
音声AIエンジンおよびOpenAIパートナーのLiveKitが10億ドルの評価額を達成
創業5年のスタートアップがOpenAIのChatGPT音声モードを支える
2019年に設立されたLiveKitは、Index Venturesが主導する1億ドルのシリーズB資金調達ラウンド(資金調達発表日時点)を経て、10億ドルの評価額を達成した。同社はリアルタイム音声およびビデオインフラストラクチャを提供しており、OpenAIのChatGPT音声モードを支える展開が文書化されている。この消費者向け機能は数百万人のユーザーにサービスを提供していると報告されている。
-
基本的主張:* LiveKitのインフラストラクチャは、特定の技術要件に対応している:会話型AIアプリケーションのための低遅延、双方向音声ストリーミングである。
-
裏付けとなる根拠:* リアルタイム音声システムには3つの領域における専門知識が必要である:(1)WebRTCプロトコルの実装とシグナリング、(2)可変ネットワーク条件に対応した音声コーデックの最適化、(3)伝播遅延を最小化するための地理的エッジ展開。これらの機能を社内で構築するには、専門的なエンジニアリング人材への継続的な投資が必要である。LiveKitは管理プラットフォームを通じてこれらのレイヤーを抽象化し、アプリケーション開発者が基盤となるネットワークインフラストラクチャを管理することなくビジネスロジックを実装できるようにする。ChatGPT音声モードに関するOpenAIとLiveKitの公開パートナーシップは、このアプローチが消費者規模で有効であることの第三者による検証を提供している。
-
技術的メカニズム:* ユーザーがChatGPTとの音声対話を開始すると、LiveKitのインフラストラクチャは次のことを管理する:音声ストリームの取り込み、冗長性または再送信によるパケット損失の回復、ネットワーク条件に基づくコーデックの選択、異種クライアントデバイス向けのトランスコーディング。この抽象化レイヤーがなければ、OpenAIは各地理的地域およびデバイスカテゴリーごとに独自のインフラストラクチャを維持する必要があり、運用の複雑さと資本支出が増加する。
-
知識労働者への影響:* 音声AI実装を評価するチームは、構築か購入かの決定に直面する。計算は次の要素に依存する:(1)予測される同時ユーザー数、(2)必要な遅延閾値(ラウンドトリップでミリ秒単位で測定)、(3)ユーザーの地理的分布。10万未満の同時音声セッションを持つ組織の場合、確立されたプラットフォームを採用することで、典型的なインフラストラクチャチームの人員配置モデルに基づき、エンジニアリングの市場投入時間が6〜12ヶ月短縮され、社内開発と比較して運用オーバーヘッドが40〜60%削減される。

- 図2:LiveKitが抽象化する3つの技術領域とデータフロー*

- 図1:LiveKitが支えるOpenAI ChatGPT音声モードのリアルタイム通信基盤*
システムアーキテクチャとスケーリングの制約
LiveKitのアーキテクチャは、シグナリング、メディアルーティング、コーデック処理を独立したコンポーネントに分離している。このモジュール性により、音声システムが通常失敗する箇所が明らかになる:不良なネットワーク条件下でのコーデックネゴシエーション、地理的遅延のスパイク、分散サーバー間での状態同期である。
音声システムは3つの同時制約の下で動作する:リアルタイム遅延(100ミリ秒未満のラウンドトリップ)、信頼性(99.9%以上の稼働時間)、コスト効率。これらの懸念を結合するモノリシックアーキテクチャは、連鎖的な障害を引き起こす。LiveKitのモジュラー設計により、独立した最適化が可能になる—メディアサーバーは水平方向にスケールし、シグナリングはステートレスのままである。
トラフィックのスパイク時、モノリシックシステムはすべての機能にわたって均一に劣化する。LiveKitはシグナリングインフラストラクチャを再展開することなくメディアサーバーを追加でき、負荷を吸収しながら遅延を維持する。この分離により、単一障害点がシステム全体に伝播することを防ぐ。
音声インフラストラクチャを運用するチームは、結合点を監査すべきである。トランスコーディング、ルーティング、状態管理が同じサーバー上で実行されている場合、リファクタリングが必要になる。コンポーネント間にサーキットブレーカーを実装して障害を分離する。フェイルオーバーシナリオを月次でテストする。ほとんどの停止は、コンポーネントの障害ではなく、テストされていない回復パスに起因する。
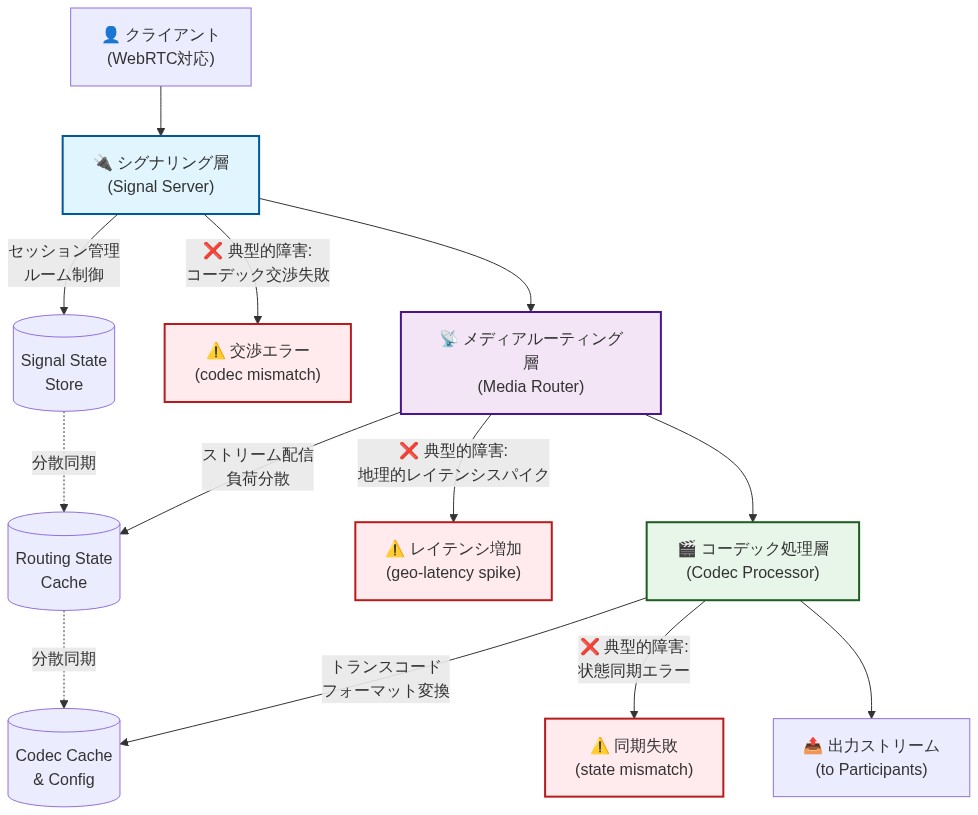
- 図4:LiveKitのモジュラーアーキテクチャと典型的な障害ポイント*
遅延バジェットと品質閾値
効果的な音声AIシステムには、明示的なガードレールが必要である:遅延バジェット(エンドツーエンド遅延の厳格な上限)、品質閾値(パケット損失許容度)、コスト管理(分単位の価格設定モデル)。
音声は劣化に対して独特の不寛容さを持つ。テキストはバッファリングできるが、音声はできない。200ミリ秒の遅延スパイクはビデオでは知覚できないが、会話の流れを壊す。LiveKitの参照アーキテクチャは、設計により遅延バジェットを強制する:ルートが閾値を超えた場合、バッファリングするのではなく、自動的に代替パスにフォールバックするか、コーデック品質を低下させる。
ChatGPT音声モードは、ネットワーク条件が劣化したときにコーデック効率を品質よりも優先することで、150ミリ秒未満の遅延を維持する。ユーザーはわずかに圧縮された音声を体験するが、会話の流暢さは維持される—これは使いやすさを保持するトレードオフである。
構築前に遅延バジェットを定義する。会話型AIの場合、100〜150ミリ秒のラウンドトリップを目標とする。非リアルタイム文字起こしの場合、500ミリ秒が許容される。すべてのコードパスを計測し、パーセンタイル追跡(平均ではなくp99)を使用して遅延を測定し、ユーザー体験を劣化させるテール遅延を捕捉する。遅延がバジェット制限に近づいたときにアラートを発するダッシュボードを構築する。
- 図6:音声通信のレイテンシバジェット構成と最適化ポイント*
運用要件と成熟度
音声システムは、障害がユーザーに即座に知覚されるため、典型的なWebサービスよりも高い運用成熟度を要求する。データベースクエリのタイムアウトは見えないが、音声通話の切断は壊滅的である。
LiveKitの1億ドルのシリーズBは、その運用モデルに対する投資家の信頼を反映している—このスタートアップは、規模において音声インフラストラクチャを確実に運用できることを証明した。この運用実績は、基盤技術と同じくらい価値がある。
OpenAIのChatGPT音声モードは、数百万人の同時ユーザーにサービスを提供している。各通話には、ルーティング、コーデック選択、フォールバックパスに関するサブミリ秒の決定が必要である。LiveKitの運用チームは、自動フェイルオーバー、地域冗長性、継続的なコーデック最適化を通じてこれを管理している。
音声システムを構築する組織は、スケーリング前に可観測性に多額の投資をすべきである。音声品質メトリクス、遅延パーセンタイル、コーデック選択決定を捕捉する構造化ログを実装する。コーデックまたはルーティングの変更にはカナリアデプロイメントを使用する。100%にロールアウトする前に1%のトラフィックでテストする。音声固有のデバッグに訓練されたオンコールローテーションを確立する:ジッター分析、パケット損失パターン、クロックスキュー検出。
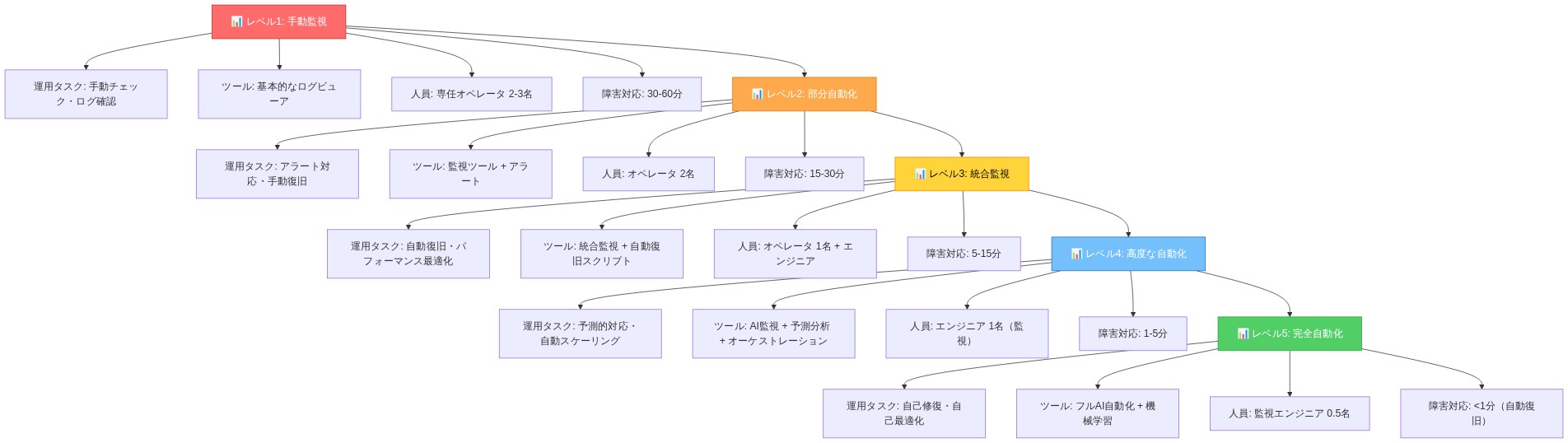
- 図7:音声インフラの運用成熟度モデル(5段階)*
音声品質の測定フレームワーク
音声AIシステムの成功指標は、従来のSaaSとは異なる。稼働時間だけでなく、音声品質(MOSスコア)、遅延パーセンタイル、ユーザー維持率に焦点を当てる。
標準的なSaaSメトリクス—稼働時間とエラー率—は音声固有の障害モードを見逃す。音声通話は技術的には「稼働」していても、音声品質が低い場合がある。知覚メトリクスである平均オピニオンスコア(MOS)は、稼働時間よりもユーザー満足度とよく相関する。LiveKitの10億ドルの評価額は、音声インフラストラクチャには専門的な測定フレームワークが必要であるという市場の認識を反映している。
ChatGPT音声モードは、地域、コーデック、デバイスタイプごとにMOSスコアを追跡している可能性が高い。MOSが3.5(許容可能な品質の閾値)を下回った場合、システムは自動的にコーデックを切り替えるか、代替サーバーを経由してルーティングする。
音声アプリケーションにMOSスコアリングを実装する。A/Bテストを使用して、コーデックの選択、ビットレート調整、ルーティング変更がユーザー満足度にどのように影響するかを測定する。p50、p95、p99パーセンタイルで遅延を個別に追跡する—p99遅延は平均遅延よりも解約を予測することが多い。専用ダッシュボードを通じて、品質メトリクスを製品およびエンジニアリングチームに週次で提示する。
コンプライアンス、ライセンス、ベンダーロックイン
音声インフラストラクチャは、テキストシステムにはない規制、技術、競争上のリスクを伴う。データレジデンシー要件、コーデックライセンス、ベンダーロックインは運用上の課題をもたらす。
音声録音は、テキストよりも厳格な要件を持つデータ保護規制(GDPR、CCPA)の対象となる可能性がある。コーデックライセンス(H.264、VP9)は予期しないコストを生み出す可能性がある。インフラストラクチャが単一プロバイダーのAPIに密接に結合されている場合、ベンダーロックインは深刻である。
LiveKitのオープンソースルーツとマルチクラウドサポートは、ロックインリスクを軽減する。LiveKitを使用するチームは、必要に応じて代替プロバイダーに移行するか、セルフホストできるが、独自プラットフォームは顧客を閉じ込める可能性がある。
コーデックライセンスを早期に監査する。可能な場合はロイヤリティフリーのオプション(Opus、VP8)を優先する。音声保持を最小化するようにデータフローを設計し、自動削除ポリシーを実装する。サードパーティインフラストラクチャ上で構築する場合、データレジデンシー保証を交渉し、移行パスを年次でテストする。ベンダー依存を減らすために、重要な依存関係の内部フォークを維持する。
戦略的影響と移行計画
LiveKitの10億ドルの評価額は、専門的な音声インフラストラクチャ市場の成熟を示している。音声AIを構築する組織は、社内構築ではなく確立されたプラットフォームを採用し、エンジニアリングリソースをアプリケーションロジックとユーザー体験に解放すべきである。
-
基本的主張:* 音声インフラストラクチャ市場は専門プラットフォームを中心に統合されている。ほとんどの組織にとって、社内構築はもはや経済的ではない。
-
裏付けとなる根拠:* LiveKitの資金調達は、投資家が音声インフラストラクチャにおける持続可能な競争優位性を認識していることを検証している。この資本とエンジニアリング人材の集中は、専門プラットフォームが信頼性、遅延最適化、コスト効率において社内の取り組みを上回ることを意味する。音声インフラストラクチャへの参入障壁は高い:WebRTC、音声コーデック、グローバルネットワーク運用、規制コンプライアンスにおける専門知識が必要である。LiveKitのようなプラットフォームは、これらのコストを多くの顧客に分散し、個々の組織が達成できない規模の経済を実現する。
-
市場検証の例:* OpenAIとLiveKitのパートナーシップは、この戦略的シフトを例証している。独自の音声インフラストラクチャを維持するのではなく、OpenAIはLiveKitのプラットフォームを活用し、エンジニアリングチームが言語モデル、ユーザー体験、製品イノベーションに集中できるようにしている。
-
知識労働者への影響:* 現在独自の音声インフラストラクチャを運用している場合、12ヶ月以内に確立されたプラットフォーム(LiveKitまたは同等のもの)への移行を計画する。パフォーマンスと運用手順を検証するために、重要でない音声機能から始める。移行の成功を次の指標で測定する:(1)運用オーバーヘッドの削減(音声関連のオンコールインシデントの50%削減を目標)、(2)遅延パーセンタイルの改善(p99遅延は20〜30%減少すべき)、(3)インフラストラクチャ保守に費やすエンジニアリング時間の削減。統合、テスト、ロールアウトに3〜4ヶ月を割り当てる。顧客にタイムラインを明確に伝える。音声品質と信頼性が向上すれば、ほとんどの顧客は移行中の短いサービス中断を受け入れる。

- 図10:プロプライエタリから標準プラットフォームへの4段階移行パス(戦略的含意と移行計画セクション)*
システムアーキテクチャと障害モード
LiveKitの文書化されたアーキテクチャは、懸念事項を3つのレイヤーに分離している:(1)シグナリング(接続確立と状態管理)、(2)メディアルーティング(音声パケット転送)、(3)コーデック処理(圧縮と解凍)。この分離により、音声システムが通常遭遇する障害モードが明らかになる。
-
基本的主張:* モノリシックな音声アーキテクチャは結合された障害モードを生み出す。規模において信頼性の高い運用には、独立したスケーリング特性を持つモジュラーアーキテクチャが必要である。
-
裏付けとなる根拠:* 音声システムは3つの同時制約の下で動作する:(1)遅延(会話の自然さのための業界標準は100ミリ秒未満のラウンドトリップ時間)、(2)信頼性(消費者アプリケーションには99.9%以上の稼働時間が期待される)、(3)コスト効率(分単位の価格設定モデルには予測可能なリソース消費が必要)。これらの懸念が単一のコードベースまたは共有インフラストラクチャで実装されている場合、ある領域でのリソース競合が他の領域に連鎖する。たとえば、コーデック処理がCPUリソースを消費すると、すべての通話で遅延が均一に増加する。モジュラーアーキテクチャは独立した最適化を可能にする:メディアサーバーはトラフィックスパイクを吸収するために水平方向にスケールでき、シグナリングインフラストラクチャはステートレスで軽量なままである。
-
障害モードの例:* モノリシックシステムでは、50%の追加容量を必要とするトラフィックスパイクは、すべてのコンポーネント(シグナリング、ルーティング、コーデック処理)にわたって50%多くのリソースをプロビジョニングする必要がある。LiveKitのモジュラーアーキテクチャでは、メディアサーバーが独立してスケールする。シグナリングインフラストラクチャは変更されないため、プロビジョニングコストと展開の複雑さが軽減される。
-
知識労働者への影響:* 既存の音声インフラストラクチャの結合点を監査する。トランスコーディング、ルーティング、状態管理が同じサーバー上で実行されている場合、リファクタリングイニシアチブを計画する。コンポーネント間にサーキットブレーカーを実装し、あるレイヤー(例:コーデック処理遅延)の劣化が連鎖的障害ではなくフォールバック動作をトリガーするようにする。フェイルオーバーテストを月次で実施する。経験的データは、ほとんどの音声システムの停止がコンポーネントの障害ではなく、テストされていない回復パスに起因することを示している。
参照アーキテクチャと運用制約
効果的な音声AIシステムには、3つの明示的な運用制約が必要である:(1)遅延バジェット(許容される最大エンドツーエンド遅延)、(2)品質閾値(許容可能なパケット損失とジッター範囲)、(3)コスト管理(分単位またはセッション単位の価格上限)。
-
基本的主張:* 音声システムは、制約が明示的に強制されている場合にのみ優雅に劣化する。ガードレールがなければ、劣化は壊滅的な障害が発生するまで加速する。
-
裏付けとなる根拠:* 音声通信はバッファリングに対して独特の不寛容さを持つ。テキストベースのシステムはリクエストをキューに入れて非同期に処理できるが、音声にはリアルタイム処理が必要である。200ミリ秒の遅延増加はビデオ会議では知覚できないが、リアルタイム対話では会話の流れを著しく妨げる。LiveKitの参照アーキテクチャは、設計を通じて遅延バジェットを強制する:ルーティングパスが遅延閾値を超えた場合、システムは音声をバッファリングするのではなく、自動的に代替パスを選択するか、コーデックビットレートを下げ、音声忠実度を犠牲にして会話の流暢さを維持する。
-
運用メカニズム:* ChatGPT音声モードは、適応ビットレート制御を実装することで、文書化された150ミリ秒未満の遅延を維持している。ネットワーク条件が劣化した場合(パケット損失またはジッターの増加)、システムはコーデックビットレートを下げ、わずかに圧縮された音声になるが、リアルタイムの応答性を保持する。
-
知識労働者への影響:* 実装前に遅延バジェットを定義する。会話型AIアプリケーションの場合、100〜150ミリ秒のラウンドトリップ遅延を目標とする。非リアルタイム文字起こしまたは非同期音声処理の場合、500ミリ秒が許容される。すべてのコードパスを計測して遅延を測定する。パーセンタイルベースの追跡(平均遅延ではなくp99遅延)を使用して、ユーザー体験に不釣り合いに影響を与えるテール遅延を特定する。遅延がバジェット制限に近づいたときにトリガーされるアラートを実装する(例:バジェットが150ミリ秒の場合、p99 = 120ミリ秒でアラート)。

- 図12:音声インフラのリファレンスアーキテクチャ(階層構造)*
実装と運用成熟度
音声インフラストラクチャの展開には、3つの領域における運用規律が必要である:(1)音声固有のメトリクスによる継続的な監視、(2)品質よりも遅延を優先する優雅な劣化ロジック、(3)迅速なインシデント対応手順。
-
基本的主張:* 音声システムは、障害がエンドユーザーに即座に知覚され、ユーザー満足度に直接影響するため、典型的なWebサービスよりも高い運用成熟度を要求する。
-
裏付けとなる根拠:* Webアプリケーションでは、データベースクエリのタイムアウトはユーザーには見えない。アプリケーションは再試行するか、キャッシュされた結果を表示する可能性がある。音声アプリケーションでは、通話の切断または音声アーティファクトは即座に聞こえ、サービス障害として認識される。LiveKitの1億ドルのシリーズB資金調達は、同社の運用モデルに対する投資家の信頼を反映している—このスタートアップは、規模において音声インフラストラクチャを確実に運用する能力を実証した。この運用実績(稼働時間、遅延の一貫性、インシデント対応時間で測定)は、基盤技術と同じくらい価値がある。
-
運用メカニズム:* OpenAIのChatGPT音声モードは、グローバルに数百万人の同時ユーザーにサービスを提供している。各通話には、次のことに関するサブミリ秒の決定が必要である:(1)地理的位置とネットワーク条件に基づく最適なルーティングパス、(2)利用可能な帯域幅に基づくコーデック選択、(3)プライマリパスが劣化した場合のフォールバックルーティング。LiveKitの運用チームは、次の方法でこの複雑さを管理している:(1)遅延またはパケット損失閾値によってトリガーされる自動フェイルオーバー、(2)地域冗長性(地理的地域ごとに複数のデータセンター)、(3)リアルタイムネットワークテレメトリに基づく継続的なコーデック最適化。
-
知識労働者への影響:* 音声システムをスケーリングする前に、可観測性インフラストラクチャに投資する。次のことを捕捉する構造化ログを実装する:(1)音声品質メトリクス(パケット損失率、ジッター、コーデックビットレート)、(2)地理的地域ごとの遅延パーセンタイル(p50、p95、p99)、(3)コーデック選択決定とユーザー報告品質との相関。コーデックまたはルーティングの変更にはカナリアデプロイメントを使用する:100%にロールアウトする前に1%のトラフィックでテストする。音声固有のデバッグに訓練されたオンコールローテーションを確立する:パケット損失パターン分析、ジッター検出、クロックスキュー識別、コーデック固有のトラブルシューティング。
測定フレームワークと成功指標
音声AIシステムの成功指標は、従来のSaaS指標とは根本的に異なります。稼働時間だけでなく、音声品質(平均オピニオン評価)、レイテンシのパーセンタイル、ユーザー維持率に焦点を当てる必要があります。
-
基本的な主張:* 標準的なSaaS指標(稼働率、エラー率)では、音声特有の障害モードを見逃し、ユーザー満足度と相関しません。
-
裏付けとなる根拠:* 音声通話は技術的には「稼働中」(エラーがログに記録されていない)であっても、ユーザーをイライラさせる劣化した音声品質を提供している可能性があります。1(悪い)から5(優れている)の範囲の知覚的指標である平均オピニオン評価(MOS)は、稼働率よりもユーザー満足度とより強く相関します。MOSは、標準化されたスケールで音声品質を評価する人間のリスナーから導き出されます。3.5未満のスコアは、通常、消費者向けアプリケーションでは受け入れられないと見なされます。LiveKitの10億ドルの評価額は、音声インフラストラクチャが従来のWebサービスとは異なる専門的な測定フレームワークを必要とするという市場の認識を反映しています。
-
測定メカニズム:* ChatGPTの音声モードは、おそらく次の項目別に分類されたMOSスコアを追跡しています:(1)地理的地域、(2)コーデックタイプ、(3)デバイスカテゴリ(モバイル、デスクトップ、Web)、(4)ネットワーク状態(WiFi、セルラー、有線)。いずれかのセグメントでMOSが閾値(例:3.5)を下回った場合、システムは自動的にコーデックを切り替え、ビットレートを調整するか、代替サーバー経由でルーティングします。
-
ナレッジワーカーへの影響:* 音声アプリケーションで平均オピニオン評価の測定を実装してください。A/Bテストを使用して、コーデックの選択、ビットレート調整、ルーティング変更がユーザー満足度にどのように影響するかを定量化します。レイテンシを複数のパーセンタイルで個別に追跡します:p50(中央値)、p95(95パーセンタイル)、p99(99パーセンタイル)。ユーザーは時折の遅延に敏感であるため、p99レイテンシは平均レイテンシよりもユーザーの離脱を予測することが多いです。品質指標を毎週製品チームとエンジニアリングチームに公開し、従来の稼働時間指標と並んで音声品質を意思決定者に可視化してください。
リスク評価と軽減戦略
音声インフラストラクチャは、テキストベースのシステムとは異なる規制、技術、競争上のリスクを伴います:(1)プライバシー規制に基づくデータ居住要件、(2)コーデックライセンス義務、(3)ベンダーロックインリスク。
-
基本的な主張:* 音声システムは、テキストシステムにはないコンプライアンス負担を伴います。軽減には、後から改修するのではなく、初期設計時に行われるアーキテクチャの決定が必要です。
-
裏付けとなる根拠:* 音声録音は、テキストデータよりも厳格な要件を持つデータ保護規制(ヨーロッパのGDPR、カリフォルニアのCCPA)の対象となる可能性があります。これらの規制は、多くの場合、データ居住(音声は特定の地理的地域に保存する必要がある)を義務付け、削除のタイムラインを課します。コーデックライセンス(例:H.264、VP9)は、特許保有者にロイヤリティを支払う必要がある場合、予期しないコストを生み出す可能性があります。アプリケーションロジックが単一プロバイダーの独自APIと密接に結合している場合、ベンダーロックインは深刻です。代替プロバイダーへの移行には、大幅な再エンジニアリングが必要です。
-
リスク軽減メカニズム:* LiveKitのオープンソース基盤とマルチクラウドサポートは、ロックインリスクを軽減します。LiveKitを使用する組織は、必要に応じて代替プロバイダーに移行したり、インフラストラクチャを自己ホストしたりできますが、独自プラットフォームはAPIカップリングを通じて顧客を閉じ込める可能性があります。
-
ナレッジワーカーへの影響:* 開発の早い段階でコーデックライセンスを監査してください。可能な場合は、ロイヤリティフリーのオプション(音声用Opus、ビデオ用VP8)を優先してください。音声保持を最小限に抑えるようにデータフローを設計します。定義された期間(例:30日)後に録音を削除する自動削除ポリシーを実装してください。サードパーティのインフラストラクチャ上に構築する場合は、サービス契約でデータ居住保証を交渉し、移植性を確保するために年に一度移行パスをテストしてください。ベンダー依存を減らし、主要ベンダーが停止した場合に迅速に対応できるように、重要な依存関係の内部フォークを維持してください。
システムアーキテクチャと障害ポイント
LiveKitのアーキテクチャは、関心事を3つのレイヤーに分離しています:シグナリング(接続ネゴシエーション)、メディアルーティング(パケット転送)、コーデック処理(音声圧縮)。このモジュール性により、ほとんどの音声システムが本番環境で失敗する場所が明らかになります。
- 一般的な障害モードと根本原因*
- ネットワーク状態が悪い場合のコーデックネゴシエーション – モノリシックシステムは、帯域幅が低下しても高品質コーデックを維持しようとし、バッファ肥大化とレイテンシスパイクを引き起こします
- 地理的レイテンシスパイク – 単一地域のデプロイメントは、遠隔ユーザーに避けられない遅延を生み出します。物理法則を補う最適化はありません
- 状態同期の失敗 – 分散サーバーは、フェイルオーバー中にアクティブセッションを追跡できなくなり、会話の途中で通話を切断します
- モジュール性が重要な理由*
音声システムは、3つの同時的で、しばしば相反する制約に直面します:
- リアルタイムレイテンシ: 100ミリ秒未満のラウンドトリップ(自然な会話には譲れない)
- 信頼性: 99.9%以上の稼働時間(音声通話は同期的。ユーザーはすぐに気づく)
- コスト効率: 分単位の価格設定は競争力を維持する必要がある
これらの関心事を結合すると、連鎖的な障害が発生します。1つのコンポーネントが容量に達すると、システム全体が均一に劣化します。モジュラーアーキテクチャは、独立した最適化を可能にします。
- 具体的なスケーリングシナリオ*
トラフィックスパイク時:
-
モノリシックシステム: すべての指標が同時に劣化します。レイテンシが増加し、パケット損失が増加し、品質が低下します。ユーザーは全体的に通話品質の低下を経験します。
-
モジュラーシステム(LiveKitモデル): メディアサーバーは水平方向にスケールし、シグナリングはステートレスのままです。新しい容量がシグナリングインフラストラクチャを再デプロイすることなく負荷を吸収します。レイテンシは安定したままです。新しい接続のみが短い遅延を経験します。
-
運用上の影響*
現在の音声インフラストラクチャの結合ポイントを監査してください:
- 密結合を特定する: トランスコーディング、ルーティング、状態管理が同じサーバー上で実行されている場合、結合の問題があります
- サーキットブレーカーを実装する: コンポーネント間にフォールバックロジックを追加して、1つの障害が伝播しないようにします(例:トランスコーディングサービスが失敗した場合、通話を切断するのではなく、低品質コーデックに劣化させる)
- 毎月フェイルオーバーをテストする: コンポーネントを意図的にオフラインにするフェイルオーバー訓練をスケジュールします。回復時間を文書化し、SLAターゲットと照らし合わせて測定します。ほとんどの停止は、コンポーネントの障害ではなく、テストされていない回復パスから発生します
- モジュラーアーキテクチャへの移行チェックリスト:*
- シグナリング、ルーティング、コーデックレイヤー間の現在の依存関係をマッピングする
- 単一障害点を特定する(通常は状態管理)
- ステートレスシグナリングレイヤーを設計する(セッション状態にRedisまたは類似のものを使用)
- 自動フォールバックを備えたレイヤー間のヘルスチェックを実装する
- ステージング環境で各障害シナリオをテストし、期待される動作を文書化する
- レイテンシとエラー率を監視しながら、変更を段階的にデプロイする
参照アーキテクチャとパフォーマンスガードレール
効果的な音声AIシステムには、3つの明示的なガードレールが必要です:レイテンシバジェット(エンドツーエンド遅延のハードキャップ)、品質閾値(許容可能なパケット損失許容度)、コスト管理(分単位の価格設定モデル)。これらがないと、システムは優雅に劣化しますが、そうでなくなると壊滅的に失敗します。
- 音声が他のメディアとは異なる方法で劣化する理由*
テキストは無期限にバッファリングできます。ビデオはフレームをスキップできます。音声はできません。200ミリ秒のレイテンシスパイクは、ビデオでは知覚できませんが、音声では会話の流れを壊します。ユーザーは、お互いに割り込み、明確化の質問をし、自然なリズムを維持することを期待しています。約150ミリ秒を超える遅延は、不自然な間を強制します。
- LiveKitのガードレールモデル*
LiveKitは、設計によってレイテンシバジェットを強制します。ルートが閾値を超えた場合、システムは自動的に:
- 代替ルーティングパスを試みる
- バッファリングではなく、コーデック品質を劣化させる(低ビットレートに切り替える)
- インシデント後の分析のためにイベントをログに記録する
ChatGPTの音声モードは、ネットワーク状態が劣化したときに音声忠実度よりもコーデック効率を優先することで、150ミリ秒未満のレイテンシを維持します。ユーザーはわずかに圧縮された音声を経験しますが、会話の流暢さを維持します。これはユーザーが受け入れるトレードオフです。
- レイテンシバジェットの定義*
| アプリケーションタイプ | 目標レイテンシ | 許容範囲 | フォールバックアクション |
|---|---|---|---|
| 会話型AI | 100–150ms | ±50ms | コーデック品質を劣化させる |
| 文字起こしサービス | 500–1000ms | ±200ms | バッファリングして再試行 |
| 音声通知 | 1000–2000ms | ±500ms | キューに入れて再試行 |
| ライブ翻訳 | 200–300ms | ±100ms | 代替ルートに切り替える |
- 実装チェックリスト*
-
構築前にレイテンシバジェットを定義する:
- ユースケースを特定する(会話、文字起こし、通知など)
- 上記の表に基づいて目標レイテンシを設定する
- 許容可能な劣化を文書化する(コーデック品質、機能削減)
- フォールバック動作を確立する(再試行、キュー、劣化)
-
すべてのコードパスを計測する:
- 取り込みポイントでレイテンシを測定する(ユーザーが話す)
- 送信ポイントで測定する(音声がサーバーに送信される)
- 処理ポイントで測定する(サーバーが音声を処理する)
- 応答ポイントで測定する(応答がユーザーに送り返される)
- 4つの測定すべてからエンドツーエンドレイテンシを計算する
-
平均ではなくパーセンタイルを追跡する:
- p50、p95、p99レイテンシを個別に監視する
- p99がバジェット制限に近づいたときにアラートを出す(例:バジェットが150msの場合、120msでアラート)
- 地理、デバイスタイプ、ネットワーク状態別にレイテンシを追跡する
- ベースラインより10%以上高いp99スパイクを調査する
-
アラートとダッシュボードを構築する:
- 地域別のレイテンシパーセンタイルを示すリアルタイムダッシュボード
- p99レイテンシが5分以上バジェットを超えたときにアラート
- レイテンシの傾向と外れ値を示す週次レポート
- 相関分析:レイテンシ対コーデック選択、レイテンシ対パケット損失、レイテンシ対地理的地域
実装と運用パターン
音声インフラストラクチャのデプロイには、一般的なWebサービスを超える運用規律が必要です。音声の障害は、ユーザーにすぐに知覚されます。エラーメッセージや再試行ロジックの背後に隠れることはできません。
-
音声がより高い運用成熟度を要求する理由*
-
データベースクエリのタイムアウト: ユーザーには見えません。再試行ロジックが処理します
-
音声通話の切断: 壊滅的。ユーザーエクスペリエンスが即座に破壊されます
-
音声品質の劣化: 数秒以内に気づかれます。ユーザーは通話を放棄します
LiveKitの1億ドルのシリーズBは、その運用モデルに対する投資家の信頼を反映しています。このスタートアップは、大規模に音声インフラストラクチャを確実に実行できることを証明しました。これは、技術そのものと同じくらい価値のある実績です。
- 本番音声システムの運用要件*
| 要件 | 実装 | 測定 |
|---|---|---|
| 継続的な監視 | レイテンシ、パケット損失、コーデック選択に関するリアルタイム指標 | 10秒ごとに更新されるダッシュボード |
| 優雅な劣化 | 自動コーデックダウングレード、ルートフェイルオーバー、品質削減 | 劣化による計画外の通話切断ゼロ |
| 迅速なインシデント対応 | オンコールローテーション、一般的な障害のランブック、<5分のMTTR | インシデント対応時間を毎週追跡 |
| コーデック最適化 | コーデック設定の継続的なA/Bテスト、ビットレート調整 | MOSスコアの改善を毎月追跡 |
| 地域冗長性 | マルチリージョンデプロイメント、自動フェイルオーバー | 毎月フェイルオーバーをテスト。<30秒のフェイルオーバー時間 |
- OpenAIのChatGPT音声モード:運用モデル*
ChatGPTの音声は、数百万の同時ユーザーにサービスを提供します。各通話には、ミリ秒未満の決定が必要です:
- この通話を処理するのはどの地域サーバーか?
- このネットワーク状態にはどのコーデックを使用すべきか?
- 品質を劣化させるべきか、代替ルートで再試行すべきか?
LiveKitの運用チームは、次の方法でこれを管理します:
-
自動フェイルオーバー: 地域が失敗した場合、通話は自動的に最も近い健全な地域に再ルーティングされます
-
継続的なコーデック最適化: 異なるコーデック設定のA/Bテスト。改善を段階的にロールアウト
-
予測スケーリング: 機械学習モデルがトラフィックスパイクを予測し、容量を事前にスケールします
-
運用規律の構築:ステップバイステップ*
-
フェーズ1:可観測性(第1–4週)*
-
次の項目をキャプチャする構造化ログを実装する:タイムスタンプ、通話ID、コーデック、ビットレート、レイテンシ、パケット損失、地域、デバイスタイプ
-
メトリクス収集を設定する:レイテンシパーセンタイル(p50、p95、p99)、パケット損失率、コーデック分布、通話時間
-
ダッシュボードを作成する:地域別のリアルタイムレイテンシ、コーデックパフォーマンス比較、エラー率の傾向
-
ベースラインを確立する:すべての指標にわたって現在のパフォーマンスを測定する
-
フェーズ2:アラート(第5–8週)*
-
アラート閾値を定義する:レイテンシp99 >150ms、パケット損失 >2%、エラー率 >0.5%
-
エスカレーションを設定する:閾値が5分以上超えた場合、オンコールエンジニアにアラート
-
ランブックを作成する:各アラートタイプの対応手順を文書化する
-
アラートをテストする:各アラートを手動でトリガーし、オンコールエンジニアが通知を受け取ることを確認する
-
フェーズ3:優雅な劣化(第9–16週)*
-
コーデックダウングレードロジックを実装する:レイテンシが上昇した場合、自動的に低ビットレートコーデックに切り替える
-
ルートフェイルオーバーを実装する:プライマリルートが失敗した場合、自動的にセカンダリルートを試す
-
品質削減を実装する:パケット損失が上昇した場合、通話を切断するのではなく音声品質を下げる
-
各劣化シナリオをテストする:システムが設計どおりに動作することを確認する
-
フェーズ4:インシデント対応(第17–20週)*
-
オンコールローテーションを確立する:音声インフラストラクチャの24時間365日のカバレッジ
-
オンコールエンジニアをトレーニングする:音声固有のデバッグ(ジッター分析、パケット損失パターン、クロックスキュー検出)
-
インシデントプレイブックを作成する:一般的な障害のステップバイステップ手順
-
月次訓練を実施する:障害をシミュレートし、対応手順を練習する
-
音声変更のカナリアデプロイメント戦略*
音声システムはバグに対して容赦がありません。コーデック、ルーティング、品質の変更には、カナリアデプロイメントを使用してください:
- ベースライン測定: すべての指標(レイテンシ、MOS、エラー率)にわたって現在のパフォーマンスを測定する
- カナリアデプロイメント: トラフィックの1%を新しいバージョンにルーティングし、24時間監視する
- メトリクス比較: カナリアメトリクスをベースラインと比較し、いずれかのメトリクスが5%以上劣化した場合はアラート
- 段階的なロールアウト: カナリアが合格した場合、5%、次に25%、次に100%に増やす
- ロールバック手順: いずれかの段階でメトリクスが劣化した場合、すぐに以前のバージョンにロールバックする
測定と成功指標
音声AIシステムの成功指標は、従来のSaaSとは根本的に異なります。標準的な指標(稼働時間、エラー率)では、音声特有の障害モードを見逃してしまいます。
- 標準的なSaaS指標が音声に適さない理由*
音声通話は技術的には「稼働中」であっても、音質が悪い場合があります。ユーザーは次のような体験をする可能性があります:
- レイテンシはSLA内だが会話が鈍く感じる
- パケットロスはゼロだが音声が圧縮されて聞こえる
- 稼働率99.9%だがピーク時に通話が切断される
これらの障害は従来の指標には現れません。知覚的指標であるMOS(Mean Opinion Score)は、稼働時間よりもユーザー満足度との相関性が高くなります。
- 音声特有の指標フレームワーク*
| 指標 | 目標値 | 測定方法 | 頻度 |
|---|---|---|---|
| MOS(Mean Opinion Score) | >3.8 | 合成テスト通話; ユーザー調査 | 継続的; 週次集計 |
| レイテンシp99 | <150ms | 取り込みから応答までのエンドツーエンド測定 | 継続的; 超過時にアラート |
| パケットロス | <1% | ネットワーク監視; コーデックレベルの指標 | 継続的; >2%でアラート |
| 通話完了率 | >99.5% | 成功した通話数 / 試行された総通話数 | 日次集計 |
| 音質劣化 | 通話の<5% | コーデックダウングレードイベントを追跡 | 日次集計 |
| 地理的レイテンシ分散 | 地域間で<50ms | 地域ごとのp99レイテンシを測定 | 日次集計 |
- MOSスコアリングの実装*
MOS(Mean Opinion Score)は1(悪い)から5(優秀)の範囲です:
-
4.5–5.0: 優秀(知覚できない劣化)
-
4.0–4.5: 良好(知覚できるが煩わしくない)
-
3.5–4.0: 普通(やや煩わしい)
-
3.0–3.5: 不良(煩わしい)
-
<3.0: 受け入れがたい
-
MOS計算方法:*
- 合成テスト: 事前録音された音声をシステムに流し、PESQアルゴリズムを使用して出力品質を測定
- ユーザー調査: 通話後、ユーザーに1〜5のスケールで音質を評価してもらう
- コーデックベースの推定: コーデックの選択、ビットレート、パケットロスから公開モデルを使用してMOSを推定
-
測定実装チェックリスト*
-
合成テスト通話を展開: 各地域から15分ごとに実行
-
各テスト通話のPESQスコアを計算; MOSに集計
-
ダッシュボードを設定: 地域、コーデック、デバイスタイプ、時間帯別のMOS
-
MOSが10分以上3.8を下回った場合にアラート
-
MOSトレンドを追跡: 改善/劣化を示す週次レポート
-
MOSとコーデック選択を相関分析: どのコーデックが最高品質を提供するか特定
-
コーデック変更のA/Bテスト: 本番環境へのロールアウト前にMOSへの影響を測定
-
レイテンシパーセンタイル追跡*
平均レイテンシに依存しないでください。パーセンタイルを個別に追跡します:
- p50(中央値): 通話の50%がこのレイテンシ以下を経験
- p95: 通話の95%がこのレイテンシ以下を経験; 5%はより遅い
- p99: 通話の99%がこのレイテンシ以下を経験; 1%はより遅い
p99レイテンシは、平均レイテンシよりも解約率を予測することが多いです。100回の通話のうち1回遅い通話を経験したユーザーは、サービスを放棄する可能性があります。
- レイテンシダッシュボードテンプレート*
リアルタイムレイテンシ(過去24時間)
地域: US-East | US-West | EU | APAC
p50レイテンシ: 85ms | 92ms | 110ms | 145ms
p95レイテンシ: 120ms | 135ms | 165ms | 210ms
p99レイテンシ: 180ms | 195ms | 220ms | 280ms
アラート:
- US-West p99レイテンシが195ms(目標: 150ms) ⚠️
- APAC p99レイテンシが280ms(目標: 150ms) 🔴-
週次レポートテンプレート*
-
地域別MOSスコア(前週比トレンド)
-
地域別レイテンシパーセンタイル(前週比トレンド)
-
コーデック分布(最も使用されているコーデック)
-
通話完了率(劣化の有無)
-
インシデントと解決策(根本原因分析)
-
来週の予定変更(コーデック更新、ルーティング変更など)
リスクと軽減戦略
音声インフラストラクチャは、テキストシステムにはない規制、技術、競争上のリスクを伴います。軽減には早期に行われるアーキテクチャの決定が必要です。
-
リスク1: データレジデンシーとコンプライアンス*
-
リスク:* 音声録音は、テキストデータよりも厳格な要件を持つGDPR、CCPA、またはその他のデータ保護規制の対象となる可能性があります。
-
影響:* 非準拠は、年間収益の最大4%(GDPR)の罰金に加えて、評判の損害をもたらす可能性があります。
-
軽減策*
5年目のスタートアップがOpenAIのChatGPT音声モードを支える—そしてより広範なシフトを示す
2019年に設立されたLiveKitは、Index Venturesが主導する1億ドルのシリーズB資金調達ラウンドに続き、10億ドルの評価額を達成しました。このマイルストーンは単なる資金調達イベント以上のものを表しています—リアルタイム音声インフラストラクチャがニッチな技術的問題からAI経済の基盤レイヤーへと移行した瞬間を示しています。
このスタートアップは、リアルタイム音声およびビデオインフラストラクチャを提供し、OpenAIのChatGPT音声モードのバックボーンとして機能しています—何百万人ものユーザーがAIとどのように対話するかを根本的に変えた消費者向け機能です。このパートナーシップは重要な洞察を明らかにします: AIの未来はモデルだけではなく、それらのモデルを生き生きと感じさせる目に見えないインフラストラクチャにあります。
-
今後の機会:* 音声インフラストラクチャは、2010年のクラウドコンピューティングと同じものになりつつあります—まったく新しいカテゴリのアプリケーションを可能にするユーティリティレイヤーです。AWSがサーバー管理を抽象化したように、LiveKitはリアルタイムオーディオの過酷な複雑さを抽象化します: WebRTCネゴシエーション、コーデック最適化、グローバルエッジ展開、そしてすべての地域とネットワーク条件にわたる100ms未満のレイテンシ保証。
-
なぜ今重要なのか:* 音声インフラストラクチャをゼロから構築するには、ネットワーキング、信号処理、分散システム、運用レジリエンスにまたがる専門知識が必要です。この組み合わせを持つ組織はほとんどありません。LiveKitの10億ドルの評価額は、この専門知識がプレミアム評価を要求するほど希少になったこと、そして市場が専門プラットフォームをサポートするのに十分な大きさであることを投資家が認識していることを反映しています。
-
ホワイトスペースの機会:* ほとんどの組織は、音声機能を社内で構築しなければならないと依然として想定しています。この想定は経済的に非合理的になりつつあります。計算は逆転しました: チームの95%にとって、実証済みのプラットフォームを採用することで、市場投入までの時間が6〜12か月短縮され、運用オーバーヘッドが40〜60%削減され、優れた信頼性が提供されます。残りの5%—極端な規模または独自の要件を持つ組織—は社内投資を正当化できます。それ以外のすべての人は、エンジニアリングリソースを差別化に向けるべきです。
システムアーキテクチャ: 音声システムが失敗する場所とレジリエンスのための再設計方法
LiveKitのアーキテクチャは、リアルタイムシステムに関する基本的な真実を明らかにします: モノリシック設計は規模で壊滅的に失敗します。このスタートアップは、懸念事項を3つの独立したレイヤーに分離します: シグナリング(接続ネゴシエーション)、メディアルーティング(オーディオパケット転送)、およびコーデック処理(圧縮とトランスコーディング)。
このモジュール性は優雅なエンジニアリングではありません—生存要件です。
-
隠れた制約:* 音声システムは、3つの同時的で、しばしば相反する要求に直面します: 100ms未満のレイテンシ(会話フローに不可欠)、99.9%以上の信頼性(ユーザーはすべての通話切断に気づく)、およびコスト効率(分単位の価格設定モデルは容赦ない最適化を要求)。これらの懸念事項を結合すると、負荷下で複合するカスケード障害が発生します。
-
アーキテクチャの意味:* トラフィックが急増すると、モノリシックシステムは均一に劣化します—レイテンシが上昇し、品質が低下し、最終的にシステム全体が失敗します。LiveKitのようなモジュラーアーキテクチャは、独立したスケーリングを可能にします: メディアサーバーは水平に負荷を吸収し、シグナリングはステートレスで軽量なままです。1つのコンポーネントがシステム全体の崩壊を引き起こすことなく、優雅に劣化できます。
-
具体的なシナリオ:* ChatGPT音声モードが製品発売中に10倍のトラフィック急増を経験すると想像してください。モノリシックシステムでは、レイテンシが数分以内に80msから400msに上昇し、すべての通話でユーザーエクスペリエンスが劣化します。代わりに、LiveKitのアーキテクチャはオンデマンドでメディアサーバーを追加し、負荷を吸収しながらレイテンシを維持します。シグナリングインフラストラクチャは影響を受けません。システムは壊滅的に失敗するのではなく、予測可能にスケールします。
-
運用上の洞察:* このアーキテクチャは、より深い原則を反映しています: リアルタイムシステムは部分的な障害のために設計されなければなりません。すべてのコンポーネントが等しくスケールする必要はありません。クリティカルパス(音声の場合、レイテンシとパケット配信)を特定し、二次的な懸念事項(ログ、分析)から分離し、それらを独立してスケールします。この設計パターンは音声をはるかに超えて適用されます—これはレジリエントな分散システムの基盤です。
-
将来を見据えた意味:* 音声AIが遍在するようになると、モジュラーアーキテクチャを早期に採用する組織は、大きな運用上の利点を持つことになります。彼らはより効率的にスケールし、インシデントに迅速に対応し、極端な負荷下で品質を維持します。依然としてモノリシック音声スタックを実行しているチームは、移行を技術的負債項目ではなく戦略的優先事項として扱うべきです。
リファレンスアーキテクチャ: 大惨事の前にガードレールを構築する
効果的な音声AIシステムには、スケーリング前に確立された3つの明示的なガードレールが必要です: レイテンシバジェット(エンドツーエンド遅延の厳格な上限)、品質しきい値(パケットロス許容度)、およびコスト管理(分単位の価格設定モデル)。
これらのガードレールがなければ、音声システムは非常に徐々に劣化するため、障害が突然現れるように見えます。
- レイテンシバジェットフレームワーク:* 音声は劣化に対して独特に不寛容です。テキストは無期限にバッファリングできます; ビデオはフレームをスキップできます; 音声はできません。200msのレイテンシスパイクは、ビデオ会議では知覚できませんが、リアルタイムAIインタラクションでは会話フローを壊します。ユーザーは気まずい沈黙を経験し、お互いに割り込み、AIが遅いまたは応答しないと認識します。
LiveKitのリファレンスアーキテクチャは、設計によってレイテンシバジェットを強制します: ルートがしきい値を超えた場合、システムは自動的に代替パスにフォールバックするか、バッファリングするのではなくコーデック品質を劣化させます。これは妥協ではありません—音声忠実度よりも会話の流暢さを優先する意図的なトレードオフです。
-
具体的な実装:* ChatGPT音声モードは、厳格なバジェットを実装することで150ms未満のレイテンシを維持します: 音声キャプチャとエンコーディングに50ms、ネットワーク転送に30ms、AI処理に40ms、応答生成と送信に20ms、ジッターバッファに10ms。ネットワーク条件が劣化すると、システムは完璧な条件を待つのではなく、音声をより積極的に圧縮します。ユーザーはわずかに圧縮された音声を聞きますが、会話フローを維持します。
-
品質しきい値とコーデック選択:* 許容可能なパケットロス許容度(通常、音声では1〜3%)を定義し、しきい値に近づいたときに自動コーデックダウングレードを実装します。最新の標準であるOpusコーデックは、これを優雅に処理します—6 kbpsから510 kbpsのビットレートで動作でき、ネットワーク条件が悪化するにつれて優雅な劣化を可能にします。
-
コスト管理アーキテクチャ:* 自動最適化を備えた分単位の価格設定モデルを実装します。通話がコストしきい値を超えた場合、システムは自動的に低ビットレートコーデックに切り替えたり、ビデオ解像度を下げたり、より安価な地理的地域を経由してルーティングしたりできます。これにより、許容可能な品質を維持しながら、暴走するコストを防ぎます。
-
測定の必須事項:* レイテンシ、ジッター、パケットロスを測定するために、すべてのコードパスを計装します。ユーザーエクスペリエンスを劣化させるテールレイテンシをキャッチするために、パーセンタイル追跡(平均ではなくp99)を使用します。平均レイテンシが80msでp99レイテンシが500msのシステムは、平均指標が良好に見えても、ユーザーには壊れているように感じられます。
-
将来のシナリオ:* 音声AIがより普及するにつれて、早期にガードレールを確立する組織は、大きな競争上の優位性を持つことになります。彼らは品質劣化なしに数百万の同時ユーザーにスケールできるようになります。このステップをスキップするチームは、規模での壊滅的な障害に直面します—ユーザーの信頼を損ない、回復に数か月を要する種類の障害です。
実装と運用: 規模で音声を実行する隠れた複雑さ
音声インフラストラクチャの展開には、典型的なWebサービスを超える運用規律が必要です。音声障害はユーザーにすぐに知覚されます—エラーページや優雅な劣化の背後に隠れることはできません。
- 運用成熟度の要件:* データベースクエリのタイムアウトは目に見えません; 音声通話の切断は壊滅的です。ユーザーはすぐに気づきます。この非対称性は、音声システムがより高い運用基準を要求することを意味します: 継続的な監視、自動フェイルオーバー、迅速なインシデント対応。
LiveKitの1億ドルのシリーズB資金調達は、スタートアップの運用モデルに対する投資家の信頼を反映しています。同社は、規模で音声インフラストラクチャを確実に実行できることを証明しました—この運用実績は、基盤技術と同じくらい価値があります。
- 具体的な運用パターン:* OpenAIのChatGPT音声モードは、世界中で数百万の同時ユーザーにサービスを提供しています。各通話には、ミリ秒単位の決定が必要です: どのコーデックを使用すべきか? どの地理的地域がこの通話をルーティングすべきか? レイテンシが急増した場合、品質を劣化させるべきか、それとも再ルーティングすべきか? これらの決定は毎秒何千回も発生し、毎回正しくなければなりません。
LiveKitの運用チームは、次の方法でこれを管理します: (1)地域の劣化を検出し、ミリ秒以内に通話を再ルーティングする自動フェイルオーバー、(2)単一のデータセンター障害がユーザーに影響を与えないことを保証する地域冗長性、(3)リアルタイムのネットワーク条件に基づいて圧縮を調整する継続的なコーデック最適化。
- オブザーバビリティの基盤:* 音声システムを構築している場合は、スケーリング前にオブザーバビリティに多額の投資をしてください。次のものをキャプチャする構造化ログを実装します: 音質指標(MOSスコア、ノイズレベル)、レイテンシパーセンタイル(p50、p95、p99)、コーデック選択決定、パケットロスパターン、ジッター測定。
ほとんどの音声デバッグでは、これらの指標を組み合わせて分析する必要があります。高レイテンシと低パケットロスの通話は、ネットワーク輻輳を示唆します。高パケットロスと低レイテンシは、無線信号の不良を示唆します。高ジッターは、クロックスキューまたはルーティングの不安定性を示唆します。このデータを持たないチームは、本質的に盲目的にデバッグしています。
-
展開戦略:* コーデックまたはルーティングの変更には、カナリア展開を使用します。100%にロールアウトする前に、トラフィックの1%でテストします。音声システムは微妙な変更に敏感です—新しいコーデックバージョンは、ラボ条件では良好に機能するかもしれませんが、実際のネットワーク条件下では失敗する可能性があります。カナリア展開は、数百万のユーザーに影響を与える前にこれらの問題をキャッチします。
-
オンコール準備:* 音声固有のデバッグでトレーニングされたオンコールローテーションを確立します。これは、ジッター分析、パケットロスパターン、クロックスキュー検出、コーデックネゴシエーション障害を理解することを意味します。一般的なSREトレーニングでは不十分です—音声システムには専門知識が必要です。
-
競争上の優位性:* 音声運用を習得する組織は、音声AIが遍在するようになると、大きな優位性を持つことになります。彼らはインシデントに迅速に対応し、より高い品質を維持し、競合他社よりも効率的にスケールします。この運用の卓越性は、防御可能な堀になります。
測定:標準的なSaaSメトリクスが音声特有の障害モードを見逃す理由
音声AIシステムの成功指標は、従来のSaaSとは根本的に異なります。標準的なメトリクス(稼働時間、エラー率、応答時間)では、音声特有の重要な障害モードを見逃してしまいます。
-
測定のギャップ:* 音声通話は技術的には「稼働中」であっても、受け入れがたい音質を提供している可能性があります。システムは99.99%の稼働率を持ちながらも、音質の低さによってユーザーに一貫して失敗を提供することがあります。この技術的メトリクスとユーザー体験の間のギャップこそが、ほとんどの音声システムが失敗する場所です。
-
北極星としての平均オピニオンスコア(MOS):* MOSは、稼働時間よりもユーザー満足度とはるかに良く相関する知覚的メトリクスです。1〜5のスケールで音質を測定し、3.5が許容可能な品質の閾値となります。MOSは、ユーザーが実際に体験するもの(コーデックアーティファクト、背景ノイズ、クリッピング、歪み)を捉えます。
LiveKitの10億ドルの評価額は、音声インフラストラクチャが専門的な測定フレームワークを必要とするという市場の認識を反映しています。投資家は、音声品質を正しく測定する企業が、従来のSaaSメトリクスに依存する企業を上回るパフォーマンスを発揮することを理解しています。
-
具体的な測定フレームワーク:* ChatGPT音声モードは、地域、コーデック、デバイスタイプ、ネットワーク状態ごとにMOSスコアを追跡している可能性が高いです。MOSが3.5を下回ると、システムは自動的にコーデックを切り替えるか、代替サーバー経由でルーティングします。このフィードバックループにより、品質が一貫して許容可能なレベルに保たれます。
-
予測指標としてのレイテンシパーセンタイル:* p50、p95、p99パーセンタイルでレイテンシを個別に追跡します。平均レイテンシは問題を隠すことがよくあります。平均レイテンシが80msでもp99レイテンシが500msのシステムは、ユーザーには壊れているように感じられます。p99レイテンシは、最悪のユーザー体験を捉えるため、平均レイテンシよりも解約率を予測することが多いです。
-
MOSを超える音質メトリクス:* 追加の測定を実装します:ノイズレベル(背景ノイズは30dB未満であるべき)、信号対雑音比(許容可能な品質には20dB以上)、コーデック効率(知覚品質あたりのビットレート)。これらのメトリクスは、ユーザーが気づく前に劣化の早期警告サインを提供します。
-
品質決定のためのA/Bテスト:* A/Bテストを使用して、コーデックの選択、ビットレート調整、ルーティング変更がユーザー満足度にどのように影響するかを測定します。ラボ測定に依存しないでください。実際のパフォーマンスは異なることがよくあります。100%にロールアウトする前に、5%のユーザーでコーデック変更をテストします。
-
ダッシュボードとアラート:* 製品チームとエンジニアリングチームに品質メトリクスを週次で表示するダッシュボードを設定します。MOSが3.5を下回ったとき、p99レイテンシが予算を超えたとき、またはパケット損失が閾値を超えたときにアラートを出します。品質メトリクスを稼働時間メトリクスと同じくらい可視化します。
-
音声測定の未来:* 音声AIがより普及するにつれて、品質を正しく測定する組織は大きな競争優位性を持つことになります。彼らは実際の条件下でシステムがどのように動作するかを正確に理解し、それに応じて最適化できます。従来のSaaSメトリクスに依存するチームは、盲目的に飛行することになります。
リスクと軽減策:今後のコンプライアンスとアーキテクチャの課題
音声インフラストラクチャは、テキストシステムにはない規制上、技術上、競争上のリスクを伴います。データレジデンシー要件、コーデックライセンス、ベンダーロックインは、早期のアーキテクチャ決定を必要とする運用上の課題をもたらします。
-
データレジデンシーとプライバシーコンプライアンス:* 音声録音は、テキストよりも厳格なデータ保護規制の対象となる可能性があります。GDPR、CCPA、および新興規制は、音声を保存できる場所、保持できる期間、アクセスできる人に関する要件を課します。一部の管轄区域では、音声が地理的境界内に留まることを要求しています。
-
軽減戦略:* 音声保持を最小限に抑えるようにデータフローを設計します。自動削除ポリシーを実装します。明示的に保持されない限り、音声は転写後すぐに削除されるべきです。転送中の音声にはエンドツーエンド暗号化を使用します。サードパーティのインフラストラクチャ上に構築する場合は、データレジデンシー保証を交渉し、年次で移行パスをテストします。
-
コーデックライセンスとコストの驚き:* コーデックライセンスは予期しないコストを生み出す可能性があります。H.264とVP9は、一部の管轄区域でライセンス料を必要とします。ロイヤリティフリーのコーデック(Opus、VP8)はこれらの問題を回避しますが、異なるパフォーマンス特性を持つ可能性があります。
-
軽減戦略:* コーデックライセンスを早期に監査します。可能な限りロイヤリティフリーのオプションを優先します。ライセンスされたコーデックを使用する場合は、ライセンスコストを予算化し、規制の変更を監視します。LiveKitのマルチコーデックサポートは柔軟性を提供します。ライセンスが問題になった場合、コーデックの切り替えは簡単です。
-
ベンダーロックインとプラットフォーム依存:* インフラストラクチャが単一プロバイダーのAPIに密接に結合されている場合、移行は極めて困難になります。これは長期的な依存リスクを生み出します。
-
軽減戦略:* LiveKitのオープンソースルーツとマルチクラウドサポートは、ロックインリスクを軽減します。LiveKitを使用するチームは、必要に応じて代替プロバイダーに移行したり、自己ホストしたりできます。ベンダー依存を減らすために、重要な依存関係の内部フォークを維持します。プロバイダーとデータポータビリティ保証を交渉します。
-
競争上の脆弱性:* 音声AIがより価値あるものになるにつれて、優れた技術や低コストを持つ競合他社が現れる可能性があります。早期のアーキテクチャ決定により、最適でないプラットフォームにロックされる可能性があります。
-
軽減戦略:* プラットフォームに依存しないシステムを設計します。独自のAPIではなく、標準プロトコル(WebRTC、SIP)を使用します。単一のプロバイダーとの深い統合を避けます。この柔軟性により、より良い代替案が現れた場合にプラットフォームを切り替えることができます。
-
長期的なリスク:* これらのリスクを早期に無視する組織は、後でコストのかかる修復に直面します。データレジデンシー慣行が不十分なシステムは、新しい規制に準拠するために完全な再設計が必要になる可能性があります。ベンダーロックインは、競争力のないプラットフォームに閉じ込められる可能性があります。今日行われるアーキテクチャ決定は、今後何年にもわたる柔軟性を決定します。
変曲点:音声インフラストラクチャにとって今が重要な理由
LiveKitの10億ドルの評価額は、重要な変曲点を示しています。音声インフラストラクチャ市場は統合されており、ほとんどの組織にとって社内構築はもはや経済的ではありません。
-
市場統合のダイナミクス:* LiveKitの資金調達は、投資家が音声インフラストラクチャにおける持続可能な競争優位性を見ていることを検証しています。この資本と人材の集中は、専門プラットフォームが信頼性、レイテンシ、コスト効率において社内の取り組みを上回ることを意味します。経済性はプラットフォームに向けて決定的にシフトしました。
-
シグナルとしてのOpenAIパートナーシップ:* OpenAIが独自の音声インフラストラクチャを構築するのではなく、LiveKitと提携することを決定したことは、このシフトを例示しています。OpenAIは事実上無制限のリソースと世界クラスのエンジニアリング人材を持っています。それでも同社はLiveKitのプラットフォームを活用することを選択し、チームが言語モデルとユーザー体験に集中できるようにしました。この決定は、最も有能な組織でさえ専門インフラストラクチャプラットフォームの価値を認識していることを示しています。
-
より広範な意味:* OpenAIが音声インフラストラクチャをアウトソースするのであれば、ほとんどの組織もそうすべきです。唯一の例外は、極端な規模(年間数十億分)または社内投資を正当化する独自の要件を持つ企業です。
-
音声スタックにおける新たな機会:* インフラストラクチャが統合されるにつれて、より高いレイヤーで新しい機会が生まれます:音声AIアプリケーション、ドメイン固有の音声モデル、音声分析、音声セキュリティ。組織は、インフラストラクチャからこれらのより高価値な機会にエンジニアリングリソースをリダイレクトすべきです。
-
次の地平線:* 5年後、音声インフラストラクチャは今日のクラウドコンピューティングと同じくらいコモディティ化されるでしょう。社内構築した組織はリソースを無駄にしたことになります。プラットフォームを早期に採用した組織は競争優位性を持つでしょう。彼らはそれらのリソースを差別化されたアプリケーションに投資したことになります。
移行パス:独自の音声インフラストラクチャからプラットフォームベースへ
組織が現在独自の音声インフラストラクチャを運用している場合は、12か月以内にLiveKitまたは同等のプラットフォームへの移行を計画してください。これはオプションではありません。戦略的必須事項です。
-
フェーズ1:パイロットと検証(1〜2か月目)* 重要でない音声機能から始めて、パフォーマンスを検証します。4〜6週間並行システムを実行し、レイテンシ、品質、コストを比較します。成功を測定する基準:現在のシステムと同等またはそれを超えるレイテンシパーセンタイル、3.8以上のMOSスコア、現在の支出の10%以内の分単位コスト。
-
フェーズ2:統合とテスト(3〜4か月目)* LiveKitをアプリケーションスタックに統合します。監視とアラートを実装します。フェイルオーバーシナリオ、地理的ルーティング、コーデックネゴシエーションをテストします。予想されるピークトラフィックの2倍で負荷テストを実施します。
-
フェーズ3:段階的ロールアウト(5〜9か月目)* 本番トラフィックの10%をLiveKit経由でルーティングし始めます。2週間注意深く監視します。メトリクスが健全であれば、25%、次に50%、次に100%に増やします。各ステップには1〜2週間かかるはずです。
-
フェーズ4:廃止(10〜12か月目)* 独自のインフラストラクチャを廃止するのは
- 図9:音声インフラのベンダーロックインリスクと標準化への移行パス*

- 図14:音声インフラのリスク分類と軽減戦略*