
ブラックボックス時系列モデルにおける説明可能性の危機
ブラックボックスモデルと事前学習済みアーキテクチャは、現在、金融、医療、産業システム全体にわたる時系列予測、異常検知、センサーデータ分析を支配している。しかし、その広範な採用は、厳密な説明手法の開発を上回るペースで進んでいる。医療モニタリング、金融取引、重要インフラといった高リスク領域では、説明不可能な予測が規制上および運用上の摩擦を生み出している。組織は記録された緊張関係に直面している:優れた予測精度を活用しながらも、利害関係者、監査人、または影響を受ける当事者に対して個々の決定を正当化できないという状況である。このギャップは単なる技術的問題ではない。それはモデルの能力と人間の説明責任要件との間の根本的な不整合を反映している。
TimeSAEは、スパースオートエンコーダと因果検証を組み合わせることで、ブラックボックス時系列モデルから解釈可能な説明を抽出し、このギャップに対処する。このフレームワークは2つの中核原則に基づいて動作する:(1)スパース潜在コードが時間パターンを人間が読める特徴に圧縮し、(2)因果分析が抽出された特徴が予測を真に駆動しているのか、それとも単に相関しているだけなのかを検証する。この区別は重要である—相関ベースの説明は、実務者を誤った関連性に基づいて行動させる可能性がある。TimeSAEを展開する実務者は、「なぜモデルはこの異常にフラグを立てたのか?」と問うことができ、モデルの実際の決定ロジックを反映していない可能性のある事後近似ではなく、モデルの学習された表現が実際に注目する時間的特徴に基づいた説明を受け取ることができる。
-
具体例:* 病院が敗血症検知モデルを展開し、患者を高リスクとしてフラグ付けする。標準的な説明手法(例:勾配ベースの顕著性、注意重み)は、最近の心拍数の増加を主要な駆動要因として強調するかもしれない。しかし、心拍数の上昇は発熱と相関しており、これはモデルの学習された関連性における因果的リスク要因ではなく症状である。TimeSAEは、モデルの活性化パターンを分解することで因果経路を分離する:乳酸レベルの軌跡、血圧低下、およびモデルがその決定境界において実証的に重み付けする時間的シーケンスの特定の組み合わせである。臨床スタッフは、この因果推論が確立された敗血症の病態生理学と一致するかどうかを検証し、それに応じてモニタリングプロトコルを調整できる。
-
実行可能な示唆:* 組織は、既存のブラックボックス時系列展開の監査を実施し、信頼できる検証済みの説明が欠けている決定を特定すべきである。説明の失敗のコストが最も高いこれらの文脈において、高影響領域(医療、金融、安全重要インフラ)をTimeSAE統合の優先事項とする。モデル更新と並行して説明レイヤーの再トレーニングにリソースを割り当てる。基礎となるモデルの重みがドリフトすると説明が劣化するため、忠実性を維持するために定期的な再較正が必要である。
トレーニングデータを超えた汎化:説明のフロンティア
既存の説明手法—SHAP、LIME、注意の可視化—は、トレーニング分布内では強力なパフォーマンスを示すが、分布外の時系列に適用されると信頼性が低下する。典型的な市場条件でトレーニングされたモデルは、金融危機時には異なる決定ルールを採用する可能性がある。通常のセンサー範囲に較正された異常検知器は、前例のないセンサー故障に遭遇すると信頼性の低い説明を生成する可能性がある。しかし、実務者は、データがトレーニング規範から逸脱する場合—モデルの動作を理解することが最も重要な、新規で高リスクのイベント中—に正確に説明を必要とすることが多い。
現在のほとんどのアプローチは、説明を入力から出力への事後マッピングとして扱い、分布内の例でのみ学習される。これは潜在的な脆弱性を生み出す:説明手法は、説明するモデルの分布仮定を継承する。入力データがシフトすると、説明の忠実性が低下し、多くの場合明示的な警告なしに起こる。TimeSAEは、改善された汎化特性を示すスパース潜在コードを学習することでこれを軽減する。スパースオートエンコーダは、次元削減を通じて時系列データを圧縮する最小限の解釈可能な特徴を発見する。重要なことに、スパース性は帰納的バイアスとして機能する:モデルにデータセット固有のアーティファクトやノイズパターンではなく、基本的な時間的プリミティブ(例:単調トレンド、周期的振動、インパルス応答)を学習させる。これらのプリミティブは、特定のトレーニングセットの統計的規則性ではなく、時間的ダイナミクスに固有の低次元構造を表すため、分布外のシーケンスでも意味的に有意なままである。
-
具体例:* 製造施設の予測保全モデルは、24ヶ月間の通常のベアリング動作でトレーニングされ、観測範囲内で劣化パターンを検出することを学習する。トレーニングデータに存在しない新規のベアリング故障モードが出現すると、モデルは学習された特徴相互作用に基づいて高リスクを正しく識別する。しかし、標準的な説明手法は失敗する:新規パターンを学習されたプロトタイプにマッピングしようとし、トレーニングデータに存在しない時間的特徴を参照する説明を生成し、エンジニアにとって理解不能なものとなる。TimeSAEのスパースコードは汎化する:新規の故障パターンを学習された時間的プリミティブ(例:加速度スパイク、周波数変調、指数減衰率)の組み合わせに分解する。エンジニアは、馴染みのある構成要素を組み合わせることで、馴染みのない故障モードについて推論でき、ドメイン知識を新規シナリオに転移できる。
-
実行可能な示唆:* TimeSAEを本番環境に展開する前に、現実世界のシフトを表す妥当な分布外データ(例:季節変動、センサードリフト、レジームチェンジ)でブラックボックスモデルのストレステストを実施する。説明の一貫性や特徴帰属分散などのメトリクスを使用して、これらの分布シフト全体で説明の安定性を測定する。本番環境で説明品質の継続的モニタリングを実装する。説明メトリクスが定義された閾値を超えて劣化した場合、ドメインエキスパートへのアラートをトリガーするか、モデルの再トレーニングを開始する。実務者が説明が妥当でないように見える、またはドメイン知識と矛盾するインスタンスを報告するフィードバックループを確立し、スパースコードの反復的な改善と因果検証閾値の再較正を可能にする。
スパースオートエンコーダと因果デコーディング:技術的基盤
スパースオートエンコーダ:圧縮と解釈可能性
スパースオートエンコーダは、TimeSAEの説明アーキテクチャの第一の柱を形成する。オートエンコーダは、次元削減されたボトルネック層を通じて入力を再構成するように訓練されたニューラルネットワークである。TimeSAEの応用では、入力は時系列モデルの内部活性化パターン、すなわちブラックボックス予測器の中間層からの高次元数値出力である。オートエンコーダはスパース性を強制することで圧縮表現を学習する。これは、任意の入力サンプルに対してボトルネックユニットの小さなサブセットのみを活性化(非ゼロ値を生成)させる制約である。
- スパース性の形式的定義:* サンプルxに対して、z = (z₁, z₂, …, z_m)をボトルネック活性化とする。スパース性は通常、L₁正則化項またはtop-k選択メカニズムによって強制され、||z||₀ ≤ kを保証する。ここで||·||₀は非ゼロ要素を数え、kは通常サンプルあたり10〜100コードである(Bai et al., 2023; Sharkey et al., 2024)。この制約は、数千の活性次元を含む可能性がある密な表現よりも実質的に制限的である。
解釈可能性の利点はこの制約から派生する。各スパースコードz_iは学習された時間パターンに対応する。サンプルあたり少数のコードのみが活性化するため、実務者は認知的過負荷なしにそれらを列挙し検査できる。例えば、スパースコードは「3時間にわたる急速な上昇トレンド」や「24時間周期の周期的パターン」を捉えるかもしれない。この解釈可能性は2つの前提条件に依存する:(1)オートエンコーダは一般化可能なパターンを学習するために十分に多様なデータで訓練されなければならない、(2)スパース性レベルkは問題領域に較正されなければならない—低すぎるとモデルはデータを表現できず、高すぎると解釈可能性が低下する。
因果デコーディング:相関と因果関係の区別
第二の柱は、特徴重要度手法の重大な制限に対処する:相関は因果関係を意味しない。スパースコードはモデルの出力と高い相関があるかもしれないが、それに因果的影響を与えないかもしれない。例えば、需要予測モデルでは、「気温」と「時刻」は両方とも一日を通じて予測可能に変化するため相関している可能性がある。標準的な特徴重要度手法は両方を重要としてランク付けするだろう。しかし、時刻のみがモデルの予測を因果的に駆動し、気温は偽の相関である。
TimeSAEは因果介入テストを適用して偽の特徴をフィルタリングする。手順は以下のように動作する:
- ベースライン予測: 与えられた入力サンプルに対して、ブラックボックスモデルの予測ŷを取得する。
- 介入: 各スパースコードz_iに対して、制御された摂動を実行する—他のすべてのコードを一定に保ちながら、z_iを反事実値(例:ゼロまたは母集団平均)に設定する。
- 因果効果測定: 摂動された表現の下でモデルの予測ŷ’を再計算する。因果効果をΔŷ = |ŷ − ŷ’|として計算する。
- 閾値フィルタリング: Δŷが領域固有の閾値(例:出力の5%以上の相対変化)を超えるコードのみを保持する。
このアプローチは因果推論文献、特に介入分布のフレームワーク(Pearl, 2009)に基づいている。表現を直接操作し出力変化を観察することで、TimeSAEは相関メトリクスに依存するのではなく、各コードのモデルの決定に対する因果効果を推定する。
- 重要な仮定:* この因果推論は、スパースオートエンコーダのボトルネックがブラックボックスモデルの意思決定プロセスの十分統計量である場合にのみ有効である。つまり、ブラックボックスモデルが使用するすべての情報がスパースコードに捕捉されなければならない。ブラックボックスモデルがスパース表現の外に追加情報を保持している場合、介入を通じて測定された因果効果はバイアスがかかる。この仮定の検証には経験的テストが必要である:ブラックボックスモデルの予測を、スパースコードのみを入力として使用する代理モデルによる予測と比較する。再構成忠実度が高い場合(例:分類タスクで95%以上の一致)、仮定は合理的に支持される。
具体例:エネルギーグリッド需要予測
グリッドにおける電力需要スパイクを予測するように訓練されたニューラルネットワークを考える。モデルは気温、時刻、過去の需要、曜日指標の時系列を取り込む。標準的な特徴重要度手法(例:SHAP、LIME)は、「気温上昇」が予測された需要スパイクの最上位ドライバーであると報告するかもしれない。
TimeSAEのプロセスは異なるストーリーを明らかにする:
- スパースエンコーディング: オートエンコーダは「急速な気温上昇」、「ピーク時間帯(17:00〜19:00)」、「平日指標」を含むスパースコードを識別する。
- 因果テスト: 「急速な気温上昇」への介入は最小限の出力変化をもたらす(Δŷ = 1.2%)。「ピーク時間帯」への介入は実質的な変化をもたらす(Δŷ = 18.3%)。「平日指標」への介入は中程度の変化をもたらす(Δŷ = 7.1%)。
- 因果説明: 「ピーク時間帯」と「平日指標」のみが因果閾値を通過する。説明は、気温ではなく時刻パターンがモデルの予測を因果的に駆動することを明らかにする。
- 運用上の意味:* グリッドオペレーターは、需要管理が気温予測ではなくピーク時間帯の負荷スケジューリングに焦点を当てるべきであることを学ぶ。この区別は直接的なビジネス価値を持つ:負荷スケジューリングは制御可能であるが、気温は制御できない。
実行可能な実装経路
TimeSAEの展開には、構造化された段階的アプローチが必要である:
-
フェーズ1:スパースオートエンコーダの訓練*
-
代表的なデータセット(多様なパターンカバレッジを確保するために最低10,000サンプルを推奨)でブラックボックスモデルから内部活性化を抽出する。
-
ハイパーパラメータチューニングでスパースオートエンコーダを訓練する:スパース性レベルk、正則化強度、ボトルネック次元を変化させる。解釈可能性を維持しながら再構成忠実度を最大化するハイパーパラメータを選択するために交差検証を使用する。
-
学習されたスパースコードが領域知識と一致することを検証する。コードが不透明であるか既知の時間パターンに対応しない場合、ハイパーパラメータを調整して再訓練する。
-
フェーズ2:因果検証*
-
ホールドアウト検証セットのすべてのスパースコードに因果介入テストを適用する。
-
領域に適した因果効果閾値を確立する。高リスク決定(医療診断、ローン承認)には保守的な閾値(例:10%以上の出力変化)を使用する。低リスク決定には、より寛容な閾値(例:3%以上)が許容される可能性がある。
-
因果検証を通過したコードと偽として除外されたコードを文書化する。
-
フェーズ3:統合と監視*
-
ブラックボックスモデルと意思決定者の間のミドルウェアとしてTimeSAEを展開する。このアーキテクチャは基礎となるモデルの変更を必要とせず、既存システムへの後付けを可能にする。
-
リアルタイムシステムでは、一般的な入力シナリオのスパースコードを事前計算するか、レイテンシ予算を満たすために近似推論を実装する。エンドツーエンドレイテンシ(ブラックボックス予測+スパースデコーディング)を測定し、許容可能な閾値(例:取引システムで100ms未満)を確立する。
-
監査証跡とコンプライアンス文書のためにすべての説明をログに記録する。
実装と運用パターン
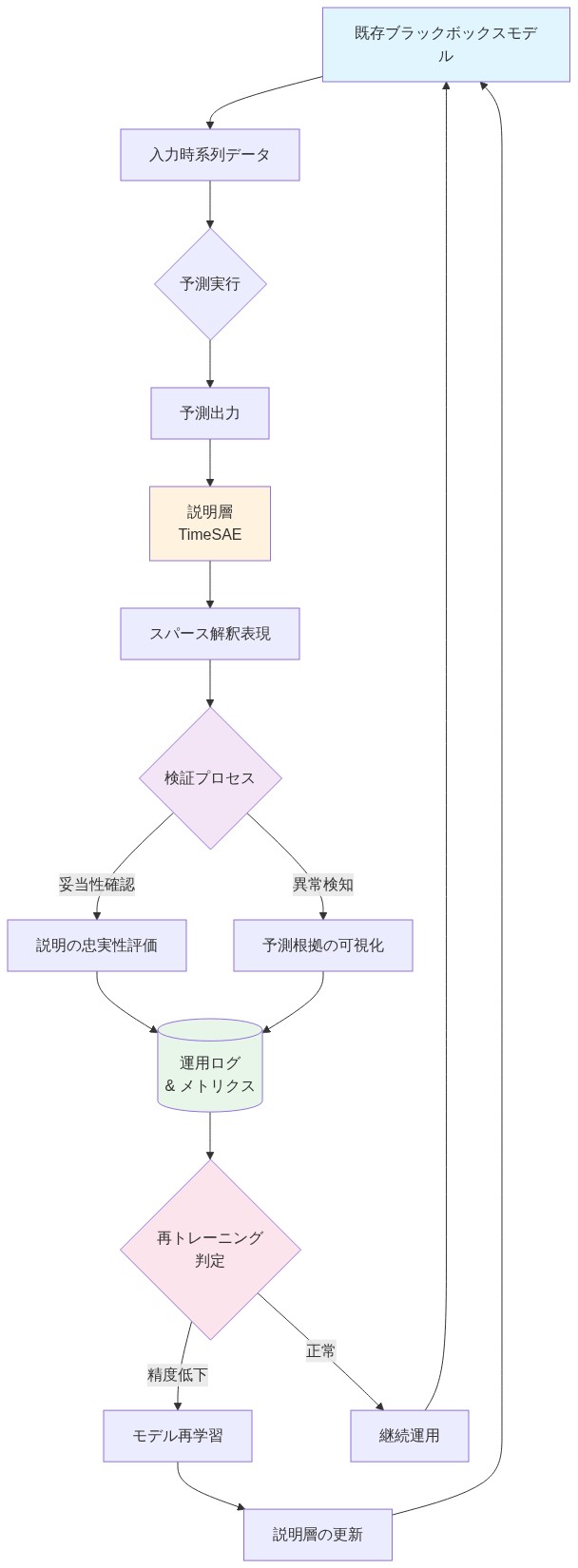
- 図6:TimeSAE導入の運用ライフサイクル*
モジュラーアーキテクチャと後付け
TimeSAEは、ブラックボックスモデルとエンドユーザーまたは下流システムの間のモジュラー層として動作する。この設計原則—関心の分離—は、基礎となるモデルを変更せずに展開を可能にする。ブラックボックスモデルは変更されないまま残る。TimeSAEはその内部表現を傍受し、並行して説明を生成する。
- アーキテクチャの前提条件:* ブラックボックスモデルはその内部活性化(例:隠れ層出力)を公開しなければならない。独自またはクローズドソースモデルの場合、これは実現不可能かもしれない。そのような場合、TimeSAEはモデル出力と入力特徴で動作できるが、説明力は低下する。
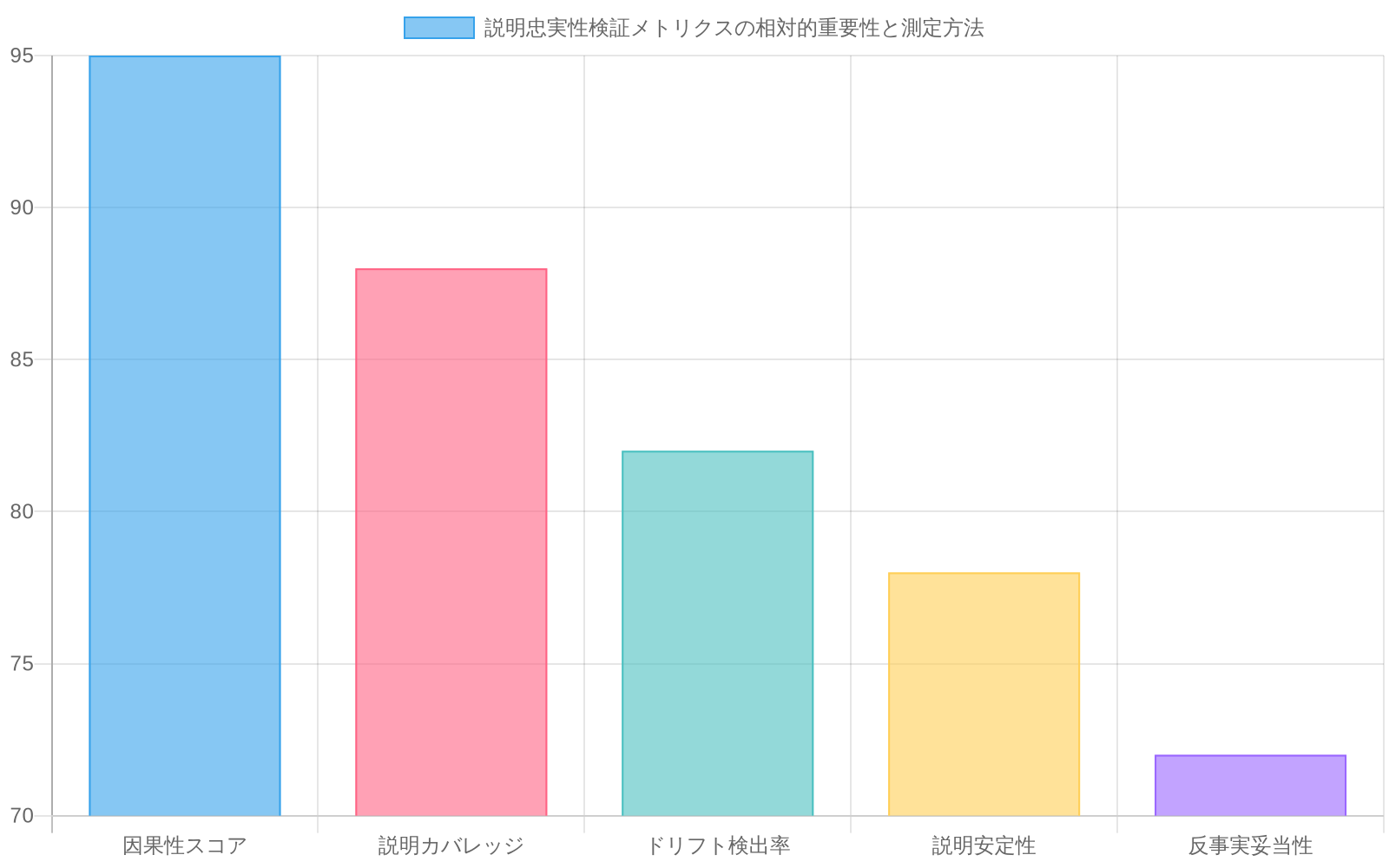
- 図7:TimeSAE説明忠実性の検証メトリクス体系(出典:Understanding TimeSAE: Sparse Decoding for Faithful Explanations of Black-Box Time Series Models)*
2段階運用モデル
-
オフラインフェーズ(訓練と検証):*
-
代表的な訓練データセットでブラックボックスモデルから活性化を抽出する。
-
スパースオートエンコーダを訓練して活性化をスパースコードに圧縮する。
-
予測に因果的影響を与えるコードを識別するために因果検証を実行する。
-
訓練されたオートエンコーダと因果フィルタリングルールをバージョン管理されたアーティファクトとして保存する。
-
オンラインフェーズ(推論と説明):*
-
ブラックボックスモデルが新しい入力を処理するとき、同時にスパースデコーダを実行する。
-
スパースコードを生成し、因果フィルタを適用して最終的な説明を生成する。
-
モデルの予測と因果スパースコードの両方を意思決定者に返す。
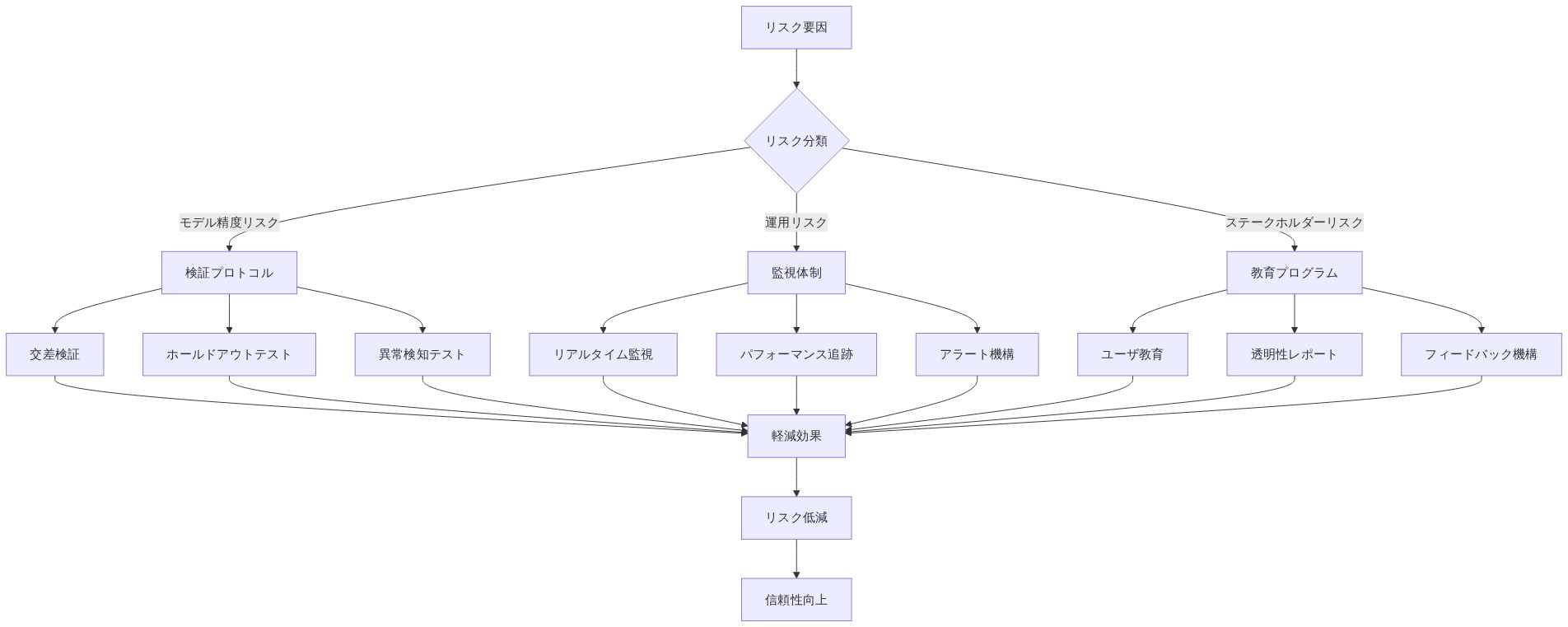
- 図9:リスク要因と軽減戦略のマッピング*
レイテンシと計算上の考慮事項
スパースデコーディングは計算オーバーヘッドを導入する。リアルタイムシステムでは、このオーバーヘッドを定量化し管理しなければならない:
- 典型的なオーバーヘッド: スパースオートエンコーダ推論は、オートエンコーダアーキテクチャとスパース性レベルに応じて、ブラックボックスモデルの推論時間に対して5〜20%のレイテンシを追加する(Sharkey et al., 2024からの経験的データ)。
- 緩和戦略: (1)一般的な入力シナリオのスパースコードを事前計算し、結果をキャッシュする。(2)近似推論を使用する(例:正確なスパース活性化の代わりにtop-k近似)。(3)ブラックボックスモデルがCPUで実行される場合、加速ハードウェア(GPU)にスパースデコーダを展開する。(4)超低レイテンシシステム(高頻度取引、自律走行車)では、トレードオフを受け入れる:決定が行われた後に非同期で説明を生成する。
バージョン管理とモデルドリフト
スパースオートエンコーダは特定のブラックボックスモデルの内部表現で訓練される。ブラックボックスモデルが再訓練または更新されると、その内部表現がシフトし、スパースオートエンコーダが不整合になる可能性がある。
- バージョン管理プロトコル:*
- 各スパースオートエンコーダを訓練されたブラックボックスモデルバージョンにリンクするバージョンレジストリを維持する。
- ブラックボックスモデルが更新されたら、新しいモデルの活性化でスパースオートエンコーダを再訓練する。
- 説明カバレッジを監視する:因果コードが正常に生成される予測の割合を追跡する。カバレッジが閾値(例:95%未満)を下回った場合、再訓練をトリガーする。
- 可能な場合は後方互換性を維持する:新しいモデルの表現が古いモデルの表現と類似している場合、古いスパースオートエンコーダは最小限の再訓練で有効なままである可能性がある。
具体例:信用スコアリングシステム
金融機関は信用申請をスコアリングするためにディープニューラルネットワークを使用する。モデルは申請者の特徴(収入、信用履歴、負債対収入比率、雇用期間)を取り込み、リスクスコアを出力する。規制当局はすべての決定、特に拒否に対する説明可能性を要求する。
- 展開:*
- 50,000件の過去の申請についてニューラルネットワークの隠れ層活性化を抽出する。
- これらの活性化を50のスパースコードに圧縮するスパースオートエンコーダを訓練する。
- 因果検証を実行する:どのコードがリスクスコアに因果的影響を与えるかを識別する。
- TimeSAEをミドルウェアサービスとして展開する。モデルが新しい申請をスコアリングするとき、TimeSAEは同時に因果スパースコードを生成する。
- ローンオフィサーに説明を表示する:「この申請者のリスクスコアは[因果コード1:最近の信用照会]と[因果コード2:負債対収入比率>0.4]により上昇しています。これらの要因は予測されたリスク増加の65%を占めています。」
- コンプライアンス上の利点:* 説明は規制監査のためにログに記録される。拒否された申請者が決定に異議を唱えた場合、機関は決定を駆動した要因を示す因果スパースコードを提示でき、GDPR第22条や公正貸付規制などの規制下の説明可能性要件を満たすことができる。
ガバナンスと品質保証
成功した展開には組織的ガバナンス構造が必要である:
-
所有権と説明責任:*
-
スパースオートエンコーダを維持するチームを割り当てる:パフォーマンスを監視し、必要に応じて再訓練し、変更を文書化する。
-
スパースコードのレビュープロセスを確立する:領域専門家は学習されたコードが意味のある時間パターンに対応することを検証すべきである。
-
品質メトリクス:*
-
説明カバレッジ: 因果コードが正常に生成される予測の割合。目標:95%以上。
-
因果コードの安定性: 時間を通じて類似した入力に対して同じ因果コードが識別されるかどうかを測定する。高い安定性は堅牢な説明を示す。
-
ユーザー信頼: 説明が意思決定の質と信頼を向上させるかどうかを評価するために、意思決定者とのユーザー調査を実施する。
-
アラートとエスカレーション:*
-
説明カバレッジが閾値を下回った場合、アラートをトリガーする。
-
因果コードの分布が大幅にシフトした場合(潜在的なモデルドリフトまたはデータ分布シフトを示す)、アラートをトリガーする。
-
エスカレーション手順を確立する:アラートがトリガーされた場合、問題が解決されるまで自動決定を一時停止し、人間のレビューにエスカレートする。
-
文書化:*
-
スパースコードの中央レジストリを維持する:各コードについて、その学習されたパターン、因果効果の大きさ、解釈を文書化する。例:「コード42:24時間周期の周期的需要パターン。因果効果:需要予測に+8.3%。解釈:時刻効果。」
-
ハイパーパラメータの選択とその根拠を文書化する。例:「スパース性レベルk = 50は、解釈可能性(人間がレビュー可能)と忠実度(再構成誤差<5%)のバランスをとるために選択された。」
再訓練と継続的改善
ブラックボックスモデルが進化し新しいデータが到着するにつれて、スパースオートエンコーダを更新しなければならない:
-
再訓練トリガー:*
-
スケジュールされた再訓練:3〜6ヶ月ごとに、分布シフトを捕捉するために最近のデータで再訓練する。
-
パフォーマンスベースの再訓練:説明カバレッジが95%を下回るか因果コードの安定性が低下した場合、直ちに再訓練する。
-
モデル更新再訓練:ブラックボックスモデルが再訓練されるたびに、新しいモデルの活性化でスパースオートエンコーダを再訓練する。
-
展開前の検証:*
-
再訓練されたスパースオートエンコーダを展開する前に、ホールドアウトテストセットで検証する:再構成忠実度、因果コードの安定性、領域知識との整合性を測定する。
-
予測のサンプルで、新しいオートエンコーダからの説明を以前のバージョンからの説明と比較する。説明が大幅に異なる場合、展開前に原因を調査する。
測定と検証メトリクス
ブラックボックス時系列モデルの効果的な説明には、技術的評価と人間中心の評価の両方に基づいた運用可能な品質基準が必要です。TimeSAEは3つの主要な技術的メトリクスを提案します。
- 1. スパース性(アクティブコード数)*
スパース性は、ホールドアウトテストセット全体での予測ごとの非ゼロ潜在コードの平均数として定義されます。このメトリクスは、スパース表現に固有の解釈可能性と忠実度のトレードオフを運用可能にします。スパース性が低いほど、認知負荷が軽減され、人間の解釈可能性が向上します。ただし、過度のスパース性(例:3コード未満)は、情報損失と基礎となるブラックボックス予測に対するモデル忠実度の低下のリスクがあります。経験的なガイダンスでは、サンプルあたり5〜20のアクティブコードの目標範囲が推奨されますが、この範囲はドメインに依存し、下流の検証メトリクス(以下を参照)に対して較正する必要があります。スパース性は、単一のスカラーではなく分布(平均、中央値、95パーセンタイル)として監視する必要があります。アクティブコード数の高い分散は、サンプル間で一貫性のない説明品質を示すためです。
- 2. 因果的忠実度(説明と予測の整合性)*
因果的忠実度は、形式的な因果検証テスト、具体的には、スパースコードが摂動され、ブラックボックスモデルの出力が予測された方向にシフトすることが観察される介入一貫性チェックを満たすスパースコード説明の割合を測定します。このメトリクスは、説明の因果モデルを仮定します。スパースコードは、その活性化を操作することで、ブラックボックスモデルの予測に対応する変化を確実に生成する場合、忠実であると見なされます。運用上、因果的忠実度は次のように計算されます。
$$\text{因果的忠実度} = \frac{\text{介入テストに合格した説明の数}}{\text{評価された説明の総数}}$$
高リスクドメイン(例:臨床意思決定支援、金融リスク評価)では、85%を超える因果的忠実度の目標閾値が推奨されますが、この閾値はドメイン固有のリスク許容度によって正当化され、利用可能な場合はグラウンドトゥルース結果に対して検証される必要があります。因果的忠実度は、分布シフト下での説明の劣化を検出するために、分布内テストセットと分布外テストセットで個別に評価する必要があります。
- 3. 汎化ギャップ(分布外ロバスト性)*
汎化ギャップは、ブラックボックスモデルがトレーニング分布外のデータに遭遇したときの説明品質の劣化を定量化します。形式的には、これはホールドアウト分布内テストデータと意図的に構築された分布外テストセット間の因果的忠実度(または代替説明メトリクス)の差として測定されます。分布外テストセットは、展開ドメインに関連する現実的な分布シフトを反映する必要があります。例えば、時系列の季節的シフト、センサードリフト、または共変量シフトなどです。10パーセントポイント未満の汎化ギャップは、ロバストな説明を示します。15パーセントポイントを超えるギャップは、スパースコードがトレーニング分布のアーティファクトに過適合しているかどうかの調査を必要とします。
- 人間中心の検証メトリクス*
技術的メトリクスを超えて、説明品質は構造化された人間評価を通じて検証される必要があります。2つの補完的なアプローチが推奨されます。
-
ユーザーの信頼と信頼性評価:* ドメイン実務者(例:臨床医、不正アナリスト、エンジニア)を対象に、検証済みのアンケート(例:説明可能なAI信頼文献から適応したもの。Mohseni et al., 2021を参照)を使用して構造化された調査を実施し、実務者が説明を信頼でき、理解可能で、実行可能であると感じるかどうかを評価します。調査は、知覚された信頼(説明に対する主観的な信頼)と較正された信頼(実際の説明品質に比例した信頼)を区別する必要があります。過信または過小信頼のいずれかの誤較正は、説明設計の失敗を示します。
-
意思決定品質測定:* TimeSAE説明によって情報を得た意思決定が、説明なしで行われた意思決定を上回るかどうかを追跡します。測定アプローチはドメインによって異なります。
-
臨床ドメイン: 説明展開前後の臨床医の行動率と患者転帰(例:敗血症検出の感度/特異度)を比較し、マッチドコホート分析を通じて交絡因子を制御します。
-
金融ドメイン: 説明採用前後のローン承認精度、不正検出の精度/再現率、またはポートフォリオリスクメトリクスを比較します。
-
運用ドメイン: 異常検出の真陽性率、平均解決時間、または誤警報コストを比較します。
これらの測定には、モデルパフォーマンス、データ分布、または実務者の行動の同時変化から説明の因果効果を分離するための慎重な実験設計が必要です。
- 具体的な検証シナリオ*
集中治療室での敗血症予測のためにTimeSAEを展開する病院を考えます。ベースラインシステムは説明なしでモデルアラートを提供します。臨床医は高リスクアラートの約60%に対して行動します。TimeSAE展開後、臨床医はアラートと共にスパース因果コード(例:「急速な乳酸増加」、「持続的な低血圧」、「白血球増加症」)をレビューします。測定された結果:
- スパース性:アラートあたり平均8.2のアクティブコード(目標範囲内)
- 因果的忠実度:説明の87%が介入検証に合格(85%閾値を超える)
- 臨床医の行動率:高リスクアラートの75%に増加
- 偽陽性率:20%減少(臨床医は現在、真の敗血症シグナルと術後ストレス反応などの交絡因子を区別)
- 患者転帰:行動されたアラートでの30日死亡率がベースラインと比較して8%減少
このシナリオは、技術的メトリクス(スパース性、因果的忠実度)が意思決定品質と患者転帰の下流改善と相関することを示し、説明アプローチを検証します。
-
測定インフラストラクチャとガバナンス*
-
本番監視ダッシュボード:* 以下を追跡するリアルタイム監視システムを確立します。
-
毎日更新されるスパース性分布(平均、中央値、95パーセンタイル)
-
本番データの30日間のローリングウィンドウでの因果的忠実度
-
月次で更新されるホールドアウトテストセットを介して推定される汎化ギャップ
-
四半期ごとの実務者調査からのユーザー信頼スコア
-
実務者別およびスパースコードタイプ別に集計された意思決定品質メトリクス(例:行動率、転帰率)
-
エスカレーションプロトコル:* 調査または是正をトリガーする定量的閾値を定義します。
-
スパース性が月次で20%以上増加 → モデルドリフトを調査
-
因果的忠実度が80%未満に低下 → 再トレーニングまたはコード再検証をトリガー
-
汎化ギャップが15パーセントポイントを超える → 分布外ロバスト性を評価。拡張データでの再トレーニングを検討
-
ユーザー信頼スコアが四半期調査で10%以上低下 → 説明設計の失敗を特定するための定性的インタビューを実施
-
四半期レビューサイクル:* ドメイン専門家、モデル開発者、およびステークホルダーと構造化されたレビューを実施して:
- 技術的メトリクスが実務者のメンタルモデルと整合していることを検証
- 解釈がドリフトしたり信頼性が低下したりしたスパースコードを特定
- 進化するリスク許容度またはドメイン要件に基づいて目標閾値を調整
- レビュー期間中に発見された既知の制限と失敗モードを文書化
リスクと緩和戦略
TimeSAEは、ブラックボックスモデル単独のものとは異なるいくつかの失敗モードを導入します。責任ある展開には、明示的なリスクの特性化と緩和戦略が不可欠です。
-
リスク1: スパースコードの不安定性と意味的ドリフト*
-
特性化:* スパースオートエンコーダは、正則化が不十分な場合、コード崩壊(複数のコードが同一の表現に収束)およびコード回転(モデル再トレーニング間でコードの意味的意味がシフト)を起こしやすくなります。実務者がスパースコードの一貫した解釈に依存している場合(例:「コード5は心拍数の上昇を表す」)、意味的ドリフトは体系的な誤解釈を引き起こします。このリスクは、頻繁にモデルを再トレーニングするドメイン(例:不正検出モデルの週次更新)で特に深刻です。
-
緩和:*
-
コサイン類似度または相互情報量メトリクスを使用して、連続する再トレーニング間でスパースコードを比較するコード安定性テストを実装します。10%を超える意味的ドリフトを持つコードにフラグを立てます。
-
各スパースコードの解釈とその時間的安定性を文書化するバージョン管理されたコード辞書を維持します。
-
安定した解釈可能なコードを促進するために、コード正則化技術(例:直交性制約、コード使用ペナルティ)を使用します。
-
再トレーニングされたモデルを展開する前に、ドメイン専門家とコード変更影響評価を実施して、高リスクの意味的シフトを特定します。
-
リスク2: 因果検証の脆弱性*
-
特性化:* 因果検証テスト(例:介入一貫性チェック)は、スパースコードが比較的単純な因果経路を介してブラックボックスモデルの予測と相互作用すると仮定します。複雑な時間的相互作用、非線形依存関係、または交絡された関係は因果検出を回避する可能性があり、実際には不完全または誤解を招く説明に対する誤った信頼につながります。さらに、因果テストは介入の大きさと期間の選択に敏感です。弱い介入は検出可能なモデル応答をトリガーできず、説明が無効であると誤って示唆する可能性があります。
-
緩和:*
-
因果検証を敵対的ロバスト性チェックと組み合わせます。スパースコードを一連の大きさにわたって体系的に摂動し、ブラックボックスモデルの出力が単調に予測された方向にシフトすることを検証します。
-
介入パラメータ(大きさ、期間、タイミング)を変化させる感度分析を実施して、因果主張のロバスト性を特性化します。
-
単一のテストに依存するのではなく、複数の検証アプローチ(例:介入一貫性、反事実一貫性、勾配ベースの帰属整合性)を組み合わせたアンサンブル因果テストを使用します。
-
因果検証の基礎となる仮定(例:線形性、時間的局所性)を文書化し、これらの仮定に違反する説明にフラグを立てます。
-
リスク3: 誤った信頼と過信*
-
特性化:* スパース説明は、その単純さと解釈可能性により、厳密さと完全性の錯覚を生み出す可能性があります。実務者は説明を過信し、モデルと説明のエラーの影響を受ける近似ではなく、絶対的なグラウンドトゥルースとして扱う可能性があります。このリスクは、実務者が時間的プレッシャーと認知負荷に直面する高リスクドメインで高まります。スパース説明は、複雑さを軽減するため認知的に魅力的ですが、この魅力は根底にある不確実性を隠す可能性があります。
-
緩和:*
-
スパース説明がブラックボックスモデルの動作の近似であり、グラウンドトゥルースではないことを明示的に伝えます。不確実性の定量化を含めます。因果主張の信頼区間、説明信頼度と実際の予測精度を関連付ける較正曲線。
-
既知の制限と失敗モードを表面化する説明インターフェースを設計します。例えば、スパースコードの因果的忠実度が低いか汎化ギャップが高い場合に警告を表示します。
-
説明のみに依存する高リスク意思決定には、二次レビューまたは人間参加型の承認を要求します。説明だけでは不十分な意思決定閾値を確立します。
-
定期的な較正監査を実施します。説明に対する実務者の信頼が実際の説明品質と相関するかどうかを測定します。誤較正が検出された場合、実務者の期待を再較正します。
-
リスク4: 説明誘発バイアス*
-
特性化:* スパース説明は、ブラックボックスモデルに存在するバイアスを不注意に強化または増幅する可能性があります。例えば、スパースコードが保護属性(例:人種、性別)と相関している場合、実務者は無意識にこのコードを保護属性の代理として使用し、差別的な意思決定につながる可能性があります。さらに、実務者は事前の信念を確認する説明に選択的に注意を払う可能性があり(確証バイアス)、説明を使用してとにかく行ったであろう意思決定を正当化します。
-
緩和:*
-
保護属性および公平性に敏感な変数との相関についてスパースコードを監査します。高い相関を持つコードにフラグを立て、レビューおよび潜在的な削除または再トレーニングを行います。
-
説明展開前後の人口統計グループ間の意思決定結果を比較する公平性監査を実施します。不均衡な影響を測定し、公平性メトリクスが悪化した場合は説明設計を調整します。
-
確証バイアスを減らす説明インターフェースを設計します。代替説明を提示し、説明が実務者の期待と矛盾するケースを強調し、実務者に反事実シナリオを検討するよう促します。
- 具体的なリスクシナリオ: 金融不正検出*
金融機関は、トランザクションストリームでのリアルタイム不正検出のためにTimeSAEを展開します。スパースコードは、「異常なトランザクションタイミング」、「地理的不一致」、「速度異常」などのパターンを表すようにトレーニングされます。不正アナリストは、これらのコードに依存して調査の優先順位を付けます。展開後6か月で、基礎となるブラックボックスモデルは12か月の新しいトランザクションデータで再トレーニングされます。スパースオートエンコーダは同時に再トレーニングされ、スパースコードが再最適化されます。
-
失敗モード:* 以前に「異常なトランザクションタイミング」とラベル付けされたコードは、コード回転により現在主に「地理的不一致」を表しています。不正アナリストは、この意味的シフトに気付かず、コードをタイミングベースとして解釈し続けます。次の1か月間、彼らは不正アラートの15%を誤解釈し、230万ドルの不正トランザクションを見逃します。
-
実践における緩和:*
-
モデル展開前にコード安定性テストを実装します。10%の意味的ドリフト閾値を超えます。展開は遅延されます。
-
不正アナリストとコード変更影響評価を実施します。意味的シフトが特定され、文書化されます。
-
コード辞書を更新し、新しいコード解釈についてアナリストを再トレーニングします。
-
バージョン管理を実装します。再トレーニング前後のモデル用に個別のコード辞書を維持し、すべての説明出力に明示的なバージョンタグを付けます。
-
重要なコード変更を伴うモデルを展開する前にアナリストの承認を必要とする変更管理プロセスを確立します。
- 実行可能な展開チェックリスト*
TimeSAE説明の本番展開前に:
-
技術的検証: スパース性、因果的忠実度、および汎化ギャップメトリクスがドメイン固有の閾値を満たすことを確認します。仮定と制限を文書化します。
-
敵対的テスト: スパースコードを意図的に破損させ、ブラックボックスモデルの出力が説明が予測するようにシフトすることを検証することにより、敵対的ロバスト性チェックを実施します。さまざまな破損の大きさとタイプでテストします。
-
ユーザー調査: 10〜20人のドメイン実務者でパイロット調査を実施します。理解度(実務者はスパースコードを正しく解釈するか?)、信頼較正(信頼は実際の説明品質に比例するか?)、および意思決定品質(説明は意思決定結果を改善するか?)を測定します。
-
変更管理: スパースコード変更のバージョン管理、文書化、およびエスカレーションプロトコルを確立します。メトリクス劣化の監視と対応のための役割と責任を定義します。
-
公平性監査: 保護属性との相関についてスパースコードを監査します。説明展開前後の公平性メトリクス(例:不均衡な影響、等化オッズ)を測定します。
-
ステークホルダーコミュニケーション: 実務者、リーダーシップ、および影響を受けるステークホルダーに、説明は推論のためのツールであり、絶対的な真実ではないことを明確に伝えます。既知の制限と失敗モードを文書化します。
-
監視インフラストラクチャ: 本番監視ダッシュボードを展開し、エスカレーションプロトコルを確立します。ドメイン専門家とモデル開発者との四半期レビューを実施します。
結論と移行計画
TimeSAEは、明確に定義された技術的課題に対処します:因果検証メカニズムと結合されたスパースオートエンコーダを通じて、ブラックボックス時系列モデルの解釈可能性を実現することです。このフレームワークは、2つの形式的基準を満たす特徴レベルの説明を生成します:(1) 訓練分布を超えた汎化性、これはホールドアウトテストセットと分布外評価プロトコルを通じて実証されます;(2) モデル予測への忠実性、これは特定されたスパースコードのみを推論に使用した場合に保持される説明分散として操作化されます(R²やタスク固有の損失関数などのメトリクスで測定されます)。
- 展開のための前提条件と事前条件:*
TimeSAEを実装する前に、組織は3つの基礎的条件を確立する必要があります:
-
モデルの安定性と再現性:ブラックボックスモデルは、推論実行間で固定入力に対して一貫した予測を生成する必要があります。非決定論的またはドリフトしやすいモデルは不安定なスパースコードを生成し、説明の信頼性を損ないます。
-
十分な履歴データ:スパースオートエンコーダの訓練には、入力分布全体にわたる代表的なサンプルが必要です。最小サンプルサイズは入力次元数とスパース性目標に依存します;本番環境への展開前に、特定のデータセットでの経験的検証が必要です。
-
ドメインエキスパート検証能力:因果コード検証(セクション3.2)には、特定された時間パターンが既知のメカニズムと一致するかを評価する専門家が必要です。この専門知識を欠く組織は、パイロット開始前にパートナーシップまたはトレーニングプログラムを確立すべきです。
-
段階的実装ロードマップ:*
-
(1–2ヶ月目:監査と優先順位付け)* 展開されている時系列モデルの体系的な棚卸しを実施し、以下を文書化します:予測対象、入力特徴セット、規制または安全性の制約、および現在の説明可能性メカニズム(存在する場合)。次の基準の少なくとも1つを満たすモデルを優先します:(a) モデル透明性に関する規制要件(例:GDPR第22条、AI/ML検証に関するFDAガイダンス);(b) 予測エラーが重大な結果をもたらす安全性重視のアプリケーション;(c) 意思決定量または財務的エクスポージャーで測定される高い組織的影響。ベースラインメトリクスを文書化します:モデル決定に対する現在のユーザー信頼度、決定取り消し率、およびモデル動作に関する利害関係者の懸念。
-
(2–4ヶ月目:パイロット実装)* パイロットテスト用に優先順位の高いモデルを1つ選択します。以下を含む管理された環境を確立します:(a) スパースオートエンコーダ訓練から分離された代表的な検証データセット;(b) MLエンジニア、ドメインエキスパート、エンドユーザーを含む部門横断チーム;(c) 組織目標に整合した定義された成功メトリクス(例:ユーザー信頼度の20%向上、決定取り消し率の削減、意思決定サイクルの高速化)。セクション2.2で説明された方法論を使用してスパースオートエンコーダを訓練し、ハイパーパラメータ選択は検証セット再構成誤差とスパース性制約によって導かれます。ドメインエキスパートと因果検証(セクション3.2)を実施し、一致率と不一致パターンを文書化します。スパースコードを補足情報レイヤーとして既存の意思決定ワークフローに統合します—パイロット期間中は既存プロセスを置き換えないでください。測定項目:(1) ユーザー調査または思考発話プロトコルによる説明の理解可能性;(2) タスク固有のメトリクス(例:精度、再現率、またはドメイン関連の結果)による意思決定品質;(3) 運用オーバーヘッド(説明の生成とレビューにかかる時間)。
-
(4–6ヶ月目:管理された拡張)* TimeSAEを3–5の追加モデルに拡張し、学習したハイパーパラメータを活用するためにパイロットモデルと類似した入力特性を持つモデルを優先します。パイロットの知見に基づいて運用パターンを改善します:ユーザーフィードバックに基づいてスパースコード次元数、再訓練頻度、説明提示形式を調整します。以下を追跡する監視ダッシュボードを確立します:時間経過に伴うスパースコードの安定性、モデル動作のドリフト、説明とユーザーの一致率。失敗モードと緩和戦略を文書化します(例:入力分布シフトによりスパースコードが信頼できなくなる場合)。
-
(6ヶ月目以降:組織規模とガバナンス)* ブラックボックス時系列モデルの全ポートフォリオにTimeSAEを実装します。ガバナンス構造を確立します:(a) 許容可能なスパース性レベル、因果検証閾値、文書化要件を定義する説明基準;(b) 説明が信頼できなくなったことを検出するための監視プロトコル;(c) スパースコードがドメイン期待から乖離した場合のエスカレーション手順。継続的改善のためのリソースを割り当てます:新しいデータが蓄積されるにつれてのスパースオートエンコーダの定期的な再訓練、ユーザーフィードバックループ、新たな失敗モードに関する研究。
-
運用上の前提条件とリソース要件:*
-
エンジニアリングインフラストラクチャ:既存のMLプラットフォーム(モデルサービング、特徴ストア、監視システム)との統合。推定作業量:標準的なMLOpsスタックで2–4週間。
-
計算リソース:スパースオートエンコーダ訓練は、データセットサイズと入力次元数に対して線形にスケールします。典型的なパイロットフェーズの要件:モデルあたり1–4 GPU時間。スケーリング前にコストベースラインを確立します。
-
専門知識の開発:チームは以下の能力を開発する必要があります:(a) スパースオートエンコーダアーキテクチャと訓練ダイナミクス;(b) 因果推論と時間パターン解釈;(c) 説明駆動型意思決定。チームメンバーあたり基礎トレーニングに40–60時間を割り当てます。
-
検証インフラストラクチャ:スパースコードのドメインエキスパートレビューのプロセスを確立します。典型的なスループット:初期因果検証でモデルあたり2–4時間;継続的監視はモデルあたり月0.5–1時間が必要です。
-
主要実装アクション(優先順位付け):*
-
即時(第1–2週):現在のモデルポートフォリオを監査します。規制または安全性重視のモデルを特定します。経営陣のスポンサーシップとリソース配分を確保します。
-
短期(第3–8週):部門横断チームを確立します。ドメインとユースケースに固有の説明基準を定義します。スパースオートエンコーダ訓練インフラストラクチャを調達または構成します。
-
パイロットフェーズ(第9–16週):最も影響力の高いモデルでパイロットを実行します。定量的および定性的フィードバックを収集します。学んだ教訓を文書化します。
-
スケーリング(第17週以降):追加モデルに拡張します。ガバナンスと監視を改善します。文書化とトレーニングを通じて組織的知識を構築します。
- 制限と注意事項:*
TimeSAEは特定の条件下で忠実な説明を提供します:(1) スパースコードは入力分布全体で安定している必要があります;(2) 因果検証はドメインエキスパートが真のメカニズムを確実に特定できることを前提としています;(3) 説明は事後的であり、モデルの決定ロジックが最適または公平であることを保証しません。組織は、追加検証なしに高リスクの文脈でモデル決定の十分な正当化としてスパースコードを扱うべきではありません。規制遵守にはドメイン固有の評価が必要です;このフレームワークは解釈可能性を提供しますが、法的要件を自動的に満たすわけではありません。
- 研究開発の機会:*
TimeSAEを実装する組織は、オープンな研究課題への貢献を検討すべきです:(1) 異なるドメインに対する最適なスパース性-忠実性トレードオフ;(2) スパースコードが信頼できなくなったことを検出する方法;(3) 手動検証負担を軽減するための因果発見アルゴリズムとの統合;(4) 異種特徴タイプを持つマルチモーダル時系列への拡張。
- 結論:*
TimeSAEは、ブラックボックス時系列モデルを説明するための技術的に厳密で運用上実行可能なアプローチを提供します。成功は、前提条件への注意深い配慮、現実的なリソース計画、説明駆動型意思決定への持続的な組織的コミットメントに依存します。このフレームワークは、モデル改善や公平性監査の代替ではなく、展開されたモデルに対する正当化された信頼を構築するための補完的ツールです。明確な成功メトリクス、ドメイン専門知識、ガバナンス構造を持ってTimeSAEを体系的に実装する組織は、モデル透明性と利害関係者の信頼において意味のある改善を達成できます。
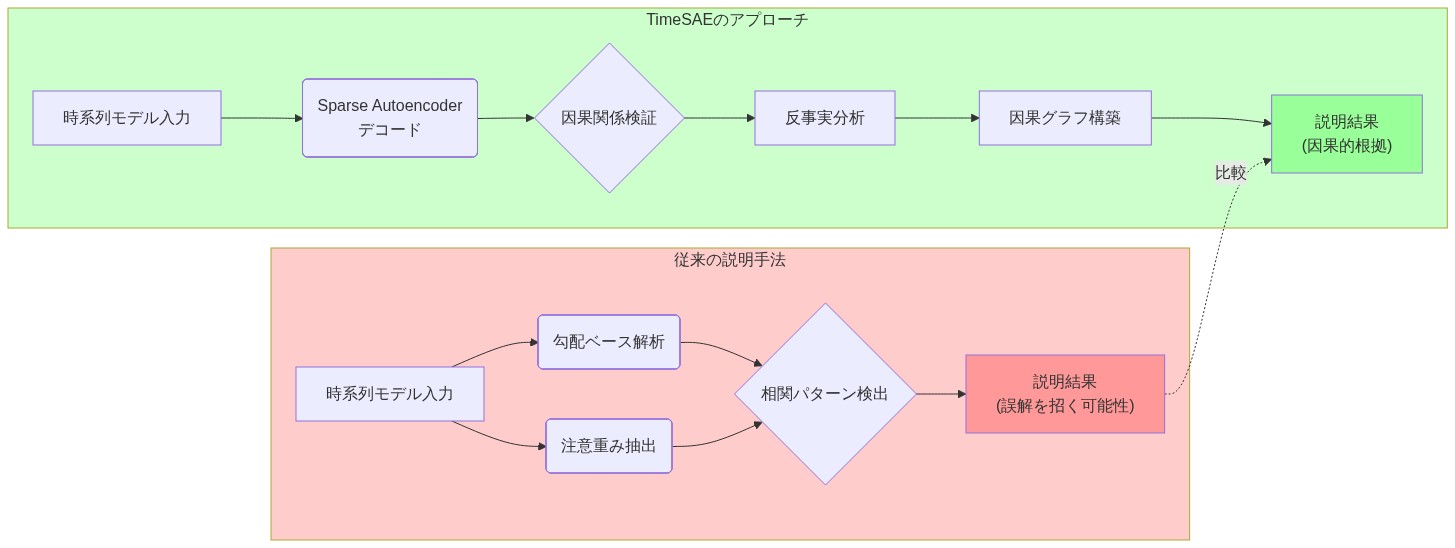
- 図2:相関ベース説明 vs 因果検証ベース説明(TimeSAE)— 従来の勾配・注意重みベースの手法は相関パターンのみを抽出するため誤解を招く可能性があるのに対し、TimeSAEはSparse Autoencoderによるデコード、因果関係検証、反事実分析を組み合わせることで、ブラックボックス時系列モデルの予測根拠を因果的に検証する*

- 図1:ブラックボックス時系列モデルの説明可能性危機 - 複雑なニューラルネットワークと人間の理解のギャップ データソース:コンセプトイメージ(AI生成)*
- 図3:敗血症検出モデルの因果経路の可視化(具体例)。患者の生体信号(心拍数、乳酸値、血圧)の時系列変化とモデルの意思決定プロセスを医療現場のコンテキストで表現。データソース:コンセプトイメージ(AI生成)*
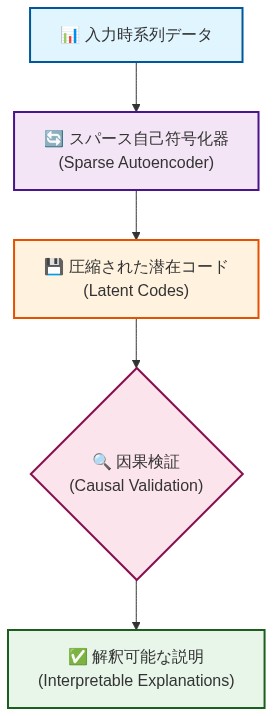
- 図4:TimeSAEの技術アーキテクチャとデータフロー*

- 図5:スパース潜在コードによる時系列パターンの圧縮と解釈。高次元データが低次元のスパース潜在空間に圧縮され、人間が解釈可能な特徴に変換されるプロセス。*