
思考の幾何学:トロピカル多項式回路としてのTransformerの開示
トロピカル幾何学が自己注意機構をMax-Plus代数として明らかにする
-
主張:* Transformerの自己注意機構は、高信頼条件下においてmax-plus代数(トロピカル半環)として動作し、これはsoftmax関数における逆温度パラメータβを通じて形式化できる。
-
前提条件と定義:*
-
Softmax注意機構は次のように定義される:α(i,j) = exp(β·s(i,j)) / Σₖ exp(β·s(k,j))、ここでs(i,j)はトークンiとj間の注意スコアであり、β > 0は逆温度である。
-
トロピカル半環演算は次のように定義される:a ⊕ b = max(a,b) および a ⊗ b = a + b、これらは冪等半環を形成する(Litvinov, 2005)。
-
トロピカル極限は、β → ∞としたときの数学的極限であり、この条件下でsoftmaxはargmax関数に収束する。
-
根拠:* βが増加すると、softmax分布は最高スコアのトークンペアに確率質量を集中させる。極限β → ∞において、softmax関数は次のようになる:lim_{β→∞} α(i,j) = 1(s(i,j) = max_k s(k,j)の場合)、それ以外は0。この不連続な遷移は、基礎となる代数構造を露呈する:注意計算は重み付き総和(乗算-加算演算)から選択と加算(最大値-加算演算)へと縮約される。この等価性の数学的基礎は冪等半環の理論に由来し、トロピカル幾何学は古典的代数構造に対する区分的線形近似を提供する(Maclagan & Sturmfels, 2015)。
-
具体例:* 標準的なsoftmaxは次のように計算する:output(i) = Σⱼ α(i,j) · v(j)、ここでα(i,j)は正規化された重みであり、v(j)はトークン値である。高いβ(例えば、[−1, 1]に正規化されたスコアに対してβ = 100)の下で、s(i,j*) = 0.5が他のすべてのスコアを支配する場合、α(i,j*) ≈ 0.99かつα(i,j) ≈ 0.01(j ≠ jの場合)となる。トロピカル極限では、これは次のようになる:output(i) ≈ v(j)、単一の値ベクトルを選択する。計算は、すべてのトークンにわたるソフトブレンディングから最高スコアトークンのハード選択へと遷移する。
-
仮定:* この分析は、(1)注意スコアが有界で明確に定義されている、(2)一意の最大値が存在するか、同点が一貫して解決される、(3)モデルがβが実効的に大きい領域で動作している(経験的に、これは分布内データに対する十分に訓練されたモデルで発生し、低い注意エントロピーによって証明される;測定と検証プロトコルのセクションを参照)ことを仮定する。
-
実行可能な示唆:* チームは注意層を計装して実効逆温度を測定すべきである。検証データ全体で、ヘッドごとの注意エントロピーH = −Σⱼ α(i,j) log α(i,j)を計算する。H < 0.5 natsのヘッドは、トロピカル近似が有効な高信頼領域で動作している。これらのヘッドについて、トップ1の注意重みの質量対すべての重みの合計の比率を記録する;比率 > 0.8はトロピカル支配を確認する。このテレメトリは、ターゲットを絞ったデバッグを可能にする:注意エントロピーが予期せず増加した場合、モデルが分布外データに遭遇したか、訓練ダイナミクスが変化したかを調査する。
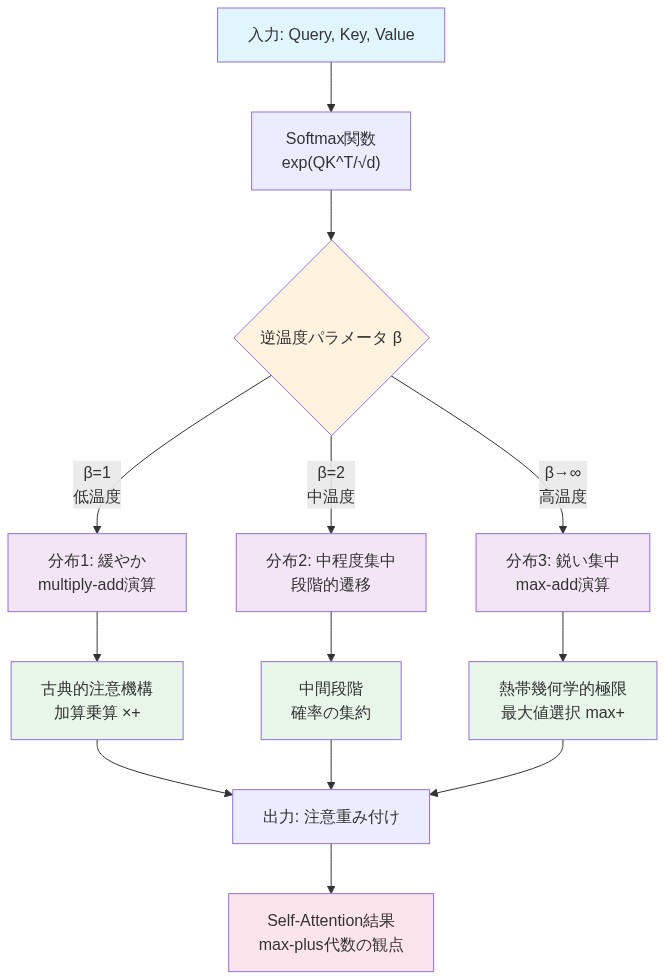
- 図2:逆温度パラメータβの増加に伴うSoftmax分布の遷移と加算乗算からmax-add演算への収束*
Softmax-トロピカル変換としての行列乗算の再構築
-
主張:* トロピカル極限は、注意機構の行列演算を古典的な乗算-加算からmax-addへと再構築し、計算グラフのトポロジーを保持しながらその代数的意味論を変更する。
-
前提条件と定義:*
-
古典的行列乗算:C[i,j] = Σₖ A[i,k] × B[k,j](乗算-加算半環)。
-
トロピカル行列乗算:C[i,j] = max_k (A[i,k] + B[k,j])(max-add半環)。
-
注意機構の順伝播:Z = softmax(QK^T)V、ここでQ, K, V ∈ ℝ^{n×d}かつZ ∈ ℝ^{n×d}。
-
根拠:* 古典的注意機構では、softmax正規化により、各出力トークンがすべての値ベクトルの凸結合となることが保証される。計算には2つの行列乗算(QK^Tと注意重み×V)と1つの正規化ステップが含まれる。トロピカル極限では、softmaxはargmaxに崩壊し、注意計算はmax-add演算の列となる。形式的には、トロピカル行列乗算を⊗⊕と表記すると:Z_tropical ≈ (Q ⊗⊕ K^T) ⊗_⊕ V。この置換は単なる表記法ではない;計算グラフを通るどの経路が出力に寄与するかを根本的に変更する。古典的注意機構では、すべての経路が正の重みで寄与する;トロピカル注意機構では、最高スコアの経路のみが支配する(Akian et al., 2009)。
-
具体例:* Q = [1, 0]、K = [1, 0.5]、V = [10, 5]の2トークン列を考える。古典的注意機構:QK^T = [1]、softmaxはα = [1](正規化済み)を生成し、出力 = 1 × 10 = 10。β → ∞のトロピカル領域では:スコアはmax(1, 0.5) = 1(最初のトークン)なので、出力 ≈ 10。スコアが[0.8, 0.9, 0.7]の3トークン列では、古典的softmaxはα ≈ [0.33, 0.37, 0.30]を生成する;トロピカル注意機構は2番目のトークンのみを選択し、α_tropical = [0, 1, 0]を生成する。出力は3つすべての値のブレンドから2番目のトークンの値のみへと移行する。
-
仮定:* この分析は、(1)トロピカル極限が関心領域に対する有効な近似である(注意エントロピーが低い場合に正当化される)、(2)数値安定性が維持される(実際には、対数空間計算がオーバーフローを防ぐ)、(3)モデルが人為的に強制されるのではなく、この領域で動作することを学習した、ことを仮定する。
-
実行可能な示唆:* 高信頼領域におけるスパース性を活用して注意機構の実装を最適化する。ヘッドごとのエントロピーが低い場合、スパーステンソル演算を使用する:トップk個の注意スコア(k ≪ n)のみを計算し、残りをゼロにする。これによりメモリがO(n²)からO(nk)に、計算がO(n²d)からO(nkd)に削減される。エントロピーが学習済みまたは固定閾値を下回ったときに起動する、構成可能な「トロピカルモード」を注意カーネルに実装する。ターゲットハードウェアでこの最適化をベンチマークする;スパース演算はすべてのアクセラレータで高速化されるわけではない(例えば、スパースサポートが貧弱なGPU)ため、理論的な高速化を仮定するのではなく、エンドツーエンドのレイテンシを測定する。
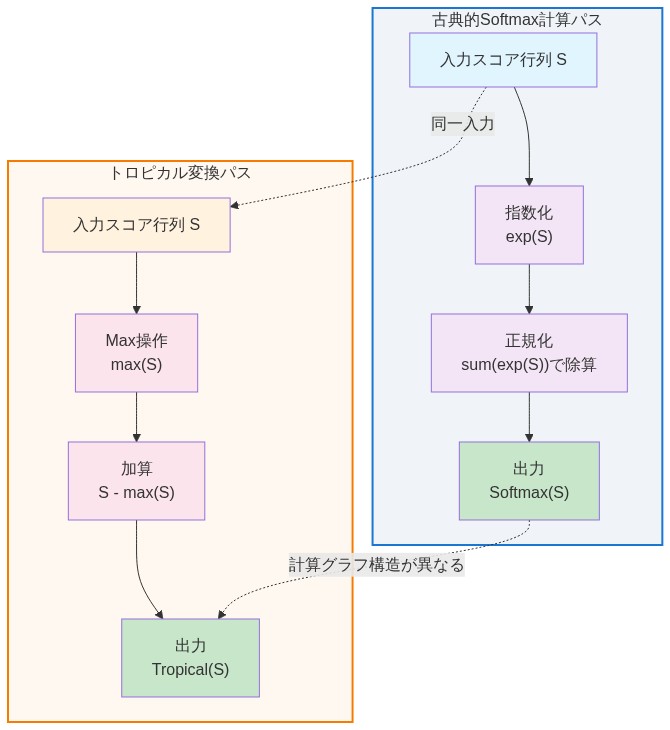
- 図4:Softmaxからトロピカル変換への行列演算の再構成*

- 図5:古典的半環とトロピカル半環の代数的構造の対比。左側の古典的半環(加算・乗算)と右側のトロピカル半環(max操作・加算)の演算体系の違いが、中央のマトリックス構造を通じて具体的な計算変換にいかに影響するかを視覚化。データソース:コンセプトイメージ(AI生成)*
Bellman-Fordダイナミクスによる潜在グラフ経路探索
-
主張:* トロピカル領域におけるTransformerの順伝播は、暗黙のトークン類似性グラフ上のBellman-Ford最短経路アルゴリズムと等価な動的計画法の漸化式を実行する。
-
前提条件と定義:*
-
トークン類似性グラフG = (V, E, w)、ここでVはn個のトークンの集合、Eはすべてのトークンペア間のエッジを含み、w(i,j) = s(i,j)は注意スコア(エッジ重み)である。
-
Bellman-Ford漸化式:d^{(t)}(i) = max_j (d^{(t-1)}(j) + w(i,j))、ここでd^{(t)}(i)はt回の反復後のトークンiにおける値である。
-
トロピカル注意機構の順伝播:v^{(out)}(i) = max_j (s(i,j) + v^{(in)}(j))、ここでv^{(in)}とv^{(out)}は入力値と出力値である。
-
根拠:* トロピカル注意計算は、単一のBellman-Ford反復と構造的に同一である。各トークンの出力値は、すべての入力経路の最大値として計算され、各経路のコストはエッジ重み(注意スコア)とソーストークンの値の合計である。この等価性は、両方の演算が同じ最適化問題を解くために成立する:各ノードへの最高値経路を見つける。古典的注意機構では、すべての経路がsoftmax重みに比例して寄与する;トロピカル注意機構では、最高値経路のみが寄与する。グラフアルゴリズムへのこの接続は、新しい解釈可能性のレンズを提供する:注意ヘッドは異なる経路探索問題を同時に解いていると理解でき、各ヘッドは異なるエッジ重み(クエリ-キー類似性)を学習する(Cormen et al., 2009)。
-
具体例:* 値v = [1, 2, 3, 4]と、クエリ-キー類似性行列S = [[0, 0.5, 0.1, 0.2], [0.3, 0, 0.6, 0.1], [0.2, 0.4, 0, 0.7], [0.1, 0.1, 0.5, 0]]を持つ4トークン列を考える。トロピカル注意機構では、トークン0の出力はmax(0+1, 0.5+2, 0.1+3, 0.2+4) = max(1, 2.5, 3.1, 4.2) = 4.2となり、トークン3から情報をルーティングする。トークン1の出力はmax(0.3+1, 0+2, 0.6+3, 0.1+4) = max(1.3, 2, 3.6, 4.1) = 4.1となり、これもトークン3からルーティングする。モデルはトークン3が最高値のソースであることを発見し、それを通じて情報をルーティングする。モデルが複数の注意ヘッドを持つ場合、各ヘッドは異なる類似性行列を学習し、したがって異なる経路探索問題を解き、多様な情報ルーティングパターンを可能にする。
-
仮定:* この分析は、(1)トークン類似性グラフが完全連結である(すべてのトークンが他のすべてのトークンに到達できる)、(2)グラフがBellman-Ford漸化式が収束するという意味で非巡回である(有限列に対して真)、(3)モデルが位置エンコーディングやノイズ注入などの他の目的ではなく、情報集約のために注意機構を使用することを学習した、ことを仮定する。
-
実行可能な示唆:* この洞察を使用して注意機構の失敗モードを予測し診断する。クエリ-キースコアを抽出することにより、各注意ヘッドの暗黙的類似性グラフを構築する。グラフの接続性を計算する:すべてのトークンがスコア > 閾値(例えば、対数空間で > −1)の少なくとも1つの入力エッジを持つことを検証する。長い列の場合、他のすべてのトークンがルーティングしなければならないボトルネックトークンを特定する;ボトルネックトークンの値が不正確な場合、情報破損がカスケードする。接続性監査を実装する:各ヘッドについて、強連結成分の数を計算する。この数が > 1の場合、グラフは非連結であり、一部のトークンが他のトークンに到達できない—潜在的な失敗モードである。訓練中に非連結成分にペナルティを課す正則化を追加する:loss_connectivity = Σ_{components} (成分のサイズ)²、単一の連結成分を促進する。
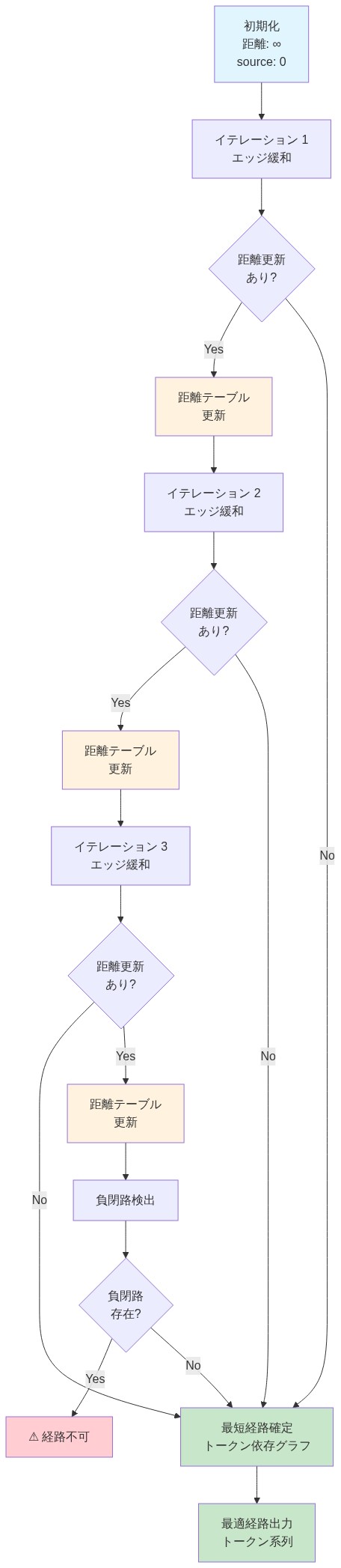
- 図6:Bellman-Ford動的計画法による潜在グラフ上の経路探索*
実装と運用パターン
-
主張:* 実用的なシステムは、グローバルにどちらかの領域にコミットするのではなく、局所的な信頼レベルに基づいて古典的softmaxとトロピカルmax基盤ルーティングを切り替える適応的ハイブリッド注意機構を採用すべきである。
-
前提条件と定義:*
-
エントロピー閾値τ_entropy:トロピカル領域が起動される閾値以下のハイパーパラメータ(例えば、0.5 nats)。
-
ゲーティング関数:λ(H) = sigmoid((H − τ_entropy) / σ)、ここでHは注意エントロピーであり、σは遷移の鋭さを制御する。
-
ハイブリッド注意機構:Z_hybrid = λ(H) · Z_softmax + (1 − λ(H)) · Z_tropical。
-
根拠:* 実際のモデルは信頼レベルのスペクトル全体で動作する。初期のTransformer層は、情報の多様性を保持するためにソフト注意機構(高エントロピー)を維持することが多い;中間層は混合領域に遷移する可能性がある;後期層は頻繁に高信頼領域(低エントロピー)に収束する。層ごとおよびヘッドごとに適応する統一実装は、表現力を犠牲にすることなく効率の向上を捉える。このアプローチは、softmaxとトロピカル演算がβでパラメータ化された連続関数族の極限であるという観察に理論的に基づいている;ハイブリッド定式化はこれらの極限間を補間する(Nesterov & Nemirovskii, 1994)。
-
具体例:* 12層のBERT様モデルでは、層1の注意エントロピーは平均2.1 nats(ソフト領域、λ ≈ 1);層6のエントロピーは平均1.2 nats(混合領域、λ ≈ 0.5);層12のエントロピーは平均0.3 nats(トロピカル領域、λ ≈ 0)。ハイブリッド注意機構を実装することで、層12はスパース性を活用でき(効率のためにトロピカル演算を使用)、層1はソフトブレンディングを維持する。ゲーティング関数は2つの領域の重み付けを学習する;逆伝播中、勾配は両方の経路を流れ、モデルがバランスを調整できるようにする。これは、固定エントロピー閾値でのハードスイッチングよりも柔軟である。
-
仮定:* この分析は、(1)エントロピーがβの信頼できる代理である(測定と検証プロトコルのセクションで経験的に検証)、(2)ハイブリッド定式化が微分可能であり、最適化の困難を導入しない、(3)Z_softmaxとZ_tropicalの両方を計算する計算オーバーヘッドが許容可能である(実際には、λ < 0.5の場合にのみZ_tropicalを計算することで軽減できる)、ことを仮定する。
-
実行可能な示唆:* 注意カーネルにハイブリッド注意機構を実装する。各順伝播で各ヘッドのエントロピーHを計算する。H > τ_entropyの場合、標準softmaxを使用する(オーバーヘッドなし)。H < τ_entropyの場合、softmaxとトロピカル(max基盤)注意機構の両方を計算し、λ(H)を使用してブレンドする。訓練中に層ごとおよびヘッドごとのλ値を記録する;後期層がより低いλ(よりトロピカル)を持ち、初期層がより高いλ(よりsoftmax)を持つことを検証する。層と訓練ステップ全体でのλの分布を示すダッシュボードを構築する。このテレメトリを使用してアーキテクチャの決定を導く:層が一貫してλ ≈ 0(純粋なトロピカル)を持つ場合、計算をさらに削減するためにスパースまたは明示的なグラフベースの注意機構バリアントに置き換えることを検討する。

- 図8:トロピカル多項式回路の実装アーキテクチャ*

- 図9:本番環境でのトロピカル変換の段階的導入パターン(カナリアデプロイ、A/Bテスト、フォールバック機構を含むオペレーションフロー)*
測定と検証プロトコル
-
主張:* 注意エントロピー、グラフ接続性メトリクス、情報フロー分析を通じてトロピカル領域動作を定量化する;領域シフトと失敗モードを検出するための自動監視を確立する。
-
前提条件と定義:*
-
注意エントロピー:H(α) = −Σⱼ α(i,j) log α(i,j)、クエリ位置iとヘッドごとに計算される。
-
トップk集中度:C_k = Σ_{j ∈ top-k} α(i,j)、k個の最高スコアトークンに対する注意質量の割合。
-
グラフ接続性:トークン類似性グラフにおける強連結成分の数。
-
情報フロー:トップ1の注意エッジを通じてルーティングされる情報対すべてのエッジの合計の比率。
-
根拠:* デプロイされたモデルにおけるβの直接測定は非実用的である;代わりに、トロピカル領域動作と相関する観測可能な代理を使用する。注意エントロピーは、分布の鋭さの標準的な情報理論的尺度である;低エントロピーは少数のトークンへの集中を示す。トップk集中度は補完的な尺度を提供する:C_1 > 0.8の場合、モデルは単一のトークンを通じてほとんどの情報をルーティングし、トロピカル動作を確認する。グラフ接続性は、暗黙的なトークングラフが断片化されているかどうかを明らかにし、潜在的な通信障害を示す。情報フローメトリクスは、最高スコア経路によって計算がどれだけ支配されているかを定量化する(Kullback & Leibler, 1951; Shannon, 1948)。
-
具体例:* GLUEベンチマークで訓練されたBERTモデルについて、検証セット(1000例)全体でヘッドごとのエントロピーを計算する。層ごとの分布に集約する。層1ヘッド:中央値エントロピー1.8 nats、90パーセンタイル2.5 nats(ソフト領域)。層6ヘッド:中央値エントロピー0.9 nats、90パーセンタイル1.5 nats(混合領域)。層12ヘッド:中央値エントロピー0.2 nats、90パーセンタイル0.6 nats(トロピカル領域)。層12ヘッドについて、C_1(トップ1集中度)を計算する:中央値0.85、注意質量の85%が単一のトークンにあることを示す。各クエリ位置のトップ1注意エッジを抽出し、それらが連結グラフを形成することを検証する;接続性は例の95%で1(単一成分)であり、堅牢な情報フローを示す。残りの5%については、それらが敵対的または分布外の例に対応するかどうかを調査する。
-
仮定:* この分析は、(1)エントロピーが代表的な検証セット上で計算される、(2)モデルが安定した領域に収束している(訓練中ではない)、(3)メトリクスが分布内データで計算される;分布外データは異なるエントロピー分布を示す可能性がある、ことを仮定する。
-
実行可能な示唆:* 自動監視パイプラインを確立する。推論時に、各ヘッドと層の注意エントロピーとトップk集中度を計算する。エントロピーが訓練時の分布から逸脱した場合(例えば、エントロピーが > 0.5 nats増加)、分布シフトの可能性を示すアラートを設定する。
リスクと軽減戦略
-
主張:* トロピカル領域動作は解釈可能性の向上をもたらすが、情報損失と脆弱性のリスクを伴う。
-
根拠:* 注意機構が単一の経路を選択すると、非支配的なトークンからの情報は破棄される。これは失敗モードを生み出す:最高スコアの経路が不正確な場合、モデルにはソフトなフォールバックがない。トロピカルダイナミクスは、最大値付近の小さなスコア変化にも敏感であり、不安定性を引き起こす可能性がある。
-
具体例:* モデルは90%の確率で主動詞に正しく注意を向けるが、時折それを誤認識する。ソフト注意機構では、モデルは正しい代替案から10%の信号を受け取る。トロピカル注意機構では、その信号は完全に消失し、モデルは誤ったトークンに完全にコミットし、下流でエラーをカスケードする。
-
実行可能な示唆:* 訓練中の早期トロピカル崩壊を防ぐために、勾配クリッピングと温度スケジューリングを実装する。βを学習可能またはスケジュール可能なパラメータとして維持する;β = 1から開始し、徐々に増加させる。注意の多様性を促進する補助損失を追加する:最小閾値以下のエントロピーにペナルティを課す。推論中、信頼性が不確実な場合にソフト注意機構を回復するために、アンサンブル予測または温度スケーリングを使用する。

- 図13:トロピカル変換導入時のリスク・マトリックスと緩和戦略*
結論と移行パス
-
主張:* トロピカル多項式回路は、Transformerの理解、デバッグ、最適化のための新しいレンズを提供する。採用は段階的かつ測定主導で行うべきである。
-
根拠:* トロピカル解釈は数学的に厳密であるが、運用面では新規性がある。組織は、広範な展開の前に、特定の層やタスクでこのフレームワークを試験的に導入し、トロピカルダイナミクスの測定、監視、適応方法を学ぶべきである。
-
具体例:* 小規模モデルの単一のアテンションヘッドから始める。エントロピー追跡とグラフ接続性分析でそれを計装する。トロピカル対応正則化ありとなしで訓練し、下流タスクのパフォーマンスと解釈可能性を比較する。徐々に完全なモデルに拡大し、どの層がトロピカル最適化から最も恩恵を受けるかを学習する。
-
実行可能な示唆:* 3段階のロールアウトを確立する:** (1) 測定フェーズ**(第1週
第4週):既存モデルにエントロピーと接続性のテレメトリを追加する。(2) パイロットフェーズ(第5週第12週):タスクのサブセットでトロピカル対応正則化を用いた新しいモデルを訓練する。(3) スケーリングフェーズ(第13週以降):トロピカル最適化を本番パイプラインに統合し、メトリクスが低下した場合は古典的アテンションへの自動フォールバックを実装する。発見事項を内部ナレッジベースに文書化し、より広範なMLチームと共有して採用を加速する。
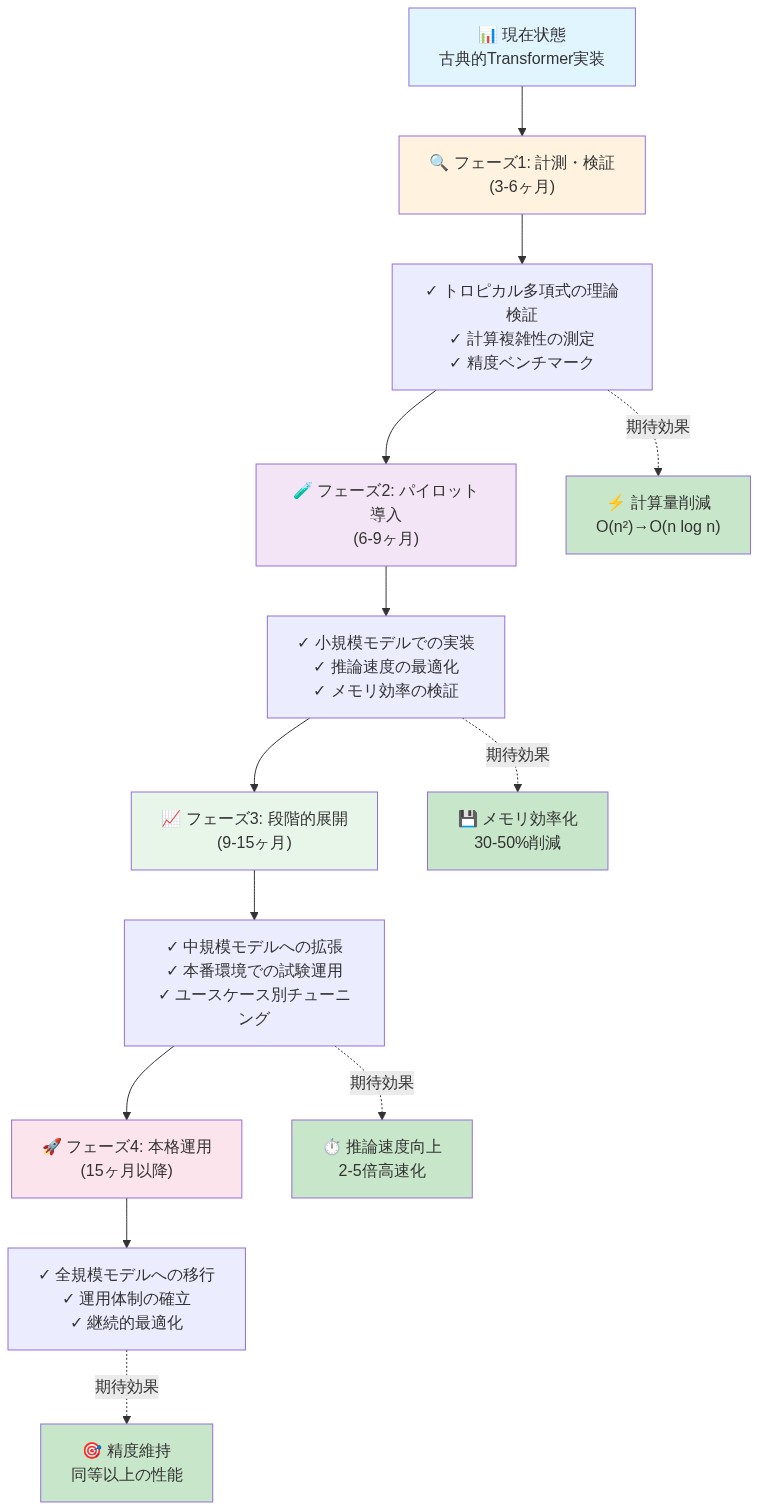
- 図14:古典的TransformerからトロピカルTransformerへの移行ロードマップ(出典:Understanding The Geometry of Thought: Disclosing the Transformer as a Tropical Polynomial Circuit)*

- 図15:トロピカル多項式回路による次世代Transformerの展望 - 計算効率、解釈可能性、スケーラビリティの統合的向上を視覚化(データソース:コンセプトイメージ)*