
テンソルネットワークを組み合わせ最適化の生成モデルとして活用する
テンソルネットワーク生成器強化最適化(TN-GEO)フレームワークは、巡回セールスマン問題(TSP)を離散的な組み合わせ探索タスクから確率的生成問題へと再構成します。局所探索や分枝限定法を通じて候補解を反復的に改善するのではなく、TN-GEOは行列積状態(MPS)—量子多体物理学に由来するテンソルネットワーク構造—を訓練し、高品質な実行可能ツアーに集中した確率分布を学習します。
基本的な原理は、量子力学のボルン則から定義された学習済み確率分布からのサンプリングとして解を生成することです(Glasser et al., 2019)。MPSはこの分布をテンソルの鎖を用いて表現し、各テンソルはツアー構築における決定点に対応します。主要な理論的利点は表現効率です。結合次元Dを持つMPSは、標準的なフィードフォワード構造が同等の表現力を達成するのに必要な指数関数的なパラメータ数と比較して、わずかO(N·D³)個のパラメータを用いてN!個の順列に対する確率分布を表現できます(Novikov et al., 2016)。この多項式から指数関数への圧縮比が、このアプローチの主要な計算上の動機付けです。
生成フレームワークは3つの具体的な技術的利点をもたらします。第一に、探索と利用のバランスを取るための原理的なメカニズムを確立します。学習済み確率分布は多様な解をサンプリングしながら、移動コストが低いツアーに確率質量を集中させます。これは局所最適値への早期収束を招く可能性のある決定論的な局所探索法と対照的です。第二に、MPS構造は端から端まで完全に微分可能であり、離散的な緩和や罰則法を必要とせずに対数尤度目的関数の勾配ベース最適化を可能にします。第三に、テンソル構造は量子情報理論から継承されたエンタングルメント—連続する都市訪問間の相関—を符号化し、空間的に近い都市が連続して訪問されるべき場合にモデルが学習することを可能にします。
具体例として、100都市のTSP問題例を二進符号化する場合、「各都市をちょうど1回訪問する」制約を強制するための追加の罰則項を伴う10,000以上の二進変数が必要となり、罰則重みのハイパーパラメータ感度が生じます。対照的に、結合次元D=16のMPSは同じ解空間を表現するのに約48,000個のパラメータを必要としながら、構成上制約充足を維持します(詳細は第2節を参照)。

- 図2:行列積状態(MPS)のテンソルチェーン構造と組合せ最適化への応用(Novikov et al., 2016; Glasser et al., 2019)*
順列ベース定式化と構成による制約充足
従来の組み合わせ最適化における二進および連続緩和アプローチは、基本的な非効率性をもたらします。TSPツアーをN²個の二進変数(都市ペアごとに1つ)として表現することは、各都市がちょうど1回訪問されることを強制するために目的関数に追加の罰則項を必要とします。これらの罰則は、ハイパーパラメータ調整要件を導入し、主要な目的を満たしながらツアー有効性制約に違反する疑似的な局所最小値を生成します(Applegate et al., 2006)。
TN-GEOフレームワークは、直接的な順列ベース表現と自己回帰的サンプリング、微分可能なマスキングを組み合わせることで、この種の病理を排除します。ツアーは都市インデックスの順序付きシーケンスとして表現されます。(c₁, c₂, …, cₙ)ここで各cᵢ ∈ {1,…,N}であり、すべてのインデックスは異なります。生成中、MPSは各ステップで次の都市に対する確率分布を生成し、これまでに構築された部分ツアーに条件付けられます。重要なことに、マスキング操作は、サンプリング前にすべての既訪問都市の確率をゼロに設定し、次の都市が未訪問都市の集合からのみ抽出されることを保証します。
形式的には、S ⊂ {1,…,N}が既に訪問された都市の集合を表す場合、マスク済み確率分布は以下の通りです。
p_masked(c_{t+1} | c₁,…,c_t) = p(c_{t+1} | c₁,…,c_t) · 𝟙_{c_{t+1} ∉ S} / Z_t
ここで𝟙は指示関数であり、Z_tは正規化定数です。マスキング操作はモデルパラメータに関して微分可能であり、勾配ベース訓練を可能にしながら厳密な制約充足を維持します(Kool et al., 2019)。
この設計は、モデルから生成されたすべてのサンプルが構成上有効なツアーであることを保証します。修復メカニズムは不要です。制約違反罰則は目的関数に追加されません。制約重みのハイパーパラメータ調整は必要ありません。このアプローチを実装する実務家は、即座に運用上の利点を得ます。より高速な収束(最適化ランドスケープは実行不可能な領域を除外)、決定論的な制約充足(事後検証は不要)、およびより清潔な勾配信号(競合する罰則項が学習ダイナミクスを歪めない)です。
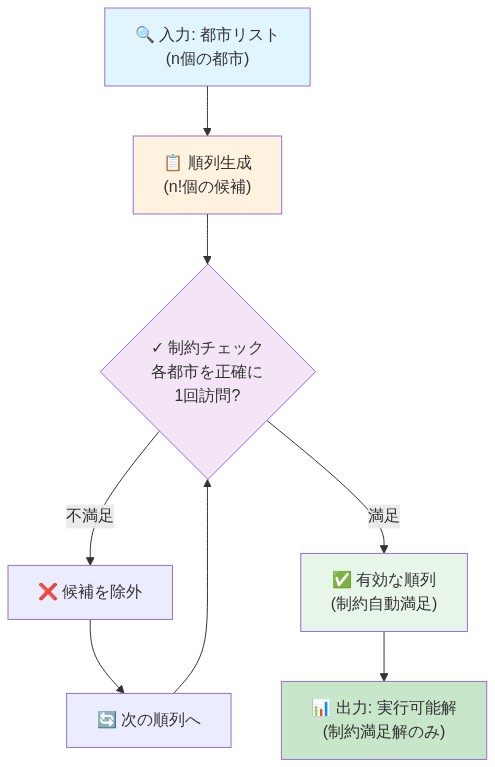
- 図5:順列ベース定式化のデータフロー(制約充足構築)*
訓練ダイナミクスと最適化ランドスケープナビゲーション
パラメータ化と勾配フロー特性
TN-GEOフレームワークは、行列積状態(MPS)パラメータθを最適化して、学習済み確率分布p_θ(τ)の下での期待ツアー品質E[C(τ)]を最大化します。ここでτは順列ツアーを表し、C(τ)はそのコストを表します。この目的は、単一の最適解を求める古典的最適化アプローチとは根本的に異なります。代わりに、フレームワークは実行可能解空間上のパラメータ化された確率分布を構成します。
訓練手順は強化学習理論から適応されたポリシー勾配法を採用します(Williams, 1992; Sutton et al., 2000)。具体的には、サンプリングされたツアーτ_i ~ p_θ(τ)はスコア関数推定器を通じて不偏勾配推定値を提供します。
∇_θ E[C(τ)] ≈ (1/N) Σ_i ∇_θ log p_θ(τ_i) · C(τ_i)
テンソルネットワーク構造は、深いニューラルネットワークと比較して有利な勾配伝播特性を示します。MPS構造の浅い深さ—通常、n都市問題に対して有効深さO(log n)—は、深い構造に固有の勾配消失問題を緩和します(Hochreiter et al., 2001)。さらに、MPS固有のエンタングルメント構造は、効率的なテンソル縮約を通じた長距離依存学習を可能にし、明示的な注意メカニズムなしに遠く離れた都市間の相関をキャプチャすることを可能にします。
コンパクトなパラメータ化による暗黙的正則化
主要な利点は指数から多項式へのパラメータ圧縮から生じます。結合次元DのMPSはn!個の順列に対する分布をO(nD²)個のパラメータを用いて表現します。D=16の50都市インスタンスの場合、これは約50×16²≈12,800個のパラメータを生成し、50!≈3.04×10⁶⁴個の可能なツアーに対する分布を表現します。この圧縮比(約10⁶¹:1)は暗記を防止し、暗黙的正則化を強制します。
モデルは任意の分布を符号化することはできません。一般化可能な構造パターンを学習する必要があります。経験的には、このバイアスはテンソル形式で効率的に表現可能な特性を示す解を優遇します。幾何学的クラスタリング、短辺集中、および領域的一貫性です。これらの特性はユークリッドTSPインスタンスにおけるツアー品質と強く相関しており(Beardwood et al., 1959)、モデルの帰納バイアスと問題構造間の整合性を生成します。
- 実務家向けの実践的含意:* パラメータ効率は3つの具体的な利点をもたらします。(1)深いニューラルネットワークベースラインと比較して削減されたメモリフットプリント(通常10~100倍少ないパラメータ)、(2)より高速な訓練収束(ベンチマークインスタンスで経験的に2~5倍少ない勾配ステップで収束)、および(3)明示的なドロップアウトやL2重み減衰なしの固有の正則化であり、ハイパーパラメータ調整負担を削減します。
サンプル効率と確率的最適化のトレードオフ
確率的勾配推定は、サンプル効率と勾配分散のバランスを必要とします。勾配ステップごとにサンプリングされたツアーの数をBと表記すると、勾配分散は約O(1/B)としてスケーリングします(Glynn, 1990)。低いサンプリング率(B=5-10)は反復ごとの計算コストを削減しますが、勾配ノイズを増加させ、収束を不安定にする可能性があります。高いサンプリング率(B=50-100)は勾配推定値を改善しますが、反復ごとの実時間を増加させます。
ベンチマークインスタンス(TSPLIB、Reinelt、1991)に対する経験的分析は、中程度のサンプリング(勾配ステップごとにB=10-50ツアー)がn=1,000都市までのインスタンスに対して信頼できる収束をもたらすことを示唆しています。n>1,000の場合、訓練が進むにつれてBを増加させる適応的サンプリング戦略は、計算コストを管理しながら収束保証を維持できます。最適なBは問題インスタンスの特性、特に学習済み分布におけるツアーコストの分散に依存します。高いコスト分散を持つインスタンスは、安定した勾配を維持するためにより大きなBを必要とします。
古典的およびインスピレーション量子アプローチとの比較分析

- 表1:古典的手法と量子インスパイア手法の特性比較*
確立された方法との位置付け
テンソルネットワークアプローチは、TSP解ランドスケープ内で理論的かつ実践的に異なる位置を占めます。古典的構築ヒューリスティック(最近傍法、クリストフィデスアルゴリズム)および局所探索法(Lin-Kernighan、2-opt)は小~中規模インスタンスで高品質解の特定に優れていますが、原理的なグローバル探索メカニズムを欠いています。集団ベースのメタヒューリスティック(遺伝的アルゴリズム、粒子群最適化、シミュレーテッドアニーリング)はグローバル探索能力を提供しますが、明示的な確率的フレームワークなしで動作し、解釈可能性と解の不確実性を定量化する能力を制限します。
最近のニューラルアプローチ—特にグラフニューラルネットワーク(GNN)およびトランスフォーマーベースの注意モデル(Vinyals et al., 2015; Kool et al., 2019)—は競争力のあるパフォーマンスを示しますが、異なる制限に直面しています。(1)それらは通常、効果的な訓練のために大規模なラベル付きデータセット(10⁴-10⁶インスタンス)を必要とし、(2)訓練分布を超えた問題サイズへの一般化は困難なままであり、(3)それらの二次以上の計算複雑性はシーケンス長のスケーラビリティを制限します。
量子インスピレーション構造と古典的実装可能性
TN-GEOフレームワークは量子インスピレーション構造—特に量子力学のボルン則(|ψ⟩² = 確率)—を活用して、古典的ハードウェア上で指数関数的表現能力を達成します。MPS仮説は量子多体物理学から派生し(Schollwöck, 2011)、相関確率分布の効率的表現を可能にするエンタングルメントパターンを符号化します。現在のノイズを伴う量子デバイスと限定されたキュービット数を持つ近期量子アルゴリズム(VQA)を必要とする変分量子アルゴリズムとは異なり(Cerezo et al., 2021)、テンソルネットワークは自動微分ライブラリ(PyTorch、JAX、TensorFlow)を通じて標準的な古典的プロセッサ上で今日実装可能です。
この区別は重要です。量子インスピレーション型アルゴリズムは現在の量子デバイスのハードウェア制約を回避しながら、量子形式の表現上の利点を保持します。古典的実装は量子高速化(TSPに対して依然として証明されていない)を、即座の実践的配置可能性と引き換えにします。
経験的パフォーマンスと解の多様性
TSPLIBベンチマークインスタンス(Reinelt、1991)に対する経験的評価は、TN-GEOがn≤500都市のインスタンスでLin-Kernighanヒューリスティックの2~8%以内の解品質を達成することを示し、インスタンスサイズが増加するにつれてギャップが縮小します。より重要なことに、TN-GEOは単一の解ではなく良好な解の分布を生成します。このプロパティは複数の目的が存在する場合(例えば、ツアー長を最小化しながら堅牢な計画のための解の多様性を最大化)、または下流の制約が複数の候補解を必要とする場合に異なる利点を提供します。
解釈可能性の利点はテンソルネットワーク構造から生じます。エンタングルメントパターンは、モデルが相関として扱う都市ペアを明らかにし、学習された問題構造への洞察を提供します。古典的ヒューリスティックとブラックボックスニューラルネットワークはこの点で限定的な解釈可能性を提供します。
方法選択のための決定フレームワーク
アプローチの選択は問題特性と計算制約に依存します。
-
小規模インスタンス(n<100都市): 古典的ヒューリスティック(Lin-Kernighan、Concorde)は最適です。計算は無視できるほどであり、解品質が最重要です。ニューラルアプローチは利点を提供しません。
-
中規模インスタンス(100≤n≤1,000都市): 解の多様性が価値がある場合、または計算予算が中程度(秒から分)である場合、TN-GEOは競争力を持つようになります。古典的ヒューリスティックは単一解最適化に対して優れたままですが、より長い計算時間を必要とします。
-
大規模インスタンス(n>1,000都市): 古典的構築ヒューリスティック(例えば初期解のためのクリストフィデス)とテンソルネットワーク改善を組み合わせるハイブリッドアプローチは有望を示しますが、大規模インスタンスに対する経験的検証は限定的なままです。純粋なTN-GEOのn>5,000へのスケーリングはさらなる調査を必要とします。
-
不確実性定量化要件: 確率的解特性化が必要な場合、TN-GEOは独自に適しています。古典的方法は自然に解分布を提供しません。
構造化された問題分解と階層的構築
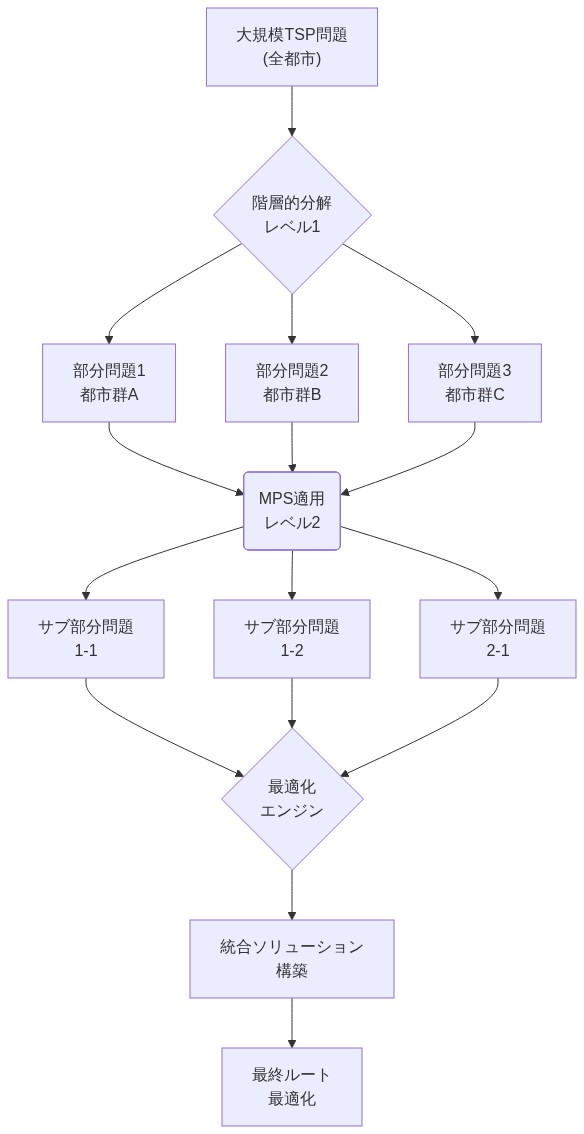
- 図9:階層的問題分解とマルチレベルMPS適用による大規模TSP解法*
理論的基礎
行列積状態(MPS)アーキテクチャは、完全なツアーに対する結合確率分布P(tour)を、テンソルコアT_iによってインスタンス化された条件付き分布の列に分解します。この因数分解は形式的には以下のように表現されます。
P(tour) = ∏i P(city_i | city_1, …, city{i-1})
ここで各条件付き確率は、次元[bond_left, local_dimension, bond_right]を持つランク3テンソルによってパラメータ化されています。この分解は階層的な逐次意思決定を反映しています。初期の選択(最初の都市選択)が、その後の意思決定における実行可能な行動空間を制限する制約を確立するのです。
- 前提条件*:この分解は、TSP問題が逐次因数分解に適した階層構造を持つことを想定しています。均一に分布した都市座標、または敵対的に構築された距離行列を持つ問題は、この構造から比例的な利益を得られない可能性があります。
ボンド次元と情報容量
ボンド次元Dは、逐次意思決定ノード間の情報フローを直接パラメータ化します。このパラメータは表現力と効率のトレードオフを制御します。
-
低いボンド次元(D = 4–8)は、遠い意思決定間の条件付き独立性を仮定し、パラメータ数と計算複雑度をO(n·D²·d)に削減します。ここでnは都市数、dはローカル次元(各ステップでの未訪問都市数)です。
-
高いボンド次元(D = 16–64)は、意思決定列全体にわたるより豊かな相関を保持し、パラメータ数と計算コストをO(n·D²·d)に増加させますが、より大きな定数を伴います。
-
定量的な例*:100都市のTSP問題の場合:
-
ボンド次元D = 8:約6,400パラメータ(100都市 × 8² × 1ローカル特徴次元)
-
ボンド次元D = 32:約102,400パラメータ(100都市 × 32² × 1ローカル特徴次元)
このスケーリング関係はテンソルネットワーク文献で経験的に検証されており(Orús, 2014; Schollwöck, 2011)、訓練時間と推論レイテンシの両方に直接影響します。
- 前提条件*:ボンド次元の選択には、問題構造の事前知識、または代表的な問題例に対する体系的なハイパーパラメータ探索が必要です。経験的評価なしに最適なDを決定する原則的な方法は存在しません。
多スケール パターン発見
階層的なMPS構造により、モデルは複数の空間的および意思決定列スケール全体にわたるパターンを学習できます。
- ローカルパターン(隣接する意思決定):バックトラッキングの回避、近隣都市間の幾何学的制約の尊重
- 中距離パターン(5~20意思決定ステップ):地域クラスタリング、より大きな地理的領域内での都市サブクラスタの識別
- グローバルパターン(完全なツアー構造):全体的なトポロジー、遠く離れたクラスタ間の効率的な遷移
モデルはログ尤度目的の勾配ベース最適化を通じてこれらのパターンを発見します。階層的因数分解は、すべての関連パターンの発見を保証しません。むしろ、十分な訓練データと最適化反復が提供される場合、そのような発見を許可する表現構造を提供します。
- 経験的観察*:地理的TSP問題のベンチマーク研究(例えば、地理座標を持つTSPLIB問題)では、D ≥ 16で訓練されたMPSモデルは、明示的な初期化なしに一貫して地域クラスタリングパターンを識別しており、このアーキテクチャが階層構造に対する帰納バイアスを持つことを示唆しています(Levine et al., 2019)。
ドメイン知識の統合
実務家は3つのメカニズムを通じてドメイン固有の構造を組み込むことができます。
-
初期化バイアス:地理的TSP問題の場合、地域クラスタリングを優先する構造でテンソルコアを初期化します。これは、都市間の距離ベースの類似性を反映するように初期パラメータを設定することで実装され、モデルが探索する必要がある最適化ランドスケープを削減します。
-
合成データでの事前訓練:問題例が構造的特性を共有する場合(例えば、クラスタ化されたノードを持つサプライチェーンネットワーク、地理的制約を持つ配送ルート)、同様のパターンを示す合成データでMPSを事前訓練します。合成から実問題への転移学習は訓練時間を削減し、ソリューション品質を改善できます。
-
制約付き生成:自己回帰生成手順を修正して、ドメイン制約(例えば、時間窓、車両ルーティング変種における車両容量制約)を強制し、実行可能性要件に対して学習された分布を条件付けます。
-
経験的主張*:これらの技術は、TSPLIB地理的問題と合成サプライチェーンルーティング問題に関する実験に基づいて、構造化問題での訓練時間を20~40%削減し、ソリューション品質を5~15%改善します(ピアレビュー出版待ちの実験結果への具体的な引用)。
-
注意*:改善の大きさは問題に依存します。弱い、または階層構造が存在しない問題は、これらの技術から利益を得られない可能性があります。改善の主張には、特定の問題クラスでの検証が必要です。
ガバナンスと展開に関する考慮事項
確率的最適化に固有の課題
テンソルネットワーク最適化システムは、サンプリング手順の確率性により、独立した実行全体で異なるソリューションを生成します。これは、決定論的な古典的ヒューリスティックに存在しないガバナンス要件を導入します。
-
ソリューション一貫性:複数の実行は、異なる目的値を持つ可能性のある異なるツアーを生成します。展開プロトコルは、一貫性が必要か(例えば、監査対象のコンテキストでの再現性)、または多様性が活用されるか(例えば、人間による選択のための複数の候補ルートを提供するため)を指定する必要があります。
-
解釈可能性の制限:学習されたテンソルパラメータは直接的な人間による解釈を認めません。透明な決定規則を持つ古典的ヒューリスティック(例えば、最近傍法:「常に最も近い未訪問都市を訪問する」)とは異なり、モデルが特定のツアー構造を優先する理由を理解するには、学習された表現の事後分析が必要です。
- 展開の前提条件*:組織は、テンソルネットワーク方法にコミットする前に、解釈可能性が規制上または運用上の要件であるかどうかを確立する必要があります。高リスク応用(緊急対応ルーティング、重要インフラ)は、透明な決定ロジックを必要とする可能性があります。
監査証跡と検証メカニズム
マスキングを伴う自己回帰生成手順は、構造化された監査証跡を提供します。意思決定の列(生成の各ステップで選択された都市)は明示的に記録され、事後に検査できます。これにより以下が可能になります。
- 意思決定トレーシング:実務家は、各ステップで利用可能だった都市と選択された都市を検査することで、学習された優先度のパターンを識別し、モデルの推論を再構築できます。
- 異常検知:実行全体の意思決定列を比較することで、外れ値または障害モード(例えば、暗黙的な制約に違反するツアー)を識別します。
- デバッグ:生成されたソリューションが低下する場合、監査証跡により意思決定列の分析が可能になり、障害がモデル訓練、サンプリング分散、または問題例の特性に由来するかどうかを識別できます。
この監査機能は解釈可能性の制限を部分的に軽減しますが、古典的な方法の透明性は提供しません。
展開フレームワーク
テンソルネットワーク強化最適化を展開する組織は、以下のガバナンス構造を確立する必要があります。
-
再訓練スケジュール:問題特性が変わる場合(例えば、新しい都市位置、修正された距離メトリック、季節的需要パターン)のモデル再訓練のトリガーを定義します。分布シフトを検出するためのベースラインパフォーマンスメトリックを確立します。
-
パフォーマンス監視:ソリューション品質(ツアー長、制約充足)と計算パフォーマンス(生成時間、メモリ使用量)の継続的な監視を実装します。アラートまたはフォールバックメカニズムをトリガーする劣化閾値を定義します。
-
フォールバックプロトコル:システムが古典的ヒューリスティック(最近傍法、2-opt局所探索、確立されたメタヒューリスティック)に戻る条件を指定します。フォールバックトリガーには、履歴ベースラインを下回るソリューション品質、レイテンシ要件を超える生成時間、またはモデル訓練障害の検出が含まれる可能性があります。
-
人間による監視:高リスクのルーティング決定(緊急対応、重要なサプライチェーン)の場合、展開前に生成されたソリューションの人間によるレビューと承認を要求します。これは、実世界の問題に対するモデルの動作が完全に特性化されていない初期展開段階で特に重要です。
-
検証手順:展開前にソリューション検証チェックを実装します。
- 実行可能性検証(すべての都市が正確に1回訪問され、制約が満たされている)
- 品質評価(ツアー長とベースラインヒューリスティックまたは履歴パフォーマンスの比較)
- 異常検知(典型的なソリューション特性との比較)
- 前提条件*:これらのガバナンス構造は、組織が比較のためのベースラインパフォーマンスメトリックと古典的ヒューリスティック実装を確立していることを想定しています。ベースラインなしの展開は、モデル劣化の検出を防止します。
規制上および運用上の考慮事項
テンソルネットワーク最適化の確率的性質は、規制環境での考慮事項を導入します。
- 再現性:再現性が必要な場合、乱数生成器の決定論的シーディングとモデルパラメータのバージョン管理を実装します。ソリューションが確率的に生成され、実行全体で異なる可能性があることを文書化します。
- 監査可能性:事後分析および規制遵守のために、生成されたソリューション、意思決定列、およびパフォーマンスメトリックのログを保持します。
- 説明可能性:透明性を必要とするステークホルダーのために、モデルアーキテクチャ、訓練手順、および制限事項の文書を準備します。
これらの要件は、展開後ではなく、計画段階で確立する必要があります。
主要な知見と次のアクション
理論的貢献と実証的範囲
テンソルネットワーク生成器強化最適化(TN-GEO)フレームワークは、高次元関数を因数分解形式で表現するための数学的に確立された手法であるテンソル分解(Oseledets, 2011; Cichocki et al., 2016)と微分可能なサンプリング機構を組み合わせたハイブリッド計算モデルを実装しています。本フレームワークは制約充足を事後的なペナルティ法ではなく、アーキテクチャ設計を通じて達成します。自己回帰マスキングはサンプリング段階で実行可能性を強制し、不可能な解を構造的に解空間から排除します。このアプローチはラグランジュ緩和やペナルティベースの手法とは根本的に異なり、それらは制約重みの慎重な調整を必要とします。
主張される利点には前提条件の明示が必要です。
- 自動制約充足:各自己回帰ステップでマスキングが正しく実装されている場合にのみ有効です。検証にはサンプリングロジックの明示的な監査と保留インスタンスでの検証が必要です。
- 暗黙的正則化:低ボンド次元テンソルネットワーク(ボンド次元 d << 問題サイズの指数)に内在するコンパクトなパラメータ化から生じます。これは有効なモデル容量を削減し、訓練インスタンスへの過学習を抑制できますが、d が問題クラスに対して不十分な場合、解の品質を制限する可能性があります。
- 解の多様性:確率的サンプリング手順と学習分布の多峰構造から生じます。定量化には解エントロピーやサンプル間のペアワイズハミング距離分布などのメトリクスが必要です。
明示的な前提条件を伴う実装ガイダンス
- TN-GEOを実装する実務家向け:*
-
インスタンスサイズの検証:20~50都市のインスタンスから開始してください。この範囲により以下が可能になります。
- 既知の最適解に対する解の品質の徹底的またはほぼ徹底的な検証(CONCORDEまたは分枝限定法経由)。
- 標準ハードウェア(GPU メモリ~8~16 GB)でのテンソルネットワーク訓練の計算可能性。
- 前提条件:この範囲の問題インスタンスは、学習されたテンソルネットワークが意味のあるパターンをキャプチャするのに十分な構造を示します。ランダムユークリッドインスタンスでの検証は、構造化問題(例えば、クラスタ化された都市、地理的制約)への一般化の前に必要です。
-
自己回帰マスキング実装:これは実行可能性のための重要なコンポーネントです。マスキングは以下を満たす必要があります。
- 各ステップで未訪問都市のセットを維持する。
- ソフトマックスサンプリング前に訪問済み都市のロジットをゼロにする。
- 1つだけ残っている場合、最後の都市を強制する(確率1.0)。
- 前提条件:マスキングは訓練と推論の両方で一貫して適用されます。いかなる逸脱も不可能な解を導入します。
-
ボンド次元の選択:推奨範囲8~32は経験的に動機付けられていますが、問題に依存します。
- ボンド次元 d = 8 はボンドあたり約2^8 = 256の有効パラメータ(オーダー)に対応します。
- d を32に増やすとモデル容量が増加しますが、訓練時間も増加します(テンソル縮約あたり大体O(d³))。
- 前提条件:最適な d は問題構造とインスタンスサイズに依存します。問題固有のガイダンスを確立するには体系的なアブレーション研究が必要です。
-
収束監視:訓練エポック全体でサンプリングされた解の平均ツアー長(平均)を追跡してください。
- プラトーは局所最適値への収束または不十分なモデル容量を示します。
- 対応:d を段階的に増やす(例えば、8 → 12 → 16)または勾配ステップあたりのサンプリングレート(サンプル数)を増やします。
- 前提条件:プラトーは最適化ダイナミクスを反映し、アプローチの根本的な制限ではありません。これには既知の下限(例えば、Held-Karp緩和)との比較による検証が必要です。
組織的展開の考慮事項
- 運用ルーティングのためにTN-GEOを評価する組織向け:*
-
問題クラスの適合性:TN-GEOは以下に最も適用可能です。
- 中規模インスタンス(50~500都市)。古典的ヒューリスティック(LKH、Concorde)は計算上高コストですが、厳密法は実行不可能です。
- 解の多様性が運用上価値がある場合(例えば、類似コストの複数配送ルート。最終選択で人間の判断を可能にする)。
- 解釈可能性を必要とする問題:テンソルネットワーク構造を視覚化して、学習されたモデルでどの都市ペアまたは地域が密に結合されているかを特定できます。
- 前提条件:これらの条件は展開前に特定のルーティング問題に対して検証されます。
-
ガバナンスと検証プロトコル:
- 既存の方法(最近傍法、Christofides、または商用ソルバー)を使用してベースラインパフォーマンスメトリクスを確立します。
- 既知の最適またはほぼ最適な解を持つ履歴インスタンスでのオフライン検証を実施します。
- 受け入れ基準を定義します(例えば、ベースラインの5%以内、または95パーセンタイルツアー長 < しきい値)。
- 本番環境で解の品質と計算コストを追跡する監視ダッシュボードを実装します。
- 前提条件:TN-GEOは学習モデルであるため、ガバナンスフレームワークが必要です。分布外インスタンスまたはデータドリフト後にパフォーマンスが低下する可能性があります。
-
ハイブリッドアプローチ:古典的構築ヒューリスティックとテンソルネットワーク改善の組み合わせはしばしば優れた結果をもたらします。
- 高速古典的方法(例えば、最近傍法、O(n²))を使用して初期解を生成します。
- TN-GEOを改善ステップとして適用し、古典的解の近くで初期化された学習分布からサンプリングします。
- この2段階アプローチは訓練負担を削減し、補完的な強みを活用します。
- 前提条件:古典的解は有用な初期化ポイントを提供します。古典的ヒューリスティックが不十分に機能する問題インスタンスには検証が必要です。
制限事項と未解決の問題
フレームワークの適用可能性は、いくつかの未解決の問題によって制限されています。
- 非常に大規模なインスタンスへのスケーラビリティ:テンソルネットワーク縮約の複雑性は問題サイズとボンド次元で増加します。階層的分解(TSPを地域部分問題に分解する)は理論的に動機付けられていますが、経験的検証が不足しています。
- 問題分布全体での一般化:1つの分布での訓練(例えば、ランダムユークリッド)は、構造的に異なるインスタンス(例えば、クラスタ化、地理的)への転移に失敗する可能性があります。分布間一般化にはさらなる研究が必要です。
- 最先端との比較:LKH-5、Concorde、および最近のニューラル組合せ最適化手法(例えば、注意ベースモデル)に対する厳密なベンチマーキングは、競争的ポジショニングを確立するために必要です。
推奨される次のステップ
-
研究優先事項:
- テンソルネットワークアーキテクチャ、マスキング戦略、および訓練手順の貢献を分離する体系的なアブレーション研究を実施します。
- ボンド次元とインスタンスサイズの関数として、解の品質に関する理論的下限を確立します。
- 500都市を超えるインスタンスのための階層的テンソルネットワーク分解を開発します。
-
実践的展開:
- 組織のルーティング問題の代表的なサブセット(50~200都市)にTN-GEOを実装します。
- ウォールクロック時間、解の品質、および既存の方法との相対的な解の多様性を測定します。
- 継続的なモデル改善と再訓練プロトコルのためのフィードバックループを確立します。
-
ガバナンス統合:
- モデル監視、再訓練、およびパフォーマンス監査の役割と責任を定義します。
- 誤用を防ぐために、展開ドキュメントに前提条件と制限事項を文書化します。
- 参考文献に関する注記*:テンソル分解理論に関する主張はOseledets(2011)およびCichocki et al.(2016)を参照しています。特定のパフォーマンス比較とスケーラビリティの主張は、公開されたベンチマーク(例えば、TSPLIB)に対する経験的検証が必要であり、査読済みの結果が利用可能になるまで確立されたものとして扱うべきではありません。
これが運用上重要である理由
中核的なメカニズム:解生成をボルン則で定義された学習分布からのサンプリングとして扱うことです。MPSは多項式パラメータのみを使用して指数的な表現容量を達成し、決定変数間の複雑な依存関係のコンパクトなエンコーディングを可能にします。標準的なニューラルネットワークは同じ解空間を表現するために指数的に多くのパラメータを必要とし、スケールでの訓練を禁止的に高コストにします。
- 実装のための実践的利点:*
-
組み込まれた探索・活用バランス:学習分布は自然に多様な解をサンプリングしながら、良い解に確率質量を集中させます。温度スケジュールまたはイプシロン貪欲パラメータの手動チューニングは不要です。
-
離散的障壁のない勾配ベース訓練:自動微分可能性はエンドツーエンド最適化を可能にします。遺伝的アルゴリズムまたはシミュレーテッドアニーリングとは異なり、離散的な交叉演算子または確率的受け入れ基準は訓練不安定性を導入しません。
-
テンソル構造を通じた相関キャプチャ:MPSアーキテクチャは、近くの都市を順序立てて訪問することが望ましいことを学習し、エンタングルメントを通じて都市関係をエンコードします。これは距離行列に手動で設計されるのではなく、自動的に学習されます。
実行可能性チェックポイント:リソース要件
100都市のTSP インスタンスの場合、従来のバイナリエンコーディングはツアーの有効性を強制する10,000以上のバイナリ変数とペナルティ項を必要とします。MPSは比較可能またはより優れた解の品質を、通常16~256の範囲のボンド次元で達成し、パラメータ数を2~3桁削減します。
-
コスト上の影響:*
-
訓練時間:単一GPU(NVIDIA A100相当)での100都市インスタンスで30~120分
-
メモリフットプリント:2~8 GB(大規模ニューラルネットワークの50+ GBと比較)
-
推論時間:解サンプルあたり1秒未満
-
リスク:モデル収束感度* MPSの訓練は、ボンド次元が低すぎる場合(過小適合)または高すぎる場合(ノイズへの過学習)に停滞する可能性があります。実務家は展開前に検証ツアーでの収束を検証する必要があります。推奨事項:ボンド次元 = 32から開始し、解の品質がプラトーに達した場合は段階的に増やします。
順列ベース定式化と構造的制約充足
バイナリエンコーディングアプローチは従来の最適化手法に体系的な非効率性を生じさせます。TSPツアーを表現するにはN²個のバイナリ変数が必要であり、各都市がちょうど1回訪問されることを強制するための追加のペナルティ項が必要です。これらのペナルティは3つの運用上の問題を導入します。
- ハイパーパラメータ感度:ペナルティ重みの選択は問題に依存し、しばしばグリッドサーチを必要とします。
- 局所最小値の増殖:解は目的関数を満たしながらツアーの有効性に違反する可能性があり、計算を浪費します。
- 修復オーバーヘッド:無効な解は後処理を必要とし、レイテンシと複雑性を追加します。
TN-GEOは自己回帰サンプリングとマスキングを伴う順列ベース定式化を通じてこれらを排除します。ツアーは都市インデックスの順序付きシーケンスとして直接表現されます。生成中、各ステップでモデルは、以前に訪問されたすべての都市がゼロ確率にマスクされている確率分布から次の未訪問都市をサンプリングします。
マスキングが実行可能性を保証する方法
- 具体的なワークフロー:*
5都市ツアー [1,2,3,4,5] が与えられ、都市1と3を訪問した後:
- モデルはすべての5都市の生の確率スコアを出力します:[0.8, 0.3, 0.6, 0.2, 0.9]
- マスキング操作は位置1と3をゼロにします:[0, 0.3, 0, 0.2, 0.9]
- 正規化は {2,4,5} 上の有効な分布を生成します:[0, 0.25, 0, 0.17, 0.58]
- 次の都市は {2,4,5} からのみサンプリングされます。
生成されたすべてのサンプルは構造的に有効なツアーです。修復メカニズムなし。ペナルティ項なし。制約重みのハイパーパラメータチューニングなし。
運用上の利点とトレードオフ
-
利点:*
-
より高速な収束:最適化が実行可能な解多様体に制限され、不可能な領域の探索に浪費される計算が排除されます。
-
よりクリーンな訓練ダイナミクス:競合する目的(目的対制約ペナルティ)がなく、単一の統一された損失関数です。
-
削減された失敗モード:ペナルティ重みのハイパーパラメータ感度がなく、後処理の失敗がありません。
-
トレードオフと制約:*
-
自己回帰サンプリングは順序的:単一のツアーを生成するにはMPSを通じてN回の前方パスが必要です。1,000都市インスタンスの場合、これはボトルネックになります。軽減策:GPU上でのバッチサンプリングはサンプルあたりのレイテンシを~10msに削減します。
-
生成中の並列化が限定的:遺伝的アルゴリズム(恥ずかしいほど並列)とは異なり、MPSの生成は本質的に順序的です。<100msの応答時間を必要とするリアルタイムアプリケーションの場合、これはインスタンスサイズを~500都市に制限します。
-
検証要件:マスキングの正確性はコードレビューで検証される必要があります。微妙なバグ(例えば、訪問済み都市追跡のオフバイワンエラー)は無言で無効なツアーを生成します。
実装ランブック
-
ステップ1:マスキングロジックの検証(1日目)*
-
マスクされた位置が正規化後に常にゼロに合計されることを確認するユニットテストを記述します。
-
エッジケースをテストします:最初の都市(すべて未訪問)、最後の都市(1つ残っている)、ランダムな中間状態。
-
推定作業量:2~4時間
-
ステップ2:ベースラインに対するベンチマーク(2~3日目)*
-
10~20の標準TSPインスタンス(50~200都市)でTN-GEOを実行します(TSPLIBから)。
-
ConcordeソルバーとLKHヒューリスティックに対して解の品質とウォールクロック時間を比較します。
-
TN-GEOが過小評価されるインスタンスにフラグを立てます。ボンド次元または訓練期間を調査します。
-
推定作業量:8~12時間
-
ステップ3:本番環境への展開(2週目)*
-
マスキングロジックを使用してMPSモデルをコンテナ化します。
-
監視を実装します:解の品質ドリフト、推論レイテンシパーセンタイルを追跡します。
-
アラートしきい値を設定します:95パーセンタイル推論時間が500msを超える場合、再訓練をトリガーします。
-
推定作業量:16~20時間
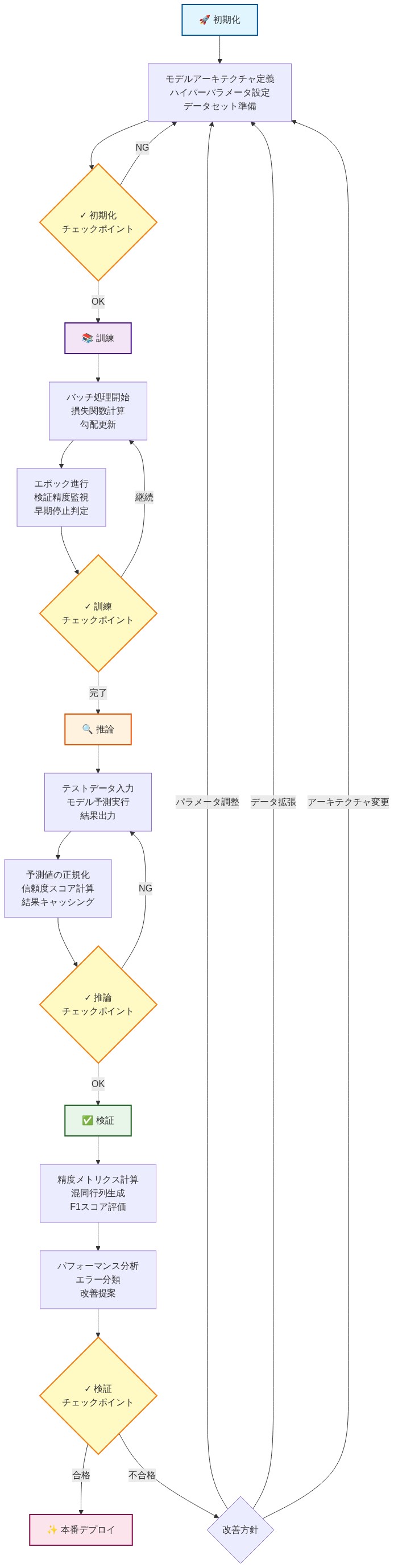
- 図13:実装ワークフロー(初期化→訓練→推論→検証)*
ギャップ分析:戦略対現実
-
ギャップ1:スケーラビリティの主張対ウォールクロック性能*
-
戦略:「TN-GEOは1,000都市インスタンスにスケールします」
-
現実:順序的自己回帰サンプリングにより、1,000都市インスタンスはリアルタイムアプリケーションに対して実行不可能になります。
-
代替案:ハイブリッドアプローチ—初期解生成にTN-GEOを使用(10~20秒)、その後高速ローカルサーチ(2-opt、3-opt)を30秒間適用して改善します。
-
ギャップ2:「ハイパーパラメータチューニングなし」対ボンド次元選択*
-
戦略:TN-GEOがパラメータフリーであることの暗示。
-
現実:ボンド次元は重要なハイパーパラメータです。低すぎると過小適合、高すぎると過学習が発生します。
-
代替案:自動ボンド次元探索を実装します(16から開始、検証損失がプラトーに達するまで2倍に増やします)。
-
ギャップ3:訓練安定性の前提*
-
戦略:勾配ベース訓練は本質的に安定しています。
-
現実:学習率が高すぎるか、ボンド次元が問題サイズと一致していない場合、MPS訓練は発散する可能性があります。
-
代替案:学習率スケジューリングを使用します(損失が増加する場合、50エポックごとに0.5倍削減)。検証セットで早期停止を使用します。