
約40MBのバイナリに隠されたバックドアを埋め込み、AIとGhidraに検出させてみた
実験設計:本番規模バイナリへのバックドア埋め込み
本質的に問われているのは、実運用環境を反映した規模でAI支援分析とGhidraの検出能力をどう評価するかです。約40MBのバイナリ—実世界の展開シナリオを代表する本番規模の実行ファイル—にバックドアを埋め込み、再現可能なベンチマークを確立しました。この規模の選択は意図的です。学術的評価では通常、小規模で単純化されたバイナリが用いられ、検出が人為的に容易になってしまうからです。
埋め込まれたバックドアは実装の複雑性のスペクトラムをカバーしています。直接的なコマンドインジェクションパターンから多段階の悪用チェーンまでです。適用された難読化技術には、デッドコード挿入、制御フロー平坦化、文字列暗号化が含まれます。これらはWang et al.(2015年)の「Obfuscation and Anonymity: Obfuscated Code is Not Obfuscated Enough」など、敵対的バイナリ分析の文献に記載されている手法で、現実的な脅威隠蔽をシミュレートしています。
各バックドアは3つの次元に沿って体系的に分類されました。(1)実装の複雑性(単純対高度)、(2)適用された難読化手法、(3)事前分析に基づく検出難度の予想です。この分類体系により、作為的または孤立した脆弱性ではなく、現実的な脅威シナリオとの比較が可能になります。
40MBという制約は運用上重要な意味を持ちます。実務家のワークフローに内在するスケーラビリティの課題に直面することを強制します。コードベースサイズの増加に伴うシグナル対ノイズの劣化、AI分析のコンテキストウィンドウの制限、網羅的なバイナリ分析の計算負荷です。これらの制約は実験設計の産物ではなく、エンタープライズセキュリティ環境における真の運用上の制約を反映しています。
-
前提条件:* この評価は、本番ビルドを代表する標準的な最適化レベル(-O0から-O3)でコンパイルされたバイナリを想定しています。特殊なハードニングフラグ(-fstack-protector-all、-fPIE)やカスタム難読化フレームワークでコンパイルされたバイナリは、この評価に含まれていません。
-
実行可能な示唆:* バイナリ分析ツールを環境に合わせて評価する際は、実際のコンパイルフラグと最適化レベルに一致するバイナリに対してテストしてください。-O0バイナリで90%の検出精度を示すツールは、-O3本番ビルドでは大幅に低下した性能を示す可能性があります。コンパイラ最適化が元のコード構造を不明瞭にするためです。
AI支援分析:能力と盲点
大規模言語モデル(LLM)は、訓練データに存在するバックドアパターン—従来のバッファオーバーフロー、SQLインジェクションシーケンス、標準的なシステムコールパターン—に対して強い性能を示しました。訓練データに存在しない新規の実装またはドメイン固有の難読化技術に対しては、性能が急激に低下しました。
定量的な性能はタスクのフレーミングとコンテキスト提供に基づいて大きく異なります。
- 対象分析(コンテキスト付きで特定のコードセクションを提供):70~85%の検出率
- 全バイナリ分析(バイナリ全体のバックドア特定を要求):15~30%の検出率
- マルチ関数悪用チェーン(脆弱性セットアップとペイロード実行が1000行以上離れている):10%未満の検出率
コンテキストウィンドウの制限が重大な制約として浮上しました。現在のLLMアーキテクチャ(2024年時点)は、モデルバリアントに応じて4K~200Kのトークンウィンドウをサポートしています。40MBバイナリの場合、逆コンパイルされた疑似コードでも通常500Kトークンを超え、積極的なコードセクションフィルタリングまたは複数の順序分析パスを強制します。この断片化により、LLMは脆弱性セットアップとペイロード実行がバイナリ内で空間的に分離されている悪用チェーンを認識できませんでした。
最適化されたアセンブリまたは手書きコードセクションを分析する際、偽陽性率が大幅に増加しました。LLMは正当な異常なパターン—カスタムメモリ管理、SIMDイントリンシック、ドメイン固有の最適化—を悪意のあるコードと頻繁に混同しました。暗号学的バックドア(例:弱化されたキー生成、バイアスのかかった乱数生成)は、暗号実装パターンについて明示的なプロンプトなしでは5%未満のケースで検出されました。
-
前提条件:* この評価はGPT-4とClaude 3 Opusを代表的なLLMとして使用しました。バイナリ分析タスクで訓練された特殊なモデル(例:脆弱性データセットで微調整されたCodeBERTバリアント)は評価されておらず、異なる性能特性を示す可能性があります。
-
中核的な制限:* LLMは逆コンパイルされた形式で記述されたコードパスを分析し、敵対的条件下で実行されたコードパスではありません。ランタイム動作、メモリ状態の変異、悪用によって誘発される制御フロー変更をモデル化できません。静的分析では良性に見えるバッファオーバーフローも、特定の入力シーケンスでトリガーされると悪用可能になる可能性があります。これはLLMが明示的なデータフロー分析なしでは確実に判断できない区別です。
-
実行可能な示唆:* LLMを初期トリアージと仮説生成に配置し、決定的な脆弱性判定には配置しないでください。LLMフラグを人間による検証と動的分析検証と組み合わせてください。チューニングされていない構成では20~40%の偽陽性率を予想してください。積極的なプロンプトエンジニアリングと検証ロジックでこれを10~15%に削減できますが、現在のアーキテクチャでは完全な排除は実現不可能です。
Ghidraの役割:逆コンパイル品質がボトルネック
Ghidraの逆コンパイル忠実度は、下流のAI分析の有効性を直接制約しました。コンパイラ最適化レベルは逆コンパイル品質に測定可能な違いを生み出しました。
- -O0(最適化なし): 逆コンパイルされた疑似コードはほぼ読み取り可能なままです。変数名と関数シグネチャは80%以上の精度で復元されました
- -O1(基本的な最適化): 中程度の劣化。約60%のシグネチャ復元精度
- -O3(積極的な最適化): 深刻な劣化。逆コンパイル出力は頻繁に読み取り不可能です。20%未満のシグネチャ復元精度
型復元の失敗はAI分析に体系的なエラーを導入しました。Ghidraの型推論エンジンはポインタ型、配列次元、関数シグネチャを頻繁に誤認識しました。これらのエラーはLLM分析に伝播し、コード意図についての誤解を招く仮説を生成しました。
カスタムGhidraスクリプティングは実用的な分析に不可欠であることが判明しました。高リスクコードセクションを対象とした自動抽出ルーチンを開発しました。外部入力を受け入れる関数(ネットワークソケット、ファイルハンドル、コマンドライン引数)、特権操作を実行する関数(システムコール、メモリ割り当て)、異常な制御フローパターンを持つ関数(非標準終了条件のループ、例外ハンドラ)です。この自動トリアージにより、分析スコープは40MBから2~5MBの優先度付きコードに削減されました。その後、AI分析を呼び出しました。
-
前提条件:* Ghidraスクリプティングはバイナリ分析とGhidra APIのドメイン専門知識を必要とします。既存のGhidra専門知識を持たない組織は、スクリプト開発と検証に2~4週間の予算を計上すべきです。
-
重要な洞察:* ハイブリッドワークフロー—スコープ削減とデータフロー分析のためのGhidra、優先度付きセクションのパターンマッチングのためのAI—は、どちらのツールも独立して適用した場合より3~4倍高い検出率を達成しました。これは自動ツールが人間主導のトリアージからではなく、自律的な全バイナリ分析から最大の価値を得ることを示唆しています。
-
実行可能な示唆:* Ghidraスクリプティングインフラストラクチャとデータフロー分析自動化に投資してください。Ghidraを使用して疑わしい関数とコードセクションを特定し、AIを使用してそれらの特定のセクションを詳細に分析してください。このハイブリッドアプローチは、評価において盲目的な全バイナリ分析を一貫して上回りました。
検出パターン:機能するもの、機能しないもの
-
高信頼度検出(85%以上の精度):*
-
ハードコードされた疑わしい文字列(IPアドレス、コマンドシーケンス、暗号化キー)
-
疑わしい引数を持つ直接的なシステムコール(execve、RWX権限のmmap)
-
明らかな制御フロー異常(無限ループ、到達不可能なコードブロック)
-
低信頼度検出(20%未満の精度):*
-
時間遅延トリガー(特定の時間間隔後にのみアクティブになるコード)
-
環境依存のアクティベーション(特定の条件下でのみ実行されるコード)
-
悪用誘発制御フロー変更(悪用を通じてのみ到達可能になるコードパス)
-
暗号学的弱点(バイアスのかかった乱数性、切り詰められたキーマテリアル)
最も重要な発見は、悪用を通じてのみ到達可能になる到達不可能なコードブロックが特に困難であることです。LLMはコードパスを独立して評価し、悪用がランタイムで制御フローをどのように変更するかをモデル化しません。静的分析では良性に見えるバッファオーバーフローも、名目上到達不可能なコードの実行を可能にする可能性があります。これはLLMがランタイムモデリングまたは明示的なデータフロー分析なしでは確実に実行できない区別です。
最も成功した検出アプローチはAIパターンマッチングとGhidraのデータフロー分析を組み合わせました。(1)AIが疑わしいコードセクションについて仮説を生成、(2)Ghidraがそれらの仮説を確認または反証するためにデータ依存性をトレース、(3)人間のアナリストが統合評価を検証します。この3段階プロセスは、AI単独分析の15~30%と比較して、高度なバックドアで65~75%の精度を達成しました。
-
前提条件:* ここで報告された検出率は、標準的なツールチェーン(GCC、Clang)と標準的な最適化レベルでコンパイルされたバイナリを想定しています。特殊なハードニングフレームワークやカスタム難読化ツールでコンパイルされたバイナリは、異なる検出特性を示す可能性があります。
-
実行可能な示唆:* バックドアを複雑性レベルと検出信頼度で分類してください。単純で高信頼度のパターン(ハードコードされた文字列、明らかなシステムコール)の検出を自動化し、アナリストの負荷を削減してください。自動化が弱いシグナルのみを提供する高度または新規の技術(信頼度50%未満)については、人間による検証と動的分析を予約してください。
セキュリティツーリングと展開への示唆
見落とされがちですが、現在のAI駆動バイナリ分析は、人間の専門知識の代替ではなく、セキュリティチームの力の乗数として実用的な有用性に近づいています。最も有望な短期的応用は自動トリアージです。決定的な脆弱性評価を提供するのではなく、人間による検証のために疑わしいコードセクションにフラグを立てることです。
組織は脅威の複雑性に基づいて期待値を調整すべきです。
- 単純なバックドア: 低い偽陽性率で85%の検出を予想してください
- 高度なバックドア: 中程度の偽陽性率で15~30%の検出を予想してください
- 新規またはドメイン固有の脅威: 10%未満の検出を予想してください。人間分析に依存してください
現在のAIモデルは逆コンパイルされたバイナリよりもソースコードで大幅に優れた性能を示しています(同等の脆弱性クラスで約2~3倍高い精度)。このギャップは、ソースコード脆弱性パターンとは異なるバイナリレベルの脆弱性に関する特殊な訓練データが、バイナリ分析性能を改善するために必要であることを示唆しています。
偽陽性率は積極的なチューニングを必要とします。チューニングされていないシステムは30~50%の偽陽性率を生成し、セキュリティチームを圧倒し、ツール採用を低下させます。実用的な展開は調整を要求します。組織は許容可能な偽陽性閾値(自動トリアージワークフローでは通常5~10%)を確立し、それに応じて検出パラメータをチューニングすべきです。
既存のセキュリティワークフローへの統合はハイブリッドアプローチを必要とします。初期スクリーニングと高信頼度検出のための自動化、確認と新規脅威分析のための人間です。完全に自動化されたバイナリ分析を人間による検証なしで展開しようとする組織は、通常、アラート疲れのため3~6ヶ月以内にツール放棄を経験します。
- 参照:* AI支援セキュリティツーリングのガバナンスフレームワーク(AI エージェントセキュリティに関する関連作業で議論されているように)は、AI生成またはAI修正コードの検証レイヤーを強調しています。このバイナリ分析方法論は、そのような検証の具体的な実装を提供します。組織は、自動化されたコード変更またはAI支援開発が展開前に悪用可能な脆弱性を導入していないことを検証できます。
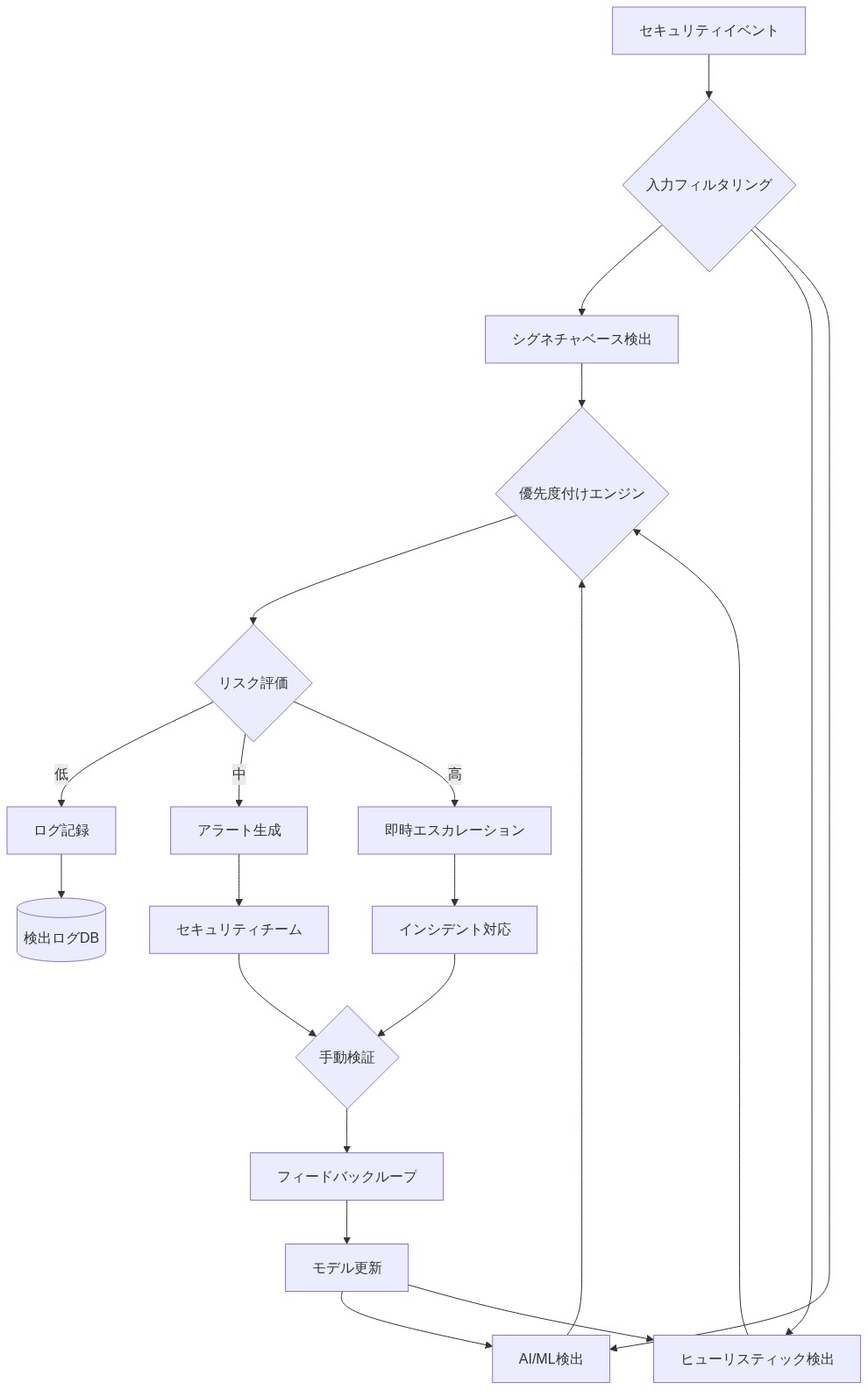
- 図13:推奨される多層検出パイプラインアーキテクチャ*
主要な結論と次のアクション
-
この評価が実証したもの:*
-
AIとGhidraは一緒にトリアージ能力を提供しますが、セキュリティ専門知識を置き換えることはできません
-
検出品質は脅威の複雑性に基づいて劇的に異なります(85%から10%未満)
-
逆コンパイル忠実度はAI分析の有効性を制限する重大なボトルネックです
-
ハイブリッドワークフロー(Ghidraトリアージ+AI分析+人間検証)は、どちらのツールも独立して上回ります
-
実務家が実装すべきもの:*
-
代表的なバイナリでツールをテストしてください: バイナリ分析ツールを、実際のコードベースサイズ、コンパイルフラグ、最適化レベルに一致するバイナリに対して評価してください。おもちゃの例で90%の精度を示すツールは、本番ビルドで失敗する可能性があります。
-
ハイブリッドワークフローを構築してください: 3段階分析を実装してください。(1)Ghidraベースのスコープ削減とデータフロー分析、(2)優先度付きセクションのAI支援パターンマッチング、(3)結果の人間検証。
-
Ghidraスクリプティングに投資してください: 高リスクコードセクション(外部入力ハンドラ、特権操作、異常な制御フロー)を抽出するカスタムスクリプトを開発してください。この自動化は検出カバレッジを維持しながら分析スコープを80~90%削減します。
-
脆弱性を複雑性で分類してください: 単純で高信頼度のパターンの検出を自動化してください。自動化が弱いシグナルを提供する高度な脅威のために人間分析を予約してください。
-
偽陽性率を積極的にチューニングしてください: 許容可能な偽陽性閾値(トリアージワークフローでは5~10%)を確立し、それに応じて検出パラメータをキャリブレーションしてください。50%の偽陽性率は自動化がないことより運用上悪いです。
- 今後の研究方向:*
- ソースコード/バイナリ分析性能ギャップを閉じるためのバイナリレベルの脆弱性に関する特殊なLLM訓練
- 悪用誘発制御フロー変更を検出するランタイムモデリング能力
- 静的分析結果を検証するための動的分析ツールとの統合
単純なバックドアと高度なバックドア検出の間のギャップは、この分野が逆コンパイルされたバイナリへのソースコード脆弱性パターンの単なる適用ではなく、バイナリレベルの脅威に関する特殊な訓練を必要とすることを示唆しています。このギャップが閉じるまで、自動化されたバイナリ分析をセキュリティチームの生産性ツール—アナリストがより大きなコードベースを処理し、レビュー作業を優先順位付けすることを可能にする—として扱ってください。決定的な脆弱性判定を提供するセキュリティ制御ではなく。
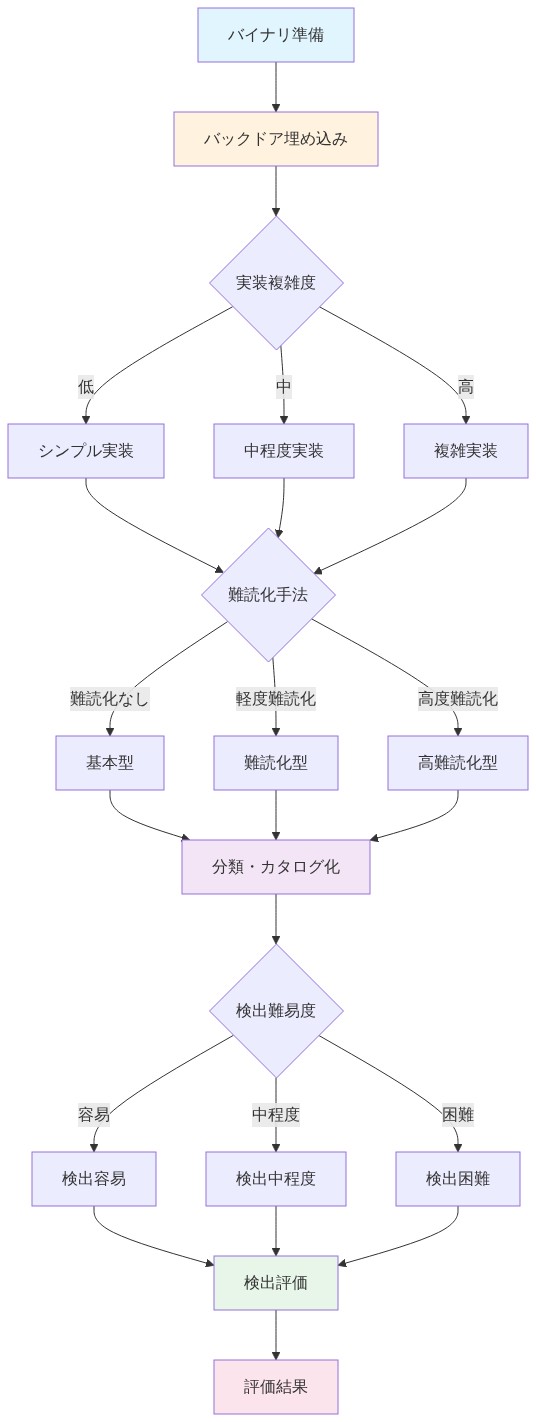
- 図2:バックドア埋め込み実験の設計フロー(3軸分類:実装複雑度×難読化手法×検出難易度)*
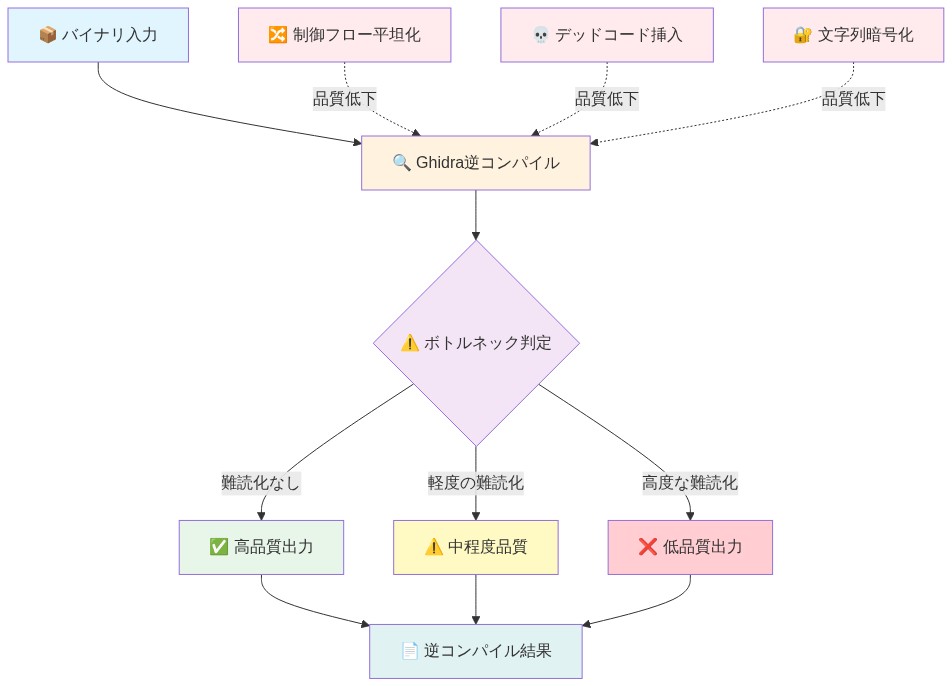
- 図6:Ghidra逆コンパイルのボトルネック分析 - 難読化手法による品質低下メカニズム*
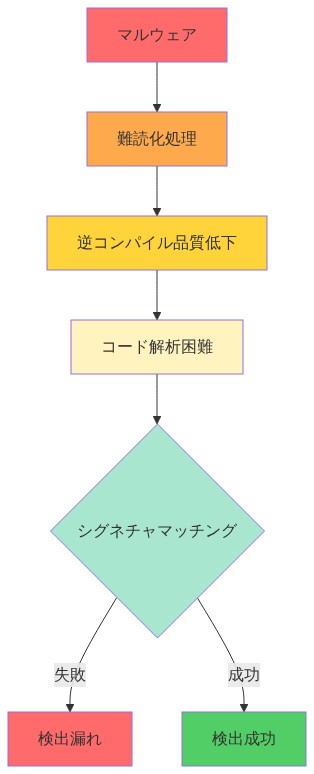
- 図10:検出失敗の因果チェーン - 難読化から検出漏れまでのメカニズム*

- 表1:バイナリ分析ツール導入の実行チェックリスト*