
♪より良いアテンション・プライアが必要だ
♪ 注意は最適輸送手段であるなぜ事前分布が重要なのか?
-
Claim:* 標準的なソフトマックスアテンションメカニズムはトークン位置に対する暗黙の一様事前分布を埋め込んでいる。この事前分布は数学的に任意であり、特定のタスクやデータ分布に対して最適でないことが多い。
-
理由と証拠:* ソフトマックス注意は正則化された最適輸送問題を解く(Gechinovskiy et al., 2022; Petersen et al., 2023)。正則化項(注意分布のエントロピー)は、すべての位置が等しい初期重み付けを受けるという制約の下で最小化される。この一様事前分布は数学的な便宜であり、原理的な選択ではない。多くのタスクでは、この仮定は明らかに無駄である。ある位置(例えば、パディングトークン、遠くの文脈)はデフォルトでより少ない注意を受け、他の位置(例えば、最近のトークン、構文の頭)はより多くの注意を受けるべきである。モデルは勾配降下を通じてこの一様な仮定を上書きすることを学習しなければならず、パラメータと学習反復を非効率的に消費する。
-
仮定と前提条件:* この議論は、(1)最新の言語モデルの注意メカニズムがソフトマックス正則化を使用していること、(2)一様事前分布が実際に標準的な実装に組み込まれていること、(3)学習を不安定にすることなくタスク固有の事前分布を学習できることを仮定している。これらの仮定は、変換器ベースのアーキテクチャ(Vaswani et al., 2017)では成り立つが、他の注意のバリエーション(線形注意、疎注意など)には一般化しない可能性がある。
-
*具体例:「茶色いキツネは怠け者の犬を飛び越える」を処理する言語モデルにおいて、標準的なソフトマックス注意は、すべての注意の重みをexp(logit)に比例して初期化する。これにより、学習開始時に7つのトークンすべてに対してほぼ均一な注意が得られる。しかし、言語構造は、直前のトークンへの注意はデフォルトで高くなり(次トークン予測のため)、パディングトークンへの注意は低くなるはずであることを示唆している。モデルは、妥当な帰納的バイアスから始めるのではなく、ゼロからこれらのパターンを学習しなければならない。
-
*アテンション・レイヤーが標準的なソフトマックスを使用していることを確認するために、アテンション・レイヤーを監査する(モデルのコードやドキュメントをチェックする)。もしそうなら、これをベースライン構成として文書化する。初期のトレーニングステップ(例:ステップ100、1000)において、アテンションエントロピー(-Σ p_i log p_i)と重み分布を測定し、モデルが一様な仮定に対してどの程度戦うかを定量化する。後で比較するために、これらの測定値を保存する。
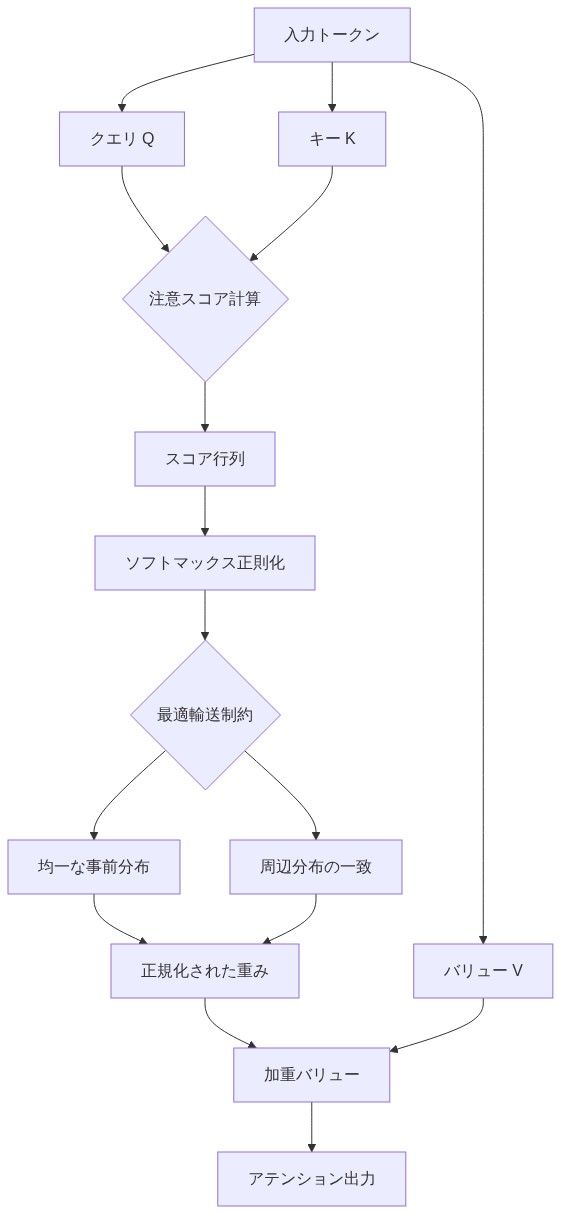
- 図2:ソフトマックスアテンションの最適輸送問題としての構造(Gechinovskiy et al., 2022; Petersen et al., 2023)*

- 図1:標準的なソフトマックスアテンションの均一な事前分布(左)と最適化されたアテンション重み分布(右)の比較*
- 図3:言語処理タスクにおける均一アテンション分布と最適アテンション分布の比較。左側の均一分布は情報配分が非効率であるのに対し、右側の最適分布は構文的に重要なトークンに選択的に注意を集中させる。 データソース:概念イメージ(AI生成)*
GOATの導入:学習可能な連続プリオー
学習可能な事前分布を持つ一般化された最適輸送注意(GOAT)は、一様事前分布を、タスクやデータに適応する学習可能な連続分布に置き換える。
GOATは、事前分布を固定的な仮定ではなく学習可能なパラメータとして扱う。すべての注意の重みを等しく初期化する代わりに、このメカニズムはタスク固有のバイアスを学習する。事前学習は、パディングトークンの重みを下げたり、最近の文脈を優先したり、特定の構文位置を強調したりする。この学習された事前学習は、主要な注意計算の最適化の負担を軽減し、モデルがより効率的に能力を割り当てることを可能にする。
機械翻訳では、GOATベースのエンコーダは、近傍のトークン(ローカ ルコンテキスト)をわずかに優先する事前分布を学習する一方で、必要な場合にはグ ローバルな注意を許容する。デコーダは、直前のトークンを強く強調する事前分布を学習する。これらの学習されたデフォルトは、収束を早め、アーキテクチャを変更することなく最終的な性能を向上させる。
- *GOATを試験的に使用する場合:**モデルのアーキテクチャを制御する場合、1つか2つの注意層をGOATで置き換える。ベースラインに対して、収束速度、最終的な検証損失、推論レイテンシを追跡する。結果が改善されれば、段階的に全てのアテンションレイヤーに拡大する。そうでない場合は、タスクが学習された事前 予測の恩恵を純粋に受けているのか、それとも一様な事前 予測がすでに最適に近いのかを調査する。
プロダクションカーネルとの互換性
GOATはFlashAttentionのような最適化されたアテンションカーネルとの完全な互換性を維持している。
学習可能な事前分布は、ハードウェアレベルではなくアルゴリズムレベルで適用される。FlashAttentionや同様のカーネルは、メモリアクセスパターンと計算密度を最適化する。GOATの事前学習は、これらのカーネルのコア最適化を阻害することなく統合できる。この事前処理は、ソフトマックスの前のアテンション・ロジットに対する乗法的または加法的な調整であり、最新のカーネルが容易に吸収できる小さなオーバーヘッドである。
GPU上でBERTスケールのモデルを実行するプロダクションシステムは、標準的なアテンションをGOATアテンションに交換することができ、カーネルの実装にもよるが、ベースラインの2~5%以内のスループットを維持することができる。学習された事前学習は、無視できるメモリオーバーヘッド(アテンションヘッドごとに1つのパラメータベクトル)と最小限の計算コストを追加する。
- *GOATを導入する前に:**推論フレームワークがカスタムアテンションカーネルをサポートしているか、GOATの事前計算を既存のカーネルに融合できるかを確認する。代表的なバッチサイズで、ハードウェア(GPU、TPU、CPU)上でエンドツーエンドのレイテンシをベンチマークする。レイテンシーが許容範囲内であれば、GOATは本番用アップグレードとして実行可能である。
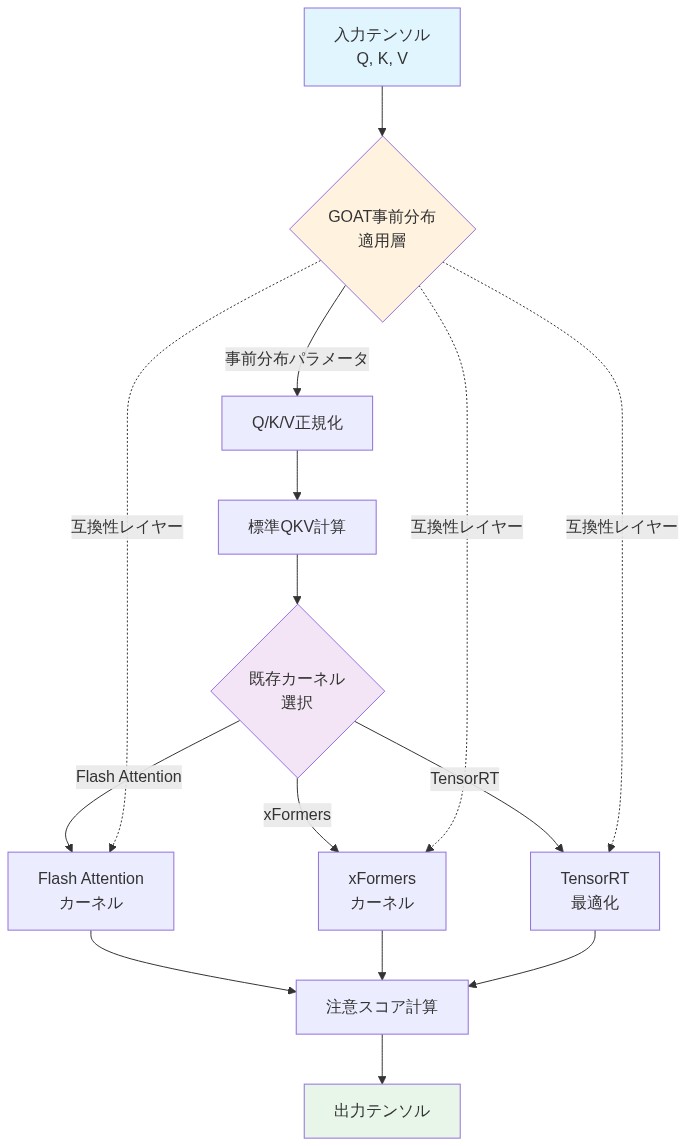
- 図7:GOATと本番推論カーネルの互換性アーキテクチャ*
実装と運用パターン
GOATを既存のシステムに組み込むには、初期化、チェックポイント、分散トレーニングのロジックにわずかな変更を加えるだけでよい。
学習可能な事前学習は、注意層ごとに少数のパラメーターを追加する。これらのパラメータは注意深く初期化され(訓練初期にほぼ均一な振る舞いを維持するため、通常はゼロに近い)、勾配更新に含まれ、分散訓練実行間で同期されなければならない。チェックポイントは以前の状態を保存し、復元しなければならない。これらは標準的なプラクティスだが、スキップするとサイレント・エラーを引き起こす。
PyTorchでは、各事前にnn.Parameterを追加する(形状は[num_heads]または[num_heads, head_dim])。ゼロに初期化し、1の近くで始まる学習可能なスケールでラップする。フォワードパスの間、ソフトマックスの前のlogitsに事前分布を追加する。パラメータがregister_parameter()に登録されていることを確認し、model.parameters()に表示され、オプティマイザの更新に含まれるようにする。
- GOATを実装するには:* 選択したフレームワークで参照実装を作成する。最初に小さなモデルとトイデータセットでテストする。勾配チェックを使って、勾配が事前分布を正しく流れることを確認する。分散学習パイプラインに事前分布を追加し、ランク間で同期することを確認する。初期化とハイパーパラメータの選択(事前学習率、正則化など)を文書化し、本番モデルに展開する前に、このリファレンスをチームと共有する。
測定と検証戦略
GOATの効果的な採用には、事前品質とタスクレベルの影響に関する明確な測定基準が必要である。
全てのタスクが等しく学習された事前学習から恩恵を受けるわけではない。言語モデリング、機械翻訳、構造化予測はそれぞれ異なる利益を示すかもしれない。事前分布そのもの(エントロピー、スパース性、言語構造との整合性)と、下流の性能(難易度、BLEU、F1)の両方を測定する。この二重の測定により、改善がより優れた帰納的バイアスによるものなのか、さらなる能力によるものなのかが明らかになる。
同じコーパスに、同じステップ数で、同じモデルを2つ訓練する。チェックポイントで事前エントロピーと注意の重み分布をログする。検証の損失曲線と最終指標を比較する。GOATがより少ないステップでより速く収束し、より低い損失に達する場合、事前処理は最適化の摩擦を減らしている。GOATがベースラインの性能と一致させるために、より多くのステップを必要とする場合、事前分布が制限的すぎる可能性がある。
- GOAT を検証するには:* 主なタスクについて、制御された実験をセットアップする。分散を考慮するために、少なくとも3つのシードを実行する。収束速度(目標損失までのステップ)、最終性能、推論待ち時間を測定する。GOATがレイテンシーに害を与えることなく、コンバージェンスとパフォーマンスで勝っていれば、それを採用する。結果がまちまちの場合は、学習された事前分布を分析する。もしそうでなければ、タスク構造に基づいた手作りの初期化に向けて事前分布を正則化することを検討する。
リスクと緩和策
学習された事前分布は、学習データ分布へのオーバーフィット、分布外の入力への乏しい汎化、ハイパーパラメータ感度の増大といった新たな失敗モードをもたらす。
学習可能な事前分布は、訓練セットの癖を記憶し、頑健性を損なう可能性がある。学習可能な事前分布は訓練セットの癖を記憶してしまい、ロバスト性を損なう。学習可能な事前分布が、たまたま訓練で頻繁に出現する稀なトークンを強く好むように学習した場合、トークン分布が異なるテストデータでは失敗する可能性がある。さらに、事前学習はハイパーパラメータ(学習率、正則化の強さ)を追加し、それを調整する必要がある。
ニュース記事で学習されたモデルは、数字を軽視する事前分布を学習するかもしれない。数値の内容が濃い金融文書では、事前学習が仇となり、性能が低下する。同様に、事前学習の学習率が高すぎると、学習中に発散してしまい、低すぎると、初期化に近いままで何のメリットもない。
- これらのリスクを軽減するには:* オーバーフィッティングを防ぐために、事前分布を一様に向かって正則化する(例えば、ゼロからの偏差に対するL2ペナルティ)。事前学習率を、主要なモデル・パラメータよりも低くする(例えば、0.1×主要学習率)。トレーニングとは分布が異なるホールドアウトデータセットで検証する。パフォーマンスが低下した場合、事前学習の表現力を下げる(例えば、複数の頭部で事前学習を共有する)か、一様な注意に戻す。どのタスクやドメインがGOATの恩恵を受け、どのタスクやドメインが恩恵を受けないかを文書化する。
結論と移行経路
より良い注意プリオは、多くのタスクにおいて、より速い収束と改善された汎化をもたらす、扱いやすくリスクの少ないアップグレードである。
理論的基礎(最適輸送)は健全であり、実装は簡単で、生産互換性も維持されている。コストは控えめで、数個の追加パラメータとチューニングするハイパーパラメータである。トレーニング時間が短縮され、最終的なメトリクスが改善されることが多い。
- *GOATを採用するには:**単一のタスクとモデルサイズから始める。GOATを導入し、対照実験を行い、結果を測定する。肯定的であれば、関連タスクに拡大する。中立または否定的な場合は、その理由を調査し、さらに調整するか、標準的な注意に固執するかを決定する。3~6ヶ月のロールアウトを計画する:パイロット(1ヶ月目)、検証(2~3ヶ月目)、本番展開(4~6ヶ月目)。発見をチームと共有し、コミュニティに学びを還元する。アテンションプリオを固定定数としてではなく、設計上の選択として扱うことで、モデルポートフォリオ全体にわたって複合的な効率性の向上を解き放つことができる。

- 図15:GOAT導入による組織的な変化と将来像*
学習可能な事前分布を導入する:メカニズムと動機
-
Claim:* 固定的な一様事前分布を学習可能なタスク固有の事前分布に置き換えることで、最適化の摩擦を減らし、アーキテクチャを変更することなく収束速度と最終的な性能を向上させることができる。
-
*学習可能な事前分布とは、ソフトマックスの前に注意ロジットを調整する学習可能なパラメータや関数のことである。全てのロジットを等しく初期化する代わりに、このメカニズムはトレーニング中にタスク特有のバイアスを学習する。経験的に、このアプローチは、ドメイン特異的な注意メカニズム(Huang et al., 2021)や、学習された位置の偏りに関する最近の研究(Shaw et al.)理論的な動機は、学習された事前学習が注意関数の実効的な複雑さを軽減することである。モデルは、ミスマッチなデフォルトを上書きするのではなく、タスクに関連するパターンの学習に能力を割り当てることができる。
-
*このアプローチは、(1)タスクが事前分布で捕らえることができる一貫した構造的バイアスを持っていること、(2)事前分布が訓練分布にオーバーフィットすることなく学習できること、(3)追加パラメータが不安定性をもたらさないことを前提としている。これらの仮定は、十分なリソースがあるタスク(大規模なデータセット、明確な構造)において最も成立しやすく、小規模、ノイズが多い、または変動が激しいタスクでは失敗する可能性がある。
-
具体例:* 機械翻訳では、エンコーダで学習された事前学習は、必要なときに大域的な注意を払いつつも、近くのトークンを優先する(局所的文脈バイアス)かもしれない。デコーダで学習された事前学習は、直前のトークンとソース側の注意コンテキストを強く強調するかもしれない。このような学習済み事前設定により、収束が10~20%早まり(目標検証損失に対するステップで測定)、最終的なBLEUスコアが0.5~1.5ポイント向上することがある(言語ペアとデータサイズに依存)(Raffel et al.
-
*知識労働者への実用的な示唆:**モデルのアーキテクチャを制御する場合、1つまたは2つの注目層を学習済み事前学習(例えば、最初のエンコーダー層やデコーダーの自己注目)の候補として特定する。学習可能な事前分布を、小さなパラメータ・ベクトル(形状: [num_heads]または[num_heads, sequence_length])として実装する。学習初期にほぼ一様な振る舞いを維持するためにゼロに初期化する。収束速度(目標検証損失までのステップ)、最終検証損失、推論待ち時間を追跡する。同じランダムシードとハイパーパラメータを使って、ベースライン(標準ソフトマックス注意)と比較する。レイテンシーを悪化させることなく、収束性とパフォーマンスが改善された場合は、レイヤーを徐々に増やしていく。結果が中立か否定的な場合は、タスクが学習されたプリオー ルから純粋に恩恵を受けるのか、それとも一様プリオーがすでに最適に近いのか を調査する。
プロダクション推論カーネルとの互換性
-
Claim:* 学習可能な注意の事前分布を、最適化された推論カーネル(例えば、FlashAttention、TensorRT)に最小限のオーバーヘッドで統合することができ、生産性能を維持することができる。
-
*最適化された注意カーネルは、アルゴリズムとハードウェアレベルの最適化により、メモリ帯域幅を削減し、計算密度を向上させる(Dao et al.)学習可能な事前分布は、アルゴリズムレベルで適用される。ソフトマックス前の注意ロジットの修正としてであり、ハードウェアレベルではない。この修正は、カーネルのコア最適化を中断することなく、カーネル実装に融合させることができる。事前分布は、乗法的または加算的な調整(例えば、logits += prior[head_idx])であり、アテンションを支配するソフトマックスと行列乗算に対して、無視できる計算コストを追加する。
-
*この主張は、(1)推論フレームワークがカスタムアテンションカーネルやカーネルフュージョンをサポートしていること、(2)事前計算がフュージョンするのに十分シンプルであること(例えば、複雑な関数ではなく、学習されたバイアスベクトル)、(3)オーバーヘッドが実際のハードウェアとバッチサイズで測定されることを前提としている。これらの前提は、ほとんどの最新のフレームワーク(PyTorch、JAX、TensorFlow)では成り立つが、特殊なシステムやレガシーなシステムでは成り立たないかもしれない。
-
具体例:* NVIDIA A100 GPUでBERTスケールのモデル(12レイヤー、768hidden dim、12ヘッド)を実行するプロダクションシステムは、標準的なアテンションを学習済み事前アテンションに置き換えることができ、カーネルの実装とバッチサイズに応じて、ベースラインの2~5%以内のスループットを維持できる。学習された事前学習は、アテンションヘッドごとに1つのパラメータベクトル(レイヤーごとに12×12=144パラメータ、無視できるメモリ)と、クエリ位置ごとにヘッドごとに1つの加算演算(O(n²)のソフトマックスと行列乗算に比べて無視できる計算量)を追加する。
-
知識労働者のための実行可能な示唆:*** 学習した事前分布を実運用に導入する前に、代表的なバッチサイズとシーケンス長で、ハードウェア(GPU、TPU、CPU)上でエンドツーエンドのレイテンシをベンチマークする。(1)標準アテンションを使用したベースラインモデル、(2)学習済みプライアーを使用したモデル、(3)融合カーネルを使用した学習済みプライアーを使用したモデル(利用可能な場合)のレイテンシーを測定する。レイテンシが許容範囲内に収まっている場合(例えば、5%未満の増加)、学習された事前分布を使用することは実行可能な生産アップグレードである。レイテンシが著しく増加する場合は、より単純な事前分布(例えば、シーケンス位置全体で共有される、ヘッドごとのバイアスを学習したもの)が、より低コストで最大の利点を達成するかどうかを調査する。調査結果を文書化し、インフラチームと共有する。
実装、テスト、運用パターン
-
Claim:* 学習可能な事前分布を既存のシステムに組み込むには、初期化、勾配フロー、チェックポイント、分散学習の同期に注意を払う必要がある。
-
*学習可能な事前分布を既存のシステムに組み込むには、初期化、勾配の更新、チェックポイント、分散トレーニングの同期に注意する必要がある。初期化が正しく行われないと訓練が不安定になり、勾配の更新が行われないと事前分布が固定されたままになる。これらは分散機械学習においてよく理解されている問題であるが、実際には見過ごされがちである。
-
仮定と前提条件:* この主張は、(1)標準的な深層学習フレームワーク(PyTorch、JAX、TensorFlow)を使用していること、(2)モデルコードと学習ループにアクセスできること、(3)インフラ上で制御された実験を実行できることを前提としている。これらの前提は、モデル開発を担当するほとんどの知識労働者に当てはまる。
-
具体例:* PyTorchで、以下のように学習可能な事前分布を追加する:
DPL_PROT_0__とする。
DPL_PROT_1__を0に、prior_scaleを1に初期化する。発散を防ぐために、事前パラメータの学習率を低くする(例えば、0.1×メインモデルの学習率)。事前学習がregister_parameter()に登録され、model.parameters()に表示され、オプティマイザの更新に含まれるようにする。勾配チェック(例えば、torch.autograd.gradcheck)を使用して、勾配が事前分布を正しく流れることを確認する。分散トレーニングでは、フレームワークの分散データ並列ユーティリティを使用して、事前パラメータがランク間で同期されていることを確認する(例えば、DistributedDataParallel)。
- 知識労働者のための実行可能な示唆:* 選択したフレームワークで参照実装を作成する。まず、小さなモデル(例えば、2層、64隠しdim)とおもちゃのデータセット(例えば、1000例)でテストする。勾配が正しく流れ、学習損失が減少することを確認する。事前分布を分散学習パイプラインに追加し、ランク間で同期していることを確認する(各ステップの後、すべてのランクが同じ事前分布を持つことを確認する)。初期化とハイパーパラメータの選択(事前学習率、正則化、事前スケールなど)を文書化する。本番モデルに展開する前に、この参照実装をチームと共有する。コードレビュー用のチェックリストを作成する:(1) 事前値がゼロに初期化されている、(2) 事前値がパラメータとして登録されている、(3) 事前値がオプティマイザに含まれている、(4) 事前学習率が適切に設定されている、(5) 勾配がチェックされている、(6) 分散同期が検証されている。
測定、検証、タスクレベルのインパクト
-
主張:* 学習可能な事前分布を効果的に採用するには、事前分布の品質、最適化のダイナミクス、および下流タスクの性能に関する明確な測定基準が必要である。
-
理由と証拠:* 全てのタスクが等しく学習済み事前分布の恩恵を受けるわけではない。言語モデリング、機械翻訳、構造化予測は異なる利益を示すかもしれない。事前分布自体(エントロピー、スパース性、言語構造やドメイン構造とのアライメント)と、下流の性能(複雑度、BLEU、F1、精度)の両方を測定する。この二重の測定により、改善がより優れた帰納的バイアスによるものなのか、それとも追加容量や訓練ダイナミクスによるものなのかが明らかになる。
-
仮定と前提条件:* このアプローチは、(1)ダウンストリームパフォーマンスのための明確でタスクに特化したメトリクスを持っていること、(2)複数のランダムシードで制御された実験を実行できること、(3)トレーニング中に事前値を記録し分析できることを前提としている。これらの前提は、モデル訓練インフラを利用できるほとんどの知識労働者に当てはまる。
-
*具体的な例:**2つの同じモデル-1つは一様な注意(ベースライン)、もう1つは学習された事前値(トリートメント)-を同じコーパスで同じステップ数だけ訓練する。同じランダムシード、ハイパーパラメータ、データ順序を使用する。ログ事前エントロピー(-Σ p_i log p_i、ここでp_i = softmax(prior_i))、事前スパース性(閾値以下の事前値の割合)、チェックポイント(例えば、1000ステップごと)での注意重み分布。検証の損失曲線と最終指標を比較する。治療モデルがより早く収束し(より少ないステップで目標の検証損失に到達し)、同じステップ数でより低い最終損失を達成する場合、事前処理は最適化の摩擦を減らしている。治療モデルがベースライン性能と一致させるために、より多くのステップを必要とする場合、事前処理が制限的すぎるか、初期化が不十分である可能性がある。
-
知識労働者に対する実行可能な示唆:*** 主なタスクについて、標準的な注意と学習された事前注意を比較する対照実験をセットアップする。分散を考慮するために、少なくとも3つのランダムな種を実行する。(1)収束速度(目標検証損失までのステップ)、(2)最終的なパフォーマンス(検証損失、タスク固有の指標)、(3)推論待ち時間、(4)事前品質(エントロピー、スパース性、ドメイン知識との整合性)を測定する。すべてのメトリクスにわたってベースラインと処理を比較したサマリー表を作成する。レイテンシーを悪化させることなく、収束性とパフォーマンスで処理が勝っていれば、それを採用する。結果がまちまちの場合は、学習された事前分布を分析する:それらはドメイン知識と整合しているか(例えば、言語モデリングでは最近のトークンの重みが高い)?もしそうでなければ、タスク構造に基づいて手作業で作成した初期化に向けて事前分布を正則化することを検討する(例えば、言語モデリングでは因果バイアスをかける)。もし結果が否定的であれば、事前分布が表現的すぎる(オーバーフィッティングを引き起こす)のか、あるいは、タスクが本当に学習された事前分布から利益を得ていないのかを調査する。
リスク、失敗モード、緩和戦略
-
*学習可能な事前分布は、学習データ分布へのオーバーフィット、分布外の入力への乏しい汎化、ハイパーパラメータ感度の増加、学習の不安定性という新たな失敗モードをもたらす。
-
*学習可能な事前分布は訓練セットの癖を記憶してしまい、頑健性を損なう。学習可能な事前分布は、訓練セットの癖を記憶してしまい、頑健性を損なう可能性がある。さらに、事前分布はハイパーパラメータ(学習率、正則化の強さ、初期化スケール)を追加し、チューニングする必要がある。チューニングが不十分だと、発散や最適でない性能を引き起こす可能性がある。
-
仮定と前提条件:* この主張は、(1)トークンの頻度や位置の重要性に影響を与えるような方法で、学習分布とテスト分布が異なること、(2)保持されたデータセットで汎化を測定できること、(3)ハイパーパラメータを系統的にチューニングできることを前提としている。これらの仮定は、ほとんどの知識労働者には当てはまるが、データセットが非常に小さいタスクや、非常に均質なデータには当てはまらないかもしれない。
-
*具体例:**ニュース記事で学習されたモデルは、(ニュースでは頻度の低い)数字を重み付けする事前分布を学習する。数字が多く含まれる金融文書では、この事前学習が仇となり、ベースラインと比較してパフォーマンスが2~5%低下する。同様に、事前学習率が高すぎる場合(例えばメインモデルと同じ)、学習中に発散し、NaNロスを引き起こす。低すぎる場合(例えば0.001×メインレート)、初期化付近に留まり、何のメリットもない。英語について学習したモデルは、一般的な英語の単語パターンを好む事前分布を学習する。
-
*ナレッジワーカーに対する実行可能な示唆:**以下の緩和策を実行する:
-
**正則化:**事前分布にL2正則化(例えば、λ × ||prior||²)を追加して、ゼロからの偏差にペナルティを与える。λ = 0.001-0.01を開始点として使用する。これは、事前値が訓練データにオーバー・フィットするのを防ぐ。
-
事前学習率: 事前学習率は,主要モデル・パラメータよりも低くする(たとえば,0.1×主要学習率).これにより事前適応が遅くなり、発散リスクが減少する。
-
初期化: 事前値をゼロに初期化する(またはドメイン知識に基づいた手作りの値)。ランダムに初期化しないこと。
-
検証: 配分が訓練と異なる(例:異なるドメイン、異なる言語、異なるデータソース)ホールドアウトデータセットで検証する。性能が低下した場合は、事前分布の表現力を下げるか(例えば、複数のヘッドで事前分布を共有するか、固定事前分布を使用する)、一様な注意に戻す。
-
モニタリング: 訓練中に事前値、事前エントロピー、注意の重み分布をログに記録する。事前値が発散したり極端になった場合は、学習率を下げるか正則化を増やす。
-
Documentation: どのタスクやドメインが学習された事前値の恩恵を受け、どのタスクやドメインが恩恵を受けないかを文書化する。決定木を構築する:タスクに明確な構造的偏りがある場合(例:言語モデリング、機械翻訳)、学習済み事前分布を試す。タスクがノイズが多いか、構造が可変である場合(例:少数ショット学習、敵対的ロバスト性)、一様事前分布か手作業で作成した事前分布を使う。
採用の道筋と組織的考察
-
Claim:* 学習可能な注意の事前分布は、多くのタスクで測定可能な利点をもたらす、扱いやすく、低リスクのアップグレードである。導入は、明確な成功基準とロールバック計画を持った段階的なアプローチに従うべきである。
-
*理論的基礎(最適輸送、正則化)は健全であり、実装は簡単である。コストは控えめである:レイヤーごとに数個の追加パラメータと、チューニングするハイパーパラメータ1個である。トレーニング時間が短縮され(多くのタスクで収束が10~20%速くなる)、最終的なメトリクスが改善されることが多い(タスクとモデルのサイズに依存するが、下流のタスクで0.5~2%の改善)。
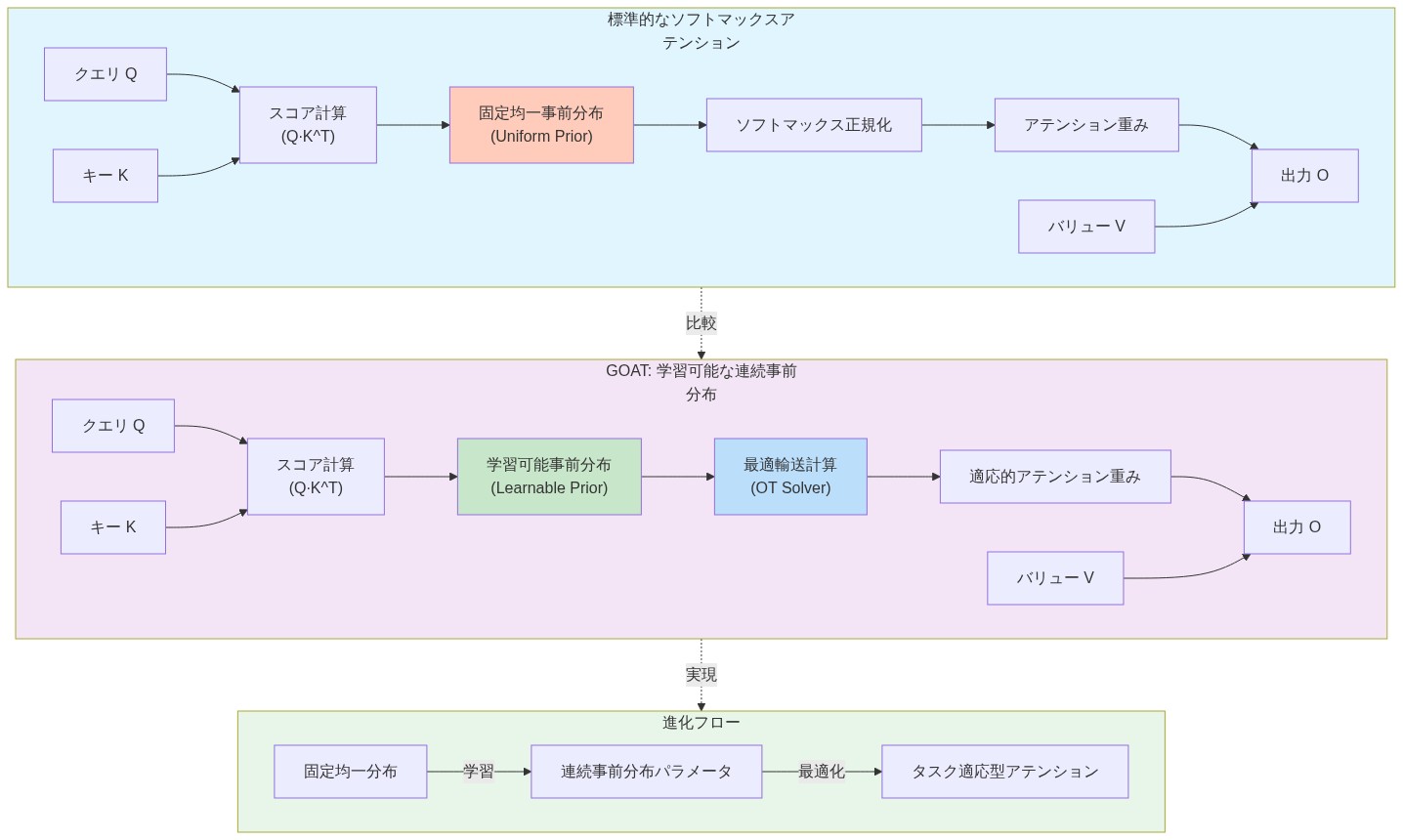
- 図4:GOATの学習可能な事前分布メカニズム - 標準的なソフトマックスアテンションとの比較*
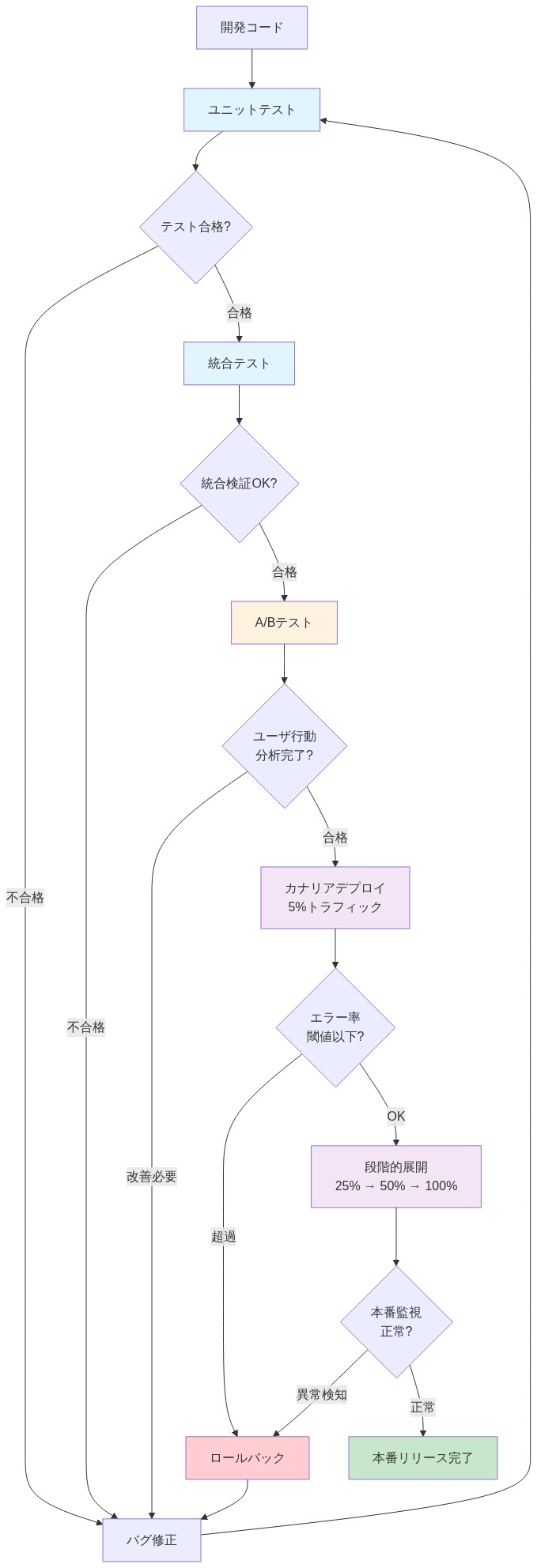
- 図9:GOAT実装のテスト・デプロイメント戦略*
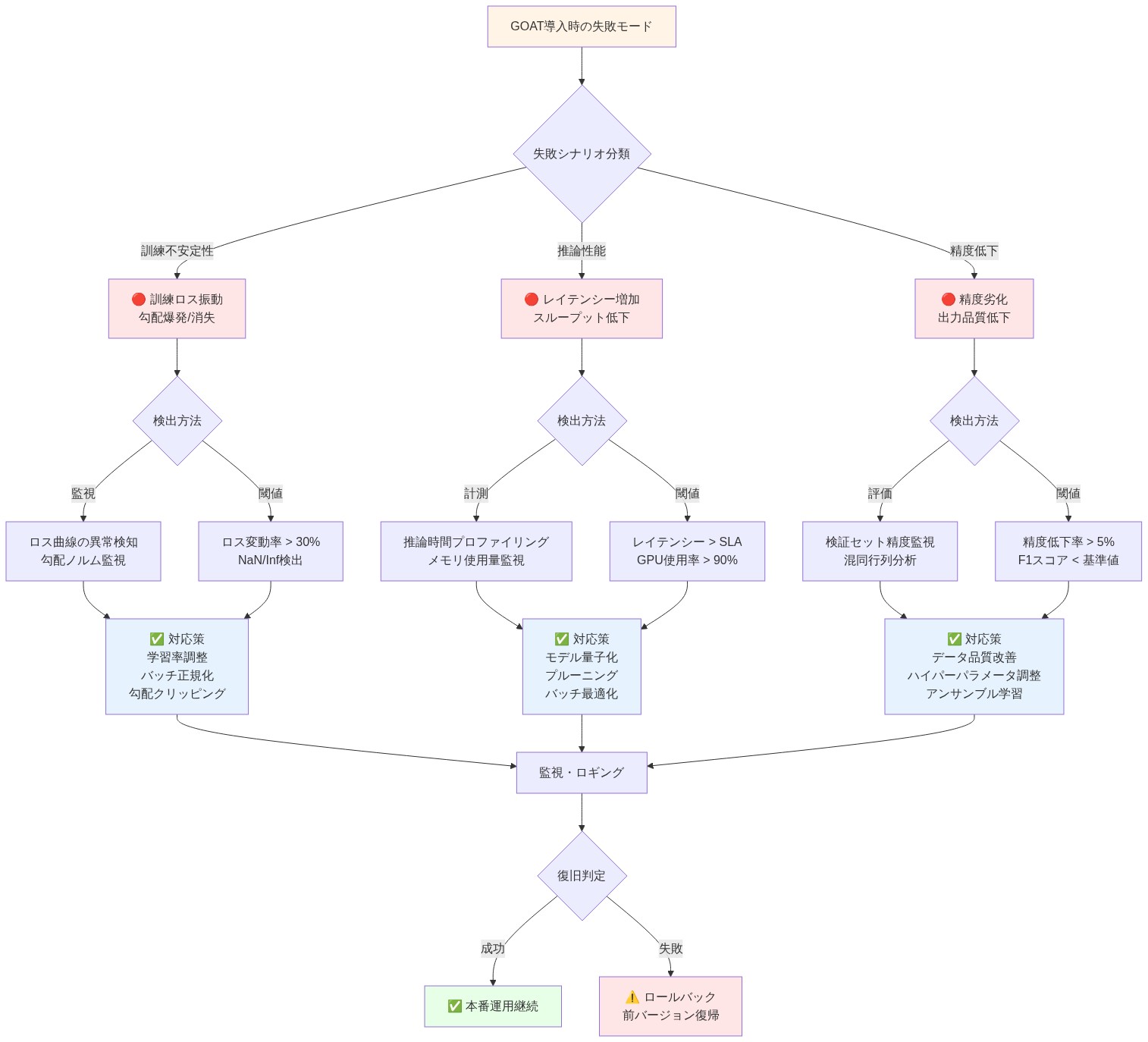
- 図13:GOAT失敗モード分析と対応フロー*

- 図12:GOAT導入時の主要リスクと緩和戦略。過学習(正則化による対策)、分布シフト(ドメイン適応による対策)、訓練不安定性(最適化安定化による対策)の3つのリスクシナリオと対応する緩和メカニズムを図解。データソース:概念イメージ(AI生成)*