NEPSE指数予測のための機械学習フレームワークの構築
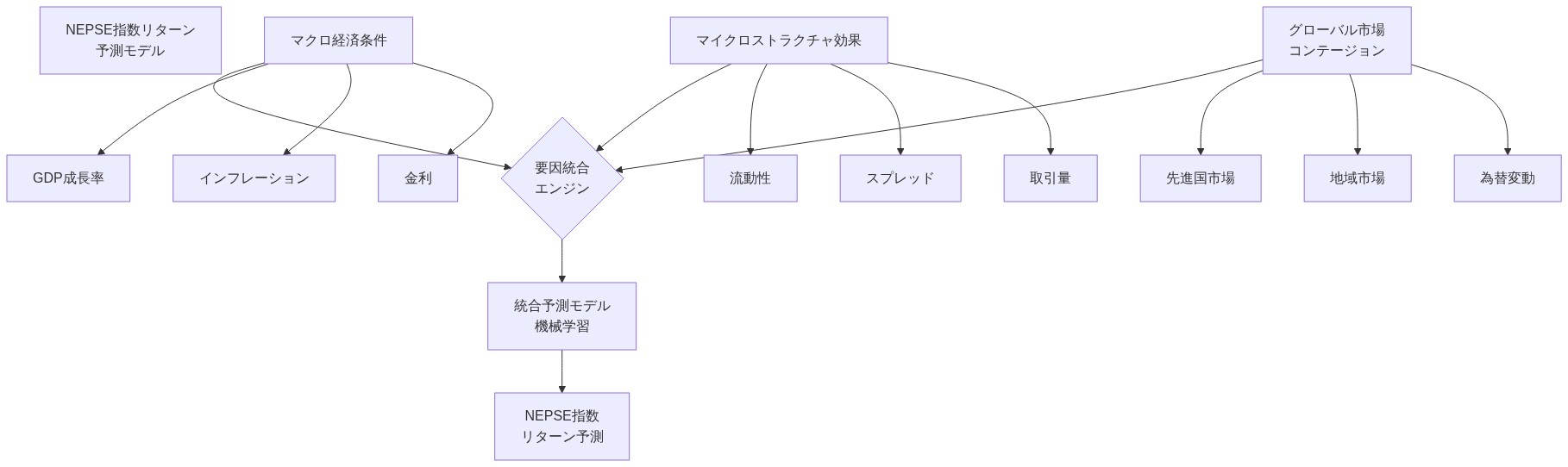
- 図2:NEPSE指数リターンの影響要因分解図*
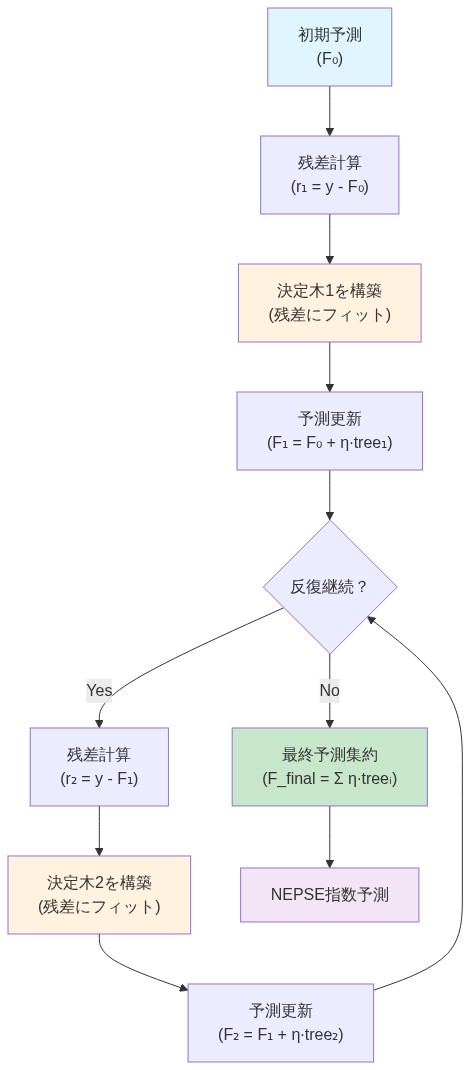
- 図3:XGBoostの逐次的アンサンブル学習メカニズム(Chen & Guestrin, 2016)*

- 図1:NEPSE指数予測のための機械学習フレームワーク概念図*
理論的基礎と問題の定式化
日次株式指数リターンの予測は、計量ファイナンスにおける非自明な問題を構成し、高いノイズ対シグナル比、非定常分布、およびレジーム依存的なダイナミクスによって特徴付けられる(Cont, 2001)。ネパール証券取引所(NEPSE)指数は、ネパールの株式市場センチメントの主要なバロメーターとして機能し、そのリターンは3つの異なる要因カテゴリーによって影響を受ける:(1)国内マクロ経済状況(インフレ、金利、通貨変動)、(2)マイクロストラクチャー効果(流動性、ビッド・アスク・スプレッド、注文フロー不均衡)、および(3)グローバル株式市場からの伝染。予測目的は次のように正式に定義される:
$$\hat{r}{t+1} = f(r_t, r{t-1}, \ldots, r_{t-k}; X_t)$$
ここで、$r_{t+1}$は時点$t+1$における対数リターンを示し、$k$はラグ次数を表し、$X_t$は外生的特徴量を包含する。この1ステップ先予測フレームワークは、ポートフォリオ管理における運用上の制約と整合しており、投資決定は時点$t$で利用可能な情報を使用して実行されなければならない。
市場予測におけるXGBoostの根拠
XGBoost(Extreme Gradient Boosting; Chen & Guestrin, 2016)は、決定木を逐次的に構築するアンサンブル学習アルゴリズムであり、各後続の木はその前任者の残差に適合される。数学的定式化は次のようになる:
$$\hat{y}i = \sum{m=1}^{M} f_m(x_i)$$
ここで、$f_m$は$m$番目の木を表し、$M$はブースティング反復の総数を示す。この反復的誤差修正メカニズムにより、XGBoostは線形モデル(通常最小二乗回帰、ARIMA)では表現できない非線形関係と交互作用効果を捉えることができる。
- NEPSE予測における主要な運用上の利点:*
-
特徴量の異質性処理: XGBoostは、正規化や標準化を必要とせずに混合データ型(連続的なラグリターン、離散的な取引量、カテゴリカルな市場レジーム)を処理し、前処理のオーバーヘッドと関連する情報損失を削減する。
-
計算効率: 正則化メカニズム(木の重みに対するL1/L2ペナルティ、縮小パラメータ)は、特徴量重要度ランキングを通じて解釈可能性を維持しながら過学習を防ぐ。訓練時間はデータセットサイズに対して準二次的にスケールし、迅速な再訓練サイクルを可能にする。
-
外れ値に対する頑健性: 木ベースの分割は単調変換と極値に対して不変であり、XGBoostは市場ストレス期間中に時折ファットテール分布を示す株式リターンに適している。
- 仮定:* 我々は、過去のNEPSEリターンが1から20取引日の間の周波数で利用可能なパターンを含み、これらのパターンが訓練期間と検証期間にわたって十分に安定しており、サンプル外汎化を支援することを仮定する。
目的変数としての対数リターン
対数リターンは$r_t = \ln(P_t / P_{t-1})$として定義され、ここで$P_t$は時点$t$における終値指数レベルを示す。この変換は、生の価格変化に対して3つの統計的利点を提供する:
-
スケール不変性: 対数リターンは無次元であり、異なる時間期間と市場レジーム間で比較可能であり、一貫したモデル較正を促進する。
-
近似正規性: 穏健な市場条件下では、対数リターンは生リターンよりも正規分布により近似し、パラメトリック統計推論(仮説検定、信頼区間)を支援する。
-
時間的加法性: 複数期間リターンは対数空間で加法的に分解され($r_{t,t+n} = \sum_{i=0}^{n-1} r_{t+i}$)、ポートフォリオレベルの分析のための直接的な集約を可能にする。
- 注意事項:* 極端な市場イベント(市場クラッシュ、流動性危機)の間、対数リターン分布は有意な負の歪度と過剰尖度を示し、正規性の仮定に違反する。我々は、異なる市場レジーム間でモデルの安定性を明示的にテストするウォークフォワード検証を通じてこれに対処する。