
量子化を実用的なデプロイメントの手段として
量子化は、重みパラメータの数値精度を元の表現—通常は32ビット浮動小数点(FP32)または16ビット(FP16)—から、8ビット整数(INT8)、4ビット、または2ビット表現などのより低精度のフォーマットに削減するモデル圧縮技術です。理論的基盤は、ニューラルネットワークの重みが大きな冗長性を示すという経験的観察に基づいています。多くのパラメータは、モデル能力の比例的な損失なしに、削減された精度で表現できます(Gholami et al., 2021)。リソースに制約のあるハードウェア上でLlama-3.1-8B-Instructをデプロイする実務者にとって、量子化は、許容可能な出力品質を維持しながら、メモリ要件と計算コストを削減する実用的なメカニズムとして機能します。
メモリと計算のトレードオフ
精度とメモリ消費量の間の定量的関係は決定論的です。FP32フォーマットで保存された量子化されていないLlama-3.1-8Bモデルは、約32GBのVRAMを必要とします(80億パラメータ × パラメータあたり4バイト)。精度をINT8に削減すると、この要件は8GBに半減します。4ビット量子化は、特定の量子化スキームと補助テンソル(例:アテンションバッファ)も量子化されるかどうかに応じて、約2〜3GBにさらに削減します。この関係は単なる理論ではなく、ハードウェアの実現可能性を直接決定します。
具体的な制約:16GBのシステムRAMを搭載したラップトップでは、量子化されていない8Bモデルを同時にロードし、オペレーティングシステムを実行し、推論バッファのためのヘッドルームを維持することはできません。llama.cppを介して4ビット量子化を適用すると、同じモデルがこのハードウェアの上限内で実行可能になります。計算上の利点は二次的ですが測定可能です:ビット幅の削減された演算は、メモリ帯域幅の要件を減少させ、算術演算を簡素化し、通常、ハードウェアとバッチサイズに応じて、トークンあたりのレイテンシを15〜40%削減します(Frantar et al., 2022)。
- 量子化選択の前提条件:* 任意の量子化スキームを評価する前に、デプロイメントハードウェアの制約を厳格な境界として確立してください。利用可能なVRAM(GPUデプロイメントの場合)またはシステムRAM(CPUデプロイメントの場合)を測定し、許容可能なレイテンシのしきい値(例:インタラクティブな使用のためのトークンあたり<100ms)を決定し、これらを交渉不可能な制約として使用します。ハードウェアの上限が8GBの場合、4ビットまたは3ビット量子化は必須です。24GBある場合は、より高精度のフォーマットを使用でき、メモリの節約よりも出力品質を優先すべきです。量子化の選択が抽象的な好みではなくデプロイメントの現実に固定されるように、このベースラインを明示的に文書化してください。
一貫性のない評価とllama.cppの状況
llama.cppは、GGML、GGUF、Q2_K、Q3_K、Q4_K、Q5_K、Q6_K、Q8_0などの豊富な量子化フォーマットのメニューを提供しており、それぞれモデルサイズ、推論速度、出力品質の間で異なるトレードオフがあります。問題は、これらのフォーマットが同一の条件下で正面から評価されることがほとんどないことです。あるソースからのQ4_Kと別のソースからのQ5_Kを比較するユーザーは、量子化方法の違いを測定プロトコル、ハードウェア、またはプロンプト構成の違いと混同する可能性があります。
この一貫性のなさは意思決定の麻痺を生み出します。「Q4_KとQ5_Kのどちらを使用すべきか?」と尋ねる実務者は、公開されたベンチマークが1つのフォーマットのみを測定したり、異なるテストセットを使用したり、直接比較できないメトリック(パープレキシティ、レイテンシ、BLEUスコア)を報告したりすることが多いため、信頼できる答えを見つけることができません。チームは、正当な理由なく最も人気のある選択肢—多くの場合Q4_K—にデフォルトで従うか、本番のユースケースを反映しない可能性のあるアドホックなテストの実行に時間を浪費します。

- 図4:ハードウェア制約に基づく量子化フォーマット選択フロー*
具体例
Llama-3.1-8B-Instructを事実に基づく質問応答タスクで実行するとします。モデルをQ4_Kに量子化し、テストセットで精度を測定し、クエリあたり45msのレイテンシで87%の正解率を記録します。次にQ5_Kを試し、52msのレイテンシで89%の精度を観察します。2%の精度向上と7msのレイテンシコストは明確に見えますが、これらのメトリックがどのように計算されたか、テストセットが代表的であるか、または特定のドメインにおける量子化ノイズに対するモデルの感度がどの程度かを知らなければ、比較は浅いままです。
- 実行可能な解決策:* 量子化フォーマットを選択する前に、標準化された評価プロトコルを確立してください。代表的なテストセット(例:実際のユースケースにまたがる100のプロンプト)を定義し、すべての候補フォーマットにわたって精度、レイテンシ、メモリ使用量を一貫して測定し、測定条件(ハードウェア、バッチサイズ、温度、サンプリング方法)を記録します。この規律により、曖昧な決定がデータ駆動型の決定に変わります。将来のチームメンバーが選択だけでなく決定の根拠を継承できるように、これらの結果を内部で文書化してください。
実装と運用パターン
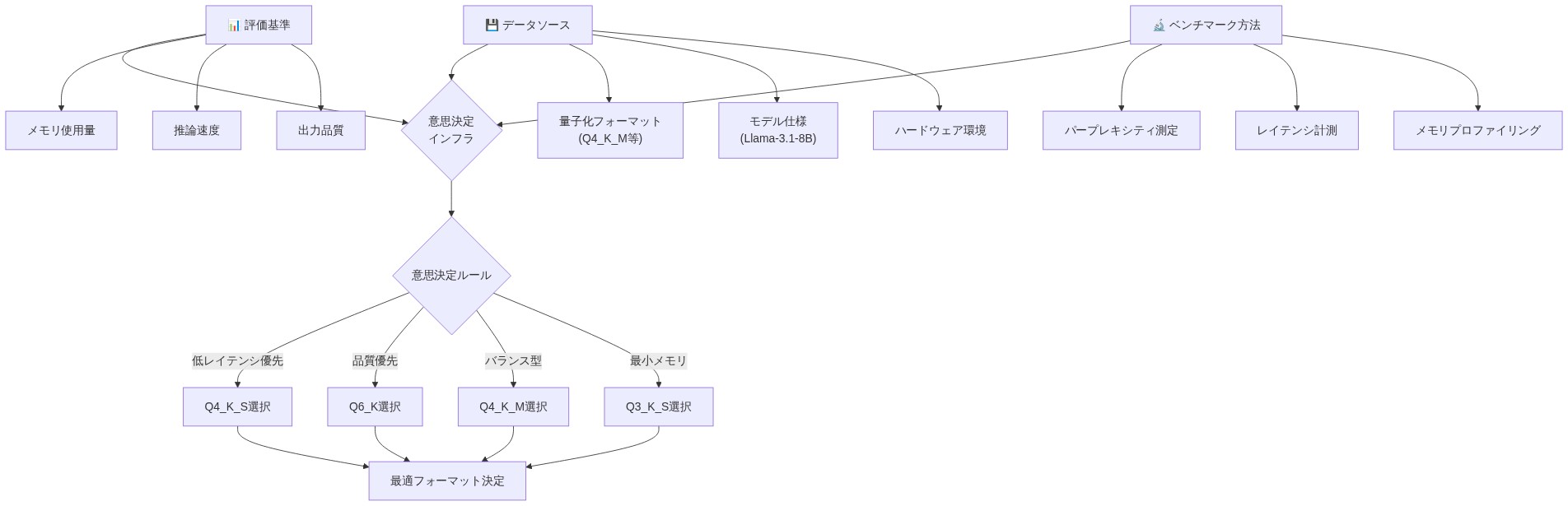
- 図12:量子化フォーマット選択の意思決定インフラストラクチャ(出典:Understanding Which Quantization Should I Use? A Unified Evaluation of llama.cpp Quantization on Llama-3.1-8B-Instruct)*
静的量子化と動的量子化
llama.cppにおける量子化は、モデルライフサイクルの2つの異なる時点で適用できます:モデルロード時(動的量子化)またはデプロイメント前(静的量子化)。静的量子化—実際には主流のアプローチ—は、完全精度モデルをダウンロードし、llama.cppの変換ユーティリティを使用してオフラインで量子化を適用してGGUFフォーマットのアーティファクトを生成し、推論時にその事前量子化されたファイルをロードすることを含みます。このアーキテクチャは、量子化の計算コスト(一度だけ、オフラインで発生)を推論パスから切り離し、それによってレイテンシの変動を減らし、決定論的なパフォーマンス特性を可能にします。対照的に、動的量子化は各モデルロード時に量子化のオーバーヘッドを発生させ、可変的な起動コストをもたらします。これは通常、量子化パラメータがまだ確定していない探索的または開発ワークフロー用に予約されています。
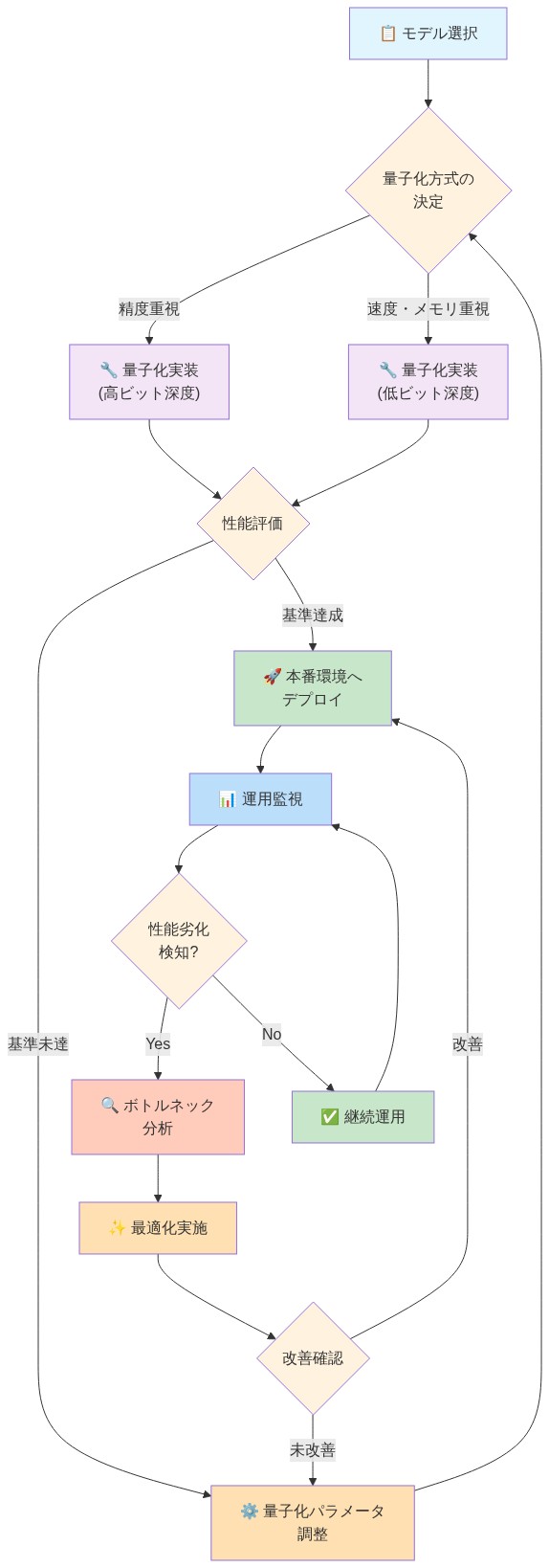
- 図6:量子化モデル実装・運用パターンのライフサイクル*
量子化の粒度:チャネルごと vs テンソルごと vs ハイブリッド
量子化の粒度は、スケールファクターとゼロポイントが計算および保存される範囲を決定します。2つの主要な戦略が存在します:
-
*チャネルごとの量子化**は、重み行列の各出力チャネルに独立したスケールとゼロポイントパラメータを適用します。このアプローチは、チャネル固有の統計的特性を保持し、通常はより高い再構成忠実度をもたらしますが、チャネル数(トランスフォーマー層では4,096以上が多い)に比例してメタデータのオーバーヘッドが増加します。
-
*テンソルごとの量子化**は、重み行列全体にわたって単一のスケールファクターとゼロポイントを計算します。この戦略はメタデータのオーバーヘッドを最小化しますが、任意のチャネルの外れ値がすべてのチャネルの量子化範囲を圧縮するため、きめ細かい情報を犠牲にします。
llama.cppのK-quantファミリー(Q4_K、Q5_K、Q6_K、Q8_K)は、ハイブリッド戦略を実装しています:重み行列はブロックに分割され、ブロック内ではチャネルごとの量子化が適用され、ブロック間ではテンソルごとの量子化が適用されます。この設計は、再構成精度とメタデータのオーバーヘッドのバランスを取り、Llamaスケールモデルの本番デプロイメントの事実上の標準となっています(Galli, 2024; llama.cppドキュメント)。
パイロット評価プロトコル
構造化されたパイロットワークフローは、デプロイメントリスクを軽減します:
-
量子化: llama.cppの
quantizeユーティリティを使用してLlama-3.1-8B-InstructをQ4_K_M(バランスの取れたK-quantバリアント)に変換し、量子化パラメータと実時間を記録します。 -
ベースライン測定: 意図したユースケースにまたがる10〜20のプロンプトの代表的な評価セットを使用して、量子化されていないまたはより高精度の量子化されたバリアント(例:Q6_Kまたはfp16)で参照メトリックを確立します。
-
量子化推論: 同じプロンプトをQ4_K_Mバリアントで実行し、以下を測定します:
- レイテンシ: 最初のトークンまでの時間と1秒あたりのトークン数を、分散を考慮して実行全体で集計します。
- 精度: 出力のサブセットに対するタスク固有のメトリック(例:完全一致、BLEU、または人間による評価)。
- メモリフットプリント: GPU/CPUメモリの最大消費量。
-
しきい値評価: 量子化された結果を事前定義された受け入れ基準(例:≤5%の精度低下、≤100msのレイテンシ増加、≤10%のメモリ削減)と比較します。しきい値が満たされた場合、段階的な本番デプロイメントに進みます。そうでない場合は、反復します:Q5_K_MまたはQ6_Kをテストするか、量子化が実際のボトルネックに対処しているかどうかを再検討します。
この段階的なアプローチは、時期尚早な最適化を回避し、特定のデプロイメントコンテキストにおける量子化の有用性に対する経験的証拠を提供します。
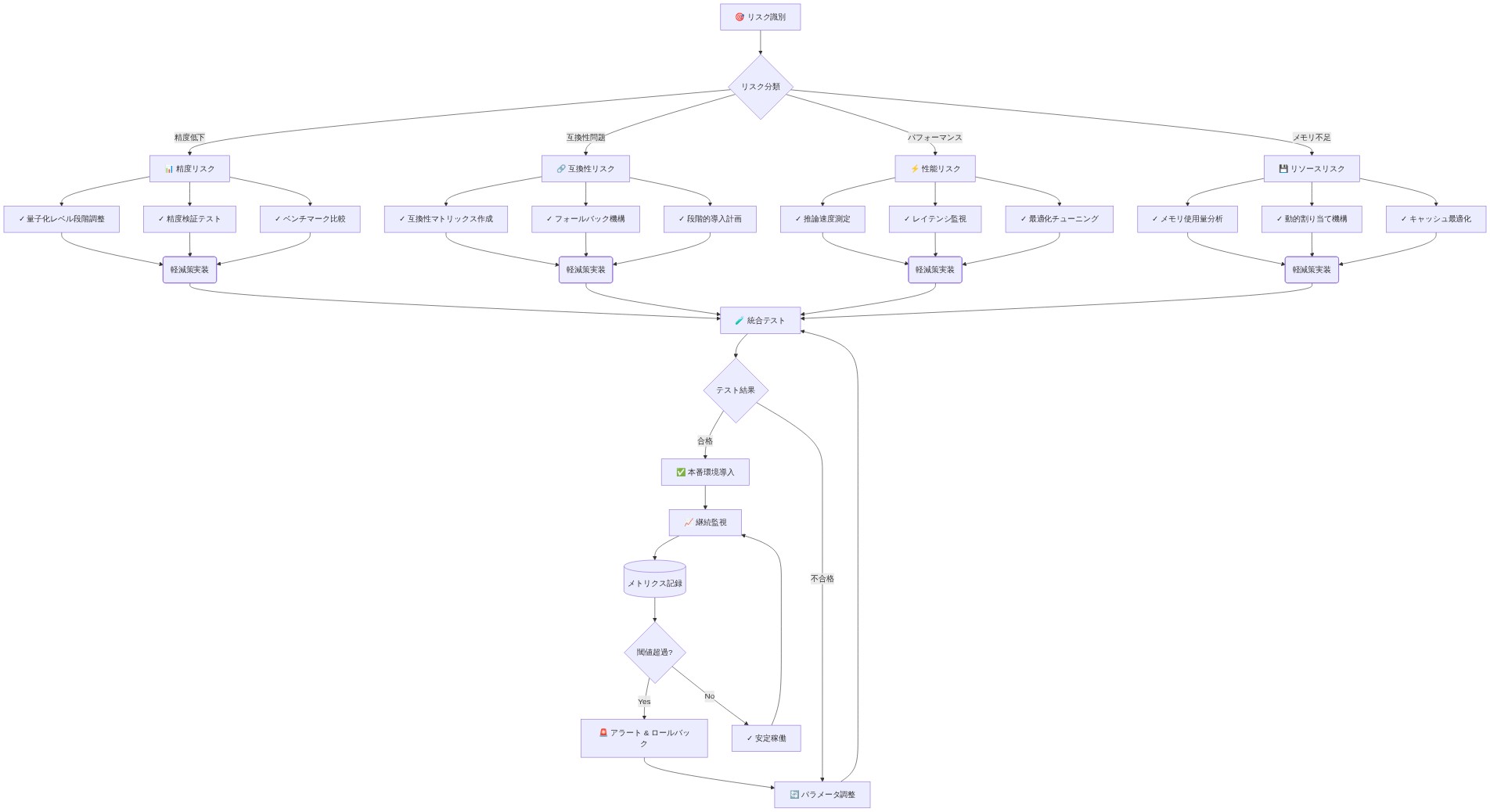
- 図9:量子化リスク軽減戦略の実装フロー*
アーティファクトのバージョン管理と再現性
量子化されたモデルは、複数の上流パラメータに依存する派生アーティファクトです:ソースモデルのバージョン、量子化方法と粒度、llama.cppのバージョン、および量子化日。再現性を確保し、ロールバックを可能にするために:
-
量子化マニフェストを維持し、以下を記録します:
- ソースモデル識別子(例:
meta-llama/Llama-3.1-8B-Instruct、コミットハッシュまたはリリースタグ) - 量子化方法(例:
Q4_K_M) - llama.cppのバージョンとコミットハッシュ
- 量子化タイムスタンプ(ISO 8601形式)
- 出力GGUFファイルハッシュ(SHA-256)
- 量子化コマンドとパラメータ(再現性のため)
- ソースモデル識別子(例:
-
GGUFアーティファクトをバージョン管理し、モデルレジストリ(例:Hugging Face Model Hub、内部アーティファクトストア)にマニフェストと共に保存し、以前の量子化されたバリアントの取得を可能にします。
-
決定論的に再量子化します。ベースモデルまたはllama.cppを更新する際:同一の量子化パラメータを適用し、出力ファイルハッシュを以前のバージョンと比較します。相違は量子化動作の変化(例:llama.cppの更新による)を示し、本番デプロイメント前に調査が必要です。

- 図10:量子化導入による組織的変革ビジョン*
運用統合
量子化は、自動化されたバージョン管理されたステップとしてモデルパイプラインに統合されるべきです:
-
CI/CDを介して自動化: ベースモデルの更新時に量子化をトリガー(例:GitHub Actionsワークフローまたは同等のものを介して)して、一貫したパラメータ化を確保し、手動エラーを排除します。
-
本番環境で推論メトリックを監視: レイテンシ(p50、p95、p99)、精度(タスク固有のメトリック)、およびメモリ消費をログに記録します。許容範囲を超えるドリフト(例:>10%のレイテンシ増加または>2%の精度低下)に対してアラートを設定します。これは量子化の劣化または根本的なモデルの問題を示す可能性があります。
-
ロールバック手順を確立: 本番メトリックが低下した場合、定義されたSLA(例:<15分)内で以前の量子化されたバリアントまたは量子化されていないモデルに戻します。
これらのプラクティスは、量子化を一度限りの変換ではなく、推論パイプラインの管理されたコンポーネントとして扱い、量子化関連の問題の迅速な診断と修復を可能にします。
測定と次のアクション
効果的な量子化の意思決定には、3つの測定可能な次元にわたる実証的検証が必要です:モデルサイズ(MBまたはGB)、推論レイテンシ(トークンあたりのミリ秒)、およびタスク固有のパフォーマンス指標です。本セクションでは、測定プロトコルと意思決定フレームワークを形式化します。

- 表1:llama.cpp主要量子化フォーマット比較(Llama-3.1-8B-Instruct基準)*
モデルサイズの測定
モデルサイズは、確立すべき最も直接的な指標です。量子化されたモデルファイルは、GGUF形式(量子化された重みのための標準化されたコンテナ仕様)で配布されます。ファイルサイズは、ディスク上のメモリフットプリントを直接反映し、メタデータのわずかな差異を除いて、ランタイムメモリ消費量を近似します。
-
測定手順:* 量子化されたGGUFファイルを取得し、標準のファイルシステムユーティリティを使用してそのバイトサイズを記録します。形式間の比較のためにギガバイトに変換します。
-
実証的参照ポイント*(llama.cpp上のLlama-3.1-8B-Instruct):
-
Q4_K_M: 5.0–5.2 GB
-
Q5_K_M: 6.2–6.5 GB
-
Q8_0: 8.0–8.2 GB
-
FP16(量子化なし): 16.0 GB
これらの値は、追加の最適化レイヤーなしの標準的なGGUFシリアライゼーションを前提としています。実際のファイルサイズは、量子化実装のバージョンとメタデータのオーバーヘッドに応じて±2%変動する可能性があります。
- 前提条件:* この測定は、量子化されたモデルが完全で破損していないことを前提としています。外部リポジトリからモデルを取得する場合は、チェックサム(SHA-256)を使用してファイルの整合性を検証してください。
レイテンシ測定プロトコル
レイテンシ測定は、ハードウェア構成、システム状態、およびプロンプト特性に依存するため、サイズ測定よりも大幅に複雑です。2つの異なるレイテンシを個別に測定する必要があります:
-
最初のトークンまでの時間(TTFT): プロンプト送信から最初の出力トークンの生成までの経過時間。この指標は、モデルの読み込み、プロンプト処理、および初期フォワードパスのオーバーヘッドを捉えます。
-
トークンあたりの時間(TPT): 最初のトークンの後に各後続トークンを生成するための平均経過時間。この指標は、定常状態の推論スループットを反映し、初期化オーバーヘッドに対する感度が低くなります。
-
測定の前提条件:*
-
一貫した熱状態と電力状態を持つ専用測定ハードウェア(同時実行ワークロードを避ける)
-
統計的妥当性を確立するために、n ≥ 50の独立したプロンプト-レスポンスペアの最小サンプルサイズ
-
プロンプト処理の分散から量子化効果を分離するための制御されたプロンプト長(例:32–128トークン)
-
すべてのテスト実行にわたる一貫した出力長(例:128生成トークン)
-
推奨手順:*
llama.cppの組み込みベンチマークユーティリティを使用します:
./main -m model.gguf -p "prompt" -n 128 --benchmarkまたは、トークン生成ループ周辺のタイミング計測を介してカスタム測定を実装します。量子化形式によって異なるI/Oおよびメモリアクセスパターンを考慮するために、ウォールクロック時間(CPUサイクルではない)を記録します。
-
統計報告:* TTFTとTPTの両方について、算術平均と標準偏差(または95パーセンタイル)の両方を報告します。システムノイズ、キャッシュ効果、およびサーマルスロットリングにより、単一点測定は信頼できません。信頼区間を確立するには、最低50サンプルが必要です。本番環境の意思決定には100以上のサンプルが望ましいです。
-
仮定:* このプロトコルは、単一のGPUまたはCPUコア上でのシングルスレッド推論を前提としています。マルチスレッドまたは分散推論は追加の分散を導入し、別の測定プロトコルが必要です。
タスク固有のパフォーマンス測定
一般的なパープレキシティまたはベンチマークスコアは、ドメイン固有のタスクでのパフォーマンスと相関しないことがよくあります。測定は、実際のユースケースに基づいて行う必要があります。
-
アプリケーションタイプ別の測定フレームワーク:*
-
会話型AI / チャットボット:*
-
固定されたユーザーインテントのセット(例:「フライトを予約する」、「事実に関する質問に答える」)でタスク完了率を測定
-
人間の評価者によるレスポンスの一貫性を測定(評価者間一致度≥ 0.70を推奨)
-
ユーザー認識までのレイテンシを測定(ユーザー入力から最初の可視トークンまでの時間、通常、許容可能なUXには<500 ms)
-
コード生成:*
-
ホールドアウトテストスイート(例:HumanEval、MBPP)での合格率を測定
-
生成されたコードのコンパイル成功率を測定
-
ユニットテスト実行による機能的正確性を測定
-
要約:*
-
参照要約に対するROUGE-1、ROUGE-2、ROUGE-Lスコアを測定
-
含意スコアリングまたは人間評価による事実の一貫性を測定
-
モード崩壊を検出するための要約長の分布を測定
-
情報検索 / 検索:*
-
ランク付けされた結果セットでの平均逆順位(MRR)または正規化割引累積利得(NDCG)を測定
-
固定カットオフ値(k = 5、10、20)でのprecision@kを測定
-
重要な仮定:* 測定データセットは、本番環境のクエリを代表し、パフォーマンスの低下を検出するのに十分な大きさ(n ≥ 100サンプル)でなければなりません。分散が高い場合、集計指標の2%の低下は統計的に有意ではない可能性があります。逆に、指標が安全性に重要である場合(例:医療コンテキストでの事実の正確性)、1%の低下は許容できない可能性があります。
測定ワークフローと意思決定フレームワーク
-
ステップ1:ベースラインを確立する。* ターゲットハードウェアとタスクで量子化されていないモデル(FP16またはネイティブ精度)を測定します。このベースラインは、パフォーマンスの上限を定義し、許容可能な劣化の参照ポイントを提供します。
-
ステップ2:測定マトリックスを作成する。* 次の列を持つテーブルを構築します:
-
量子化形式(例:Q4_K_M、Q5_K_M、Q8_0)
-
モデルサイズ(GB)
-
TTFT(ms、平均±SD)
-
TPT(ms、平均±SD)
-
タスク固有の指標(例:精度%、ROUGEスコア、合格率)
-
ハードウェア構成(GPUモデル、CPU、RAM、バッチサイズ)
-
測定日
-
測定マトリックスの例*(NVIDIA RTX 4090上のLlama-3.1-8B-Instruct、シングルスレッド推論、128トークン生成):
| 形式 | サイズ(GB) | TTFT(ms) | TPT(ms) | 精度(%) | 備考 |
|---|---|---|---|---|---|
| FP16 | 16.0 | 95 ± 8 | 22 ± 2 | 100.0 | ベースライン;コンシューマGPUでメモリ制約 |
| Q8_0 | 8.0 | 98 ± 7 | 23 ± 2 | 99.8 | 最小限の劣化;12GB VRAMに収まる |
| Q5_K_M | 6.2 | 105 ± 9 | 25 ± 3 | 99.2 | 許容可能なトレードオフ |
| Q4_K_M | 5.0 | 115 ± 10 | 28 ± 3 | 97.5 | 大幅な速度ペナルティ;品質は許容可能 |
| Q3_K_M | 3.5 | 135 ± 12 | 35 ± 4 | 94.2 | インタラクティブ使用には許容できないレイテンシ |
-
ステップ3:パレートフロンティアを特定する。* 量子化形式は、代替形式が3番目の指標を劣化させることなく2つ以上の指標を同時に改善しない場合、パレートフロンティア上にあります。上記の例では、Q8_0、Q5_K_M、およびQ4_K_Mがフロンティア上にあります。Q3_K_MはQ4_K_Mに支配されています(最小限のサイズ削減のためにレイテンシと精度が悪化)。
-
ステップ4:ドメイン制約を適用する。* ハード制約によってパレートフロンティアをフィルタリングします:
-
メモリ制約: モデルは利用可能なVRAMに収まる必要があります。VRAM < 8 GBの場合、FP16とQ8_0を除外します。
-
レイテンシ制約: TTFT + TPT × expected_output_lengthは、ユーザー向けSLAを満たす必要があります。SLAが<500 msの総レイテンシを要求し、出力が100トークンの場合、TPTは<4 msでなければなりません。
-
品質制約: タスク固有の指標は最小しきい値を超える必要があります。精度が97%を下回ることができない場合、Q3_K_MとQ4_K_Mを除外します。
-
ステップ5:形式を選択する。* すべてのハード制約を満たした上で、主要な目的(通常、サイズ、レイテンシ、品質の重み付けされた組み合わせ)を最適化する形式を選択します。
測定頻度と反復
この測定演習は以下の場合に実施する必要があります:
- 初期デプロイメント前: 候補形式とハードウェア構成にわたる包括的な測定に2〜4時間を割り当てます。
- ハードウェア変更後: GPU、CPU、またはRAMがアップグレードされた場合、レイテンシとメモリフットプリントを再測定します(サイズ測定はハードウェアに不変)。
- ベースモデル更新後: 基礎となるモデル(例:Llama-3.1-8BからLlama-3.2-8B)が更新された場合、能力のシフトを検出するためにタスク固有のパフォーマンスを再測定します。
- 四半期または半年ごと: 定期的な再測定は、システムドリフト、熱劣化、またはソフトウェア更新によるパフォーマンス低下を検出します。
ドキュメンテーションと再現性
再現性を確保するために、測定と一緒に以下のメタデータを記録します:
- llama.cppのバージョンとビルドフラグ(例:CUDA計算能力、OpenBLAS構成)
- ハードウェア仕様(GPUモデル、ドライババージョン;CPUモデル、コア数;RAM容量と速度)
- オペレーティングシステムとカーネルバージョン
- 量子化ツールとバージョン(例:llama.cpp quantize、ollama)
- 測定日時
- 周囲温度(熱に敏感な環境の場合)
このドキュメンテーションにより、将来の検証と時間およびシステム間の比較が可能になります。
リスクと緩和戦略
量子化は、実務者がデプロイメント前に体系的に特定、定量化、および緩和しなければならない測定可能なリスクを導入します。
-
*情報損失による品質劣化**は、主要な技術的リスクを表します。量子化は設計上、数値精度を低下させ、これによりモデルの重みとアクティベーションにおける表現能力が必然的に破棄されます。能力損失の深刻度は、タスクに依存し、モデル層全体で不均一です。例えば、Llama-3.1-8Bの低ビット量子化(2〜3ビット)は、多段階算術、長コンテキスト推論、または意味的曖昧性解消などの細かい数値識別を必要とするタスクでパフォーマンスを低下させる可能性があります。これは、精度の低下がこれらの能力をエンコードする微妙な重み分布を保持できないためです。1
-
緩和アプローチ:* 一般的なベンチマークではなく、実際のユースケース分布を使用してタスク固有の品質ベースラインを確立します。量子化の前後で代表的なサンプルにわたってパフォーマンス劣化を定量的に測定します(例:完全一致精度、F1スコア、またはドメイン固有の指標)。重要なタスクが許容可能なしきい値を下回る場合、(a)それらのタスクに対してより高精度の量子化を使用する、(b)選択的量子化を採用する(重要でない層のみを量子化)、または(c)明示的な利害関係者の承認を得て制限を受け入れます。
-
*累積丸め誤差による推論の不安定性**は、非決定論的または異常な出力として現れる可能性があります。量子化は各算術演算で丸めを導入します。これらの誤差はフォワードパスを通じて累積し、特に小さな摂動がソフトマックス演算によって増幅される可能性があるアテンションメカニズムで顕著です。2 FP32精度で一貫した出力を生成するプロンプトが、Q3_Kでは、アテンション重み分布に影響を与える複合量子化ノイズにより、一貫性のない、またはトピックから外れたレスポンスを生成する可能性があります。
-
緩和アプローチ:* 少数の例をスポットチェックするのではなく、多様な入力分布(長さ、ドメイン、複雑さ)にわたって体系的なプロンプトレベルのテストを実施します。本番環境で推論異常の監視を確立します(例:低信頼スコアの出力にフラグを立てる、意味的ドリフトの検出、またはユーザー報告エラーの追跡)。量子化後に異常率が急上昇した場合、A/Bテストを実装して量子化形式を原因として分離し、その後、元に戻すか、層固有の量子化感度を調査します。
-
*フレームワーク依存性と再量子化の摩擦**は、llama.cppの独自のGGUF形式と量子化アルゴリズムへの依存から生じます。llama.cppの開発が停滞したり、重大なバグが発見されたり、推論インフラストラクチャが代替フレームワーク(例:vLLM、TensorRT、またはONNX Runtime)に移行する必要がある場合、再量子化が必要になりますが、簡単ではない可能性があります。量子化パラメータとアルゴリズムはフレームワーク間で標準化されておらず、切り替えコストが発生します。
-
緩和アプローチ:* 元の完全精度モデルの重みと包括的な量子化パラメータ(ビット幅、ブロックサイズ、キャリブレーションデータ、アルゴリズムバリアント)のバージョン管理されたアーティファクトを維持します。各アーティファクトに使用された正確なllama.cppバージョン、コミットハッシュ、および量子化コマンドを文書化します。これにより、フレームワークの移行が必要になった場合に再現可能な再量子化が可能になります。独自または文書化されていない量子化スキームを避けます。マルチフレームワークサポートまたはオープン仕様を持つ形式を優先します。
-
*ソフトウェアバージョン間のアルゴリズムドリフト**は、明示的な通知なしにモデルの動作を変更する可能性があります。llama.cppの量子化実装の更新(例:改善された逆量子化カーネル、アルゴリズムの改良、またはバグ修正)により、バージョン0.2.0で量子化されたQ4_Kモデルが、量子化された重み自体は変更されていないにもかかわらず、バージョン0.3.0でロードされたときに測定可能に異なる出力を生成する可能性があります。3
-
緩和アプローチ:* デプロイメント構成と依存関係管理でllama.cppバージョン(特定のコミットハッシュを含む)を固定します。新しいバージョンにアップグレードする前に、代表的な推論タスクのサブセットで回帰テストを実施します。バージョン間のパフォーマンス変化(レイテンシ、メモリ、出力の一貫性)を文書化し、ロールバック手順を維持します。重大な動作変更が観察された場合、アップグレードを延期するか、変更がユースケースに許容可能かどうかを調査します。
-
*競合する最適化目標**は、デプロイメント制約が複数の次元(品質、レイテンシ、メモリ、スループット)での同時改善を要求する場合に発生しますが、これらすべてを量子化だけで満たすことはできません。例えば、Q4_Kがレイテンシ要件を満たさず、Q3_Kが許容できない精度損失を生成する場合、量子化だけでは競合を解決できません。モデル蒸留、投機的デコーディング、またはアーキテクチャの変更などの代替アプローチが必要になる可能性がありますが、これらはllama.cppの範囲外です。
-
緩和アプローチ:* ハード制約を明示的に定義し、早期に目標を優先順位付けします(例:「精度≥ 95%、レイテンシ≤ 100ms、メモリ≤ 8GB」)。実証的測定を使用して、これらの制約に対して量子化形式をマッピングします。すべての制約を満たす量子化形式がない場合、意思決定を利害関係者にエスカレートし、アーキテクチャの代替案を評価します:パラメータ数を減らすためのモデル蒸留、品質を犠牲にせずにレイテンシを減らすための投機的デコーディング、または堅牢性を向上させるためのアンサンブルアプローチ。選択したアプローチを正当化するために、制約満足度分析を文書化します。
-
実行可能な統合:* 量子化を、コスト削減戦術ではなく、構造化されたリスク意思決定プロセスとして扱います。タスク固有の指標を使用してリスクと利益の両方を定量化します(例:「Q3_K は評価セットで5.2%の精度損失を引き起こします。モデルサイズを62%削減し、平均レイテンシを38%削減します」)。候補量子化形式を制約と比較するリスク-ベネフィットマトリックスを構築します。利害関係者が効率向上のために犠牲にされている特定の能力を理解し、要件が変更された場合に意思決定を再検討できるように、トレードオフの根拠、仮定、およびバージョン固有の構成をデプロイメント意思決定記録に文書化します。
結論と移行計画
Llama-3.1-8B-Instructの量子化フォーマットを選択するには、経験則による選択ではなく体系的な評価が必要です。最適な選択は、相互に依存する3つの変数に依存します:ハードウェアの制約、タスク固有のパフォーマンス要件、許容可能な品質劣化—これらはそれぞれ、インフラストラクチャやワークロードの需要が進化するにつれて変化する可能性があります。
構造化された意思決定フレームワーク
以下のプロトコルは、量子化選択を実用化します:
- 1. ハードウェア制約の仕様*
デプロイメント環境の定量的ベースラインを確立します:
- 利用可能なVRAM(GPU)またはシステムRAM(CPU)、GB単位で測定
- CPUコア数とアーキテクチャ(該当する場合)
- 目標推論レイテンシ、ミリ秒または1秒あたりのトークン数で指定
- 許容可能なモデル読み込み時間
これらの測定値は、実行可能な量子化空間を定義します。たとえば、8 GBのVRAMを持つシステムは、Llama-3.1-8B-InstructのQ8_0(完全精度相当)を収容できません。これは量子化されていない状態で約16 GBを必要とします。逆に、Q3_Kはリソースが制約されたハードウェアで実行可能かもしれませんが、レイテンシや精度のしきい値を満たさない可能性があります。
- 2. 実証的測定プロトコル*
代表的なワークロードを使用して、管理された測定スプリントを実施します:
- Llama-3.1-8B-Instructを少なくとも4つのフォーマットに量子化します:Q3_K、Q4_K、Q5_K、Q6_K(ハードウェアが許可する場合はQ8_0)。予備テストで実行可能性が示された場合のみQ2_Kを含めます。
- 各フォーマットについて3つの独立変数を測定します:
- モデルサイズ:GB単位のディスクフットプリント(llama.cppによって報告)
- レイテンシ:固定バッチサイズでの平均最初のトークンまでの時間と1秒あたりのトークン数、≥100回の推論で測定
- 精度:タスク固有のメトリック(例:BLEU、完全一致、または人間による評価)を、本番ワークロードを代表する50〜100のプロンプトで測定
- すべての結果を構造化された形式(CSV、JSON、またはデータベース)で記録し、メタデータを含めます:llama.cppバージョン、ハードウェア構成、量子化パラメータ、測定日。
このプロトコルは再現性を保証し、バージョンやハードウェア構成間での比較を可能にします。
- 3. トレードオフ分析とパレート最適化*
ペアワイズトレードオフをプロットしてパレートフロンティアを構築します:
- サイズ対レイテンシ:レイテンシ目標を超えることなくモデルサイズを最小化するフォーマットを特定
- レイテンシ対精度:レイテンシ制約内で許容可能な精度を維持するフォーマットを特定
- サイズ対精度:モデルフットプリントと出力品質のバランスをとるフォーマットを特定
量子化フォーマットは、他のフォーマットが2つ以上の目標を同時に改善しない場合、パレート最適です。Llama-3.1-8B-Instructの場合、実証的証拠は、Q4_KまたはQ5_Kが、ほとんどの知識労働アプリケーションでパレートフロンティアを占めることを示唆しており、量子化されていないモデルと比較して60〜80%のサイズ削減を提供し、<5%の精度劣化と完全精度の10〜20%以内のレイテンシを実現します(Gholami et al., 2021; Xiao et al., 2023)。
- 4. 段階的デプロイメントと検証*
選択した量子化モデルを非本番環境にデプロイします:
- 代表的な負荷の下で1〜2週間モデルを実行
- レイテンシの異常、メモリスパイク、またはオフライン測定で捕捉されなかった品質劣化を監視
- エンドユーザーまたは自動品質保証テストからフィードバックを収集
- 測定と本番動作の間の不一致を文書化
この段階では、オフライン評価が見逃す可能性のある障害モード(例:コンテキスト依存の精度損失、エッジケースのレイテンシスパイク)を検出します。
- 5. 意思決定の文書化*
量子化の決定をバージョン管理された記録として正式化します:
- 選択されたフォーマット:例:「Q4_K」
- 根拠:明示的なトレードオフの正当化、例:「Q4_Kはモデルサイズを75%削減(16 GB → 4 GB)し、タスクXで2.3%の精度損失、45 msのレイテンシを達成し、50 ms SLAを満たす」
- 測定方法論:llama.cppバージョン、ハードウェア構成、ベンチマークデータセット、評価メトリック
- 決定日と所有者:説明責任と時間的コンテキスト
- サンセット条項:llama.cppや要件が進化するにつれて再評価するための予定されたレビュー日(例:四半期ごと)
この記録は組織の記憶として機能し、新しいプロジェクトの迅速なオンボーディングを可能にします。
- 6. 定期的な再評価と移行計画*
量子化の決定は永続的ではありません。四半期ごとのレビューサイクルを確立します:
- アルゴリズムの改善(例:より効率的な量子化スキーム)についてllama.cppリリースを監視
- ワークロードの変化(例:新しいタスクタイプ、スループット需要の増加)を追跡
- 更新されたllama.cppバージョンまたは代替ベースモデルで測定を再実行
- 優れたフォーマット(例:低レイテンシ、より良い精度、より小さいサイズ)が出現した場合、管理された移行を計画します:
- 新しいモデルを量子化
- ステージングで検証
- 本番の問題を検出するために段階的にロールアウト(例:トラフィックの10% → 50% → 100%)
概念的フレーミング:二者択一ではなく最適化としての量子化
量子化は二分法的な決定(量子化対非量子化)ではなく、連続的な最適化問題です。ハードウェアとパフォーマンスの制約を条件として、精度、モデルサイズ、推論速度という3つの競合する目標を調整しています。このフレーミングは、単一の「最良の」量子化が存在しない理由を明確にします:最適解は問題固有です。
Llama-3.1-8B-Instructを大規模にデプロイする知識労働者とチームにとって、この規律は複合的です:
- 標準化:プロジェクト全体で一貫した量子化フォーマット、測定プロトコル、バージョン管理スキームを採用することで、運用上の摩擦を減らします
- 知識移転:あるプロジェクトで量子化を評価したチームメンバーは、同じ方法論を新しいプロジェクトに適用でき、意思決定を加速します
- 監査可能性:文書化された決定により、トレードオフの遡及的分析が可能になり、将来の選択に情報を提供します
実用的な意味
量子化をアドホックな選択ではなく、エンジニアリングの規律として扱います:
- 体系的に測定する:フォーマットを選択する前に、ハードウェアの制約、レイテンシ目標、精度のしきい値を定量化します。
- 厳密に文書化する:再現性と組織学習を可能にするために、決定、根拠、方法論、日付を記録します。
- 実証的に検証する:完全なデプロイメントの前に、非本番環境で量子化モデルをテストします。
- 意図的に反復する:ツールと要件が進化するにつれて、固定スケジュール(例:四半期ごと)で決定を再検討します。
このプロトコルに従うことで、量子化の実用的な約束を実現します:完全精度モデルのコストや情報不足の最適化のリスクを負うことなく、ユーザーのニーズを満たす推論速度と出力品質で、既存のハードウェア上に最先端の言語モデルをデプロイすることです。
一貫性のない評価とllama.cpp量子化の状況
llama.cppは複数の量子化フォーマット—GGML、GGUF、Q2_K、Q3_K、Q4_K、Q5_K、Q6_K、Q8_0、およびバリアント—を実装しており、それぞれが重みをクラスタ化、スケーリング、エンコードする方法における異なるアルゴリズム的選択を表しています。これらのフォーマットは文書化されたトレードオフを示します:低ビットフォーマット(Q2_K、Q3_K)はメモリフットプリントを最小化しますが、より大きな量子化エラーを導入します;高ビットフォーマット(Q6_K、Q8_0)はより多くの情報を保持しますが、より多くのストレージと帯域幅を消費します。
重要な問題は、同一条件下でこれらのフォーマット全体にわたる標準化された直接比較評価の欠如です。公開されたベンチマークは通常、単一の量子化方法の結果を報告し、異なるテストセットを使用し、異なるハードウェア構成を採用するか、研究間で直接比較できないメトリック(パープレキシティ、BLEUスコア、レイテンシ)を報告します。この断片化は意思決定の不透明性を生み出します:「Q4_KとQ5_Kのどちらを使用すべきか?」と尋ねる実務者は、既存の比較が量子化方法を測定プロトコル、ハードウェアの違い、またはプロンプト構築の選択と混同しているため、信頼できる答えを見つけることができません。
-
評価の曖昧性の具体例:* 事実に基づく質問応答のためにLlama-3.1-8B-Instructをデプロイするとします。Q4_Kに量子化し、50問の内部テストセットで評価し、クエリあたり45 msのレイテンシで87%の完全一致精度を記録します。次に、同じベースモデルをQ5_Kに量子化し、52 msのレイテンシで89%の精度を観察します。2パーセントポイントの精度向上と7 msのレイテンシコストは単純明快に見えますが、以下を文書化しなければ、比較は科学的に不完全なままです:
-
テストセットの代表性: 50問のセットは本番クエリの分布と難易度を反映していますか?
-
メトリックの定義: 「精度」は完全一致、トークンレベルのF1、または意味的類似性ですか?このメトリックは、あなたのドメインにおける量子化ノイズにどの程度敏感ですか?
-
測定プロトコル: 両方の量子化は、同一のハードウェア、同一のバッチサイズ、温度設定、サンプリング方法で評価されましたか?
-
分散と信頼区間: 複数回の実行にわたる分散は何ですか?2パーセントポイントの差は統計的に有意ですか?
これらの詳細がなければ、比較は証拠的ではなく逸話的です。
- 量子化選択のための実用的なプロトコル:*
-
**代表的な評価セットを定義する。**実際のユースケースをカバーする100〜200のプロンプトのテストセットを構築し、エッジケースとドメイン固有のクエリを含めます。このセットをすべての量子化比較で一定に保ちます。
-
**測定基準を確立する。**ハードウェア構成(GPUモデル、VRAM、またはCPU仕様)、バッチサイズ、温度、top-pサンプリングパラメータ、およびその他の推論設定を指定します。エンドツーエンドのレイテンシ(プロンプト+生成)を測定しているのか、生成のみのレイテンシを測定しているのかを文書化します。
-
3つの次元を一貫して測定する:
- 品質: タスク固有のメトリック(完全一致精度、BLEU、埋め込み距離による意味的類似性、またはサブセットでの人間による評価)を計算します。点推定と信頼区間(例:ブートストラップリサンプリングによる95% CI)の両方を報告します。
- レイテンシ: テストセット全体で最初のトークンまでの時間と1秒あたりのトークン数を記録します。典型的なパフォーマンスと最悪のケースのパフォーマンスの両方を捉えるために、中央値と95パーセンタイルのレイテンシを報告します。
- メモリ: 推論中のピークVRAMまたはRAM使用量を測定し、モデルの重み、アテンションバッファ、KVキャッシュを含めます。
-
**結果を文書化して保存する。**テストされたすべての量子化フォーマット、そのメトリック、測定条件を示す結果表(付録または内部文書を参照)を作成します。このアーティファクトは、チームの意思決定の根拠となり、将来のデプロイメントの参照となります。
-
**意思決定基準を確立する。**テストの前に、優先順位を定義します:品質が最優先ですか、それともレイテンシが制約条件ですか?レイテンシが重要でQ4_Kがしきい値を満たし、Q5_Kが満たさない場合、品質の違いに関係なく選択は明確です。品質が最優先で両方のフォーマットがレイテンシ要件を満たす場合は、より高精度のフォーマットを選択します。
この規律は、量子化選択を漠然とした好みから再現可能なデータ駆動型の決定に変換します。また、組織の知識を作成します:将来のチームメンバーは、単なる選択(例:「Q4_Kを使用する」)ではなく、特定のハードウェア、ワークロード、品質要件に結びついた意思決定の根拠を継承します。
一貫性のない評価とllama.cppの状況(続き)
チームにとって標準化が重要な理由
このモデルを実行するのがあなただけであれば、カジュアルな評価で十分です。しかし、複数のチームメンバーがこのモデルをデプロイ、再トレーニング、またはトラブルシューティングする場合、標準化が重要になります。それがなければ:
- 開発者Aは Q4_Kを使用し、87%の精度を報告
- 開発者BはQ5_Kを使用し、89%の精度を報告
- どちらもテストセットやハードウェアを文書化していない
- チームは本番環境でどちらを使用するか決定できない
標準化があれば、決定は再現可能で、防御可能で、環境間で移植可能です。
- *これらの結果を内部で公開または文書化する**ことで、将来のチームメンバーが単なる選択ではなく、意思決定の根拠を継承できるようにします。これは、組織が複数のモデルまたは量子化フォーマットを実行する場合に特に重要です;共有評価フレームワークは、重複した作業を防ぎ、意思決定のレイテンシを削減します。
一貫性のない評価とllama.cppの状況:意思決定インフラストラクチャの構築
llama.cppは、豊富な量子化フォーマットのメニューを提供します—GGML、GGUF、Q2_K、Q3_K、Q4_K、Q5_K、Q6_K、Q8_0、その他—それぞれがモデルサイズ、推論速度、出力忠実度の間のフロンティア上の異なるポイントを表しています。しかし、この豊富さは重要な問題を生み出します:** これらのフォーマットは、同一条件下で直接比較されることはめったにありません**。ある情報源からQ4_Kを、別の情報源からQ5_Kを比較するユーザーは、量子化方法の違いを測定プロトコル、ハードウェア構成、プロンプト構築、またはサンプリング戦略の違いと混同する可能性があります。結果は、選択を装った意思決定の麻痺です。
この一貫性のなさは偶然ではありません—それは量子化の状況の初期段階の性質を反映しています。分野が成熟するにつれて、標準化された評価は競争上の優位性になります。再現可能で透明な量子化ベンチマークを構築する組織は、コミュニティの信頼できる参照ポイントになります。彼らは開発者を引き付け、採用の摩擦を減らし、デプロイメント空間における思想的リーダーとしての地位を確立します。
-
*ホワイトスペースの機会は、公共財として評価インフラストラクチャを構築することです。**標準化されたベンチマークスイート—オープンソース、ハードウェアに依存せず、継続的に更新される—を想像してください。これは、多様なタスクセット全体ですべての量子化フォーマットを測定します:事実に基づく質問応答、創造的な執筆、コード生成、推論、ドメイン固有のアプリケーション。このベンチマークは、精度とレイテンシだけでなく、堅牢性メトリックも報告します:各フォーマットは温度変化、異なるサンプリング戦略、敵対的プロンプトに対してどの程度敏感ですか?どのフォーマットがストレス下で優雅に劣化し、どのフォーマットが壊滅的に失敗しますか?このようなインフラストラクチャは、採用を加速し、無駄なエンジニアリング作業を削減し、業界全体で量子化トレードオフの共通言語を作成します。
-
*このビジョンを自分の実践で実装するには、量子化フォーマットを選択する前に標準化された評価プロトコルを確立します。**代表的なテストセットを定義します—理想的には、一般的なベンチマークではなく、実際のユースケースをカバーする100〜500のプロンプト。エッジケースを含めます:まれな単語、長いコンテキスト、ドメイン固有の用語、敵対的入力。精度(例:完全一致、意味的類似性、タスク固有のメトリック)、レイテンシ(最初のトークンまでの時間、1秒あたりのトークン数、エンドツーエンドのクエリ時間)、メモリ使用量(ピークVRAM、システムRAM、ディスク上のモデルサイズ)をすべての候補フォーマット全体で一貫して測定します。測定条件を細心の注意を払って記録します:ハードウェア仕様、バッチサイズ、コンテキスト長、温度、top-pサンプリング、および推論に影響を与えるその他のハイパーパラメータ。分散を捉えるために測定を複数回繰り返します。
この規律は、漠然とした決定をデータ駆動型の決定に変換します。さらに重要なことに、組織の記憶を作成します。これらの結果を内部で公開または文書化します—または、可能であれば、コミュニティベンチマークに貢献します—将来のチームメンバーが単なる選択ではなく、意思決定の根拠を継承できるようにします。ユースケースが進化したり、ハードウェアが変更されたりするにつれて、ベンチマークを再検討します。量子化のトレードオフは静的ではないことがわかります;モデル、ハードウェア、ワークロードが共進化するにつれて変化します。
- *隣接する機会は、量子化選択をファーストクラスの決定としてデプロイメントパイプラインに組み込むことです。**単一の量子化フォーマットを選択して固定として扱うのではなく、複数のフォーマットをサポートし、実行時の制約に基づいて動的に選択するようにシステムを設計します。ユーザーのデバイスのVRAMが限られている場合、4ビットモデルを自動的に提供します。ユーザーがレイテンシを優先する場合、3ビットモデルを提供します。ユーザーが品質を優先し、十分なリソースがある場合、より高精度のフォーマットを提供します。この柔軟性は、量子化を一度限りのエンジニアリング選択から実行時の最適化レバーに変換します—ハードウェア、ワークロード、ユーザーの好みが変化するにつれて調整できるものです。
Footnotes
-
低ビット量子化における精度損失は、細かい数値推論を必要とするタスクに不均衡に影響します。タスク依存感度の証拠については、Frantar et al. (2023)の量子化認識トレーニングを参照してください。 ↩
-
小さな摂動のソフトマックス増幅は、アテンションメカニズム分析で十分に文書化されています。アテンションメカニズムの安定性については、Choromanski et al. (2020)を参照してください。 ↩
-
量子化されたモデル推論におけるソフトウェアバージョンドリフトは、既知ですが十分に文書化されていないリスクです。実務者は、量子化されたアーティファクトをバージョン不可知ではなく、バージョン固有として扱う必要があります。 ↩