
スプーンは存在しない。ソフトウェアエンジニアのための機械学習入門
知能の幻想:機械学習が実際に行うこと
機械学習システムは認知的な意味での学習ではなく、統計的パターンマッチングを通じた関数最適化を実行します。この区別は基本的なものであり、機械学習システムを取り巻く多くの神秘性を払拭します。
決定論的な制御フローを持つ従来のソフトウェアとは異なり、機械学習システムは訓練データで発見された統計的関連性を高次元パラメータ空間にエンコードします。形式的には、訓練済みモデルは入力特徴から出力への学習済みマッピングを表し、最適化を通じて発見された重みによってパラメータ化されます。モデルが画像を分類したりテキストを生成したりする場合、それは学習した確率分布全体にわたる高度な補間を実行しており、意味的理解ではありません。
-
具体例:* 95%の精度を達成するスパムフィルタは、訓練コーパス内の単語頻度とスパムラベルの間の統計的関連性を学習しています。このシステムはスパムを概念的に「理解」していません。訓練データ内の相関関係を発見し、それが新しいメールに測定可能な精度で一般化しているのです。この一般化は、訓練分布と展開分布がどの程度一致しているかを反映しており、これは検証可能で定量化可能な特性です。
-
なぜこれが重要か:* デバッグは論理的トレースから統計分析へと移行します。障害は論理的なコードパスエラーではなく、学習表現における分布シフトと境界条件から生じます。正確性は絶対的ではなく確率的になります。モデルは同時に95%の精度を持ちながら、特定の入力部分集合で壊滅的に失敗する可能性があります。これは機械学習を神秘的な現象から、予測可能な特性と定量化可能な制限を持つ特定の数学的ツールのクラスへと再構成します。存在しない「スプーン」は本当の理解です。残されているのは測定可能なパフォーマンス境界を持つ高度なパターンマッチングです。
コードから勾配へ:エンジニアリングパラダイムの転換
従来のソフトウェアエンジニアリングは明示的な制御フローで動作します。エンジニアが命令を書き、コンパイラがそれを翻訳し、実行は決定論的なパスに従います。機械学習はこの関係を反転させます。エンジニアがアーキテクチャと損失関数を定義し、最適化アルゴリズムが損失を最小化するパラメータを発見します。この反転は、AI採用における大きなスキルギャップを説明しています。進歩する実践者は、この根本的に異なるメンタルモデルを内面化した者たちです。
開発サイクルは書き込み・コンパイル・テストから準備・訓練・評価へと変わります。反復はコード論理ではなく、データセットとハイパーパラメータレベルで発生します。バージョン管理はソースコードを超えて、モデルの重み、訓練設定、データ系統、ランダムシードを含むようになります。これらすべてが再現性と結果に影響します。
-
具体例:* データの部分集合で誤った予測をするモデルをデバッグするには、勾配可視化、活性化分析、損失曲面検査が必要です。ステップスルーデバッグではありません。調査者はパラメータ空間で最適化プロセスが何を発見したかを調べており、実行されたコード命令ではありません。
-
実行可能な示唆:* 決定論的デバッグを主要なツールとして放棄してください。勾配分析、統計的検証技法、データセット検査に習熟を深めてください。「プログラム」は明示的な作成ではなく、最適化ダイナミクスから出現します。これには異なるメンタルモデルと異なるツール化が必要です。
データ・コード二重性:訓練セットがアプリケーションである理由
従来のソフトウェアでは、データは明示的な論理に従ってコードを流れます。機械学習では、データが学習動作を定義し、コードが最適化スキャフォルディングを提供します。訓練データセットはシステム動作を決定する主要な成果物です。モデルアーキテクチャは二次的です。
エンジニアは体系的なデータレビュー慣行を開発する必要があります。特徴分布の検査、潜在的なバイアスパターンの特定、ラベル品質の検証、サンプリング方法論の理解、データ由来の文書化です。バイアスのあるデータで訓練されたモデルは、適用されるアーキテクチャの洗練さや正則化技法に関わらず、そのバイアスをエンコードします。
-
具体例:* 成功した男性従業員の履歴データを中心に訓練された採用モデルは、その母集団の統計的パターンを複製することを学習します。モデルは「適格性」を発見していません。むしろ、どの候補者が訓練母集団に似ているかを予測することを学習しています。バイアスは最適化を通じて学習パラメータにエンコードされます。これはコードバグではなく、訓練データ構成の直接的な結果です。
-
実行可能な示唆:* データバージョニングはコードバージョニングと同じくらい重要になります。データセットキュレーションはコードリファクタリングと同等の厳密性を要求します。エッジケースはバグではなく、分布の尾部です。オーバーサンプリング、制限として受け入れる、または明示的に除外するかのいずれかです。訓練セットを仕様として扱ってください。それはモデルが何を学習するかを定義します。
損失関数と目的のミスアライメント
損失関数は最適化アルゴリズムが最小化する数学的目的を定義しますが、この数学的目的は実際のビジネス要件と頻繁に乖離します。微分可能に測定できるものだけを最適化できます。しかし、最も重要なメトリクス(ユーザー満足度、公平性、堅牢性、安全性)は、きれいな数学的定式化に抵抗します。
クロスエントロピーを最小化する分類モデルは、訓練ラベル分布を予測することを学習します。これは数学的に正確ですが、望ましい意思決定動作と一致しない可能性があります。これは、モデルが印象的なベンチマークスコアを達成しながら、展開時に壊滅的に失敗する現象を説明しています。
-
具体例:* エンゲージメント(ページ滞在時間またはクリックスルー率で測定)を最適化するコンテンツ推奨モデルは、注意を引くコンテンツを促進することを学習します。これはしばしば怒りを誘発する素材と相関しています。損失関数は設計通りに動作しました。仕様が間違っていました。最適化は成功しました。目的がミスアライメントしていました。
-
実行可能な示唆:* 損失関数を望ましい動作のプロキシとして作成し、根本的なミスアライメントが持続することを理解してください。正則化、マルチ目的訓練、敵対的堅牢性を緩和戦略として使用してください。解決策ではなく。これは、十分なデータと計算が自動的にアライメントされたシステムを生成するという魔法的思考を防ぎます。ミスアライメントは設計問題であり、データ問題ではありません。
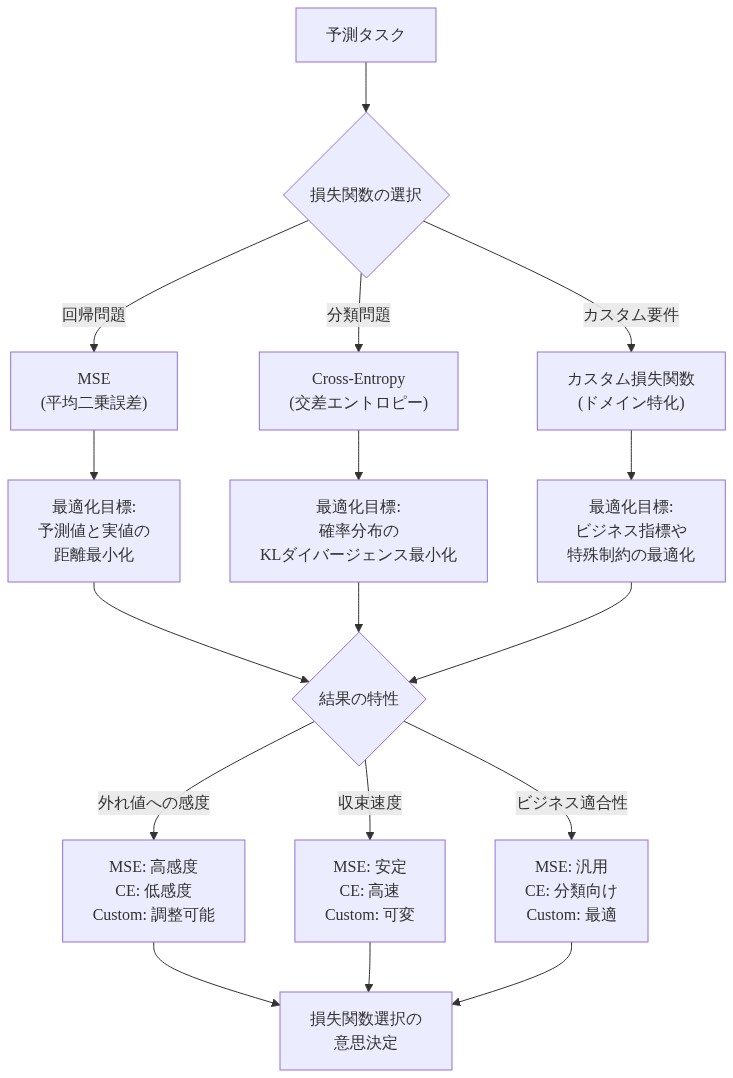
- 図6:損失関数の選択による最適化目標の違いと結果特性の比較*
一般化と分布シフト:展開の現実
モデルは展開条件が訓練条件から乖離する場合、パフォーマンス低下を示します。これは従来のソフトウェアに直接的な類似物がない現象です。決定論的なアプリケーションはコンテキスト全体で同じように動作します。機械学習システムは、展開データが訓練データ分布にどの程度一致しているかに基づいてパフォーマンス分散を示します。
これは従来のソフトウェアリリースとは根本的に異なる展開を作ります。エンジニアは分布ドリフトの統計的監視を実装し、分布外入力に対するフォールバック戦略を設計し、壊滅的な障害モードではなく段階的な劣化を設計する必要があります。
-
具体例:* 都市運転データで訓練されたモデルは、農村道路で危険な障害を示します。コードは壊れていません。学習パラメータの基礎となる統計的仮定はもはや成立しません。分布がシフトしました。モデルの学習関連性はもはや適用されません。
-
実行可能な示唆:* 従来のテストピラミッドを反転させてください。ユニットテストは訓練インフラストラクチャとデータパイプラインの正確性を検証します。広範な統計テストは、多様なシナリオと分布シフト全体でモデル動作を検証します。本番環境でのパフォーマンス低下を検出するための継続的な監視を実装してください。再訓練サイクルをワンタイム展開ではなくメンテナンス操作として設計してください。本番機械学習システムは、継続的な統計的検証とメンテナンスを必要とする生きた成果物です。
解釈可能性の劇場:制限の理解
注意可視化、顕著性マップ、特徴重要度スコアなどの技法は、因果説明ではなく、モデル動作の事後的な合理化を提供します。機械的解釈可能性(実行される数学的操作の理解)と意味的解釈可能性(それらの操作が人間の概念的用語で「意味する」ことの理解)を区別してください。前者は勾配分析を通じて達成可能です。後者は高次元学習表現に対してはほぼ完全に幻想的なままです。
-
具体例:* 顕著性マップは、勾配の大きさを測定することで、分類決定に影響を与えたピクセルを示します。それはこれらのピクセルが決定に影響を与えるべき理由を説明しません。相関が因果的であるかどうか、または学習関連性が展開条件の変化時に持続するかどうかも説明しません。
-
実行可能な示唆:* 虚偽の精度を追求するのではなく、これらの制限を受け入れてください。モデルが失敗する場合、解釈可能性ツールは影響力のある特徴を強調できます。しかし、それらの特徴が決定に影響を与えるべきかどうかを判断するには、アルゴリズムの洞察ではなく、領域専門知識と因果推論が必要です。数学が提供できるよりも多くの明確性を約束する説明の追求をやめてください。解釈可能性ツールをデバッグと検証に使用してください。不確実性を曖昧にする事後的な物語を生成するためではなく。
実践的統合:ソリューションではなくコンポーネントとしての機械学習
モデルを、より大きな決定論的システム内の確率的コンポーネントとして扱ってください。推奨モデルは電子商取引プラットフォームを置き換えません。ビジネスロジックがフィルタリング、ランク付け、提示するスコア付き提案を提供します。分類器は最終決定を下しません。ダウンストリームコードがビジネスルールに従って解釈する確率推定を生成します。
このハイブリッドアーキテクチャは、機械学習のパターンマッチング強度を活用しながら、弱点を含みます。従来のコードはエッジケースを処理し、ビジネスルールを実装し、決定論的な保証を提供します。モデルの不確実性を明示的に公開するコンポーネントインターフェースを設計し、パフォーマンス低下に対するサーキットブレーカーを実装し、非機械学習フォールバックパスを維持してください。
-
具体例:* 不正検出モデルは異常スコアを生成します。ビジネスポリシー、リスク許容度、規制要件に基づいた決定論的ルールが最終的なブロック・または・許可決定を下します。モデルは入力を提供します。システムが決定を下します。
-
実行可能な示唆:* 最も価値のあるシステムは、機械学習スキャフォルディングを持つ機械学習システムではなく、機械学習コンポーネントを持つ主に従来のコードのままです。AI への経営層の熱意と個別貢献者の懐疑論のギャップは、イノベーションへの抵抗ではなく、現実的なエンジニアリング制約を反映しています。機械学習を従来のエンジニアリング規律の中に位置付けてください。バージョン管理、テスト、監視、段階的な劣化です。機械学習が特定の問題(高次元データのパターンマッチング)を解決し、一般的な問題ではないことを認識してください。それに応じて使用してください。
主要なポイント
機械学習システムはパターンマッチングを通じた数学的関数を最適化します。本当の学習ではありません。これは神秘的なものから理解可能なものへと再構成します。予測可能な特性と実際の制限を持つ特定のツール。
エンジニアリングパラダイムは明示的な制御フローから最適化駆動動作へと転換します。決定論的デバッグより統計的思考を受け入れてください。訓練データを仕様として扱ってください。目的がビジネス要件と一致しないこと、分布が展開時にシフトすることを受け入れてください。解釈可能性には実際の制限があります。モデルをソリューションではなくコンポーネントとして統合してください。
- ここから始めてください:* 現在の機械学習プロジェクトを損失関数のミスアライメントについて監査してください。データバージョニングとレビュー慣行を実装してください。分布シフトの監視を設計してください。決定論的フォールバックパスを構築してください。解釈可能性の劇場より勾配分析と統計的検証に投資してください。機械学習をエンジニアリング規律の置き換えではなく、エンジニアリングツールキットの1つのツールとして扱ってください。
主要なポイントと次のアクション
機械学習システムはパターンマッチングを通じた数学的関数を最適化します。認知的な意味での学習ではありません。これは神秘的なものから理解可能なものへと再構成します。予測可能な特性、定量化可能な制限、明確に定義された障害モードを持つ特定のツール。
エンジニアリングパラダイムは明示的な制御フローから最適化駆動動作へと転換します。決定論的デバッグより統計的思考と分布分析を受け入れてください。訓練データを主要な仕様として扱ってください。損失関数がビジネス目的と一致しないこと、分布が展開時にシフトすることを受け入れてください。解釈可能性には実際の制限があることを認識してください。モデルをエンジニアリング規律の置き換えではなく、決定論的システム内のコンポーネントとして統合してください。
- 次のアクション:* 現在の機械学習プロジェクトをビジネス目的との損失関数ミスアライメントについて監査してください。すべての訓練データセットに対してデータバージョニングと体系的なデータレビュー慣行を実装してください。分布シフトとパフォーマンス低下の監視を設計してください。決定論的フォールバックパスとサーキットブレーカーを構築してください。解釈可能性の劇場より勾配分析と統計的検証に投資してください。機械学習をその数学的特性と展開現実によって制約された、エンジニアリングツールキットの1つのツールとして扱ってください。
主要なポイントと実行チェックリスト
機械学習システムはパターンマッチングを通じた数学的関数を最適化します。本当の学習ではありません。これは神秘的なものから理解可能なものへと再構成します。予測可能な特性、実際の制限、定量化可能なコストを持つ特定のツール。
エンジニアリングパラダイムは明示的な制御フローから最適化駆動動作へと転換します。決定論的デバッグより統計的思考を受け入れてください。訓練データを仕様として扱ってください。目的がビジネス要件と一致しないこと、分布が展開時にシフトすることを受け入れてください。解釈可能性には実際の制限があります。モデルをソリューションではなくコンポーネントとして統合してください。
-
即座のアクション(第1週):*
-
現在の機械学習プロジェクトを監査:損失関数とビジネスメトリクスとの一致を文書化
-
ギャップを特定:数学的目的がビジネス目標とどこで乖離しているか
-
データバージョニングを確立:すべての訓練データセットに対してDVCまたは同等のものを実装
-
データセット文書化テンプレートを作成:ソース、方法論、既知の制限、バイアス監査結果
-
短期(第1ヶ月):*
-
分布シフト監視を実装:本番パイプラインに統計テストを追加
-
サーキットブレーカーを設計:フォールバックパスをトリガーするパフォーマンス閾値を定義
-
再訓練インフラストラクチャを構築:スケジュールまたはドリフト検出時にモデル再訓練を自動化
-
監視ダッシュボードを確立:モデルパフォーマンス、データドリフト、フォールバック活性化率を追跡
-
中期(第1四半期):*
-
すべての分類モデルでバイアス監査を実施:層別パフォーマンス分析
-
マルチ目的訓練を実装:公平性、堅牢性、多様性のための正則化を追加
-
A/Bテストを設計:ベンチマーク精度ではなくビジネスメトリクスに対してモデルを検証
-
障害モードを文書化:どの条件がモデル劣化を引き起こすか。フォールバック動作は何か。
-
継続的:*
-
月次損失関数レビュー:数学的目的がビジネス優先度と一致しているか
-
四半期ごとのデータ品質監査:ラベルドリフト、サンプリングバイアス、分布変化をチェック
-
継続的な監視:予測信頼度、特徴分布、部分群別パフォーマンスを追跡
-
再訓練サイクル:高速度システムは週次、安定したシステムは月次
-
リソース配分:*
-
モデル開発:努力の30%
-
データキュレーションと検証:努力の40%
-
監視と再訓練インフラストラクチャ:努力の20%
-
文書化と知識移転:努力の10%
この分布は学術研究ではなく本番現実を反映しています。ほとんどの機械学習プロジェクト障害は、モデルアーキテクチャの選択ではなく、不十分なデータ作業と監視に由来します。
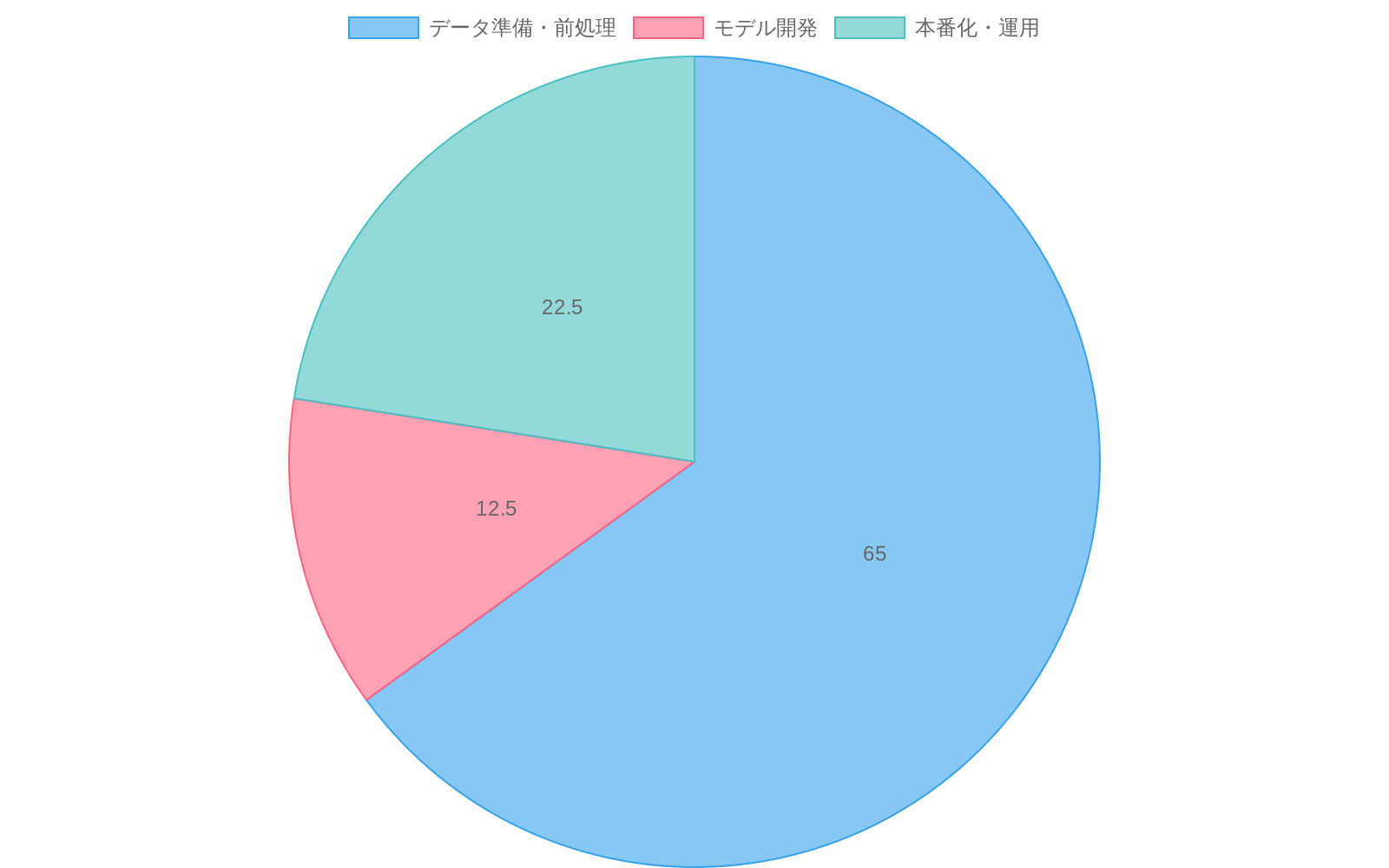
- 図13:ML開発プロジェクトの時間配分—データ準備・前処理が大部分を占める(出典:業界標準的なML開発プロジェクトの工数配分)*

- 図11:ML統合アーキテクチャ—モデルをシステムコンポーネントとして設計*
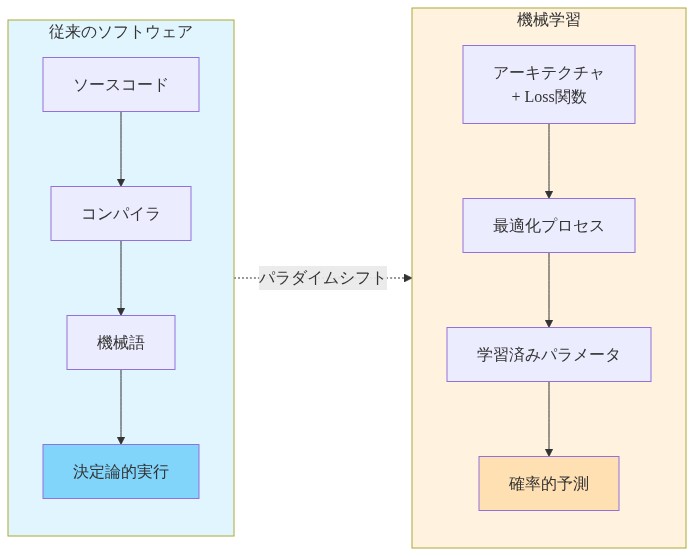
- 図2:従来のソフトウェアとML開発のパラダイムシフト*
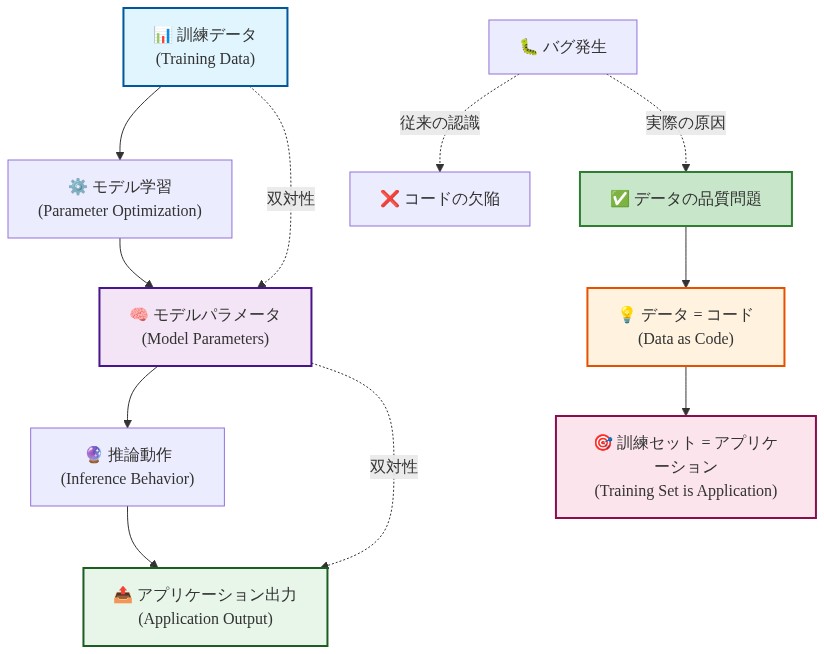
- 図4:データ・コード双対性—訓練データがアプリケーション動作を決定する*
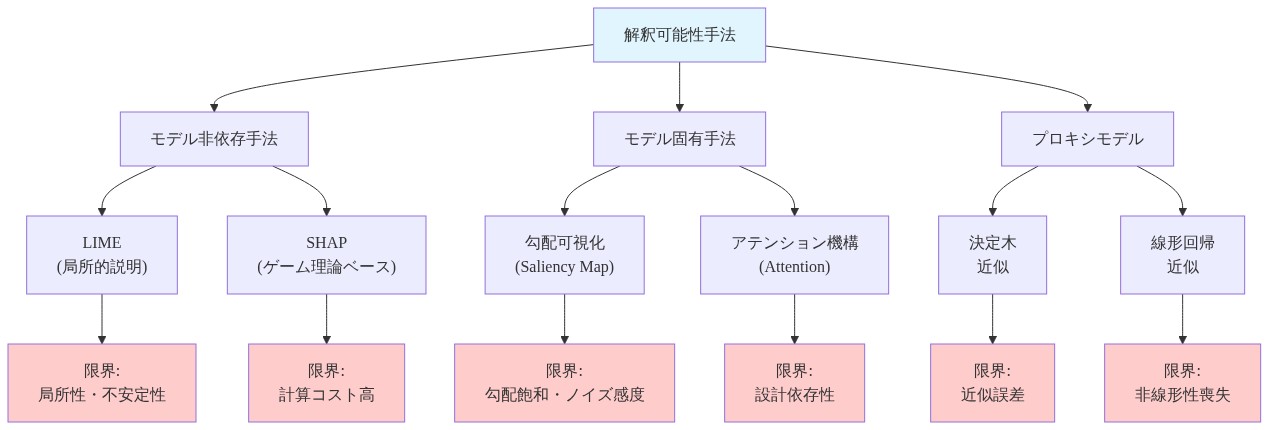
- 図10:解釈可能性手法の分類と各々の限界*