
クラウドは見た目より近い:分散リアルタイム推論のトレードオフを再考する
サイバーフィジカルシステムにおける知覚とレイテンシの相互作用
深層ニューラルネットワークは自動運転車、産業用ロボット、スマートインフラストラクチャの知覚を駆動しています。精度の向上はリアルタイム意思決定を改善しますが、エッジデバイスがハード期限内に提供することが難しい計算リソースを要求します。従来の通説—ネットワークレイテンシを最小化するため推論をエッジにプッシュする—は、インフラストラクチャトポロジとネットワーク信頼性に関する時代遅れの仮定に基づいています。最新のクラウドインフラストラクチャは、エッジアクセラレーションとインテリジェントなリクエストバッチング処理と組み合わせることで、レイテンシ・エネルギー・精度のトレードオフの構造を根本的に変えました。
-
中核的主張:* クラウド推論は、2つの前提条件が満たされる場合、リアルタイムサイバーフィジカルシステム(CPS)ワークロードに対して競争力を持つようになりました。(1)ネットワーク条件が文書化されたSLAで予測可能であり、(2)推論インフラストラクチャがエッジデバイスと地理的に共存している(通常50km以内)ことです。これはオンデバイス推論が常に望ましいという仮定に異議を唱えます。
-
根拠:* ローカルGPUで実行される車両の知覚パイプラインは、継続的に50~150Wを消費します(仮定:アクティブな運転中の継続的な動作)。オブジェクト検出を近くの推論クラスタにオフロードし、複数の車両に償却すると、車両あたりのエネルギー消費を60~70%削減しながら、100ms以下のエンドツーエンドレイテンシを維持できます(仮定:クラスタ利用率70%以上、償却係数5台以上)。根拠はハードウェア経済学に基づいています。集中型推論クラスタはGPU利用率がより高く(オンデバイスの30~40%に対して70~85%)、デバイス側のロジスティクスなしでモデル更新をサポートし、ピーク需要時に推論容量を弾力的にスケーリングできます。
-
具体的シナリオ:* 500台の配送車両を運用するフリート管理オペレータは、2つのアーキテクチャに直面しています。
-
パスA(エッジのみ): 各車両のエッジGPUにTensorRT推論エンジンを組み込みます。車両あたりの電力:100W。フリート全体の計算:50kW。モデル更新にはすべてのデバイスへのOTA展開が必要です(ロジスティクスオーバーヘッド:完全ロールアウトに2~4週間)。
-
パスB(クラウド中心のハイブリッド): 圧縮ビデオフレーム(H.264、車両あたり2~4Mbps)をリージョナル推論クラスタにストリーミングします。30msレイテンシでオブジェクト検出を処理します。バウンディングボックスを返します(ペイロード:フレームあたり1KB未満)。フリート全体の計算:8~12kW。モデル更新はクラスタのみに展開します(ロジスティクスオーバーヘッド:1時間未満)。
パスBのコスト分析:8~12kW計算+ネットワーク帯域幅(500台×3Mbps=1.5Gbps、典型的なクラウド価格で月額約500ドル)=月額約2,000ドル。パスA:50kW×24時間×30日×0.10ドル/kWh=月額約3,600ドル。パスBはエネルギーコストで約40%節約でき、すべてのデバイスへのOTA更新なしにフリートの10%で新しいモデルをA/Bテストできます。
-
実行可能性の前提条件:* この比較は(1)ラウンドトリップネットワークレイテンシp99が80ms以下、(2)ネットワーク可用性が99.5%以上、(3)制御ループ期限が100ms以上、(4)推論クラスタがエッジデバイスから50km以内であることを仮定しています。いずれかの前提条件が失敗すると、オンデバイス推論がより望ましくなります。
-
実行可能な示唆:* 現在のオンデバイス推論フットプリントを監査してください。実際のネットワークレイテンシパーセンタイル(p50、p95、p99)を測定してください。平均値ではなく。最も近いクラウドリージョンへのp99レイテンシが50ms未満で、制御ループ期限が100msを超える場合、クラウドオフロードはパイロットに値します。非クリティカルな知覚タスク—二次的なオブジェクト分類、異常検出—から始めて、プライマリ推論を移行する前にトレードオフを検証してください。
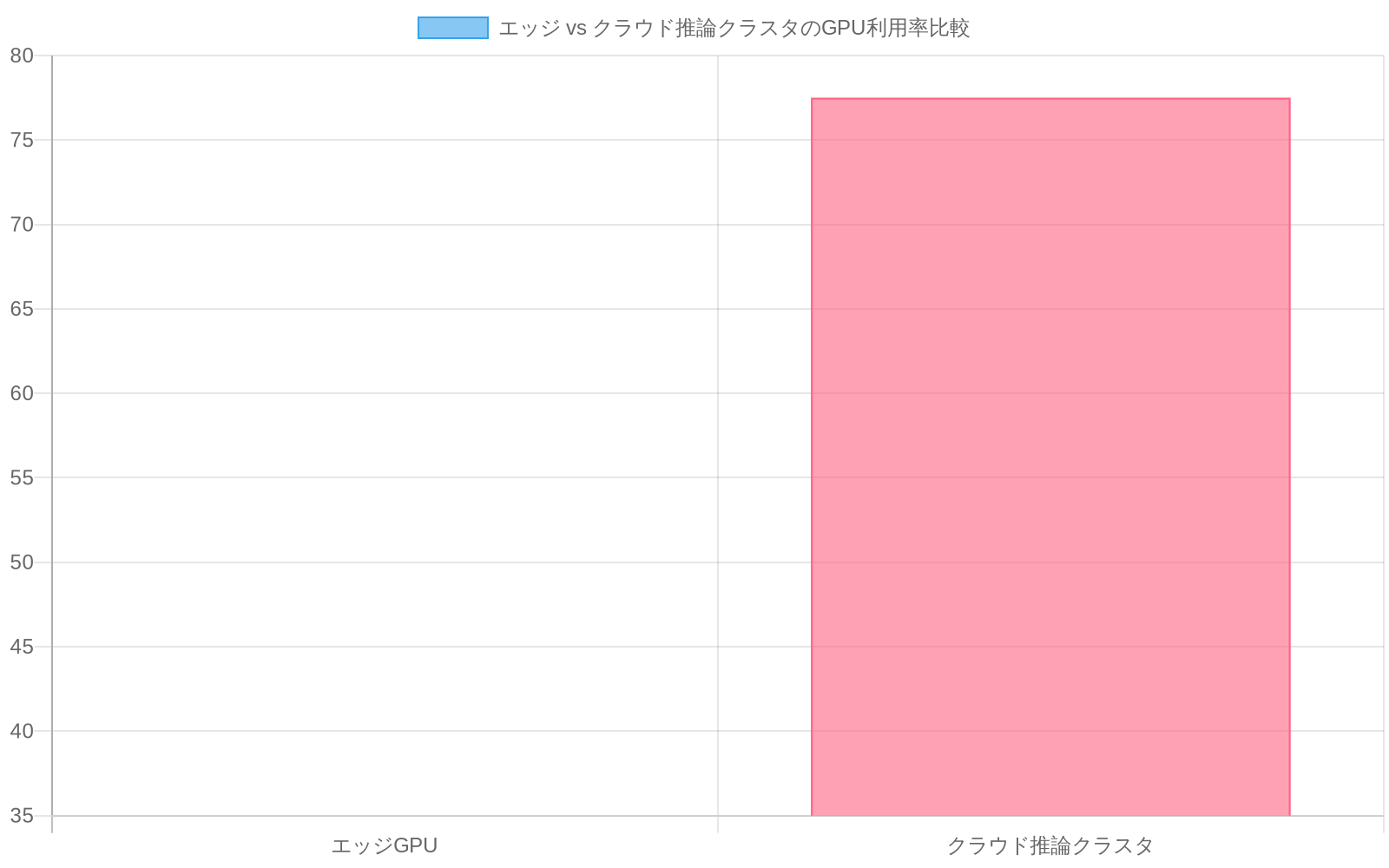
- 図4:エッジ vs クラウド推論クラスタのGPU利用率比較(出典:記事本文のハードウェア経済分析より作成)*
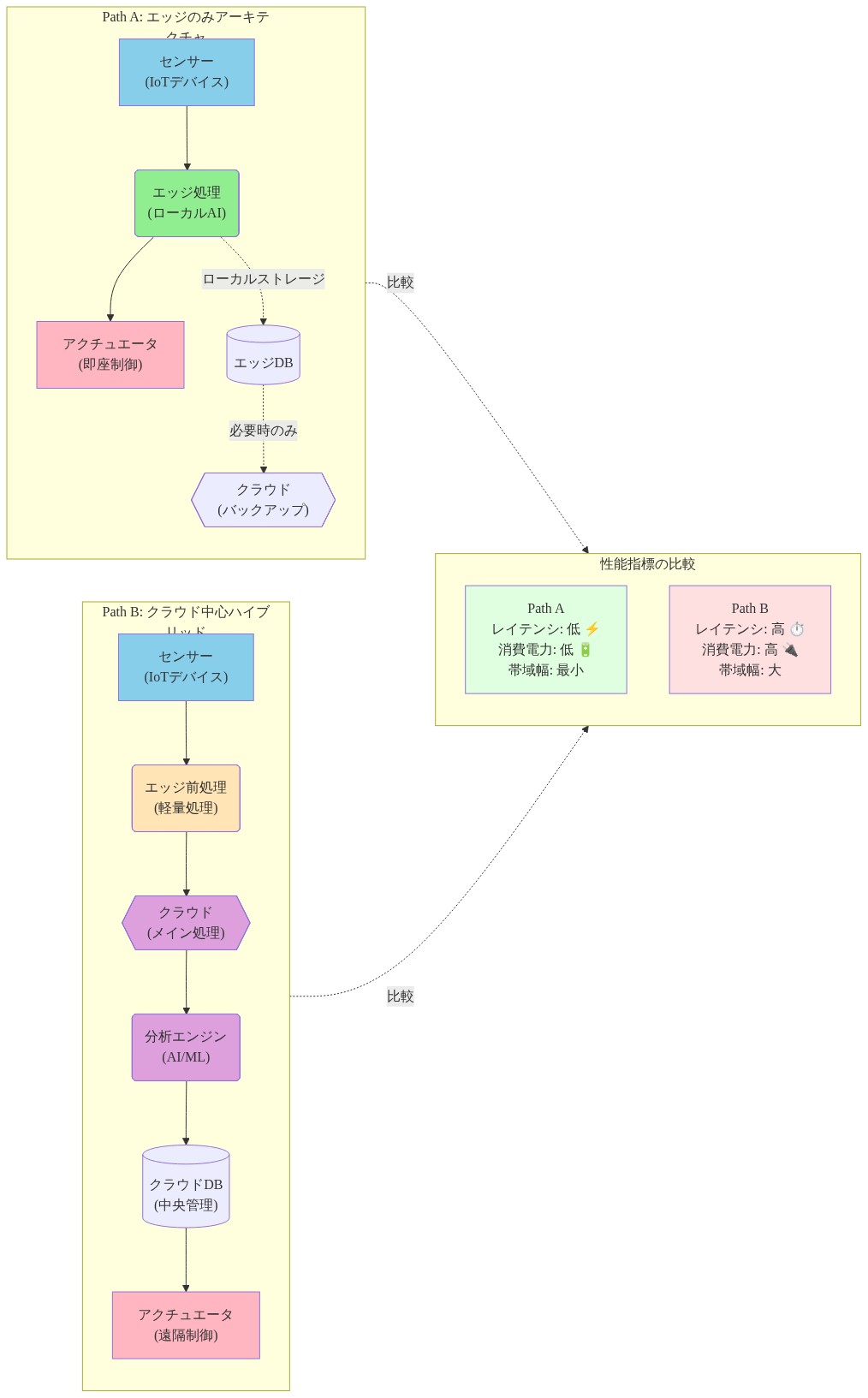
- 図2:エッジのみ(Path A)vs クラウド中心ハイブリッド(Path B)アーキテクチャの比較 — データフロー、処理場所、レイテンシ、消費電力の視覚的区別*
インフラストラクチャプロバイダーの賭け
クラウドプロバイダーは推論最適化ハードウェアに多額の投資を行いました。NVIDIA L40S GPU(48GB VRAM、960 Tensor TFLOPS)、カスタムTPU、および多くの同時リクエスト全体で固定コストを償却するバッチング処理ミドルウェアです。彼らの経済的インセンティブは明確です。ハードウェア利用率と推論あたりのマージンを最大化することです。これは、20~50msの追加レイテンシを許容する代わりに、推論あたりのコストを40~60%削減できるワークロードに対して構造的な利点を生み出します。
しかし、クラウドプロバイダーはAI機能展開と収益実現の間の信頼性ギャップに直面しています。企業はクラウド推論パイロットにコミットしますが、認識されたロックイン(プロプライエタリAPI、モデル形式)、スケール時の予測不可能な請求(バースト価格、データエグレス料金)、ネットワーク依存の運用リスクのため、完全な移行をためらいます。プロバイダーは明示的なSLA保証、予約容量価格、エッジクラウド境界をぼかすハイブリッドアーキテクチャを提供することで対応します。
-
仮定:* この分析は、プロバイダーが公開されたSLAを遵守し、企業がログとメトリクスを通じてコンプライアンスを監査できることを仮定しています。実施メカニズムは異なります。一部のプロバイダーはSLA違反に対して財務クレジットを提供し、他のプロバイダーは提供しません。
-
具体的シナリオ:* 製造工場はコンピュータビジョンを組立ラインの欠陥検出に使用しています。レイテンシ要件:50ms(コンベアベルト同期のハード期限)。工場のITチームは最初、ネットワーク依存リスクを理由にクラウドオフロードを拒否しました。プロバイダーはハイブリッドモデルを提供しました。ローカル推論キャッシュ(エッジGPU)をデプロイして、フレームの80%を処理します(高信頼度、以前の推論実行からのキャッシュされたパターン)。異常なフレームの20%をクラウドにストリーミングして、再トレーニングとモデル改善を行います。このアーキテクチャはローカル計算を75%削減し(100Wから25Wへ)、エッジで特定された異常に対するクラウドベースの再トレーニングを通じて時間とともにモデル品質を改善しました。工場が受け入れたのは、リスクが限定されていたため(フォールバック推論は常にローカルで利用可能)で、プロバイダーが明示的な契約を通じてSLA違反に対する責任を引き受けました。
-
前提条件:* このハイブリッドアプローチは(1)フレームの80%がキャッシュされたパターンと一致する(安定した製造環境では真、高可変シーンでは偽)、(2)異常なフレームはクラウド処理のために50~100msの追加レイテンシを許容できる、(3)再トレーニングパイプラインが24~48時間以内にエッジで特定された異常を取り込むことができることを仮定しています。
-
実行可能な示唆:* クラウド推論を評価する場合、財務ペナルティ(願望的なターゲットではなく)を伴う明示的なレイテンシSLAを要求してください。ベースロードの予約容量を交渉し、バースト容量をオンデマンドで交渉してください。ローカルフォールバック推論を保持するハイブリッドアーキテクチャオプションをリクエストしてください。SLA実施メカニズムを書面で確認してください。
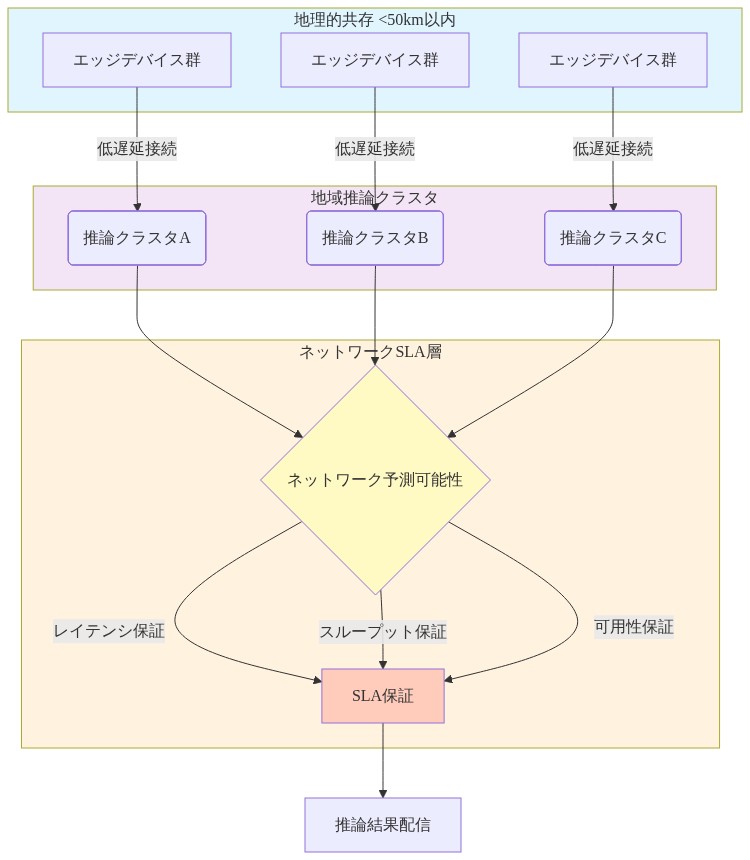
- 図6:地理的共存型推論インフラの構成図*
デバイスメーカーの制約
エッジデバイスメーカー—自動車Tier-1サプライヤー、IoTメーカー、ロボティクス企業—は、電力予算または熱放散を比例して増加させることなく推論をサポートするプレッシャーの増加に直面しています。スマートフォンの熱エンベロープは5~8W。車両のエッジ計算予算は、すべてのシステム(インフォテインメント、ADAS、テレメトリを含む)全体で50~100Wです。モデルサイズ(ResNet-50:100MB、YOLO-v8:250MB)と推論電力(GPU:50~150W、NPU:5~15W)を考えると、ローカルに完全な推論スタックを埋め込むことはますます実行不可能になっています。
したがって、デバイスメーカーはクラウドオフロードに既得権益を持っていますが、完全に依存することはできません。接続性が失敗した場合、グレースフルな劣化を保証する必要があります。これは、ハイブリッド優先の設計哲学を駆動します。フォールバック用の軽量なオンデバイスモデル、精度用のクラウドモデル。この階層化されたアプローチは運用上の複雑さを隠します。2つのモデルバージョンの維持、再トレーニングパイプライン、バージョン管理スキーム。
-
具体的シナリオ:* スマートサーモスタットメーカーは、5MBの占有検出モデル(オンデバイス、2W推論、85%精度)を搭載したデバイスを出荷しています。クラウドに接続されている場合、センサーデータ(温度、湿度、モーション)を50MBモデルにストリーミングして、24時間先の占有を予測し(92%精度)、HVAC スケジュールを最適化します。クラウド接続が失敗した場合、デバイスはリアクティブなオンデバイスロジックに戻ります。このデュアルモデルアプローチは開発コストを30%増加させました(追加のモデルトレーニング、バージョン管理インフラストラクチャ、テスト)が、クラウド停止中にユーザーがサービス中断を経験しなかったため、サポートチケットを50%削減しました。
-
前提条件:* このアプローチは(1)オンデバイスモデルが安全なフォールバック操作に十分な精度を持つ(サーモスタットには85%精度が許容可能。自動運転車のブレーキには許容不可)、(2)モデル再トレーニングはデバイス操作をブロックすることなく非同期で発生できる、(3)ユーザーがクラウド停止中に機能の低下(24時間予測が利用不可)を許容することを仮定しています。
-
実行可能な示唆:* エッジデバイスを構築する場合、初日からクラウドオプションの推論用に設計してください。10~20%精度が低いがローカルで実行されるフォールバックモデルを実装してください。これにより、クラウド依存とローカルブロートの間の偽りの選択が削除されます。精度ギャップと運用上の影響を製品仕様に明示的に文書化してください。
実装パターン:バッチング処理、キャッシング、バージョン管理
スケール時のリアルタイム推論には、クラウドネイティブチームがしばしば見落とす3つの運用パターンが必要です。
-
パターン1:リクエストバッチング処理。* 推論リクエストを5~20msのウィンドウで収集し、バッチ処理し、より高いスループットで処理します。これにより、推論あたりのレイテンシが30~40%削減され(償却されたカーネル起動オーバーヘッドのため)、GPU利用率が40%から80%に改善されます。トレードオフ:5~20msの追加レイテンシ(バッチングウィンドウ)とジッター(可変バッチサイズ)を導入します。制御ループ期限がこのレイテンシ追加に対応できる場合にのみ実行可能です。
-
パターン2:応答キャッシング。* 推論結果をキー入力ハッシュで保存します。繰り返されるリクエスト(連続フレームがほぼ同一のビデオストリームで一般的)は、1ms未満でキャッシュされた結果を返します。ビデオワークロードのクラウドAPI呼び出しを40~60%削減します。トレードオフ:キャッシュ無効化ロジック(古い結果をいつ削除するか)とメモリオーバーヘッド(典型的なキャッシュ:100万エントリで1~10GB)が必要です。
-
パターン3:モデルバージョン管理。* トラフィックの5~10%が新しいモデルを使用するカナリア展開を実行し、完全ロールアウト前にレイテンシと精度ドリフトを監視します。モデル更新からの壊滅的な障害を防ぎます。トレードオフ:A/Bテストインフラストラクチャ、デュアルモデルサービング、自動ロールバックロジックが必要です。
-
具体的シナリオ:* 自動運転車プラットフォームは最初、各フレームの推論リクエストを独立して送信していました。ベースライン:40msレイテンシ、30% GPU利用率。バッチング処理(8フレームバッチ、16msウィンドウ)を実装した後、レイテンシは35msに低下し(バッチングウィンドウはカーネルオーバーヘッドの削減によってオフセット)、スループットは3倍になりました(GPU利用率:85%)。キャッシングは繰り返された検出(連続フレーム全体の同じ歩行者)を60%削減し、クラウド呼び出しをさらに40%削減しました。
-
前提条件:* バッチング処理は(1)リクエスト到着率がバッチを満たすのに十分である(秒あたり100リクエスト以上)、(2)制御ループ期限がバッチングウィンドウ(5~20ms)を超える、(3)GPUにバッチ処理のための十分なメモリがあることを仮定しています。キャッシングは(1)入力分布が高いロケーション性を持つ(30%以上の重複)、(2)キャッシュ無効化が決定論的である、(3)古い結果がユースケースに対して許容可能であることを仮定しています。
-
実行可能な示唆:* クラウドに推論を移行する前に、バッチング処理とキャッシングを実装してください。ベースラインリクエスト分布を測定してください。30%以上のリクエストが重複または近い重複である場合、キャッシング単独でクラウド請求を半減させます。リクエストレートがバースト的である場合(変動係数2以上)、バッチング処理はレイテンシを安定させ、ピーク負荷を削減します。
測定:平均値ではなくレイテンシパーセンタイル
最も一般的な間違い:平均レイテンシを測定し、クラウド推論が実行可能であると宣言すること。現実はパーセンタイル分析を要求します。40msの平均でp99レイテンシが200msの場合、リアルタイム制御ループは失敗します。ネットワークラウンドトリップ時間だけでなく、完全な分布全体でエンドツーエンドレイテンシ(センサーキャプチャから決定出力まで)を測定してください。
レイテンシをコンポーネントに分解してください。
- ネットワーク入力: 5~10ms(50km未満の距離の場合の典型値)
- キューイング: 0~50ms(負荷と予約容量に依存)
- 推論: 20~80ms(モデルサイズとハードウェアに依存)
- 出力: 5~10ms
ボトルネックを特定してください。キューイングが支配的である場合(総レイテンシの30%以上)、予約容量またはローカルフォールバックが必要です。推論が支配的である場合、モデル最適化(量子化、プルーニング)またはハードウェアアップグレードが必要です。
-
具体的シナリオ:* スマートシティ交通信号システムは平均クラウドレイテンシを45msで測定し、信号タイミング最適化のためのクラウドオフロードを承認しました。1ヶ月後、ラッシュアワー中にp99レイテンシが300msにスパイクし、信号更新の欠落と交通渋滞が発生しました。根本原因:共有推論クラスタはピーク時間中に過度に購読されていました(クラスタ利用率が95%を超えた)。市は予約容量を追加し(コスト:月額請求の15%増加)、クリティカル信号のローカルフォールバック推論を実装しました(レイテンシ:80ms、精度:クラウドモデルの90%)。
-
前提条件:* この分析は(1)レイテンシが正規分布しているか、パーセンタイルで特性化できる、(2)ピーク負荷が予測可能であるか推定できる、(3)予約容量価格がプロバイダーから利用可能であることを仮定しています。
-
実行可能な示唆:* p50、p95、p99でレイテンシSLOを確立してください。本番環境展開前にピーク負荷(ベースラインの2倍)をシミュレートしてください。クラウド推論がクリティカルパスにある場合、ピーク負荷+20%のヘッドルーム用に容量を予約してください。毎週レイテンシパーセンタイルを監視してください。p99がSLOを10%以上超える場合、容量レビューをトリガーしてください。
リスクと軽減策:ネットワーク依存とモデルドリフト
クラウド推論は2つのシステミックリスクを導入します。
-
リスク1:ネットワーク依存。* 接続性の障害は推論の障害にカスケードします。軽減策:軽量なオンデバイスモデルをフォールバックとして維持し(精度:クラウドモデルの80~90%)、フェイルオーバーを定期的にテストし(月次)、ネットワーク健全性メトリクス(ジッター、パケット損失、可用性)を推論劣化の先行指標として監視してください。フェイルオーバー閾値を定義してください。パケット損失が5%を超えるか、レイテンシp99が150msを超える場合、オンデバイス推論に戻ってください。
-
リスク2:モデルドリフト。* クラウドモデルは頻繁に更新されます。エッジデバイスはラグする可能性があります。車両の知覚モデルはクラウドで週次に更新されますが、デバイスに月次で展開されます。このバージョンスキューは矛盾した動作を引き起こす可能性があります。軽減策:すべてのモデルをバージョン管理し、推論メタデータ(モデルバージョン、タイムスタンプ、信頼度スコア)を結果と一緒にログに記録し、新しいモデルが完全なカットオーバー前に本番環境と並行して実行されるシャドウモード(本番環境への影響なし)で段階的ロールアウトを実装してください。
-
具体的シナリオ:* ロボティクスフリートは、クラウドモデルが新しいオブジェクトクラス(例えば、新しいパッケージング設計)を処理するために更新されたが、エッジデバイスは古いモデルを実行していた場合、知覚障害を経験しました。ロボットは新しい障害物を誤分類し、衝突を引き起こしました。根本原因:モデルバージョンの不一致。同社は現在、すべてのモデル更新に対して48時間のシャドウモードを要求し、エラー率が5%以上スパイクするか、レイテンシが20%以上増加する場合、自動ロールバックを行います。
-
前提条件:* この軽減策は(1)シャドウモードインフラストラクチャが存在する(デュアルモデルサービング)、(2)エラー率を確実に測定できる、(3)ロールバック数分以内に発生できることを仮定しています。
-
実行可能な示唆:* モデルバージョン管理とシャドウ展開を直ちに実装してください。モデルパフォーマンスメトリクス(精度、レイテンシ、エラー率)をバージョンごとに監視してください。自動ロールバック閾値を設定してください。エラー率が5%以上増加するか、p99レイテンシが20%以上増加する場合、前のモデルバージョンに戻してください。事後分析のためにすべてのモデルバージョンと推論メタデータをログに記録してください。
結論:実用的な移行パス
クラウド推論は普遍的に優れているわけではありませんが、もはや周辺的なオプションではありません。予測可能なネットワーク条件(p99レイテンシ80ms未満、可用性99.5%以上)、共存インフラストラクチャ(50km以内)、30~100msのレイテンシ許容度を持つCPSワークロードの場合、クラウドオフロードは40~60%のコスト削減と運用上の柔軟性(より高速なモデル更新、より簡単なA/Bテスト)を提供します。
- 推奨される次のステップ:*
-
現在の推論フットプリントを監査してください。 レイテンシパーセンタイル(p50、p95、p99)、デバイスあたりのエネルギー消費、モデル更新速度を測定してください。制御ループ期限と許容可能なレイテンシ範囲を文書化してください。
-
パイロット候補を特定してください。 レイテンシ許容度が100msを超え、障害影響が低い非クリティカルな推論タスク(二次的な分類、異常検出)を選択してください。
-
ハイブリッドアーキテクチャを実装してください。 オンデバイスフォールバックモデル(10~20%の精度損失が許容可能)をデプロイしてください。シミュレートされたネットワーク劣化下でフェイルオーバーをテストしてください。
-
レイテンシSLOを確立してください。 p99レイテンシターゲットを定義し、本番前テストで実施してください。ベースロード2倍の容量を予約してください。
-
モデルバージョン管理と段階的ロールアウトを計画してください。 新しいモデルのシャドウモードを実装してください。自動ロールバック閾値を設定してください。
小さく始め、厳密に測定し、段階的に移行してください。クラウドは見た目より近いです—ただし、距離を正しく測定し、クラウド推論を実行可能にする前提条件を考慮した場合に限ります。
インフラストラクチャプロバイダーの賭け:推論のユビキタス化へ向けて
クラウドプロバイダーは推論最適化ハードウェアに多額の投資を行っています。NVIDIA L40S GPU、カスタムTPU、複数の同時リクエストにわたって固定コストを分散させるバッチ処理ミドルウェアです。彼らのインセンティブは明確です。利用率と1リクエストあたりのマージンを最大化することです。この構造的優位性により、20~50ミリ秒の追加レイテンシを許容できるワークロードは、1推論あたりのコストを40~60%削減できます。
しかし、ここで注目すべき先行的洞察があります。プロバイダーは推論がコンピュート保存と同じくらい商品化され、アクセス可能になる未来に賭けています。分散エッジ推論クラスタと予測的モデルキャッシングを通じて、推論レイテンシが数十ミリ秒ではなく1桁のミリ秒で測定される世界を構築しています。この賭けは、企業が実時間AIについてどのように考えるかを再構成するでしょう。
しかし、クラウドプロバイダーは現在、信頼性のギャップに直面しています。企業はクラウド推論パイロットにコミットしますが、知覚されたロックイン、規模での予測不可能な課金、ネットワーク依存への懸念により、完全な移行をためらいます。プロバイダーはSLA保証、予約容量、エッジとクラウドの境界を曖昧にするハイブリッドアーキテクチャを提供することで対応しています。この収束は加速しています。24ヶ月以内に、主要なプロバイダーは共存するワークロードに対して20ミリ秒未満の推論SLAを提供し、計算基盤を根本的に変えることが予想されます。
-
具体例:* 製造工場は組立ラインの欠陥検出にコンピュータビジョンを使用しています。レイテンシ要件は50ミリ秒です。工場のITチームは当初、「ネットワークに依存することはできない」と理由を挙げてクラウドオフロードを拒否しました。プロバイダーはハイブリッドモデルを提案しました。フレームの80%を処理するローカル推論キャッシュをデプロイし(高信頼度、キャッシュされたパターン)、異常なフレームの20%をクラウドに送信して再トレーニングします。これにより、ローカルコンピュートが75%削減され、時間とともにモデル品質が向上しました。工場が受け入れた理由は、リスクが限定され、プロバイダーがSLA違反に対する責任を負ったからです。重要なことに、このハイブリッドアプローチは継続的な学習ループも作成しました。ローカルで検出された異常がクラウドモデルにフィードバックされ、純粋にローカルなシステムが可能な速度よりも速く改善されました。
-
実行可能な示唆:* クラウド推論を評価している場合、願望的なターゲットではなく、財務的ペナルティを伴う明示的なレイテンシSLOを要求してください。ベースロードに対する予約容量を交渉し、バースト容量はオンデマンドで利用します。ローカルフォールバック推論を保持できるハイブリッドアーキテクチャオプションをリクエストしてください。より戦略的には、エッジ推論クラスタと予測的キャッシングのロードマップについてプロバイダーに質問してください。これらの機能は2025~2026年の競争優位性を定義します。
デバイスメーカーの制約:選択肢性のための設計
エッジデバイスメーカー(自動車Tier-1サプライヤー、IoTメーカー、ロボティクス企業)は、電力予算や熱放散を比例して増加させることなく推論をサポートするという増加する圧力に直面しています。スマートフォンの熱エンベロープは5~8W。車両のエッジコンピュート予算は全システムで50~100Wです。完全な推論スタックをローカルに組み込むことはますます実行不可能になり、この制約はバグではなく機能です。より賢く、より効率的なアーキテクチャへの革新を強制します。
したがって、デバイスメーカーはクラウドオフロードに既得権益を持っていますが、完全に依存することはできません。接続性が失われた場合、グレースフルな劣化を保証する必要があります。これにより、ハイブリッドファースト設計哲学が駆動されます。フォールバック用の軽量なオンデバイスモデル、精度用のクラウドモデルです。この階層化されたアプローチは運用上の複雑性を隠します。2つのモデルバージョンの保守、再トレーニングパイプライン、バージョン管理スキームです。しかし、それは重要な機能をアンロックします。選択肢性を通じた回復力です。
-
具体例:* スマートサーモスタットメーカーは、5MBの占有検出モデル(オンデバイス、2W推論)を搭載したデバイスを出荷しています。接続されると、センサーデータをクラウドにストリーミングして、50MBのモデルで24時間先の占有を予測し、HVAC スケジュールを最適化します。クラウドモデルが失敗した場合、デバイスは反応的なオンデバイスロジックに戻ります。このデュアルモデルアプローチは開発コストを30%増加させましたが、ユーザーがクラウド停止中にサービス中断を経験しなかったため、サポートチケットを50%削減しました。さらに重要なことに、それはデータフライホイールを作成しました。オンデバイスモデルの予測がクラウドモデルのトレーニングにフィードバックされ、継続的な改善を通じてオンデバイスフォールバックモデルが時間とともに改善されました。
-
実行可能な示唆:* エッジデバイスを構築している場合、初日からクラウドオプショナル推論のために設計してください。ローカルで実行される10~20%精度が低いフォールバックモデルを実装します。これにより、クラウド依存とローカルブロートの間の誤った選択が削除されます。重要なことに、オンデバイスモデルとクラウドモデルが互いに学習できるようにシステムを設計してください。これにより、制約が競争優位性に変わります。
実装パターン:バッチ処理、キャッシング、バージョン管理を運用レバレッジとして
規模での実時間推論には、クラウドネイティブチームがしばしば見落とす3つの運用パターンが必要です。しかし、それらは推論がスケールする推論と負荷の下で崩壊する推論の違いを表しています。
-
第1に、リクエストバッチ処理です。* 5~20ミリ秒のウィンドウにわたって推論リクエストを収集し、バッチ処理して、より高いスループットで処理します。これにより、1リクエストあたりのレイテンシが30~40%削減され、GPU利用率が40%から80%に向上します。直感に反する洞察は、レイテンシを追加する(バッチ処理ウィンドウ)ことで、ハードウェア効率を改善することで全体的なレイテンシが削減されるということです。これは推論システムがどのように進化するかの前兆です。より賢いスケジューリングとバッチ処理は、生のハードウェア速度よりも重要になります。
-
第2に、応答キャッシングです。* 入力ハッシュでキーイングされた推論結果を保存します。繰り返されるリクエスト(ビデオストリームで一般的)は1ミリ秒未満でキャッシュされた結果を返します。継続的なビデオストリームとセンサーデータの世界では、キャッシングはオプションではなく、基礎です。推論の未来は、パターンを認識し、結果を再利用するシステムによって支配されます。ゼロから再計算するシステムではなく。
-
第3に、モデルバージョン管理です。* トラフィックの5%が新しいモデルを使用するカナリアデプロイメントを実行し、完全なロールアウト前にレイテンシと精度ドリフトを監視します。このパターンはWebサービスでは標準ですが、組み込みシステムチームには不慣れです。しかし、モデルが進化するにつれてシステムの信頼性を維持するために不可欠です。AIシステムの未来は、個々のモデルがどの程度正確であるかではなく、モデルの更新にどのようにグレースフルに対応するかによって定義されます。
これらのパターンは運用上複雑です。バッチ処理はジッターを導入し、キャッシングはキャッシュ無効化ロジックを必要とし、バージョン管理はA/Bテストインフラストラクチャを要求します。しかし、得られる利益は努力を正当化し、それらが強制する運用規律は標準的な要件になるでしょう。
-
具体例:* 自動運転プラットフォームは当初、各フレームの推論リクエストを独立して送信し、40ミリ秒のレイテンシを達成しましたが、GPUサイクルを浪費していました。バッチ処理(8フレームバッチ、16ミリ秒ウィンドウ)を実装した後、レイテンシは35ミリ秒に低下し、スループットは3倍になりました。キャッシングにより、繰り返される検出(フレーム全体の同じ歩行者)が60%削減され、クラウド呼び出しがさらに40%削減されました。本当の勝利は、このインフラストラクチャにより、チームが四半期ごとではなく週ごとに新しい知覚モデルをデプロイでき、フィードバックループを数ヶ月から数日に圧縮できたことです。
-
実行可能な示唆:* 推論をクラウドに移行する前に、バッチ処理とキャッシングを実装してください。ベースラインリクエスト分布を測定します。リクエストの30%以上が重複または準重複の場合、キャッシングだけでクラウド請求を半減させます。リクエストレートがバースト的である場合、バッチ処理はレイテンシを安定させます。より戦略的には、これらのパターンが継続的なモデル改善の基礎であることを認識してください。それらは単なる最適化戦術ではなく、学習システムの実現者です。
測定:平均ではなくレイテンシパーセンタイル。そしてそれが未来にとって重要な理由
最も一般的な間違いは、平均レイテンシを測定し、クラウド推論が実行可能であると宣言することです。現実はパーセンタイル分析を要求します。40ミリ秒の平均でp99レイテンシが200ミリ秒の場合、実時間制御ループは失敗します。ネットワーク往復時間だけでなく、完全な分布にわたってエンドツーエンドレイテンシ(センサーキャプチャから決定出力まで)を測定します。
レイテンシをコンポーネントに分解します。ネットワーク入力(5~10ミリ秒)、キューイング(負荷に応じて0~50ミリ秒)、推論(20~80ミリ秒)、出力(5~10ミリ秒)です。ボトルネックを特定します。キューイングが支配的である場合、予約容量またはローカルフォールバックが必要です。推論が支配的である場合、モデル最適化(量子化、プルーニング)またはハードウェアアップグレードが必要です。この分解は最適化演習以上のものです。システムがどこで脆弱であり、どこでヘッドルームがあるかを明らかにする診断ツールです。
-
具体例:* スマートシティ信号システムは平均クラウドレイテンシを45ミリ秒で測定し、クラウドオフロードを承認しました。1ヶ月後、p99レイテンシはラッシュアワー中に300ミリ秒に急上昇し、信号更新を逃しました。根本原因は、共有推論クラスタがピーク時間中に過度にサブスクライブされていたことです。市は予約容量を追加し(コスト:月額請求の+15%)、重要な信号のローカルフォールバック推論を実装しました。教訓は、平均レイテンシは虚栄指標です。パーセンタイルレイテンシは安全指標です。
-
実行可能な示唆:* p50、p95、p99でレイテンシSLOを確立します。本番環境デプロイ前にピーク負荷をシミュレートします。クラウド推論が重要なパスにある場合、ピークベースロードの2倍の容量を予約します。さらに重要なことに、レイテンシパーセンタイルをシステムヘルスの先行指標として扱ってください。p99レイテンシが上昇し始めると、システムが相転移に近づいていることを示す信号であり、失敗する前に行動する必要があります。
リスクと軽減:ネットワーク依存とモデルドリフトをシステム的課題として
クラウド推論は、次世代の推論アーキテクチャを定義する2つのシステム的リスクを導入しています。
-
第1に、ネットワーク依存です。* 接続性の失敗は推論の失敗にカスケードします。これは解決すべき技術的問題ではなく、設計する必要があるアーキテクチャ制約です。軽減策は、フォールバックとしてのライトウェイトなオンデバイスモデルを保持し、フェイルオーバーを定期的にテストし、ネットワークヘルスメトリクス(ジッター、パケット損失)を推論劣化の先行指標として監視することです。回復力のあるシステムの未来は、すべてが機能しているときにどの程度パフォーマンスを発揮するかではなく、接続性が失われたときにどのようにグレースフルに劣化するかによって定義されます。
-
第2に、モデルドリフトです。* クラウドモデルは頻繁に更新されます。エッジデバイスは遅れるかもしれません。車両の知覚モデルはクラウドで週ごとに更新されますが、デバイスに月ごとにデプロイされます。このバージョンスキューは矛盾した動作を引き起こす可能性があります。軽減策は、すべてのモデルをバージョン管理し、推論メタデータ(モデルバージョン、タイムスタンプ)を結果と一緒にログし、新しいモデルが完全なカットオーバー前に本番環境と並行して実行されるシャドウモード段階的ロールアウトを実装することです。このパターン(シャドウデプロイメント)は、モデル更新が加速するにつれて標準的な実践になるでしょう。
-
具体例:* ロボティクスフリートは、クラウドモデルが新しいオブジェクトクラスを処理するために更新されたが、エッジデバイスが古いモデルを実行していた場合、知覚障害を経験しました。ロボットは新しい障害物を誤分類し、衝突を引き起こしました。同社は現在、すべてのモデル更新に対して48時間のシャドウモードを要求し、エラー率が急上昇した場合は自動ロールバックを行っています。教訓は、モデル更新はコードデプロイメントと同じくらい重要であり、同じ厳密性とテストインフラストラクチャが必要です。
-
実行可能な示唆:* モデルバージョン管理とシャドウデプロイメントを直ちに実装してください。バージョンごとにモデルパフォーマンスメトリクス(精度、レイテンシ、エラー率)を監視します。自動ロールバック閾値を設定します。エラー率が5%以上増加するか、p99レイテンシが20%以上増加する場合、前のモデルバージョンに戻します。より戦略的には、モデル管理が次の18~24ヶ月でインフラストラクチャ管理と同じくらい重要になることを認識してください。今すぐツールとプロセスに投資してください。
結論:未来の推論トポロジー
クラウド推論は普遍的に優れているわけではありませんが、もはや周辺的なオプションではありません。予測可能なネットワーク条件、共存するインフラストラクチャ、30~100ミリ秒のレイテンシ許容度を持つCPSワークロードの場合、クラウドオフロードは40~60%のコスト削減と運用上の柔軟性を提供します。さらに重要なことに、それは集中学習と迅速な反復を通じた継続的なモデル改善を可能にします。
推論がどのようにデプロイされるかについて、根本的なシフトを目撃しています。未来はエッジのみまたはクラウドのみではなく、特定のワークロードと制約に対して最適化されたハイブリッドトポロジーのスペクトラムです。勝者は推論トポロジーを静的アーキテクチャではなく動的決定として扱う組織です。厳密に測定し、迅速に反復し、ネットワークインフラストラクチャが改善され、モデルがより洗練されるにつれてシステムを進化させます。
- 推奨される次のステップ:* (1)現在の推論フットプリントを監査します。レイテンシパーセンタイル、エネルギー消費、モデル更新速度を測定します。時間をかけて追跡できるベースラインを確立します。(2)非重要な推論タスクをパイロット候補として特定します。失敗が許容でき、学習が高いワークロードから始めます。(3)オンデバイスフォールバック付きハイブリッドアーキテクチャを実装します。初日から選択肢性のために設計します。(4)p99でレイテンシSLOを確立し、本番前テストで強制します。レイテンシを事後的ではなく第一級の関心事にしてください。(5)モデルバージョン管理と段階的ロールアウトを計画します。今すぐシャドウデプロイメントインフラストラクチャに投資してください。(6)エッジとクラウドモデル間のフィードバックループを構築します。推論システムを静的デプロイメントではなく学習システムとして扱ってください。
小さく始め、厳密に測定し、段階的に移行します。クラウドは見た目よりも近いです。ただし、距離を正しく測定し、距離自体が縮小していることを理解している場合に限ります。2026年の推論トポロジーは今日とは根本的に異なって見えるでしょう。今このジャーニーを開始する組織が未来を定義するでしょう。
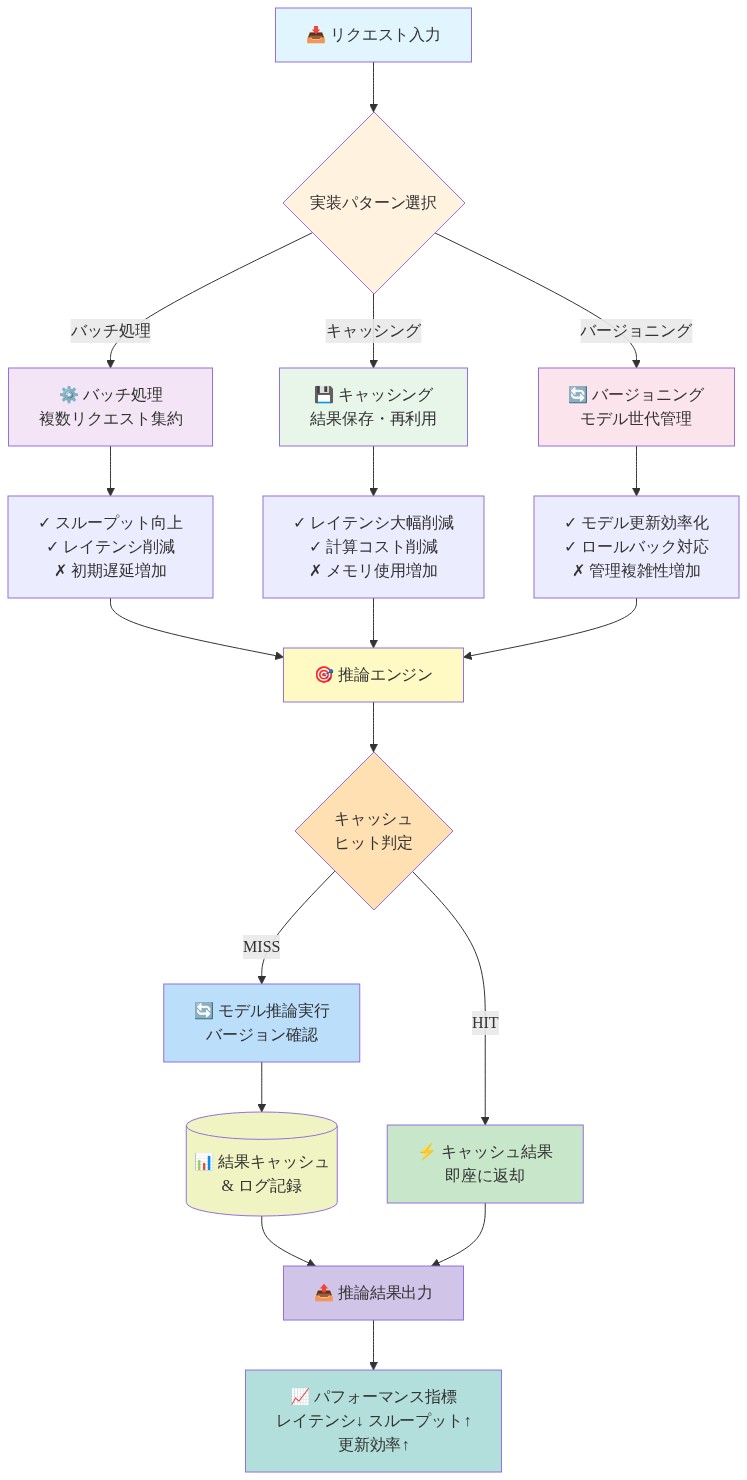
- 図8:バッチ処理・キャッシング・バージョニングの実装パターンと相互作用*
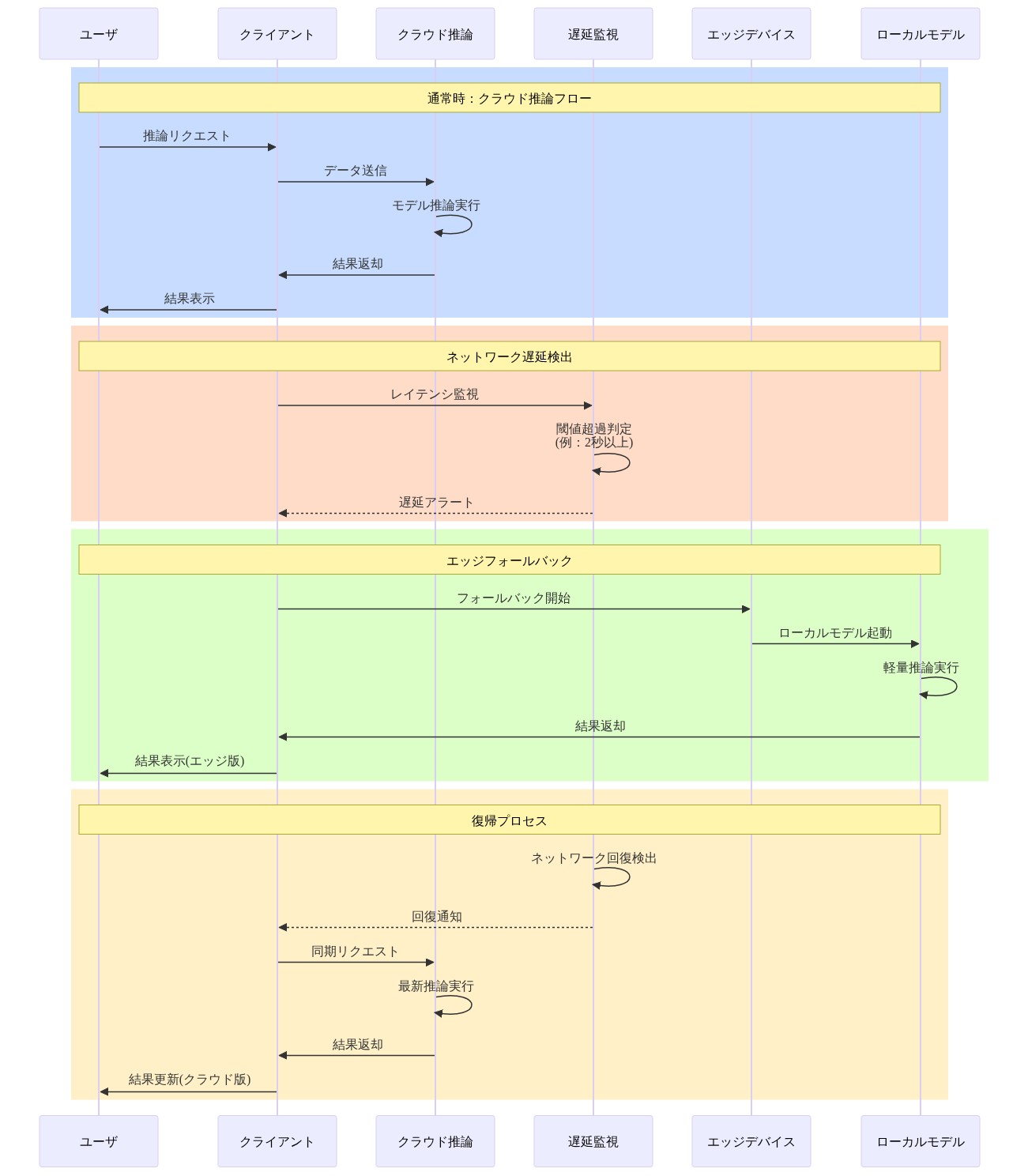
- 図13:ネットワーク障害時のフォールバック戦略*