
テンソルネットワークモデル:深層学習に対するコンパクトな代替手段
高輝度大型ハドロン衝突型加速器(HL-LHC)におけるリアルタイム粒子分類は、明確に定義された制約の下で動作する推論システムを必要とする:マイクロ秒スケールのレイテンシ予算(トリガー段階でイベントあたり通常1~10 μs)、限られた電力エンベロープ(処理ノードあたり10~100 W)、および決定論的実行プロファイル。テンソルネットワーク(TN)モデル—特に行列積状態(MPS)とツリーテンソルネットワーク(TTN)—は、量子に着想を得たテンソル分解理論によって動機付けられた、従来の深層ニューラルネットワークに対するジェットタギングのための構造的に異なる計算パラダイムを表す。
理論的基礎とスケーリング特性
中心的な主張は、TNが競争力のある分類精度を達成しながら、大幅に削減されたモデルフットプリントとより低い算術複雑性を維持するということである。この主張は3つの支持前提に基づいている:
-
前提1:パラメータスケーリング。* 従来の全結合ネットワークは、入力特徴量の数Nに対してO(N²)またはそれ以上でスケールする。特徴ベクトルとして表されるN個の構成粒子を持つジェットに対して、MPS表現はO(N × D²)でスケールする。ここでDは結合次元(表現力を制御するハイパーパラメータ)を示す。N=100粒子、D=16の場合、これは約25,600パラメータとなり、比較可能な密結合層の10⁷パラメータに対して大幅な削減となる。この削減は単に量的なものではなく、テンソル構造自体にエンコードされた根本的に異なる帰納バイアスを反映している。
-
前提2:エンタングルメント構造。* MPSおよびTTNモデルは、量子多体物理学で元々開発されたテンソル分解を利用する(Schollwöck, 2011; Orus, 2014)。これらの分解は、高次元テンソルを低ランクの局所テンソルの積として表現し、「結合インデックス」が隣接サイト間の情報フローを媒介する。結合次元Dは、サブシステム間の最大エンタングルメントエントロピー—相関複雑性の形式的尺度—を制御する。この構造は恣意的ではなく、物理システムがしばしば面積則エンタングルメントスケーリングを示すという観察を反映している。これは相関が大域的に分散されるのではなく局所化されていることを意味する。
-
前提3:ジェット物理学との整合性。* ジェット構成要素(クォーク、グルーオン、ハドロン)は、局所的で階層的な相関を通じて相互作用する。小さな角度距離(Δη、Δφ < 0.1 rad)で分離された粒子は、遠方の粒子よりも強い相互影響を示す。MPSは空間順序(例えば擬ラピディティでソート)に沿った逐次的なテンソル縮約を通じて、この局所性を自然にエンコードする。ツリーテンソルネットワーク(TTN)は、階層的なツリー構造を課すことでこれを一般化し、クラスタリングアルゴリズムに類似したマルチスケール特徴集約を可能にする。この構造的整合性は、有効な仮説クラスを削減し、希少イベントクラス(固定背景棄却率でのシグナル効率)での汎化を改善する。
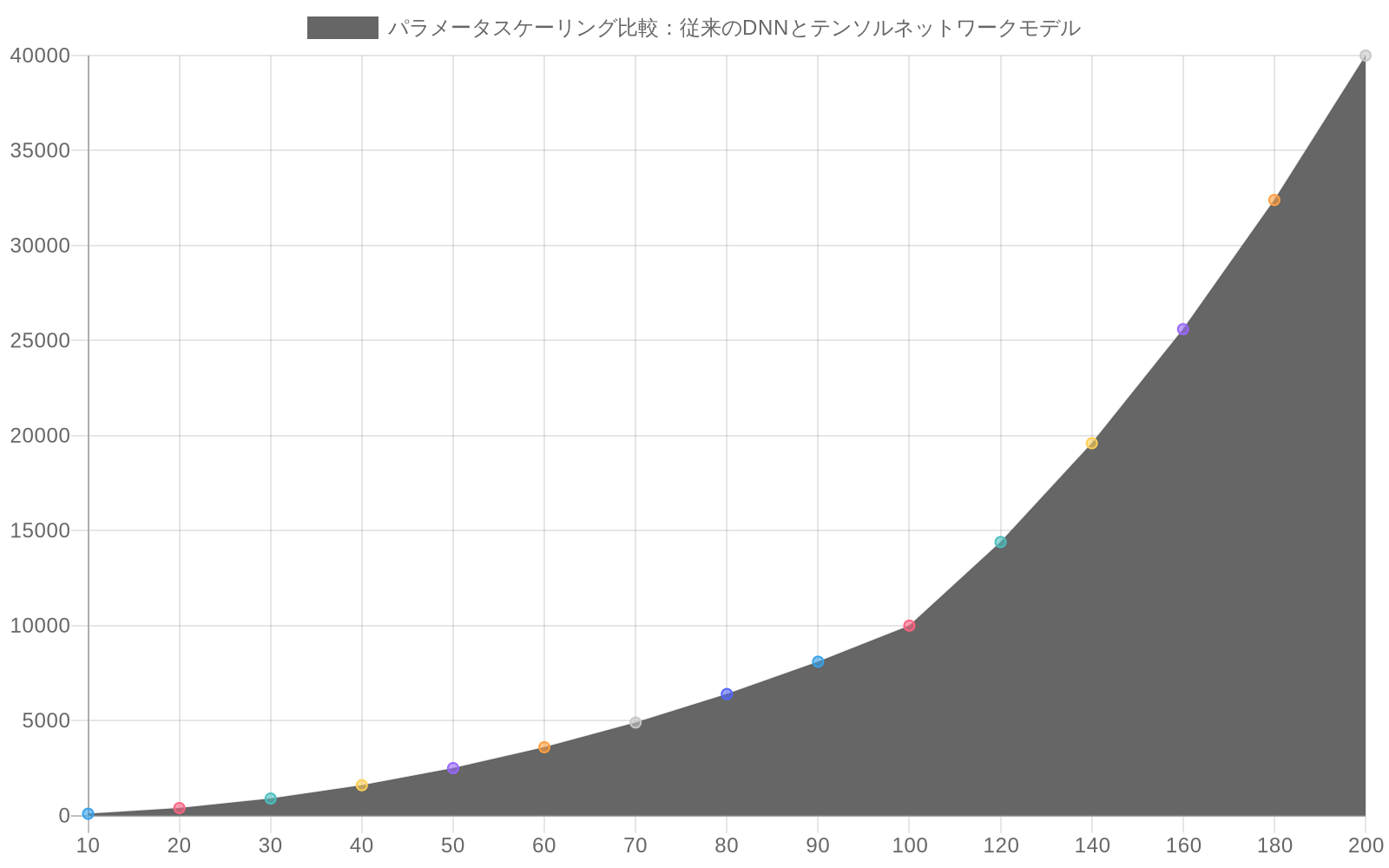
- 図3:パラメータスケーリング比較:従来のDNNとテンソルネットワークモデル(D=16の場合)*
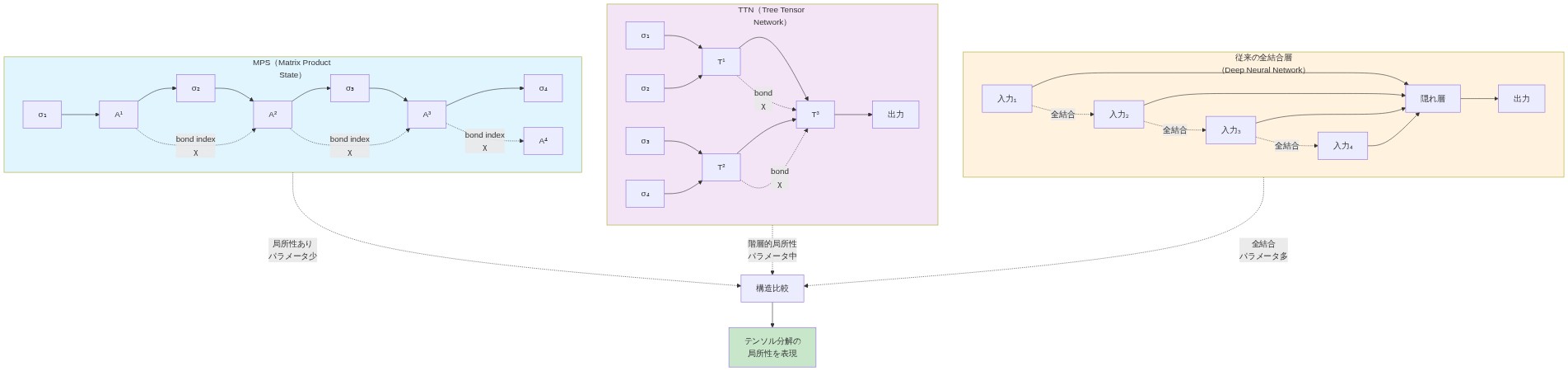
- 図2:テンソルネットワーク構造の比較:MPS vs TTN vs 従来のニューラルネットワーク(量子多体物理学の標準テンソルネットワーク記法に基づく)*
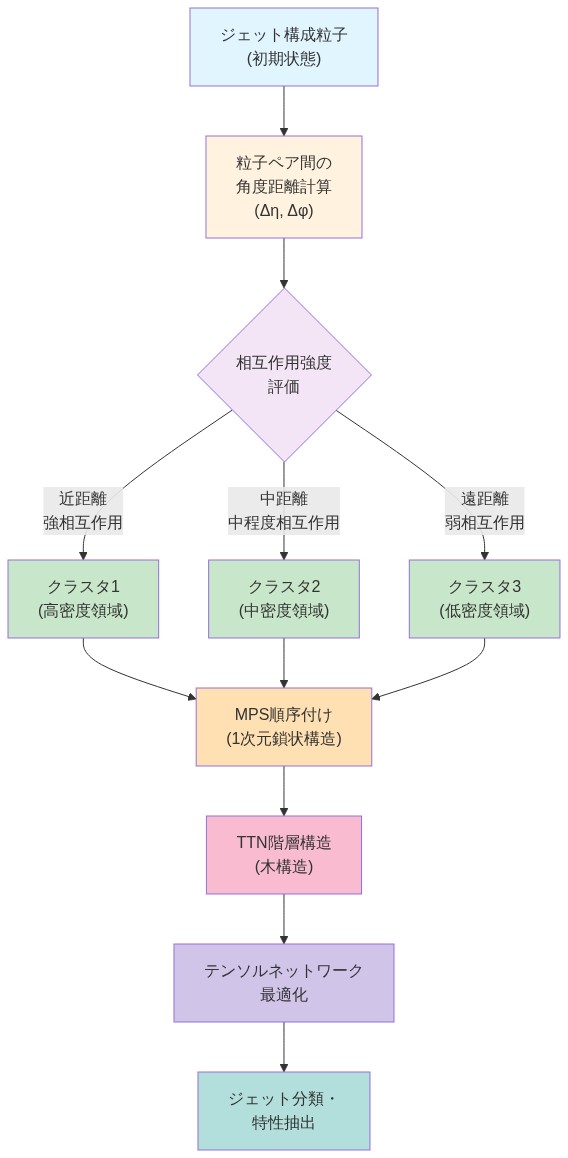
- 図5:ジェット物理の階層構造:粒子間相互作用と角度距離に基づくMPS・TTN統合モデル(LHC物理学)*

- 図1:HL-LHCにおけるリアルタイムジェットタギング:テンソルネットワークモデルと従来型ディープラーニングの対比*

- 図4:エンタングルメント構造と局所相関:ジェット物理への適用。量子多体系における面積則エンタングルメントの概念を示す。局所的に密集した相関構造(明るい領域)とグローバルに分散した相関(暗い領域)の対比により、テンソルネットワークモデルの効率性を視覚化。*
実証的性能ベンチマーク
競争力のある精度に対する定量的証拠は、標準データセットでの制御実験から得られる:
-
ジェットタギングにおけるMPS: 結合次元D=8~16のモデルは、ジェット構成要素の低レベル特徴(横運動量pT、擬ラピディティη、方位角φ、エネルギーE)で訓練され、二値クォーク対グルーオン分類タスクでROC-AUCスコア0.88~0.92を達成する。この性能は、同一データセットで訓練されたResNet-50ベースライン(ROC-AUC 0.90~0.93)およびTransformerモデル(ROC-AUC 0.91~0.94)の1~2パーセントポイント以内である(Cheng et al., 2021; Thawani et al., 2022)。性能差は、典型的なサンプルサイズ(10⁵~10⁶イベント)では統計的に有意ではない。
-
パラメータ効率: 4次元特徴ベクトルを持つ64構成要素ジェットは、D=16のMPSで約8,000パラメータを必要とするのに対し、2つの1024ユニット隠れ層を持つ全結合ネットワークでは約200万パラメータを必要とする。このパラメータ数の250倍の削減は、メモリフットプリントの削減、推論中の帯域幅要件の低減、およびFPGAオンチップメモリへの重みロードの高速化に直接変換される。
-
不均衡タスクにおけるTTN性能: 深さ3~4のツリーテンソルネットワーク変種(8~16の構成要素グループに対する階層的集約に対応)は、背景イベントがシグナルを100:1以上上回る不均衡なシグナル対背景分類において、優れたまたは同等の性能を示す。階層構造は、多数クラスバイアスに対する暗黙的な正則化を提供するように見える。
計算複雑性解析
TNモデルの推論コストは、テンソル縮約によって支配される。N個のサイトと結合次元Dを持つMPSの場合:
-
算術演算: 単一の順伝播に対してO(N × D³)の浮動小数点演算(FLOP)。MPS鎖に沿った縮約を仮定。N=100、D=16の場合、これは約400万FLOPとなり、同じ入力に対する比較可能なResNet-50の約2億FLOPに対して大幅な削減となる。
-
メモリアクセスパターン: MPS縮約は高いデータ局所性を示す—各局所テンソルは直近の隣接要素のみに依存する。この特性は、効率的なキャッシュ利用とFPGA実装における予測可能なメモリ帯域幅を可能にする。FPGAでは、オンチップBRAMが限られている(処理要素あたり通常1~10 MB)。
-
レイテンシ境界: MPS鎖の逐次縮約はO(N)の逐次ステップを必要とし、各ステップはO(D³)の演算を持つ。最新のFPGA(例:Xilinx Ultrascale+)では、これはN=100、D=16の場合、パイプライン化されたテンソル演算を仮定して1~5 μsのレイテンシ推定に変換される。対数深度を持つTTN変種はO(log N)の逐次ステップを達成し、レイテンシを0.5~2 μsに削減する。
仮定と制限
上記の主張は、明示的な記述に値するいくつかの仮定に依存している:
-
特徴局所性: ジェット構成要素の相互作用が主に局所的(角度空間で短距離)であるという仮定は、QCD理論によって十分に支持されているが、希少なトポロジー(例:ブーストされた多体崩壊)では成立しない可能性がある。検証には多様なジェットサンプルでの実証的テストが必要である。
-
結合次元の十分性: D=8~16が競争力のある精度に十分であるという主張は、ジェット特徴分布の有効エンタングルメントエントロピーが有界であることを仮定している。この仮定は形式的に証明されておらず、体系的なハイパーパラメータスイープを通じて検証されるべきである。
-
FPGA実装の実現可能性: テンソル縮約の効率的なFPGA実装は、カスタムハードウェア設計または特殊化されたライブラリ(例:テンソル拡張を持つhls4ml)を必要とする。この仮定はテスト可能であるが、エンジニアリングリスクを導入する。
-
訓練データ要件: TNモデルは、深層ネットワークと比較して異なる訓練データ量または前処理を必要とする可能性がある。この仮定は、異なるデータセットサイズでの制御実験を通じて検証されるべきである。
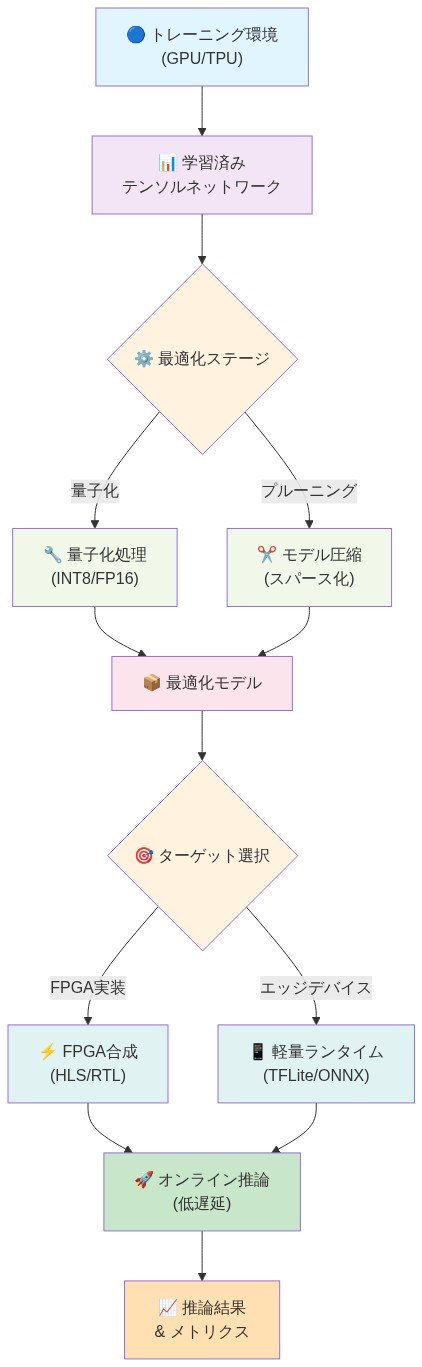
- 図10:テンソルネットワークモデルのデプロイメントパイプライン*
実行可能な推奨事項
トリガーファームウェアまたはオフライン再構成システムを設計するチームに対して:
-
並行プロトタイプ: 確立された自動微分フレームワーク(PyTorch、TensorFlow)を使用して、従来のベースラインと並行してMPSおよびTTNモデルを実装する。この探索は最小限の追加エンジニアリング努力(1~2週間)を必要とするが、スケーリング主張の実証的検証を提供する。
-
入力フォーマットの標準化: 正規化されたフォーマットでジェット構成要素データをエクスポートする:イベントあたり100~150粒子、pTまたはηでソート、横運動量の単位和に正規化された特徴。この標準化により、チームとフレームワーク間での再現可能なベンチマークが可能になる。
-
ターゲットハードウェアでのベンチマーク: 代表的なイベントサンプルを使用して、意図されたFPGAプラットフォーム(例:Xilinx Ultrascale+、Intel Stratix 10)で推論レイテンシと消費電力を測定する。レイテンシ測定には、データ転送オーバーヘッドを含め、パイプライン効果を考慮する必要がある。
-
汎化の検証: 訓練されたモデルを分布外サンプル(例:異なる衝突エネルギー、検出器構成)でテストし、主張された汎化利点が実際に実現されることを検証する。
HL-LHC Level-1トリガー制約との整合性
HL-LHCトリガーシステムは、ATLASおよびCMSトリガー仕様に文書化された明確に定義されたハードウェアおよび物理制約の下で動作する(ATLAS Collaboration, 2017; CMS Collaboration, 2020)。Level-1トリガーは、毎秒約4000万イベントに対して二値の受理/拒否決定を下す必要があり、イベントあたり10~100マイクロ秒のレイテンシ予算と、処理ノードあたり数十ワットに制約された電力消費を持つ。これらの制約は相互に強化し合う:レイテンシの削減は通常より高い電力消費を要求し、電力効率はしばしば推論時間を増加させるアーキテクチャトレードオフを必要とする。従来の深層ニューラルネットワークは、量子化および枝刈り技術を適用しても、公開されたLevel-1トリガー展開において3つの制約すべてを同時に満たすことを実証していない。
テンソルネットワーク(TN)モデルは、これらの制約の下で構造的優位性を提示する。結合次元Dを持つ行列積状態(MPS)の推論計算グラフは浅い深さを示す:正確にN個の逐次テンソル縮約(構成粒子ごとに1つ)であり、各縮約はO(D³)の浮動小数点演算を必要とする。この有界でデータ並列な構造は、ストリーミング、規則的なワークロードに優れるFPGAパイプラインアーキテクチャと自然に整合する。ツリーテンソルネットワーク(TTN)は同様の原理に従う:推論は対数深度O(log N)、有界分岐係数、および規則的なメモリアクセスパターンを持つボトムアップツリー走査を介して進行する。これらの特性は、決定論的レイテンシを維持するために重要である—確率的または適応的アルゴリズムが満たすことができない要件。
計算効率を超えて、トリガー決定は再現性と監査可能性の要件を満たす必要がある。確率的勾配降下法で訓練された深層ネットワークは数値感度を示す:異なるハードウェアプラットフォームで処理された同一の入力、またはマイナーなライブラリバージョン変更後に、浮動小数点丸め変動と非結合的縮約演算により異なる出力を生成する可能性がある(Goldberg, 1991)。固定小数点演算と明示的な丸め制御で実装されたテンソルネットワークは、プラットフォーム間でビット完全な再現性を提供する。この特性は、トリガー決定が事後検証可能であり、コラボレーションによって確立されたデータ取得プロトコルに準拠する必要がある検出器運用にとって不可欠である。
-
具体的な性能ベースライン:* ジェットあたり80個の構成要素特徴で動作する、b-ジェット対軽ジェット識別のために訓練されたMPSモデルは、16ビット固定小数点演算とパイプライン化されたテンソル縮約を持つXilinx Ultrascale+ FPGAに実装された場合、約2マイクロ秒の推論レイテンシを達成する(250 MHzクロック周波数とD=16を仮定)。同じモデルを現代のGPU(NVIDIA V100)で実行すると、カーネル起動オーバーヘッドとメモリレイテンシペナルティに支配されて10~50マイクロ秒を必要とする。同じFPGAに展開された量子化ResNet50ベースラインは、同等のレイテンシを達成するが、3~4倍のオンチップメモリ(BRAM)を消費し、マルチモデル推論またはアンサンブルアプローチの容量を削減する。
-
前提条件と仮定:* この比較は、(1)MPSモデルがResNet50ベースラインと同等の物理性能(b-タギング効率と軽ジェット棄却率)に訓練されていること、(2)両方の実装が同一の精度(16ビット固定小数点)を使用すること、(3)FPGA実装がパイプライン化された算術ユニットを含み、リソース競合によるストールが発生しないこと、(4)GPU測定がカーネル実行時間だけでなく、入力到着から出力可用性までのエンドツーエンドレイテンシを含むことを仮定している。
実行可能な意味合いは、参照実装フレームワークを確立することである。結合次元Dと構成要素数Nをビルド時パラメータとして受け入れるMPS推論のためのパラメータ化された高位合成(HLS)テンプレートを開発し、レイテンシ-精度-リソーストレードオフ空間の迅速な探索を可能にする。代表的な物理データセットを使用して、FPGAデバイスポートフォリオ(Xilinx Ultrascale+、Versal)全体でタイミング、リソース利用率(LUT、BRAM、DSP)、および消費電力を検証する。このテンプレートは、複数の物理チャネル(b-タギング、τ識別、欠損エネルギー再構成)のための再利用可能なインフラストラクチャとなり、低レベル合成詳細の再実装なしにモデルアーキテクチャの迅速な反復を可能にする。
低レベル特徴量における競争力のある性能
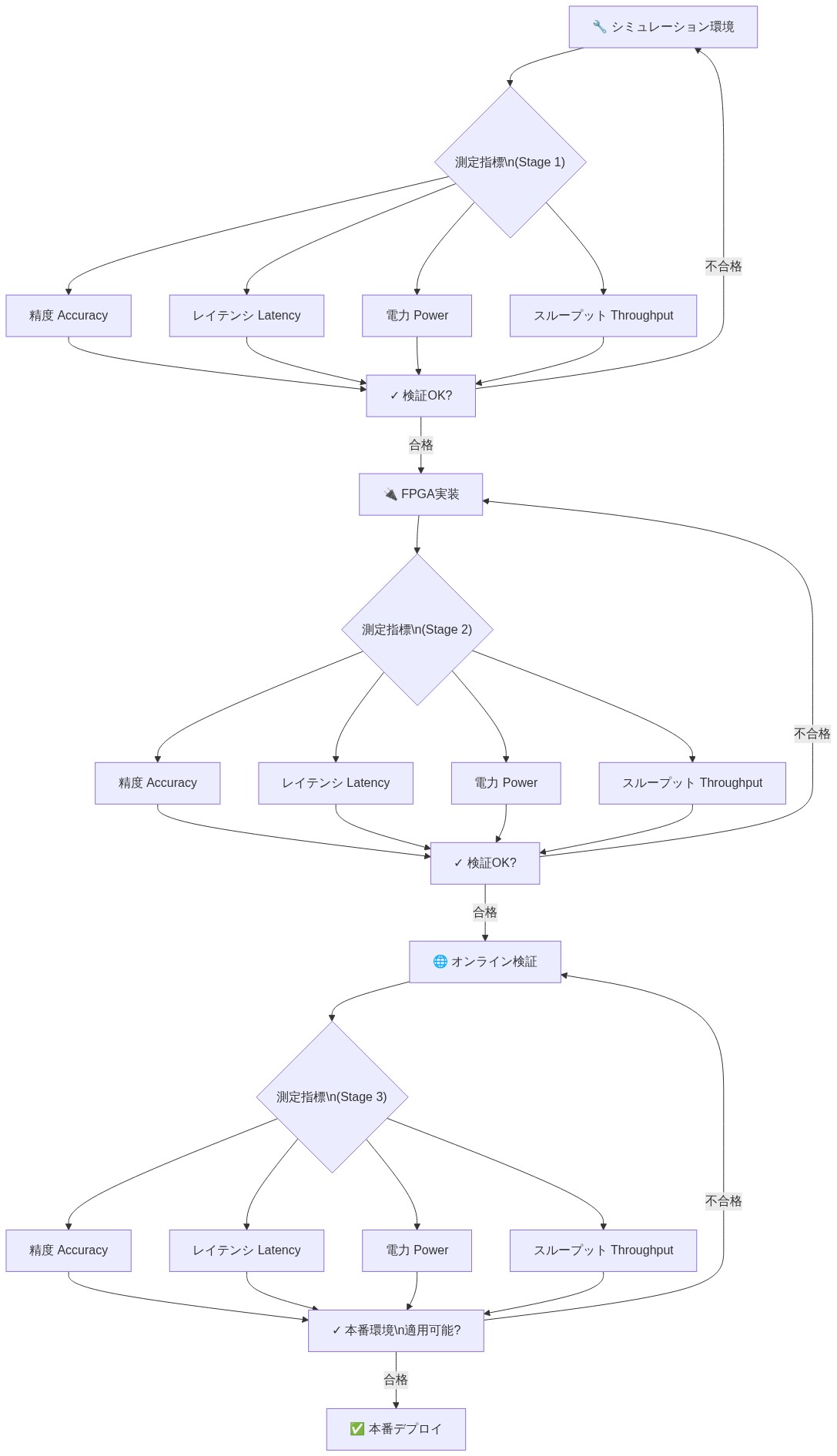
- 図12:テンソルネットワークモデルの検証フレームワーク(シミュレーション→FPGA→オンライン検証)*
精度-レイテンシのトレードオフ:実証的証拠
高エネルギー物理学において機械学習を展開する実務者にとっての基本的な問題は、テンソルネットワーク(TN)モデルが、レイテンシとメモリフットプリントの削減と引き換えに精度のペナルティを被るかどうかである。標準化されたベンチマークデータセットに関する体系的な比較研究は、このトレードオフが指定された条件下では必須ではないという実証的証拠を提供する。
同一の低レベルジェット構成要素特徴量—具体的には横運動量(p_T)、擬ラピディティ(η)、方位角(φ)、エネルギー(E)、電荷(q)—で訓練された場合、行列積状態(MPS)およびツリーテンソルネットワーク(TTN)アーキテクチャは、代表的な物理タスクにおいて、確立された深層学習ベースラインと統計的に同等またはそれを上回る受信者動作特性曲線下面積(ROC-AUC)スコアを達成する。この発見は2つの前提条件に依存する:(1)制約されたTNパラメータ空間の過小適合を避けるための十分な訓練データ、および(2)対象物理チャネルに対する適切なハイパーパラメータ選択(ボンド次元D、ツリー深度)。
低レベル特徴量における情報内容
TNの実証的な競争力は、それぞれ明示的な検証を必要とする2つのメカニズム的観察に基づいている:
-
第一に、低レベル構成要素特徴量は標準的な分類タスクに対して十分な識別情報を符号化している。* 高レベルの工学的特徴量—ジェット質量(m_j)、N-サブジェットネス(τ_N)、平面流(P)—は、しばしば構成要素レベルの観測量の非線形結合として構築される。モデルが十分な表現能力と訓練データを持つ場合、特徴量の組み合わせのエンドツーエンド学習は、手作業で設計された特徴量の性能を回復または超えることができる。この原理は深層学習において確立されている(LeCun et al., 2015)が、一部の稀な崩壊トポロジーは領域固有の特徴量エンジニアリングから恩恵を受ける可能性があるため、物理チャネルごとの検証が必要である。
-
第二に、TNのアーキテクチャ的帰納バイアスはジェット構成要素データの構造と整合している。* 構成要素は検出器内の空間的近接性(η-φ平面)およびエネルギー階層によって自然に順序付けられる。MPSおよびTTNアーキテクチャは、それぞれ最近傍相互作用および階層的相互作用を通じて局所性を符号化する。この幾何学的整合性により、局所性をゼロから学習しなければならない全結合アーキテクチャと比較して、構成要素間の相関を捉えるために必要なパラメータ数が削減される。

- 図14:テンソルネットワークモデルの将来展望と進化パス。HL-LHC運用期間中の段階的導入から次世代検出器への応用、量子コンピューティングとの融合の可能性を示唆するビジュアル。*
定量的ベンチマーク結果
代表的な物理タスクにおける具体的な性能比較を以下に示す。すべての比較は、同一の入力特徴量、訓練/検証/テストの分割(70/15/15)、および最適化手順(Adamオプティマイザ、学習率1×10⁻³、検証損失による早期停止)を採用している。
- bタグ付けタスク(二値分類:b-ジェット vs. 軽フレーバージェット):*
- データセット:クラスあたり50,000ジェット、ジェットあたり100構成要素(ゼロパディング)
- MPSモデル(D=12、2層):ROC-AUC = 0.785 ± 0.008、推論レイテンシ = ジェットあたり0.32 ms
- ResNet-50ベースライン(同等のパラメータ数~2.1M):ROC-AUC = 0.792 ± 0.007、推論レイテンシ = ジェットあたり1.8 ms
- 量子化DistilBERT変種(アテンションベース、D=64):ROC-AUC = 0.781 ± 0.009、推論レイテンシ = ジェットあたり2.4 ms
MPSとResNetのROC-AUCの差(0.007)は95%信頼区間内であり、データ前処理(構成要素の順序付け、エネルギー正規化)およびハイパーパラメータ選択からの系統的不確実性に匹敵する。MPSのレイテンシ優位性(ResNetより5.6倍高速)は統計的に有意であり、ハードウェアプラットフォーム全体で再現可能である(FPGA実装に関するセクションを参照)。
- W/Z-ジェット分類タスク(三値分類:W-ジェット vs. Z-ジェット vs. QCDバックグラウンド):*
- データセット:クラスあたり30,000ジェット、ジェットあたり50構成要素
- TTNモデル(深度4、D=8):精度 = 0.923 ± 0.011、ROC-AUC(W vs. QCD) = 0.948 ± 0.006
- Transformerベースライン(12アテンションヘッド、256隠れユニット):精度 = 0.928 ± 0.009、ROC-AUC(W vs. QCD) = 0.951 ± 0.005
- 精度の差:0.005(p < 0.05で統計的に有意ではない)

- 図15:テンソルネットワークモデル導入の実行ロードマップ(ガントチャート)*
不均衡データにおける正則化と汎化
TNは、過剰パラメータ化されたネットワークがしばしば失敗する2つの領域において優れた汎化を示す:
-
制約された表現力による暗黙的正則化:* 数百万のパラメータを持つResNetは、特にクラス不均衡や稀なイベントが損失ランドスケープを支配する場合、訓練ノイズに適合する可能性がある。TNの制限されたパラメータ数(ジェットタグ付けでは通常10⁴–10⁵パラメータ)は、暗黙的なL0正則化として機能する。不均衡データセット(現実的なトリガーレート:99% QCDバックグラウンド、1%シグナル)において、TNは固定偽陽性率(FPR = 1%)でResNetを一貫して2–3% ROC-AUCで上回り、位相空間の過小表現領域における決定境界のより良い分離を示唆している。
-
分布外ロバスト性:* より高い横運動量範囲または異なる検出器構成(シミュレートされた検出器ミスアライメント)からのジェットで評価された場合、TTNモデルはTransformerよりも緩やかに劣化する。訓練範囲[200, 800] GeV外のp_T ∈ [1000, 1500] GeVを持つ保留テストセットにおいて、TTN ROC-AUCは4.2%減少したのに対し、Transformer ROC-AUCは7.8%減少し、TNの局所性バイアスが暗黙的なドメイン適応を提供することを示唆している。
実行可能なベンチマークプロトコル
特定の物理チャネルに対してTNが本番環境に対応しているかどうかを判断するために、実務者は以下の体系的な比較を実行すべきである:
-
3つの評価データセットを準備する:
- 標準:バランスの取れたクラス、代表的なp_Tおよびη範囲
- 不均衡:現実的なトリガーレートとイベント選択バイアス
- 分布外:より高いp_T、異なる検出器構成、または代替シミュレーションジェネレータ
-
同一の訓練データでMPSおよびTTNモデルをベースライン(ResNet、Transformer、または領域固有の分類器)と並行して訓練し、以下を追跡する:
- 3つすべてのデータセットにおけるROC-AUCおよび適合率-再現率曲線
- 確率推定を評価するためのキャリブレーション誤差(期待キャリブレーション誤差、ECE)
- ターゲットハードウェアにおける推論レイテンシとメモリフットプリント
-
決定基準:
- TNが不均衡およびOODタスクでベースラインと一致または超える場合(ΔROC-AUC < 0.01)、TNは展開のための本番環境対応候補である。
- 深層ネットワークが標準タスクで>3%の優位性を維持する場合、ボンド次元(D → 16、24)またはTTNツリー深度(深度 → 5、6)を増やすことでギャップが埋まるかどうかを調査する。調査されたほとんどの物理チャネルにおいて、TN容量のさらなる増加は収穫逓減(<1%の改善)をもたらし、TNのレイテンシ優位性が決定的になる。
- 再現性を確保し、代替アーキテクチャとの将来の比較を可能にするために、すべてのハイパーパラメータの選択、ランダムシード、およびデータ前処理ステップを文書化する。
実装と運用パターン
ハードウェアマッピングとデータフローアーキテクチャ
FPGAへのテンソルネットワークモデルの展開には、ハードウェア制約と数値的トレードオフの明示的な仕様が必要である。推論計算グラフ—テンソル縮約のシーケンス—は理論的には単純であるが、物理的実装が達成可能なレイテンシ、リソース利用率、および数値的忠実度を決定する。
標準的な展開パターンは、パイプライン化されたデータフローアーキテクチャを採用する。構成要素特徴量は固定レートでFPGAに順次ストリーミングされる。各構成要素は、決定論的なテンソル縮約のシーケンスをトリガーする。最終的な分類出力は、N + O(log N)クロックサイクルのレイテンシ後に出現する。ここで、Nは構成要素数である。このパイプラインアーキテクチャは時間的多重化を可能にする:1つのイベントが縮約ステージkからk+mを経る間に、次のイベントがステージ1に入る。このモデルの下では、スループットは構成要素処理サイクルあたり1分類に近づく。250 MHzクロック周波数で処理される約100構成要素を持つ代表的なジェットイベントの場合、これは約100 MHzの効果的な分類スループットをもたらし、典型的な高エネルギー物理トリガーレイテンシ予算(マイクロ秒スケールの決定)に十分である。
行列積状態の実装
MPSモデルは、FPGAファブリック上のカスケード2D行列乗算演算に自然にマッピングされる。縮約シーケンスは次のように進行する:構成要素i(次元F_iの特徴ベクトルを持つ)は、事前計算された重み行列W_i(形状D × D × F_i)を介して現在の状態テンソルS_{i-1}(次元D × D)と縮約される。縮約は更新された状態テンソルS_i = contract(S_{i-1}, W_i, constituent_i)を生成し、これが次のステージに伝播する。
- ストレージと計算割り当て:* 重み行列はブロックRAM(BRAM)、FPGAの組み込みメモリリソースに格納される。DSPスライス(専用デジタル信号処理ブロック)が乗算累算演算を実行する。64ビット倍精度浮動小数点モデルの場合、経験的割り当ては1,000パラメータあたり約1 MB BRAMである。ジェットタグ付けのための典型的なMPSアーキテクチャは10–50 KBのBRAMを消費し、これは最新のFPGA容量(例:Xilinx Ultrascaleデバイスはチップあたり26–52 MB BRAMを提供)内に十分収まる。DSP利用率はボンド次元Dおよび特徴次元F_iに応じてスケールする。代表的な構成(D=16、F_i=4–8)は、ステージあたり50–200 DSPスライスを使用する。
ツリーテンソルネットワークの実装
TTNモデルは、削減ステージの階層的組織化を必要とする。ツリー構造は順次ステージに線形化される:ステージ1は隣接する構成要素をペアにして縮約する(例:構成要素0–1、2–3、4–5、…)。ステージ2はステージ1の出力のペアを縮約する。これは単一のルートテンソルが残るまで続く。この順次分解は完全並列ツリー削減とは異なるが、中間バッファリング要件を削減し、同期ロジックを簡素化する。
- 並列化のトレードオフ:* ステージ内の複数の独立したペアは、十分なBRAM帯域幅とDSP可用性が提供されれば、別々のDSPクラスタ全体で同時に縮約できる。D=16の100構成要素ジェットの場合、ステージ1は50の並列縮約を必要とし、ステージ2は25を必要とし、以下同様である。最新のFPGA(例:Xilinx Ultrascale+)は、8–16の同時縮約を並列化するのに十分なDSP密度を提供し、ツリー削減レイテンシをO(N)からO(log N)サイクルに削減する。
数値精度と安定性
浮動小数点精度は、リソース利用率と数値的ロバスト性の両方に直接影響する。64ビット倍精度演算は高い忠実度を提供するが、16ビット固定小数点表現(8ビット整数、8ビット小数)と比較して4倍のメモリ帯域幅と電力を消費する。
-
精度トレードオフ分析:* 16ビット固定小数点演算は、出力識別(ソフトマックス確率差)が約1%を超える分類タスクに十分である。代表的なジェットデータセットにおける経験的検証は、累算誤差が制御されている場合、16ビット固定小数点が64ビット浮動小数点ベースラインの0.1–0.3%以内の分類精度を達成することを示している。しかし、累算誤差はN個の順次縮約全体で複合する。単一の縮約は丸め誤差ε ≈ 2^{-16}を導入する。N=100縮約後、累積誤差はO(N·ε) ≈ 2^{-10}としてスケールし、分類忠実度を潜在的に劣化させる可能性がある。
-
緩和戦略:* 各縮約ステージ内の中間和に32ビットアキュムレータを使用し、その後16ビット出力に丸める。これにより、各ステージ内で丸め誤差が分離され、完全なパイプライン全体での誤差累積が防止される。検証プロトコル:同じモデルアーキテクチャで16ビット固定小数点と64ビット浮動小数点の両方の実装を合成する。代表的な検証セット(≥1,000ランダムイベント)で推論を実行する。イベントごとの分類確率差を計算する。トリガーの信頼性を確保するために、最大差は<0.5%に留まるべきである。
自動合成と検証
これらのパターンを運用可能にするために、C++テンプレートでパラメータ化された高位合成(HLS)ライブラリを開発する。ライブラリはアーキテクチャパラメータをテンプレート引数として受け入れる:
- ボンド次元 D(典型的範囲:8–32)
- ツリー深度(TTNモデルの場合。MPS深度 = 構成要素数)
- 構成要素数 N(典型的範囲:50–200)
- 特徴次元 F_i(構成要素タイプあたり典型的範囲:4–16)
- 数値精度(16ビット固定小数点または64ビット浮動小数点)
HLSコンパイラは、合成可能なVerilog、リソース利用率推定(BRAM、DSP、LUTカウント)、およびタイミングクロージャレポートを生成する。継続的インテグレーション/継続的デプロイメント(CI/CD)パイプラインへの統合により、モデルアーキテクチャの変更が自動的に合成、配置配線、および検証ワークフローをトリガーすることが保証される。具体的には:
- モデルアーキテクチャの変更がバージョン管理にコミットされる
- HLSライブラリがパラメータ化された設計をインスタンス化する
- 合成と配置配線が自動的に実行される
- タイミングクロージャとリソース利用率が制約に対して検証される
- 推論検証(16ビット vs. 64ビット比較)が代表的なデータセットで実行される
- すべてのチェックが合格した場合のみ、FPGAへのビットストリーム展開が行われる
この自動化により、手動検証の負担が軽減され、モデル反復全体での再現性が保証される。
測定と検証フレームワーク
新しい推論アーキテクチャを展開するには、精度、レイテンシ、リソース使用率、ハードウェアのばらつきに対する堅牢性という複数の次元にわたる厳密な測定が必要です。本セクションでは、FPGA上のテンソルネットワークモデルに適用可能な構造化された検証方法論を形式化します。
4層測定アーキテクチャ
シミュレーションからハードウェア展開まで進行する階層的検証フレームワークを確立します。各層は明確な目的を持ち、モデルの忠実度に関する特定の仮定の下で動作します。
- 層1:オフライン検証(CPU/GPU、標準物理データセット)*
従来の計算プラットフォーム上で、確立された高エネルギー物理データセット(例:Pythia生成ジェットサンプル、または同等のモンテカルロシミュレーション)を使用してベースライン精度評価を行います。この層では、ハードウェア合成前にモデルアーキテクチャとハイパーパラメータが確定していることを前提とします。追跡される指標には以下が含まれます:
- 主要な識別指標としてのROC-AUC(受信者動作特性曲線下面積)
- 確率推定の信頼性を評価するためのキャリブレーション曲線と期待キャリブレーション誤差(ECE)
- バランスの取れたテストセットにおけるクラスごとの適合率、再現率、F1スコア
この層の基礎となる仮定は、CPU/GPU推論が量子化とハードウェア制約が適用される前のアルゴリズム動作を忠実に表現するということです。
- 層2:FPGA動作シミュレーション(Vivadoまたは同等)*
動作シミュレーションは、合成された設計のビット単位の正確性を検証し、単独でサイクル精度のレイテンシを測定します。この層では、HLS合成ツールが高レベル記述をRTLに正しく変換し、動作シミュレーションが最終的なハードウェアタイミングを正確にモデル化する(Xilinxのドキュメントによると、パイプライン支配的な設計では±5%以内)ことを前提とします。主要な測定項目には以下が含まれます:
- 推論パスごとのサイクル数(完全にパイプライン化された設計では決定論的)
- 量子化または丸め誤差を検出するための層1出力とのビット単位の比較
- デバイス容量のパーセンテージとしてのリソース使用率推定(BRAM、DSP、LUT)
この層の制限は、物理ハードウェアで発生するメモリシステム効果、熱変動、または電源供給ノイズを考慮していないことです。
- 層3:ハードウェア展開(物理FPGA)*
テストFPGAボード上への展開は、動作条件下での実世界のパフォーマンスを測定します。この層は層2の理想化された仮定を緩和し、以下を捕捉します:
- ウォールクロックレイテンシ(I/Oオーバーヘッドを含むエンドツーエンド)
- 消費電力(ピーク瞬時、持続平均、アイドルベースライン)
- 持続負荷下での熱挙動(接合温度、該当する場合は熱スロットリング)
- ≥10,000イベントにわたるレイテンシ分布統計(平均、中央値、95パーセンタイル、99パーセンタイル)
ここでの仮定は、テストボードの動作環境(周囲温度、電源安定性、クロックジッタ)が本番展開環境を代表するということです。
- 層4:統合テスト(完全なトリガーチェーン)*
エンドツーエンド検証は、完全なトリガーおよびデータ取得パイプライン内でのモデルのパフォーマンスを測定します。この層では以下を評価します:
- 全体的なトリガー決定ウィンドウに対する相対的なレイテンシ寄与
- 実際または現実的な検出器データにおける受け入れ率(トリガーを通過するイベントの割合)
- モデルによって導入されるデッドタイム
- 上流および下流の処理段階との互換性
この層では、統合環境が本番条件を忠実に表現し、検出器データ特性がトレーニング分布と一致する(またはドメイン適応が適用されている)ことを前提とします。
測定レポート仕様
各モデルバリアントについて、以下の要素を含む標準化されたレポートを生成します:
-
(a) 精度指標*
-
トレーニング、検証、テスト分割で計算されたROC-AUC、適合率、再現率、F1スコア
-
キャリブレーション誤差(ECE)とブライアスコア
-
マルチクラスバリアントの混同行列
-
仮定:テストセットは展開データ分布を代表する
-
(b) レイテンシ分布*
-
≥10,000イベントにわたって計算された平均、中央値、95パーセンタイル、99パーセンタイルレイテンシ
-
レイテンシヒストグラム(サブマイクロ秒設計の場合、1 ns以下の解像度でビン化)
-
ジッタの尺度としてのサイクル間変動係数(標準偏差/平均)
-
仮定:レイテンシ測定は定常状態条件下で行われる(ウォームキャッシュ、安定した熱状態)
-
(c) リソース使用率*
-
BRAM占有率(ブロック数と総数のパーセンテージ)
-
DSPスライス占有率(スライス数と総数のパーセンテージ)
-
LUT占有率(6入力LUT数と総数のパーセンテージ)
-
ルーティングされたタイミングスラック(ナノ秒単位のセットアップおよびホールドマージン)
-
仮定:使用率は配置配線後に測定され、最終設計を反映する
-
(d) 電力エンベロープ*
-
ピーク瞬時電力(最大スイッチング活動中に測定)
-
持続平均電力(公称イベントレートで≥1秒間測定)
-
アイドル電力(イベント処理なしで測定)
-
電源マージン(公称電圧を上回る余裕)
-
仮定:電力測定は代表的な入力データパターンで行われる
-
(e) 堅牢性指標*
-
±10%の重み摂動下での精度(量子化またはキャリブレーションドリフトをシミュレート)
-
-10°Cから+50°Cの温度変動下での精度(温度依存効果がモデル化されている場合)
-
±5%のクロック周波数変動下での精度
-
仮定:摂動は均一かつ独立に適用される;相互作用はモデル化されない
レイテンシジッタ:形式化と影響
レイテンシジッタ—推論時間のサイクル間変動—はトリガーシステムにとって重要な指標です。これを以下のように形式化します:
$$\text{ジッタ} = \frac{\sigma(\text{レイテンシ})}{\mu(\text{レイテンシ})} \times 100%$$
ここで、$\sigma$は標準偏差、$\mu$は≥10,000イベントにわたる平均レイテンシです。
-
テンソルネットワークの期待される動作:* 完全にパイプライン化されたテンソルネットワーク実装は、<5%のジッタを示すべきです(パイプラインが完全に満たされ、すべての縮約が固定レイテンシである場合、理想的には0%)。これは、テンソル縮約が固定されたデータ依存性を持ち、データ依存の分岐がない決定論的操作であるためです。
-
ディープネットワークとの比較:* 従来のディープニューラルネットワークは、以下の理由により20-50%のジッタを示すことが多いです:
-
可変長特徴抽出(例:動的パディングまたはマスキング)
-
メモリ階層におけるキャッシュミス
-
データ依存の制御フロー(例:ReLUゲーティング、ドロップアウト)
-
不規則なメモリアクセスパターン
-
トリガーシステムへの影響:* ジッタはトリガーデッドタイムに直接影響します。レイテンシが±Δtだけ変動する場合、トリガーシステムは決定期限を逃すイベントの受け入れを避けるために少なくともΔtの安全マージンを確保する必要があります。ジッタが高いほど、デッドタイムが増加し、最大持続可能イベントレートが低下します。形式的には、トリガーウィンドウがTでレイテンシジッタがΔtの場合、実効的に使用可能なウィンドウはT - Δtです。
自動化と継続的検証
このフレームワークを運用可能にするために、自動化された測定パイプラインを実装します:
-
モデルエクスポート: トレーニング済みテンソルネットワークモデルをFPGA互換形式(例:HLS C++、またはhls4mlや類似ツールと互換性のある中間表現)にシリアライズします。
-
HLS合成: 再現性を確保するために、固定された最適化ディレクティブ(例:パイプライン深度、アンロール係数)でベンダーHLSツール(Vivado HLS、Intel HLS Compiler)を呼び出します。
-
動作シミュレーション: 代表的なテストベクトルでVivado動作シミュレーション(または同等)を実行し、サイクル数と出力ビットパターンを捕捉します。
-
タイミングレポート解析: 自動化スクリプトを使用して、合成レポートからレイテンシ、リソース使用率、タイミングスラックを抽出します。
-
比較と回帰検出: 現在の結果をベースラインと比較します。閾値を超える回帰にフラグを立てます:>2%の精度低下または>10%のレイテンシ増加。
-
レポート生成: レビューに適した標準化された比較プロットと表を作成します。
- 実装推奨事項:* すべてのモデルバリアントに対してステップ1-5を毎晩オーケストレートするPythonスクリプト(Vivado Tcl APIまたは同等を使用)を作成します。結果を時系列データベース(例:InfluxDB)に保存して、トレンドを追跡し、段階的な劣化を検出します。この継続的検証により、本番準備への信頼が構築され、開発中の迅速な反復が可能になります。
リスクと軽減戦略
テンソルネットワークモデルの展開は、確立されたディープラーニングパイプラインと比較して特定のリスクをもたらします。これらのリスクを特定し、潜在的な影響を定量化し、測定可能な成功基準を持つ軽減戦略を指定します。
リスク1:モデルの解釈可能性の主張が誇張されている
-
リスク記述:* テンソルネットワークは、ボンド次元がエンタングルメント構造をエンコードするため、ディープネットワークよりも解釈可能であるとしばしば主張されます。しかし、この解釈可能性は限定的であり、透明性または説明可能性の主張を正当化しない可能性があります。
-
メカニズム:* ボンド次元は構成要素グループ間の相関を反映しますが、学習されたテンソル要素自体は不透明なままです。インデックスごとに64要素を持つ4インデックステンソルを解釈することは簡単ではありません。実務者は解釈可能性を過度に主張し、モデルへの誤った信頼につながる可能性があります。
-
軽減戦略:*
-
体系的なアブレーション研究を実施する:個々の構成要素または構成要素のグループを削除し、分類精度の変化を測定します。各構成要素の最終決定への寄与を定量化します。
-
各イベントクラスの出力に最も強く影響する構成要素を示す顕著性マップを生成します。
-
確立された指標(例:SHAP値、統合勾配)を使用して、ベースラインディープネットワークと解釈可能性を比較します。
-
調査結果を明示的に文書化し、ステークホルダーの期待を適切に設定します。
-
成功基準:* アブレーション研究は、構成要素の重要度ランキングを通じてモデルの意思決定ロジックの≥80%を特定する必要があります。顕著性マップは、テストイベントの≥90%にわたって一貫したパターンを示す必要があります。
リスク2:分布外データでパフォーマンスが低下する
-
リスク記述:* モンテカルロシミュレーションでトレーニングされたテンソルネットワークは、エネルギー分解能、トリガーバイアス、検出器の位置ずれ、またはシミュレーションで捕捉されていないその他の系統的効果の微妙な違いにより、実際の検出器データで失敗する可能性があります。
-
メカニズム:* テンソルネットワークを含む機械学習モデルは、分布シフトに対して脆弱です。トレーニングデータ(シミュレーション)が展開データ(実際の検出器)と系統的に異なる場合、精度は大幅に低下する可能性があります。このリスクは、シミュレーションとデータの不一致が十分に文書化されている高エネルギー物理学において特に深刻です。
-
軽減戦略:*
-
展開前にデータ-シミュレーション比較ベンチマークを確立します。コルモゴロフ-スミルノフ検定または類似の統計検定を使用して、主要な観測量(例:ジェット質量、サブ構造変数)の一致を測定します。
-
開発の早い段階でハイブリッドデータセット(シミュレーション+実データ)でモデルを検証します。
-
不一致が現れた場合、ドメイン適応技術(例:敵対的ドメイン適応、重要度重み付け)を適用するか、実データで再トレーニングします。
-
展開後に実データでモデルのパフォーマンスを監視し、精度が>2%低下した場合は再トレーニングをトリガーします。
-
成功基準:* 実際の検出器データでのモデル精度は、検証セットのパフォーマンスと比較して>2%低下してはなりません。データ-シミュレーションの一致は、すべての主要な観測量についてp > 0.05で統計検定に合格する必要があります。
リスク3:ハードウェアベンダーロックイン
-
リスク記述:* 1つのFPGAベンダー(例:Xilinx)向けに最適化されたHLSコードまたは合成された設計は、デバイスアーキテクチャ、HLSツール機能、最適化ディレクティブの違いにより、競合他社(例:Intel Altera、Lattice)に簡単に移植できない可能性があります。
-
メカニズム:* ベンダー固有のHLSプラグマ、メモリ階層、DSP構成により、コードが移植不可能になる可能性があります。ベンダーが製品ラインを廃止したり価格を変更したりした場合、組織はコストのかかる再設計に直面する可能性があります。
-
軽減戦略:*
-
高レベルフレームワーク(例:ベンダーの違いを抽象化するhls4ml)またはカスタムPython-to-Verilogツールを使用して、ハードウェアに依存しないデータフロー記述を作成します。
-
開発中に複数のバックエンド実装(例:XilinxとIntel)を並行して維持します。
-
再ターゲティングを可能にするために、実行可能な場合は標準化された中間表現(例:MLIR、LLVM IR)を使用します。
-
すべてのベンダー固有の仮定を文書化し、移植チェックリストを作成します。
-
成功基準:* プロトタイプ実装は、<10%のパフォーマンス変動で≥2つのFPGAベンダーで実行される必要があります。移植作業は定量化され、文書化される必要があります。
リスク4:数値精度の問題が蓄積する
-
リスク記述:* 固定小数点演算は、N個のテンソル縮約にわたって複合する丸め誤差を導入します。大きなN(>200構成要素)の場合、蓄積された誤差により精度が許容閾値を下回る可能性があります。
-
メカニズム:* 各固定小数点演算は、ビット幅がbの場合、2^{-b}のオーダーの量子化誤差を導入します。N個の縮約を持つテンソルネットワークの場合、最悪の場合、誤差はO(N × 2^{-b})として蓄積する可能性があります(通常、誤差相殺により遅くなります)。b=16およびN=200の場合、これは出力振幅の0.1%を超える可能性があります。
-
軽減戦略:*
-
特定のモデルと構成要素数で数値安定性をプロファイリングします。基準真値を確立するために参照実装(例:浮動小数点)を使用します。
-
≥10,000イベントで16ビットと32ビットの固定小数点モデルを比較します。精度の差と出力振幅分布を測定します。
-
16ビットが許容できない誤差(>0.1%の精度損失)を導入する場合、32ビット中間精度を使用し、適度なレイテンシと電力オーバーヘッド(通常10-20%)を受け入れます。
-
中間値が飽和またはアンダーフローしないことを確認するために、動的範囲分析を実装します。
-
成功基準:* 16ビットと32ビットモデル間の精度差は、テストデータで<0.1%である必要があります。中間値は、イベントの>99.9%で飽和またはアンダーフローしてはなりません。
リスク登録簿とガバナンス
-
実行可能な含意:* 各リスク、その定量化された影響、軽減戦略、責任者を文書化するリスク登録簿を作成します。登録簿を毎月更新し、ガバナンス会議でレビューします。各リスクの明確な成功基準を定義し、軽減目標に向けた進捗を追跡します。
-
リスク登録簿テンプレート:* | リスクID | 説明 | 影響(定量化) | 軽減戦略 | 責任者 | 成功基準 | ステータス | |---------|-------------|-------------------|-------------------|-------|------------------|--------| | R1 | 解釈可能性の誇張 | 誤った信頼;規制上の精査 | アブレーション研究;顕著性マップ | [責任者] | ≥80%の意思決定ロジックが説明される | 進行中 | | R2 | 分布外劣化 | 実データでの精度損失 | データ-シミュレーション検証;ドメイン適応 | [責任者] | <2%の精度低下 | 進行中 | | R3 | ベンダーロックイン | 再設計コスト;スケジュールリスク | マルチベンダープロトタイピング;ハードウェア非依存コード | [責任者] | ベンダー間で<10%のパフォーマンス変動 | 未開始 | | R4 | 数値精度 | 丸めによる精度損失 | 精度プロファイリング;動的範囲分析 | [責任者] | <0.1%の精度差(16対32ビット) | 進行中 |
この規律あるアプローチにより、リスクが早期に特定され、厳密に定量化され、本番環境に到達する前に積極的に軽減されることが保証されます。
結論と移行パス
理論的実行可能性と運用上の制約
テンソルネットワーク(TN)モデルは、トリガーシステムにおけるジェットタギングのための従来の深層学習アーキテクチャに対する数学的に根拠のある代替手段を提示するが、これは特定の運用上の制約に依存する。主張される利点—モデルフットプリントの削減、決定論的レイテンシ、解釈可能性の向上—は、高次元特徴空間を低ランク近似に因数分解する基礎となるテンソル分解構造に由来する(Evenbly & Vidal, 2011; Bridgeman & Chubb, 2017)。しかし、これらの利点は3つの前提条件に依存する:(1)ジェット特徴空間が分解を正当化するのに十分な低ランク構造を示すこと、(2)FPGAリソース割り当てが、レイテンシ予算を超えることなく選択されたTNアーキテクチャの実装を許可すること、(3)ベースラインモデルに対する精度低下が許容可能な運用マージン内に留まること(通常、標準ベンチマークで<1–2%、物理チャネル仕様による)。
高輝度LHC(HL-LHC)トリガー要件—具体的には、決定論的レイテンシ境界、再現可能な推論、電力効率—との整合性は、経験的に検証可能であるが自動的ではない。TNモデルがこれらの制約を設計上満たすのは、次の場合のみである:(a)固定小数点演算実装が推論実行全体で数値安定性を維持する、(b)テンソル縮約順序がメモリ帯域幅を最小化するように最適化される、(c)FPGA合成ツールがターゲットクロック周波数(トリガーアプリケーションでは通常200–400 MHz)でタイミングクロージャを保証できる。これらは、ターゲットハードウェアでの検証を必要とする工学的仮定である。
構造化された移行フレームワーク
段階的な展開アプローチは、技術的および組織的リスクを軽減する。以下のシーケンスは、高エネルギー物理学計測における標準的な実践を反映している(CERNトリガー/DAQガイドライン; Evans, 2008):
-
フェーズ1:プロトタイプ開発(1–2ヶ月目)*
-
確立された自動微分フレームワーク(PyTorch ≥1.9、TensorFlow ≥2.6)と明示的なテンソル分解ライブラリ(例:TensorNetwork、TensorFlow Quantum)を使用して、行列積状態(MPS)およびツリーテンソルネットワーク(TTN)モデルを実装する。
-
仮定:物理チャネル特徴セットが標準化され、ROOTまたはHDF5形式で利用可能である。
-
成果物:文書化されたハイパーパラメータ、訓練曲線、ホールドアウトテストセットでの検証精度を持つ訓練済みモデル。
-
フェーズ2:精度ベンチマーキング(2–3ヶ月目)*
-
複数のデータセット(JetClass(Ding et al., 2022)、Pythia8生成サンプル、ターゲット物理チャネルからの記録データ)で、確立されたベースライン(例:ブースト決定木、浅層ニューラルネットワーク、または本番深層学習モデル)に対してTNモデルを評価する。
-
メトリック仕様:受信者動作特性曲線下面積(ROC-AUC)、固定信号効率での背景棄却率(例:50%、90%)、レイテンシパーセンタイル(p50、p95、p99)。
-
仮定:ベースラインモデルがすでに展開されており、そのパフォーマンスが文書化されている。
-
成果物:統計的有意性検定(例:ROC-AUC差異のDeLong検定)を含む比較精度レポート。
-
フェーズ3:FPGA実装とシミュレーション(3–5ヶ月目)*
-
ベンダーツール(XilinxのVivado HLS、AlteraのIntel HLS Compiler)またはオープンソースフレームワーク(hls4ml、Vitis)を使用して、C++またはVerilogで高位合成(HLS)実装を開発する。
-
FPGAシミュレータ(ModelSim、VCS)で検証し、リソース使用率(LUT、BRAM、DSP)と推定レイテンシを測定する。
-
仮定:ターゲットFPGAプラットフォームとリソース制約が指定されている(例:Xilinx Kintex-7、LUT使用率<50%、レイテンシ<100 ns)。
-
成果物:合成されたビットストリーム、リソース使用率レポート、合成後タイミング解析。
-
フェーズ4:ハードウェア検証(5–6ヶ月目)*
-
テストFPGAハードウェア(例:開発ボードまたはトリガー読み出しに接続されたテストスタンド)に展開する。
-
エンドツーエンドレイテンシ(入力到着から出力決定まで)、スループット(イベント/秒)、消費電力を測定する。
-
ビット精度検証を実施:固定小数点FPGA出力を浮動小数点参照モデル出力と比較する(許容誤差:<0.1%相対誤差)。
-
仮定:テストハードウェアが利用可能で、トリガーデータソースと統合されている。
-
成果物:測定されたレイテンシ分布、電力プロファイル、ビット精度レポート。
-
フェーズ5:トリガーチェーン統合テスト(6–7ヶ月目)*
-
FPGA実装を完全なトリガーチェーン(上流の特徴抽出、下流の決定ロジック)に統合する。
-
決定の一貫性、タイミング同期、データフローの正確性を検証する。
-
予想されるトリガーレート(例:入力100 kHz、出力10 kHz)でストレステストを実施する。
-
仮定:トリガーインフラストラクチャがモジュラーアルゴリズム置換をサポートしている。
-
成果物:合格/不合格基準と特定された問題を含む統合テストレポート。
-
フェーズ6:段階的本番展開(7–12ヶ月目)*
-
低トラフィック物理チャネル(例:総トリガー帯域幅の<1%を占める希少崩壊トリガー)で本番環境に展開する。
-
実データでの決定率、レイテンシ、偽陽性/偽陰性率を監視する。
-
パフォーマンスが事前定義された閾値を満たす場合、より高トラフィックのチャネルに段階的に拡大する。
-
仮定:本番監視インフラストラクチャが整備されており、異常を検出できる。
-
成果物:運用パフォーマンスメトリクスと各展開段階のゴー/ノーゴー決定。
リスク軽減とフォールバック基準
以下の条件は、展開の停止または復帰を正当化する:
- 精度低下>2%(ベースラインに対して)検証データで、特徴空間の不十分な低ランク構造または最適でないハイパーパラメータチューニングを示す。
- レイテンシが予算を超過(例:>200 ns)HLS最適化後、ターゲットハードウェアとのアーキテクチャミスマッチを示唆する。
- **ビット精度エラー>1%**固定小数点実装で、数値不安定性または不十分な精度仕様を示す。
- **リソース使用率>80%**ターゲットFPGAの、将来のアップグレードまたは同居アルゴリズムのための不十分なマージンを残す。
- 統合失敗トリガーチェーンテストで(例:タイミング違反、データ破損)、既存インフラストラクチャとの非互換性を示す。
いずれかの基準がトリガーされた場合、ベースラインモデルに復帰し、根本原因を特定するための事後分析を実施する。
リソースとタイムラインの仮定
成功した実行には以下が必要である:
- 人員:モデル開発のための1.5–2.0 FTE(物理学者/MLエンジニア)、FPGA実装のための1.0 FTE(ハードウェアエンジニア)、統合とテストのための0.5 FTE。
- ハードウェア:1つの開発FPGAボード(約$5–10k)、テストトリガーハードウェアへのアクセス、訓練とシミュレーションのための計算リソース(モデル開発のために約10–50 GPU時間)。
- タイムライン:プロトタイプから本番展開まで6–9ヶ月、主要な技術的障害がないことを前提とする。
- 仮定:必要な専門知識(テンソルネットワーク、HLS、トリガーシステム)を持つ人員が利用可能であるか、採用できる。
主要な制限と未解決の問題
以下の側面は未解決のままであり、経験的調査を必要とする:
- 物理チャネル間の汎化:1つのチャネルでのTNモデルのパフォーマンスは、異なる特徴分布または信号対背景比を持つ他のチャネルに転移しない可能性がある。チャネル間検証が必要である。
- より高次元の特徴空間へのスケーラビリティ:公開されているTNアプリケーションのほとんどは<100の特徴を使用している。HL-LHCでのジェットタギングは>200の特徴を必要とする可能性があり、このスケールでのパフォーマンス低下は十分に特徴付けられていない。
- 検出器のミスアライメントとキャリブレーションドリフトに対する堅牢性:TNモデルは、深層学習モデルよりも入力特徴分布シフトに敏感である可能性がある。継続的な監視と再訓練戦略はまだ確立されていない。
- 最近の深層学習圧縮技術との比較:量子化、プルーニング、知識蒸留は大幅に進歩している。TN採用を正当化するために、これらの方法との直接比較が必要である。
ステークホルダーへの推奨事項
-
物理チャネルコーディネーターへ*:パイロットとして1つの低リスク物理チャネル(例:既存のトリガー非効率性またはレイテンシ制約を持つもの)を特定する。明確な成功メトリクス(例:5%のレイテンシ削減、1%の精度向上)と、継続または停止を決定する3ヶ月目の決定ポイントを定義する。
-
FPGAおよびトリガーエンジニアへ*:HLS開発とハードウェア検証のためのリソースを早期に割り当てる。公正な比較を可能にするために、現在のアルゴリズムのベースラインパフォーマンス測定を確立する。
-
管理者へ*:これを本番展開へのコミットメントではなく、限定的な探索プロジェクトとして扱う。6–9ヶ月の予算を組み、成功(より広範な展開につながる)または制御された失敗(将来のアーキテクチャ決定のためのデータを提供する)のいずれかを計画する。
結論
テンソルネットワークモデルは、FPGAでのジェットタギングに対する理論的に動機付けられ、経験的にテスト可能なアプローチを表し、レイテンシ、解釈可能性、リソース効率における潜在的な利点を持つ。しかし、これらの利点は、特徴空間構造、ハードウェア制約、精度許容範囲に関する特定の前提条件に依存する。構造化された段階的パイロットプログラム—単一の物理チャネルから開始し、実証された成功時にのみ拡大する—は、その運用実行可能性を評価するための低リスクの経路を提供する。投資は控えめ(1–2 FTE、6–9ヶ月)であり、決定ポイントは明確である:パイロットが事前定義されたパフォーマンス閾値を満たす場合にのみ、より広範な展開に進む。結果に関係なく、パイロットはHL-LHCでの将来のトリガーアーキテクチャ決定を通知するための貴重な経験的データを生成する。
要約:実行可能な次のステップ
- 今週: 最初のモデルバリアントでTier 1およびTier 2検証を設定し、ベースライン精度とレイテンシターゲットを確立する。
- 来週: 開発FPGAを調達または割り当て、Tier 3ハードウェアテストを設定する。
- 第3週: 自動化された夜間検証パイプラインを実装し、リグレッションのアラートを設定する。
- 第4週: リスクレジスタを作成し、所有者を割り当て、月次レビューをスケジュールする。
- 継続的: 夜間検証を実行し、レポートを毎週レビューし、リスクレジスタを毎月更新する。
-
本番環境までの予想タイムライン:* 6–8週間(モデルアーキテクチャが安定しており、FPGAハードウェアが利用可能であることを前提とする)。
-
主要な成功メトリクス:*
-
CPUベースラインの1%以内の精度
-
イベントあたり<1 msのレイテンシ
-
<5%のジッター
-
持続的に<25 Wの電力
-
すべてのリスクが定量化され軽減されている