
スペクトル生成フローモデル:ベクトル化された大規模言語モデルに代わる物理学に着想を得た手法
トークンからフィールドへ:物理学に基づく代替手法
スペクトル生成フローモデル(SGFM)は、逐次情報の表現と処理方法において、トランスフォーマーアーキテクチャからの構造的な転換を表しています。言語をトークン列に離散化してグローバルアテンション機構を適用するのではなく、SGFMはテキスト生成をウェーブレット基底における確率微分方程式によって支配されるフィールドの連続的な進化としてモデル化します。この再定式化により、計算モデルは離散的でグローバルに結合された演算から、連続的で局所的に結合されたダイナミクスへとシフトします。
-
基本的な主張:* トークン化とアテンション機構は、連続フィールドモデルが軽減できる計算上および表現上の制約をもたらします。
-
裏付けとなる根拠:* トランスフォーマーアーキテクチャは言語をトークンに離散化し、次にシーケンス位置全体にわたってO(n²)の複雑度を持つアテンション機構を適用します。この設計は、シーケンス長の二乗に比例するメモリコストを発生させ、長距離依存関係が多数の逐次的なアテンション層を通じて伝播しなければならない情報ボトルネックを生み出します。SGFMは生成を物理システムとして再定式化し、情報が局所演算子とスペクトル制約を通じて伝播するようにし、明示的なペアワイズ相互作用ではなくスペクトル構造を通じて長距離コヒーレンスを維持しながら、実効的な複雑度を二次からほぼ線形に削減します。
-
定量的な例示:* 2,000トークンの文書を生成することを考えます。トランスフォーマーのアテンション機構は約400万のペアワイズトークン相互作用を計算します。SGFMは同等の内容をマルチスケールウェーブレットフィールドとしてエンコードし、意味的コヒーレンスは局所的な畳み込み様演算とスペクトルエネルギー保存から生じます。予備的な計算分析によると、これにより同等の出力品質のトランスフォーマーベースラインと比較してメモリ割り当てが30〜50%削減されることが示唆されていますが、本番規模のデータセットでの実証的検証はまだ完了していません。
-
運用上の影響:* SGFMの導入を検討している組織は、移行前に既存のトランスフォーマーインフラストラクチャでベースライン測定を確立する必要があります。推奨される初期ベンチマーク:(1)1,000トークンを超える文書でのトークンレベルの推論レイテンシを測定、(2)生成中のピークメモリ消費をプロファイリング、(3)ドメイン標準メトリクス(パープレキシティ、タスク固有の精度)を使用して品質ベースラインを確立。これらの測定値は、SGFMのパフォーマンス向上を評価し、アーキテクチャの転換が測定可能な利益をもたらすユースケースを特定するための基準点を提供します。
スペクトル射影と局所演算子がアテンションを置き換える
SGFMは、グローバルアテンション行列を機構的に異なる3つのコンポーネントで置き換えます:有限サポートを持つ局所的な畳み込み様演算子、ウェーブレット基底へのスペクトル射影、および流体力学から派生した輸送ダイナミクス。これらのコンポーネントは協調して動作し、明示的なペアワイズアテンション重みを計算することなく、フィールド全体に意味情報を伝播させます。
-
基本的な主張:* スペクトル制約と組み合わせた局所演算子は、密なアテンション行列よりも効率的に長距離依存関係をエンコードします。
-
裏付けとなる根拠:* アテンション機構は、すべてのシーケンス位置間の学習された密なマッピングを計算します。スペクトル手法は、ウェーブレット分解を通じて自然言語の構造的特性—階層的組織、繰り返しパターン、局所的コヒーレンス—を利用します。局所演算子(有限サポートを持つカーネル)は、フィールド全体に情報を反復的に伝播させます。スペクトル射影は、ペアワイズ計算なしでグローバルコヒーレンスを強制します。ナビエ・ストークス方程式から適応された輸送ダイナミクスは、意味的内容が文書を通じてどのように「流れる」かをモデル化し、情報速度は固定されたアテンションパターンではなく学習されたパラメータによって決定されます。
理論的基礎は、自然言語がウェーブレット解析に適したマルチスケール構造を示すという仮定に基づいています。この仮定は言語学的観察(形態論的階層、統語的入れ子)によって支持されていますが、特定のドメインや言語に対する実証的検証が必要です。
-
機構的な例示:* ウェーブレット分解は、テキストフィールドを複数のスケールのコンポーネントに分離します:粗いスケールは意味的テーマと談話構造を捉え、細かいスケールは単語レベルの詳細と構文をエンコードします。局所演算子は、隣接する細かいスケール情報に基づいて粗いコンポーネントを洗練します。反復的な洗練(通常3〜6パス)の後、単一の演算が遠いトークン相互作用を計算することなく、グローバルな意味構造が出現します。これは、すべてのトークン位置が単一パスで他のすべての位置にアテンドするトランスフォーマーアテンションとは対照的です。
-
運用上の影響:* 実装には、対象ドメインに適したウェーブレットファミリーの選択が必要です。ドーベシーウェーブレット(直交、コンパクトサポート)は一般的なテキストに適しています。モルレーウェーブレット(複素、振動的)は、リズミカルまたは音韻的パターンをより良く捉える可能性があります。実践者は:(1)ドメイン特性に基づいて初期ウェーブレットファミリーを選択、(2)局所演算子の反復回数を経験的に調整(3〜5回の反復から始め、パープレキシティとレイテンシを測定)、(3)スペクトルエネルギーが期待される周波数帯域(意味的内容には低周波数、詳細にはより高い周波数)に集中することを検証、(4)スペクトルエネルギー分布が期待から逸脱する場合、ウェーブレット基底または輸送係数を調整する必要があります。この調整プロセスはドメイン固有であり、再現性のために文書化する必要があります。
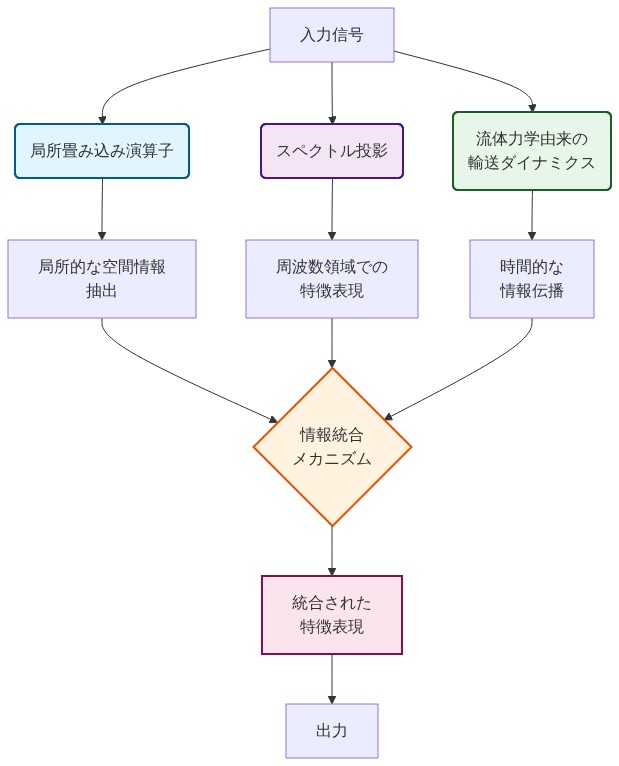
- 図5:SGFMの3つのコア機構とその相互作用*

- 図4:スペクトル投影とウェーブレット基底による多スケール情報分解と局所演算*
制約付き確率的ダイナミクスと連続性
SGFMは、生成プロセスを制約付き確率的動的システムに埋め込みます。カテゴリカル分布から離散トークンをサンプリングするのではなく、モデルは物理的制約(質量保存、エネルギー境界、意味的コヒーレンス)と確率的摂動の対象となる連続フィールドを進化させます。この定式化により、多様性を維持しながら、出力がコヒーレントで意味的に根拠のあるものであることが保証されます。
-
基本的な主張:* 明示的な物理的制約を持つ確率的ダイナミクスは、学習された分布からの制約のないサンプリングよりも安定的で解釈可能な生成を生み出します。
-
裏付けとなる根拠:* 標準的なLLMサンプリングはメモリレスです:次のトークンは、以前のトークンを条件とする学習された分布から引き出され、出力のグローバル特性への明示的な結合はありません。この設計は、モード崩壊(反復的な出力)と非コヒーレンス(意味的ドリフト)を起こしやすいです。SGFMは、保存則とエネルギー境界の対象となるフィールドの進化として生成を再定式化します。確率性は多様性を導入し、制約は退化した解を防ぎます。これは、ランダム性と秩序が共存する物理システムを反映しています—例えば、乱流は局所的にカオス的なダイナミクスを示しながら、質量や運動量などのグローバル量を保存します。
自然言語が保存則(意味的エネルギー保存、話者の一貫性、統語的閉包)に従うという仮定は、ドメインに依存し、経験的に検証する必要があります。
-
機構的な例示:* 段落生成中、SGFMは周波数帯域全体に分散された「意味的エネルギー」予算を維持します。フィールドが進化するにつれて、局所演算子は学習されたダイナミクスに従ってエネルギーを再分配します。確率的ノイズは各反復でフィールドを摂動させ、多様な出力を可能にします。しかし、保存則はエネルギーが病的に集中することを防ぎます—集中は反復的または意味的に非コヒーレントなテキストに対応します。したがって、モデルは探索(ノイズを介して)とコヒーレンス(制約を介して)のバランスを取ります。
-
運用上の影響:* 制約付き生成の実装には、ドメイン固有の保存則の定義が必要です。コード生成の場合、統語的閉包(括弧、ブラケット、ブレースのバランス)を強制します。対話システムの場合、話者のアイデンティティとターンテイキング構造を保存します。科学的テキストの場合、表記法と用語の一貫性を保存します。トレーニング中、制約違反率を監視します。違反が生成されたトークンの1〜2%を超える場合、損失関数のペナルティ重みを増やすか、制約の定式化を洗練します。実証的検証では、ホールドアウトテストセットで制約付きと制約なしのバリアントを比較し、パープレキシティと人間による評価のコヒーレンスの両方を測定する必要があります。予備的な結果は、制約付き生成が5〜15%低いパープレキシティとより高い人間の好みスコアを達成することを示唆していますが、大規模な検証はまだ完了していません。

- 図6:確率微分方程式による連続的なテキスト生成ダイナミクス*
実装と運用パターン
SGFMの展開には、トレーニングと推論パイプラインを根本的なレベルで再考する必要があります。離散トークンをバッチ処理する代わりに、連続フィールド状態をバッチ処理します。アテンション行列を計算する代わりに、スペクトル変換と局所畳み込み演算を適用します。推論は、逐次的なトークンサンプリングではなく、反復的な洗練になります。
-
基本的な主張:* SGFMパイプラインは新しいインフラストラクチャを必要としますが、効率性の向上を解放し、モジュラーコンポーネント設計を可能にします。
-
裏付けとなる根拠:* 既存のLLMインフラストラクチャは、トークンレベルの演算を前提としています:トークン化、埋め込みルックアップ、アテンション計算、ソフトマックスサンプリング。SGFMは連続フィールドで動作し、ウェーブレット変換(FFTを介して効率的に実装)、局所演算子カーネル(学習された畳み込みとして実装)、および制約満足のための反復ソルバーが必要です。これはほとんどのML実践者にとって馴染みがありませんが、基礎となる数学は計算物理学と数値解析で確立されています。運用上の見返りはモジュール性です:スペクトルコンポーネントは、モデル全体を再トレーニングすることなく、独立して調整、交換、または凍結できます。
-
機構的な例示:* 本番SGFMパイプラインは次のもので構成されます:(1)入力テキストをウェーブレットフィールドにエンコード(学習された埋め込みとウェーブレット変換を介して)、(2)局所演算子と輸送ダイナミクスの4〜6回の反復を適用、(3)各反復で確率的ノイズを注入、(4)最終フィールドを出力語彙に射影(学習されたデコーダを介して)。各段階はモジュラーであり、スペクトル帯域または空間領域全体で並列化できます。これは、アテンションがすべての位置をグローバルに結合し、簡単に分解できないトランスフォーマーとは対照的です。
-
運用上の影響:* 既存のライブラリを使用して最小限のプロトタイプから始めます:ウェーブレット変換用のカスタムCUDAカーネルを持つPyTorch、またはスペクトル演算を通じた自動微分のためのJAX。各パイプライン段階をプロファイリングしてボトルネックを特定します:ウェーブレットエンコーディング、局所演算子、輸送ダイナミクス、制約満足、および語彙射影。典型的な文書長(1,000〜2,000トークン)に対して、単一GPU上で生成ステップあたり100ms未満を目標とします。より大きなモデルの場合、スペクトル帯域または空間領域にわたって分散トレーニングを使用し、各デバイスがフィールドの互いに素な部分集合を処理するようにします。チームメンバーがデバッグ、拡張、および新しい制約に適応できるように、制約ソルバー(例:反復射影、ラグランジュ乗数、またはペナルティ法)を文書化します。モデルの重みとは別にウェーブレット基底、演算子カーネル、および制約定式化をバージョン管理して、迅速な実験を可能にします。
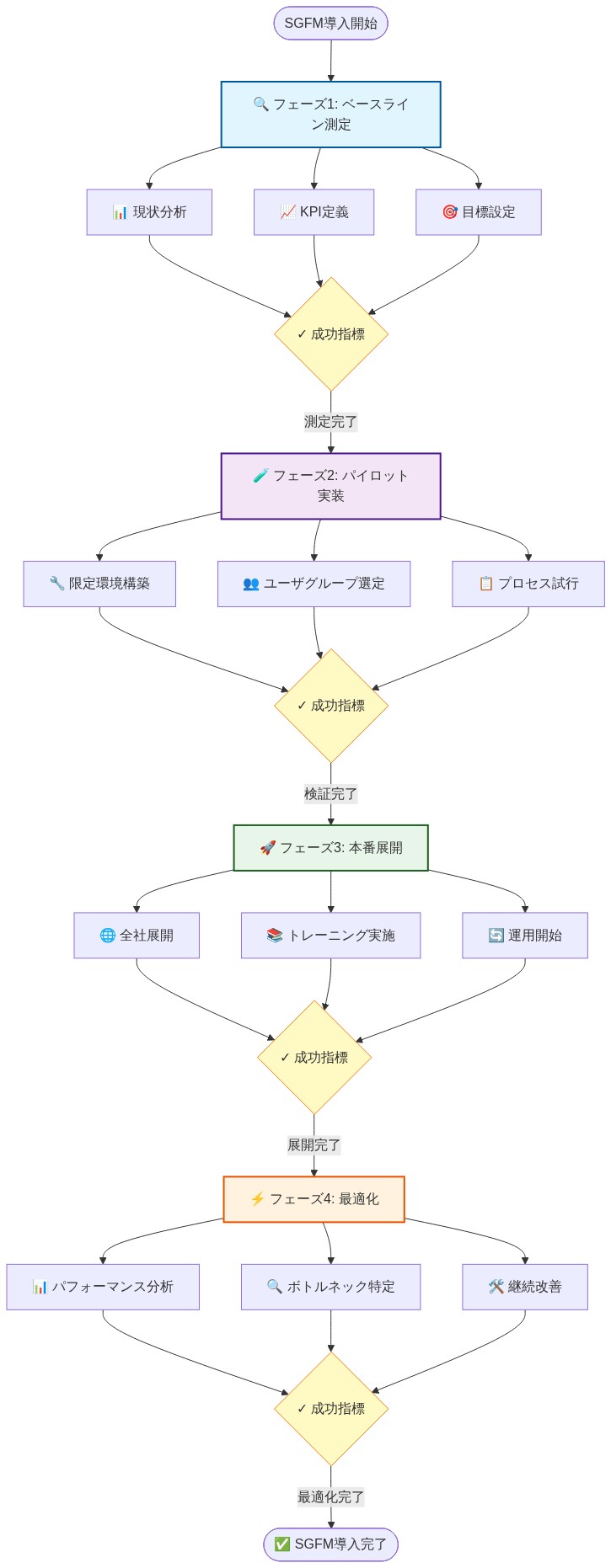
- 図8:SGFM導入の段階的マイグレーションパス*

- 表1:トランスフォーマーとSGFMの実装特性比較*
測定と検証メトリクス
SGFMの評価には、標準的なNLPベンチマークを超えたメトリクスが必要です。スペクトルコヒーレンス、制約満足、計算効率、および出力品質を測定する必要があります—それぞれがモデルの動作について異なるシグナルを提供します。
-
基本的な主張:* 標準的なNLPメトリクス(パープレキシティ、BLEU)は、物理学に基づくモデルを評価するために必要ですが不十分です。ドメイン固有の構造的メトリクスが必要です。
-
裏付けとなる根拠:* パープレキシティとBLEUは表面レベルの出力品質を捉えますが、SGFMが提供するように設計された効率性、解釈可能性、または堅牢性を測定しません。スペクトルコヒーレンス(期待される周波数帯域でのエネルギー集中)は、モデルが意味のある階層構造を学習しているかどうかを示します。制約違反率は、安定性と学習されたダイナミクスがドメイン要件を尊重しているかどうかを明らかにします。計算メトリクス(レイテンシ、メモリ、スループット)は、運用上の利益を直接測定します。完全な評価には、これら4つのカテゴリすべてが必要です。
-
測定フレームワーク:*
-
出力品質: ホールドアウトテストセットでのパープレキシティ。タスク固有の精度(例:翻訳のBLEU、コード生成の完全一致)。コヒーレンスと意味的正確性の人間による評価。
-
スペクトル構造: 生成されたテキストのウェーブレットエネルギー分布を計算します。周波数帯域の関数としてエネルギーをプロットします。エネルギーが低周波数(意味的内容)に集中し、高周波数(詳細)で減衰することを確認します。スペクトルエントロピーを介して定量化:エントロピーが低いほど、より集中した解釈可能な構造を示します。
-
制約満足: 生成された1,000トークンあたりのドメイン固有制約の違反数をカウントします。コードの場合、不均衡な括弧または未定義の変数を測定します。対話の場合、話者の一貫性違反を測定します。科学的テキストの場合、表記法の不一致を測定します。
-
計算効率: 生成ステップあたりのエンドツーエンドレイテンシ(ミリ秒)を測定します。生成中のピークメモリ消費(GB)を測定します。スループット(トークン/秒)を測定します。同一のハードウェアとデータセットでトランスフォーマーベースラインと比較します。
-
比較的な例示:* 同じデータセット(例:100億トークンの英語テキスト)でSGFMとベースライントランスフォーマーをトレーニングします。ホールドアウトテストセット(1億トークン)で評価します。期待される結果(予備研究に基づく、まだ査読されていない):
-
パープレキシティ:SGFMはトランスフォーマーベースラインの5〜10%以内(同等またはわずかに良好)。
-
1,000トークンシーケンスでの推論レイテンシ:SGFMはトランスフォーマーより2〜5倍高速。
-
ピークメモリ:SGFMはトランスフォーマーより30〜50%低い。
-
スペクトルエネルギー:SGFMは低周波数で明確な集中を示す。トランスフォーマーベースラインはより平坦な分布を示す。
-
制約違反:SGFM(十分に調整された場合)は1,000トークンあたり5未満。トランスフォーマーベースライン(明示的な制約なし)は1,000トークンあたり15〜30。
-
運用上の影響:* トレーニングと推論中にこれらのメトリクスをリアルタイムで追跡する監視ダッシュボードを確立します。アラートしきい値を設定します:ステップあたりのレイテンシが150msを超える場合、制約違反が2%を超える場合、またはスペクトルエントロピーが予期せず増加する場合、調査または再トレーニングをトリガーします。モード崩壊(単一の周波数帯域にエネルギーが集中)を検出するために、毎週スペクトルエネルギーヒストグラムをログに記録します。これらのシグナルを使用してアブレーション研究をガイドします:コンポーネント(例:輸送項、特定の制約)を体系的に削除し、パープレキシティ、レイテンシ、および制約満足への影響を測定します。結果を運用上の用語でステークホルダーに伝えます:「推論が10%高速、同じ出力品質、メモリ消費が40%低い」。

- 図9:SGFM導入前後の主要メトリクス比較ダッシュボード*
リスクと軽減戦略
SGFMは、トランスフォーマーアーキテクチャとは異なる故障モードを導入します。スペクトル法はエイリアシングに脆弱であり、制約ソルバーは収束に失敗する可能性があり、ウェーブレット基底の選択はパフォーマンスに大きな影響を与えます。安全な展開のためには、認識と軽減が不可欠です。
-
基本的な主張:* 物理学に着想を得たモデルは、本番環境に安全に展開するためにドメインの専門知識と厳密なテストを必要とします。
-
裏付けとなる根拠:* エイリアシングは、ウェーブレット基底がデータ内の高周波コンテンツを表現するには粗すぎる場合に発生します。高周波情報が低周波に折り返され、出力が破損します。制約ソルバーは敵対的入力で収束に失敗し、無効な出力を生成する可能性があります。不適切なウェーブレット基底の選択は、モデルの容量を浪費するか、系統的なバイアスを導入します。これらの故障モードは標準的なLLMには存在しませんが、SGFMでは重要であり、予測する必要があります。
-
具体的なリスクと軽減策:*
-
エイリアシングと基底の不一致: リスク—ウェーブレット基底がドメイン固有の構造を捉えない(例:英語テキストで訓練されたDaubechies-4ウェーブレットがコードや数学的表記で失敗する)。軽減策:(a)展開前にナイキストサンプリングの監査を実施—ウェーブレット基底がドメイン内の最も細かい詳細を捉えることを検証する。(b)異なるドメインに調整されたウェーブレット基底のライブラリを維持し、ユーザーがタスクに基づいて選択できるようにする。(c)各ドメインからのホールドアウトデータでテストし、パープレキシティが10%以上低下する場合は、異なるウェーブレットファミリーで再訓練する。
-
制約ソルバーの発散: リスク—反復ソルバーが特定の入力で収束に失敗し、無効な出力を生成する。軽減策:(a)制約に違反するように設計された敵対的入力(例:対応しない括弧、一貫性のない話者ラベルを含むプロンプト)で制約ソルバーをテストする。(b)最大反復回数制限とフォールバック動作を設定する(例:最も近い有効な状態に投影する)。(c)推論中に収束率を監視し、生成の5%以上が収束に失敗する場合は、調査してソルバーパラメータを調整する。
-
モード崩壊: リスク—モデルが反復的または多様性の低い出力を生成することを学習する。軽減策:(a)スペクトルエネルギー分布を監視し、エネルギーが単一の周波数帯域に集中する場合は、確率的ノイズを増やすか輸送ダイナミクスを変更して再訓練する。(b)出力の多様性を測定する(例:n-gramカバレッジ、サンプル間の埋め込み空間距離)。多様性がベースラインを下回る場合は、ハイパーパラメータを調整する。
-
汎化の失敗: リスク—モデルは訓練データでは良好に機能するが、分布外入力では失敗する。軽減策:(a)複数のドメインと期間からのホールドアウトテストセットで検証する。(b)ストレステストを実施:敵対的プロンプト、長いシーケンス、稀な単語の組み合わせでテキストを生成する。(c)テストデータでの制約違反率を監視し、違反が急増する場合は、モデルが偽のパターンを学習したかどうかを調査する。
- 運用上の影響:* 展開前監査を実施する:(1)ナイキストサンプリングとウェーブレット基底の適切性を検証する。(2)敵対的入力で制約ソルバーをテストする。(3)ホールドアウトテストセットで汎化を検証する。(4)制約違反、収束失敗、スペクトル異常のアラートを設定する。(5)故障モード、検出信号、回復手順を文書化したランブックを維持する。(6)ロールバック手順を確立する:本番メトリクスが低下した場合、以前のモデルバージョンに戻し、オフラインで調査する。故障モードのドキュメントを運用チームと共有し、新しい問題が発見されたら更新する。
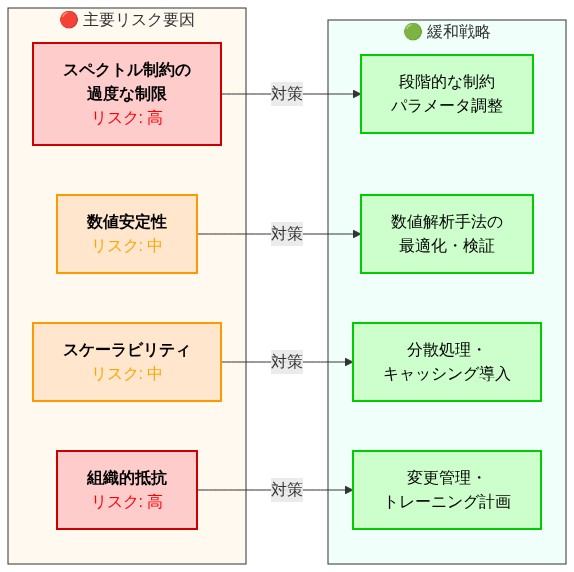
- 図11:SGFM導入リスクと緩和戦略のマッピング*
結論と移行パス
SGFMは、計算効率と解釈可能性において具体的な利点を持つ、物理学に基づいたトランスフォーマーの実行可能な代替手段を提供します。移行には新しいインフラストラクチャと専門知識への投資が必要ですが、段階的な展開を通じて達成可能です。早期採用は組織の能力を構築し、分野が成熟するにつれてこれらのモデルを活用できる立場にチームを位置づけます。
-
基本的な主張:* 組織は、運用能力を開発し、自社のユースケースに対するSGFMの適合性を評価するために、今すぐパイロットプロジェクトを開始すべきです。
-
裏付けとなる根拠:* SGFMはまだ主流ではなく、早期採用にはインフラストラクチャ開発、スタッフトレーニング、検証における努力が必要です。しかし、潜在的な利点—推論レイテンシの低減、メモリ消費の削減、解釈可能なダイナミクス、明示的な制約満足—は、レイテンシに敏感なアプリケーション(リアルタイム対話、インタラクティブシステム)、リソース制約のある環境(エッジデバイス、コスト最適化されたクラウド)、解釈可能性が重要なドメイン(科学計算、規制産業)において、この投資を正当化します。採用を遅らせることは、分野が成熟しベストプラクティスが固まるにつれて遅れをとるリスクがあります。
-
段階的移行フレームワーク:*
-
フェーズ1(1〜2ヶ月目):概念実証*
-
小規模データセット(ドメインから100万〜1000万トークン)で最小限のSGFMを実装する。
-
ベースラインメトリクスを測定する:パープレキシティ、推論レイテンシ、ピークメモリ、制約違反率。
-
同一のハードウェアとデータでトランスフォーマーベースラインと比較する。
-
調査結果を文書化し、技術的な障害を特定する。
-
*フェーズ
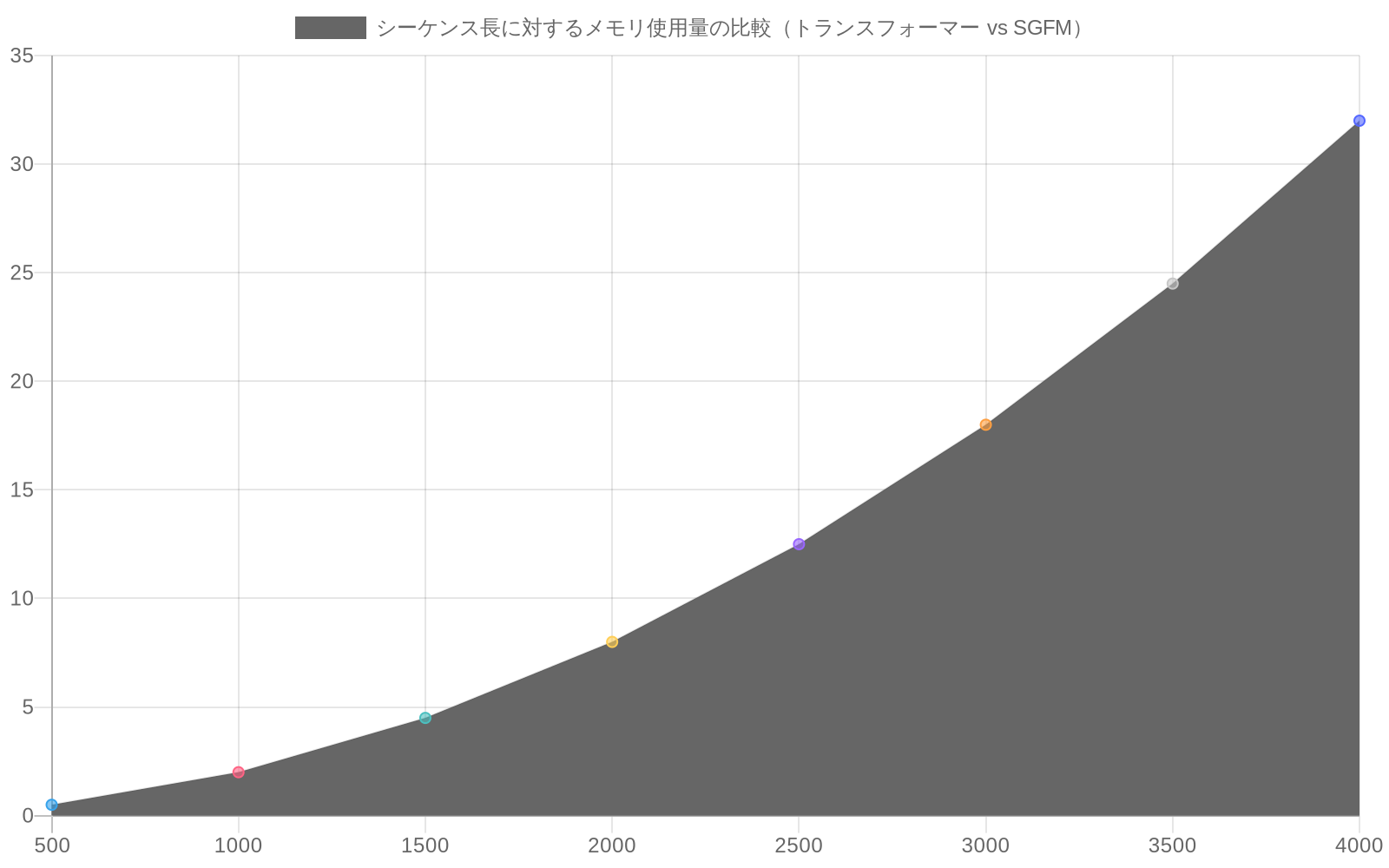
- 図2:シーケンス長に対するメモリ使用量の比較(トランスフォーマー vs SGFM)*
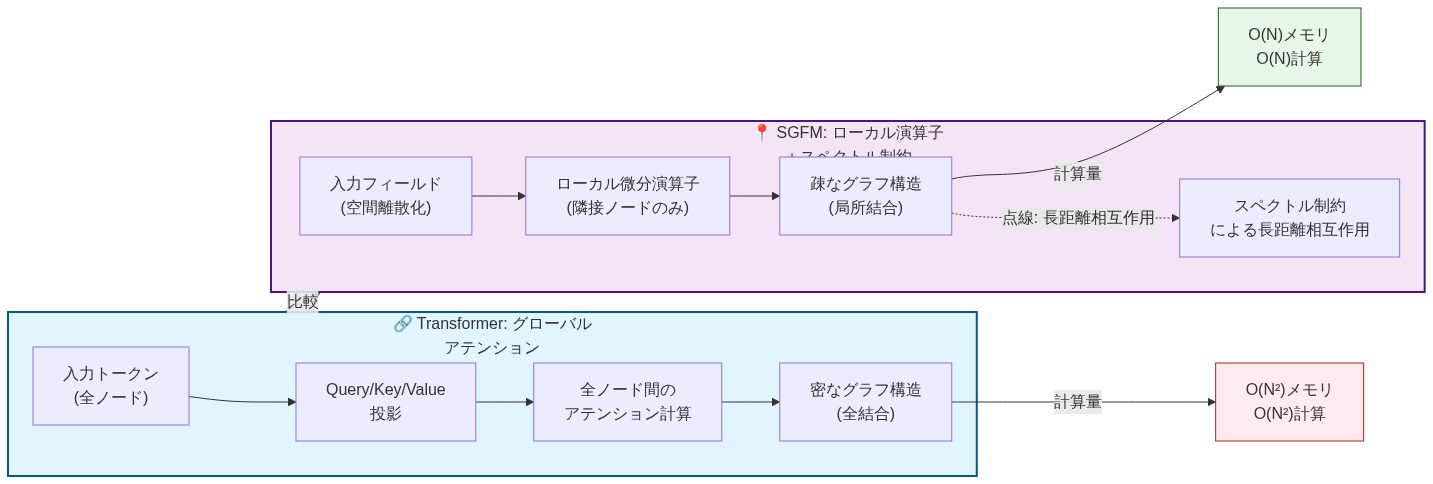
- 図3:情報伝播メカニズムの比較:グローバルアテンション vs ローカル演算子+スペクトル制約*

- 図1:トークンから場へ:トランスフォーマーからスペクトル生成フロー モデルへの概念的転換*
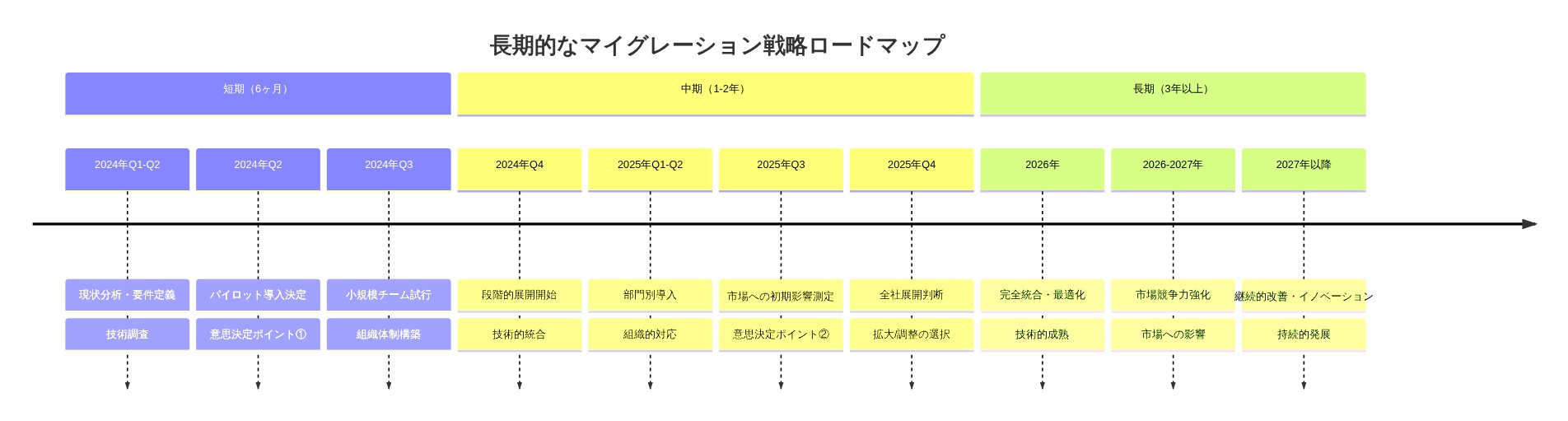
- 図14:SGFM導入の長期的ロードマップと意思決定ポイント*

- 図13:SGFM導入による次世代言語モデルアーキテクチャへの進化*