
なぜシニアエンジニアは悪いプロジェクトを失敗させるのか
救済よりも認識
-
主張:* シニアエンジニアがプロジェクトを失敗させることが多いのは、根本的な問題が技術的なものではなく組織的なものであることを早期に認識し、どれだけエンジニアリングスキルがあっても、ずれたインセンティブ、不明確な要件、リソース制約を修正できないことを理解しているからである。
-
根拠と前提:* この主張は2つの基本的な前提に基づいている:(1)シニアエンジニアはプロジェクトの失敗パターンに繰り返し触れることでパターン認識を発達させる、(2)組織の機能不全は技術的問題とは構造的に異なるため、異なる介入が必要である。根拠は次のように展開される:プロジェクトが組織的な不整合の症状—競合するステークホルダーの優先順位、定義されていない意思決定権限、または述べられた範囲と一致しないリソースコミットメント—を示す場合、技術的な実行だけではこれらの制約を解決できない。エンジニアリング努力の増加による介入は、根本的な機能不全を隠蔽し、必要な組織的決定を遅らせ、技術チームが組織的リスクを吸収するという前例を確立する。このサイクルを観察してきたシニアエンジニアは、英雄的な努力によって問題を曖昧にするのではなく、問題を表面化させ、目に見える形で失敗させることを選択する。
-
具体例:* あるチームが、レガシーな決済システムを8週間以内に再構築するという依頼を受ける。範囲には、別々の部門からの3つの相互に互換性のないビジネス要件が含まれ、指定されたプロダクトオーナーはおらず、リーダーシップの優先順位はスプリント間で変動する。ジュニアエンジニアは、長時間労働とテストの削減による加速配信を提案する。シニアエンジニアは代わりに制約を文書化する:3つの互換性のない要件をリストアップし、意思決定権限の欠如を特定し、2つのシナリオを提示する—範囲を40%削減するか、現在のチーム能力で16週間にタイムラインを延長するか。リーダーシップは分析を認めるが、どちらのオプションにもコミットせず、チームが「効率を見つける」ことを期待する。プロジェクトが10週目に失敗したとき、失敗はエンジニアリング能力ではなく組織的制約に起因する。もしシニアエンジニアが個人的な努力によってリスクを吸収していたら、失敗は遅延し、技術的実行に誤って帰属され、組織がより明確なコミットメントを行うことを学ぶ機会を妨げていただろう。
-
実行可能な示唆:* 救済努力にコミットする前に、構造化された評価を実施する:(1)ステークホルダーの立場をマッピングし、対立を特定する。(2)範囲、タイムライン、リソースに対する意思決定権限を誰が持っているかを判断する—不明確な場合、これは警告サインである。(3)述べられた制約(タイムライン、予算、チームサイズ)が固定されているか交渉可能かを検証する。(4)調査結果を具体的な推奨事項とともに文書化する:所有権の明確化、範囲の削減、またはタイムラインの延長。(5)リーダーシップが評価を認めても行動しない場合、もう一度文書で段階的に報告し、その後追加のリスクを吸収せずに割り当てられた作業を進める。これにより説明責任が生まれ、あなたが恒久的な組織的緩衝材になることを防ぐ。
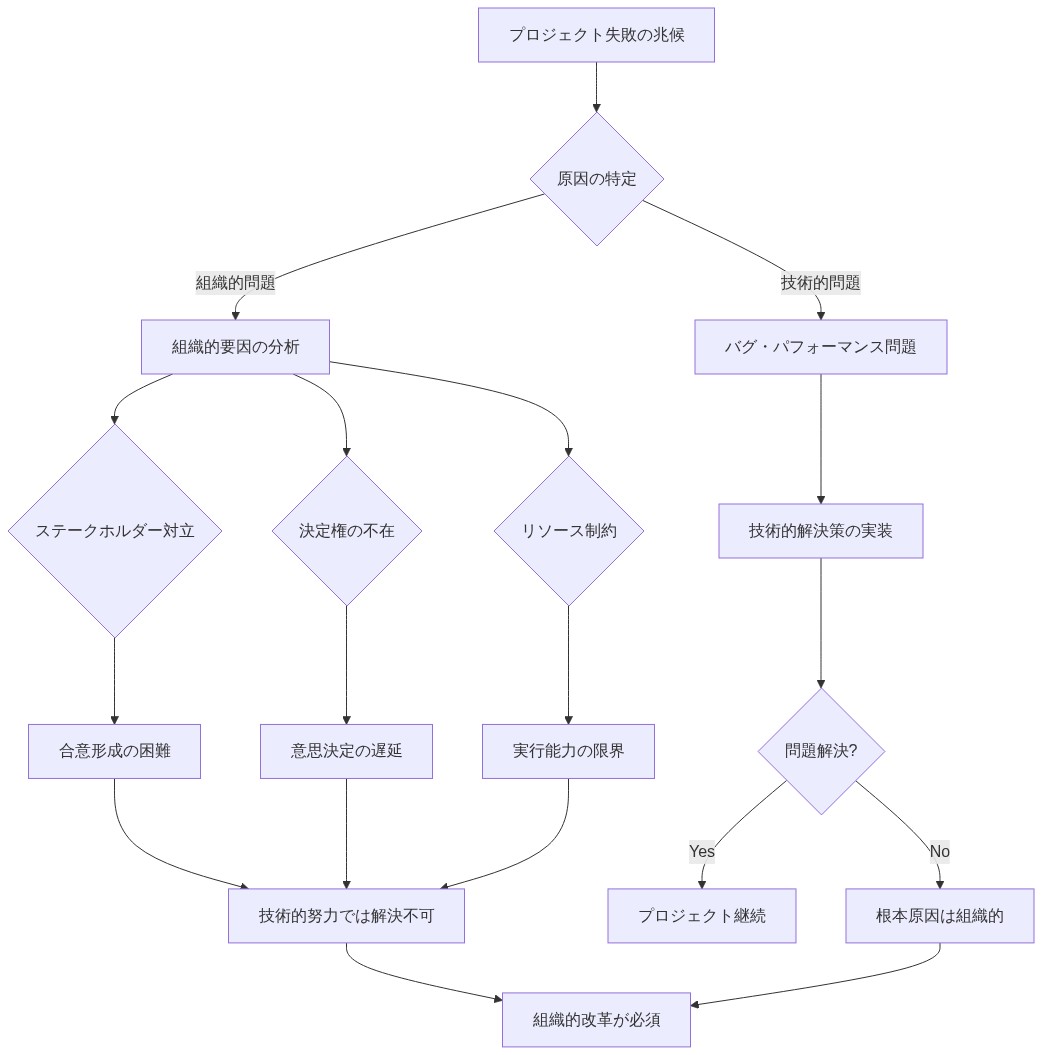
- 図2:プロジェクト失敗の原因判別フロー(技術的問題 vs 組織的問題)*

- 図1:シニアエンジニアが組織的問題を認識し、技術的救済ではなく問題の可視化を選択する(コンセプトイメージ)*
システム構造とボトルネック
-
主張:* プロジェクトが失敗するのは、構造的なボトルネック—連続的な意思決定ゲート、不明確な所有権、欠落したフィードバックループ—のためであり、個々のエンジニアがスキルや能力を欠いているからではない。
-
根拠と前提:* この主張は、プロジェクトの速度は最も遅い連続プロセスによって制約され、個々の努力の合計によって制約されるのではないという前提に基づいている(待ち行列理論とシステム思考から導かれる原則)。根拠は次のように展開される:連続的な承認ゲートや未定義の所有権を持つプロジェクトにエンジニアリング能力を追加しても、ボトルネックは減少しない;キューの深さとオーバーヘッドが増加する。明確な所有権と並列ワークフローを持つ適切に構造化されたプロジェクトは、適度な努力で成功できる。構造が不十分なプロジェクトは、英雄的な努力にもかかわらず失敗する。なぜなら制約は個人の行動によって除去できないからである。
-
具体例:* データパイプラインプロジェクトが6週間停滞する。調査により、すべてのスキーマ変更が、競合する優先順位を持ち明確な意思決定権限のない3つのチームからの書面による承認を必要とすることが明らかになる。プロジェクトには十分なエンジニアリング能力があるが、意思決定が直列化されているため進行できない。シニアエンジニアは構造的変更を提案する:1つのチームをスキーマオーナーとして指定し、変更を承認する権限を与える;他のチームは48時間の応答時間を持つ定義されたプロセスを通じてリクエストを提出する。これにより、ボトルネックが意思決定(直列的、予測不可能)から技術的実行(並列化可能、予測可能)に移行する。プロジェクトは人員を追加することなくブロック解除される。2週間以内に、パイプラインは本番環境に到達する。
-
実行可能な示唆:* 追加リソースを段階的に報告する前に、プロジェクト構造のボトルネックを監査する:(1)各主要な意思決定カテゴリーのRACIマトリックスを作成する:誰が責任を負うか(作業を行う)、誰が説明責任を負うか(最終決定)、誰に相談するか(インプットを提供)、誰に通知するか(更新を受け取る)。(2)並列化できる直列ゲートを特定する。(3)明確な権限のない意思決定を見つける。(4)構造的変更を提案する:意思決定権限の統合、承認ワークフローの並列化、応答時間のコミットメントの確立。(5)組織が所有権を明確にできない、または直列ゲートを除去できない場合、これはプロジェクトが組織的に進行する準備ができていないことを示す。この評価を文書化し、構造が解決されるまで一時停止することを推奨する。
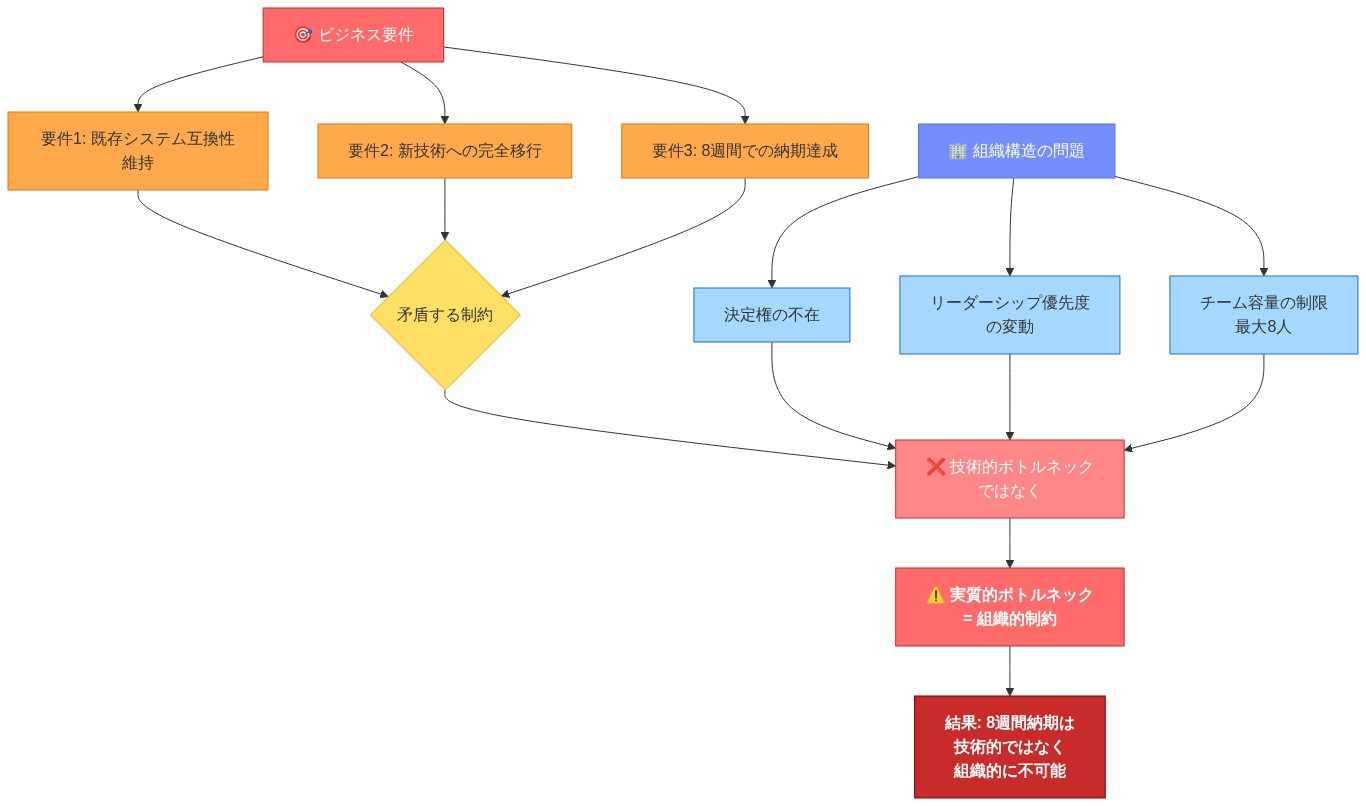
- 図3:ペイメントシステム再構築プロジェクトの制約構造(8週間納期の不可能性)*

- 図4:組織的ボトルネック:技術的努力では解決不可能な構造的問題*
参照アーキテクチャとガードレール
-
主張:* シニアエンジニアは、チームが共有された参照アーキテクチャまたは合意された技術的制約を欠いている場合にプロジェクトを失敗させる。なぜなら、すべての実装決定が議論になり、コードベースが断片化し、配信が遅くなるからである。
-
根拠と前提:* この主張は、(1)技術的決定は等しく価値があるわけではない—一部の決定(エラー処理、ロギング、データベース選択)はシステムの一貫性に大きな影響を与える、(2)これらの決定が一度行われ文書化されると、すべてのスプリントで再議論されるよりもチームが速く動くという前提に基づいている。根拠は次のように展開される:参照アーキテクチャがなければ、各チームまたはスプリントはエラー処理、ロギング、データベースパターン、テスト戦略について独立した選択を行う。これらの選択は個別には防御可能だが、集合的には一貫性がなく、統合の摩擦、予測不可能なデバッグ、アーキテクチャのドリフトを生み出す。参照アーキテクチャは完璧である必要はない;明示的で強制される必要がある。
-
具体例:* マイクロサービスプロジェクトには合意されたエラー処理戦略がない。チームAはカスタムヘッダー付きのHTTPステータスコードを使用する。チームBはエラーを汎用JSONレスポンスオブジェクトでラップする。チームCはメインレスポンス内のネストされたフィールドとしてエラーを返す。呼び出し側がエラーを確実に解析できないため、統合テストは予測不可能に失敗する。シニアエンジニアは参照アーキテクチャを提案する:標準エラーエンベロープ(コード、メッセージ、コンテキスト)、リトライロジック(ジッター付き指数バックオフ)、サーキットブレーカーしきい値(5回連続エラー後に失敗、60秒後にリセット)。チームは1スプリントでこれを実装する。デバッグ時間は60%減少する。プロジェクトはアーキテクチャの不整合のために失敗しなくなる;ビジネスロジックとパフォーマンスのメリットで成功または失敗する。
-
実行可能な示唆:* プロジェクト時間の最初の10%を参照アーキテクチャの決定に割り当てる。各主要カテゴリーの決定木を作成する:(1)データベースをどのように選択するか?(基準:一貫性要件、クエリパターン、スケール期待。)(2)テスト戦略は何か?(ユニットテストカバレッジしきい値、統合テスト範囲、本番監視。)(3)いつ水平スケールと垂直スケールを行うか?(しきい値:CPU使用率>80%、レイテンシ>500ms。)(4)エラーをどのように処理するか?(標準エンベロープ、リトライロジック、サーキットブレーカー。)これらの決定を書き留める。助言的ではなく拘束力のあるものにする。これは過剰エンジニアリングではない;再エンジニアリングを防ぎ、チームの認知負荷を減らすことである。
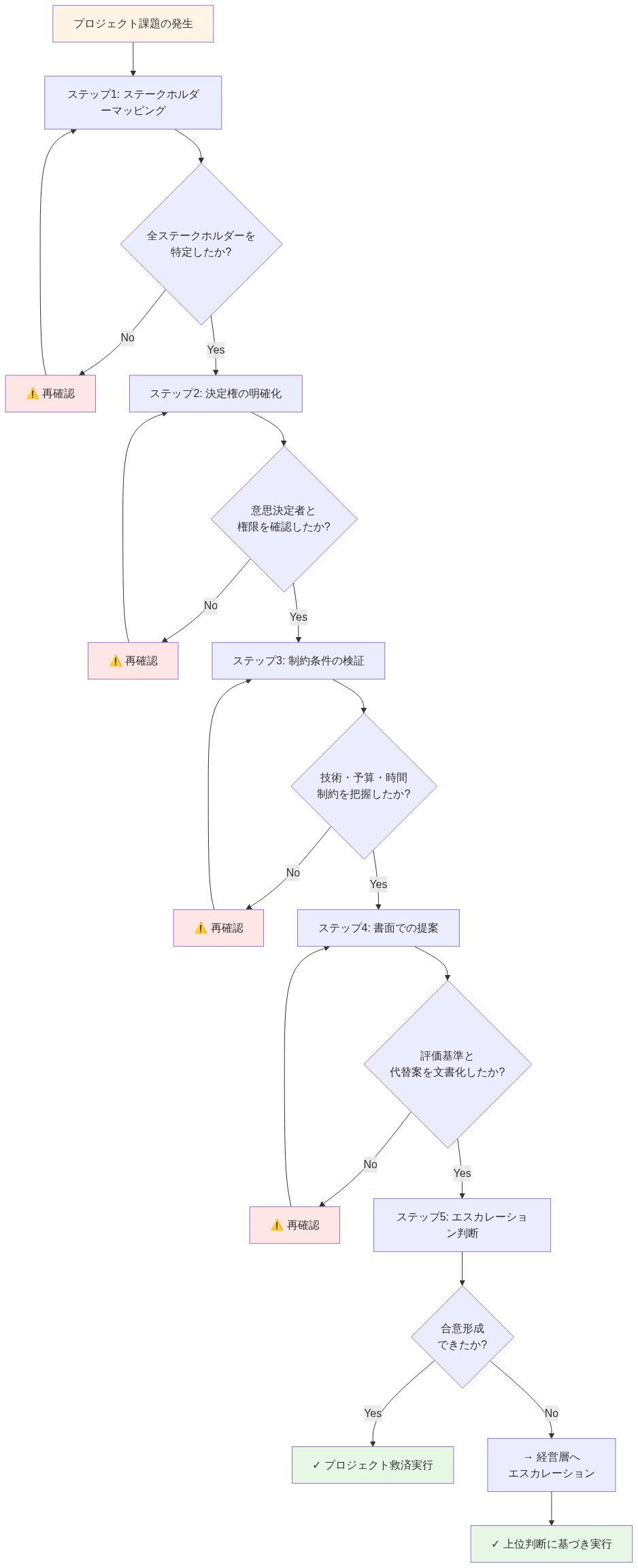
- 図5:プロジェクト救済前の構造化評価プロセス(5ステップ)*

- 図6:問題の可視化による組織学習と長期的信頼構築*
実装と運用パターン
-
主張:* プロジェクトが失敗するのは、チームが作業の進め方—コードレビューの厳格さ、インシデント対応、デプロイメント手順—について合意していないためであり、シニアエンジニアはプロセス文書を実際の遵守の代替とすることを拒否する。
-
根拠と前提:* この主張は、(1)プロセスは一貫して従われた場合にのみ価値がある、(2)規律のないプロセスは誤った自信を生み出し、プロセスがない場合よりも悪い結果につながるという前提に基づいている。根拠は次のように展開される:強制されないコードレビューポリシーはバグをキャッチしない;品質管理の外観を作り出す。時間的プレッシャーの下でスキップされるデプロイメントチェックリストはインシデントを防がない;誤った安全感を作り出す。シニアエンジニアは、プロセスシアター—従われない文書化された手順—は実際の実践についての透明性よりも悪いことを認識している。解決策は、遵守を自動化するか、スキップを不可能にすることである。
-
具体例:* あるチームは、デプロイメント中に設定ステップを見逃したことによる本番インシデントを経験する。対応として、12ステップのデプロイメントチェックリストを文書化する。2週間、エンジニアはそれに従う。3週目までに、時間的プレッシャーの下で、エンジニアはステップ8〜10(検証チェック)をスキップし始める。インシデントが増加する。シニアエンジニアはチェックリストの自動化を推奨する:ステップ8〜10をデプロイメントツールに組み込むことでスキップを不可能にする。検証が失敗すると、デプロイメントが停止する。エンジニアは問題を解決せずに進行できない。インシデントは減少し、低いままである。違いは、パターンが規律ではなくシステムによって強制されるようになったことである。
-
実行可能な示唆:* チームをスケールする前に、運用パターンを成文化し自動化する:(1)重要な実践を特定する:コードレビュー、テスト、デプロイメント、インシデント対応。(2)各実践について、自動化できるかどうかを判断する。できる場合は、ツールに組み込む。できない場合は、自動化が可能になるまで簡素化する。(3)遵守を測定する。遵守が95%未満の場合、パターンはスケールする準備ができていない;再設計する。(4)パターンとそれを強制するツールを文書化する。(5)採用時に、新しいチームメンバーをスキップする可能性のある手動プロセスではなく、自動化されたパターンにオンボードする。
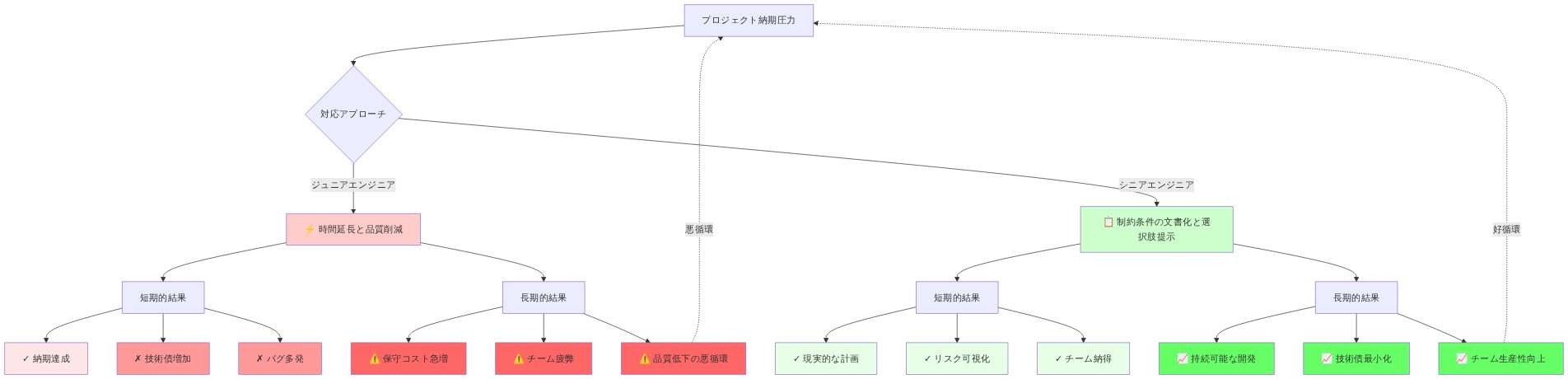
- 図7:ジュニア vs シニアエンジニアの対応パターン比較*

- 図8:技術的救済による問題隠蔽のサイクルと学習機会の喪失*
測定と成果
-
主張:* シニアエンジニアがプロジェクトを失敗させるのは、間違ったもの—ベロシティ、コード行数、スプリント完了—を測定し、ビジネスにとって重要な成果を測定しないからである。
-
根拠:* ベロシティは計画ツールであり、健全性指標ではない。チームは、誰も使用しない機能を出荷しながら高いベロシティを持つことができる。シニアエンジニアは、実際に重要なものを測定することを主張する:ユーザー採用、価値までの時間、インシデント率、顧客満足度。プロジェクトがこれらの指標を明確にできない場合、進行する準備ができていない。
-
具体例:* あるチームは計画されたストーリーポイントの95%を完了するが、ユーザーは予測の20%で機能を採用する。プロジェクトは技術的には順調だが戦略的には失敗している。シニアエンジニアは、実際の使用状況を測定しフィードバックを収集するために一時停止することを推奨する。チームは、機能が誰も持っていない問題を解決していることを発見する。彼らはデータに基づいてピボットする。シニアエンジニアが正しいものを測定することを主張したため、プロジェクトは生き残る。
-
実行可能な示唆:* プロジェクトを開始する前に成功指標を定義する。完了とはどのように見えるか?それが機能したかどうかをどのように知るか?1文で答えられない場合、プロジェクトは準備ができていない。毎週指標をレビューする。2スプリント後に指標が正しい方向に動いていない場合、より懸命に努力するのではなく段階的に報告する。
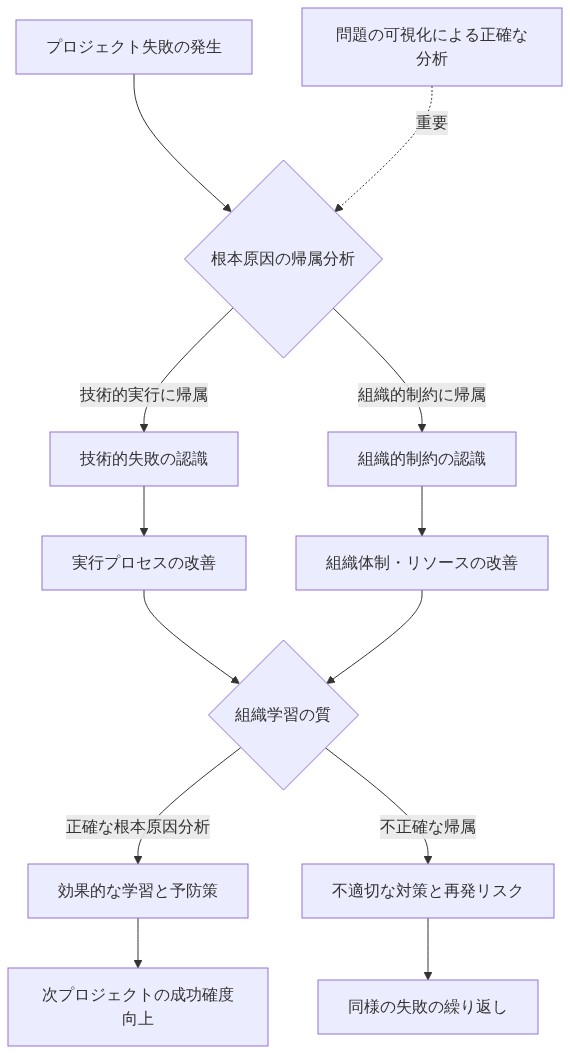
- 図9:プロジェクト失敗の帰属分析と組織学習への影響*
- 図10:問題の可視化による組織的成熟度の向上サイクル*
リスクの特定とコミュニケーション
-
主張:* シニアエンジニアがプロジェクトを失敗させるのは、リスクを早期に特定し明確に伝え、リーダーシップがリスクを認めても軽減しない場合、予測可能な失敗の共犯者になるのではなく後退するからである。
-
根拠と前提:* この主張は、(1)リスク特定は悲観主義ではなく専門的責任である、(2)シニアエンジニアはリスクを明確に伝え、リーダーシップの対応を文書化する義務があるという前提に基づいている。根拠は次のように展開される:不明確な範囲、不整合なステークホルダー、複雑さと一致しないタイムラインを持つプロジェクトを観察するシニアエンジニアは、リスクを明確にする責任がある。沈黙を保ち最善を望むことは忠誠心ではない;それは怠慢である。リスクが認められても無視される場合に後退することが唯一の倫理的な行動である。
-
具体例:* リプラットフォーミングプロジェクトは、12ヶ月の述べられたタイムラインと5人のエンジニアのチームを持つ。範囲には、データ移行(推定4ヶ月)、API再設計(推定5ヶ月)、ゼロダウンタイムカットオーバー(推定3ヶ月)が含まれる。シニアエンジニアは、統合テスト、文書化、運用準備を考慮して、8人のチームで18ヶ月の現実的なタイムラインを計算する。彼女は信頼レベルとともにリーダーシップに書面でこれを伝える:8人のエンジニアで18ヶ月の推定に高い信頼(80%);範囲の拡大や大きな技術的驚きがないと仮定して、5人のエンジニアで12ヶ月の推定に中程度の信頼(50%)。リーダーシップはリスクを認めるが、効率の向上と範囲の削減に賭けて元の計画にコミットする。データ移行の複雑さが推定を超えたとき、プロジェクトは10ヶ月目に失敗する。リスクが理由とともに文書化されていたため、失敗は驚きではない;それはデータポイントである。組織はリスク評価を信頼することを学ぶ。
-
実行可能な示唆:* 3つのコンポーネントでリスクを文書化する:(1)リスクステートメント:何が間違う可能性があるか?(2)信頼レベル:これはどのくらい可能性があるか?(高:>70%、中:40〜70%、低:<40%。)(3)軽減:このリスクを減らすために何ができるか?制御できるリスク(チームスキル、アーキテクチャ決定、テストの厳格さ)と制御できないリスク(市場の変化、リーダーシップの優先順位、外部依存関係)を区別する。制御できないリスクについては、意思決定ゲートを提案する:日付YまでにXが発生した場合、ピボットする。ゲートについて書面による合意を得る。ゲートがトリガーされたとき、危機としてではなく計画された緊急時対応として冷静に段階的に報告する。これにより説明責任が生まれ、驚きが防がれる。
結論:失敗を通じた学習
-
主張:* シニアエンジニアが悪いプロジェクトを失敗させるのは、失敗がしばしば組織学習への最速の道であることを理解しており、個人的な犠牲を通じてその失敗を防ぐことは間違った教訓を教えるからである。
-
根拠と前提:* この主張は、(1)組織はフィードバックを通じて学習する、(2)英雄的な努力を通じてフィードバックを防ぐことは組織学習を遅らせるという前提に基づいている。根拠は次のように展開される:プロジェクトの失敗を経験したことがない組織は、脆弱な意思決定を発展させる。彼らは、適切に見積もること、明確に範囲を定めること、またはステークホルダーを整合させることを学ばない。なぜなら、彼らは貧弱な決定の結果に直面したことがないからである。個人的な犠牲を通じてすべての失敗を防ぐシニアエンジニアは、組織からこの学習を奪う。最良の長期的な行動は、プロジェクトを失敗させ、理由を文書化し、組織がより良い実践を構築するのを助けることである。
-
実行可能な示唆:* 構造的問題を持つプロジェクトのシニアエンジニアである場合、次のシーケンスに従う:(1)文書化:具体的な例とともに構造的問題を文書化する:不明確な所有権、直列ゲート、不整合なステークホルダー、非現実的なタイムライン。(2)提案:具体的な修正を提案する:意思決定権限の明確化、範囲の削減、タイムラインの延長、またはリソースの追加。(3)段階的報告:推奨事項と変更なしで進行するリスクとともに、リーダーシップにもう一度書面で報告する。(4)後退。割り当てられた作業を適切に行うが、組織の機能不全を隠すために時間や健康を犠牲にしない。(5)非難のない事後分析を実施:プロジェクト終了後。個人のパフォーマンスではなく、システムと決定に焦点を当てる。それを使用してより良い実践を構築する:より明確なスコーピングプロセス、より早期のリスク特定、定義された意思決定権限。これにより、組織は次回より良い決定を行うことを学ぶ。それがシニアエンジニアが永続的な価値を生み出す方法である—個々のプロジェクトを救うことによってではなく、組織が良い決定を行う能力を向上させることによって。
測定と成果の整合性
-
主張:* シニアエンジニアがプロジェクトを失敗させるのは、ベロシティやストーリーポイント完了率のような活動指標ではなく、ユーザー採用率、価値実現までの時間、インシデント発生率など、ビジネスにとって重要な成果を測定するからである。
-
根拠と前提:* この主張は、(1) ベロシティは計画ツールであり、健全性指標ではないこと、(2) 活動指標(完了したストーリーポイント、出荷した機能)の最適化は、成果(ユーザー価値、ビジネスインパクト)の最適化から乖離する可能性があることを前提としている。根拠は次のとおりである:チームは計画されたストーリーポイントの95%を完了しながら、ユーザーが採用しない機能を出荷することができる。高いベロシティと低い採用率は、成功ではなくプロジェクト失敗の先行指標である。シニアエンジニアは、活動指標が戦略的失敗を隠蔽する可能性があることを理解しているため、実際に重要なことを測定することにこだわる。
-
具体例:* あるチームが四半期に計画されたストーリーポイントの95%を完了した。機能は予定通りに出荷された。しかし、ユーザー採用率は予測の20%にしか達しなかった。プロジェクトは戦術的には順調だが、戦略的には失敗している。シニアエンジニアは、実際の使用パターンを測定し、定性的なフィードバックを収集するために一時停止することを推奨する。チームは、その機能がユーザーが重要だと認識していない問題を解決していることを発見する。彼らには回避策がある。チームはデータに基づいてピボットし、実際のユーザーニーズに対応するために機能を再設計する。シニアエンジニアが正しい成果の測定にこだわったため、プロジェクトは存続する。
-
実行可能な示唆:* プロジェクト開始前に成功指標を定義する:(1) 完了とはどのような状態か? (2) それが機能したかどうかをどのように知るか? (3) ベースラインは何で、目標は何か? (4) 指標ごとに一文で答えられない場合、プロジェクトは準備ができていない。成果指標の例:ユーザー採用率(目標:90日以内に対象ユーザーの60%)、価値実現までの時間(目標:ユーザーが最初のセッション内で利益を実感)、インシデント発生率(目標:本番環境で週1回未満)、顧客満足度(目標:NPS >40)。(5) 指標を毎週レビューする。2スプリント後に指標が正しい方向に動いていない場合、より懸命に取り組むのではなくエスカレーションする。これはデータであり、失敗ではない。
測定と次のアクション
-
主張:* シニアエンジニアがプロジェクトを失敗させるのは、ビジネスにとって重要な成果ではなく、ベロシティ、コード行数、スプリント完了率など、間違ったものを測定するからである。
-
根拠:* ベロシティは計画ツールであり、健全性指標ではない。チームは誰も使わない機能を出荷しながら高いベロシティを持つことができる。コード行数は虚栄の指標である。より多くのコードがより良いわけではない。スプリント完了は遅行指標である。スプリントが失敗したことを知る頃には、軌道修正するには遅すぎる。シニアエンジニアはこれを知っており、間違ったシグナルの最適化を拒否する。彼らは実際に重要なことを測定することにこだわる:ユーザー採用率、価値実現までの時間、インシデント発生率、顧客満足度。プロジェクトがこれらの指標を明確にできない場合、進める準備ができていない。
-
具体例:* あるチームが四半期に計画されたストーリーポイントの95%を完了した。ベロシティは安定している。スプリント完了は順調である。しかし、ユーザーは予測の20%でその機能を採用している。プロジェクトは技術的には順調だが、戦略的には失敗している。シニアエンジニアは、実際の使用状況を測定し、フィードバックを収集するために一時停止することを推奨する。チームは、その機能が誰も持っていなかった問題を解決していることを発見する。彼らはデータに基づいてピボットする。シニアエンジニアが正しいことを測定することにこだわったため、プロジェクトは存続する。代替案—残りのスプリントを完遂して100%完了を達成する—は、誰も望まない機能を出荷することになっただろう。
-
実行可能なワークフロー:*
-
成功指標の定義(第1週): プロジェクト開始前に、成功を一文で定義する。例:
- 「支払い処理時間を取引の80%について5分から30秒に短縮する。」
- 「ローンチから90日以内にユーザー維持率を40%から60%に増加させる。」
- 「インシデント対応時間を30分から5分に短縮する。」
一文で定義できない場合、プロジェクトは準備ができていない。
-
指標の階層(第1週): 以下を区別する:
- ノーススター: 究極のビジネス成果(例:ユーザー維持率、収益)。
- 先行指標: ノーススターを予測する指標(例:機能採用率、最初の価値実現までの時間)。
- 遅行指標: ノーススターを確認する指標(例:解約率、ユーザーあたりの収益)。
- 運用指標: 実行を追跡する指標(例:デプロイ頻度、インシデント発生率)。
プロジェクト中は先行指標に焦点を当てる。ローンチ後にノーススターをレビューする。
-
測定計画(第2週): 各指標について、以下を定義する:
- どのように測定するか?(計装、ロギング、調査、分析)
- ベースラインは何か?(プロジェクト前の現状)
- 目標は何か?(プロジェクト後の望ましい状態)
- SLAは何か?(どのくらいの頻度でレビューするか?)
例:「分析を通じて機能採用率を測定する。ベースライン:0%。目標:30日以内にユーザーの60%が採用。毎週レビュー。」
-
週次レビュー(継続中): 毎週、指標をプロットする。指標が正しい方向に動いている場合は続行する。2スプリント後に指標が横ばいまたは低下している場合は、より懸命に取り組むのではなくエスカレーションする。「なぜこの指標は動いていないのか?それは製品の問題か、技術的な問題か、測定の問題か?」と問う。
-
ピボット基準(第2週): ピボットする条件を定義する:
- 「4週間後に採用率が20%未満の場合、一時停止してユーザーフィードバックを収集する。」
- 「インシデント発生率が1日5回を超える場合、一時停止して安定性に焦点を当てる。」
- 「価値実現までの時間が10分を超える場合、オンボーディングフローを再設計する。」
プロジェクト開始前にピボット基準について合意を得る。基準が満たされたら、危機としてではなく計画された緊急時対応として冷静にエスカレーションする。
- リスクに関する解説:* コストは計装をセットアップするためのシニアエンジニアの時間1〜2週間である。利点は、プロジェクト失敗の早期検出(第12〜13週ではなく第2〜3週)である。リスクは、間違ったものを測定するか、誤って測定することである。プロダクトマネージャーとデータアナリストを指標定義に関与させることで軽減する。
リスクと軽減戦略
-
主張:* シニアエンジニアがプロジェクトを失敗させるのは、リスクを早期に特定し、明確に伝達し、リーダーシップが警告を無視した場合、予測可能な失敗に加担するのではなく、身を引くからである。
-
根拠:* リスクの特定は悲観主義ではなく、プロフェッショナリズムである。不明確なスコープ、整合性のないステークホルダー、複雑さに見合わないタイムラインを持つプロジェクトを見るシニアエンジニアには、そう言う責任がある。沈黙を守り、最善を望むことは忠誠心ではなく、怠慢である。リスクが認識されても無視された場合に身を引くことは、唯一の倫理的な行動である。それはエンジニアと組織の両方を保護する。
-
具体例:* あるリプラットフォーミングプロジェクトには12ヶ月のタイムラインと5人のチームがある。スコープには、データ移行(推定4ヶ月)、API再設計(推定3ヶ月)、ゼロダウンタイムカットオーバー(推定2ヶ月)が含まれる。合計:
結論と移行計画
-
主張:* シニアエンジニアが悪いプロジェクトを失敗させるのは、失敗がしばしば学習への最速の道であり、英雄的な努力によってその失敗を防ぐことは間違った教訓を教えることを理解しているからである。プロジェクトを目に見える形で失敗させることで、組織の成熟を加速させる。
-
根拠:* プロジェクトの失敗を一度も経験しない組織は、脆弱な意思決定を発展させる。彼らは適切に見積もること、明確にスコープを定めること、ステークホルダーを整合させることを学ばない。個人的な犠牲を通じてすべての失敗を防ぐシニアエンジニアは、組織からこの学習を奪う。長期的に最善の行動は、プロジェクトを失敗させ、その理由を文書化し、組織がより良い実践を構築するのを支援することである。これが、企業が個人の英雄主義に依存することから、スケールするシステムの構築へと移行する方法である。これはまた、シニアエンジニアが永続的な価値を創造する方法でもある—今日の問題を解決することによってではなく、明日の問題がより良く解決されることを保証することによって。
-
実行可能な示唆:* 運命づけられたプロジェクトに携わるシニアエンジニアであれば、次のことを行う:(1) 構造的な問題を具体性と証拠を持って書面で文書化する。(2) 具体的な修正を提案する—所有権を明確にする、スコープを削減する、タイムラインを延長する、リソースを追加する—トレードオフを明確に述べる。(3) リーダーシップが行動しない場合、書面でもう一度エスカレーションし、その後身を引く。仕事はよく行うが、組織の機能不全を隠すために時間や健康を犠牲にしない。(4) プロジェクト終了後、非難のない事後分析を実施する。人ではなくシステムに焦点を当てる。異なる選択が結果を変えたであろう意思決定ポイントを特定する。(5) 事後分析を使用してより良い実践を構築する:より明確なプロジェクト受け入れ基準、より早期のリスクゲート、より強力なステークホルダー整合プロセス。これは、組織が次回より良い意思決定を行うことを教える。これが、シニアエンジニアが永続的な価値を創造する方法である—英雄的行為によってではなく、組織の将来にわたって複利的に増大するシステム的改善によって。