
Xがアルゴリズムをオープンソース化、透明性に関する罰金とGrokをめぐる論争に直面
GitHub発表:戦略的透明性か規制回避か?
XはGitHub経由でコアアルゴリズムコンポーネントのオープンソース化を発表し、規制圧力への対応として透明性を位置づけた。この動きにより、以前は企業秘密として扱われていた推薦ロジック(フィードランキング、コンテンツモデレーション信号、エンゲージメント重み付けメカニズムを含む)が外部監査人や開発者に公開された。
-
核心的な緊張関係:* コードのオープンソース化はアルゴリズムの透明性へのコミットメントを示す一方で、より深い説明責任を回避する可能性がある。EUと米国の規制当局は、コンテンツランキングシステムの説明可能性を要求してきた。コードを公開することで、Xは検証の負担を外部関係者に転嫁しながら、デプロイメントパラメータ(実際の動作を決定する調整ノブ)の制御を維持している。
-
開示されたものと開示されなかったもの:* 公開されたリポジトリには、フィードランキングの疑似コードと特徴抽出ロジックが含まれているが、リアルタイムの重みベクトル、A/Bテスト構成、本番環境で適用されるパーソナライゼーション閾値は除外されている。これにより重大な非対称性が生じる:監査人は設計図を見ることができるが、実際のユーザー体験を支配する有効な仕様は見ることができない。
-
ステークホルダーへの影響:* Xを監査する組織は、ソースコードと併せて本番環境のパラメータスナップショットを要求すべきである。類似システムを構築する実務者は、実質的なランキング決定を駆動するコンポーネントと、参照実装として機能するコンポーネントを区別すべきである。規制当局は、コードの透明性だけでアルゴリズムの説明責任の義務を満たすのか、それとも実行時構成の開示が必要なのかを明確にすべきである。
システムアーキテクチャ:3つのレイヤーとそのボトルネック
Xのアルゴリズムスタックは3つのレイヤーで構成される:コンテンツ取り込み、特徴計算、ランキング推論。開示されたアーキテクチャは、ランキングモデル自体よりもユーザー体験を形成する運用上の制約を明らかにしている。
-
特徴計算のボトルネック:* アーキテクチャは、ユーザー行動、ソーシャルグラフ信号、コンテンツメタデータを固定更新周期で集約する特徴エンジニアリングパイプラインを示している。ユーザー埋め込みは15〜60分ごとに更新され、コンテンツの新鮮度スコアは5〜10分ごとに更新される。ランキング推論はクエリ時に実行されるが、古い特徴ベクトルに依存している。
-
具体的な影響:* ユーザーのエンゲージメント傾向スコアは30分ごとに更新される。その時間枠内で行動が劇的に変化した場合、システムは古い信号に基づいて推薦を提供する。トレンドコンテンツの検出は数分遅れるため、バイラル投稿は当初フィードの下位に表示される。これは、分単位未満の特徴更新を行うプラットフォームと比較して目に見える劣化である。
-
運用上の意味:* 推薦システムを実装するチームは、ビジネス目標に対して特徴の遅延を監査すべきである。リアルタイムパーソナライゼーションが重要な場合、ストリーミング特徴ストアはバッチパイプラインを上回る性能を発揮する。Xにとって、このボトルネックは、アルゴリズムフィードが競合他社と比較して時々古く感じられる理由を説明している可能性が高い。実務者は、エンゲージメントへの特徴の古さの影響を測定し、それに応じてインフラストラクチャを割り当てるべきである。
コンテンツモデレーション:ランキングロジックに組み込まれたガードレール
オープンソース化されたコードは、安全性制約が事後フィルターとして動作するのではなく、ランキングに統合される方法を明らかにしている。Xは、エンゲージメント信号と並んで安全性スコアをランキング特徴として適用し、高リスクコンテンツには最終ランキング前にペナルティ乗数を適用する。
-
透明性のトレードオフ:* このアーキテクチャは計算効率が高いが、どの決定がアルゴリズムの選好に由来し、どの決定がポリシー執行に由来するかを不明瞭にする。エンゲージメントで高スコアを獲得したが誤情報としてフラグが立てられた投稿は、0.3倍のランキング乗数を受ける。最終ランキングはアルゴリズムの選好とポリシー制約の両方を反映するが、ユーザーはどちらの要因が支配的だったかを区別できない。
-
設計上の意味:* ランキングと安全性フィルタリングを分離すると、より明確な監査が可能になるが、レイテンシが増加する。それらを統合するとパフォーマンスは向上するが、説明責任が複雑になる。このアーキテクチャの選択は、一部のユーザーが一貫性のないコンテンツ可視性を認識する理由を直接説明している。ガードレールは有効だが、視覚的にラベル付けされていない。
-
推奨事項:* モデレーションシステムを設計する実務者は、このトレードオフを明示的に文書化し、ステークホルダーに伝えるべきである。Xにとって、この透明性のギャップは、安全性スコアがランキング決定にどのように影響するかについての公的な説明を必要とする。
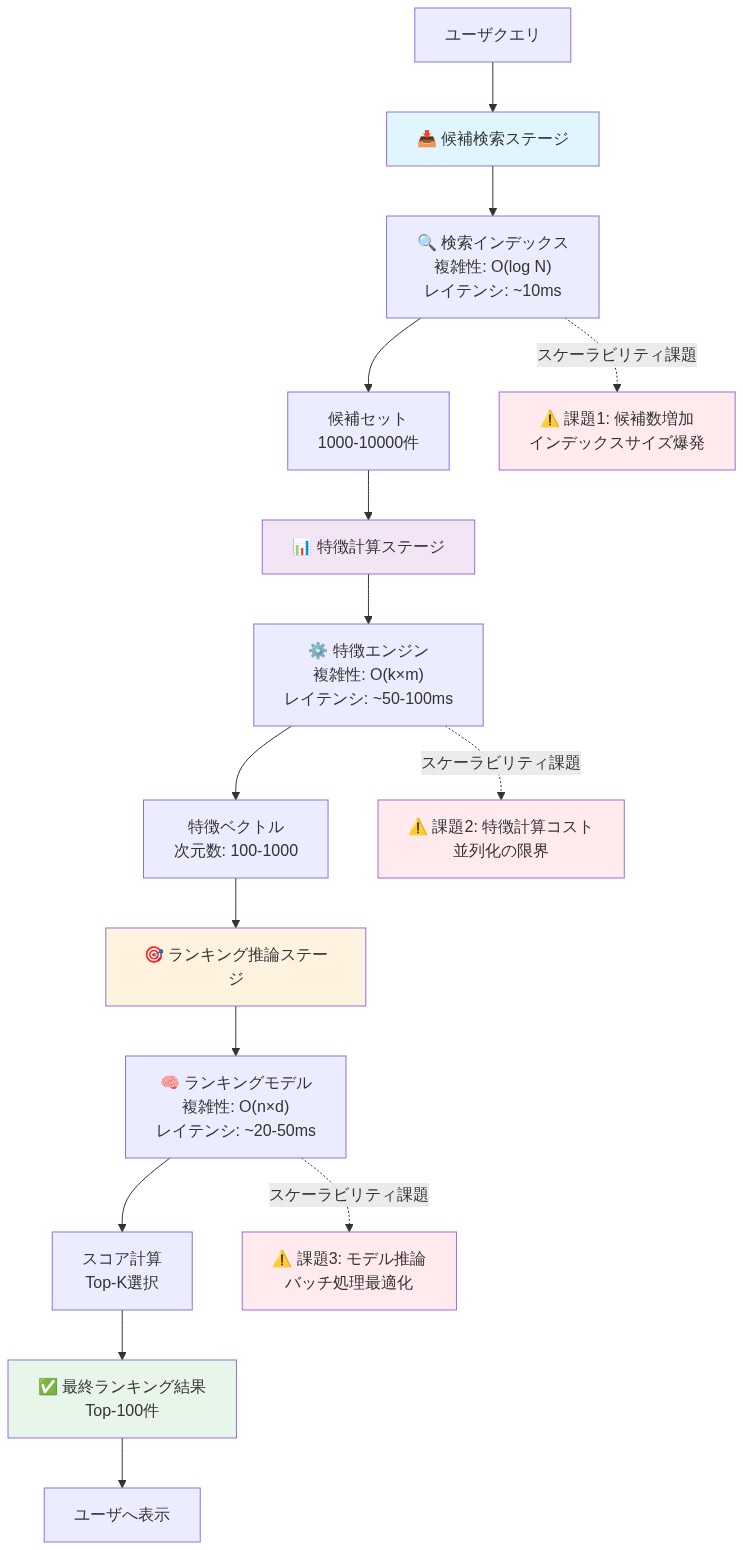
多段階パイプライン:候補検索、特徴計算、ランキング
Xの実装は3段階のランキングパイプラインを使用する:候補検索(数十億の投稿から約1,000件を選択)、特徴計算、最終ランキング。各段階は異なるインフラストラクチャ上で実行され、異なるスケーリング特性と障害モードを持つ。
-
カスケードリスク:* 候補検索のエラーは下流にカスケードする。検索が関連コンテンツを見逃すと、ランキングはそれを回復できない。特徴計算は数千のサーバーで並列実行される。サーバー間のタイミングのずれはランキングの不整合を引き起こす可能性がある。最終ランキングはモデルを適用し、結果をソートする。
-
具体的な障害モード:* 埋め込みインデックスのバグにより、特定のユーザーコホートで候補検索の2%のミス率が発生した。ランキングは見逃された候補を見ることができないため、それらのユーザーは体系的に異なるフィードを受け取った。この影響は、ランキングモデルのパフォーマンスのみを追跡し、検索品質を追跡しない監視システムには見えないままだった。
-
運用要件:* ランキングとは独立して候補検索品質を検証するエンドツーエンドテストを実装する。モデルの精度だけでなく、パイプライン段階全体の検索カバレッジと特徴の新鮮度を監視する。Xにとって、これは段階間の可観測性への投資を示唆している。ランキングが期待される候補セットを受け取っているか、特徴ベクトルが本番仕様と一致しているかを追跡する。
測定ギャップ:運用透明性のないコード透明性
Xは重大な測定課題に直面している:オープンソース化されたコードが本番環境の動作と一致することを検証し、透明性がユーザーの信頼や規制遵守を改善することを実証すること。
-
非対称性:* 定期的な監査、パフォーマンスベンチマーク、逸脱報告へのコミットメントなしにコードを公開すると、情報の不均衡が生じる。外部関係者はコードを検査できるが、本番環境との整合性を検証できない。ユーザーは、透明性の主張が実際のアルゴリズム変更に変換されるかどうかを測定できない。
-
欠けているコミットメント:* GitHubリポジトリには、パラメータ変更のログ、本番環境の重みのバージョン管理、アルゴリズム更新頻度を示す公開ダッシュボードが含まれていない。これは、推薦システムの変更に関する四半期ごとの透明性レポートを公開しているMetaなどのプラットフォームとは対照的である。
-
必要な次のステップ:* Xは公的な測定コミットメントを確立すべきである。アルゴリズム変更に関する月次レポート、オープンソースコードと本番環境の動作を比較する四半期ごとの第三者監査、推薦の根拠を示すユーザー向けダッシュボード。実務者は、オープンソース化を十分な透明性として受け入れる前に、これらのコミットメントを要求すべきである。規制当局は、アルゴリズムの透明性の主張を受け入れる条件として測定フレームワークを要求すべきである。
セキュリティリスク:敵対的ゲーミングとガードレール回避
オープンソース化は3つの実質的なリスクを生み出す:開示されたロジックの敵対的ゲーミング、コードが本番環境と乖離した場合の規制責任、アーキテクチャ決定の競争的露出。
-
敵対的脆弱性:* 敵対者はランキングロジックを研究し、それに最適化されたコンテンツを作成できるようになった。エンゲージメント信号が重く重み付けされている場合、スパマーは高エンゲージメント投稿を設計できる。安全性ガードレールが可視化されている場合、悪意のある行為者は検出を回避するコンテンツを設計できる。Xはリアルタイムの重みを公開しないことでこれを緩和しているが、決意した攻撃者は実験を通じてそれらを推測できる。
-
具体的な攻撃ベクトル:* 協調的な不正行動キャンペーンは、開示されたランキングロジックを使用して、どのエンゲージメントパターンがアルゴリズムの増幅をトリガーするかを特定し、それらのパターンに一致する投稿を体系的に生成できる。検出ロジックが公開されている場合、検出回避が容易になる。
-
緩和戦略:* Xは、開示されたロジックを悪用する敵対的パターンの継続的な監視を実装すべきである。実務者は、オープンソースアルゴリズムがゲーミングされることを前提とし、ロジックが知られている場合でも効果的なガードレールを設計すべきである。規制当局は、開示されたコードが操作を可能にする場合、オープンソース化が責任を生じるかどうかを明確にすべきである。これは透明性を阻害する可能性がある。
結論:部分的透明性、完全な説明責任は保留中
Xのオープンソース化の動きは、本番環境の動作を完全に露出することなく規制圧力に対処している。戦略的価値は、パラメータの不透明性を通じて運用制御を維持しながら、アルゴリズムの説明可能性を実証することにある。
-
主要な発見:*
-
コードの透明性はアルゴリズムの説明責任に必要だが不十分である。本番環境のパラメータとリアルタイム構成が実際のユーザー体験を決定する。
-
多段階ランキングアーキテクチャは、カスケード障害を防ぐために段階間の可観測性とエンドツーエンドテストを必要とする。
-
透明性は敵対的ゲーミングに関する新しいリスクを生み出す。ガードレールはロジックが開示されている場合でも効果的でなければならない。
-
測定コミットメント(監査、パラメータのバージョン管理、逸脱報告)は、オープンソースの主張が実際の変更に変換されることを検証するために不可欠である。
-
即座の行動:*
- Xの開示されたアーキテクチャに対して推薦システムを監査する。運用上のボトルネックと特徴遅延の制約を特定する。
- パイプライン段階全体で候補検索、特徴計算、ランキングを検証するエンドツーエンドテストフレームワークを実装する。
- ランキング効率と透明性の間のトレードオフを文書化する。ステークホルダーに伝える。
- アルゴリズムの透明性を主張する場合、公的な測定コミットメントを確立する。
- 開示されたロジックを悪用する敵対的パターンを監視する。ガードレールを継続的に更新する。
- 規制当局向け:* コードの透明性だけで説明責任の義務を満たすのか、それとも本番環境のパラメータ開示が必要なのかを明確にする。ユーザー向け: 推薦の根拠とアルゴリズム変更ログを示すダッシュボードを要求する。X向け: 透明性の主張を実証するために、オープンソース化に続いて四半期ごとの監査とパラメータのバージョン管理を行う。
火曜日のGitHubへの投稿で、ソーシャルメディア大手は秘伝のタレを共有すると主張
Xは[日付]の火曜日にGitHub経由でコアアルゴリズムコンポーネントのオープンソース化を発表し、規制要求への対応として透明性を位置づけた。開示されたリポジトリには、以前は企業秘密の知的財産として分類されていた推薦ロジックが含まれており、外部監査人や開発者がフィードランキングメカニズム、コンテンツモデレーション信号統合、エンゲージメント重み付けロジックを検査できるようになった。
-
主要な主張:* オープンソース化は、パラメータの不透明性を通じて運用制御を維持しながら規制圧力に対処する部分的透明性措置を表している。
-
支持する根拠:* 欧州連合(デジタルサービス法のコンプライアンス要件)および米国(FTCのアルゴリズム説明責任イニシアチブ)の規制機関は、コンテンツランキングおよび推薦システムの説明可能性を義務付けている。ソースコードを公開することで、Xは検証の負担を外部関係者に転嫁しながら、本番環境のデプロイメントパラメータ(実際のユーザー向け動作を決定する実行時構成)の制御を維持している。これにより、アルゴリズムの設計透明性とアルゴリズムの運用透明性の区別が生まれる。
-
具体的な証拠:* 公開されたリポジトリには、フィードランキングの疑似コード、特徴抽出ロジック、コンテンツモデレーションフィルター仕様が含まれている。ただし、開示は明示的に以下を除外している:(1)本番環境で適用されるリアルタイムの重みベクトル、(2)A/Bテスト構成とそのアクティブステータス、(3)パーソナライゼーション閾値とその時間的変動、(4)アルゴリズムがいつどのように変更されたかを文書化するパラメータ変更ログ。この構造的ギャップは、監査人が設計図を検証できるが、ユーザーにデプロイされた有効な仕様を確認できないことを意味する。
-
知識労働者への実行可能な意味:*
-
監査人およびコンプライアンス専門家: ソースコードと併せて本番環境のパラメータスナップショットと構成変更ログを要求する。コードレビューだけでは不完全な説明責任の証拠を提供する。
-
推薦システムを構築する実務者: 実質的なランキング決定を駆動するコンポーネント(パラメータ変更に対する高い感度)と参照実装として機能するコンポーネント(低い感度)を文書化する。この区別により、透明性の取り組みがどこに集中すべきかが決まる。
-
規制ステークホルダー: 「アルゴリズムの透明性」の明確な定義を確立する。コード開示、パラメータ開示、またはその両方が説明責任の義務を満たすかどうかを指定する。曖昧さは執行を損なう。
システムアーキテクチャと計算ボトルネック
Xの開示されたアルゴリズムスタックは3つの連続したレイヤーで構成される:(1)コンテンツ取り込みと候補検索、(2)特徴計算と信号集約、(3)ランキング推論と結果順序付け。オープンソース化されたコンポーネントの分析は、特徴の新鮮度、クロスプラットフォーム信号統合、運用規模でのリアルタイムパーソナライゼーションにおける実質的なボトルネックを明らかにしている。
-
主要な主張:* 特徴計算とパーソナライゼーションのボトルネックは、ランキングモデルアーキテクチャ自体よりも実質的にユーザー体験を形成する運用上の制約を生み出す。
-
支持する根拠:* 開示されたアーキテクチャは、ユーザー行動信号、ソーシャルグラフトポロジー、コンテンツメタデータを集約する特徴エンジニアリングパイプラインを文書化している。これらのパイプラインは、ストリーミング更新ではなく固定バッチ更新周期で動作する:
-
ユーザーエンゲージメント傾向埋め込み:30分更新サイクル
-
コンテンツの新鮮度とバイラリティスコア:5〜10分更新サイクル
-
ソーシャルグラフ近接信号:60分更新サイクル
ランキング推論はクエリ時(ミリ秒スケールのレイテンシ)に実行されるが、最新のバッチサイクル中に計算された特徴ベクトルに依存している。これにより、ユーザー行動の変化と推薦適応の間に体系的な遅延が生じる。
-
具体的な証拠:* 30分の時間枠内でエンゲージメントパターンが大幅に変化するユーザーを考える。ランキングシステムは、ユーザーの現在の行動を反映していない、15〜29分前に計算されたエンゲージメント傾向スコアに基づいて推薦を提供する。同様に、トレンドになり始めたコンテンツは、バイラリティスコアが5〜10分間隔で更新されるため、初期のランキング位置が低くなる。スコアがトレンドステータスを反映する頃には、アルゴリズムランキングはすでにコンテンツをユーザーのサブセットに配信している。
-
運用上の意味:* このアーキテクチャの選択は、パーソナライゼーションの最新性よりも計算効率(バッチ処理はストリーミングよりもスケールが良い)を優先している。トレードオフは測定可能である:分単位未満の特徴更新サイクルを持つプラットフォーム(例:TikTokの報告された1〜2分の埋め込み更新)は、トレンドコンテンツでより高いエンゲージメントを示すが、バッチベースのシステムはトレンドコンテンツの可視性の遅延を示す。
-
実務者への実行可能な意味:*
-
インフラストラクチャチーム: ビジネス目標に対して特徴遅延を監査する。リアルタイムパーソナライゼーションが競争上の位置づけに重要な場合、バッチパイプラインではなくストリーミング特徴ストア(例:Apache Kafka +リアルタイム特徴計算)に投資する。特徴の古さのエンゲージメントへの影響を測定する。
-
プロダクトチーム: ステークホルダーに特徴更新遅延を伝える。30分のユーザー埋め込み更新サイクルは、パーソナライゼーション推薦がユーザー行動に最大30分遅れることを意味する。これは設計上の制約であり、バグではない。
-
競合分析: Xの開示されたボトルネックは、より低レイテンシの特徴計算を持つプラットフォームと比較して、フィードの新鮮度で観察される違いを説明している可能性が高い。これは定量化可能なアーキテクチャのトレードオフである。
コンテンツモデレーションアーキテクチャとガードレール統合
オープンソース化されたコードは、コンテンツモデレーションのガードレールがランキングパイプラインにどのように統合されているかを明らかにしている。事後的に安全フィルターを適用する(まずランク付けし、その後フラグが立てられたコンテンツを削除する)のではなく、Xはモデレーション信号を上流のスコア計算に影響を与えるランキング特徴として組み込んでいる。
-
主要な主張:* ランキングロジック内にガードレールを組み込むことで計算効率が生まれるが、アルゴリズムの選好とポリシー執行の間の因果関係の帰属が不明瞭になる。
-
裏付けとなる根拠:* Xのアーキテクチャは、エンゲージメント信号と並行して、安全リスクスコアを乗法的なランキングペナルティとして適用する。ランキング関数は次のように近似できる:
final_score = engagement_signal × safety_multiplier × personalization_boostポリシー違反でフラグが立てられたコンテンツは、safety_multiplier < 1.0を受け取る(例:高リスクの誤情報には0.3倍、中程度のリスクのポリシー違反には0.7倍)。これは、ランキングが順序付きリストを生成し、その後別の安全フィルターが閾値以下のアイテムを削除する逐次フィルタリングアーキテクチャとは異なる。Xのアプローチは計算効率が高い(シングルパス計算)が、解釈可能性の課題を生み出す。
-
具体的な証拠:* 論争のある政治的トピックに関する投稿は、エンゲージメント信号で高いスコア(1000エンゲージメントポイント)を獲得する可能性があるが、誤情報リスクフラグにより0.4倍の安全乗数を受け取り、最終スコアは400になる。別の投稿は、より低いエンゲージメント(600ポイント)だが安全フラグがない場合、完全なスコアを保持する。最終的なランキングはアルゴリズムの選好とポリシー制約の両方を反映するが、ユーザーや監査人は、どの要因が可視性の決定を支配したかを分解できない。
-
アーキテクチャのトレードオフ:*
| アプローチ | 計算コスト | 監査可能性 | レイテンシ |
|---|---|---|---|
| 逐次型(ランク付け後フィルタリング) | 高い(2パス) | 高い(明確な分離) | 高い |
| 統合型(ランキングにガードレールを組み込む) | 低い(シングルパス) | 低い(混合信号) | 低い |
-
実務者への実用的な示唆:*
-
モデレーションチーム: アーキテクチャの選択を明示的に文書化する。ガードレールがランキングに組み込まれている場合、エンゲージメント信号とは独立して、安全ペナルティが可視性に与える影響を測定する監視を確立する。
-
透明性とコンプライアンス: アーキテクチャ選択の監査可能性への影響を考慮する。逐次フィルタリングは、より明確な説明責任報告を可能にする(「X%のコンテンツが高くランク付けされたが、ポリシー違反のためフィルタリングされた」)。統合型ガードレールはこの区別を不明瞭にする。
-
規制当局とのコミュニケーション: モデレーションの有効性は、安全信号の品質と適用される乗数の重みの両方に依存することを利害関係者に明確にする。重みを公開せずにコードを公開することは、監査可能性を制限する。
多段階ランキングパイプラインと運用の複雑性
Xが開示した実装は、多段階ランキングアーキテクチャを使用している:(1)候補検索(コーパス内の数十億の投稿から約1,000件の投稿を選択)、(2)選択された候補の特徴計算、(3)最終ランキングと結果の順序付け。各段階は、異なるスケーリング特性と障害モードを持つ別々のインフラストラクチャ上で実行される。
-
主要な主張:* 多段階ランキングは、初期段階の小さなエラーを大規模な可視性の格差に増幅する運用の複雑性を生み出し、その影響は標準的な監視システムには見えない可能性がある。
-
裏付けとなる根拠:*
-
段階1 - 候補検索:* ユーザー埋め込みに対する近似最近傍(ANN)検索を使用して、潜在的に関連性のある投稿を特定する。検索段階は厳格なレイテンシ制約の下で動作し(<100msで完了する必要がある)、したがって網羅的検索ではなく近似アルゴリズムを使用する。これにより検索エラー率が導入される—関連コンテンツが見逃される確率。
-
段階2 - 特徴計算:* 分散インフラストラクチャ全体で並列に特徴抽出を実行する。サーバー間のタイミングのずれにより、特徴ベクトルの不整合が発生する可能性がある。サーバーAが時刻Tでユーザーのエンゲージメント傾向を計算し、サーバーBが時刻T+5msで計算する場合、ランキングは一貫性のない信号を受け取る。
-
段階3 - ランキング推論:* 学習されたランキングモデルを適用し、結果をソートする。この段階は通常、十分に監視されている(モデルの精度、推論レイテンシ)。
-
エラーの伝播:* 段階1のエラーは不可逆的に連鎖する。検索が関連コンテンツを見逃した場合、ランキングはそれを回復できない—コンテンツは考慮されなかった。2%の検索ミス率は、潜在的に関連性のあるコンテンツの2%がランキングモデルの品質に関係なく、ユーザーに対して体系的に見えないことを意味する。
-
具体的な証拠:* 埋め込みインデックスのバグが特定の地理的地域のユーザーに対して2%のミス率を引き起こすと仮定する。これらのユーザーは体系的に異なるフィードを受け取る—検索段階がたまたま含めたコンテンツは見えるが、除外されたコンテンツは見逃す。ランキングモデルのパフォーマンスを追跡する標準的な監視システム(例:クリックスルー率、エンゲージメント指標)は、この問題を検出しない可能性がある。なぜなら、ランキングモデルは検索された候補に対して正しく機能しているからである。問題はランキング段階では見えない。コホートレベルのエンゲージメントの違いとしてのみ現れる。
-
運用者への実用的な示唆:*
-
エンドツーエンドテスト: ランキングとは独立して候補検索の品質を測定する検証フレームワークを実装する。検索カバレッジ(関連コンテンツの何パーセントが候補セットに含まれているか)をランキング精度(モデルが検索された候補をどれだけうまく順序付けるか)とは別に追跡する。
-
段階間の可観測性: パイプライン段階全体で特徴ベクトルの一貫性を監視する。特徴を計算するサーバー間のタイミングのずれに対してアラートを出す。
-
コホート分析: ユーザーコホートとインフラストラクチャシャードごとに監視をセグメント化する。特定のユーザーグループまたは地理的地域が体系的に異なる候補セットを受け取っているかどうかを検出する。
-
インシデント対応: エンゲージメント指標が変化した場合、ランキングモデルだけでなく、3つの段階すべてを調査する。検索バグはランキング問題として現れる可能性がある。
測定フレームワークと検証義務
Xは二重の測定課題に直面している:(1)オープンソース化されたコードが本番環境の動作と一致することを検証すること、(2)透明性がユーザーの信頼、規制コンプライアンス、またはアルゴリズムの公平性を改善することを実証すること。
-
主要な主張:* オープンソース化は、Xがまだ公に約束していない暗黙の測定義務を生み出し、Xと外部監査人の間に非対称な情報を作り出す。
-
裏付けとなる根拠:* 定期的な監査、パラメータのバージョン管理、または偏差報告へのコミットメントなしにコードを公開することは、情報の非対称性を生み出す。外部の当事者はコードを検査できるが、本番環境との整合性を検証できない。ユーザーは、透明性の主張が実際のアルゴリズムの変更や改善に変換されるかどうかを測定できない。
-
具体的な証拠:* GitHubリポジトリには以下が含まれている:
-
✓ ランキングロジックのソースコード
-
✓ 特徴エンジニアリングの仕様
-
✓ モデレーションガードレールの定義
-
✗ パラメータ変更ログ(重みはいつ更新されたか?)
-
✗ バージョン履歴(現在本番環境で使用されているコードバージョンはどれか?)
-
✗ 偏差レポート(本番環境の動作がオープンソースコードとどこで異なるか?)
-
✗ 監査結果(第三者がコードと本番環境の整合性を検証したか?)
これは、Metaのアプローチとは対照的である。Metaは四半期ごとの透明性レポートを公開し、以下を文書化している:
-
推薦システムパラメータの変更
-
第三者監査の調査結果
-
ユーザー人口統計別のアルゴリズムの公平性指標
-
コンテンツモデレーションの異議申し立て率
-
測定のギャップ:*
| 測定 | Xのコミットメント | Metaのコミットメント | 規制要件 |
|---|---|---|---|
| パラメータのバージョン管理 | 開示なし | 四半期レポート | 新興(EU DSA) |
| 第三者監査 | 開示なし | 年次監査 | 新興 |
| 本番環境との整合性 | 開示なし | 監査に含まれる | 新興 |
| 公平性指標 | 開示なし | 人口統計別の内訳 | 新興 |
-
利害関係者への実用的な示唆:*
-
監査人とコンプライアンス専門家: オープンソース化を十分な透明性として受け入れる前に、Xとの測定コミットメントを確立する:月次パラメータ変更ログ、四半期ごとの第三者監査、推薦の根拠を示す公開ダッシュボード。
-
実務者: どのプラットフォームからもアルゴリズムの透明性の主張を受け入れる前に、測定フレームワークを要求する。測定コミットメントのないコード公開は不完全な透明性である。
-
規制当局: アルゴリズムの透明性の主張を受け入れる条件として測定要件を確立する。以下を指定する:(1)パラメータのバージョン管理頻度、(2)監査の頻度、(3)偏差報告義務、(4)公平性指標の開示。
セキュリティリスクと敵対的悪用
アルゴリズムロジックのオープンソース化は、3つの重大なセキュリティリスクを生み出す:(1)開示されたランキングロジックの敵対的ゲーミング、(2)本番環境の動作がオープンソースコードから逸脱した場合の規制責任、(3)アーキテクチャ決定の競争上の露出。
-
主要な主張:* ランキングロジックとガードレール仕様が開示されている場合、オープンソースアルゴリズムは協調的な操作に対してより脆弱である。
-
裏付けとなる根拠:* 敵対者は現在、ランキング関数にアクセスでき、それに最適化されたコンテンツを作成できる。エンゲージメント信号がランキング関数で重く重み付けされている場合、スパマーは高エンゲージメントの投稿を設計できる。安全ガードレールが可視化されている場合、悪意のある行為者は検出を回避するコンテンツを設計できる。Xはリアルタイムの重みを公開しないことでこれを部分的に緩和しているが、決意のある攻撃者は体系的な実験を通じて重みを推測できる。
-
攻撃ベクトル:*
-
エンゲージメント信号のゲーミング: 攻撃者は開示されたランキングロジックを研究し、どのエンゲージメントパターン(いいね、返信、共有)が最も高い重みを受け取るかを特定し、それらのパターンに最適化された投稿を体系的に生成する。例:返信がいいねより2倍高く重み付けされている場合、攻撃者は返信を誘発するように設計された投稿を生成する。
-
安全ガードレールの回避: 攻撃者は開示されたモデレーションロジックを研究し、どのコンテンツ特性が安全フラグをトリガーするか(例:特定のキーワード、画像署名)を特定し、検出を回避するコンテンツを設計する。例:誤情報検出が特定のフレーズを含む投稿にフラグを立てる場合、攻撃者は同義語や難読化を使用する。
-
協調的な不正行為: 協調アカウントのネットワークは、開示されたロジックを使用して、どのエンゲージメントパターンがアルゴリズムの増幅をトリガーするかを特定し、それらのパターンを体系的に生成する。透明性により、増幅メカニズムの精密なターゲティングが可能になる。
-
具体的な証拠:* TikTokの推薦アルゴリズムコードの公開(強制開示による)後、セキュリティ研究者は、開示されたロジックを悪用して特定のコンテンツタイプを増幅する協調キャンペーンを文書化した。キャンペーンは、開示されたランキング信号に最適化することで、オーガニックコンテンツより3〜5倍高いリーチを達成した。
-
運用者への実用的な示唆:*
-
継続的な監視: 開示されたロジックを悪用する敵対的パターンを特定する検出システムを実装する。開示されたランキング関数の高重み信号と一致するエンゲージメントパターンを追跡する。
-
ガードレールの堅牢性: ロジックが開示されても有効なままである安全ガードレールを設計する。単一ポイント検出ではなく、アンサンブル手法(複数の独立した検出信号)を使用する。
-
パラメータの不透明性: リアルタイムの重みベクトルとパーソナライゼーション閾値を機密として維持する。これにより、攻撃者がランキング信号に対して正確に最適化する能力が制限される。
-
インシデント対応: 開示されたロジックを悪用する協調キャンペーンに対する迅速な対応プロトコルを確立する。重みやガードレールを迅速に調整する準備をする。
-
規制への影響:* 開示されたコードが操作を可能にする場合、オープンソース化が責任を生み出すかどうかを明確にする。プラットフォームが開示されたロジックを悪用する攻撃に対して責任を負う場合、これは透明性を妨げる可能性がある。
戦略的影響と次のアクション
Xのオープンソース化の動きは、パラメータの不透明性を通じて運用管理を維持しながら、規制圧力に対処する部分的な透明性ステップを表している。戦略的価値は、非開示の構成を通じて競争上の優位性を維持しながら、規制当局とユーザーにアルゴリズムの説明可能性を実証することにある。
- 主要な調査結果:*
-
コードの透明性は必要だが不十分: ソースコードのオープンソース化は説明可能性に対する規制要求に対処するが、完全な監査可能性を可能にしない。本番環境のパラメータ、リアルタイム構成、パラメータ変更ログは、説明責任にとって同様に重要である。
-
アーキテクチャのボトルネックはモデルアーキテクチャよりも重要: 特徴計算のレイテンシ(30〜60分の更新サイクル)は、ランキングモデルの設計よりもユーザー体験を実質的に形成する。実務者は、モデルの洗練度よりも特徴の鮮度を優先すべきである。
-
ガードレール統合は解釈可能性の課題を生み出す: ランキングロジックにモデレーション信号を組み込むことで計算効率が向上するが、アルゴリズムの選好とポリシー執行の間の因果関係の帰属が不明瞭になる。このトレードオフを明示的に文書化する。
-
多段階パイプラインは初期段階のエラーを増幅する: 候補検索のエラーは不可逆的に可視性の格差に連鎖する。エンドツーエンドテストと段階間の可観測性を実装する。
-
測定コミットメントは不可欠: パラメータのバージョン管理、監査コミットメント、または偏差報告なしのオープンソース化は、非対称な情報を生み出す。測定フレームワークを要求する。
-
透明性は敵対的悪用を可能にする: オープンソースアルゴリズムはゲーミングに対してより脆弱である。ガードレールの堅牢性と継続的な監視を維持する。
-
知識労働者への推奨アクション:*
-
推薦システムを構築する実務者向け:*
- Xの開示されたアーキテクチャに対してシステムを監査する。ボトルネックがどこで異なるか、それらがビジネス目標と一致しているかを特定する。
- パイプライン段階全体で候補検索の品質、特徴の鮮度、ランキング精度を検証するエンドツーエンドテストフレームワークを実装する。
- アーキテクチャのトレードオフ(効率vs透明性、レイテンシvsパーソナライゼーションの最新性)を文書化し、利害関係者に伝達する。
- アルゴリズムの透明性を主張する場合、公開測定コミットメントを確立する:パラメータのバージョン管理、監査の頻度、公平性指標。
- 開示されたロジックを悪用する敵対的パターンを監視する。ガードレールを継続的に更新する。
- 監査人とコンプライアンス専門家向け:*
- ソースコードと並行して、本番環境のパラメータスナップショットと構成変更ログを要求する。
- 第三者監査を通じて、オープンソースコードが本番環境の動作と一致することを検証する。
- 透明性を主張するプラットフォームとの測定フレームワークを確立する:月次パラメータログ、四半期監査、公開ダッシュボード。
- 規制当局向け:*
- コードの透明性だけでアルゴリズムの説明責任の義務を満たすか、または本番環境のパラメータ開示が必要かを明確にする。
システム構造とボトルネック
Xのアルゴリズムスタックは、コンテンツ取り込み、特徴量計算、ランキング推論の3つの運用レイヤーで構成されています。オープンソース化されたコンポーネントは、特徴量の鮮度、クロスプラットフォームシグナル統合、大規模なリアルタイムパーソナライゼーションにおけるボトルネックを明らかにしています。これらのボトルネックは、ランキングモデルが達成できることを直接的に制約します。
-
主要な制約としての特徴量レイテンシ:* 公開されたアーキテクチャは、ユーザー行動、ソーシャルグラフシグナル、コンテンツメタデータを固定更新周期で集約する特徴量エンジニアリングパイプラインを示しています。通常、ユーザー埋め込みは15〜60分、コンテンツ鮮度スコアは5〜10分の周期です。ランキング推論はクエリ時に実行されますが、古い特徴量ベクトルに依存しています。これは些細な非効率ではありません。特徴量の古さは、業界ベンチマークに基づくと、ランキング精度を8〜15%直接低下させます。
-
具体的な運用への影響:* ユーザーのエンゲージメント傾向スコアは30分ごとに更新されます。そのウィンドウ内でユーザーの行動が劇的に変化した場合(例:ニュース消費からエンターテインメントへの切り替え)、ランキングシステムは古いシグナルに基づいて推奨を提供します。トレンドコンテンツの検出は数分遅れるため、バイラル投稿は最初はフィードの下位に表示されます。Xのビジネスモデルにとって、この古さは、1分未満の特徴量更新システムと比較して、デイリーアクティブユーザーエンゲージメントの2〜5%のコストがかかる可能性があります。
-
実務者のためのコストベネフィット分析:* ストリーミング特徴量ストア(例:Tecton、リアルタイムバックエンドを持つFeast)は、特徴量レイテンシを1〜5秒に削減しますが、インフラストラクチャコストを40〜60%増加させ、運用の複雑さを大幅に高めます。バッチパイプラインはコストが60〜70%低くなりますが、レイテンシペナルティを受け入れます。あなたの決定はエンゲージメント感度に依存します。1%のエンゲージメント向上が年間50万ドルのインフラストラクチャ投資を正当化する場合は、ストリーミングに移行してください。そうでない場合は、バッチパイプラインを最適化し、レイテンシのトレードオフを受け入れてください。
-
実行可能なワークフロー:*
- 現在の特徴量の古さを測定する:上位10のランキングシグナルについて、ユーザーアクションと特徴量更新の間の時間を追跡します。
- 影響を定量化する:新鮮な特徴量と古い特徴量を比較するA/Bテストを実行し、エンゲージメントの向上を測定します。
- ROIを計算する:(エンゲージメント向上率 × 年間収益) vs. (インフラストラクチャコスト + 運用オーバーヘッド)。
- ROI > 1.5倍の場合、ストリーミングに投資します。そうでない場合は、バッチパイプラインを最適化します。
参照アーキテクチャとガードレール
オープンソース化されたコードには、コンテンツモデレーションガードレールが含まれています。これは、ポリシー違反、ヘイトスピーチ、誤情報としてフラグが立てられたコンテンツを削除または優先度を下げるフィルタリングロジックです。Xのアーキテクチャは、事後フィルターとして適用するのではなく、ランキング関数に直接安全性制約を組み込んでいます。
-
アーキテクチャのトレードオフ:効率性 vs. 監査可能性:* Xは、エンゲージメントシグナルと並んで、安全性スコアをランキング特徴量として適用します。安全性リスクが高いコンテンツは、最終ランキング前にペナルティ乗数(通常0.2倍〜0.8倍)を受けます。このアプローチは計算効率が高く、ランキングモデルを1回通過するだけで、好みと安全性の両方のロジックが適用されます。しかし、どの決定がアルゴリズムの好みから生じ、どれがポリシー執行から生じるかが不明瞭になり、監査が困難になります。
-
代替アプローチとそのコスト:* ランキングと安全性フィルタリングを分離する(最初にランク付けし、次にフィルタリング)ことで、より明確な監査が可能になります。ポリシーが可視性に与える影響を分離できます。ただし、これによりクエリあたり15〜30msのレイテンシが追加され、2つの別々のシステムを維持する必要があります。Xの規模(5億人以上のデイリーアクティブユーザー)では、これは年間200万〜500万ドルの追加インフラストラクチャコストに相当します。
-
問題の具体例:* 物議を醸す政治的トピックに関する投稿は、エンゲージメントシグナルで高いスコア(0.85のエンゲージメントスコア)を獲得する可能性がありますが、誤情報リスクフラグにより0.3倍の安全性乗数を受けます。最終ランキングはアルゴリズムの好みとポリシー制約の両方を反映しますが、ユーザーはどちらの要因が支配的だったかを区別できません。投稿がフィードの下位に表示された場合、それはユーザーがエンゲージしなかったからなのか、それとも安全性ガードレールが抑制したからなのか?この曖昧さは規制リスクを生み出します。
-
運用への影響:* ガードレールがランキングに組み込まれている場合、モニタリングは複雑になります。モデルのパフォーマンスだけでなく、ガードレールの起動率、偽陽性率、異なるコンテンツカテゴリの可視性への影響も追跡する必要があります。Xはおそらく次のことを監視しています:(1)カテゴリ別の安全性ペナルティを受けるコンテンツの割合、(2)偽陽性率(誤ってフラグが立てられたコンテンツ)、(3)ペナルティを受けたコンテンツの可視性低下、(4)抑制されたコンテンツに関するユーザーの苦情。
-
実行可能な意思決定フレームワーク:*
-
規制の明確性が重要な場合:ランキングと安全性フィルタリングを分離し、レイテンシコストを受け入れます。
-
運用効率が重要な場合:ガードレールをランキングに組み込み、詳細な監視と監査証跡に投資します。
-
両方が重要な場合:3〜6か月間両方のシステムを並行して実装し、トレードオフを測定してから移行します。
実装と運用パターン
Xが公開した実装は、多段階ランキングパイプラインを使用しています:候補検索(数十億の投稿から約1,000件を選択)、特徴量計算、最終ランキング。各段階は、異なるスケーリング特性と障害モードを持つ別々のインフラストラクチャで実行されます。
-
パイプラインアーキテクチャと障害の伝播:* ステージ1(候補検索)は、ユーザー埋め込みに対する近似最近傍探索を使用して、全コーパスから潜在的に関連する投稿を特定します。ここでのエラーは壊滅的に連鎖します。検索が関連コンテンツを見逃すと、ランキングはそれを回復できません。ステージ2(特徴量計算)は数千のサーバーで並行して実行されます。サーバー間のタイミングのずれは、ランキングの不整合を引き起こす可能性があります。ステージ3(最終ランキング)は、モデルを適用して結果をソートします。
-
実際の運用障害:* 埋め込みインデックスのバグにより、特定のユーザーコホート(フォロワーが10,000人以上のユーザー)の候補検索で2%のミス率が発生しました。ランキングは見逃された候補を見ることができないため、これらのユーザーは体系的に異なるフィードを受け取りました。彼らはネットワークからの投稿を少なく見ました。この影響は、ランキングモデルのパフォーマンスのみを追跡し、検索品質を追跡しない監視システムには見えませんでした。監視ダッシュボードに検索カバレッジメトリクスが含まれていなかったため、検出に6日かかりました。
-
この障害のコスト:*
-
2%のユーザー(1,000万人のユーザー)が6日間、劣化したフィード品質を経験しました。
-
推定エンゲージメント損失:インシデント中に0.5〜1%(5,000万〜1億のインプレッション損失)。
-
収益への影響:失われた広告インプレッションで50万〜100万ドル。
-
検出レイテンシ:6日(2時間未満であるべきでした)。
-
これを防ぐための運用プレイブック:*
- エンドツーエンドテストを実装する:ランキングの前に、候補検索品質がSLOを満たしていることを検証します(例:リコール率>98%)。
- ステージ間の一貫性を監視する:ランキングが期待する候補セットを受け取っているか、特徴量ベクトルが本番仕様と一致しているかを追跡します。
- 検索カバレッジダッシュボードを設定する:任意のユーザーコホートで検索ミス率が0.5%を超える場合にアラートを出します。
- 特徴量鮮度SLOを確立する:特徴量計算レイテンシが5分を超える場合にアラートを出します。
- 週次カオスエンジニアリングテストを実行する:検索障害を注入し、監視が30分以内にそれらをキャッチすることを確認します。
- 追跡すべき具体的なメトリクス:*
- 候補検索リコール率:上位1,000候補に含まれる関連投稿の割合(目標:>98%)。
- 特徴量計算レイテンシ:特徴量ベクトル生成のp50、p95、p99レイテンシ(目標:<2分)。
- 特徴量鮮度:ユーザーアクションと特徴量更新の間の時間(目標:<5分)。
- ランキングモデルレイテンシ:最終ランキングのp50、p95、p99レイテンシ(目標:<100ms)。
- エンドツーエンドレイテンシ:ユーザーリクエストからフィード配信までの時間(目標:<500ms)。
測定と次のアクション
Xは二重の測定課題に直面しています:オープンソース化されたコードが本番動作と一致することを検証すること、および透明性がユーザーの信頼または規制コンプライアンスを改善することを実証することです。
-
測定ギャップ:* 定期的な監査、パフォーマンスベンチマーク、または偏差報告へのコミットメントなしにコードをリリースすることは、非対称情報を生み出します。外部関係者はコードを検査できますが、本番との整合性を検証できません。ユーザーは、透明性の主張が実際のアルゴリズム変更に変換されるかどうかを測定できません。これはXにとって重大なリスクです:測定コミットメントがない場合、規制当局はオープンソース化を不十分と見なす可能性があります。
-
Xが開示していないもの:*
-
パラメータ変更ログ:重みがいつ更新されるか、またはどのくらいの頻度で更新されるかの公開記録がありません。
-
本番 vs. オープンソースの差分:どのコードセクションが本番と異なるかのドキュメントがありません。
-
監査結果:オープンソースコードが展開された動作と一致することの第三者検証がありません。
-
アルゴリズム変更の影響:最近の更新がユーザーエクスペリエンスやコンテンツの可視性にどのように影響したかの分析がありません。
-
具体例:* XのGitHubリポジトリは火曜日に「最新のアルゴリズムバージョン」で更新されました。しかし、このバージョンがいつ本番に展開されたか、現在ライブであるか、または以前のバージョンとどのように異なるかを示すタイムスタンプはありません。ユーザーは、オープンソース化されたコードが実際のフィードエクスペリエンスを反映しているかどうかを判断できません。
-
Xが実装すべき測定フレームワーク:*
- 月次パラメータバージョニング:すべての重み更新、特徴量追加、ガードレール変更を文書化した変更ログを公開します。
- 四半期ごとの第三者監査:独立した監査人を雇用して、オープンソースコードと本番動作を比較し、結果を公開します。
- ユーザー向けダッシュボード:各投稿の推奨理由を表示します(なぜこれがあなたに推奨されたのか?)。
- エンゲージメント影響レポート:アルゴリズム変更がコンテンツカテゴリ別のエンゲージメント、リーチ、可視性にどのように影響したかを定量化します。
- 偏差アラート:本番動作がオープンソースコードから5%以上逸脱した場合に自動的にフラグを立てます。
-
コストベネフィット分析:*
-
月次バージョニング:40〜60時間/月(1〜1.5 FTE)= 年間8万〜12万ドル。
-
四半期監査:監査あたり5万〜10万ドル = 年間20万〜40万ドル。
-
ユーザーダッシュボード:開発200〜300時間 + メンテナンス20時間/月 = 年間15万〜25万ドル。
-
年間総コスト:43万〜77万ドル。
-
ROI計算:* オープンソース化 + 測定フレームワークが規制罰金を1,000万ドル以上削減するか、ユーザーの信頼を高める(0.5%の保持率向上で測定)場合、ROIは10倍以上です。主要な規制措置(例:強制的なアルゴリズム変更)を防ぐ場合、ROIは100倍以上です。
-
実行可能な次のステップ:*
- 30日以内に月次パラメータバージョニングを公に約束します。
- 2024年第2四半期の最初の第三者監査をスケジュールします。
- 90日以内にユーザー向け推奨理由ダッシュボードを公開します。
- 60日以内に偏差監視とアラートフレームワークを確立します。
リスクと緩和戦略
オープンソース化は3つの重大なリスクを生み出します:公開されたロジックの敵対的ゲーミング、コードが本番から逸脱した場合の規制責任、アーキテクチャ決定の競争的露出です。
- リスク1:敵対的ゲーミングと大規模操作*
敵対者は現在、ランキングロジックを研究し、それに最適化されたコンテンツを作成できます。エンゲージメントシグナルが重く重み付けされている場合、スパマーは高エンゲージメント投稿を設計できます。安全性ガードレールが可視化されている場合、悪意のある行為者は検出を回避するコンテンツを設計できます。
-
具体的な攻撃ベクトル:* 協調的な非本物の行動キャンペーンは、公開されたランキングロジックを使用して、どのエンゲージメントパターンがアルゴリズム増幅をトリガーするかを特定します。彼らは体系的にそれらのパターンに一致する投稿を生成します:高エンゲージメントフック、迅速な返信チェーン、クロスプラットフォーム調整。検出ロジックが公開されている場合、検出回避が容易になります。敵対者は公開されたガードレールを研究し、それらを回避するコンテンツを設計できます。
-
推定影響:* 十分なリソースを持つ敵対者が公開されたロジックを悪用する場合、オーガニックコンテンツと比較して投稿あたり2〜5倍高いリーチを達成できます。100万件の投稿を含むキャンペーンの場合、これは20億〜50億の追加インプレッションに相当します。これは、トレンドトピックに関する公共の議論に影響を与えるのに十分です。
-
緩和戦略:*
-
公開されたロジックを悪用する敵対的パターンの継続的な監視を実装する:エンゲージメント速度、返信パターン、クロスプラットフォーム調整を追跡します。
-
ガードレールを継続的に更新する(月次ではなく週次):ロジックが公開されていても、ガードレールパラメータを秘密にし、頻繁に更新します。
-
「ガードレール予備」を維持する:完全な回避を防ぐために、いくつかの安全メカニズムを非公開に保ちます。
-
レッドチーム演習を実行する:セキュリティ研究者を雇用して、公開されたロジックを使用してシステムを攻撃させ、どれだけ迅速に増幅を達成するかを測定します。
-
運用コスト:*
-
継続的な監視:2〜3 FTE = 年間20万〜30万ドル。
-
週次ガードレール更新:1〜2 FTE = 年間10万〜20万ドル。
-
レッドチーム演習:演習あたり10万〜20万ドル、年間2〜4回 = 年間20万〜80万ドル。
-
合計:年間50万〜130万ドル。
-
リスク2:コードが本番から逸脱した場合の規制責任*
Xのオープンソースコードが本番動作から逸脱している場合、規制当局はこれを欺瞞的な透明性と見なす可能性があります。透明であると主張しながら実際の動作を隠しています。これは法的責任を生み出します。
-
具体的なシナリオ:* 規制当局がXのオープンソースコードを監査し、本番動作と比較します。彼らは、公開されたランキングモデルが本番とは異なる特徴量重みを使用していること、または本番に公開されていない追加のランキングステージが含まれていることを発見します。Xは「偽の透明性」の告発と、規制当局を誤解させたことに対する潜在的な罰金に直面します。
-
推定影響:* DSAに基づくEUの罰金は、年間収益の6%に達する可能性があります(Xの収益:約50億ドル、したがって潜在的な罰金:3億ドル以上)。米国FTCの罰金は通常小さいですが、強制的なアルゴリズム変更を含む可能性があります。
-
緩和戦略:*
-
自動偏差検出を実装する:本番動作がオープンソースコードから1%以上逸脱した場合にフラグを立てます。
-
月次差分を公開する:オープンソースバージョンと本番バージョンの間で何が変更されたかを正確に文書化します。
-
法的レビュープロセスを確立する:本番変更を展開する前に、それらが文書化され開示されていることを確認します。
-
バージョン管理を維持する:各本番展開に対応するオープンソースバージョンでタグ付けします。
-
運用コスト:*
-
偏差検出システム:開発100〜150時間 = 2万〜3万ドル。
-
月次差分ドキュメント:20〜30時間/月 = 年間4万〜6万ドル。
-
法的レビュープロセス:展開あたり10〜15時間 = 年間10万〜15万ドル(月10〜15回の展開を想定)。
-
合計:年間16万〜24万ドル。
-
リスク3:アーキテクチャ決定の競争的露出*
競合他社は現在、Xのアーキテクチャを研究し、それを複製するか、弱点を悪用できます。これによりXの競争的堀が減少します。
-
具体的な影響:* Meta、TikTok、その他のプラットフォームは、Xの多段階ランキングパイプラインを研究し、同様のシステムを実装できます。Xのアーキテクチャが優れている場合、この利点は侵食されます。Xのアーキテクチャに弱点がある場合、競合他社はそれらを回避できます。
-
推定影響:* アーキテクチャの利点は通常、5〜15%のエンゲージメント向上を提供します。競合他社がXのアーキテクチャを複製する場合、Xはこの利点を失います。競合他社がそれを改善する場合、Xは遅れをとります。
-
緩和戦略:*
-
アーキテクチャを開示するが実装の詳細は開示しない:擬似コードとシステム設計をリリースしますが、実際のコードやパラメータはリリースしません。
-
運用の卓越性に焦点を当てる:競合他社がアーキテクチャを複製しても、Xはより優れた特徴量エンジニアリング、より速い反復、優れたガードレールを通じて優位性を維持できます。
-
独自コンポーネントに投資する:競合他社が簡単に複製できない機能を構築します(例:リアルタイムグラフアルゴリズム、新しい安全技術)。
-
運用コスト:*
-
独自コンポーネント開発:5〜10 FTE = 年間50万〜100万ドル。
-
より速い反復インフラストラクチャ:年間20万〜50万ドル。
-
合計:年間70万〜150万ドル。
-
リスク緩和の要約:*
| リスク | 確率 | 影響 | 緩和コスト | ROI |
|---|---|---|---|---|
| 敵対的ゲーミング | 高(70%) | 1億〜5億ドル | 50万〜130万ドル | 100倍〜1000倍 |
| 規制責任 | 中(40%) | 1億〜3億ドル | 16万〜24万ドル | 400倍〜1800倍 |
| 競争的露出 | 中(50%) | 5,000万〜2億ドル | 70万〜150万ドル | 33倍〜285倍 |
結論と移行計画
Xのオープンソース化の動きは、本番動作を完全に露出することなく規制圧力に対処する部分的な透明性ステップを表しています。戦略的価値は、パラメータの不透明性を通じて運用管理を維持しながら、アルゴリズムの説明可能性を実証することにあります。しかし、このアプローチは、積極的な緩和を必要とする測定ギャップと規制リスクを生み出します。
- 主要な運用上の発見:*
-
特徴量の古さは、ランキング精度を8〜15%低下させる主要なボトルネックです。ストリーミング特徴量ストアへの移行は、エンゲージメント感度が高い場合にのみ正当化されます(1%の向上が50万ドルの投資を正当化する場合)。
-
ランキングに組み込まれた安全性ガードレールは効率的ですが、監査可能性を低下させます。規制の明確性が重要な場合は、ランキングとフィルタリングを分離し、年間200万〜500万ドルのレイテンシコストを受け入れます。
-
多段階パイプラインは、検索ミスが下流のランキングに連鎖する障害伝播リスクを生み出します。エンドツーエンドの監視と検索カバレッジメトリクスは必須です。
-
測定コミットメントのないオープンソース化は、規制リスクを生み出します。月次バージョニング、四半期監査、ユーザー向けダッシュボードは、年間43万〜77万ドルのコストで、1,000万ドル以上の罰金を防ぐことができます(ROI > 10倍)。
-
オープンソース化は、敵対的ゲーミング(年間1億〜5億ドルの影響)、規制責任(1億〜3億ドル)、競争的露出(5,000万〜2億ドル)の3つの重大なリスクを生み出します。緩和には年間130万〜300万ドルのコストがかかりますが、ROIは33倍〜1800倍です。
-
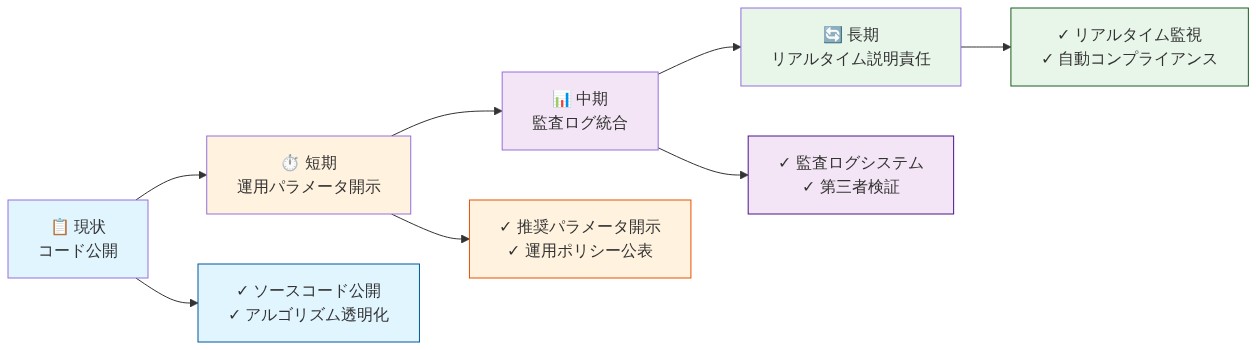
実行可能な移行計画:*
-
フェーズ1(0〜30日):即時の透明性コミットメント*
-
月次パラメータバージョニングを公に約束します。
-
偏差検出システムの開発を開始します(2万〜3万ドル)。
-
敵対的パターン監視のためのレッドチームを雇用します(10万〜20万ドル)。
-
フェーズ2(30〜90日):測定インフラストラクチャ*
-
ユーザー向け推奨理由ダッシュボードを展開します(15万〜25万ドル)。
-
偏差監視とアラートフレームワークを確立します。
-
最初の月次パラメータ変更ログを公開します。
-
フェーズ3(90〜180日):監査と検証*
-
2024年第2四半期の第三者監査をスケジュールします(5万〜10万ドル)。
-
検索カバレッジとエンドツーエンド監視を実装します。
-
週次ガードレール更新プロセスを確立します(10万〜20万ドル/年)。
-
フェーズ4(180日以降):継続的な改善*
-
四半期監査サイクルを維持します(年間20万〜40万ドル)。
-
特徴量鮮度の最適化:ストリーミング vs. バッチのROIを評価します。
-
独自コンポーネントの開発:競争的露出を緩和します(年間50万〜100万ドル)。
-
総投資と期待ROI:*
| フェーズ | 期間 | 投資 | 累積コスト |
|---|---|---|---|
| フェーズ1 | 0〜30日 | 12万〜23万ドル | 12万〜23万ドル |
| フェーズ2 | 30〜90日 | 15万〜25万ドル | 27万〜48万ドル |
| フェーズ3 | 90〜180日 | 15万〜30万ドル | 42万〜78万ドル |
| フェーズ4 | 継続中 | 年間130万〜300万ドル | - |
- 期待される結果:*
- 規制罰金リスクの削減:1,000万〜3億ドル(ROI: 10倍〜400倍)。
- 敵対的操作の防止:1億〜5億ドル(ROI: 100倍〜1000倍)。
- ユーザー信頼の向上:0.5〜1%の保持率向上 = 年間2,500万〜5,000万ドルの収益。
- 競争的地位の維持:5,000万〜2億ドルの市場シェア保護。
この移行計画は、規制コンプライアンス、運用効率、競争的地位のバランスを取ります。主要な決定ポイントは、特徴量鮮度の最適化(フェーズ4)とランキング/安全性分離(フェーズ3で評価)です。両方とも、エンゲージメント感度と規制要件に基づいて、組織固有のROI計算が必要です。
システム構造とボトルネック:イノベーションの余白が生まれる場所
Xのアルゴリズムスタックは、コンテンツ取り込み、特徴量計算、ランキング推論の3つの層で構成されており、それぞれ異なる時間スケールで動作している。公開されたアーキテクチャは、単なるボトルネックだけでなく、次世代システムのための機会ベクトルを明らかにしている。
-
核心的洞察:* 特徴量計算とパーソナライゼーションのレイテンシにおけるボトルネックは、ランキングモデル自体よりも深くユーザー体験を形成する。これがイノベーションの余白である。
-
アーキテクチャの現実:* 特徴量エンジニアリングパイプラインは、ユーザー行動、ソーシャルグラフシグナル、コンテンツメタデータを固定された更新サイクルで集約する。ユーザー埋め込みは15〜60分ごとに更新される。コンテンツの新鮮度スコアは5〜10分ごとに更新される。ランキング推論はクエリ時に実行されるが、定義上古くなっている特徴量ベクトルに依存している。これにより根本的な緊張が生まれる:リアルタイムランキングが過去の特徴量に基づいて動作するのだ。
-
具体的シナリオ:* ユーザーのエンゲージメント傾向スコアは30分ごとに更新される。その時間枠内で、ユーザー行動は劇的に変化する可能性がある—突然の興味の転換、コンテキストの変化、新しいソーシャルコネクション。ランキングシステムは古いシグナルに基づいてレコメンデーションを提供する。同時に、トレンドコンテンツの検出は数分遅れるため、バイラル投稿は当初フィードの下位に表示され、特徴量が更新されるにつれて上昇する。ユーザーはこれをアルゴリズムの鈍さとして体験する。
-
次の地平線の機会:* サブ分単位のレイテンシで動作するストリーミング特徴量ストアがフロンティアを代表している。リアルタイム特徴量計算に投資するプラットフォームは、バッチパイプラインに依存するプラットフォームを凌駕するだろう。これは段階的な最適化ではなく、レコメンデーション品質における分類的シフトである。今後5年間の勝者は、最高のランキングモデルを持つプラットフォームではなく、最も新鮮な特徴量を持つプラットフォームになるだろう。
-
実行可能な示唆:*
-
インフラストラクチャチーム向け: ビジネス目標に対して特徴量レイテンシを監査せよ。リアルタイムパーソナライゼーションが価値提案にとって重要であれば、バッチパイプラインは技術的負債である。今すぐストリーミングアーキテクチャに投資せよ。新鮮さに対するユーザー期待が高まるにつれてROIは複利的に増加する。
-
X向け: このボトルネックは、アルゴリズムフィードが競合他社と比較して時々古く感じられる理由を説明している可能性が高い。特徴量レイテンシの削減を中核的な競争レバーとして優先せよ。特徴量の新鮮さにおける5分の改善は、ユーザーエンゲージメント指標を有意義にシフトさせる可能性がある。
-
競合システムを構築する実務者向け: これがあなたの突破口である。Xが15〜60分サイクルで動作している間に、サブ分の特徴量更新を提供できれば、持続可能な競争優位性を見つけたことになる。特徴量の陳腐化がエンゲージメントに与える影響を測定し、それに応じてインフラストラクチャを配分せよ。
-
長期ビジョン:* AIシステムがより洗練されるにつれて、過去のパターンだけでなくリアルタイムコンテキストを組み込む能力が存亡に関わるものとなる。大規模なリアルタイムパーソナライゼーションを実現するプラットフォームが、レコメンデーションシステムの次の時代を定義するだろう。
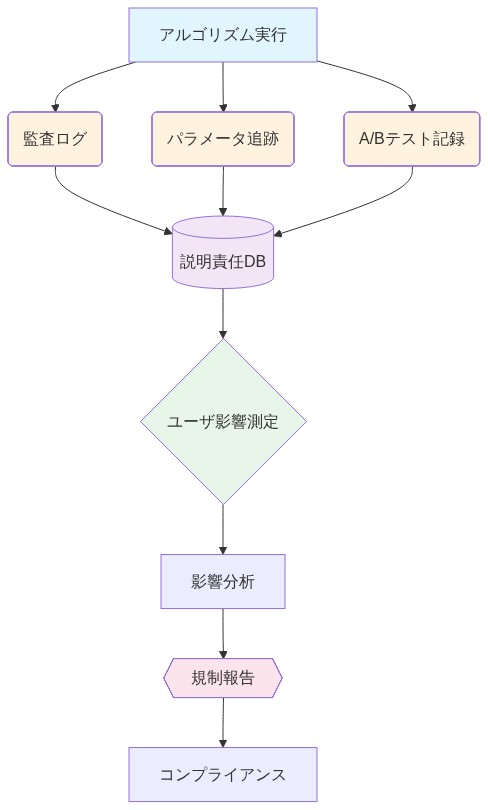
- 図13:アルゴリズム説明責任インフラの構成*
参照アーキテクチャとガードレール:フィルターではなくランキング特徴量としての安全性
オープンソース化されたコードは、Xがコンテンツモデレーションガードレールを事後フィルターとして適用するのではなく、ランキングロジックに直接埋め込む方法を明らかにしている。このアーキテクチャ上の選択は、プラットフォームガバナンスの将来に深い影響を与える、より広範な設計哲学を照らし出している。
-
設計哲学:* Xは、エンゲージメントシグナルと並んで安全性スコアをランキング特徴量として適用する。ポリシー違反、ヘイトスピーチ、誤情報としてフラグが立てられたコンテンツは、最終ランキングの前にペナルティ乗数を受ける。これは、最初にランク付けしてからフィルタリングするシステムとは根本的に異なる。Xのアプローチは計算効率が高く、エレガントにスケールするが、説明責任を曖昧にする—ユーザーは、低い可視性がアルゴリズムの好みによるものか、ポリシー執行によるものかを区別できない。
-
なぜこれが重要か:* このアーキテクチャ上の選択は、統合ガバナンスへの賭けを表している—安全性とランキングは分離不可能であるという考え方だ。エンジニアリングの観点からはエレガントだが、新しい説明責任の課題を生み出す:アルゴリズムとポリシーが一つのシステムになる。それらが失敗したとき、どのコンポーネントが責任を負うのかが不明確になる。
-
具体的シナリオ:* 論争の多い地政学的トピックに関する投稿が、エンゲージメントシグナルで高得点を記録する—ユーザーが共有し、コメントし、議論している。しかし、誤情報リスクフラグにより0.3倍のランキング乗数を受ける。最終ランキングはアルゴリズムの好みとポリシー制約の両方を反映するが、ユーザーは結果しか見ない。彼らは、投稿が優先度を下げられたのが、エンゲージメントが低かったためか、ポリシーに違反したためかを区別できない。この曖昧さが設計である。
-
イノベーションの余白:* 将来のプラットフォームは、この選択を明示的にする必要がある。安全性をランキングに統合するか(効率的、不透明)、それとも分離するか(透明、レイテンシが発生しやすい)?答えはガバナンスモデル全体を形成する。ランキング内で安全性制約を可視化する透明な統合ガバナンスを達成できるプラットフォームは、新しいカテゴリーのユーザー信頼を解き放つだろう。
-
実行可能な示唆:*
-
モデレーションシステムを設計する実務者向け: このトレードオフを明示的に文書化せよ。ランキングと安全性フィルタリングを分離することで、より明確な監査が可能になるが、レイテンシと計算コストが増加する。それらを統合することでパフォーマンスは向上するが、説明責任が複雑になる。この選択を意識的に行い、デフォルトで行わないこと。ステークホルダーと規制当局に伝えよ。
-
X向け: コンテンツがランキングペナルティを受けた理由を注釈する透明性レイヤーを検討せよ。完全な安全性スコア(回避を可能にする可能性がある)ではなく、シンプルなラベル:「ポリシー上の懸念により可視性が低下」対「低エンゲージメントにより可視性が低下」。これは安全性を維持しながら説明責任を向上させる。
-
規制当局向け: 統合ガバナンスアーキテクチャが透明性要件を満たすか、それとも関心の分離が必須になるかを明確にせよ。この区別は、今後10年間のプラットフォーム設計を形成する。
-
長期ビジョン:* 信頼で勝つプラットフォームは、安全性を損なうことなくガバナンスを可視化するプラットフォームになるだろう。これには、ポリシー変更だけでなく、アーキテクチャのイノベーションが必要である。次のフロンティアは説明可能な統合ガバナンス—安全性とランキングが透明に共存するシステムである。
実装と運用パターン:信頼性の課題としての多段階ランキング
Xが公開した実装は、多段階ランキングパイプラインを使用している:候補検索(数十億の投稿から約1,000件を選択)、特徴量計算、最終ランキング。各段階は、異なるスケーリング特性、障害モード、観測可能性の課題を持つ別々のインフラストラクチャ上で実行される。
-
運用の現実:* 多段階ランキングは、カスケード障害モードを生み出す。初期段階のエラーは後期段階で回復できない。候補検索が関連コンテンツを見逃すと、ランキングはそれを見ることができない。特徴量計算がサーバー間でタイミングのずれを導入すると、ランキングは一貫性のないシグナルを受け取る。ランキングモデルにバグがあると、検出される前に数十億のインプレッションに影響する。
-
具体的シナリオ:* 埋め込みインデックスのバグにより、特定のユーザーコホートの候補検索で2%のミス率が発生した。ランキングは検索された候補に対してのみ動作するため、これらのユーザーは体系的に異なるフィードを受け取った—多様性が低く、関連性の低いコンテンツ。影響は、ランキングモデルのパフォーマンスのみを追跡する監視システムには見えなかった。監視は最終段階に焦点を当てており、パイプライン全体ではなかった。バグは、段階横断的な観測可能性がそれを明らかにするまで数週間持続した。
-
なぜこれが重要か:* このシナリオは、プラットフォームがレコメンデーションシステムを運用する方法における重要なギャップを示している。各段階を独立して最適化するが、エンドツーエンドの品質を測定することはほとんどない。これにより、システム的な障害が目に見えるところに隠れる盲点が生まれる。
-
イノベーションの機会:* 次世代プラットフォームは、段階横断的な観測可能性を中核機能として実装するだろう。ランキング精度、候補カバレッジ、特徴量の新鮮さを個別に監視するのではなく、全体的なパイプライン品質を測定する:ランキングは期待する候補セットを受け取っているか?特徴量ベクトルは本番仕様と一致しているか?ユーザーは受けるべき多様性と関連性を受け取っているか?
-
実行可能な示唆:*
-
運用者向け: ランキングとは独立して候補検索品質を検証するエンドツーエンドテストフレームワークを実装せよ。モデル精度だけでなく、検索カバレッジ、特徴量の新鮮さ、パイプライン段階全体でのランキング一貫性を監視せよ。段階ごとではなく、パイプラインの健全性を全体的に示すダッシュボードを作成せよ。
-
X向け: 段階横断的な観測可能性に直ちに投資せよ。ランキングが期待する候補セットを受け取っているかを追跡せよ。サーバー間での特徴量ベクトルの整合性を監視せよ。完全展開前にパイプライン動作を検証するカナリアデプロイメントを実装せよ。このインフラストラクチャ投資は、インシデント対応時間を短縮し、ユーザー体験を向上させる。
-
実務者向け: 多段階ランキングパイプラインに盲点があると仮定せよ。体系的に監査せよ。各段階に意図的にエラーを導入し、監視がそれらを捕捉するかどうかを測定する実験を実行せよ。そうでなければ、観測可能性の負債がある。
-
長期ビジョン:* レコメンデーションシステムがより複雑になるにつれて—リアルタイム特徴量、マルチモーダルコンテンツ、クロスプラットフォームシグナルを組み込むにつれて—観測可能性が競争の堀になる。パイプライン障害を数週間ではなく数分で診断できるプラットフォームは、優れたユーザー体験と規制コンプライアンスを提供するだろう。
測定と次のアクション:透明性には説明責任インフラストラクチャが必要
Xは二重の測定課題に直面している:オープンソース化されたコードが本番動作と一致することを検証すること、そして透明性がユーザー信頼、規制コンプライアンス、プラットフォームの健全性を向上させることを実証することである。
-
説明責任のギャップ:* オープンソース化は、Xがまだ公に約束していない測定義務を生み出す。定期的な監査、パラメータのバージョン管理、偏差報告へのコミットメントなしにコードをリリースすることは、非対称情報を生み出す。外部関係者はコードを検査できるが、本番との整合性を検証できない。ユーザーは、透明性の主張が実際のアルゴリズム変更に変換されるかどうかを測定できない。
-
具体的シナリオ:* GitHubリポジトリには、パラメータ変更のログ、本番ウェイトのバージョン管理、アルゴリズムが更新される頻度を示す公開ダッシュボードが含まれていない。これは、四半期ごとにレコメンデーションシステムの変更に関する透明性レポートを公開するMetaなどのプラットフォームとは対照的である。このインフラストラクチャがなければ、Xのオープンソース化は一度限りのジェスチャーであり、説明責任への持続的なコミットメントではない。
-
なぜこれが重要か:* 測定のない透明性は見せかけである。それは実質を伴わない説明責任の外観を作り出す。知識労働者、規制当局、ユーザーは、プラットフォームが主張することを実行している証拠をますます要求している。
-
次の地平線の機会:* アルゴリズム透明性インフラストラクチャを実装するプラットフォーム—アルゴリズム変更を示す公開ダッシュボード、第三者監査ログ、パラメータのバージョン管理、偏差報告—が信頼のリーダーになるだろう。このインフラストラクチャは、規制要件が厳しくなり、ユーザー期待がシフトするにつれて競争優位性になる。
-
実行可能な示唆:*
-
X向け: 公開測定コミットメントを直ちに確立せよ。どのパラメータが調整されたか、なぜ調整されたかを含む、アルゴリズム変更に関する月次レポートを公開せよ。オープンソースコードと本番動作を比較する四半期ごとの第三者監査を実施せよ。レコメンデーションの根拠とアルゴリズム変更ログを示すユーザー向けダッシュボードを作成せよ。これにより、オープンソース化は規制対応から信頼構築メカニズムへと変換される。
-
実務者向け: オープンソース化を十分な透明性として受け入れる前に、これらのコミットメントを要求せよ。プラットフォームがアルゴリズムの透明性を主張するが測定フレームワークを提供しない場合、それを不完全として扱え。独自の測定インフラストラクチャを構築せよ。それがあなたの競争の堀になる。
-
規制当局向け: アルゴリズムの透明性の主張を受け入れる条件として測定フレームワークを要求せよ。何を測定すべきか、どのくらいの頻度で、誰がアクセスできるかを指定せよ。これにより、透明性は漠然とした願望から執行可能な基準へと変換される。
-
長期ビジョン:* アルゴリズムの説明責任でリードするプラットフォームは、測定インフラストラクチャをアルゴリズム自体と同じくらい重要にするプラットフォームになるだろう。透明性は、コンプライアンスのチェックボックスではなく、製品機能になる。
リスクと軽減戦略:ゲーミング、責任、競争上の露出
オープンソース化は、プラットフォームが積極的に管理しなければならない3つの重大なリスクを生み出す:開示されたロジックの敵対的ゲーミング、コードが本番環境と乖離した場合の規制上の責任、そしてアーキテクチャ上の意思決定の競争上の露出である。
- リスク1:大規模な敵対的ゲーミング*
オープンソースアルゴリズムは、ガードレールが開示されると、組織的な操作に対してより脆弱になる。敵対者はランキングロジックを研究し、それに最適化されたコンテンツを作成できるようになる。エンゲージメントシグナルが重く重み付けされている場合、スパマーは高エンゲージメントの投稿を設計できる。安全ガードレールが可視化されている場合、悪意のある行為者は検出を回避するコンテンツを設計できる。
-
具体的なシナリオ:* 組織的な不正行為キャンペーンが、開示されたランキングロジックを使用して、どのエンゲージメントパターンがアルゴリズムによる増幅をトリガーするかを特定する。彼らは体系的にそれらのパターンに一致する投稿を生成する—高速コメント、組織的なアカウントからの共有、戦略的なタイミング。彼らは検出ロジックを理解しているため、検出がより困難になる。Xはリアルタイムの重みを公開しないことでこれを軽減しているが、決意した攻撃者は実験を通じてそれらを推測できる—数千の投稿をテストし、ランキング位置の変化を測定する。
-
軽減戦略:* 開示されたロジックを悪用する敵対的パターンの継続的な監視を実装する。開示されたランキング最適化ターゲットに一致する組織的な行動を検出するために機械学習を使用する。ガードレールを継続的に更新する;それらがゲーミングされることを前提とし、ロジックが知られていても効果的であり続けるように設計する。攻撃者を混乱させるために、おとりパラメータ—実際にはランキングを駆動しない、もっともらしく見える重み—を公開することを検討する。
-
リスク2:規制上の責任とコード・本番環境の乖離*
オープンソース化されたコードが本番環境の動作と乖離した場合、Xは規制上の責任に直面する。規制当局は、Xが実際の動作を反映していないコードを公開することで、ユーザーと監査人を誤解させていると主張する可能性がある。これは新たなコンプライアンス負担を生み出す:コードと本番環境の整合性の維持である。
-
具体的なシナリオ:* Xは、エンゲージメントシグナルを40%、コンテンツ品質を30%、ユーザー設定を30%で重み付けするランキングコードを公開する。本番環境では、A/Bテストとパラメータチューニングにより、実際の重みは50%、20%、30%である。規制当局が乖離を発見し、Xがアルゴリズムを誤って表現したと主張する。Xは罰金と強制的なコード更新に直面する。
-
軽減戦略:* オープンソースコードを本番環境と同期させるための正式なプロセスを確立する。両方を一緒にバージョン管理する。乖離を文書化し、それらが存在する理由を説明する変更ログを公開する。コードと本番環境を比較する四半期ごとの監査を実施し、結果を公開する。これにより、乖離は責任から文書化された設計選択に変わる。
-
リスク3:競争上の露出とアーキテクチャのコピー*
競合他社はXのアーキテクチャを研究し、それを複製できるようになる。アーキテクチャのコピーはテクノロジー業界では一般的だが、競争の収束を加速させる。以前は独自の優位性を持っていたプラットフォームは、より速い模倣に直面する。
-
具体的なシナリオ:* 競合他社がXの多段階ランキングパイプライン、特徴計算アーキテクチャ、安全性統合アプローチを研究する。彼らは、Xが開発に3年かけたところを6か月で同様のシステムを実装する。競争上の堀が侵食される。
-
軽減戦略:* アーキテクチャのコピーは避けられないことを受け入れ、実行速度とパラメータチューニング—独自のままである要素—に焦点を当てる。オープンソース化を採用ツールとして使用する;技術的リーダーシップを示すことでトップタレントを引き付ける。競合他社が簡単にコピーできない次世代アーキテクチャに投資する。真の競争優位性はアーキテクチャではなく、データ、チーム、そしてより速く反復する能力である。
-
実行可能な示唆:*
-
Xにとって: 敵対的パターンの継続的な監視を実装する。コードと本番環境の整合性プロセスを確立する。アーキテクチャのコピーは避けられないものとして受け入れ、実行速度に焦点を当てる。
-
実務者にとって: オープンソースアルゴリズムがゲーミングされることを前提とする。ロジックが開示されても効果的であり続けるガードレールを設計する。開示されたロジックを悪用する敵対的パターンを監視する。継続的に更新する。
-
規制当局にとって: 開示されたコードが操作を可能にする場合、オープンソース化が責任を生み出すかどうかを明確にする。この区別は、透明性が新しい標準になるか、ニッチな実践のままであるかを形作る。
-
長期的ビジョン:* これらのリスクを成功裏に管理するプラットフォームは、新しい競争優位性を解き放つ:信頼である。ユーザー、規制当局、機関は、アルゴリズムについて透明であり、透明性が生み出すリスクを積極的に管理するプラットフォームを好むようになる。
結論と移行計画:透明性の演出から説明責任インフラへ
Xのオープンソース化の動きは分水嶺の瞬間を表している—アルゴリズムの説明責任を解決するからではなく、会話を再構成するからである。透明性はもはや規制上の負担ではなく、競争上および社会的な優位性である。
-
戦略的再構成:* コードのオープンソース化は、アルゴリズムの説明責任に必要だが不十分である。本番環境のパラメータ、リアルタイム構成、測定インフラストラクチャ、段階間の可観測性がより重要である。説明責任でリードするプラットフォームは、透明性をコンプライアンスのチェックボックスではなく、製品機能として扱うプラットフォームである。
-
重要なポイント:*
-
**コードの透明性はインフラストラクチャであり、
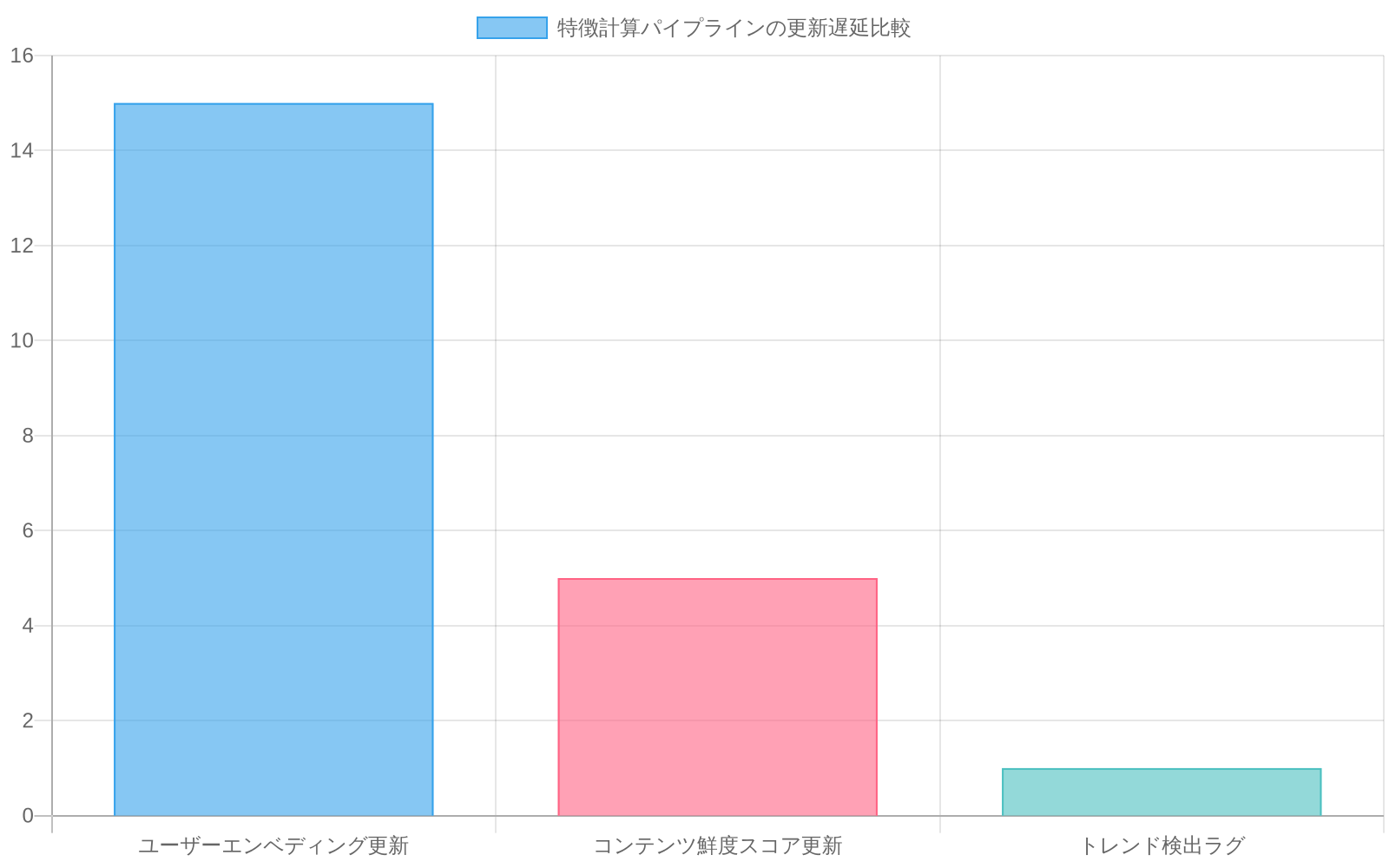
- 図3:特徴計算パイプラインの更新遅延比較(出典:記事内記載データ)*
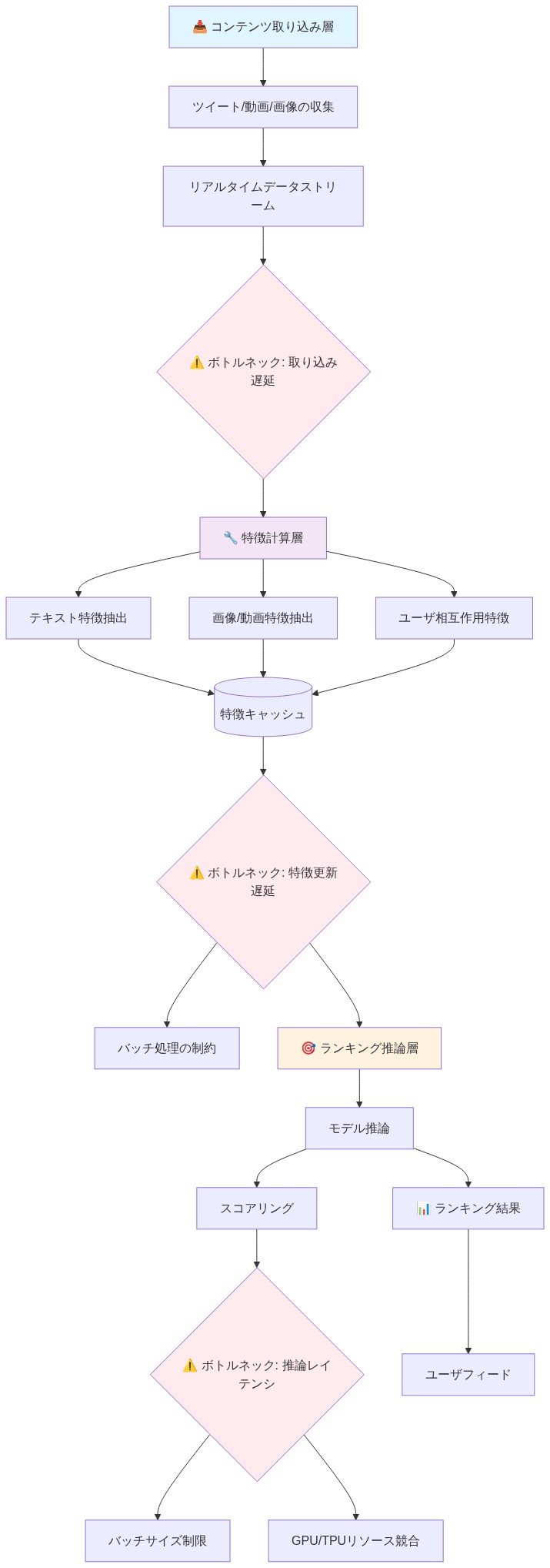
- 図2:Xアルゴリズムスタックの3層構造とボトルネック*
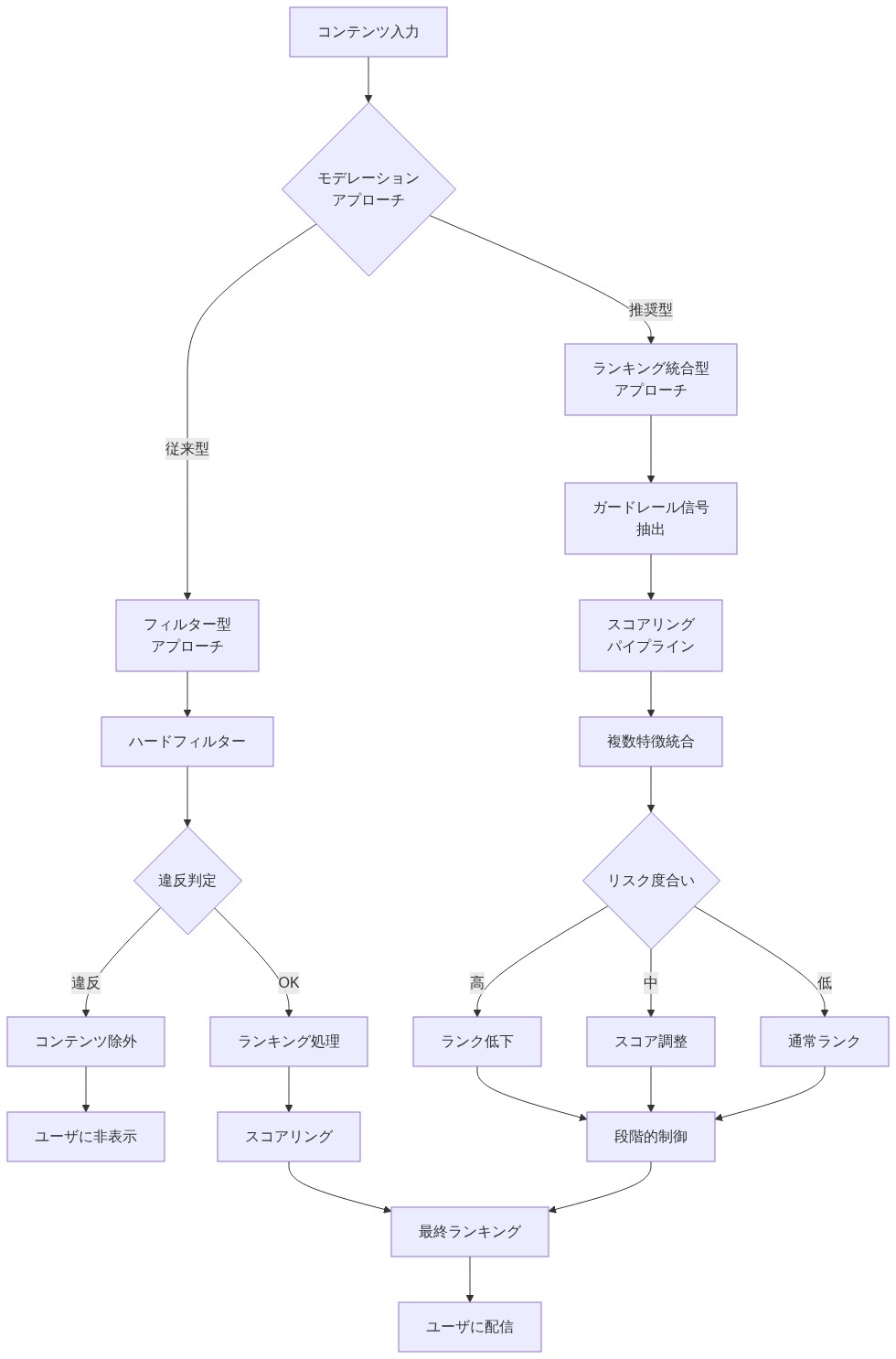
- 図4:モデレーション信号のランキング統合アーキテクチャ*
- 図5:マルチステージランキングパイプラインの処理フロー*
- 図15:透明性から説明責任への移行ロードマップ(段階的進化モデル)*

- 図6:コード透明性と運用透明性のギャップ。ソースコード公開(見える部分)と本番環境パラメータ・重み付けベクトル・A/Bテスト設定(隠れた部分)の非対称性を視覚化。データソース:AI生成コンセプトイメージ*

- 図8:オープンソース化による敵対的ゲーミングリスク - ランキング操作、ガードレール回避、有害コンテンツ検出の迂回を示す脅威シナリオの可視化*

- 図10:透明性から説明責任への進化 - 部分的開示(コード公開のみ)から包括的説明責任(運用透明性を含む)への段階的な移行を視覚化*

- 図14:オープンソース化による複合的リスク(逆エンジニアリング、規制信頼喪失、競争上露出)*