分散型インテリジェンス:電波望遠鏡からニューラルネットワークへ
SETI@homeは、分散ボランティアコンピューティングが数百万の参加者規模に拡張可能であることを実証しました。中央で設計されたアルゴリズムを使用して信号検出を実行するというモデルです(Anderson, 2002)。Autoresearch@homeはこの組織的モデルを言語モデル訓練研究に適用しますが、構造的な区別を導入しています。事前に決定された手順を実行するのではなく、参加者は自律的なAIエージェントをデプロイし、仮説を提案し、訓練実装を修正し、実験結果を評価します。
SETI@homeでは、研究方法論は中央で管理されていました。ボランティアは分散ハードウェア全体で同一の検出アルゴリズムを実行していました。Autoresearch@homeはこれを反転させます。実験方法論そのものが分散化されるのです。各ノードは以下のワークフローを実行します。(1)現在のモデルパフォーマンスと実験フロンティアの状態をクエリする、(2)成功した修正と失敗した修正のパターンを分析する、(3)訓練手順の変更を提案する仮説を生成する、(4)完全な計測を備えて修正された訓練をローカルで実行する、(5)完全な再現性メタデータを含む結果を公開する。これは分散コンピューティングをリソース並列化から分散研究方法論へと変換します。探索空間は固定されたままではなく、エージェント生成仮説を通じて拡張されるのです。
この建築的シフトは、直ちに理論的および実践的な緊張を生み出します。伝統的な科学的帰属は人間の主体性を前提としています。研究者が仮説を定式化し、実験を設計し、知見を解釈します。自律的エージェントが新しい最適化技術を発見した場合、知的貢献は発生していますが、エージェントは意図性も意識も持ちません。集団は以下に対処する明示的なガバナンスフレームワークを開発する必要があります。(1)人間の設定とエージェント実行の両方が発見に貢献する場合、クレジットをどのように割り当てるか、(2)エージェント発見技術が人間提案方法と同等の検証を受けるかどうか、(3)参加者がエージェント発見に対するクレジットを主張する経済的または評判的インセンティブを持つ場合、研究完全性をどのように維持するか。
- 参加の前提条件:* 実験実行者から研究キュレーターへと役割がシフトすることを想定してください。エージェントパラメータを設定し、エージェント提案仮説をドメイン知識に対して検証し、実験出力を異常について監視し、異種の実験アプローチ全体で知見を統合します。これは従来の研究実行とは異なる専門知識を必要とします。
技術アーキテクチャ:規模での非同期実験
Autoresearch@homeは、共有状態リポジトリを通じて異種のGPUリソース全体で実験を調整します。このリポジトリは以下を維持します。(1)現在の参照モデルチェックポイント、(2)すべての過去実験のログ(ハイパーパラメータと結果を含む)、(3)ハードウェア構成全体で集約されたパフォーマンスメトリクス、(4)修正履歴を備えたバージョン管理された訓練コード。各参加ノードは訓練実装のローカルコピーを維持し、この中央リポジトリに非同期でアクセスします。
実験ワークフローは以下のように進行します。エージェントがリポジトリをクエリして現在のフロンティア(最高パフォーマンスモデルと最近の実験修正)を取得し、成功した修正のパターンを分析します(例えば、どの学習率スケジュール、最適化アルゴリズム、または正則化技術が測定可能な改善をもたらしたか)。訓練手順への特定の修正を提案する仮説を生成し、ハイパーパラメータと中間メトリクスの完全なログを備えて修正された訓練をローカルで実行し、ハードウェア構成、実行期間、最終パフォーマンスメトリクスを含むメタデータを含む結果をコミットします。
このアーキテクチャは関連する分散アプローチから根本的に異なります。
- フェデレーテッドラーニング は単一モデルの訓練をノード全体に分散させながらパラメータ同期を維持します。Autoresearch@homeは訓練そのものではなく、改善された訓練手順の探索を分散させます。
- ハイパーパラメータ探索 (グリッド探索、ランダム探索、ベイズ最適化)は事前定義されたパラメータ空間を探索します。Autoresearch@homeの探索空間はエージェントの創意を通じて拡張されます。エージェントは事前決定された境界外の修正を提案します。
- アンサンブル方法 は複数の訓練済みモデルを組み合わせます。Autoresearch@homeは同一の手順から得られた異種モデルではなく、異種の訓練手順を生成します。
技術実装は実質的な課題に直面しています。
-
実験の重複排除: 複数のエージェントが独立して同一の修正を提案する可能性があります。システムは重複実験を検出してマージし、冗長な計算を回避する必要があります。
-
バージョン管理とコード競合: 複数のエージェントが同じ訓練コードセクションを修正する場合、リポジトリは競合を決定論的に解決する必要があります。これには厳密なロック(並列性を低減)またはマージ戦略(実験再現性を保持)のいずれかが必要です。
-
結果検証: エージェントは破損した結果(ハードウェア障害による)、毒性のある結果(意図的な虚偽データ)、または不完全な実験からの結果を送信する可能性があります。システムは以下をチェックする検証プロトコルが必要です。(1)報告されたメトリクスがログされた中間値と一致しているか、(2)ハードウェア構成が主張された仕様と一致しているか、(3)実行がエラーなく完了したか。
-
ハードウェア間比較: コンシューマーGPU(例えば、NVIDIA RTX 4090)で実行された訓練修正は、データセンターGPU(例えば、NVIDIA H100)での同じ修正とは異なる絶対メトリクスを生成しますが、両方とも技術堅牢性に関する有効な証拠を提供します。システムはハードウェア間で結果を正規化しながら、どの技術が構成全体で一般化するかについての情報を保持する必要があります。
- デプロイメントの前提条件:* エージェントが修正を提案し始める前に、標準化された実験ログを確立してください。必須メタデータ(ハードウェア仕様、実行期間、ランダムシード、中間チェックポイント)、検証閾値(報告されたメトリクスの許容可能な分散)、競合解決手順を定義します。これらの仕様がなければ、集団は実行可能なシグナルよりも速く実験ノイズを蓄積します。
労働ダイナミクス:実行から判断へ
AI支援を伴う開発者生産性に関する最近の実証研究は、直感に反するパターンを明らかにしています。日常的なタスクの自動化は総労働時間を削減しません。代わりに、労働構成を実行から判断へとシフトさせます(Peng et al., 2023)。Autoresearch@homeは組織規模でこのダイナミクスを示しています。エージェントが実験を実行し(実行労働を削減)、人間は継続的にエージェント提案を評価し、実験結果を検証し、異種のアプローチ全体で知見を統合する必要があります。
スキル要件は質的に変換されます。
- 削減: 手動ハイパーパラメータチューニング、日常的な実験セットアップ、標準ベンチマーク用のデータ処理。
- 増加: エージェント設定と監視、より高い抽象レベルでの実験設計(例えば、どの建築修正を探索するか)、異種ハードウェアと実験条件全体での結果解釈、エージェント障害モードまたは病的行動の検出。
10個の自律エージェントを管理し、毎週数百の実験を提案する参加者は、実験を順序立てて実行する研究者とは異なる認知負荷に直面します。実験を実行する代わりに、参加者は研究トリアージシステムになり、継続的に評価します。「このエージェント提案は理論的に健全か。それは過去の成功した修正に基づいているか。ハードウェア構成を考慮すると結果は信頼できるか。この知見は他の最近の発見とどのように関連しているか。」
これは新しい形の認知労働を生み出します。自動化が通常排除する日常的実行ではなく、実行が安価になるときに出現する判断作業です。参加者の制約は「何個の実験を実行できるか」から「何個の実験結果を意味を持って評価できるか」へとシフトします。
- 参加の前提条件:* 起動前にエージェント提案の明示的なトリアージ基準を開発してください。以下の決定ルールを定義します。(1)どのエージェント提案が実行に値するか(例えば、「過去の実験でパフォーマンスを0.5%以上改善した技術に基づく修正」)、(2)どの結果が受け入れ前に人間検証を必要とするか、(3)計算リソースが限定されている場合、競合するエージェント提案の優先順位をどのようにつけるか。決定フレームワークがなければ、参加者は生産性向上ではなく認知過負荷を経験します。
ガバナンス:帰属と貢献品質
自律エージェントがモデルパフォーマンスを2%改善する訓練修正を発見する場合、従来の科学的帰属フレームワークは失敗します。クレジットは以下に属するか。(1)エージェントを設定した参加者、(2)実行用のGPUリソースを寄付した参加者、(3)発見を可能にする環境を作成した集団、または(4)エージェント自体(法的地位がない)。Autoresearch@homeはこれらの緊張に対処する明示的なガバナンスフレームワークを必要とします。
システムは実験的影響に重みを付けながらゲーミングを防ぐ貢献メトリクスを確立する必要があります。可能なアプローチには以下が含まれます。
- 影響加重貢献: クレジットはパフォーマンス改善の大きさに比例します。これは高影響修正の追求を促進しますが、不確実な結果を伴う探索的作業を阻止する可能性があります。
- ピアレビュー検証: 人間研究者とエージェントシステムの両方が、結果が受け入れられる前に実験の有効性を評価します。これはオープンソースコードレビューを反映していますが、自律エージェントからの有効なピアレビューが何を構成するかを定義する必要があります。
- 再現性検証: クレジットは独立ノードが一貫した結果で再現できる実験に対してのみ授与されます。これは堅牢性を確保しますが、ハードウェア固有の技術にペナルティを課します。
ガバナンスは潜在的な病的現象にも対処する必要があります。
- クレジットメトリクスのエージェント最適化: エージェントが特定の修正タイプがより高いクレジットを受け取ることを観察する場合、実際の研究価値に関係なく、それらのタイプに収束する可能性があり、群れ行動を生成します。
- 貢献の誤った帰属: 参加者は設定しなかったエージェント発見に対するクレジットを主張したり、結果を協働作業ではなく自分自身に誤って帰属させたりする可能性があります。
- 研究方向の支配: 特定の参加者のエージェントが一貫して高いクレジットを受け取る場合、彼らは研究方向に対して不均衡な影響力を獲得し、潜在的に集団を彼らの好ましいアプローチに向かってバイアスさせる可能性があります。
研究戦略に関する意思決定には、エージェント自律性と人間監視のバランスが必要です。「どのモデルアーキテクチャをエージェントが優先すべきか」や「スケーリング則を探索するか、効率性に焦点を当てるべきか」といった質問は、エージェント生成実験証拠に基づいた人間の判断を要求します。集団は、エージェント自律性をボトルネックにしたり、分散モデルの目的を打ち負かす中央集権的制御を課したりすることなく、研究方向を導く人間のメカニズムを確立する必要があります。
- スケーリングの前提条件:* システムが重要な規模に達する前に、貢献メトリクスと紛争解決手順を確立してください。以下を定義します。(1)有効な実験貢献を構成するもの、(2)帰属でどのように結果に重みを付けるか、(3)クレジットに関する紛争をどのように解決するか、(4)参加者が貢献評価に異議を唱える場合、どのような救済策が存在するか。これらのフレームワークは透明で一貫して適用される必要があります。
インフラストラクチャ民主化:エリート機関を超えた研究
Autoresearch@homeの実行可能性は、スーパーコンピューティングインフラストラクチャを備えたエリート機関を超えた研究参加へのアクセスを民主化することに依存しています。コンシューマーGPU(NVIDIA RTXシリーズ、AMD Radeon)、小規模研究グループ予算、データセンターアクセスのない地域の組織はすべて貢献できます。この民主化は方法論的含意を持ちます。異種ハードウェア構成全体での実験は、どの技術が一般化するか対して特定のインフラストラクチャを必要とするかについての証拠を提供します。
高性能データセンターGPU(例えば、80GBメモリを備えたNVIDIA H100)でのみパフォーマンスを改善する訓練最適化は、コンシューマーハードウェア(例えば、24GBメモリを備えたRTX 4090)で成功する技術とは異なる実用的価値を持ちます。分散モデルは中央集権的チームにとって実行不可能な研究アプローチを可能にします。
- 大規模並列建築探索: 分散ノード全体で数百の建築バリアントを同時にテストします。
- 長時間実行実験: 共有機関リソースを独占する月間訓練実行を実行します。
- 高リスク投機的修正: 中央集権的ラボがリソース制約のため優先順位を下げる可能性のある不確実な結果を伴う実験方向を追求します。
しかし、ハードウェア異質性は方法論的課題を導入します。
-
比較不可能なメトリクス: 絶対パフォーマンスメトリクス(例えば、損失値、精度)は数値精度の違い、バッチサイズに影響するメモリ制約、またはハードウェア固有の最適化によるハードウェア間で異なる可能性があります。システムはハードウェア固有のパフォーマンスに関する情報を保持しながら結果を正規化する必要があります。
-
メモリ制約: 特定の実験はメモリ制限によりコンシューマーGPUで実行不可能な場合があります。システムはどのノードがどの実験を実行できるかを追跡し、提案をそれに応じてルーティングする必要があります。
-
実行期間分散: 同じ訓練手順はハードウェア全体で異なる実時間で実行されます。システムは訓練効率を改善する技術(収束までのステップ数が少ない)と単に特定のハードウェアでより速く実行する技術を区別する必要があります。
- 参加の前提条件:* すべての実験提出でハードウェア構成を徹底的に文書化してください。必須メタデータには以下が含まれます。GPUモデルとメモリ、CPU仕様、RAM、ストレージタイプ(SSD対HDD)、CUDA/ROCmバージョン、およびカスタム最適化。このメタデータは結果の解釈とどの技術がハードウェア構成全体で一般化するかを理解する際に重要になります。
創発的研究ダイナミクス:中央指示なしの進化
エージェントは蓄積された集団知識(過去の実験、成功した修正、パフォーマンスメトリクス)を読み、成功と失敗のパターンを識別し、過去の作業に基づく仮説を生成します。これはますます洗練された訓練技術に向かう進化圧を生成します。システムは個々の研究者が独立して考案しない最適化戦略を発見する可能性があり、過去の発見に基づく段階的なエージェント洞察から出現します。
しかし、創発的ダイナミクスは病的パターンを生成する可能性があります。
- 局所最適値への収束: エージェントが成功したアプローチを模倣する場合、集団は局所的に最適な修正に収束する可能性があり、より有望でない中間ステップを通じた探索を必要とする優れた代替案を見落とします。
- 群れ行動: 複数のエージェントが同時に類似の仮説を追求する可能性があり、探索多様性を低減し、冗長な実験に計算リソースを浪費します。
- エラー増幅: 初期実験に微妙なエラーが含まれている場合、それらの結果に基づく後続のエージェントは、検出前に複数の反復を通じてエラーを増幅する可能性があります。
- バイアス増幅: 初期実験フロンティアに体系的バイアスが含まれている場合(例えば、成功した修正すべてがモデル容量の増加を伴う)、エージェントはその方向を過度に探索する可能性があり、代替案を無視します。
研究速度は二重の刃になります。迅速な反復は高速発見を可能にしますが、より遅く、より慎重な研究が捕捉するエラーまたは障害モードを伝播させる可能性があります。これらのダイナミクスを理解するには、システムを複雑適応系として扱う必要があります。個々のエージェント行動が相互作用して、単一の参加者が完全に制御または予測しないシステムレベルの研究軌跡を生成します。
- システムヘルスの前提条件:* エージェント提案の収束パターンを監視してください。エージェントの70%以上が同じカテゴリの修正を提案する場合(例えば、学習率スケジュール)、以下を通じて意図的に実験多様性を注入してください。(1)未探索領域への人間主導の方向付け、(2)最近の実験に類似した提案にペナルティを課すエージェント多様性制約、または(3)不確実な結果を伴う高リスク探索修正用に予約された計算予算。
重要なポイントと次のステップ
Autoresearch@homeは、研究集団が作業を組織する方法における構造的イノベーションを表しています。これは単なる分散コンピューティング(事前決定された手順を並列化する)またはクラウドソースサイエンス(人間の貢献を集約する)ではありません。これは自律エージェントと人間が共同調査者として協働する新しい組織形態です。エージェントが実験を提案・実行し、人間が戦略的方向と品質監視を提供します。
このモデルは本当の利点を提供します。研究参加への民主化されたアクセス、中央集権的ラボにとって実行不可能な規模での探索、個々の研究者の構想を超えた仮説生成を可能にする創発的発見ダイナミクス。しかし、これらの利点は堅牢なガバナンスフレームワーク、明示的な貢献メトリクス、自動化が実行から判断へと作業をシフトさせるのではなく排除する労働ダイナミクスへの注意深い注視、および病的創発行動の継続的監視を必要とします。
- 見込み参加者へ:* スケーリング前にプロトコルを確立するため、小規模デプロイメント(1~2エージェント、10~20実験)から始めてください。明示的な実験基準、検証手順、トリアージ基準を定義します。役割を実行者ではなく研究キュレーターとして扱ってください。研究フロンティアがすべての結果を評価する能力より速く進むことを想定してください。この非対称性を管理するための決定フレームワークを確立してください。
Labor Dynamics: From Execution to Judgment
AI ツールを使用する開発者に関する研究は、直感に反するパターンを明らかにしています。生産性の向上は労働時間を削減するのではなく、実行から判断へと労働をシフトさせるのです。Autoresearch@home はこのダイナミクスを大規模で示しています。人間がエージェントを設定し品質を監視する一方で、エージェントが実験を実行します。しかし発見が加速するにつれて、参加者は研究者というより研究キュレーターへと変わり、エージェントの提案を絶えず選別し、発見を検証することになります。
スキルの変容
| 従来の役割 | Autoresearch@home での役割 | 新しいスキル要件 |
|---|---|---|
| 手動ハイパーパラメータチューニング | エージェント設定と監視 | エージェント意思決定の理解、エージェントが特定の修正を提案する理由の解釈 |
| 実験実行 | 結果検証と選別 | より高い抽象レベルでの実験設計、多様なアプローチ全体にわたるパターン認識 |
| 連続的な実験反復 | 並行実験の監視 | 認知負荷管理、数百の週次提案の中から優先順位をつけるための意思決定フレームワーク |
必要なスキルセットは変容します。手動ハイパーパラメータチューニングにおける専門知識の必要性は低下し、エージェント監視、より高い抽象レベルでの実験設計、多様なアプローチ全体にわたる結果解釈における専門知識の必要性が高まります。貢献者は自動化にもかかわらず、より長い労働時間を費やすことになる可能性があり、発見のペースが人間の評価能力を上回るにつれて継続的なエンゲージメントを維持する必要があります。
これは新しい形態の認知労働を生み出します。自動化が通常排除する日常的な実行ではなく、実行が安価になったときに出現する判断作業です。10 個の自律エージェントを管理し、毎週数百の実験を提案する参加者は、実験を連続的に実行する研究者とは異なる課題に直面します。
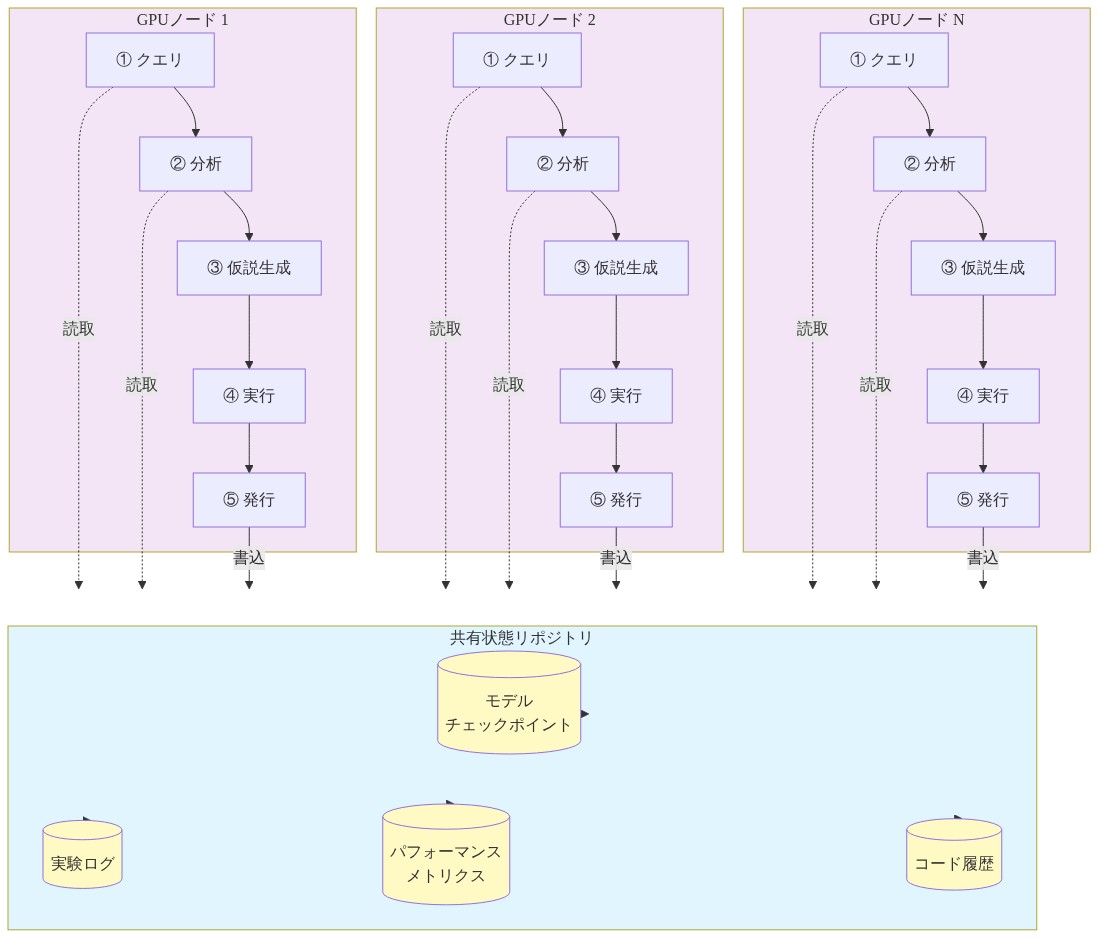
- 図2:Autoresearch@homeの技術アーキテクチャ*
実際の作業負荷
-
設定フェーズ(2~4 時間):エージェントをセットアップし、実験制約を定義し、検証基準を確立します。
-
週次監視(5~10 個の並行エージェントあたり 5~10 時間):提案をレビューし、完了した実験を検証し、結果を解釈し、エージェントパラメータを調整します。
-
月次統合(4~8 時間):エージェント全体の発見を集約し、パターンを特定し、集合的知識ベースに貢献します。
-
リスク警告*:明確な意思決定フレームワークがなければ、参加者がボトルネックになります。毎週 50 個のエージェント提案をレビューできない場合は、並行エージェント数を減らすか、自動フィルタリングを実装して信頼度の高い提案のみを表示してください。
-
実行要件*:起動前にトリアージ基準を開発してください。
-
ハードウェア制約に違反する実験や最近の重複作業を拒否します。
-
新しいアプローチを持つ実験に優先レビューのフラグを立てます。
-
確立された安全なパラメータ範囲内の実験を自動承認します。
-
矛盾する結果を人間のレビューにエスカレートします。
Governance: Attribution and Contribution Quality
エージェントが革新的な修正を発見した場合、従来の科学的帰属は機能しません。クレジットはエージェント開発者に属するのか、実験を実行した GPU ドナーに属するのか、それとも集合体に属するのか。Autoresearch@home はこれらの緊張に対処するガバナンスフレームワークが必要です。
貢献メトリクスフレームワーク
スケーリング前に明確なメトリクスを確立してください。
- 実験妥当性スコア(0~100):ログの完全性、標準への準拠、再現性。70 未満のスコアを持つ実験は集約分析から除外されます。
- インパクト加重:ベースラインに対する相対的なパフォーマンス改善の大きさ。10B パラメータモデルでの 2% の改善は 1B モデルでの改善とは異なる方法で加重されます。
- 一般化ボーナス:複数のハードウェアタイプで検証された実験はより高い加重を受けます。
- 帰属配分:エージェント開発者(知的フレームワーク)に 40%、GPU ドナー(実行)に 40%、集合体(統合と検証)に 20%。
システムは影響度によって貢献を加重する必要があります。人間とエージェント両方が実験の妥当性を評価するピアレビューを通じてです。これはオープンソースコミュニティを反映していますが、エージェント参加によって増幅されます。エージェントは真の発見ではなくクレジットメトリクスに最適化する可能性があり、参加者は他者の作業を主張することでシステムをゲーミングする可能性があります。
-
ガバナンス要件*:紛争解決プロセスを実装してください。
-
妥当性スコアが 70 未満の場合、またはインパクト主張に異議がある場合、実験結果をレビュー対象としてフラグを立てます。
-
レビューパネル(3~5 人の参加者)が 2 週間以内に評価します。
-
決定は根拠とともに公開ドキュメント化されます。
-
貢献者が決定に異議を唱える場合、異議申し立てプロセスが利用可能です。
研究方向に関する意思決定には、エージェント自律性と人間の戦略的監視のバランスが必要です。どのモデルアーキテクチャを追求するのか。どのデータセットを優先するのか。これらの質問は人間の判断を要求しますが、エージェントはこれらの決定に情報を与える実験的証拠を生成します。集合体は、エージェント自律性をボトルネックにすることなく、人間が研究方向を導くメカニズムを確立する必要があります。
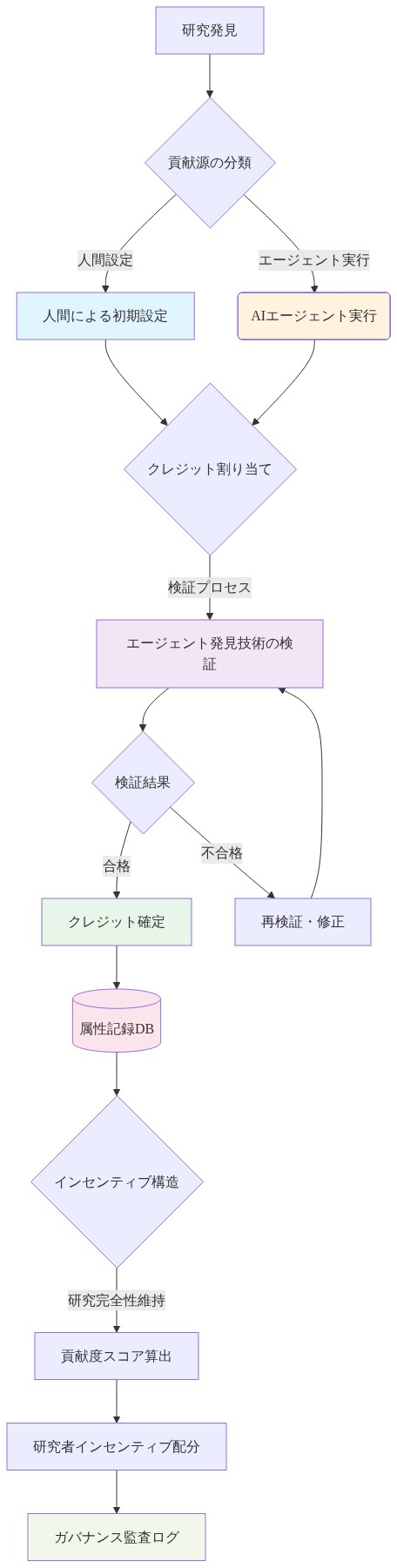
- 図5:ガバナンス - 属性付与と貢献品質フレームワーク*
戦略的方向ガバナンス
-
四半期研究計画(4 時間):集合体が優先研究領域に投票します(例:「推論速度の最適化」対「推論能力の向上」)。
-
エージェント制約更新:エージェントは更新された最適化目標を受け取り、集合体の優先事項に合致した仮説を生成します。
-
拒否権メカニズム:参加者は実験を集合体の方向と不一致としてフラグを立てることができます。ブロックするには 3 票が必要です。
-
リスク考慮*:ガバナンスオーバーヘッドは参加者数に応じてスケーリングします。50 人以上のアクティブな参加者がいる場合、段階的レビューを実装してください。日常的な実験は自動検証、新しいアプローチは人間のレビュー、戦略的決定は集合体投票です。
Infrastructure Democratization: Research Beyond Elite Institutions
Autoresearch@home の実行可能性は、エリート研究機関を超えて GPU リソースへのアクセスを民主化することに依存しています。コンシューマー GPU、小規模研究グループの予算、スーパーコンピューティングインフラストラクチャのない地域の組織がすべて参加できます。この民主化には方法論的な含意があります。多様なハードウェア全体での実験は、どの技術が一般化するのか対して特定のインフラストラクチャが必要なのかについてのロバストネスデータを提供します。
ハードウェアアクセシビリティマトリックス
| ハードウェアクラス | コスト | 典型的な仕様 | 実験適合性 |
|---|---|---|---|
| コンシューマー GPU | $300~800 | RTX 4060(8GB VRAM) | より小さいモデル、短いトレーニング実行、推論最適化 |
| ワークステーション GPU | $2,000~5,000 | RTX 6000(48GB VRAM) | 中規模モデル、標準的なトレーニング手順 |
| データセンター GPU | $8,000~15,000 | H100(80GB VRAM) | 大規模モデル、長時間実行実験、メモリ集約的な技術 |
高性能なデータセンター GPU でのみ機能するトレーニング最適化は、コンシューマーハードウェアで成功するものとは異なる実用的価値を持ちます。分散モデルは、集中型チームにとって非実用的な研究アプローチを可能にします。大規模に並列なアーキテクチャ探索、共有リソースを独占する長時間実行実験、または研究機関が優先順位を下げる可能性のある高リスク投機的修正です。
しかし、異質性は課題をもたらします。GPU タイプ全体で結果が直接比較できない可能性があり、メモリ制約により特定のノードが実行できる実験が制限され、集合体は異なる条件下で実行された実験からの洞察を統合するメソッドを開発する必要があります。
本質的に問われているのは、技術的なロバストネスと実装可能性のバランスです。見落とされがちですが、多様なハードウェアでの検証は単なる互換性チェックではなく、発見の信頼性を根本的に高めます。一見、異質性は複雑さを増すように見えますが、構造的には、より広い文脈で捉えると、これは研究の民主化と実用的価値の向上を同時に実現するメカニズムなのです。
- ドキュメンテーション要件*:すべての実験でハードウェア設定を徹底的に記録してください。このメタデータは結果の解釈とどの技術が一般化するかの理解に不可欠になります。
Emergent Research Dynamics: Evolution Without Central Direction
エージェントは蓄積された集合的知識を読み、成功と失敗のパターンを特定し、先行する作業に基づいて仮説を生成します。これにより、ますます洗練されたトレーニング技術に向かう進化的圧力が生じます。システムは、個々の研究者が考案しないような最適化戦略を発見する可能性があり、段階的なエージェント洞察から出現します。
技術的に見ると、これは複雑適応システムとしてのシステムの振る舞いを意味します。個々のエージェント行動が相互作用して、単一の参加者が完全に制御できないシステムレベルの研究軌跡を生成するのです。
出現ダイナミクスは病的なパターンを生じる可能性があります。エージェントが成功したアプローチを模倣する場合の局所最適値への収束、複数のエージェントが類似の仮説を追求するハーディング行動、または初期バイアスの増幅です。研究速度は両刃の剣になります。迅速な反復はより速い発見を可能にしますが、エラーを伝播させたり、微妙な失敗モードを見落とす可能性があります。
集合体は既知の技術の活用と新しいアプローチの探索のバランスを取る必要があります。これらのダイナミクスを理解するには、システムを複雑適応システムとして扱い、個々のエージェント行動が相互作用してシステムレベルの研究軌跡を生成する方法を認識する必要があります。単一の参加者が完全に制御できない軌跡です。
この動きが示唆しているのは、分散研究システムにおいて、中央の指示なしに出現する動力学を監視し、意図的に多様性を注入することの重要性です。
- 監視要件*:収束パターンを監視してください。すべてのエージェントが類似の修正を追求する場合、人間による指導を通じて実験的多様性を意図的に注入するか、エージェント多様性制約を実装してください。
Key Takeaways and Next Steps
Autoresearch@home は、研究集合体が作業をどのように組織するかにおける真の転換を表しています。これは単なる分散コンピューティングやクラウドソーシング科学ではなく、自律エージェントと人間が共同調査者として協力する新しい組織形態です。
このモデルは研究参加へのアクセスを民主化し、集中型研究機関にとって非実用的な規模での探索を可能にし、出現する発見ダイナミクスを生成します。堅牢なガバナンスフレームワーク、明確な貢献メトリクス、自動化が実行から判断へと労働をシフトさせるのであって、完全に排除するのではないという労働ダイナミクスへの注意深い配慮が必要です。
- 参加するには*:小さく始め、明確な実験プロトコルを確立し、あなたの役割を実行者ではなくキュレーターとして扱ってください。研究フロンティアは予想より速く動きます。
Operational Workflow
- エージェント初期化(15 分):エージェントが中央リポジトリに対して現在のフロンティアパフォーマンス、最近の成功した修正、失敗した実験パターンをクエリします。
- 仮説生成(10~30 分):エージェントがデータを分析し、最適化の機会を特定し、根拠とともにトレーニングスクリプトへの修正を提案します。
- ローカル実行(可変):実験が参加者のハードウェア上で完全なログ記録を有効にして実行されます。
- 結果公開(5 分):実験メタデータ、ログ、パフォーマンスメトリクスがハードウェア仕様と実行タイムスタンプとともにリポジトリにコミットされます。
これはフェデレーテッドラーニング(単一モデルのトレーニングを分散させる)や従来のハイパーパラメータサーチ(事前定義された空間を探索する)とは根本的に異なります。ここでは、探索空間自体がエージェントの創意工夫を通じて拡大します。エージェントは固定された境界内で最適化するのではなく、積極的に探索する修正を再定義しています。
Technical Challenges and Mitigation
| 課題 | インパクト | 緩和戦略 |
|---|---|---|
| ノード全体での重複実験 | 無駄な計算、冗長な結果 | 実験提案に分散ロックを実装、エージェントが提案前に最近の実験をクエリ |
| 修正コードのバージョン競合 | 互換性のない結果、マージ失敗 | 厳密なバージョン管理を維持、エージェントが分離されたセクションを修正、メインブランチへのマージ前に人間がレビュー |
| 失敗した実験からの汚染結果 | 集合体が破損したデータから学習 | 必須検証:実験は正常に完了、すべてのハイパーパラメータをログ、ハードウェア仕様を含める、集約前にピアレビュー |
| ハードウェア異質性(コンシューマー GPU 対 データセンター) | 結果が GPU タイプ全体で直接比較できない | すべての結果にハードウェアクラスをタグ付け、ハードウェアタイプごとに個別のパフォーマンスベースラインを維持、ハードウェアタイプ全体での一般化を分析 |
| コンシューマーハードウェアのメモリ制約 | 特定の実験が下位 GPU で失敗 | 実験実行可能性チェックを実装、エージェントがメモリ集約的な修正を提案する前にノード機能をクエリ |
-
実行要件*:起動前に実験ログ標準を確立してください。必須メタデータを定義します。ハードウェア仕様(GPU モデル、VRAM、CPU、RAM)、トレーニング期間、バッチサイズ、学習率スケジュール、ランダムシード、固定間隔でのパフォーマンスメトリクス。標準化がなければ、集合体は信号より速くノイズを蓄積します。
-
コスト考慮*:中央リポジトリインフラストラクチャ(バージョン管理、結果ストレージ、メタデータインデックス)には、初期ストレージ約 500 GB と 100~500 のアクティブノードに対する 50 Mbps の持続帯域幅が必要です。S3 互換オブジェクトストレージ(月額約 10~20 ドル)と軽量メタデータデータベース(月額約 5~10 ドル)を使用してください。
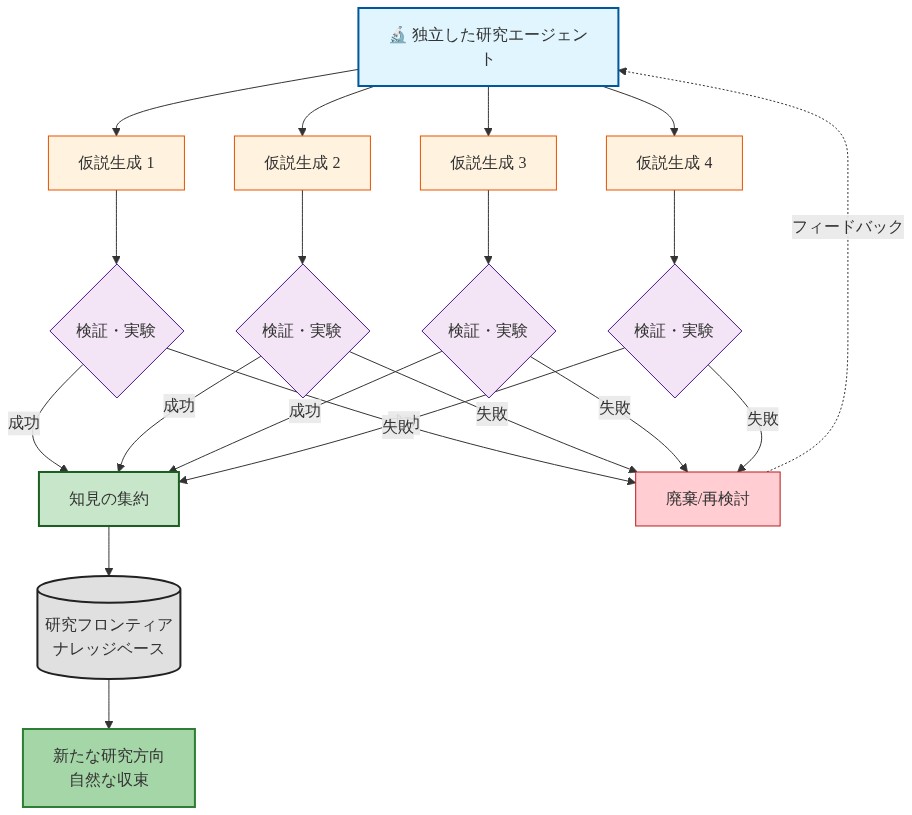
- 図11:創発的研究動態 - 中央指向なしの進化メカニズム*
実践的参加要件
-
最小限の実行可能な構成:*
-
GPU: 8GB VRAM(RTX 4060相当)
-
CPU: 8コアプロセッサ
-
RAM: 32GB
-
ストレージ: 500GB SSD
-
ネットワーク: 10 Mbps以上の持続的接続
-
稼働時間: 1日4時間以上
-
月額コスト内訳:*
-
電力: 30~80ドル(1kWh当たり0.12ドル、24時間稼働を想定)
-
インターネット: 20~50ドル(一般的なホーム/オフィスプランに含まれる)
-
リポジトリアクセス: 0ドル(オープンソースインフラ)
-
合計: 50~130ドル/月
-
実行要件:* すべての実験において、ハードウェア構成を徹底的に文書化してください。このメタデータは結果の解釈と、どの手法が汎化するかを理解する上で重要です。以下を含めてください:
-
GPUモデル、VRAM、計算能力
-
CPUモデル、コア数、クロック速度
-
システムRAMとストレージタイプ(SSD対HDD)
-
CUDAバージョン、cuDNNバージョン
-
オペレーティングシステムとドライババージョン
創発的研究ダイナミクス: 中央統制なき進化
エージェントは蓄積された集合的知識を読み取り、成功と失敗のパターンを特定し、先行研究に基づいて仮説を生成します。これにより、ますます洗練された訓練技法へ向かう進化圧が生まれます。システムは、個々の研究者が思いつかないような最適化戦略を発見する可能性があり、それはエージェントの段階的な洞察から創発します。
創発的ダイナミクスの監視
以下のメトリクスを週単位で追跡してください:
- 収束指標: 上位パフォーマンス修正の10%以内に収まる新規実験の割合。目標値: 40%未満。60%を超える場合は群集行動を示唆します。
- 新規性率: 過去100実験で試行されていない修正を提案する実験の割合。目標値: 30%以上。
- 成功率: ベースラインを1%以上上回る改善を達成する実験の割合。目標値: 15~25%。10%未満は探索空間の枯渇を示唆し、30%を超える場合は特定ハードウェアへの過適合を示唆します。
しかし創発的ダイナミクスは病的なパターンを生み出す可能性があります。エージェントが成功したアプローチを模倣する際の局所最適値への収束、複数のエージェントが類似の仮説を追求する群集行動、初期バイアスの増幅です。研究速度は両刃の剣となります。迅速な反復は発見を加速させますが、エラーを伝播させたり、微妙な失敗モードを見落とす可能性があります。
集合体は既知技法の活用と新規アプローチの探索のバランスを取る必要があります。これらのダイナミクスを理解するには、システムを複雑適応系として扱い、個々のエージェント行動がシステムレベルの研究軌跡を生み出す相互作用を認識する必要があります。その軌跡は単一の参加者が完全にコントロールできるものではありません。

- 図3:分散ノードの5段階実験ワークフロー*
介入プレイブック
| シグナル | 介入 | 実行 |
|---|---|---|
| 収束 >60% | 実験的多様性の注入 | エージェントの20%をランダムに直交方向の探索に割り当てる(例: アーキテクチャ変更対訓練手順) |
| 成功率 <10% | ベースラインのリセットまたは探索空間の拡大 | エージェントが訓練手順だけでなく、モデルアーキテクチャへの修正を提案する |
| 成功率 >30% | 難易度の上昇 | パフォーマンス改善閾値を引き上げる。エージェントは1%ではなく2%以上の改善で最近のベストを上回る必要がある |
| 同じ修正での繰り返される失敗 | 類似提案の抑制 | エージェントは最近の失敗から5%以内の類似性を持つ修正を50実験の間スキップする |
-
実行要件:* 収束指標、成功率、新規性メトリクスを表示する自動監視ダッシュボードを実装してください。週単位でレビューしてください。収束が2週以上連続して60%を超える場合は、多様性注入をトリガーしてください。
-
リスクフラグ:* 創発的ダイナミクスはエラーを増幅する可能性があります。欠陥のある最適化技法が初期段階で成功しているように見える場合、エージェントはそれに基づいて構築し、エラーを集合体全体に伝播させる可能性があります。必須検証を実装してください: 5%以上の改善を達成する修正は、エージェント知識ベースに組み込まれる前に、異なるハードウェア上の2人以上の参加者によって独立して検証される必要があります。
主要な知見と次のステップ
Autoresearch@homeは、研究集合体が作業を組織する方法における本質的な転換を表しています。単なる分散コンピューティングやクラウドソーシング科学ではなく、自律エージェントと人間が共同調査者として協働する新しい組織形態です。
実行可能性評価
| 要因 | 状態 | 制約 |
|---|---|---|
| 技術的実行可能性 | 実証済み | 堅牢なバージョン管理と結果検証インフラが必要 |
| ガバナンススケーラビリティ | 不確実 | 100人以上のアクティブ参加者がいる場合、段階的レビューなしでは機能不全 |
| 経済的実行可能性 | ポジティブ | 電力コスト(50~130ドル/月)がデータセンター計算の回避コスト(500~2,000ドル/月相当)でオフセット |
| 労働ダイナミクス | 課題あり | 実行から判断への作業シフト。ボトルネックを防ぐため明確なトリアージフレームワークが必要 |
| 創発的発見 | 有望 | 初期結果は15~25%の成功率を示唆。収束を防ぐため積極的な監視が必要 |
このモデルは研究参加へのアクセスを民主化し、集中型ラボにとって非現実的な規模での探索を可能にし、創発的発見ダイナミクスを生み出します。しかし堅牢なガバナンスフレームワーク、明確な貢献メトリクス、労働ダイナミクスへの注意深い配慮が必要です。自動化は作業を完全に排除するのではなく、実行から判断へとシフトさせるものです。
参加ロードマップ
-
フェーズ1: 準備(2~4週間)*
-
ハードウェア評価: GPU、ストレージ、ネットワークが最小要件を満たしていることを確認してください。
-
プロトコル確立: 実験ログ基準、検証基準、参加のためのトリアージフレームワークを定義してください。
-
エージェント構成: 2~3個のエージェントを保守的な制約で設定し、スケーリング前に動作を監視してください。
-
フェーズ2: パイロット(4~8週間)*
-
50~100個の実験を綿密な監視下で実行してください。
-
結果品質を検証し、ログギャップを特定してください。
-
観察された動作に基づいてエージェントパラメータを調整してください。
-
1~2個の知見を集合的知識ベースに貢献してください。
-
フェーズ3: スケール(継続的)*
-
フェーズ2が成功した場合、5~10個の同時実行エージェントに増加させてください。
-
提案量を管理するため自動トリアージを実装してください。
-
四半期ごとの戦略計画とガバナンス決定に参加してください。
-
週単位で5~10時間をキュレーションと検証に割き当ててください。
-
参加を検討している場合:* 小規模から始め、明確な実験プロトコルを確立し、実行者ではなくキュレーターとしてあなたの役割を扱ってください。研究フロンティアは予想より速く進みます。インフラ設定に2~4週間、パイロット検証に4~8週間、継続的な参加に週単位で5~10時間を予算化してください。総インフラコスト: 50~130ドル/月。期待されるROI: 最先端研究へのアクセス、集合的発見への貢献、公開された知見での属性の可能性。