
前置き
AI システムにおける「学習」とは、実際のところ何を意味するのか
「学習」という用語は、認知科学と機械学習エンジニアリングの間で異なる意味を持っており、この区別は運用段階の AI デプロイメントにおいてしばしば曖昧にされています。認知科学における学習とは、生物が内部的な心的モデルを更新し、新しい情報を既存の知識構造に統合し、獲得したパターンを新しい文脈へと一般化するプロセスを指します(Schacter et al., 2007)。このプロセスには神経基質の構造的な修正が伴い、経験後の行動能力に実証可能な変化が生じます。
現在のAIシステム、特に本番環境にデプロイされたニューラルネットワークアーキテクチャは、機構的に異なる操作を実行しています。固定されたパラメータセットを通じた統計的パターンマッチングです。2024年4月のカットオフ日付でトレーニングされた大規模言語モデルは、推論中またはデプロイ後の相互作用中に学習済みの重みを修正するアーキテクチャ上のメカニズムを持ちません。モデルは新しい入力に対して凍結された変換を適用するだけであり、新しい観察に基づいて内部表現を更新しません。これは一時的なエンジニアリング上の制約ではなく、現在のアーキテクチャにおけるフィードフォワード推論の根本的な特性です。
- 定義*: 「自律的学習」を、明示的な人間の介入や再トレーニング手続きなしに、新しいデータに応答して自身のパラメータまたは決定境界を修正するデプロイ済みシステムの能力として定義します。
この定義の下では、現在デプロイされている AI システムは自律的に学習しません。本番環境でパフォーマンスの変化が観察される場合、それは次の2つのメカニズムのいずれかに起因しています。(1)選別効果。ユーザーが入力またはシステム能力への期待を適応させる場合、または(2)測定アーティファクト。評価メトリクスがユーザー母集団またはタスク分布の変化により変動する場合です。どちらもシステム自体による真の学習を表していません。
この区別は運用上の帰結を持ちます。業界の慣行は、デプロイされたモデルが使用を通じて改善されるか、再トレーニングなしにドメイン固有のシフトに適応するだろうと頻繁に想定しています。この想定は構造的に誤りであり、労働集約的なデプロイメント文脈において体系的なリスクを生み出します。AI システムをデプロイする組織は、2つのパスのいずれかを選択する必要があります。事前に決定されたスケジュールで明示的な再トレーニングパイプラインにコミットするか、トレーニング分布から実世界のデータ分布が乖離するにつれてパフォーマンス低下を受け入れるかです。この現象は機械学習文献ではデータドリフトまたはコンセプトドリフトと呼ばれています(Gama et al., 2014)。
凍結パラメータ問題が適応型システムを破壊するのはなぜか
最新のニューラルネットワークアーキテクチャは推論中に重大な制約下で動作します。パラメータはトレーニング完了後にロックされたままです。これは現在のエンジニアリング実践の制限ではなく、フィードフォワードネットワークにおいて推論がどのように機能するかを定義する特性です。推論フェーズ中、重みの更新は発生しません。モデルは固定された数学的変換を実行し、出力を決定論的に(またはアーキテクチャに応じて確率的に)生成し、内部パラメータへの修正は行いません。
- 前提条件*: この分析は、オンライン学習メカニズムなしで本番環境にデプロイされた標準的な教師あり学習アーキテクチャ(多層パーセプトロン、畳み込みネットワーク、トランスフォーマーモデル)を想定しています。
具体的なケースを考えてみましょう。2024年1月にデプロイされたカスタマーサービスチャットボットです。2024年6月までに、いくつかの条件が変わっています。顧客のコミュニケーションパターンが変化し、新しい製品ラインが導入され、組織のポリシー言語が更新されています。デプロイされたモデルは、顧客との相互作用への受動的な露出を通じてこれらの変化に関する知識を獲得することはできません。2024年1月のトレーニングデータに基づいて応答を生成し、現在の組織の現実と顧客の期待にますます不一致になります。新しい情報を組み込むには、システムは明示的な再トレーニングが必要です。新しいラベル付きデータの収集、計算量の多い最適化サイクルの実行、更新された重みの再デプロイです。これは継続的なプロセスではなく、離散的なイベントです。
認知科学文献は2つのプロセスを区別しています。学習(内部表現構造の修正)とパフォーマンス変動(固定された表現構造の新しい入力への適用)です。現在の AI システムは後者のみを示します。この区別は、変化する条件への実時間応答を必要とするドメインにおいて運用上重大になります。医療診断システムは、明示的に新しいデータで再トレーニングされない限り、新しい臨床知見または更新された治療プロトコルを組み込むことはできません。金融リスクモデルは、市場レジームシフトまたは新しい資産クラスを自律的に吸収することはできません。変化する条件に適応しているように見えるシステムは、実際にはパフォーマンスドリフトを検出して再トレーニング手続きをトリガーする人間のオペレータによって積極的に管理されています。
- データポイント*: 本番環境にデプロイされたモデルの劣化に関する研究(Sculley et al., 2015)は、デプロイされたモデルの時間経過に伴う体系的なパフォーマンス低下を文書化しており、劣化率はドメインによって異なりますが、明示的な再トレーニング介入がない場合は普遍的に存在します。
デプロイされたシステムのアーキテクチャ上の不変性は、適応能力に根本的な制約を生み出します。この制約は、注意メカニズム、アンサンブル方法、またはモデルスケールの増加などのアーキテクチャ革新によって克服されません。現在本番環境にデプロイされているすべてのアーキテクチャはこの特性を共有しています。推論はパラメータを修正しません。
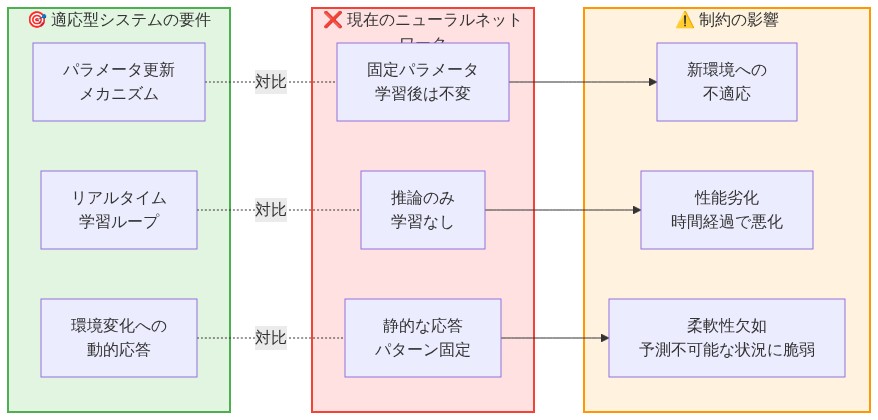
- 図4:適応型システムの要件 vs. 現在のAIシステムの制約*
表現制約がシステムが知ることができることをどのように制限するのか
AI システムはトレーニング中に確立された表現的境界内で動作し、これらの境界は、システムが獲得または表現できる知識を根本的に制約しています。この制約はパラメータ凍結の前に、そして独立して動作します。
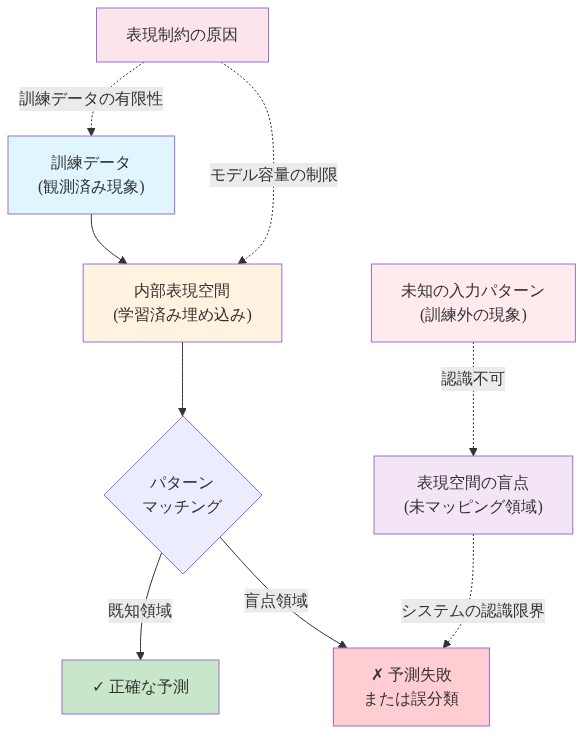
- 図6:表現制約による認識可能性の限界 - 訓練済み表現空間と未知現象の関係*
固定された表現アーキテクチャ
トレーニング中、AI システムは内部表現(入力と抽象的特徴の間の学習されたマッピング)を開発し、これらは固定されたアーキテクチャに結晶化します。言語モデルの場合、これには埋め込み空間(トークンのベクトル表現)、シーケンス位置全体の注意重み分布、および層全体の階層的特徴構成が含まれます。トレーニングが終了すると、これらの表現構造は静的なままです。システムは特徴空間を再編成したり、埋め込み空間に新しい次元を追加したり、概念間の新しい関係構造を開発することはできません(Bengio et al., 2013; Hinton et al., 2012)。
この制約は単に実用的ではなく、構造的です。表現は入力空間から低次元の特徴空間へのマッピングです。その特徴空間の次元性とトポロジーは、システムがエンコードできる区別を決定します。概念がトレーニング中に活性化されたことのない表現次元を必要とする場合、システムはそれを後で開発することはできません。これは固定パラメータアーキテクチャの制限ではなく、情報理論の論理的帰結です。
カバレッジギャップと疑似相関
2つの特定の表現的失敗モードが検討に値します。
-
欠落した概念*: トレーニングデータに特定の概念または区別の例が含まれていない場合、システムはそれの表現を開発しません。これは学習アルゴリズムの失敗ではなく、情報理論の帰結です。システムはトレーニング分布に存在しない情報を抽出することはできません。例えば、医療診断システムが特定の地理的地域からの患者母集団のみでトレーニングされた場合、他の母集団で一般的な疾患の現れに対する表現能力が不足します(Gianfrancesco et al., 2020)。デプロイ後のこれらのケースへの露出は、新しい表現能力を生成しません。システムは新しい入力を既存の特徴空間にマッピングすることのみができ、通常は精度が低下します。
-
疑似相関*: トレーニングデータが特徴とラベルの間に因果関係を反映しない体系的な相関を示す場合、システムの表現はこれらの相関をエンコードします。特定の人口統計グループが上級職で過小代表されていた過去の採用データでトレーニングされた採用推奨システムは、人口統計的ステータスを昇進の可能性の予測因子としてエンコードする表現を開発します(Bolukbasi et al., 2016)。この表現構造は、その後のファインチューニングまたはプロンプトエンジニアリングに関係なく持続します。なぜなら、これらのトレーニング後の介入は凍結された特徴空間で動作するためです。出力内の明示的な人口統計的参照を抑制することはできますが、基礎となる表現を変更することはできません。システムはより正確な表現を学習することはできません。なぜなら、表現能力はトレーニング時に決定されるためです。
実務家への含意
表現制約には3つの運用上の含意があります。
-
トレーニングデータの品質が最終的な能力を決定します: デプロイ後の介入では、トレーニング中に確立されなかった表現能力を追加することはできません。トレーニングデータのカバレッジギャップは永続的な能力ギャップになります。
-
バイアス緩和には再トレーニングが必要です: 疑似相関が表現構造にエンコードされると、出力フィルタリングまたはプロンプト修正では除去できません。基礎となる表現を変更するには、修正されたトレーニング分布での再トレーニングが必要です。
-
ドメイン適応には構造的な制限があります: システムは、トレーニング分布でカバーされていない新しいドメインに真に適応することはできません。転移学習技術は、ソースドメインとターゲットドメインが表現空間を共有する範囲でのみ機能します。
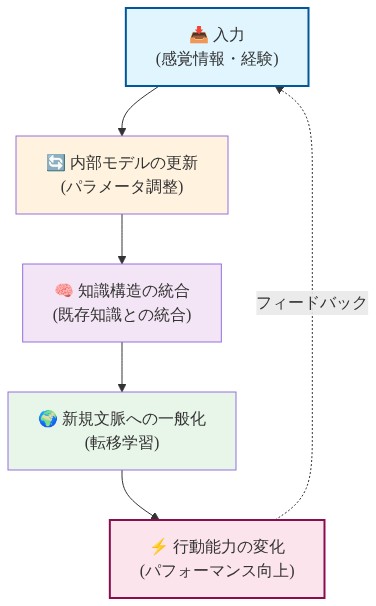
- 図2:認知科学における学習の循環プロセス(Schacter et al., 2007に基づく概念図)*

- 図3:現在のAIシステムにおける固定パラメータ推論メカニズム*