
問題:大規模コードベースの理解
大規模なコードベースを理解することは、ソフトウェア開発実務において重大な認知的・時間的負担を表します。この課題は複数の運用コンテキストにわたって顕在化します:エンジニアのオンボーディング、レガシーシステムのリファクタリング、分散バグ調査、およびアーキテクチャ分析です。困難さはリポジトリサイズに対して非線形にスケールします。経験的観察によれば、コードベースが10万行を超えて拡大すると、理解時間は線形ではなく指数関数的に増加することが示唆されています(Letovsky & Soloway, 1986; LaToza et al., 2007)。
従来のコードベースナビゲーションアプローチ—テキスト検索(grep)、静的ドキュメント、および組織的知識移転—は、エンタープライズ環境において文書化された失敗モードを示します。具体的には:
- ドキュメントの劣化:技術ドキュメントは初期作成から2〜4週間以内に実装から乖離し(Forward & Lethbridge, 2002)、オンボーディングとアーキテクチャ推論に信頼性の問題を生じさせます。
- 検索コンテキストの貧困:全文検索は意図の意味的理解なしに構文的一致を返すため、開発者はファイル境界を越えて呼び出しチェーンとデータフローを手動で再構築する必要があります。
- 組織的知識の集中:重要なアーキテクチャの根拠は、クエリ可能な形式ではなく主に開発者の記憶に存在し、単一障害点とオンボーディングの摩擦を生み出します。
- モノレポのスケール:エンタープライズモノレポは日常的に100万〜1000万行のコードを超え(Google、Meta、Microsoftのケーススタディ)、線形検索戦略を計算的に高コストで認知的に圧倒的なものにします。
根本原因はアーキテクチャにあります:既存のツールはコードベースを進化するシステムではなく、静的で不変のアーティファクトとして扱います。この仮定は、コードが週次または日次で変更されるにもかかわらず、ドキュメントと検索インデックスが頻繁にまたは手動で更新される場合に破綻します。
さらに、クラウド依存のコード分析ツールは二次的な制約を導入します:多くの組織は、規制要件(HIPAA、SOC 2、GDPR)または競争上の機密性により、独自のソースコードをサードパーティサーバーにアップロードできません。これにより、規制産業および厳格なデータガバナンスポリシーを持つエンタープライズにとって、AI駆動ソリューションのカテゴリが排除されます。
ChunkHoundは、ローカルファーストアーキテクチャを通じてこれらの制約に対処します:セマンティックインデックス作成と検索はローカルインフラストラクチャ上で実行され、外部へのコード送信を排除しながら、継続的なリポジトリ監視を通じてインデックスの最新性を維持します。システムは静的アーティファクトではなくライブソースコードからドキュメントと依存関係分析を生成し、ドキュメントと実装の一貫性を保証します。
-
具体例:* フィンテックスタートアップに参加するバックエンドエンジニアは、モノレポ内の500ファイルに分散された決済処理ロジックを理解する必要があります。従来のアプローチでは、これにはコード読解、ドキュメントレビュー(しばしば古い)、および既存チームメンバーからの同期的知識移転に2〜3日を要します。ChunkHoundを使用すると、エンジニアは「APIリクエストから台帳エントリまでの決済決済パイプラインをトレースする」とクエリし、現在のリポジトリ状態から派生したインラインコード抜粋と生成されたドキュメントを含む依存関係グラフを受け取ります。ドキュメントはクエリ時にライブソースコードから生成されるため、定義上最新です。
-
実行可能な示唆:* 新規エンジニアの生産性到達時間を測定することで、現在のオンボーディング摩擦を定量化します。コードベース理解が採用あたり16時間以上を要する場合、ローカルファーストセマンティックインデックスは測定可能なROIを提供します。パイロット展開からの証拠は、開発者が検索や同期的知識移転に依存するのではなく、コードベース構造と意図を直接クエリできる場合、オンボーディング時間が40〜60%削減されることを示唆しています。
ローカルファーストアーキテクチャ:なぜ重要か
ローカルファーストアーキテクチャ—データ処理とストレージが明示的に送信されない限りユーザー制御のインフラストラクチャに留まる—は、開発ツール設計における構造的シフトを表します。このアプローチは3つの測定可能な利点を解放します:セキュリティコンプライアンス、レイテンシ削減、およびコスト予測可能性です。
-
*セキュリティとコンプライアンス**は、規制産業にとって主要な制約を形成します。医療(HIPAA)、金融(PCI-DSS、SOX)、および政府(FedRAMP)の組織は、ソースコードをサードパーティクラウドサービスに送信することに対する明示的な禁止に直面しています。したがって、クラウドベースのコード分析ツールは、広範なコンプライアンスレビューと契約交渉なしにはこれらのセクターで利用できません。ローカルファーストツールはこの摩擦を排除します:ソースコードはプライベートインフラストラクチャに留まり、埋め込みとセマンティックインデックスはローカルで計算され、外部LLMクエリ(使用される場合)はオプションでオペレーター制御です。このアーキテクチャ選択は、コンプライアンス制約のある環境での採用を直接可能にします。
-
*レイテンシ**は二次的ですが重要な要因です。クラウド依存のコードクエリは、ネットワークラウンドトリップ時間(典型的に200〜500ms)、APIキューイング遅延、およびサーバーレスインフラストラクチャのコールドスタートオーバーヘッドを招きます。インタラクティブワークフロー—モジュール構造の探索、呼び出しチェーンのトレース、ドキュメント生成—では、累積レイテンシがユーザーエクスペリエンスを低下させる摩擦を生み出します。ローカル埋め込みと検索システムは、ほとんどのクエリに50〜150msで応答でき、非同期サービスリクエストではなく知識豊富なシステムとの同期的インタラクションに近い流動的な探索パターンを可能にします。
-
*コスト構造**は、クラウド依存モデルとローカルファーストモデルの間で根本的に異なります。クラウドベースのコードインテリジェンスは通常、クエリごとまたはトークンごとに課金し、使用量に応じてスケールする変動コストを生み出します。1000万行のモノレポを持ち、200人のエンジニアが開発者あたり週5〜10クエリを実行する場合、月額コストはプロバイダーの価格設定に応じて10,000〜25,000ドルに達する可能性があります。ローカルファーストツールは、クエリごとのコストがゼロの固定インフラストラクチャコスト(ハードウェア、ストレージ)にシフトします。損益分岐点分析は、30〜50人以上のエンジニアのチームまたは高クエリ量の組織にとって、ローカルファーストアプローチがコスト面で有利になることを示唆しています。
-
具体例:* 200人のエンジニアと200万行のモノレポを持つ中堅SaaS企業は、クラウドコードインテリジェンスコストで月額15,000ドルを負担していました。ローカルGPUインフラストラクチャ(初期コスト:8,000ドル、月額運用コスト:2,000ドル)にChunkHoundを展開した後、組織は経常費用を87%削減し、以前はエンタープライズ顧客の展開を遅らせていたコンプライアンスレビューサイクルを排除しました。投資回収期間:6ヶ月。
-
実行可能な示唆:* 組織全体でコード分析、ドキュメント生成、およびコード検索ツールに対する現在の支出を監査します。APIコスト、ストレージ料金、コンプライアンスレビューオーバーヘッド、およびツールセットアップに費やされる開発者時間を含めます。50人以上のエンジニアまたは月額10,000ドル以上のコードインテリジェンス支出を持つ組織の場合、ローカルファースト代替案は通常3〜6ヶ月以内にROIを達成します。固定インフラストラクチャコストと現在の変動クラウド費用を比較して損益分岐点を計算します。
プロバイダー非依存インテリジェンス:ロックインなしの柔軟性
ChunkHoundのアーキテクチャは、埋め込み層を言語モデル推論層から切り離す階層化された抽象化を実装します。この設計により、以下の独立した選択が可能になります:(1)埋め込みプロバイダー(例:VoyageAI、OpenAI、Qwen3、またはローカルホスト代替案)、および(2)推論モデルプロバイダー(例:Anthropic、OpenAI、Gemini、Grok)、コスト、レイテンシ、および能力要件を含む組織的制約に応じて。
-
アーキテクチャの根拠:* 埋め込みと推論機能は異なる計算問題に対処します。埋め込みはテキストをセマンティック類似性に最適化されたベクトル表現に変換し、推論モデルは検索されたコンテキストからコンテキスト応答を生成します。現在、すべての次元で支配的な単一プロバイダーは存在しません—OpenAIは広範な能力を提供しますが高コストで、オープンソースモデルはライセンス費用を削減しますがインフラストラクチャ投資を必要とし、専門プロバイダー(例:セマンティック検索のVoyageAI)は狭いドメインで優れていますが推論能力を欠いています。これらの機能を切り離すことで、組織は各々を独立して最適化できます。
-
制約駆動構成シナリオ:*
-
コスト最適化シナリオ: 予算が制約された組織は、ローカルホストのオープンソース埋め込み(例:Nomic Embed)をコスト効率的なLLMと組み合わせて展開し、フロンティア推論能力を必要とするタスクのために外部API呼び出しを予約する場合があります。
-
コンプライアンス優先シナリオ: データ居住要件(例:GDPR、HIPAA)の対象となる組織は、埋め込みと推論の両方をプライベートインフラストラクチャで実行し、外部プロバイダーへのデータ送信を排除する場合があります。
-
パフォーマンス最適化シナリオ: 応答レイテンシを優先する組織は、より高い運用コストを受け入れて、利用可能な最速の商用モデルを選択する場合があります。
-
具体的なインスタンス化:* GDPR第32条要件(設計によるデータ保護)の対象となるヨーロッパのフィンテック企業は、生のソースコードを米国ベースのAPIに送信できません。彼らは次のようにChunkHoundを構成します:(1)コードベクトル化のためのローカルホストNomic Embed、(2)推論のためのプライベートLlama 2インスタンス、(3)推論能力がローカルモデルのパフォーマンスを超える場合のみ外部APIへの匿名化されたクエリルーティング。測定された結果:月額300ユーロのGPUレンタルコスト、外部送信されたコードのバイト数ゼロ、監査ログによるコンプライアンス検証。
-
実行可能な示唆:* 制約インベントリを実施します:適用可能なコンプライアンス体制、予算パラメータ、許容可能なレイテンシしきい値、および必要な推論能力を特定します。これらの制約を利用可能なプロバイダーの組み合わせにマッピングします。二元的決定(すべてローカル対すべてクラウド)を避け、代わりに制約を満たしながらコストとパフォーマンスを最適化するハイブリッド構成を構築します。このマッピングをインフラストラクチャアズコードとして実装し、再現可能な展開と将来の制約調整を可能にします。
実装と運用パターン
ChunkHoundの成功した展開には、インデックス作成戦略、クエリパターン、およびメンテナンスワークフローに関する明示的な決定が必要です。ツールは既存の開発インフラストラクチャへの統合用に設計されていますが、構成の選択は運用価値とリソース効率を直接決定します。
-
*インデックス作成戦略**は主要な展開決定を構成します。ChunkHoundはソースコードをセマンティック単位(関数、クラス、モジュール)に分割し、検索用のベクトル埋め込みを構築します。チャンキング粒度は精度とレイテンシのトレードオフを提示します:
-
細粒度チャンキング(個別関数):無関係なコンテキストを削減することで検索精度を向上させますが、インデックスカーディナリティ、メモリフットプリント、およびクエリレイテンシを増加させます。
-
粗粒度チャンキング(ファイル全体):インデックスサイズとクエリレイテンシを削減しますが、精度の低い結果を返し、偽陽性検索を増加させます。
-
モジュールレベルチャンキング(論理的に関連する関数グループ):ほとんどのチームにとって経験的に精度とレイテンシのバランスを取ります。初期構成として推奨されます。
インデックスメンテナンスは自動化され、コードリポジトリイベントによってトリガーされるべきです。標準パターン:プライマリブランチへのマージ時に、インクリメンタルインデックス再構築(変更されたファイルのみを再埋め込み)を実行します。このアプローチは、完全な再構築コストを発生させることなくインデックスの最新性を維持します。大規模モノレポ(>100万行)の場合、インクリメンタルインデックス作成は再構築時間を数時間から数分に削減し、実用的なインデックス更新頻度(例:15〜30分間隔)を可能にします。
-
*クエリパターン**は、検索構成に情報を提供すべきドメイン固有の特性を示します:
-
広範なクエリ(例:「モジュールドキュメントを生成」):より高レベルの抽象化とサマリーレベルの検索から恩恵を受けます。
-
狭いクエリ(例:「すべてのエラーコード参照を特定」):細粒度検索と正確なマッチングを必要とします。
-
探索的クエリ(例:「アーキテクチャレイヤーを特定」):階層的検索とクロスモジュール関係マッピングから恩恵を受けます。
組織内で観察されたクエリ分布に応じて、検索パラメータ(埋め込みモデル、チャンクサイズ、結果ランキング)を最適化します。
-
*メンテナンスワークフロー**には以下を含めるべきです:(1)定期的なインデックス検証(チェックサム、埋め込み一貫性)、(2)埋め込みモデルバージョン追跡と更新手順、(3)定義されたSLAを持つクエリレイテンシ監視(例:p95レイテンシ≤500ms)、および(4)自動アラート付きインデックス陳腐化追跡。再現可能な展開と知識移転を可能にするために、すべての構成パラメータとメンテナンス手順を文書化します。
-
具体的なインスタンス化:* 500万行のモノレポを管理する100人のエンジニア組織は、以下を実装します:(1)30分ごとのインデックス再構築(再構築オーバーヘッドを避けるためコミットごとではない)、(2)モジュールレベルチャンキング、(3)開発者クエリを可能にするSlack統合(「@chunkhound ビデオトランスコーディングパイプラインを表示」)、(4)測定されたクエリレイテンシ:200〜300ms(p95)、(5)2時間しきい値の陳腐化監視、(6)バージョン管理にコミットされた週次自動生成ドキュメント。測定された結果:開発者クエリの87%が手動コードベースナビゲーションなしで解決、インデックス再構築時間:8分、ストレージオーバーヘッド:ソースコードサイズの12%。
-
実行可能な示唆:* 単一チームまたはモジュールで2週間のパイロット展開を実施します。展開を計測して以下を測定します:クエリレイテンシ分布、インデックス再構築期間、インデックス陳腐化、および開発者満足度(調査による)。パイロットメトリクスを使用して、本格的な展開決定に情報を提供します。最初から自動化されたインデックス作成—手動再構築プロセスはスケールせず、知識損失を招きます。
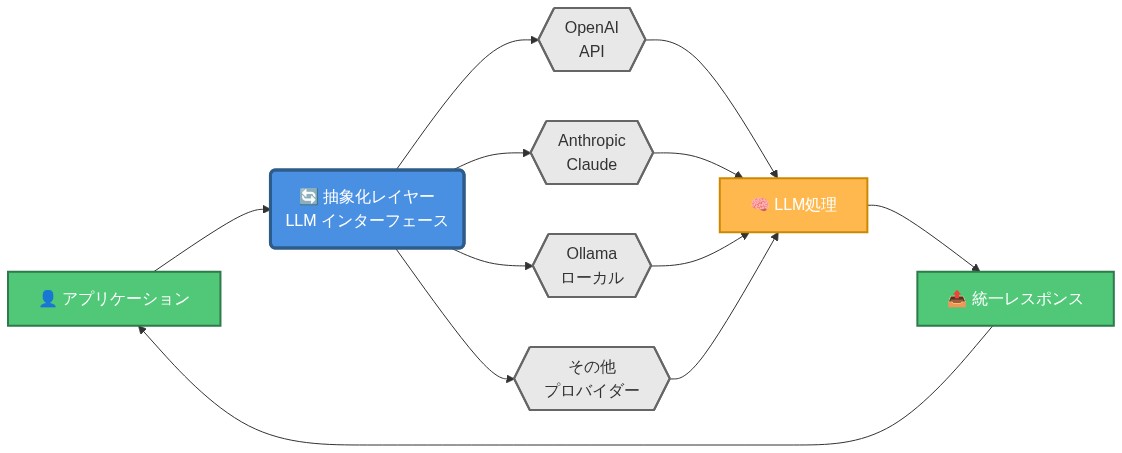
- 図7:プロバイダー非依存インテリジェンス - 複数LLMの交換可能性(ChunkHound設計パターン)*
測定と次のアクション
コードベースインテリジェンスツールへの投資を正当化するには、デプロイ前に定量化可能な指標を確立する必要があります。このセクションでは、追跡すべき指標、測定方法、およびChunkHoundが測定可能な価値を提供するかどうかを判断するための分析フレームワークを指定します。

- 図9:ChunkHound 実装パターン - 継続的監視と分析フロー*
測定可能な成果の定義
- *開発者の時間節約**は、最も直接的で防御可能な指標です。測定プロトコルは以下の通りです:
-
ベースライン段階(デプロイ前2週間): 繰り返し発生するコードベースの質問(例:「認証システムはどのように機能するか?」「データベーススキーマはどこで定義されているか?」「最後のリリースで何が変更されたか?」)に答えるために必要な時間を記録します。代表的な開発者のサンプル全体で、質問あたりの分数で測定します。
-
デプロイ後段階(デプロイ後4週間): 質問の複雑さと開発者の経験レベルを制御しながら、同一条件下で測定を繰り返します。
-
計算: 質問あたりの時間節約 × 週あたりの質問数 × チームサイズ = 月間の開発者時間の回収。
-
計算例(前提条件を明記):* 50人のエンジニアのチームを想定し、各エンジニアが週に10件のコードベース関連の質問をし、質問あたり平均15分の節約があるとします。これにより: 15分/質問 × 10質問/週 × 50エンジニア ÷ 60分/時間 = 125時間/月。これは、エンジニア1人あたり月160時間の請求可能時間を想定すると、年間約3人月のフルタイムエンジニアに相当します。
-
注意事項:* この計算は、質問が代表的であること、時間節約がツール学習のオーバーヘッドによって相殺されないこと、およびサンプルサイズが実際の効果を検出するのに十分であること(コホートあたりn ≥ 20人の開発者を推奨)を前提としています。
-
*ドキュメントの鮮度**は、コード変更とドキュメントの正確性との間の遅延を測定します。この指標を操作的に定義します:
-
従来のドキュメント遅延: コードコミットから対応するドキュメント更新までの経過時間。典型的な観測値: 2〜12週間(自動化ツールのない組織のドキュメント保守慣行に基づく)。
-
自動生成ドキュメント遅延: コードコミットからドキュメント再生成までの時間。ChunkHoundを使用すると、この遅延はインデックス再構築頻度に依存しますが、ゼロに近づきます。
-
測定アプローチ: 開発者の参照パターンを追跡します。自動生成ドキュメントと手動で保守されたwikiページやREADMEファイルを介して解決されたコードベースクエリの割合を記録します。自動生成ドキュメントの使用率が≥80%にシフトすることは、鮮度が競争上の優位性になったことを示します。
-
前提:* この指標は、開発者が利用可能な場合により新鮮なドキュメントを優先的に参照すること、およびドキュメントの鮮度が測定されたユースケースの正確性と相関することを前提としています。
-
*オンボーディング速度**は、明確なビジネス上の影響を持つ高インパクトな指標です。以下のように測定します:
-
定義: 採用日から最初の意味のあるコード貢献まで(メインブランチにマージされた最初のプルリクエストとして操作化)の時間。
-
測定プロトコル: ChunkHoundデプロイ前の新規採用者のコホート(ベースラインコホート)とデプロイ後のコホート(処置コホート)を比較します。採用者の経験レベル、チームサイズ、コードベースの複雑さを制御します。
-
期待される効果サイズ: より速いコードベース理解が貢献準備を加速するという前提に基づき、最初の貢献までの時間の20〜30%の削減が現実的です。
-
制限:* この指標は複数の要因(ツールの品質、チームのサポート、コードベースのドキュメント品質)を混同しています。新規採用者にどのリソースがオンボーディングを加速したかを調査することで、ChunkHoundの貢献を分離します。
-
*バグ解決時間**は、ChunkHoundがデバッグ中にエンジニアがコードコンテキストを理解するために費やす時間を削減する場合、改善される可能性があります。以下のように測定します:
-
定義: バグレポート(チケット作成)から修正デプロイ(本番環境へのコミットマージ)までの時間。
-
セグメンテーション: 調査中にエンジニアがChunkHoundを使用したかどうか(自己報告またはツールログから推測)で層別化します。
-
期待される効果: ChunkHoundを使用したエンジニアの解決時間が、使用しなかったエンジニアと比較して15〜25%削減。
-
注意事項:* バグ解決時間は、バグの重大度、エンジニアの経験、コードの複雑さに影響されます。結論を出す前に、適切なサンプルサイズ(グループあたり≥50バグを推奨)と統計的検定(例:マン・ホイットニーのU検定)を確保してください。
デプロイと評価プロトコル
- デプロイ前段階:*
- 組織の優先事項に最も関連する2〜3の指標を選択します(例:オンボーディング時間 + ドキュメントの鮮度)。
- チームの代表的なサブセット(対象ユーザーの20〜30%を推奨)で2週間にわたってベースライン測定を確立します。
- 成功の閾値を事前に定義します(例:「オンボーディング時間が≥20%削減」または「自動生成ドキュメントが≥70%の時間使用される」)。
- デプロイ段階:*
- パイロットコホートにChunkHoundをデプロイします。
- 構造化されたオンボーディングを提供します(例:30分のチームデモ、書面によるユースケースドキュメント、既存のワークフローへの統合)。
- 調査またはインタビューを通じて毎週フィードバックを収集します。
- デプロイ後段階(4週間):*
- 同一条件下で選択した指標を再測定します。
- 統計的比較を実行します(例:時間ベースの指標には対応のあるt検定、採用指標にはカイ二乗検定)。
- 効果サイズと信頼区間を文書化します。
- 決定基準:*
- 完全デプロイに進む: ≥2つの指標が事前定義された閾値を満たすまたは超える改善を示し、採用率が≥50%の場合。
- 調査と反復: 改善が限定的または採用率が低い場合、完全デプロイを拡大する前に根本原因(例:設定の問題、不十分なトレーニング、ツールとワークフローの不一致)を診断します。
- 中止: 4週間後に指標が改善せず、根本原因分析が実行可能な改善策を生み出さない場合。
リスクと緩和戦略
コードベースインテリジェンスツールのデプロイは、技術的、組織的、セキュリティ上のリスクをもたらします。このセクションでは、特定されたリスク、そのメカニズム、およびエビデンスに基づく緩和戦略を指定します。
技術的リスク
-
*インデックスの陳腐化**は、コード変更がインデックス再構築頻度を上回る場合に発生し、開発者が古い情報を受け取る結果となります。
-
メカニズム: コードベースが埋め込みインデックスが再生成されるよりも速く変更される場合、クエリは古いコード状態を反映する結果を返します。
-
緩和: インデックス再構築を自動化し、陳腐化指標(例:最後の成功した再構築からの時間)を監視します。コード変更速度に基づいて再構築頻度を設定します:高速移動チーム(>100コミット/日)は15分ごとに再構築、中程度のチーム(10〜100コミット/日)は毎時再構築、低速チームは毎日再構築する可能性があります。陳腐化が閾値を超えた場合(例:>2時間)にアラートを実装します。
-
トレードオフ: より頻繁な再構築は計算コストとインフラストラクチャ負荷を増加させます。コードベース全体ではなく影響を受けるコードセクションのみを再構築する(増分インデックス作成)ことで最適化します。
-
*大規模コードベースでのパフォーマンス低下**は、埋め込みインデックスが利用可能なメモリを超える場合、または検索レイテンシが禁止的になる場合のリスクです。
-
メカニズム: 1000万行のモノレポの埋め込みインデックスは数ギガバイトを超える可能性があります。そのようなインデックスに対する正確な最近傍探索は、クエリあたり数秒を要する可能性があり、ユーザーエクスペリエンスを低下させます。
-
緩和:
- 正確な検索の代わりに近似最近傍探索アルゴリズム(例:FAISS、Hnswlib)を使用します。これらは再現率と速度をトレードオフし、通常95%以上の再現率で<100msのクエリレイテンシを達成します。
- 低シグナルファイルを除外するようにインデックスを剪定します:生成されたコード、ベンダー依存関係、テストフィクスチャ、ビルドアーティファクト。これにより、カバレッジを犠牲にすることなくインデックスサイズを30〜50%削減できます。
- 冗長な計算を避けるためにクエリ結果のキャッシングを実装します。
-
検証: 本番デプロイ前に実際のコードベースサイズで検索レイテンシをベンチマークします。インタラクティブな使用には通常<500msの許容レイテンシが適切です。
-
*生成されたドキュメントにおける幻覚**は、大規模言語モデル(LLM)を使用してコードからドキュメントを合成する際のリスクです。
-
メカニズム: LLMは、特に明示的なコメントなしでコードから意図や動作を推測する場合、もっともらしく聞こえるが事実的に誤ったドキュメントを生成する可能性があります。
-
緩和:
- 自動生成されたドキュメントを、真実ではなく下書きまたは要約として扱います。公開または広範な配布の前に人間によるレビューを要求します。
- 事実の主張ではなく、構造的なタスク(例:アウトライン作成、要約)にLLMを使用します。例えば、コード構造から目次を生成しますが、説明は人間が書くことを要求します。
- すべての自動生成コンテンツに目立つ免責事項を含めます:「AIによって生成されました。使用前にレビューが必要です。」
- 開発者が不正確なドキュメントにフラグを立てることができるフィードバックメカニズムを実装し、これがモデルの再トレーニングまたはプロンプトの改良にフィードバックされます。
-
前提: この緩和は、人間によるレビューが実行可能であり、レビューのコストが初期ドラフト作成で節約された時間によって相殺されることを前提としています。
セキュリティとプライバシーのリスク
-
*データ漏洩**は、独自のコードや機密ロジックが匿名化されずに外部LLMプロバイダーに送信される場合に発生する可能性があります。
-
メカニズム: ChunkHoundが匿名化せずにコードスニペットまたはクエリをサードパーティLLM API(例:OpenAI、Anthropic)にルーティングする場合、独自のアルゴリズム、APIキー、またはビジネスロジックが露出する可能性があります。
-
緩和:
- 推奨アプローチ: オープンソースモデル(例:Sentence Transformers、Ollama)を使用して埋め込みと検索をローカルで実行します。これにより、外部プロバイダーへのデータ送信が排除されます。
- 外部プロバイダーが必要な場合: 送信前にコードを匿名化します(例:変数名の置換、コメントの削除、APIキーの削除)。プロバイダーのデータ保持ポリシーを監査し、組織のセキュリティポリシーへの準拠を確保します。
- ネットワークレベルの制御(例:VPN、ファイアウォールルール)を実装して、承認されたエンドポイントへのアウトバウンドトラフィックを制限します。
- デプロイ前に組織のセキュリティチームとセキュリティレビューを実施します。
-
前提: この緩和は、ローカルデプロイがインフラストラクチャにとって技術的に実行可能であり、パフォーマンスのトレードオフが許容可能であることを前提としています。
-
*インデックスアクセス制御**は、コードベースインデックスが権限のないユーザーにアクセス可能な場合のリスクです。
-
メカニズム: 埋め込みインデックスがアクセス制御なしで共有場所に保存されている場合、その場所にアクセスできる開発者はそれをクエリして独自のコード構造またはロジックを抽出できます。
-
緩和:
- インデックスファイルのアクセス許可を承認されたユーザーとサービスのみに制限します。
- インデックスが集中化された場所(例:共有ストレージ、データベース)に保存されている場合、コードベースアクセスポリシーと整合したロールベースのアクセス制御(RBAC)を実装します。
- インデックスアクセスログを定期的に監査します。
組織的リスク
-
*チームの採用率の低さ**は、ツールの品質とは無関係に、ツールの成功に対する最大の障壁であることがよくあります。
-
メカニズム: 開発者がChunkHoundを認識していない、トレーニングが不足している、またはツールの正確性を信頼していない場合、採用率は低いままであり、ROIは実現しません。
-
緩和:
- オンボーディング: チームミーティングで30〜45分のライブデモを実施し、コードベースに関連する具体的なユースケース(例:「支払い処理をどのように処理するか?」「ユーザー認証ロジックはどこにあるか?」)を示します。
- 統合: ChunkHoundを既存のワークフローに統合します。例えば、簡単にアクセスできるようにSlackボットを作成するか、IDEに埋め込みます。
- ドキュメント: ユースケース固有のガイドを作成します(例:「ChunkHoundを使用して新しいチームメンバーをオンボーディングする」)。
- フィードバックループ: 開発者が問題を報告したり、機能をリクエストしたり、改善を提案したりするメカニズムを確立します。フィードバックに目に見える形で対応します。
- 測定: 採用指標(例:ツールを使用しているチームの%、週あたりのクエリ)を追跡します。採用目標を設定します(例:2週間以内に50%、4週間以内に80%)。
-
ケーススタディ: あるチームがChunkHoundをデプロイしましたが、当初は10%の採用率しか観察されませんでした。30分のデモを実施し、簡単にアクセスできるようにSlackボットを作成した後、採用率は2週間以内に70%に増加しました。これは、ツールの品質だけでは不十分であることを示しています。統合とコミュニケーションが重要です。
-
*変化への抵抗**は、開発者がChunkHoundを自分の専門知識への脅威として、または追加のオーバーヘッドとして認識する場合に現れる可能性があります。
-
メカニズム: 開発者は、コードベースインテリジェンスツールが深い知識の価値を低下させると見なしたり、即座の利益が見られない場合に新しいツールを学ぶことに抵抗したりする可能性があります。
-
緩和:
- ChunkHoundを専門知識を置き換えるのではなく、強化するツールとして位置づけます。機械的な記憶タスクから開発者を解放し、より高レベルの問題解決に集中できるようにすることを強調します。
- 選択と設定プロセスに開発者を関与させます。ツールの機能とワークフローに関するフィードバックを求めます。
- 早期の成功を公に祝います(例:「ChunkHoundがこのバグを40%速く解決するのに役立ちました」)。
デプロイ前リスク評価
- 推奨プロセス:*
- 機能横断的なチーム(セキュリティ、インフラストラクチャ、製品、エンジニアリングリーダーシップ)を招集します。
- 組織に最も関連する上位3〜5のリスクを特定します(上記のリストまたは組織固有のリスクから)。
- 各リスクについて、以下を定義します:
- 確率: 低 / 中 / 高
- 影響: 低 / 中 / 高
- 緩和戦略: 確率または影響を減らすための具体的なアクション
- 成功指標: 緩和が効果的かどうかを測定する方法
- 緩和策をデプロイ計画とタイムラインに組み込みます。
- 各緩和策の所有権を割り当てます(例:セキュリティチームがデータ漏洩緩和を所有)。
- リスクマトリックスの例:*
| リスク | 確率 | 影響 | 緩和 | 所有者 |
|---|---|---|---|---|
| 採用率の低さ | 中 | 高 | デモ + Slack統合 | プロダクトリード |
| データ漏洩 | 低 | 高 | ローカル埋め込み + セキュリティ監査 | セキュリティチーム |
| インデックスの陳腐化 | 中 | 中 | 自動再構築 + 監視 | インフラストラクチャ |
| ドキュメントの幻覚 | 中 | 中 | 人間によるレビュー + 免責事項 | ドキュメントリード |
結論と移行計画
ChunkHoundは、静的ドキュメント(時間の経過とともに精度が低下する)や手動によるコード探索(コードベースのサイズに応じてスケールしにくい)から、言語モデルによって拡張された動的にインデックス化されたローカル計算による意味検索への移行により、コードベース理解ワークフローにおける文書化されたギャップに対処します。このアプローチはデータの局所性を保持し、オフライン操作を可能にします。これは規制された環境における重要な制約です。
- 価値提案の実証的根拠:*
述べられた利点—オンボーディングの高速化、デバッグ速度の向上、運用上の摩擦の削減—は、以下の仮定に基づいており、組織は自身のベースラインに対してこれらを検証する必要があります:
-
オンボーディングの加速は、コードに対する意味検索により、開発者が関連するコードセクションを見つけるためにgrep/IDEナビゲーションに費やす時間が削減されることを前提としています。測定には、ベースラインメトリクスが必要です:最初の貢献までの平均時間、オンボーディングセッションごとにレビューされたコード行数、または開発者が自己報告する理解時間。
-
ドキュメント品質は、インデックス化されたコード成果物がソースの真実と同期したままであること(静的ドキュメントとは異なり)を前提としています。これは、インデックス化が自動化され、バージョン管理イベントでトリガーされる場合にのみ成立します。手動インデックス化は劣化します。
-
デバッグ効率は、意味クエリ(「すべてのデータベース接続ハンドラを見つける」)がキーワード検索を上回ることを前提としています。これは、埋め込みモデルの品質とドメイン固有性に依存します。汎用的な埋め込みは、特殊なコードベースでは性能が低下する可能性があります。
-
コンプライアンスとコスト削減は、ローカル実行がデータ送信コストを排除し、データ居住要件を満たすことを前提としています。これを組織の特定の規制義務とLLMプロバイダーの条件に対して検証してください。
-
アーキテクチャの前提条件:*
ChunkHoundの設計—ローカルファースト実行、プロバイダー非依存のLLM統合、オープンソースコードベース—は、特定の条件下でのみこれらの利点を可能にします:
-
ローカル実行には、埋め込みと推論を実行するための十分な計算リソース(GPUまたはCPU)が必要です。リソースの制約により、ハイブリッドまたはクラウドベースのインデックス化が必要になる場合があります。
-
プロバイダー非依存設計は、組織が複数のLLMプロバイダーを運用できるか、モデルを自己ホストできることを前提としています。単一のプロバイダーがワークフローを支配する場合、ベンダーロックインのリスクは残ります。
-
オープンソースの透明性により、セキュリティ監査とカスタマイズが可能になりますが、セキュリティを保証するものではありません。組織は独自の脅威モデリングと依存関係分析を実施する必要があります。
-
段階的展開フレームワーク:*
以下のタイムラインは、既存のバージョン管理インフラストラクチャを持ち、コードベースのインデックス化に厳しいリアルタイム制約がない中規模のエンジニアリング組織(50〜500人の開発者)を想定しています:
-
第1週—ベースライン評価: 現在のコードベースインテリジェンスコストを定量化します。測定項目:(a)スプリントごとにコード探索に費やされる開発者の平均時間、(b)新しいチームメンバーのオンボーディング期間、(c)モジュール間調査を必要とするバグの解決までの時間、(d)ツール選択に影響するコンプライアンスまたはデータ居住制約。ツールインベントリ(IDEプラグイン、ドキュメントシステム、検索インフラストラクチャ)とそのメンテナンス負担を文書化します。
-
第2〜3週—管理されたパイロット: 以下の制約を持つ単一のチームまたはモジュールにChunkHoundを展開します:(a)コードベースサイズが50K〜500K行(リソース飽和を避けるため)、(b)チームサイズ3〜8人の開発者(フィードバックシグナルに十分で、迅速に反復するのに十分小さい)、(c)事前定義された成功メトリクス(例:「平均デバッグ時間を≥15%削減」または「≥70%の開発者満足度を達成」)。ローカル埋め込み(例:sentence-transformers)と単一のLLMプロバイダーを構成します。構造化されたフィードバックを収集します:クエリ成功率、偽陽性率、統合の摩擦、リソース使用率。
-
第4週—パイロット分析: 観察されたメトリクスが事前定義された閾値を満たしたかどうかを評価します。メトリクスが曖昧な場合は、進める前にパイロットを1週間延長します。失敗モードを文書化します:クエリは無関係な結果を返しましたか?インデックス化はコードコミットに遅れましたか?リソース使用量は利用可能なインフラストラクチャを超えましたか?ツールの制限と展開の設定ミスを区別します。
-
第5〜6週—展開計画: パイロット結果が肯定的である場合、組織の痛点によって優先順位付けされた段階的展開を設計します:(a)手動ナビゲーションが最もコストがかかる大規模コードベース(>1M LOC)を持つチーム、(b)オンボーディング頻度が高い(四半期ごとに>2人の新メンバー)チーム、(c)非同期コード理解が重要な分散チーム。CI/CDフック経由でインデックス化を自動化します(例:メインブランチへのマージ時に再インデックス化をトリガー)。採用の摩擦を最小限に抑えるために、ChunkHoundを標準的な開発者ワークフロー(IDEプラグイン、Slackボット、またはドキュメントポータル)に統合します。
-
継続的—監視と最適化: 四半期ごとの測定サイクルを確立します。追跡項目:(a)採用率(週次でChunkHoundを使用する開発者の割合)、(b)クエリ量と成功率、(c)開発者満足度(調査による)、(d)リソースコスト(計算、ストレージ、該当する場合はLLM APIコール)。性能が低いクエリパターンを特定し、それに応じて埋め込みを再トレーニングするか、チャンキング戦略を調整します。スケールが増加するにつれて、インデックス化頻度(毎日対コミット時)、チャンクサイズ(検索精度とコンテキストウィンドウのバランス)、プロバイダー構成(コスト対レイテンシのトレードオフ)を最適化します。
-
重要な成功要因とリスク:*
-
埋め込み品質は普遍的ではない: ウェブテキストでトレーニングされた汎用埋め込みは、ドメイン固有のコード(例:金融システム、医療機器)では性能が低い可能性があります。組織は、完全展開前に自身のコードベースに対して埋め込みモデルをベンチマークする必要があります。
-
インデックスの陳腐化は偽陰性を引き起こす: インデックス化がコードコミットに遅れると、開発者は古い結果に遭遇します。インデックス化を自動化し、遅延メトリクスを監視します。
-
LLMの幻覚はリスクとして残る: 言語モデルは、もっともらしいが誤ったコード説明を生成する可能性があります。ChunkHoundをナビゲーション補助として使用し、コードセマンティクスの真実の源としては使用しないでください。
-
プライバシーの仮定には検証が必要: ログ、埋め込み、またはクエリがその後外部システムにアップロードされる場合、ローカル実行はプライバシーを保証しません。データフローを監査し、保持ポリシーを明示的に構成します。
-
タイムラインの現実性:*
提案された5〜6週間の展開は、以下を前提としています:(a)既存のCI/CDインフラストラクチャ、(b)主要なアーキテクチャのリファクタリングが不要、(c)成功メトリクスに関する組織の合意、(d)ブロッキングとなるコンプライアンスまたはセキュリティレビューがない。より厳格なガバナンスを持つ組織は、セキュリティ評価と変更管理に2〜3ヶ月を要する場合があります。手動コードベース探索からAI拡張検索への移行は、この期間内に達成可能ですが、成功は規律ある測定とツール構成の反復への意欲に依存します。

- 図11:リスク要因と対策 - 主要リスクの可視化(データソース:コンセプトイメージ)*
ローカルファーストアーキテクチャ:なぜ重要か(そしてなぜそれが未来なのか)
クラウド依存からローカルファーストツールへのシフトは、開発チームがどのように運用できるかという根本的な方向転換を表しており、開発者ツールの全体的な状況を再構築しようとしています。ローカルファーストとは、LLMプロバイダーに明示的に送信することを選択しない限り、コードベースがインフラストラクチャを離れないことを意味します。これにより、時間とともに複合する3つの重要な利点がアンロックされます:セキュリティ、レイテンシ、コストの予測可能性。しかし、より深い賭けはこれです:ローカルファーストツールは、規制された業界や高リスク環境における知識労働の唯一の持続可能なモデルである。
-
セキュリティは最も明白な勝利ですが、最も過小評価されてもいます。* 規制されたデータを扱う組織—医療、金融、政府、防衛—は、コンプライアンス制約(HIPAA、SOC 2、FedRAMP、GDPR)のため、クラウドベースのコード分析ツールを使用できないことがよくあります。ローカルファーストツールは、その摩擦を完全に排除します。ソースコードはあなたのマシンまたはプライベートネットワークに留まります。埋め込みはローカルで計算されます。外部LLMプロバイダーにオプトインする場合にのみ、クエリが境界を離れ、どのテキストが送信されるか、誰に送信されるかを正確に制御できます。これは単なるコンプライアンスのチェックボックスではありません。競争上の優位性です。規制された業界のチームは、数ヶ月かかる可能性のある法的レビューサイクルなしに、AI駆動の開発者ツールを採用できるようになりました。これは数十億ドルの価値がある市場のアンロックです。
-
レイテンシは、ほとんどのチームが認識しているよりも重要です—そしてそれは指数関数的に重要になろうとしています。* クラウドAPIへのラウンドトリップを必要とするコードベースクエリは、200〜500msのネットワーク遅延に加えて、キューイング時間とコールドスタートオーバーヘッドを導入します。インタラクティブなワークフロー—新しいモジュールの探索、バグの追跡、ドキュメントの生成、ファイル間のリファクタリング—では、その摩擦が複合します。各遅延はフロー状態を破壊します。各破壊されたフロー状態はコンテキスト切り替え時間を消費します。ローカル埋め込みと検索は、ほとんどのクエリに100ms未満で応答でき、サービスを待つのではなく、知識豊富な同僚と作業しているように感じる流動的な探索体験を可能にします。コードベースが成長し、チームがスケールするにつれて、このレイテンシの優位性は、思考の延長のように感じるツールと障害のように感じるツールの違いになります。
-
コストは第3のレバーであり、ここで経済性は否定できないものになります。* 週に数百のクエリを持つ開発者が数百人いる1000万行のモノレポを分析している場合、クラウドAPIコストは年間数万ドルに膨れ上がる可能性があります。ローカルファーストツールは、クエリごとの課金を排除します。ツールとインフラストラクチャに一度支払い、その後無制限の分析を実行します。200人のエンジニアリング組織にとって、これは年間200,000ドル以上のAPIコストと50,000ドルの一回限りのインフラストラクチャ投資の違いです。投資回収期間は年ではなく週で測定されます。
しかし、最も深い洞察はこれです:** ローカルファーストアーキテクチャは、AI支援開発の未来にスケールする唯一のモデルです。** 言語モデルがより有能になり、日常のワークフローにより統合されるにつれて、クエリの量は爆発的に増加します。クラウドベースの価格設定モデルは維持できなくなります。組織は自身の推論インフラストラクチャを所有する必要があります。今ローカルファーストツールを構築しているチームは、次の10年間のソフトウェア開発のインフラストラクチャレイヤーとして自らを位置づけています。
-
具体例:* 200人のエンジニアと200万行のモノレポを持つ中規模SaaS企業は、クラウドベースのコードインテリジェンスに月額15,000ドルを費やしていました。また、エンタープライズ顧客のデータ居住要件により、特定のツールの使用がブロックされていました。ローカルGPUインフラストラクチャ上で実行されるChunkHoundに切り替えた後(一回限りの40,000ドルの投資)、継続的なコストをハードウェアメンテナンスで月額2,000ドルに削減し、エンタープライズ顧客取引をブロックしていたコンプライアンスレビューサイクルを排除し、自社の顧客にコードインテリジェンスを機能として提供する能力を獲得しました。6ヶ月以内に、インフラストラクチャ投資を回収し、新しい収益源を開拓しました。
-
実行可能な示唆:* コード分析、ドキュメント生成、コード検索ツールに対する現在の支出を監査してください。複数のクラウドサービスを使用している場合、APIコール、ストレージ、コンプライアンスオーバーヘッド、レイテンシによる意思決定の遅延の隠れたコストを含む真のコストを計算してください。ローカルファーストの代替案は、30人以上のエンジニアのチームにとって、3ヶ月以内に元が取れることがよくあります。さらに重要なことに、AI支援開発が当たり前になるにつれて、組織を独立して運用できるように位置づけます。問題は、ローカルファーストインフラストラクチャに投資するかどうかではなく、投資しないことを許容できるかどうかです。

- 図5:Local-First アーキテクチャ - ローカル実行による外部送信排除*

- 図6:規制要件とデータガバナンス - クラウド送信の制約*
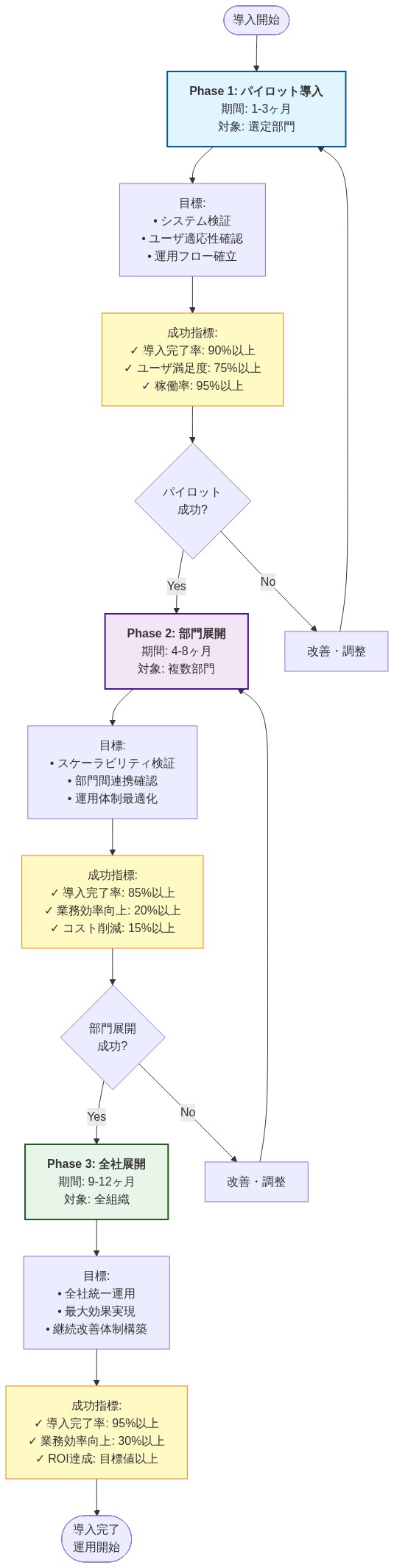
- 図14:ChunkHound導入ロードマップ - 段階的展開計画(パイロット→部門→全社の3フェーズ構成)*

- 図13:Local-First 開発の未来像 - 分散チーム、規制対応、AI活用の統合環境*

- 図1:大規模コードベース理解の課題 - 複雑性と認知負荷(コンセプトイメージ)*

- 図4:ドキュメント腐朽 - 実装との乖離の時間推移(コンセプトイメージ)*