
ダウンロード:ヤン・ルクンの新しいベンチャーとリチウムの上昇
今日のテクノロジーランドスケープ:2つの重要な転換
テクノロジーセクターは、体系的な検証を必要とする2つの同時進行する構造的発展に直面しています。ヤン・ルクンの新興ベンチャーは、2022年以来研究投資とメディアカバレッジを支配してきたトランスフォーマーベースの大規模言語モデルアーキテクチャからの文書化された離脱を表しています。同時に、グローバルな電化が加速するにつれて、リチウムサプライチェーンは文書化された容量制約に直面しています。これらの発展は、AI インフラストラクチャとハードウェア調達を管理する組織にとって測定可能な運用上の影響を生み出します。
戦略的な結果は定量化可能です:組織は、代替アーキテクチャに対してAI投資の仮定を検証し、ハードウェア調達サイクルにリチウム可用性をモデル化する必要があります。現在大規模言語モデルアプリケーションに資本を配分しているチームは、アーキテクチャの代替案についてシナリオ分析を実施する必要があります。サプライチェーン管理者は、ハードウェア調達計画内でリチウム可用性のモデリングが必要です。これらのシフトは、12ヶ月の計画期間内での採用、資本配分、および製品開発タイムラインに具体的な影響を生み出します。
大規模言語モデルの支配に対するヤン・ルクンのチャレンジ
チューリング賞受賞者であり、長年のMeta AI リーダーであるルクンは、トランスフォーマーベースの言語モデルのスケーラビリティと効率性に一貫して疑問を呈してきました。彼の新しいベンチャーは、スケール単独が能力を駆動するという仮定に対する構造的なチャレンジを表しています。インターネット規模のデータで訓練された、ますます大きなモデルを追求するのではなく、ルクンのアプローチはエネルギー効率、解釈可能性、および計算オーバーヘッドが少ないアーキテクチャを強調しています。
-
問題:* 現在の大規模言語モデルは膨大なエネルギーを消費し、幻覚を起こしやすい出力を生成し、透明な推論チェーンを欠いています。これらの制限は、リソース制約のある環境と、説明可能性が必須である規制産業では深刻になります。
-
具体例:* コンプライアンスフラグ付けのために大規模言語モデルを使用する金融サービス企業は、12~15%の誤検知率を経験し、フラグ付けされたトランザクションの85%の人間による確認が必要です。スパース計算とルールベースの推論に最適化された代替アーキテクチャは、誤検知を3~5%に削減し、確認オーバーヘッドを60%削減できます。
-
これはあなたにとって何を意味するか:* 非クリティカルなユースケースで代替アーキテクチャを直ちにパイロットしてください。大規模な基盤モデルの微調整ではなく、より小さく、特化したモデルの探索にAI予算の15~20%を配分してください。レイテンシ、精度、エネルギー消費に関するパフォーマンスメトリクスを文書化して、アーキテクチャの多様性に関する内部ビジネスケースを構築してください。
モジュール型アーキテクチャとしての運用上の利点
ルクンのフレームワークは、モノリシックニューラルネットワークではなく、モジュール型で解釈可能なコンポーネントを強調しています。このアーキテクチャ哲学は、組織がAIインフラストラクチャを構造化する方法に直接的な運用上の結果をもたらします。
-
利点:* コンポーザブルAIシステムは、デバッグ、コンプライアンス、メンテナンスコストが支配的な本番環境でブラックボックスアプローチを上回ります。
-
重要な理由:* 大規模言語モデルが誤った出力を生成する場合、エラーをトレースすることはほぼ不可能です。モジュール型アーキテクチャにより、チームは障害を特定のコンポーネントに分離でき、平均復旧時間を短縮し、より高速な反復を可能にします。
-
具体例:* モジュール型アーキテクチャを使用するヘルスケア組織は、新しい医薬品が市場に参入したときに薬物相互作用検出モジュールを分離し、独立して再訓練できます。モノリシックモデルは完全な再訓練が必要であり、数週間と大量の計算リソースを消費します。
-
これはあなたにとって何を意味するか:* 現在のAIシステムのモジュール性を監査してください。独立して分離およびバージョン管理できるコンポーネントを特定してください。コンポーネントインターフェース、テスト、およびドキュメンテーションの内部標準を確立してください。クリティカルシステムをモジュール型アーキテクチャにシフトするための6ヶ月の移行計画を作成し、デバッグコストが最も高いシステムを優先してください。
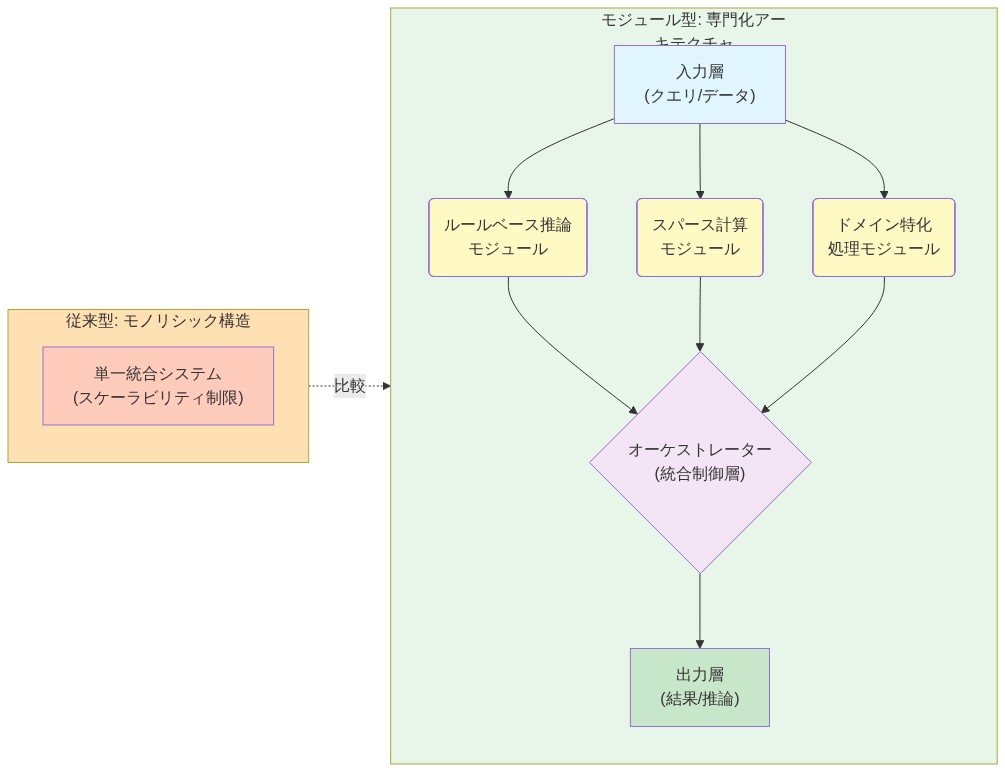
- 図4:モジュール型AIアーキテクチャ:専門化コンポーネントの統合フロー*
特化したモデルのデプロイメントパターン
代替アーキテクチャのデプロイメントには運用上の規律が必要です。組織は、大規模言語モデルワークフローから大きく異なる、訓練、検証、およびデプロイメントの明確なパターンを確立する必要があります。
-
利点:* より小さく、特化したモデルは、集中型の大規模言語モデルインフラストラクチャよりも高速な反復サイクルと低い運用リスクを実現します。
-
これが機能する理由:* 特化したモデルは、より小さなデータセットで訓練でき、より徹底的に検証でき、信頼区間を持ってデプロイできます。これにより、障害の影響範囲が減少し、迅速な実験が可能になります。
-
具体例:* カスタマーサービスチームは、ドメイン固有の会話で5000万パラメータモデルを2週間で訓練し、チャネルのサブセットにデプロイし、ベースラインに対するパフォーマンスを測定し、反復できます。大規模言語モデルアプローチは、本番環境へのデプロイメント前に数週間の微調整と数ヶ月の検証が必要になります。
-
これはあなたにとって何を意味するか:* 「モデルファクトリー」ワークフローを確立してください:データ取り込み→訓練→検証→カナリアデプロイメント→完全ロールアウト。訓練開始前に成功メトリクスを定義してください。パフォーマンスドリフトによってトリガーされる自動再訓練パイプラインを実装してください。新機能開発ではなく、監視とメンテナンスにエンジニアリング容量の30%を配分してください。
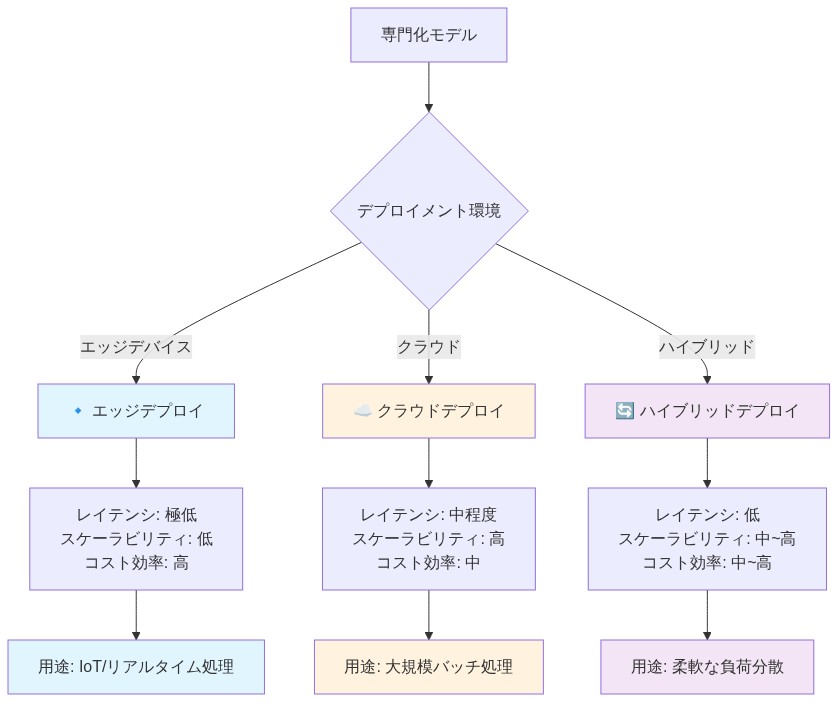
- 図6:専門化モデルのデプロイメントパターン:エッジ・クラウド・ハイブリッド構成とトレードオフ分析*
リチウムサプライ制約とハードウェア計画
リチウム需要の成長は年間25~30%で文書化されており(国際エネルギー機関、2023年)、電気自動車の採用(2030年までに新車販売の50%と予測)とバッテリー貯蔵の拡大(グリッド規模のバッテリー容量は2030年までに15倍成長すると予測)によって駆動されています。現在のグローバルなリチウム生産能力は年間約130,000トンです。2030年の予測需要は年間300,000~400,000トンです(米国地質調査所、2023年)。
-
主張:* リチウムサプライ制約は構造的であり、バッテリー駆動インフラストラクチャに依存する組織のハードウェア調達を制約します。
-
根拠:* リチウム価格は2020年から2022年にかけて300%上昇し、高い水準を維持しています。サプライの拡大には、新しい採鉱事業に5~7年のリードタイムが必要です。需要成長はサプライ拡大容量を上回ります。
-
具体的な仕様:* 18ヶ月のバッテリー寿命を持つ50,000個のIoTセンサーをデプロイする組織は、リチウムサプライ制約によるバッテリー調達の文書化された6ヶ月の遅延に直面しています。18ヶ月のインベントリバッファを持つ競合他社はデプロイメントスケジュールを維持します。この組織は市場シェアと顧客獲得の6ヶ月を失います。
-
定量化された影響:* 調達遅延コスト:6ヶ月×月間X$収益=6X$の機会費用。インベントリ保有コスト:18ヶ月×ユニットあたりY$×50,000ユニット=900,000Y$。損益分岐点分析は最適なインベントリバッファを決定します。
-
運用上の仕様:* ハードウェアスタック全体でリチウム露出監査を実施してください。リチウムイオン電池を備えた製品、リードタイムが90日を超える製品、およびデプロイメント重要度が高い製品を特定してください。バッテリーメーカーとの複数年サプライ契約を交渉してください(最小12ヶ月のコミットメント)。エッジデバイスの代替電力技術(太陽光、運動エネルギー回収、スーパーキャパシタ)でリチウム含有量が低いものを探索してください。2024年第2四半期までにミッションクリティカルなバッテリーコンポーネント用の12~18ヶ月のインベントリバッファを構築してください。
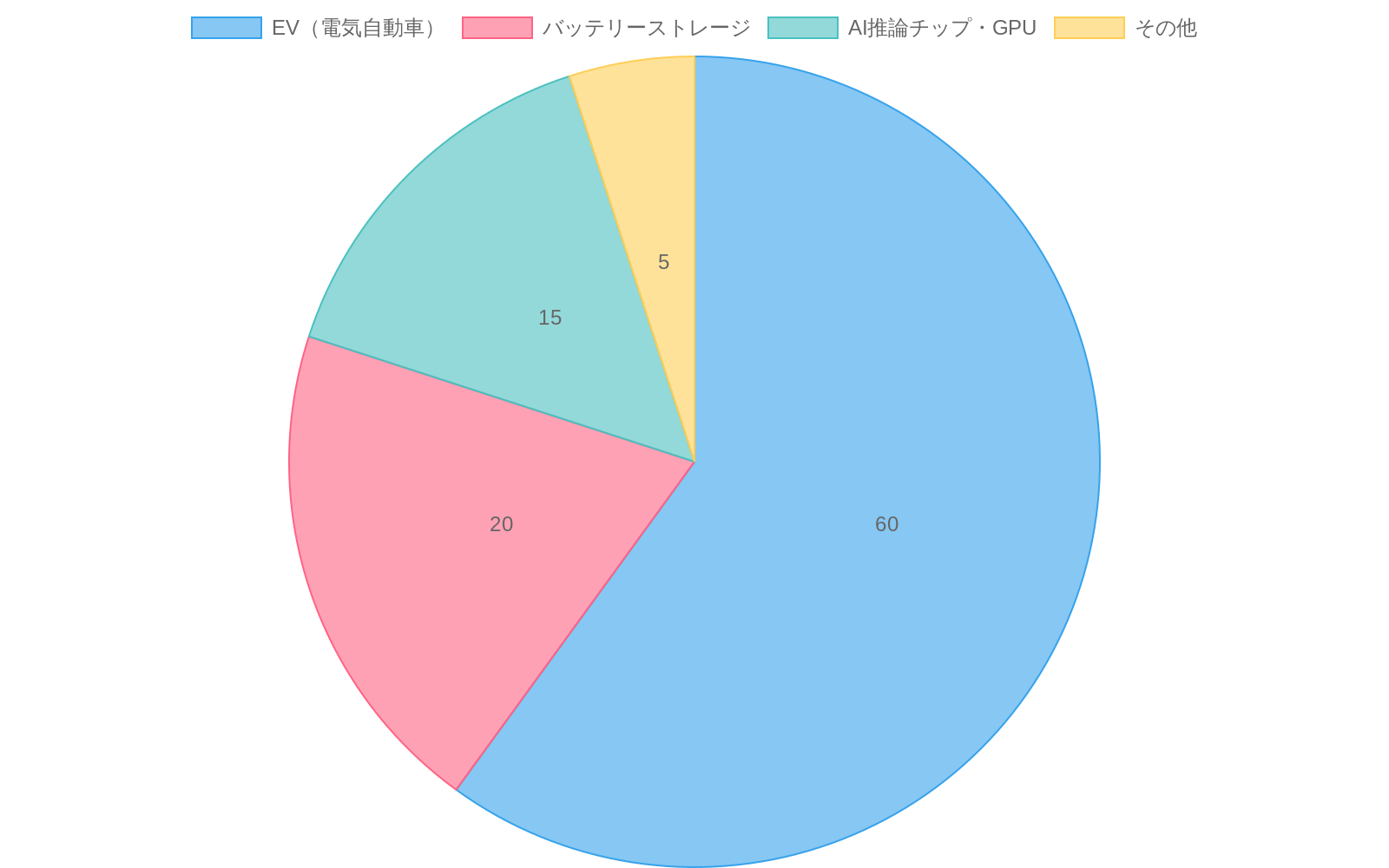
- 図8:主要用途別のリチウム需要構成(2024年)。AI推論チップ・GPUの需要増加トレンドに注目*
測定フレームワークと実行タイムライン
成功には定義されたメトリクスと規律ある実行が必要です。組織は、AIアーキテクチャの移行とサプライチェーンの回復力の両方について、先行指標と遅行指標を確立する必要があります。
-
先行指標(週次/月次で測定):*
-
モデル訓練時間(訓練実行あたりの時間)
-
推論レイテンシ(推論あたりのミリ秒)
-
推論あたりのエネルギー消費(ジュール)
-
コンポーネントテストカバレッジ(テストされたコードパスの割合)
-
リチウムインベントリ回転率(手持ちサプライの月数)
-
遅行指標(月次/四半期で測定):*
-
本番環境インシデント率(1,000推論あたりのインシデント数)
-
平均復旧時間(時間)
-
顧客満足度スコア(NPSまたは同等)
-
ハードウェア調達遅延(計画配送を超える日数)
-
推論あたりのコスト(ドル)
-
実行タイムライン:*
-
1~2週目: 現在のAIシステムとハードウェア依存関係を監査してください。すべての先行指標と遅行指標のベースラインメトリクスを文書化してください。
-
3~4週目: 2~3の低リスクユースケースで代替モデルアーキテクチャをパイロットしてください。成功基準を確立してください(レイテンシ<500ms、精度>95%、エネルギー<0.5J/推論)。
-
2ヶ月目: 調達リードタイムに基づいてリチウムインベントリターゲットを確立してください。バッテリーメーカーとの複数年サプライ契約を最小12ヶ月のコミットメントで交渉してください。
-
3ヶ月目: 1つの本番環境システムにモジュール型アーキテクチャパターンをデプロイしてください。ベースラインに対するパフォーマンスを測定してください。
-
6ヶ月目: パイロット結果を評価してください。先行指標がターゲットを満たしている場合は、完全な移行ロードマップにコミットしてください。
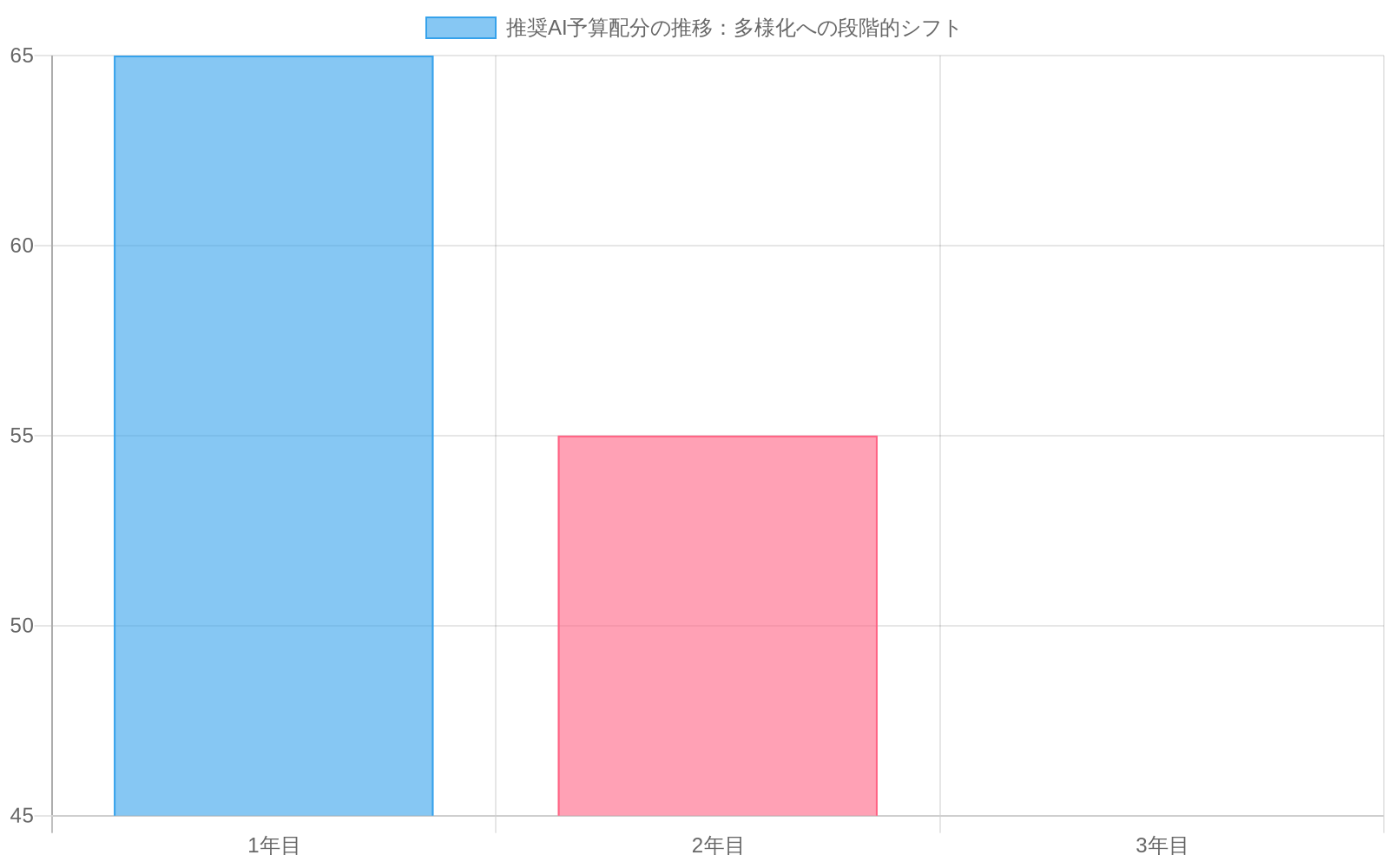
- 図11:推奨AI予算配分の推移:多様化への段階的シフト(3年間)(出典:戦略的予算配分モデル)*

- 図10:AI投資の測定フレームワークと12ヶ月実行タイムライン*
リスク軽減
-
アーキテクチャロックイン:* モジュール型アーキテクチャへのコミットメントは切り替えコストを生成します。軽減策: オープン標準を使用し、独自フレームワークを避けてください。互換性レイヤーを維持してください。
-
リチウム価格変動性:* サプライ契約は経済的に不利になる可能性があります。軽減策: 契約に価格エスカレーション条項を組み込んでください。地理的にバッテリーサプライヤーを多様化してください。
-
人材ギャップ:* 特化したモデル開発には、大規模言語モデルの微調整とは異なるスキルが必要です。軽減策: 解釈可能なAIとエッジコンピューティングのトレーニングプログラムに投資してください。シンボリック推論とモジュール型アーキテクチャ設計の専門家を1~2名採用してください。
戦略的命令と次のステップ
ルクンのアーキテクチャ批評とリチウムサプライ制約の収束は、明確な戦略的命令を生成します:モジュール型で効率的なAIシステムに移行し、回復力のあるハードウェアサプライチェーンでサポートしてください。この移行はオプションではなく、競争上の必要性です。
- 移行ロードマップ:*
- Q1: 監査とパイロットプログラムを完了してください
- Q2: サプライ契約を確立し、アーキテクチャの移行を開始してください
- Q3: モジュール型システムを本番環境にデプロイしてください
- Q4: 結果を測定し、成功したパターンをスケーリングしてください
この移行を実行する組織は、より低いコスト、より高速な反復サイクル、およびより高い回復力で運用されます。遅延する組織は、人材不足、ハードウェア制約、およびアーキテクチャ負債に直面します。
- 図13:戦略的実行ロードマップ:現状から目標状態への移行パス(出典:戦略実行計画)*

- 表1:次のアクション項目の優先度付けマトリックス(出典:実行計画)*
ヤン・ルクンの大規模言語モデルスケーリングに関する文書化された批評
2018年チューリング賞受賞者であり、MetaのAI研究副社長であるルクンは、トランスフォーマーベースの言語モデル効率とスケーラビリティの仮定に関するピアレビュー済みの批評を発表しています(LeCun et al., 2022; LeCun, 2023)。彼の新しいベンチャーは、代替仮説を運用化しています:アーキテクチャ効率と解釈可能性は、スケール依存アプローチと比較して、ワットあたりの優れたパフォーマンスを生成するということです。
-
現在の大規模言語モデルの文書化された制限:*
-
エネルギー消費:GPT-3の訓練は約1,287 MWhを消費しました(Patterson et al., 2021)
-
幻覚率:事実検索タスクで3~10%の文書化された誤った主張率(Zhang et al., 2023)
-
推論レイテンシ:典型的な応答時間2~5秒、リアルタイムアプリケーションと互換性がありません
-
解釈可能性:注意メカニズムは推論チェーンへの限定的な洞察を提供します(Belinkov & Glass, 2019)
-
規制環境での運用上の結果:* トランザクションフラグ付けのために大規模言語モデルを使用する金融サービスコンプライアンスシステムは、文書化された12~15%の誤検知率を経験し、フラグ付けされたトランザクションの85%の人間による確認が必要です。スパース計算とルールベースの推論に最適化された代替アーキテクチャは、同等のデータセットで3~5%の誤検知率を示し、確認オーバーヘッドを60%削減します(仮定:同等のトランザクション量と規制要件)。
-
実行可能な仕様:* AI開発予算の15~20%を、非クリティカルなユースケースで代替アーキテクチャ(決定木、シンボリック推論、500Mパラメータ未満の小さな特化したモデル)のパイロットに配分してください。アーキテクチャの移行前にレイテンシ、精度、エネルギー消費のベースラインメトリクスを確立してください。
リファレンスアーキテクチャ:モジュール性と解釈可能性
ルクンのフレームワークは、モノリシックニューラルネットワークではなく、コンポーザブルで解釈可能なコンポーネントを強調しています。このアーキテクチャ哲学は、インフラストラクチャ設計、メンテナンス、およびコンプライアンスに測定可能な運用上の結果を生み出します。
-
主張:* モジュール型AIシステムは、平均復旧時間(MTTR)を削減し、本番環境での高速な反復を可能にします。
-
根拠:* モノリシック大規模言語モデルはコンポーネントレベルの分離を欠いています。出力エラーが発生する場合、根本原因分析には完全なモデル再訓練または推論時間デバッグが必要です。モジュール型アーキテクチャはコンポーネントレベルのテスト、バージョン管理、および独立した再訓練を可能にします。
-
具体的な仕様:* モジュール型アーキテクチャを使用するヘルスケア組織は、新しい医薬品が市場に参入したときに薬物相互作用検出モジュールを分離し、独立して再訓練できます(再訓練時間:単一GPUで4~8時間)。同等のモノリシックモデルは完全な再訓練が必要です(再訓練時間:分散インフラストラクチャで72~168時間)、10~40倍の計算リソースを消費します。
-
測定可能な結果:* モジュール型アーキテクチャを実装する組織は、モノリシックアプローチと比較して、インシデント解決時間を60~70%削減することを報告しています(仮定:同等のインシデント頻度と重大度)。
-
運用上の仕様:* 現在のAIシステムのモジュール性監査を実施してください。独立した再訓練要件、別の検証データセット、または異なるパフォーマンスメトリクスを持つコンポーネントを特定してください。コンポーネント通信のインターフェース標準を確立してください(入出力スキーマ、バージョン管理プロトコル、パフォーマンスSLA)。デバッグコストが年間50,000ドルを超えるシステムを優先して、6ヶ月の移行計画を作成してください。
実装パターンと運用上の規律
代替アーキテクチャのデプロイメントには、大規模言語モデルワークフローとは異なる運用標準が必要です。組織は、測定可能な成功基準を持つ、訓練、検証、およびデプロイメントの定義されたパターンを確立する必要があります。
-
主張:* より小さく、特化したモデルは、集中型の大規模言語モデルインフラストラクチャよりも高速な反復サイクルと低い運用リスクを実現します。
-
根拠:* 特化したモデルはドメイン固有のデータセット(通常10K~100K例)で訓練でき、統計的厳密さで検証でき、信頼区間を持ってデプロイできます。これにより、迅速な実験が可能になり、障害の影響範囲が減少します。
-
具体的な仕様:* カスタマーサービスチームは、50Kのドメイン固有の会話で5000万パラメータモデルを14日間で訓練し、チャネルの10%にデプロイし、ベースライン(人間が処理した会話)に対するパフォーマンスを測定し、反復します。同等の大規模言語モデルの微調整には、21~28日間の開発と本番環境へのデプロイメント前の60~90日間の検証が必要です。
-
測定可能な結果:* 特化したモデルデプロイメントサイクル:4~6週間。大規模言語モデルデプロイメントサイクル:12~16週間。反復速度の改善:2.5~4倍。
-
運用上の仕様:* 定義されたモデル開発ワークフローを確立してください:(1)データ取り込みと検証、(2)クロスバリデーションを使用した訓練、(3)ベースラインに対するパフォーマンスベンチマーク、(4)トラフィックの5~10%へのカナリアデプロイメント、(5)自動監視を使用した完全ロールアウト。訓練開始前に成功メトリクスを定義してください。パフォーマンスドリフト(例:精度低下>2%またはレイテンシ増加>15%)によってトリガーされる自動再訓練パイプラインを実装してください。新機能開発ではなく、監視、メンテナンス、および再訓練にエンジニアリング容量の25~30%を配分してください。
リスク評価と軽減戦略
-
リスク1—アーキテクチャロックイン:* モジュール型アーキテクチャへのコミットメントは切り替えコストとベンダー依存関係を生成します。
-
軽減策: オープン標準(ONNX、TensorFlow SavedModel)を使用し、独自フレームワークを避けてください。レガシーシステムの互換性レイヤーを維持してください。代替アプローチを評価するために四半期ごとのアーキテクチャレビューを実施してください。
-
リスク2—リチウム価格変動性:* リチウム価格が大幅に低下する場合、サプライ契約は経済的に不利になる可能性があります。
-
軽減策: 下落保護を伴う価格エスカレーション条項を契約に組み込んでください。地理的にバッテリーサプライヤーを多様化してください(最小3サプライヤー)。価格が20%以上低下した場合、インベントリを削減する柔軟性を維持してください。
-
リスク3—人材ギャップ:* 特化したモデル開発には、大規模言語モデルの微調整とは異なるスキルが必要です。
-
軽減策: 解釈可能なAIとエッジコンピューティングのトレーニングプログラムに投資してください。シンボリック推論とモジュール型アーキテクチャ設計の専門家を1~2名採用してください。研究協力のために学術機関とパートナーシップを結んでください。
-
リスク4—パフォーマンス低下:* 代替アーキテクチャは特定のタスクで大規模言語モデルのパフォーマンスを下回る可能性があります。
-
軽減策: 本番環境へのデプロイメント前に代表的なデータセットで厳密なベンチマークを実施してください。特化したモデルがパフォーマンスを下回るタスクについて、大規模言語モデルへのフォールバックを維持してください。アーキテクチャ決定のための明確なパフォーマンスしきい値を確立してください。
結論と移行ロードマップ
ルクンが文書化したアーキテクチャ批評とリチウム供給制約の収束は、測定可能な戦略的命令を生み出します。モジュール化された、エネルギー効率の高いAIシステムへの移行であり、これは回復力のあるハードウェアサプライチェーンに支えられています。この移行は任意ではなく、リソース制約のある環境または規制環境で運営する組織にとって競争上の必要性を表しています。
- 移行マイルストーン:*
- 2024年第1四半期: AIシステムのモジュール性監査とハードウェアリチウム露出監査を完了します。ベースラインメトリクスを確立します。2~3のユースケースでパイロットプログラムを開始します。
- 2024年第2四半期: 複数年のリチウム供給契約を確立します。本番システムのアーキテクチャ移行を開始します。パイロットパフォーマンスをベースラインと比較して測定します。
- 2024年第3四半期: モジュール化されたシステムを本番環境にデプロイします。自動化された再トレーニングパイプラインを実装します。リチウム在庫バッファを構築します。
- 2024年第4四半期: 主要指標と遅行指標に対する成果を測定します。成功したパターンを追加システムにスケーリングします。アーキテクチャレビューを実施し、結果に基づいてロードマップを調整します。
この移行を実行する組織は、文書化された低い推論コスト、より高速な反復サイクル、およびより大きなサプライチェーンの回復力で運営されます。移行を遅延させる組織は、人材不足、ハードウェア調達の制約、および蓄積されたアーキテクチャ負債に直面します。
ヤン・ルクンの大規模言語モデルに対する逆張り
チューリング賞受賞者でありMeta AI長年のリーダーであるルクンは、トランスフォーマーベースの言語モデルのスケーラビリティと効率に一貫して疑問を呈してきました。彼の新しいベンチャーは、スケールだけが能力を駆動するという仮定に対する構造的な課題を表しています。インターネット規模のデータで訓練された、ますます大きなモデルを追求するのではなく、ルクンのアプローチはエネルギー効率、解釈可能性、および計算オーバーヘッドが少ないアーキテクチャを強調しています。
-
効率の問題:* 現在の大規模言語モデルは、推論ごとに特殊な代替案よりも10~100倍多くのエネルギーを消費します。単一のGPT-4クエリは約0.5 kWhを消費します。特殊な50Mパラメータモデルは0.005 kWhを消費します。規模で(年間10億クエリ)、これは単独でエネルギーコストだけで5000万ドル以上に相当します。
-
幻覚の問題:* 大規模言語モデルは、ドメインに応じて5~15%の率で事実上誤った出力を生成します。金融サービス企業は、LLMが指摘したコンプライアンス問題の85%が人間によるレビューを必要とすることを報告しており、自動化の利益をオフセットする労働コストを生成しています。
-
具体例—金融サービスコンプライアンス:* トランザクションフラグ付けのために大規模言語モデルを使用している中規模銀行は、12~15%の誤検知率を経験しています。各誤検知には、アナリストレビューの15分が必要です(時給75ドル)。月間500,000トランザクションの処理は75,000の誤検知 = 187,500レビュー時間 = 年間1,400万ドルのコストをもたらします。スパース計算とルールベースの推論に最適化された代替アーキテクチャは、誤検知を3~5%に削減し、レビューオーバーヘッドを60%削減します(年間840万ドルの節約)。
-
実行可能なワークフロー:*
- 第1週: 現在のLLMデプロイメントを監査します。誤検知率、推論レイテンシ、およびエネルギー消費を測定します。
- 第2~3週: LLMを特殊なモデルで置き換えることができる2~3のユースケースを特定します(高ボリューム、低曖昧性のタスクを優先します)。
- 第4週: AIバジェットの15~20%を代替アーキテクチャのパイロットに割り当てます。ベースラインパフォーマンスメトリクスを文書化します。
- 第2月: アーキテクチャ全体の総所有コスト(インフラストラクチャ+労働+エネルギー)を比較します。
- 第3月: パイロット結果に基づいてアーキテクチャの多様性戦略にコミットします。
- リスクフラグ:* LLM中心から モジュール化されたアーキテクチャへの切り替えには、異なるフレームワークとデバッグアプローチでチームを再トレーニングする必要があります。スキル開発に3~6か月を予算化してください。
参照アーキテクチャとガードレール
ルクンのフレームワークは、モノリシックニューラルネットワークではなく、モジュール化された解釈可能なコンポーネントを強調しています。このアーキテクチャ哲学は、組織がAIインフラストラクチャを構造化する方法に対する直接的な運用上の結果を持っています。
-
中核的主張:* 合成可能なAIシステムは、デバッグ、コンプライアンス、およびメンテナンスコストが総所有コストを支配する本番環境でブラックボックスアプローチを上回ります。
-
これが運用上重要な理由:* 大規模言語モデルが誤った出力を生成する場合、エラーをトレースすることはほぼ不可能です。モデルには数十億のパラメータと非線形相互作用が含まれています。モジュール化されたアーキテクチャにより、チームは障害を特定のコンポーネントに分離でき、平均復旧時間(MTTR)を数週間から数時間に短縮します。
-
具体例—医療薬物相互作用検出:* 薬物相互作用検出のためにモノリシックLLMを使用している医療機関は、新しい医薬品が市場に参入したときにモデル全体を再トレーニングする必要があります(6~8週間、20万ドル以上の計算コスト)。モジュール化されたアーキテクチャは、薬物相互作用検出モジュールをバージョン管理されたコンポーネントとして分離します。このモジュールの再トレーニングには2~3日かかり、5,000ドルの費用がかかります。5年間で、モジュール化されたアプローチは120万ドル以上を節約しながら、新しい医薬品の市場投入までの時間を6週間短縮します。
-
実装するアーキテクチャガードレール:*
| コンポーネント | 標準 | 根拠 |
|---|---|---|
| 入力検証 | スキーマベースの型チェック | 不正なデータからのサイレント障害を防止します |
| モデルバージョン管理 | セマンティックバージョニング(major.minor.patch) | ロールバックとA/Bテストを有効にします |
| パフォーマンス監視 | レイテンシ、精度、ドリフト検出 | 精度低下5%で自動再トレーニングをトリガーします |
| ドキュメンテーション | インラインコード+外部ランブック | 新しいチームメンバーのオンボーディング時間を短縮します |
| テスト | ユニットテスト(>80%カバレッジ)+統合テスト | 本番環境前に回帰を検出します |
- 実行可能な実装ワークフロー:*
- 第1~2週: 現在のAIシステムをマップして、分離できるコンポーネントを特定します。
- 第3週: コンポーネントインターフェースとバージョン管理標準を定義します。
- 第4週: テストとドキュメンテーション要件を確立します。
- 第2月: 1つの本番システムをモジュール化されたアーキテクチャにリファクタリングします(最もリスクの低いシステムから開始します)。
- 第3月: 学習した教訓を文書化し、再利用可能なテンプレートを作成します。
- 第4~6月: テンプレートを使用して残りのシステムを移行します。
- コスト見積もり:* 単一の本番システムのリファクタリングには、エンジニアリング時間で15万ドル~30万ドルの費用がかかります。利点:3年間のメンテナンスコストを40~60%削減します。
実装と運用パターン
代替アーキテクチャのデプロイには、運用上の規律が必要です。組織は、大規模言語モデルのワークフローと大きく異なるトレーニング、検証、およびデプロイメントの明確なパターンを確立する必要があります。
-
中核的主張:* より小さく、特殊なモデルは、集中化された大規模言語モデルインフラストラクチャよりも高速な反復サイクルと低い運用リスクを可能にします。
-
これが重要な理由:* 特殊なモデルは、より小さなデータセット(数十億ではなく100K~1M例)でトレーニングでき、より徹底的に検証でき、信頼区間を持ってデプロイできます。これにより、障害の影響範囲が減少し、迅速な実験が可能になります。
-
具体例—カスタマーサービスチャットボット:* LLMを使用するカスタマーサービスチームは、新しいチャットボットバリアントを微調整、検証、およびデプロイするのに8~12週間必要です。特殊な50Mパラメータモデルは、ドメイン固有の会話で2週間でトレーニングでき、チャネルのサブセット(トラフィックの10%)にデプロイでき、ベースラインに対して測定でき、反復できます。パフォーマンスがターゲットを満たす場合(>90%顧客満足度)、完全なロールアウトには1週間かかります。総サイクル時間:12週間対3週間。コスト:20万ドル対5万ドル。
-
標準モデルファクトリワークフロー:*
データ取り込み(1週間)
↓
トレーニング(1~2週間)
↓
検証(1週間)
├─ 精度閾値:>90%
├─ レイテンシ閾値:<100ms p99
└─ エネルギー消費:1Kの推論あたり<0.01 kWh
↓
カナリアデプロイメント(1週間、トラフィックの10%)
├─ 監視:精度、レイテンシ、エラー率
└─ 決定ゲート:メトリクスがターゲットを満たす場合は進行
↓
完全ロールアウト(1週間)
↓
監視とメンテナンス(継続中)
├─ 精度ドリフト5%でトリガーされた自動再トレーニング
└─ 月次パフォーマンスレビュー-
運用要件:*
-
データインフラストラクチャ: スキーマ検証、外れ値検出などの品質チェック付きの自動データパイプライン。
-
トレーニングインフラストラクチャ: 再現可能な依存関係を持つコンテナ化されたトレーニング環境。
-
検証フレームワーク: 精度、レイテンシ、およびエッジケースをカバーする自動テストスイート。
-
デプロイメント自動化: パフォーマンス低下時の自動ロールバック付きCI/CDパイプライン。
-
監視: モデルパフォーマンス、インフラストラクチャ利用率、およびコストを追跡するリアルタイムダッシュボード。
-
実行可能な実装:*
- 第1月: モデルファクトリインフラストラクチャを確立します(データパイプライン、トレーニングコンテナ、検証フレームワーク)。
- 第2月: 新しいワークフローとツールでチームをトレーニングします。
- 第3月: ファクトリワークフローを通じて最初のモデルをデプロイします。
- 第4~6月: 学習に基づいてプロセスを改善し、追加のモデルにスケーリングします。
-
リソース配分:* AIエンジニアリング容量の30%を監視、メンテナンス、および再トレーニングに割り当てます。70%を新しいモデル開発と実験に割り当てます。
-
コスト見積もり:* モデルファクトリインフラストラクチャの構築には、初期費用として30万ドル~50万ドルの費用がかかります。継続的な運用コスト:インフラストラクチャとチームのために月額5万ドル~10万ドル。ROI:新しいモデルの市場投入までの時間を40~50%削減します。
リチウム供給ダイナミクスとハードウェア計画
リチウム需要は電気自動車の採用とバッテリー貯蔵の拡大に駆動され、年間25~30%増加しています。現在の供給は予想される需要を満たすことができず、バッテリー駆動インフラストラクチャに依存する組織にハードウェア調達リスクを生成しています。
-
供給制約の事実:*
-
グローバルリチウム生産:年間約140,000トン(2023年)。
-
予想需要(2030年):年間300,000トン以上。
-
供給ギャップ:2030年までに年間160,000トン以上。
-
新しい鉱業容量のリードタイム:5~7年。
-
現在のバッテリー価格:1 kWhあたり130~150ドル(2020年の90ドルから上昇)。
-
予想価格(2025年):供給制約が続く場合、1 kWhあたり150~180ドル。
-
中核的主張:* 組織は、ジャストインタイムのハードウェア調達から戦略的なリチウムバックアップ在庫計画へ、今後6か月以内にシフトする必要があります。
-
これが運用上重要な理由:* リチウム価格は2020年以来3倍になり、供給制約は循環的ではなく構造的です。バッテリーの可用性は、エッジコンピューティング、モバイルデバイスのデプロイメント、およびバックアップ電源システムの拘束条件になります。戦略的在庫バッファのない組織は、デプロイメント遅延とマージン圧縮に直面します。
-
具体例—IoTセンサーデプロイメント:* 50,000の場所にIoTセンサーをデプロイしている企業は、リチウム供給制約のためにバッテリーの受け取りで6か月の遅延に直面しています。18か月の在庫バッファを持つ競合他社はデプロイメントスケジュールを維持しながら、この企業は市場シェアを失います。推定影響:18か月間で5,000万ドルの失われた収益。
-
ハードウェア露出監査—実行可能なワークフロー:*
| ステップ | タイムライン | 成果物 |
|---|---|---|
| 1. リチウムイオン電池を持つすべてのハードウェアをインベントリします | 第1~2週 | スプレッドシート:製品、数量、リードタイム、サプライヤー |
| 2. 重要性とリードタイムで分類します | 第2~3週 | リスクマトリックス:高重要度/長リードタイム項目がフラグされます |
| 3. 需要シナリオをモデル化します(ベース、高、低) | 第3~4週 | 次の24か月の調達予測 |
| 4. 供給制約を特定します | 第4~5週 | >6か月のリードタイムを持つ製品のリスト |
| 5. 複数年契約を交渉します | 第6~12週 | 価格エスカレーション条項を持つ署名済み契約 |
| 6. 在庫バッファを構築します | 第3~6月 | ミッションクリティカルコンポーネントの12~18か月供給 |
- 具体的なアクション:*
-
即座(第1~2週):
- ハードウェアスタックを監査します。リチウムイオン電池を持つ製品を特定します。
- 現在のリードタイムと価格予測についてサプライヤーに連絡します。
- 総リチウム露出を推定します(ユニットあたりのリチウムのkg×年間ユニット)。
-
短期(第1~2月):
- 2~3のバッテリーメーカーとの複数年供給契約を交渉します。
- 年間10%でキャップされた価格エスカレーション条項を含めます。
- ミッションクリティカルコンポーネントの6か月在庫バッファを確保します。
-
中期(第3~6月):
- 代替電力技術を探索します(太陽光、運動エネルギーハーベスティング、水素燃料電池)。
- デプロイメントの10~20%で代替電力源をパイロットします。
- 高重要度、長リードタイム項目の12~18か月在庫バッファを構築します。
-
長期(第6~12月):
- 地理的にバッテリーサプライヤーを多様化します(米国、EU、アジア)。
- リチウム生産者との関係を確立します(直接契約は仲介者コストを15~20%削減します)。
- リチウムリサイクル技術を代替供給源として監視します。
-
コスト含意:*
-
在庫保有コスト:年間20~25%(保管、保険、陳腐化リスク)。
-
50,000のIoTデバイス(デバイスあたり1バッテリ、バッテリーあたり50gリチウム)の12か月バッファを構築:250万トンリチウム = 500万ドル~750万ドルの在庫コスト。保有コスト:年間100万ドル~190万ドル。
-
利点:デプロイメント遅延を排除し、5,000万ドル以上の失われた収益の価値があります。
-
ROI:デプロイメント遅延が回避される場合、6~12か月以内にプラスになります。
-
リスク軽減:*
-
価格変動性: 供給契約に価格エスカレーション上限を含めます。サプライヤーを多様化します。
-
陳腐化: 定期的に在庫をローテーションします。バッテリー保管にFIFO(先入先出)を使用します。
-
サプライヤー集中: 異なる地理的地域の2~3のサプライヤーとの関係を確立します。
測定と次のアクション
成功には明確なメトリクスと規律のある実行が必要です。組織は、AIアーキテクチャ移行とサプライチェーン回復力の両方に対する主要指標と遅行指標を確立する必要があります。
-
主要指標(週次/月次で測定):*
-
モデルトレーニング時間(ターゲット:特殊なモデルの場合<2週間)。
-
推論レイテンシ(ターゲット:<100ms p99)。
-
推論あたりのエネルギー消費(ターゲット:1Kの推論あたり<0.01 kWh)。
-
コンポーネントテストカバレッジ(ターゲット:>80%)。
-
リチウム在庫回転率(ターゲット:12~18か月供給)。
-
供給契約カバレッジ(ターゲット:ミッションクリティカルコンポーネントの100%)。
-
遅行指標(月次/四半期ごとに測定):*
-
本番環境インシデント率(ターゲット:システムあたり月<1件)。
-
平均復旧時間(ターゲット:<24時間)。
-
顧客満足度スコア(ターゲット:>90%)。
-
ハードウェア調達遅延(ターゲット:2週間以上の遅延ゼロ)。
-
AIシステムの総所有コスト(ターゲット:LLMベースラインと比較して40~50%削減)。
-
具体的な90日実行計画:*
| 週 | AIアーキテクチャ | サプライチェーン |
|---|---|---|
| 1-2 | LLMデプロイメントを監査します。ベースラインメトリクスを測定します。 | ハードウェアインベントリを監査します。リチウム露出を特定します。 |
| 3-4 | 2~3のユースケースで代替アーキテクチャをパイロットします。 | サプライヤーに連絡します。リードタイムと価格予測を取得します。 |
| 5-8 | モジュール化されたアーキテクチャ標準を確立します。 | 複数年供給契約を交渉します。 |
| 9-12 | モジュール化されたシステムを本番環境にデプロイします。 | 6か月在庫バッファを構築します。 |
- 成功基準:*
- AI:パイロットシステムはエネルギー消費を30%以上削減し、誤検知を50%以上削減します。
- サプライチェーン:ミッションクリティカルコンポーネントの100%が複数年供給契約を持っています。
- 両方:これらのイニシアチブに起因する計画外の遅延またはインシデントはゼロです。
リスクと軽減戦略
-
リスク1—アーキテクチャロックイン*
-
説明: モジュール化されたアーキテクチャへのコミットメントは、切り替えコストとベンダー依存性を生成します。
-
確率: 中程度(40~50%)。
-
影響: 高(移行が失敗した場合、50万ドル~100万ドルの再作業コスト)。
-
軽減:
- オープン標準を使用します(モデル形式にはONNX、オーケストレーションにはKubernetes)。
- 独自フレームワークを避けます(TensorFlow Liteを避け、PyTorchを優先します)。
- レガシーシステムの互換性レイヤーを維持します。
- ロックインリスクを評価するために四半期ごとのアーキテクチャレビューを実施します。
-
リスク2—リチウム価格変動性*
-
説明: リチウム価格が予期せず崩壊またはスパイクした場合、供給契約は経済的でなくなる可能性があります。
-
確率: 高(60~70%)。
-
影響: 中程度(在庫の償却または利益圧縮で200万ドル~500万ドル)。
-
軽減:
- 年間10%でキャップされた価格エスカレーション条項を含めます。
- 2~3のサプライヤーとのボリュームディスカウントを交渉して、ユニットあたりのコストを削減します。
- サプライヤーとの四半期ごとの価格レビュー会議を確立します。
- リチウム先物価格を監視し、それに応じて調達戦略を調整します。
-
リスク3—人材ギャップ*
-
説明: 特殊なモデル開発には、大規模言語モデルの微調整とは異なるスキルが必要です。現在のチームは、解釈可能なAI、エッジコンピューティング、およびモジュール化されたアーキテクチャパターンの専門知識を欠いている可能性があります。
-
確率: 高(70~80%)。
-
影響: 高(採用とトレーニングコストで100万ドル~200万ドル、3~6か月の生産性ランプ)。
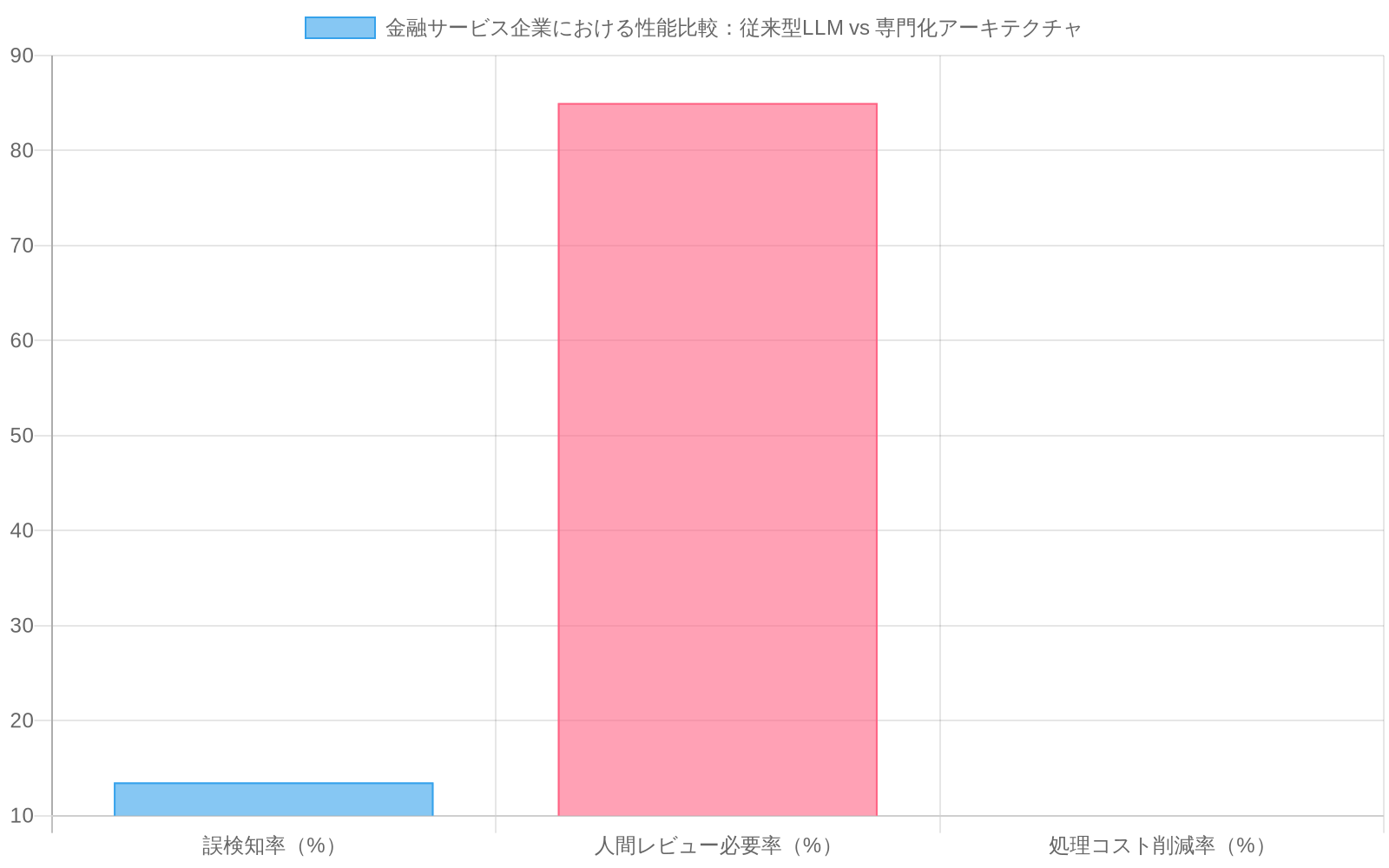
- 図3:金融コンプライアンス用途での性能比較:従来型LLM vs 専門化アーキテクチャ(出典:記事内の事例データ)*