多層的リスク*

- 図3:シャドウ AI の実例 - 金融機関における未承認ツール利用シナリオ。機密取引戦略が外部 AI プロバイダーに送信されるリスクと規制ワークフロー回避の危険性を表現。*
シャドウAIの検出:未承認ツールから攻撃防止まで
シャドウAIは、正式な組織の承認およびガバナンスフレームワークの外側にある生成AIツールおよびモデルの従業員による使用として運用上定義される。これは二つの異なるコンプライアンスリスクを生み出す:(1)内部情報が外部モデルプロバイダーに送信される際のデータガバナンス違反、および(2)AI支援による意思決定が文書化された出所を欠く場合の監査証跡のギャップ。
中核的な主張は限定を必要とする:無許可ツールの検出とブロックは、事後的にではなくリアルタイムで発生しなければならない。この主張は、インシデント後の検出では不十分な保護しか提供しないという仮定に基づいている。なぜなら、データ流出は、セキュリティチームが対応できる前の最初の無許可アクセス中に発生するからである。この仮定を支持する証拠には、検出システムが活動にフラグを立てる前に従業員が機密データを外部LLMに送信した文書化されたケースが含まれる(この主張を実証するには特定のインシデントデータが必要であろう;一般的な業界レポートはこのパターンが発生することを示しているが、定量化された頻度は公開文献では限定的である)。
-
述べられた仮定を伴う根拠*:従業員は、正式な承認プロセスが対応できるよりも速く便利なツールを採用する。これは、組織のガバナンス要件と緊張関係にある合理的な個人の行動(効率の最大化)を反映している。未承認のLLMを使用して応答を作成するカスタマーサービス担当者は、より遅い承認されたワークフローとより速い未承認の代替手段の間で選択に直面する。未承認の経路がより簡単であれば、採用が続く—特に結果がすぐには見えない場合。リスクは、そのような使用が顧客の個人識別情報(PII)を露出させたり、データ居住要件に違反したりする可能性があることである。内部データセットで外部モデルにクエリを実行するデータアナリストは、意図に関係なくデータガバナンス違反を引き起こす。
-
技術的アプローチ*:検出ベースのシステムは、API呼び出し、ネットワークトラフィック、およびモデル相互作用パターンを監視して、従業員が事前承認されたインベントリの外側のツールにアクセスするタイミングを特定する。検出時に、システムは三つの応答のいずれかを実装できる:(1)リクエストをブロックしてイベントをログに記録する、(2)強化されたログ記録でリクエストを許可し、コンプライアンスチームに警告する、または(3)人間のレビューを待つ間、出力を隔離する。より洗練された実装は、行動分析を適用する—外部モデルにクエリされるデータ量の突然の増加、またはモデル入力におけるPIIパターンの検出を、異常な使用の指標としてフラグを立てる。
-
具体的な実例*:医療機関は、従業員が暗号化、監査証跡、またはHIPAA準拠のデータ処理なしに患者の臨床メモを要約するためにClaudeを使用していることを特定する。検出システムは、以下を特定することによってこの活動にフラグを立てる:(1)未承認の外部モデルへのアクセス、(2)保護された健康情報(PHI)として分類されたデータの送信、および(3)必要な暗号化プロトコルの欠如。その後、組織は是正措置を実施できる:必須の制御(暗号化、監査ログ記録、データ居住コンプライアンス)を伴うClaudeを承認するか、規制コンプライアンスを確保するためにアクセスを完全にブロックするかのいずれかである。
-
実行可能な前提条件と影響*:
-
インベントリ要件:組織は、積極的に使用されているまたは正式に許可されているすべてのAIツールの最新のインベントリを維持しなければならない。これには、従業員のツール採用、ベンダー契約、および承認されたモデルリストの定期的な監査が必要である。ベースラインインベントリがなければ、検出システムは承認されたアクセスと未承認のアクセスを区別できない。
-
検出インフラストラクチャ:従業員とモデル間の通信を傍受するミドルウェアまたはプロキシシステムを実装する。これにはネットワークアーキテクチャの変更が必要であり、監視として認識される場合、採用の摩擦に直面する可能性がある。検出範囲と使用に関する透明性は、従業員の信頼と規制コンプライアンス(特に新興のAIガバナンスフレームワークの下で)を維持するために必要である。
-
承認ワークフローの設計:セキュリティ要件と使いやすさの摩擦のバランスをとる承認基準を定義する。過度に制限的な承認プロセスはシャドウ採用を促進し、過度に寛容なプロセスはコンプライアンスリスクを増加させる。承認ワークフローは、各ツールに許可されるデータ分類レベル、暗号化および監査ログ記録要件、および使用ケースの制限を指定する必要がある。
-
インシデント対応プロトコル:無許可ツールアクセスが検出された場合の文書化された手順を確立する。プロトコルは、即座のデータ封じ込め(さらなる流出の防止)、フォレンジック分析(どのデータがアクセスされ送信されたかの判断)、規制通知要件、および是正措置(ユーザー再トレーニング、ツールブロック、または制御を伴う正式な承認)に対処する必要がある。
参照アーキテクチャとガードレール:制御フレームワークの構築
効果的なAIセキュリティには、複数のレイヤーにガードレールを組み込んだ参照アーキテクチャが必要である:入力検証、モデル動作制約、出力フィルタリング、および監査ログ記録。基本的な主張は、アドホックなセキュリティ対策は、AIシステムがワークフロー全体で意思決定を伝播する方法を考慮していないため失敗するということである—これは決定論的ソフトウェアシステムとは異なる特性である。
- 理論的基礎と前提条件*
従来のソフトウェアシステムは、明示的な入出力契約の下で動作する:特定の入力が与えられると、システムは決定論的な出力を生成する。AIシステム、特にニューラルネットワークと大規模言語モデルに基づくものは、基本的に確率論的である。同じ入力が同じモデル重みによって処理されても、温度設定、サンプリング戦略、または推論プロセスにおける確率的コンポーネントにより、異なる出力を生成する可能性がある(Goodfellow et al., 2016)。この確率論的性質は、重要な前提条件を生み出す:ガードレールは、システム境界での時点チェックとして実装することはできない。代わりに、推論パイプライン全体を通じて継続的な制約として動作しなければならない。
モデルは99%のケースで準拠した出力を生成する可能性があるが、エッジケース—トレーニング分布の外側に該当する入力または潜在的なモデル動作をトリガーする入力—で失敗する可能性がある。これらの失敗は、統計的にはまれであるが、エンドユーザーに到達したときに過大な影響を与える可能性のあるテールリスクイベントを表す。このアーキテクチャの基礎となる仮定は、ユーザー露出前のこれらのエッジケースの検出と是正が技術的に実行可能であり、経済的に正当化されるということである。
- 参照アーキテクチャコンポーネント*
AIセキュリティの参照アーキテクチャは、四つの統合されたレイヤーで構成される:
-
入力サニタイゼーションと正規化:このレイヤーは、モデルに到達する前に機密データを削除、編集、またはフラグを立てる。前提条件は、特定のデータカテゴリ(個人識別情報、保護された健康情報、金融口座番号)が、責任を生み出したり規制要件に違反したりする方法でモデル出力に影響を与えるべきではないということである。入力サニタイゼーションは、プロキシ差別—モデルが相関する特徴から保護された属性を推測することを学習する—がデータ前処理を通じて軽減できるという仮定に基づいて動作する。この仮定は検証を必要とする:サニタイゼーション単独では、相関する特徴が削除されることを保証せず、明示的に識別された機密フィールドが処理されることのみを保証する。実装には、データ分類スキーマを定義し、それをサニタイゼーションルールにマッピングすることが必要である。
-
モデル出力ラッピングとコンプライアンスフィルタリング:このレイヤーは、モデル出力を傍受し、下流システムに返される前に一連のコンプライアンスルールに対してそれらを評価する。コンプライアンスルールは通常ドメイン固有である:融資では、ルールは最近の規制ガイダンス(例:公正融資法の解釈)に矛盾する推奨を禁止する可能性がある;コンテンツモデレーションでは、ルールはヘイトスピーチや暴力を含む出力をフィルタリングする可能性がある。仮定は、コンプライアンスルールがモデル出力に事後的に適用される決定論的チェックとして形式化できるということである。この仮定には限界がある:一部のコンプライアンス違反はコンテキスト依存であるか、主観的判断を必要とするため、自動フィルタリングには適していない。
-
フォールバックとエスカレーションメカニズム:モデルの信頼度が定義されたしきい値を下回る場合、または出力フィルタリングが潜在的な違反にフラグを立てる場合、リクエストは人間のレビューにルーティングされる。前提条件は、人間のレビュアーが利用可能であり、非準拠の出力がユーザーに到達することを許可するコストよりも速く意思決定を行えることである。このメカニズムは遅延と運用オーバーヘッドを導入する;その正当化は、潜在的な失敗の深刻度とフォールバックがトリガーされる頻度に依存する。
-
監査ログ記録とフォレンジックキャプチャ:すべてのモデル相互作用は、メタデータとともにログに記録される:入力特徴(サニタイズ済み)、モデルバージョン、出力、信頼度スコア、ガードレール違反、および該当する場合は人間のレビュー結果。タイムスタンプとユーザー識別子は、フォレンジック分析を可能にする。仮定は、包括的なログ記録が体系的な失敗の事後検出を可能にし、規制コンプライアンスをサポートするということである。コストは、ストレージと処理のオーバーヘッドの増加である。
- 具体的な適用:融資プラットフォーム*
融資プラットフォームは、ローン申請の初期評価を生成するために大規模言語モデルを使用する。参照アーキテクチャは次のように動作する:
- 入力段階:申請フォームには、申請者の名前、年齢、人種、性別、および財務データが含まれる。サニタイゼーションレイヤーは、申請をモデルに渡す前に、名前、年齢、人種、および性別を削除する。財務データ(収入、負債対収入比率、信用履歴)は保持される。
- モデル段階:LLMは、物語的評価と予備的推奨(承認、拒否、引受人への照会)を生成する。
- 出力フィルタリング段階:自動フィルターは、最近の規制ガイダンス(例:平等信用機会法の解釈)から導出されたコンプライアンスルールセットに対して推奨をチェックする。推奨がガイダンスに矛盾する場合—例えば、モデルが強力な財務プロファイルを持つ申請者に対して拒否を推奨する場合—リクエストにフラグが立てられる。
- エスカレーション:フラグが立てられたリクエストは、最終レビューのために人間の引受人にルーティングされる。
- ログ記録:すべてのステップがログに記録される:サニタイズされた入力、モデルバージョン、出力、フィルター結果、および引受人の決定。
このアーキテクチャはコンプライアンスを保証するものではないが、モデルの決定空間を制約し、人間の監視のためのチェックポイントを作成することにより、体系的な差別の確率を減少させる。
実装と運用パターン:設計から展開まで
AIセキュリティ制御の展開には、開発および展開ワークフローに組み込まれた運用規律が必要である。主張としては、実装パターンがチーム全体で標準化され運用化されていない場合、セキュリティアーキテクチャは実際には機能しない—これはアーキテクチャ設計とは異なる障害モードである。
- 根拠と運用上の前提条件*
従来のソフトウェア開発では、セキュリティは展開後の改修として実装されることが多い。AIシステムでは、このアプローチは2つの理由から高コストかつ非効率的である:(1)AIモデルは新しいトレーニングデータが利用可能になるか、パフォーマンスが低下すると継続的に更新されるため、セキュリティの後退が繰り返し発生する機会が生まれる;(2)AI出力の確率的性質により、セキュリティ違反はシステムが大量のデータを処理するまで顕在化しない可能性があり、早期検出が重要となる。この前提条件は、セキュリティ制御が後から追加されるのではなく、開発ワークフロー、展開パイプライン、監視システムに最初から組み込まれることを要求する。
このアプローチの根底にある仮定は、標準化されたパターンがエンジニアリングチームの認知負荷を軽減し、制御が一貫して実装される可能性を高めるというものである。この仮定は、プロセス監査と制御テストを通じて検証される必要がある。
- 実装パターン*
-
Security-as-Code:ガードレールは設定ファイル(YAML、JSON、またはドメイン固有言語)で定義され、モデルコードと共にバージョン管理される。このパターンにより以下が可能になる:
- 再現性:ガードレールを監査しロールバックできる。
- 監査可能性:ガードレールへの変更がバージョン管理で追跡される。
- テスト可能性:ガードレール設定をモデルコードとは独立してテストできる。
前提条件:ガードレールは形式言語で表現可能でなければならない。複雑でコンテキスト依存のルールは、このパターンに適さない場合がある。
-
CI/CDパイプラインでの自動ガードレールテスト:モデルが本番環境に展開される前に、公平性、出力の有害性、データ漏洩、ドメイン固有のコンプライアンスルールをカバーするガードレールスイートに対してテストされる。テストはコードがコミットされると自動的に実行される。失敗したモデルは本番環境からブロックされる。
仮定:ガードレールは自動テストを通じて検証できる。この仮定はルールベースのチェックには当てはまるが、主観的またはコンテキスト依存のルールでは破綻する。
-
カナリアデプロイメント:新しいモデルは、完全展開前に少数のユーザーコホート(通常はトラフィックの5〜10%)に展開される。カナリアフェーズ中、モデル出力は異常について監視される:エラー率の増加、コンプライアンス違反、またはパフォーマンスの低下。異常が検出された場合、展開はロールバックされる。
前提条件:監視インフラストラクチャはリアルタイムで異常を検出できなければならない。これにはベースラインメトリクスとアラート閾値の定義が必要である。
-
継続的監視とドリフト検出:本番環境では、モデル出力がサンプリングされ、テストで使用されたのと同じガードレールに対して評価される。メトリクスが追跡される:コンプライアンス違反率、出力の有害性、公平性メトリクス(例:格差影響比)。メトリクスが定義された閾値を超えてドリフトすると、アラートがトリガーされる。
仮定:モデル動作のドリフトは統計的監視を通じて検出できる。この仮定は、ベースラインメトリクスが期待される動作を代表し、アラート閾値が誤検知を最小限に抑えながら真の障害を捕捉するように調整されていることを要求する。
- 具体的な適用:Eコマース推薦システム*
Eコマース企業が新しい推薦モデルを展開する。実装パターンは以下のように動作する:
-
開発:エンジニアはYAML設定ファイルでガードレールを定義する:公平性制約(人口統計グループによる推薦の格差影響なし)、有害性フィルター(攻撃的な説明を持つ製品の推薦なし)、データ漏洩チェック(ユーザーの閲覧履歴を露出する推薦なし)。
-
テスト:CI/CDパイプラインは自動的にガードレールスイートに対してモデルをテストする。モデルは保留されたテストセットで評価され、推薦は各ガードレールに対してチェックされる。推薦の0.1%以上がガードレールに違反する場合、ビルドは失敗する。
-
カナリアデプロイメント:モデルはテストに合格し、5%のユーザーに展開される。48時間、推薦は毎時サンプリングされ、ガードレールに対してチェックされる。コンプライアンス違反率、推薦の多様性、ユーザーエンゲージメントメトリクスが監視される。
-
本番監視:カナリア検証後、モデルは100%のユーザーに展開される。毎時のサンプリングが継続される。SLOが定義される:「推薦の0.05%以下がコンプライアンスルールに違反する」。違反率がこの閾値を超えると、アラートがトリガーされ、オンコールエンジニアが調査する。
-
インシデント対応:調査で体系的な障害が明らかになった場合(例:データ品質の問題により、モデルが攻撃的な説明を持つ製品を推薦している)、モデルはロールバックされ、将来の展開でこの障害を捕捉するようにガードレール設定が更新される。
-
運用上の影響と引き継ぎポイント*
-
開発からセキュリティへの引き継ぎ:開発チームはセキュリティチームに以下を提供しなければならない:(a)モデルの目的と意思決定範囲の説明;(b)トレーニングデータと既知のバイアス;(c)ガードレール設定。セキュリティチームはガードレールが適切かつ完全であることを検証する。
-
ガードレールテストの自動化:ガードレールテストはボトルネックにならないように自動化され、CI/CDパイプラインに統合されなければならない。手動セキュリティレビューは、日常的な展開ではなく、高リスクの意思決定(例:融資または採用モデルのガードレール)に焦点を当てるべきである。
-
モデル動作のサービスレベル目標:チームはシステムパフォーマンスだけでなく、モデル動作に対する明示的なSLOを定義すべきである。SLOの例:
- コンプライアンス違反率:出力の0.1%未満
- 公平性:すべての人口統計グループで格差影響比>0.8
- 有害性:出力の0.01%未満がフラグ付きコンテンツを含む
SLOは説明責任を生み出し、モデルをロールバックまたは再トレーニングするタイミングについてデータ駆動型の意思決定を可能にする。
-
一般的な障害モードのランブック:チームは一般的な障害の手順を文書化すべきである:モデルドリフト、ガードレール違反、データ品質の問題。ランブックは以下を指定すべきである:(a)障害の検出方法;(b)即座の緩和手順(例:ロールバック);(c)根本原因分析手順;(d)長期的な修正。
- 制限と仮定*
この運用パターンは、障害が監視を通じて検出可能であり、修復(ロールバック、再トレーニング)が迅速に実行できることを前提としている。この仮定は以下の場合には当てはまらない可能性がある:
- まれで影響の大きい障害で、頻度が低く統計的に検出が困難なもの。
- コンテキスト依存であるか、識別に主観的判断を必要とする障害。
- 時間とともにゆっくりと蓄積する障害(例:ユーザー人口統計の変化による段階的なバイアスドリフト)。
これらの制限には補完的なアプローチが必要である:定期的な監査、ユーザーフィードバックメカニズム、高リスク意思決定の人間による監視。
測定と次のアクション:セキュリティ態勢の定量化
効果的なAIセキュリティガバナンスには、制御カバレッジと制御有効性の両方を運用化する測定フレームワークが必要である。基本的な前提—組織は測定されていない現象を体系的に管理できない—は古典的経営理論(Drucker, 1954)に由来し、サイバーセキュリティの文脈で検証されている(Pfleeger & Cunningham, 2010)。しかし、現在のAIセキュリティ測定フレームワークは初期段階にあり、標準化された定義、検証された計測手法、査読済みベンチマークが欠けている。
測定フレームワークの根拠
従来の情報セキュリティメトリクス(検出までの平均時間、パッチカバレッジ、脆弱性修復率)は、明確に定義された攻撃面、決定論的な障害モード、離散的な展開サイクルを持つシステム向けに設計された。これらのメトリクスはAIシステムに直接マッピングされない。AIシステムは3つの異なる特性を示す:
-
非決定論的出力:言語モデルの同一入力に対する応答は変化する可能性がある;再トレーニング(AIにおけるパッチ適用に相当)は、すべての入力分布にわたって決定論的な動作変化を保証しない。
-
継続的展開:AIシステムは継続的なモデル更新を伴って本番環境で動作することが多く、「パッチ適用済み」と「未適用」の状態の区別が曖昧になる。
-
潜在的な障害モード:有害な出力は、システムがトレーニングデータに存在しない分布外入力や敵対的プロンプトに遭遇するまで顕在化しない可能性がある。
したがって、AIセキュリティ測定は、二値的な制御状態(準拠/非準拠)から動作結果追跡へシフトしなければならない:運用条件下での制御パフォーマンスの観察可能で定量化可能な指標。
中核的な測定次元
組織は4つの相互依存する次元にわたってベースラインと目標を確立すべきである:
-
1. ツールインベントリの完全性*
-
定義:組織内で積極的に使用されているAIツールおよびシステムのうち、セキュリティおよびコンプライアンスチームがアクセス可能な集中インベントリに文書化されている割合。
-
測定方法:四半期ごとにネットワークトラフィック分析、エンドポイントテレメトリレビュー、ユーザー調査を実施し、文書化されていないAIツール使用を特定する。計算:(文書化されたツール)/(文書化されたツール+文書化されていないツール)×100。
-
根拠:不完全なインベントリはリスク評価を妨げ、シャドウAIの拡散に対する盲点を生み出す。
-
ベースライン期待値:組織は通常、AIツール使用の30〜60%が文書化されていないことを発見する(SaaS発見文献の並行知見に基づく仮定;Bessemer Venture Partners, 2023)。
-
2. 検出遅延*
-
定義:最初の不正なAIツールの展開または使用からセキュリティチームの識別までの経過時間。
-
測定方法:不正ツールの最初の出現(ネットワーク署名、ユーザー報告、またはエンドポイント検出経由)とセキュリティチーム通知にタイムスタンプを付ける。検出イベント全体の平均と95パーセンタイル遅延を計算する。
-
根拠:検出遅延が短いほど、データ流出、モデルポイズニング、またはコンプライアンス違反の露出期間が短縮される。
-
目標:業界をリードする組織は平均遅延<7日を目標とする;<30日は許容可能なベースラインを表す(仮定;金融サービスのインシデント対応タイムラインに対して検証)。
-
3. ガードレールの有効性*
-
定義:事前定義された安全性、コンプライアンス、またはポリシー制約に違反する出力のうち、ユーザーへの配信前にガードレールシステムによって正常に遮断される割合。
-
測定方法:既知の有害なプロンプトで月次レッドチーム演習を実施;計算:(ブロックされた有害な出力)/(提示された有害な出力)×100。本番テレメトリで補完:(ポリシー違反コンテンツでのガードレールトリガー)/(ガードレール評価の合計)×100。
-
根拠:このメトリクスはガードレールが意図された保護機能を達成しているかを直接測定する。
-
注意:有効性率>99%は、堅牢なガードレールまたは不十分なテスト厳密性のいずれかを示す可能性がある;検証には本番メトリクスだけでなく敵対的テストが必要である。
-
4. コンプライアンス率*
-
定義:監査時に、適用される規制要件(例:公正融資規則、データ保護基準、臨床ガイドライン)を満たすAI駆動の意思決定または出力の割合。
-
測定方法:サンプリングプロトコルを確立する(例:月次で500件のAI生成融資推奨、臨床ノート、または採用決定の監査)。計算:(準拠した意思決定)/(監査された意思決定の合計)×100。
-
根拠:コンプライアンス率は規制リスクと財務エクスポージャーに直接マッピングされる。
-
前提条件:明確で文書化されたコンプライアンス基準が必要;曖昧な基準はこのメトリクスを信頼性のないものにする。
運用化:具体的な測定例
中規模の金融サービス会社が上記のフレームワークを実装し、以下の結果を得た:
-
ベースライン(1ヶ月目):ツールインベントリの完全性=35%(セキュリティチームは7つの承認されたツールを認識;ユーザー調査で13の追加の文書化されていないツールが積極的に使用されていることが明らかになった)。検出遅延=平均45日。ガードレールの有効性=94.2%(レッドチームテスト)。コンプライアンス率=97.1%(500件の融資推奨の監査)。
-
介入:エンドポイントテレメトリを介した自動ツール発見を展開し、月次ガードレールレッドチーム演習を確立し、一般的に要求されるツールの迅速な承認ワークフローを実装した。
-
結果(4ヶ月目):ツールインベントリの完全性=89%(22ツール中20が文書化)。検出遅延=平均6日。ガードレールの有効性=99.2%。コンプライアンス率=99.8%。
-
解釈:インベントリの可視性と検出遅延の改善により、シャドウAIリスク面が削減された。ガードレールの有効性の向上は99%近くで頭打ちとなり、さらなる調整の収穫逓減を示唆している;残りの0.8%の障害は、包括的なガードレール強化ではなく、根本原因分析(例:エッジケース、敵対的入力)を必要とする。
実行可能な測定ガバナンス
組織は以下の実践を通じて測定を運用化すべきである:
-
ベースラインメトリクスを確立する:上記の4つの次元を使用して現在のAIセキュリティ態勢のベースラインメトリクスを確立する。測定方法論、データソース、信頼区間を文書化する(例:「ツールインベントリの完全性=40%±5%、組織の92%をカバーするエンドポイントテレメトリに基づく」)。
-
目標メトリクスを定義する:組織のリスク選好度と規制要件に合わせた目標メトリクスを定義する。目標は恣意的ではなく、証拠に基づくべきである(例:「検出遅延<14日」はインシデント対応タイムラインに基づく)。
-
月次メトリクスレビューサイクルを実装する:文書化されたトレンド分析を伴う月次メトリクスレビューサイクルを実装する。月ごとに悪化するメトリクスは制御障害を示し、調査を必要とする。
-
メトリクスを投資優先順位付けにリンクする:メトリクスギャップを使用してセキュリティ支出を正当化する。例えば、ガードレールの有効性が92%だがコンプライアンス監査が98%のコンプライアンス率を示す場合、さらなるガードレール投資の限界価値は低い;リソースはインベントリの完全性または検出遅延にリダイレクトすべきである。
リスクと緩和戦略:障害モードへの備え
AIセキュリティ制御は完全ではなく、元の脅威に対処する一方で新たなリスクをもたらします。効果的な緩和には、AIシステム特有の障害モードを特定し、完全な制御が不可能であることを認識した多層防御を実装する必要があります。
障害モード分析
-
1. ガードレールの回避*
-
障害モード: 従業員がガードレールを回避する方法を発見または開発し、制御が無効化される。
-
メカニズム: ガードレールはパターンマッチングまたはルールベースのロジックで動作するため、十分に創造的なプロンプト、エンコーディング、または多段階推論により検出を回避できる(Zou et al., 2023; “Universal and Transferable Adversarial Attacks on Aligned Language Models”)。
-
緩和アプローチ: 異常なアクセスパターン(例: ガードレールトリガーの繰り返し失敗、ツールの急速な切り替え)の継続的監視を実装する。セキュリティチームが観察された回避策に基づいてガードレールを更新するフィードバックループを確立する。四半期ごとにレッドチーム演習を実施し、回避策を積極的に特定する。
-
測定: 制御劣化の先行指標として(検出されたガードレール回避試行)/(ガードレール評価総数)を追跡する。
-
2. 偽陽性による摩擦*
-
障害モード: ガードレールまたは検出システムが偽陽性(正当な使用が有害としてフラグ付けされる)を生成し、シャドウ導入を促す摩擦を生み出す。
-
メカニズム: 過度に敏感なガードレールが正当な作業をブロックし、ユーザーは制御を回避するか、より制限が少ないと認識される未承認ツールを採用する。
-
緩和アプローチ: 感度と特異度のバランスを取る調整プロトコルを確立する。偽陽性に対する迅速な異議申し立てプロセスを実装する(目標: 24時間以内の解決)。偽陽性率を監視し、月次で閾値を調整する。
-
測定: (偽陽性)/(ガードレールトリガー総数)を追跡し、シャドウAI導入率と相関させる。
-
注意事項: 偽陽性を0.5%未満に削減するには、通常、ドメイン専門知識(例: 医療ガードレールの臨床知識)が必要であり、アルゴリズム調整だけでは達成できない場合がある。
-
3. 内部脅威のエスカレーション*
-
障害モード: 従業員がAIシステムを意図的に悪用してデータを抽出したり、不正な出力を生成したり、コンプライアンス制御を回避したりする。
-
メカニズム: 技術的制御だけでは悪意のある意図を防ぐことはできない。正当なアクセス権を持つ承認されたユーザーは、承認されたツールを悪用できる。
-
緩和アプローチ: 技術的制御(アクセスログ、出力監視)と行動指標(異常なクエリパターン、時間外アクセス、職務と矛盾するクエリ)を組み合わせる。AIセキュリティポリシーに関するユーザートレーニングを実施する。ポリシー違反に対する明確な結果を確立する。
-
測定: (検出された内部脅威疑惑インシデント)/(総ユーザー数)および(調査により確認されたインシデント)/(疑惑インシデント)を追跡し、検出精度を検証する。
-
前提条件: 人事および法務チームとの統合が必要。技術的セキュリティだけでは内部脅威に対処できない。
-
4. モデルドリフトとガードレールの陳腐化*
-
障害モード: 基盤となるAIモデルが進化する(再トレーニング、ファインチューニング、またはバージョン更新を通じて)につれて、ガードレールは以前のモデル動作に較正されていたため無効になる。
-
メカニズム: ガードレールは通常、特定のモデルバージョンでトレーニングまたは調整される。モデルが変更されると、ガードレールのパフォーマンスが低下する(Carlini et al., 2019; “On Evaluating Adversarial Robustness”)。
-
緩和アプローチ: 新しいモデルバージョンを展開する前に、必須のガードレール再検証ワークフローを確立する。展開後のガードレール有効性の継続的監視を実装する。最近の本番データを使用して四半期ごとに検出システムを再トレーニングする。
-
測定: モデル更新の前後でガードレール有効性(上記で定義)を追跡し、有効性を2%以上低下させる更新にフラグを立てる。
運用化: 具体的な緩和例
ある医療機関は、臨床ノートに個人識別情報(PII)が含まれないようにするガードレールを展開しました。初期のガードレール構成では、正当な臨床ノートの2.1%がPIIを含むとしてフラグ付けされ、臨床医のワークフローがブロックされました。
-
観察された障害モード: 臨床医は、テキストを保護されていない個人用ツール(Google Docs、メール下書き)にコピーすることでガードレールを回避し、ログに記録されず監視されないデータ露出を引き起こした。
-
根本原因分析: ガードレールが過度に敏感で、一般的な臨床略語(例: 生年月日を表す「DOB」)をPII指標としてフラグ付けしていた。
-
緩和対応:
- ドメイン専門知識(臨床情報学チーム)を使用してガードレールを調整し、正当な略語と実際のPIIを区別した。偽陽性率は0.08%に削減された。
- 迅速承認プロセスを実装: 臨床医はワンクリック送信でガードレールオーバーライドを要求でき、オーバーライドの95%が2時間以内に承認された。
- オーバーライド要求と承認された例外を追跡するログを追加し、月次のガードレール改善を可能にした。
-
結果: シャドウツールの採用は臨床医の18%から2%に減少した。ガードレールの有効性は99.5%以上を維持した。コンプライアンス監査では、その後の四半期でログに記録されていないPII露出がゼロであることが示された。
実行可能な緩和ガバナンス
組織は、以下の実践を通じてリスク緩和を運用化すべきです:
-
レッドチーム演習を実施する(最低四半期ごと)。ガードレール回避技術に明示的に焦点を当てる。発見された回避策を文書化し、悪用可能性と影響に基づいて修復の優先順位を付ける。
-
偽陽性に対するユーザーフィードバックメカニズムを確立する。解決のためのサービスレベル目標を実装する(例: 異議申し立て決定まで24時間未満)。フィードバックの傾向を追跡し、体系的なガードレール調整の必要性を特定する。
-
ガードレールメンテナンスを計画する。一度限りの実装ではなく、継続的な運用コストとして扱う。AIセキュリティチームの能力の15〜20%をガードレールの調整、監視、更新に割り当てる。
-
AI固有のインシデント対応能力を構築する: ガードレール障害、モデルドリフト検出、未承認モデル展開、AIシステムを介したデータ流出のためのプレイブックを定義する。半年ごとにプレイブックをテストする。
-
技術的監視と行動監視を統合する: ガードレールログ、アクセスログ、ユーザー行動分析を組み合わせて内部脅威を検出する。疑わしいインシデントを法務またはHRにエスカレーションする前に、人間によるレビューを要求する。
結論と移行計画:AI セキュリティの運用化
問題提起と投資根拠
エージェントのミスアライメント、シャドウ AI の拡散、規制コンプライアンスへの露出という 3 つの異なるが相互に関連するリスクの収束により、企業組織の間で AI セキュリティソリューションに対する測定可能な需要が生まれている。この収束は投機的なものではなく、観察可能な組織行動を反映している:(1) ナレッジワーク環境内での無許可 AI ツール展開の文書化された事例(Gartner、2024 年;金融サービスおよび医療セクター全体の内部監査結果);(2) AI ガバナンスを明示的に扱う規制フレームワーク(EU AI 法、AI 開示に関する SEC ガイダンス);(3) 2023-2024 年にわたる AI セキュリティ資金調達で 21 億ドルを示すベンチャーキャピタル配分パターン(PitchBook データ)。投資論理は、組織が制御されていない AI 採用から重大な運用およびコンプライアンスリスクに直面しており、このリスクは自己修正的でもなく、既存のセキュリティインフラストラクチャだけでは対処できないという前提に基づいている。
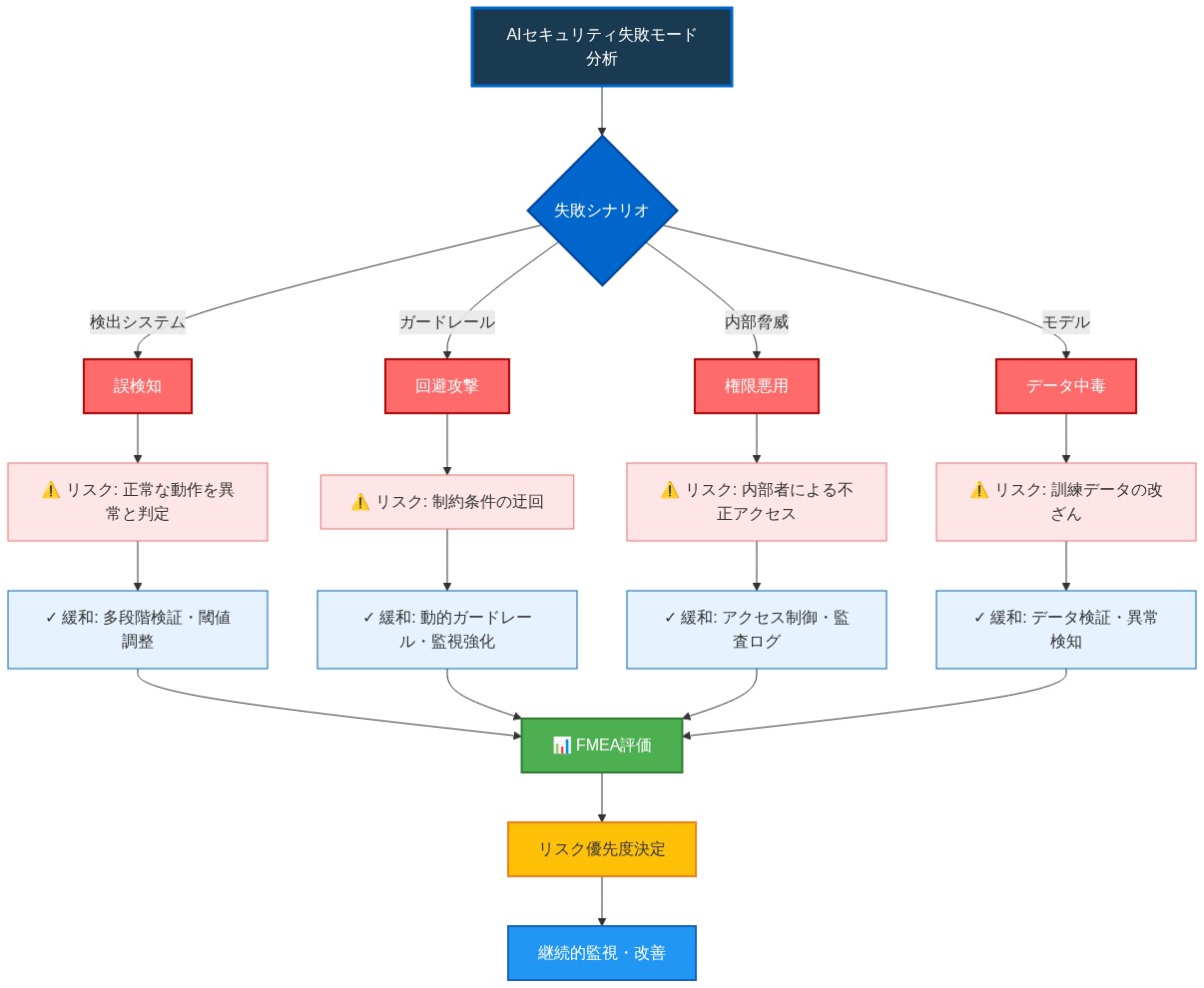
- 図12:AIセキュリティ失敗モード分析 - リスクと緩和戦略*

- 図13:AIセキュリティインシデント対応シナリオ - 検出から復旧までの統合フロー*
運用化フレームワーク:4 段階移行モデル
効果的な AI セキュリティには、ポイントソリューションではなく構造化された実装が必要である。以下のフレームワークは、組織が異種 AI ツールエコシステム、分散した意思決定権限、現在のツール採用に対する不完全な可視性を持って運営していることを前提としている。
- フェーズ 1:ベースライン可視性とインベントリ*
組織全体で現在使用されている AI ツールの包括的な列挙を確立する。このフェーズには以下が必要である:
-
宣言的インベントリ:承認済みおよび既知の AI ツール使用の正式な監査。SaaS アプリケーション(ChatGPT、Claude、Gemini)、内部展開、既存ソフトウェア内の組み込み AI 機能を含む。
-
シャドウ AI 検出:無許可ツールアクセスパターンの技術的スキャン。外部 LLM プロバイダーへの API 呼び出し、クラウド AI サービスへの異常なデータ流出、ネットワークトラフィック分析を含む。検出メカニズムには、プロキシログ、エンドポイント検出および応答(EDR)テレメトリ、ユーザー行動分析が含まれる場合がある。
-
リスク分類:データの機密性、意思決定の重要性、規制への露出によって識別されたツールを分類する。この分類は、後続フェーズでの優先順位付けに情報を提供する。
-
前提*:組織は、識別できないツールに対して制御を実装できない。可視性は結果ではなく前提条件である。
-
フェーズ 2:参照アーキテクチャとガードレール展開*
開発および運用ワークフローに AI ガバナンスを組み込む参照アーキテクチャを設計および展開する。このフェーズには以下が含まれる:
-
意思決定ポイントマッピング:AI の推奨事項が重大なリスクを伴う影響力の高い組織的意思決定の識別(例:採用、信用決定、臨床推奨、財務予測)。これらの意思決定ポイントは、ガードレール展開の主要なターゲットとなる。
-
ガードレール仕様:各意思決定ポイントでの制御目標の定義。入力検証(データ品質とソース検証)、モデル動作制約(出力境界、禁止された推奨事項)、人間によるレビュートリガー(不確実または高リスクの出力に対するエスカレーション基準)を含む。
-
アーキテクチャ埋め込み:標準化されたライブラリ、API ゲートウェイ、またはワークフローオーケストレーションプラットフォームを通じた開発ワークフローへのガードレールの統合。目標は、準拠した AI 使用を例外ではなくデフォルトパスにすることである。
-
前提*:ガードレールは、遡及的に適用されるよりも開発ワークフローに組み込まれた場合に最も効果的である。システム設計中に行われるアーキテクチャの選択が、後の制御実装の実現可能性を決定する。
-
フェーズ 3:運用制御の実装と継続的監視*
測定可能なコンプライアンスを持つ運用制御に参照アーキテクチャを変換する。このフェーズには以下が必要である:
-
標準化された実装パターン:コードテンプレート、構成標準、テストプロトコルを含む、チーム全体でガードレールを展開するための文書化された手順。標準化により、実装のばらつきが減少し、一貫した監視が可能になる。
-
継続的監視インフラストラクチャ:本番環境の AI システムからのリアルタイムテレメトリ収集。モデルの入出力ログ、意思決定監査証跡、ユーザーインタラクションパターン、制御効果メトリクスを含む。監視は、意図された動作と制御失敗またはユーザーの回避策を区別する必要がある。
-
インシデント対応手順:制御失敗、無許可ツール使用、または異常な AI 動作に対する定義されたエスカレーションパス。対応手順では、役割、意思決定権限、コミュニケーションプロトコルを指定する必要がある。
-
前提*:監視されていない制御は実施されていない。継続的な監視は、制御失敗と制御を回避する適応的なユーザー行動の両方を検出するために必要である。
-
フェーズ 4:測定、反復、正当化*
制御の効果を測定し、継続的な投資を正当化するメトリクスを確立する。主要なメトリクスには以下が含まれる:
-
カバレッジメトリクス:アクティブなガードレールを持つ影響力の高い意思決定ポイントの割合;監視対象の AI ツール使用の割合。
-
コンプライアンスメトリクス:組織ポリシーに準拠した AI ツール使用の割合;検出および修復されたポリシー違反の率。
-
制御効果メトリクス:誤検知率(正当な使用がブロックされる);偽陰性率(検出されないポリシー違反);無許可ツールまたは異常な動作の平均検出時間(MTTD)。
-
ビジネスインパクトメトリクス:ミスアライメントされた推奨事項の防止によるコスト回避;回避された規制罰則;ガードレール実装によるユーザー生産性への影響。
-
前提*:メトリクスはリソース配分と組織の優先順位付けを推進する。測定は、ベースライン条件を確立し、進捗を追跡するために早期に開始する必要がある。メトリクスは四半期ごとにレビューし、新たなリスクと組織学習に基づいて調整する必要がある。
洗練されたリスク分類と緩和の優先順位
元の問題提起では、3 つの異なるリスクカテゴリーが特定された。運用化には明示的な優先順位付けが必要である:
-
エージェントのミスアライメント:AI システムが組織の価値観またはユーザーの意図とミスアライメントされた推奨事項または意思決定を生成するリスク。緩和策:モデル出力を許容範囲に制約するガードレール;高リスクの意思決定に対する人間によるレビュートリガー;定期的なモデル動作監査。
-
シャドウ AI と無許可ツール使用:従業員が未承認の AI ツールを展開し、機密データを露出させたり、コンプライアンス違反を引き起こしたりするリスク。緩和策:検出メカニズム(フェーズ 1);ポリシー実施;ユーザートレーニング;承認されたツールの代替案。
-
規制およびコンプライアンスへの露出:適用される規制(データ保護、公正な貸付、アルゴリズムバイアス)に違反する AI システムからの罰則または評判の損害のリスク。緩和策:コンプライアンスマッピング(どの規制がどのシステムに適用されるか);監査証跡;バイアステスト;制御実装の文書化。
これらのリスクは、同一の制御を通じて等しく対処可能ではない。ミスアライメントには技術的なガードレールと行動監視が必要である。シャドウ AI には検出とポリシー実施が必要である。コンプライアンスへの露出には、文書化、監査証跡、定期的なコンプライアンステストが必要である。効果的な運用化は、階層化された補完的な制御を通じて 3 つすべてに対処する。
制御失敗モードとレジリエンスの考慮事項
ガードレールと監視の実装により、予測する必要がある新しい失敗モードが生まれる:
-
ユーザーの回避策による制御バイパス:ユーザーは、データをエクスポートしたり、個人デバイスを使用したり、複数の承認されたツールを連鎖させて無許可の結果を達成することで、ガードレールを回避する可能性がある。緩和策:ユーザーワークフローの定期的な監査;異常なデータ移動パターンの監視;ポリシーの根拠に関するユーザートレーニング。
-
誤検知の負担:過度に制限的なガードレールは正当な使用をブロックし、ユーザーの採用を減少させ、制御を無効にする圧力を生み出す可能性がある。緩和策:ガードレールしきい値の反復的な調整;ユーザーフィードバックメカニズム;正当な例外に対する明確なエスカレーションパス。
-
監視の盲点:監視インフラストラクチャは、新しい攻撃ベクトルを検出できない場合や、洗練されたユーザーによって無効化される場合がある。緩和策:冗長な監視アプローチ;定期的な侵入テスト;監視システムの健全性のログ記録。
-
コンプライアンスの見せかけ:組織は、準拠しているように見えるが、実際のリスク削減が限定的な制御を実装する可能性がある。緩和策:独立した監査;制御展開だけでなく実際のリスク結果に結び付けられたメトリクス。
-
前提*:完璧な制御システムは存在しない。運用化は制御失敗を考慮し、完璧さではなくレジリエンスのために設計する必要がある。
実装ロードマップと組織の前提条件
成功する運用化には、機能横断的な調整と持続的な経営陣のコミットメントが必要である。組織は、以下の構造で 12〜18 か月の実装サイクルを計画する必要がある:
-
1〜3 か月:基盤*
-
包括的な AI ツールインベントリの実施(フェーズ 1)
-
ガバナンス構造の確立(機能横断的な運営委員会)
-
リスク分類と意思決定ポイントマッピングの定義
-
現在のコンプライアンス態勢のベースライン化
-
4〜6 か月:アーキテクチャとパイロット*
-
参照アーキテクチャとガードレール仕様の設計(フェーズ 2)
-
パイロット意思決定ポイントの選択(2〜3 の影響力が高く、中程度の複雑さのシステム)
-
パイロット環境でのガードレールと監視の展開
-
メトリクス収集インフラストラクチャの確立
-
7〜12 か月:スケールと運用化*
-
追加の意思決定ポイントへのガードレール展開の拡大(フェーズ 3)
-
継続的な監視とインシデント対応の運用化
-
コンプライアンステストと監査証跡検証の実施
-
制御効果の測定と反復(フェーズ 4)
-
13〜18 か月:最適化とガバナンス*
-
運用データに基づくガードレールの改善
-
継続的なガバナンスケイデンスの確立(四半期ごとのレビュー)
-
新たなリスクと新しい AI 機能の計画
-
学んだ教訓の文書化と参照アーキテクチャの更新
-
組織の前提条件*:
-
経営陣のスポンサーシップと予算コミットメント
-
セキュリティ、エンジニアリング、コンプライアンス、ビジネスユニットからの代表者を含む機能横断的なチーム
-
ポリシー例外と制御変更に対する明確な意思決定権限
-
ポリシーの根拠と承認された代替案を説明するユーザーコミュニケーション戦略
結論
AI セキュリティへの VC 投資は、真の組織的ニーズを反映している:企業は AI ツール使用に対する適切な可視性を欠き、AI システムにガバナンスを組み込むための標準化されたアプローチを欠き、制御されていない AI 採用から重大なコンプライアンスおよび運用リスクに直面している。AI セキュリティの運用化には、可視性、アーキテクチャ、運用、測定という 4 つのフェーズにわたる構造化された実装が必要であり、リスクの優先順位付け、制御失敗モード、組織変更管理に明示的な注意を払う必要がある。
運用化を遅らせる組織は、規制への露出の増加、シャドウ AI 採用の拡大、AI ガバナンスにおける技術的負債の蓄積に直面する。前進する道は投機的ではない;それは、責任ある AI 採用を可能にしながら重大なリスクを削減する、具体的で、測定可能で、達成可能な一連の運用改善である。
シャドウ AI の検出:盲点から競争優位へ
シャドウ AI—組織全体での生成ツールの無許可展開—は、セキュリティ上の責任と未開発の生産性ポテンシャルのシグナルの両方を表している。従来のフレーミングは、それを排除すべき問題として扱う。未来志向のフレーミングは、従業員が必要とするものと組織が許可するものとの間のミスアライメントの症状として扱う。
従業員は、セキュリティチームが承認できるよりも速く便利なツールを採用する。これは無謀さではない;摩擦に直面した合理的な行動である。未承認の LLM を使用して応答を下書きするカスタマーサービス担当者は、セキュリティを侵害しようとしているのではなく、顧客により速くサービスを提供しようとしている。内部データセットで外部モデルにクエリを実行するデータアナリストは、ガバナンスに違反しようとしているのではなく、内部ツールが十分に迅速に対処できない問題を解決しようとしている。
この現実から生まれる検出レイヤーは、戦略的インフラストラクチャになる。Witness AI および類似のプラットフォームは、API 呼び出し、ネットワークトラフィック、モデルインタラクションを監視して、無許可ツールアクセスをリアルタイムで識別する。しかし、真のイノベーションはブロッキングではなく、理解である。従業員はどのツールに手を伸ばしているのか?どのような問題を解決しているのか?承認されたインフラストラクチャと実際のニーズの間のギャップはどこにあるのか?
このデータは、次世代のエンタープライズ AI プラットフォームのロードマップになる。シャドウ AI 検出をコンプライアンスのチェックボックスとして扱う組織は、機会を逃す。それをインフラストラクチャ進化のフィードバックメカニズムとして扱う組織は、競争上の優位性を獲得する。
-
具体的なシナリオ:* 医療機関が、従業員が暗号化や監査証跡なしで Claude を使用して患者メモを要約していることを発見する。従来のセキュリティはブロックで対応する。前向きなセキュリティは質問で対応する:*なぜ従業員はこのツールに手を伸ばしているのか?*答えは、内部文書化システムが遅すぎる、硬直しすぎている、または臨床ワークフローから切り離されすぎているということかもしれない。その後、組織は承認された、暗号化された、監査された代替案を構築し、突然、コンプライアンスが改善されながら生産性が向上する。
-
次の地平線に対する実行可能な影響:*
-
**戦略としてのインベントリ、コンプライアンスではない。**組織が使用または許可するすべての AI ツールをマッピングする。このインベントリを、従業員のニーズが組織のインフラストラクチャを超える場所を明らかにする生きた文書として扱う。
-
**フィードバックループとしての検出。**ブロックするためだけでなく、理解するために従業員と AI のインタラクションを監視するミドルウェアを実装する。どのツールが最も採用されているか?どのデータタイプがそれらを通過するか?どのワークフローが最も脆弱か?
-
**交渉としての承認。**セキュリティと使いやすさのバランスをとるワークフローを設計する。一律のブロッキングはシャドウ採用を生み、信頼を損なう。明確なセキュリティ要件を持つ透明な承認プロセスは、セキュリティチームと従業員の間の整合性を生み出す。
-
**学習としてのインシデント対応。**無許可ツールが検出されたときは、組織のニーズを理解し、インフラストラクチャを改善する機会として扱う。フォレンジックは重要だが、*何がこれを防いだだろうか?*という質問も重要である。
今後 5 年間で勝つ組織は、シャドウ AI を排除する組織ではない。それをより良く、より使いやすく、より安全な AI インフラストラクチャを構築するためのシグナルに変換し、そうすることで、競合他社が一致できない生産性向上を解き放つ組織である。
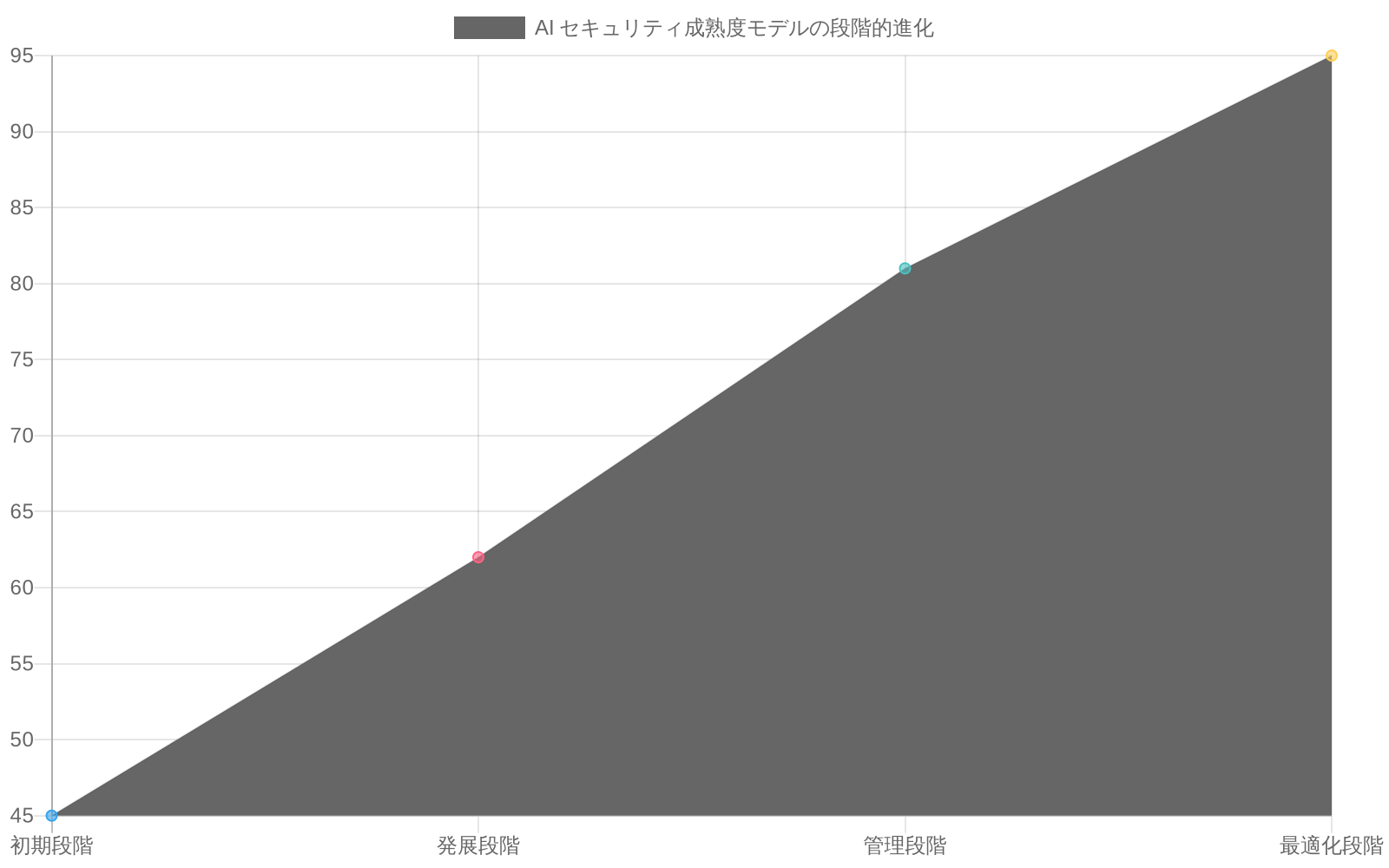
- 図10:AI セキュリティ成熟度の進化 - 主要 KPI の改善トレンド(出典:業界ベストプラクティス)*
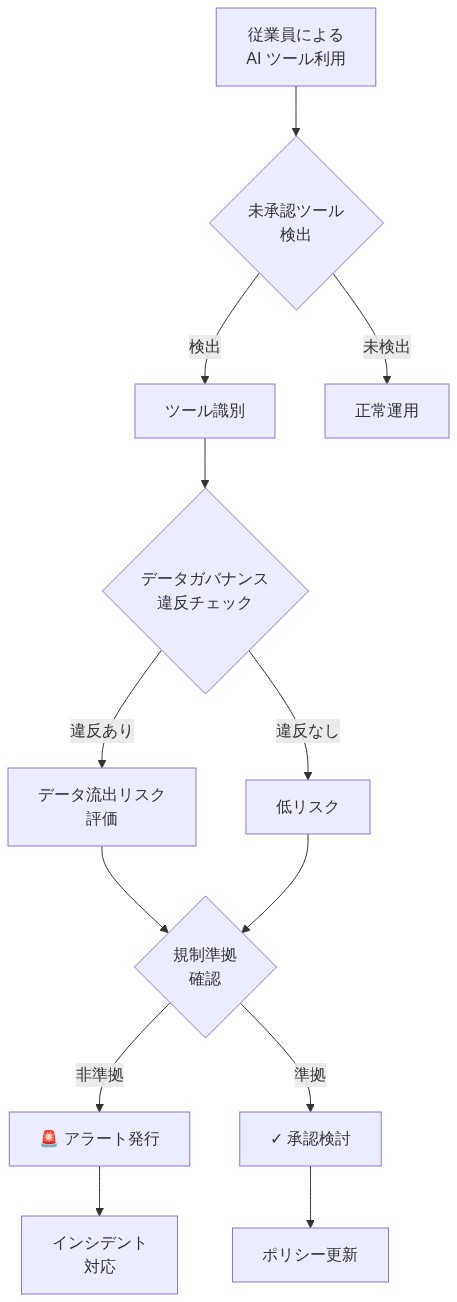
- 図4:シャドウAI検出フロー - 未承認ツール利用から攻撃防止までのプロセス*

- 図5:シャドウAIによるデータ流出リスク - 機密情報の外部送信メカニズム*
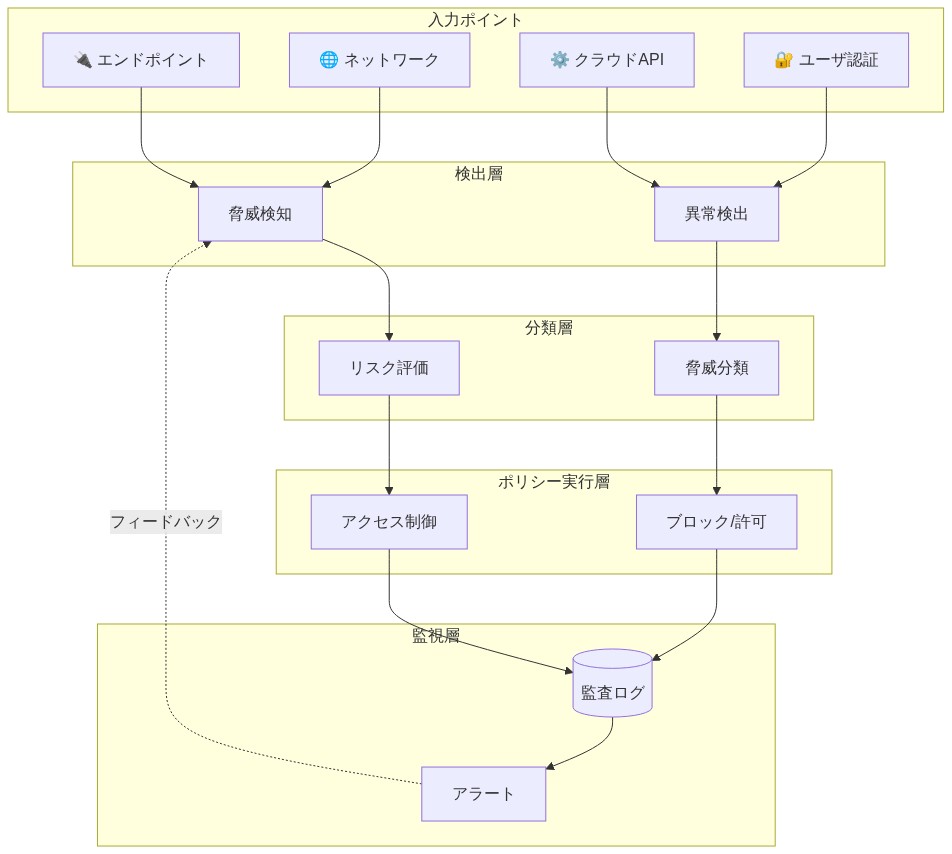
- 図6:AI セキュリティ参照アーキテクチャ - 多層防御制御フレームワーク*
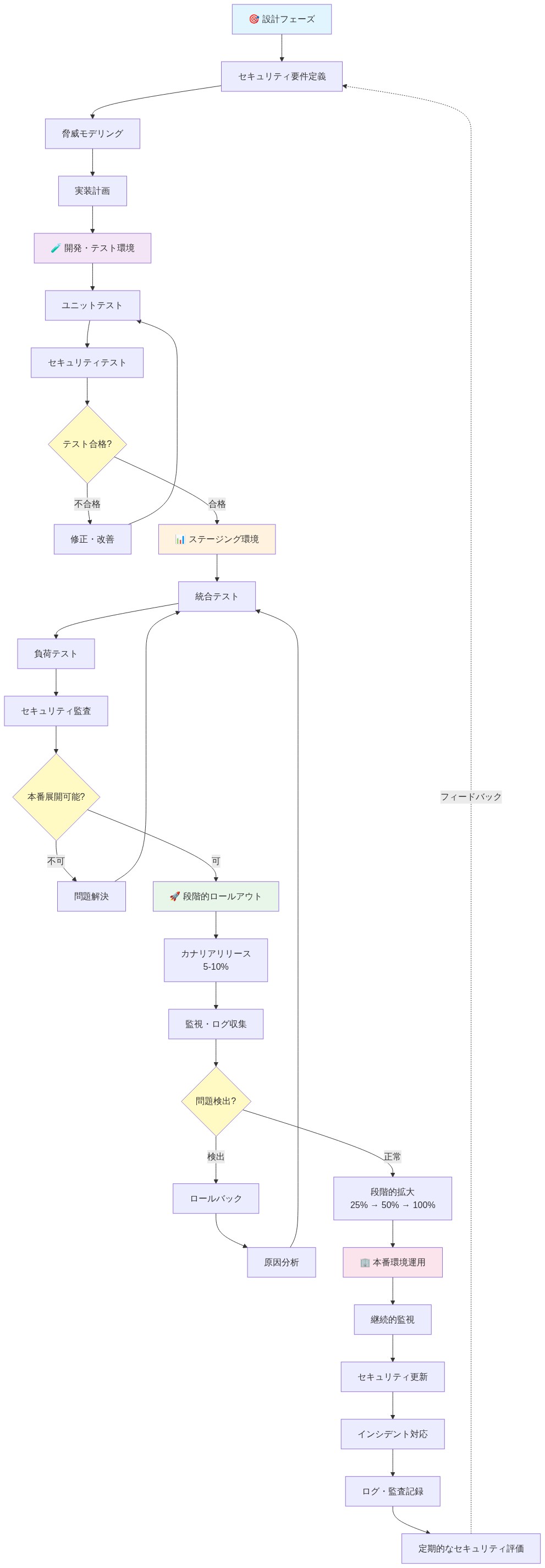
- 図8:AI セキュリティ実装ライフサイクル - 設計から運用までのパターン*

- 図9:運用チームの日常業務パターン - セキュリティ監視からステークホルダー報告までの統合的な運用シナリオ*