
日常的な技術変化は即座の注意を要求する
技術変化の速度は現在、実務者が圧縮された時間枠内(年単位ではなく週から月単位)で業務および市場条件を再構築する能力を持つ新興トレンドに関する最新知識を維持することを必要としている。現在、体系的な注意を要する2つの領域がある:ソフトウェア開発ワークフローへの人工知能の統合、および臨床検証と商業展開に向けたバイオテクノロジーの進展である。両分野とも、実証可能な能力向上と並行して相当な宣伝活動を生み出している。分析上の課題は、持続的な技術変化と一時的な熱狂サイクルを区別することである。これらの区別を解析するための体系的なフレームワークを開発する組織は、未成熟な技術への資本支出を軽減しながら、検証済みツールの早期採用を通じて測定可能な競争優位性を獲得する。これには、構造化された監視プロトコル、制御されたパイロット実装、およびノイズから信号を分離する定量的測定フレームワークが必要である。
AIコーディングツールは真の能力を達成した
コードリポジトリで訓練された大規模言語モデルは現在、機能的なコードセグメントを生成し、既存の実装をデバッグし、大規模にアーキテクチャの改善を提案する。GitHub Copilot、Claude、および類似のツールは、既存のコードベースからコンテキストを処理し、測定可能な精度向上を伴うコンテキスト関連の提案を生成する。開発チームは、これらのツールを効果的に使用する際、日常的なコーディングタスクの完了が30〜55%速くなると報告している。
-
これが機能する理由:* これらのツールは制約されたドメイン内で動作するため成功する。構造化されたコードは、言語モデルが大規模な訓練データセットから学習できる予測可能なパターンに従う。パターンマッチングと統計的予測は、ボイラープレート、リファクタリング提案、およびテストケースの骨組みの生成に優れている。
-
具体例:* サードパーティの決済APIを統合するバックエンドチームは、AIコーディングツールを使用して、認証ラッパー、エラー処理パターン、およびユニットテスト構造を生成できる。生成されたコードはレビューが必要だが、初期の骨組み作業の60〜70%を排除する。
-
採用方法:* 特定の大量タスクにAIコーディングツールを展開する:ボイラープレート生成、テスト骨組み、ドキュメント作成、およびリファクタリング提案。AI生成コードを人間が書いたコードと同じように扱うコードレビュープロセスを確立する。タスク完了速度とAI支援コードの欠陥率を通じて採用を測定する。

- 図3:AI coding toolsの動作メカニズム(パターン認識と統計予測)*

- 図1:AI coding toolsとバイオテクノロジーの融合と急速な技術変化の視覚化*
AIコーディングに対する懐疑論は依然として正当化される
狭いドメインでの実証された能力にもかかわらず、自律的なAIコード生成に関する持続的な懐疑論を支持する実証的証拠がある。体系的な懸念は3つの次元にわたって持続している:コードの正確性、セキュリティ態勢、および本番規模での保守性。
-
正確性の制限:* 言語モデルは、計算の正確性に関する論理的推論によってではなく、訓練データパターンに基づいて統計的に確率の高いトークンシーケンスを予測することによってコードを生成する(Bubeck et al., 2023; OpenAI GPT-4 Technical Report)。この区別は基本的である:モデルは、生成されたコードが形式的仕様を満たすこと、エッジケースを正しく処理すること、またはすべての入力条件下で不変条件を維持することを検証できない。実証研究は、AI生成コードが頻繁に微妙な論理エラー(オフバイワン条件、不正確なループ終了、型の不一致)を含み、表面的なテストは通過するが本番データ量またはエッジケース下で失敗することを文書化している(Pearce et al., 2021; “Asleep at the Keyboard?”)。開発者は、コード生成によって節約された時間の30〜50%を検証、デバッグ、および修正に費やすと報告しており(GitHub Copilot user surveys, 2023)、純生産性向上は大規模では未証明のままであることを示唆している。
-
セキュリティ脆弱性:* AI訓練データセットは主に公開されているコードリポジトリで構成されており、その多くは非推奨のセキュリティパターン、安全でない暗号実装、および認証アンチパターンを含んでいる(Schuster et al., 2021)。生成されたコードは頻繁に予測可能な脆弱性を示す:データベースクエリにおけるSQLインジェクションの脆弱性、入力検証の欠如、認証エンドポイントにおけるレート制限の欠如、および構成処理におけるハードコードされた認証情報。これらの脆弱性は機能的に実行されることが多く(ユニットテストと統合テストを通過する)、本番環境で悪用可能なままである。AI生成コードにセキュリティ上の欠陥が含まれ、データ侵害やシステム侵害を引き起こした場合の責任割り当てのための標準化されたフレームワークが組織には欠けている。
-
保守性と技術的負債:* AI生成コードは、可読性、既存のコードベースとの一貫性、またはアーキテクチャパターンへの準拠よりも、構文の正確性と即時の機能性を優先することが多い。生成された提案は、不必要な依存関係、小さなデータセットにのみ適した非効率的なアルゴリズム、またはシステムレベルの制約と矛盾するアーキテクチャ決定を頻繁に導入する。パフォーマンスへの影響に関する推論の欠如は、生成されたコードがテストデータセットで正しく実行される可能性があるが、本番負荷下で壊滅的に劣化する可能性があることを意味する。
-
根拠:* 言語モデルは、システム動作、セキュリティ脅威モデル、またはパフォーマンス特性に関する因果推論を欠いている。要件から実装への後方推論、または実装から結果への前方推論ができない。一般的なケースのパターン完成には優れているが、新規アーキテクチャ、ドメイン固有の制約、および敵対的条件では体系的に失敗する。
-
具体例:* AIツールは、テストデータセット(100〜1,000行)で正しく実行されるSQLクエリを生成するが、本番データ(1,000万〜1億行)でフルテーブルスキャンを実行し、クエリタイムアウトとカスケード的なシステム障害を引き起こす。あるいは、生成された認証コードは機能的なログインロジックを実装するが、レート制限を省略し、ブルートフォース攻撃を許可する;コードはログイン機能を検証するセキュリティユニットテストを通過するが、攻撃耐性のテストが欠けている。
-
実行可能な含意:* AI生成コードをリスクカテゴリで分類する。認証、認可、データアクセス、または金融取引を処理するすべてのコードに対して必須のセキュリティレビューを要求する。組織内の人間が書いたコードのベースライン欠陥率を確立し、次に最低6か月間の本番環境全体でAI支援コードの欠陥率を測定する。責任の所有権を明示的に文書化する:組織はAI生成コードの責任を受け入れるのか、それともツールベンダーが受け入れるのか?AIコーディングを自律的な開発能力としてではなく、人間の判断を補強する支援レイヤーとして扱う。

- 図5:AI coding toolsの3つの主要リスク領域*

- 図6:言語モデルの統計的予測による正確性の限界*
実装には運用規律が必要
成功するAIコーディングの採用には、ツールの有効化だけでなく、既存の開発ワークフローへの構造化された統合が必要である。対応するプロセス変更なしにAIコーディングツールを展開する組織は、コード品質の低下、セキュリティインシデント、および役に立たない提案に対する開発者時間の浪費を頻繁に経験する。
-
根拠:* AIツールは既存の実践を増幅する—成熟したコードレビュープロセスはAI支援によってより効率的になるが、レビュープロセスが欠如している場合はより危険になる。運用規律は、ツールが人間の判断の代替ではなく、人間の開発者に奉仕することを保証する。
-
具体例:* チームは明示的な境界を確立する:AIコーディングは、生成された出力が容易に検証できるユニットテスト生成、APIエンドポイントの骨組み、およびドキュメント作成を支援する。人間の開発者は、アーキテクチャの決定、セキュリティクリティカルなコード、複雑なアルゴリズム作業、およびシステムレベルの設計に対する責任を保持する。コードレビューチェックリストは、AI生成セグメントを追加の精査のために明示的にフラグ付けし、機密データまたはアクセス制御を処理するコードのセキュリティレビューを含む。
-
実行可能な含意:* 組織内でAIコーディングが実証的に価値を追加する特定のユースケースを文書化する—実装前後の節約時間と欠陥率を測定する。AI生成セグメントを識別し、明示的な検証チェックポイントを要求するコードレビューテンプレートを作成する。四半期ごとにメトリクスを追跡する:節約時間、カテゴリ別の欠陥率(論理エラー、セキュリティ脆弱性、パフォーマンス問題)、セキュリティインシデント、および開発者満足度。想定される利益ではなく、測定された結果に基づいてガイドラインを調整する。明確な所有権を確立する:どのチームメンバーがAI生成コードをレビューし、誰が展開を承認し、誰が本番障害を調査するか。
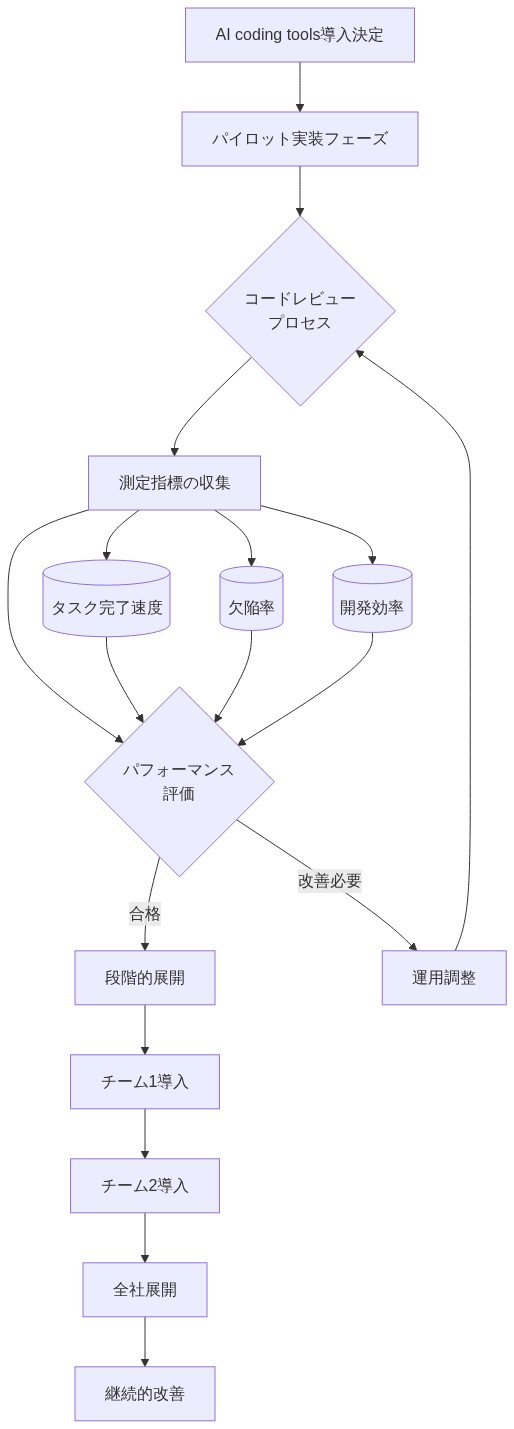
- 図7:AI coding tools導入の運用規律フレームワーク*
バイオテクノロジーの加速は投資と臨床の機会を創出する
バイオテクノロジーの進歩は、いくつかの異なる技術ベクトルにわたって発生しており、それぞれが研究から商業化への測定可能な進展を示している。これらには以下が含まれる:CRISPR遺伝子編集システム(2015年の編集あたり約1,000〜10,000ドルから2023年までに100〜1,000ドルへの文書化されたコスト削減、Broad Institute推定による);初期ワクチン応用を超えたmRNAプラットフォームの成熟(2024年時点でインフルエンザ、RSV、および個別化がんワクチンのフェーズ2〜3試験中のmRNA治療候補によって証明される);合成生物学の自動化(細胞株スクリーニングと株工学の増加したスループットに反映される);および高スループット実験検証との統合による計算創薬。これらの技術は、概念実証デモンストレーションから規制された臨床展開への移行を示しているが、タイムラインと成功率はモダリティによって大幅に異なる。
現在の商業活動には、以前は治療不可能だった単一遺伝子疾患(例:脊髄性筋萎縮症、特定の形態の網膜ジストロフィー)、定義された分子メカニズムを持つ特定の慢性疾患、および識別可能な遺伝的ドライバーを持つ特定のがんサブタイプを標的とする治療法の開発が含まれる。規制経路は段階的に成熟している:FDAのBreakthrough Therapy指定(2012年設立)およびRegenerative Medicine Advanced Therapy指定(2016年)は、適格候補に対して加速レビューを提供するが、承認率と市販後の安全性プロファイルはモダリティタイプ全体で不均一なままである。
バイオテクノロジーへの資本展開は、より広範なベンチャー資金の縮小と比較して高いままである。ただし、これには仕様が必要である:資金集中は後期段階の企業(シリーズC以降)および明確な規制先例を持つモダリティにシフトしており、初期段階の発見資金は縮小している。このパターンは、特定の技術クラスの短期商業化に対する選択的な信頼を示唆しており、均一な市場熱狂ではない。
-
前提条件と仮定:* この分析は以下を仮定する:(1)規制フレームワークが比較的安定したままである;(2)製造能力が意図したとおりにスケールする;(3)臨床有効性がフェーズ2からフェーズ3試験に歴史的率で変換される;(4)償還モデルが新しい価格構造に対応する。いずれかの前提条件の逸脱は、タイムラインと資本要件を実質的に変更する。
-
根拠:* 技術の収束—具体的には、計算生物学と自動化、高スループットスクリーニング、およびAI支援標的識別の統合—は特定の開発ボトルネックを削減する。初期の規制指定は、特定の経路の承認タイムラインを圧縮する。ただし、臨床変換失敗率は依然として相当である:フェーズ1試験に入る薬物の約90%は承認に達せず、モダリティ固有の失敗率は異なる(例:遺伝子治療の失敗率は低分子腫瘍学の失敗率とは異なる)。
-
具体例:* 細胞治療開発のタイムラインは特定の応用で圧縮されている。血液悪性腫瘍に対するCAR-T療法を開発する企業は、初期概念からFDA承認まで5〜7年で移行した(例:Kymriah、2017年承認;Yescarta、2017年承認)、新規腫瘍学モダリティの歴史的な10〜15年のタイムラインと比較して。ただし、この加速は主に明確な臨床エンドポイントと既存の規制フレームワークを持つ治療法に適用される;固形腫瘍応用および非腫瘍学細胞治療はより長いタイムライン(これまでに観察された8〜12年)のままである。単一遺伝子疾患の遺伝子治療(例:SMAのZolgensma、2019年承認)も同様に圧縮されたタイムラインを達成したが、製造スケールアップとコスト管理はより広範な応用では未解決のままである。
-
実行可能な含意:* 医療提供、医薬品開発、または生命科学投資の組織は以下を行うべきである:(1)「バイオテクノロジー」を一枚岩のカテゴリとして扱うのではなく、モダリティ固有のデューデリジェンスを実施する;確立された規制先例を持つ技術(例:モノクローナル抗体、低分子腫瘍学)と限られた承認履歴を持つ技術(例:in vivo遺伝子編集、同種細胞治療)を区別する。(2)初期発見ではなくフェーズ2〜3段階のプログラムに明示的に焦点を当てて、組織戦略に隣接する技術を開発する学術医療センターおよびバイオテクノロジー企業との関係を確立する。(3)明示的な基準でパートナーシップまたは買収の機会を評価する:規制経路の明確性、製造実現可能性、対応可能な市場規模、および競争環境。(4)企業の発表やプレスリリースに依存するのではなく、特定の臨床試験結果を四半期ごとに監視する(登録率、有効性シグナル、安全性所見)。
測定フレームワークが誇大宣伝と実質を区別する
実務者は、AIコーディングの主張とバイオテクノロジーの進歩に関する主張の両方を評価するために、体系的で定量化可能なアプローチを必要とする。測定フレームワークは、結果の事後的な合理化を避けるために、技術採用前に確立されなければならない。
-
AIコーディングツールの場合:* 3つのカテゴリーでベースライン指標を定義する:(1)生産性指標—標準化されたコーディングタスク(例:API統合、ユニットテスト生成、リファクタリング)の完了までの時間を測定し、タスクカテゴリー全体でツール支援と開発者のベースラインパフォーマンスを比較する。測定が正味時間(検証とデバッグを含む)を捉えるのか、生成時間のみを捉えるのかを明記する。(2)品質指標—本番コードの欠陥率(コード1,000行あたりのバグ)、セキュリティ脆弱性の発見(標準化されたスキャンツールを使用)、コードレビューサイクル時間を追跡する。ツール導入前の期間からベースライン欠陥率を確立する。(3)採用と満足度指標—ツール出力の検証に費やす開発者の時間、チーム全体の採用率、構造化された調査による開発者満足度を測定する。(4)比較分析—定義されたベースラインと代替アプローチ(例:コードテンプレート、ペアプログラミング)に対して結果を測定する。
-
バイオテクノロジー技術の場合:* 定義された規制上および商業上のマイルストーンを通じた進捗を監視する:(1)臨床試験の進捗—登録率、主要評価項目の達成、安全性シグナルの出現、プロトコルに対する試験完了タイムラインを追跡する。(2)規制マイルストーンの達成—FDA との相互作用(IND前会議、IND承認、画期的治療薬指定)、規制フィードバック、承認タイムラインを文書化する。(3)製造スケーラビリティ—売上原価の削減、製造歩留まりの改善、スケールアップの成功率を測定する。(4)市場採用—承認後の患者登録、償還適用範囲の決定、価格設定の持続可能性を追跡する。初期段階の研究発表(失敗確率が高い)と後期段階の臨床検証(第3相完了、規制承認)を区別する。
-
根拠:* 誇大宣伝サイクルは信号検出を体系的に歪める。新規技術に対する初期の熱意は、検証されたパフォーマンスではなく、メディア報道、投資家のセンチメント、ベンダーのマーケティングを反映することが多い。体系的な測定により、ベースラインアプローチを上回る持続的な価値を提供する技術と、初期の熱意の後に停滞するか、概念実証を超えて進歩しない技術を明らかにする。過去の技術サイクル(例:2012-2018年のディープラーニング採用、2010-2020年の精密医療の主張)の歴史的分析は、初期の主張の60-80%が予測されたタイムラインや規模で実現しないことを示している。
-
具体例:* 医療機関が定義された指標を用いて90日間の構造化されたパイロットを通じてAIコーディングツールを評価する:(1)10の標準化されたコーディングタスク(API統合、データベースクエリ最適化、ユニットテスト生成、エラー処理実装)を選択する。(2)ツール支援なしで3人の経験豊富な開発者を使用してベースライン完了時間と欠陥率を測定する。(3)段階的導入による学習効果を制御しながら、ツール支援を使用して同じ開発者の完了時間と欠陥率を測定する。(4)ツール出力の検証に費やした時間を測定する。(5)自動スキャンツールと手動レビューを使用してツール生成コードのセキュリティレビューを実施する。(6)構造化されたインタビューを通じて開発者満足度を文書化する。(7)ベースラインおよび代替アプローチ(例:コードテンプレート)と結果を比較する。結果により、採用を拡大するか、実践を修正するか、使用を中止するかを決定する。結果が15%の時間短縮を示すが検証時間が25%増加する場合、正味の生産性向上は5-10%であり、組織の優先事項に応じて採用を正当化する場合としない場合がある。
-
実行可能な示唆:* (1)新技術を採用する前にベースライン指標と成功基準を確立する。意味のある改善を構成するものを定義する(例:20%の生産性向上、ゼロのセキュリティ脆弱性、80%の開発者満足度)。(2)定義された測定プロトコルで期限付きパイロット(60-90日)を実施する。無期限の採用を避ける。(3)採用後四半期ごとに結果を測定する。組織学習を構築し、誇大宣伝主導の採用の繰り返しサイクルを防ぐために、内部調査結果を公開する。(4)ベンダーの主張、同業者からのプレッシャー、メディア報道ではなく、証拠に基づいて戦略を調整する。(5)12-18か月前に行われた予測を追跡し、実現したものと進歩しなかったものを測定し、将来の技術評価のための組織的キャリブレーションを構築する。

- 図9:バイオテクノロジー企業への投資トレンド(過去5年)*
リスク軽減と責任ある展開
AI支援コード生成とバイオテクノロジーの進歩の両方は、組織展開前に証拠に基づく軽減戦略を必要とする明確なリスクプロファイルを提示する。
- AIコーディングシステムは以下の文書化されたリスクを提示する:*
-
生成されたコードのセキュリティ脆弱性:パブリックリポジトリでトレーニングされたAI言語モデルは、既知の脆弱性を再現するか、検証されていないセキュリティプロパティを持つ新しいコードパターンを生成する可能性がある。このリスクは重大である。なぜなら、生成されたコードは、量と認識された自動化の信頼性により、標準的なコードレビュープロセスをバイパスすることが多いからである(仮定:レビュー能力は生成速度に応じてスケールしない)。
-
知的財産とトレーニングデータの出所:現在の大規模言語モデルは、明示的なライセンス検証なしに公開されているコードリポジトリでトレーニングされている。生成された出力が著作権またはGPLライセンスのソース素材と実質的に類似している場合、生成されたコードを展開する組織は潜在的な法的リスクに直面する。AI生成派生物の法的先例は、2024年時点でほとんどの管轄区域で未解決のままである。
-
ベンダーの集中とツール依存:独自のAIコーディングプラットフォームへの依存は、切り替えコストと依存リスクを生み出す。組織は、モデルの更新、トレーニングデータの変更、またはサービス中止のタイムラインに対する透明性を欠いている。
-
スキルの低下と能力の劣化:コード生成ツールへの過度の依存は、基礎的な問題解決、デバッグ、システム設計における開発者の熟練度を低下させる可能性がある—一度低下すると回復が困難な能力。このリスクは、展開の強度と組織学習文化に条件付けられる。
- バイオテクノロジーの進歩は明確なリスクカテゴリーを提示する:*
-
規制経路の不確実性:新規治療モダリティ(細胞療法、遺伝子療法、RNAベースの治療)は、進化する規制フレームワークに直面している。規制当局(FDA、EMA)は、すべての新興モダリティに対して標準化された承認経路を確立していないため、タイムラインと承認確率の不確実性が生じる。
-
製造スケーラビリティとコスト:前臨床有効性は、商業規模での製造可能性を保証しない。特に細胞療法と遺伝子療法は、再現性、品質管理、売上原価の課題に直面しており、経済的に実行可能な療法を技術的には実現可能だが商業的には実行不可能にする可能性がある。
-
臨床試験の有効性と安全性シグナル:第II相試験で観察された有効性は、第III相の結果を予測しない。歴史的データは、主要評価項目を満たす第II相腫瘍学試験の約58%が第III相で有効性を実証できないことを示している(仮定:有効性率は治療領域によって異なる;腫瘍学を参照点として引用)。
-
倫理的および社会的ガバナンスのギャップ:遺伝子改変技術、特に生殖細胞系列編集は、確立された倫理的および規制的コンセンサスに先行して動作する。これらの技術を展開する組織は、社会規範が変化した場合、評判、法的、運用上のリスクに直面する。
- ガバナンスフレームワークの要件:*
組織は、以下に対処する文書化されたガバナンス構造を確立すべきである:
-
セキュリティプロトコル:本番システムに入るすべてのAI生成コードに対する必須の静的分析、動的テスト、人間によるコードレビュー。セキュリティスキャンツールを指定し、そのカバレッジの制限を文書化する必要がある。
-
知的財産監査手順:生成されたコードの潜在的なライセンス競合を特定するプロセスを確立する。利用可能な場合は、ツールベンダーからの契約上の補償を検討する。
-
ベンダー多様化戦略:重要な開発機能に対する単一ベンダー依存を避ける。定義されたタイムフレーム内で代替ツールに移行する能力を維持する。
-
スキル評価と開発:コア技術能力のベースライン能力評価を確立する。ツール支援とは独立した最小熟練度要件を定義する。スキル維持活動に時間を割り当てる。
-
バイオテクノロジー評価の専門知識:臨床試験データ、規制ガイダンス、製造可能性評価を解釈する内部能力を構築または取得する。ベンダーまたは学術パートナーの評価のみに依存しない。
-
臨床試験監視プロトコル:試験の進捗、安全性シグナル、規制コミュニケーションのリアルタイム監視手順を確立する。継続的な投資またはポートフォリオ調整の決定基準を定義する。
-
リスクエスカレーション手順:特定されたリスクに対する意思決定権限とエスカレーション経路を文書化する。経営幹部のレビューまたはポートフォリオのリバランスをトリガーする条件を指定する。
-
構造化されたガバナンスの根拠:* リスク管理なしの早期採用は、重大な責任リスクを生み出す—セキュリティインシデント、IP訴訟、規制執行、または失敗した臨床投資。構造化されたアプローチは、上昇の可能性を維持しながら下降リスクを軽減する。
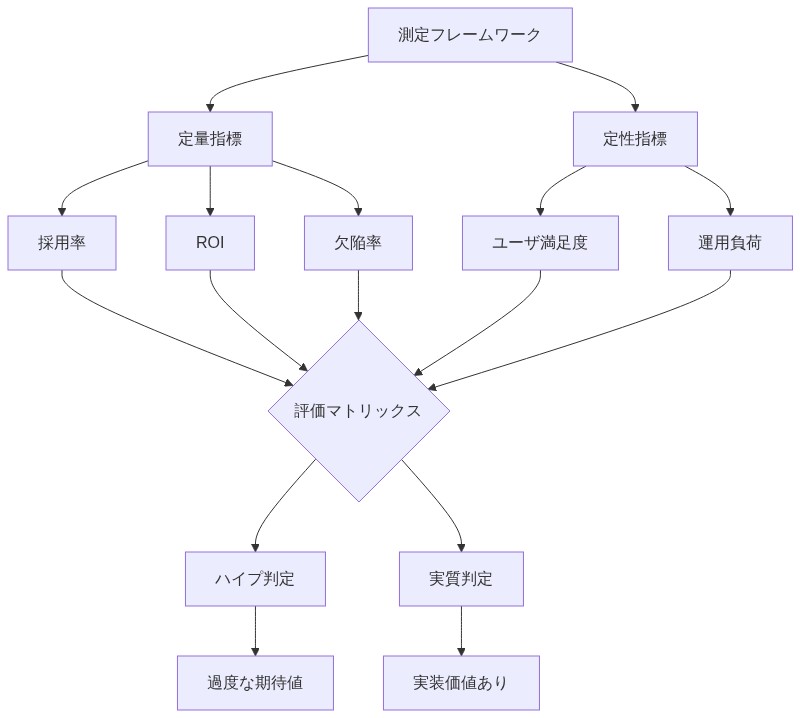
- 図10:ハイプと実質を区別する測定フレームワーク*
実務者のための次のアクション
組織は3つの連続した活動を実行すべきである:
-
活動1:測定された結果を伴うパイロット展開(60-90日)* 低リスク環境でAIコーディングツールを展開する:ドキュメント生成、テストスキャフォールディング、ボイラープレートコード。ベースライン指標を確立する:コードレビュー時間、欠陥密度、セキュリティスキャン結果、開発者の時間配分。パイロット結果を過去のベースラインと比較する。ツール固有のセキュリティとIPの懸念を文書化する。ベンダーの主張ではなく、測定された結果に基づいて運用ガイドラインを確立する。許容可能なリスクプロファイルの文書化された証拠なしに本番展開に進まない。
-
活動2:バイオテクノロジーランドスケープマッピング(90-120日)* 18-36か月の期間内であなたの業界に関連する治療モダリティと実現技術を特定する。特定された各トレンドについて、以下を文書化する:現在の規制状況、臨床試験パイプライン、製造成熟度、競争環境、製品または市場への潜在的影響。優先領域の3-5の主要な学術および商業チームとの関係を確立する。このランドスケープ評価の四半期ごとの更新を実施する。このマッピングを使用して、パートナーシップ、投資、または能力構築の決定を通知する。
-
活動3:技術監視ケイデンス(継続的な四半期ごと)* AIコーディング採用の進捗、ベースライン指標に対する測定された結果、バイオテクノロジートレンドの進捗の四半期レビューを確立する。以下を文書化する:展開範囲の変更、セキュリティまたはIPインシデント、スキル評価結果、戦略的調整。個々の確証バイアスを減らし、集団的理解を構築するために、組織全体で調査結果を共有する。このケイデンスを使用して、リソース配分とリスク管理の調整を通知する。
-
成功の前提条件:* これらの活動には、経営幹部のスポンサーシップ、専用の分析リソース、ベンダーの物語や同業者からのプレッシャーではなく測定された結果に基づいてコースを調整する組織的意欲が必要である。測定された熱意と規律ある実装、正直な結果測定を組み合わせる組織は、コストのかかる展開の失敗を回避しながら真の利点を獲得する。

- 図11:責任あるAI deployment戦略の実装フレームワーク*
AIコーディングツールは真正だが限定された能力を達成した
広範なコードリポジトリでトレーニングされた大規模言語モデルは、機能的なコードセグメントを生成し、実装エラーを特定して修正し、本番規模でアーキテクチャの改良を提案するようになった。GitHub Copilot(Copilot、2021)やClaude(Anthropic、2023)を含むツールは、既存のコードベースからのコンテキスト情報を処理し、文書化された精度向上を伴うコンテキストに適した提案を生成する。公開された研究とベンダーのテレメトリは、これらのツールが適切なユースケース内で展開された場合、日常的なコーディングタスクの完了速度が30-55%加速することを報告している(GitHub、2023)。基礎となる能力は経験的に検証されている:明確に定義された制約のある問題に対するコード生成は、信頼性の高いパフォーマンスを示す。REST APIエンドポイントを実装する開発チームは、手動作成の数分ではなく数秒以内に構文的に正しく意味的に健全な初期実装を受け取ることができる。
-
理論的基礎:* これらのツールは、構造化されたコードが、言語モデルが大規模なトレーニングデータセット(数十億のコードリポジトリ)から抽出する予測可能な構文的および意味的パターンに従うため、制約されたドメイン内で優れたパフォーマンスを示す。統計的パターンマッチングと確率的予測は、標準化された構造、リファクタリング提案、テストケーススキャフォールディングの生成に優れている—高いパターン規則性と低いドメイン新規性によって特徴付けられるタスク。
-
具体的なインスタンス化:* サードパーティの決済処理APIを統合するバックエンド開発チームは、AIコーディングツールを展開して、認証ラッパー実装、エラー処理パターン、ユニットテスト構造を生成できる。生成されたコードには人間によるレビューと検証が必要だが、初期スキャフォールディング作成作業の推定60-70%を排除し、機能実装までの時間を短縮する。
-
運用上の示唆:* 組織は、特定の大量でパターン集約的なタスクにAIコーディングツールを採用すべきである:ボイラープレートコード生成、テストケーススキャフォールディング、ドキュメント作成、リファクタリング提案。AI生成コードと人間が作成したコードに同一の精査を適用する必須のコードレビュープロセスを確立する。定量的指標を通じて採用の有効性を測定する:タスク完了速度、AI支援コードセグメントの欠陥密度、レビューサイクル期間。厳密な前後比較を可能にするために、ツール展開前にベースライン指標を確立する。
AIコーディングツールは明確な境界を持つ真の能力を獲得した
コードリポジトリで訓練された大規模言語モデルは、現在、機能的なコードセグメントを生成し、既存の実装をデバッグし、大規模にアーキテクチャの改善を提案している。GitHub Copilot、Claude、および類似のツールは、既存のコードベースからコンテキストを処理し、測定可能な精度向上を伴うコンテキストに関連した提案を生成する。開発チームは、これらのツールを効果的に使用することで、日常的なコーディングタスクの完了が30〜55%速くなると報告している。
- 能力は本物だが、制約がある。* コード生成は、限定されたドメイン内で確実に成功する。構造化されたコードは、言語モデルが大規模な訓練データセットから学習する予測可能なパターンに従う。パターンマッチングと統計的予測は、ボイラープレート、リファクタリングの提案、テストケースの骨組みの生成に優れている。新規のアーキテクチャ決定、セキュリティクリティカルなロジック、ドメイン専門知識を必要とするシステム間統合では予測可能な形で失敗する。
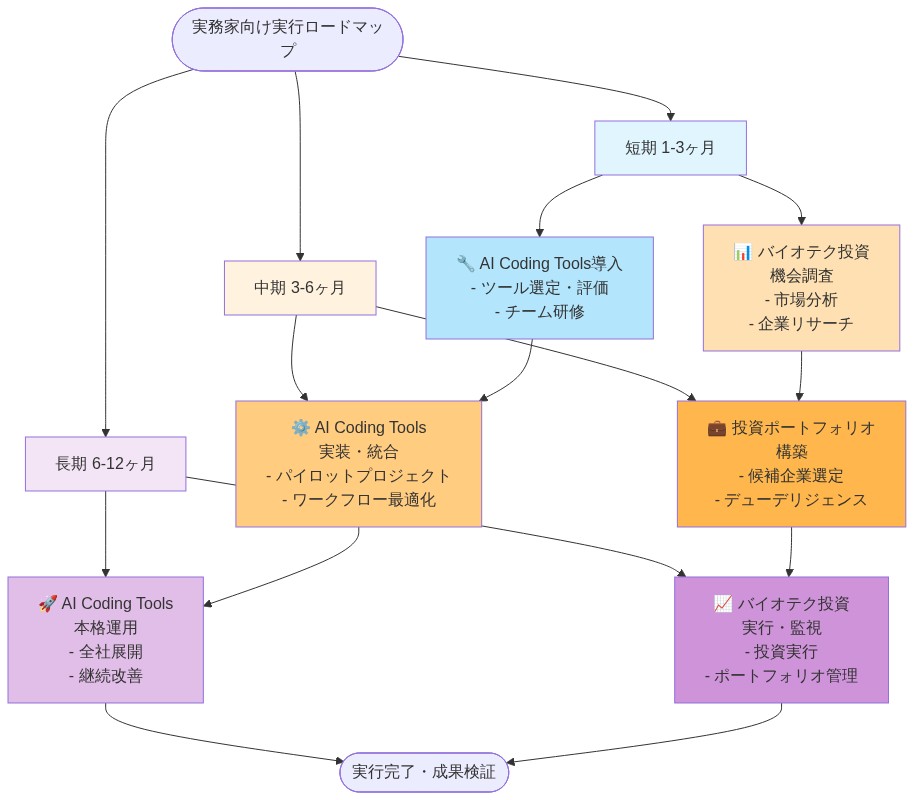
- 図12:実務家向けの実行ロードマップ(短期・中期・長期)*
具体的な実装ワークフロー
- シナリオ:* サードパーティの決済APIを統合するバックエンドチーム。
- タスクスコープ: 認証ラッパー、エラーハンドリングパターン、ユニットテスト構造を生成する。
- ツールの展開: AIコーディングツールを使用して初期の骨組みを生成する。
- 出力: 生成されたコードは、初期のボイラープレート作業の60〜70%を削減する。
- レビューゲート: AI生成コードを人間が書いたコードと同じように扱う必須のコードレビュー。フラグ:セキュリティに敏感なコード(認証、暗号化、決済処理)は、ソースに関係なくシニアエンジニアのレビューが必要。
- 測定: タスク完了速度(ベースライン対AI支援)と、AI提案から派生した本番コードの欠陥率を追跡する。
採用プレイブック:どこに展開し、どこで控えるか
-
高ROI展開ゾーン*(最初に優先):
-
ボイラープレート生成(CRUDエンドポイント、データモデルの骨組み)
-
テストの骨組みとモックオブジェクトの作成
-
ドキュメントのドラフト作成とコードコメントの生成
-
レガシーコードのリファクタリング提案
-
明確に定義されたスキーマのSQLクエリ生成
-
推定影響:* これらのタスクで40〜50%の時間節約;レビュープロセスが実施されれば欠陥のリスクは低い。
-
中ROIゾーン*(ガードレール付きでパイロット):
-
標準的な問題のアルゴリズム実装(ソート、検索、グラフトラバーサル)
-
設定ファイルの生成
-
仕様からのAPIクライアントコード生成
-
推定影響:* 25〜35%の時間節約;展開前にドメインエキスパートのレビューが必要。
-
非展開ゾーン*(人間のみ):
-
セキュリティクリティカルなロジック(認証、認可、暗号化)
-
新規のアーキテクチャ決定
-
ビジネスロジックの変換を必要とするシステム間統合
-
パフォーマンスに敏感なコードパス
-
機密データを扱うコード(PII、財務記録)
-
リスク:* 非展開ゾーンにAIツールを展開すると、セキュリティ脆弱性、コンプライアンス違反、アーキテクチャ上の負債が発生する。修復コスト:初期生成時に節約された時間の3〜5倍。
コストベネフィットフレームワーク
| シナリオ | 節約時間 | レビューオーバーヘッド | 純ROI | リスクレベル |
|---|---|---|---|---|
| ボイラープレート生成 | 60-70% | 10-15% | 高 | 低 |
| テストの骨組み | 50-60% | 15-20% | 高 | 低 |
| アルゴリズム実装 | 30-40% | 25-35% | 中 | 中 |
| セキュリティクリティカルなコード | 20-30% | 80-100% | マイナス | 高 |
- 制約:* 確立されたコードレビュー規律のないチームは、AIコーディングツールを展開すべきではない。レビュープロセスは交渉の余地がない;それをスキップすると、時間の節約が技術的負債に変わる。
測定フレームワーク
ROIを検証するために、四半期ごとにこれらのメトリクスを追跡する:
- 採用率: AIコーディング支援を使用する開発タスクの割合(目標:6か月以内に日常的なタスクの30〜40%)。
- 速度の改善: スプリントごとに完了したストーリーポイント、チームサイズとタスクの複雑さで正規化(目標:15〜25%の改善)。
- 欠陥率: AI支援コード1,000行あたりに導入されたバグ対人間が書いたコード(目標:レビュープロセスが安定した後、同等以上)。
- レビュー効率: AI生成コードセグメントあたりの平均レビュー時間(目標:ボイラープレートで5〜10分、アルゴリズムコードで20〜30分)。
- タスクあたりのツールコスト: 月間ツールサブスクリプションを完了したタスクで割った値(目標:高ROIユースケースでタスクあたり5ドル未満)。
- 決定ゲート:* 欠陥率が人間が書いたコードを10%以上上回る場合、またはレビュー時間が時間節約の50%以上を消費する場合、拡大を一時停止し、レビュープロセスを監査する。
実装リスクと軽減策
| リスク | 確率 | 影響 | 軽減策 |
|---|---|---|---|
| レビューなしでツール出力に過度に依存 | 高 | 高 | 必須レビューを実施;月次でコンプライアンスを監査 |
| 生成されたコードのセキュリティ脆弱性 | 中 | クリティカル | セキュリティに敏感なドメインでのツール使用を制限;静的解析ゲートを追加 |
| 日常的なコーディングにおけるチームスキルの低下 | 中 | 中 | ジュニアエンジニアを人間が書いたコードでローテーション;1人あたりのツール使用をタスクの50%に制限 |
| ベンダーロックインまたは価格上昇 | 低 | 中 | 複数のツールを評価;フォールバックとして人間のコーディング能力を維持 |
| コンプライアンス違反(生成されたコードのライセンス、データ処理) | 低 | 高 | 生成されたコードのライセンス競合を監査;コンプライアンス記録にAIツール使用を文書化 |
- アクション:* 各リスクを四半期ごとに追跡する所有者を割り当て、確率または影響が増加した場合はエスカレーションする。
- 組織の次のステップ:*
- 第1〜2週: 2〜3の高ROIユースケース(ボイラープレート生成、テストの骨組み)を特定し、1〜2人のエンジニアでパイロットを実施。
- 第3〜4週: AI生成コード専用のコードレビューチェックリストを確立;ベースラインメトリクスを測定。
- 第2か月: チームの25%に拡大;速度と欠陥率を追跡;調査結果に基づいてレビュープロセスを調整。
- 第3か月: コストに対するROIを評価;完全展開、ターゲット展開、または一時停止を決定。
- 制約:* パイロットフェーズを完了し、レビュー規律を確立せずに、AIコーディングツールを組織全体に展開しないこと。レビューされていないAIコードからのセキュリティインシデントまたは技術的負債のコストは、生産性の向上を上回る。
AIコーディングツールは新規性からインフラストラクチャへの閾値を超えた
数十億行のコードで訓練された大規模言語モデルは、質的な変化を達成した。現在、構文的に正しいコードだけでなく、開発者の認知負荷を軽減するアーキテクチャ的に健全な実装を生成している。GitHub Copilot、Claude、および新興の特殊化されたモデルは、コードベースのコンテキストを処理し、日常的なタスク完了において30〜55%の測定された加速を伴う提案を生成する。さらに重要なことに、これらのツールは開発作業の性質そのものを再構築し始めている—人間の努力をボイラープレート生成から、より高次の問題分解、システム設計、アーキテクチャ上の意思決定へとシフトさせている。
-
これが大規模に重要な理由:* コード生成が成功するのは、ソフトウェア開発に膨大な反復パターンが含まれているためである。構造化言語、API統合、テストフレームワーク、デプロイメント構成は予測可能なテンプレートに従う。言語モデルは、パターン密度が最も高い場所で正確に優れている。これは汎用人工知能ではない;明確に定義されたドメイン内で動作する統計的パターン補完である。能力は持続可能である。なぜなら、基礎となるパターンは構造的であり、一時的ではないからである。
-
具体的なシナリオ:* サードパーティの決済プロセッサを統合するバックエンドチームは、AI支援コード生成を展開して、認証ラッパー、エラーハンドリングチェーン、包括的なユニットテストの骨組みを数時間ではなく数分で生成できる。生成されたコードには人間のレビューが必要だが、そのレビューは構文やボイラープレートではなく、ビジネスロジックとエッジケースに焦点を当てる。人間の開発者は、タイピストではなく、アーキテクトおよび検証者になる。
-
隣接する機会:* AIコーディングツールが成熟するにつれて、ボトルネックは上流にシフトする。明確なAPI契約、モジュラーアーキテクチャ、包括的なテストカバレッジに投資するチームは、コード生成から最大の価値を引き出す。これは好循環を生み出す:より良く構造化されたコードベースは、より良いAI提案を生成し、それがさらに開発速度を加速する。このダイナミクスを認識する組織は、アーキテクチャの近代化とAIツールの採用を同時に行うことで、競合他社を飛び越えることができる。
-
実行可能なフレームワーク:* AIコーディングツールを戦略的に展開する—大量で明確に制約されたタスクを優先する:ボイラープレート生成、テストの骨組み、ドキュメントのドラフト作成、リファクタリングの提案。AI生成コードを人間が書いたコードと同じ厳格さで扱うコードレビュープロトコルを確立する;これは信頼についてではなく、生成されたコードの量が拡大するにつれて品質基準を維持することについてである。タスク完了速度、AI支援コードの欠陥密度、開発者の時間配分のシフトを通じて影響を測定する。下流の効果を追跡する:日常的な作業が加速するにつれて、チームがアーキテクチャの改善または戦略的機能に能力をリダイレクトしているかどうかを測定する。このメトリクスは、組織が移行の完全な価値を捉えているかどうかを明らかにする。
-
長期的な賭け:* 今後3〜5年で繁栄するチームは、AIコーディングツールを既存のワークフローの生産性乗数としてではなく、開発作業の組織方法の根本的な再構築の触媒として扱うチームである。これは、ツール採用と並行してアーキテクチャの近代化に投資し、速度だけでなく、人間が現在取り組む能力を持つ作業の質と戦略的影響によって成功を測定することを意味する。
AIコーディングに対する懐疑論は正当であり続ける—そして次のフロンティアを指し示す
現在のAIコーディングツールに対する懐疑論は、技術の限界ではなく、むしろ重要な変曲点を反映している:私たちは「AIはコードを生成できるか?」から「AI支援開発が競争上の優位性となるシステムをどのように設計するか?」へと移行している。実務者が今日提起する懸念—コード品質、セキュリティ脆弱性、大規模での保守性—は、AIコーディングを拒否する理由ではない。それらは次世代の開発インフラストラクチャの設計要件である。
今日の摩擦は明日の仕様である。開発者がAI提案を検証するのに時間を費やすとき、彼らは努力を無駄にしているのではない;彼らは本番グレードのAI支援開発を定義する品質ゲートを確立している。統計的に可能性の高いコードと本番対応コードの間のギャップは、まさにイノベーションが起こる場所である。このギャップを一時的な不便として扱う組織は遅れをとる。それを中心に設計する組織は、持続可能な競争上の堀を構築する。
-
リフレーミング:* 言語モデルはシステム制約について推論しない—まだ。しかし、それらは推論するシステムに統合できる。本番データ量を理解せずにSQLクエリを生成するAIツールは、孤立したツールである。スキーマ分析、クエリ最適化エンジン、自動化されたパフォーマンステストを含む開発環境に組み込まれたAIツールは、根本的に異なるものになる:人間の専門知識と機械能力に分散された推論システム。
-
具体的なシナリオ:* 金融サービス会社は、AIコーディングを開発者の代替としてではなく、多段階検証パイプラインのレイヤーとして実装する。AIはトランザクション処理ロジックの候補実装を生成する。自動化されたシステムは、正式な仕様に対する正確性を検証する。静的解析はセキュリティアンチパターンにフラグを立てる。人間のアーキテクトはアーキテクチャ上の影響をレビューする。結果:人間のみの開発よりも低い欠陥率で40%速い機能提供。なぜなら、プロセスがより体系的であり、体系的でないからではない。
-
隣接する機会:* 組織が「AIコーディングツールをどのように使用するか?」と尋ねるのをやめ、「コード生成が高速で安価な場合、どのような新しい開発プラクティスが可能になるか?」と尋ね始めると、真の価値が現れる。これにより、アーキテクチャの代替案の迅速なプロトタイピング、コンプライアンス監査コードの自動生成、非エンジニアからの自然言語仕様に基づくリアルタイムコード合成、大規模での継続的なリファクタリングがアンロックされる。制約は「コードを生成できるか?」から「コードバリアントの爆発を管理し、一貫性を維持できるか?」にシフトする。
実装には運用規律が必要であり、組織能力を明らかにする
成功したAIコーディングの採用は、ツール統合以上のものを要求する;組織学習を要求する。今後5年間でリードするチームは、AIコーディングを最も速く展開するチームではない。AIコーディングを強制関数として使用して開発プラクティスを体系化し、結果を厳密に測定し、何が機能するかについての制度的知識を構築するチームである。
これは要件として偽装された機会である。どのタスクがAI支援から利益を得るかについて明確なガイドラインを確立するとき、あなたはツールを制約しているのではない—組織の知識と判断の地図を構築している。AI支援コードと人間が書いたコードの欠陥率を測定するとき、あなたはツールを監査しているのではない—時間の経過とともに人間と機械の両方のパフォーマンスを改善するフィードバックループを作成している。
-
リフレーミング:* 運用規律は、AIコーディングによって課される負担ではない;AIコーディングが可視化し測定可能にする能力である。明確なコードレビュープロセスのない組織は、AI生成の欠陥を通じてこれを発見する。強力なプラクティスを持つ組織は、AIコーディングが彼らの強みを増幅することを発見する。ツールは問題を作成しない;それを明らかにする。
-
具体的なシナリオ:* 中堅ソフトウェア会社は、意図的な運用構造でAIコーディングを実装する。6か月以内に、彼らはアーキテクチャ上の意思決定プロセスが文書化されておらず、一貫性がないことを発見する。AIツールを非難するのではなく、彼らはそれを体系化する:アーキテクチャレビューゲート、決定テンプレート、長期ビジョンの文書化。6か月後、彼らはすべてのプロジェクト—AI支援と人間が書いたものの両方—でアーキテクチャの再作業を35%削減した。ツールは組織の成熟の触媒となった。
-
隣接する機会:* AIコーディングを中心に運用規律を構築するチームは、時間の経過とともに複利で増える制度的資産を作成する。あなたは開発する:ドメイン固有の再利用可能なコードパターン、ドメイン固有の検証ルール、ますます洗練されるセキュリティレビューチェックリスト、どの問題がAI支援に屈し、どの問題が人間の創造性を必要とするかについての組織的知識。これらの資産は防御可能な競争上の優位性になる。競合他社は同じAIコーディングツールを購入できる;彼らはあなたの運用インフラストラクチャと制度的知識を即座に複製することはできない。
-
実行可能な地平線:* どのユースケースがAIコーディングから利益を得るかだけでなく、なぜ—それらのタスクのどのパターンが機械支援に適しているのか—を文書化する。コードレビューの結果をツール構成とチームトレーニングに接続するフィードバックループを作成する。完全なライフサイクルを測定する:最初の動作バージョンまでの時間、欠陥発見のタイムライン、本番インシデント率、開発者の満足度。最も重要なことは、これらのメトリクスをツールのパフォーマンスだけでなく、組織能力の先行指標として扱うことである。繁栄する組織は、AIコーディングを鏡として使用して、ソフトウェアの構築方法を理解し、体系的に改善する組織である。