
Codexエージェントループの展開
Codexエージェントループの理解
-
定義:* Codexエージェントループは、言語モデルがコードまたはアクションを生成し、実行結果を観察し、エラーを分類し、改善された出力を再生成するという構造化された反復サイクルであり、タスク完了またはリソース枯渇まで繰り返されます。
-
理論的基礎:* 従来のコード生成は単一パス推論として機能します:意図→モデル→出力。エージェントループは、マルチステップの推論を可能にするフィードバックメカニズムを導入します。このアーキテクチャの転換は、強化学習の原理(Sutton & Barto, 2018)に基づいており、人間のデバッグワークフローを反映しています。モデルは生成器と批評家の両方として機能し、実行結果がエラー修正の根拠として機能します。
-
有効性の前提条件:*
-
決定論的または再現可能な実行環境(一貫したエラー信号を確保するため)
-
構造化されたエラー報告(モデルの正確な解釈を可能にするため)
-
明確に定義されたタスク境界(反復全体でのスコープクリープを防ぐため)
-
具体例:* 「ユーザーデータを取得し、月間収益を計算する」というタスクを与えられたモデルは、初期SQLクエリを生成します。実行はスキーマ不一致エラーを返します(例:列
user_idがテーブルaccountsに存在しない)。ループはこのエラーメッセージをキャプチャし、修正されたスキーマを含むモデルに再度プロンプトを送ります。修正されたクエリは正常に実行されます。ループがなければ、初期の失敗でタスクは終了します。 -
運用上の含意:* コード生成パイプラインを計測して、構造化された実行結果とエラー分類をキャプチャします。これらを後続の反復のためのコンテキストとしてモデルにルーティングします。これには最小限のアーキテクチャ修正が必要です。通常は実行環境の周りのラッパーとループカウンターですが、マルチステップタスクの信頼性を測定可能に向上させます。制限付き再試行メカニズムを実装します:エラーフィードバック付きで最大N回の反復(通常3~5回)を許可してから、人間によるレビューまたはタスク失敗にエスカレートします。
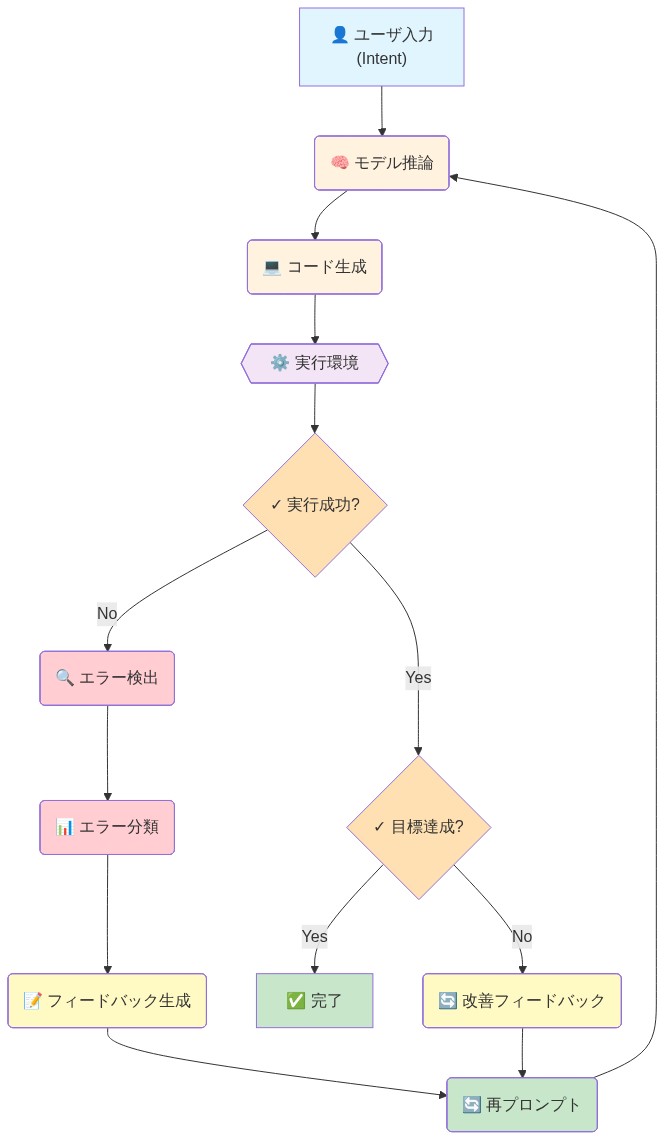
- 図2:Codex Agent Loopの詳細フロー(入力から完了まで)*
システム構造とボトルネック
エージェントループはレイテンシーとコストのトレードオフを導入します。スケーリング前に、ボトルネック(解析、実行時間、トークンオーバーヘッド)を特定することが重要です。
各ループ反復は、モデル推論時間、実行時間、およびトークン消費を追加します。素朴な実装は無限に再試行する可能性があり、コストが膨らみます。ボトルネックは異なるステージで発生します:遅いコード実行はフィードバックを遅延させ、冗長なエラーメッセージはトークン数を増加させ、不十分なプロンプト設計は繰り返される失敗を引き起こします。
データベーススキーマ探索のためにエージェントを展開したチームは、反復の60%がクエリ実行の待機に費やされていることを発見しました(試行ごとに5~10秒)。スキーマメタデータをキャッシュし、一般的なクエリを事前計算することで、フィードバックレイテンシーを8秒から2秒に短縮し、総タスク時間を40%削減しました。
最適化前にループをプロファイルします。測定:(1)モデル推論レイテンシー、(2)コード実行時間、(3)反復ごとのトークン、(4)反復ごとのエラー率。最も時間またはコストを消費するものを特定します。実行が支配的な場合は、並列化または軽量サンドボックスを使用します。トークンオーバーヘッドが支配的な場合は、エラーメッセージを構造化されたコードに圧縮します(例:完全なスキーマダンプの代わりにERR_SCHEMA_MISMATCH)。最大反復予算を設定します。通常3~5回の再試行で、暴走コストを防ぎます。
- 図4:スキーマ探索タスクの最適化効果(改善前後の比較)*
参照アーキテクチャとガードレール
-
主張:* 効果的なエージェントループには、明示的なガードレールが必要です:制限付き反復カウント、実行タイムアウト、出力検証、および高リスクタスク用の人間参加チェックポイント。
-
根拠:* 制約がなければ、エージェントは無限ループに入り、リソースを枯渇させるか、安全でないコードを生成する可能性があります。ガードレールは、継続的な人間の介入を必要とせずに安全境界を強制します。検証ゲート(構文チェック、サンドボックス、出力スキーマ検証)は、エラーが反復全体で複合する連鎖的な失敗を防ぎます。
-
ガードレールカテゴリー:*
- 反復境界: タスクごとの最大再試行回数(典型的な範囲:3~5)
- 実行制約: タイムアウト制限(秒)、メモリ制限(MB)、CPU制限
- コード検証: 構文チェック、静的分析、権限/ホワイトリストチェック
- 出力検証: スキーマ検証、異常検出、信頼度閾値
- 人間へのエスカレーション: 手動レビューをトリガーする条件(例:信頼度<閾値、高リスク操作)
- 具体例:* 財務報告エージェントは以下のガードレールでデプロイされました:
- タスクごとの最大4回の反復
- 反復ごとの30秒実行タイムアウト
- 生成されたSQLは許可されたテーブルと列のホワイトリストに対して検証
- モデルの信頼度スコア<85%の場合、または機密テーブルにアクセスするクエリの場合、結果は人間によるレビュー用にフラグ付け
- 1時間以内のエラー率が10%を超える場合、自動ロールバック
この構成により、エージェントはリスクのあるクエリを試行することを防ぎながら、95%の自律成功率と確認済み結果の99.5%の精度を維持しました。
- 参照アーキテクチャ:*
入力タスク
↓
[実行前検証レイヤー]
- 構文チェック
- 静的分析(例:AST検証)
- 権限/ホワイトリストチェック
- プロンプトインジェクション検出
↓
[サンドボックス実行レイヤー]
- 隔離環境(コンテナ、VM、またはサンドボックス)
- リソース制限の実施(CPU、メモリ、時間)
- I/O制限(該当する場合は読み取り専用アクセス)
↓
[実行後検証レイヤー]
- 出力スキーマ検証
- 異常検出(例:サイズ、値の範囲)
- 履歴ベースラインとの比較
↓
[決定ゲート]
- 成功? → 結果を返す
- 回復可能なエラー? → 反復カウンターをインクリメント
- カウンター<最大? → エラーコンテキストを含むモデルに再度プロンプト
- カウンター≥最大または回復不可能なエラー? → 人間によるレビューにエスカレート- 実行可能な含意:* 上記で概説した3層検証アーキテクチャを実装します。ドメインとリスクプロファイルに固有のガードレールを定義します。反復予算、タイムアウト閾値、およびエスカレーション基準を構成ファイルに文書化します。本番環境デプロイ前に、敵対的入力と失敗シナリオでガードレールをテストします。SLAターゲット付きの人間によるレビューキューを確立します(例:4時間以内にレビュー)。ガードレール有効性を監視:各ガードレールがトリガーされる頻度と、実際の失敗を防ぐか単に誤検知を作成するかを追跡します。
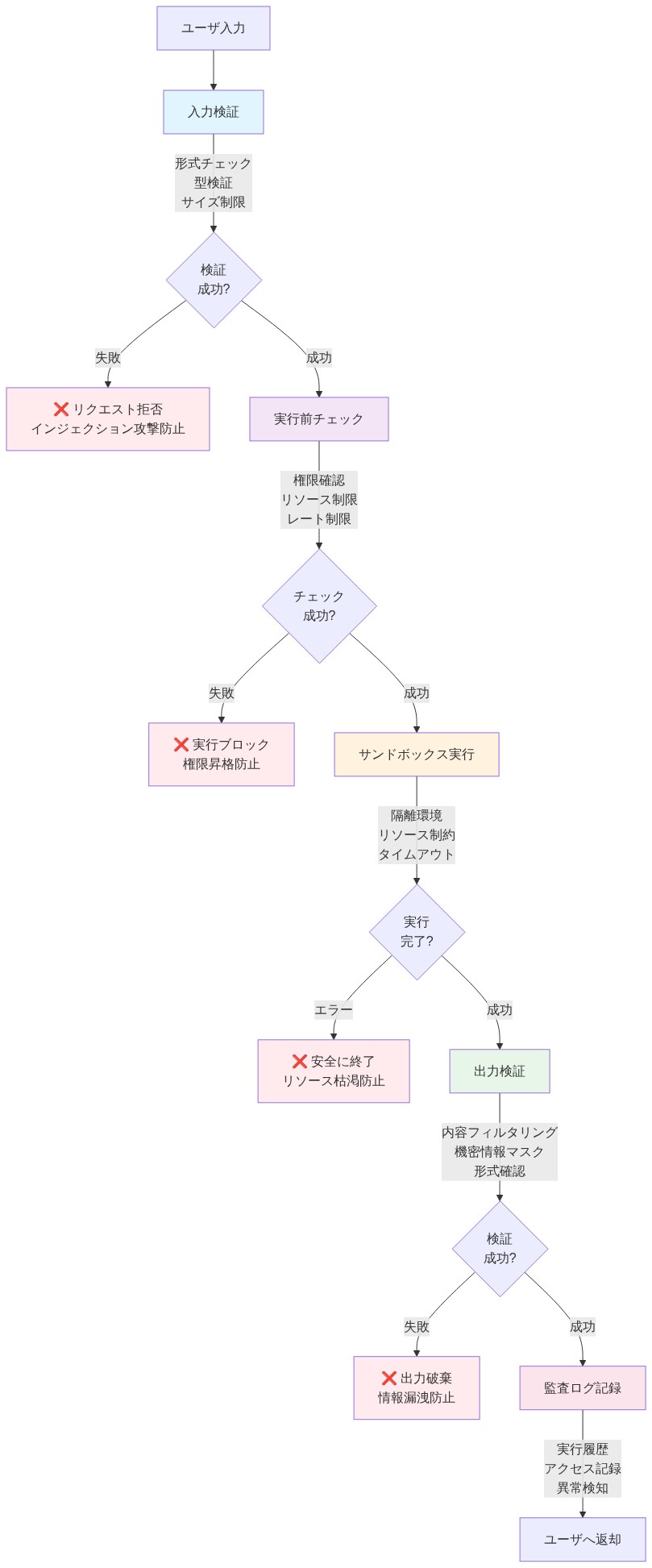
- 図7:多層防御型Guardrails実装パターン*
実装と運用パターン
-
主張:* 本番環境のエージェントループには、標準化された運用パターンが必要です:構造化ログ、エラー分類、状態管理、およびロールバック機能。非構造化アプローチはデバッグを妨げ、継続的な改善を阻止します。
-
根拠:* 本番環境システムは可観測性を要求します。非構造化またはアドホックなログは、エージェント失敗の根本原因分析を困難にし、体系的な改善を防ぎます。構造化パターン(モデル入力、出力、実行状態、およびエラーを一貫した、クエリ可能な形式でキャプチャ)は、迅速な診断、パフォーマンストレンド、およびデータ駆動型最適化を可能にします。
-
構造化イベントスキーマ:* 各反復は以下を含むイベントをログに記録する必要があります:
-
iteration_num(整数、1からインデックス付け) -
timestamp(ISO 8601) -
task_id(全体的なタスクの一意の識別子) -
prompt_hash(プロンプトのSHA-256ハッシュ、重複排除用) -
model_id(モデル名とバージョン) -
model_output(生成されたコードまたはアクション、>10KBの場合は切り詰め) -
execution_status(列挙型:success、timeout、error、invalid_syntax) -
error_code(構造化コード、例:ERR_SCHEMA_MISMATCH、ERR_TIMEOUT) -
error_message(エラー出力の最初の500文字) -
tokens_used(入力+出力トークン) -
latency_ms(総反復時間) -
resolution(列挙型:success、retry、escalated、failed) -
具体例:* 10,000のタスク全体でエージェント動作を追跡していたチームは、失敗の30%が単一のプロンプト表現の問題が原因であることを特定しました。プロンプトはモデルに「テーブル
usersを使用する」ことを指示しましたが、実際のテーブルはuser_accountsという名前でした。プロンプトを更新して正しいテーブル名を含め、スキーマリファレンスを追加することで、モデルの変更なしに失敗率を15%から3%に削減しました。 -
状態管理:* 反復全体で明示的な状態を維持します:
-
現在の反復カウント
-
前のモデル出力(繰り返しを検出するため)
-
累積エラー履歴(パターンを特定するため)
-
リソース消費(トークン、実行時間)
-
エスカレーションフラグ(人間によるレビューが必要な場合)
-
ロールバック機能:* パフォーマンスが低下した場合、前のモデルバージョンまたはプロンプトに戻す機能を維持します:
-
すべてのプロンプトとモデル構成をバージョン管理
-
ベースラインパフォーマンスメトリック(例:前週の成功率)を維持
-
成功率が5%以上低下するか、エラー率が1時間以内に10%以上急増した場合、自動ロールバックを実装
-
すべてのロールバックイベントをログに記録し、インシデントレビューをトリガー
-
実行可能な含意:* エージェントループの標準イベントスキーマを定義し、クエリ可能なバックエンド(例:クラウドログ、データウェアハウス)に構造化ログを実装します。失敗だけでなく、すべての反復をログに記録します。このデータを使用して体系的な問題を特定します:週次クエリを実行して、最上位のエラーコード、最も一般的な失敗パターン、および最も遅い反復を見つけます。A/Bテストフレームワークを実装します:2つのプロンプトバリアントまたはモデルバージョンをタスクのサンプル(バリアントごとに最小100)で並列実行し、成功率とレイテンシーを測定し、勝者を昇格させます。異常に対する自動アラートを設定します(例:成功率が90%以下に低下、中央値レイテンシーが10秒を超過、エラースパイク検出)。週次レビューケーデンスを確立して、ログデータを検査し、改善に優先順位を付けます。

- 図9:Agent Loop運用のライフサイクルと意思決定ポイント*
測定と次のアクション
エージェントループの有効性は、複数の次元にわたって測定する必要があります:成功率、レイテンシー、タスクごとのコスト、およびユーザー満足度。精度だけではありません。
30秒かかり、タスクごとに5ドルかかる高精度エージェントは、2秒で完了し、タスクごとに0.10ドルかかる90%精度のエージェントより価値が低い可能性があります。測定フレームワークはビジネスの優先事項を反映する必要があります。
データ分析チームは、4つのメトリックでエージェントループを測定しました:(1)タスク成功率(92%)、(2)中央値レイテンシー(3.2秒)、(3)成功したタスクごとのコスト(0.08ドル)、(4)ユーザー満足度(4.1/5)。前の手動プロセス(100%成功、45秒、タスクごとに12ドル、満足度3.8/5)と比較すると、エージェントループはより高速で安価であり、許容可能な精度トレードオフがありました。
デプロイ前に成功メトリックを定義し、現在のプロセスからベースラインを確立します。週次で更新されるダッシュボードでメトリックを追跡します。ターゲットを設定します:例えば「95%成功率、<5秒レイテンシー、<0.50ドル/タスクコスト」。実際のパフォーマンスをターゲットと比較して月次レビューを実施します。このデータを使用して改善に優先順位を付けます:レイテンシーがターゲットを超過しているがコストが許容可能な場合は、実行最適化に投資します。コストが高い場合は、反復の削減に焦点を当てます。
リスクと軽減戦略
-
主張:* エージェントループは異なる失敗モード(幻想的なコード、無限ループ、リソース枯渇、連鎖的エラー)を導入し、層状の防御とインシデント対応手順が必要です。
-
根拠:* エージェントが反復全体で自律的に動作するため、失敗は複合する可能性があります。モデルは構文的に有効だが意味的に不正なコードを生成する可能性があります。エラーメッセージが曖昧な場合、次の反復は同じ間違いを繰り返します。軽減には、予防的制御(ガードレール)と検出的制御(監視、異常検出)の両方が必要です。
-
失敗モード分類法:*
| 失敗モード | メカニズム | 影響 | 軽減 |
|---|---|---|---|
| 幻想的なコード | モデルが妥当だが不正なコードを生成 | サイレント データ破損、不正な結果 | 出力検証、アサーションチェック、異常検出 |
| 無限ループ | モデルが無限にループするコードを生成 | リソース枯渇、タイムアウト | 実行タイムアウト、ループ検出、コード分析 |
| 曖昧なエラー | エラーメッセージが曖昧または誤解を招く | モデルが反復全体で同じ間違いを繰り返す | 構造化エラーコード、行番号付き詳細エラーメッセージ |
| 連鎖的エラー | 反復Nのエラーが反復N+1のエラーを引き起こす | 指数関数的な失敗成長 | 反復制限、エラーパターン検出、ロールバック |
| リソース枯渇 | 繰り返される反復がすべての利用可能なリソースを消費 | システム利用不可 | メモリ制限、CPU制限、反復予算 |
| 権限昇格 | 生成されたコードが許可されていないリソースにアクセス | データ漏洩、コンプライアンス違反 | ホワイトリスト検証、サンドボックス、監査ログ |
- 具体例:* データ変換タスクを与えられたエージェントは、オフバイワンエラーを含むコードを生成しました。エラーメッセージは曖昧でした(「インデックス範囲外」)。エージェントは反復制限に達する前に同じコードを4回再実行し、リソースを消費し、タスク完了を遅延させました。実装された軽減:
- 生成されたコードにアサーションチェックを追加(例:
assert len(data) > 0) - 行番号と変数値を含む詳細なエラーメッセージを提供
- 異常検出を実装:出力サイズが予想から>20%異なる場合にフラグ付け
- このタスクタイプの反復制限を5から3に削減
- 軽減レイヤー:*
-
予防的制御:
- プロンプトエンジニアリング:正しいコードの例と一般的な落とし穴を含める
- コードテンプレート:一般的な操作用の安全なボイラープレートを提供
- 静的分析:実行前に生成されたコードを検証(構文、型チェック)
- ホワイトリスト検証:生成されたコードを承認された関数とテーブルに制限
-
検出的制御:
- 実行監視:生成されたすべてのコードと結果をログに記録
- 異常検出:予想される範囲またはパターンから逸脱する出力にフラグ付け
- エラーパターン検出:同じエラーが繰り返し発生する場合を特定
- リソース監視:CPU、メモリ、または時間制限に近づいている場合にアラート
-
応答的制御:
- 自動ロールバック:エラー率が急増した場合、前のモデルバージョンに戻す
- インシデントログ:失敗のすべての詳細をキャプチャして事後分析用
- 人間へのエスカレーション:高リスクまたは繰り返される失敗を人間によるレビューにルーティング
- サーキットブレーカー:失敗率が閾値を超える場合、タスクタイプのエージェントを無効化
- 実行可能な含意:* ドメイン固有のリスク評価を実施:アプリケーション内で最も可能性の高い失敗モード(例:SQLインジェクション、データ破損、リソース枯渇)を特定します。それぞれについて、上記の軽減レイヤーから制御を設計します。本番環境デプロイ前に、敵対的プロンプトと失敗シナリオで制御をテストします。失敗シナリオと回復手順をランブックに文書化します。インシデントレビュープロセスを確立:エージェントが本番環境で失敗した場合、ログに記録し、根本原因を分類し、ガードレールまたはプロンプトを更新して再発を防ぎます。オンコール エンジニアがアクセス可能な「失敗プレイブック」を維持し、四半期ごとに新しい失敗モードと軽減で更新します。異常に対する自動アラートを設定します(例:エラー率スパイク、リソース制限に近づいている、繰り返されるエラー)。
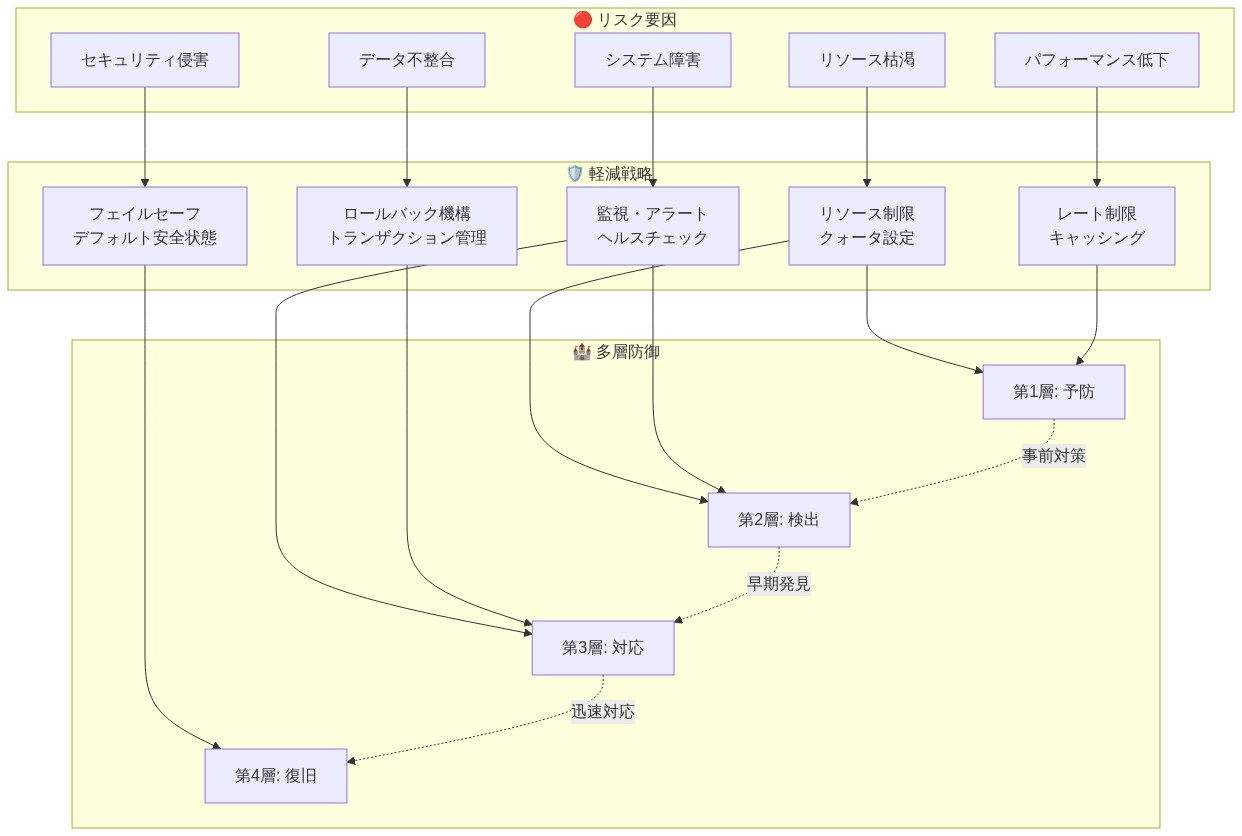
- 図13:リスク要因と軽減戦略のマッピング(多層防御アプローチ)*
結論と移行計画
Codexエージェントループは運用上実行可能であり、スケールで価値を提供しますが、意図的なロールアウトが必要です:低リスクタスクでパイロット、厳密に測定、その後拡張。
重要なシステムで本番環境のエージェントループに直接ジャンプすることはリスクです。段階的なアプローチは信頼を構築し、運用上の問題を明らかにし、チームがプロセスを段階的に改善することを可能にします。
ある企業は内部データ取得タスク(ビジネスインパクトが低く、スキーマが明確に定義されている)でエージェントをパイロットしました。2週間の98%成功率と肯定的なチームフィードバックの後、顧客向けアナリティクスに拡張しました。6か月後、エージェントは日常的なタスクの70%を処理し、エンジニアを複雑な作業に解放しました。
単一の明確にスコープされたタスクで2週間のパイロットから始めます。成功率、レイテンシー、およびコストを測定します。メトリックがターゲットを満たす場合(>90%成功、<10秒レイテンシー、<1ドルコスト)、2~3の関連タスクに拡張します。月次レビューを実施します。3か月の安定したパフォーマンスの後、より広いロールアウトを検討します。学んだ教訓を文書化し、運用プレイブックを更新します。エージェントの健全性を監視し、失敗に対応する専任の所有者を割り当てます。人間による監視を計画:常にユーザーが人間のエージェントにエスカレートするか、エージェントの決定を確認する能力を維持します。

- 図14:段階的ロールアウト戦略のタイムライン(4フェーズ)*

- 図15:Agent Loop統合による組織の未来像*
システム構造とボトルネック分析
-
主張:* エージェントループは測定可能なレイテンシとコストのトレードオフをもたらします。スケーリングの前提条件は体系的なボトルネック特定です。
-
根拠:* 各イテレーションは3つのコストが発生します:(1) モデル推論レイテンシ、(2) コード実行時間、(3) トークン消費(入力と出力の両方)。無制限の再試行ロジックは指数関数的なコスト増加を引き起こす可能性があります。ボトルネックはタスク依存であり、仮定ではなく経験的に測定する必要があります。
-
ボトルネックカテゴリ:*
-
推論バウンド: モデルレイテンシが支配的(大規模モデルまたは高並行性の場合が典型的)
-
実行バウンド: コード実行時間が支配的(データベースまたはI/O集約的なタスクで一般的)
-
トークンバウンド: イテレーションあたりのトークン消費が多く、タスクあたりのコストが増加
-
具体例:* データベーススキーマ探索用のエージェントをデプロイしたチームがイテレーションタイミングを測定しました:クエリ実行がループ全体時間の60%を消費し(試行あたり5~10秒)、モデル推論が30%、オーバーヘッドが10%でした。スキーマメタデータをキャッシュし、一般的なクエリパターンを事前計算することで、実行レイテンシをイテレーションあたり8秒から2秒に削減し、モデルまたはアルゴリズムの変更なしにタスク全体時間を40%削減しました。
-
測定プロトコル:* 最適化前に、代表的なタスクサンプル全体でループをプロファイルします(最小100回実行):
- モデル推論レイテンシを記録(プロンプト送信から出力受信までの時間)
- コード実行時間を記録(コード送信から結果返却までの時間)
- イテレーションあたりのトークンをカウント(入力+出力、モデルのトークナイザーを使用)
- イテレーションあたりのエラー率を追跡(失敗/試行総数)
- タスクの95%が完了するイテレーションを特定
- 実行可能な含意:* パフォーマンスベースラインを確立します。最も時間またはコストを消費するコンポーネントを特定します。実行が支配的な場合は、並列化、軽量サンドボックス、またはクエリ結果キャッシングを検討してください。トークンオーバーヘッドが支配的な場合は、エラーメッセージを構造化コード(例:完全なスキーマダンプの代わりに
ERR_SCHEMA_MISMATCH)に圧縮するか、エラー要約を実装してください。推論が支配的な場合は、モデル量子化またはエラー修正ステップ用の小規模モデルバリアントを検討してください。ハード最大イテレーション予算を設定します。通常は3~5回の再試行。タイムアウトまたはカウンターで強制して、暴走コストを防止してください。これらのしきい値をコンフィグファイルに文書化(ハードコードしない)して、再デプロイなしで迅速な調整を可能にしてください。
測定とパフォーマンスターゲット
-
主張:* エージェントループの有効性は、精度だけでなく、複数の次元にわたって測定する必要があります。成功率、レイテンシ、コスト、ユーザー満足度。ビジネス価値はトレードオフプロファイルに依存します。
-
根拠:* 95%以上の高精度エージェントが30秒を要し、タスクあたり$5のコストがかかる場合、90%の精度で2秒で完了し、$0.10のコストの9%精度エージェントよりもビジネス価値が低い可能性があります。測定フレームワークは組織の優先事項を反映し、トレードオフ決定を可能にする必要があります。
-
推奨メトリクス:*
| メトリクス | 定義 | 典型的なターゲット | 注記 |
|---|---|---|---|
| 成功率 | エスカレーションなしで完了したタスクの% | 90~98% | ドメイン依存。低リスクタスクではより高い |
| レイテンシ(p50) | タスク完了までの中央値時間 | <5秒 | ユーザー体験とスループットに影響 |
| レイテンシ(p95) | 95パーセンタイルの完了時間 | <15秒 | テールレイテンシの問題を特定 |
| タスクあたりのコスト | 成功したタスクあたりの総コスト(モデル+実行) | <$1 | モデルサイズとイテレーション数でスケール |
| イテレーションあたりのエラー率 | 失敗して再試行が必要なイテレーションの% | <20% | プロンプトまたはモデル品質を示す |
| ユーザー満足度 | エージェント支援タスクの調査またはNPSスコア | >4.0/5 | 認識される価値と信頼を捉える |
| エスカレーション率 | 人間のレビューが必要なタスクの% | <10% | ガードレール有効性を示す |
- 具体例:* データ分析チームがデプロイ前後に6つのメトリクスでエージェントループを測定しました:
| メトリクス | 手動プロセス | エージェントループ | デルタ |
|---|---|---|---|
| タスク成功率 | 100% | 92% | –8% |
| 中央値レイテンシ | 45秒 | 3.2秒 | –93% |
| タスクあたりのコスト | $12 | $0.08 | –99% |
| ユーザー満足度 | 3.8/5 | 4.1/5 | +8% |
| エスカレーション率 | N/A | 8% | – |
| 月間コスト(1000タスク) | $12,000 | $80 | –99% |
成功率の控えめな低下にもかかわらず、エージェントループはレイテンシとコストの大幅な改善をもたらし、ユーザー満足度が向上しました(おそらく速度が原因)。
- 実行可能な含意:* デプロイ前に成功メトリクスを定義します。現在のプロセス(手動または自動化)からベースラインを確立します。週単位で更新されるダッシュボードを作成します。ビジネス優先事項に合わせたターゲットを設定します(例:「95%成功率、<5秒レイテンシ、<$0.50タスクあたりコスト、>4.0/5満足度」)。実際のパフォーマンスをターゲットと比較する月次レビューを実施します。このデータを使用して改善を優先順位付けします:レイテンシがターゲットを超えているがコストが許容可能な場合は、実行最適化またはモデルキャッシングに投資してください。コストが高い場合は、イテレーション数の削減またはエラー修正用の小規模モデルの使用に焦点を当ててください。メトリクスを月次でステークホルダーに公開して、可視性を維持し、リソース配分決定をサポートしてください。
結論と段階的ロールアウト戦略
- 主張:* Codexエージェントループは運用上実行可能であり、スケールで測定可能な価値を提供しますが、意図的な段階的ロールアウトが必要です:低リスクタスクでパイロットを実施し、厳密に測定してから拡張
システム構造とボトルネック:隠れた効率性のロック解除
-
主張:* エージェントループは制約として現れるレイテンシとコストのトレードオフをもたらしますが、実は最適化の機会を明らかにします。ボトルネックを特定して排除することで、指数関数的な効率向上が得られ、AI支援作業の経済学を再構成します。
-
根拠:* 各ループイテレーションはモデル推論時間、実行時間、トークン消費を追加します。これをコスト問題として見るのではなく、シグナルとして再構成してください:ボトルネックはシステムがリソースを非効率に費やしている場所を明らかにします。素朴な実装は無限に再試行するかもしれませんが、洗練された実装はボトルネック分析を使用してフィードバックサイクルを圧縮します。これは運用上の卓越性がイノベーションと出会う場所です。エージェントループで勝利しているチームは最速のモデルを持つチームではなく、最もタイトなフィードバックループを設計したチームです。レイテンシを8秒から2秒に削減することで、時間を節約するだけでなく、AIが瞬時で人間らしく感じられる質的に異なるユーザー体験を可能にします。
-
具体例:* データベーススキーマ探索用のエージェントをデプロイしたチームは、イテレーション時間の60%がクエリ実行の待機に費やされていることを発見しました(試行あたり5~10秒)。これを避けられないものとして受け入れるのではなく、アーキテクチャを再想像しました:スキーマメタデータをキャッシュし、一般的なクエリを事前計算し、軽量クエリプランニングを使用します。フィードバックレイテンシは8秒から2秒に低下し、タスク全体時間を40%削減しました。しかし、より深い洞察:これは認知帯域幅を解放しました。ユーザーはより速く反復でき、より多くの仮説を探索し、以前はレイテンシ摩擦のため放棄していた洞察を発見できるようになりました。
-
実行可能な含意:* 最適化前にループをプロファイルしてください。これは交渉の余地がありません。測定:(1) モデル推論レイテンシ、(2) コード実行時間、(3) イテレーションあたりのトークン、(4) イテレーションあたりのエラー率、(5) タスクあたりの実時間。最も時間またはコストを消費するものを特定します。実行が支配的な場合は、並列化または軽量サンドボックスを使用してください。トークンオーバーヘッドが支配的な場合は、エラーメッセージを構造化コード(例:完全なスキーマダンプの代わりに
ERR_SCHEMA_MISMATCH)に圧縮してください。最大イテレーション予算を設定します。通常は3~5回の再試行。暴走コストを防止してください。しかし、ここが前向きな動きです:このプロファイリングデータを使用してタスク複雑性の予測モデルを構築してください。時間とともに、より多くのイテレーションから利益を得るタスクと、迅速に失敗すべきタスクを特定します。これは動的予算配分を可能にします:高価値タスクにより多くのイテレーションを割り当て、ルーチンなものにはより少なくします。これはAIシステムがインテリジェントにリソースを割り当てる始まりです。
参照アーキテクチャとガードレール:制約ではなく機能としての安全性
-
主張:* 効果的なエージェントループは、摩擦ではなくイネーブラーとしてのガードレールが必要です。制限されたイテレーション数、実行タイムアウト、出力検証、人間参加チェックポイントは、自律型AIを責任から信頼できるパートナーに変換します。
-
根拠:* ガードレールはしばしば制限として構成されます。それらを再構成してください:それらは高リスク環境で自律型AIを受け入れ可能にするインフラストラクチャです。明確な境界を確立することで、イテレーション制限、実行タイムアウト、検証ゲートを設定することで、エージェントを制約しているのではなく、信頼を構築しています。これは採用に重要です。知識労働者はAIエージェントを受け入れるのは、失敗モードと回復パスを理解する場合だけです。ガードレールはこれを明示的にします。仕事の未来は「AIが人間を置き換える」でも「人間がAIを無視する」でもなく、「人間とAIが相互に理解された制約内で動作し、価値を最大化し、リスクを最小化する」ことです。
-
具体例:* 金融報告エージェントにガードレールが与えられました:(1) タスクあたり最大4イテレーション、(2) 30秒実行タイムアウト、(3) 生成されたSQLは許可されたテーブルのホワイトリストに対して検証、(4) 信頼度<85%の場合、結果は人間のレビュー用にフラグ付け。これは95%の自律成功率を達成しながら、リスキーなクエリを防止しました。重要な洞察:レビューが必要な5%のタスクは失敗ではなく、高価値エスカレーションでした。人間はエッジケースをレビューし、そこから学び、洞察をシステムにフィードバックしました。これは好循環を作成しました:AIはルーチン作業を処理し、人間は例外に焦点を当て、システムは継続的に改善しました。
-
実行可能な含意:* 3層アーキテクチャを実装します:(1) 実行前検証:構文チェック、静的分析、権限チェック。悪いコードが実行される前に防止します。(2) サンドボックス実行:生成されたコードを分離環境でリソース制限で実行します。失敗を含みます。(3) 実行後検証:出力スキーマを検証し、異常をチェックし、履歴ベースラインと比較します。微妙なエラーを検出します。ボトルネックではなく学習メカニズムとして、エッジケース用の人間レビューキューを追加してください。イテレーション予算とタイムアウトしきい値をコンフィグファイルに文書化します。ハードコードしないでください。これにより、学習に応じた迅速な調整が可能になります。ガードレールをシステムの「憲法」と考えてください。ユーザーに見える状態にし、推論を説明し、透過的に更新してください。これは信頼を構築し、知識労働者がエージェントを信頼する時期と介入する時期について情報に基づいた決定を下すことを可能にします。
実装と運用パターン:制度的記憶の構築
-
主張:* エージェントループの運用化には、標準化されたパターンが必要です。構造化ログ、エラー分類、状態管理、ロールバック機能。これらは運用データを制度的知識に変換し、スケールでの継続的改善を可能にします。
-
根拠:* 本番システムは可観測性が必要ですが、さらに重要なのは、学習システムが必要です。非構造化ログはデバッグを困難にします。構造化パターンはスケールでのパターン認識を可能にします。すべてのエージェント失敗はデータポイントです。数千のデータポイントを集約すると、個々のオペレーターには見えないシステム問題が見えます。これは運用上の卓越性が競争上の優位性になる場所です。エージェントループを厳密に計測するチームは、他のチームが見逃す最適化機会を発見します。最適なプロンプト、最も一般的なエラーパターン、追加イテレーションから利益を得るタスクを特定します。このデータは継続的改善の基礎になります。
-
具体例:* エージェント動作を追跡するチームは、各イテレーションを構造化イベントとしてログしました:
{iteration_num, timestamp, prompt_hash, model_output, execution_status, error_code, tokens_used, resolution_time}。10,000タスク後、失敗の30%が単一のプロンプト表現の問題が原因であることを発見しました。プロンプトを更新すると、失敗率は15%から3%に低下しました。さらに重要なのは、特定のタスクタイプが一貫してより多くのイテレーションを必要とすることを特定しました。これらのタスク用に特別なプロンプトを作成し、平均イテレーションを2.1から1.3に削減しました。これは構造化データの力です:小さな改善は数千のタスク全体で複合します。 -
実行可能な含意:* エージェントループの標準イベントスキーマを定義します。ログ:プロンプトバージョン、モデルパラメータ、生成されたコード、実行結果、エラー分類、解決、結果。このデータを使用してシステム失敗と機会を特定します。A/Bテストフレームワークを実装します:2つのプロンプトバリアントをタスクのサンプルで並行実行し、成功率を測定し、勝者を昇格させます。ロールバックメカニズムを確立します。新しいモデルバージョンまたはプロンプトがパフォーマンスを低下させる場合、自動的に元に戻します。異常なエラーパターンのアラートを設定します(例:タイムアウトエラーの急激な増加)。フィードバックループを作成します:週次、上位10のエラーパターンをレビュー。月次、修正を実装。四半期ごと、累積的な影響を測定します。これは運用を反応的(失敗への対応)から積極的(失敗の防止)に変換します。運用データが戦略的決定を推進する学習組織の基礎と考えてください。
測定と次のアクション:成功の再定義
-
主張:* エージェントループの有効性は、精度だけでなく、複数の次元にわたって測定する必要があります。成功率、レイテンシ、タスクあたりのコスト、ユーザー満足度、長期的な価値創造。この再構成は、AIエージェントが最も価値があるのは完璧な場合ではなく、有用な場合であることを明らかにします。
-
根拠:* 30秒かかり、タスクあたり$5のコストがかかる高精度エージェントは、2秒で完了し、$0.10のコストの90%精度エージェントより価値が低い可能性があります。測定フレームワークはビジネス優先事項とユーザーニーズを反映する必要があります。しかし、より深い洞察があります:最も価値のあるエージェントは知識労働者が高価値の作業に焦点を当てることを解放するものです。100%のタスクを99%の精度で処理するが継続的な監視が必要なエージェントより、70%のルーチンタスクを95%の精度で処理するエージェントの方が価値があります。測定はこれをキャプチャする必要があります。技術メトリクスだけでなく、人間への影響メトリクスも。
-
具体例:* データ分析チームは4つの次元でエージェントループを測定しました:(1) タスク成功率(92%)、(2) 中央値レイテンシ(3.2秒)、(3) 成功したタスクあたりのコスト($0.08)、(4) ユーザー満足度(4.1/5)。以前の手動プロセス(100%成功、45秒、タスクあたり$12、5/5満足度3.8)と比較すると、エージェントループはより速く、より安く、許容可能な精度トレードオフでした。しかし、隠れたメトリクス:分析者が戦略的作業に焦点を当てるために解放された時間。分析者は以前、ルーチンデータ取得に時間の60%を費やしていました。エージェントでは、これは15%に低下しました。この解放された時間は探索的分析とビジネス戦略にリダイレクトされました。かなり多くの価値を生成した作業。エージェントの真のROIはコスト削減ではなく、人間の専門知識が高次の問題に適用されることで生成された価値でした。
-
実行可能な含意:* デプロイ前に成功メトリクスを定義しますが、多次元にしてください。追跡:(1) 技術メトリクス(成功率、レイテンシ、コスト)、(2) ユーザーメトリクス(満足度、採用、時間節約)、(3) ビジネスメトリクス(価値創造、戦略的影響)。現在のプロセスからベースラインを確立します。ダッシュボードを週単位で更新。メトリクスを月次でレビュー。ターゲットを設定します:例えば、「95%成功率、<5秒レイテンシ、<$0.50タスクあたりコスト、4.0以上ユーザー満足度、分析者あたり週10時間以上解放」。このデータを使用して改善を戦略的に優先順位付けします。レイテンシがターゲットを超えているがコストが許容可能な場合は、実行最適化に投資してください。コストが高い場合は、イテレーション削減に焦点を当ててください。満足度が低い場合は、ユーザー体験摩擦を調査してください。四半期ごとのレビューを実施して、ターゲットが達成されたかどうかだけでなく、ターゲットが組織のニーズと一致し続けているかどうかを評価します。これにより、エージェントループが組織のニーズとともに進化することが保証されます。
リスクと緩和戦略:レジリエンスの構築
-
主張:* エージェントループは新しい障害モード(幻覚コード、無限ループ、リソース枯渇、カスケード障害)をもたらしますが、これらはエージェントループを避ける理由ではなく、解決すると従来のアプローチよりも回復力のあるシステムを生み出す設計上の課題です。
-
根拠:* すべてのテクノロジーは新しいリスクをもたらします。問題はエージェントループがリスキーかどうかではなく、そのリスクが管理可能であり、利益がリスクを上回るかどうかです。階層化された防御(実行タイムアウト、メモリ制限、出力検証、異常検知)により、エージェントループは既存の多くのシステムよりも安全になります。さらに、エージェントループは障害モードへの可視性を生み出します。従来のシステムは静かに失敗するかもしれませんが、エージェントループは詳細なエラーメッセージと回復パスとともに大きく失敗します。この可視性はバグではなく、機能です。
-
具体例:* データ変換タスクを与えられたエージェントは、構文的には有効だが意味的には不正なコード(オフバイワンエラー)を生成しました。エラーメッセージは曖昧でした(「インデックス範囲外」)。エージェントは反復制限に達する前に同じコードを4回実行しました。緩和策:(1)生成されたコードにアサーションチェックを追加して意味的エラーを早期に検出、(2)行番号とコンテキストを含む詳細なエラーメッセージを提供、(3)異常検知を実装して出力サイズが予想値から20%以上異なる場合にフラグを立てる、(4)「多様性チェック」を追加—エージェントが同じコードを2回生成した場合は再試行ではなくエスカレーション。これらの緩和策は障害モードを学習機会に変えました。チームは特定のデータパターンが一貫してオフバイワンエラーをトリガーすることを発見し、これらのパターンに対する専門的な処理を作成して堅牢性を向上させました。
-
実行可能な含意:* ドメイン固有の包括的なリスク評価を実施してください。障害モードをリストアップします:幻覚コード、無限ループ、リソース枯渇、カスケード障害、データ破損、セキュリティ脆弱性。それぞれについて、制御を設計します:実行タイムアウト、メモリ制限、出力検証、異常検知、セキュリティスキャン。敵対的プロンプトで制御をテストしてください—意図的にシステムを破壊しようとしてください。障害シナリオと回復手順を文書化してください。インシデントレビュープロセスを確立してください。エージェントが本番環境で失敗した場合、ログに記録し、根本原因を分類し、再発を防ぐためにガードレールまたはプロンプトを更新してください。オンコールエンジニアがアクセスできる「障害プレイブック」を維持してください。重要なことに、このプレイブックをユーザーと共有してください—障害モードと回復パスについての透明性は信頼を構築します。これを回復力のあるシステムの基礎と考えてください。このシステムでは、障害が予想され、検出され、優雅に回復されます。
結論と移行計画:前進への道
-
主張:* Codexエージェントループは運用上実行可能であり、規模に応じて複合的な価値を提供しますが、意図的なロールアウトが必要です—低リスクタスクでパイロット、厳密に測定、戦略的に拡張、そして競争優位性となる組織知識を構築してください。
-
根拠:* ナレッジワークの未来は、人間をAIに置き換えることではなく、ルーチンワークを処理するAIエージェントで人間の専門知識を拡張し、人間が戦略的、創造的、高価値のタスクに焦点を当てられるようにすることです。エージェントループはこれを可能にするインフラストラクチャです。しかし、この移行には意図性が必要です。重要なシステムで本番環境のエージェントループに急いで移行する組織は、運用上の混乱に直面するでしょう。慎重にパイロット、厳密に測定、戦略的に拡張する組織は、持続可能な競争優位性を構築するでしょう。勝者は最高のモデルを持つ組織ではなく、最高の運用慣行とエージェントループを効果的にデプロイする方法についての最も深い組織知識を持つ組織です。
-
具体例:* ある企業は内部データ取得タスク(ビジネスインパクトが低く、スキーマが明確に定義されている)でエージェントをパイロットしました。2週間の98%成功率とチームからの肯定的なフィードバックの後、顧客向けアナリティクスに拡張しました。6か月後、エージェントはルーチンタスクの70%を処理し、エンジニアを複雑な作業に解放しました。しかし、より深い話:パイロットと拡張の間に、チームは運用知識を蓄積しました—どのプロンプトが最も効果的か、どのエラーパターンが最も一般的か、どのタスクが追加の反復から利益を得るか。この知識はシステム設計、運用プレイブック、チームの専門知識に組み込まれました。競合他社が同様のエージェントをデプロイしようとしたとき、彼らはこの組織知識を欠いており、苦労しました。ファーストムーバーアドバンテージは技術的ではなく、運用的で組織的でした。
-
実行可能な含意:* ビジネスインパクトが低く、成功基準が明確な単一の適切なスコープのタスクで2週間のパイロットを開始してください。測定してください:成功率(目標>90%)、レイテンシ(目標<10秒)、コスト(目標<1ドル/タスク)、ユーザー満足度(目標4.0以上)。メトリクスが目標を満たしている場合、2~3の関連タスクに拡張してください。月次レビューを実施してください。3か月の安定したパフォーマンスの後、より広範なロールアウトを検討してください。学習した教訓を文書化してください—何が機能したか、何が機能しなかったか、何があなたを驚かせたか—そして運用プレイブックを更新してください。エージェントの健全性を監視し、障害に対応する専任の所有者を割り当ててください。人間による監視を計画してください。常にユーザーが人間のエージェントにエスカレーションするか、エージェントの決定をレビューする能力を維持してください。重要なことに、ロールアウト計画をステークホルダーに透過的に伝えてください。段階的な拡張の根拠、追跡しているメトリクス、緩和しているリスクを説明してください。これは信頼を構築し、情報に基づいた意思決定を可能にします。最後に、これはより長い旅の始まりであることを認識してください。エージェントループは進化するでしょう—モデルは改善され、新しいアーキテクチャが出現し、ユーザーの期待は変わるでしょう。この進化を念頭に置いてシステムを構築してください。繁栄する組織は、エージェントループのデプロイを1回限りのプロジェクトではなく、継続的な改善、学習、適応の継続的な実践として扱う組織です。