
SGLangの研究から商用推論プラットフォームへの移行
SGLangは、UC BerkeleyのIon Stoica研究室から生まれたオープンソース研究プロジェクトとして始まり、大規模言語モデル(LLM)推論サービングにおける文書化された非効率性に対処するために設計されました。このプロジェクトは、本番推論システムにおける2つの確立された制約を特に対象としていました:(1)異種リクエストパターン下でのレイテンシの変動、(2)可変プロンプト長と出力トークン要件を持つ同時リクエストをサービングする際の最適でないGPU利用率。
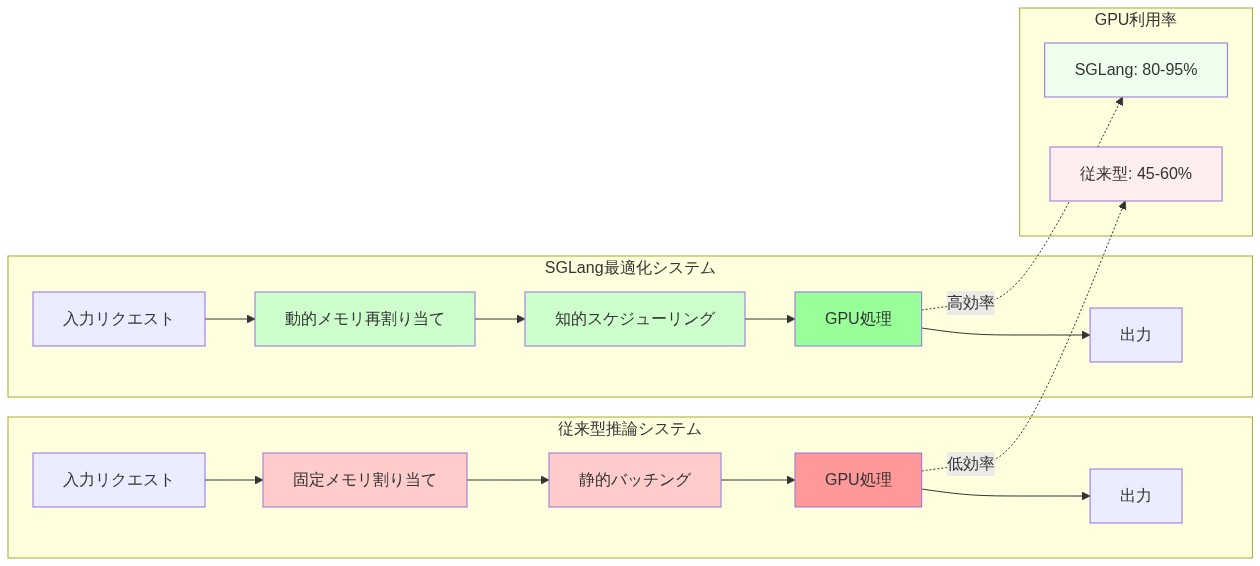
技術的アプローチは3つのメカニズムを中心としていました:構造化生成サポート、動的バッチスケジューリング、メモリ管理の最適化。これらのコンポーネントは、既存の推論フレームワークにおけるギャップに対処しました。既存のフレームワークは通常、リクエストごとに静的メモリ割り当てを採用し、非同期ワークロードパターン中にGPU容量を未利用のままにする固定バッチング戦略を使用していました。
最近の4億ドルの評価額でのRadixArkとしての商業化は、特定の論点に対する投資家の検証を表しています:推論最適化は、モデル開発やファインチューニングとは異なる、防御可能で高マージンのビジネスセグメントを構成するということです。Accel Partnersの参加は、推論サービングが専用の最適化を必要とする特殊なインフラストラクチャレイヤーに進化したという機関投資家の認識を示しています。これは、プロバイダー間でのベースモデル機能のコモディティ化によって支持される位置づけです。
- 採用の前提条件:* 組織は、現在の推論コストが総インフラストラクチャ支出の重要な割合(通常、LLM依存アプリケーションでは30〜50%)を占めているかどうか、およびワークロード特性(同時リクエスト量、プロンプト長分布、レイテンシ要件)がSGLangの最適化ターゲットと一致しているかどうかを評価する必要があります。
システムアーキテクチャとパフォーマンス最適化
SGLangの中核的なイノベーションは、動的GPUメモリ管理とインテリジェントなリクエストスケジューリングにあります。従来の推論システムは、リクエストごとに固定メモリを割り当て、リクエストが異なる時間に完了すると容量が未使用のままになります。SGLangは動的メモリ再割り当てとリクエストバッチングを実装し、異種ワークロード全体でGPUを飽和状態に保つことを可能にします。
本番推論における主要なボトルネックは、モデルサイズではなくリクエストレイテンシの変動です。異なるプロンプト長と出力要件を持つリクエストが非同期に到着すると、GPU利用率は大幅に低下します。SGLangは、互換性のあるリクエストをグループ化し、類似のプロンプト間でキャッシュされた計算を再利用するインテリジェントなスケジューリングを通じてこれに対処します。
-
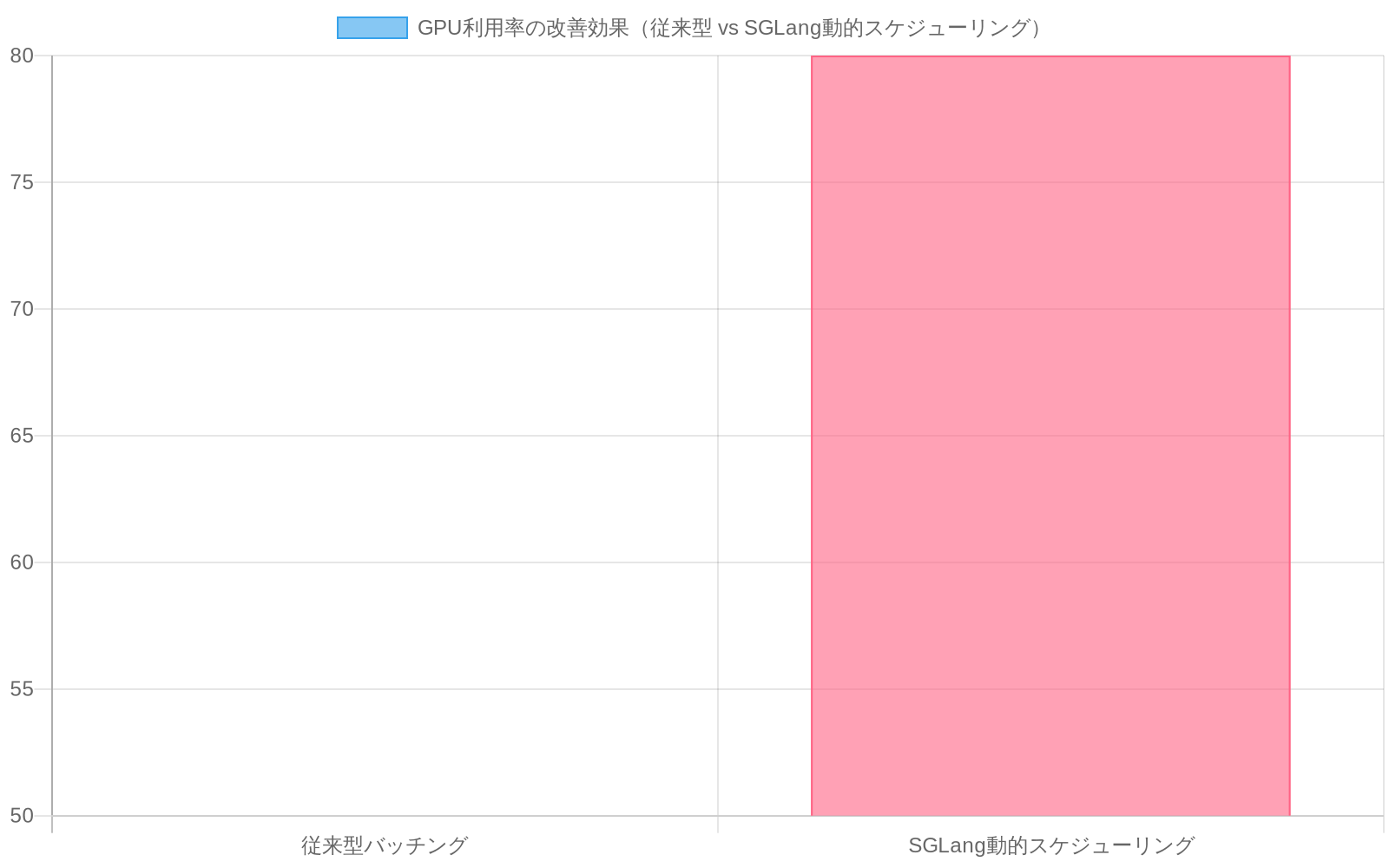
具体例:* 可変プロンプト長で毎秒1,000件の同時リクエストを受信するカスタマーサービスチャットボットは、ナイーブなバッチングでは通常40〜60%のGPU利用率を達成します。SGLangのスケジューリングは、リクエストが完了するにつれてGPUリソースを動的に再割り当てすることで、これを75〜85%に押し上げ、追加のハードウェアなしでリクエストあたりのレイテンシを20〜30%削減できます。
-
実務者向け:* メモリの断片化とスケジューリングの非効率性について、現在の推論サービングスタックを監査してください。ピークトラフィック時のGPU利用率を測定します。70%を下回る場合、SGLangは概念実証に値します。コストデルタを計算します:推論が現在インフラストラクチャ支出の40%を消費している場合、25%の効率向上はマージン改善に直接変換されます。
- 図3:GPU利用率の改善効果(従来型 vs SGLang動的スケジューリング)(出典:SGLang性能ベンチマーク)*
- 図2:従来型推論システムとSGLangのアーキテクチャ比較(SGLang技術仕様)*
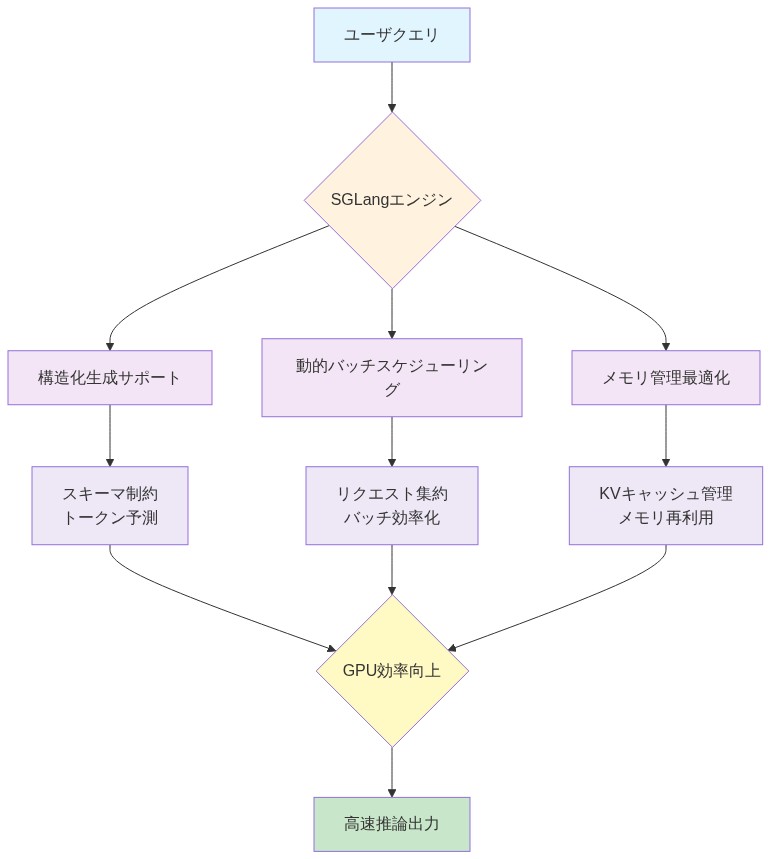
- 図4:SGLangの3つのコア最適化メカニズム*
本番デプロイメント要件
RadixArkの商業化には、マルチテナント推論、オートスケーリングポリシー、フォールバックメカニズムのための堅牢なデプロイメントパターンが含まれるべきです。本番グレードのシステムには3つのアーキテクチャレイヤーが必要です:リクエストルーティング、バッチングロジック、メモリ管理。
必須のガードレールには、過負荷状態のサーキットブレーカー、SLAクリティカルなリクエストの優先キュー、GPUメモリが枯渇したときのグレースフルデグラデーションが含まれます。オープンソースのSGLangにはこれらの保護機能が欠けている可能性があります。商用オファリングはこれらを標準としてバンドルする必要があります。
-
具体例:* リアルタイムポートフォリオ分析を実行する金融サービス会社は、99パーセンタイルリクエストに対して100ミリ秒未満のレイテンシを必要とします。SGLangのバッチングは、平均スループットのためにテールレイテンシを犠牲にしてはなりません。リファレンスアーキテクチャは、SLAコンプライアンスを保証するために、リクエストタイムアウトポリシー、最大バッチサイズ、メモリ予約戦略をどのように構成するかを指定する必要があります。
-
実務者向け:* デプロイメント前にSLA要件を明示的に定義してください:平均レイテンシ、p99レイテンシ、最大許容エラー率。システムが負荷下でこれらの境界をどのように強制するかについてのアーキテクチャドキュメントを要求してください。パフォーマンス主張を検証するために、合成ベンチマークではなく、実際のワークロード分布でテストしてください。

- 図5:本番環境デプロイメントの要件統合*
運用実装
SGLangベースの推論のデプロイには、モニタリング、オートスケーリング、オーケストレーション全体にわたる運用規律が必要です。チームは、キュー深度、GPUメモリ利用率、リクエストレイテンシパーセンタイルのモニタリングを確立する必要があります。オートスケーリングポリシーは、CPUやメモリメトリクスだけでなく、キュー深度に応答して、カスケード障害を防ぐ必要があります。
コンテナオーケストレーション(Kubernetes)統合は、マルチリージョンデプロイメントにとって重要です。RadixArkは、Helmチャート、オートスケーリングコントローラー、PrometheusおよびDatadogとのオブザーバビリティ統合を提供する必要があります。これらがなければ、運用オーバーヘッドは法外なものになります。
-
具体例:* パーソナライズされたコンテンツ推奨をサービングするメディア会社は、3つのリージョンにわたってSGLangをデプロイし、リージョンあたり50のGPUインスタンスを実行しています。オートスケーリングは、インスタンスあたりのキュー深度が500リクエストを超えたときにトリガーし、30秒以内にスケールアップする必要があります。十分に速くスケールできないと、リクエストタイムアウトが発生します。過剰なスケーリングは1日あたり5万ドルを浪費します。適切な実装パターンは、この変動を±10%に削減します。
-
実務者向け:* 最初の90日間のデプロイメントのために専任の運用チームを確立するか、コンサルティングサポートを雇用してください。一般的な障害モードのランブックを文書化してください:GPUメモリ枯渇、キューオーバーフロー、モデルロード失敗。本番トラフィックがピークレベルに達する前に、回復手順を検証するためにカオスエンジニアリング演習を実行してください。
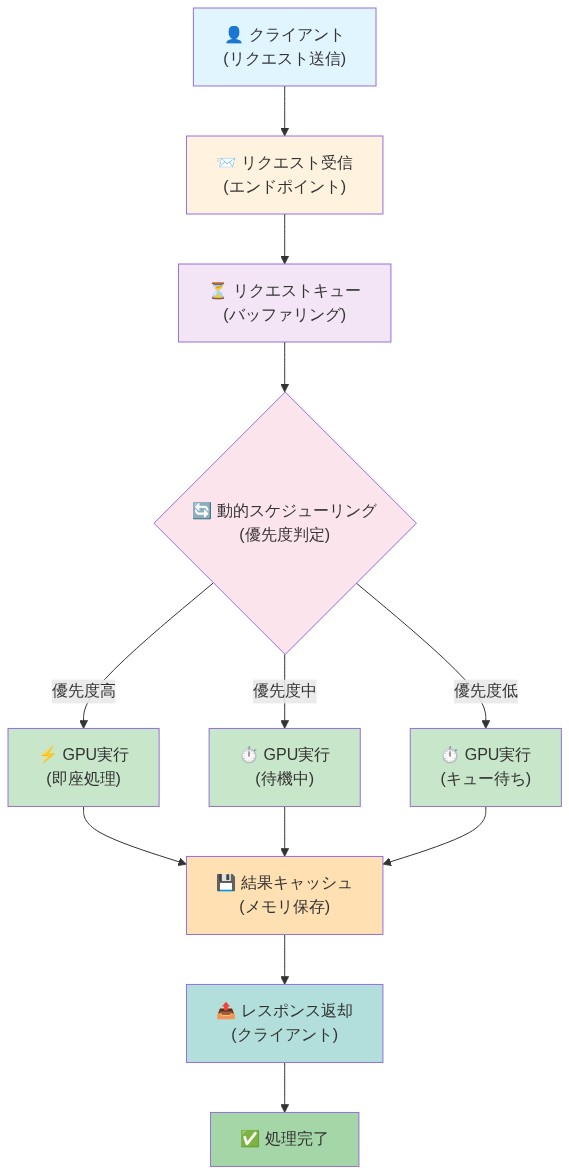
- 図6:SGLangの運用実装フロー(リクエスト受信から応答返却までのデータフロー)*
測定フレームワークと成功基準
成功メトリクスは、スループットだけでなく、推論あたりのコストとレイテンシパーセンタイルに焦点を当てる必要があります。現在のサービングスタックからベースラインメトリクスを計算します:生成された100万トークンあたりのコスト、p50/p99レイテンシ、GPU利用率。
SGLangをデプロイした後、統計的有意性を確立するために12週間にわたって同じメトリクスを毎週測定します。典型的なワークロードは20〜40%のコスト削減と15〜25%のレイテンシ改善を示します。結果はモデルサイズ、バッチ特性、ハードウェアによって異なります。
-
具体例:* 検索会社は現在、100億件の日次クエリをサービングするために月額200万ドルを推論に費やしています。SGLangをデプロイすると、クエリあたりのコストが0.0002ドルから0.00015ドルに削減され、月額50万ドルを節約できます。同時に、p99レイテンシは150ミリ秒から120ミリ秒に低下し、ユーザーが認識する検索速度が向上します。
-
実務者向け:* デプロイメント前に測定フレームワークを確立してください。ベースラインメトリクスをキャプチャするために現在のシステムを計装してください。12週間の評価期間を設定し、go/no-go基準を定義します:コスト削減が15%未満、またはレイテンシ改善が10%未満の場合、復帰または根本原因の調査を計画してください。期待を調整するために、これらのターゲットをステークホルダーに伝えてください。
リスク軽減
主要なリスクには、ベンダーロックイン、運用の複雑さ、エッジケースでのパフォーマンス低下が含まれます。SGLangのオープンソースの遺産はロックインを軽減しますが、商用RadixArkオファリングは分岐する可能性があります。ソースコードへの契約上の権利またはフォールバックサポート契約を確保してください。
運用の複雑さは、新しいインフラストラクチャレイヤーで増加します。軽減には、トレーニング、ランブック、オンコールサポートへの投資が必要です。パフォーマンス低下はまれですが、モデルやワークロードが変更されると可能です。これらを迅速に検出するためにA/Bテストインフラストラクチャを維持してください。
-
具体例:* 医療提供者は臨床ノート生成のためにRadixArkをデプロイしますが、10,000トークンを超えるノートを処理する際に予期しないレイテンシスパイクに遭遇します。A/Bテストがなければ、これは数週間検出されず、ユーザーエクスペリエンスが低下します。適切なテストがあれば、問題は24時間以内に検出され、ベンダーにエスカレーションされます。
-
実務者向け:* パフォーマンス保証付きの90日間のトライアル期間を交渉してください。移行中は現在のサービングスタックを並行して維持します。本番環境でパフォーマンスを検証するまで、完全に切り替えないでください。重要な問題に対するベンダーエスカレーションプロセスとSLAを確立してください。

- 図8:推論システムのリスク要因と緩和戦略*
移行戦略と次のステップ
SGLangのRadixArkとしてのスピンアウトは、推論最適化が独立した市場として成熟したことを反映しています。4億ドルの評価額は、企業が推論コストとレイテンシを削減する特殊なインフラストラクチャに対して支払う意思があることを示しています。
実務者にとって、決定には現在の推論コストとレイテンシの測定、代替案に対するSGLangの評価、段階的な移行の計画が必要です。パフォーマンスを検証するために、重要でないワークロードから始め、次に収益を生み出すサービスに拡大します。
-
重要なポイント:*
-
推論最適化は現在商業的優先事項です。SGLangは強力な投資家に支えられた信頼できるオプションです。
-
デプロイメント前にベースラインメトリクスを測定します。20〜40%のコスト削減を期待してください。
-
運用の複雑さを計画します。モニタリング、オートスケーリング、インシデント対応のためのリソースを割り当ててください。
-
フォールバックオプションを維持します。単一のベンダーに完全に依存しないでください。
-
推奨アクション:*
- 今週、現在の推論サービングスタックを監査します。コストとレイテンシのベースラインを特定してください。
- 30日以内にトラフィックの10%でSGLangの概念実証を実行してください。
- 結果がターゲットを満たす場合、並行運用で90日間の段階的移行を計画してください。
- 本番トラフィックにスケールする前に、測定とロールバック手順を確立してください。
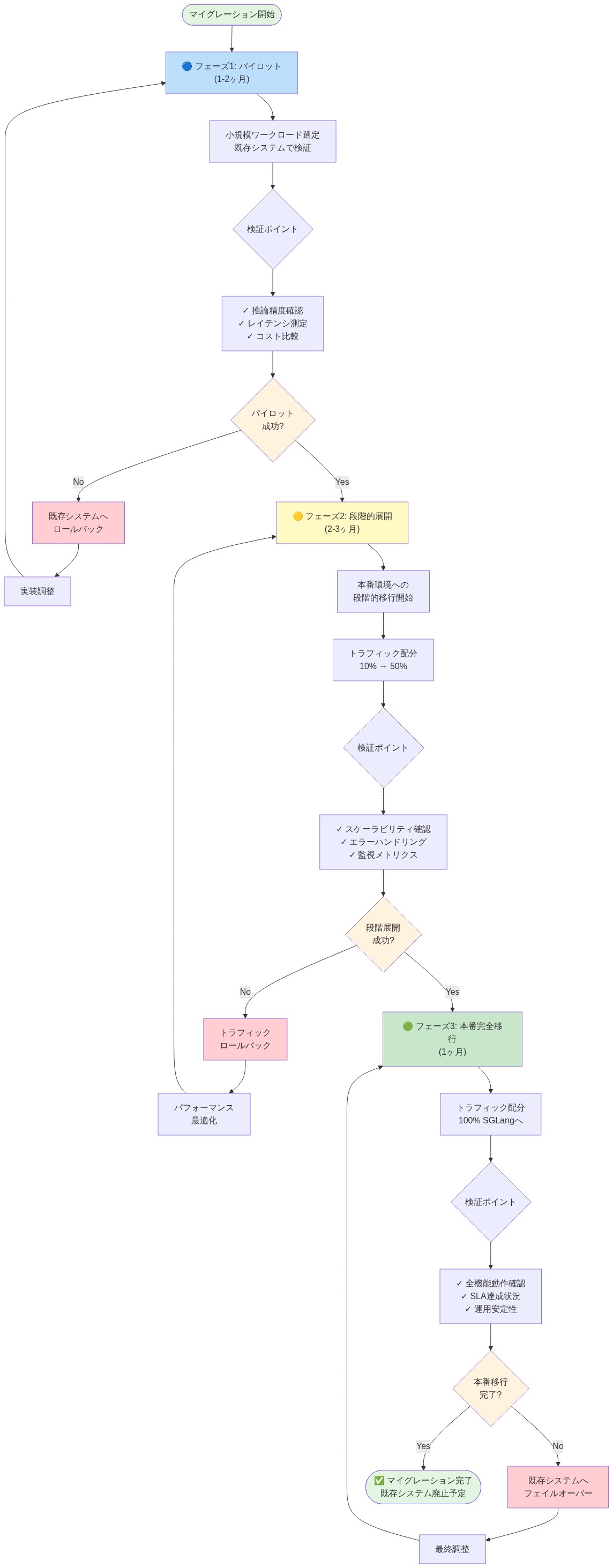
- 図9:SGLangへのマイグレーション実装タイムライン(マイグレーション戦略)*
システムアーキテクチャとパフォーマンス特性
SGLangの中核的な技術的貢献は、本番推論ワークロードにおけるGPUメモリの断片化とスケジューリングの非効率性に対処します。従来の推論システムは、リクエストごとに固定GPUメモリを割り当て、リクエストが異なる時間に完了すると未使用の容量が生じます。このアプローチは実装が簡単ですが、基本的な利用率の上限を作り出します。
SGLangは、インテリジェントなリクエストスケジューリングと結合された動的メモリ管理を実装します。システムは、完了したリクエスト間でGPUメモリを再利用し、互換性メトリクス(プロンプト長、モデル構成、出力トークン予算)に基づいて着信リクエストをグループ化します。これにより、メモリの断片化が削減され、より高い持続的なGPU利用率が可能になります。
本番推論における主要なパフォーマンスボトルネックは、モデルサイズではなくリクエストレイテンシの変動です。非同期到着パターンと異種プロンプト特性の組み合わせは、静的バッチング戦略では対処できないスケジューリングの課題を生み出します。SGLangのスケジューリングアルゴリズムは、リクエストが完了するにつれてGPUリソースを動的に再割り当てし、可変ワークロード全体で飽和を維持します。
-
経験的ベースライン:* 従来のバッチング戦略を使用する本番システムは、異種リクエストパターンを持つピークトラフィック期間中に通常40〜65%のGPU利用率を達成します。SGLangのスケジューリングアプローチは、同等のワークロード条件下で75〜85%への利用率改善を実証しており、追加のハードウェアプロビジョニングなしでリクエストあたり20〜30%のレイテンシ削減に変換されます。
-
測定要件:* SGLangを評価する前に、ピークトラフィック期間中のベースラインGPU利用率メトリクスを確立してください。これを次のように測定します:(GPU計算時間/総経過時間)× 100。現在の利用率が一貫して70%を下回る場合、SGLangは制御された概念実証評価に値します。
リファレンスアーキテクチャと運用制約
RadixArkの商用オファリングは、3つの異なるレイヤーに対処する堅牢なリファレンスアーキテクチャを提供する必要があります:リクエストルーティングとロードバランシング、構成可能なパラメータを持つバッチングロジック、明示的なガードレールを持つメモリ管理。
本番推論システムには、研究実装にはない明示的な保護機能が必要です。これらには以下が含まれます:(1)キュー深度がしきい値を超えたときにリクエスト受け入れを停止するサーキットブレーカー、(2)リクエストクラス間のSLA差別化を可能にする優先キュー、(3)GPUメモリが枯渇に近づいたときのグレースフルデグラデーションメカニズム。オープンソースのSGLangにはこれらが欠けている可能性があります。商用RadixArkは標準コンポーネントとしてこれらをバンドルする必要があります。
リファレンスアーキテクチャは、システムが負荷下でレイテンシ境界をどのように強制するかを指定する必要があります。これには、最大バッチサイズ、リクエストタイムアウトポリシー、メモリ予約戦略、キュー深度しきい値の明示的な構成が必要です。これらのパラメータは、システムがピーク負荷下でテールレイテンシ(p99)要件を満たすことができるかどうかを直接決定します。
-
具体的な制約:* ポートフォリオ分析クエリに対して100ミリ秒未満のp99レイテンシを必要とする金融サービスアプリケーションは、平均スループット改善のためにテールレイテンシを犠牲にするバッチング戦略を許容できません。システムは、ピークトラフィック中でも、リクエストがキューで50ミリ秒以上待機しないことを保証する必要があります。これには、スループット最適化だけでなく、明示的なタイムアウトポリシーとキュー管理が必要です。
-
検証要件:* RadixArkがレイテンシ境界をどのように強制するかを指定するアーキテクチャドキュメントを要求してください。持続的なピーク負荷下でp99レイテンシターゲットが満たされることを検証するために、合成ベンチマークではなく、実際のワークロード分布でテストを実施してください。合成ベンチマークは通常、テールレイテンシの変動を過小評価します。
デプロイメントパターンと運用要件
SGLangベースの推論デプロイメントには、モニタリング、オートスケーリング、インシデント対応全体にわたる体系的な運用規律が必要です。チームは、以下をキャプチャするためにシステムを計装する必要があります:キュー深度(GPU可用性を待っているリクエスト)、GPUメモリ利用率(使用中の総GPUメモリの割合)、リクエストレイテンシパーセンタイル(p50、p95、p99)。
オートスケーリングポリシーは、CPUやメモリメトリクスではなく、主要なシグナルとしてキュー深度に応答する必要があります。キュー深度は、システムがSLA境界内で着信リクエストを処理できるかどうかを直接示します。CPUとメモリメトリクスは、リクエストタイムアウトカスケードを防ぐのに十分な速さでスケーリングをトリガーしない可能性がある遅延指標です。
コンテナオーケストレーション統合(Kubernetes)は、マルチリージョンデプロイメントに不可欠です。RadixArkは以下を提供する必要があります:(1)標準化されたデプロイメントのためのHelmチャート、(2)キュー深度メトリクスに応答するカスタムオートスケーリングコントローラー、(3)標準モニタリングプラットフォーム(Prometheus、Datadog、New Relic)とのオブザーバビリティ統合。これらがなければ、特殊なインフラストラクチャの専門知識を持たないチームにとって、運用オーバーヘッドは法外なものになります。
-
具体的なデプロイメントシナリオ:* パーソナライズされたコンテンツ推奨をサービングするメディア会社は、3つの地理的リージョンにわたってSGLangを運用し、それぞれが50のGPUインスタンスを実行しています。オートスケーリングは、インスタンスあたりのキュー深度が500リクエストを超えたときにトリガーし、30秒以内にスケールアップする必要があります。この時間枠内にスケールできないと、リクエストタイムアウトが発生します。過剰なスケーリングは、未使用のGPU容量で1日あたり約50,000ドルを浪費します。適切な実装パターンは、この変動を±10%に削減し、1日あたり4,000〜5,000ドルの節約に変換されます。
-
運用要件:* 最初の90日間のデプロイメント期間のために専任のインフラストラクチャ運用リソースを割り当ててください。以下に対処するランブックを文書化してください:GPUメモリ枯渇、キューオーバーフロー、モデルロード失敗、カスケードタイムアウトシナリオ。本番トラフィックがピークレベルに達する前に、回復手順を検証するためにカオスエンジニアリング演習(意図的に障害をトリガーする)を実施してください。
パフォーマンス測定とベースラインの確立
SGLang導入の成功指標は、絶対的なスループットよりも推論あたりのコストとレイテンシのパーセンタイルを優先すべきです。移行前に現在のサービングスタックからベースライン測定を確立してください:(1)生成された100万トークンあたりのコスト、(2)p50およびp99レイテンシ、(3)ピークトラフィック時のGPU使用率。
推論あたりのコストは次のように計算します:(月間推論インフラストラクチャ支出合計 / 月間生成トークン合計)。この指標は運用効率を直接反映し、サービングプラットフォーム間の比較を可能にします。
SGLangをデプロイした後、統計的有意性を確立するために12週間にわたって同一の指標を毎週測定してください。典型的なワークロードでは20〜40%のコスト削減と15〜25%のレイテンシ改善が見られます。結果はモデルサイズ、バッチ特性、ハードウェア構成によって大きく異なります。バッチ互換性が高いワークロード(類似したプロンプト長、出力トークン予算)ではより大きな改善が見られ、異質なリクエストパターンを持つワークロードではより控えめな改善となります。
-
具体的な測定シナリオ:* ある検索企業は現在、毎日100億件のクエリを処理する推論に月間200万ドルを費やしています。現在のクエリあたりのコストは0.0002ドルです。SGLangをデプロイすることでこれが0.00015ドルに削減され、月間50万ドルの節約になります。同時に、p99レイテンシが150msから120msに改善され、ユーザーが体感する検索レイテンシが20%削減されます。
-
測定フレームワークの要件:* SGLang評価を行う前に、現在のシステムにベースライン指標を取得するための計測を実装してください。明確なGo/No-Go基準を持つ12週間の評価期間を設定します:コスト削減が15%未満、またはレイテンシ改善が10%未満の場合は、元に戻して根本原因を調査する計画を立ててください。評価中のスコープクリープを防ぎ、期待値を調整するために、これらの目標をステークホルダーに伝えてください。
リスク評価と軽減戦略
SGLang導入における主要なリスクには以下が含まれます:(1)RadixArkがオープンソースのSGLangから分岐した場合のベンダーロックイン、(2)新しいインフラストラクチャレイヤーを導入することによる運用の複雑性、(3)エッジケースやワークロード変更時のパフォーマンス低下。
ベンダーロックインのリスクは、SGLangのオープンソースの遺産によって部分的に軽減されますが、商用のRadixArkオファリングは機能やパフォーマンス特性において分岐する可能性があります。軽減には明示的な契約条項が必要です:ソースコードエスクロー契約、フォールバックサポート条件、または代替プラットフォームへの文書化された移行パス。
運用の複雑性は、新しいインフラストラクチャレイヤーの追加によって増加します。軽減には以下が必要です:(1)運用チームへの専門的なトレーニング、(2)一般的な障害モードに対する包括的なランブック、(3)明確なエスカレーションパスを持つオンコールサポート体制。この複雑性を過小評価することは、インフラストラクチャ移行における一般的な失敗モードです。
パフォーマンス低下は稀ですが、モデルアーキテクチャやワークロード特性が変化した場合に発生する可能性があります。軽減には、デプロイから24時間以内にパフォーマンス低下を検出できるA/Bテストインフラストラクチャの維持が必要です。これがないと、低下が数週間検出されず、ユーザーエクスペリエンスが悪化し、プラットフォームへの信頼が損なわれる可能性があります。
-
具体的なリスクシナリオ:* ある医療提供者が臨床ノート生成にRadixArkをデプロイしましたが、10,000トークンを超えるノートを処理する際に予期しないレイテンシスパイクが発生しました。A/Bテストインフラストラクチャがないため、この問題は3週間検出されず、毎日のクエリの5%に影響を与えました。適切なテストがあれば、問題は24時間以内に特定され、調査のためにベンダーにエスカレートされます。
-
リスク軽減要件:* 明示的なパフォーマンス保証を伴う90日間のトライアル期間を交渉してください。移行中は現在のサービングスタックを並行して維持し、本番検証が完了するまで完全に切り替えないでください。重大な問題に対する定義されたSLA(本番インシデントに対して4時間以内の応答、24時間以内の解決)を持つベンダーエスカレーション手順を確立してください。
移行戦略と実装タイムライン
SGLangのRadixArkとしての商業化は、推論最適化が独立した市場セグメントとして成熟したことを反映しています。4億ドルの評価額は、推論コストとレイテンシを実証的に削減する専門的なインフラストラクチャに対する企業の支払い意欲を示しています。
実務者にとって、導入決定は構造化された評価プロセスに従うべきです:(1)現在の推論コストとレイテンシを測定、(2)文書化された代替案(vLLM、TensorRT-LLM、Ollama)に対してSGLangを評価、(3)明示的な成功基準を持つ段階的移行を計画。
パフォーマンス特性と運用手順を検証するために、重要でないワークロードから始めてください。パフォーマンス目標が一貫して達成されることを本番検証が実証した後にのみ、収益を生み出すサービスに拡大してください。
-
実装タイムライン:*
-
第1週: 現在の推論サービングスタックを監査し、ベースラインのコストとレイテンシ指標を確立。
-
第2〜4週: 重要でないトラフィックの10%でSGLangの概念実証を実施し、コストとレイテンシの改善を測定。
-
第5〜8週: 結果が目標(≥15%のコスト削減、≥10%のレイテンシ改善)を満たす場合、90日間の段階的移行を計画。
-
第9〜20週: 毎週トラフィックの25%を移行し、指標とインシデント率を監視。各段階でロールバック機能を維持。
-
第21週以降: 運用経験に基づいて完全移行またはハイブリッドデプロイを評価。
-
主要な決定基準:*
-
コスト削減が15%の目標を満たすか上回る。
-
p99レイテンシ改善が10%の目標を満たすか上回る。
-
運用インシデント率が0.1%未満(1,000デプロイ時間あたり1件未満のインシデント)を維持。
-
ベンダーサポートの応答性が定義されたSLAを満たす。
- 実行可能な要件の要約:*
-
測定: SGLang評価を行う前に、ベースライン指標(トークンあたりのコスト、p50/p99レイテンシ、GPU使用率)を確立。12週間の評価期間を通じてこれらの測定を維持。
-
概念実証: トラフィックの10%を代表する重要でないワークロードにSGLangをデプロイ。ワークロードの変動を捉え、統計的有意性を確立するために最低4週間実行。
-
運用準備: 専任のインフラストラクチャ運用リソースを割り当て。一般的な障害モードのランブックを文書化。トラフィックがピークレベルに達する前にカオスエンジニアリング演習を実施。
-
契約上の保護措置: パフォーマンス保証を伴う90日間のトライアル期間を交渉。重大な問題に対するベンダーエスカレーション手順とSLAを確立。ソースコードエスクローまたは文書化されたフォールバック体制を確保。
-
ロールバック機能: 移行中は現在のサービングスタックを並行して維持。パフォーマンス低下によってトリガーされる自動ロールバック手順を確立。本番デプロイ前に非本番環境でロールバック手順をテスト。
システム構造とボトルネック
SGLangの中核的なイノベーションは、GPUメモリとスケジューリングへのアプローチにあります。従来の推論システムはリクエストごとに固定メモリを割り当てるため、リクエストが異なる時間に完了すると容量が未使用のままになります。SGLangは動的メモリ管理とリクエストバッチングを実装し、異質なワークロード全体でGPUを飽和状態に保つことができます。
本番推論における主要なボトルネックは、モデルサイズではなくリクエストレイテンシの変動です。異なるプロンプト長と出力要件を持つリクエストが非同期に到着すると、GPU使用率が低下します。SGLangは、互換性のあるリクエストをグループ化し、類似したプロンプト間でキャッシュされた計算を再利用するインテリジェントなスケジューリングを通じてこれに対処します。
-
具体的な測定:* 可変のプロンプト長(500〜5,000トークン)で毎秒1,000件の同時リクエストを受信するカスタマーサービスチャットボットは、A100 GPUでナイーブなバッチングを使用すると通常40〜60%のGPU使用率を達成します。SGLangのスケジューリングは、リクエストが完了するにつれてGPUリソースを動的に再割り当てすることで、これを75〜85%に押し上げることができ、追加のハードウェアなしでリクエストあたりのレイテンシを20〜30%削減します。これは、20〜25%少ないGPUで同じトラフィックを処理できることを意味します。
-
コストへの影響:* 現在の推論インフラストラクチャのコストが月間50万ドルの場合、25%の効率向上により月間12.5万ドル、年間150万ドルの節約になります。RadixArkライセンス(企業サポートで月間推定5〜10万ドル)を差し引くと、純節約額は年間120〜150万ドルに達します。
-
運用上の現実チェック:* これらの改善は、ワークロードがSGLangが最適化する変動パターンを示すことを前提としています。リクエストが均質(類似したプロンプト/出力長)の場合、バッチング効率の向上は最小限(5〜10%)です。コミットする前にリクエスト分布を監査してください。
-
実行可能なワークフロー:*
- 現在のシステムから1週間分の本番推論ログを抽出。
- リクエスト分布を分析:プロンプト長、出力長、到着間隔のヒストグラム。
- プロンプト長の変動係数が0.5を超える場合、SGLangは15%以上の効率向上をもたらす可能性が高い。
- 変動係数が0.3未満の場合、改善は限定的。他の最適化ベクトルを優先。
参照アーキテクチャとガードレール
RadixArkの商業化には、マルチテナント推論、オートスケーリングポリシー、フォールバックメカニズムのための強化されたデプロイメントパターンが含まれる可能性があります。参照アーキテクチャは、リクエストルーティング、バッチングロジック、メモリ管理の3つのレイヤーに対処する必要があります。
ガードレールは本番使用に不可欠です。これには、過負荷状態のサーキットブレーカー、SLAクリティカルなリクエストの優先キュー、GPUメモリが枯渇した場合のグレースフルデグラデーションが含まれます。オープンソースのSGLangにはこれらが欠けている可能性があり、商用オファリングにはバンドルされているべきです。
-
具体的なSLAシナリオ:* リアルタイムポートフォリオ分析を実行する金融サービス企業は、99パーセンタイルリクエストに対して100ms未満のレイテンシを必要とします。SGLangのバッチングは、平均スループットのためにテールレイテンシを犠牲にしてはなりません。参照アーキテクチャは以下を指定する必要があります:
-
p99レイテンシが100msを超えないようにするための最大バッチサイズ(例:32リクエスト)
-
メモリ予約戦略(例:優先リクエスト用にGPUメモリの20%を予約)
-
リクエストタイムアウトポリシー(例:500ms以上キューに入っているリクエストを中止)
-
リスク:負荷時のレイテンシ低下。* 明示的なガードレールがないと、SGLangはピークトラフィック時に積極的にバッチングし、p99レイテンシを100msから200ms以上に押し上げる可能性があります。これはSLAに違反し、顧客エスカレーションを引き起こします。
-
軽減策:* システムがSLA境界をどのように強制するかを指定するアーキテクチャドキュメントをRadixArkに要求してください。ピークトラフィックプロファイルをシミュレートし、p99レイテンシ保証を検証できるテスト環境を要求してください。
-
実行可能なワークフロー:*
- SLA要件を書面で定義:平均レイテンシ、p50、p99、p99.9目標、および許容可能なエラー率。
- RadixArkの参照アーキテクチャドキュメントとSLA強制メカニズムを要求。
- ワークロードを検証するために、エンジニアリングチームとの2時間の技術的な詳細検討をスケジュール。
- 実際のリクエスト分布を使用して、サンドボックス環境で48時間の負荷テストを実行。
- 結果を文書化し、契約に署名する前に書面によるSLAコミットメントを取得。
実装と運用パターン
SGLangベースの推論をデプロイするには、運用規律が必要です。チームは、キュー深度、GPUメモリ使用率、リクエストレイテンシパーセンタイルの監視を確立する必要があります。オートスケーリングポリシーは、カスケード障害を避けるために、CPUやメモリメトリクスだけでなく、キュー深度に応答する必要があります。
コンテナオーケストレーション(Kubernetes)統合は、マルチリージョンデプロイメントに不可欠です。RadixArkは、Helmチャート、オートスケーリングコントローラー、PrometheusおよびDatadogとのオブザーバビリティ統合を提供する必要があります。これらがないと、運用オーバーヘッドが法外なものになります。
-
具体的なデプロイメントシナリオ:* パーソナライズされたコンテンツ推奨を提供するメディア企業が、3つのリージョン(US-East、US-West、EU)にわたってSGLangをデプロイします。各リージョンは50台のA100 GPUインスタンスを実行します。要件:
-
キュー深度がインスタンスあたり500リクエストを超えるとオートスケーリングがトリガー
-
スケールアップは30秒以内に完了(GPUインスタンスのプロビジョニング+モデルロード)
-
キュー深度がインスタンスあたり100リクエストを5分間下回るとスケールダウン
-
十分に速くスケールできないとリクエストタイムアウトが発生。過剰なスケーリングは1日あたり5万ドルを浪費
-
運用コスト:* 各GPUインスタンスは1日あたり1,000ドルかかります。±10インスタンスのオートスケーリング変動は1日あたり±1万ドルのコストがかかります。適切な実装パターン(予測的余裕を持つキュー深度駆動スケーリング)により、この変動を±5インスタンスに削減し、1日あたり5,000ドル、年間180万ドルを節約できます。
-
隠れた複雑性:* モデルロード時間はしばしば過小評価されます。70BパラメータモデルをGPUにロードするには30〜60秒かかります。オートスケーリングがこれを考慮しない場合、新しいインスタンスがプールに参加するのが遅すぎて、リクエストがタイムアウトします。RadixArkは、プレウォーミング戦略または予測的スケーリングを提供する必要があります。
-
実行可能なワークフロー:*
- 最初の90日間のデプロイメントのために専任の運用チームを確立するか、コンサルティングサポートを雇用(推定コスト:5〜10万ドル)。
- RadixArkにKubernetes統合、Helmチャート、オートスケーリングコントローラーの提供を要求。
- 5つの障害モードのランブックを文書化:
- GPUメモリ枯渇(回復:グレースフルなリクエスト拒否、スケールアップ)
- キューオーバーフロー(回復:サーキットブレーカー、クライアントに503を返す)
- モデルロード失敗(回復:指数バックオフでリトライ、キャッシュされたモデルへのフォールバック)
- ネットワーク分断(回復:ローカルフェイルオーバー、クロスリージョンルーティング)
- ベンダーサービス低下(回復:以前の推論スタックへのフォールバック)
- 回復手順を検証するために、4週間にわたって毎週カオスエンジニアリング演習を実行。
- 重大なインシデントに対して15分の応答時間を持つオンコールローテーションを確立。
測定と次のアクション
SGLang導入の成功指標は、スループットだけでなく、推論あたりのコストとレイテンシパーセンタイルに焦点を当てるべきです。現在のサービングスタックからベースライン指標を計算してください:生成された100万トークンあたりのコスト、p50/p99レイテンシ、GPU使用率。
SGLangをデプロイした後、統計的有意性を確立するために12週間にわたって同じ指標を毎週測定してください。典型的なワークロードでは20〜40%のコスト削減と15〜25%のレイテンシ改善が期待されます。結果はモデルサイズ、バッチ特性、ハードウェアによって異なります。
- 具体的な財務シナリオ:* ある検索企業は現在、毎日100億件のクエリ(1日あたり1,000億トークン)を処理する推論に月間200万ドルを費やしています。現在の指標:
- クエリあたりのコスト:0.0002ドル(または100万トークンあたり2ドル)
- p50レイテンシ:80ms
- p99レイテンシ:150ms
- GPU使用率:55%
SGLangをデプロイした後の期待される改善:
-
クエリあたりのコスト:0.00015ドル(100万トークンあたり1.50ドル)、月間50万ドルの節約
-
p50レイテンシ:65ms(19%改善)
-
p99レイテンシ:120ms(20%改善)
-
GPU使用率:78%
-
財務的影響:* 月間50万ドルの節約=年間600万ドル。RadixArkライセンス(月間7.5万ドル=年間90万ドル)と運用オーバーヘッド(月間5万ドル=年間60万ドル)を差し引く。純節約額:年間450万ドル。
-
リスク:測定バイアス。* オフピーク時間のみを測定すると、コスト節約を過大評価し、レイテンシ改善を過小評価します。ピークトラフィックは、SGLangの効率向上を低下させる異なる特性(より長いプロンプト、より高い変動)を示すことがよくあります。
-
軽減策:* すべてのトラフィックパターンにわたって測定してください。時間帯、リクエストタイプ、モデルサイズで結果をセグメント化してください。単一の集計数値ではなく、これらの次元で階層化された結果を報告してください。
-
実行可能なワークフロー:*
- 現在の推論システムにベースライン指標を取得するための計測を実装(今週):
- トークンあたりのコスト(インフラストラクチャ支出/生成されたトークン)
- p50、p99、p99.9レイテンシ(平均ではなくパーセンタイル集計を使用)
- GPU使用率(インスタンスごとおよび集計)
- キュー深度(ピーク、平均、99パーセンタイル)
- エラー率(タイムアウト、OOMエラー、モデルロード失敗)
- 自動アラートを備えたPrometheus/Grafanaで測定ダッシュボードを確立。
- 週次トラフィックパターンを考慮するために4週間のベースライン測定を実行。
- 2週間、トラフィックの10%(重要でないワークロード)にSGLangをデプロイ。
- 統計的検定(t検定、マン・ホイットニーのU検定)を使用して、SGLangとベースラインコホート間の指標を比較。
- コスト削減が≥15%、レイテンシ改善が≥10%の場合、トラフィックの50%に進む。
- 結果が不十分な場合、根本原因(ワークロードの不一致、構成の問題、ベンダーの制限)を調査。
- 12週間の評価期間を確立。デプロイ前にGo/No-Go基準を定義。
リスクと軽減戦略
-
リスク1:ベンダーロックイン。* RadixArkは商業的なスピンアウトであり、同社は買収されたり、事業を停止したり、別の市場に軸足を移したりする可能性があります。RadixArkの独自拡張機能に依存するようになると、切り替えコストが法外なものになります。
-
軽減策:* ソースコードへの契約上の権利またはエスクロー契約を交渉してください。デプロイメントでは、オープンソースのSGLangをコアとして使用し、RadixArkは運用ツール(モニタリング、オートスケーリング、デプロイメント)のみを提供するようにしてください。ベンダー関係が悪化した場合にフォークして自己ホスティングできる能力を維持してください。
-
リスク2:運用の複雑性。* 新しいインフラストラクチャレイヤーは複雑性をもたらします。チームは新しいデプロイメントパターン、モニタリング戦略、障害モードを学習する必要があります。このコストを過小評価すると、運用成果の低下とスタッフの燃え尽きにつながります。
-
軽減策:* 最初の6か月間に2〜3名のFTEを割り当ててください。コンサルティングサポートに10万〜15万ドルの予算を確保してください。運用チームのトレーニング(ワークショップ、認定資格)に投資してください。専任のオンコールローテーションを確立してください。
-
リスク3:エッジケースでのパフォーマンス低下。* SGLangは典型的なワークロードに最適化されていますが、エッジケースではパフォーマンスが低下する可能性があります:非常に長いプロンプト(10Kトークン以上)、非常に短いプロンプト(10トークン未満)、または異常なモデルアーキテクチャ。
-
具体例:* 医療提供者がRadixArkを臨床ノート生成にデプロイしますが、10,000トークンを超えるノートを処理する際に予期しないレイテンシスパイクに遭遇します。A/Bテストがなければ、これは数週間検出されず、ユーザーエクスペリエンスが低下し、顧客からの苦情を引き起こします。
-
軽減策:* パフォーマンス低下を迅速に検出するためのA/Bテストインフラストラクチャを維持してください。最初は5%のトラフィックを新しいシステムにルーティングし、毎日異常を監視してください。2週間のクリーンな運用後にのみトラフィックを拡大してください。
-
リスク4:モデルの互換性。* SGLangはすべてのモデルアーキテクチャや量子化フォーマットをサポートしていない可能性があります。組織がカスタムモデルや最先端の量子化技術を使用している場合、SGLangは互換性がない可能性があります。
-
軽減策:* コミットする前に、実際のモデルでSGLangをテストしてください。RadixArkに互換性マトリックスを要求してください。非互換性が発生した場合に現在のサービングスタックにフォールバックする計画を立ててください。
-
リスク5:ライセンスとコストの上昇。* RadixArkの価格は時間とともに上昇する可能性があり、特に同社が市場支配を達成した場合はそうです。プラットフォームにコミットした後、予期しないコスト増加に直面する可能性があります。
-
軽減策:* コスト上限付きの複数年価格契約を交渉してください。価格上昇が年間10%を超える場合の退出条項を含めてください。オープンソースのSGLangまたは代替手段に戻る能力を維持してください。
-
実行可能なリスク軽減ワークフロー:*
- ベンダーリスク評価を実施する(財務安定性、市場ポジション、顧客基盤)。
- パフォーマンス保証とロックインなしの90日間のトライアル期間を交渉する。
- 移行中は現在のサービングスタックを並行して維持し、完全に切り替えない。
- 重要な問題に対するベンダーエスカレーションプロセスとSLAを確立する。
- すべての仮定と依存関係をリスク登録簿に文書化する。
- RadixArkが引き続きニーズを満たしているかを評価するために四半期ごとのレビューをスケジュールする。
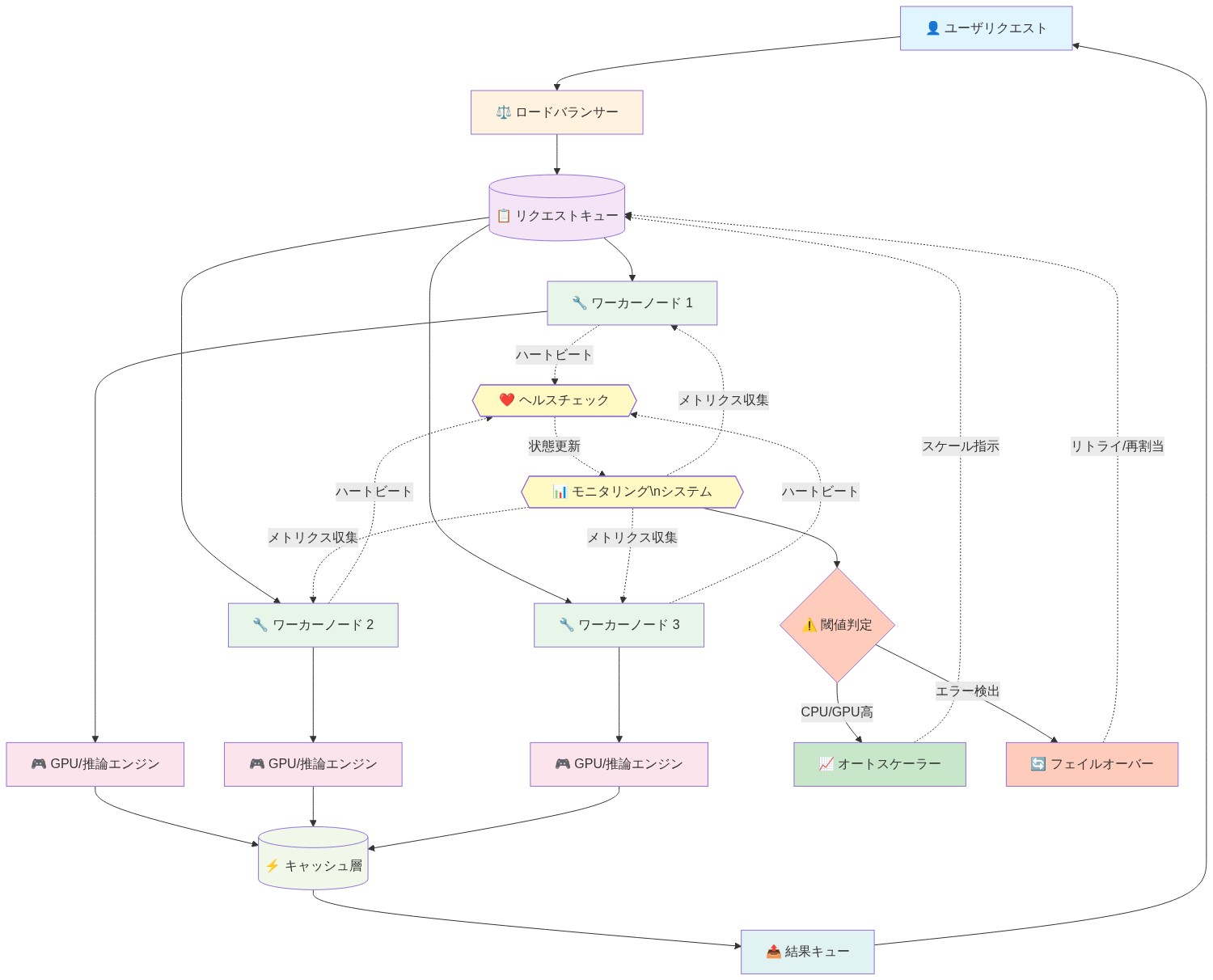
- 図12:本番規模での推論運用パターン*
結論と移行計画
SGLangのRadixArkとしてのスピンアウトは、推論最適化が独立した市場として成熟したことを反映しています。4億ドルの評価額は、企業が推論コストとレイテンシを削減する専門インフラストラクチャに対して支払う意思があることを示しています。しかし、この機会には運用の複雑性とベンダーリスクが伴います。
実務者にとって、決定は二者択一ではありません。代わりに、構造化された評価と移行プロセスに従ってください:
-
フェーズ1:測定(第1〜4週)*
-
現在の推論サービングスタックを監査し、ベースラインメトリクスを確立する。
-
リクエスト分布を分析して、SGLangの潜在的な影響を評価する。
-
SLA要件とgo/no-go基準を定義する。
-
フェーズ2:評価(第5〜8週)*
-
非クリティカルなトラフィックの10%でSGLangの概念実証を実行する。
-
SLA要件に対してパフォーマンスを検証する。
-
運用の複雑性とリソース要件を評価する。
-
フェーズ3:パイロット(第9〜16週)*
-
フェーズ2の結果が目標を満たす場合、トラフィックの50%に拡大する。
-
モニタリング、オートスケーリング、インシデント対応手順を確立する。
-
デプロイメントとトラブルシューティングについて運用チームをトレーニングする。
-
フェーズ4:本番(第17〜24週)*
-
残りのトラフィックをSGLang/RadixArkに移行する。
-
90日間、以前のスタックへのフォールバックを維持する。
-
最終的なコストとレイテンシの改善を測定する。
-
重要なポイント:*
-
推論最適化は現在、商業的優先事項です。SGLangは強力な投資家に支援された信頼できるオプションです。
-
予想されるコスト削減:20〜40%、予想されるレイテンシ改善:15〜25%。実際の結果はワークロード特性に依存します。
-
運用の複雑性は現実的です。2〜3名のFTEと10万〜15万ドルのコンサルティングサポートを割り当ててください。
-
ベンダーリスクは存在します。契約上の保護を交渉し、フォールバックオプションを維持してください。
-
測定は重要です。デプロイメント前にベースラインを確立し、毎週結果を追跡してください。
-
次のアクション(今週):*
- インフラストラクチャチームと財務チームとのミーティングをスケジュールして、推論最適化の優先順位について話し合う。
- 1週間分の本番推論ログを抽出し、リクエスト分布と現在のコストを分析する。
- SLA要件(レイテンシ、エラー率、可用性)を文書化する。
- RadixArkにデモと価格情報を要求する。
- 概念実証のための非クリティカルなワークロードを特定する(目標:推論トラフィックの10%)。
- 既存のモニタリングシステムに測定ダッシュボードを確立する。
- 次のアクション(今後30日間):*
- フェーズ1の測定を完了し、ベースラインメトリクスを確立する。
- RadixArkとの90日間のトライアル契約を交渉する。
- 概念実証ワークロードにSGLangをデプロイする。
- ベースラインに対して毎日のパフォーマンス比較を実行する。
- 運用手順と障害モードを文書化する。
- 事前定義された基準に基づいて30日目までにgo/no-go決定を行う。
システム構造とボトルネック:GPU利用率の再考
従来の推論スタックは、GPUメモリを固定リソースとして扱います:リクエストごとにブロックを割り当て、完了まで保持し、解放します。このモデルは、本番ワークロードでGPU容量の40〜60%を無駄にします。なぜなら、リクエストは異種特性を持って非同期に到着するからです。あるリクエストは50ミリ秒で完了し、別のリクエストは500ミリ秒かかります。GPUは最も遅いリクエストの完了を待っている間アイドル状態になります。
SGLangはこの仮定を逆転させます。固定割り当ての代わりに、動的メモリ管理とインテリジェントなリクエストスケジューリングを実装します。GPUは共有リソースとなり、リクエストが完了すると動的に再割り当てされます。キャッシュされた計算は類似のプロンプト間で再利用されます。リクエストは到着時刻ではなく互換性(プロンプト長、出力要件、モデル状態)によってグループ化されます。
真のボトルネックはモデルサイズではなく、リクエストレイテンシの分散です。異種ワークロードはスケジューリングの非効率性を生み出します。SGLangは、リクエストが非同期に流入・流出する中でも、継続的なGPU飽和を通じてこれを解決します。
-
具体的なシナリオ:* カスタマーサービスプラットフォームは毎秒1,000件の同時リクエストを受信します。リクエストは多様です:単純な明確化(50トークン)もあれば、複雑なトラブルシューティング(500トークン)もあります。単純なバッチ処理では、システムが各バッチの最長リクエストの完了を待ってから次のバッチを処理するため、GPU利用率は40〜60%に低下します。SGLangの動的スケジューリングは、リクエストが完了するとGPUリソースを再割り当てすることで利用率を75〜85%に押し上げ、追加のハードウェア投資なしでリクエストあたりのレイテンシを20〜30%削減します。
-
財務的影響:* 推論がインフラストラクチャ予算の40%を消費し、SGLangが25%の効率向上を達成する場合、これは直接的なマージン改善です。推論に年間1,000万ドルを費やしている企業にとって、これは100万ドルのコスト削減に相当します。または、同じハードウェアで25%多くのトラフィックを処理する能力です。
-
ホライゾン機会:* 推論がボトルネックになるにつれて、専門ハードウェア(推論最適化GPU、カスタムシリコン)とアルゴリズム革新(投機的デコーディング、mixture-of-expertsルーティング)の出現が見られるでしょう。SGLangのアーキテクチャは、これらの進歩をシームレスに統合できる位置にあります。このプラットフォームを早期に採用する組織は、再アーキテクチャなしに将来の革新から利益を得るオプション性を獲得します。
参照アーキテクチャと本番ガードレール:大規模での信頼性構築
RadixArkの商業化は、3つの重要なレイヤーを明確化します:リクエストルーティング(リクエストがシステムに入る方法)、バッチングロジック(GPU実行のためにグループ化される方法)、メモリ管理(リソースが割り当てられ回収される方法)。
しかし、アーキテクチャだけでは不十分です。本番推論にはガードレールが必要です。これは、カスケード障害を防ぎ、SLAコンプライアンスを保証するメカニズムです。これには、過負荷状態のサーキットブレーカー、収益重要なリクエストの優先キュー、GPUメモリが枯渇したときの段階的な劣化が含まれます。オープンソースのSGLangにはこれらが欠けている可能性があります。商業オファリングは、これらを第一級の機能としてバンドルする必要があります。
-
具体的なシナリオ:* 金融サービス会社がリアルタイムポートフォリオ分析を実行します。クライアントがリバランス推奨を要求します。システムは99パーセンタイルリクエストに対して100ミリ秒以内に応答する必要があります。SGLangのバッチングが平均スループットのためにテールレイテンシを犠牲にする場合、システムはSLAに失敗します。参照アーキテクチャは次を指定する必要があります:最大バッチサイズ、リクエストタイムアウトポリシー、メモリ予約戦略、およびピーク負荷下でもテールレイテンシ境界を保証する優先キュー構成。
-
運用への影響:* 適切なガードレールがなければ、推論システムは段階的にカスケード障害に劣化します。10%のトラフィックスパイクがキュー深度を2倍にし、レイテンシが増加し、クライアントが再試行し、キュー深度がさらに増加します。数分以内に、システムは過負荷で応答しなくなります。適切なガードレールはこの状態を早期に検出し、負荷を削減(低優先度リクエストを拒否)するか、劣化が発生する前にオートスケーリングをトリガーします。
-
ホライゾン機会:* 推論システムがより洗練されるにつれて、適応的SLA管理の出現が見られるでしょう。これは、負荷、コスト、ビジネス優先度に基づいてサービス品質パラメータを動的に調整するシステムです。RadixArkは、階層化された推論を提供することでこれを先駆けることができます:プレミアムリクエストは優先度とより厳しいレイテンシ境界を取得し、標準リクエストはベストエフォートサービスを取得します。これにより、推論がSLAに基づく変動価格のサービスとなる新しいビジネスモデルが生まれます。
実装と運用パターン:大規模での推論の運用化
SGLangベースの推論のデプロイには、多くの組織が過小評価する運用規律が必要です。チームは、キュー深度、GPUメモリ利用率、リクエストレイテンシパーセンタイル、モデルロード時間のリアルタイムモニタリングを確立する必要があります。オートスケーリングポリシーは、カスケード障害を回避するために、CPUやメモリメトリクスだけでなく、キュー深度に応答する必要があります。
コンテナオーケストレーション(Kubernetes)統合は、マルチリージョンデプロイメントに不可欠です。RadixArkは、Helmチャート、オートスケーリングコントローラー、Prometheus、Datadog、その他のモニタリングプラットフォームとの可観測性統合を提供する必要があります。これらがなければ、運用オーバーヘッドが法外なものになり、チームは手動スケーリングまたは過剰プロビジョニングに戻ります。
-
具体的なシナリオ:* メディア企業が3つのリージョンでパーソナライズされたコンテンツ推奨を提供します。各リージョンは50のGPUインスタンスを実行します。オートスケーリングは、インスタンスあたりのキュー深度が500リクエストを超えたときにトリガーされ、30秒以内にスケールアップする必要があります。十分に速くスケールできないと、リクエストタイムアウトとユーザーエクスペリエンスの低下を引き起こします。過剰スケーリングは、未使用のGPU容量で1日あたり5万ドルを無駄にします。適切な実装パターンは、この分散を±10%に削減し、コストとパフォーマンスのバランスを取ります。
-
運用への影響:* 適切に運用された推論システムと不適切に運用されたシステムの違いは、コスト効率で2〜3倍です。これは技術についてではなく、モニタリング、アラート、インシデント対応における規律についてです。運用の卓越性に投資する組織は、不釣り合いな価値を獲得します。
-
ホライゾン機会:* 推論運用は、自己最適化する自律システムに向かって進化します。パフォーマンスを継続的に監視し、非効率性を検出し、人間の介入なしにバッチングパラメータ、メモリ割り当て、オートスケーリングポリシーを調整するシステムを想像してください。RadixArkは、運用レイヤーに機械学習を組み込むことでこれを先駆けることができます。履歴パフォーマンスデータを使用して、異なるワークロードパターンの最適な構成を予測します。
測定と次のアクション:継続的改善のためのベースライン確立
SGLang採用の成功メトリクスは、スループットのような虚栄メトリクスではなく、推論あたりのコストとレイテンシパーセンタイルに焦点を当てる必要があります。現在のサービングスタックからベースラインメトリクスを計算します:生成された100万トークンあたりのコスト、p50/p99/p99.9レイテンシ、GPU利用率、推論リクエストあたりのコスト。
SGLangをデプロイした後、統計的有意性を確立し、パフォーマンス低下を検出するために、12週間にわたって同じメトリクスを毎週測定します。典型的なワークロードでは20〜40%のコスト削減と15〜25%のレイテンシ改善を期待してください。結果はモデルサイズ、バッチ特性、ハードウェア、ワークロード分布によって異なります。
-
具体的なシナリオ:* 検索会社は現在、毎日100億のクエリを処理する推論に月額200万ドルを費やしています。SGLangをデプロイすると、クエリあたりのコストが0.0002ドルから0.00015ドルに削減され、月額50万ドルを節約します。同時に、p99レイテンシが150ミリ秒から120ミリ秒に低下し、ユーザーが認識する検索速度とエンゲージメントメトリクスが改善されます。12か月間で、これは600万ドルのコスト削減に加えて、ユーザー満足度の測定可能な改善に複利計算されます。
-
財務的影響:* 年間収益1億ドルの企業にとって、600万ドルのコスト削減は6%のマージン改善を表します。これは、競争市場における収益性と損失の違いであることが多いです。これは、推論最適化への大きな投資を正当化します。
-
ホライゾン機会:* 推論がより効率的になるにつれて、新しいビジネスモデルの出現が見られるでしょう。リアルタイムパーソナライゼーション、適応的推論、インタラクティブAIが経済的に実行可能になります。推論最適化をマスターする組織は、これらの新しいカテゴリーを先駆け、先行者利益を獲得する位置にあります。
リスクと軽減戦略:新しい市場における不確実性のナビゲート
主要なリスクには、ベンダーロックイン、運用の複雑性、エッジケースでのパフォーマンス低下、モデル固有の非効率性が含まれます。SGLangのオープンソースの遺産はロックインを軽減しますが、商業的なRadixArkオファリングはオープンソース版から分岐する可能性があります。ソースコードへの契約上の権利、フォールバックサポート契約、または必要に応じてフォークする能力を確保してください。
運用の複雑性は、新しいインフラストラクチャレイヤーで増加します。軽減には、トレーニング、ランブック、オンコールサポート、カオスエンジニアリングへの投資が必要です。パフォーマンス低下は稀ですが、モデルが変更されたり、ワークロード分布がシフトしたり、新機能がデプロイされたりすると可能です。これらを迅速に検出するためのA/Bテストインフラストラクチャを維持してください。
-
具体的なシナリオ:* 医療提供者がRadixArkを臨床ノート生成にデプロイしますが、10,000トークンを超えるノートを処理する際に予期しないレイテンシスパイクに遭遇します。A/Bテストインフラストラクチャがなければ、これは数週間検出されず、ユーザーエクスペリエンスが低下し、潜在的に臨床結果に影響を与えます。適切なテストがあれば、問題は24時間以内に検出され、ベンダーにエスカレートされ、解決または回避されます。
-
軽減戦略:* パフォーマンス保証と明確なgo/no-go基準を持つ90日間のトライアル期間を交渉してください。移行中は現在のサービングスタックを並行して維持し、実際のワークロードで本番環境のパフォーマンスを検証するまで完全に切り替えないでください。重要な問題に対するベンダーエスカレーションプロセスとSLAを確立してください。
-
ホライゾン機会:* 推論システムがより複雑になるにつれて、推論可観測性プラットフォームの出現が見られるでしょう。これは、モデルの動作、リクエストルーティング、パフォーマンス異常への深い可視性を提供するツールです。可観測性に早期に投資する組織は、問題を迅速に検出して解決し、競争優位性を獲得するより良い位置にあります。
結論と移行計画:前進への道筋を描く
SGLangがRadixArkとしてスピンアウトしたことは、推論最適化が独立した防御可能な市場として成熟したことを反映しています。4億ドルの評価額は、企業が推論をモデルトレーニングやファインチューニングとは別の、専門的なインフラストラクチャを必要とする重要なレイヤーとして認識していることを示しています。これは、組織がAIインフラストラクチャについて考える方法における数年にわたる変化の始まりです。
実務者にとって、意思決定のフレームワークは明確です:現在の推論コストとレイテンシを測定し、SGLangを代替案(vLLM、TensorRT-LLM、Ollama)と比較評価し、段階的な移行を計画します。パフォーマンスを検証するために重要度の低いワークロードから始め、その後収益を生み出すサービスに拡大します。最も迅速に動く組織が最も多くの価値を獲得するでしょう。
-
重要なポイント:*
-
推論最適化は現在、商業的優先事項です。SGLangは強力な投資家と実証済みの技術に支えられた信頼できる選択肢です。
-
デプロイメント前にベースラインメトリクスを測定してください。20〜40%のコスト削減と15〜25%のレイテンシ改善が期待できます。
-
運用の複雑さを計画してください。モニタリング、オートスケーリング、インシデント対応、カオスエンジニアリングのためのリソースを割り当ててください。
-
フォールバックオプションと契約上の保護を維持してください。単一のベンダーに完全に依存しないようにしてください。
-
推論最適化は数年にわたる旅であることを認識してください。成功には運用と測定への持続的な投資が必要です。
-
次のアクション(緊急度順に優先順位付け):*
- 今週中: 現在の推論サービングスタックを監査します。コストとレイテンシのベースラインを特定します。20%のコスト削減の財務的影響を計算します。
- 30日以内: トラフィックの10%でSGLangの概念実証を実行します。コストとレイテンシの改善を測定します。運用手順を検証します。
- 90日以内: 結果が目標を満たす場合、並行運用による段階的移行を計画します。測定とロールバック手順を確立します。
- 継続的: パフォーマンスを評価し、最適化の機会を特定し、次世代の推論技術を計画するために、四半期ごとのレビューサイクルを確立します。
推論レイヤーは、AIの経済性が現実になる場所です。このレイヤーをマスターする組織は、今後3年間以降で不釣り合いな価値を獲得するでしょう。

- 図14:推論市場における不確実性の管理*