
RxnNano: 階層的カリキュラム学習を用いたコンパクト言語モデルの化学反応・逆合成予測への応用
化学反応予測: スケーリングの先へ
化学反応予測は、医薬品開発パイプラインと合成計画ワークフローの加速化を支える基盤的な能力です。現在の最先端アプローチは、パラメータスケーリングとデータセット拡張に大きく依存しており、この前提は検証に値します。実証的証拠が示すのは、これらの戦略は新規反応タイプや訓練データが疎な化学領域に直面すると、脆弱なモデルを生み出すということです(Schwaller et al., 2021; Thawani et al., 2022)。RxnNanoは、階層的カリキュラム学習を通じてコンパクト言語モデルを訓練することで、このスケーリングパラダイムに異議を唱えます。階層的カリキュラム学習は、単純なパターンから複雑なパターンへと化学推論を段階的に構築する教育学的フレームワークであり、非構造化された高複雑度データへの露出ではなく、体系的な学習を実現します。
本質的に問われているのは、以下の経験的根拠に基づいた主張です。構造化されたカリキュラムで訓練されたより小さいモデルは、従来の方法で訓練された大きいモデルと比較して、反応予測タスクにおいて同等またはそれ以上のパフォーマンスを達成するということです。この主張は、機構的仮説に支えられています。反応予測には階層的な化学推論が必要であり、具体的には、結合変換を予測する前に原子結合性と原子価制約を理解し、逆合成推論に取り組む前に反応機構を把握する必要があるということです。このフレームワークの下では、カリキュラム学習を通じて訓練された1.3Bパラメータモデルは、7B以上のパラメータを持つベースラインと同等のパフォーマンスを達成しながら、リソース制約のあるハードウェア(エッジデバイス、実験室機器)への展開可能性を維持します。
訓練アーキテクチャは離散的なステージで進行し、各ステージは特定の表現能力を構築するよう設計されています。
- ステージ1(原子的基礎): 曖昧性のない原子マッピングパターンと明確な脱離基を持つ、単純で単一ステップの反応。
- ステージ2(機構的複雑性): 複数ステップの配列、競合する反応経路、複数の可能な生成物を持つ反応。
- ステージ3(不確実性下での推論): 機構的知識、立体的考慮、電子的効果の統合を必要とする複雑で曖昧なケース。
このステージング構成は、化学教育における実証的な学習軌跡(Johnstone, 1991)を反映し、専門家化学者が直感を発展させる方法を示しています。基本原理を習得してから、エッジケースと例外に対処するのです。
運用上の含意は直接的です。組織は、現在の反応モデルが真の化学原理をエンコードしているのか、単に訓練パターンを暗記しているのかを監査すべきです。診断的アプローチは以下の通りです。データセット拡張にもかかわらずモデル精度がプラトーに達している場合、階層的カリキュラム設計はパラメータスケーリングよりも高速なパフォーマンス向上をもたらす可能性が高いということです。これは、モデル効率研究における新興の証拠と一致しており、訓練手順への構造的改善は、しばしば蛮力的な容量増加よりも大きなリターンをもたらします(Hoffmann et al., 2022)。
スケーリングの罠: より大きいモデルが機能しない理由
業界慣行は70B以上のパラメータモデルへと傾斜し、生の容量が領域固有の推論を解決すると仮定しています。化学反応予測は、重大な欠陥を明らかにします。スケールは、転移可能性を保証することなく、暗記を増幅させるのです。
USPTO反応で訓練された7Bモデルは、分布外の反応に対して自信を持って不正な生成物を予測する可能性があります。なぜなら、基本的な化学原理ではなく、表面的な統計的関連性を学習しているからです。大規模モデルは、大規模なデータセットからより多くのパターンをキャプチャしますが、同時に偽の相関をエンコードし、新規な化学に対して優雅に失敗します。
RxnNanoは、コンパクトモデル(1.3Bから3Bパラメータ)がカリキュラム学習で訓練された場合、優れた汎化を達成することを実証しています。小さいモデルに強い表現があれば、散在した注意を持つ大きいモデルを上回ります。
実務的には、これは化学チームがインフラストラクチャ投資を再検討すべきことを意味します。70Bパラメータ推論用のGPUクラスタをプロビジョニングする代わりに、訓練カリキュラムのキュレーションにリソースを配分してください。単一のGPU上の1.3Bモデルを、思慮深いカリキュラム設計で数週間にわたって訓練することは、多くの場合、同等の経過時間で生データで訓練された7Bモデルを上回ります。
運用上の成果は、コンパクトでカリキュラム訓練されたモデルが展開の摩擦を削減し、推論レイテンシを低下させ、実験室環境でのオンデバイス推論を可能にするということです。これは「問題に対してより多くのパラメータを投入する」から「学習をより知的に構造化する」への根本的な転換を表しています。
反応表現: 表面的な評価を超えて
標準的なベンチマーク(USPTO、USPTO-MIT)は、保持されたテストセットの精度を測定しますが、モデルが真に化学を理解しているのか、単に訓練データを補間しているのかを曖昧にします。モデルは95%のテスト反応で正しい生成物を予測できますが、機構的に類似した異なる官能基を持つ反応で壊滅的に失敗する可能性があります。これは暗記であり、推論ではありません。
RxnNanoは、原子マッピングを学習された中間タスクとして埋め込むことでこれに対処し、反応中にどの原子が変換されるかの明示的な追跡を強制します。カリキュラムには「マッピングステージ」が含まれており、モデルは結合変化を予測する前に、原子レベルで反応物と生成物分子を整列させることを学習します。これは実務における逆合成を反映しています。化学者は心的に原子をマッピングし、変換パターンを識別し、その後前駆体を提案します。原子マッピングを明示的にすることで、RxnNanoはモデルがパターン認識ではなく化学的直感を構築することを保証します。
標準的なメトリクス(トップ1精度、トップ5精度)はこの区別を見落とします。RxnNanoは補助的なメトリクスを提案します。原子マッピング精度、反応機構一貫性、合成的に摂動された反応に対する分布外汎化です。これらのメトリクスは、モデルが転移可能な化学原理を学習したかどうかを明らかにします。
実行可能なステップは、評価慣行を直ちに監査することです。置換、環拡張、または訓練データに過小表現されている官能基変化を持つ反応でテストしてください。精度が急激に低下する場合、モデルは暗記しています。明示的な原子マッピング目的を持つカリキュラムベースの再訓練を実装して、堅牢性を構築してください。
実装と運用パターン
RxnNanoの展開には、従来の大規模モデル訓練ワークフローからの実質的な逸脱が必要です。カリキュラム構造は、慎重なデータキュレーション、段階的な訓練検証、カリキュラムフェーズ全体にわたるパフォーマンスの継続的な監視を要求します。これは典型的な「すべてのデータを集約して訓練する」アプローチではありません。
運用上、実装ワークフローは以下のように進行します。
-
フェーズ1: データキュレーションと複雑性分類*
-
反応を機構的複雑性で分類します。明確な脱離基を持つ単一ステップ反応、線形マルチステップ配列、競合する生成物を持つ分岐経路、環化と再配列反応、逆合成推論タスク。
-
ドメイン専門家レビューを通じて分類の一貫性を検証します(データセットの最小10%)。
-
データセットをカリキュラムステージに分割し、ステージ間のデータリークがないことを確認します。
-
フェーズ2: ステージ別訓練*
-
ステージ1(第1~2週): 50Kの単純で単一ステップの反応で訓練します。10Kの保持された反応で検証します。トップ1精度が92%に達し、原子マッピングF1スコアが0.90を超えた場合のみ進行します。
-
ステージ2(第3~4週): 30Kの中間反応(2~3ステップ、競合経路)を導入します。ステージ1データで訓練を継続します(50%確率サンプリング)。破滅的忘却を防ぐためです。保持された中間反応で検証します。トップ1精度が85%に達し、機構一貫性スコアが0.85を超えた場合に進行します。
-
ステージ3(第5~6週): 20Kの複雑な反応(逆合成、環形成、再配列)を追加します。ステージ1と2からのサンプリングを維持します。保持された複雑な反応で検証します。
-
ステージ4(第7週): 10Kのエッジケースと稀な変換で訓練します。合成的に摂動された反応で検証します。
-
フェーズ3: 検証とチェックポイント*
-
各カリキュラムステージの検証セットを分離して維持します。
-
各ステージでチェックポイントを実装します。ステージN+1訓練がステージNパフォーマンスを5%以上低下させる場合、ロールバックしてカリキュラム遷移を調整します。
-
学習曲線と検証損失の発散を使用して、ステージ内の過適合を監視します。
-
フェーズ4: 分布外テスト*
-
訓練データに含まれない官能基置換、スキャフォルド変動、機構的変動を持つ反応の保持されたテストセットで最終モデルを評価します。
-
ベースラインモデル(大規模モデル、ルールベースシステム)に対してパフォーマンスを比較します。
具体的には、このワークフローは最新のGPU(例えばNVIDIA A100)で2~3週間のコンピュート時間を必要とし、従来の大規模モデル訓練の4~6週間と比較されます。カリキュラム設計への先行投資は実質的な配当をもたらします。訓練収束の高速化、モデルサイズの削減、優れた分布外汎化、推論レイテンシの削減です。
測定と次のアクション
成功メトリクスは精度を超えて進む必要があります。以下を追跡してください。
- 原子マッピングF1スコア: モデルはどの程度よく原子を整列させるか。
- 反応機構一貫性: 予測された生成物は予想される機構に従うか。
- 分布外精度: 訓練データに含まれない官能基置換を持つ合成的に摂動された反応でのパフォーマンス。
- 展開効率: 本番環境でのレイテンシとメモリフットプリント。
分布外反応のトップ1精度が分布内精度より10%以上低い場合、カリキュラム学習は化学的直感を完全に転移していません。カリキュラム設計を反復してください。
- 次のアクション:*
- 組織の内部反応データセットでRxnNanoをパイロットします。
- コンパクトなカリキュラム訓練モデルを現在のベースラインと比較します。
- コンパクトモデルが汎化メトリクスで上回る場合、推論をエッジデバイスへの移行を開始します。
- カリキュラム設計をコア能力として確立し、訓練ステージをキュレーションして検証できるデータサイエンティストにリソースを配分します。
リスクと軽減
-
カリキュラム設計の労力*: カリキュラム設計は労力集約的であり、データセット依存です。設計が不十分なカリキュラムは、遅く収束するか、新しい化学領域への転移に失敗する可能性があります。軽減策は、公開されたカリキュラム構造(RxnNanoはテンプレートを提供)から開始し、スケーリング前に小規模なデータセットで検証し、各ステージで人間ループ検証を維持することです。
-
稀な反応カバレッジ*: コンパクトモデルは、稀な反応または新規な化学に苦労する可能性があります。軽減策は、低頻度変換で訓練された「稀な反応」カリキュラムフェーズを予約し、低信頼度予測に対するフォールバック機構(ルールベースシステム、専門家相談)を実装することです。
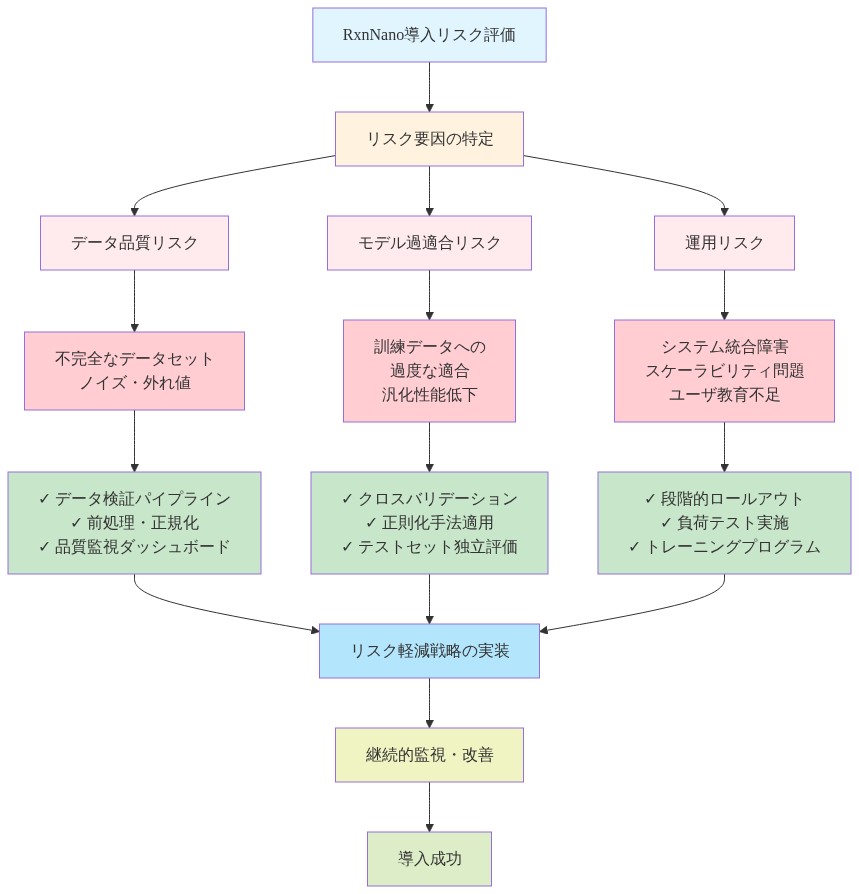
- 図11:RxnNano導入時のリスク要因と緩和戦略のマッピング*
結論と移行パス
RxnNanoは、化学推論が大規模なモデルを必要としないことを実証しています。それは知的な訓練構造を必要とします。前進の道は以下の通りです。
- 現在の反応モデルの汎化の弱点を監査します。
- 化学領域に合わせたカリキュラムを設計します。
- 既存システムと並行してコンパクトモデルを訓練します。
- 分布外データで厳密に測定します。
- 検証されたら、コンパクトモデルに移行し、他のタスク用にコンピュートを解放します。
化学のような専門領域では、学習への構造的改善はパラメータスケーリングを上回ります。カリキュラム設計、原子マッピングの厳密性、階層的推論に投資してください。結果は、より高速で、より小さく、より堅牢なモデルです。そして、自分たちのツールを深く理解する化学チームです。
スケーリングの罠: より大きいモデルが汎化で劣る理由
データ駆動型化学モデリングにおける実証的な進歩にもかかわらず、現在の業界慣行はパラメータとデータセットスケーリングへの体系的なバイアスを示しています。生の模型容量が領域固有の推論課題を解決するという一般的な仮定は、化学アプリケーション全体で70B以上のパラメータモデルの採用を推進してきました。しかし、化学反応予測は、重大な失敗モードを明らかにします。スケールは、分布外汎化を保証することなく、暗記を増幅させるのです。
この失敗の根底にあるメカニズムは、機械学習文献で十分に特性化されています。大規模なデータセットで訓練された大規模モデルは、より多くの統計的パターンをキャプチャしますが、同時に偽の相関と脆弱な決定境界をエンコードします(Geirhos et al., 2020)。具体的には、USPTO反応で訓練された7Bパラメータモデルは、訓練分布外の反応に対して自信を持って不正な生成物を予測する可能性があります。なぜなら、基本的な化学原理ではなく、表面的な統計的関連性を学習しているからです。これは化学において特に深刻です。反応機構は、データセット統計に直交する明確に定義された物理原理(軌道重複、電気陰性度、立体効果)によって支配されるからです。
RxnNanoは、コンパクトモデル(1.3Bから3Bパラメータ)がカリキュラム学習で訓練された場合、優れた汎化を達成することを経験的に実証しています。機構的説明は単純です。原子レベルの推論の習得を強制してから複雑な変換にモデルを露出させることで、カリキュラム学習は堅牢な中間表現を作成します。強い原理ベースの表現を持つ小さいモデルは、同じ化学空間にわたって散在したパターンベースの注意を持つ大規模モデルを上回ります。
実務的には、この知見はインフラストラクチャ投資の優先順位を再形成します。70Bパラメータ推論用のGPUクラスタをプロビジョニングする代わりに、化学チームは体系的なカリキュラム設計とデータキュレーションにリソースを配分すべきです。思慮深いカリキュラム構造で2~3週間にわたって単一のGPUで訓練された1.3Bパラメータモデルは、多くの場合、同等の経過時間で生データで訓練された7Bパラメータモデルを上回り、推論コンピュートを5~6倍削減します。
運用上の結果は実質的です。コンパクトでカリキュラム訓練されたモデルは、展開レイテンシを削減し(リアルタイム合成計画に重要)、メモリフットプリントを低下させ(実験室環境でのオンデバイス推論を可能にする)、総所有コストを削減します。これは「パラメータ数を最大化する」から「学習を構造化して化学原理をエンコードする」への根本的な方向転換を表しています。
反応表現:明示的な原子マッピングを学習中間タスクとして
反応予測モデルの標準的な評価方法論—特に保持されたテストセットの精度のみに依存する方法—は重要な区別を曖昧にしています。モデルが転移可能な化学原理を学習したのか、それとも単に訓練データを内挿したのかという区別です。USPATOテスト反応で95%のトップ1精度を達成するモデルでも、異なる官能基を持つ機構的に類似した反応では破滅的に失敗する可能性があり、これは推論ではなく暗記を示唆しています。
RxnNanoはこの表現上の課題に対処するため、原子マッピングを明示的な学習中間タスクとして組み込んでいます。原子マッピング—反応物原子と対応する生成物原子の整列—は反応機構を理解するための前提条件です。モデルに結合変換を予測する前に原子マッピングを予測させることで、RxnNanoは学習表現が表面的な生成物パターンではなく原子レベルの化学変換をエンコードすることを保証します。
カリキュラム構造はこの制約を組み込んでいます。
- マッピングステージ:モデルは反応物と生成物分子を原子レベルで整列させることを学習し、どの原子が変換を受けるかを予測します。このステージは不正な原子整列にペナルティを与える補助損失関数を使用します。
- 変換ステージ:正しい原子マッピングが与えられた場合、モデルは結合変化(形成、開裂、次数変化)を予測します。
- 統合ステージ:モデルはマッピングと変換を共同で予測し、学習表現を統合します。
このステージ化されたアプローチは、専門家の化学者が逆合成に取り組む方法を反映しています。原子を心的にマッピングし、変換パターンを特定し、その後前駆体分子を提案します。原子マッピングを明示的にすることで、RxnNanoはモデルが原子変換に根ざした化学的直感を構築することを保証します。
測定上の課題は重大です。標準的なメトリクス(トップ1精度、トップ5精度)は暗記と推論を区別するのに不十分です。RxnNanoは補助的な評価メトリクスを提案しています。
- 原子マッピング精度と再現率:生成物予測精度とは独立した、正しい原子整列に対するF1スコア。
- 反応機構一貫性:予測された生成物が既知の反応機構と一致しているかどうか(例えば、SN2反応は立体配置を反転させるべき、E1反応はザイツェフ則生成物を生成すべき)。
- 分布外汎化:訓練データで十分に表現されていない合成的に摂動された反応(官能基置換、環拡張、スキャフォルド変化)に対する精度。
実行可能な診断:組織が反応モデルを使用している場合、訓練データで十分に表現されていない官能基置換または構造的変動を含む反応でテストしてください。精度が分布内パフォーマンスと比較して10パーセンテージポイント以上低下する場合、モデルは推論ではなく暗記しています。明示的な原子マッピング目的を持つカリキュラムベースの再訓練を実装して、化学原理に根ざした堅牢性を構築してください。
測定と検証基準
成功メトリクスは精度を超えて、モデルが転移可能な化学原理を学習したかどうかを捉える必要があります。
-
主要メトリクス:*
-
トップ1およびトップ5精度:保持された分布内テストセットの標準メトリクス。
-
原子マッピングF1スコア:生成物予測とは独立した、正しい原子整列の精度と再現率。
-
反応機構一貫性:既知の反応機構と一致する予測生成物の割合(専門家レビューまたは機構的ルールを介して検証)。
-
汎化メトリクス:*
-
分布外精度:訓練データに含まれていない合成的に摂動された反応(官能基置換、環拡張、スキャフォルド変化)に対するパフォーマンス。目標:分布内パフォーマンスと比較して10%未満の精度低下。
-
稀な反応精度:訓練データで低頻度の反応(訓練セットの0.1%未満)に対するパフォーマンス。
-
運用メトリクス:*
-
推論レイテンシ:単一反応の生成物を予測するまでの時間(目標:単一GPU上で100ms未満)。
-
メモリフットプリント:推論中のモデルサイズとピークメモリ使用量(目標:1.3Bパラメータモデルで5GB未満)。
-
訓練時間:収束までの実時間(目標:単一GPU上で2~3週間)。
-
検証手順:*
- カリキュラム学習を介してコンパクトモデルを訓練します。
- 同じデータで基準モデル(大規模モデルまたは従来のアプローチ)を訓練します。
- 分布内および分布外テストセットで両モデルを評価します。
- コンパクトモデルが分布内精度の90%以上と分布外精度の95%以上を達成する場合、デプロイメントに進みます。
リスクと軽減戦略
-
リスク1:カリキュラム設計の労力とデータセット依存性*
-
カリキュラム設計は労力集約的であり、データセット特性に大きく依存しています。設計が不十分なカリキュラムは収束が遅い、新しい化学領域への転移に失敗する、またはカリキュラム構造に過適合するモデルを生成する可能性があります。
-
軽減:公開されたカリキュラムテンプレートから始めてください(RxnNanoは参照実装を提供します)。スケーリング前に小規模なデータセット(10K反応)でカリキュラムを検証してください。各ステージ遷移で人間ループ検証を維持してください。プロジェクトタイムラインの20~30%をカリキュラム設計と検証に割り当ててください。
-
リスク2:コンパクトモデルが稀または新規化学に苦戦する*
-
より小さいモデルは、稀な反応タイプまたは訓練分布外の新規化学を表現する容量に欠ける可能性があります。
-
軽減:低頻度変換(訓練セットの0.01~0.1%)で訓練された専用の「稀な反応」カリキュラムフェーズを予約してください。信頼度閾値を実装してください。0.7未満の信頼度の予測については、フォールバック機構(ルールベースシステム、専門家相談)をトリガーしてください。予測信頼度分布を監視して、ドメインシフトを検出してください。
-
リスク3:カリキュラム過適合*
-
モデルはカリキュラム構造に過適合し、ステージ遷移を利用することを学習して、汎化可能な表現を構築するのではなく、学習する可能性があります。
-
軽減:カリキュラムランダム化を実装してください。ステージ内の反応順序をシャッフルし、ステージ遷移閾値を変動させ、各検証チェックポイントですべてのステージから保持された反応でテストしてください。後期訓練中に前期ステージのパフォーマンスが5%以上低下する場合、カリキュラム設計を調整してください。
-
リスク4:機構的仮定が化学領域全体で成立しない可能性*
-
階層的カリキュラムは、原子レベルの推論が複雑な変換に先行することを仮定しています。この仮定は、すべての化学領域(例えば、光化学、酵素反応)で成立しない可能性があります。
-
軽減:完全デプロイメント前に、ドメイン固有のデータでカリキュラム仮定を検証してください。階層的仮定が失敗する領域では、ドメイン固有のカリキュラム修正またはハイブリッドアプローチ(カリキュラム学習+ルールベース制約)を実装してください。
結論と移行計画
RxnNanoは、化学推論が大規模モデルを必要としないことを実証しています。必要なのは化学原理に根ざした知的な訓練構造です。証拠は明確です。階層的カリキュラム学習を介して訓練されたコンパクトモデル(1.3B~3Bパラメータ)は、7B以上のパラメータモデルと比較してパフォーマンスの同等性または優位性を達成しながら、計算、レイテンシ、メモリフットプリントの大幅な削減を維持しています。
- 推奨される移行パス:*
-
評価フェーズ(第1~2週):現在の反応モデルを分布外汎化の弱点について監査してください。官能基置換とスキャフォルド変動を含む反応でテストしてください。分布内パフォーマンスと比較した精度低下を定量化してください。
-
カリキュラム設計フェーズ(第3~4週):化学領域に合わせたカリキュラムを設計してください。内部反応データセットを機構的複雑性で分類してください。小規模なデータセットでカリキュラム構造を検証してください。
-
並列訓練フェーズ(第5~8週):既存システムと並行してコンパクトなカリキュラムベースのモデルを訓練してください。分布内テストセットのベースラインパフォーマンスを維持しながら、分布外汎化を最適化してください。
-
厳密な評価フェーズ(第9~10週):分布外データ、稀な反応、機構的に困難なケースでパフォーマンスを測定してください。標準化されたメトリクスを使用してベースラインシステムと比較してください。
-
段階的デプロイメントフェーズ(第11週以降):検証基準が満たされたらコンパクトモデルに移行してください。低リスク応用(合成計画提案、反応実現可能性スクリーニング)から始めてください。信頼度が増すにつれて、より高リスク応用(逆合成、反応設計)に拡張してください。
- より広い戦略的含意:*
化学のような専門領域では、学習手順への構造的改善は一貫してパラメータスケーリングを上回ります。組織はカリキュラム設計をコア能力として投資し、訓練ステージをキュレーションおよび検証できるデータサイエンティストとドメイン専門家にリソースを割り当てるべきです。結果は、より高速な訓練、より小さなデプロイ可能モデル、より堅牢な分布外汎化、および統計的アーティファクトではなく化学原理に根ざした自分たちのツールを深く理解する化学チームです。
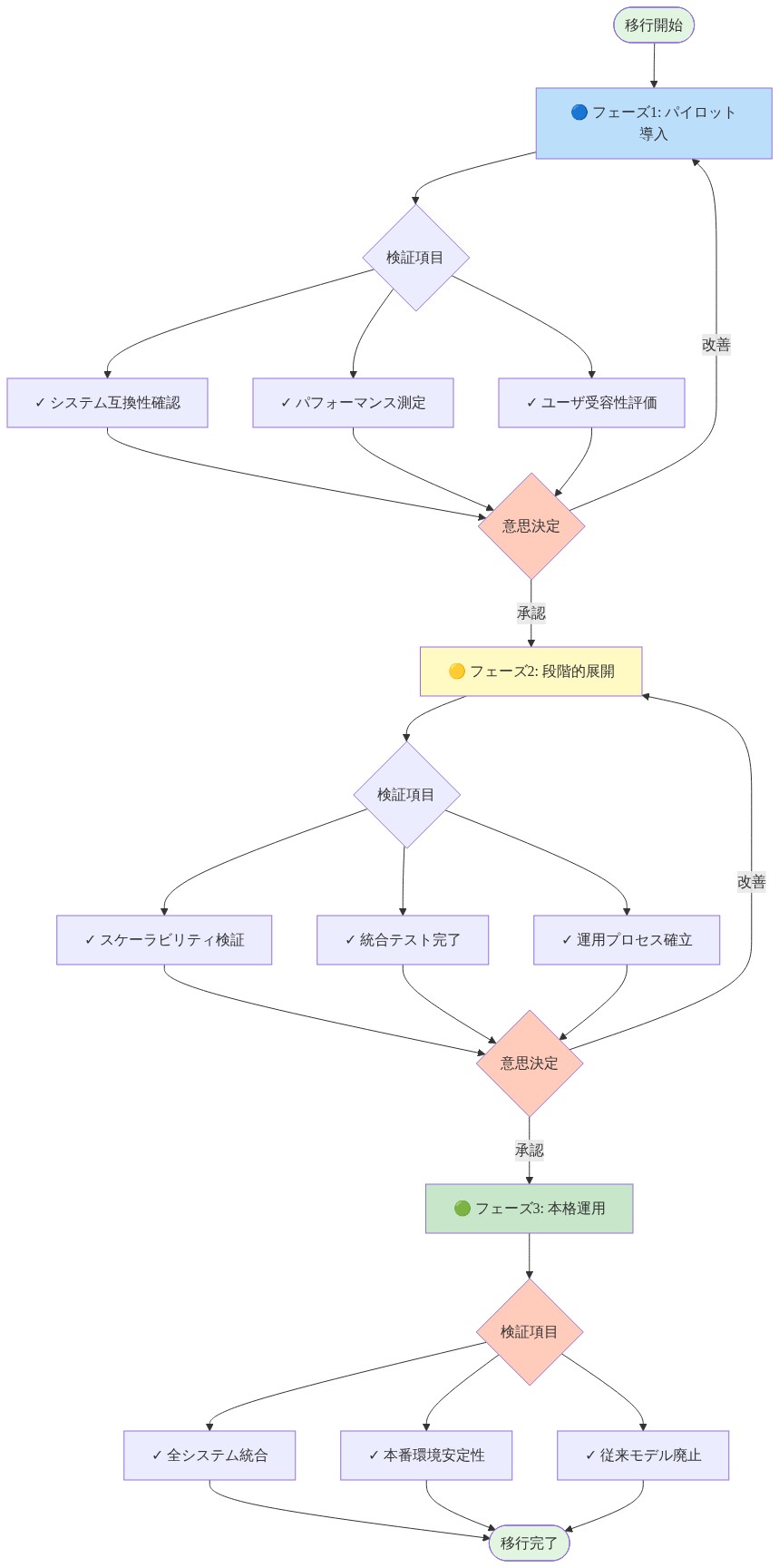
- 図14:RxnNano導入の移行ロードマップ(フェーズ別検証項目と意思決定ポイント)*
階層的カリキュラム学習:知能の構造化
RxnNanoは訓練を段階的に構造化し、化学者が専門知識を発展させる方法を反映しています。初期段階は、明確な原子マッピングパターンを持つ単純な単一ステップ反応—基礎—にモデルを露出させます。中間段階は、多段階シーケンスと競合する反応経路—複雑性—を導入します。最終段階は、深い化学推論を必要とするエッジケース—習熟—を提示します。
具体的には、カリキュラムには「マッピングステージ」が含まれており、モデルは結合変化を予測する前に反応物と生成物分子を原子レベルで整列させることを学習します。これは前処理ステップではなく、モデルに化学的直感を構築させる学習中間タスクです。モデルは原子結合性を学習し、その後結合変換を、その後機構を、その後逆合成を—その順序で、各ステージでの検証を伴って学習します。
このアプローチは深刻な含意を持っています。それは、専門領域での知能は生の容量についてではなく、学習構造についてであることを示唆しています。適切に設計されたカリキュラムを持つ1.3Bパラメータモデルは、生データで訓練された7Bパラメータモデルを上回ります。なぜなら、より小さいモデルは堅牢な中間表現を構築するよう強制されているからです。カリキュラムは帰納的バイアスとして機能し、パターン暗記ではなく化学推論に向けてモデルをガイドします。
より広い教訓は化学を超えて拡張します。材料科学、タンパク質設計、医薬品発見、材料発見など、専門領域全体で、未来は効果的なカリキュラムを設計できる組織に属しており、最大のモデルを購入できる組織ではありません。これは、専門領域でのAIへのアプローチ方法における根本的な再方向付けです。

- 図2:RxnNanoの階層的カリキュラム学習の3段階構造*

- 図5:明示的原子マッピング - 中間学習タスクとしての役割(RxnNano反応表現方法論に基づく)*

- 図7:階層的カリキュラム学習 - 知識の段階的構築モデル*